diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000..d3eb82c
Binary files /dev/null and b/.DS_Store differ
diff --git a/README.md b/README.md
index d092ed8..1acebcf 100644
--- a/README.md
+++ b/README.md
@@ -5,47 +5,37 @@
 +这是我学习Java的知识总结,我会按照下面的技术栈一步步完善整个知识体系。
-**文章首发公众号**。如果有帮助到大家,希望点个**Star**!让我有持续的动力,感谢🤝
+分享给正在学习Java的你们,希望可以帮助你们少走一些弯路,一起学习进步!
-每周至少一篇的更新频率,没链接的是之后打算写的。
-
-:pencil2: [写作自述](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486050&idx=1&sn=1105d28b8d3553715f425419ec9d8d18&chksm=cf8479a7f8f3f0b19425e08a00332bbce4e5333843cfd6dd6f35e892139810d86b778cd57d55#rd)
+**文章首发公众号,每周至少一更。如果有帮助到大家,希望点个Star!让我有持续的动力,感谢🤝**
### :star: Java ###
- [深入详解ThreadLocal](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486776&idx=1&sn=f4425cb88bc5393e4d5125f5fd08ed68&chksm=cf847efdf8f3f7ebc79c5bcd3c47f1fc2f83abf119c2b22782cc90a1c69f606a95a4051dab53#rd)
-
- [使用Optional优雅避免空指针异常](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486914&idx=1&sn=b2b0f2c41b8168fbfcf1df21a3e00acb&chksm=cf847e07f8f3f711de06cb9269ba41541ec9399a56963768add081031566bf7fa49cbb6f7fa0#rd)
-
- [我画了35张图就是为了让你深入 AQS](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486172&idx=1&sn=b39cccd87dcd21176597dce0b15f7232&chksm=cf847919f8f3f00f86219d44cd95badee969d754aec89e644992437f2e8e0f7ad784695b4d90#rd)
-
- [一个 static 还能难得住我?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486175&idx=1&sn=041c85c052c11d2d15243994bc46d90a&chksm=cf84791af8f3f00c90a18b29d1fa47c9bcd713651514fc5ce4a9f82d656fe637bb21d45c42be#rd)
-
- [原来这才是动态代理!!!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486178&idx=1&sn=9610c1a0fa1df4c69558408ab2a3fcae&chksm=cf847927f8f3f0315b0c86f9b577926820c3d264d605149f850b597fcd17fafe432d82aaffcf#rd)
-
- [synchronized 的超多干货!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486181&idx=1&sn=4cb9340ba2f19ccb19ccec0c54d61b86&chksm=cf847920f8f3f036cd752455290a97f6584f8a4ce9662d1102515dd5ed967c94e14cec7a767d#rd)
-
+- [ExecutorCompletionService详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487958&idx=1&sn=2ace7ac53d596cd909d1d1c7e96fbff2&chksm=cf846213f8f3eb05c9de1fab2c609f4774ca86497ad5542a26aae5928efd808bfd865738aa4f#rd)
+- [CompletableFuture深度解析](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488046&idx=1&sn=2bb0b6dc4576278ff2e7f9b917cb6fe8&chksm=cf8461ebf8f3e8fd013d08c5028d41281444b1ac1d60f1706c841c4b444a4235d82c84644b9b#rd)
+- [面试官:响应式编程和虚拟线程怎么选?看完这篇不再被问倒](https://mp.weixin.qq.com/s/V7H_hyjycT3n1Rr7FBOrYQ)
### :page_facing_up: JVM ###
- [面试官:JVM是如何判定对象已死的?学JVM必会的知识!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486087&idx=1&sn=c6f1a9932961095ffdf2aef8a789e115&chksm=cf847942f8f3f0549c798671fe804c93378586b4fc547cce14db2359852ff0723a3aab64a187#rd)
-
- [GC的前置工作,聊聊GC是如何快速枚举根节点的](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486168&idx=1&sn=9eef35ec701b5c2f8097641b7e69ae71&chksm=cf84791df8f3f00b1e85039f31b17e00bf9cb624bbee638efeca110e51df6c6b6ba6363705ee#rd)
-
- [GC面临的困境,JVM是如何解决跨代引用的?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486242&idx=1&sn=83d4ace26fea86b0f16e93e25b3cdadf&chksm=cf8478e7f8f3f1f17a65a7fc0d25237e8f25b90f300085bb5a7e8128f7d80f5ba1a02e5a6c2f#rd)
-
- [昨晚做梦面试官问我三色标记算法](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486265&idx=1&sn=1464f25915c2c09ef65b784985b76fa3&chksm=cf8478fcf8f3f1ea80715ae949c1b4aec988368ead269c746d38244ae62028948a199f099d14#rd)
-
- [深入解析CMS垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486628&idx=1&sn=984b273af7d1d0398517a2f5442ffb38&chksm=cf847f61f8f3f677372a5ebc9f81403a8324be1bed49bf92e763882715c943324de4f1b0139a#rd)
-
- [深入解析G1垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486736&idx=1&sn=5e0710485783c3bcc4854a10412b9a40&chksm=cf847ed5f8f3f7c3826fa8c67bc76ce8dd218a725ee04f54cdafa27e14d190f5c92332589ae2#rd)
-
- [深入解析ZGC垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486746&idx=1&sn=7257ecf8c36509d06be359e3889400f2&chksm=cf847edff8f3f7c96edc667051d9ef70537000202c1ec77699fa5e30e46c2c8ddabd122297f3#rd)
### :hammer: MySQL ###
-- [MySQL双写缓冲区(Doublewrite Buffer)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484456&idx=1&sn=b5154c5eb26b969655c1b430792e0cb6&chksm=cf8477edf8f3fefbe0c95c2074a461ab12c01926654d995ad7844cba332fda7744da6b47ddc5#rd)
+- [深入解析 MySQL 双写缓冲区](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487013&idx=1&sn=beae861ca0f148e010d4170d14f67fdd&chksm=cf847de0f8f3f4f631273fbc7b9739239772cf90ad94fe78e83eb006d6a700ba2f00faffac09#rd)
- [再深入一点|binlog和relay-log到底长啥样?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486183&idx=1&sn=adc83df6c78e53ed1aefec7edc40ed63&chksm=cf847922f8f3f034beb08fc0a6fa2df8acb64902adff6927b71b5582e54444baa5c7265f7db8#rd)
@@ -53,29 +43,35 @@
- [听说你对explain 很懂?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486188&idx=1&sn=4ebf475e7287e4b9cc0e37fdff0c18af&chksm=cf847929f8f3f03fba7173a17f8a04a677db9af91355cba552f5156b7fc9424ccf0fd87f8488#rd)
-- [MMR(Multi-Range Read Optimization)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484466&idx=1&sn=29b6a9adfa2fee52e6391509d1b8c73f&chksm=cf8477f7f8f3fee1ea1793924cf8475f7581a2770f8804a54a60c61f57aac4ce64dff723c308#rd)
+- [深入浅出MySQL MRR(Multi-Range Read)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487041&idx=1&sn=66921cd6949db1389a0f02b3764b250f&chksm=cf847d84f8f3f4925b6506aeabe55308c85a68cb1fb8bf09aa99eca721d881246700bd9851a4#rd)
- [拿捏!隔离级别、幻读、Gap Lock、Next-Key Lock](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486190&idx=1&sn=c274fbc3daed3d1ac3a1ce5bd0009b68&chksm=cf84792bf8f3f03d07e2855570164cbfc0f0a7fbb0bba1fd50c8b7b2155c555c4438b625f395#rd)
-- [MySQL中的Join 的算法(NLJ、BNL、BKA)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484480&idx=1&sn=e75482a0fd8a866d9a9565aa9e659009&chksm=cf847785f8f3fe93195de380f7cff3efc8950a2cb49127a669f6b14a30e2fa5c13285e905f6b#rd)
+- [深入理解MySQL中的Join算法](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487068&idx=1&sn=042ab289718dbdaaea1b62854610efb7&chksm=cf847d99f8f3f48fd0aa04eeb2f6932bc826770f80911eec2fc571bdc7a50abc387714488d72#rd)
-- [MySQL分区表详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484856&idx=1&sn=ffb350c8b1e74667fe15a5e808faec57&chksm=cf84767df8f3ff6b30ff91dd14a6f802eaac01076dcc8b988a18f1a529f21a6266d34e34c4d7#rd)
+- [MySQL分区表详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487126&idx=1&sn=d81d7fa7b2befa0637bc9df5f4292915&chksm=cf847d53f8f3f445c92c1ae37478e47be947829a70b68d1e0f7f7d74af2d7ee15e6fca657845#rd)
- [缓存和数据库一致性问题,看这篇就够了](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486196&idx=1&sn=e9dcd1824583546aada0096e457afda0&chksm=cf847931f8f3f02780828e9fb2b2f36d018d74583fb7091bdbe6b7565bdfa10a396b4bfa9965#rd)
+- [全网最详细MVCC讲解,一篇看懂](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487999&idx=1&sn=8abdf89c27bbedd788d6ea260cb981c3&chksm=cf84623af8f3eb2cd63c4f6f80fda0822d14c3bbf49487f254377f13963ccaf89b1d04344128#rd)
+
+- [六个案例搞懂间隙锁](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488470&idx=1&sn=2a2b56e35ac6e1bae83e1a7eadc743f1&chksm=cf846013f8f3e9051b5e0d3636bcf135b994d77039409f92b7faeccdedddb6d5cfda6eaf0984#rd)
+
### :envelope: Redis ###
- [Redis类型(Type)与编码(Encoding)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486922&idx=1&sn=98b7e28fc9ed20b69dc236605dfd1c34&chksm=cf847e0ff8f3f7197ece7d7b96c7fa82328d7e66b969a37246ac51f4c4dd21056540b046cbe6#rd)
+
+- [Redis性能优化:理解与使用Redis Pipeline](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486953&idx=1&sn=76365046920ead36714bbdf64300739b&chksm=cf847e2cf8f3f73ab5dc16d82817bde96a5ba5f16903896bae2943773df87a11153c612eeeb9#rd)
-- [布隆过滤器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484400&idx=1&sn=8d480b6b87ee2330e1e5f181fbf5f71a&chksm=cf847035f8f3f923699cd0b3c9137aa6bd596abd0242abe73abeee3179392794538e87e2dc42#rd)
+- [布隆过滤器:原理与应用](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487003&idx=1&sn=c98c8a0643ae56ac0d81572aeabcc279&chksm=cf847ddef8f3f4c86f14b317375e395124f9278e5dbd7daec854a8a342f77992f1e6b9775249#rd)
-- [Redis跟MySQL的双写问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484390&idx=1&sn=de37dc02c20f3b471404c507c3741550&chksm=cf847023f8f3f935233feb3c575c7798e41d695347f11f502a75f25ba02b479ad152572c666e#rd)
+- [探索 Redis 与 MySQL 的双写问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486966&idx=1&sn=1aa2fc4d096242a8b725e01d45327a0c&chksm=cf847e33f8f3f72529da952b0621f7faf1756e5fd24e50c0d1896d98eab097e5bbf74aa218dd#rd)
- [Redis内存碎片:深度解析与优化策略](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486935&idx=1&sn=0b41d8807b6f0cdd06172f587884aa7a&chksm=cf847e12f8f3f70469ee692017388360a767175c9a3cbe482f2d93232c52540e43e5c8c8034e#rd)
-- [Redis中的BigKey问题:排查与解决思路](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484415&idx=1&sn=39cb685de9880bbe8fb108518cd5d54d&chksm=cf84703af8f3f92ca802e8e567a1f9bcdd038574113fe7aa68091db9f32cd86f6957862ee83a#rd)
+- [Redis中的Big Key问题:排查与解决思路](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487157&idx=1&sn=9cc48fd498f6633fdc49c11f7cd6b88f&chksm=cf847d70f8f3f466319083703cff3623d0ec92a6d47d9594c4b0547d9489805dfefba2ecd179#rd)
-- [非看不可的Redis持久化](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484435&idx=1&sn=e02f552e3d943787fdd5442ab49eb95a&chksm=cf8477d6f8f3fec05b7b8441cc19898bf9a4c4e9ffaa72827eba2e20735a0f37f840c4e2e495#rd)
+- [超详细!彻底说明白Redis持久化](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488849&idx=1&sn=d15830cf43364a8c9e3c9292d53cce05&chksm=cf846694f8f3ef825cb84436e2c931d9e22c2cdf810a546a3edb301a539168e0ce33c868d115#rd)
- [深度剖析:Redis分布式锁到底安全吗?看完这篇文章彻底懂了!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486194&idx=1&sn=59c36ccae0a67063e4b29aba5084ffe0&chksm=cf847937f8f3f0211b989c65ff07c8b142ddd7752592f018488cb852a9062b587bbe8b2b3d3e#rd)
@@ -84,28 +80,40 @@
- [Redis最佳实践:7个维度+43条使用规范,带你彻底玩转Redis | 附实践清单](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486200&idx=1&sn=52dc758e32d138efcba25a7a47aec23d&chksm=cf84793df8f3f02b497d68f6f9407f7681b7eda3b2c88c87ac0f0411a7d0df4cf2ec8b9ba781#rd)
- [颠覆认知——Redis会遇到的15个「坑」,你踩过几个?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486202&idx=1&sn=5fee614b5272fb9e3522f446bddc6132&chksm=cf84793ff8f3f02961bdccd2310d052231bc3023cd609afe71d7e648bcda48aa2c57eed65371#rd)
-### :lock:Elasticsearch ###
-- [学好Elasticsearch系列-核心概念](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485450&idx=1&sn=b23b362f8baac883e6a64b0cb05b184d&chksm=cf847bcff8f3f2d98ef829ff3f7c8cee59600b6b2c683564e2ab6af2c0547fc67b8ccbc837e9#rd)
-
-- [学好Elasticsearch系列-索引的CRUD](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485479&idx=1&sn=eb2b57e78d1f08c398558b2f23063df0&chksm=cf847be2f8f3f2f4567bd65048aba533355c70733bef9a14580ffcfadd01678acf01d62a92f4#rd)
-
-- [学好Elasticsearch系列-Mapping](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485492&idx=1&sn=e33d0689502b043723b0c2e4f0660a1d&chksm=cf847bf1f8f3f2e75fc2a8dd4542572f2dc7e4706f4817d2f9cd2ae18d3f28a1455da7873207#rd)
-
-- [学好Elasticsearch系列-Query DSL](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485520&idx=1&sn=97803ad983c80a90158b5b9efabcc8b7&chksm=cf847b95f8f3f2839fec2550df3dccb55e91b5cadcfc11ea2e9e25b27a882aceb5dca5fe2b96#rd)
-
-- [学好Elasticsearch系列-分词器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485544&idx=1&sn=cfa20adbb5c7328ea0cab85966d95c02&chksm=cf847badf8f3f2bbefd1b9e893cccf10a24c2a83f8052b613c62c999566e4c8616fded236552#rd)
-
-- [学好Elasticsearch系列-聚合查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485562&idx=1&sn=dd965afcd5697a152dae32d46e3996cd&chksm=cf847bbff8f3f2a91c7c75af03809359f7c9963c32e1da19b79939ccc283c46b3cf8038bd917#rd)
-
-- [学好Elasticsearch系列-索引的批量操作](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485594&idx=1&sn=71da9fcc473e3891b19c37af782ae7cb&chksm=cf847b5ff8f3f249e7f42ccac125982aa3abd8617bb5cc5466b2c5d381dae51f4d76b9f11d3c#rd)
-
-- [学好Elasticsearch系列-脚本查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485648&idx=1&sn=a0b075e6c2bad836a4c4eb6cacbaff5a&chksm=cf847b15f8f3f2033b5e18b8376b14205902898fb14c40a955a10619a74b1d35552a046dd7d1#rd)
+### :lock: Elasticsearch ###
+
+- [一起学Elasticsearch系列-核心概念](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487646&idx=1&sn=381af0374eb1d512046315164a541211&chksm=cf84635bf8f3ea4d650dc00e277d273d9a1e7358ae884b3cfedaf9d172cb1f44df7775bf355a#rd)
+- [一起学Elasticsearch系列-索引的CRUD](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487642&idx=1&sn=ea2cc5a3e0be25a0a81abe860b183f09&chksm=cf84635ff8f3ea49944ad35ee9bba7e60bf3f9c9c72d83c3d103403739d58a49fe2ff4779314#rd)
+- [一起学 Elasticsearch 系列 -Mapping](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487661&idx=1&sn=40c8a1a43c172c8500b975c6e1b35b39&chksm=cf846368f8f3ea7e451022e0e72b1a9d57c2641d56f9d0158fb8849d2806294e3dc7e3f71cde#rd)
+- [一起学Elasticsearch系列-Query DSL](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487687&idx=1&sn=9622f7220358daab3a5dddd9fef3d2b7&chksm=cf846302f8f3ea147dac58d003d20495ce1feeec910423e59d917272e890590d7b769ec71510#rd)
+- [一起学 Elasticsearch 系列-分词器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487710&idx=1&sn=bce31911a3259f77cd5f5874c255e74c&chksm=cf84631bf8f3ea0dd8c2b816950f1fe7f04f529abf02512ca778b8e2fa2b66b117f15d6d44bb#rd)
+- [一起学Elasticsearch系列-聚合查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487728&idx=1&sn=f4e43d386925b7cec5115fb388e00843&chksm=cf846335f8f3ea2371df0bfbb16b1f6c2dfb553d90762edd9bec9c2b9839f6043de4625c1a36#rd)
+- [一起学Elasticsearch系列-脚本查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487750&idx=1&sn=b7b7bdcc8736d4bfc2092bd5c3511084&chksm=cf8462c3f8f3ebd526b06d283b723844d548299957e4a8d1c5cf60e1a6fa70b5e97477f7cca8#rd)
+- [一起学Elasticsearch系列-索引的批量操作](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487779&idx=1&sn=54d06ae4f6a1aa62702cc61349e763b2&chksm=cf8462e6f8f3ebf026fe41fc0c8fb77b743687f0460a5eae970c2af95264e3556764911b2f1d#rd)
+- [一起学Elasticsearch系列-模糊搜索](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487791&idx=1&sn=5878be01f10e3834445c64cb6351a872&chksm=cf8462eaf8f3ebfcb0a49c57d68721448d649b1dfcd91f3af549ef1192c95fb6a00d25c386db#rd)
+- [一起学Elasticsearch系列-搜索推荐](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487818&idx=1&sn=ee11f629be04cf427193d0fee36bc6e2&chksm=cf84628ff8f3eb99baaa38cfcd126a5c11143a5e14e8571e33b1ddada1403001a7c955f1486f#rd)
+- [一起学Elasticsearch系列 -Nested & Join](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487856&idx=1&sn=d13fbb78f8093ef1ac85f4f4b4abe543&chksm=cf8462b5f8f3eba3ad95ad2cead38c8413565262917cb2a10c5f7c5287189f600a93014ffcca#rd)
+- [一起学Elasticsearch系列-深度分页问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487873&idx=1&sn=37c93764bd0ddad6c5d7a7b01d9eca3a&chksm=cf846244f8f3eb529197122f0bc15256c7cf865d1c2f7b23d2fee8dcd1259a5d02e2fc12da54#rd)
+- [一起学Elasticsearch系列-并发控制](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487882&idx=1&sn=9afba52dddff1e9a7269bc9dc23e4893&chksm=cf84624ff8f3eb597c445f21a71df24bc334d58b1108432fcf5acf92498cfb8a22fee07af059#rd)
+- [一起学Elasticsearch系列-写入原理](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487898&idx=1&sn=b9960c61fb853619d1e52258cb5819a0&chksm=cf84625ff8f3eb492810d73713742b8459688fe7f9ef803354734bd9aceb7cdbc550a0ba6a17#rd)
+- [一起学Elasticsearch系列-写入和检索调优](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487903&idx=1&sn=45211a9d2b39c8433208f95af3ff3922&chksm=cf84625af8f3eb4c542e4b4082064e5abd2f2e21806a8f3e15409e02660afd820a4e5b854a9b#rd)
+- [一起学Elasticsearch系列-索引管理](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487926&idx=1&sn=3e7a6e6de02de000657b142d4bee5e82&chksm=cf846273f8f3eb656a9be4fa060dc23f1aba6ac3ca0b41087511a5787fe8b523a4c1db9bda15#rd)
+- [一起学Elasticsearch系列-Pipeline](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488897&idx=1&sn=2d4adc6d38813efa5a66a4f7c2763375&chksm=cf846644f8f3ef52577656d9a6d9cf5dbaef7f6dc61d21df181c61279237380f9ddd111fad69#rd)
+
+### :mag_right: DDD ###
+
+- [熬夜整理的2W字DDD学习笔记](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489048&idx=1&sn=6dc6f884fe7ca0e07d86aaa6e37ba4ab&chksm=cf8465ddf8f3eccbae516e3405dff032dfcc0c2820b187f4188caca2e63bed88d99fbb11b8c1#rd)
-### :date:框架 ###
+### :birthday: Spring ###
+
+- [如何优雅地Spring事务编程](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489087&idx=1&sn=60d6e29a87753beb69754bb633cbfe6e&chksm=cf8465faf8f3ececad33d8f42a7644e44eb05081c613761b39fc4bf46425058e9e3e5bbcf52b#rd)
+
+### :date: 框架 ###
- [本地缓存无冕之王Caffeine Cache](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486885&idx=1&sn=37c7a9461402bd97822295cf51361777&chksm=cf847e60f8f3f776eb3b477decfbac55dc8b7ae1cf607ef68fbee89dbe02d40a800a92fabec7#rd)
+- [响应式编程不只有概念!万字长文 + 代码示例,手把手带你玩转 RxJava](https://mp.weixin.qq.com/s/r0DJiOxR8wnZZ6tIKrSPzg)
-### :fire:架构设计 ###
+### :fire: 架构设计 ###
- [高并发系统设计之负载均衡](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486811&idx=1&sn=5422c62878ee1ddcc6ee1da45deb78d7&chksm=cf847e9ef8f3f7889c94fe93796c87083ebb47680ef13b40a35f5127c293e5d44fd3621abd57#rd)
@@ -115,22 +123,67 @@
- [搞懂异地多活,看这篇就够了](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486192&idx=1&sn=6c82786cf2403486d81f375be684f228&chksm=cf847935f8f3f023a167ea3272a35979ee623dd0207acb70a0898148a1b18a15df01a49e54d8#rd)
-### :dash:编程语言 ###
+- [12306技术内幕](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489137&idx=1&sn=9f5857733a5bed241902fb4c4421adf3&chksm=cf8465b4f8f3eca2d7d65af8cd8a1b3e9b1b3b56d482eb09cdd5fdd0ae3b7744a3994c495cbf#rd)
-- [Scala初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484574&idx=1&sn=85ac7b748ec8f22e3e8f8f42efca02d1&chksm=cf84775bf8f3fe4d2779871e106e1946293bb57d6f85ad44aa1f20fe467e9402a26807a532b4#rd)
-
-- [Groovy初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484641&idx=1&sn=7243e662d2b0a811f1be745777c30420&chksm=cf847724f8f3fe329f4414fb3fa9c262e0d2985f6996b64b519b79b1c6ae3f65fb894d27bb76#rd)
+- [业务幂等性设计的六种方案](https://mp.weixin.qq.com/s/HZAkGPNrC05aeHabhqT-zA)
-### :eyes:大数据 ###
+### :dash: 编程语言 ###
-- [Spark入门这篇就够了(万字长文)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484731&idx=1&sn=033b31376869f2046219dfe28707e43d&chksm=cf8476fef8f3ffe86a1910e5948afddba464e6cc186adb3ecb8ca62f612a4110b71ada2370cc#rd)
-
-- [一篇文章带你入门HBase](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484823&idx=1&sn=4f8204e007c2201962cd707fc5668242&chksm=cf847652f8f3ff443ef516bf490656b21891eee42382970435a25451948daf89c2d72cfad96f#rd)
-
-- [全网最详细4W字Flink入门笔记(上)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485174&idx=1&sn=4cbd4ce941458fa576febb5021d1942f&chksm=cf847533f8f3fc25fa6e9c0c6de69b68b3f424aad52e6846dca8641d11a8be7ea8614682ad64#rd)
+- [Scala语言入门:初学者的基础语法指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487245&idx=1&sn=d089e22890f1f7449b7cf34e3cf2f6ed&chksm=cf847cc8f8f3f5deb39556f4229bafb6f1498906dc1d75040f90817bf0396117a7c2cdb498f9#rd)
+- [Groovy 初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487066&idx=1&sn=da9e3a9aff377d383e34e537e2f55666&chksm=cf847d9ff8f3f489011f26a784302ee68b9c1d7d57d52bc2c924a7c9b1a5f528ef2a417114c0#rd)
+- [自研 DSL 神器:万字拆解 ANTLR 4 核心原理与高级应用](https://mp.weixin.qq.com/s/nFiEqhi1B_SxrZGCAqLgLw)
+
+### :satellite: 设计模式 ###
+
+- [一文搞懂设计模式—策略模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488583&idx=1&sn=2e4758ee1b48dc5884289d5ecb841491&chksm=cf846782f8f3ee946d514e6267a326facb6880002fb663ffdbc3347e1d89fab32b8c0f5764d9#rd)
-- [全网最详细4W字Flink入门笔记(下)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485365&idx=1&sn=c99d1e392440cad85342fdc950afc7f9&chksm=cf847470f8f3fd6632b34a42d8008f94430902630e4f5c8fb6ead1475facdc6e4ab39a5f828b#rd)
+- [一文搞懂设计模式—责任链模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488600&idx=1&sn=dd004bacfe0262fcc0fd1d72ae506b7a&chksm=cf84679df8f3ee8bf7117c5bed745470475c1a35ee96fe2bb99e093d895b7b776ecf51bb31c2#rd)
+
+- [一文搞懂设计模式—单例模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488615&idx=1&sn=1f0f92f6180856dbf206706c071438a3&chksm=cf8467a2f8f3eeb4e24e6c42f7f8cd265c03939ffa7742d1445ed7dddc6b11bb63aa6b0eb95e#rd)
+
+- [一文搞懂设计模式—观察者模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488718&idx=1&sn=9486e6b494c666e805e321a74bac5591&chksm=cf84670bf8f3ee1da0e7f26963e007da8fa77e7190596c9a6f6296cf2cc70af2ec4c066b5906#rd)
+
+- [一文搞懂设计模式—门面模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488730&idx=1&sn=0f63b2f54615d0647d4be22964dadea2&chksm=cf84671ff8f3ee0900b2cd3174ab8e66131308049648cc4e65d25215a54cc457cea1e73c8698#rd)
+
+- [一文搞懂设计模式—工厂方法模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488747&idx=1&sn=025c94f5b66b4dae3ab6f62dc043a083&chksm=cf84672ef8f3ee38bfce967135b5d23a93c0d59ae502b06b3c85ac629e336d28a21f1e13784f#rd)
+
+- [一文搞懂设计模式—模板方法模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488758&idx=1&sn=40385dc2cd049ab06c6403c47e1d5efa&chksm=cf846733f8f3ee2596eb459b9114e654e5ffd0ca1565931b742c65879a8603fc75c74880be58#rd)
+
+- [一文搞懂设计模式—适配器模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488766&idx=1&sn=78bf2e392394bb28272cceb3dd300618&chksm=cf84673bf8f3ee2d8b6308d272e8cd3a0173bfd540639cd7c17c4c40f6bc3e25561a0889930d#rd)
+
+- [一文搞懂设计模式—装饰器模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488773&idx=1&sn=287d0323b84eec284a56edceb1e5840e&chksm=cf8466c0f8f3efd6e8a8e5270ed10cf991c7b27a93521359274c2120d9e45e29b637e948650f#rd)
+
+- [一文搞懂设计模式—代理模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488866&idx=1&sn=d293faa2c918d85cc9cd8f6bc408b5a1&chksm=cf8466a7f8f3efb11ae68d7f7712bb22ceafae6f9d0529c235a1b1e02d183296c400211910b2#rd)
+
+- [一文搞懂设计模式—享元模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488879&idx=1&sn=2cb5edc9bbb088fd6de2bf9d46cb76cf&chksm=cf8466aaf8f3efbce988a6bf96035714e5125ba8ddc6cfe02871ca73e61c814271608576ff13#rd)
+
+
+### :eyes: 大数据 ###
+
+- [Spark入门指南:从基础概念到实践应用全解析](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487398&idx=1&sn=077859e1109e07b1469d242ec2b8091a&chksm=cf847c63f8f3f575e50012ef3667d9724998f07e32ebd27b6e3a37c5bdf2251d02e89030cff0#rd)
+
+- [HBase入门指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487105&idx=1&sn=2ee82c9b239aa502bd3dffcf320b3f93&chksm=cf847d44f8f3f452e1b8ac83b9f62f380e349615b67da92343539d4014077c2ad9e787e256cc#rd)
+
+- [全网最详细4W字Flink全面解析与实践(上)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487459&idx=1&sn=a1826b2d592fff29b5e11a374468796a&chksm=cf847c26f8f3f53073cc24584264fa2752a26c98bbd31c86bcf519296789eff05d72904d27ac#rd)
+
+- [全网最详细4W字Flink全面解析与实践(下)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487535&idx=1&sn=736f1adda56cc550191f17e7111598b5&chksm=cf8463eaf8f3eafc38819e342705df1884683e03d5d39e9df876834ab0a84f61cc55923a5a03#rd)
+
+### :watch:AI
+
+- [深度解析Skills:从Prompt到能力复用的技术革命](https://mp.weixin.qq.com/s/Se6_L1PbhlEUGaBSY8sZsQ)
+- [为什么ChatGPT能听懂你说的话?Embedding技术揭秘](https://mp.weixin.qq.com/s/CoHcpXIaamdfmXCf-3qlgw)
+- [RAG详解:让大模型看见你的私有知识](https://mp.weixin.qq.com/s/mAC3DeqPLM41LyfGh2QjUw)
+- ReAct:让大模型学会边想边做
+- 10分钟掌握 JSON-RPC 协议,面试加分、设计不踩坑
+
+
+### :jack_o_lantern: 其他 ###
+- [良心推荐!几款收藏的神级IDEA插件分享](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488457&idx=1&sn=f771ccebb84f226e7302b89caa5c056b&chksm=cf84600cf8f3e91aab4564d91feacb8822b53a2b3a79547439d64d2c0b7b293435a1ae79f994#rd)
+- [实战Arthas:常见命令与最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488559&idx=1&sn=4b5003cb33446ab4a6173285fe9d83d3&chksm=cf8467eaf8f3eefc033de8f63cba9f0d7b2b5eb0ccfb5209f458a9ab447367b34954f296638b#rd)
+- [Maven实战](https://mp.weixin.qq.com/s/ErtWrRNzjJcR2ettUhAxsQ)
+- [不用Mockito写单元测试?你可能在浪费一半时间](https://mp.weixin.qq.com/s/NICubD9Yq0pn6qwpVIznfg)
+- [用好PowerMock,轻松搞定那些让你头疼的单元测试](https://mp.weixin.qq.com/s/rWIjqJKBQOe72RWW6qyJmA)
### :bulb: 资源 ###
diff --git a/docs/.DS_Store b/docs/.DS_Store
new file mode 100644
index 0000000..1b0a35f
Binary files /dev/null and b/docs/.DS_Store differ
diff --git a/docs/md/.DS_Store b/docs/md/.DS_Store
new file mode 100644
index 0000000..e79a8fe
Binary files /dev/null and b/docs/md/.DS_Store differ
diff --git "a/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md" "b/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md"
new file mode 100644
index 0000000..f4328dd
--- /dev/null
+++ "b/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md"
@@ -0,0 +1,291 @@
+分布式系统中,不同服务之间需要一种可靠的方式来通信。远程过程调用(RPC)是一种常见的选择,而 **JSON-RPC** 是其中比较简单的一种。
+
+这篇文章介绍 JSON-RPC 2.0 协议的核心内容,包括消息格式、错误处理和实际应用场景。
+
+## JSON-RPC 概述
+
+### 什么是 JSON-RPC
+
+JSON-RPC 是一种无状态、轻量级的远程过程调用协议,使用 JSON 作为数据格式。它的设计目标就是简单——协议规范只有几页文档。
+
+JSON 作为数据交换格式,几乎所有主流编程语言都有良好的支持,包括 JavaScript、Python、Java、C#、Go 等。这使得 JSON-RPC 能够轻松实现跨语言调用。
+
+协议本身不绑定传输层,可以跑在 HTTP、WebSocket、TCP Socket 等各种消息传输环境上。开发者可以根据业务需求选择合适的传输方式。
+
+### JSON-RPC 的发展历程
+
+JSON-RPC 有两个主要版本:1.0 和 2.0。
+
+1.0 版本最早提出了基于 JSON 的 RPC 概念,但在规范性方面有所欠缺。2010 年发布的 2.0 版本做了重要升级,加入了批量调用支持、统一的错误对象结构。两个版本通过 `jsonrpc` 字段来区分。
+
+### JSON-RPC 的核心特点
+
+JSON-RPC 有几个值得注意的特点:
+
+- **简洁性**:规范文档很短,请求和响应结构清晰明了。
+- **跨语言支持**:任何能解析 JSON 的语言都可以实现 JSON-RPC 客户端或服务端。
+- **无状态设计**:每个请求独立,协议不维护会话状态。这种设计简化了服务端的实现,也更容易水平扩展。
+- **批量处理能力**:2.0 版本支持在单个请求中包含多个 RPC 调用,服务端返回结果数组。
+- **双向通信**:通过长连接和通知机制,JSON-RPC 也支持服务端主动向客户端推送消息。
+
+## 协议规范详解
+
+### 协议约定与术语
+
+JSON-RPC 规范中使用了 RFC 2119 定义的关键字:MUST、MUST NOT、SHOULD、SHOULD NOT、MAY。这些术语描述了实现者必须、应该或可以遵循的行为规范。
+
+**客户端(Client)**:发起请求的实体,负责构造请求对象并处理响应。
+
+**服务端(Server)**:接收请求并返回响应的实体,处理请求并生成响应。
+
+同一个实现可以同时扮演客户端和服务端。比如在对等网络中,两个节点可能既向对方发起请求,也响应来自对方的请求。
+
+### 数据类型系统
+
+JSON-RPC 继承自 JSON 的类型系统,包含六种数据类型:
+
+基本类型:String(字符串)、Number(数值)、Boolean(布尔值)、Null(空值)
+
+结构化类型:Object(对象)、Array(数组)
+
+这些类型名称首字母必须大写,包括 True 和 False。
+
+成员名称(字段名)在客户端与服务端之间交换时必须区分大小写。函数、方法、过程这三个术语可以互换使用,都指向可以被调用的可执行单元。
+
+## 消息格式深度解析
+
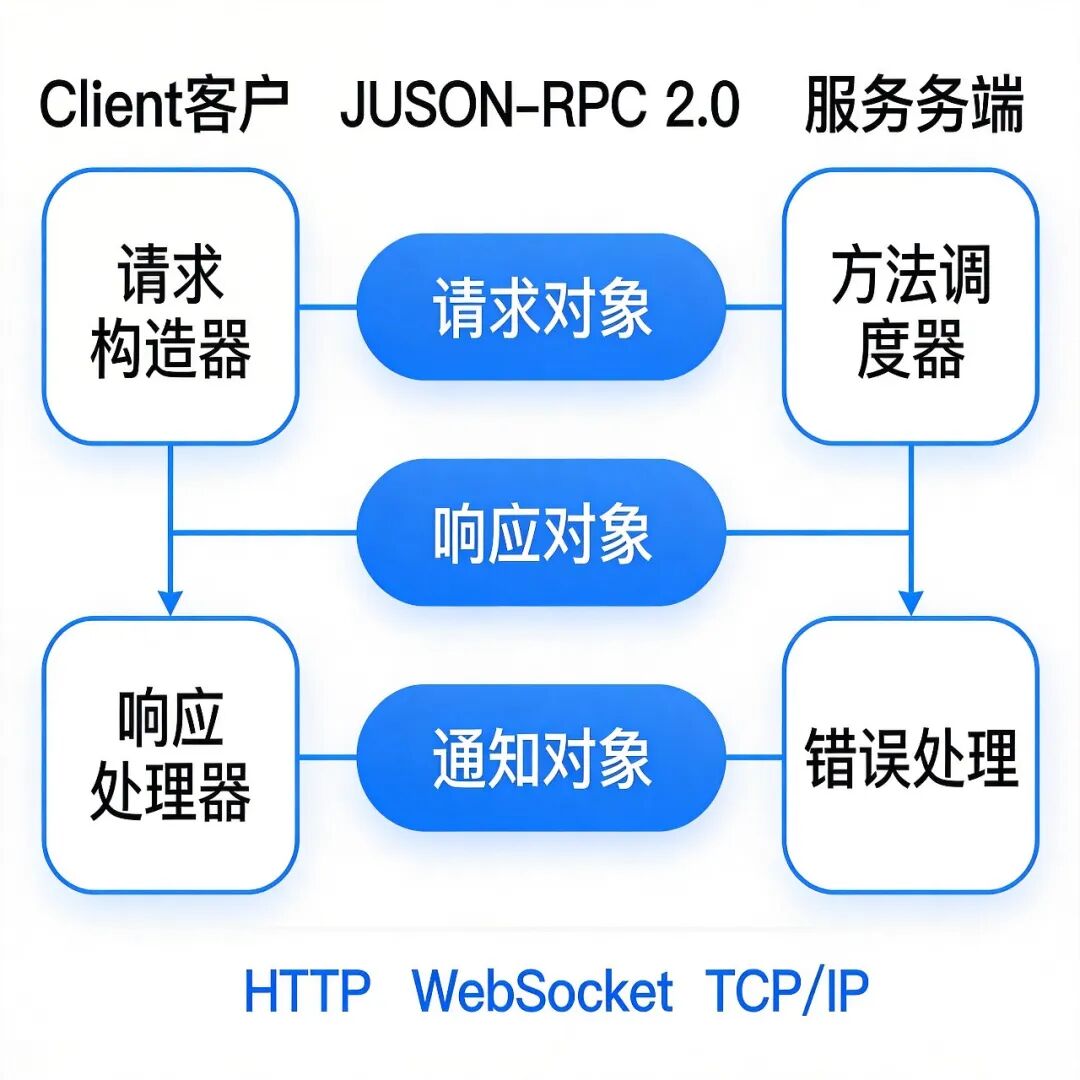
+JSON-RPC 2.0 定义了三种核心消息类型:**请求对象(Request Object)**、**响应对象(Response Object)** 和 **通知对象(Notification Object)**。
+
+
+
+### 请求对象结构
+
+请求对象是客户端向服务端发起 RPC 调用的载体:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "subtract",
+ "params": [42, 23],
+ "id": 1
+}
+```
+
+- **jsonrpc 字段**:协议版本标识,值必须是字符串 "2.0"。
+- **method 字段**:要调用的方法名称,区分大小写。以 "rpc." 开头的方法名预留给 JSON-RPC 内部扩展,如 `rpc.subscribe`、`rpc.notify`。
+- **params 字段**:方法参数,可以是数组(按顺序)或对象(按名称)。参数可选,不需要时可以省略。
+
+```json
+// 索引数组参数:参数顺序与服务端预期一致
+{"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": 1}
+
+// 命名对象参数:参数名需与服务端方法签名匹配
+{"jsonrpc": "2.0", "method": "subtract", "params": {"minuend": 42, "subtrahend": 23}, "id": 2}
+```
+
+- **id 字段**:客户端生成的唯一标识符,用于关联请求和响应。id 可以是字符串、数值或 null。建议避免使用 null,因为 JSON-RPC 1.0 的通知机制使用 null,可能引起混淆。使用数值作为 id 时,应避免小数。
+
+### 响应对象结构
+
+响应对象是服务端返回给客户端的执行结果:
+
+```json
+// 成功响应
+{
+ "jsonrpc": "2.0",
+ "result": 19,
+ "id": 1
+}
+
+// 错误响应
+{
+ "jsonrpc": "2.0",
+ "error": {
+ "code": -32601,
+ "message": "Method not found",
+ "data": "详细错误信息"
+ },
+ "id": 1
+}
+```
+
+响应对象必须包含 `result` 或 `error` 之一,不能同时包含两者。`id` 必须与对应请求中的 id 保持一致。
+
+如果请求本身存在错误(如无效的 JSON 格式或非法请求结构),导致服务端无法确定原始 id 时,响应中的 id 必须为 null。
+
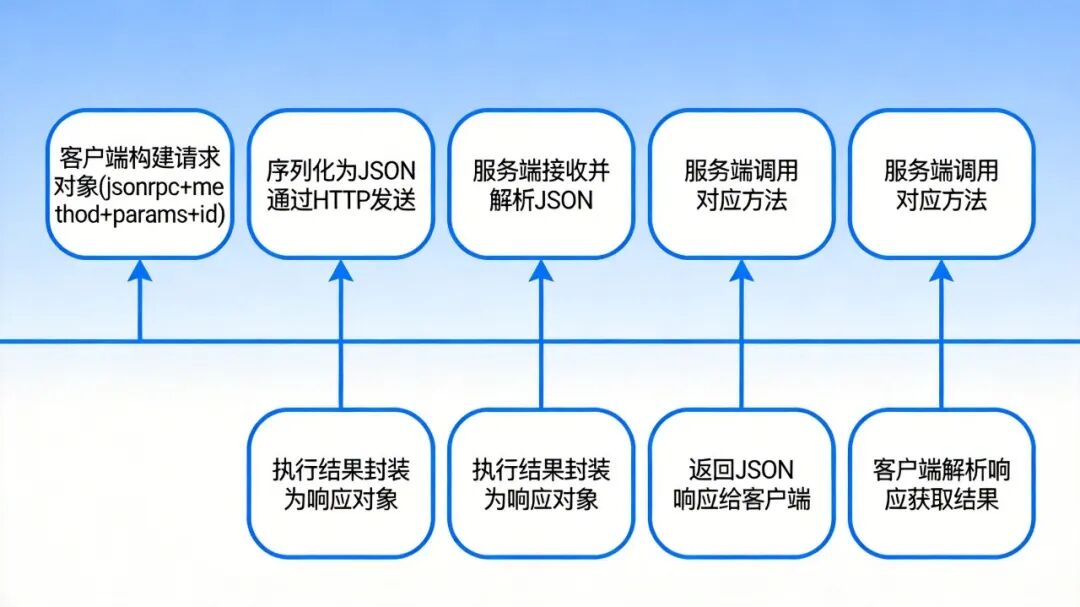
+### 通知机制
+
+通知是一种不需要响应的请求,通过省略 `id` 字段来标识:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "update",
+ "params": [1, 2, 3, 4, 5]
+}
+```
+
+通知适用于日志记录、事件发布、进度通知等场景。客户端只负责发送消息,不需要处理响应。
+
+由于没有响应机制,客户端无法得知通知是否被成功处理。在批量请求中,通知请求不会产生对应的响应。
+
+
+
+## 错误处理机制
+
+### 错误对象结构
+
+JSON-RPC 2.0 定义了标准化的错误对象:
+
+```json
+{
+ "code": -32603,
+ "message": "Internal error",
+ "data": { "details": "数据库连接失败" }
+}
+```
+
+- **code 字段**:整数错误码,标识错误类型。
+- **message 字段**:简短的人类可读错误描述,通常是一句话。
+- **data 字段**:可选,携带错误的附加信息,可以是字符串、对象或任何有效的 JSON 值。
+
+### 预定义错误码
+
+JSON-RPC 2.0 在 -32768 到 -32000 范围内预留了预定义错误码:
+
+| 错误码 | 名称 | 说明 |
+|--------|------|------|
+| -32700 | Parse Error | 解析错误,服务端收到的 JSON 格式无效 |
+| -32600 | Invalid Request | 无效请求,发送的不是有效的请求对象 |
+| -32601 | Method Not Found | 方法不存在或不可调用 |
+| -32602 | Invalid Params | 参数无效 |
+| -32603 | Internal Error | JSON-RPC 内部错误 |
+
+
+
+-32000 到 -32099 范围内的错误码保留给服务端自定义使用。应用程序也可以定义自己的错误码(通常为负数且绝对值小于 32767)。
+
+### 错误处理建议
+
+- **合理使用 data 字段**:code 和 message 提供错误的基本分类,data 可以包含调试信息、堆栈跟踪或业务相关的详细信息。生产环境中注意控制敏感信息暴露。
+- **统一错误处理中间件**:在服务端统一拦截和处理错误,将业务异常转换为标准化的 JSON-RPC 错误格式,避免暴露内部实现细节。
+- **区分错误类型**:某些错误(如参数校验失败)是客户端问题,可以提示用户修正;另一些错误(如数据库故障)需要服务端介入处理。
+
+## 批量调用与性能优化
+
+### 批量请求机制
+
+JSON-RPC 2.0 支持在单个请求中发送多个 RPC 调用,服务端返回相应的响应数组。这一机制在高并发场景下可以减少网络往返次数。
+
+```json
+// 批量请求
+[
+ {"jsonrpc": "2.0", "method": "sum", "params": [1, 2, 4], "id": "1"},
+ {"jsonrpc": "2.0", "method": "notify_hello", "params": [7]},
+ {"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": "2"},
+ {"jsonrpc": "2.0", "method": "get_data", "id": "9"}
+]
+```
+
+对应的批量响应:
+
+```json
+[
+ {"jsonrpc": "2.0", "result": 7, "id": "1"},
+ {"jsonrpc": "2.0", "result": 19, "id": "2"},
+ {"jsonrpc": "2.0", "result": ["hello", 5], "id": "9"}
+]
+```
+
+通知请求(没有 id 字段)不会产生响应。响应数组中各元素的顺序与请求顺序无关,客户端通过匹配 id 来关联请求和响应。
+
+### 批量调用的边界情况
+
+规范对批量调用中的边界情况有明确定义:
+
+如果批量请求本身不是有效的 JSON 或不是包含至少一个值的数组,服务端应返回单对象响应而非数组。空数组 `[]` 被视为无效请求。
+
+如果批量请求中的所有请求都是通知,服务端不需要返回任何响应。其他情况下,即使某些请求处理失败,响应数组中仍应包含对应请求的错误响应。
+
+### 性能优化策略
+
+- **连接复用**:使用持久化连接(如 HTTP Keep-Alive 或 WebSocket)可以避免频繁建立和销毁连接的开销。
+- **批量聚合**:将多个相关的小请求合并为一个批量请求,减少网络往返次数。
+- **压缩传输**:启用 HTTP 压缩(如 gzip)可以减少大型 JSON 响应体的传输体积。
+- **异步处理**:使用异步调用和通知机制,提高客户端的并发处理能力。
+
+## 与 RESTful API 的对比分析
+
+### 设计理念差异
+
+JSON-RPC 和 RESTful 代表了两种不同的 API 设计哲学。JSON-RPC 是过程导向的,关注的是"做什么操作";RESTful 是资源导向的,关注的是"操作什么资源"。
+
+以用户操作为例:
+
+```json
+// JSON-RPC: 直接调用方法
+{"jsonrpc": "2.0", "method": "createUser", "params": {"name": "张三", "email": "zhang@example.com"}, "id": 1}
+
+// RESTful: 操作资源
+POST /users
+{"name": "张三", "email": "zhang@example.com"}
+```
+
+### 通信模式对比
+
+| 维度 | JSON-RPC | RESTful |
+|------|----------|---------|
+| 语义抽象 | 方法调用 | 资源操作 |
+| URL 角色 | 仅作为端点地址 | 表示资源路径 |
+| HTTP 方法 | 仅使用 POST | 充分利用 GET/POST/PUT/DELETE |
+| 状态管理 | 可维护会话状态 | 倡导无状态设计 |
+| 灵活性 | 更紧凑,适合精确控制 | 更灵活,适合通用场景 |
+
+
+
+### 选型建议
+
+**适合使用 JSON-RPC 的场景**:
+
+- 内部服务间通信,接口相对稳定
+- 需要精确的方法语义和参数控制
+- 对带宽敏感,需要紧凑的消息格式
+- 团队对 RPC 模式更熟悉
+
+**适合使用 RESTful 的场景**:
+
+- 公开 API,需要良好的可发现性
+- 资源概念明确的 CRUD 操作
+- 需要利用 HTTP 缓存机制
+- 追求 API 的自我描述能力
+
+## 安全性考量
+
+### 常见安全威胁
+
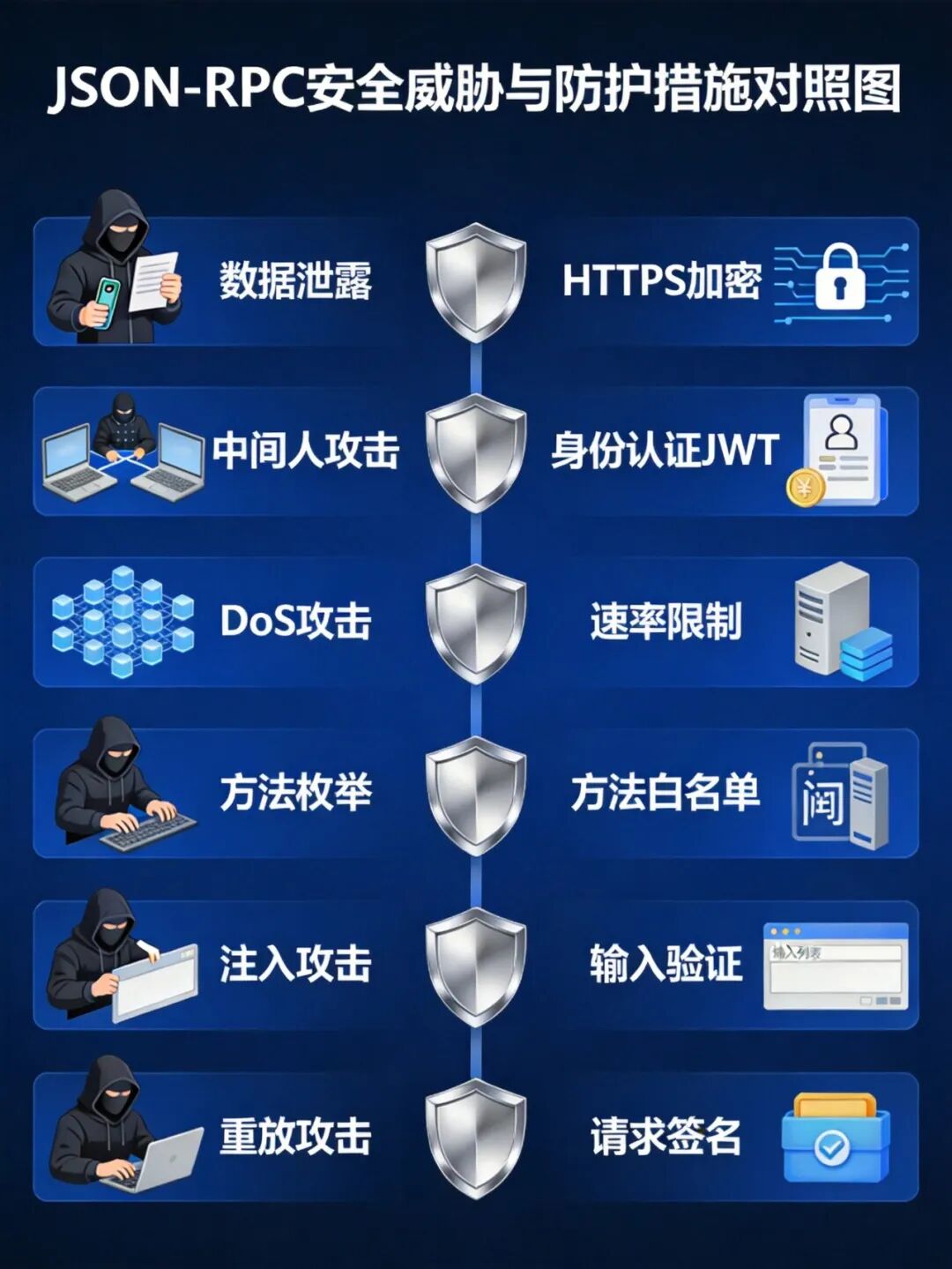
+JSON-RPC 的简洁设计虽然降低了实现复杂度,但也带来了一些安全考量:
+
+- **数据泄露**:JSON-RPC 通常通过 HTTP 传输,未加密的通信可能被中间人攻击截获。
+- **方法枚举**:如果服务端没有正确限制可调用方法,攻击者可能通过枚举方法名发现未公开的接口。
+- **拒绝服务**:恶意客户端可能发送大量请求或构造超大的批量请求,耗尽服务端资源。
+- **注入攻击**:不安全的参数处理可能导致 SQL 注入、命令注入等安全漏洞。
+- **重放攻击**:截获的有效请求可能被攻击者重放,造成非预期的重复操作。
+
+
+
+### 安全加固措施
+
+- **传输层加密**:使用 HTTPS 协议,确保通信内容的机密性和完整性。
+- **身份认证与授权**:实现身份验证机制(如 JWT、OAuth 2.0),在方法层面实施细粒度的授权控制。
+- **输入验证**:对所有参数进行严格的类型检查和值域验证。
+- **速率限制**:实施请求速率限制,防止恶意高频访问。
+- **方法白名单**:仅暴露必要的方法,对未公开的方法返回 -32601 错误。
+- **日志与监控**:记录详细的请求日志,监控异常模式,及时发现潜在攻击。
+
+## 结语
+
+JSON-RPC 2.0 协议设计简洁,在分布式系统通信中有其适用场景。规范本身很短,学习和实现成本都不高,JSON 格式的请求/响应便于调试和日志记录。
+
+当然,JSON-RPC 也有局限性。它缺少内置的元数据机制,类型系统相对简单。在需要高度标准化、复杂类型系统或强类型安全的场景中,可以考虑 gRPC、Thrift 等方案。
+
+如果你的业务场景需要简单、透明的服务间通信方式,JSON-RPC 是一个值得考虑的选择。
diff --git "a/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md" "b/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md"
new file mode 100644
index 0000000..2204101
--- /dev/null
+++ "b/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md"
@@ -0,0 +1,223 @@
+在把大语言模型用到实际业务时,开发者很快会遇到一个问题:通用模型很难满足特定场景的需求。
+
+主要卡在三个地方:
+
+- **知识过时**:模型的训练数据有截止日期,问它最近发生的事基本白问。
+
+- **幻觉严重**:模型经常一本正经地胡说八道,在需要准确性的场景这是致命的。
+
+- **数据安全**:企业不可能把内部文档上传给第三方,但不上传模型又不会。
+
+
+
+基于这个问题,**RAG(检索增强生成)** 出现了。它的思路很简单:不把数据交给模型,而是让模型"看到"它需要的部分。
+
+用户提问时,系统从私有知识库中检索相关片段,把这些片段和问题一起发给大模型。模型结合真实信息来回答,而不是靠"记忆"里不知道哪来的东西生成。
+
+## 为什么需要 RAG
+
+### 知识的局限性
+
+大语言模型的知识完全来自训练数据。GPT-4、文心一言、通义千问这些主流模型,训练数据主要来自网络公开数据。这带来两个问题:
+
+- **时效性**:模型的"知识"被定格在训练截止时间点。GPT-4 的知识库可能停在 2023 年 12 月,之后的新事件、新政策、新技术,它无法直接给出准确答案。
+- **私有领域缺失**:企业的产品规格文档、内部流程规范、医疗机构的诊断指南、法律机构的判例汇编——这些数据从没出现在公开网络上,通用大模型对此一无所知。不借助外部手段,模型在这些领域的回答质量会大打折扣。
+
+### 幻觉问题
+
+大语言模型在生成文本时,实际上是在计算下一个 token 出现的概率分布。这种机制导致模型在面对不确定性问题时,经常编造看似合理实则错误的答案——学名叫"幻觉"(Hallucination)。
+
+更麻烦的是,模型不具备某一方面知识时,它不会选择"不知道",而是倾向于根据训练数据中学习到的语言模式,自信满满地瞎编。在需要高度准确性的生产环境中,这绝对不可接受。
+
+### 数据安全
+
+对企业来说,数据安全是生死攸关的议题。没人愿意承担核心商业机密泄露的风险,因此几乎没有企业愿意将私有数据上传到第三方平台进行模型训练或推理。
+
+这意味着,完全依赖通用大模型自身能力的应用方案,不得不在**数据安全**和**应用效果**之间做取舍。传统方案要么保数据安全牺牲模型能力,要么提升模型能力却承担数据泄露风险。
+
+## RAG 的破局思路
+
+RAG 提供了第三条路:不把数据交给模型,而是让模型"看到"它需要的那部分数据。
+
+用户提问时,系统从私有知识库中检索相关片段,把这些片段作为上下文提供给大模型。大模型在回答时,既能"参考"检索到的真实信息,又能结合自身的语言理解能力生成流畅的回答。数据始终留在本地,模型获得了"感知"私有知识的能力。
+
+## RAG 的技术架构
+
+RAG 的完整工作流程分为两个阶段:**数据准备阶段(离线索引)** 和 **应用阶段(在线推理)**。
+
+
+
+### 数据准备阶段:构建知识的向量化索引
+
+数据准备是离线过程,目标是将私有数据转化为可高效检索的向量形式。流程包含四个环节:
+
+**数据提取**。从多种格式的原始文件中提取纯文本内容,包括 PDF、Word、HTML、数据库记录等。技术挑战在于处理各种格式解析、特殊字符清理、无用内容过滤。常用 LangChain 的 DocumentLoaders 来统一处理不同来源的数据。
+
+**文本分割(Chunking)**。直接影响检索质量。需要综合考虑两个因素:一是 embedding 模型对 token 长度的限制;二是语义完整性对检索效果的影响。
+
+固定长度分割实现简单,但容易切断语义边界,导致检索时丢失关键上下文。语义分割通过识别句子边界或段落结构来进行切分,能更好地保留语义完整性,但实现复杂度更高。业界常用策略是设置合适的 chunk size(如 512 tokens)和 overlap(如 50-100 tokens),在保证语义完整性的同时避免边界效应。
+
+**向量化(Embedding)**。将文本转化为高维向量,让语义相似的文本在向量空间中具有相近的位置关系。常见的 embedding 模型:
+
+| 模型名称 | 特点 | 适用场景 |
+|---------|------|---------|
+| OpenAI text-embedding-3 | API 调用,稳定可靠 | 通用场景 |
+| BGE (BAAI) | 开源、支持中英文 | 自部署场景 |
+| M3E (MokaAI) | 开源、多语言支持 | 中文场景 |
+| ERNIE-Embedding | 百度自研、中文优化 | 国产化需求 |
+
+**数据入库**。将向量及其关联的原始文本、元数据写入向量数据库。主流选择包括 FAISS、Chroma、Milvus、Weaviate 和 Qdrant 等。这些数据库采用近似最近邻(ANN)算法,能够在海量向量中快速找到与查询向量最相似的结果。
+
+### 应用阶段
+
+
+
+用户提出问题时,RAG 系统进入在线推理阶段,包含四个关键步骤:
+
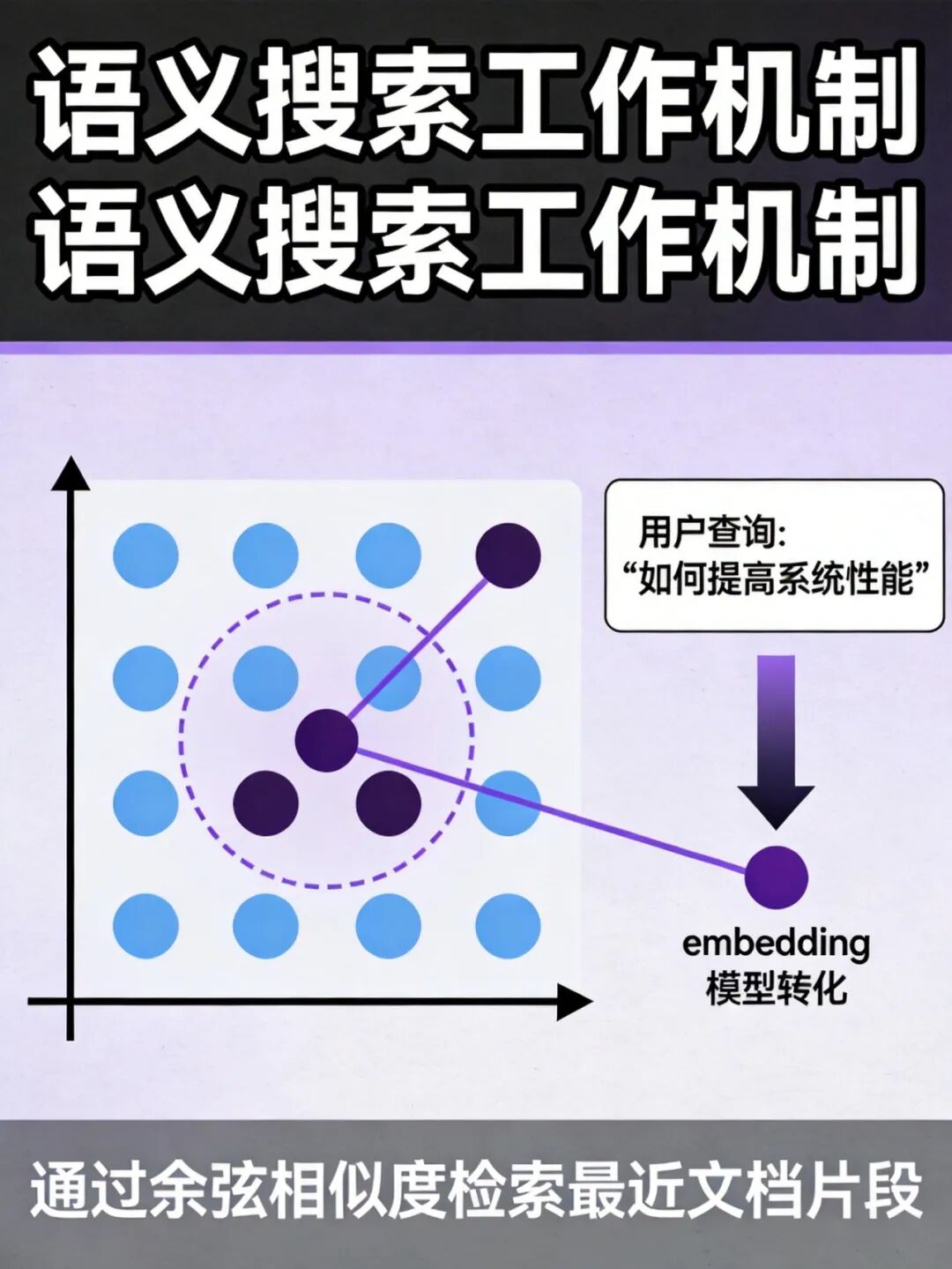
+**查询向量化**。使用与索引阶段相同的 embedding 模型,将用户的自然语言问题转化为语义向量。这个向量的质量直接决定后续检索的准确性。
+
+**信息检索(Retrieval)**。通过计算查询向量与所有存储向量的相似度(如余弦相似度、欧氏距离),找出 top-k 个最相关的文档片段。现代向量数据库通常采用 HNSW(Hierarchical Navigable Small World)等算法,在保证检索精度的同时实现毫秒级响应。
+
+**上下文构建**。将检索到的相关片段与原始问题组装成完整的提示模板。一个典型的 RAG 提示模板:
+
+```
+【任务描述】
+假如你是一个专业的客服机器人,请参考【背景知识】中的内容,准确回答用户的问题。
+
+【背景知识】
+{检索到的相关文档片段}
+
+【用户问题】
+{用户原始问题}
+
+【回答要求】
+- 仅根据【背景知识】中的内容回答
+- 如果【背景知识】中没有相关信息,请明确告知
+- 回答要简洁、准确、有条理
+```
+
+**答案生成(Generation)**。大语言模型接收包含问题和上下文的提示后,结合检索到的真实信息生成最终答案。由于有明确的参考资料作为约束,模型产生幻觉的概率大大降低。
+
+## 高级 RAG 技术
+
+基础 RAG 流程能工作,但在实际应用中往往面临检索质量不足、生成效果不稳定等问题。业界发展出一系列高级 RAG 技术来优化系统性能。
+
+
+
+### 搜索索引的演进
+
+**平面索引(Flat Index)** 直接计算查询向量与所有存储向量的相似度。实现简单,但数据规模达到数万条时,线性扫描的计算开销变得不可接受。
+
+**向量索引** 采用近似最近邻算法来解决效率问题。FAISS 库提供了多种索引类型:
+
+- **IVF(Inverted File Index)**:通过聚类将向量分组,检索时只搜索最相关的聚类中心,显著减少计算量。
+- **HNSW(Hierarchical Navigable Small World)**:构建多层图结构,实现对数级别的检索复杂度。
+- **PQ(Product Quantization)**:对高维向量进行压缩,大幅降低内存占用。
+
+**分层索引** 应对大型知识库。系统维护两个层级的索引:一个由文档摘要组成,用于快速过滤;另一个由文档块组成,用于精确检索。这种设计在保证检索召回率的同时,大幅提升检索效率。
+
+### 混合搜索
+
+单纯的向量检索在处理精确术语匹配时往往表现不佳。比如用户搜索"如何重置密码",向量检索可能无法准确识别"重置"和"修改"之间的细微差别。
+
+**混合搜索** 结合传统关键词检索(如 BM25、TF-IDF)和现代语义向量检索。两种检索结果通过 **Reciprocal Rank Fusion(RRF)算法** 进行融合:对不同检索方法的结果按排名赋分,综合排名最高的文档被选中。
+
+关键词检索确保精确匹配的召回,语义检索捕捉同义词和语义关联。两者互补,能够应对更广泛的查询类型。
+
+### 内容增强
+
+**语句窗口检索器(Sentence Window Retriever)** 采用"小块索引、大窗口上下文"的策略。文档中的每个句子单独嵌入向量索引以保证检索精度,但检索后扩展上下文窗口,额外获取前后各 k 个句子,提供更完整的语义信息给大模型。
+
+**自动合并检索器(Parent Document Retriever)** 采用层级分割策略:文档被递归分割为较小的子块,每个子块与较大的父块存在引用关系。检索时获取相关子块,当多个相关子块指向同一父块时,自动升级为使用父块作为上下文。这种设计让系统同时获得精确检索和宏观语义。
+
+### HyDE:假设性答案增强检索
+
+**HyDE(Hypothetical Document Embeddings)** 是一种逆向思维的方法:不直接用问题检索,而是先用大模型根据问题生成一个假设性的答案,然后用这个假设答案去检索相关文档。
+
+前提假设是:假设答案与真实文档在语义空间中可能更接近,因为两者都是"回答性"的文本。HyDE 在处理抽象概念或模糊查询时表现尤为出色。
+
+### 查询转换
+
+用户的原始问题往往不够"检索友好"。**查询转换** 系列技术利用大模型的推理能力来优化查询:
+
+**查询分解(Query Decomposition)** 将复杂问题拆分为多个简单子问题。例如,"LangChain 和 LlamaIndex 哪个更适合做 RAG 开发?"这个问题难以直接检索,但可以拆分为"LangChain 做 RAG 开发的优缺点"和"LlamaIndex 做 RAG 开发的优缺点"两个子问题,分别检索后再综合回答。
+
+**Step-back Prompting** 生成更通用的查询来获取高层次上下文,与原始查询的检索结果一起输入模型,实现"由面到点"的推理。
+
+**查询重写(Query Rewriting)** 使用大模型改写问题表达,尝试用不同的表述方式检索,提高召回率。
+
+### 重排与过滤
+
+检索返回的 top-k 结果可能存在质量问题:相关性参差不齐、信息冗余、噪声干扰。**重排(Reranking)** 技术应运而生。
+
+**交叉编码器重排** 将查询和每个候选文档一起输入专门的交叉编码模型,输出精细化的相关性评分。这种方法比向量相似度计算更准确,但计算开销更大,通常用于对初始检索结果的二次筛选。
+
+**基于元数据的过滤** 利用文档的元数据(时间、来源、类别等)进行条件筛选,快速排除不相关的结果。
+
+## RAG 融合
+
+**RAG 融合(RAG Fusion)** 通过 LLM 生成多个变体查询来增强检索效果。单一查询可能无法覆盖用户问题的所有方面,通过让 LLM 生成多个不同角度的查询,可以从知识库中召回更丰富、更多样化的相关信息。
+
+
+
+### 技术流程
+
+1. **多查询生成**:使用 LLM 根据用户原始问题生成 n 个相关查询。
+2. **并行向量搜索**:用所有生成的查询分别进行向量检索。
+3. **结果融合排序**:应用 RRF 算法对所有检索结果进行综合排名。
+4. **上下文注入**:将融合后的相关文档注入提示模板。
+5. **答案生成**:LLM 基于融合后的上下文生成最终答案。
+
+### 优势
+
+**多样性增强**:不同查询从不同角度切入问题,最终结果涵盖更广泛的视角,减少单一视角带来的偏差。
+
+**鲁棒性提升**:某个查询因表述偏差导致检索不佳时,其他查询可以弥补缺陷,提升整体系统的稳定性。
+
+**语义纠偏**:LLM 生成的查询往往是对原始问题的语义扩展,能够捕捉隐含的语义关联。
+
+### 注意事项
+
+**延迟增加**:额外的 LLM 调用会引入额外延迟,在延迟敏感的场景中需要权衡。
+
+**专业术语处理**:如果知识库包含大量内部术语或行话,LLM 可能因不了解这些术语而产生无关查询,此时需要针对性优化提示词。
+
+**成本考量**:额外的 LLM 调用意味着额外的 token 消耗,需要评估 ROI。
+
+## 评估体系
+
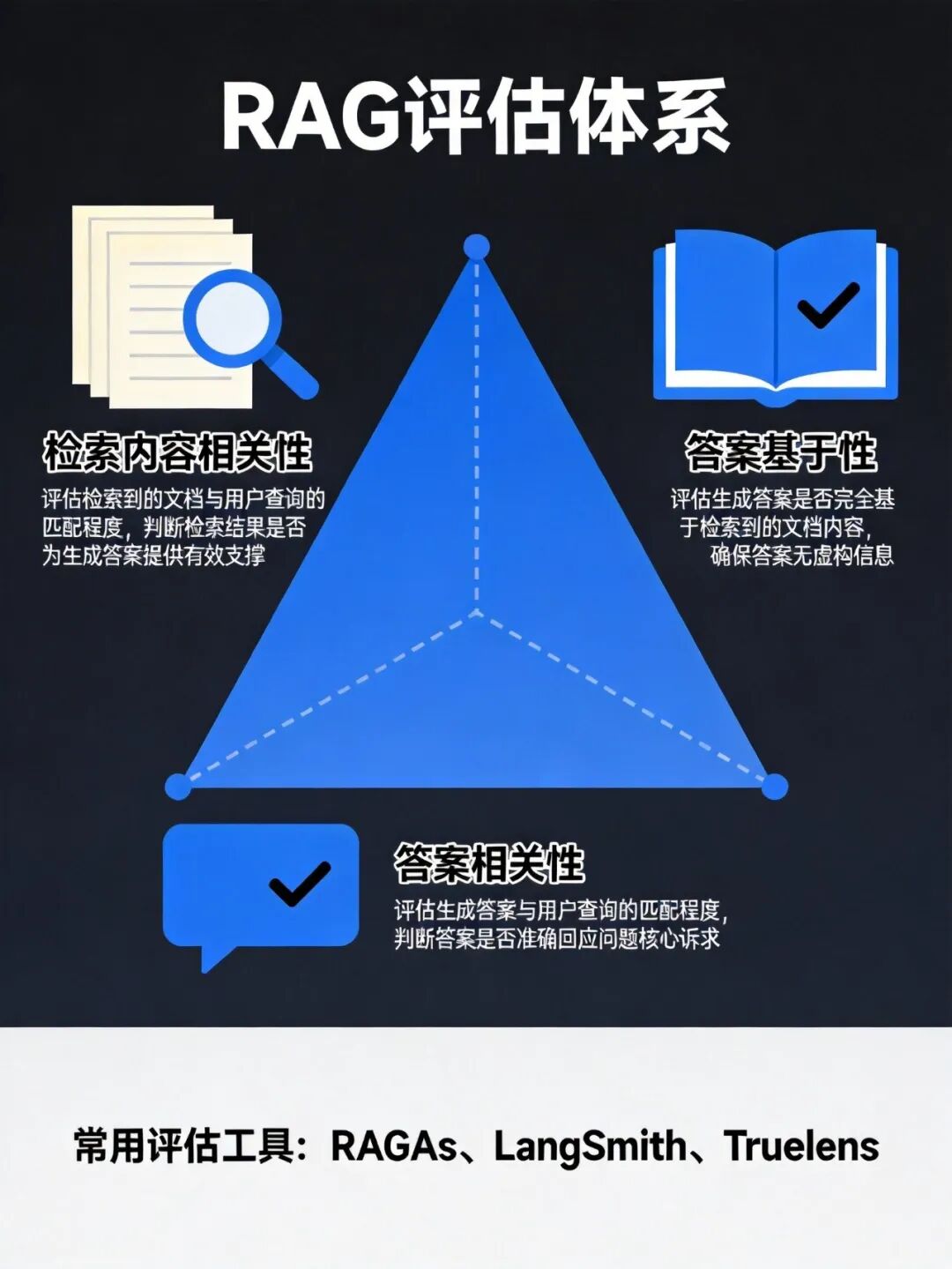
+RAG 系统的质量评估是工程实践中的重要环节。业界通常采用 **RAG 三元组** 评估框架:
+
+- 检索内容相关性(Context Relevance):评估检索到的文档与用户问题的相关程度。高相关性意味着检索阶段工作良好,能够召回真正有用的信息。常用指标包括召回率(Recall)和精确率(Precision)。
+- 答案基于性(Answer Groundedness):衡量 LLM 的回答是否基于检索到的上下文,而非依赖自身知识或产生幻觉。这一指标直接反映 RAG 机制的有效性。
+- 答案相关性(Answer Relevance):评估生成的回答是否有效解决了用户的问题。高相关性意味着即使检索和基于性都良好,最终答案也能真正满足用户需求。
+
+
+
+### 评估框架与工具
+
+**RAGAs** 是当前流行的 RAG 评估框架,提供标准化的评估流程和指标计算方法。
+
+**LangSmith** 是 LangChain 官方提供的评估平台,支持自定义评估器、运行时监控和调试追踪。
+
+**Truelens** 由 LlamaIndex 团队推出,专注于 RAG 系统的可观测性和评估。
+
+## 发展趋势
+
+RAG 技术正在快速演进,几个方向值得关注:
+
+**端到端优化**。传统 RAG 将检索和生成视为独立环节,但最新研究开始探索联合优化的可能性。Meta AI 提出的 **RA-DIT** 技术同时微调 LLM 和 Retriever,让两个组件在学习过程中相互适应,在知识密集型任务上取得了显著提升。
+
+**多模态 RAG**。随着多模态大模型的发展,RAG 的边界正在从纯文本扩展到图像、视频、音频等多种模态。未来的 RAG 系统需要能够处理跨模态的知识检索和生成。
+
+**主动学习与持续优化**。结合用户反馈和评估结果,构建自适应优化机制,让 RAG 系统能够从实际使用中持续学习和改进。
+
+**轻量化与边缘部署**。随着模型压缩技术的发展,更小、更快的 LLM 将成为 RAG 系统的新选择。Mistral Mixtral、Microsoft Phi-2 等小参数模型的崛起,为 RAG 在边缘设备上的部署开辟了新的可能性。
+
+## 结语
+
+RAG 技术通过将检索能力与大语言模型的生成能力相结合,为 LLM 的实际应用提供了一条切实可行的路。它解决了知识时效性、私有数据访问和幻觉抑制等核心问题。
+
+当然,RAG 不是万能药。检索质量、响应延迟、系统复杂度等挑战依然存在。开发者需要根据具体场景权衡利弊,选择合适的技术组合。
+
+至于未来会怎样,让时间来检验。
diff --git "a/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md" "b/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md"
new file mode 100644
index 0000000..d43addd
--- /dev/null
+++ "b/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md"
@@ -0,0 +1,286 @@
+传统聊天机器人相信大家都用过——你问一句,它答一句。线性,简单,但遇到复杂问题就露馅了。比如问"特斯拉股价相比去年涨了多少",它要么瞎编,要么说"我无法获取实时信息"。
+
+2022年,Google Research提出了ReAct框架。它要解决的就是这个问题:**让大模型像人一样,一边想一边做,做完再看结果,接着想下一步**。
+
+## ReAct的核心原理
+
+### 先看个例子
+
+想象你在一个陌生城市旅行。
+
+早上醒来,你想:今天天气怎么样?要不要带伞?
+
+你打开天气APP看了一眼——有阵雨。
+
+于是你调整计划:上午去博物馆躲雨,晚上再去看夜景。
+
+这个"想→做→看→再想"的过程,就是ReAct在做的事。
+
+### 三个阶段
+
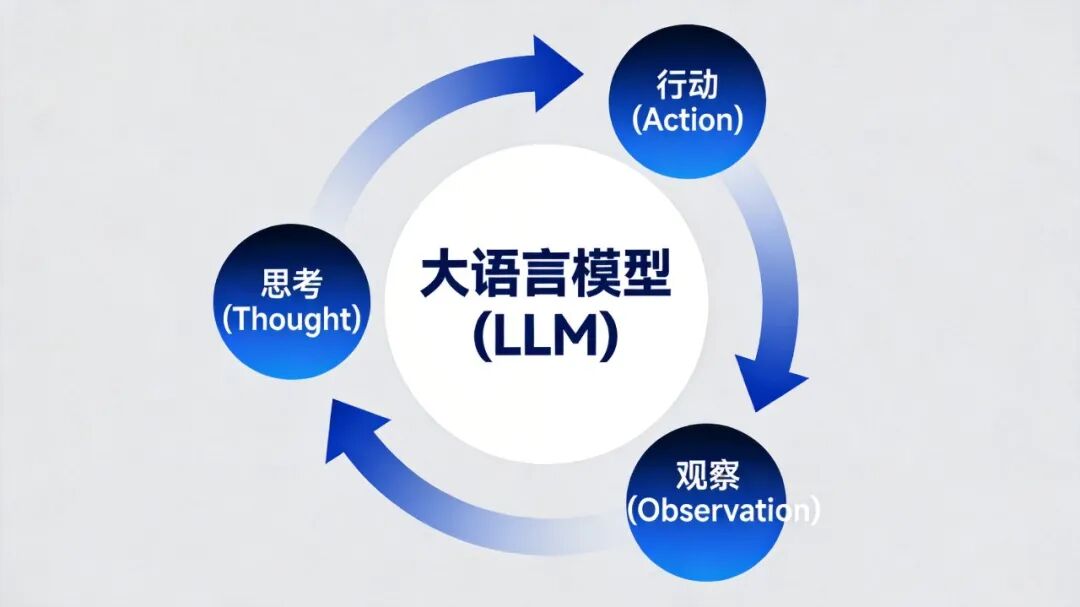
+ReAct由三个部分构成:
+
+**思考(Thought)**:分析当前问题,决定下一步做什么。比如"用户问的是某国人口,我需要查数据"。
+
+**行动(Action)**:调用外部工具。输出格式类似`search(query="某国人口")`。
+
+**观察(Observation)**:工具返回结果,成为下一轮思考的依据。比如`{"population": "1.4亿"}`。
+
+循环往复,直到任务完成。
+
+
+
+### 什么时候停下来
+
+两种方式:
+
+- **硬限制**:设个最大迭代数,比如`max_iterations=10`,到了就强制结束。
+- **条件触发**:模型觉得自己很有把握了,或者连续失败好几次,就主动收手。
+
+## 技术实现
+
+### 工具怎么设计
+
+三个原则:
+
+**原子性**:一个工具只做一件事。计算器就做计算,搜索就做搜索,别搞大而全。
+
+**强契约**:用JSON Schema定义清楚输入输出格式:
+
+```json
+{
+ "name": "get_weather",
+ "description": "查询指定城市的天气信息",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "location": {
+ "type": "string",
+ "description": "城市名称,如北京、上海"
+ }
+ },
+ "required": ["location"]
+ }
+}
+```
+
+**安全第一**:删数据、转账这类敏感操作必须有权限控制。
+
+### 提示词怎么写
+
+ReAct提示包含四个部分:
+
+- 要求模型展示思考过程。
+- 告诉它有哪些工具可以用。
+- 提示它在每个操作后重新评估。
+- 设定循环退出条件。
+
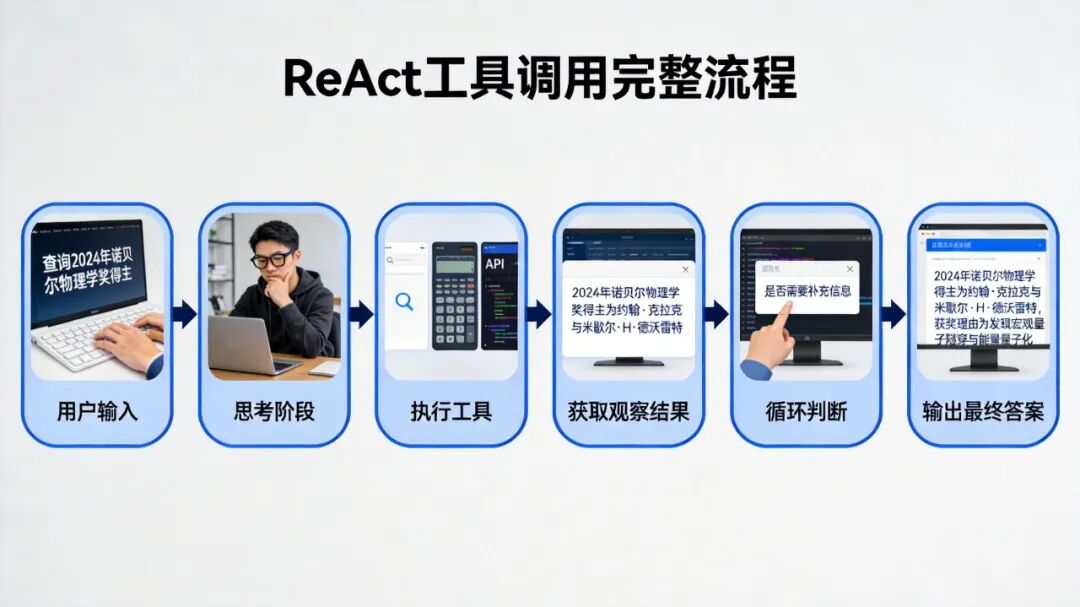
+### 从提示词到原生工具调用
+
+早期做法是在提示词里格式化输出:
+
+```
+思考:我需要查询北京的天气
+行动:get_weather(location="北京")
+观察:{"temperature": "25℃", "condition": "晴"}
+```
+
+问题很明显:模型可能"废话连篇",格式也可能乱套。
+
+后来有了**原生工具调用**,直接微调模型让它输出结构化JSON。稳定多了,还能并行执行多个工具。
+
+
+
+### 在Java中使用ReAct:LangChain4j示例
+
+如果你是Java开发者,可以用 LangChain4j 快速实现 ReAct。核心思路是:用 `@Tool` 注解定义工具,框架自动处理推理-行动-观察的循环。
+
+**第一步:定义工具**
+
+```java
+import dev.langchain4j.agent.tool.Tool;
+
+public class WeatherTools {
+
+ @Tool("获取指定城市的实时天气信息")
+ public String getWeather(String location) {
+ // 实际项目中调用天气API
+ return switch (location) {
+ case "北京" -> "晴天,15℃,空气质量良好";
+ case "上海" -> "多云,18℃,有轻度雾霾";
+ default -> "未找到该城市的天气信息";
+ };
+ }
+
+ @Tool("查询股票实时价格")
+ public String getStockPrice(String stockCode) {
+ // 实际项目中调用股票API
+ return "股票" + stockCode + "当前价格:168.5元,涨幅+2.3%";
+ }
+}
+```
+
+**第二步:创建助手接口**
+
+```java
+import dev.langchain4j.service.AiServices;
+
+public interface Assistant {
+ String chat(String userMessage);
+}
+```
+
+**第三步:构建并使用**
+
+```java
+import dev.langchain4j.model.openai.OpenAiChatModel;
+
+public class Main {
+ public static void main(String[] args) {
+ // 配置模型
+ OpenAiChatModel model = OpenAiChatModel.builder()
+ .apiKey("your-api-key")
+ .modelName("gpt-4")
+ .build();
+
+ // 构建助手,绑定工具
+ Assistant assistant = AiServices.builder(Assistant.class)
+ .chatLanguageModel(model)
+ .tools(new WeatherTools()) // 注册工具
+ .build();
+
+ // 提问——框架会自动执行ReAct循环
+ String answer = assistant.chat("北京今天天气怎么样?适合户外运动吗?");
+ System.out.println(answer);
+ }
+}
+```
+
+**运行时发生了什么?**
+
+当用户问"北京天气怎么样"时,LangChain4j 内部会:
+
+1. **思考**:模型分析问题,决定调用 `getWeather` 工具。
+2. **行动**:执行 `getWeather("北京")`。
+3. **观察**:得到 "晴天,15℃,空气质量良好"。
+4. **再思考**:模型结合天气数据,判断适合户外运动。
+5. **最终答案**:返回完整回答。
+
+整个过程对开发者透明,你只需定义工具,剩下的交给框架。
+
+**两种模式的区别**
+
+| 模式 | 适用场景 | 特点 |
+|-----|---------|------|
+| 函数调用(推荐) | OpenAI、Claude等支持工具调用的模型 | 稳定可靠,直接输出结构化调用 |
+| 文本解析 | 开源模型、不支持工具调用的模型 | 通过提示词让模型输出 `Action: xxx` 格式,再解析 |
+
+LangChain4j 会根据模型类型自动选择模式。如果你的模型支持函数调用,优先用这个——更稳定,不容易出错。
+
+## 为什么ReAct管用
+
+
+
+### 减少胡说八道
+
+假设用户问:"今天A股涨得最多的是哪只?"
+
+普通模型可能直接猜"茅台"——反正训练数据里有。
+
+ReAct模型会:
+1. 想到:我得查实时数据。
+2. 调用股票API。
+3. 看结果:涨最多的是XXX。
+4. 根据真实数据回答。
+
+不靠记忆,靠查证。
+
+### 出了问题能追溯
+
+用ReAct,系统可以展示完整的推理链条。客服答错了?直接看:它问了什么、查了什么、最后怎么答的。开发者定位问题快多了。
+
+传统模型只能两手一摊:"抱歉,我不知道为什么会那样。"
+
+### 能随机应变
+
+比如订餐场景:用户说"帮我订个餐厅,要近、评分高、适合商务"。
+
+ReAct会:
+1. 获取用户位置。
+2. 搜附近高评分餐厅。
+3. 筛选适合商务的。
+4. 发现首选满了,自动推荐备选。
+
+脚本做不到这种灵活调整——它只会报错或者返回固定结果。
+
+### 能组合多个工具
+
+写一份市场分析报告?ReAct可以协调搜索工具查数据、代码工具做分析、图表工具可视化、写作工具生成报告。模拟的是一个真实分析师的工作方式。
+
+## 工程实践
+
+
+
+### 避免死循环
+
+智能客服常见问题:用户问"客服电话多少",系统没有这个功能,模型就一直绕圈。
+
+解决办法:
+
+**硬限制**:
+
+```python
+max_iterations = 10
+for i in range(max_iterations):
+ # 执行循环
+ if i >= max_iterations:
+ return "处理超时,请稍后重试"
+```
+
+**循环检测**:同一个操作重复3次,直接判定无法回答,退出。
+
+**系统提示引导**:告诉模型"最多试3次,还是不行就说不知道"。
+
+### 上下文管理
+
+长对话容易爆窗口。比如分析50份简历,每份都查背景信息,上下文直接撑满。
+
+处理方式:
+
+**截断**:只保留最近10轮对话,早期内容丢掉。
+
+**摘要**:把前面的分析压缩成一句话,比如"20份简历分析完成,12份通过初筛"。只留结论,不留过程。
+
+省Token,效果差不多。
+
+### 并行调用
+
+问:"对比北京、上海、深圳国庆期间的天气和机票价格。"
+
+串行做法:查北京天气→等,查上海天气→等,查深圳天气→等,查北京机票→等……6次等待。
+
+并行做法:三个城市天气一起查,三张机票一起查。2次等待搞定。
+
+性能差距明显。
+
+### 错误处理
+
+订机票时支付API返回"网络超时",怎么办?
+
+**分级处理**:
+- 网络超时:等1秒重试,最多3次
+- API限流:换备用支付渠道
+- 余额不足:提示充值
+- 系统维护:告知稍后再试
+
+**回退机制**:主渠道失败自动试备用渠道,都失败了保存订单状态,让用户晚点再试。
+
+## 结语
+
+ReAct让AI从被动应答变成主动规划。通过把推理和外部工具结合起来,AI能处理远超传统聊天机器人的复杂任务。
+
+它的核心其实很朴素:**像人一样做事**。想一下、做一下、看结果、接着想。
+
+挑战也不少。循环控制、上下文管理、错误处理,都需要认真对待。但随着技术成熟,基于ReAct的AI智能体正在各个场景里发挥作用。
+
+如果你在搞AI应用,ReAct值得深入了解。
diff --git "a/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md" "b/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md"
new file mode 100644
index 0000000..f14955d
--- /dev/null
+++ "b/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md"
@@ -0,0 +1,196 @@
+ChatGPT、Claude这些AI助手能理解我们说的话,还能给出像样的回答。做到这点,靠的是Embedding技术。
+
+没有它,大语言模型根本没法处理文字输入。Embedding把人类语言变成数字,让机器能"读懂"。
+
+## 什么是Embedding
+
+Embedding就是把词语、句子变成一串数字。听起来简单,但背后的想法很有意思。
+
+我们说"北京"这个词时,脑子里会想到:城市、首都、政治中心、文化古都。这些概念连在一起,构成我们对"北京"的理解。Embedding做的,就是把这种理解映射到数学空间里。
+
+每个词变成一个向量——一组数字。有意思的是,语义相近的词,向量也靠得近。"北京"和"上海"的向量距离很近,都是城市。但"北京"和"苹果"就离得远,语义完全不同。
+
+
+这是我学习Java的知识总结,我会按照下面的技术栈一步步完善整个知识体系。
-**文章首发公众号**。如果有帮助到大家,希望点个**Star**!让我有持续的动力,感谢🤝
+分享给正在学习Java的你们,希望可以帮助你们少走一些弯路,一起学习进步!
-每周至少一篇的更新频率,没链接的是之后打算写的。
-
-:pencil2: [写作自述](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486050&idx=1&sn=1105d28b8d3553715f425419ec9d8d18&chksm=cf8479a7f8f3f0b19425e08a00332bbce4e5333843cfd6dd6f35e892139810d86b778cd57d55#rd)
+**文章首发公众号,每周至少一更。如果有帮助到大家,希望点个Star!让我有持续的动力,感谢🤝**
### :star: Java ###
- [深入详解ThreadLocal](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486776&idx=1&sn=f4425cb88bc5393e4d5125f5fd08ed68&chksm=cf847efdf8f3f7ebc79c5bcd3c47f1fc2f83abf119c2b22782cc90a1c69f606a95a4051dab53#rd)
-
- [使用Optional优雅避免空指针异常](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486914&idx=1&sn=b2b0f2c41b8168fbfcf1df21a3e00acb&chksm=cf847e07f8f3f711de06cb9269ba41541ec9399a56963768add081031566bf7fa49cbb6f7fa0#rd)
-
- [我画了35张图就是为了让你深入 AQS](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486172&idx=1&sn=b39cccd87dcd21176597dce0b15f7232&chksm=cf847919f8f3f00f86219d44cd95badee969d754aec89e644992437f2e8e0f7ad784695b4d90#rd)
-
- [一个 static 还能难得住我?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486175&idx=1&sn=041c85c052c11d2d15243994bc46d90a&chksm=cf84791af8f3f00c90a18b29d1fa47c9bcd713651514fc5ce4a9f82d656fe637bb21d45c42be#rd)
-
- [原来这才是动态代理!!!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486178&idx=1&sn=9610c1a0fa1df4c69558408ab2a3fcae&chksm=cf847927f8f3f0315b0c86f9b577926820c3d264d605149f850b597fcd17fafe432d82aaffcf#rd)
-
- [synchronized 的超多干货!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486181&idx=1&sn=4cb9340ba2f19ccb19ccec0c54d61b86&chksm=cf847920f8f3f036cd752455290a97f6584f8a4ce9662d1102515dd5ed967c94e14cec7a767d#rd)
-
+- [ExecutorCompletionService详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487958&idx=1&sn=2ace7ac53d596cd909d1d1c7e96fbff2&chksm=cf846213f8f3eb05c9de1fab2c609f4774ca86497ad5542a26aae5928efd808bfd865738aa4f#rd)
+- [CompletableFuture深度解析](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488046&idx=1&sn=2bb0b6dc4576278ff2e7f9b917cb6fe8&chksm=cf8461ebf8f3e8fd013d08c5028d41281444b1ac1d60f1706c841c4b444a4235d82c84644b9b#rd)
+- [面试官:响应式编程和虚拟线程怎么选?看完这篇不再被问倒](https://mp.weixin.qq.com/s/V7H_hyjycT3n1Rr7FBOrYQ)
### :page_facing_up: JVM ###
- [面试官:JVM是如何判定对象已死的?学JVM必会的知识!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486087&idx=1&sn=c6f1a9932961095ffdf2aef8a789e115&chksm=cf847942f8f3f0549c798671fe804c93378586b4fc547cce14db2359852ff0723a3aab64a187#rd)
-
- [GC的前置工作,聊聊GC是如何快速枚举根节点的](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486168&idx=1&sn=9eef35ec701b5c2f8097641b7e69ae71&chksm=cf84791df8f3f00b1e85039f31b17e00bf9cb624bbee638efeca110e51df6c6b6ba6363705ee#rd)
-
- [GC面临的困境,JVM是如何解决跨代引用的?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486242&idx=1&sn=83d4ace26fea86b0f16e93e25b3cdadf&chksm=cf8478e7f8f3f1f17a65a7fc0d25237e8f25b90f300085bb5a7e8128f7d80f5ba1a02e5a6c2f#rd)
-
- [昨晚做梦面试官问我三色标记算法](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486265&idx=1&sn=1464f25915c2c09ef65b784985b76fa3&chksm=cf8478fcf8f3f1ea80715ae949c1b4aec988368ead269c746d38244ae62028948a199f099d14#rd)
-
- [深入解析CMS垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486628&idx=1&sn=984b273af7d1d0398517a2f5442ffb38&chksm=cf847f61f8f3f677372a5ebc9f81403a8324be1bed49bf92e763882715c943324de4f1b0139a#rd)
-
- [深入解析G1垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486736&idx=1&sn=5e0710485783c3bcc4854a10412b9a40&chksm=cf847ed5f8f3f7c3826fa8c67bc76ce8dd218a725ee04f54cdafa27e14d190f5c92332589ae2#rd)
-
- [深入解析ZGC垃圾回收器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486746&idx=1&sn=7257ecf8c36509d06be359e3889400f2&chksm=cf847edff8f3f7c96edc667051d9ef70537000202c1ec77699fa5e30e46c2c8ddabd122297f3#rd)
### :hammer: MySQL ###
-- [MySQL双写缓冲区(Doublewrite Buffer)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484456&idx=1&sn=b5154c5eb26b969655c1b430792e0cb6&chksm=cf8477edf8f3fefbe0c95c2074a461ab12c01926654d995ad7844cba332fda7744da6b47ddc5#rd)
+- [深入解析 MySQL 双写缓冲区](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487013&idx=1&sn=beae861ca0f148e010d4170d14f67fdd&chksm=cf847de0f8f3f4f631273fbc7b9739239772cf90ad94fe78e83eb006d6a700ba2f00faffac09#rd)
- [再深入一点|binlog和relay-log到底长啥样?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486183&idx=1&sn=adc83df6c78e53ed1aefec7edc40ed63&chksm=cf847922f8f3f034beb08fc0a6fa2df8acb64902adff6927b71b5582e54444baa5c7265f7db8#rd)
@@ -53,29 +43,35 @@
- [听说你对explain 很懂?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486188&idx=1&sn=4ebf475e7287e4b9cc0e37fdff0c18af&chksm=cf847929f8f3f03fba7173a17f8a04a677db9af91355cba552f5156b7fc9424ccf0fd87f8488#rd)
-- [MMR(Multi-Range Read Optimization)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484466&idx=1&sn=29b6a9adfa2fee52e6391509d1b8c73f&chksm=cf8477f7f8f3fee1ea1793924cf8475f7581a2770f8804a54a60c61f57aac4ce64dff723c308#rd)
+- [深入浅出MySQL MRR(Multi-Range Read)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487041&idx=1&sn=66921cd6949db1389a0f02b3764b250f&chksm=cf847d84f8f3f4925b6506aeabe55308c85a68cb1fb8bf09aa99eca721d881246700bd9851a4#rd)
- [拿捏!隔离级别、幻读、Gap Lock、Next-Key Lock](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486190&idx=1&sn=c274fbc3daed3d1ac3a1ce5bd0009b68&chksm=cf84792bf8f3f03d07e2855570164cbfc0f0a7fbb0bba1fd50c8b7b2155c555c4438b625f395#rd)
-- [MySQL中的Join 的算法(NLJ、BNL、BKA)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484480&idx=1&sn=e75482a0fd8a866d9a9565aa9e659009&chksm=cf847785f8f3fe93195de380f7cff3efc8950a2cb49127a669f6b14a30e2fa5c13285e905f6b#rd)
+- [深入理解MySQL中的Join算法](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487068&idx=1&sn=042ab289718dbdaaea1b62854610efb7&chksm=cf847d99f8f3f48fd0aa04eeb2f6932bc826770f80911eec2fc571bdc7a50abc387714488d72#rd)
-- [MySQL分区表详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484856&idx=1&sn=ffb350c8b1e74667fe15a5e808faec57&chksm=cf84767df8f3ff6b30ff91dd14a6f802eaac01076dcc8b988a18f1a529f21a6266d34e34c4d7#rd)
+- [MySQL分区表详解](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487126&idx=1&sn=d81d7fa7b2befa0637bc9df5f4292915&chksm=cf847d53f8f3f445c92c1ae37478e47be947829a70b68d1e0f7f7d74af2d7ee15e6fca657845#rd)
- [缓存和数据库一致性问题,看这篇就够了](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486196&idx=1&sn=e9dcd1824583546aada0096e457afda0&chksm=cf847931f8f3f02780828e9fb2b2f36d018d74583fb7091bdbe6b7565bdfa10a396b4bfa9965#rd)
+- [全网最详细MVCC讲解,一篇看懂](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487999&idx=1&sn=8abdf89c27bbedd788d6ea260cb981c3&chksm=cf84623af8f3eb2cd63c4f6f80fda0822d14c3bbf49487f254377f13963ccaf89b1d04344128#rd)
+
+- [六个案例搞懂间隙锁](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488470&idx=1&sn=2a2b56e35ac6e1bae83e1a7eadc743f1&chksm=cf846013f8f3e9051b5e0d3636bcf135b994d77039409f92b7faeccdedddb6d5cfda6eaf0984#rd)
+
### :envelope: Redis ###
- [Redis类型(Type)与编码(Encoding)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486922&idx=1&sn=98b7e28fc9ed20b69dc236605dfd1c34&chksm=cf847e0ff8f3f7197ece7d7b96c7fa82328d7e66b969a37246ac51f4c4dd21056540b046cbe6#rd)
+
+- [Redis性能优化:理解与使用Redis Pipeline](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486953&idx=1&sn=76365046920ead36714bbdf64300739b&chksm=cf847e2cf8f3f73ab5dc16d82817bde96a5ba5f16903896bae2943773df87a11153c612eeeb9#rd)
-- [布隆过滤器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484400&idx=1&sn=8d480b6b87ee2330e1e5f181fbf5f71a&chksm=cf847035f8f3f923699cd0b3c9137aa6bd596abd0242abe73abeee3179392794538e87e2dc42#rd)
+- [布隆过滤器:原理与应用](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487003&idx=1&sn=c98c8a0643ae56ac0d81572aeabcc279&chksm=cf847ddef8f3f4c86f14b317375e395124f9278e5dbd7daec854a8a342f77992f1e6b9775249#rd)
-- [Redis跟MySQL的双写问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484390&idx=1&sn=de37dc02c20f3b471404c507c3741550&chksm=cf847023f8f3f935233feb3c575c7798e41d695347f11f502a75f25ba02b479ad152572c666e#rd)
+- [探索 Redis 与 MySQL 的双写问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486966&idx=1&sn=1aa2fc4d096242a8b725e01d45327a0c&chksm=cf847e33f8f3f72529da952b0621f7faf1756e5fd24e50c0d1896d98eab097e5bbf74aa218dd#rd)
- [Redis内存碎片:深度解析与优化策略](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486935&idx=1&sn=0b41d8807b6f0cdd06172f587884aa7a&chksm=cf847e12f8f3f70469ee692017388360a767175c9a3cbe482f2d93232c52540e43e5c8c8034e#rd)
-- [Redis中的BigKey问题:排查与解决思路](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484415&idx=1&sn=39cb685de9880bbe8fb108518cd5d54d&chksm=cf84703af8f3f92ca802e8e567a1f9bcdd038574113fe7aa68091db9f32cd86f6957862ee83a#rd)
+- [Redis中的Big Key问题:排查与解决思路](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487157&idx=1&sn=9cc48fd498f6633fdc49c11f7cd6b88f&chksm=cf847d70f8f3f466319083703cff3623d0ec92a6d47d9594c4b0547d9489805dfefba2ecd179#rd)
-- [非看不可的Redis持久化](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484435&idx=1&sn=e02f552e3d943787fdd5442ab49eb95a&chksm=cf8477d6f8f3fec05b7b8441cc19898bf9a4c4e9ffaa72827eba2e20735a0f37f840c4e2e495#rd)
+- [超详细!彻底说明白Redis持久化](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488849&idx=1&sn=d15830cf43364a8c9e3c9292d53cce05&chksm=cf846694f8f3ef825cb84436e2c931d9e22c2cdf810a546a3edb301a539168e0ce33c868d115#rd)
- [深度剖析:Redis分布式锁到底安全吗?看完这篇文章彻底懂了!](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486194&idx=1&sn=59c36ccae0a67063e4b29aba5084ffe0&chksm=cf847937f8f3f0211b989c65ff07c8b142ddd7752592f018488cb852a9062b587bbe8b2b3d3e#rd)
@@ -84,28 +80,40 @@
- [Redis最佳实践:7个维度+43条使用规范,带你彻底玩转Redis | 附实践清单](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486200&idx=1&sn=52dc758e32d138efcba25a7a47aec23d&chksm=cf84793df8f3f02b497d68f6f9407f7681b7eda3b2c88c87ac0f0411a7d0df4cf2ec8b9ba781#rd)
- [颠覆认知——Redis会遇到的15个「坑」,你踩过几个?](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486202&idx=1&sn=5fee614b5272fb9e3522f446bddc6132&chksm=cf84793ff8f3f02961bdccd2310d052231bc3023cd609afe71d7e648bcda48aa2c57eed65371#rd)
-### :lock:Elasticsearch ###
-- [学好Elasticsearch系列-核心概念](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485450&idx=1&sn=b23b362f8baac883e6a64b0cb05b184d&chksm=cf847bcff8f3f2d98ef829ff3f7c8cee59600b6b2c683564e2ab6af2c0547fc67b8ccbc837e9#rd)
-
-- [学好Elasticsearch系列-索引的CRUD](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485479&idx=1&sn=eb2b57e78d1f08c398558b2f23063df0&chksm=cf847be2f8f3f2f4567bd65048aba533355c70733bef9a14580ffcfadd01678acf01d62a92f4#rd)
-
-- [学好Elasticsearch系列-Mapping](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485492&idx=1&sn=e33d0689502b043723b0c2e4f0660a1d&chksm=cf847bf1f8f3f2e75fc2a8dd4542572f2dc7e4706f4817d2f9cd2ae18d3f28a1455da7873207#rd)
-
-- [学好Elasticsearch系列-Query DSL](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485520&idx=1&sn=97803ad983c80a90158b5b9efabcc8b7&chksm=cf847b95f8f3f2839fec2550df3dccb55e91b5cadcfc11ea2e9e25b27a882aceb5dca5fe2b96#rd)
-
-- [学好Elasticsearch系列-分词器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485544&idx=1&sn=cfa20adbb5c7328ea0cab85966d95c02&chksm=cf847badf8f3f2bbefd1b9e893cccf10a24c2a83f8052b613c62c999566e4c8616fded236552#rd)
-
-- [学好Elasticsearch系列-聚合查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485562&idx=1&sn=dd965afcd5697a152dae32d46e3996cd&chksm=cf847bbff8f3f2a91c7c75af03809359f7c9963c32e1da19b79939ccc283c46b3cf8038bd917#rd)
-
-- [学好Elasticsearch系列-索引的批量操作](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485594&idx=1&sn=71da9fcc473e3891b19c37af782ae7cb&chksm=cf847b5ff8f3f249e7f42ccac125982aa3abd8617bb5cc5466b2c5d381dae51f4d76b9f11d3c#rd)
-
-- [学好Elasticsearch系列-脚本查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485648&idx=1&sn=a0b075e6c2bad836a4c4eb6cacbaff5a&chksm=cf847b15f8f3f2033b5e18b8376b14205902898fb14c40a955a10619a74b1d35552a046dd7d1#rd)
+### :lock: Elasticsearch ###
+
+- [一起学Elasticsearch系列-核心概念](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487646&idx=1&sn=381af0374eb1d512046315164a541211&chksm=cf84635bf8f3ea4d650dc00e277d273d9a1e7358ae884b3cfedaf9d172cb1f44df7775bf355a#rd)
+- [一起学Elasticsearch系列-索引的CRUD](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487642&idx=1&sn=ea2cc5a3e0be25a0a81abe860b183f09&chksm=cf84635ff8f3ea49944ad35ee9bba7e60bf3f9c9c72d83c3d103403739d58a49fe2ff4779314#rd)
+- [一起学 Elasticsearch 系列 -Mapping](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487661&idx=1&sn=40c8a1a43c172c8500b975c6e1b35b39&chksm=cf846368f8f3ea7e451022e0e72b1a9d57c2641d56f9d0158fb8849d2806294e3dc7e3f71cde#rd)
+- [一起学Elasticsearch系列-Query DSL](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487687&idx=1&sn=9622f7220358daab3a5dddd9fef3d2b7&chksm=cf846302f8f3ea147dac58d003d20495ce1feeec910423e59d917272e890590d7b769ec71510#rd)
+- [一起学 Elasticsearch 系列-分词器](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487710&idx=1&sn=bce31911a3259f77cd5f5874c255e74c&chksm=cf84631bf8f3ea0dd8c2b816950f1fe7f04f529abf02512ca778b8e2fa2b66b117f15d6d44bb#rd)
+- [一起学Elasticsearch系列-聚合查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487728&idx=1&sn=f4e43d386925b7cec5115fb388e00843&chksm=cf846335f8f3ea2371df0bfbb16b1f6c2dfb553d90762edd9bec9c2b9839f6043de4625c1a36#rd)
+- [一起学Elasticsearch系列-脚本查询](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487750&idx=1&sn=b7b7bdcc8736d4bfc2092bd5c3511084&chksm=cf8462c3f8f3ebd526b06d283b723844d548299957e4a8d1c5cf60e1a6fa70b5e97477f7cca8#rd)
+- [一起学Elasticsearch系列-索引的批量操作](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487779&idx=1&sn=54d06ae4f6a1aa62702cc61349e763b2&chksm=cf8462e6f8f3ebf026fe41fc0c8fb77b743687f0460a5eae970c2af95264e3556764911b2f1d#rd)
+- [一起学Elasticsearch系列-模糊搜索](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487791&idx=1&sn=5878be01f10e3834445c64cb6351a872&chksm=cf8462eaf8f3ebfcb0a49c57d68721448d649b1dfcd91f3af549ef1192c95fb6a00d25c386db#rd)
+- [一起学Elasticsearch系列-搜索推荐](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487818&idx=1&sn=ee11f629be04cf427193d0fee36bc6e2&chksm=cf84628ff8f3eb99baaa38cfcd126a5c11143a5e14e8571e33b1ddada1403001a7c955f1486f#rd)
+- [一起学Elasticsearch系列 -Nested & Join](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487856&idx=1&sn=d13fbb78f8093ef1ac85f4f4b4abe543&chksm=cf8462b5f8f3eba3ad95ad2cead38c8413565262917cb2a10c5f7c5287189f600a93014ffcca#rd)
+- [一起学Elasticsearch系列-深度分页问题](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487873&idx=1&sn=37c93764bd0ddad6c5d7a7b01d9eca3a&chksm=cf846244f8f3eb529197122f0bc15256c7cf865d1c2f7b23d2fee8dcd1259a5d02e2fc12da54#rd)
+- [一起学Elasticsearch系列-并发控制](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487882&idx=1&sn=9afba52dddff1e9a7269bc9dc23e4893&chksm=cf84624ff8f3eb597c445f21a71df24bc334d58b1108432fcf5acf92498cfb8a22fee07af059#rd)
+- [一起学Elasticsearch系列-写入原理](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487898&idx=1&sn=b9960c61fb853619d1e52258cb5819a0&chksm=cf84625ff8f3eb492810d73713742b8459688fe7f9ef803354734bd9aceb7cdbc550a0ba6a17#rd)
+- [一起学Elasticsearch系列-写入和检索调优](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487903&idx=1&sn=45211a9d2b39c8433208f95af3ff3922&chksm=cf84625af8f3eb4c542e4b4082064e5abd2f2e21806a8f3e15409e02660afd820a4e5b854a9b#rd)
+- [一起学Elasticsearch系列-索引管理](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487926&idx=1&sn=3e7a6e6de02de000657b142d4bee5e82&chksm=cf846273f8f3eb656a9be4fa060dc23f1aba6ac3ca0b41087511a5787fe8b523a4c1db9bda15#rd)
+- [一起学Elasticsearch系列-Pipeline](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488897&idx=1&sn=2d4adc6d38813efa5a66a4f7c2763375&chksm=cf846644f8f3ef52577656d9a6d9cf5dbaef7f6dc61d21df181c61279237380f9ddd111fad69#rd)
+
+### :mag_right: DDD ###
+
+- [熬夜整理的2W字DDD学习笔记](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489048&idx=1&sn=6dc6f884fe7ca0e07d86aaa6e37ba4ab&chksm=cf8465ddf8f3eccbae516e3405dff032dfcc0c2820b187f4188caca2e63bed88d99fbb11b8c1#rd)
-### :date:框架 ###
+### :birthday: Spring ###
+
+- [如何优雅地Spring事务编程](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489087&idx=1&sn=60d6e29a87753beb69754bb633cbfe6e&chksm=cf8465faf8f3ececad33d8f42a7644e44eb05081c613761b39fc4bf46425058e9e3e5bbcf52b#rd)
+
+### :date: 框架 ###
- [本地缓存无冕之王Caffeine Cache](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486885&idx=1&sn=37c7a9461402bd97822295cf51361777&chksm=cf847e60f8f3f776eb3b477decfbac55dc8b7ae1cf607ef68fbee89dbe02d40a800a92fabec7#rd)
+- [响应式编程不只有概念!万字长文 + 代码示例,手把手带你玩转 RxJava](https://mp.weixin.qq.com/s/r0DJiOxR8wnZZ6tIKrSPzg)
-### :fire:架构设计 ###
+### :fire: 架构设计 ###
- [高并发系统设计之负载均衡](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486811&idx=1&sn=5422c62878ee1ddcc6ee1da45deb78d7&chksm=cf847e9ef8f3f7889c94fe93796c87083ebb47680ef13b40a35f5127c293e5d44fd3621abd57#rd)
@@ -115,22 +123,67 @@
- [搞懂异地多活,看这篇就够了](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247486192&idx=1&sn=6c82786cf2403486d81f375be684f228&chksm=cf847935f8f3f023a167ea3272a35979ee623dd0207acb70a0898148a1b18a15df01a49e54d8#rd)
-### :dash:编程语言 ###
+- [12306技术内幕](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247489137&idx=1&sn=9f5857733a5bed241902fb4c4421adf3&chksm=cf8465b4f8f3eca2d7d65af8cd8a1b3e9b1b3b56d482eb09cdd5fdd0ae3b7744a3994c495cbf#rd)
-- [Scala初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484574&idx=1&sn=85ac7b748ec8f22e3e8f8f42efca02d1&chksm=cf84775bf8f3fe4d2779871e106e1946293bb57d6f85ad44aa1f20fe467e9402a26807a532b4#rd)
-
-- [Groovy初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484641&idx=1&sn=7243e662d2b0a811f1be745777c30420&chksm=cf847724f8f3fe329f4414fb3fa9c262e0d2985f6996b64b519b79b1c6ae3f65fb894d27bb76#rd)
+- [业务幂等性设计的六种方案](https://mp.weixin.qq.com/s/HZAkGPNrC05aeHabhqT-zA)
-### :eyes:大数据 ###
+### :dash: 编程语言 ###
-- [Spark入门这篇就够了(万字长文)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484731&idx=1&sn=033b31376869f2046219dfe28707e43d&chksm=cf8476fef8f3ffe86a1910e5948afddba464e6cc186adb3ecb8ca62f612a4110b71ada2370cc#rd)
-
-- [一篇文章带你入门HBase](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247484823&idx=1&sn=4f8204e007c2201962cd707fc5668242&chksm=cf847652f8f3ff443ef516bf490656b21891eee42382970435a25451948daf89c2d72cfad96f#rd)
-
-- [全网最详细4W字Flink入门笔记(上)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485174&idx=1&sn=4cbd4ce941458fa576febb5021d1942f&chksm=cf847533f8f3fc25fa6e9c0c6de69b68b3f424aad52e6846dca8641d11a8be7ea8614682ad64#rd)
+- [Scala语言入门:初学者的基础语法指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487245&idx=1&sn=d089e22890f1f7449b7cf34e3cf2f6ed&chksm=cf847cc8f8f3f5deb39556f4229bafb6f1498906dc1d75040f90817bf0396117a7c2cdb498f9#rd)
+- [Groovy 初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487066&idx=1&sn=da9e3a9aff377d383e34e537e2f55666&chksm=cf847d9ff8f3f489011f26a784302ee68b9c1d7d57d52bc2c924a7c9b1a5f528ef2a417114c0#rd)
+- [自研 DSL 神器:万字拆解 ANTLR 4 核心原理与高级应用](https://mp.weixin.qq.com/s/nFiEqhi1B_SxrZGCAqLgLw)
+
+### :satellite: 设计模式 ###
+
+- [一文搞懂设计模式—策略模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488583&idx=1&sn=2e4758ee1b48dc5884289d5ecb841491&chksm=cf846782f8f3ee946d514e6267a326facb6880002fb663ffdbc3347e1d89fab32b8c0f5764d9#rd)
-- [全网最详细4W字Flink入门笔记(下)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247485365&idx=1&sn=c99d1e392440cad85342fdc950afc7f9&chksm=cf847470f8f3fd6632b34a42d8008f94430902630e4f5c8fb6ead1475facdc6e4ab39a5f828b#rd)
+- [一文搞懂设计模式—责任链模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488600&idx=1&sn=dd004bacfe0262fcc0fd1d72ae506b7a&chksm=cf84679df8f3ee8bf7117c5bed745470475c1a35ee96fe2bb99e093d895b7b776ecf51bb31c2#rd)
+
+- [一文搞懂设计模式—单例模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488615&idx=1&sn=1f0f92f6180856dbf206706c071438a3&chksm=cf8467a2f8f3eeb4e24e6c42f7f8cd265c03939ffa7742d1445ed7dddc6b11bb63aa6b0eb95e#rd)
+
+- [一文搞懂设计模式—观察者模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488718&idx=1&sn=9486e6b494c666e805e321a74bac5591&chksm=cf84670bf8f3ee1da0e7f26963e007da8fa77e7190596c9a6f6296cf2cc70af2ec4c066b5906#rd)
+
+- [一文搞懂设计模式—门面模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488730&idx=1&sn=0f63b2f54615d0647d4be22964dadea2&chksm=cf84671ff8f3ee0900b2cd3174ab8e66131308049648cc4e65d25215a54cc457cea1e73c8698#rd)
+
+- [一文搞懂设计模式—工厂方法模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488747&idx=1&sn=025c94f5b66b4dae3ab6f62dc043a083&chksm=cf84672ef8f3ee38bfce967135b5d23a93c0d59ae502b06b3c85ac629e336d28a21f1e13784f#rd)
+
+- [一文搞懂设计模式—模板方法模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488758&idx=1&sn=40385dc2cd049ab06c6403c47e1d5efa&chksm=cf846733f8f3ee2596eb459b9114e654e5ffd0ca1565931b742c65879a8603fc75c74880be58#rd)
+
+- [一文搞懂设计模式—适配器模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488766&idx=1&sn=78bf2e392394bb28272cceb3dd300618&chksm=cf84673bf8f3ee2d8b6308d272e8cd3a0173bfd540639cd7c17c4c40f6bc3e25561a0889930d#rd)
+
+- [一文搞懂设计模式—装饰器模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488773&idx=1&sn=287d0323b84eec284a56edceb1e5840e&chksm=cf8466c0f8f3efd6e8a8e5270ed10cf991c7b27a93521359274c2120d9e45e29b637e948650f#rd)
+
+- [一文搞懂设计模式—代理模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488866&idx=1&sn=d293faa2c918d85cc9cd8f6bc408b5a1&chksm=cf8466a7f8f3efb11ae68d7f7712bb22ceafae6f9d0529c235a1b1e02d183296c400211910b2#rd)
+
+- [一文搞懂设计模式—享元模式](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488879&idx=1&sn=2cb5edc9bbb088fd6de2bf9d46cb76cf&chksm=cf8466aaf8f3efbce988a6bf96035714e5125ba8ddc6cfe02871ca73e61c814271608576ff13#rd)
+
+
+### :eyes: 大数据 ###
+
+- [Spark入门指南:从基础概念到实践应用全解析](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487398&idx=1&sn=077859e1109e07b1469d242ec2b8091a&chksm=cf847c63f8f3f575e50012ef3667d9724998f07e32ebd27b6e3a37c5bdf2251d02e89030cff0#rd)
+
+- [HBase入门指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487105&idx=1&sn=2ee82c9b239aa502bd3dffcf320b3f93&chksm=cf847d44f8f3f452e1b8ac83b9f62f380e349615b67da92343539d4014077c2ad9e787e256cc#rd)
+
+- [全网最详细4W字Flink全面解析与实践(上)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487459&idx=1&sn=a1826b2d592fff29b5e11a374468796a&chksm=cf847c26f8f3f53073cc24584264fa2752a26c98bbd31c86bcf519296789eff05d72904d27ac#rd)
+
+- [全网最详细4W字Flink全面解析与实践(下)](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487535&idx=1&sn=736f1adda56cc550191f17e7111598b5&chksm=cf8463eaf8f3eafc38819e342705df1884683e03d5d39e9df876834ab0a84f61cc55923a5a03#rd)
+
+### :watch:AI
+
+- [深度解析Skills:从Prompt到能力复用的技术革命](https://mp.weixin.qq.com/s/Se6_L1PbhlEUGaBSY8sZsQ)
+- [为什么ChatGPT能听懂你说的话?Embedding技术揭秘](https://mp.weixin.qq.com/s/CoHcpXIaamdfmXCf-3qlgw)
+- [RAG详解:让大模型看见你的私有知识](https://mp.weixin.qq.com/s/mAC3DeqPLM41LyfGh2QjUw)
+- ReAct:让大模型学会边想边做
+- 10分钟掌握 JSON-RPC 协议,面试加分、设计不踩坑
+
+
+### :jack_o_lantern: 其他 ###
+- [良心推荐!几款收藏的神级IDEA插件分享](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488457&idx=1&sn=f771ccebb84f226e7302b89caa5c056b&chksm=cf84600cf8f3e91aab4564d91feacb8822b53a2b3a79547439d64d2c0b7b293435a1ae79f994#rd)
+- [实战Arthas:常见命令与最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488559&idx=1&sn=4b5003cb33446ab4a6173285fe9d83d3&chksm=cf8467eaf8f3eefc033de8f63cba9f0d7b2b5eb0ccfb5209f458a9ab447367b34954f296638b#rd)
+- [Maven实战](https://mp.weixin.qq.com/s/ErtWrRNzjJcR2ettUhAxsQ)
+- [不用Mockito写单元测试?你可能在浪费一半时间](https://mp.weixin.qq.com/s/NICubD9Yq0pn6qwpVIznfg)
+- [用好PowerMock,轻松搞定那些让你头疼的单元测试](https://mp.weixin.qq.com/s/rWIjqJKBQOe72RWW6qyJmA)
### :bulb: 资源 ###
diff --git a/docs/.DS_Store b/docs/.DS_Store
new file mode 100644
index 0000000..1b0a35f
Binary files /dev/null and b/docs/.DS_Store differ
diff --git a/docs/md/.DS_Store b/docs/md/.DS_Store
new file mode 100644
index 0000000..e79a8fe
Binary files /dev/null and b/docs/md/.DS_Store differ
diff --git "a/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md" "b/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md"
new file mode 100644
index 0000000..f4328dd
--- /dev/null
+++ "b/docs/md/AI/10\345\210\206\351\222\237\346\216\214\346\217\241 JSON-RPC \345\215\217\350\256\256\357\274\214\351\235\242\350\257\225\345\212\240\345\210\206\343\200\201\350\256\276\350\256\241\344\270\215\350\270\251\345\235\221.md"
@@ -0,0 +1,291 @@
+分布式系统中,不同服务之间需要一种可靠的方式来通信。远程过程调用(RPC)是一种常见的选择,而 **JSON-RPC** 是其中比较简单的一种。
+
+这篇文章介绍 JSON-RPC 2.0 协议的核心内容,包括消息格式、错误处理和实际应用场景。
+
+## JSON-RPC 概述
+
+### 什么是 JSON-RPC
+
+JSON-RPC 是一种无状态、轻量级的远程过程调用协议,使用 JSON 作为数据格式。它的设计目标就是简单——协议规范只有几页文档。
+
+JSON 作为数据交换格式,几乎所有主流编程语言都有良好的支持,包括 JavaScript、Python、Java、C#、Go 等。这使得 JSON-RPC 能够轻松实现跨语言调用。
+
+协议本身不绑定传输层,可以跑在 HTTP、WebSocket、TCP Socket 等各种消息传输环境上。开发者可以根据业务需求选择合适的传输方式。
+
+### JSON-RPC 的发展历程
+
+JSON-RPC 有两个主要版本:1.0 和 2.0。
+
+1.0 版本最早提出了基于 JSON 的 RPC 概念,但在规范性方面有所欠缺。2010 年发布的 2.0 版本做了重要升级,加入了批量调用支持、统一的错误对象结构。两个版本通过 `jsonrpc` 字段来区分。
+
+### JSON-RPC 的核心特点
+
+JSON-RPC 有几个值得注意的特点:
+
+- **简洁性**:规范文档很短,请求和响应结构清晰明了。
+- **跨语言支持**:任何能解析 JSON 的语言都可以实现 JSON-RPC 客户端或服务端。
+- **无状态设计**:每个请求独立,协议不维护会话状态。这种设计简化了服务端的实现,也更容易水平扩展。
+- **批量处理能力**:2.0 版本支持在单个请求中包含多个 RPC 调用,服务端返回结果数组。
+- **双向通信**:通过长连接和通知机制,JSON-RPC 也支持服务端主动向客户端推送消息。
+
+## 协议规范详解
+
+### 协议约定与术语
+
+JSON-RPC 规范中使用了 RFC 2119 定义的关键字:MUST、MUST NOT、SHOULD、SHOULD NOT、MAY。这些术语描述了实现者必须、应该或可以遵循的行为规范。
+
+**客户端(Client)**:发起请求的实体,负责构造请求对象并处理响应。
+
+**服务端(Server)**:接收请求并返回响应的实体,处理请求并生成响应。
+
+同一个实现可以同时扮演客户端和服务端。比如在对等网络中,两个节点可能既向对方发起请求,也响应来自对方的请求。
+
+### 数据类型系统
+
+JSON-RPC 继承自 JSON 的类型系统,包含六种数据类型:
+
+基本类型:String(字符串)、Number(数值)、Boolean(布尔值)、Null(空值)
+
+结构化类型:Object(对象)、Array(数组)
+
+这些类型名称首字母必须大写,包括 True 和 False。
+
+成员名称(字段名)在客户端与服务端之间交换时必须区分大小写。函数、方法、过程这三个术语可以互换使用,都指向可以被调用的可执行单元。
+
+## 消息格式深度解析
+
+JSON-RPC 2.0 定义了三种核心消息类型:**请求对象(Request Object)**、**响应对象(Response Object)** 和 **通知对象(Notification Object)**。
+
+
+
+### 请求对象结构
+
+请求对象是客户端向服务端发起 RPC 调用的载体:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "subtract",
+ "params": [42, 23],
+ "id": 1
+}
+```
+
+- **jsonrpc 字段**:协议版本标识,值必须是字符串 "2.0"。
+- **method 字段**:要调用的方法名称,区分大小写。以 "rpc." 开头的方法名预留给 JSON-RPC 内部扩展,如 `rpc.subscribe`、`rpc.notify`。
+- **params 字段**:方法参数,可以是数组(按顺序)或对象(按名称)。参数可选,不需要时可以省略。
+
+```json
+// 索引数组参数:参数顺序与服务端预期一致
+{"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": 1}
+
+// 命名对象参数:参数名需与服务端方法签名匹配
+{"jsonrpc": "2.0", "method": "subtract", "params": {"minuend": 42, "subtrahend": 23}, "id": 2}
+```
+
+- **id 字段**:客户端生成的唯一标识符,用于关联请求和响应。id 可以是字符串、数值或 null。建议避免使用 null,因为 JSON-RPC 1.0 的通知机制使用 null,可能引起混淆。使用数值作为 id 时,应避免小数。
+
+### 响应对象结构
+
+响应对象是服务端返回给客户端的执行结果:
+
+```json
+// 成功响应
+{
+ "jsonrpc": "2.0",
+ "result": 19,
+ "id": 1
+}
+
+// 错误响应
+{
+ "jsonrpc": "2.0",
+ "error": {
+ "code": -32601,
+ "message": "Method not found",
+ "data": "详细错误信息"
+ },
+ "id": 1
+}
+```
+
+响应对象必须包含 `result` 或 `error` 之一,不能同时包含两者。`id` 必须与对应请求中的 id 保持一致。
+
+如果请求本身存在错误(如无效的 JSON 格式或非法请求结构),导致服务端无法确定原始 id 时,响应中的 id 必须为 null。
+
+### 通知机制
+
+通知是一种不需要响应的请求,通过省略 `id` 字段来标识:
+
+```json
+{
+ "jsonrpc": "2.0",
+ "method": "update",
+ "params": [1, 2, 3, 4, 5]
+}
+```
+
+通知适用于日志记录、事件发布、进度通知等场景。客户端只负责发送消息,不需要处理响应。
+
+由于没有响应机制,客户端无法得知通知是否被成功处理。在批量请求中,通知请求不会产生对应的响应。
+
+
+
+## 错误处理机制
+
+### 错误对象结构
+
+JSON-RPC 2.0 定义了标准化的错误对象:
+
+```json
+{
+ "code": -32603,
+ "message": "Internal error",
+ "data": { "details": "数据库连接失败" }
+}
+```
+
+- **code 字段**:整数错误码,标识错误类型。
+- **message 字段**:简短的人类可读错误描述,通常是一句话。
+- **data 字段**:可选,携带错误的附加信息,可以是字符串、对象或任何有效的 JSON 值。
+
+### 预定义错误码
+
+JSON-RPC 2.0 在 -32768 到 -32000 范围内预留了预定义错误码:
+
+| 错误码 | 名称 | 说明 |
+|--------|------|------|
+| -32700 | Parse Error | 解析错误,服务端收到的 JSON 格式无效 |
+| -32600 | Invalid Request | 无效请求,发送的不是有效的请求对象 |
+| -32601 | Method Not Found | 方法不存在或不可调用 |
+| -32602 | Invalid Params | 参数无效 |
+| -32603 | Internal Error | JSON-RPC 内部错误 |
+
+
+
+-32000 到 -32099 范围内的错误码保留给服务端自定义使用。应用程序也可以定义自己的错误码(通常为负数且绝对值小于 32767)。
+
+### 错误处理建议
+
+- **合理使用 data 字段**:code 和 message 提供错误的基本分类,data 可以包含调试信息、堆栈跟踪或业务相关的详细信息。生产环境中注意控制敏感信息暴露。
+- **统一错误处理中间件**:在服务端统一拦截和处理错误,将业务异常转换为标准化的 JSON-RPC 错误格式,避免暴露内部实现细节。
+- **区分错误类型**:某些错误(如参数校验失败)是客户端问题,可以提示用户修正;另一些错误(如数据库故障)需要服务端介入处理。
+
+## 批量调用与性能优化
+
+### 批量请求机制
+
+JSON-RPC 2.0 支持在单个请求中发送多个 RPC 调用,服务端返回相应的响应数组。这一机制在高并发场景下可以减少网络往返次数。
+
+```json
+// 批量请求
+[
+ {"jsonrpc": "2.0", "method": "sum", "params": [1, 2, 4], "id": "1"},
+ {"jsonrpc": "2.0", "method": "notify_hello", "params": [7]},
+ {"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": "2"},
+ {"jsonrpc": "2.0", "method": "get_data", "id": "9"}
+]
+```
+
+对应的批量响应:
+
+```json
+[
+ {"jsonrpc": "2.0", "result": 7, "id": "1"},
+ {"jsonrpc": "2.0", "result": 19, "id": "2"},
+ {"jsonrpc": "2.0", "result": ["hello", 5], "id": "9"}
+]
+```
+
+通知请求(没有 id 字段)不会产生响应。响应数组中各元素的顺序与请求顺序无关,客户端通过匹配 id 来关联请求和响应。
+
+### 批量调用的边界情况
+
+规范对批量调用中的边界情况有明确定义:
+
+如果批量请求本身不是有效的 JSON 或不是包含至少一个值的数组,服务端应返回单对象响应而非数组。空数组 `[]` 被视为无效请求。
+
+如果批量请求中的所有请求都是通知,服务端不需要返回任何响应。其他情况下,即使某些请求处理失败,响应数组中仍应包含对应请求的错误响应。
+
+### 性能优化策略
+
+- **连接复用**:使用持久化连接(如 HTTP Keep-Alive 或 WebSocket)可以避免频繁建立和销毁连接的开销。
+- **批量聚合**:将多个相关的小请求合并为一个批量请求,减少网络往返次数。
+- **压缩传输**:启用 HTTP 压缩(如 gzip)可以减少大型 JSON 响应体的传输体积。
+- **异步处理**:使用异步调用和通知机制,提高客户端的并发处理能力。
+
+## 与 RESTful API 的对比分析
+
+### 设计理念差异
+
+JSON-RPC 和 RESTful 代表了两种不同的 API 设计哲学。JSON-RPC 是过程导向的,关注的是"做什么操作";RESTful 是资源导向的,关注的是"操作什么资源"。
+
+以用户操作为例:
+
+```json
+// JSON-RPC: 直接调用方法
+{"jsonrpc": "2.0", "method": "createUser", "params": {"name": "张三", "email": "zhang@example.com"}, "id": 1}
+
+// RESTful: 操作资源
+POST /users
+{"name": "张三", "email": "zhang@example.com"}
+```
+
+### 通信模式对比
+
+| 维度 | JSON-RPC | RESTful |
+|------|----------|---------|
+| 语义抽象 | 方法调用 | 资源操作 |
+| URL 角色 | 仅作为端点地址 | 表示资源路径 |
+| HTTP 方法 | 仅使用 POST | 充分利用 GET/POST/PUT/DELETE |
+| 状态管理 | 可维护会话状态 | 倡导无状态设计 |
+| 灵活性 | 更紧凑,适合精确控制 | 更灵活,适合通用场景 |
+
+
+
+### 选型建议
+
+**适合使用 JSON-RPC 的场景**:
+
+- 内部服务间通信,接口相对稳定
+- 需要精确的方法语义和参数控制
+- 对带宽敏感,需要紧凑的消息格式
+- 团队对 RPC 模式更熟悉
+
+**适合使用 RESTful 的场景**:
+
+- 公开 API,需要良好的可发现性
+- 资源概念明确的 CRUD 操作
+- 需要利用 HTTP 缓存机制
+- 追求 API 的自我描述能力
+
+## 安全性考量
+
+### 常见安全威胁
+
+JSON-RPC 的简洁设计虽然降低了实现复杂度,但也带来了一些安全考量:
+
+- **数据泄露**:JSON-RPC 通常通过 HTTP 传输,未加密的通信可能被中间人攻击截获。
+- **方法枚举**:如果服务端没有正确限制可调用方法,攻击者可能通过枚举方法名发现未公开的接口。
+- **拒绝服务**:恶意客户端可能发送大量请求或构造超大的批量请求,耗尽服务端资源。
+- **注入攻击**:不安全的参数处理可能导致 SQL 注入、命令注入等安全漏洞。
+- **重放攻击**:截获的有效请求可能被攻击者重放,造成非预期的重复操作。
+
+
+
+### 安全加固措施
+
+- **传输层加密**:使用 HTTPS 协议,确保通信内容的机密性和完整性。
+- **身份认证与授权**:实现身份验证机制(如 JWT、OAuth 2.0),在方法层面实施细粒度的授权控制。
+- **输入验证**:对所有参数进行严格的类型检查和值域验证。
+- **速率限制**:实施请求速率限制,防止恶意高频访问。
+- **方法白名单**:仅暴露必要的方法,对未公开的方法返回 -32601 错误。
+- **日志与监控**:记录详细的请求日志,监控异常模式,及时发现潜在攻击。
+
+## 结语
+
+JSON-RPC 2.0 协议设计简洁,在分布式系统通信中有其适用场景。规范本身很短,学习和实现成本都不高,JSON 格式的请求/响应便于调试和日志记录。
+
+当然,JSON-RPC 也有局限性。它缺少内置的元数据机制,类型系统相对简单。在需要高度标准化、复杂类型系统或强类型安全的场景中,可以考虑 gRPC、Thrift 等方案。
+
+如果你的业务场景需要简单、透明的服务间通信方式,JSON-RPC 是一个值得考虑的选择。
diff --git "a/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md" "b/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md"
new file mode 100644
index 0000000..2204101
--- /dev/null
+++ "b/docs/md/AI/RAG\350\257\246\350\247\243\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\347\234\213\350\247\201\344\275\240\347\232\204\347\247\201\346\234\211\347\237\245\350\257\206.md"
@@ -0,0 +1,223 @@
+在把大语言模型用到实际业务时,开发者很快会遇到一个问题:通用模型很难满足特定场景的需求。
+
+主要卡在三个地方:
+
+- **知识过时**:模型的训练数据有截止日期,问它最近发生的事基本白问。
+
+- **幻觉严重**:模型经常一本正经地胡说八道,在需要准确性的场景这是致命的。
+
+- **数据安全**:企业不可能把内部文档上传给第三方,但不上传模型又不会。
+
+
+
+基于这个问题,**RAG(检索增强生成)** 出现了。它的思路很简单:不把数据交给模型,而是让模型"看到"它需要的部分。
+
+用户提问时,系统从私有知识库中检索相关片段,把这些片段和问题一起发给大模型。模型结合真实信息来回答,而不是靠"记忆"里不知道哪来的东西生成。
+
+## 为什么需要 RAG
+
+### 知识的局限性
+
+大语言模型的知识完全来自训练数据。GPT-4、文心一言、通义千问这些主流模型,训练数据主要来自网络公开数据。这带来两个问题:
+
+- **时效性**:模型的"知识"被定格在训练截止时间点。GPT-4 的知识库可能停在 2023 年 12 月,之后的新事件、新政策、新技术,它无法直接给出准确答案。
+- **私有领域缺失**:企业的产品规格文档、内部流程规范、医疗机构的诊断指南、法律机构的判例汇编——这些数据从没出现在公开网络上,通用大模型对此一无所知。不借助外部手段,模型在这些领域的回答质量会大打折扣。
+
+### 幻觉问题
+
+大语言模型在生成文本时,实际上是在计算下一个 token 出现的概率分布。这种机制导致模型在面对不确定性问题时,经常编造看似合理实则错误的答案——学名叫"幻觉"(Hallucination)。
+
+更麻烦的是,模型不具备某一方面知识时,它不会选择"不知道",而是倾向于根据训练数据中学习到的语言模式,自信满满地瞎编。在需要高度准确性的生产环境中,这绝对不可接受。
+
+### 数据安全
+
+对企业来说,数据安全是生死攸关的议题。没人愿意承担核心商业机密泄露的风险,因此几乎没有企业愿意将私有数据上传到第三方平台进行模型训练或推理。
+
+这意味着,完全依赖通用大模型自身能力的应用方案,不得不在**数据安全**和**应用效果**之间做取舍。传统方案要么保数据安全牺牲模型能力,要么提升模型能力却承担数据泄露风险。
+
+## RAG 的破局思路
+
+RAG 提供了第三条路:不把数据交给模型,而是让模型"看到"它需要的那部分数据。
+
+用户提问时,系统从私有知识库中检索相关片段,把这些片段作为上下文提供给大模型。大模型在回答时,既能"参考"检索到的真实信息,又能结合自身的语言理解能力生成流畅的回答。数据始终留在本地,模型获得了"感知"私有知识的能力。
+
+## RAG 的技术架构
+
+RAG 的完整工作流程分为两个阶段:**数据准备阶段(离线索引)** 和 **应用阶段(在线推理)**。
+
+
+
+### 数据准备阶段:构建知识的向量化索引
+
+数据准备是离线过程,目标是将私有数据转化为可高效检索的向量形式。流程包含四个环节:
+
+**数据提取**。从多种格式的原始文件中提取纯文本内容,包括 PDF、Word、HTML、数据库记录等。技术挑战在于处理各种格式解析、特殊字符清理、无用内容过滤。常用 LangChain 的 DocumentLoaders 来统一处理不同来源的数据。
+
+**文本分割(Chunking)**。直接影响检索质量。需要综合考虑两个因素:一是 embedding 模型对 token 长度的限制;二是语义完整性对检索效果的影响。
+
+固定长度分割实现简单,但容易切断语义边界,导致检索时丢失关键上下文。语义分割通过识别句子边界或段落结构来进行切分,能更好地保留语义完整性,但实现复杂度更高。业界常用策略是设置合适的 chunk size(如 512 tokens)和 overlap(如 50-100 tokens),在保证语义完整性的同时避免边界效应。
+
+**向量化(Embedding)**。将文本转化为高维向量,让语义相似的文本在向量空间中具有相近的位置关系。常见的 embedding 模型:
+
+| 模型名称 | 特点 | 适用场景 |
+|---------|------|---------|
+| OpenAI text-embedding-3 | API 调用,稳定可靠 | 通用场景 |
+| BGE (BAAI) | 开源、支持中英文 | 自部署场景 |
+| M3E (MokaAI) | 开源、多语言支持 | 中文场景 |
+| ERNIE-Embedding | 百度自研、中文优化 | 国产化需求 |
+
+**数据入库**。将向量及其关联的原始文本、元数据写入向量数据库。主流选择包括 FAISS、Chroma、Milvus、Weaviate 和 Qdrant 等。这些数据库采用近似最近邻(ANN)算法,能够在海量向量中快速找到与查询向量最相似的结果。
+
+### 应用阶段
+
+
+
+用户提出问题时,RAG 系统进入在线推理阶段,包含四个关键步骤:
+
+**查询向量化**。使用与索引阶段相同的 embedding 模型,将用户的自然语言问题转化为语义向量。这个向量的质量直接决定后续检索的准确性。
+
+**信息检索(Retrieval)**。通过计算查询向量与所有存储向量的相似度(如余弦相似度、欧氏距离),找出 top-k 个最相关的文档片段。现代向量数据库通常采用 HNSW(Hierarchical Navigable Small World)等算法,在保证检索精度的同时实现毫秒级响应。
+
+**上下文构建**。将检索到的相关片段与原始问题组装成完整的提示模板。一个典型的 RAG 提示模板:
+
+```
+【任务描述】
+假如你是一个专业的客服机器人,请参考【背景知识】中的内容,准确回答用户的问题。
+
+【背景知识】
+{检索到的相关文档片段}
+
+【用户问题】
+{用户原始问题}
+
+【回答要求】
+- 仅根据【背景知识】中的内容回答
+- 如果【背景知识】中没有相关信息,请明确告知
+- 回答要简洁、准确、有条理
+```
+
+**答案生成(Generation)**。大语言模型接收包含问题和上下文的提示后,结合检索到的真实信息生成最终答案。由于有明确的参考资料作为约束,模型产生幻觉的概率大大降低。
+
+## 高级 RAG 技术
+
+基础 RAG 流程能工作,但在实际应用中往往面临检索质量不足、生成效果不稳定等问题。业界发展出一系列高级 RAG 技术来优化系统性能。
+
+
+
+### 搜索索引的演进
+
+**平面索引(Flat Index)** 直接计算查询向量与所有存储向量的相似度。实现简单,但数据规模达到数万条时,线性扫描的计算开销变得不可接受。
+
+**向量索引** 采用近似最近邻算法来解决效率问题。FAISS 库提供了多种索引类型:
+
+- **IVF(Inverted File Index)**:通过聚类将向量分组,检索时只搜索最相关的聚类中心,显著减少计算量。
+- **HNSW(Hierarchical Navigable Small World)**:构建多层图结构,实现对数级别的检索复杂度。
+- **PQ(Product Quantization)**:对高维向量进行压缩,大幅降低内存占用。
+
+**分层索引** 应对大型知识库。系统维护两个层级的索引:一个由文档摘要组成,用于快速过滤;另一个由文档块组成,用于精确检索。这种设计在保证检索召回率的同时,大幅提升检索效率。
+
+### 混合搜索
+
+单纯的向量检索在处理精确术语匹配时往往表现不佳。比如用户搜索"如何重置密码",向量检索可能无法准确识别"重置"和"修改"之间的细微差别。
+
+**混合搜索** 结合传统关键词检索(如 BM25、TF-IDF)和现代语义向量检索。两种检索结果通过 **Reciprocal Rank Fusion(RRF)算法** 进行融合:对不同检索方法的结果按排名赋分,综合排名最高的文档被选中。
+
+关键词检索确保精确匹配的召回,语义检索捕捉同义词和语义关联。两者互补,能够应对更广泛的查询类型。
+
+### 内容增强
+
+**语句窗口检索器(Sentence Window Retriever)** 采用"小块索引、大窗口上下文"的策略。文档中的每个句子单独嵌入向量索引以保证检索精度,但检索后扩展上下文窗口,额外获取前后各 k 个句子,提供更完整的语义信息给大模型。
+
+**自动合并检索器(Parent Document Retriever)** 采用层级分割策略:文档被递归分割为较小的子块,每个子块与较大的父块存在引用关系。检索时获取相关子块,当多个相关子块指向同一父块时,自动升级为使用父块作为上下文。这种设计让系统同时获得精确检索和宏观语义。
+
+### HyDE:假设性答案增强检索
+
+**HyDE(Hypothetical Document Embeddings)** 是一种逆向思维的方法:不直接用问题检索,而是先用大模型根据问题生成一个假设性的答案,然后用这个假设答案去检索相关文档。
+
+前提假设是:假设答案与真实文档在语义空间中可能更接近,因为两者都是"回答性"的文本。HyDE 在处理抽象概念或模糊查询时表现尤为出色。
+
+### 查询转换
+
+用户的原始问题往往不够"检索友好"。**查询转换** 系列技术利用大模型的推理能力来优化查询:
+
+**查询分解(Query Decomposition)** 将复杂问题拆分为多个简单子问题。例如,"LangChain 和 LlamaIndex 哪个更适合做 RAG 开发?"这个问题难以直接检索,但可以拆分为"LangChain 做 RAG 开发的优缺点"和"LlamaIndex 做 RAG 开发的优缺点"两个子问题,分别检索后再综合回答。
+
+**Step-back Prompting** 生成更通用的查询来获取高层次上下文,与原始查询的检索结果一起输入模型,实现"由面到点"的推理。
+
+**查询重写(Query Rewriting)** 使用大模型改写问题表达,尝试用不同的表述方式检索,提高召回率。
+
+### 重排与过滤
+
+检索返回的 top-k 结果可能存在质量问题:相关性参差不齐、信息冗余、噪声干扰。**重排(Reranking)** 技术应运而生。
+
+**交叉编码器重排** 将查询和每个候选文档一起输入专门的交叉编码模型,输出精细化的相关性评分。这种方法比向量相似度计算更准确,但计算开销更大,通常用于对初始检索结果的二次筛选。
+
+**基于元数据的过滤** 利用文档的元数据(时间、来源、类别等)进行条件筛选,快速排除不相关的结果。
+
+## RAG 融合
+
+**RAG 融合(RAG Fusion)** 通过 LLM 生成多个变体查询来增强检索效果。单一查询可能无法覆盖用户问题的所有方面,通过让 LLM 生成多个不同角度的查询,可以从知识库中召回更丰富、更多样化的相关信息。
+
+
+
+### 技术流程
+
+1. **多查询生成**:使用 LLM 根据用户原始问题生成 n 个相关查询。
+2. **并行向量搜索**:用所有生成的查询分别进行向量检索。
+3. **结果融合排序**:应用 RRF 算法对所有检索结果进行综合排名。
+4. **上下文注入**:将融合后的相关文档注入提示模板。
+5. **答案生成**:LLM 基于融合后的上下文生成最终答案。
+
+### 优势
+
+**多样性增强**:不同查询从不同角度切入问题,最终结果涵盖更广泛的视角,减少单一视角带来的偏差。
+
+**鲁棒性提升**:某个查询因表述偏差导致检索不佳时,其他查询可以弥补缺陷,提升整体系统的稳定性。
+
+**语义纠偏**:LLM 生成的查询往往是对原始问题的语义扩展,能够捕捉隐含的语义关联。
+
+### 注意事项
+
+**延迟增加**:额外的 LLM 调用会引入额外延迟,在延迟敏感的场景中需要权衡。
+
+**专业术语处理**:如果知识库包含大量内部术语或行话,LLM 可能因不了解这些术语而产生无关查询,此时需要针对性优化提示词。
+
+**成本考量**:额外的 LLM 调用意味着额外的 token 消耗,需要评估 ROI。
+
+## 评估体系
+
+RAG 系统的质量评估是工程实践中的重要环节。业界通常采用 **RAG 三元组** 评估框架:
+
+- 检索内容相关性(Context Relevance):评估检索到的文档与用户问题的相关程度。高相关性意味着检索阶段工作良好,能够召回真正有用的信息。常用指标包括召回率(Recall)和精确率(Precision)。
+- 答案基于性(Answer Groundedness):衡量 LLM 的回答是否基于检索到的上下文,而非依赖自身知识或产生幻觉。这一指标直接反映 RAG 机制的有效性。
+- 答案相关性(Answer Relevance):评估生成的回答是否有效解决了用户的问题。高相关性意味着即使检索和基于性都良好,最终答案也能真正满足用户需求。
+
+
+
+### 评估框架与工具
+
+**RAGAs** 是当前流行的 RAG 评估框架,提供标准化的评估流程和指标计算方法。
+
+**LangSmith** 是 LangChain 官方提供的评估平台,支持自定义评估器、运行时监控和调试追踪。
+
+**Truelens** 由 LlamaIndex 团队推出,专注于 RAG 系统的可观测性和评估。
+
+## 发展趋势
+
+RAG 技术正在快速演进,几个方向值得关注:
+
+**端到端优化**。传统 RAG 将检索和生成视为独立环节,但最新研究开始探索联合优化的可能性。Meta AI 提出的 **RA-DIT** 技术同时微调 LLM 和 Retriever,让两个组件在学习过程中相互适应,在知识密集型任务上取得了显著提升。
+
+**多模态 RAG**。随着多模态大模型的发展,RAG 的边界正在从纯文本扩展到图像、视频、音频等多种模态。未来的 RAG 系统需要能够处理跨模态的知识检索和生成。
+
+**主动学习与持续优化**。结合用户反馈和评估结果,构建自适应优化机制,让 RAG 系统能够从实际使用中持续学习和改进。
+
+**轻量化与边缘部署**。随着模型压缩技术的发展,更小、更快的 LLM 将成为 RAG 系统的新选择。Mistral Mixtral、Microsoft Phi-2 等小参数模型的崛起,为 RAG 在边缘设备上的部署开辟了新的可能性。
+
+## 结语
+
+RAG 技术通过将检索能力与大语言模型的生成能力相结合,为 LLM 的实际应用提供了一条切实可行的路。它解决了知识时效性、私有数据访问和幻觉抑制等核心问题。
+
+当然,RAG 不是万能药。检索质量、响应延迟、系统复杂度等挑战依然存在。开发者需要根据具体场景权衡利弊,选择合适的技术组合。
+
+至于未来会怎样,让时间来检验。
diff --git "a/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md" "b/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md"
new file mode 100644
index 0000000..d43addd
--- /dev/null
+++ "b/docs/md/AI/ReAct\357\274\232\350\256\251\345\244\247\346\250\241\345\236\213\345\255\246\344\274\232\350\276\271\346\203\263\350\276\271\345\201\232.md"
@@ -0,0 +1,286 @@
+传统聊天机器人相信大家都用过——你问一句,它答一句。线性,简单,但遇到复杂问题就露馅了。比如问"特斯拉股价相比去年涨了多少",它要么瞎编,要么说"我无法获取实时信息"。
+
+2022年,Google Research提出了ReAct框架。它要解决的就是这个问题:**让大模型像人一样,一边想一边做,做完再看结果,接着想下一步**。
+
+## ReAct的核心原理
+
+### 先看个例子
+
+想象你在一个陌生城市旅行。
+
+早上醒来,你想:今天天气怎么样?要不要带伞?
+
+你打开天气APP看了一眼——有阵雨。
+
+于是你调整计划:上午去博物馆躲雨,晚上再去看夜景。
+
+这个"想→做→看→再想"的过程,就是ReAct在做的事。
+
+### 三个阶段
+
+ReAct由三个部分构成:
+
+**思考(Thought)**:分析当前问题,决定下一步做什么。比如"用户问的是某国人口,我需要查数据"。
+
+**行动(Action)**:调用外部工具。输出格式类似`search(query="某国人口")`。
+
+**观察(Observation)**:工具返回结果,成为下一轮思考的依据。比如`{"population": "1.4亿"}`。
+
+循环往复,直到任务完成。
+
+
+
+### 什么时候停下来
+
+两种方式:
+
+- **硬限制**:设个最大迭代数,比如`max_iterations=10`,到了就强制结束。
+- **条件触发**:模型觉得自己很有把握了,或者连续失败好几次,就主动收手。
+
+## 技术实现
+
+### 工具怎么设计
+
+三个原则:
+
+**原子性**:一个工具只做一件事。计算器就做计算,搜索就做搜索,别搞大而全。
+
+**强契约**:用JSON Schema定义清楚输入输出格式:
+
+```json
+{
+ "name": "get_weather",
+ "description": "查询指定城市的天气信息",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "location": {
+ "type": "string",
+ "description": "城市名称,如北京、上海"
+ }
+ },
+ "required": ["location"]
+ }
+}
+```
+
+**安全第一**:删数据、转账这类敏感操作必须有权限控制。
+
+### 提示词怎么写
+
+ReAct提示包含四个部分:
+
+- 要求模型展示思考过程。
+- 告诉它有哪些工具可以用。
+- 提示它在每个操作后重新评估。
+- 设定循环退出条件。
+
+### 从提示词到原生工具调用
+
+早期做法是在提示词里格式化输出:
+
+```
+思考:我需要查询北京的天气
+行动:get_weather(location="北京")
+观察:{"temperature": "25℃", "condition": "晴"}
+```
+
+问题很明显:模型可能"废话连篇",格式也可能乱套。
+
+后来有了**原生工具调用**,直接微调模型让它输出结构化JSON。稳定多了,还能并行执行多个工具。
+
+
+
+### 在Java中使用ReAct:LangChain4j示例
+
+如果你是Java开发者,可以用 LangChain4j 快速实现 ReAct。核心思路是:用 `@Tool` 注解定义工具,框架自动处理推理-行动-观察的循环。
+
+**第一步:定义工具**
+
+```java
+import dev.langchain4j.agent.tool.Tool;
+
+public class WeatherTools {
+
+ @Tool("获取指定城市的实时天气信息")
+ public String getWeather(String location) {
+ // 实际项目中调用天气API
+ return switch (location) {
+ case "北京" -> "晴天,15℃,空气质量良好";
+ case "上海" -> "多云,18℃,有轻度雾霾";
+ default -> "未找到该城市的天气信息";
+ };
+ }
+
+ @Tool("查询股票实时价格")
+ public String getStockPrice(String stockCode) {
+ // 实际项目中调用股票API
+ return "股票" + stockCode + "当前价格:168.5元,涨幅+2.3%";
+ }
+}
+```
+
+**第二步:创建助手接口**
+
+```java
+import dev.langchain4j.service.AiServices;
+
+public interface Assistant {
+ String chat(String userMessage);
+}
+```
+
+**第三步:构建并使用**
+
+```java
+import dev.langchain4j.model.openai.OpenAiChatModel;
+
+public class Main {
+ public static void main(String[] args) {
+ // 配置模型
+ OpenAiChatModel model = OpenAiChatModel.builder()
+ .apiKey("your-api-key")
+ .modelName("gpt-4")
+ .build();
+
+ // 构建助手,绑定工具
+ Assistant assistant = AiServices.builder(Assistant.class)
+ .chatLanguageModel(model)
+ .tools(new WeatherTools()) // 注册工具
+ .build();
+
+ // 提问——框架会自动执行ReAct循环
+ String answer = assistant.chat("北京今天天气怎么样?适合户外运动吗?");
+ System.out.println(answer);
+ }
+}
+```
+
+**运行时发生了什么?**
+
+当用户问"北京天气怎么样"时,LangChain4j 内部会:
+
+1. **思考**:模型分析问题,决定调用 `getWeather` 工具。
+2. **行动**:执行 `getWeather("北京")`。
+3. **观察**:得到 "晴天,15℃,空气质量良好"。
+4. **再思考**:模型结合天气数据,判断适合户外运动。
+5. **最终答案**:返回完整回答。
+
+整个过程对开发者透明,你只需定义工具,剩下的交给框架。
+
+**两种模式的区别**
+
+| 模式 | 适用场景 | 特点 |
+|-----|---------|------|
+| 函数调用(推荐) | OpenAI、Claude等支持工具调用的模型 | 稳定可靠,直接输出结构化调用 |
+| 文本解析 | 开源模型、不支持工具调用的模型 | 通过提示词让模型输出 `Action: xxx` 格式,再解析 |
+
+LangChain4j 会根据模型类型自动选择模式。如果你的模型支持函数调用,优先用这个——更稳定,不容易出错。
+
+## 为什么ReAct管用
+
+
+
+### 减少胡说八道
+
+假设用户问:"今天A股涨得最多的是哪只?"
+
+普通模型可能直接猜"茅台"——反正训练数据里有。
+
+ReAct模型会:
+1. 想到:我得查实时数据。
+2. 调用股票API。
+3. 看结果:涨最多的是XXX。
+4. 根据真实数据回答。
+
+不靠记忆,靠查证。
+
+### 出了问题能追溯
+
+用ReAct,系统可以展示完整的推理链条。客服答错了?直接看:它问了什么、查了什么、最后怎么答的。开发者定位问题快多了。
+
+传统模型只能两手一摊:"抱歉,我不知道为什么会那样。"
+
+### 能随机应变
+
+比如订餐场景:用户说"帮我订个餐厅,要近、评分高、适合商务"。
+
+ReAct会:
+1. 获取用户位置。
+2. 搜附近高评分餐厅。
+3. 筛选适合商务的。
+4. 发现首选满了,自动推荐备选。
+
+脚本做不到这种灵活调整——它只会报错或者返回固定结果。
+
+### 能组合多个工具
+
+写一份市场分析报告?ReAct可以协调搜索工具查数据、代码工具做分析、图表工具可视化、写作工具生成报告。模拟的是一个真实分析师的工作方式。
+
+## 工程实践
+
+
+
+### 避免死循环
+
+智能客服常见问题:用户问"客服电话多少",系统没有这个功能,模型就一直绕圈。
+
+解决办法:
+
+**硬限制**:
+
+```python
+max_iterations = 10
+for i in range(max_iterations):
+ # 执行循环
+ if i >= max_iterations:
+ return "处理超时,请稍后重试"
+```
+
+**循环检测**:同一个操作重复3次,直接判定无法回答,退出。
+
+**系统提示引导**:告诉模型"最多试3次,还是不行就说不知道"。
+
+### 上下文管理
+
+长对话容易爆窗口。比如分析50份简历,每份都查背景信息,上下文直接撑满。
+
+处理方式:
+
+**截断**:只保留最近10轮对话,早期内容丢掉。
+
+**摘要**:把前面的分析压缩成一句话,比如"20份简历分析完成,12份通过初筛"。只留结论,不留过程。
+
+省Token,效果差不多。
+
+### 并行调用
+
+问:"对比北京、上海、深圳国庆期间的天气和机票价格。"
+
+串行做法:查北京天气→等,查上海天气→等,查深圳天气→等,查北京机票→等……6次等待。
+
+并行做法:三个城市天气一起查,三张机票一起查。2次等待搞定。
+
+性能差距明显。
+
+### 错误处理
+
+订机票时支付API返回"网络超时",怎么办?
+
+**分级处理**:
+- 网络超时:等1秒重试,最多3次
+- API限流:换备用支付渠道
+- 余额不足:提示充值
+- 系统维护:告知稍后再试
+
+**回退机制**:主渠道失败自动试备用渠道,都失败了保存订单状态,让用户晚点再试。
+
+## 结语
+
+ReAct让AI从被动应答变成主动规划。通过把推理和外部工具结合起来,AI能处理远超传统聊天机器人的复杂任务。
+
+它的核心其实很朴素:**像人一样做事**。想一下、做一下、看结果、接着想。
+
+挑战也不少。循环控制、上下文管理、错误处理,都需要认真对待。但随着技术成熟,基于ReAct的AI智能体正在各个场景里发挥作用。
+
+如果你在搞AI应用,ReAct值得深入了解。
diff --git "a/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md" "b/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md"
new file mode 100644
index 0000000..f14955d
--- /dev/null
+++ "b/docs/md/AI/\344\270\272\344\273\200\344\271\210ChatGPT\350\203\275\345\220\254\346\207\202\344\275\240\350\257\264\347\232\204\350\257\235\357\274\237Embedding\346\212\200\346\234\257\346\217\255\347\247\230.md"
@@ -0,0 +1,196 @@
+ChatGPT、Claude这些AI助手能理解我们说的话,还能给出像样的回答。做到这点,靠的是Embedding技术。
+
+没有它,大语言模型根本没法处理文字输入。Embedding把人类语言变成数字,让机器能"读懂"。
+
+## 什么是Embedding
+
+Embedding就是把词语、句子变成一串数字。听起来简单,但背后的想法很有意思。
+
+我们说"北京"这个词时,脑子里会想到:城市、首都、政治中心、文化古都。这些概念连在一起,构成我们对"北京"的理解。Embedding做的,就是把这种理解映射到数学空间里。
+
+每个词变成一个向量——一组数字。有意思的是,语义相近的词,向量也靠得近。"北京"和"上海"的向量距离很近,都是城市。但"北京"和"苹果"就离得远,语义完全不同。
+
+ +
+这就让机器能通过距离来理解语义,不是简单匹配关键词。
+
+## 怎么把词变成数字
+
+举个通俗的例子。描述几个水果:
+
+- 苹果:红色的、中等大小、甜度适中、脆的、圆形的。
+- 香蕉:黄色的、细长的、很甜、软的、弯曲的。
+- 西瓜:绿色的、很大的、甜度中等、多汁的、圆形的。
+
+用数字表示这些特征,比如给每个特征打分(0到1):
+
+- 苹果:[0.9(红色),0.5(大小),0.7(甜度),0.8(脆度),1.0(圆润)]。
+- 香蕉:[0.1(红色), 0.3(大小),0.9(甜度),0.2(脆度), 0.2(圆润)]。
+- 西瓜:[0.1(红色),0.95(大小),0.6(甜度),0.3(脆度),1.0(圆润)]。
+
+真实的Embedding要复杂得多,通常是几百到几千维。但思路就是这样:用数字刻画特征。
+
+模型怎么学会这些特征?它看上下文。就像通过朋友圈了解一个人,模型通过观察一个词周围经常出现什么词,理解这个词的含义。
+
+比如"银行":
+- "我去银行存钱"——周围是"存钱",指金融机构。
+- "他坐在银行边钓鱼"——周围是"钓鱼",指河岸。
+
+模型通过阅读海量文本,学会根据上下文判断词义。语义相近的词,向量也接近。
+
+## 怎么衡量向量的相似度
+
+用余弦相似度。计算两个向量的夹角:
+
+- 夹角小,相似度接近1,语义相似。
+- 夹角大,相似度接近0,语义不相关。
+
+余弦相似度关注向量的方向,不是长度。在自然语言里,概念的相似性更多体现在"方向"上。
+
+
+
+这就让机器能通过距离来理解语义,不是简单匹配关键词。
+
+## 怎么把词变成数字
+
+举个通俗的例子。描述几个水果:
+
+- 苹果:红色的、中等大小、甜度适中、脆的、圆形的。
+- 香蕉:黄色的、细长的、很甜、软的、弯曲的。
+- 西瓜:绿色的、很大的、甜度中等、多汁的、圆形的。
+
+用数字表示这些特征,比如给每个特征打分(0到1):
+
+- 苹果:[0.9(红色),0.5(大小),0.7(甜度),0.8(脆度),1.0(圆润)]。
+- 香蕉:[0.1(红色), 0.3(大小),0.9(甜度),0.2(脆度), 0.2(圆润)]。
+- 西瓜:[0.1(红色),0.95(大小),0.6(甜度),0.3(脆度),1.0(圆润)]。
+
+真实的Embedding要复杂得多,通常是几百到几千维。但思路就是这样:用数字刻画特征。
+
+模型怎么学会这些特征?它看上下文。就像通过朋友圈了解一个人,模型通过观察一个词周围经常出现什么词,理解这个词的含义。
+
+比如"银行":
+- "我去银行存钱"——周围是"存钱",指金融机构。
+- "他坐在银行边钓鱼"——周围是"钓鱼",指河岸。
+
+模型通过阅读海量文本,学会根据上下文判断词义。语义相近的词,向量也接近。
+
+## 怎么衡量向量的相似度
+
+用余弦相似度。计算两个向量的夹角:
+
+- 夹角小,相似度接近1,语义相似。
+- 夹角大,相似度接近0,语义不相关。
+
+余弦相似度关注向量的方向,不是长度。在自然语言里,概念的相似性更多体现在"方向"上。
+
+ +
+## 向量和张量的关系
+
+机器学习里有个更广的概念——张量(Tensor),就是N维数组:
+
+- 0维张量是标量(单个数字)。
+- 1维张量是向量(一维数组)。
+- 2维张量是矩阵(二维数组)。
+- 更高维张量表示更复杂的数据结构。
+
+Embedding向量是一维张量。在大语言模型里,虽然每个词的Embedding是向量,但批量处理时会组织成矩阵或更高维张量。
+
+## 技术演进
+
+Embedding技术从简单到复杂,走了一段路。
+
+### Word2Vec:早期的尝试
+
+Word2Vec是早期代表,关注单个词的向量化。思路是:通过上下文学习词的语义。
+
+模型观察大量文本,学习哪些词经常出现在相似的语境中。"猫"和"老虎"都会出现在"动物园"、"宠物"这些上下文里。通过统计学习,这些词在向量空间中位置靠近。
+
+这揭示了一个特性:语义相似性可以通过上下文分布的相似性来捕捉。
+
+但Word2Vec有局限:每个词只有固定向量,处理不了一词多义。"苹果"可以指水果,也可以指科技公司,Word2Vec把它们映射到同一个向量。
+
+### 自注意力机制:突破
+
+Transformer引入的自注意力机制(Self-Attention)是重大突破。模型生成某个词的向量时,能同时考虑句子中所有其他词。
+
+两个优势:
+
+- **长距离依赖**:传统序列模型里,词与词的依赖关系随距离增加而减弱。自注意力机制能直接计算句子中任意两个词的关联强度,不管它们离多远。这帮助模型理解复杂的句法和语义。
+- **动态上下文表示**:Word2Vec给每个词分配固定向量,自注意力机制根据上下文生成不同向量。"我吃了一个苹果"和"苹果公司发布了新产品",两个"苹果"向量完全不同。
+
+### BERT:双向理解
+
+BERT(Bidirectional Encoder Representations from Transformers)实现了双向上下文理解。预训练时同时考虑一个词左右两侧的所有词。
+
+以"很长"这个词组为例:
+- "这条河很长"——指河流长度。
+- "他当了很长时间的厂长"——指时间持续。
+
+BERT根据不同上下文为"很长"生成不同向量。Embedding技术从静态表示迈向动态、上下文感知的语义理解。
+
+
+
+## 向量和张量的关系
+
+机器学习里有个更广的概念——张量(Tensor),就是N维数组:
+
+- 0维张量是标量(单个数字)。
+- 1维张量是向量(一维数组)。
+- 2维张量是矩阵(二维数组)。
+- 更高维张量表示更复杂的数据结构。
+
+Embedding向量是一维张量。在大语言模型里,虽然每个词的Embedding是向量,但批量处理时会组织成矩阵或更高维张量。
+
+## 技术演进
+
+Embedding技术从简单到复杂,走了一段路。
+
+### Word2Vec:早期的尝试
+
+Word2Vec是早期代表,关注单个词的向量化。思路是:通过上下文学习词的语义。
+
+模型观察大量文本,学习哪些词经常出现在相似的语境中。"猫"和"老虎"都会出现在"动物园"、"宠物"这些上下文里。通过统计学习,这些词在向量空间中位置靠近。
+
+这揭示了一个特性:语义相似性可以通过上下文分布的相似性来捕捉。
+
+但Word2Vec有局限:每个词只有固定向量,处理不了一词多义。"苹果"可以指水果,也可以指科技公司,Word2Vec把它们映射到同一个向量。
+
+### 自注意力机制:突破
+
+Transformer引入的自注意力机制(Self-Attention)是重大突破。模型生成某个词的向量时,能同时考虑句子中所有其他词。
+
+两个优势:
+
+- **长距离依赖**:传统序列模型里,词与词的依赖关系随距离增加而减弱。自注意力机制能直接计算句子中任意两个词的关联强度,不管它们离多远。这帮助模型理解复杂的句法和语义。
+- **动态上下文表示**:Word2Vec给每个词分配固定向量,自注意力机制根据上下文生成不同向量。"我吃了一个苹果"和"苹果公司发布了新产品",两个"苹果"向量完全不同。
+
+### BERT:双向理解
+
+BERT(Bidirectional Encoder Representations from Transformers)实现了双向上下文理解。预训练时同时考虑一个词左右两侧的所有词。
+
+以"很长"这个词组为例:
+- "这条河很长"——指河流长度。
+- "他当了很长时间的厂长"——指时间持续。
+
+BERT根据不同上下文为"很长"生成不同向量。Embedding技术从静态表示迈向动态、上下文感知的语义理解。
+
+ +
+## Embedding在LLM里的作用
+
+Embedding是大语言模型(LLM)运转的基石。
+
+### LLM内部怎么工作
+
+用户向ChatGPT输入问题时,系统内部经历几个步骤:
+
+- **第一步:Tokenization(分词)**:分词器把文本拆成token。一个token可能是一个词、一个字,也可能是一个词组。"请写一首关于秋天的诗"会被拆为["请"、"写"、"一首"、"关于"、"秋天"、"的"、"诗"]。
+- **第二步:Embedding Lookup(向量查询)**:每个token有唯一ID。LLM内部维护巨大Embedding矩阵,类似字典。模型看到token ID,在矩阵中查找对应向量。
+- **第三步:Position Encoding(位置编码)**。模型要知道每个token在句子中的位置。给每个token加上位置编码向量,保留顺序信息。
+- **第四步:向量处理与生成**:语义向量和位置编码结合,形成最终输入。这些向量经过Transformer多层网络计算,生成输出。
+
+Embedding把人类可读的语言变成机器可计算的数字。没有这一步,推理、理解、生成都无从谈起。
+
+
+
+## Embedding在LLM里的作用
+
+Embedding是大语言模型(LLM)运转的基石。
+
+### LLM内部怎么工作
+
+用户向ChatGPT输入问题时,系统内部经历几个步骤:
+
+- **第一步:Tokenization(分词)**:分词器把文本拆成token。一个token可能是一个词、一个字,也可能是一个词组。"请写一首关于秋天的诗"会被拆为["请"、"写"、"一首"、"关于"、"秋天"、"的"、"诗"]。
+- **第二步:Embedding Lookup(向量查询)**:每个token有唯一ID。LLM内部维护巨大Embedding矩阵,类似字典。模型看到token ID,在矩阵中查找对应向量。
+- **第三步:Position Encoding(位置编码)**。模型要知道每个token在句子中的位置。给每个token加上位置编码向量,保留顺序信息。
+- **第四步:向量处理与生成**:语义向量和位置编码结合,形成最终输入。这些向量经过Transformer多层网络计算,生成输出。
+
+Embedding把人类可读的语言变成机器可计算的数字。没有这一步,推理、理解、生成都无从谈起。
+
+ +
+### 理解和推理的数学基础
+
+Embedding的重要性不只体现在输入阶段。在向量空间里,复杂语义操作通过数学运算实现:
+
+- 语义相似性:向量余弦相似度度量。
+- 语义关系:向量运算捕捉("国王" - "男人" + "女人" ≈ "女王")。
+- 语义组合:向量加权求和。
+
+这些数学操作让LLM进行推理和生成,不是简单模式匹配。
+
+## RAG框架里的Embedding
+
+除了在LLM内部,Embedding在实际应用中也很重要,特别是在RAG(Retrieval-Augmented Generation,检索增强生成)框架中。
+
+### RAG是什么
+
+RAG把大语言模型和可搜索的外部知识库结合。核心想法:让模型访问训练时没见过的新信息,提升回答准确性和时效性。
+
+传统LLM应用里,模型知识来自训练数据。GPT-4的训练数据截止到2023年,之后发生的事它不知道。RAG通过连接外部知识库,让模型实时获取最新信息。
+
+### Embedding在RAG里的作用
+
+在RAG框架中,Embedding连接外部知识库与大语言模型。工作流程:
+
+- **知识库准备**:把外部文档(PDF、网页等)分割成文本块。用Embedding模型把每个文本块转换为向量,存储在向量数据库。文本内容变成可计算的数学表示。
+- **查询与检索**:用户提问时,系统把查询语句转换为查询向量。在向量数据库中通过余弦相似度计算,找出最相似的top-k个文本块。这是语义检索,不是关键词匹配。
+- **生成**:检索出的文本块和用户查询一起传给大语言模型。模型基于这些信息生成回答。
+
+
+
+### 理解和推理的数学基础
+
+Embedding的重要性不只体现在输入阶段。在向量空间里,复杂语义操作通过数学运算实现:
+
+- 语义相似性:向量余弦相似度度量。
+- 语义关系:向量运算捕捉("国王" - "男人" + "女人" ≈ "女王")。
+- 语义组合:向量加权求和。
+
+这些数学操作让LLM进行推理和生成,不是简单模式匹配。
+
+## RAG框架里的Embedding
+
+除了在LLM内部,Embedding在实际应用中也很重要,特别是在RAG(Retrieval-Augmented Generation,检索增强生成)框架中。
+
+### RAG是什么
+
+RAG把大语言模型和可搜索的外部知识库结合。核心想法:让模型访问训练时没见过的新信息,提升回答准确性和时效性。
+
+传统LLM应用里,模型知识来自训练数据。GPT-4的训练数据截止到2023年,之后发生的事它不知道。RAG通过连接外部知识库,让模型实时获取最新信息。
+
+### Embedding在RAG里的作用
+
+在RAG框架中,Embedding连接外部知识库与大语言模型。工作流程:
+
+- **知识库准备**:把外部文档(PDF、网页等)分割成文本块。用Embedding模型把每个文本块转换为向量,存储在向量数据库。文本内容变成可计算的数学表示。
+- **查询与检索**:用户提问时,系统把查询语句转换为查询向量。在向量数据库中通过余弦相似度计算,找出最相似的top-k个文本块。这是语义检索,不是关键词匹配。
+- **生成**:检索出的文本块和用户查询一起传给大语言模型。模型基于这些信息生成回答。
+
+ +
+### 模型一致性原则
+
+RAG里有个原则必须遵守:导入数据和查询时,必须用同一个Embedding模型。
+
+不同模型把相同文本映射到不同向量空间。导入和查询用不同模型,就像用英语语法规则理解中文句子,匹配会失败。保持模型一致,检索才准确。
+
+### Embedding质量影响RAG效果
+
+Embedding模型性能直接决定RAG效果。高质量模型能准确捕捉文本语义,检索出最相关的信息。模型性能不佳会:
+
+- 检索不准确:返回的内容相关性不高。
+- 遗漏关键信息:没检索到有用的信息。
+- 引入噪音:检索出不相关内容,干扰模型判断。
+
+选合适的Embedding模型,是RAG系统成功的关键。
+
+## 向量数据库
+
+Embedding技术广泛应用后,专门存储和检索高维向量的向量数据库出现了。这类数据库的核心能力是相似性搜索,根据向量距离查找最相似的向量。
+
+### 两类向量数据库
+
+- **专用向量数据库**:完全为向量检索构建,采用高级索引算法(HNSW、IVF)在海量数据中实现毫秒级查询。代表产品有Pinecone、Milvus、Weaviate。优势是检索快、性能优化好,适合大规模向量检索。
+- **集成向量检索功能的通用数据库**:传统关系型或文档型数据库,通过插件或内置功能支持向量检索。代表产品有Elasticsearch(dense_vector字段)、PostgreSQL(pgvector插件)、Redis。优势是同时处理结构化数据和向量数据,适合混合检索场景。
+
+
+
+### 模型一致性原则
+
+RAG里有个原则必须遵守:导入数据和查询时,必须用同一个Embedding模型。
+
+不同模型把相同文本映射到不同向量空间。导入和查询用不同模型,就像用英语语法规则理解中文句子,匹配会失败。保持模型一致,检索才准确。
+
+### Embedding质量影响RAG效果
+
+Embedding模型性能直接决定RAG效果。高质量模型能准确捕捉文本语义,检索出最相关的信息。模型性能不佳会:
+
+- 检索不准确:返回的内容相关性不高。
+- 遗漏关键信息:没检索到有用的信息。
+- 引入噪音:检索出不相关内容,干扰模型判断。
+
+选合适的Embedding模型,是RAG系统成功的关键。
+
+## 向量数据库
+
+Embedding技术广泛应用后,专门存储和检索高维向量的向量数据库出现了。这类数据库的核心能力是相似性搜索,根据向量距离查找最相似的向量。
+
+### 两类向量数据库
+
+- **专用向量数据库**:完全为向量检索构建,采用高级索引算法(HNSW、IVF)在海量数据中实现毫秒级查询。代表产品有Pinecone、Milvus、Weaviate。优势是检索快、性能优化好,适合大规模向量检索。
+- **集成向量检索功能的通用数据库**:传统关系型或文档型数据库,通过插件或内置功能支持向量检索。代表产品有Elasticsearch(dense_vector字段)、PostgreSQL(pgvector插件)、Redis。优势是同时处理结构化数据和向量数据,适合混合检索场景。
+
+ +
+### Elasticsearch的语义检索
+
+Elasticsearch通过dense_vector字段和kNN(最近邻)搜索功能,把Embedding转换、存储和检索封装在一起。用户可以直接把Elasticsearch作为RAG框架的向量存储:
+
+- 导入文档时,配置处理管道让Elasticsearch自动调用模型把文本转换为向量并存储。
+- 查询时,系统自动把查询转换为向量,执行相似性搜索。
+
+这降低了技术门槛,开发者不用单独部署向量数据库,就能实现语义检索。
+
+## Embedding的价值
+
+Embedding技术把语言变成数学,让计算机能"理解"人类语言。
+
+从技术演进看,Embedding从简单的词向量发展到上下文感知的动态表示。从Word2Vec到BERT,再到如今的大语言模型,每次技术突破都伴随着Embedding能力提升。
+
+从应用看,Embedding在LLM内部把自然语言转化为数学表示。在RAG等应用中,Embedding实现从关键词匹配到语义检索,大幅提升信息检索准确性。
+
+未来,Embedding还会承担更多:
+
+- 多模态融合:把文本、图像、音频映射到统一的向量空间,实现跨模态理解和生成。
+- 知识图谱构建:通过向量表示构建大规模知识网络,支持复杂推理和决策。
+- 个性化推荐:基于用户行为和偏好的向量表示,实现精准个性化服务。
+- 隐私保护计算:在向量空间进行加密计算,保护数据隐私同时实现智能分析。
+
+理解Embedding的原理和应用,有助于更好地使用AI工具,也为探索AI技术未来提供视角。在AI时代,Embedding将继续连接人类智慧与机器能力。
\ No newline at end of file
diff --git "a/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md" "b/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md"
new file mode 100644
index 0000000..8ac1184
--- /dev/null
+++ "b/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md"
@@ -0,0 +1,428 @@
+## 从Prompt到Skills的转变
+
+2023年到2024年是"Prompt工程"的黄金时期。到了2025年底,AI圈开始频繁讨论一个新概念——**Skills(技能)**。
+
+GitHub上Skills相关仓库获得上万star,各行各业的专业人士开始分享自己封装的Skills。Skills到底是什么?它为什么能引发如此关注?
+
+### Skills的本质:模块化能力包
+
+**Agent Skills是模块化的能力包,包含指令、元数据和可选资源(脚本、模板),让AI Agent在需要时自动加载和使用**。
+
+Skills就像AI助手的"工作手册库"。它不是每次对话都要重新输入的临时指令,而是一套可以长期保存、随时调用的能力模块。
+
+### 从"带新人"到"给手册"
+
+要理解Skills,先看传统AI交互的问题。
+
+想象你在公司带一个新人。他聪明、理解能力强,但不熟悉规矩。
+
+- Prompt方式就像你每次都口头交代任务:"今天写一段公众号开头"、"把这个语气改得更克制"、"按我的结构写一页PPT"。这适合一次性指令,但一旦关闭对话,所有指令就消失,下次得从头教。
+- Rules或记忆机制相当于在工位贴一张"公司行为守则",只能管态度和格式这类宽泛要求。
+- MCP和工具调用更像是给他的电脑装一堆软件和API,他能调用外部工具,但不知道什么时候该用、怎么组合。
+
+**Skills**改变了这一局面。它就像给新人一本完整的公司内部SOP手册——不是长到让人窒息的Word文档,而是一个知识库文件夹,里面有规范、脚本、模板、参考资料。AI会在需要时自己翻阅,按需加载。
+
+### Skills的物理形态
+
+很多人问:"这不就是Prompt吗?"实际上两者在形态上有本质区别:
+
+- **Prompt**:一段文本(通常是Markdown格式)。
+- **Skills**:一个文件夹结构,包含多种资源。
+
+一个标准的Skill目录:
+
+```
+skill-name/
+├── SKILL.md # 核心指令文件(必需)
+├── scripts/ # 可执行脚本(可选)
+├── references/ # 参考文档(可选)
+├── templates/ # 模板文件(可选)
+└── assets/ # 其他资源(可选)
+```
+
+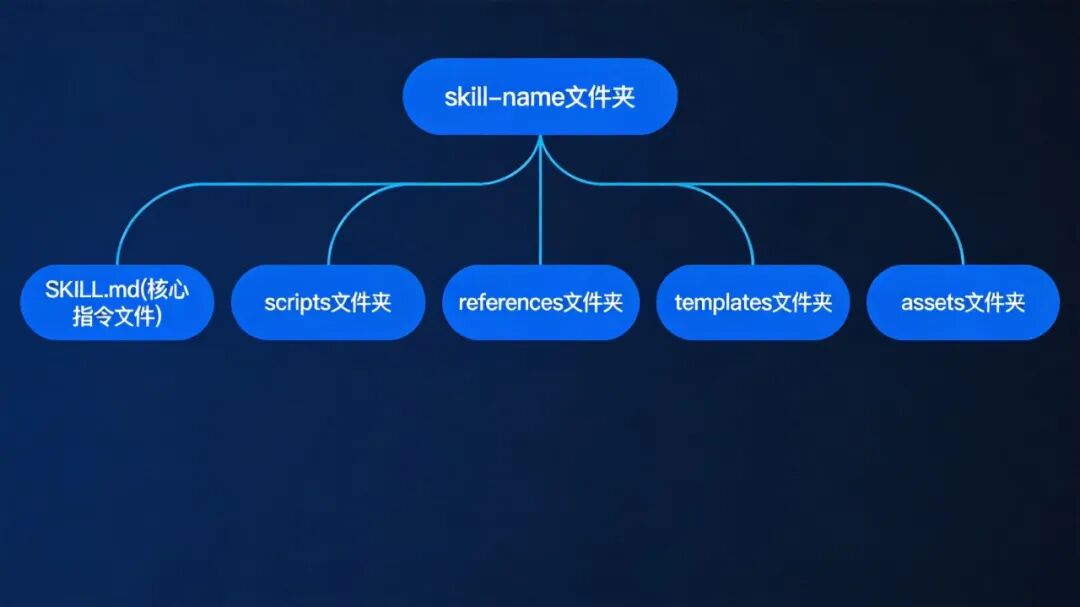
+
+**SKILL.md是唯一必需的文件**,它采用YAML前导格式(类似简历开头的个人信息区),包含元数据和详细指令。这种设计让Skills不仅能承载知识,还能承载工具和流程。
+
+## 渐进式披露架构
+
+### 为什么"一次性塞进所有信息"行不通?
+
+Skills采用了**渐进式披露(Progressive Disclosure)**架构。这个概念在移动互联网时代曾是用户体验设计的核心原则之一。
+
+打开一个APP,如果它一次性把所有功能、设置、选项都堆在你面前,你会怎样?认知负荷爆炸,不知所措。
+
+人的瞬时记忆区非常有限,一瞬间只能接受最多7±2个信息块。AI也是如此——受限于Token窗口,对话越长,模型越"笨"。Token在Agent架构上寸土寸金。
+
+传统做法:每次对话都把完整指令塞进上下文。一个详细的PDF处理工作流可能需要3000+ tokens。如果同时处理Excel、写代码、生成报告,上下文窗口很快爆满。
+
+### 三层加载机制
+
+Skills通过三层渐进式加载解决这个问题:
+
+**第一层:元数据——目录索引**
+
+这是Skills的"封面",包含技能名称和一句话描述。
+
+- **加载时机**:每次对话开始时。
+- **Token消耗**:约100 tokens/Skill。
+- **作用**:让AI知道有哪些Skills可用,何时该用。
+
+你可以安装数十个Skills,几乎没有性能损失。AI就像看图书馆的目录,知道有哪些书,但不必都翻开。
+
+**第二层:指令——详细手册**
+
+当AI通过元数据判断某个任务需要特定Skill时,它会读取完整的SKILL.md文件。
+
+- **加载时机**:任务匹配时触发。
+- **Token消耗**:数千tokens(按实际文件大小)。
+- **作用**:提供详细的操作指南和最佳实践。
+
+用户说"帮我处理这个PDF",AI会判断匹配PDF Skill,然后加载详细的处理流程:先提取文本,再识别表单字段,最后填写并保存。
+
+**第三层:资源和代码——深度参考**
+
+这层包括参考文档、可执行脚本、模板文件等。
+
+- **加载时机**:SKILL.md中引用时。
+- **Token消耗**:按需加载。
+- **关键优势**:脚本执行不消耗上下文(仅结果消耗)。
+
+一个包含复杂Python脚本的Skill,脚本本身的代码不会进入上下文,只有执行结果会返回。这让Skills可以承载几乎无限的资源,而不必担心Token限制。
+
+
+
+### 一个真实的加载流程
+
+以PDF处理为例,看Skills如何工作:
+
+**阶段1:初始状态**
+
+```
+用户输入:"用PDF技能填写这份合同"
+系统提示 + 技能目录 + 用户消息
+Token消耗:约100 tokens
+```
+
+**阶段2:加载主手册**
+
+```
+AI判断:这个任务匹配PDF Skill
+执行:bash cat ~/.claude/skills/pdf/SKILL.md
+Token消耗:+3000 tokens
+```
+
+**阶段3:按需加载参考资料**
+
+```
+AI判断:需要表单填写规则
+执行:bash cat ~/.claude/skills/pdf/references/forms.md
+Token消耗:+500 tokens
+```
+
+**阶段4:执行脚本**
+
+```
+执行:python scripts/fill_form.py --input contract.pdf --output filled.pdf
+Token消耗:+200 tokens(仅输出结果)
+```
+
+**总Token消耗**:约3800 tokens。
+
+对比传统方式:一次性加载所有相关文档和脚本定义,可能需要10,000+ tokens。Skills节省了60-70%的上下文空间。
+
+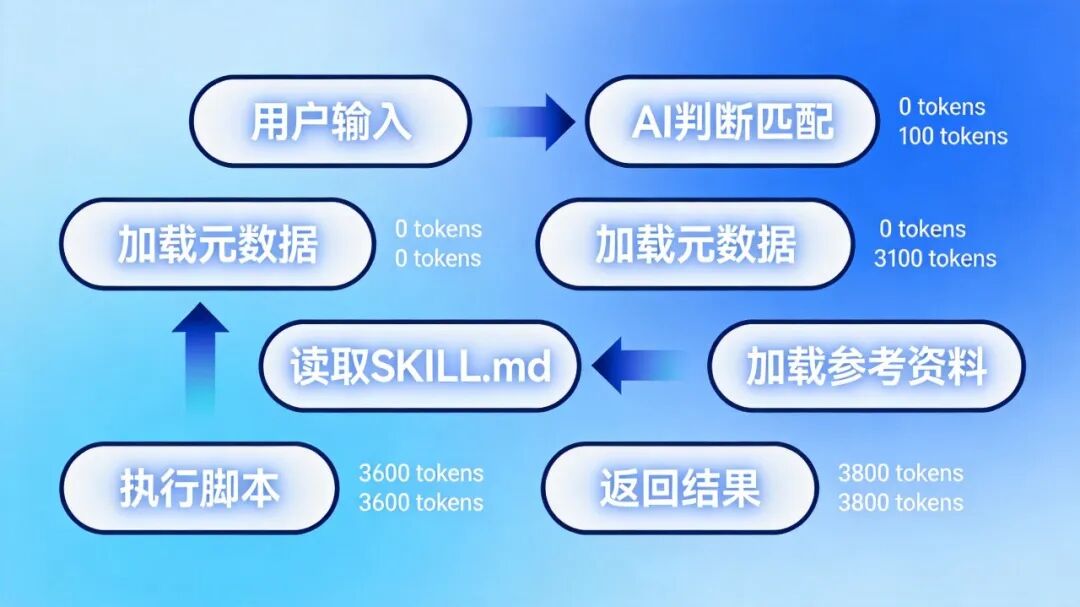
+
+## Skills vs MCP vs Prompt:互补关系
+
+### 三者的核心定位
+
+Skills、MCP、Prompt不是竞争关系,而是互补关系:
+
+| 维度 | Skills | MCP | Prompt |
+|------|--------|-----|--------|
+| **核心定位** | 工作流程指南(How) | 外部系统连接(What) | 临时指令 |
+| **解决问题** | 如何使用能力 | 提供什么数据/能力 | 当下做什么 |
+| **形象比喻** | 使用说明书 | 工具箱 | 口头指令 |
+| **Token效率** | 高(渐进加载) | 低(全量加载) | 中(每次重复) |
+| **复用性** | 强(文件系统) | 中(协议层面) | 弱(手动复制) |
+
+
+
+### Skills与MCP:工作手册 vs 门禁卡
+
+**Skills解决"怎么做"(方法论/工作流),MCP解决"连到哪儿"(连接外部系统)**。
+
+用职场类比:
+- **MCP**:给AI一张门禁卡,让它能进入公司的各个系统(数据库、API、外部工具)。
+- **Skills**:给AI一本工作手册,教它如何使用这些系统完成具体任务。
+
+一个组合场景:
+
+**生成销售报告**
+
+1. **MCP提供数据连接**
+ - 连接Salesforce获取客户数据。
+ - 连接PostgreSQL查询销售记录。
+ - 连接Google Sheets读取目标数据。
+
+2. **Skills提供工作流程**
+ - 数据提取顺序(先查哪个系统)。
+ - 计算逻辑(增长率、完成率)。
+ - 报告格式和模板。
+ - 异常处理规则。
+
+MCP解决"能访问什么数据",Skills解决"如何使用这些数据生成报告"。
+
+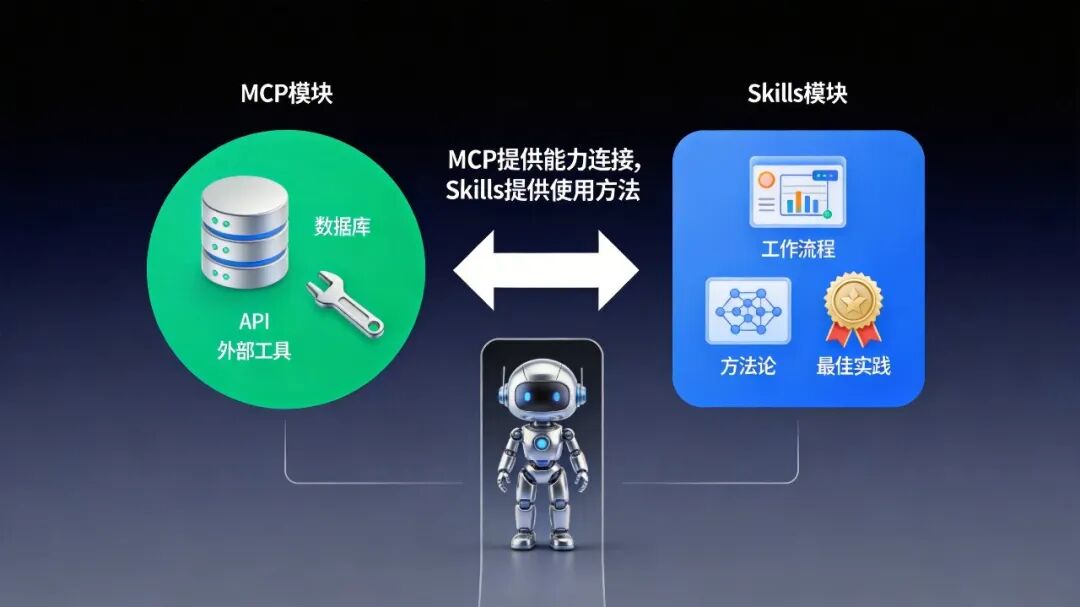
+
+### Skills vs Prompt:从临时指令到持久能力
+
+**Skills不就是高级一点的Prompt吗?**
+
+答案既是肯定的,也是否定的。
+
+**相同点**:Skills的核心确实是自然语言指令,这与Prompt一致。
+
+**根本区别**:
+
+- **生命周期**:Prompt是对话级的,Skills是系统级的。
+- **复用方式**:Prompt需要手动复制粘贴,Skills自动匹配触发。
+- **承载能力**:Prompt只能承载文本,Skills可以承载脚本、模板、参考文档。
+- **Token效率**:Prompt每次都全量加载,Skills按需渐进加载。
+
+用一个实际例子:
+
+**没有Skills时**,每次都要说:
+
+```
+帮我总结这篇文章 → 翻译成英文 → 改成公众号风格 → 加标题 → 输出Markdown格式
+```
+
+**有了Skills后**,只需要一句:
+```
+使用「技术文章转公众号」Skill
+```
+
+AI会自动按照预设的完整流程执行。
+
+## 实际应用
+
+### 个人场景:把重复工作封装成能力包
+
+**案例1:AI选题系统**
+
+一个内容团队用Skills构建了自动化选题系统,包含:
+- 1个总控Agent。
+- 3个Skill(热点采集、选题生成、选题审核)。
+
+每天只需要一句:"开始今日选题生成",系统就会自动:
+1. 从多个平台采集全网热点。
+2. 筛选并生成TOP10选题(包含事件描述、核心角度、标题)。
+3. 按照内部方法论自动审核。
+4. 不通过时给出修改意见并迭代优化。
+
+过去需要2-3小时的工作,现在几分钟就能完成初筛。
+
+**案例2:整合包生成器**
+
+很多GitHub开源项目没有前端界面,环境配置复杂。有人用Skills做了一个"整合包生成器":
+
+提供一个GitHub链接,Skill就会:
+1. 分析项目结构。
+2. 自动生成前端界面。
+3. 编写启动脚本。
+4. 打包成开箱即用的整合包。
+
+解决了"想用但不会配置"的痛点。
+
+### 团队场景:知识资产沉淀与共享
+
+**传统方式的问题**:
+- 每个团队各自维护长Prompt。
+- 写法、风格不统一。
+- 复用靠复制粘贴。
+- 难以版本管理和评审。
+
+**Skills带来的改变**:
+- 把"怎么做好一件事"固化成SKILL.md + 脚本 + 参考文档。
+- 放入Git版本库,走标准开发流程。
+- 团队间共享、评审、复用。
+- 形成企业内部的"技能库"(Skill Library)。
+
+**组织架构示例**:
+```
+公司级Agent产品
+├── 市场部维护:品牌文案Skill
+├── 法务部维护:合同审阅Skill
+├── 财务部维护:报销审核Skill
+└── 技术部维护:代码审查Skill
+```
+
+所有技能装在同一个Agent身上,用户只跟一个界面打交道。
+
+### 行业场景:专业知识标准化
+
+**医疗诊断流程**:将诊断标准、注意事项、药物禁忌等封装成Skill,确保AI遵循医疗规范
+
+**法律文书审查**:将审查要点、风险识别、合规要求标准化,提高审查质量和一致性
+
+**代码审计规范**:将安全检查项、代码风格要求、最佳实践固化
+
+**ML实验配置**:将实验设计规范、参数推荐范围、结果记录模板封装
+
+这些领域知识需要结构化存储、团队共享、版本管理、跨平台使用——正是Skills的强项。
+
+## 技术实现
+
+### 最小可行Skill
+
+创建一个Skill只需要一个SKILL.md文件:
+
+```markdown
+---
+name: hello-skill
+description: A simple skill that greets users
+---
+
+# Hello Skill
+
+When user says hello, respond with a friendly greeting.
+```
+
+**必填字段**:
+- `name`:技能名称(小写字母、数字、连字符符)。
+- `description`:功能描述。
+
+**简单到人人可创建,强大到专业团队可用**。
+
+### 完整Skill:PDF处理案例
+
+```
+pdf-skill/
+├── SKILL.md
+├── scripts/
+│ ├── extract_text.py
+│ ├── fill_form.py
+│ └── merge_pdfs.py
+├── references/
+│ ├── FORMS.md
+│ └── API_REFERENCE.md
+└── templates/
+ └── report_template.md
+```
+
+**SKILL.md内容**:
+
+```markdown
+---
+name: pdf-processing
+description: Extract text and tables from PDF files, fill forms, merge documents.
+ Use when working with PDF files or when the user mentions PDFs.
+---
+
+# PDF Processing
+
+## Quick Start
+
+1. For text extraction, use `python {baseDir}/scripts/extract_text.py`
+2. For form filling, see [FORMS.md](references/FORMS.md)
+3. For merging PDFs, execute the merge script
+
+## Supported Operations
+
+- Text extraction from text-based PDFs
+- OCR for scanned PDFs (requires Tesseract)
+- Form field identification and filling
+- Multi-document merging
+
+## Best Practices
+
+- Always validate PDF integrity before processing
+- Use OCR only when necessary (higher token cost)
+- Keep extracted text under 10,000 tokens for best performance
+```
+
+**关键点**:
+
+- `{baseDir}`是自动替换变量,表示Skill的安装路径。
+- 可以引用其他文件(如FORMS.md),AI会在需要时加载。
+- 指令清晰、结构化,便于AI理解和执行。
+
+### 安装和使用
+
+**方法1:命令安装**
+
+```bash
+# 安装官方Skill
+claude skill install https://github.com/anthropics/skills/tree/main/skills/pdf
+
+# 或在对话中直接说
+"安装这个skill:https://github.com/xxx/skill-name"
+```
+
+**方法2:手动放置**
+
+将Skill文件夹放到对应目录:
+- Claude Code:`~/.claude/skills/`。
+- Cursor:`~/.cursor/skills/。`
+- OpenCode:`~/.config/opencode/skill/`。
+
+**使用方式**:
+
+直接对话:
+```
+用户:"帮我处理这个PDF"
+AI会自动识别并调用PDF Skill
+```
+
+或者显式指定:
+```
+用户:"使用PDF Skill提取这份文档的文本"
+```
+
+## 未来展望
+
+### 从工具到生态
+
+目前Skills还处于早期阶段,但已经有了生态雏形:
+
+- **官方Skills库**:Anthropic开源了官方Skills仓库,包含PDF、Excel、PPT、Word等常用技能。
+- **社区贡献**:GitHub上涌现大量社区贡献的Skills,涵盖数据分析、代码审查、文档生成等多个领域。
+- **工具支持**:Claude Code、Cursor、OpenCode等主流工具均已支持Skills。
+- **技能市场**:扣子等平台开始提供技能市场,支持搜索、安装、分享Skills。
+
+### 潜在挑战
+
+Skills也面临挑战:
+
+- **标准化问题**:不同平台、不同团队的Skills格式可能不统一,需要建立行业标准。
+- **安全与隐私**:Skills可以执行脚本,需要沙箱隔离和权限控制。
+- **质量参差**:开放的生态意味着质量良莠不齐,需要评价和筛选机制。
+- **学习曲线**:虽然创建简单,但要设计高质量的Skill仍需要经验。
+
+### 对AI发展的意义
+
+Skills代表一个重要趋势:**从让AI"理解"到让AI"执行"**。
+
+过去几年,我们主要关注如何让AI更好地理解自然语言、理解上下文、理解意图。这是必要的基础,但还不够。
+
+Skills的出现,标志着我们开始关注如何让AI系统地、可重复地、高质量地执行复杂任务。这不仅需要理解能力,还需要方法论、最佳实践、工具链的支持。
+
+**这是AI从"对话伙伴"进化为"工作伙伴"的关键一步。**
+
+## 今天就开始你的第一个Skill
+
+Skills的热度已不亚于当年的Prompts。但这不只是流行趋势,而是实实在在的生产力革命。
+
+如果你还在犹豫是否要尝试Skills,建议从最简单的开始:
+
+**今天**,安装一个官方Skill(比如skill-creator),感受一下"一个命令安装能力"的便捷。
+
+**明天**,把最常用的一个动作固化成Skill——比如选题筛热点、报错日志分析、链接摘要生成。
+
+**后天**,你会想把更多工作流程都搬进去。
+
+到那一步,你就进入了另一个状态:**自由,创造的状态**。
+
+Skills的核心价值,在于**复用**。当你把一次性的努力转化为可重复调用的能力,你就不再是每次都从零开始,而是站在前人的肩膀上持续前进。
diff --git "a/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md" "b/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md"
new file mode 100644
index 0000000..93a2374
--- /dev/null
+++ "b/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md"
@@ -0,0 +1,922 @@
+> DDD 不是架构,而是一种架构设计方法论,它通过边界划分将复杂业务领域简单化,帮我们设计出清晰的领域和应用边界,可以很容易地实现架构演进。
+
+# 基础概念
+
+## 领域
+
+领域就是用来确定范围的,范围即边界,这也是 DDD 在设计中不断强调边界的原因。
+
+**简言之,DDD 的领域就是这个边界内要解决的业务问题域**。
+
+领域可以进一步划分为子领域。我们把划分出来的多个子领域称为子域,每个子域对应一个更小的问题域或更小的业务范围。领域可以拆分为多个子领域。一个领域相当于一个问题域,领域拆分为子域的过程就是大问题拆分为小问题的过程。
+
+其实很好理解,DDD 的研究方法与自然科学的研究方法类似。当人们在自然科学研究中遇到复杂问题时,通常的做法就是将问题一步一步地细分,再针对细分出来的问题域,逐个深入研究,探索和建立所有子域的知识体系。当所有问题子域完成研究时,我们就建立了全部领域的完整知识体系了。
+
+在领域不断划分的过程中,领域会细分为不同的子域,子域可以根据自身重要性和功能属性划分为三类子域,它们分别是:**核心域、通用域和支撑域**。
+
+决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。没有太多个性化的诉求,同时被多个子域使用的通用功能子域是通用域。还有一种功能子域是必需的,但既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,它就是支撑域。
+
+这三类子域相较之下,核心域是最重要的,通用域和支撑域如果对应到企业系统,举例来说的话,通用域则是你需要用到的通用系统,比如认证、权限等等,这类应用很容易买到,没有企业特点限制,不需要做太多的定制化。而支撑域则具有企业特性,但不具有通用性,例如数据代码类的数据字典等系统。
+
+聚合根与领域服务负责封装实现业务逻辑。领域服务负责对聚合根进行调度和封装,同时可以对外提供各种形式的服务,对于不能直接通过聚合根完成的业务操作就需要通过领域服务。
+
+说白了就是,聚合根本身无法完全处理这个逻辑,例如支付这个步骤,订单聚合不可能支付,所以在订单聚合上架一层领域服务,在领域服务中实现支付逻辑,然后应用服务调用领域服务。
+
+**遵守以下规范**:
+
+- 同限界上下文内的聚合之间的领域服务可直接调用。
+- 两个限界上下文的交互必须通过应用服务层抽离 接口->适配层 适配。
+
+例子,用户升职,上级领导要变,上级领导的下属要变,代码如下:
+
+```java
+@Service
+public class UserDomainServiceImpl implements UserDomainService {
+
+ @Override
+ public void promote(User user, User leader) {
+
+ //保存领导
+ user.saveLeader(leader);
+
+ //领导增加下属
+ leader.increaseSubordination(user);
+ }
+}
+```
+
+## 限界上下文
+
+我们可以将限界上下文拆解为两个词:限界和上下文。
+
+限界就是领域的边界,而上下文则是语义环境。通过领域的限界上下文,我们就可以在统一的领域边界内用统一的语言进行交流,简单来说限界上下文可以理解为语义环境。
+
+综合一下,我认为限界上下文的定义就是:**用来封装通用语言和领域对象,提供上下文环境,保证在领域之内的一些术语、业务相关对象等(通用语言)有一个确切的含义,没有二义性**。
+
+这个边界定义了模型的适用范围,使团队所有成员能够明确地知道什么应该在模型中实现,什么不应该在模型中实现。
+
+举个例子:
+
+在一个明媚的早晨,孩子起床问妈妈:“今天应该穿几件衣服呀?”,妈妈回答:“能穿多少就穿多少!”那到底是穿多还是穿少呢?
+
+如果没有具体的语义环境,还真不太好理解。但是,如果你已经知道了这句话的语义环境,比如是寒冬腊月或者是炎炎夏日,那理解这句话的涵义就会很容易了。
+
+**所以语言离不开它的语义环境**。
+
+而业务的通用语言就有它的业务边界,我们不大可能用一个简单的术语没有歧义地去描述一个复杂的业务领域。限界上下文就是用来细分领域,从而定义通用语言所在的边界。
+
+正如电商领域的商品一样,商品在不同的阶段有不同的术语,在销售阶段是商品,而在运输阶段则变成了货物。同样的一个东西,由于业务领域的不同,赋予了这些术语不同的涵义和职责边界,这个边界就可能会成为未来微服务设计的边界。看到这,我想你应该非常清楚了,领域边界就是通过限界上下文来定义的。
+
+**理论上限界上下文就是微服务的边界。我们将限界上下文内的领域模型映射到微服务,就完成了从问题域到软件的解决方案**。
+
+限界上下文之间的映射关系:
+
+- 合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
+- 共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
+- 客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
+- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
+- 防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
+- 开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
+- 发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
+- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。
+- 另谋他路(SeparateWay):两个完全没有任何联系的上下文。
+
+可以说,限界上下文是微服务设计和拆分的主要依据。在领域模型中,如果不考虑技术异构、团队沟通等其它外部因素,一个限界上下文理论上就可以设计为一个微服务。
+
+## 贫血模型和充血模型
+
+**贫血模型**
+
+贫血模型具有一堆属性和set get方法,存在的问题就是通过 pojo 这个对象上看不出业务有哪些逻辑,一个 pojo 可能被多个模块调用,只能去上层各种各样的service 来调用,这样以后当梳理这个实体有什么业务,只能一层一层去搜 service,也就是贫血失忆症,不够面向对象。
+
+
+
+**充血模型**
+
+比如如下 user 用户有改密码,改手机号,修改登录失败次数等操作,都内聚在这个 user 实体中,每个实体的业务都是清晰的,就是充血模型,充血模型的内存计算会多一些,内聚核心业务逻辑处理。
+
+说白了就是,不只是有贫血模型中的setter getter方法,还有其他的一些业务方法,这才是面向对象的本质,通过 user 实体就能看出有哪些业务存在。
+
+```java
+@NoArgsConstructor
+@Getter
+public class User extends Aggregate {
+
+ /**
+ * 用户名
+ */
+ private String userName;
+
+ /**
+ * 姓名
+ */
+ private String realName;
+
+ /**
+ * 手机号
+ */
+ private String phone;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+ /**
+ * 锁定结束时间
+ */
+ private Date lockEndTime;
+
+ /**
+ * 登录失败次数
+ */
+ private Integer failNumber;
+
+ /**
+ * 用户角色
+ */
+ private List roles;
+
+ /**
+ * 部门
+ */
+ private Department department;
+
+ /**
+ * 用户状态
+ */
+ private UserStatus userStatus;
+
+ /**
+ * 用户地址
+ */
+ private Address address;
+
+ public User(String userName, String phone, String password) {
+
+ saveUserName(userName);
+ savePhone(phone);
+ savePassword(password);
+ }
+
+ /**
+ * 保存用户名
+ * @param userName
+ */
+ private void saveUserName(String userName) {
+ if (StringUtils.isBlank(userName)){
+ Assert.throwException("用户名不能为空!");
+ }
+
+ this.userName = userName;
+ }
+
+ /**
+ * 保存电话
+ * @param phone
+ */
+ private void savePhone(String phone) {
+ if (StringUtils.isBlank(phone)){
+ Assert.throwException("电话不能为空!");
+ }
+
+ this.phone = phone;
+ }
+
+ /**
+ * 保存密码
+ * @param password
+ */
+ private void savePassword(String password) {
+ if (StringUtils.isBlank(password)){
+ Assert.throwException("密码不能为空!");
+ }
+
+ this.password = password;
+ }
+
+ /**
+ * 保存用户地址
+ * @param province
+ * @param city
+ * @param region
+ */
+ public void saveAddress(String province,String city,String region){
+ this.address = new Address(province,city,region);
+ }
+
+ /**
+ * 保存用户角色
+ * @param roleList
+ */
+ public void saveRole(List roleList) {
+
+ if (CollectionUtils.isEmpty(roles)){
+ Assert.throwException("角色不能为空!");
+ }
+
+ this.roles = roleList;
+ }
+}
+```
+
+## 实体和值对象
+
+**实体**
+
+实体和值对象这两个概念都是领域模型中的领域对象。实体和值对象是组成领域模型的基础单元。
+
+在代码模型中,实体的表现形式是实体类,这个类包含了实体的属性和方法,通过这些方法实现实体自身的业务逻辑。
+
+在 DDD 里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现,**跨多个实体的领域逻辑则在领域服务中实现**。
+
+实体以 DO(领域对象)的形式存在,每个实体对象都有唯一的 ID。比如商品是商品上下文的一个实体,通过唯一的商品 ID 来标识,不管这个商品的数据如何变化,商品的 ID 一直保持不变,它始终是同一个商品。
+
+在领域模型映射到数据模型时,一个实体可能对应 0 个、1 个或者多个数据库持久化对象。大多数情况下实体与持久化对象是一对一。在某些场景中,有些实体只是暂驻静态内存的一个运行态实体,它不需要持久化。比如,基于多个价格配置数据计算后生成的折扣实体。
+
+而在有些复杂场景下,实体与持久化对象则可能是一对多或者多对一的关系。比如,用户 user 与角色 role 两个持久化对象可生成权限实体,一个实体对应两个持久化对象,这是一对多的场景。
+
+再比如,有些场景为了避免数据库的联表查询,提升系统性能,会将客户信息 customer 和账户信息 account 两类数据保存到同一张数据库表中,客户和账户两个实体可根据需要从一个持久化对象中生成,这就是多对一的场景。
+
+权限管理系统——用户实体,代码如下:
+
+```java
+@NoArgsConstructor
+@Getter
+public class User extends Aggregate {
+
+ /**
+ * 用户id-聚合根唯一标识
+ */
+ private UserId userId;
+
+ /**
+ * 用户名
+ */
+ private String userName;
+
+ /**
+ * 姓名
+ */
+ private String realName;
+
+ /**
+ * 手机号
+ */
+ private String phone;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+ /**
+ * 锁定结束时间
+ */
+ private Date lockEndTime;
+
+ /**
+ * 登录失败次数
+ */
+ private Integer failNumber;
+
+ /**
+ * 用户角色
+ */
+ private List roles;
+
+ /**
+ * 部门
+ */
+ private Department department;
+
+ /**
+ * 领导
+ */
+ private User leader;
+
+ /**
+ * 下属
+ */
+ private List subordinationList = new ArrayList<>();
+
+ /**
+ * 用户状态
+ */
+ private UserStatus userStatus;
+
+ /**
+ * 用户地址
+ */
+ private Address address;
+
+ public User(String userName, String phone, String password) {
+
+ saveUserName(userName);
+ savePhone(phone);
+ savePassword(password);
+ }
+
+ /**
+ * 保存用户名
+ * @param userName
+ */
+ private void saveUserName(String userName) {
+ if (StringUtils.isBlank(userName)){
+ Assert.throwException("用户名不能为空!");
+ }
+
+ this.userName = userName;
+ }
+
+ /**
+ * 保存电话
+ * @param phone
+ */
+ private void savePhone(String phone) {
+ if (StringUtils.isBlank(phone)){
+ Assert.throwException("电话不能为空!");
+ }
+
+ this.phone = phone;
+ }
+
+ /**
+ * 保存密码
+ * @param password
+ */
+ private void savePassword(String password) {
+ if (StringUtils.isBlank(password)){
+ Assert.throwException("密码不能为空!");
+ }
+
+ this.password = password;
+ }
+
+ /**
+ * 保存用户地址
+ * @param province
+ * @param city
+ * @param region
+ */
+ public void saveAddress(String province,String city,String region){
+ this.address = new Address(province,city,region);
+ }
+
+ /**
+ * 保存用户角色
+ * @param roleList
+ */
+ public void saveRole(List roleList) {
+
+ if (CollectionUtils.isEmpty(roles)){
+ Assert.throwException("角色不能为空!");
+ }
+
+ this.roles = roleList;
+ }
+
+ /**
+ * 保存领导
+ * @param leader
+ */
+ public void saveLeader(User leader) {
+ if (Objects.isNull(leader)){
+ Assert.throwException("leader不能为空!");
+ }
+ this.leader = leader;
+ }
+
+ /**
+ * 增加下属
+ * @param user
+ */
+ public void increaseSubordination(User user) {
+
+ if (null == user){
+ Assert.throwException("leader不能为空!");
+ }
+
+ this.subordinationList.add(user);
+ }
+}
+```
+
+**值对象**
+
+简单来说,值对象本质上就是一个集。
+
+那这个集合里面有什么呢?若干个用于描述目的、具有整体概念和不可修改的属性。
+
+那这个集合存在的意义又是什么?在领域建模的过程中,值对象可以保证属性归类的清晰和概念的完整性,避免属性零碎。
+
+举例代码如下:
+
+```java
+/**
+ * 地址数据
+ */
+@Getter
+public class Address extends ValueObject {
+ /**
+ * 省
+ */
+ private String province;
+
+ /**
+ * 市
+ */
+ private String city;
+
+ /**
+ * 区
+ */
+ private String region;
+
+ public Address(String province, String city, String region) {
+ if (StringUtils.isBlank(province)){
+ Assert.throwException("province不能为空!");
+ }
+ if (StringUtils.isBlank(city)){
+ Assert.throwException("city不能为空!");
+ }
+ if (StringUtils.isBlank(region)){
+ Assert.throwException("region不能为空!");
+
+ }
+ this.province = province;
+ this.city = city;
+ this.region = region;
+ }
+}
+```
+
+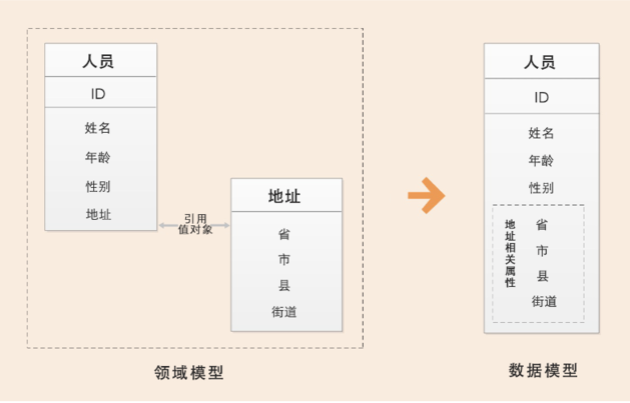
+
+人员实体原本包括:姓名、年龄、性别以及人员所在的省、市、县和街道等属性。这样显示地址相关的属性就很零碎了对不对?现在,我们可以将“省、市、县和街道等属性”拿出来构成一个“地址属性集合”,这个集合就是值对象了。
+
+当你决定一个领域概念是否是 一个值对象时,你需要考虑它是否拥有以下特征:
+
+- 它度量或者描述了领城中的一件东西。
+- 它可以作为不变量。
+- 度量和描述改变时,可以用另一个值对象予以替换。
+- 它可以和其他值对象进行相等性比较。
+- 它不会对协作对象造成副作用。
+
+值对象与实体一起构成聚合。**值对象逻辑上是实体属性的一部分,用于描述实体的特征。值对象创建后就不允许修改了,只能用另外一个值对象来整体替换**。
+
+值对象是一些不会修改,只能完整替换的属性值的集合,你更关注他的属性和值,它没有太多的业务行为,用于描述实体的一些属性集,被实体引用,依附于实体的值对象基本没有自己的数据库表。
+
+是否要设计成值对象,你要看这个对象是否后续还会来回修改,会不会有生命周期。如果不可修改,并且以后也不会专门针对它进行查询或者统计,你就可以把它设计成值对象,如果不行,那就设计成实体吧。
+
+在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。
+
+关于值对象,我还要多说几句。其实,DDD引入值对象还有一个重要的原因,就是到底领域建模优先还是数据建模优先?
+
+DDD提倡从领域模型设计出发,而不是先设计数据模型。前面讲过了,传统的数据模型设计通常是一个表对应一个实体,一个主表关联多个从表,当实体表太多的时候就很容易陷入无穷无尽的复杂的数据库设计,领域模型就很容易被数据模型绑架。可以说,值对象的诞生,在一定程度上,和实体是互补的。
+
+同样的对象在不同的场景下,可能会设计出不同的结果。有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
+
+**唯一的身份标识和可变性(mutability)特征将实体对象和值对象区分开来**。
+
+比如,如果系统提供根据人名查找功能,但此时一个Person实体的唯一标识极有可能不是人名,因为存在大量重名的情况。 另 一方面,如果 一个系统提供根据公司税号的查找功能,此时税号便可以作为 Company 实体的唯一标识,因为政府为每个公司分配了唯一的税号。
+
+值对象可以用于存放实体的唯 一标识。值对象是不变(immutable)的,这可以保证实体身份的稳定性,并且与身份标识相关的行为也可以得到集中处理。
+
+以下是一些常用的创建实体身份标识的策略,从简单到复杂依次为:
+
+- 用户提供一个或多个初始唯一值作为程序输入,程序应该保证这些初始值是唯 一的。
+- 程序内部通过某种算法自动生成身份标识,此时可以使用一些类库或框架,当然程序自身也可以完成这样的功能。
+- 程序依赖于持久化存储,比如数据库,来生成唯一标识。
+- 另一个限界上下文 (系统或程序)已经决定出了唯一标识,这作为程序的输入,用户可以在一组标识中进行选择。
+
+## 聚合
+
+实体和值对象是很基础的领域对象。实体一般对应业务对象,它具有业务属性和业务行为;而值对象主要是属性集合,对实体的状态和特征进行描述。但实体和值对象都只是个体化的对象,它们的行为表现出来的是个体的能力。
+
+那聚合在其中起什么作用呢?
+
+举个例子。社会是由一个个的个体组成的,象征着我们每一个人。随着社会的发展,慢慢出现了社团、机构、部门等组织,我们开始从个人变成了组织的一员,大家可以协同一致的工作,朝着一个最大的目标前进,发挥出更大的力量。
+
+领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
+
+比如创建一个订单,必然会生成订单详情,订单详情肯定会有商品信息,我们在修改商品信息的时候,肯定就不能影响到这个订单详情中的商品信息。再比如:用户在下单的时候,会选择一个地址作为邮寄地址,如果该用户立刻下另一个订单,并对自己个人中心的地址进行修改,肯定就不能影响刚刚下单的邮寄地址信息。
+
+你可以这么理解,聚合就是由业务和逻辑紧密关联的实体和值对象组合而成的,聚合是数据修改和持久化的基本单元,**每一个聚合对应一个仓储,实现数据的持久化**。
+
+聚合在 DDD 分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。
+
+跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现。比如有的业务场景需要同一个聚合的A和B两个实体来共同完成,我们就可以将这段业务逻辑用领域服务来实现;而有的业务逻辑需要聚合C和聚合D中的两个服务共同完成,这时你就可以用应用服务来组合这两个服务。
+
+**聚合根**
+
+如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
+
+首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。
+
+最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。**也就是说,聚合之间通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体**。
+
+下面以保险的投保业务场景为例,看一下聚合的构建过程主要都包括哪些步骤:
+
+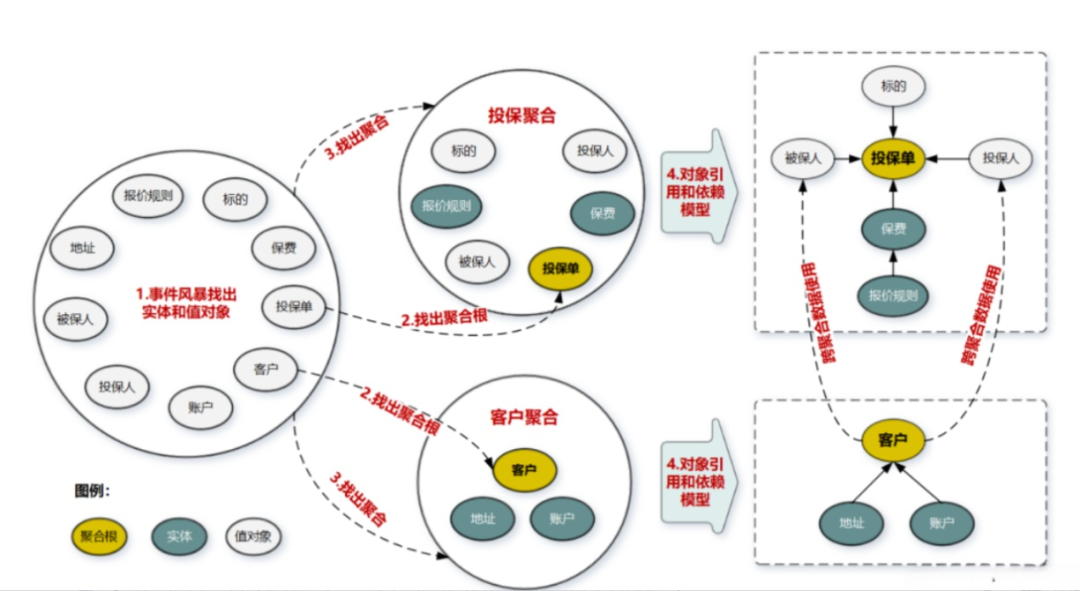
+
+- 第1步:采用事件风暴,根据业务行为,梳理出在投保过程中发生这些行为的所有的实体和值对象,比如投保单、标的、客户、被保人等等。
+- 第2步:从众多实体中选出适合作为对象管理者的根实体,也就是聚合根。判断一个实体是否是聚合根,你可以结合以下场景分析:是否有独立的生命周期?是否有全局唯一ID?是否可以创建或修改其它对象?是否有专门的模块来管这个实体。图中的聚合根分别是投保单和客户实体。
+- 第3步:根据业务单一职责和高内聚原则,找出与聚合根关联的所有紧密依赖的实体和值对象。构建出1个包含聚合根(唯一)、多个实体和值对象的对象集合,这个集合就是聚合。在图中我们构建了客户和投保这两个聚合。
+- 第4步:在聚合内根据聚合根、实体和值对象的依赖关系,画出对象的引用和依赖模型。这里我需要说明一下:投保人和被保人的数据,是通过关联客户ID从客户聚合中获取的,在投保聚合里它们是投保单的值对象,这些值对象的数据是客户的冗余数据,即使未来客户聚合的数据发生了变更,也不会影响投保单的值对象数据。从图中我们还可以看出实体之间的引用关系,比如在投保聚合里投保单聚合根引用了报价单实体,报价单实体则引用了报价规则子实体。
+- 第5步:多个聚合根据业务语义和上下文一起划分到同一个限界上下文内。
+
+这就是一个聚合诞生的完整过程了。
+
+## 领域事件
+
+举例来说的话,领域事件可以是业务流程的一个步骤,比如投保业务缴费完成后,触发投保单转保单的动作;也可能是定时批处理过程中发生的事件,比如批处理生成季缴保费通知单,触发发送缴费邮件通知操作;或者一个事件发生后触发的后续动作,比如密码连续输错三次,触发锁定账户的动作。
+
+在做用户旅程或者场景分析时,我们要捕捉业务、需求人员或领域专家口中的关键词:“如果发生……,则……”“当做完……的时候,请通知……”“发生……时,则……”等。在这些场景中,如果发生某种事件后,会触发进一步的操作,那么这个事件很可能就是领域事件。
+
+**领域事件相关案例**
+
+我来给你介绍一个保险承保业务过程中有关领域事件的案例。
+
+一个保单的生成,经历了很多子域、业务状态变更和跨微服务业务数据的传递。这个过程会产生很多的领域事件,这些领域事件促成了保险业务数据、对象在不同的微服务和子域之间的流转和角色转换。在下面这张图中,我列出了几个关键流程,用来说明如何用领域事件驱动设计来驱动承保业务流程。
+
+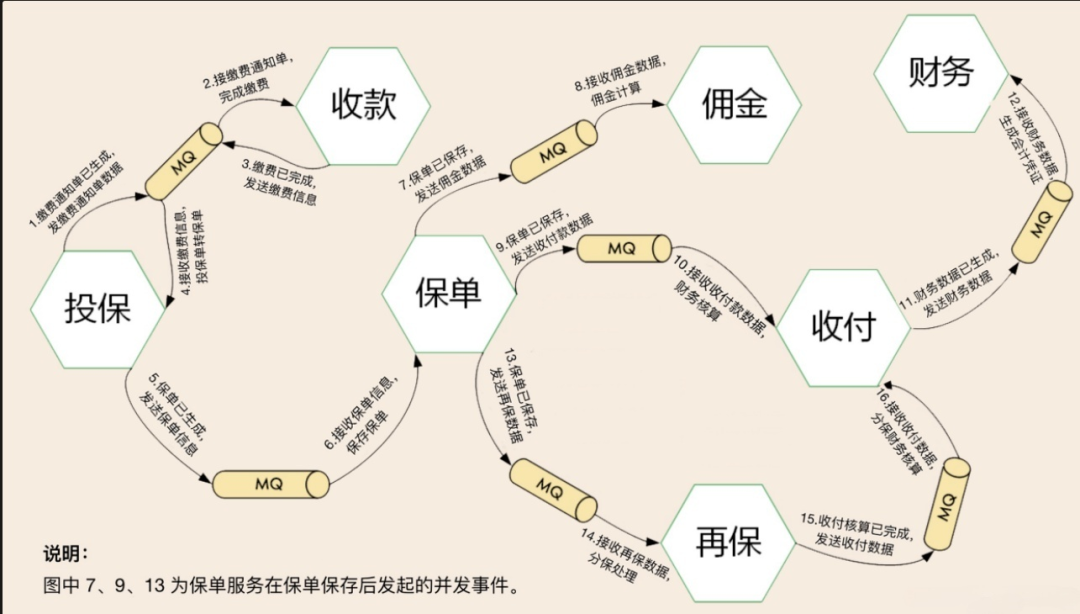
+
+事件起点:客户购买保险-业务人员完成保单录入-生成投保单-启动缴费动作。
+
+1. 投保微服务生成缴费通知单,发布第一个事件:缴费通知单已生成,将缴费通知单数据发布到消息中间件。收款微服务订阅缴费通知单事件,完成缴费操作。缴费通知单已生成,领域事件结束。
+2. 收款微服务缴费完成后,发布第二个领域事件:缴费已完成,将缴费数据发布到消息中间件。原来的订阅方收款微服务这时则变成了发布方。原来的事件发布方投保微服务转换为订阅方。投保微服务在收到缴费信息并确认缴费完成后,完成投保单转成保单的操作。缴费已完成,领域事件结束。
+3. 投保微服务在投保单转保单完成后,发布第三个领域事件:保单已生成,将保单数据发布到消息中间件。保单微服务接收到保单数据后,完成保单数据保存操作。保单已生成,领域事件结束。
+4. 保单微服务完成保单数据保存后,后面还会发生一系列的领域事件,以并发的方式将保单数据通过消息中间件发送到佣金、收付费和再保等微服务,一直到财务,完后保单后续所有业务流程。这里就不详细说了。
+
+总之,通过领域事件驱动的异步化机制,可以推动业务流程和数据在各个不同微服务之间的流转,实现微服务的解耦,减轻微服务之间服务调用的压力,提升用户体验。
+
+一个完整的领域事件 = 事件发布 + 事件存储 + 事件分发 + 事件处理。
+
+- 事件发布:构建一个事件,需要唯一标识,然后发布;
+
+- 事件存储:发布事件前需要存储,因为接收后的事件也会存储,可用于重试或对账等;就是每次执行一次具体的操作时,把行为记录下来,执行持久化。
+
+- 事件分发:服务内的应用服务或者领域服务直接发布给订阅者,服务外需要借助消息中间件,比如Kafka,RabbitMQ等,支持同步或者异步。
+
+- 事件处理:先将事件存储,然后再处理。
+
+当然了,实际开发中事件存储和事件处理不是必须的。
+
+因此实现方案:**发布订阅模式,分为跨上下文(Kafka,RocketMq)和上下文内(Spring事件,Guava Event Bus)的领域事件**。
+
+举个例子,用户注册后,发送短信和邮件,使用Spring事件实现领域事件代码如下:
+
+```java
+/**
+ * 用户注册事件
+ **/
+public class UserRegisterEvent extends ApplicationEvent {
+
+ public UserRegisterEvent(Object source) {
+ super(source);
+ }
+}
+
+
+/**
+ * 用户监听事件
+ **/
+@Component
+public class UserListener {
+
+ @EventListener(UserRegisterEvent.class)
+ public void userRegister(UserRegisterEvent event) {
+ User user = (User) event.getSource();
+ System.out.println("用户注册。。。发送短信。。。" + user);
+ System.out.println("用户注册。。。发送邮件。。。" + user);
+ }
+
+ @EventListener(UserCancelEvent.class)
+ public void userCancelEvent(UserCancelEvent event) {
+ User user = (User) event.getSource();
+ System.out.println("用户注销。。。" + user);
+ }
+
+}
+
+/**
+ * 发布用户注册事件
+ */
+@RunWith(value = SpringJUnit4ClassRunner.class)
+@SpringBootTest(classes = DemoApplication.class)
+public class MyClient {
+
+ @Autowired
+ private ApplicationContext applicationContext;
+
+ @Test
+ public void test() {
+ User user = new User();
+ //发布事件
+ applicationContext.publishEvent(new UserRegisterEvent(user));
+ }
+}
+```
+
+**事件风暴**
+
+事件风暴是一项团队活动,领域专家与项目团队通过头脑风暴的形式,罗列出领域中所有的领域事件,整合之后形成最终的领域事件集合,然后对每一个事件,标注出导致该事件的命令,再为每一个事件标注出命令发起方的角色。命令可以是用户发起,也可以是第三方系统调用或者定时器触发等,最后对事件进行分类,整理出实体、聚合、聚合根以及限界上下文。而事件风暴正是 DDD 战略设计中经常使用的一种方法,它可以快速分析和分解复杂的业务领域,完成领域建模。
+
+# DDD分层架构
+
+DDD 的分层架构在不断发展。最早是传统的四层架构;再后来领域层和应用层之间增加了上下文环境(Context)层,五层架构(DCI)就此形成了。
+
+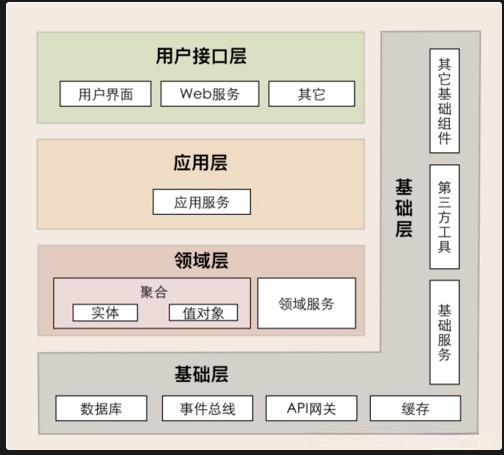
+
+DDD分层架构中的要素其实和三层架构类似,只是在DDD分层架构中,这些要素被重新归类,重新划分了层,确定了层与层之间的交互规则和职责边界。
+
+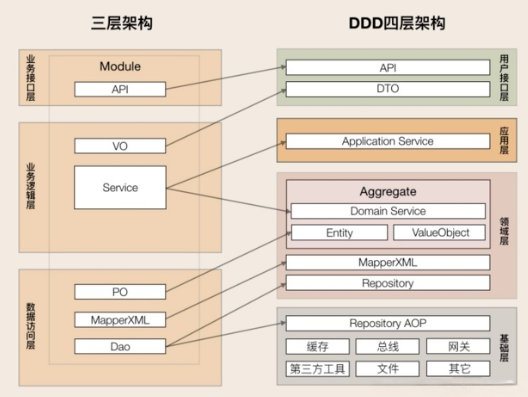
+
+## 用户接口层
+
+用户接口层是前端应用和微服务之间服务访问和数据交换的桥梁。它处理前端发送的 Restful 请求和解析用户输入的配置文件等,将数据传递给应用层。或获取应用服务的数据后,进行数据组装,向前端提供数据服务。主要服务形态是 Facade 服务。
+
+Facade 服务分为接口和实现两个部分。完成服务定向,DO 与 DTO 数据的转换和组装,实现前端与应用层数据的转换和交换。
+
+- 一般包括用户接口、Web 服务、rpc请求,mq消息等外部输入均被视为外部输入的请求。对外暴露API,具体形式不限于RPC、Rest API、消息等。
+
+- 一般都很薄,提供必要的参数校验和异常捕获流程。
+
+- 一般会提供VO或者DTO到Entity或者ValueObject的转换,用于前后端调用的适配,当然dto可以直接使用command和query,视情况而定。
+
+用户接口层很重要,在于前后端调用的适配。**若你的微服务要面向很多应用或渠道提供服务,而每个渠道的入参出参都不一样,你不太可能开发出太多应用服务,这样Facade接口就起很好的作用了,包括DO和DTO对象的组装和转换等**。
+
+## 应用层
+
+应用层是很薄的一层,理论上不应该有业务规则或逻辑,主要面向用例和流程相关的操作。但应用层又位于领域层之上,因为领域层包含多个聚合,所以它可以协调多个聚合的服务和领域对象完成服务编排和组合,协作完成业务操作。除了同步方法调用外,还可以发布或者订阅领域事件,权限校验、事务控制,一个事务对应一个聚合根。
+
+**应用层负责不同聚合之间的服务和数据协调,负责微服务之间的事件发布和订阅**。
+
+通过应用服务对外暴露微服务的内部功能,这样就可以隐藏领域层核心业务逻辑的复杂性以及内部实现机制。
+
+应用层的主要服务形态有:应用服务、事件发布和订阅服务。应用服务内用于组合和编排的服务,主要来源于领域服务,也可以是外部微服务的应用服务。
+
+## 领域层
+
+**领域层包含聚合根、实体、值对象、领域服务等领域模型中的领域对象**。
+
+这里我要特别解释一下其中几个领域对象的关系,以便你在设计领域层的时候能更加清楚。
+
+首先,领域模型的业务逻辑主要是由实体和领域服务来实现的,其中实体会采用充血模型来实现所有与之相关的业务功能。
+
+其次,你要知道,实体和领域对象在实现业务逻辑上不是同级的,当**领域中的某些功能,单一实体(或者值对象)不能实现时,领域服务就会出马,它可以组合聚合内的多个实体(或者值对象),实现复杂的业务逻辑**。
+
+领域层主要的服务形态有实体方法和领域服务。实体采用充血模型,在实体类内部实现实体相关的所有业务逻辑,实现的形式是实体类中的方法。实体是微服务的原子业务逻辑单元。在设计时我们主要考虑实体自身的属性和业务行为,实现领域模型的核心基础能力。不必过多考虑外部操作和业务流程,这样才能保证领域模型的稳定性。
+
+**DDD 提倡富领域模型,尽量将业务逻辑归属到实体对象上,实在无法归属的部分则设计成领域服务**。
+
+领域服务会对多个实体或实体方法进行组装和编排,实现跨多个实体的复杂核心业务逻辑。对于严格分层架构,**如果单个实体的方法需要对应用层暴露,则需要通过领域服务封装后才能暴露给应用服务**。
+
+## 基础层
+
+**基础层也叫基础设施层,基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等,比较常见的功能还是提供数据库持久化**。
+
+基础层的服务形态主要是仓储服务。仓储服务包括接口和实现两部分。仓储接口服务供应用层或者领域层服务调用,仓储实现服务,完成领域对象的持久化或数据初始化。
+
+DDD分层架构的数据库等基础资源访问,采用了仓储(Repository)设计模式,通过依赖到置实现各层对基础资源的解耦。
+
+仓储又分为两部分:仓储接口和仓储实现。
+
+**仓储接口放在领域层中,仓储实现放在基础层。原来三层架构通用的第三方工具包、驱动、Common、Utility、Config等通用的公共的资源类统一放到了基础层**。
+
+比如说,在传统架构设计中,由于上层应用对数据库的强耦合,很多公司在架构演进中最担忧的可能就是换数据库了,因为一旦更换数据库,就可能需要重写大部分的代码,这对应用来说是致命的。那采用依赖倒置的设计以后应用层就可以通过解耦来保持独立的核心业务。
+
+- 为业务逻辑提供支撑能力,提供通用的技术能力,仓库写增删改查类似DAO。
+- 防腐层实现(封装变化)用于业务检查和隔离第三方服务,内部 try catch。
+
+# 防腐层(ACL)
+
+当某个功能模块需要依赖第三方系统提供的数据或者功能时,我们常用的策略就是直接使用外部系统的API、数据结构。
+
+这样存在的问题就是,**因使用外部系统,而被外部系统的质量问题影响,从而“腐化”本身设计的问题**。
+
+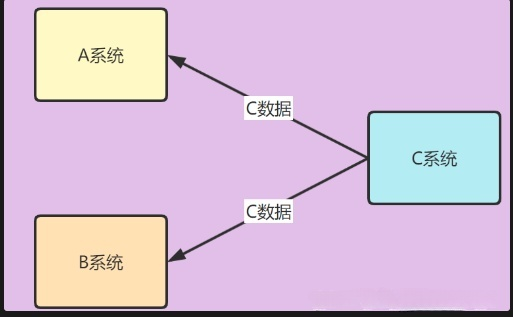
+
+因此我们的解决方案就是在两个系统之间加入一个中间层,隔离第三方系统的依赖,对第三方系统进行通讯转换和语义隔离,这个中间层,我们叫它防腐层。
+
+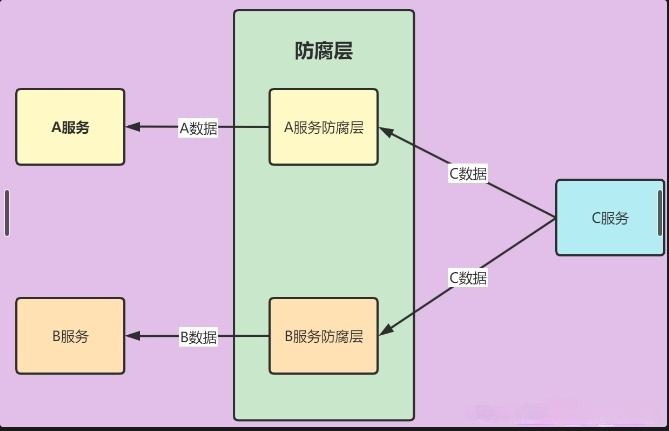
+
+说白了就是,两个系统之间加了中间层,中间层类似适配器模式,解决接口差异的对接,接口转换是单向的(即从调用方向被调用方进行接口转换),防腐层强调两个子系统语义解耦,接口转换是双向的。
+
+# 服务调用
+
+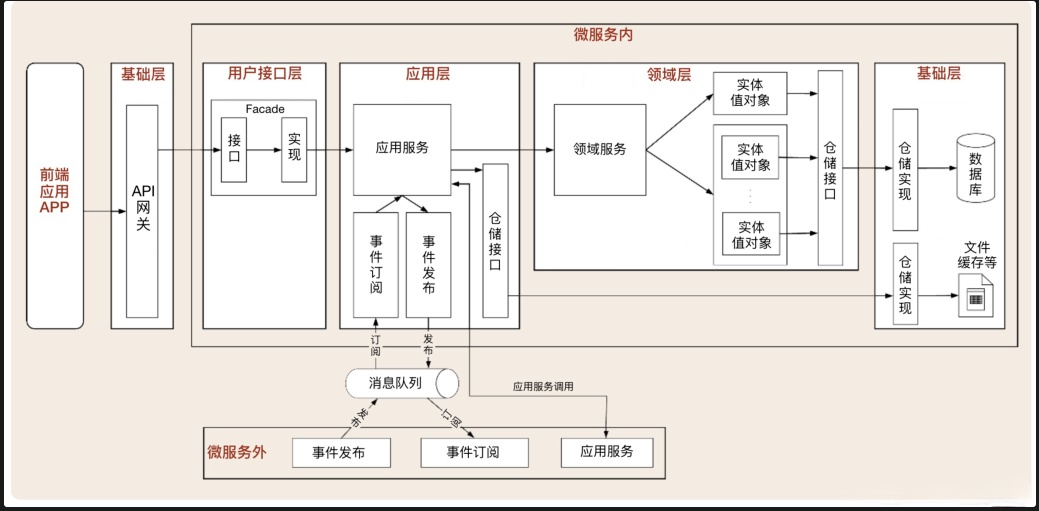
+
+**微服务内跨层服务调用**
+
+微服务架构下往往采用前后端分离的设计模式,前端应用独立部署。前端应用调用发布在API 网关上的 Facade 服务,Facade 定向到应用服务。应用服务作为服务组织和编排者,它的服务调用有这样两种路径:
+
+- 第一种是应用服务调用并组装领域服务。此时领域服务会组装实体和实体方法,实现核心领域逻辑。领域服务通过仓储服务获取持久化数据对象,完成实体数据初始化。
+- 第二种是应用服务直接调用仓储服务。这种方式主要针对像缓存、文件等类型的基础层数据访问。这类数据主要是查询操作,没有太多的领域逻辑,不经过领域层,不涉及数据库持久化对象。
+
+**微服务之间的服务调用**
+
+微服务之间的应用服务可以直接访问,也可以通过 API 网关访问。由于跨微服务操作,在进行数据新增和修改操作时,你需关注分布式事务,保证数据的一致性。
+
+**领域事件驱动**
+
+领域事件驱动包括微服务内和微服务之间的事件。微服务内通过事件总线(EventBus)完成聚合之间的异步处理。微服务之间通过消息中间件完成。异步化的领域事件驱动机制是一种间接的服务访问方式。当应用服务业务逻辑处理完成后,如果发生领域事件,可调用事件发布服务,完成事件发布。当接收到订阅的主题数据时,事件订阅服务会调用事件处理领域服务,完成进一步的业务操作。
+
+# 服务依赖
+
+在《实现领域驱动设计》一书中,DDD 分层架构有一个重要的原则:**每层只能与位于其下方的层发生耦合**。
+
+而架构根据耦合的紧密程度又可以分为两种:严格分层架构和松散分层架构。
+
+**优化后的DDD 分层架构模型就属于严格分层架构,任何层只能对位于其直接下方的层产生依赖。而传统的 DDD 分层架构则属于松散分层架构,它允许某层与其任意下方的层发生依赖**。
+
+那我们怎么选呢?综合我的经验,为了服务的可管理,我建议你采用严格分层架构。
+
+**在严格分层架构中,领域服务只能被应用服务调用,而应用服务只能被用户接口层调用,服务是逐层对外封装或组合的,依赖关系清晰**。
+
+而在松散分层架构中,领域服务可以同时被应用层或用户接口层调用,服务的依赖关系比较复杂且难管理,甚至容易使核心业务逻辑外泄。试想下,如果领域层中的某个服务发生了重大变更,那该如何通知所有调用方同步调整和升级呢?但在严格分层架构中,你只需要逐层通知上层服务就可以了。
+
+# 服务封装
+
+在严格分层架构模式下,不允许服务的跨层调用,每个服务只能调用它的下一层服务。服务从下到上依次为:实体方法、领域服务和应用服务。如果需要实现服务的跨层调用,我们应该怎么办?我建议你采用服务逐层封装的方式。
+
+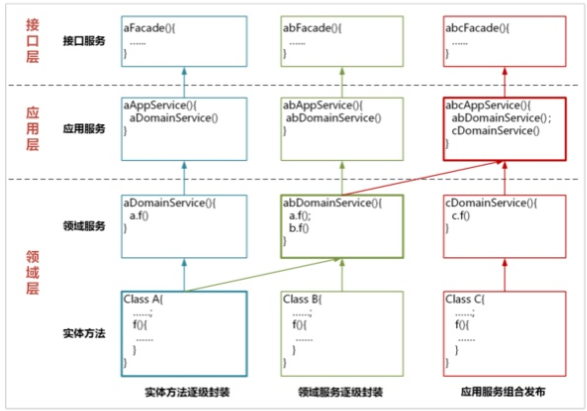
+
+我们看一下上面这张图,服务的封装和调用主要有以下几种方式:
+
+**实体方法的封装**
+
+实体方法是最底层的原子业务逻辑。如果单一实体的方法需要被跨层调用,你可以将它封装成领域服务,这样封装的领域服务就可以被应用服务调用和编排了。如果它还需要被用户接口层调用,你还需要将这个领域服务封装成应用服务。经过逐层服务封装,实体方法就可以暴露给上面不同的层,实现跨层调用。
+
+封装时服务前面的名字可以保持一致,你可以用 DomainService 或 *AppService 后缀来区分领域服务或应用服务。
+
+**领域服务的组合和封装**
+
+领域服务会对多个实体和实体方法进行组合和编排,供应用服务调用。如果它需要暴露给用户接口层,领域服务就需要封装成应用服务。
+
+**应用服务的组合和编排**
+
+应用服务会对多个领域服务进行组合和编排,暴露给用户接口层,供前端应用调用。
+
+在应用服务组合和编排时,你需要关注一个现象:多个应用服务可能会对多个同样的领域服务重复进行同样业务逻辑的组合和编排。当出现这种情况时,你就需要分析是不是领域服务可以整合了。你可以将这几个不断重复组合的领域服务,合并到一个领域服务中实现。这样既省去了应用服务的反复编排,也实现了服务的演进。这样领域模型将会越来越精炼,更能适应业务的要求。
+
+应用服务类放在应用层 Service 目录结构下。领域事件的发布和订阅类放在应用层 Event。
+
+# DDD建模步骤
+
+设计领域模型的一般步骤如下:
+
+1. 根据需求划分出初步的领域和限界上下文,以及上下文之间的关系。
+2. 进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象。
+3. 对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根。
+4. 为聚合根设计仓储,并思考实体或值对象的创建方式。
+5. 在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
+
+# DDD代码模型
+
+微服务—级目录是按照DDD分层架构的分层职责来定义的。从下面这张图中,我们可以看到,在代码模型里分别为用户接口层、应用层、领域层和基础层,建立了interfaces、application、domain 和 infrastructure 四个—级代码目录。
+
+
+
+- Interfaces(用户接口层)∶它主要存放用户接口层与前端交互、展现数据相关的代码。前端应用通过这一层的接口,向应用服务获取展现所需的数据。这一层主要用来处理用户发送的Restful请求,解析用户输入的配置文件,并将数据传递给Application层。数据的组装、数据传输格式以及Facade接口等代码都会放在这一层目录里。
+- Application(应用层)︰它主要存放应用层服务组合和编排相关的代码。应用服务向下基于微服务内的领域服务或外部微服务的应用服务完成服务的编排和组合,向上为用户接口层提供各种应用数据展现支持服务。应用服务和事件等代码会放在这一层目录里。
+- Domain(领域层)︰它主要存放领域层核心业务逻辑相关的代码。领域层可以包含多个聚合代码包,它们共同实现领域模型的核心业务逻辑。聚合以及聚合内的实体、方法、领域服务和事件等代码会放在这一层目录里。
+- Infrastructure(基础层)∶它主要存放基础资源服务相关的代码,为其它各层提供的通用技术能力、三方软件包、数据库服务、配置和基础资源服务的代码都会放在这一层目录里。
+
+## 用户接口层
+
+Interfaces 的代码目录结构有:assembler、dto 和 facade 三类。
+
+- Assembler:实现 DTO 与领域对象之间的相互转换和数据交换。一般来说 Assembler 与DTO 总是一同出现。
+
+- DTO:它是数据传输的载体,内部不存在任何业务逻辑,我们可以通过 DTO 把内部的领域对象与外界隔离。
+- Facade:提供较粗粒度的调用接口,将用户请求委派给一个或多个应用服务进行处理。
+
+## 应用层
+
+Application 的代码目录结构有:event 和 service。
+
+- Event(事件):这层目录主要存放事件相关的代码。它包括两个子目录:publish 和subscribe。前者主要存放事件发布相关代码,后者主要存放事件订阅相关代码(事件处理相关的核心业务逻辑在领域层实现)。
+
+这里提示一下:**虽然应用层和领域层都可以进行事件的发布和处理,但为了实现事件的统一管理,我建议你将微服务内所有事件的发布和订阅的处理都统一放到应用层,事件相关的核心业务逻辑实现放在领域层。通过应用层调用领域层服务,来实现完整的事件发布和订阅处理流程**。
+
+- Service(应用服务):这层的服务是应用服务。应用服务会对多个领域服务或外部应用服务进行封装、编排和组合,对外提供粗粒度的服务。应用服务主要实现服务组合和编排,是一段独立的业务逻辑。你可以将所有应用服务放在一个应用服务类里,也可以把一个应用服务设计为一个应用服务类,以防应用服务类代码量过大。
+
+## 领域层
+
+Domain 是由一个或多个聚合包构成,共同实现领域模型的核心业务逻辑。聚合内的代码模型是标准和统一的,包括:entity、event、repository 和 service 四个子目录。
+
+而领域层聚合内部的代码目录结构是这样的:
+
+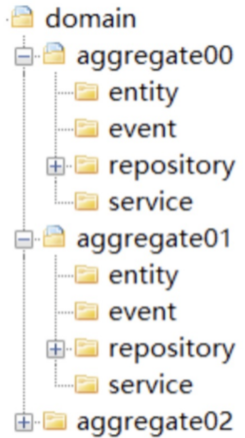
+
+- Aggregate(聚合):它是聚合软件包的根目录,可以根据实际项目的聚合名称命名,比如权限聚合。在聚合内定义聚合根、实体和值对象以及领域服务之间的关系和边界。聚合内实现高内聚的业务逻辑,它的代码可以独立拆分为微服务。以聚合为单位的代码放在一个包里的主要目的是为了业务内聚,而更大的目的是为了以后微服务之间聚合的重组。聚合之间清晰的代码边界,可以让你轻松地实现以聚合为单位的微服务重组,在微服务架构演进中有着很重要的作用。
+
+- Entity(实体):它存放聚合根、实体、值对象以及工厂模式(Factory)相关代码。实体类采用充血模型,同一实体相关的业务逻辑都在实体类代码中实现。跨实体的业务逻辑代码在领域服务中实现。
+- Event(事件):它存放事件实体以及与事件活动相关的业务逻辑代码。
+- Service(领域服务):它存放领域服务代码。一个领域服务是多个实体组合出来的一段业务逻辑。你可以将聚合内所有领域服务都放在一个领域服务类中,你也可以把每一个领域服务设计为一个类。如果领域服务内的业务逻辑相对复杂,我建议你将一个领域服务设计为一个领域服务类,避免由于所有领域服务代码都放在一个领域服务类中,而出现代码臃肿的问题。领域服务封装多个实体或方法后向上层提供应用服务调用。
+- Repository(仓储):它存放所在聚合的查询或持久化领域对象的代码,通常包括仓储接口和仓储实现方法。为了方便聚合的拆分和组合,我们设定了一个原则:一个聚合对应一个仓储。
+
+特别说明:按照 DDD 分层架构,仓储实现本应该属于基础层代码,但为了在微服务架构演进时,保证代码拆分和重组的便利性,可以将聚合仓储实现的代码放到聚合包内。这样,如果需求或者设计发生变化导致聚合需要拆分或重组时,我们就可以将包括核心业务逻辑和仓储代码的聚合包整体迁移,轻松实现微服务架构演进。
+
+## 基础层
+
+Infrastructure 的代码目录结构有:config 和 util 两个子目录。
+
+- Config:主要存放配置相关代码。
+- Util:主要存放平台、开发框架、消息、数据库、缓存、文件、总线、网关、第三方类库、通用算法等基础代码,你可以为不同的资源类别建立不同的子目录。
+
+------
+
+关于代码模型还需要强调两点内容。
+
+- 第一点:聚合之间的代码边界一定要清晰。聚合之间的服务调用和数据关联应该是尽可能的松耦合和低关联,聚合之间的服务调用应该通过上层的应用层组合实现调用,原则上不允许聚合之间直接调用领域服务。这种松耦合的代码关联,在以后业务发展和需求变更时,可以很方便地实现业务功能和聚合代码的重组,在微服务架构演进中将会起到非常重要的作用。
+- 第二点:你一定要有代码分层的概念。写代码时一定要搞清楚代码的职责,将它放在职责对应的代码目录内。应用层代码主要完成服务组合和编排,以及聚合之间的协作,它是很薄的一层,不应该有核心领域逻辑代码。领域层是业务的核心,领域模型的核心逻辑代码一定要在领域层实现。如果将核心领域逻辑代码放到应用层,你的基于DDD分层架构模型的微服务慢慢就会演变成传统的三层架构模型了。
+
+## 目录结构
+
+以下是一个 DDD 工程的代码目录结构,提供参考:
+
+```
+│
+│ ├─interface 用户接口层
+│ │ └─controller 控制器,对外提供(Restful)接口
+│ │ └─facade 外观模式,对外提供本地接口和dubbo接口
+│ │ └─mq mq消息,消费者消费外部mq消息
+│ │
+│ ├─application 应用层
+│ │ ├─assembler 装配器
+│ │ ├─dto 数据传输对象,xxxCommand/xxxQuery/xxxVo
+│ │ │ ├─command 接受增删改的参数
+│ │ │ ├─query 接受查询的参数
+│ │ │ ├─vo 返回给前端的vo对象
+│ │ ├─service 应用服务,负责领域的组合、编排、转发、转换和传递
+│ │ ├─repository 查询数据的仓库接口
+│ │ ├─listener 事件监听定义
+│ │
+│ ├─domain 领域层
+│ │ ├─entity 领域实体
+│ │ ├─valueobject 领域值对象
+│ │ ├─service 领域服务
+│ │ ├─repository 仓库接口,增删改的接口
+│ │ ├─acl 防腐层接口
+│ │ ├─event 领域事件
+│ │
+│ ├─infrastructure 基础设施层
+│ │ ├─converter 实体转换器
+│ │ ├─repository 仓库
+│ │ │ ├─impl 仓库实现
+│ │ │ ├─mapper mybatis mapper接口
+│ │ │ ├─po 数据库orm数据对象
+│ │ ├─ack 实体转换器
+│ │ ├─mq mq消息
+│ │ ├─cache 缓存
+│ │ ├─util 工具类
+│ │
+│
+```
+
+# 数据对象视图
+
+- 数据持久化对象 PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一 一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。最形象的理解就是一个 PO 就是数据库中的一条记录,好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。也有团队使用DO(Data Object)表示数据对象。
+
+- 领域对象 DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体,使用的是充血模型设计的对象。也有团队使用用 BO(Business Objects)表示业务对象的概念。
+
+- 数据传输对象 DTO(Data Transfer Object):数据传输对象,主要用于远程调用之间传输的对象的地方。比如我们一张表有 100 个字段,那么对应的 PO 就有 100 个属性。但是客户端只需要 10 个字段,没有必要把整个 PO 对象传递到客户端,这时我们就可以用只有这 10 个属性的 DTO 来传递结果到客户端,这样也不会暴露服务端表结构。到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为 VO。DTO泛指用于展示层与服务层之间的数据传输对象,当然VO也相当于数据DTO的一种。
+
+- 视图对象 VO(View Object):视图对象,主要对应界面显示的数据对象。对于一个WEB页面,小程序,微信公众号等前端需要的数据对象。也有团队用VO表示领域层中的Value Object值对象,这个要根据团队的规范来定义。
+
+- 简单对象POJO(Plain Ordinary Java Object):简单对象,是只具有setter getter方法对象的统称。但是不要把对象名命名成 xxxPOJO!
+
+我们结合下面这张图,看看微服务各层数据对象的职责和转换过程。
+
+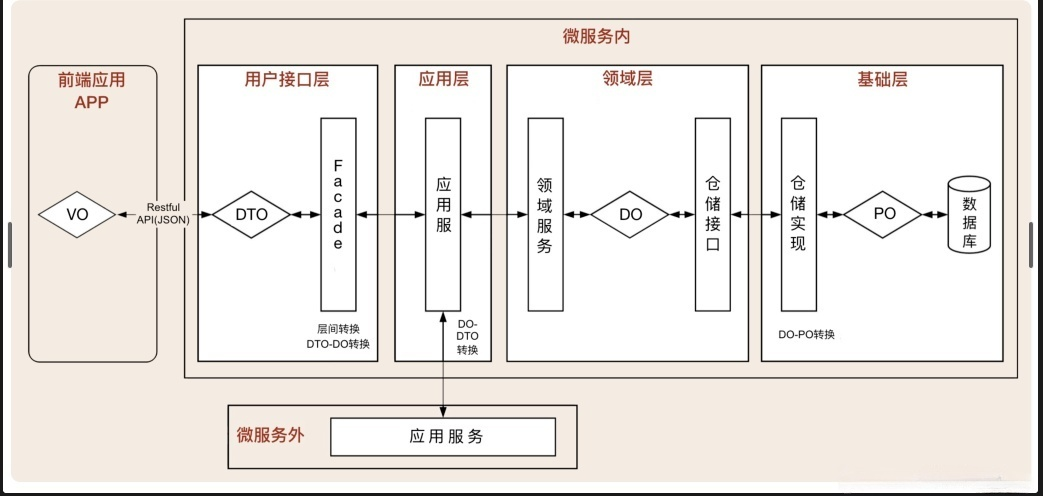
+
+**基础层**
+
+基础层的主要对象是 PO 对象。我们需要先建立 DO 和 PO 的映射关系。当 DO 数据需要持久化时,仓储服务会将 DO 转换为 PO 对象,完成数据库持久化操作。当 DO 数据需要初始化时,仓储服务从数据库获取数据形成 PO 对象,并将 PO 转换为 DO,完成数据初始化。大多数情况下 PO 和 DO 是一一对应的。但也有 DO 和 PO 多对多的情况,在 DO 和 PO数据转换时,需要进行数据重组
+
+**领域层**
+
+领域层的主要对象是 DO 对象。DO 是实体和值对象的数据和业务行为载体,承载着基础的核心业务逻辑。通过 DO 和 PO 转换,我们可以完成数据持久化和初始化。
+
+**应用层**
+
+应用层的主要对象是 DO 对象。如果需要调用其它微服务的应用服务,DO 会转换为DTO,完成跨微服务的数据组装和传输。用户接口层先完成 DTO 到 DO 的转换,然后应用服务接收 DO 进行业务处理。如果 DTO 与 DO 是一对多的关系,这时就需要进行 DO数据重组。
+
+**用户接口层**
+
+用户接口层会完成 DO 和 DTO 的互转,完成微服务与前端应用数据交互及转换。Facade服务会对多个 DO 对象进行组装,转换为 DTO 对象,向前端应用完成数据转换和传输。
+
+**前端应用**
+
+前端应用主要是 VO 对象。展现层使用 VO 进行界面展示,通过用户接口层与应用层采用DTO 对象进行数据交互。
+
+# 总结
+
+DDD 基于各种考虑,有很多的设计原则,也用到了很多的设计模式。条条框框多了,很多人可能就会被束缚住,总是担心或犹豫这是不是原汁原味的 DDD。
+
+**其实我们不必追求极致的 DDD,这样做反而会导致过度设计,增加开发复杂度和项目成本**。
+
+DDD 的设计原则或模式,是考虑了很多具体场景或者前提的。有的是为了解耦,如仓储服务、边界以及分层,有的则是为了保证数据一致性,如聚合根管理等。在理解了这些设计原则的根本原因后,有些场景你就可以灵活把握设计方法了,你可以突破一些原则,不必受限于条条框框,大胆选择最合适的方法。
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md"
new file mode 100644
index 0000000..7f9f7b5
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md"
@@ -0,0 +1,368 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+[TOC]
+
+本篇讲解Elasticsearch中非常重要的一个概念:**Mapping**,Mapping是索引必不可少的组成部分。
+
+## Mapping 的基本概念
+
+**Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分**
+
+ES 中的 Mapping 有点类似于关系型数据库中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
+
+### 查看索引 Mapping
+
+```JSON
+//查看索引完整的mapping
+GET /my_index/_mappings
+//查看索引指定字段的mapping
+GET /my_index/_mappings/field/field_name
+```
+
+例如,如果你有一个名为 "my_index" 的索引,并且你想查询字段 "my_field" 的 mapping,那么请求就像这样:
+
+```jon
+GET /my_index/_mapping/field/my_field
+```
+
+此请求会返回如下类型的输出:
+
+```json
+{
+ "my_index" : {
+ "mappings" : {
+ "my_field" : {
+ "full_name" : "my_field",
+ "mapping" : {
+ "my_field" : {
+ "type" : "text",
+ "fields" : {
+ "keyword" : {
+ "type" : "keyword",
+ "ignore_above" : 256
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+在这个响应中,你可以看到 "my_field" 是 "text" 类型,并且它也有一个子字段 "keyword"。
+
+## 字段数据类型
+
+映射的数据类型也就是 ES 索引支持的数据类型,其概念和 MySQL 中的字段类型相似,但是具体的类型和 MySQL 中有所区别,最主要的区别就在于 ES 中支持可分词的数据类型,如:Text 类型,可分词类型是用以支持全文检索的,这也是 ES 生态最核心的功能。
+
+### 数字类型
+
+- **long**:64 位有符号整形。
+- **integer**:32 位有符号整形。
+- **short**:16 位有符号整形。
+- **byte**:8位有符号整形。
+- **double**:双精度64位浮点类型。
+- **float**:单精度32位浮点类型。
+- **half_float**:半精度16位浮点数。
+- **scaled_float**:缩放类型浮点数,按固定 double 比例因子缩放。
+- **unsigned_long**:无符号 64 位整数。
+
+### 基本数据类型
+
+- **binary**:存储二进制字符串,经过Base64编码处理。
+- **boolean**:布尔类型,接收 ture 和 false 两个值。
+
+### Keywords 类型
+
+- **keyword**:这种类型被用来索引结构化数据,如 email 地址、主机名、状态码以及标签等。这类数据可以以精确值的形式进行搜索,并且可以用于过滤 (filtering),排序 (sorting) 和聚合 (aggregating)。关键词字段只和其确切的值匹配,它们的查询不会进行分词处理。
+- **constant_keyword**:这种类型适用于在所有文档中都始终有相同值的字段。比如在一次特定的索引操作中,所有的文档都需要包含一个常量字段,例如 `env` 的值可能为 "production"。
+- **wildcard**:这种类型的字段可以存储任何字符串,并且对于这种类型的字段进行的查询可以使用通配符表达式。这种类型的字段对于像 grep 这样的场景非常有用,即当你需要在一个长字符串中搜索一个较短的子串时。但是要注意,虽然 wildcard 字段提供了强大的模式匹配能力,但是这种能力是需要付出性能代价的。
+
+### 日期类型
+
+JSON 没有日期数据类型,因此 Elasticsearch 中的日期可以是以下三种:
+
+- **包含格式化日期的字符串**:例如 "2015-01-01"、 "2015/01/01 12:10:30"。
+- **时间戳**:表示自"1970年 1 月 1 日"以来的毫秒数/秒数。
+- **date_nanos**:此数据类型是对 date 类型的补充。但是有一个重要区别。date 类型存储最高精度为毫秒,而date_nanos 类型存储日期最高精度是纳秒,但是高精度意味着可存储的日期范围小,即:从大约 1970 到 2262。
+
+### 对象类型
+
+- **object**:默认情况下,Elasticsearch 使用 object 数据类型来处理 JSON 对象。
+- **flattened**:这是用来索引对象数组或者具有未知结构的字段的特殊映射类型。其将整个JSON对象作为单个键值对存储,帮助降低索引大小和提高搜索速度。
+- **nested**:这是一个类似于 object 的数据类型,但它能保存并查询对象数组内部对象的独立性,因此可以用来处理更复杂的结构。
+- **join**:这是一个特殊数据类型,用于模拟在文档之间的父/子关系。这样可以创建一对多的连接,例如,在博客文章和评论这样的场景中使用。
+
+### 空间数据类型
+
+- **geo_point**:表示地理位置的点,存储纬度和经度信息。
+- **geo_shape**:表示复杂的地理形状,如多边形、线、圆等。
+- **point**:在笛卡尔空间中表示一个点,存储X和Y坐标。
+- **shape**:在笛卡尔空间中表示任意复杂的几何形状。
+
+### 文档排名类型
+
+- **dense_vector**:记录浮点值的密集向量。这种类型常用于存储机器学习模型的输出,例如词嵌入、句子嵌入等。
+- **rank_feature**:记录单个数值特征以优化排名。当这个字段被查询时,Elasticsearch 会考虑其值来重新排序搜索结果。
+- **rank_features**:记录多个数值特征以优化排名。与`rank_feature`类似,但它能够处理包含多个特征的对象。当这些字段被查询时,Elasticsearch 会考虑它们的值来重新排序搜索结果。
+
+### 文本搜索类型
+
+- **text**:用于存储全文和进行全文搜索的数据类型。
+- **annotated-text:**这是一个特殊的文本字段,它支持包含标记的文本。这些标记表示文本中的命名实体或其他重要项,可以在后续搜索中使用。
+- **completion** :这是一个专门为自动补全和搜索建议设计的数据类型。
+- **search_as_you_type:** 这是一种特殊的文本字段,它被优化以提供按键查询时的即时反馈,从而提高用户输入时的搜索体验。
+- **token_count**:这是一种数值型字段,用于存储文本字段中的词元数量。此字段常用于信息检索场景,比如评估某个字段的长度。
+
+## 两种映射类型
+
+### 自动映射:Dynamic Field Mapping
+
+Elasticsearch的Dynamic Field Mapping是一种自动产生index mapping的机制。在通常情况下,当一个新文档被索引到Elasticsearch中,如果其中包含了未在mapping中定义的字段,Elasticsearch就会尝试根据这个新字段的数据类型自动生成相应的mapping。
+
+自动映射关系如下:
+
+| **field type** | **dynamic** |
+| -------------- | ---------------------------------- |
+| true/false | boolean |
+| 小数 | float |
+| 数字 | long |
+| object | object |
+| 数组 | 取决于数组中的第一个非空元素的类型 |
+| 日期格式字符串 | date |
+| 数字类型字符串 | float/long |
+| 其他字符串 | text + keyword |
+
+除了上述字段类型之外,其他类型都必须显式映射,也就是必须手工指定,因为其他类型ES无法自动识别。
+
+这里有几点需要注意:
+
+- 数据类型识别:Elasticsearch会按照以下顺序判断数据类型:长整数、浮点数、布尔值、日期、字符串(字符串可能会进一步映射为text或keyword)。
+- 字段名称含义:Elasticsearch不会考虑字段名称的含义,它仅仅依靠字段的数据类型来生成mapping。
+- 关闭动态映射:如果你不希望Elasticsearch自动创建mapping,可以将index的`dynamic`设置为`false`。
+- 动态模板:你可以使用动态模板来改变默认的mapping规则,例如,你可以将所有看起来像日期的字符串都映射为date类型。
+- 对象和嵌套字段:对于对象(object)和嵌套字段(nested),Elasticsearch也会递归地应用动态映射规则。
+- 更新映射:请注意,一旦字段的映射被创建,就不能再修改字段的数据类型了。因此,如果你要索引的文档中有新的字段,最好事先定义好mapping,避免让Elasticsearch自动映射可能产生不符合你期望的结果。
+- 当一个字段第一次出现时,Elasticsearch会使用先行数据类型来设置映射。如果后续数据类型与先前设置的映射类型不一致,Elasticsearch可能无法正确索引这些文档。
+
+总的来说,虽然动态字段映射可以在某些情况下提供便利,但它也可能导致未预见的问题。因此,更推荐在开始索引文档之前就定义好mapping。
+
+### 显式映射:Expllcit Field Mapping
+
+在 Elasticsearch 中,显式映射(Explicit Field Mapping)是指为索引预定义的字段类型和行为。当你创建一个索引时,你可以定义每个字段的数据类型、分词器或者其他相关的配置。这就是显式映射。
+
+以下是一些主要的显式映射类型:
+
+- **核心数据类型**:包括 string(字符串)、integer(整型)、long(长整型)、double(双精度浮点型)、boolean(布尔型)等。
+- **复合数据类型**:包括 object(对象),用于单个 JSON 对象,nested,用于 JSON 数组。
+- **地理数据类型**:如 geo_point 和 geo_shape。
+- **专门用途的数据类型**:例如 IP、自动完成、token count、join types 等。
+
+通过显式映射,Elasticsearch 可以更准确地解析和索引数据,对查询性能优化起到关键作用。如果不提供显式映射,Elasticsearch 将会根据输入数据自动推断并生成隐式映射,但可能无法达到最理想的效果。
+
+以下是一个示例,展示了怎么设置一个简单的显式映射:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "properties": {
+ "name": { "type": "text" },
+ "age": { "type": "integer" }
+ }
+ }
+}
+```
+
+上述代码中,我们在 `my_index` 索引中定义了两个字段的映射,`name` 字段类型为 `text`,`age` 字段类型为 `integer`。
+
+注意:在 Elasticsearch 7.0 之后,映射类型被废弃,所有的映射参数直接放在 "properties" 下。
+
+## 映射参数
+
+在Elasticsearch中,映射参数是用于定义如何处理文档和其包含的字段的规则。
+
+主要参数有下:
+
+- **index**:是否对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。
+- **analyzer**:指定分析器(character filter、tokenizer、Token filters)。
+- **boost**:对当前字段相关度的评分权重,默认1。
+- **coerce**:是否允许强制类型转换,为 true的话 “1”能被转为 1, false则转不了。虽然这个参数可以帮助我们强制类型转换,但是它可能会在数据质量管理中引起问题。如果原始数据包含错误的类型,使用 "coerce" 可能会隐藏这些问题,而不是将其暴露出来。
+- **copy_to**:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询。
+- **doc_values**:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间,对于text字段和annotated_text字段,无法禁用此选项,因为这些字段类型在默认情况下不使用doc values。
+- **dynamic**:控制是否可以动态添加新字段
+ - **true** :新检测到的字段将添加到映射中(默认)。
+ - **false** :新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
+ - **strict** :如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射。
+- **eager_global_ordinals**:用于聚合的字段上,优化聚合性能,但不适用于 Frozen indices。
+ - **Frozen indices**(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices 的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。
+- **enable**:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。**enable的作用和index类似,区别就是enable可以对全局进行设置**。例如:
+
+```JSON
+PUT my_index
+{
+ "mappings": {
+ "enabled": false
+ }
+}
+```
+
+- **fielddata**:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。
+- **fields**:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)。
+- **format**:格式化。例如:
+
+```JSON
+"date": {
+ "type": "date",
+ "format": "yyyy-MM-dd"
+}
+```
+
+- **ignore_above**:这是一个针对keyword类型字段的设置,对于超过指定长度的字符串,ES 不会对其建立索引。
+- **ignore_malformed**:忽略类型错误。
+- **index_options**:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段。
+- **Index_phrases**:提升 exact_value 查询速度,但是要消耗更多磁盘空间。
+- **Index_prefixes**:前缀搜索。
+ - **min_chars**:前缀最小长度> 0,默认 2(包含)。
+ - **max_chars**:前缀最大长度< 20,默认 5(包含)。
+- **meta**:附加元数据。
+- **normalizer**:normalizer 参数用于解析前(索引或者查询时)的标准化配置。
+- **norms**:是否禁用评分(在 filter 和聚合字段上应该禁用)。
+- **null_value**:为 null 值设置默认值。
+- **position_increment_gap**:对于数组或者列表类型的字段,在进行phrase query或者phrase suggest时,允许用户自定义同一字段内两个相邻元素间的位置增量,默认100。
+- **properties**:除了mapping还可用于object的属性设置。
+- **search_analyzer**:设置单独的查询时分析器,如果定义了analyzer而没有定义search_analyzer,则search_analyzer的值默认会和analyzer保持一致,如果两个都没有定义,则默认是:"standard"。analyzer针对的是元数据,而search_analyzer针对的是传入的搜索词。
+- **similarity**:为字段设置相关度算法,和评分有关。支持BM25、classic(TF-IDF)、boolean。
+- **store**:设置字段是否仅查询。
+- **term_vector**:运维参数。这个参数可以设置存储哪些信息用于更复杂的文本处理,例如在词向量建模或者更复杂的文本检索场景中使用。
+
+## Text & Keyword
+
+### Text
+
+当一个字段是要被全文检索时,比如 Email 内容、产品描述,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引之前,字符串会被分析器分成一个个词项。text类型的字段不用于排序,很少用于聚合。
+
+**注意事项**
+
+- 适用于全文检索:如 match 查询。
+- 文本字段会被分词。
+- 默认情况下,会创建倒排索引。
+- 自动映射器会为 Text 类型创建 Keyword 字段。
+
+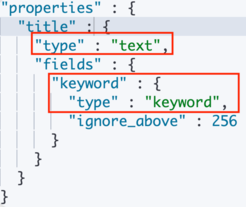
+
+### Keyword
+
+Keyword 类型适用于不分词的字段,如姓名、Id、数字等。如果数字类型不用于范围查找,用 Keyword 的性能要高于数值类型。
+
+当使用 Keyword 类型查询时,其字段值会被作为一个整体,并保留字段值的原始属性。
+
+```JSON
+GET index/_search
+{
+ "query": {
+ "match": {
+ "title.keyword": "测试文本值"
+ }
+ }
+}
+```
+
+注意事项
+
+- Keyword 不会对文本分词,会保留字段的原有属性,包括大小写等。
+- Keyword 仅仅是字段类型,而不会对搜索词产生任何影响。
+- Keyword 一般用于需要精确查找的字段,或者聚合排序字段。
+- Keyword 通常和 Term 搜索一起用。
+- Keyword 字段的 `ignore_above` 参数代表其截断长度,默认 256,如果超出长度,字段值会被忽略,而不是截断,忽略指的是会忽略这个字段的索引,搜索不到,但数据还是存在的。
+
+## 映射模板
+
+之前讲过的映射类型或者映射参数,都是为确定的某个字段而声明的。
+
+但是当我们不确定字段名字的时候该怎么设置mapping呢?映射模板就是用来解决这种场景的。
+
+如果希望对符合某类要求的特定字段制定映射,就需要用到映射模板:**Dynamic templates**。映射模板有时也被称作:自动映射模板、动态模板等。
+
+以下是一个示例:
+
+```json
+{
+ "mappings": {
+ "dynamic_templates": [
+ {
+ "strings_as_keyword": {
+ "match_mapping_type": "string",
+ "mapping": {
+ "type": "keyword"
+ }
+ }
+ },
+ {
+ "longs_as_integer": {
+ "match_mapping_type": "long",
+ "mapping": {
+ "type": "integer"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+在上述例子中,我们定义了两个模板:`strings_as_keyword` 和 `longs_as_integer`。当新字段被发现时,Elasticsearch 会检查这些模板以决定如何映射这个新字段。
+
+- `strings_as_keyword` 模板将所有新的字符串类型字段映射为 `keyword` 类型。
+- `longs_as_integer` 模板将所有新的长整数(long)类型字段映射为 `integer` 类型。
+
+注意:这些只是示例,实际的映射应该取决于实际数据和查询需求。例如,如果你需要对字符串字段进行全文搜索,那么将其映射为 `text` 可能更合适。
+
+### 参数
+
+- `match`:匹配字段名称。
+- `unmatch`:反匹配字段名称。
+- `match_mapping_type`:匹配字段类型,例如 string、long、double、boolean、date。
+- `match_pattern`:允许更复杂的名字模式,支持"starts_with"、"ends_with" 和 "contains"。
+- `path_match`:允许你用路径 (如 article.title) 来匹配字段。
+- `path_unmatch`:反匹配路径。
+- `mapping`:该字段被匹配时,应用的映射设置。
+
+### 案例
+
+```JSON
+PUT test_dynamic_template
+
+{
+ "mappings": {
+ "dynamic_templates": [{
+ "integers": {
+ "match_mapping_type": "long",
+ "mapping": {
+ "type": "integer"
+ }
+ }
+ },
+ {
+ "longs_as_strings": {
+ "match_mapping_type": "string",
+ "match": "num_*",
+ "unmatch": "*_text",
+ "mapping": {
+ "type": "keyword"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+以上代码会产生以下效果:
+
+- 所有 long 类型字段会默认映射为 integer。
+- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型。
+
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md"
new file mode 100644
index 0000000..f2e16d7
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md"
@@ -0,0 +1,289 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES的 Nested 类型用于处理在一个文档中嵌套复杂的结构数据,而 Join 类型用于建立父子文档之间的关联关系。
+
+## 嵌套类型:Nested
+
+Elasticsearch没有内部对象的概念,因此,ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表。
+
+**比如**:
+
+```json
+PUT my-index/_doc/1
+{
+ "group" : "fans",
+ "user" : [
+ {
+ "first" : "John",
+ "last" : "Smith"
+ },
+ {
+ "first" : "Alice",
+ "last" : "White"
+ }
+ ]
+}
+```
+
+上面的文档被创建之后,user数组中的每个json对象会以下面的形式存储
+
+```json
+{
+ "group" : "fans",
+ "user.first" : [ "alice", "john" ],
+ "user.last" : [ "smith", "white" ]
+}
+```
+
+`user.first`和 `user.last`字段被扁平化为多值字段,`first`和 `last`之间的关联丢失。
+
+解决方法可以使用Nested类型,Nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作,嵌套类型(Nested)允许在一个文档内部嵌套另一个文档,这使得可以在同一个文档中表示复杂的层次结构数据。
+
+下面是关于如何定义和使用嵌套类型的示例:
+
+定义映射(Mapping):
+
+```json
+PUT /my_index
+{
+ "mappings": {
+ "properties": {
+ "name": {
+ "type": "text"
+ },
+ "comments": {
+ "type": "nested",
+ "properties": {
+ "user": { "type": "keyword" },
+ "message": { "type": "text" }
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们创建了一个名为 "my_index" 的索引,并定义了一个 "comments" 字段作为嵌套类型。嵌套类型包含两个属性: "user" 和 "message"。
+
+输入数据(Indexing):
+
+```json
+POST /my_index/_doc
+{
+ "name": "Product A",
+ "comments": [
+ {
+ "user": "User 1",
+ "message": "Great product!"
+ },
+ {
+ "user": "User 2",
+ "message": "Needs improvement."
+ }
+ ]
+}
+```
+
+在上述示例中,我们向索引 "my_index" 中插入了一个文档,其中 "comments" 字段包含了两个嵌套文档。
+
+查询数据(Querying):
+
+```json
+GET /my_index/_search
+{
+ "query": {
+ "nested": {
+ "path": "comments",
+ "query": {
+ "bool": {
+ "must": [
+ { "match": { "comments.user": "User 1" } },
+ { "match": { "comments.message": "Great product!" } }
+ ]
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们使用嵌套查询(nested query)来搜索包含特定评论的文档。我们指定了路径为 "comments",并在 `must` 子句中添加了匹配条件。
+
+输出结果:
+
+```json
+{
+ "hits": {
+ "total": {
+ "value": 1,
+ "relation": "eq"
+ },
+ "hits": [
+ {
+ "_source": {
+ "name": "Product A",
+ "comments": [
+ {
+ "user": "User 1",
+ "message": "Great product!"
+ }
+ ]
+ }
+ }
+ ]
+ }
+}
+```
+
+在上述示例中,我们得到了一个匹配的文档,其中 "comments" 字段只包含了符合查询条件的嵌套文档。
+
+### 参数
+
+- `path`(必需):指定嵌套字段的路径。它告诉 Elasticsearch 在哪个字段上应用嵌套查询。
+
+- `score_mode`(可选):指定如何计算嵌套文档的评分。
+
+ avg (默认):使用所有匹配的子对象的平均相关性得分。
+
+ max:使用所有匹配的子对象中的最高相关性得分。
+
+ min:使用所有匹配的子对象中最低的相关性得分。
+
+ none:不要使用匹配的子对象的相关性分数。该查询为父文档分配得分为0。
+
+ sum:将所有匹配的子对象的相关性得分相加。
+
+- `inner_hits`(可选):允许获取与嵌套文档匹配的内部结果。使用此参数可以检索与查询匹配的特定嵌套文档,并返回有关它们的信息。
+
+- `ignore_unmapped`(可选):如果设置为 `true`,则忽略没有嵌套字段映射的文档,并将其视为无匹配。默认情况下,设为 `false`。
+
+- `nested`(可选):表示查询是否应该应用于嵌套字段的上下文。默认情况下,设为 `true`。如果设置为 `false`,则将查询视为普通的非嵌套查询。
+
+- `score_mode`(可选):指定如何计算嵌套文档的评分。可选的值包括 `"none"`、`"avg"`、`"max"`、`"sum"` 和 `"min"`。默认情况下,使用 `"avg"`。
+
+## 父子级关系:Join
+
+连接数据类型是一个特殊字段,它在同一索引的文档中创建父/子关系。关系部分在文档中定义了一组可能的关系,每个关系是一个父名和一个子名。
+
+父/子关系可以定义如下:
+
+```json
+PUT
+{
+ "mappings": {
+ "properties": {
+ "": {
+ "type": "join",
+ "relations": {
+ "": ""
+ }
+ }
+ }
+ }
+}
+```
+
+常见的一个示例是创建一个索引来存储博客的数据。每个博客可以有多个评论,我们可以使用Join类型来建立博客和评论之间的父子关系。
+
+首先,我们定义一个包含两个类型的索引:`blogs`和`comments`。`blogs`类型表示博客,而`comments`类型表示评论。我们将为`blogs`类型定义一个Join字段,用于与`comments`类型建立关联。
+
+以下是一个简化的示例:
+
+创建索引并定义映射:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "properties": {
+ "title": {
+ "type": "text"
+ },
+ "join_field": {
+ "type": "join",
+ "relations": {
+ "blogs": "comments"
+ }
+ }
+ }
+ }
+}
+```
+
+添加博客文档:
+
+```json
+PUT my_index/_doc/1
+{
+ "title": "Elasticsearch Join 示例",
+ "join_field": "blogs"
+}
+```
+
+添加评论文档,并关联到博客:
+
+```json
+PUT my_index/_doc/2?routing=1
+{
+ "title": "很棒的博客",
+ "join_field": {
+ "name": "comments",
+ "parent": "1"
+ }
+}
+```
+
+查询博客及其关联的评论:
+
+```json
+GET my_index/_search
+{
+ "query": {
+ "has_child": {
+ "type": "comments",
+ "query": {
+ "match_all": {}
+ }
+ }
+ }
+}
+```
+
+以上示例展示了如何使用Join类型在Elasticsearch中建立父子关系,并进行查询操作。实际使用时,可能需要根据自己的数据结构和查询需求进行适当的调整。
+
+使用场景
+
+**Join唯一合适应用场景是:当索引数据包含一对多的关系,并且其中一个实体的数量远远超过另一个的时候。比如:老师有 一万个学生**
+
+`join`类型不能像关系数据库中的表链接那样去用,不论是 `has_child`或者是 `has_parent`查询都会对索引的查询性能有严重的负面影响。并且会触发 global ordinals。
+
+Global Ordinals是一种用于优化字段的查询性能的技术。在使用Join类型时,如果启用了Global Ordinals特性,它将为Join字段创建全局有序的编号,以支持快速的父子文档查询。
+
+当你执行具有Join字段的查询时,ES会使用Global Ordinals来识别匹配的父文档,并快速定位到对应的子文档。这样可以避免对所有文档进行扫描和过滤的开销,提高查询的效率。
+
+需要注意的是,启用Global Ordinals可能会增加索引的内存使用量和一些额外的计算开销。因此,在决定是否启用Global Ordinals时,需要权衡查询性能和资源消耗之间的平衡。
+
+**注意**
+
+- 在索引父子级关系数据的时候必须传入routing参数,即指定把数据存入哪个分片,因为父文档和子文档必须在同一个分片上,因此,在获取、删除或更新子文档时需要提供相同的路由值。
+- 每个索引只允许有一个 `join`类型的字段映射。
+- 一个元素可以有多个子元素但只有一个父元素。
+- 可以向现有连接字段添加新关系。
+- 也可以向现有元素添加子元素,但前提是该元素已经是父元素。
+
+### 参数
+
+当使用Elasticsearch的Join类型进行查询时,以下是一些常用的参数和选项:
+
+- `has_parent`和`has_child`:这两个查询参数用于在父子文档之间执行查询。您可以指定要匹配的父文档或子文档的类型以及具体的查询条件。
+- `parent_id`:用于指定要查询的子文档的父文档ID。通过指定`parent_id`参数,您可以快速检索与特定父文档相关联的所有子文档。
+- `inner_hits`:内部命中参数允许您在查询结果中获取与父文档或子文档匹配的内部命中结果。您可以使用`inner_hits`来检索与查询条件匹配的子文档或匹配的父文档及其关联的子文档。
+- `ignore_unmapped`:当设置为true时,如果查询字段不存在映射或没有任何匹配的文档时,将忽略该查询并返回空结果。
+- `max_children`:可用于限制每个父文档返回的子文档数量。
+
+这些只是一些常见的参数和选项,根据你的实际需求,还可以使用其他参数来进一步细化查询。请参考Elasticsearch官方文档以获取更详细的参数和用法信息。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md"
new file mode 100644
index 0000000..34e71d8
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md"
@@ -0,0 +1,251 @@
+在现代的数据处理和分析场景中,数据不仅需要被存储和检索,还需要经过各种复杂的转换、处理和丰富,以满足业务需求和提高数据价值。
+
+Elasticsearch Pipeline作为Elasticsearch中强大而灵活的功能之一,为用户提供了处理数据的机制,可以在数据索引之前或之后应用多种处理步骤,例如数据预处理、转换、清洗、分析等操作。
+
+## 使用场景
+
+Elasticsearch Pipeline 可以用于多种实际场景,其中包括但不限于:
+
+- 数据预处理:对原始数据进行清洗、标准化、去除噪声等操作,保证数据质量和一致性。
+- 数据转换:将数据转换为更加符合业务需求的形式,例如字段映射、格式转换、数据合并等。
+- 日志处理:实时日志数据的解析、提取关键信息、计算指标、数据聚合等操作。
+- 数据安全:对敏感数据进行脱敏处理、数据屏蔽、权限控制等操作,确保数据安全性。
+
+## 具体使用
+
+要实现Elasticsearch Pipeline功能,需要在节点上进行以下设置:
+
+1. **启用Ingest节点**:确保节点上已启用Ingest处理模块(默认情况下,每个节点都是Ingest Node),因为Pipeline是在Ingest处理阶段应用的。可以在elasticsearch.yml配置文件中添加以下设置来启用Ingest节点:
+
+ ```yaml
+ node.ingest: true
+ ```
+
+2. **配置Pipeline的最大值**:如果需要创建复杂的Pipeline或者包含大量处理步骤的Pipeline,可能需要调整默认的Pipeline容量限制。可以通过以下方式在elasticsearch.yml配置文件中设置Pipeline的最大值:
+
+ ```yaml
+ ingest.max_pipelines: 1000
+ ```
+
+3. **检查内存和资源使用**:确保节点具有足够的内存和资源来支持Pipeline的运行,避免因为资源不足而导致Pipeline执行失败或性能下降。
+
+对上述参数进行合理的配置后,就可以定义 Pipeline,并将其应用于索引文档了。
+
+下面是一个简单的示例代码,演示如何创建和使用Pipeline:
+
+**创建Pipeline**
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description" : "My custom pipeline",
+ "processors" : [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "example"
+ }
+ },
+ {
+ "uppercase": {
+ "field": "message"
+ }
+ }
+ ]
+}
+```
+
+上面的代码定义了一个名为 `my_pipeline` 的Pipeline,包含两个处理步骤:
+
+- `set` 处理器:将字段 `new_field` 设置为固定值 `example`。
+- `uppercase` 处理器:将字段 `message` 中的文本转换为大写。
+
+一个Elasticsearch Pipeline通常由以下几个主要部分组成:
+
+- **描述(Description)**:Pipeline的描述部分包含对Pipeline的简要说明或注释,用于帮助其他人理解该Pipeline的作用和功能。
+- **处理器(Processors)**:Pipeline的核心是处理器,处理器定义了对文档进行的具体处理步骤。每个处理器都执行特定的操作,例如设置字段值、重命名字段、转换数据、条件判断等。处理器按照在Pipeline中的顺序依次执行,以完成对文档的处理。
+- **条件(Conditions)**:可选部分,条件定义了触发Pipeline应用的条件。只有当条件满足时,Pipeline才会被应用到相应的文档上。条件可以基于文档内容、字段值、索引信息等进行判断。
+- **内置变量(Built-in Variables)**:在处理器中可以使用一些内置变量来引用文档数据或上下文信息,并在处理过程中进行操作。例如,`_index`表示当前文档所属的索引名称,`_ingest.timestamp`表示处理器执行的时间戳等。
+- **标签(Tags)**:可选部分,为Pipeline添加标签,用于标识和分类不同类型的Pipeline。
+
+这些部分共同构成了一个完整的Elasticsearch Pipeline,通过定义和配置这些部分,可以实现对文档数据的灵活处理和转换。
+
+**应用Pipeline**
+
+一旦Pipeline被定义,可以在索引文档时指定应用该Pipeline:
+
+```json
+POST my_index/_doc/1?pipeline=my_pipeline
+{
+ "message": "Hello, World!"
+}
+```
+
+## 异常处理
+
+在Elasticsearch Pipeline 中处理异常情况通常通过 `on_failure` 处理器来实现。下面是一个示例代码,演示如何使用 `on_failure` 处理器来处理异常情况:
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description": "Pipeline with error handling",
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "{{field_with_value}}"
+ }
+ },
+ {
+ "on_failure": [
+ {
+ "set": {
+ "field": "error_message",
+ "value": "{{_ingest.on_failure_message}}"
+ }
+ }
+ ]
+ }
+ ]
+}
+```
+
+在上面的示例中,定义了一个名为 `my_pipeline` 的 Pipeline,其中包含两个处理器:
+
+- 第一个处理器使用 `set` 处理器来设置一个新的字段 `new_field` 的值为另一个字段 `field_with_value` 的值。
+- 第二个处理器是一个 `on_failure` 处理器,在前一个处理器执行失败时会被触发。这里使用 `on_failure_message` 变量来获取失败的原因,并将其设置到一个新的字段 `error_message` 中。
+
+当第一个处理器执行失败时,第二个处理器会被触发,并将失败信息存储到 `error_message` 字段中,以便后续处理或记录日志。这样可以帮助我们更好地处理异常情况,确保数据处理的稳定性。
+
+如果是Pipeline级别的错误,可以通过全局设置`on_failure`来处理整个Pipeline执行过程中的异常情况:
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description": "Pipeline with global error handling",
+ "on_failure": [
+ {
+ "set": {
+ "field": "error_message",
+ "value": "{{_ingest.on_failure_message}}"
+ }
+ }
+ ],
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "{{field_with_value}}"
+ }
+ }
+ ]
+}
+```
+
+在上述示例中,Pipeline `my_pipeline` 中定义了一个全局的`on_failure`处理器,在整个Pipeline执行过程中发生异常时会触发。当任何处理器执行失败时,全局`on_failure`处理器将被调用,并将失败消息存储到`error_message`字段中。
+
+通过设置全局的`on_failure`处理器,可以统一处理整个Pipeline中任何处理器可能出现的异常情况,提高数据处理的稳定性和可靠性。这样即便是Pipeline级别的错误,也能得到有效的处理和记录,帮助排查问题并保证数据处理流程的正常运行。
+
+## 为索引设置默认Pipeline
+
+从 Elasticsearch 6.5.x 开始,引入了一个名为 index.default_pipeline 的新索引设置。 这仅仅意味着所有摄取的文档都将由默认管道进行预处理:
+
+```json
+PUT my_index
+{
+ "settings": {
+ "default_pipeline": "add_last_update_time"
+ }
+}
+```
+
+## 内置Processors
+
+Elasticsearch内置的Processors提供了各种功能,用于在Ingest Pipeline中对文档进行处理。以下是一些常用的内置Processors及其作用:
+
+- **Set Processor**:设置字段的固定值或通过表达式计算值。
+- **Grok Processor**:解析文本字段并提取结构化数据。
+- **Date Processor**:解析日期字段。
+- **Convert Processor**:转换字段类型。
+- **Remove Processor**:删除指定字段。
+- **Split Processor**:根据分隔符拆分字段。
+- **GeoIP Processor**:根据IP地址查找地理位置信息。
+- **User Agent Processor**:解析User-Agent字段。
+
+## Pipeline API
+
+,以下是有关Elasticsearch Pipeline API的简要介绍和示例代码:
+
+- **Put Pipeline API**:用于创建或更新Pipeline。
+
+ ```json
+ PUT /_ingest/pipeline/my_pipeline
+ {
+ "description": "My custom pipeline",
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "default"
+ }
+ }
+ ]
+ }
+ ```
+
+- **Get Pipeline API**:用于获取Pipeline的信息。
+
+ ```json
+ GET /_ingest/pipeline/my_pipeline
+ ```
+
+- **Delete Pipeline API**:用于删除Pipeline。
+
+ ```json
+ DELETE /_ingest/pipeline/my_pipeline
+ ```
+
+- **Simulate Pipeline API**:用于模拟Pipeline对文档的处理效果。
+
+ ```json
+ POST /_ingest/pipeline/_simulate
+ {
+ "pipeline": {
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "default"
+ }
+ }
+ ]
+ },
+ "docs": [
+ {
+ "_source": {
+ "my_field": "my_value"
+ }
+ }
+ ]
+ }
+ ```
+
+- **Manage Pipelines in Index Templates**:可以在索引模板中定义Pipeline。
+
+ ```json
+ PUT /_index_template/my_template
+ {
+ "index_patterns": ["my_index*"],
+ "composed_of": ["my_pipeline"],
+ "priority": 1
+ }
+ ```
+
+## 使用建议
+
+在使用Elasticsearch Pipeline时,有几点建议可以帮助提高效率和准确性:
+
+- **测试和验证**:在应用Pipeline之前,务必进行充分的测试和验证,确保处理步骤的准确性和稳定性。
+- **监控和调优**:定期监控Pipeline的性能和效果,根据实际情况进行调优和优化,以提高数据处理和索引效率。
+- **复用Pipeline**:针对相似的数据处理需求,可以设计通用的Pipeline,以便在多个索引中重复使用,提高代码复用性和维护性。
+- **合理使用条件**:根据具体需求选择合适的条件触发Pipeline的应用,避免不必要的处理过程,提高系统性能。
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md"
new file mode 100644
index 0000000..f8972f1
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md"
@@ -0,0 +1,556 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+DSL是Domain Specific Language的缩写,指的是为特定问题领域设计的计算机语言。这种语言专注于某特定领域的问题解决,因而比通用编程语言更有效率。
+
+在Elasticsearch中,DSL指的是Elasticsearch Query DSL,是一种以JSON形式表示的查询语言。通过这种语言,用户可以构建复杂的查询、排序和过滤数据等操作。这些查询可以是全文搜索、聚合搜索,也可以是结构化的搜索。
+
+## 查询上下文
+
+搜索是Elasticsearch中最关键和重要的部分,使用`query`关键字进行检索,更倾向于相关度搜索,故需要计算评分。
+
+在查询上下文中,一个查询语句表示一个文档和查询语句的匹配程度。无论文档匹配与否,查询语句总能计算出一个相关性分数在`_score`字段上。
+
+### 相关度评分:score
+
+相关度评分用于对搜索结果排序,评分越高则认为其结果和搜索的预期值相关度越高,即越符合搜索预期值,默认情况下评分越高,则结果越靠前。在7.x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25。
+
+score是根据各种因素计算出来的,包括:
+
+- **Term Frequency(词频)**:一个词在文档中出现的次数越多,score就越高。
+- **Inverse Document Frequency(逆文档频率**):一个词在所有文档中出现的次数越少,score就越高。
+- **Field Length Norm(字段长度规范**):字段的长度越短,score就越高。
+
+这三个因素共同决定了score的值。然而,你也可以通过设置自定义评分或者禁用评分来影响score的计算。
+
+#### TF/IDF & BM25
+
+TF/IDF是一种在信息检索和文本挖掘中广泛使用的统计方法,用于评估一个词语对于一个文件集或一个语料库中的一个文件的重要程度。名称中的TF表示“术语频率”,IDF表示“逆向文件频率”。
+
+- **TF (Term Frequency)** :这是衡量词在文档中出现的频率。通常来说,一个词在文档中出现的次数越多,其重要性就可能越大。但这并不总是正确的,比如在很多英文文档中,“the”、“and”等词出现的频率非常高,但我们并不能因此认为它们就非常重要。因此,需要结合 IDF 来使用。
+- **IDF (Inverse Document Frequency)** :这是衡量词是否常见的度量。如果某个词在许多文档中都出现,那么它可能并不具有区分性,对于搜索和分类的帮助就不大。例如,每篇英文文章中都会出现的“the”对于区分文章内容就没有什么帮助。所以,如果一个词在所有文档中出现得越多,那么其 IDF 值就会越小,相反,如果一个词很少在文档中出现,那么其 IDF 值就会较大。
+
+TF-IDF 会将这两个因子结合起来,为每个词产生一个权重。具有较高 TF-IDF 分数的词被认为在文档中更重要。通过这种方式,ES 能够提供相关性排序,使得包含用户查询词汇的最相关文档排在搜索结果的前面。
+
+BM25是一种更先进的排名函数,也是基于TF/IDF的一种改进型方法。它引入了两个新概念:
+
+- **文档长度归一化**:长文档可能会有更多的关键词,但这并不意味着它与查询更相关。BM25通过调整文档长度来解决这个问题。
+- **饱和度**:在TF/IDF中,词项的出现频率越高,其重要性就越大。然而在实践中,一旦一个词在文档中出现过,再次出现时增加的相关性可能会降低。BM25通过设置一个饱和点来解决这个问题,超过这个点,词的权重增加就会变得不那么敏感。
+
+总结而言,BM25是TF/IDF的改进版,通过文档长度归一化和频率饱和度控制来优化搜索结果。
+
+### 源数据:source
+
+`_source`字段包含索引时原始的JSON文档内容,字段本身不建立索引(因此无法进行搜索),但是会被存储,所以当执行获取请求是可以返回`_source`字段。
+
+虽然很方便,但是`_source`字段的确会对索引产生存储开销,你可以通过关闭`_source`字段来节省空间,但这通常不建议,因为有了原始数据,我们可以对数据进行重新索引,并且在获取数据时也更加灵活。
+
+如果你禁用了`_source`字段,那么会有以下几个影响:
+
+- **无法获取原始数据**:当你查询某个文档时,你将无法获取到原始的`_source`字段内容,因为它没有被存储在Elasticsearch中。
+- **更新和重新索引的问题**:如果你想更新文档或者执行重新索引操作,可能会遇到问题,因为这两种操作都需要原始的`_source`字段。
+- **脚本字段和某些Aggregations可能受到影响**:如果你正在使用脚本字段或者依赖`_source`字段的Aggregations,那么禁用`_source`可能导致这些特性出问题。
+
+下面是一些使用`_source`字段的例子:
+
+
+
+1. 在索引文档时启用/禁用`_source`:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "_source": {
+ "enabled": false
+ },
+ "properties": {
+ "field1": { "type": "text" }
+ }
+ }
+}
+```
+
+在这个例子中,新创建的`my_index`索引将不会存储`_source`字段。
+
+
+
+2. 获取文档的`_source`字段:
+
+```json
+GET /my_index/_doc/1
+```
+
+返回的结果中会包含`_source`字段。
+
+
+
+3. 在获取文档时只获取`_source`字段中特定的字段:
+
+```json
+GET /my_index/_doc/1?_source=field1,field2
+```
+
+在这个例子中,返回的`_source`字段只包含`field1`和`field2`。
+
+
+
+注意:`_source`字段并不用于搜索,禁用`_source`字段不会影响你的搜索结果。
+
+## 源数据过滤
+
+假设你的应用只需要获取部分字段(如"name"和"price"),而其他字段(如"desc"和"tags")不经常使用或者数据量较大,导致传输和处理这些额外的数据会增加网络开销和处理时间。在这种情况下,通过设置`includes`和`excludes`可以有效地减少每次请求返回的数据量,提高效率。
+
+例如:
+
+```JSON
+PUT product
+{
+ "mappings": {
+ "_source": {
+ "includes": ["name", "price"],
+ "excludes": ["desc", "tags"]
+ }
+ }
+}
+```
+
+**Including**:结果中返回哪些field。
+
+**Excluding**:结果中不要返回哪些field,Excluding优先级比Including更高。
+
+> 需要注意的是,尽管这些设置会影响搜索结果中_source字段的内容,但并不会改变实际存储在Elasticsearch中的数据。也就是说,"desc"和"tags"字段仍然会被索引和存储,只是在获取源数据时不会被返回。
+
+上述这种在mapping中定义的方式不推荐,因为mapping不可变。我们可以在查询过程中指定返回的字段,如下:
+
+```JSON
+GET product/_search
+{
+ "_source": {
+ "includes": ["owner.*", "name"],
+ "excludes": ["name", "desc", "price"]
+ },
+ "query": {
+ "match_all": {}
+ }
+}
+```
+
+Elasticsearch的`_source`字段在查询时支持使用通配符(wildcards)来包含或排除特定字段。使得能够更灵活地操纵返回的数据。
+
+关于规则,可以参考以下几点:
+
+- *:匹配任意字符序列,包括空序列。
+- ?:匹配任意单个字符。
+- [abc]: 匹配方括号内列出的任意单个字符。例如,[abc]将匹配"a", "b", 或 "c"。
+
+请注意,通配符表达式可能会导致查询性能下降,特别是在大型索引中,因此应谨慎使用。
+
+## 全文检索
+
+全文检索是Elasticsearch的核心功能之一,它可以高效地在大量文本数据中寻找特定关键词。
+
+在Elasticsearch中,全文检索主要依靠两个步骤:"分析"(Analysis)和"查询"(Search)。
+
+- **分析**: 当你向Elasticsearch插入一个文档时,会进行"分析"处理,将原始文本数据转换成称为"tokens"或"terms"的小片段。这个过程可能包括如下操作:
+ - 切分文本(Tokenization)
+ - 将所有字符转换为小写(Lowercasing)
+ - 删除常见但无重要含义的单词(Stopwords)
+ - 提取词根(Stemming)
+- **查询**:当执行全文搜索时,查询字符串也会经过类似的分析过程,然后再与已经分析过的数据进行比对,找出匹配的结果并返回。
+
+Elasticsearch提供了许多种全文搜索的查询类型,例如:
+
+- **Match Query**:最基本的全文搜索查询。
+- **Match Phrase Query**:用于查找包含特定短语的文档。
+- **Multi-Match Query**:类似Match Query,但可以在多个字段上进行搜索。
+- **Query String Query**:提供了丰富的搜索语法,可以执行复杂的、灵活的全文搜索。
+
+### match:匹配包含某个term的子句
+
+`match` 查询是 Elasticsearch 中的一种全文查询方式,它包括标准分析和词项搜索。尽管它可以应用于精确字段,但其主要用途是进行全文搜索。当与全文字段一起使用时,match 查询可以解析查询字符串,并执行短语查询或者构建一个布尔查询,这意味着它会考虑字段中的每个单词。
+
+下面有一个简单的 `match` 查询示例:
+
+```json
+GET /_search
+{
+ "query": {
+ "match": {
+ "message": "this is a test"
+ }
+ }
+}
+```
+
+在这个示例中,Elasticsearch 会在 "message" 字段中搜索包含 "this"、"is"、"a" 和 "test" 的文档。
+
+请注意,`match` 查询不仅仅会匹配完全相同的短语,它还可以处理更复杂的情况,如多个单词(它会匹配任何一个)、误拼、同义词等,这主要取决于你所使用的分析器和搜索设置。
+
+`match` 查询还有一些其他参数,例如:
+
+- **operator**:定义多个搜索词之间的关系,默认为 `or`。如果设为 `and`,则返回的文档必须包含所有搜索词。
+- **minimum_should_match**:控制返回的文档应至少匹配的搜索词的数量或比例。
+- **fuzziness**:允许模糊匹配,可以找到那些拼写错误或接近的词汇。
+
+### match_all:匹配所有结果的子句
+
+`match_all`是Elasticsearch中的一个查询类型,用于获取索引中的所有文档。
+
+这是一个`match_all`查询的基本示例:
+
+```json
+{
+ "query": {
+ "match_all": {}
+ }
+}
+```
+
+在上述示例中,我们可以看到查询对象中存在一个"match_all"字段,其值是一个空对象。这表示我们希望匹配所有文档。
+
+需要注意,由于 `match_all` 查询可能返回大量的数据,所以一般在使用时都会与分页(pagination)功能结合起来,这样可以控制返回结果的数量,避免一次性加载过多数据导致的性能问题。例如,你可以使用 `from` 和 `size` 参数来限制返回结果:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "match_all": {}
+ },
+ "from": 10,
+ "size": 10
+}
+```
+
+Elasticsearch的 `match_all` 查询是最简单的查询,它不需要任何参数,但如果你想为它添加权重,可以使用 `boost` 参数。例如:
+
+```json
+GET /_search
+{
+ "query": {
+ "match_all": { "boost" : 1.2 }
+ }
+}
+```
+
+在上面的查询中,`boost` 参数被设置为1.2,给匹配到的所有文档增加了额外的相关性得分提升。
+
+### multi_match:多字段条件
+
+`multi_match` 可以用来在多个字段上进行全文搜索。它接受一个查询字符串和一组需要在其中执行查询的字段列表。
+
+例如:
+
+```json
+{
+ "query": {
+ "multi_match" : {
+ "query": "这是测试",
+ "fields": [ "field1", "field2" ]
+ }
+ }
+}
+```
+
+在此示例中,查询字符串"这是测试"将在字段"field1"和"field2"中搜索。
+
+`multi_match`查询也支持使用通配符(*)来匹配多个字段:
+
+```json
+{
+ "query": {
+ "multi_match" : {
+ "query": "这是测试",
+ "fields": [ "*_name" ]
+ }
+ }
+}
+```
+
+在这个例子中,会在所有以"_name"结尾的字段中进行搜索。
+
+此外,`multi_match` 查询还支持许多参数,包括:
+
+- **type**:设置查询类型,可选值包括:`best_fields`, `most_fields`, `cross_fields`, `phrase`, `phrase_prefix` 等。
+
+例如,“best_fields” 类型会从指定的字段中挑选分数最高的匹配结果计算最终得分,而“most_fields” 类型则会在每个字段中都寻找匹配项并将其分数累加起来。
+
+- **tie_breaker**:当一个词在多个字段中找到时,用于决定最终得分的参数。
+- **minimum_should_match**:用于控制应匹配的最小子句数。
+- **operator**:主要有两个操作符 `OR` 和 `AND`,默认为 `OR`。
+
+需要注意的是,当使用 `multi_match` 查询时,如果字段不同,其权重可能也会不同。你可以通过在字段名后面添加尖括号(^)和权重值来调整特定字段的权重。例如,`"fields": [ "name^3", "description" ]`表示在"name"字段中的匹配结果权重是"description"字段的三倍。
+
+### match_phrase:短语查询
+
+`match_phrase` 用于精确匹配包含指定短语的文档。match_phrase 查询需要字段值中的单词顺序与查询字符串中的单词顺序完全一致。
+
+例如:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "match_phrase": {
+ "message": "this is a test"
+ }
+ }
+}
+```
+
+这个查询将会找到"message"字段中包含完整短语"this is a test"的所有文档。
+
+此外,`match_phrase` 查询还有一个 `slop` 参数,可以定义词组中的词语可能存在的位置偏移量。例如,如果将 `slop` 设置为 1,则查询 "this is a test" 也可匹配 "this is test a",因为 "a" 和 "test" 只需移动一个位置即可匹配。
+
+```json
+GET /_search
+{
+ "query": {
+ "match_phrase": {
+ "query": "this is a test",
+ "slop": 2
+ }
+ }
+}
+```
+
+请注意,`match_phrase` 查询需要整个短语完全匹配,而不仅仅是查询中的所有单词都存在。如果你只是希望所有单词都存在,而不关心它们的顺序或精确出现方式,那么你应该使用 `match` 查询。
+
+## Term Query
+
+精确查询用于查找包含指定精确值的文档,而不是执行全文搜索。
+
+### term:匹配和搜索词项完全相等的结果
+
+`term` 查询主要用于查询某个字段完全匹配给定值的文档。这对精确匹配非常有效,例如数字、布尔值或者字符串。
+
+用法示例:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "term" : { "user" : "Kimchy" }
+ }
+}
+```
+
+在这个例子中,我们正在搜索"user"字段中完全匹配"Kimchy"的文档。
+
+需要注意的是,`term` 查询对于分析过的字段(例如,文本字段)可能不会像你预期的那样工作,因为它会搜索精确的词汇项,而不是单词。如果你想要对文本字段进行全文搜素,应该使用 `match` 查询。
+
+另外一个需要注意的点就是 `term` 查询对大小写敏感,所以 "Kimchy" 和 "kimchy" 是两个不同的词条。
+
+#### term和match_phrase的区别
+
+`term` 查询和 `match_phrase` 查询是 Elasticsearch 提供的两种查询方式,它们都用于查找文档,但主要的区别在于如何解析查询字符串以及匹配的精确度。
+
+- **term**:这个查询做的是精确匹配。当你使用`term`查询时,Elasticsearch会查找完全等于你指定的词汇的文档。例如,如果你搜索`term` "apple",那么只有包含完全为"apple"的文档会被匹配到,而包含"apples"或"APPLE"的文档则不会被匹配到。因此,`term`查询对大小写敏感,且不会进行任何形式的分析(如停用词移除、词干提取等)。
+- **match_phrase**:这个查询是用来匹配一系列词汇或者短语的。`match_phrase`查询会保证你查询的词汇必须以你提供的顺序完全匹配。比如,如果你使用`match_phrase`查询 "quick brown fox",那么只有包含这个完整短语的文档才会被匹配到,单独包含"quick"、"brown"或者"fox"的文档则不会被匹配到。此外,与`term`查询不同,`match_phrase`查询会进行文本分析,这意味着它会考虑词汇的大小写、复数形式等。
+
+总结来说,`term`查询更适合精确匹配,而`match_phrase`查询更适合短语匹配。但是,`match_phrase`并不能100%保证精确匹配,因为它会处理和考虑文本的各种变体(比如,大小写、单复数形式等)。
+
+### terms:匹配和搜索词项列表中任意项匹配的结果
+
+`terms` 查询用于匹配指定字段中包含一个或多个值的文档。这是一个精确匹配查询,不会像全文查询那样对查询字符串进行分析。
+
+假设你有一个 "user" 的字段,并且你想找到该字段值为 "John" 或者 "Jane" 的所有文档,你可以使用 `terms` 查询:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "terms" : {
+ "user" : ["John", "Jane"],
+ "boost" : 1.0
+ }
+ }
+}
+```
+
+上面的查询将返回所有"user" 字段等于 "John" 或者 "Jane" 的文档。
+
+其中`boost` 参数用于增加或减少特定查询的相对权重。它将改变查询结果的相关性分数(_score),以影响最终结果的排名。
+
+例如,在上述 `terms` 查询中,`boost` 参数被设置为 1.0。这意味着如果字段 "user" 的值包含 "John" 或 "Jane",那么其相关性分数(_score)就会乘以 1.0。因此,这个设置实际上并没有改变任何东西,因为乘以 1 不会改变原始分数。但是,如果你将 `boost` 参数设置为大于 1 的数,那么匹配的文档的 _score 将会提高,反之则会降低。
+
+## Range:范围查找
+
+Range查询允许我们查找某个范围内的值。假设我们有一个商品表,其中有商品价格字段,我们可以用range查询来查找价格在一定范围内的商品。
+
+以下是一个基础的范围查询的例子:
+
+```json
+GET /products/_search
+{
+ "query": {
+ "range" : {
+ "price" : {
+ "gte" : 10,
+ "lte" : 20,
+ "boost" : 2.0
+ }
+ }
+ }
+}
+```
+
+在这个例子中,我们正在查询价格大于或等于(gte)10且小于或等于(lte)20的所有商品。"boost"参数表示增加该查询的重要性。
+
+Range查询支持以下参数:
+
+- **gte**:大于或等于。
+- **lte**:小于或等于。
+- **gt**:大于。
+- **lt**:小于。
+- **boost**:增加查询的重要性。
+
+此外,对于日期类型的字段,你还可以使用如下方式进行范围查询:
+
+```json
+{
+ "query": {
+ "range" : {
+ "timestamp" : {
+ "gte" : "now-1d/d",
+ "lt" : "now/d"
+ }
+ }
+ }
+}
+```
+
+在上述查询中,我们正在查找过去24小时内的数据。"now-1d/d"表示从现在算起的一天前,而"now/d"表示当前时间。
+
+## Filter
+
+过滤器(Filter)是用于筛选数据的一种工具。过滤器和查询(query)相似,但有几个重要的区别:
+
+- **过滤不关心文档的相关度得分(relevance score)**:查询会为每个匹配的文档计算一个相关度得分,以决定返回结果的排序。相比之下,过滤器只关心文档是否匹配 - 没有“部分匹配”,只有“匹配”或“不匹配”。
+- **过滤器可以被缓存**:由于过滤器不需要计算得分,因此它们的结果可以被缓存起来用于之后的搜索请求,这可以大大提高性能。
+
+常见的过滤器类型包括:`term`、`terms`、`range`、`bool`、`match_all` 等。例如,范围过滤器 `range` 可以用于查找数字或日期字段在指定范围内的文档;布尔过滤器 `bool` 则允许你组合多个过滤器,并定义它们如何互相交互。
+
+使用过滤器时,通常会把它们放在 `bool` 查询的 `filter` 子句中。例如:
+
+```json
+{
+ "query": {
+ "bool": {
+ "filter": [
+ { "term": { "status": "active" }},
+ { "range": { "age": { "gte": 30, "lte": 40 }}}
+ ]
+ }
+ }
+}
+```
+
+这个查询会返回所有“状态为 active 并且年龄在 30 到 40 之间”的文档,而不会考虑它们的相关度得分。
+
+### Filter缓存机制
+
+在 Elasticsearch 中,过滤查询结果的缓存机制是非常重要的一个性能优化手段。由于过滤器(filter)只关心是否匹配,而不关心评分 (_score),因此它们的结果可以被缓存以提高性能。
+
+每次 filter 查询执行时,Elasticsearch 都会生成一个名为 "bitset" 的数据结构,其中每个文档都对应一个位(0 或 1),表示这个文档是否与 filter 匹配。这个 bitset 就是被存储在缓存中的部分。
+
+如果相同的 filter 查询再次执行,Elasticsearch 可以直接从缓存中获取这个 bitset,而不需要再次遍历所有的文档来找出哪些文档符合这个 filter。这大大提高了查询速度,并减少了 CPU 使用。
+
+这种缓存策略特别适合那些重复查询的场景,例如用户界面的过滤器和类似的功能,因为他们通常会产生很多相同的 filter 查询。
+
+然而,值得注意的是,虽然这种缓存可以显著改善查询性能,但也会占用内存空间。如果你有很多唯一的过滤条件,那么过滤器缓存可能会变得很大,从而导致内存问题。这就需要你对使用的过滤器进行适当的管理和限制。
+
+Filter缓存功能会遵循以下原则:
+
+- **同一Filter的多次应用**:如果在后续查询中有多次使用相同的Filter,则ES会把第一次查询的结果储存在缓存中,后续的查询将直接从缓存中获取结果,而不再做任何磁盘I/O或者其他计算。
+- **根据需求清理缓存**:ES会根据内存使用情况自动清理缓存,当然你也可以手动清空缓存。但这并不意味着我们无限制地依赖Filter缓存,大量的缓存可能导致更重的GC压力。
+- **不缓存复杂查询**:一些查询条件较复杂的过滤器可能不会被缓存,比如script filter、geo filter等。这是因为这些过滤器本身的构建和维护成本可能就超过了查询的计算成本。
+
+ES的Filter缓存机制可以大大提高查询效率,但如果不慎用,比如缓存过多或者不适合缓存的查询,可能会对性能产生负面影响。因此,在设计和优化ES查询时,应当充分考虑Filter的使用和缓存策略。
+
+## Bool Query
+
+Bool Query(组合查询)可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
+
+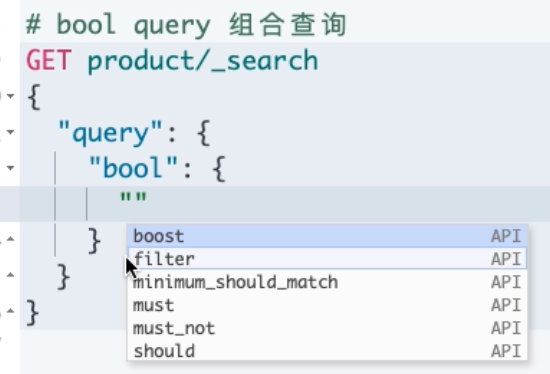
+
+`boost`和`minumum_should_match`是参数,其他四个都是查询子句。
+
+- **must**:必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分。
+- **filter**:过滤器不计算相关度分数。
+- **should**:满足 or子句(查询)应出现在匹配的文档中。
+- **must_not**:必须不满足,不计算相关度分数 ,not子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。
+
+例子1:下面的语句表示:包含"xiaomi"或"phone" 并且包含"shouji"的文档例子:
+
+```JSON
+GET product/_search
+{
+ "query": {
+ "bool": {
+ "must": [
+ {
+ "match": {
+ "name": "xiaomi phone"
+ }
+ },
+ {
+ "match_phrase": {
+ "desc": "shouji"
+ }
+ }
+ ]
+ }
+ }
+}
+```
+
+### should与must或filter一起使用
+
+当 `should` 子句与 `must` 或 `filter` 子句一起使用时,这时候需要注意了。
+
+只要满足了 `must` 或 `filter` 的条件,`should` 子句就不再是必须的。换句话说,如果存在一个或者多个 `must` 或 `filter` 子句,那么 `should` 子句的条件会被视为可选。
+
+然而,如果 `should` 子句与 `must_not` 子句单独使用(也就是没有 `must` 或 `filter`),则至少需要满足一个 `should` 子句的条件。
+
+这里有一个例子来说明:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "bool": {
+ "must": [
+ { "term": { "user": "kimchy" }}
+ ],
+ "filter": [
+ { "term": { "tag": "tech" }}
+ ],
+ "should": [
+ { "term": { "tag": "wow" }},
+ { "term": { "tag": "elasticsearch" }}
+ ]
+ }
+ }
+}
+```
+
+在这个查询中,`must` 和 `filter` 子句的条件是必须满足的,而 `should` 子句的条件则是可选的。如果匹配的文档同时满足 `should` 子句的条件,那么它们的得分将会更高。
+
+那如果我们一起使用的时候想让should满足该怎么办?这时候`minimum_should_match` 参数就派上用场了。
+
+### minimum_should_match
+
+`minimum_should_match`参数定义了在 `should` 子句中至少需要满足多少条件。
+
+例如,如果你有5个 `should` 子句并且设置了 `"minimum_should_match": 3`,那么任何匹配至少三个 `should` 子句的文档都会被返回。
+
+这个参数可以接收绝对数值(如 `2`)、百分比(如 `30%`)、和组合(如 `3<90%` 表示至少匹配3个或者90%,取其中较大的那个)等不同类型的值。
+
+注意:如果 `bool` 查询中只有 `should` 子句(没有 `must` 或 `filter`),那么默认情况下至少需要匹配一个 `should` 条件,也就是`minimum_should_match`默认值是1,除非 `minimum_should_match` 明确设定为其他值。如果包含 `must` 或 `filter`的情况下`minimum_should_match`默认值 0。
+
+所以我们可以在包含`must` 或 `filter`的情况下,设置`minimum_should_match`值来满足`should`子句中的条件。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md"
new file mode 100644
index 0000000..ce47872
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md"
@@ -0,0 +1,178 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES作为一款开源的分布式搜索和分析引擎,以其卓越的性能和灵活的扩展性而备受青睐。
+
+在实际应用中,如何最大限度地发挥ES的写入能力并保证数据的一致性和可靠性仍然是一个值得关注的话题。
+
+接下来,我们将深入了解ES的写入过程和原理。
+
+## 写入过程
+
+### 写操作
+
+ES支持四种对文档的数据写操作:
+
+- **create**:如果在PUT数据的时候当前数据已经存在,则数据会被覆盖。如果在PUT的时候加上操作类型create,此时如果数据已存在,则会返回失败,因为已经强制指定了操作类型为create,ES就不会再去执行update操作。
+- **delete**:删除文档,ES对文档的删除是懒删除机制,即标记删除,会被记录在 `.del`文件中。在后续的合并(merge)过程中,Elasticsearch会根据一定的条件和策略,将包含已删除文档的分段进行合并。在合并期间,`.del` 文件中的已删除文档将被完全删除,从而释放磁盘空间。
+- **index**:在ES中,写入操作被称为Index,这里Index为动词,即索引数据,为数据创建在ES中的索引。
+- **update**:执行partial update(全量更新,部分更新)。PUT是全量更新,POST是部分更新。
+
+### 写流程
+
+**ES中的数据写入均发生在 Primary Shard,当数据在 Primary Shard 写入完成之后会同步到相应的 Replica Shard**
+
+下图演示了单条数据写入ES的流程:
+
+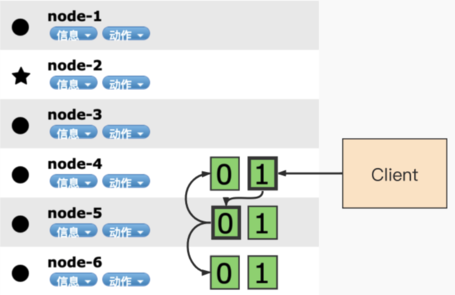
+
+以下为数据写入的步骤:
+
+1. 客户端发起写入请求至node-4。
+2. node-4通过文档 id 在路由表中的映射信息确定当前数据的位置在分片0,分片0的主分片位于node-5,并将数据转发至node-5。
+3. 数据在node-5写入,写入成功之后将数据的同步请求转发至其副本所在的node-4和node-6上面,等待所有副本数据写入成功之后,node-5将结果报告node-4,并由node-4将结果返回给客户端,报告数据写入成功。
+
+在这个过程中,接收用户请求的节点是不固定的,上述例子中,node-4 发挥了协调节点和客户端节点的作用,将数据转发至对应节点和接收以及返回用户请求。
+
+数据在由 node-4 转发至 node-5的时候,是通过以下公式来计算指定的文档具体在哪个分片的:
+
+```json
+shard_num = hash(_routing) % num_primary_shards
+```
+
+其中,`_routing` 的默认值就是文档的 id。
+
+### 写一致性策略
+
+ES 5.x 之后,一致性策略由 `wait_for_active_shards` 参数控制。
+
+ `wait_for_active_shards` 即确定客户端返回数据之前必须处于 active 的分片数(包括主分片和副本),默认值为1,即只需要主分片写入成功。
+
+最大值为 `number_of_replicas + 1` ,可以设置为 `all`或任何正整数。如果当前 active 状态的分片没有达到设定阈值,写操作必须等待并且重试,默认等待时间30秒,直到 active 状态的副本数量超过设定的阈值或者超时返回失败为止。
+
+假设我们有一个由A、B、C三个节点组成的集群。并且我们创建了一个index副本数设置为3的索引(此时共4个分片数据,比节点数多一个)。
+
+如果我们尝试索引操作,默认情况下,该操作只会确保每个主分片的主副本在继续之前可用。这意味着即使B和c出现故障被A托管主分片,索引操作仍将仅使用数据的一个副本进行。
+
+如果`wait_for_active_shards`设置为3(并且所有3个节点都已启动),那么索引操作将需要3个活动分片才能继续进行,因为集群中有3个活动节点,每个节点都持有一个活跃,所以满足这一要求。
+
+但是,如果我们设置`wait_for_active_shards`为all(或设置为4),数据写入将直接失败,因为集群此时根本不可能有四个活跃的分片。
+
+除非在集群中启动一个新节点来托管分片的第四个分片,否则该操作将超时。
+
+## 写入原理
+
+### Refresh
+
+ES中数据并不是直接写到文件系统缓存里的,在内部ES开辟了名为:`Memory Buffer`的缓存区。
+
+Memory Buffer的性能非常高,客户端发出写入请求的时候是直接写在Memory Buffer里的。
+
+**Memory Buffer的空间阈值默认大小为堆内存的10%,时间阈值为1s。空间阈值和时间阈值只要达成任意一个,就会触发 Refresh操作**
+
+也可以调用 Refresh API 来人工触发 Refresh 操作:
+
+```json
+POST /_refresh
+
+GET /_refresh
+
+POST /_refresh
+
+GET /_refresh
+```
+
+Refresh 操作会将缓存中的数据生成一个个 segment 文件。
+
+原理见下图:
+
+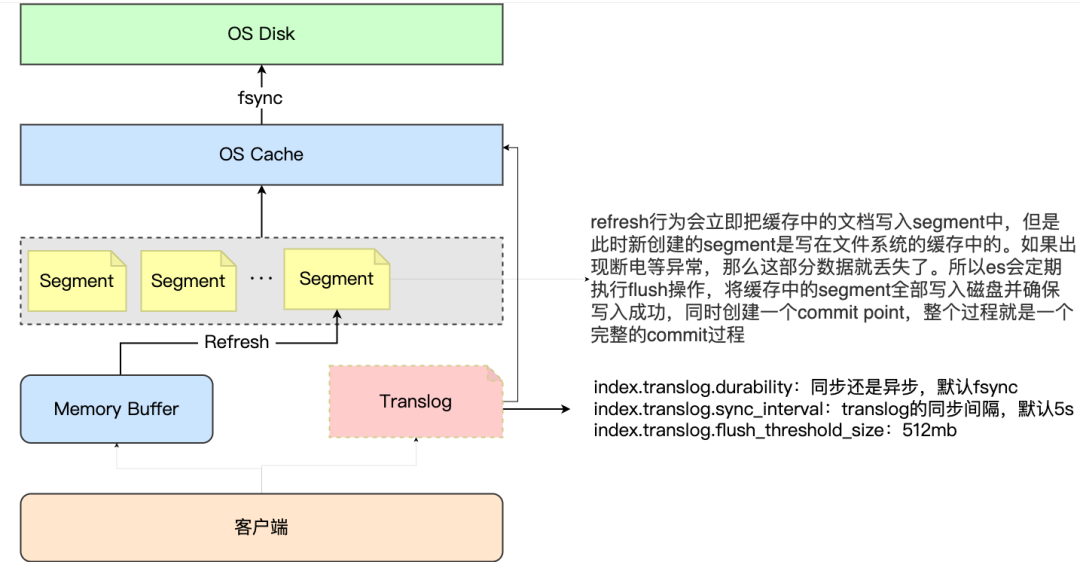
+
+内存索引缓冲区中的文档被写入新段,新段首先写入文件系统缓存(这个过程性能消耗很低),然后才刷新到磁盘(这个过程代价很高)。但是,在文件进入缓存后,它就可以像任何其他文件一样被打开和读取。
+
+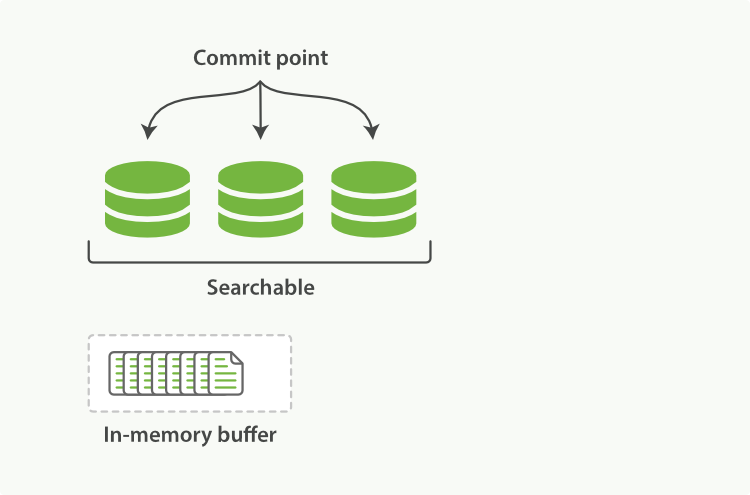
+
+Lucene 允许写入和打开新的段,使它们包含的文档对搜索可见,而无需执行完整的提交。这是一个比提交到磁盘更轻松的过程,并且可以经常执行而不会降低性能。
+
+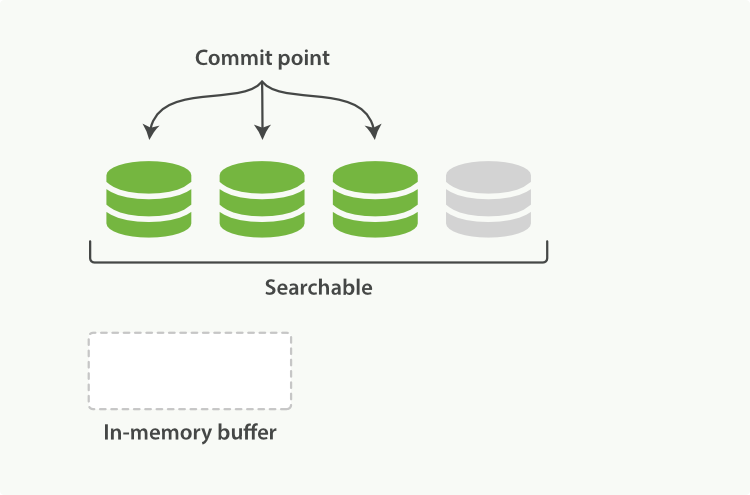
+
+这个写入和打开新段的过程即被称为 **Refresh** 。刷新使自上次刷新以来对索引执行的所有操作都可用于搜索。
+
+`index.refresh_interval`参数可以设置多久执行一次刷新操作,默认为 `1s`,可以设置 `-1` 禁用刷新。
+
+并不是所有的情况都需要每秒刷新。比如 Elasticsearch 索引大量的日志文件,此时并不需要太高的写入实时性, 可以增大刷新间隔来降低每个索引的刷新频率,从而降低因为实时性而带来的性能开销,进而提升检索效率。
+
+```json
+POST
+{
+ "settings": {
+ "refresh_interval": "30s"
+ }
+}
+```
+
+**需要注意的是,虽然此时数据能被查询到,但还没落到磁盘中,数据仍然是不安全的**
+
+### Merge
+
+由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数量太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。
+
+Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
+
+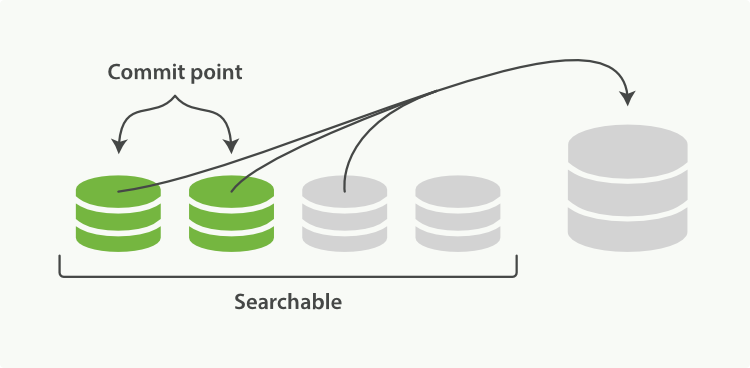
+
+Elasticsearch 中的一个 shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,并删除较小的段。
+
+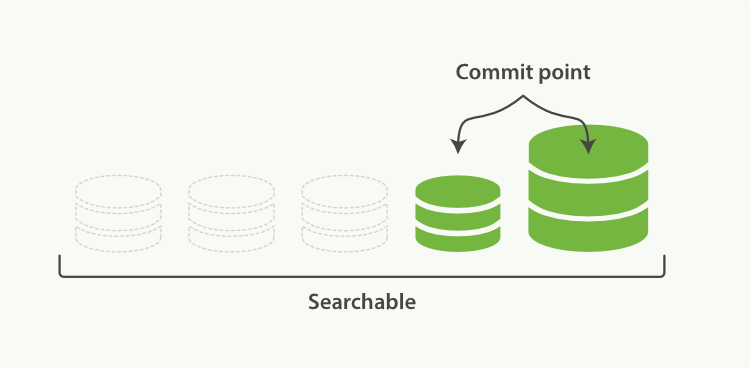
+
+**Merge是非常消耗资源的,Refesh的频率越高,生成Segment的频率就越高,Merge就执行的越频繁**
+
+合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
+
+### Flush
+
+Flush 是确保当前存储在 Translog 中的数据也永久存储在 Lucene 索引中的过程。
+
+重新启动时,Elasticsearch 会将所有未刷新的操作从 Translog 重播到 Lucene 索引,以使其恢复到重新启动前的状态。Elasticsearch 会根据需要自动触发Flush,使用启发式算法来权衡未刷新事务日志的大小与执行每次刷新的成本。
+
+一旦操作被刷新,它就会永久存储在 Lucene 索引中。这可能意味着不需要在事务日志中维护它的额外副本。事务日志由多个文件组成,称为 generation ,一旦不再需要,Elasticsearch 将删除相应的文件,从而释放磁盘空间。
+
+也可以使用 Flush API 触发一个或多个索引的刷新,尽管用户很少需要直接调用此 API。如果您在索引某些文档后调用刷新 API,并成功响应,表明 Elasticsearch 已刷新在调用刷新 API 之前索引的所有文档。
+
+```json
+POST /my_index/_flush
+```
+
+请注意,手动调用刷新操作可能会对系统性能产生一定的影响,因为它涉及到磁盘写入和索引更新。建议在必要时使用手动刷新操作,而不是频繁地调用。
+
+### Translog
+
+对索引的修改操作会在 Lucene 执行 commit 之后真正持久化到磁盘,这个过程是非常消耗资源的,因此不可能在每次索引操作或删除操作后执行。Lucene 提交的成本太高,无法对每个单独的更改执行,因此每个分片副本先将操作写入其事务日志,也就是 Translog。
+
+所有索引和删除操作在被内部 Lucene 索引处理之后,但在它们被确认之前写入到 translog。如果发生崩溃,当分片恢复时,已确认但尚未包含在最后一次 Lucene 提交中的最近操作将从 translog 中恢复。
+
+ES的 Flush 是 Lucene 执行 commit 并开始写入 translog 的过程,Flush 是在后台自动执行的,translog 中的数据仅在 translog 被执行 `fsync` 和 `commit` 时才会持久化到磁盘。如果发生硬件故障或操作系统崩溃或 JVM 崩溃或分片故障,自上次 translog 提交以来写入的任何数据都将丢失。
+
+以下参数可控制 translog 的行为:
+
+- `index.translog.sync_interval`:无论写入操作如何,translog 默认每隔 5s 被 fsync 写入磁盘并 commit 一次,不允许设置小于 100ms 的提交间隔。设置得较小,例如设置为 1s,会增加磁盘 I/O 的频率,但能提供更高的数据持久性。与之相反,若设置得较大,例如设置为 -1,表示关闭自动触发的 Translog 刷新机制,将完全依赖于系统或文件系统层面的刷新策略。这样可以提高写入性能,但可能会增加数据丢失风险。
+
+- `index.translog.durability`:此参数定义了刷新到磁盘的方式,该参数有以下可选值:
+
+ - `request`:表示 Elasticsearch 在响应客户端请求之前必须将数据刷新到磁盘。这是最安全的选项,但可能会影响写入性能。
+ - `async`:表示 Elasticsearch 在异步模式下将数据刷新到磁盘。它允许更高的写入性能,但可能会增加一定的数据丢失风险。
+ - `fsync`:表示 Elasticsearch 在将数据刷新到磁盘后,通过执行 fsync 操作来确保数据已经写入到物理介质。这是最慢的选项,但提供了最高的数据持久性。
+
+ 默认情况下,`index.translog.durability` 的值为 `request`,即 Elasticsearch 必须在响应客户端请求之前将数据刷新到磁盘,以确保数据的持久性。
+
+- `index.translog.flush_threshold_size`:此参数定义了触发 Translog 刷新的阈值大小,默认值为 512MB。这意味着当 Translog 中累积的数据大小达到或超过 512MB 时,Elasticsearch 将自动触发刷新操作,将数据刷新到磁盘。可以根据实际需求调整该参数的值。如果值设置得较小,例如设置为 128MB,会增加 Translog 刷新的频率,但可能会对系统的写入性能产生一定影响。而将其设置得较大,则会减少 Translog 刷新的频率,提高写入性能,但也会增加数据丢失风险。
+
+### 图解写入流程
+
+一图以蔽之:
+
+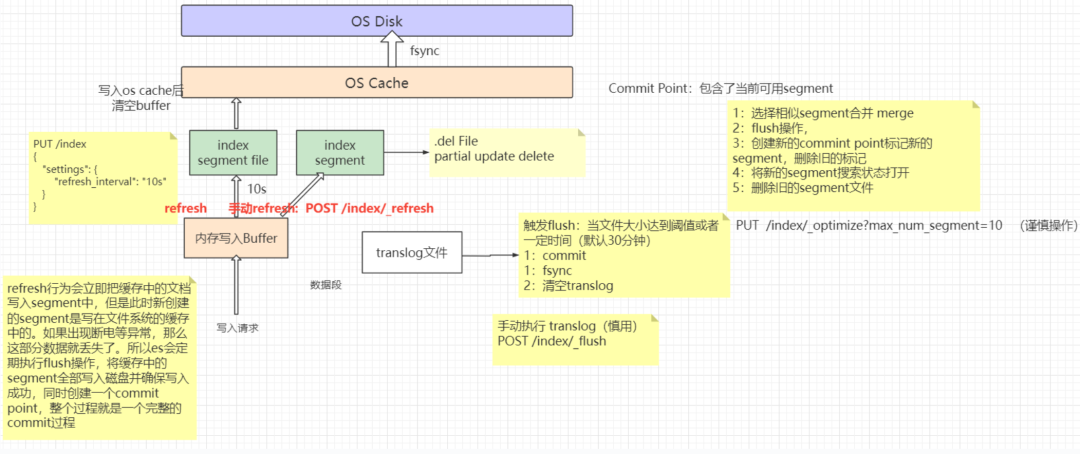
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md"
new file mode 100644
index 0000000..572208c
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md"
@@ -0,0 +1,149 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+当涉及到大规模数据存储和检索时,Elasticsearch以其快速、高效和强大的搜索能力而闻名,并被广泛应用于各种场景,例如日志分析、全文搜索和实时数据分析。
+
+然而,并不是只要将数据存入ES就可以立即获得最佳性能和查询效率。正如任何强大的工具一样,ES也需要进行调优,以充分发挥其潜力并满足特定业务需求。
+
+在这篇文章中,我们将探讨ES写入调优和查询调优的关键方面,并提供一些实用的技巧和建议,帮助您优化ES集群的性能和响应速度。
+
+## 写入调优
+
+### 基本原则
+
+写入性能调优是建立在 Elasticsearch 的写入原理之上的。
+
+ES 数据写入具有一定的延时性,这是为了减少频繁的索引文件产生。默认情况下 ES 每秒生成一个 Segment 文件,当达到一定阈值的时候会执行merge,merge 过程发生在 JVM中,频繁的生成 Segmen 文件可能会导致频繁的触发 FGC,导致 OOM。
+
+为了避免这种情况,通常采取的手段是降低 Segment 文件的生成频率,办法有两个:一个是增加时间阈值,另一个是增大Buffer的空间阈值,因为缓冲区写满也会生成 Segment 文件。
+
+生产经常面临的写入可以分为两种情况:
+
+**高频低量**:高频的创建或更新索引或文档,一般发生在 C 端业务场景下。
+
+**低频高量**:一般情况为定期重建索引或批量更新文档数据。
+
+在搜索引擎的业务场景下,用户一般并不需要那么高的写入实时性。比如你在网站发布一条征婚信息,或者二手交易平台发布一个商品信息。其他人并不是马上能搜索到的,这其实也是正常的处理逻辑。
+
+这个延时的过程需要处理很多事情,比如:你的信息需要后台审核。
+
+你发布的内容在搜索服务中需要建立索引,而且你的数据可能并不会马上被写入索引,而是等待要写入的数据达到一定数量之后,批量写入。
+
+这种操作优点类似于我们快递物流的场景,只有当快递数量达到一定量级的时候,比如能装满整个车的时候,快递车才会发车。因为反正是要跑一趟,装的越多,平均成本越低。
+
+这和我们数据写入到磁盘的过程是非常相似的,我们可以把一条文档数据看做是一个快递,而快递车每次发车就是向磁盘写入数据的一个过程,这个过程不宜太多,太多只会降低性能,就是体现在运输成本上面,而对于我们数据写入而言就是体现在我们硬件性能损耗上面。
+
+### 优化手段
+
+以下为常见数据写入的调优手段,写入调优均以提升写入吞吐量和并发能力为目标,而非提升写入实时性。
+
+#### 增加 flush 时间间隔
+
+flush的过程是非常消耗资源的。增加flush的时间间隔目的是减小数据写入磁盘的频率,降低磁盘IO频率。
+
+#### 增加 refresh_interval 参数的值
+
+增加 refresh_interval 参数的值,目的是减少segment文件的创建,降低merge次数,因为merge是发生在jvm中的,有可能导致full GC。
+
+ES的 refresh 行为非常昂贵,并且在正在进行的索引活动时经常调用,会降低索引速度。
+
+默认情况下,Elasticsearch 每秒定期刷新索引,如果没有搜索流量或搜索流量很少(例如每 5 分钟不到一个搜索请求),可以适当调大此参数的值。
+
+#### 增加Buffer大小
+
+本质也是减小refresh的时间间隔,因为导致segment文件创建的原因不仅有时间阈值,还有buffer空间大小,写满了也会创建。 默认值为JVM 空间的10%。
+
+#### 关闭副本
+
+当需要单次写入大量数据的时候,建议关闭副本,暂停搜索服务,或选择在检索请求量谷值区间时间段来完成。
+
+关闭副本可以带来如下好处:
+
+- 减小读写之间的资源抢占,读写分离。
+- 当检索请求数量很少的时候,可以减少甚至完全删除副本分片,关闭segment的自动创建以达到高效利用内存的目的,因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
+
+具体可通过设置`index.number_of_replicas` 为0以加快索引速度。没有副本意味着丢失单个节点可能会导致数据丢失,因此数据保存在其他地方很重要,以便在出现问题时可以重试初始加载。初始加载完成后,可以设置`index.number_of_replicas`改回其原始值。
+
+#### 禁用swap
+
+大多数操作系统尝试将尽可能多的内存用于文件系统缓存,并急切地换掉未使用的应用程序内存。这可能导致部分 JVM 堆甚至其可执行页面被换出到磁盘。
+
+交换对性能和节点稳定性非常不利,应该不惜一切代价避免。它可能导致垃圾收集持续几分钟而不是几毫秒,并且可能导致节点响应缓慢甚至与集群断开连接。在Elastic分布式系统中,让操作系统杀死节点更有效。
+
+#### 使用多个工作线程
+
+发送批量请求的单个线程不太可能最大化 Elasticsearch 集群的索引容量。为了使用集群的所有资源,应该从多个线程或进程发送数据。除了更好地利用集群的资源外,还有助于降低每个 fsync 的成本。
+
+确保注意 `TOO_MANY_REQUESTS` 响应代码:429。(EsRejectedExecutionException使用 Java 客户端),这是 Elasticsearch 告诉我们它无法跟上当前索引速度的方式。发生这种情况时,应该在重试之前暂停索引,最好使用随机指数退避。
+
+与调整批量请求的大小类似,只有测试才能确定最佳工作线程数量是多少。这可以通过逐渐增加线程数量来测试,直到集群上的 I/O 或 CPU 饱和。
+
+#### max_result_window参数
+
+`max_result_window`是分页返回的最大数值,默认值为10000。max_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
+
+设置一个合理的大小是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
+
+## 查询调优
+
+### 读写性能不可兼得
+
+首先要明确一点:鱼和熊掌不可兼得。读写性能调优在很多场景下是只能二选一的。牺牲 A 换 B 的行为非常常见。索引本质上也是通过空间换取时间。牺牲写入实时性就是为了提高检索的性能。
+
+当你在二手平台或者某垂直信息网站发布信息之后,是允许有信息写入的延时性的。但是检索不行,甚至 1 秒的等待时间对用户来说都是无法接受的。满足用户的要求甚至必须做到10 ms以内。
+
+### 优化手段
+
+#### 避免单次召回大量数据
+
+搜索引擎最擅长的事情是从海量数据中查询少量相关文档,而非单次检索大量文档。非常不建议动辄查询上万数据。如果有这样的需求,建议使用滚动查询
+
+#### 避免单个文档过大
+
+鉴于默认`http.max_content_length`设置为 100MB,Elasticsearch 将拒绝索引任何大于该值的文档。您可能决定增加该特定设置,但 Lucene 仍然有大约 2GB 的限制。
+
+即使不考虑硬性限制,大型文档通常也不实用。大型文档对网络、内存使用和磁盘造成了更大的压力,即使对于不请求的搜索请求也是如此。
+
+有时重新考虑信息单元应该是什么是有用的。例如,您想让书籍可搜索的事实并不一定意味着文档应该包含整本书。使用章节甚至段落作为文档可能是一个更好的主意,然后在这些文档中拥有一个属性来标识它们属于哪本书。这不仅避免了大文档的问题,还使搜索体验更好。例如,如果用户搜索两个单词 fooand bar,则不同章节之间的匹配可能很差,而同一段落中的匹配可能很好。
+
+#### 单次查询10条文档 好于 10次查询每次一条
+
+批量请求将产生比单文档索引请求更好的性能。但是每次查询多少文档最佳,不同的集群最佳值可能不同,为了获得批量请求的最佳阈值,建议在具有单个分片的单个节点上运行基准测试。
+
+首先尝试一次索引 100 个文档,然后是 200 个,然后是 400 个等。在每次基准测试运行中,批量请求中的文档数量翻倍。当索引速度开始趋于平稳时,就可以获得已达到数据批量请求的最佳大小。在相同性能的情况下,当大量请求同时发送时,太大的批量请求可能会使集群承受内存压力,因此建议避免每个请求超过几十兆字节。
+
+#### 数据建模
+
+很多人会忽略对 Elasticsearch 数据建模的重要性。
+
+nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作。Elasticsearch没有内部对象的概念,因此,ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表。
+
+特别是,应避免Join连接。Nested 可以使查询慢几倍,Join 会使查询慢数百倍。两种类型的使用场景应该是:Nested针对字段值为非基本数据类型的时候,而Join则用于当子文档数量级非常大的时候。
+
+#### 给系统留足够的内存
+
+Lucene的数据的fsync是发生在OS cache的,要给OS cache预留足够的内存大小。
+
+#### 预索引
+
+利用查询中的模式来优化数据的索引方式。例如,如果所有文档都有一个price字段,并且大多数查询 range 在固定的范围列表上运行聚合,可以通过将范围预先索引到索引中并使用聚合来加快聚合速度。
+
+#### 使用 filter 代替 query
+
+query和filter的主要区别在: filter是结果导向的而query是过程导向。query倾向于“当前文档和查询的语句的相关度”,而filter倾向于“当前文档和查询的条件是不是相符”。即在查询过程中,query是要对查询的每个结果计算相关性得分的,而filter不会。另外filter有相应的缓存机制,可以提高查询效率。
+
+#### 避免深度分页
+
+避免单页数据过大,可以参考百度或者淘宝的做法。es提供两种解决方案 scroll search 和 search after。
+
+#### 使用 Keyword 类型
+
+并非所有数值数据都应映射为数值字段数据类型。Elasticsearch为查询优化数字字段,例如integeror long。如果不需要范围查找,对于 term查询而言,keyword 比 integer 性能更好。
+
+#### 避免使用脚本
+
+Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定义编程的强大的脚本功能。相对于 DSL 而言,脚本的性能更差,DSL能解决 80% 以上的查询需求,如非必须,尽量避免使用 Script。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
similarity index 79%
rename from "docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
rename to "docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
index dccb47f..01aa2dc 100644
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
@@ -1,18 +1,35 @@
-## 规范化:normalization
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
-在Elasticsearch中,"normalization" 是指将文本数据转化为一种标准形式的步骤。这种处理主要发生在索引时,包括以下操作:
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
-1. **Lowercasing**:将所有字符转换为小写。这是最常见的标准化形式,因为搜索常常是不区分大小写的。
-2. **Removing diacritical marks**:移除重音符号或其他变音记号。例如,将 "résumé" 转换为 "resume"。
-3. **Converting characters to their ASCII equivalent**:将非ASCII字符转换为等效的ASCII字符。例如,将 "ë" 转换为 "e"。
+
+[TOC]
+
+在Elasticsearch中,分词器是用于将文本数据划分为一系列的单词(或称之为词项、tokens)的组件。这个过程是全文搜索中的关键步骤。
+
+一个分词器通常包含以下三个部分:
+
+- **字符过滤器(Character Filters)**:它接收原始文本作为输入,然后可以对这些原始文本进行各种转换,如去除HTML标签,将数字转换为文字等。
+- **分词器(Tokenizer)**:它将经过字符过滤器处理后的文本进行切分,生成一系列词项。例如,标准分词器会按照空格将文本切分成词项。
+- **词项过滤器(Token Filters)**:它对词项进行进一步的处理。比如小写化,停用词过滤(移除常见而无意义的词汇如"and", "the"),同义词处理,stemming(提取词根)等。
+
+Elasticsearch提供了许多内置的分词器,如标准分词器(Standard Tokenizer)、简单分词器(Simple Tokenizer)、空白分词器(Whitespace Tokenizer)、关键字分词器(Keyword Tokenizer)等。每种分词器都有其特定的应用场景,并且用户也可以自定义分词器以满足特殊需求。
+
+## 规范化:Normalization
+
+在Elasticsearch中,"Normalization" 是指将文本数据转化为一种标准形式的步骤。这种处理主要发生在索引时,包括以下操作:
+
+- **Lowercasing**:将所有字符转换为小写。这是最常见的标准化形式,因为搜索常常是不区分大小写的。
+- **Removing diacritical marks**:移除重音符号或其他变音记号。例如,将 "résumé" 转换为 "resume"。
+- **Converting characters to their ASCII equivalent**:将非ASCII字符转换为等效的ASCII字符。例如,将 "ë" 转换为 "e"。
这些转换有助于提高搜索的准确性,因为用户可能以各种不同的方式输入同一个词语。通过将索引和搜索查询都转换为相同的形式,可以更好地匹配相关结果。
-**说白了normalization就是将不通用的词汇变成通用的词汇。文档规范化,提高召回率**。
+**normalization的作用就是将文档规范化,提高召回率**
举个例子:
-假设我们希望在 Elasticsearch 中创建一个新的索引,该索引包含一个自定义分析器,该分析器将文本字段转换为小写并移除变音符号。你可以使用以下的请求:
+假设我们希望在 Elasticsearch 中创建一个新的索引,该索引包含一个自定义分析器,该分析器将文本字段转换为小写并移除变音符号。示例如下:
```JSON
PUT /my_index
@@ -20,7 +37,8 @@ PUT /my_index
"settings": {
"analysis": {
"analyzer": {
- "my_custom_analyzer": { "type": "custom",
+ "my_custom_analyzer": {
+ "type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "asciifolding"]
}
@@ -42,9 +60,9 @@ PUT /my_index
这个分析器包括三部分:
-- `"type": "custom"`: 这表示我们正在创建一个自定义分析器。
-- `"tokenizer": "standard"`: 这设置了标准分词器,它按空格和标点符号将文本拆分为单词。
-- `"filter": ["lowercase", "asciifolding"]`: 这是一个过滤器链,将所有文本转为小写 (lowercasing) 并移除所有的变音符号(如 accented characters)。
+- `"type": "custom"`: 这表示我们正在创建一个自定义分析器。
+- `"tokenizer": "standard"`: 这设置了标准分词器,它按空格和标点符号将文本拆分为单词。
+- `"filter": ["lowercase", "asciifolding"]`: 这是一个过滤器链,将所有文本转为小写 (lowercasing) 并移除所有的变音符号(如 accented characters)。
最后,在 `mappings` 对象中,我们指定 "my_field" 字段要使用这个自定义分析器。
@@ -59,19 +77,19 @@ POST /my_index/_doc
Elasticsearch 在索引这个文档时会将 "Méditerranéen RÉSUMÉ" 转换成 "mediterraneen resume"。这样,无论搜索查询是 "Méditerranéen", "méditerranéen", "MEDITERRANÉEN", "Resume", "résumé" 或 "RESUME",都能找到这个文档。
-## 字符过滤器:character filter
+## 字符过滤器:Character Filter
-Character filters就是在分词之前过滤掉一些无用的字符, 是 Elasticsearch 中的一种文本处理组件,它可以在分词前先对原始文本进行处理。这包括删除HTML标签、转换符号等。
+Character Filters就是在分词之前过滤掉一些无用的字符, 是 Elasticsearch 中的一种文本处理组件,它可以在分词前先对原始文本进行处理。这包括删除HTML标签、转换符号等。
-下面是一些常用的 character filter:
+下面是一些常用的 Character Filter:
-1. **HTML Strip Character Filter**:从输入中去除HTML元素,只保留文本内容。例如,`
+
+### Elasticsearch的语义检索
+
+Elasticsearch通过dense_vector字段和kNN(最近邻)搜索功能,把Embedding转换、存储和检索封装在一起。用户可以直接把Elasticsearch作为RAG框架的向量存储:
+
+- 导入文档时,配置处理管道让Elasticsearch自动调用模型把文本转换为向量并存储。
+- 查询时,系统自动把查询转换为向量,执行相似性搜索。
+
+这降低了技术门槛,开发者不用单独部署向量数据库,就能实现语义检索。
+
+## Embedding的价值
+
+Embedding技术把语言变成数学,让计算机能"理解"人类语言。
+
+从技术演进看,Embedding从简单的词向量发展到上下文感知的动态表示。从Word2Vec到BERT,再到如今的大语言模型,每次技术突破都伴随着Embedding能力提升。
+
+从应用看,Embedding在LLM内部把自然语言转化为数学表示。在RAG等应用中,Embedding实现从关键词匹配到语义检索,大幅提升信息检索准确性。
+
+未来,Embedding还会承担更多:
+
+- 多模态融合:把文本、图像、音频映射到统一的向量空间,实现跨模态理解和生成。
+- 知识图谱构建:通过向量表示构建大规模知识网络,支持复杂推理和决策。
+- 个性化推荐:基于用户行为和偏好的向量表示,实现精准个性化服务。
+- 隐私保护计算:在向量空间进行加密计算,保护数据隐私同时实现智能分析。
+
+理解Embedding的原理和应用,有助于更好地使用AI工具,也为探索AI技术未来提供视角。在AI时代,Embedding将继续连接人类智慧与机器能力。
\ No newline at end of file
diff --git "a/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md" "b/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md"
new file mode 100644
index 0000000..8ac1184
--- /dev/null
+++ "b/docs/md/AI/\346\267\261\345\272\246\350\247\243\346\236\220Skills\357\274\232\344\273\216Prompt\345\210\260\350\203\275\345\212\233\345\244\215\347\224\250\347\232\204\346\212\200\346\234\257\351\235\251\345\221\275.md"
@@ -0,0 +1,428 @@
+## 从Prompt到Skills的转变
+
+2023年到2024年是"Prompt工程"的黄金时期。到了2025年底,AI圈开始频繁讨论一个新概念——**Skills(技能)**。
+
+GitHub上Skills相关仓库获得上万star,各行各业的专业人士开始分享自己封装的Skills。Skills到底是什么?它为什么能引发如此关注?
+
+### Skills的本质:模块化能力包
+
+**Agent Skills是模块化的能力包,包含指令、元数据和可选资源(脚本、模板),让AI Agent在需要时自动加载和使用**。
+
+Skills就像AI助手的"工作手册库"。它不是每次对话都要重新输入的临时指令,而是一套可以长期保存、随时调用的能力模块。
+
+### 从"带新人"到"给手册"
+
+要理解Skills,先看传统AI交互的问题。
+
+想象你在公司带一个新人。他聪明、理解能力强,但不熟悉规矩。
+
+- Prompt方式就像你每次都口头交代任务:"今天写一段公众号开头"、"把这个语气改得更克制"、"按我的结构写一页PPT"。这适合一次性指令,但一旦关闭对话,所有指令就消失,下次得从头教。
+- Rules或记忆机制相当于在工位贴一张"公司行为守则",只能管态度和格式这类宽泛要求。
+- MCP和工具调用更像是给他的电脑装一堆软件和API,他能调用外部工具,但不知道什么时候该用、怎么组合。
+
+**Skills**改变了这一局面。它就像给新人一本完整的公司内部SOP手册——不是长到让人窒息的Word文档,而是一个知识库文件夹,里面有规范、脚本、模板、参考资料。AI会在需要时自己翻阅,按需加载。
+
+### Skills的物理形态
+
+很多人问:"这不就是Prompt吗?"实际上两者在形态上有本质区别:
+
+- **Prompt**:一段文本(通常是Markdown格式)。
+- **Skills**:一个文件夹结构,包含多种资源。
+
+一个标准的Skill目录:
+
+```
+skill-name/
+├── SKILL.md # 核心指令文件(必需)
+├── scripts/ # 可执行脚本(可选)
+├── references/ # 参考文档(可选)
+├── templates/ # 模板文件(可选)
+└── assets/ # 其他资源(可选)
+```
+
+
+
+**SKILL.md是唯一必需的文件**,它采用YAML前导格式(类似简历开头的个人信息区),包含元数据和详细指令。这种设计让Skills不仅能承载知识,还能承载工具和流程。
+
+## 渐进式披露架构
+
+### 为什么"一次性塞进所有信息"行不通?
+
+Skills采用了**渐进式披露(Progressive Disclosure)**架构。这个概念在移动互联网时代曾是用户体验设计的核心原则之一。
+
+打开一个APP,如果它一次性把所有功能、设置、选项都堆在你面前,你会怎样?认知负荷爆炸,不知所措。
+
+人的瞬时记忆区非常有限,一瞬间只能接受最多7±2个信息块。AI也是如此——受限于Token窗口,对话越长,模型越"笨"。Token在Agent架构上寸土寸金。
+
+传统做法:每次对话都把完整指令塞进上下文。一个详细的PDF处理工作流可能需要3000+ tokens。如果同时处理Excel、写代码、生成报告,上下文窗口很快爆满。
+
+### 三层加载机制
+
+Skills通过三层渐进式加载解决这个问题:
+
+**第一层:元数据——目录索引**
+
+这是Skills的"封面",包含技能名称和一句话描述。
+
+- **加载时机**:每次对话开始时。
+- **Token消耗**:约100 tokens/Skill。
+- **作用**:让AI知道有哪些Skills可用,何时该用。
+
+你可以安装数十个Skills,几乎没有性能损失。AI就像看图书馆的目录,知道有哪些书,但不必都翻开。
+
+**第二层:指令——详细手册**
+
+当AI通过元数据判断某个任务需要特定Skill时,它会读取完整的SKILL.md文件。
+
+- **加载时机**:任务匹配时触发。
+- **Token消耗**:数千tokens(按实际文件大小)。
+- **作用**:提供详细的操作指南和最佳实践。
+
+用户说"帮我处理这个PDF",AI会判断匹配PDF Skill,然后加载详细的处理流程:先提取文本,再识别表单字段,最后填写并保存。
+
+**第三层:资源和代码——深度参考**
+
+这层包括参考文档、可执行脚本、模板文件等。
+
+- **加载时机**:SKILL.md中引用时。
+- **Token消耗**:按需加载。
+- **关键优势**:脚本执行不消耗上下文(仅结果消耗)。
+
+一个包含复杂Python脚本的Skill,脚本本身的代码不会进入上下文,只有执行结果会返回。这让Skills可以承载几乎无限的资源,而不必担心Token限制。
+
+
+
+### 一个真实的加载流程
+
+以PDF处理为例,看Skills如何工作:
+
+**阶段1:初始状态**
+
+```
+用户输入:"用PDF技能填写这份合同"
+系统提示 + 技能目录 + 用户消息
+Token消耗:约100 tokens
+```
+
+**阶段2:加载主手册**
+
+```
+AI判断:这个任务匹配PDF Skill
+执行:bash cat ~/.claude/skills/pdf/SKILL.md
+Token消耗:+3000 tokens
+```
+
+**阶段3:按需加载参考资料**
+
+```
+AI判断:需要表单填写规则
+执行:bash cat ~/.claude/skills/pdf/references/forms.md
+Token消耗:+500 tokens
+```
+
+**阶段4:执行脚本**
+
+```
+执行:python scripts/fill_form.py --input contract.pdf --output filled.pdf
+Token消耗:+200 tokens(仅输出结果)
+```
+
+**总Token消耗**:约3800 tokens。
+
+对比传统方式:一次性加载所有相关文档和脚本定义,可能需要10,000+ tokens。Skills节省了60-70%的上下文空间。
+
+
+
+## Skills vs MCP vs Prompt:互补关系
+
+### 三者的核心定位
+
+Skills、MCP、Prompt不是竞争关系,而是互补关系:
+
+| 维度 | Skills | MCP | Prompt |
+|------|--------|-----|--------|
+| **核心定位** | 工作流程指南(How) | 外部系统连接(What) | 临时指令 |
+| **解决问题** | 如何使用能力 | 提供什么数据/能力 | 当下做什么 |
+| **形象比喻** | 使用说明书 | 工具箱 | 口头指令 |
+| **Token效率** | 高(渐进加载) | 低(全量加载) | 中(每次重复) |
+| **复用性** | 强(文件系统) | 中(协议层面) | 弱(手动复制) |
+
+
+
+### Skills与MCP:工作手册 vs 门禁卡
+
+**Skills解决"怎么做"(方法论/工作流),MCP解决"连到哪儿"(连接外部系统)**。
+
+用职场类比:
+- **MCP**:给AI一张门禁卡,让它能进入公司的各个系统(数据库、API、外部工具)。
+- **Skills**:给AI一本工作手册,教它如何使用这些系统完成具体任务。
+
+一个组合场景:
+
+**生成销售报告**
+
+1. **MCP提供数据连接**
+ - 连接Salesforce获取客户数据。
+ - 连接PostgreSQL查询销售记录。
+ - 连接Google Sheets读取目标数据。
+
+2. **Skills提供工作流程**
+ - 数据提取顺序(先查哪个系统)。
+ - 计算逻辑(增长率、完成率)。
+ - 报告格式和模板。
+ - 异常处理规则。
+
+MCP解决"能访问什么数据",Skills解决"如何使用这些数据生成报告"。
+
+
+
+### Skills vs Prompt:从临时指令到持久能力
+
+**Skills不就是高级一点的Prompt吗?**
+
+答案既是肯定的,也是否定的。
+
+**相同点**:Skills的核心确实是自然语言指令,这与Prompt一致。
+
+**根本区别**:
+
+- **生命周期**:Prompt是对话级的,Skills是系统级的。
+- **复用方式**:Prompt需要手动复制粘贴,Skills自动匹配触发。
+- **承载能力**:Prompt只能承载文本,Skills可以承载脚本、模板、参考文档。
+- **Token效率**:Prompt每次都全量加载,Skills按需渐进加载。
+
+用一个实际例子:
+
+**没有Skills时**,每次都要说:
+
+```
+帮我总结这篇文章 → 翻译成英文 → 改成公众号风格 → 加标题 → 输出Markdown格式
+```
+
+**有了Skills后**,只需要一句:
+```
+使用「技术文章转公众号」Skill
+```
+
+AI会自动按照预设的完整流程执行。
+
+## 实际应用
+
+### 个人场景:把重复工作封装成能力包
+
+**案例1:AI选题系统**
+
+一个内容团队用Skills构建了自动化选题系统,包含:
+- 1个总控Agent。
+- 3个Skill(热点采集、选题生成、选题审核)。
+
+每天只需要一句:"开始今日选题生成",系统就会自动:
+1. 从多个平台采集全网热点。
+2. 筛选并生成TOP10选题(包含事件描述、核心角度、标题)。
+3. 按照内部方法论自动审核。
+4. 不通过时给出修改意见并迭代优化。
+
+过去需要2-3小时的工作,现在几分钟就能完成初筛。
+
+**案例2:整合包生成器**
+
+很多GitHub开源项目没有前端界面,环境配置复杂。有人用Skills做了一个"整合包生成器":
+
+提供一个GitHub链接,Skill就会:
+1. 分析项目结构。
+2. 自动生成前端界面。
+3. 编写启动脚本。
+4. 打包成开箱即用的整合包。
+
+解决了"想用但不会配置"的痛点。
+
+### 团队场景:知识资产沉淀与共享
+
+**传统方式的问题**:
+- 每个团队各自维护长Prompt。
+- 写法、风格不统一。
+- 复用靠复制粘贴。
+- 难以版本管理和评审。
+
+**Skills带来的改变**:
+- 把"怎么做好一件事"固化成SKILL.md + 脚本 + 参考文档。
+- 放入Git版本库,走标准开发流程。
+- 团队间共享、评审、复用。
+- 形成企业内部的"技能库"(Skill Library)。
+
+**组织架构示例**:
+```
+公司级Agent产品
+├── 市场部维护:品牌文案Skill
+├── 法务部维护:合同审阅Skill
+├── 财务部维护:报销审核Skill
+└── 技术部维护:代码审查Skill
+```
+
+所有技能装在同一个Agent身上,用户只跟一个界面打交道。
+
+### 行业场景:专业知识标准化
+
+**医疗诊断流程**:将诊断标准、注意事项、药物禁忌等封装成Skill,确保AI遵循医疗规范
+
+**法律文书审查**:将审查要点、风险识别、合规要求标准化,提高审查质量和一致性
+
+**代码审计规范**:将安全检查项、代码风格要求、最佳实践固化
+
+**ML实验配置**:将实验设计规范、参数推荐范围、结果记录模板封装
+
+这些领域知识需要结构化存储、团队共享、版本管理、跨平台使用——正是Skills的强项。
+
+## 技术实现
+
+### 最小可行Skill
+
+创建一个Skill只需要一个SKILL.md文件:
+
+```markdown
+---
+name: hello-skill
+description: A simple skill that greets users
+---
+
+# Hello Skill
+
+When user says hello, respond with a friendly greeting.
+```
+
+**必填字段**:
+- `name`:技能名称(小写字母、数字、连字符符)。
+- `description`:功能描述。
+
+**简单到人人可创建,强大到专业团队可用**。
+
+### 完整Skill:PDF处理案例
+
+```
+pdf-skill/
+├── SKILL.md
+├── scripts/
+│ ├── extract_text.py
+│ ├── fill_form.py
+│ └── merge_pdfs.py
+├── references/
+│ ├── FORMS.md
+│ └── API_REFERENCE.md
+└── templates/
+ └── report_template.md
+```
+
+**SKILL.md内容**:
+
+```markdown
+---
+name: pdf-processing
+description: Extract text and tables from PDF files, fill forms, merge documents.
+ Use when working with PDF files or when the user mentions PDFs.
+---
+
+# PDF Processing
+
+## Quick Start
+
+1. For text extraction, use `python {baseDir}/scripts/extract_text.py`
+2. For form filling, see [FORMS.md](references/FORMS.md)
+3. For merging PDFs, execute the merge script
+
+## Supported Operations
+
+- Text extraction from text-based PDFs
+- OCR for scanned PDFs (requires Tesseract)
+- Form field identification and filling
+- Multi-document merging
+
+## Best Practices
+
+- Always validate PDF integrity before processing
+- Use OCR only when necessary (higher token cost)
+- Keep extracted text under 10,000 tokens for best performance
+```
+
+**关键点**:
+
+- `{baseDir}`是自动替换变量,表示Skill的安装路径。
+- 可以引用其他文件(如FORMS.md),AI会在需要时加载。
+- 指令清晰、结构化,便于AI理解和执行。
+
+### 安装和使用
+
+**方法1:命令安装**
+
+```bash
+# 安装官方Skill
+claude skill install https://github.com/anthropics/skills/tree/main/skills/pdf
+
+# 或在对话中直接说
+"安装这个skill:https://github.com/xxx/skill-name"
+```
+
+**方法2:手动放置**
+
+将Skill文件夹放到对应目录:
+- Claude Code:`~/.claude/skills/`。
+- Cursor:`~/.cursor/skills/。`
+- OpenCode:`~/.config/opencode/skill/`。
+
+**使用方式**:
+
+直接对话:
+```
+用户:"帮我处理这个PDF"
+AI会自动识别并调用PDF Skill
+```
+
+或者显式指定:
+```
+用户:"使用PDF Skill提取这份文档的文本"
+```
+
+## 未来展望
+
+### 从工具到生态
+
+目前Skills还处于早期阶段,但已经有了生态雏形:
+
+- **官方Skills库**:Anthropic开源了官方Skills仓库,包含PDF、Excel、PPT、Word等常用技能。
+- **社区贡献**:GitHub上涌现大量社区贡献的Skills,涵盖数据分析、代码审查、文档生成等多个领域。
+- **工具支持**:Claude Code、Cursor、OpenCode等主流工具均已支持Skills。
+- **技能市场**:扣子等平台开始提供技能市场,支持搜索、安装、分享Skills。
+
+### 潜在挑战
+
+Skills也面临挑战:
+
+- **标准化问题**:不同平台、不同团队的Skills格式可能不统一,需要建立行业标准。
+- **安全与隐私**:Skills可以执行脚本,需要沙箱隔离和权限控制。
+- **质量参差**:开放的生态意味着质量良莠不齐,需要评价和筛选机制。
+- **学习曲线**:虽然创建简单,但要设计高质量的Skill仍需要经验。
+
+### 对AI发展的意义
+
+Skills代表一个重要趋势:**从让AI"理解"到让AI"执行"**。
+
+过去几年,我们主要关注如何让AI更好地理解自然语言、理解上下文、理解意图。这是必要的基础,但还不够。
+
+Skills的出现,标志着我们开始关注如何让AI系统地、可重复地、高质量地执行复杂任务。这不仅需要理解能力,还需要方法论、最佳实践、工具链的支持。
+
+**这是AI从"对话伙伴"进化为"工作伙伴"的关键一步。**
+
+## 今天就开始你的第一个Skill
+
+Skills的热度已不亚于当年的Prompts。但这不只是流行趋势,而是实实在在的生产力革命。
+
+如果你还在犹豫是否要尝试Skills,建议从最简单的开始:
+
+**今天**,安装一个官方Skill(比如skill-creator),感受一下"一个命令安装能力"的便捷。
+
+**明天**,把最常用的一个动作固化成Skill——比如选题筛热点、报错日志分析、链接摘要生成。
+
+**后天**,你会想把更多工作流程都搬进去。
+
+到那一步,你就进入了另一个状态:**自由,创造的状态**。
+
+Skills的核心价值,在于**复用**。当你把一次性的努力转化为可重复调用的能力,你就不再是每次都从零开始,而是站在前人的肩膀上持续前进。
diff --git "a/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md" "b/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md"
new file mode 100644
index 0000000..93a2374
--- /dev/null
+++ "b/docs/md/DDD/\347\206\254\345\244\234\346\225\264\347\220\206\347\232\2042W\345\255\227DDD\345\255\246\344\271\240\347\254\224\350\256\260\357\274\214\344\273\216\347\220\206\350\256\272\345\210\260\345\256\236\346\210\230.md"
@@ -0,0 +1,922 @@
+> DDD 不是架构,而是一种架构设计方法论,它通过边界划分将复杂业务领域简单化,帮我们设计出清晰的领域和应用边界,可以很容易地实现架构演进。
+
+# 基础概念
+
+## 领域
+
+领域就是用来确定范围的,范围即边界,这也是 DDD 在设计中不断强调边界的原因。
+
+**简言之,DDD 的领域就是这个边界内要解决的业务问题域**。
+
+领域可以进一步划分为子领域。我们把划分出来的多个子领域称为子域,每个子域对应一个更小的问题域或更小的业务范围。领域可以拆分为多个子领域。一个领域相当于一个问题域,领域拆分为子域的过程就是大问题拆分为小问题的过程。
+
+其实很好理解,DDD 的研究方法与自然科学的研究方法类似。当人们在自然科学研究中遇到复杂问题时,通常的做法就是将问题一步一步地细分,再针对细分出来的问题域,逐个深入研究,探索和建立所有子域的知识体系。当所有问题子域完成研究时,我们就建立了全部领域的完整知识体系了。
+
+在领域不断划分的过程中,领域会细分为不同的子域,子域可以根据自身重要性和功能属性划分为三类子域,它们分别是:**核心域、通用域和支撑域**。
+
+决定产品和公司核心竞争力的子域是核心域,它是业务成功的主要因素和公司的核心竞争力。没有太多个性化的诉求,同时被多个子域使用的通用功能子域是通用域。还有一种功能子域是必需的,但既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域,它就是支撑域。
+
+这三类子域相较之下,核心域是最重要的,通用域和支撑域如果对应到企业系统,举例来说的话,通用域则是你需要用到的通用系统,比如认证、权限等等,这类应用很容易买到,没有企业特点限制,不需要做太多的定制化。而支撑域则具有企业特性,但不具有通用性,例如数据代码类的数据字典等系统。
+
+聚合根与领域服务负责封装实现业务逻辑。领域服务负责对聚合根进行调度和封装,同时可以对外提供各种形式的服务,对于不能直接通过聚合根完成的业务操作就需要通过领域服务。
+
+说白了就是,聚合根本身无法完全处理这个逻辑,例如支付这个步骤,订单聚合不可能支付,所以在订单聚合上架一层领域服务,在领域服务中实现支付逻辑,然后应用服务调用领域服务。
+
+**遵守以下规范**:
+
+- 同限界上下文内的聚合之间的领域服务可直接调用。
+- 两个限界上下文的交互必须通过应用服务层抽离 接口->适配层 适配。
+
+例子,用户升职,上级领导要变,上级领导的下属要变,代码如下:
+
+```java
+@Service
+public class UserDomainServiceImpl implements UserDomainService {
+
+ @Override
+ public void promote(User user, User leader) {
+
+ //保存领导
+ user.saveLeader(leader);
+
+ //领导增加下属
+ leader.increaseSubordination(user);
+ }
+}
+```
+
+## 限界上下文
+
+我们可以将限界上下文拆解为两个词:限界和上下文。
+
+限界就是领域的边界,而上下文则是语义环境。通过领域的限界上下文,我们就可以在统一的领域边界内用统一的语言进行交流,简单来说限界上下文可以理解为语义环境。
+
+综合一下,我认为限界上下文的定义就是:**用来封装通用语言和领域对象,提供上下文环境,保证在领域之内的一些术语、业务相关对象等(通用语言)有一个确切的含义,没有二义性**。
+
+这个边界定义了模型的适用范围,使团队所有成员能够明确地知道什么应该在模型中实现,什么不应该在模型中实现。
+
+举个例子:
+
+在一个明媚的早晨,孩子起床问妈妈:“今天应该穿几件衣服呀?”,妈妈回答:“能穿多少就穿多少!”那到底是穿多还是穿少呢?
+
+如果没有具体的语义环境,还真不太好理解。但是,如果你已经知道了这句话的语义环境,比如是寒冬腊月或者是炎炎夏日,那理解这句话的涵义就会很容易了。
+
+**所以语言离不开它的语义环境**。
+
+而业务的通用语言就有它的业务边界,我们不大可能用一个简单的术语没有歧义地去描述一个复杂的业务领域。限界上下文就是用来细分领域,从而定义通用语言所在的边界。
+
+正如电商领域的商品一样,商品在不同的阶段有不同的术语,在销售阶段是商品,而在运输阶段则变成了货物。同样的一个东西,由于业务领域的不同,赋予了这些术语不同的涵义和职责边界,这个边界就可能会成为未来微服务设计的边界。看到这,我想你应该非常清楚了,领域边界就是通过限界上下文来定义的。
+
+**理论上限界上下文就是微服务的边界。我们将限界上下文内的领域模型映射到微服务,就完成了从问题域到软件的解决方案**。
+
+限界上下文之间的映射关系:
+
+- 合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
+- 共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
+- 客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
+- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
+- 防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
+- 开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
+- 发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
+- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。
+- 另谋他路(SeparateWay):两个完全没有任何联系的上下文。
+
+可以说,限界上下文是微服务设计和拆分的主要依据。在领域模型中,如果不考虑技术异构、团队沟通等其它外部因素,一个限界上下文理论上就可以设计为一个微服务。
+
+## 贫血模型和充血模型
+
+**贫血模型**
+
+贫血模型具有一堆属性和set get方法,存在的问题就是通过 pojo 这个对象上看不出业务有哪些逻辑,一个 pojo 可能被多个模块调用,只能去上层各种各样的service 来调用,这样以后当梳理这个实体有什么业务,只能一层一层去搜 service,也就是贫血失忆症,不够面向对象。
+
+
+
+**充血模型**
+
+比如如下 user 用户有改密码,改手机号,修改登录失败次数等操作,都内聚在这个 user 实体中,每个实体的业务都是清晰的,就是充血模型,充血模型的内存计算会多一些,内聚核心业务逻辑处理。
+
+说白了就是,不只是有贫血模型中的setter getter方法,还有其他的一些业务方法,这才是面向对象的本质,通过 user 实体就能看出有哪些业务存在。
+
+```java
+@NoArgsConstructor
+@Getter
+public class User extends Aggregate {
+
+ /**
+ * 用户名
+ */
+ private String userName;
+
+ /**
+ * 姓名
+ */
+ private String realName;
+
+ /**
+ * 手机号
+ */
+ private String phone;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+ /**
+ * 锁定结束时间
+ */
+ private Date lockEndTime;
+
+ /**
+ * 登录失败次数
+ */
+ private Integer failNumber;
+
+ /**
+ * 用户角色
+ */
+ private List roles;
+
+ /**
+ * 部门
+ */
+ private Department department;
+
+ /**
+ * 用户状态
+ */
+ private UserStatus userStatus;
+
+ /**
+ * 用户地址
+ */
+ private Address address;
+
+ public User(String userName, String phone, String password) {
+
+ saveUserName(userName);
+ savePhone(phone);
+ savePassword(password);
+ }
+
+ /**
+ * 保存用户名
+ * @param userName
+ */
+ private void saveUserName(String userName) {
+ if (StringUtils.isBlank(userName)){
+ Assert.throwException("用户名不能为空!");
+ }
+
+ this.userName = userName;
+ }
+
+ /**
+ * 保存电话
+ * @param phone
+ */
+ private void savePhone(String phone) {
+ if (StringUtils.isBlank(phone)){
+ Assert.throwException("电话不能为空!");
+ }
+
+ this.phone = phone;
+ }
+
+ /**
+ * 保存密码
+ * @param password
+ */
+ private void savePassword(String password) {
+ if (StringUtils.isBlank(password)){
+ Assert.throwException("密码不能为空!");
+ }
+
+ this.password = password;
+ }
+
+ /**
+ * 保存用户地址
+ * @param province
+ * @param city
+ * @param region
+ */
+ public void saveAddress(String province,String city,String region){
+ this.address = new Address(province,city,region);
+ }
+
+ /**
+ * 保存用户角色
+ * @param roleList
+ */
+ public void saveRole(List roleList) {
+
+ if (CollectionUtils.isEmpty(roles)){
+ Assert.throwException("角色不能为空!");
+ }
+
+ this.roles = roleList;
+ }
+}
+```
+
+## 实体和值对象
+
+**实体**
+
+实体和值对象这两个概念都是领域模型中的领域对象。实体和值对象是组成领域模型的基础单元。
+
+在代码模型中,实体的表现形式是实体类,这个类包含了实体的属性和方法,通过这些方法实现实体自身的业务逻辑。
+
+在 DDD 里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现,**跨多个实体的领域逻辑则在领域服务中实现**。
+
+实体以 DO(领域对象)的形式存在,每个实体对象都有唯一的 ID。比如商品是商品上下文的一个实体,通过唯一的商品 ID 来标识,不管这个商品的数据如何变化,商品的 ID 一直保持不变,它始终是同一个商品。
+
+在领域模型映射到数据模型时,一个实体可能对应 0 个、1 个或者多个数据库持久化对象。大多数情况下实体与持久化对象是一对一。在某些场景中,有些实体只是暂驻静态内存的一个运行态实体,它不需要持久化。比如,基于多个价格配置数据计算后生成的折扣实体。
+
+而在有些复杂场景下,实体与持久化对象则可能是一对多或者多对一的关系。比如,用户 user 与角色 role 两个持久化对象可生成权限实体,一个实体对应两个持久化对象,这是一对多的场景。
+
+再比如,有些场景为了避免数据库的联表查询,提升系统性能,会将客户信息 customer 和账户信息 account 两类数据保存到同一张数据库表中,客户和账户两个实体可根据需要从一个持久化对象中生成,这就是多对一的场景。
+
+权限管理系统——用户实体,代码如下:
+
+```java
+@NoArgsConstructor
+@Getter
+public class User extends Aggregate {
+
+ /**
+ * 用户id-聚合根唯一标识
+ */
+ private UserId userId;
+
+ /**
+ * 用户名
+ */
+ private String userName;
+
+ /**
+ * 姓名
+ */
+ private String realName;
+
+ /**
+ * 手机号
+ */
+ private String phone;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+ /**
+ * 锁定结束时间
+ */
+ private Date lockEndTime;
+
+ /**
+ * 登录失败次数
+ */
+ private Integer failNumber;
+
+ /**
+ * 用户角色
+ */
+ private List roles;
+
+ /**
+ * 部门
+ */
+ private Department department;
+
+ /**
+ * 领导
+ */
+ private User leader;
+
+ /**
+ * 下属
+ */
+ private List subordinationList = new ArrayList<>();
+
+ /**
+ * 用户状态
+ */
+ private UserStatus userStatus;
+
+ /**
+ * 用户地址
+ */
+ private Address address;
+
+ public User(String userName, String phone, String password) {
+
+ saveUserName(userName);
+ savePhone(phone);
+ savePassword(password);
+ }
+
+ /**
+ * 保存用户名
+ * @param userName
+ */
+ private void saveUserName(String userName) {
+ if (StringUtils.isBlank(userName)){
+ Assert.throwException("用户名不能为空!");
+ }
+
+ this.userName = userName;
+ }
+
+ /**
+ * 保存电话
+ * @param phone
+ */
+ private void savePhone(String phone) {
+ if (StringUtils.isBlank(phone)){
+ Assert.throwException("电话不能为空!");
+ }
+
+ this.phone = phone;
+ }
+
+ /**
+ * 保存密码
+ * @param password
+ */
+ private void savePassword(String password) {
+ if (StringUtils.isBlank(password)){
+ Assert.throwException("密码不能为空!");
+ }
+
+ this.password = password;
+ }
+
+ /**
+ * 保存用户地址
+ * @param province
+ * @param city
+ * @param region
+ */
+ public void saveAddress(String province,String city,String region){
+ this.address = new Address(province,city,region);
+ }
+
+ /**
+ * 保存用户角色
+ * @param roleList
+ */
+ public void saveRole(List roleList) {
+
+ if (CollectionUtils.isEmpty(roles)){
+ Assert.throwException("角色不能为空!");
+ }
+
+ this.roles = roleList;
+ }
+
+ /**
+ * 保存领导
+ * @param leader
+ */
+ public void saveLeader(User leader) {
+ if (Objects.isNull(leader)){
+ Assert.throwException("leader不能为空!");
+ }
+ this.leader = leader;
+ }
+
+ /**
+ * 增加下属
+ * @param user
+ */
+ public void increaseSubordination(User user) {
+
+ if (null == user){
+ Assert.throwException("leader不能为空!");
+ }
+
+ this.subordinationList.add(user);
+ }
+}
+```
+
+**值对象**
+
+简单来说,值对象本质上就是一个集。
+
+那这个集合里面有什么呢?若干个用于描述目的、具有整体概念和不可修改的属性。
+
+那这个集合存在的意义又是什么?在领域建模的过程中,值对象可以保证属性归类的清晰和概念的完整性,避免属性零碎。
+
+举例代码如下:
+
+```java
+/**
+ * 地址数据
+ */
+@Getter
+public class Address extends ValueObject {
+ /**
+ * 省
+ */
+ private String province;
+
+ /**
+ * 市
+ */
+ private String city;
+
+ /**
+ * 区
+ */
+ private String region;
+
+ public Address(String province, String city, String region) {
+ if (StringUtils.isBlank(province)){
+ Assert.throwException("province不能为空!");
+ }
+ if (StringUtils.isBlank(city)){
+ Assert.throwException("city不能为空!");
+ }
+ if (StringUtils.isBlank(region)){
+ Assert.throwException("region不能为空!");
+
+ }
+ this.province = province;
+ this.city = city;
+ this.region = region;
+ }
+}
+```
+
+
+
+人员实体原本包括:姓名、年龄、性别以及人员所在的省、市、县和街道等属性。这样显示地址相关的属性就很零碎了对不对?现在,我们可以将“省、市、县和街道等属性”拿出来构成一个“地址属性集合”,这个集合就是值对象了。
+
+当你决定一个领域概念是否是 一个值对象时,你需要考虑它是否拥有以下特征:
+
+- 它度量或者描述了领城中的一件东西。
+- 它可以作为不变量。
+- 度量和描述改变时,可以用另一个值对象予以替换。
+- 它可以和其他值对象进行相等性比较。
+- 它不会对协作对象造成副作用。
+
+值对象与实体一起构成聚合。**值对象逻辑上是实体属性的一部分,用于描述实体的特征。值对象创建后就不允许修改了,只能用另外一个值对象来整体替换**。
+
+值对象是一些不会修改,只能完整替换的属性值的集合,你更关注他的属性和值,它没有太多的业务行为,用于描述实体的一些属性集,被实体引用,依附于实体的值对象基本没有自己的数据库表。
+
+是否要设计成值对象,你要看这个对象是否后续还会来回修改,会不会有生命周期。如果不可修改,并且以后也不会专门针对它进行查询或者统计,你就可以把它设计成值对象,如果不行,那就设计成实体吧。
+
+在领域建模时,我们可以将部分对象设计为值对象,保留对象的业务涵义,同时又减少了实体的数量;在数据建模时,我们可以将值对象嵌入实体,减少实体表的数量,简化数据库设计。
+
+关于值对象,我还要多说几句。其实,DDD引入值对象还有一个重要的原因,就是到底领域建模优先还是数据建模优先?
+
+DDD提倡从领域模型设计出发,而不是先设计数据模型。前面讲过了,传统的数据模型设计通常是一个表对应一个实体,一个主表关联多个从表,当实体表太多的时候就很容易陷入无穷无尽的复杂的数据库设计,领域模型就很容易被数据模型绑架。可以说,值对象的诞生,在一定程度上,和实体是互补的。
+
+同样的对象在不同的场景下,可能会设计出不同的结果。有些场景中,地址会被某一实体引用,它只承担描述实体的作用,并且它的值只能整体替换,这时候你就可以将地址设计为值对象,比如收货地址。而在某些业务场景中,地址会被经常修改,地址是作为一个独立对象存在的,这时候它应该设计为实体,比如行政区划中的地址信息维护。
+
+**唯一的身份标识和可变性(mutability)特征将实体对象和值对象区分开来**。
+
+比如,如果系统提供根据人名查找功能,但此时一个Person实体的唯一标识极有可能不是人名,因为存在大量重名的情况。 另 一方面,如果 一个系统提供根据公司税号的查找功能,此时税号便可以作为 Company 实体的唯一标识,因为政府为每个公司分配了唯一的税号。
+
+值对象可以用于存放实体的唯 一标识。值对象是不变(immutable)的,这可以保证实体身份的稳定性,并且与身份标识相关的行为也可以得到集中处理。
+
+以下是一些常用的创建实体身份标识的策略,从简单到复杂依次为:
+
+- 用户提供一个或多个初始唯一值作为程序输入,程序应该保证这些初始值是唯 一的。
+- 程序内部通过某种算法自动生成身份标识,此时可以使用一些类库或框架,当然程序自身也可以完成这样的功能。
+- 程序依赖于持久化存储,比如数据库,来生成唯一标识。
+- 另一个限界上下文 (系统或程序)已经决定出了唯一标识,这作为程序的输入,用户可以在一组标识中进行选择。
+
+## 聚合
+
+实体和值对象是很基础的领域对象。实体一般对应业务对象,它具有业务属性和业务行为;而值对象主要是属性集合,对实体的状态和特征进行描述。但实体和值对象都只是个体化的对象,它们的行为表现出来的是个体的能力。
+
+那聚合在其中起什么作用呢?
+
+举个例子。社会是由一个个的个体组成的,象征着我们每一个人。随着社会的发展,慢慢出现了社团、机构、部门等组织,我们开始从个人变成了组织的一员,大家可以协同一致的工作,朝着一个最大的目标前进,发挥出更大的力量。
+
+领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
+
+比如创建一个订单,必然会生成订单详情,订单详情肯定会有商品信息,我们在修改商品信息的时候,肯定就不能影响到这个订单详情中的商品信息。再比如:用户在下单的时候,会选择一个地址作为邮寄地址,如果该用户立刻下另一个订单,并对自己个人中心的地址进行修改,肯定就不能影响刚刚下单的邮寄地址信息。
+
+你可以这么理解,聚合就是由业务和逻辑紧密关联的实体和值对象组合而成的,聚合是数据修改和持久化的基本单元,**每一个聚合对应一个仓储,实现数据的持久化**。
+
+聚合在 DDD 分层架构里属于领域层,领域层包含了多个聚合,共同实现核心业务逻辑。
+
+跨多个实体的业务逻辑通过领域服务来实现,跨多个聚合的业务逻辑通过应用服务来实现。比如有的业务场景需要同一个聚合的A和B两个实体来共同完成,我们就可以将这段业务逻辑用领域服务来实现;而有的业务逻辑需要聚合C和聚合D中的两个服务共同完成,这时你就可以用应用服务来组合这两个服务。
+
+**聚合根**
+
+如果把聚合比作组织,那聚合根就是这个组织的负责人。聚合根也称为根实体,它不仅是实体,还是聚合的管理者。
+
+首先它作为实体本身,拥有实体的属性和业务行为,实现自身的业务逻辑。其次它作为聚合的管理者,在聚合内部负责协调实体和值对象按照固定的业务规则协同完成共同的业务逻辑。
+
+最后在聚合之间,它还是聚合对外的接口人,以聚合根 ID 关联的方式接受外部任务和请求,在上下文内实现聚合之间的业务协同。**也就是说,聚合之间通过聚合根 ID 关联引用,如果需要访问其它聚合的实体,就要先访问聚合根,再导航到聚合内部实体,外部对象不能直接访问聚合内实体**。
+
+下面以保险的投保业务场景为例,看一下聚合的构建过程主要都包括哪些步骤:
+
+
+
+- 第1步:采用事件风暴,根据业务行为,梳理出在投保过程中发生这些行为的所有的实体和值对象,比如投保单、标的、客户、被保人等等。
+- 第2步:从众多实体中选出适合作为对象管理者的根实体,也就是聚合根。判断一个实体是否是聚合根,你可以结合以下场景分析:是否有独立的生命周期?是否有全局唯一ID?是否可以创建或修改其它对象?是否有专门的模块来管这个实体。图中的聚合根分别是投保单和客户实体。
+- 第3步:根据业务单一职责和高内聚原则,找出与聚合根关联的所有紧密依赖的实体和值对象。构建出1个包含聚合根(唯一)、多个实体和值对象的对象集合,这个集合就是聚合。在图中我们构建了客户和投保这两个聚合。
+- 第4步:在聚合内根据聚合根、实体和值对象的依赖关系,画出对象的引用和依赖模型。这里我需要说明一下:投保人和被保人的数据,是通过关联客户ID从客户聚合中获取的,在投保聚合里它们是投保单的值对象,这些值对象的数据是客户的冗余数据,即使未来客户聚合的数据发生了变更,也不会影响投保单的值对象数据。从图中我们还可以看出实体之间的引用关系,比如在投保聚合里投保单聚合根引用了报价单实体,报价单实体则引用了报价规则子实体。
+- 第5步:多个聚合根据业务语义和上下文一起划分到同一个限界上下文内。
+
+这就是一个聚合诞生的完整过程了。
+
+## 领域事件
+
+举例来说的话,领域事件可以是业务流程的一个步骤,比如投保业务缴费完成后,触发投保单转保单的动作;也可能是定时批处理过程中发生的事件,比如批处理生成季缴保费通知单,触发发送缴费邮件通知操作;或者一个事件发生后触发的后续动作,比如密码连续输错三次,触发锁定账户的动作。
+
+在做用户旅程或者场景分析时,我们要捕捉业务、需求人员或领域专家口中的关键词:“如果发生……,则……”“当做完……的时候,请通知……”“发生……时,则……”等。在这些场景中,如果发生某种事件后,会触发进一步的操作,那么这个事件很可能就是领域事件。
+
+**领域事件相关案例**
+
+我来给你介绍一个保险承保业务过程中有关领域事件的案例。
+
+一个保单的生成,经历了很多子域、业务状态变更和跨微服务业务数据的传递。这个过程会产生很多的领域事件,这些领域事件促成了保险业务数据、对象在不同的微服务和子域之间的流转和角色转换。在下面这张图中,我列出了几个关键流程,用来说明如何用领域事件驱动设计来驱动承保业务流程。
+
+
+
+事件起点:客户购买保险-业务人员完成保单录入-生成投保单-启动缴费动作。
+
+1. 投保微服务生成缴费通知单,发布第一个事件:缴费通知单已生成,将缴费通知单数据发布到消息中间件。收款微服务订阅缴费通知单事件,完成缴费操作。缴费通知单已生成,领域事件结束。
+2. 收款微服务缴费完成后,发布第二个领域事件:缴费已完成,将缴费数据发布到消息中间件。原来的订阅方收款微服务这时则变成了发布方。原来的事件发布方投保微服务转换为订阅方。投保微服务在收到缴费信息并确认缴费完成后,完成投保单转成保单的操作。缴费已完成,领域事件结束。
+3. 投保微服务在投保单转保单完成后,发布第三个领域事件:保单已生成,将保单数据发布到消息中间件。保单微服务接收到保单数据后,完成保单数据保存操作。保单已生成,领域事件结束。
+4. 保单微服务完成保单数据保存后,后面还会发生一系列的领域事件,以并发的方式将保单数据通过消息中间件发送到佣金、收付费和再保等微服务,一直到财务,完后保单后续所有业务流程。这里就不详细说了。
+
+总之,通过领域事件驱动的异步化机制,可以推动业务流程和数据在各个不同微服务之间的流转,实现微服务的解耦,减轻微服务之间服务调用的压力,提升用户体验。
+
+一个完整的领域事件 = 事件发布 + 事件存储 + 事件分发 + 事件处理。
+
+- 事件发布:构建一个事件,需要唯一标识,然后发布;
+
+- 事件存储:发布事件前需要存储,因为接收后的事件也会存储,可用于重试或对账等;就是每次执行一次具体的操作时,把行为记录下来,执行持久化。
+
+- 事件分发:服务内的应用服务或者领域服务直接发布给订阅者,服务外需要借助消息中间件,比如Kafka,RabbitMQ等,支持同步或者异步。
+
+- 事件处理:先将事件存储,然后再处理。
+
+当然了,实际开发中事件存储和事件处理不是必须的。
+
+因此实现方案:**发布订阅模式,分为跨上下文(Kafka,RocketMq)和上下文内(Spring事件,Guava Event Bus)的领域事件**。
+
+举个例子,用户注册后,发送短信和邮件,使用Spring事件实现领域事件代码如下:
+
+```java
+/**
+ * 用户注册事件
+ **/
+public class UserRegisterEvent extends ApplicationEvent {
+
+ public UserRegisterEvent(Object source) {
+ super(source);
+ }
+}
+
+
+/**
+ * 用户监听事件
+ **/
+@Component
+public class UserListener {
+
+ @EventListener(UserRegisterEvent.class)
+ public void userRegister(UserRegisterEvent event) {
+ User user = (User) event.getSource();
+ System.out.println("用户注册。。。发送短信。。。" + user);
+ System.out.println("用户注册。。。发送邮件。。。" + user);
+ }
+
+ @EventListener(UserCancelEvent.class)
+ public void userCancelEvent(UserCancelEvent event) {
+ User user = (User) event.getSource();
+ System.out.println("用户注销。。。" + user);
+ }
+
+}
+
+/**
+ * 发布用户注册事件
+ */
+@RunWith(value = SpringJUnit4ClassRunner.class)
+@SpringBootTest(classes = DemoApplication.class)
+public class MyClient {
+
+ @Autowired
+ private ApplicationContext applicationContext;
+
+ @Test
+ public void test() {
+ User user = new User();
+ //发布事件
+ applicationContext.publishEvent(new UserRegisterEvent(user));
+ }
+}
+```
+
+**事件风暴**
+
+事件风暴是一项团队活动,领域专家与项目团队通过头脑风暴的形式,罗列出领域中所有的领域事件,整合之后形成最终的领域事件集合,然后对每一个事件,标注出导致该事件的命令,再为每一个事件标注出命令发起方的角色。命令可以是用户发起,也可以是第三方系统调用或者定时器触发等,最后对事件进行分类,整理出实体、聚合、聚合根以及限界上下文。而事件风暴正是 DDD 战略设计中经常使用的一种方法,它可以快速分析和分解复杂的业务领域,完成领域建模。
+
+# DDD分层架构
+
+DDD 的分层架构在不断发展。最早是传统的四层架构;再后来领域层和应用层之间增加了上下文环境(Context)层,五层架构(DCI)就此形成了。
+
+
+
+DDD分层架构中的要素其实和三层架构类似,只是在DDD分层架构中,这些要素被重新归类,重新划分了层,确定了层与层之间的交互规则和职责边界。
+
+
+
+## 用户接口层
+
+用户接口层是前端应用和微服务之间服务访问和数据交换的桥梁。它处理前端发送的 Restful 请求和解析用户输入的配置文件等,将数据传递给应用层。或获取应用服务的数据后,进行数据组装,向前端提供数据服务。主要服务形态是 Facade 服务。
+
+Facade 服务分为接口和实现两个部分。完成服务定向,DO 与 DTO 数据的转换和组装,实现前端与应用层数据的转换和交换。
+
+- 一般包括用户接口、Web 服务、rpc请求,mq消息等外部输入均被视为外部输入的请求。对外暴露API,具体形式不限于RPC、Rest API、消息等。
+
+- 一般都很薄,提供必要的参数校验和异常捕获流程。
+
+- 一般会提供VO或者DTO到Entity或者ValueObject的转换,用于前后端调用的适配,当然dto可以直接使用command和query,视情况而定。
+
+用户接口层很重要,在于前后端调用的适配。**若你的微服务要面向很多应用或渠道提供服务,而每个渠道的入参出参都不一样,你不太可能开发出太多应用服务,这样Facade接口就起很好的作用了,包括DO和DTO对象的组装和转换等**。
+
+## 应用层
+
+应用层是很薄的一层,理论上不应该有业务规则或逻辑,主要面向用例和流程相关的操作。但应用层又位于领域层之上,因为领域层包含多个聚合,所以它可以协调多个聚合的服务和领域对象完成服务编排和组合,协作完成业务操作。除了同步方法调用外,还可以发布或者订阅领域事件,权限校验、事务控制,一个事务对应一个聚合根。
+
+**应用层负责不同聚合之间的服务和数据协调,负责微服务之间的事件发布和订阅**。
+
+通过应用服务对外暴露微服务的内部功能,这样就可以隐藏领域层核心业务逻辑的复杂性以及内部实现机制。
+
+应用层的主要服务形态有:应用服务、事件发布和订阅服务。应用服务内用于组合和编排的服务,主要来源于领域服务,也可以是外部微服务的应用服务。
+
+## 领域层
+
+**领域层包含聚合根、实体、值对象、领域服务等领域模型中的领域对象**。
+
+这里我要特别解释一下其中几个领域对象的关系,以便你在设计领域层的时候能更加清楚。
+
+首先,领域模型的业务逻辑主要是由实体和领域服务来实现的,其中实体会采用充血模型来实现所有与之相关的业务功能。
+
+其次,你要知道,实体和领域对象在实现业务逻辑上不是同级的,当**领域中的某些功能,单一实体(或者值对象)不能实现时,领域服务就会出马,它可以组合聚合内的多个实体(或者值对象),实现复杂的业务逻辑**。
+
+领域层主要的服务形态有实体方法和领域服务。实体采用充血模型,在实体类内部实现实体相关的所有业务逻辑,实现的形式是实体类中的方法。实体是微服务的原子业务逻辑单元。在设计时我们主要考虑实体自身的属性和业务行为,实现领域模型的核心基础能力。不必过多考虑外部操作和业务流程,这样才能保证领域模型的稳定性。
+
+**DDD 提倡富领域模型,尽量将业务逻辑归属到实体对象上,实在无法归属的部分则设计成领域服务**。
+
+领域服务会对多个实体或实体方法进行组装和编排,实现跨多个实体的复杂核心业务逻辑。对于严格分层架构,**如果单个实体的方法需要对应用层暴露,则需要通过领域服务封装后才能暴露给应用服务**。
+
+## 基础层
+
+**基础层也叫基础设施层,基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等,比较常见的功能还是提供数据库持久化**。
+
+基础层的服务形态主要是仓储服务。仓储服务包括接口和实现两部分。仓储接口服务供应用层或者领域层服务调用,仓储实现服务,完成领域对象的持久化或数据初始化。
+
+DDD分层架构的数据库等基础资源访问,采用了仓储(Repository)设计模式,通过依赖到置实现各层对基础资源的解耦。
+
+仓储又分为两部分:仓储接口和仓储实现。
+
+**仓储接口放在领域层中,仓储实现放在基础层。原来三层架构通用的第三方工具包、驱动、Common、Utility、Config等通用的公共的资源类统一放到了基础层**。
+
+比如说,在传统架构设计中,由于上层应用对数据库的强耦合,很多公司在架构演进中最担忧的可能就是换数据库了,因为一旦更换数据库,就可能需要重写大部分的代码,这对应用来说是致命的。那采用依赖倒置的设计以后应用层就可以通过解耦来保持独立的核心业务。
+
+- 为业务逻辑提供支撑能力,提供通用的技术能力,仓库写增删改查类似DAO。
+- 防腐层实现(封装变化)用于业务检查和隔离第三方服务,内部 try catch。
+
+# 防腐层(ACL)
+
+当某个功能模块需要依赖第三方系统提供的数据或者功能时,我们常用的策略就是直接使用外部系统的API、数据结构。
+
+这样存在的问题就是,**因使用外部系统,而被外部系统的质量问题影响,从而“腐化”本身设计的问题**。
+
+
+
+因此我们的解决方案就是在两个系统之间加入一个中间层,隔离第三方系统的依赖,对第三方系统进行通讯转换和语义隔离,这个中间层,我们叫它防腐层。
+
+
+
+说白了就是,两个系统之间加了中间层,中间层类似适配器模式,解决接口差异的对接,接口转换是单向的(即从调用方向被调用方进行接口转换),防腐层强调两个子系统语义解耦,接口转换是双向的。
+
+# 服务调用
+
+
+
+**微服务内跨层服务调用**
+
+微服务架构下往往采用前后端分离的设计模式,前端应用独立部署。前端应用调用发布在API 网关上的 Facade 服务,Facade 定向到应用服务。应用服务作为服务组织和编排者,它的服务调用有这样两种路径:
+
+- 第一种是应用服务调用并组装领域服务。此时领域服务会组装实体和实体方法,实现核心领域逻辑。领域服务通过仓储服务获取持久化数据对象,完成实体数据初始化。
+- 第二种是应用服务直接调用仓储服务。这种方式主要针对像缓存、文件等类型的基础层数据访问。这类数据主要是查询操作,没有太多的领域逻辑,不经过领域层,不涉及数据库持久化对象。
+
+**微服务之间的服务调用**
+
+微服务之间的应用服务可以直接访问,也可以通过 API 网关访问。由于跨微服务操作,在进行数据新增和修改操作时,你需关注分布式事务,保证数据的一致性。
+
+**领域事件驱动**
+
+领域事件驱动包括微服务内和微服务之间的事件。微服务内通过事件总线(EventBus)完成聚合之间的异步处理。微服务之间通过消息中间件完成。异步化的领域事件驱动机制是一种间接的服务访问方式。当应用服务业务逻辑处理完成后,如果发生领域事件,可调用事件发布服务,完成事件发布。当接收到订阅的主题数据时,事件订阅服务会调用事件处理领域服务,完成进一步的业务操作。
+
+# 服务依赖
+
+在《实现领域驱动设计》一书中,DDD 分层架构有一个重要的原则:**每层只能与位于其下方的层发生耦合**。
+
+而架构根据耦合的紧密程度又可以分为两种:严格分层架构和松散分层架构。
+
+**优化后的DDD 分层架构模型就属于严格分层架构,任何层只能对位于其直接下方的层产生依赖。而传统的 DDD 分层架构则属于松散分层架构,它允许某层与其任意下方的层发生依赖**。
+
+那我们怎么选呢?综合我的经验,为了服务的可管理,我建议你采用严格分层架构。
+
+**在严格分层架构中,领域服务只能被应用服务调用,而应用服务只能被用户接口层调用,服务是逐层对外封装或组合的,依赖关系清晰**。
+
+而在松散分层架构中,领域服务可以同时被应用层或用户接口层调用,服务的依赖关系比较复杂且难管理,甚至容易使核心业务逻辑外泄。试想下,如果领域层中的某个服务发生了重大变更,那该如何通知所有调用方同步调整和升级呢?但在严格分层架构中,你只需要逐层通知上层服务就可以了。
+
+# 服务封装
+
+在严格分层架构模式下,不允许服务的跨层调用,每个服务只能调用它的下一层服务。服务从下到上依次为:实体方法、领域服务和应用服务。如果需要实现服务的跨层调用,我们应该怎么办?我建议你采用服务逐层封装的方式。
+
+
+
+我们看一下上面这张图,服务的封装和调用主要有以下几种方式:
+
+**实体方法的封装**
+
+实体方法是最底层的原子业务逻辑。如果单一实体的方法需要被跨层调用,你可以将它封装成领域服务,这样封装的领域服务就可以被应用服务调用和编排了。如果它还需要被用户接口层调用,你还需要将这个领域服务封装成应用服务。经过逐层服务封装,实体方法就可以暴露给上面不同的层,实现跨层调用。
+
+封装时服务前面的名字可以保持一致,你可以用 DomainService 或 *AppService 后缀来区分领域服务或应用服务。
+
+**领域服务的组合和封装**
+
+领域服务会对多个实体和实体方法进行组合和编排,供应用服务调用。如果它需要暴露给用户接口层,领域服务就需要封装成应用服务。
+
+**应用服务的组合和编排**
+
+应用服务会对多个领域服务进行组合和编排,暴露给用户接口层,供前端应用调用。
+
+在应用服务组合和编排时,你需要关注一个现象:多个应用服务可能会对多个同样的领域服务重复进行同样业务逻辑的组合和编排。当出现这种情况时,你就需要分析是不是领域服务可以整合了。你可以将这几个不断重复组合的领域服务,合并到一个领域服务中实现。这样既省去了应用服务的反复编排,也实现了服务的演进。这样领域模型将会越来越精炼,更能适应业务的要求。
+
+应用服务类放在应用层 Service 目录结构下。领域事件的发布和订阅类放在应用层 Event。
+
+# DDD建模步骤
+
+设计领域模型的一般步骤如下:
+
+1. 根据需求划分出初步的领域和限界上下文,以及上下文之间的关系。
+2. 进一步分析每个上下文内部,识别出哪些是实体,哪些是值对象。
+3. 对实体、值对象进行关联和聚合,划分出聚合的范畴和聚合根。
+4. 为聚合根设计仓储,并思考实体或值对象的创建方式。
+5. 在工程中实践领域模型,并在实践中检验模型的合理性,倒推模型中不足的地方并重构。
+
+# DDD代码模型
+
+微服务—级目录是按照DDD分层架构的分层职责来定义的。从下面这张图中,我们可以看到,在代码模型里分别为用户接口层、应用层、领域层和基础层,建立了interfaces、application、domain 和 infrastructure 四个—级代码目录。
+
+
+
+- Interfaces(用户接口层)∶它主要存放用户接口层与前端交互、展现数据相关的代码。前端应用通过这一层的接口,向应用服务获取展现所需的数据。这一层主要用来处理用户发送的Restful请求,解析用户输入的配置文件,并将数据传递给Application层。数据的组装、数据传输格式以及Facade接口等代码都会放在这一层目录里。
+- Application(应用层)︰它主要存放应用层服务组合和编排相关的代码。应用服务向下基于微服务内的领域服务或外部微服务的应用服务完成服务的编排和组合,向上为用户接口层提供各种应用数据展现支持服务。应用服务和事件等代码会放在这一层目录里。
+- Domain(领域层)︰它主要存放领域层核心业务逻辑相关的代码。领域层可以包含多个聚合代码包,它们共同实现领域模型的核心业务逻辑。聚合以及聚合内的实体、方法、领域服务和事件等代码会放在这一层目录里。
+- Infrastructure(基础层)∶它主要存放基础资源服务相关的代码,为其它各层提供的通用技术能力、三方软件包、数据库服务、配置和基础资源服务的代码都会放在这一层目录里。
+
+## 用户接口层
+
+Interfaces 的代码目录结构有:assembler、dto 和 facade 三类。
+
+- Assembler:实现 DTO 与领域对象之间的相互转换和数据交换。一般来说 Assembler 与DTO 总是一同出现。
+
+- DTO:它是数据传输的载体,内部不存在任何业务逻辑,我们可以通过 DTO 把内部的领域对象与外界隔离。
+- Facade:提供较粗粒度的调用接口,将用户请求委派给一个或多个应用服务进行处理。
+
+## 应用层
+
+Application 的代码目录结构有:event 和 service。
+
+- Event(事件):这层目录主要存放事件相关的代码。它包括两个子目录:publish 和subscribe。前者主要存放事件发布相关代码,后者主要存放事件订阅相关代码(事件处理相关的核心业务逻辑在领域层实现)。
+
+这里提示一下:**虽然应用层和领域层都可以进行事件的发布和处理,但为了实现事件的统一管理,我建议你将微服务内所有事件的发布和订阅的处理都统一放到应用层,事件相关的核心业务逻辑实现放在领域层。通过应用层调用领域层服务,来实现完整的事件发布和订阅处理流程**。
+
+- Service(应用服务):这层的服务是应用服务。应用服务会对多个领域服务或外部应用服务进行封装、编排和组合,对外提供粗粒度的服务。应用服务主要实现服务组合和编排,是一段独立的业务逻辑。你可以将所有应用服务放在一个应用服务类里,也可以把一个应用服务设计为一个应用服务类,以防应用服务类代码量过大。
+
+## 领域层
+
+Domain 是由一个或多个聚合包构成,共同实现领域模型的核心业务逻辑。聚合内的代码模型是标准和统一的,包括:entity、event、repository 和 service 四个子目录。
+
+而领域层聚合内部的代码目录结构是这样的:
+
+
+
+- Aggregate(聚合):它是聚合软件包的根目录,可以根据实际项目的聚合名称命名,比如权限聚合。在聚合内定义聚合根、实体和值对象以及领域服务之间的关系和边界。聚合内实现高内聚的业务逻辑,它的代码可以独立拆分为微服务。以聚合为单位的代码放在一个包里的主要目的是为了业务内聚,而更大的目的是为了以后微服务之间聚合的重组。聚合之间清晰的代码边界,可以让你轻松地实现以聚合为单位的微服务重组,在微服务架构演进中有着很重要的作用。
+
+- Entity(实体):它存放聚合根、实体、值对象以及工厂模式(Factory)相关代码。实体类采用充血模型,同一实体相关的业务逻辑都在实体类代码中实现。跨实体的业务逻辑代码在领域服务中实现。
+- Event(事件):它存放事件实体以及与事件活动相关的业务逻辑代码。
+- Service(领域服务):它存放领域服务代码。一个领域服务是多个实体组合出来的一段业务逻辑。你可以将聚合内所有领域服务都放在一个领域服务类中,你也可以把每一个领域服务设计为一个类。如果领域服务内的业务逻辑相对复杂,我建议你将一个领域服务设计为一个领域服务类,避免由于所有领域服务代码都放在一个领域服务类中,而出现代码臃肿的问题。领域服务封装多个实体或方法后向上层提供应用服务调用。
+- Repository(仓储):它存放所在聚合的查询或持久化领域对象的代码,通常包括仓储接口和仓储实现方法。为了方便聚合的拆分和组合,我们设定了一个原则:一个聚合对应一个仓储。
+
+特别说明:按照 DDD 分层架构,仓储实现本应该属于基础层代码,但为了在微服务架构演进时,保证代码拆分和重组的便利性,可以将聚合仓储实现的代码放到聚合包内。这样,如果需求或者设计发生变化导致聚合需要拆分或重组时,我们就可以将包括核心业务逻辑和仓储代码的聚合包整体迁移,轻松实现微服务架构演进。
+
+## 基础层
+
+Infrastructure 的代码目录结构有:config 和 util 两个子目录。
+
+- Config:主要存放配置相关代码。
+- Util:主要存放平台、开发框架、消息、数据库、缓存、文件、总线、网关、第三方类库、通用算法等基础代码,你可以为不同的资源类别建立不同的子目录。
+
+------
+
+关于代码模型还需要强调两点内容。
+
+- 第一点:聚合之间的代码边界一定要清晰。聚合之间的服务调用和数据关联应该是尽可能的松耦合和低关联,聚合之间的服务调用应该通过上层的应用层组合实现调用,原则上不允许聚合之间直接调用领域服务。这种松耦合的代码关联,在以后业务发展和需求变更时,可以很方便地实现业务功能和聚合代码的重组,在微服务架构演进中将会起到非常重要的作用。
+- 第二点:你一定要有代码分层的概念。写代码时一定要搞清楚代码的职责,将它放在职责对应的代码目录内。应用层代码主要完成服务组合和编排,以及聚合之间的协作,它是很薄的一层,不应该有核心领域逻辑代码。领域层是业务的核心,领域模型的核心逻辑代码一定要在领域层实现。如果将核心领域逻辑代码放到应用层,你的基于DDD分层架构模型的微服务慢慢就会演变成传统的三层架构模型了。
+
+## 目录结构
+
+以下是一个 DDD 工程的代码目录结构,提供参考:
+
+```
+│
+│ ├─interface 用户接口层
+│ │ └─controller 控制器,对外提供(Restful)接口
+│ │ └─facade 外观模式,对外提供本地接口和dubbo接口
+│ │ └─mq mq消息,消费者消费外部mq消息
+│ │
+│ ├─application 应用层
+│ │ ├─assembler 装配器
+│ │ ├─dto 数据传输对象,xxxCommand/xxxQuery/xxxVo
+│ │ │ ├─command 接受增删改的参数
+│ │ │ ├─query 接受查询的参数
+│ │ │ ├─vo 返回给前端的vo对象
+│ │ ├─service 应用服务,负责领域的组合、编排、转发、转换和传递
+│ │ ├─repository 查询数据的仓库接口
+│ │ ├─listener 事件监听定义
+│ │
+│ ├─domain 领域层
+│ │ ├─entity 领域实体
+│ │ ├─valueobject 领域值对象
+│ │ ├─service 领域服务
+│ │ ├─repository 仓库接口,增删改的接口
+│ │ ├─acl 防腐层接口
+│ │ ├─event 领域事件
+│ │
+│ ├─infrastructure 基础设施层
+│ │ ├─converter 实体转换器
+│ │ ├─repository 仓库
+│ │ │ ├─impl 仓库实现
+│ │ │ ├─mapper mybatis mapper接口
+│ │ │ ├─po 数据库orm数据对象
+│ │ ├─ack 实体转换器
+│ │ ├─mq mq消息
+│ │ ├─cache 缓存
+│ │ ├─util 工具类
+│ │
+│
+```
+
+# 数据对象视图
+
+- 数据持久化对象 PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一 一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应 PO 的一个(或若干个)属性。最形象的理解就是一个 PO 就是数据库中的一条记录,好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。也有团队使用DO(Data Object)表示数据对象。
+
+- 领域对象 DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体,使用的是充血模型设计的对象。也有团队使用用 BO(Business Objects)表示业务对象的概念。
+
+- 数据传输对象 DTO(Data Transfer Object):数据传输对象,主要用于远程调用之间传输的对象的地方。比如我们一张表有 100 个字段,那么对应的 PO 就有 100 个属性。但是客户端只需要 10 个字段,没有必要把整个 PO 对象传递到客户端,这时我们就可以用只有这 10 个属性的 DTO 来传递结果到客户端,这样也不会暴露服务端表结构。到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为 VO。DTO泛指用于展示层与服务层之间的数据传输对象,当然VO也相当于数据DTO的一种。
+
+- 视图对象 VO(View Object):视图对象,主要对应界面显示的数据对象。对于一个WEB页面,小程序,微信公众号等前端需要的数据对象。也有团队用VO表示领域层中的Value Object值对象,这个要根据团队的规范来定义。
+
+- 简单对象POJO(Plain Ordinary Java Object):简单对象,是只具有setter getter方法对象的统称。但是不要把对象名命名成 xxxPOJO!
+
+我们结合下面这张图,看看微服务各层数据对象的职责和转换过程。
+
+
+
+**基础层**
+
+基础层的主要对象是 PO 对象。我们需要先建立 DO 和 PO 的映射关系。当 DO 数据需要持久化时,仓储服务会将 DO 转换为 PO 对象,完成数据库持久化操作。当 DO 数据需要初始化时,仓储服务从数据库获取数据形成 PO 对象,并将 PO 转换为 DO,完成数据初始化。大多数情况下 PO 和 DO 是一一对应的。但也有 DO 和 PO 多对多的情况,在 DO 和 PO数据转换时,需要进行数据重组
+
+**领域层**
+
+领域层的主要对象是 DO 对象。DO 是实体和值对象的数据和业务行为载体,承载着基础的核心业务逻辑。通过 DO 和 PO 转换,我们可以完成数据持久化和初始化。
+
+**应用层**
+
+应用层的主要对象是 DO 对象。如果需要调用其它微服务的应用服务,DO 会转换为DTO,完成跨微服务的数据组装和传输。用户接口层先完成 DTO 到 DO 的转换,然后应用服务接收 DO 进行业务处理。如果 DTO 与 DO 是一对多的关系,这时就需要进行 DO数据重组。
+
+**用户接口层**
+
+用户接口层会完成 DO 和 DTO 的互转,完成微服务与前端应用数据交互及转换。Facade服务会对多个 DO 对象进行组装,转换为 DTO 对象,向前端应用完成数据转换和传输。
+
+**前端应用**
+
+前端应用主要是 VO 对象。展现层使用 VO 进行界面展示,通过用户接口层与应用层采用DTO 对象进行数据交互。
+
+# 总结
+
+DDD 基于各种考虑,有很多的设计原则,也用到了很多的设计模式。条条框框多了,很多人可能就会被束缚住,总是担心或犹豫这是不是原汁原味的 DDD。
+
+**其实我们不必追求极致的 DDD,这样做反而会导致过度设计,增加开发复杂度和项目成本**。
+
+DDD 的设计原则或模式,是考虑了很多具体场景或者前提的。有的是为了解耦,如仓储服务、边界以及分层,有的则是为了保证数据一致性,如聚合根管理等。在理解了这些设计原则的根本原因后,有些场景你就可以灵活把握设计方法了,你可以突破一些原则,不必受限于条条框框,大胆选择最合适的方法。
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md"
new file mode 100644
index 0000000..7f9f7b5
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Mapping.md"
@@ -0,0 +1,368 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+[TOC]
+
+本篇讲解Elasticsearch中非常重要的一个概念:**Mapping**,Mapping是索引必不可少的组成部分。
+
+## Mapping 的基本概念
+
+**Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分**
+
+ES 中的 Mapping 有点类似于关系型数据库中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
+
+### 查看索引 Mapping
+
+```JSON
+//查看索引完整的mapping
+GET /my_index/_mappings
+//查看索引指定字段的mapping
+GET /my_index/_mappings/field/field_name
+```
+
+例如,如果你有一个名为 "my_index" 的索引,并且你想查询字段 "my_field" 的 mapping,那么请求就像这样:
+
+```jon
+GET /my_index/_mapping/field/my_field
+```
+
+此请求会返回如下类型的输出:
+
+```json
+{
+ "my_index" : {
+ "mappings" : {
+ "my_field" : {
+ "full_name" : "my_field",
+ "mapping" : {
+ "my_field" : {
+ "type" : "text",
+ "fields" : {
+ "keyword" : {
+ "type" : "keyword",
+ "ignore_above" : 256
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+在这个响应中,你可以看到 "my_field" 是 "text" 类型,并且它也有一个子字段 "keyword"。
+
+## 字段数据类型
+
+映射的数据类型也就是 ES 索引支持的数据类型,其概念和 MySQL 中的字段类型相似,但是具体的类型和 MySQL 中有所区别,最主要的区别就在于 ES 中支持可分词的数据类型,如:Text 类型,可分词类型是用以支持全文检索的,这也是 ES 生态最核心的功能。
+
+### 数字类型
+
+- **long**:64 位有符号整形。
+- **integer**:32 位有符号整形。
+- **short**:16 位有符号整形。
+- **byte**:8位有符号整形。
+- **double**:双精度64位浮点类型。
+- **float**:单精度32位浮点类型。
+- **half_float**:半精度16位浮点数。
+- **scaled_float**:缩放类型浮点数,按固定 double 比例因子缩放。
+- **unsigned_long**:无符号 64 位整数。
+
+### 基本数据类型
+
+- **binary**:存储二进制字符串,经过Base64编码处理。
+- **boolean**:布尔类型,接收 ture 和 false 两个值。
+
+### Keywords 类型
+
+- **keyword**:这种类型被用来索引结构化数据,如 email 地址、主机名、状态码以及标签等。这类数据可以以精确值的形式进行搜索,并且可以用于过滤 (filtering),排序 (sorting) 和聚合 (aggregating)。关键词字段只和其确切的值匹配,它们的查询不会进行分词处理。
+- **constant_keyword**:这种类型适用于在所有文档中都始终有相同值的字段。比如在一次特定的索引操作中,所有的文档都需要包含一个常量字段,例如 `env` 的值可能为 "production"。
+- **wildcard**:这种类型的字段可以存储任何字符串,并且对于这种类型的字段进行的查询可以使用通配符表达式。这种类型的字段对于像 grep 这样的场景非常有用,即当你需要在一个长字符串中搜索一个较短的子串时。但是要注意,虽然 wildcard 字段提供了强大的模式匹配能力,但是这种能力是需要付出性能代价的。
+
+### 日期类型
+
+JSON 没有日期数据类型,因此 Elasticsearch 中的日期可以是以下三种:
+
+- **包含格式化日期的字符串**:例如 "2015-01-01"、 "2015/01/01 12:10:30"。
+- **时间戳**:表示自"1970年 1 月 1 日"以来的毫秒数/秒数。
+- **date_nanos**:此数据类型是对 date 类型的补充。但是有一个重要区别。date 类型存储最高精度为毫秒,而date_nanos 类型存储日期最高精度是纳秒,但是高精度意味着可存储的日期范围小,即:从大约 1970 到 2262。
+
+### 对象类型
+
+- **object**:默认情况下,Elasticsearch 使用 object 数据类型来处理 JSON 对象。
+- **flattened**:这是用来索引对象数组或者具有未知结构的字段的特殊映射类型。其将整个JSON对象作为单个键值对存储,帮助降低索引大小和提高搜索速度。
+- **nested**:这是一个类似于 object 的数据类型,但它能保存并查询对象数组内部对象的独立性,因此可以用来处理更复杂的结构。
+- **join**:这是一个特殊数据类型,用于模拟在文档之间的父/子关系。这样可以创建一对多的连接,例如,在博客文章和评论这样的场景中使用。
+
+### 空间数据类型
+
+- **geo_point**:表示地理位置的点,存储纬度和经度信息。
+- **geo_shape**:表示复杂的地理形状,如多边形、线、圆等。
+- **point**:在笛卡尔空间中表示一个点,存储X和Y坐标。
+- **shape**:在笛卡尔空间中表示任意复杂的几何形状。
+
+### 文档排名类型
+
+- **dense_vector**:记录浮点值的密集向量。这种类型常用于存储机器学习模型的输出,例如词嵌入、句子嵌入等。
+- **rank_feature**:记录单个数值特征以优化排名。当这个字段被查询时,Elasticsearch 会考虑其值来重新排序搜索结果。
+- **rank_features**:记录多个数值特征以优化排名。与`rank_feature`类似,但它能够处理包含多个特征的对象。当这些字段被查询时,Elasticsearch 会考虑它们的值来重新排序搜索结果。
+
+### 文本搜索类型
+
+- **text**:用于存储全文和进行全文搜索的数据类型。
+- **annotated-text:**这是一个特殊的文本字段,它支持包含标记的文本。这些标记表示文本中的命名实体或其他重要项,可以在后续搜索中使用。
+- **completion** :这是一个专门为自动补全和搜索建议设计的数据类型。
+- **search_as_you_type:** 这是一种特殊的文本字段,它被优化以提供按键查询时的即时反馈,从而提高用户输入时的搜索体验。
+- **token_count**:这是一种数值型字段,用于存储文本字段中的词元数量。此字段常用于信息检索场景,比如评估某个字段的长度。
+
+## 两种映射类型
+
+### 自动映射:Dynamic Field Mapping
+
+Elasticsearch的Dynamic Field Mapping是一种自动产生index mapping的机制。在通常情况下,当一个新文档被索引到Elasticsearch中,如果其中包含了未在mapping中定义的字段,Elasticsearch就会尝试根据这个新字段的数据类型自动生成相应的mapping。
+
+自动映射关系如下:
+
+| **field type** | **dynamic** |
+| -------------- | ---------------------------------- |
+| true/false | boolean |
+| 小数 | float |
+| 数字 | long |
+| object | object |
+| 数组 | 取决于数组中的第一个非空元素的类型 |
+| 日期格式字符串 | date |
+| 数字类型字符串 | float/long |
+| 其他字符串 | text + keyword |
+
+除了上述字段类型之外,其他类型都必须显式映射,也就是必须手工指定,因为其他类型ES无法自动识别。
+
+这里有几点需要注意:
+
+- 数据类型识别:Elasticsearch会按照以下顺序判断数据类型:长整数、浮点数、布尔值、日期、字符串(字符串可能会进一步映射为text或keyword)。
+- 字段名称含义:Elasticsearch不会考虑字段名称的含义,它仅仅依靠字段的数据类型来生成mapping。
+- 关闭动态映射:如果你不希望Elasticsearch自动创建mapping,可以将index的`dynamic`设置为`false`。
+- 动态模板:你可以使用动态模板来改变默认的mapping规则,例如,你可以将所有看起来像日期的字符串都映射为date类型。
+- 对象和嵌套字段:对于对象(object)和嵌套字段(nested),Elasticsearch也会递归地应用动态映射规则。
+- 更新映射:请注意,一旦字段的映射被创建,就不能再修改字段的数据类型了。因此,如果你要索引的文档中有新的字段,最好事先定义好mapping,避免让Elasticsearch自动映射可能产生不符合你期望的结果。
+- 当一个字段第一次出现时,Elasticsearch会使用先行数据类型来设置映射。如果后续数据类型与先前设置的映射类型不一致,Elasticsearch可能无法正确索引这些文档。
+
+总的来说,虽然动态字段映射可以在某些情况下提供便利,但它也可能导致未预见的问题。因此,更推荐在开始索引文档之前就定义好mapping。
+
+### 显式映射:Expllcit Field Mapping
+
+在 Elasticsearch 中,显式映射(Explicit Field Mapping)是指为索引预定义的字段类型和行为。当你创建一个索引时,你可以定义每个字段的数据类型、分词器或者其他相关的配置。这就是显式映射。
+
+以下是一些主要的显式映射类型:
+
+- **核心数据类型**:包括 string(字符串)、integer(整型)、long(长整型)、double(双精度浮点型)、boolean(布尔型)等。
+- **复合数据类型**:包括 object(对象),用于单个 JSON 对象,nested,用于 JSON 数组。
+- **地理数据类型**:如 geo_point 和 geo_shape。
+- **专门用途的数据类型**:例如 IP、自动完成、token count、join types 等。
+
+通过显式映射,Elasticsearch 可以更准确地解析和索引数据,对查询性能优化起到关键作用。如果不提供显式映射,Elasticsearch 将会根据输入数据自动推断并生成隐式映射,但可能无法达到最理想的效果。
+
+以下是一个示例,展示了怎么设置一个简单的显式映射:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "properties": {
+ "name": { "type": "text" },
+ "age": { "type": "integer" }
+ }
+ }
+}
+```
+
+上述代码中,我们在 `my_index` 索引中定义了两个字段的映射,`name` 字段类型为 `text`,`age` 字段类型为 `integer`。
+
+注意:在 Elasticsearch 7.0 之后,映射类型被废弃,所有的映射参数直接放在 "properties" 下。
+
+## 映射参数
+
+在Elasticsearch中,映射参数是用于定义如何处理文档和其包含的字段的规则。
+
+主要参数有下:
+
+- **index**:是否对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。
+- **analyzer**:指定分析器(character filter、tokenizer、Token filters)。
+- **boost**:对当前字段相关度的评分权重,默认1。
+- **coerce**:是否允许强制类型转换,为 true的话 “1”能被转为 1, false则转不了。虽然这个参数可以帮助我们强制类型转换,但是它可能会在数据质量管理中引起问题。如果原始数据包含错误的类型,使用 "coerce" 可能会隐藏这些问题,而不是将其暴露出来。
+- **copy_to**:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询。
+- **doc_values**:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间,对于text字段和annotated_text字段,无法禁用此选项,因为这些字段类型在默认情况下不使用doc values。
+- **dynamic**:控制是否可以动态添加新字段
+ - **true** :新检测到的字段将添加到映射中(默认)。
+ - **false** :新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
+ - **strict** :如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射。
+- **eager_global_ordinals**:用于聚合的字段上,优化聚合性能,但不适用于 Frozen indices。
+ - **Frozen indices**(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices 的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。
+- **enable**:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。**enable的作用和index类似,区别就是enable可以对全局进行设置**。例如:
+
+```JSON
+PUT my_index
+{
+ "mappings": {
+ "enabled": false
+ }
+}
+```
+
+- **fielddata**:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。
+- **fields**:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)。
+- **format**:格式化。例如:
+
+```JSON
+"date": {
+ "type": "date",
+ "format": "yyyy-MM-dd"
+}
+```
+
+- **ignore_above**:这是一个针对keyword类型字段的设置,对于超过指定长度的字符串,ES 不会对其建立索引。
+- **ignore_malformed**:忽略类型错误。
+- **index_options**:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段。
+- **Index_phrases**:提升 exact_value 查询速度,但是要消耗更多磁盘空间。
+- **Index_prefixes**:前缀搜索。
+ - **min_chars**:前缀最小长度> 0,默认 2(包含)。
+ - **max_chars**:前缀最大长度< 20,默认 5(包含)。
+- **meta**:附加元数据。
+- **normalizer**:normalizer 参数用于解析前(索引或者查询时)的标准化配置。
+- **norms**:是否禁用评分(在 filter 和聚合字段上应该禁用)。
+- **null_value**:为 null 值设置默认值。
+- **position_increment_gap**:对于数组或者列表类型的字段,在进行phrase query或者phrase suggest时,允许用户自定义同一字段内两个相邻元素间的位置增量,默认100。
+- **properties**:除了mapping还可用于object的属性设置。
+- **search_analyzer**:设置单独的查询时分析器,如果定义了analyzer而没有定义search_analyzer,则search_analyzer的值默认会和analyzer保持一致,如果两个都没有定义,则默认是:"standard"。analyzer针对的是元数据,而search_analyzer针对的是传入的搜索词。
+- **similarity**:为字段设置相关度算法,和评分有关。支持BM25、classic(TF-IDF)、boolean。
+- **store**:设置字段是否仅查询。
+- **term_vector**:运维参数。这个参数可以设置存储哪些信息用于更复杂的文本处理,例如在词向量建模或者更复杂的文本检索场景中使用。
+
+## Text & Keyword
+
+### Text
+
+当一个字段是要被全文检索时,比如 Email 内容、产品描述,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引之前,字符串会被分析器分成一个个词项。text类型的字段不用于排序,很少用于聚合。
+
+**注意事项**
+
+- 适用于全文检索:如 match 查询。
+- 文本字段会被分词。
+- 默认情况下,会创建倒排索引。
+- 自动映射器会为 Text 类型创建 Keyword 字段。
+
+
+
+### Keyword
+
+Keyword 类型适用于不分词的字段,如姓名、Id、数字等。如果数字类型不用于范围查找,用 Keyword 的性能要高于数值类型。
+
+当使用 Keyword 类型查询时,其字段值会被作为一个整体,并保留字段值的原始属性。
+
+```JSON
+GET index/_search
+{
+ "query": {
+ "match": {
+ "title.keyword": "测试文本值"
+ }
+ }
+}
+```
+
+注意事项
+
+- Keyword 不会对文本分词,会保留字段的原有属性,包括大小写等。
+- Keyword 仅仅是字段类型,而不会对搜索词产生任何影响。
+- Keyword 一般用于需要精确查找的字段,或者聚合排序字段。
+- Keyword 通常和 Term 搜索一起用。
+- Keyword 字段的 `ignore_above` 参数代表其截断长度,默认 256,如果超出长度,字段值会被忽略,而不是截断,忽略指的是会忽略这个字段的索引,搜索不到,但数据还是存在的。
+
+## 映射模板
+
+之前讲过的映射类型或者映射参数,都是为确定的某个字段而声明的。
+
+但是当我们不确定字段名字的时候该怎么设置mapping呢?映射模板就是用来解决这种场景的。
+
+如果希望对符合某类要求的特定字段制定映射,就需要用到映射模板:**Dynamic templates**。映射模板有时也被称作:自动映射模板、动态模板等。
+
+以下是一个示例:
+
+```json
+{
+ "mappings": {
+ "dynamic_templates": [
+ {
+ "strings_as_keyword": {
+ "match_mapping_type": "string",
+ "mapping": {
+ "type": "keyword"
+ }
+ }
+ },
+ {
+ "longs_as_integer": {
+ "match_mapping_type": "long",
+ "mapping": {
+ "type": "integer"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+在上述例子中,我们定义了两个模板:`strings_as_keyword` 和 `longs_as_integer`。当新字段被发现时,Elasticsearch 会检查这些模板以决定如何映射这个新字段。
+
+- `strings_as_keyword` 模板将所有新的字符串类型字段映射为 `keyword` 类型。
+- `longs_as_integer` 模板将所有新的长整数(long)类型字段映射为 `integer` 类型。
+
+注意:这些只是示例,实际的映射应该取决于实际数据和查询需求。例如,如果你需要对字符串字段进行全文搜索,那么将其映射为 `text` 可能更合适。
+
+### 参数
+
+- `match`:匹配字段名称。
+- `unmatch`:反匹配字段名称。
+- `match_mapping_type`:匹配字段类型,例如 string、long、double、boolean、date。
+- `match_pattern`:允许更复杂的名字模式,支持"starts_with"、"ends_with" 和 "contains"。
+- `path_match`:允许你用路径 (如 article.title) 来匹配字段。
+- `path_unmatch`:反匹配路径。
+- `mapping`:该字段被匹配时,应用的映射设置。
+
+### 案例
+
+```JSON
+PUT test_dynamic_template
+
+{
+ "mappings": {
+ "dynamic_templates": [{
+ "integers": {
+ "match_mapping_type": "long",
+ "mapping": {
+ "type": "integer"
+ }
+ }
+ },
+ {
+ "longs_as_strings": {
+ "match_mapping_type": "string",
+ "match": "num_*",
+ "unmatch": "*_text",
+ "mapping": {
+ "type": "keyword"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+以上代码会产生以下效果:
+
+- 所有 long 类型字段会默认映射为 integer。
+- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型。
+
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md"
new file mode 100644
index 0000000..f2e16d7
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Nested & Join.md"
@@ -0,0 +1,289 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES的 Nested 类型用于处理在一个文档中嵌套复杂的结构数据,而 Join 类型用于建立父子文档之间的关联关系。
+
+## 嵌套类型:Nested
+
+Elasticsearch没有内部对象的概念,因此,ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表。
+
+**比如**:
+
+```json
+PUT my-index/_doc/1
+{
+ "group" : "fans",
+ "user" : [
+ {
+ "first" : "John",
+ "last" : "Smith"
+ },
+ {
+ "first" : "Alice",
+ "last" : "White"
+ }
+ ]
+}
+```
+
+上面的文档被创建之后,user数组中的每个json对象会以下面的形式存储
+
+```json
+{
+ "group" : "fans",
+ "user.first" : [ "alice", "john" ],
+ "user.last" : [ "smith", "white" ]
+}
+```
+
+`user.first`和 `user.last`字段被扁平化为多值字段,`first`和 `last`之间的关联丢失。
+
+解决方法可以使用Nested类型,Nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作,嵌套类型(Nested)允许在一个文档内部嵌套另一个文档,这使得可以在同一个文档中表示复杂的层次结构数据。
+
+下面是关于如何定义和使用嵌套类型的示例:
+
+定义映射(Mapping):
+
+```json
+PUT /my_index
+{
+ "mappings": {
+ "properties": {
+ "name": {
+ "type": "text"
+ },
+ "comments": {
+ "type": "nested",
+ "properties": {
+ "user": { "type": "keyword" },
+ "message": { "type": "text" }
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们创建了一个名为 "my_index" 的索引,并定义了一个 "comments" 字段作为嵌套类型。嵌套类型包含两个属性: "user" 和 "message"。
+
+输入数据(Indexing):
+
+```json
+POST /my_index/_doc
+{
+ "name": "Product A",
+ "comments": [
+ {
+ "user": "User 1",
+ "message": "Great product!"
+ },
+ {
+ "user": "User 2",
+ "message": "Needs improvement."
+ }
+ ]
+}
+```
+
+在上述示例中,我们向索引 "my_index" 中插入了一个文档,其中 "comments" 字段包含了两个嵌套文档。
+
+查询数据(Querying):
+
+```json
+GET /my_index/_search
+{
+ "query": {
+ "nested": {
+ "path": "comments",
+ "query": {
+ "bool": {
+ "must": [
+ { "match": { "comments.user": "User 1" } },
+ { "match": { "comments.message": "Great product!" } }
+ ]
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们使用嵌套查询(nested query)来搜索包含特定评论的文档。我们指定了路径为 "comments",并在 `must` 子句中添加了匹配条件。
+
+输出结果:
+
+```json
+{
+ "hits": {
+ "total": {
+ "value": 1,
+ "relation": "eq"
+ },
+ "hits": [
+ {
+ "_source": {
+ "name": "Product A",
+ "comments": [
+ {
+ "user": "User 1",
+ "message": "Great product!"
+ }
+ ]
+ }
+ }
+ ]
+ }
+}
+```
+
+在上述示例中,我们得到了一个匹配的文档,其中 "comments" 字段只包含了符合查询条件的嵌套文档。
+
+### 参数
+
+- `path`(必需):指定嵌套字段的路径。它告诉 Elasticsearch 在哪个字段上应用嵌套查询。
+
+- `score_mode`(可选):指定如何计算嵌套文档的评分。
+
+ avg (默认):使用所有匹配的子对象的平均相关性得分。
+
+ max:使用所有匹配的子对象中的最高相关性得分。
+
+ min:使用所有匹配的子对象中最低的相关性得分。
+
+ none:不要使用匹配的子对象的相关性分数。该查询为父文档分配得分为0。
+
+ sum:将所有匹配的子对象的相关性得分相加。
+
+- `inner_hits`(可选):允许获取与嵌套文档匹配的内部结果。使用此参数可以检索与查询匹配的特定嵌套文档,并返回有关它们的信息。
+
+- `ignore_unmapped`(可选):如果设置为 `true`,则忽略没有嵌套字段映射的文档,并将其视为无匹配。默认情况下,设为 `false`。
+
+- `nested`(可选):表示查询是否应该应用于嵌套字段的上下文。默认情况下,设为 `true`。如果设置为 `false`,则将查询视为普通的非嵌套查询。
+
+- `score_mode`(可选):指定如何计算嵌套文档的评分。可选的值包括 `"none"`、`"avg"`、`"max"`、`"sum"` 和 `"min"`。默认情况下,使用 `"avg"`。
+
+## 父子级关系:Join
+
+连接数据类型是一个特殊字段,它在同一索引的文档中创建父/子关系。关系部分在文档中定义了一组可能的关系,每个关系是一个父名和一个子名。
+
+父/子关系可以定义如下:
+
+```json
+PUT
+{
+ "mappings": {
+ "properties": {
+ "": {
+ "type": "join",
+ "relations": {
+ "": ""
+ }
+ }
+ }
+ }
+}
+```
+
+常见的一个示例是创建一个索引来存储博客的数据。每个博客可以有多个评论,我们可以使用Join类型来建立博客和评论之间的父子关系。
+
+首先,我们定义一个包含两个类型的索引:`blogs`和`comments`。`blogs`类型表示博客,而`comments`类型表示评论。我们将为`blogs`类型定义一个Join字段,用于与`comments`类型建立关联。
+
+以下是一个简化的示例:
+
+创建索引并定义映射:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "properties": {
+ "title": {
+ "type": "text"
+ },
+ "join_field": {
+ "type": "join",
+ "relations": {
+ "blogs": "comments"
+ }
+ }
+ }
+ }
+}
+```
+
+添加博客文档:
+
+```json
+PUT my_index/_doc/1
+{
+ "title": "Elasticsearch Join 示例",
+ "join_field": "blogs"
+}
+```
+
+添加评论文档,并关联到博客:
+
+```json
+PUT my_index/_doc/2?routing=1
+{
+ "title": "很棒的博客",
+ "join_field": {
+ "name": "comments",
+ "parent": "1"
+ }
+}
+```
+
+查询博客及其关联的评论:
+
+```json
+GET my_index/_search
+{
+ "query": {
+ "has_child": {
+ "type": "comments",
+ "query": {
+ "match_all": {}
+ }
+ }
+ }
+}
+```
+
+以上示例展示了如何使用Join类型在Elasticsearch中建立父子关系,并进行查询操作。实际使用时,可能需要根据自己的数据结构和查询需求进行适当的调整。
+
+使用场景
+
+**Join唯一合适应用场景是:当索引数据包含一对多的关系,并且其中一个实体的数量远远超过另一个的时候。比如:老师有 一万个学生**
+
+`join`类型不能像关系数据库中的表链接那样去用,不论是 `has_child`或者是 `has_parent`查询都会对索引的查询性能有严重的负面影响。并且会触发 global ordinals。
+
+Global Ordinals是一种用于优化字段的查询性能的技术。在使用Join类型时,如果启用了Global Ordinals特性,它将为Join字段创建全局有序的编号,以支持快速的父子文档查询。
+
+当你执行具有Join字段的查询时,ES会使用Global Ordinals来识别匹配的父文档,并快速定位到对应的子文档。这样可以避免对所有文档进行扫描和过滤的开销,提高查询的效率。
+
+需要注意的是,启用Global Ordinals可能会增加索引的内存使用量和一些额外的计算开销。因此,在决定是否启用Global Ordinals时,需要权衡查询性能和资源消耗之间的平衡。
+
+**注意**
+
+- 在索引父子级关系数据的时候必须传入routing参数,即指定把数据存入哪个分片,因为父文档和子文档必须在同一个分片上,因此,在获取、删除或更新子文档时需要提供相同的路由值。
+- 每个索引只允许有一个 `join`类型的字段映射。
+- 一个元素可以有多个子元素但只有一个父元素。
+- 可以向现有连接字段添加新关系。
+- 也可以向现有元素添加子元素,但前提是该元素已经是父元素。
+
+### 参数
+
+当使用Elasticsearch的Join类型进行查询时,以下是一些常用的参数和选项:
+
+- `has_parent`和`has_child`:这两个查询参数用于在父子文档之间执行查询。您可以指定要匹配的父文档或子文档的类型以及具体的查询条件。
+- `parent_id`:用于指定要查询的子文档的父文档ID。通过指定`parent_id`参数,您可以快速检索与特定父文档相关联的所有子文档。
+- `inner_hits`:内部命中参数允许您在查询结果中获取与父文档或子文档匹配的内部命中结果。您可以使用`inner_hits`来检索与查询条件匹配的子文档或匹配的父文档及其关联的子文档。
+- `ignore_unmapped`:当设置为true时,如果查询字段不存在映射或没有任何匹配的文档时,将忽略该查询并返回空结果。
+- `max_children`:可用于限制每个父文档返回的子文档数量。
+
+这些只是一些常见的参数和选项,根据你的实际需求,还可以使用其他参数来进一步细化查询。请参考Elasticsearch官方文档以获取更详细的参数和用法信息。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md"
new file mode 100644
index 0000000..34e71d8
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Pipeline.md"
@@ -0,0 +1,251 @@
+在现代的数据处理和分析场景中,数据不仅需要被存储和检索,还需要经过各种复杂的转换、处理和丰富,以满足业务需求和提高数据价值。
+
+Elasticsearch Pipeline作为Elasticsearch中强大而灵活的功能之一,为用户提供了处理数据的机制,可以在数据索引之前或之后应用多种处理步骤,例如数据预处理、转换、清洗、分析等操作。
+
+## 使用场景
+
+Elasticsearch Pipeline 可以用于多种实际场景,其中包括但不限于:
+
+- 数据预处理:对原始数据进行清洗、标准化、去除噪声等操作,保证数据质量和一致性。
+- 数据转换:将数据转换为更加符合业务需求的形式,例如字段映射、格式转换、数据合并等。
+- 日志处理:实时日志数据的解析、提取关键信息、计算指标、数据聚合等操作。
+- 数据安全:对敏感数据进行脱敏处理、数据屏蔽、权限控制等操作,确保数据安全性。
+
+## 具体使用
+
+要实现Elasticsearch Pipeline功能,需要在节点上进行以下设置:
+
+1. **启用Ingest节点**:确保节点上已启用Ingest处理模块(默认情况下,每个节点都是Ingest Node),因为Pipeline是在Ingest处理阶段应用的。可以在elasticsearch.yml配置文件中添加以下设置来启用Ingest节点:
+
+ ```yaml
+ node.ingest: true
+ ```
+
+2. **配置Pipeline的最大值**:如果需要创建复杂的Pipeline或者包含大量处理步骤的Pipeline,可能需要调整默认的Pipeline容量限制。可以通过以下方式在elasticsearch.yml配置文件中设置Pipeline的最大值:
+
+ ```yaml
+ ingest.max_pipelines: 1000
+ ```
+
+3. **检查内存和资源使用**:确保节点具有足够的内存和资源来支持Pipeline的运行,避免因为资源不足而导致Pipeline执行失败或性能下降。
+
+对上述参数进行合理的配置后,就可以定义 Pipeline,并将其应用于索引文档了。
+
+下面是一个简单的示例代码,演示如何创建和使用Pipeline:
+
+**创建Pipeline**
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description" : "My custom pipeline",
+ "processors" : [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "example"
+ }
+ },
+ {
+ "uppercase": {
+ "field": "message"
+ }
+ }
+ ]
+}
+```
+
+上面的代码定义了一个名为 `my_pipeline` 的Pipeline,包含两个处理步骤:
+
+- `set` 处理器:将字段 `new_field` 设置为固定值 `example`。
+- `uppercase` 处理器:将字段 `message` 中的文本转换为大写。
+
+一个Elasticsearch Pipeline通常由以下几个主要部分组成:
+
+- **描述(Description)**:Pipeline的描述部分包含对Pipeline的简要说明或注释,用于帮助其他人理解该Pipeline的作用和功能。
+- **处理器(Processors)**:Pipeline的核心是处理器,处理器定义了对文档进行的具体处理步骤。每个处理器都执行特定的操作,例如设置字段值、重命名字段、转换数据、条件判断等。处理器按照在Pipeline中的顺序依次执行,以完成对文档的处理。
+- **条件(Conditions)**:可选部分,条件定义了触发Pipeline应用的条件。只有当条件满足时,Pipeline才会被应用到相应的文档上。条件可以基于文档内容、字段值、索引信息等进行判断。
+- **内置变量(Built-in Variables)**:在处理器中可以使用一些内置变量来引用文档数据或上下文信息,并在处理过程中进行操作。例如,`_index`表示当前文档所属的索引名称,`_ingest.timestamp`表示处理器执行的时间戳等。
+- **标签(Tags)**:可选部分,为Pipeline添加标签,用于标识和分类不同类型的Pipeline。
+
+这些部分共同构成了一个完整的Elasticsearch Pipeline,通过定义和配置这些部分,可以实现对文档数据的灵活处理和转换。
+
+**应用Pipeline**
+
+一旦Pipeline被定义,可以在索引文档时指定应用该Pipeline:
+
+```json
+POST my_index/_doc/1?pipeline=my_pipeline
+{
+ "message": "Hello, World!"
+}
+```
+
+## 异常处理
+
+在Elasticsearch Pipeline 中处理异常情况通常通过 `on_failure` 处理器来实现。下面是一个示例代码,演示如何使用 `on_failure` 处理器来处理异常情况:
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description": "Pipeline with error handling",
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "{{field_with_value}}"
+ }
+ },
+ {
+ "on_failure": [
+ {
+ "set": {
+ "field": "error_message",
+ "value": "{{_ingest.on_failure_message}}"
+ }
+ }
+ ]
+ }
+ ]
+}
+```
+
+在上面的示例中,定义了一个名为 `my_pipeline` 的 Pipeline,其中包含两个处理器:
+
+- 第一个处理器使用 `set` 处理器来设置一个新的字段 `new_field` 的值为另一个字段 `field_with_value` 的值。
+- 第二个处理器是一个 `on_failure` 处理器,在前一个处理器执行失败时会被触发。这里使用 `on_failure_message` 变量来获取失败的原因,并将其设置到一个新的字段 `error_message` 中。
+
+当第一个处理器执行失败时,第二个处理器会被触发,并将失败信息存储到 `error_message` 字段中,以便后续处理或记录日志。这样可以帮助我们更好地处理异常情况,确保数据处理的稳定性。
+
+如果是Pipeline级别的错误,可以通过全局设置`on_failure`来处理整个Pipeline执行过程中的异常情况:
+
+```json
+PUT _ingest/pipeline/my_pipeline
+{
+ "description": "Pipeline with global error handling",
+ "on_failure": [
+ {
+ "set": {
+ "field": "error_message",
+ "value": "{{_ingest.on_failure_message}}"
+ }
+ }
+ ],
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "{{field_with_value}}"
+ }
+ }
+ ]
+}
+```
+
+在上述示例中,Pipeline `my_pipeline` 中定义了一个全局的`on_failure`处理器,在整个Pipeline执行过程中发生异常时会触发。当任何处理器执行失败时,全局`on_failure`处理器将被调用,并将失败消息存储到`error_message`字段中。
+
+通过设置全局的`on_failure`处理器,可以统一处理整个Pipeline中任何处理器可能出现的异常情况,提高数据处理的稳定性和可靠性。这样即便是Pipeline级别的错误,也能得到有效的处理和记录,帮助排查问题并保证数据处理流程的正常运行。
+
+## 为索引设置默认Pipeline
+
+从 Elasticsearch 6.5.x 开始,引入了一个名为 index.default_pipeline 的新索引设置。 这仅仅意味着所有摄取的文档都将由默认管道进行预处理:
+
+```json
+PUT my_index
+{
+ "settings": {
+ "default_pipeline": "add_last_update_time"
+ }
+}
+```
+
+## 内置Processors
+
+Elasticsearch内置的Processors提供了各种功能,用于在Ingest Pipeline中对文档进行处理。以下是一些常用的内置Processors及其作用:
+
+- **Set Processor**:设置字段的固定值或通过表达式计算值。
+- **Grok Processor**:解析文本字段并提取结构化数据。
+- **Date Processor**:解析日期字段。
+- **Convert Processor**:转换字段类型。
+- **Remove Processor**:删除指定字段。
+- **Split Processor**:根据分隔符拆分字段。
+- **GeoIP Processor**:根据IP地址查找地理位置信息。
+- **User Agent Processor**:解析User-Agent字段。
+
+## Pipeline API
+
+,以下是有关Elasticsearch Pipeline API的简要介绍和示例代码:
+
+- **Put Pipeline API**:用于创建或更新Pipeline。
+
+ ```json
+ PUT /_ingest/pipeline/my_pipeline
+ {
+ "description": "My custom pipeline",
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "default"
+ }
+ }
+ ]
+ }
+ ```
+
+- **Get Pipeline API**:用于获取Pipeline的信息。
+
+ ```json
+ GET /_ingest/pipeline/my_pipeline
+ ```
+
+- **Delete Pipeline API**:用于删除Pipeline。
+
+ ```json
+ DELETE /_ingest/pipeline/my_pipeline
+ ```
+
+- **Simulate Pipeline API**:用于模拟Pipeline对文档的处理效果。
+
+ ```json
+ POST /_ingest/pipeline/_simulate
+ {
+ "pipeline": {
+ "processors": [
+ {
+ "set": {
+ "field": "new_field",
+ "value": "default"
+ }
+ }
+ ]
+ },
+ "docs": [
+ {
+ "_source": {
+ "my_field": "my_value"
+ }
+ }
+ ]
+ }
+ ```
+
+- **Manage Pipelines in Index Templates**:可以在索引模板中定义Pipeline。
+
+ ```json
+ PUT /_index_template/my_template
+ {
+ "index_patterns": ["my_index*"],
+ "composed_of": ["my_pipeline"],
+ "priority": 1
+ }
+ ```
+
+## 使用建议
+
+在使用Elasticsearch Pipeline时,有几点建议可以帮助提高效率和准确性:
+
+- **测试和验证**:在应用Pipeline之前,务必进行充分的测试和验证,确保处理步骤的准确性和稳定性。
+- **监控和调优**:定期监控Pipeline的性能和效果,根据实际情况进行调优和优化,以提高数据处理和索引效率。
+- **复用Pipeline**:针对相似的数据处理需求,可以设计通用的Pipeline,以便在多个索引中重复使用,提高代码复用性和维护性。
+- **合理使用条件**:根据具体需求选择合适的条件触发Pipeline的应用,避免不必要的处理过程,提高系统性能。
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md"
new file mode 100644
index 0000000..f8972f1
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-Query DSL.md"
@@ -0,0 +1,556 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+DSL是Domain Specific Language的缩写,指的是为特定问题领域设计的计算机语言。这种语言专注于某特定领域的问题解决,因而比通用编程语言更有效率。
+
+在Elasticsearch中,DSL指的是Elasticsearch Query DSL,是一种以JSON形式表示的查询语言。通过这种语言,用户可以构建复杂的查询、排序和过滤数据等操作。这些查询可以是全文搜索、聚合搜索,也可以是结构化的搜索。
+
+## 查询上下文
+
+搜索是Elasticsearch中最关键和重要的部分,使用`query`关键字进行检索,更倾向于相关度搜索,故需要计算评分。
+
+在查询上下文中,一个查询语句表示一个文档和查询语句的匹配程度。无论文档匹配与否,查询语句总能计算出一个相关性分数在`_score`字段上。
+
+### 相关度评分:score
+
+相关度评分用于对搜索结果排序,评分越高则认为其结果和搜索的预期值相关度越高,即越符合搜索预期值,默认情况下评分越高,则结果越靠前。在7.x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25。
+
+score是根据各种因素计算出来的,包括:
+
+- **Term Frequency(词频)**:一个词在文档中出现的次数越多,score就越高。
+- **Inverse Document Frequency(逆文档频率**):一个词在所有文档中出现的次数越少,score就越高。
+- **Field Length Norm(字段长度规范**):字段的长度越短,score就越高。
+
+这三个因素共同决定了score的值。然而,你也可以通过设置自定义评分或者禁用评分来影响score的计算。
+
+#### TF/IDF & BM25
+
+TF/IDF是一种在信息检索和文本挖掘中广泛使用的统计方法,用于评估一个词语对于一个文件集或一个语料库中的一个文件的重要程度。名称中的TF表示“术语频率”,IDF表示“逆向文件频率”。
+
+- **TF (Term Frequency)** :这是衡量词在文档中出现的频率。通常来说,一个词在文档中出现的次数越多,其重要性就可能越大。但这并不总是正确的,比如在很多英文文档中,“the”、“and”等词出现的频率非常高,但我们并不能因此认为它们就非常重要。因此,需要结合 IDF 来使用。
+- **IDF (Inverse Document Frequency)** :这是衡量词是否常见的度量。如果某个词在许多文档中都出现,那么它可能并不具有区分性,对于搜索和分类的帮助就不大。例如,每篇英文文章中都会出现的“the”对于区分文章内容就没有什么帮助。所以,如果一个词在所有文档中出现得越多,那么其 IDF 值就会越小,相反,如果一个词很少在文档中出现,那么其 IDF 值就会较大。
+
+TF-IDF 会将这两个因子结合起来,为每个词产生一个权重。具有较高 TF-IDF 分数的词被认为在文档中更重要。通过这种方式,ES 能够提供相关性排序,使得包含用户查询词汇的最相关文档排在搜索结果的前面。
+
+BM25是一种更先进的排名函数,也是基于TF/IDF的一种改进型方法。它引入了两个新概念:
+
+- **文档长度归一化**:长文档可能会有更多的关键词,但这并不意味着它与查询更相关。BM25通过调整文档长度来解决这个问题。
+- **饱和度**:在TF/IDF中,词项的出现频率越高,其重要性就越大。然而在实践中,一旦一个词在文档中出现过,再次出现时增加的相关性可能会降低。BM25通过设置一个饱和点来解决这个问题,超过这个点,词的权重增加就会变得不那么敏感。
+
+总结而言,BM25是TF/IDF的改进版,通过文档长度归一化和频率饱和度控制来优化搜索结果。
+
+### 源数据:source
+
+`_source`字段包含索引时原始的JSON文档内容,字段本身不建立索引(因此无法进行搜索),但是会被存储,所以当执行获取请求是可以返回`_source`字段。
+
+虽然很方便,但是`_source`字段的确会对索引产生存储开销,你可以通过关闭`_source`字段来节省空间,但这通常不建议,因为有了原始数据,我们可以对数据进行重新索引,并且在获取数据时也更加灵活。
+
+如果你禁用了`_source`字段,那么会有以下几个影响:
+
+- **无法获取原始数据**:当你查询某个文档时,你将无法获取到原始的`_source`字段内容,因为它没有被存储在Elasticsearch中。
+- **更新和重新索引的问题**:如果你想更新文档或者执行重新索引操作,可能会遇到问题,因为这两种操作都需要原始的`_source`字段。
+- **脚本字段和某些Aggregations可能受到影响**:如果你正在使用脚本字段或者依赖`_source`字段的Aggregations,那么禁用`_source`可能导致这些特性出问题。
+
+下面是一些使用`_source`字段的例子:
+
+
+
+1. 在索引文档时启用/禁用`_source`:
+
+```json
+PUT my_index
+{
+ "mappings": {
+ "_source": {
+ "enabled": false
+ },
+ "properties": {
+ "field1": { "type": "text" }
+ }
+ }
+}
+```
+
+在这个例子中,新创建的`my_index`索引将不会存储`_source`字段。
+
+
+
+2. 获取文档的`_source`字段:
+
+```json
+GET /my_index/_doc/1
+```
+
+返回的结果中会包含`_source`字段。
+
+
+
+3. 在获取文档时只获取`_source`字段中特定的字段:
+
+```json
+GET /my_index/_doc/1?_source=field1,field2
+```
+
+在这个例子中,返回的`_source`字段只包含`field1`和`field2`。
+
+
+
+注意:`_source`字段并不用于搜索,禁用`_source`字段不会影响你的搜索结果。
+
+## 源数据过滤
+
+假设你的应用只需要获取部分字段(如"name"和"price"),而其他字段(如"desc"和"tags")不经常使用或者数据量较大,导致传输和处理这些额外的数据会增加网络开销和处理时间。在这种情况下,通过设置`includes`和`excludes`可以有效地减少每次请求返回的数据量,提高效率。
+
+例如:
+
+```JSON
+PUT product
+{
+ "mappings": {
+ "_source": {
+ "includes": ["name", "price"],
+ "excludes": ["desc", "tags"]
+ }
+ }
+}
+```
+
+**Including**:结果中返回哪些field。
+
+**Excluding**:结果中不要返回哪些field,Excluding优先级比Including更高。
+
+> 需要注意的是,尽管这些设置会影响搜索结果中_source字段的内容,但并不会改变实际存储在Elasticsearch中的数据。也就是说,"desc"和"tags"字段仍然会被索引和存储,只是在获取源数据时不会被返回。
+
+上述这种在mapping中定义的方式不推荐,因为mapping不可变。我们可以在查询过程中指定返回的字段,如下:
+
+```JSON
+GET product/_search
+{
+ "_source": {
+ "includes": ["owner.*", "name"],
+ "excludes": ["name", "desc", "price"]
+ },
+ "query": {
+ "match_all": {}
+ }
+}
+```
+
+Elasticsearch的`_source`字段在查询时支持使用通配符(wildcards)来包含或排除特定字段。使得能够更灵活地操纵返回的数据。
+
+关于规则,可以参考以下几点:
+
+- *:匹配任意字符序列,包括空序列。
+- ?:匹配任意单个字符。
+- [abc]: 匹配方括号内列出的任意单个字符。例如,[abc]将匹配"a", "b", 或 "c"。
+
+请注意,通配符表达式可能会导致查询性能下降,特别是在大型索引中,因此应谨慎使用。
+
+## 全文检索
+
+全文检索是Elasticsearch的核心功能之一,它可以高效地在大量文本数据中寻找特定关键词。
+
+在Elasticsearch中,全文检索主要依靠两个步骤:"分析"(Analysis)和"查询"(Search)。
+
+- **分析**: 当你向Elasticsearch插入一个文档时,会进行"分析"处理,将原始文本数据转换成称为"tokens"或"terms"的小片段。这个过程可能包括如下操作:
+ - 切分文本(Tokenization)
+ - 将所有字符转换为小写(Lowercasing)
+ - 删除常见但无重要含义的单词(Stopwords)
+ - 提取词根(Stemming)
+- **查询**:当执行全文搜索时,查询字符串也会经过类似的分析过程,然后再与已经分析过的数据进行比对,找出匹配的结果并返回。
+
+Elasticsearch提供了许多种全文搜索的查询类型,例如:
+
+- **Match Query**:最基本的全文搜索查询。
+- **Match Phrase Query**:用于查找包含特定短语的文档。
+- **Multi-Match Query**:类似Match Query,但可以在多个字段上进行搜索。
+- **Query String Query**:提供了丰富的搜索语法,可以执行复杂的、灵活的全文搜索。
+
+### match:匹配包含某个term的子句
+
+`match` 查询是 Elasticsearch 中的一种全文查询方式,它包括标准分析和词项搜索。尽管它可以应用于精确字段,但其主要用途是进行全文搜索。当与全文字段一起使用时,match 查询可以解析查询字符串,并执行短语查询或者构建一个布尔查询,这意味着它会考虑字段中的每个单词。
+
+下面有一个简单的 `match` 查询示例:
+
+```json
+GET /_search
+{
+ "query": {
+ "match": {
+ "message": "this is a test"
+ }
+ }
+}
+```
+
+在这个示例中,Elasticsearch 会在 "message" 字段中搜索包含 "this"、"is"、"a" 和 "test" 的文档。
+
+请注意,`match` 查询不仅仅会匹配完全相同的短语,它还可以处理更复杂的情况,如多个单词(它会匹配任何一个)、误拼、同义词等,这主要取决于你所使用的分析器和搜索设置。
+
+`match` 查询还有一些其他参数,例如:
+
+- **operator**:定义多个搜索词之间的关系,默认为 `or`。如果设为 `and`,则返回的文档必须包含所有搜索词。
+- **minimum_should_match**:控制返回的文档应至少匹配的搜索词的数量或比例。
+- **fuzziness**:允许模糊匹配,可以找到那些拼写错误或接近的词汇。
+
+### match_all:匹配所有结果的子句
+
+`match_all`是Elasticsearch中的一个查询类型,用于获取索引中的所有文档。
+
+这是一个`match_all`查询的基本示例:
+
+```json
+{
+ "query": {
+ "match_all": {}
+ }
+}
+```
+
+在上述示例中,我们可以看到查询对象中存在一个"match_all"字段,其值是一个空对象。这表示我们希望匹配所有文档。
+
+需要注意,由于 `match_all` 查询可能返回大量的数据,所以一般在使用时都会与分页(pagination)功能结合起来,这样可以控制返回结果的数量,避免一次性加载过多数据导致的性能问题。例如,你可以使用 `from` 和 `size` 参数来限制返回结果:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "match_all": {}
+ },
+ "from": 10,
+ "size": 10
+}
+```
+
+Elasticsearch的 `match_all` 查询是最简单的查询,它不需要任何参数,但如果你想为它添加权重,可以使用 `boost` 参数。例如:
+
+```json
+GET /_search
+{
+ "query": {
+ "match_all": { "boost" : 1.2 }
+ }
+}
+```
+
+在上面的查询中,`boost` 参数被设置为1.2,给匹配到的所有文档增加了额外的相关性得分提升。
+
+### multi_match:多字段条件
+
+`multi_match` 可以用来在多个字段上进行全文搜索。它接受一个查询字符串和一组需要在其中执行查询的字段列表。
+
+例如:
+
+```json
+{
+ "query": {
+ "multi_match" : {
+ "query": "这是测试",
+ "fields": [ "field1", "field2" ]
+ }
+ }
+}
+```
+
+在此示例中,查询字符串"这是测试"将在字段"field1"和"field2"中搜索。
+
+`multi_match`查询也支持使用通配符(*)来匹配多个字段:
+
+```json
+{
+ "query": {
+ "multi_match" : {
+ "query": "这是测试",
+ "fields": [ "*_name" ]
+ }
+ }
+}
+```
+
+在这个例子中,会在所有以"_name"结尾的字段中进行搜索。
+
+此外,`multi_match` 查询还支持许多参数,包括:
+
+- **type**:设置查询类型,可选值包括:`best_fields`, `most_fields`, `cross_fields`, `phrase`, `phrase_prefix` 等。
+
+例如,“best_fields” 类型会从指定的字段中挑选分数最高的匹配结果计算最终得分,而“most_fields” 类型则会在每个字段中都寻找匹配项并将其分数累加起来。
+
+- **tie_breaker**:当一个词在多个字段中找到时,用于决定最终得分的参数。
+- **minimum_should_match**:用于控制应匹配的最小子句数。
+- **operator**:主要有两个操作符 `OR` 和 `AND`,默认为 `OR`。
+
+需要注意的是,当使用 `multi_match` 查询时,如果字段不同,其权重可能也会不同。你可以通过在字段名后面添加尖括号(^)和权重值来调整特定字段的权重。例如,`"fields": [ "name^3", "description" ]`表示在"name"字段中的匹配结果权重是"description"字段的三倍。
+
+### match_phrase:短语查询
+
+`match_phrase` 用于精确匹配包含指定短语的文档。match_phrase 查询需要字段值中的单词顺序与查询字符串中的单词顺序完全一致。
+
+例如:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "match_phrase": {
+ "message": "this is a test"
+ }
+ }
+}
+```
+
+这个查询将会找到"message"字段中包含完整短语"this is a test"的所有文档。
+
+此外,`match_phrase` 查询还有一个 `slop` 参数,可以定义词组中的词语可能存在的位置偏移量。例如,如果将 `slop` 设置为 1,则查询 "this is a test" 也可匹配 "this is test a",因为 "a" 和 "test" 只需移动一个位置即可匹配。
+
+```json
+GET /_search
+{
+ "query": {
+ "match_phrase": {
+ "query": "this is a test",
+ "slop": 2
+ }
+ }
+}
+```
+
+请注意,`match_phrase` 查询需要整个短语完全匹配,而不仅仅是查询中的所有单词都存在。如果你只是希望所有单词都存在,而不关心它们的顺序或精确出现方式,那么你应该使用 `match` 查询。
+
+## Term Query
+
+精确查询用于查找包含指定精确值的文档,而不是执行全文搜索。
+
+### term:匹配和搜索词项完全相等的结果
+
+`term` 查询主要用于查询某个字段完全匹配给定值的文档。这对精确匹配非常有效,例如数字、布尔值或者字符串。
+
+用法示例:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "term" : { "user" : "Kimchy" }
+ }
+}
+```
+
+在这个例子中,我们正在搜索"user"字段中完全匹配"Kimchy"的文档。
+
+需要注意的是,`term` 查询对于分析过的字段(例如,文本字段)可能不会像你预期的那样工作,因为它会搜索精确的词汇项,而不是单词。如果你想要对文本字段进行全文搜素,应该使用 `match` 查询。
+
+另外一个需要注意的点就是 `term` 查询对大小写敏感,所以 "Kimchy" 和 "kimchy" 是两个不同的词条。
+
+#### term和match_phrase的区别
+
+`term` 查询和 `match_phrase` 查询是 Elasticsearch 提供的两种查询方式,它们都用于查找文档,但主要的区别在于如何解析查询字符串以及匹配的精确度。
+
+- **term**:这个查询做的是精确匹配。当你使用`term`查询时,Elasticsearch会查找完全等于你指定的词汇的文档。例如,如果你搜索`term` "apple",那么只有包含完全为"apple"的文档会被匹配到,而包含"apples"或"APPLE"的文档则不会被匹配到。因此,`term`查询对大小写敏感,且不会进行任何形式的分析(如停用词移除、词干提取等)。
+- **match_phrase**:这个查询是用来匹配一系列词汇或者短语的。`match_phrase`查询会保证你查询的词汇必须以你提供的顺序完全匹配。比如,如果你使用`match_phrase`查询 "quick brown fox",那么只有包含这个完整短语的文档才会被匹配到,单独包含"quick"、"brown"或者"fox"的文档则不会被匹配到。此外,与`term`查询不同,`match_phrase`查询会进行文本分析,这意味着它会考虑词汇的大小写、复数形式等。
+
+总结来说,`term`查询更适合精确匹配,而`match_phrase`查询更适合短语匹配。但是,`match_phrase`并不能100%保证精确匹配,因为它会处理和考虑文本的各种变体(比如,大小写、单复数形式等)。
+
+### terms:匹配和搜索词项列表中任意项匹配的结果
+
+`terms` 查询用于匹配指定字段中包含一个或多个值的文档。这是一个精确匹配查询,不会像全文查询那样对查询字符串进行分析。
+
+假设你有一个 "user" 的字段,并且你想找到该字段值为 "John" 或者 "Jane" 的所有文档,你可以使用 `terms` 查询:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "terms" : {
+ "user" : ["John", "Jane"],
+ "boost" : 1.0
+ }
+ }
+}
+```
+
+上面的查询将返回所有"user" 字段等于 "John" 或者 "Jane" 的文档。
+
+其中`boost` 参数用于增加或减少特定查询的相对权重。它将改变查询结果的相关性分数(_score),以影响最终结果的排名。
+
+例如,在上述 `terms` 查询中,`boost` 参数被设置为 1.0。这意味着如果字段 "user" 的值包含 "John" 或 "Jane",那么其相关性分数(_score)就会乘以 1.0。因此,这个设置实际上并没有改变任何东西,因为乘以 1 不会改变原始分数。但是,如果你将 `boost` 参数设置为大于 1 的数,那么匹配的文档的 _score 将会提高,反之则会降低。
+
+## Range:范围查找
+
+Range查询允许我们查找某个范围内的值。假设我们有一个商品表,其中有商品价格字段,我们可以用range查询来查找价格在一定范围内的商品。
+
+以下是一个基础的范围查询的例子:
+
+```json
+GET /products/_search
+{
+ "query": {
+ "range" : {
+ "price" : {
+ "gte" : 10,
+ "lte" : 20,
+ "boost" : 2.0
+ }
+ }
+ }
+}
+```
+
+在这个例子中,我们正在查询价格大于或等于(gte)10且小于或等于(lte)20的所有商品。"boost"参数表示增加该查询的重要性。
+
+Range查询支持以下参数:
+
+- **gte**:大于或等于。
+- **lte**:小于或等于。
+- **gt**:大于。
+- **lt**:小于。
+- **boost**:增加查询的重要性。
+
+此外,对于日期类型的字段,你还可以使用如下方式进行范围查询:
+
+```json
+{
+ "query": {
+ "range" : {
+ "timestamp" : {
+ "gte" : "now-1d/d",
+ "lt" : "now/d"
+ }
+ }
+ }
+}
+```
+
+在上述查询中,我们正在查找过去24小时内的数据。"now-1d/d"表示从现在算起的一天前,而"now/d"表示当前时间。
+
+## Filter
+
+过滤器(Filter)是用于筛选数据的一种工具。过滤器和查询(query)相似,但有几个重要的区别:
+
+- **过滤不关心文档的相关度得分(relevance score)**:查询会为每个匹配的文档计算一个相关度得分,以决定返回结果的排序。相比之下,过滤器只关心文档是否匹配 - 没有“部分匹配”,只有“匹配”或“不匹配”。
+- **过滤器可以被缓存**:由于过滤器不需要计算得分,因此它们的结果可以被缓存起来用于之后的搜索请求,这可以大大提高性能。
+
+常见的过滤器类型包括:`term`、`terms`、`range`、`bool`、`match_all` 等。例如,范围过滤器 `range` 可以用于查找数字或日期字段在指定范围内的文档;布尔过滤器 `bool` 则允许你组合多个过滤器,并定义它们如何互相交互。
+
+使用过滤器时,通常会把它们放在 `bool` 查询的 `filter` 子句中。例如:
+
+```json
+{
+ "query": {
+ "bool": {
+ "filter": [
+ { "term": { "status": "active" }},
+ { "range": { "age": { "gte": 30, "lte": 40 }}}
+ ]
+ }
+ }
+}
+```
+
+这个查询会返回所有“状态为 active 并且年龄在 30 到 40 之间”的文档,而不会考虑它们的相关度得分。
+
+### Filter缓存机制
+
+在 Elasticsearch 中,过滤查询结果的缓存机制是非常重要的一个性能优化手段。由于过滤器(filter)只关心是否匹配,而不关心评分 (_score),因此它们的结果可以被缓存以提高性能。
+
+每次 filter 查询执行时,Elasticsearch 都会生成一个名为 "bitset" 的数据结构,其中每个文档都对应一个位(0 或 1),表示这个文档是否与 filter 匹配。这个 bitset 就是被存储在缓存中的部分。
+
+如果相同的 filter 查询再次执行,Elasticsearch 可以直接从缓存中获取这个 bitset,而不需要再次遍历所有的文档来找出哪些文档符合这个 filter。这大大提高了查询速度,并减少了 CPU 使用。
+
+这种缓存策略特别适合那些重复查询的场景,例如用户界面的过滤器和类似的功能,因为他们通常会产生很多相同的 filter 查询。
+
+然而,值得注意的是,虽然这种缓存可以显著改善查询性能,但也会占用内存空间。如果你有很多唯一的过滤条件,那么过滤器缓存可能会变得很大,从而导致内存问题。这就需要你对使用的过滤器进行适当的管理和限制。
+
+Filter缓存功能会遵循以下原则:
+
+- **同一Filter的多次应用**:如果在后续查询中有多次使用相同的Filter,则ES会把第一次查询的结果储存在缓存中,后续的查询将直接从缓存中获取结果,而不再做任何磁盘I/O或者其他计算。
+- **根据需求清理缓存**:ES会根据内存使用情况自动清理缓存,当然你也可以手动清空缓存。但这并不意味着我们无限制地依赖Filter缓存,大量的缓存可能导致更重的GC压力。
+- **不缓存复杂查询**:一些查询条件较复杂的过滤器可能不会被缓存,比如script filter、geo filter等。这是因为这些过滤器本身的构建和维护成本可能就超过了查询的计算成本。
+
+ES的Filter缓存机制可以大大提高查询效率,但如果不慎用,比如缓存过多或者不适合缓存的查询,可能会对性能产生负面影响。因此,在设计和优化ES查询时,应当充分考虑Filter的使用和缓存策略。
+
+## Bool Query
+
+Bool Query(组合查询)可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
+
+
+
+`boost`和`minumum_should_match`是参数,其他四个都是查询子句。
+
+- **must**:必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分。
+- **filter**:过滤器不计算相关度分数。
+- **should**:满足 or子句(查询)应出现在匹配的文档中。
+- **must_not**:必须不满足,不计算相关度分数 ,not子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。
+
+例子1:下面的语句表示:包含"xiaomi"或"phone" 并且包含"shouji"的文档例子:
+
+```JSON
+GET product/_search
+{
+ "query": {
+ "bool": {
+ "must": [
+ {
+ "match": {
+ "name": "xiaomi phone"
+ }
+ },
+ {
+ "match_phrase": {
+ "desc": "shouji"
+ }
+ }
+ ]
+ }
+ }
+}
+```
+
+### should与must或filter一起使用
+
+当 `should` 子句与 `must` 或 `filter` 子句一起使用时,这时候需要注意了。
+
+只要满足了 `must` 或 `filter` 的条件,`should` 子句就不再是必须的。换句话说,如果存在一个或者多个 `must` 或 `filter` 子句,那么 `should` 子句的条件会被视为可选。
+
+然而,如果 `should` 子句与 `must_not` 子句单独使用(也就是没有 `must` 或 `filter`),则至少需要满足一个 `should` 子句的条件。
+
+这里有一个例子来说明:
+
+```JSON
+GET /_search
+{
+ "query": {
+ "bool": {
+ "must": [
+ { "term": { "user": "kimchy" }}
+ ],
+ "filter": [
+ { "term": { "tag": "tech" }}
+ ],
+ "should": [
+ { "term": { "tag": "wow" }},
+ { "term": { "tag": "elasticsearch" }}
+ ]
+ }
+ }
+}
+```
+
+在这个查询中,`must` 和 `filter` 子句的条件是必须满足的,而 `should` 子句的条件则是可选的。如果匹配的文档同时满足 `should` 子句的条件,那么它们的得分将会更高。
+
+那如果我们一起使用的时候想让should满足该怎么办?这时候`minimum_should_match` 参数就派上用场了。
+
+### minimum_should_match
+
+`minimum_should_match`参数定义了在 `should` 子句中至少需要满足多少条件。
+
+例如,如果你有5个 `should` 子句并且设置了 `"minimum_should_match": 3`,那么任何匹配至少三个 `should` 子句的文档都会被返回。
+
+这个参数可以接收绝对数值(如 `2`)、百分比(如 `30%`)、和组合(如 `3<90%` 表示至少匹配3个或者90%,取其中较大的那个)等不同类型的值。
+
+注意:如果 `bool` 查询中只有 `should` 子句(没有 `must` 或 `filter`),那么默认情况下至少需要匹配一个 `should` 条件,也就是`minimum_should_match`默认值是1,除非 `minimum_should_match` 明确设定为其他值。如果包含 `must` 或 `filter`的情况下`minimum_should_match`默认值 0。
+
+所以我们可以在包含`must` 或 `filter`的情况下,设置`minimum_should_match`值来满足`should`子句中的条件。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md"
new file mode 100644
index 0000000..ce47872
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\216\237\347\220\206.md"
@@ -0,0 +1,178 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES作为一款开源的分布式搜索和分析引擎,以其卓越的性能和灵活的扩展性而备受青睐。
+
+在实际应用中,如何最大限度地发挥ES的写入能力并保证数据的一致性和可靠性仍然是一个值得关注的话题。
+
+接下来,我们将深入了解ES的写入过程和原理。
+
+## 写入过程
+
+### 写操作
+
+ES支持四种对文档的数据写操作:
+
+- **create**:如果在PUT数据的时候当前数据已经存在,则数据会被覆盖。如果在PUT的时候加上操作类型create,此时如果数据已存在,则会返回失败,因为已经强制指定了操作类型为create,ES就不会再去执行update操作。
+- **delete**:删除文档,ES对文档的删除是懒删除机制,即标记删除,会被记录在 `.del`文件中。在后续的合并(merge)过程中,Elasticsearch会根据一定的条件和策略,将包含已删除文档的分段进行合并。在合并期间,`.del` 文件中的已删除文档将被完全删除,从而释放磁盘空间。
+- **index**:在ES中,写入操作被称为Index,这里Index为动词,即索引数据,为数据创建在ES中的索引。
+- **update**:执行partial update(全量更新,部分更新)。PUT是全量更新,POST是部分更新。
+
+### 写流程
+
+**ES中的数据写入均发生在 Primary Shard,当数据在 Primary Shard 写入完成之后会同步到相应的 Replica Shard**
+
+下图演示了单条数据写入ES的流程:
+
+
+
+以下为数据写入的步骤:
+
+1. 客户端发起写入请求至node-4。
+2. node-4通过文档 id 在路由表中的映射信息确定当前数据的位置在分片0,分片0的主分片位于node-5,并将数据转发至node-5。
+3. 数据在node-5写入,写入成功之后将数据的同步请求转发至其副本所在的node-4和node-6上面,等待所有副本数据写入成功之后,node-5将结果报告node-4,并由node-4将结果返回给客户端,报告数据写入成功。
+
+在这个过程中,接收用户请求的节点是不固定的,上述例子中,node-4 发挥了协调节点和客户端节点的作用,将数据转发至对应节点和接收以及返回用户请求。
+
+数据在由 node-4 转发至 node-5的时候,是通过以下公式来计算指定的文档具体在哪个分片的:
+
+```json
+shard_num = hash(_routing) % num_primary_shards
+```
+
+其中,`_routing` 的默认值就是文档的 id。
+
+### 写一致性策略
+
+ES 5.x 之后,一致性策略由 `wait_for_active_shards` 参数控制。
+
+ `wait_for_active_shards` 即确定客户端返回数据之前必须处于 active 的分片数(包括主分片和副本),默认值为1,即只需要主分片写入成功。
+
+最大值为 `number_of_replicas + 1` ,可以设置为 `all`或任何正整数。如果当前 active 状态的分片没有达到设定阈值,写操作必须等待并且重试,默认等待时间30秒,直到 active 状态的副本数量超过设定的阈值或者超时返回失败为止。
+
+假设我们有一个由A、B、C三个节点组成的集群。并且我们创建了一个index副本数设置为3的索引(此时共4个分片数据,比节点数多一个)。
+
+如果我们尝试索引操作,默认情况下,该操作只会确保每个主分片的主副本在继续之前可用。这意味着即使B和c出现故障被A托管主分片,索引操作仍将仅使用数据的一个副本进行。
+
+如果`wait_for_active_shards`设置为3(并且所有3个节点都已启动),那么索引操作将需要3个活动分片才能继续进行,因为集群中有3个活动节点,每个节点都持有一个活跃,所以满足这一要求。
+
+但是,如果我们设置`wait_for_active_shards`为all(或设置为4),数据写入将直接失败,因为集群此时根本不可能有四个活跃的分片。
+
+除非在集群中启动一个新节点来托管分片的第四个分片,否则该操作将超时。
+
+## 写入原理
+
+### Refresh
+
+ES中数据并不是直接写到文件系统缓存里的,在内部ES开辟了名为:`Memory Buffer`的缓存区。
+
+Memory Buffer的性能非常高,客户端发出写入请求的时候是直接写在Memory Buffer里的。
+
+**Memory Buffer的空间阈值默认大小为堆内存的10%,时间阈值为1s。空间阈值和时间阈值只要达成任意一个,就会触发 Refresh操作**
+
+也可以调用 Refresh API 来人工触发 Refresh 操作:
+
+```json
+POST /_refresh
+
+GET /_refresh
+
+POST /_refresh
+
+GET /_refresh
+```
+
+Refresh 操作会将缓存中的数据生成一个个 segment 文件。
+
+原理见下图:
+
+
+
+内存索引缓冲区中的文档被写入新段,新段首先写入文件系统缓存(这个过程性能消耗很低),然后才刷新到磁盘(这个过程代价很高)。但是,在文件进入缓存后,它就可以像任何其他文件一样被打开和读取。
+
+
+
+Lucene 允许写入和打开新的段,使它们包含的文档对搜索可见,而无需执行完整的提交。这是一个比提交到磁盘更轻松的过程,并且可以经常执行而不会降低性能。
+
+
+
+这个写入和打开新段的过程即被称为 **Refresh** 。刷新使自上次刷新以来对索引执行的所有操作都可用于搜索。
+
+`index.refresh_interval`参数可以设置多久执行一次刷新操作,默认为 `1s`,可以设置 `-1` 禁用刷新。
+
+并不是所有的情况都需要每秒刷新。比如 Elasticsearch 索引大量的日志文件,此时并不需要太高的写入实时性, 可以增大刷新间隔来降低每个索引的刷新频率,从而降低因为实时性而带来的性能开销,进而提升检索效率。
+
+```json
+POST
+{
+ "settings": {
+ "refresh_interval": "30s"
+ }
+}
+```
+
+**需要注意的是,虽然此时数据能被查询到,但还没落到磁盘中,数据仍然是不安全的**
+
+### Merge
+
+由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数量太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段,所以段越多,搜索也就越慢。
+
+Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
+
+
+
+Elasticsearch 中的一个 shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,并删除较小的段。
+
+
+
+**Merge是非常消耗资源的,Refesh的频率越高,生成Segment的频率就越高,Merge就执行的越频繁**
+
+合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
+
+### Flush
+
+Flush 是确保当前存储在 Translog 中的数据也永久存储在 Lucene 索引中的过程。
+
+重新启动时,Elasticsearch 会将所有未刷新的操作从 Translog 重播到 Lucene 索引,以使其恢复到重新启动前的状态。Elasticsearch 会根据需要自动触发Flush,使用启发式算法来权衡未刷新事务日志的大小与执行每次刷新的成本。
+
+一旦操作被刷新,它就会永久存储在 Lucene 索引中。这可能意味着不需要在事务日志中维护它的额外副本。事务日志由多个文件组成,称为 generation ,一旦不再需要,Elasticsearch 将删除相应的文件,从而释放磁盘空间。
+
+也可以使用 Flush API 触发一个或多个索引的刷新,尽管用户很少需要直接调用此 API。如果您在索引某些文档后调用刷新 API,并成功响应,表明 Elasticsearch 已刷新在调用刷新 API 之前索引的所有文档。
+
+```json
+POST /my_index/_flush
+```
+
+请注意,手动调用刷新操作可能会对系统性能产生一定的影响,因为它涉及到磁盘写入和索引更新。建议在必要时使用手动刷新操作,而不是频繁地调用。
+
+### Translog
+
+对索引的修改操作会在 Lucene 执行 commit 之后真正持久化到磁盘,这个过程是非常消耗资源的,因此不可能在每次索引操作或删除操作后执行。Lucene 提交的成本太高,无法对每个单独的更改执行,因此每个分片副本先将操作写入其事务日志,也就是 Translog。
+
+所有索引和删除操作在被内部 Lucene 索引处理之后,但在它们被确认之前写入到 translog。如果发生崩溃,当分片恢复时,已确认但尚未包含在最后一次 Lucene 提交中的最近操作将从 translog 中恢复。
+
+ES的 Flush 是 Lucene 执行 commit 并开始写入 translog 的过程,Flush 是在后台自动执行的,translog 中的数据仅在 translog 被执行 `fsync` 和 `commit` 时才会持久化到磁盘。如果发生硬件故障或操作系统崩溃或 JVM 崩溃或分片故障,自上次 translog 提交以来写入的任何数据都将丢失。
+
+以下参数可控制 translog 的行为:
+
+- `index.translog.sync_interval`:无论写入操作如何,translog 默认每隔 5s 被 fsync 写入磁盘并 commit 一次,不允许设置小于 100ms 的提交间隔。设置得较小,例如设置为 1s,会增加磁盘 I/O 的频率,但能提供更高的数据持久性。与之相反,若设置得较大,例如设置为 -1,表示关闭自动触发的 Translog 刷新机制,将完全依赖于系统或文件系统层面的刷新策略。这样可以提高写入性能,但可能会增加数据丢失风险。
+
+- `index.translog.durability`:此参数定义了刷新到磁盘的方式,该参数有以下可选值:
+
+ - `request`:表示 Elasticsearch 在响应客户端请求之前必须将数据刷新到磁盘。这是最安全的选项,但可能会影响写入性能。
+ - `async`:表示 Elasticsearch 在异步模式下将数据刷新到磁盘。它允许更高的写入性能,但可能会增加一定的数据丢失风险。
+ - `fsync`:表示 Elasticsearch 在将数据刷新到磁盘后,通过执行 fsync 操作来确保数据已经写入到物理介质。这是最慢的选项,但提供了最高的数据持久性。
+
+ 默认情况下,`index.translog.durability` 的值为 `request`,即 Elasticsearch 必须在响应客户端请求之前将数据刷新到磁盘,以确保数据的持久性。
+
+- `index.translog.flush_threshold_size`:此参数定义了触发 Translog 刷新的阈值大小,默认值为 512MB。这意味着当 Translog 中累积的数据大小达到或超过 512MB 时,Elasticsearch 将自动触发刷新操作,将数据刷新到磁盘。可以根据实际需求调整该参数的值。如果值设置得较小,例如设置为 128MB,会增加 Translog 刷新的频率,但可能会对系统的写入性能产生一定影响。而将其设置得较大,则会减少 Translog 刷新的频率,提高写入性能,但也会增加数据丢失风险。
+
+### 图解写入流程
+
+一图以蔽之:
+
+
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md"
new file mode 100644
index 0000000..572208c
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\206\231\345\205\245\345\222\214\346\243\200\347\264\242\350\260\203\344\274\230.md"
@@ -0,0 +1,149 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+当涉及到大规模数据存储和检索时,Elasticsearch以其快速、高效和强大的搜索能力而闻名,并被广泛应用于各种场景,例如日志分析、全文搜索和实时数据分析。
+
+然而,并不是只要将数据存入ES就可以立即获得最佳性能和查询效率。正如任何强大的工具一样,ES也需要进行调优,以充分发挥其潜力并满足特定业务需求。
+
+在这篇文章中,我们将探讨ES写入调优和查询调优的关键方面,并提供一些实用的技巧和建议,帮助您优化ES集群的性能和响应速度。
+
+## 写入调优
+
+### 基本原则
+
+写入性能调优是建立在 Elasticsearch 的写入原理之上的。
+
+ES 数据写入具有一定的延时性,这是为了减少频繁的索引文件产生。默认情况下 ES 每秒生成一个 Segment 文件,当达到一定阈值的时候会执行merge,merge 过程发生在 JVM中,频繁的生成 Segmen 文件可能会导致频繁的触发 FGC,导致 OOM。
+
+为了避免这种情况,通常采取的手段是降低 Segment 文件的生成频率,办法有两个:一个是增加时间阈值,另一个是增大Buffer的空间阈值,因为缓冲区写满也会生成 Segment 文件。
+
+生产经常面临的写入可以分为两种情况:
+
+**高频低量**:高频的创建或更新索引或文档,一般发生在 C 端业务场景下。
+
+**低频高量**:一般情况为定期重建索引或批量更新文档数据。
+
+在搜索引擎的业务场景下,用户一般并不需要那么高的写入实时性。比如你在网站发布一条征婚信息,或者二手交易平台发布一个商品信息。其他人并不是马上能搜索到的,这其实也是正常的处理逻辑。
+
+这个延时的过程需要处理很多事情,比如:你的信息需要后台审核。
+
+你发布的内容在搜索服务中需要建立索引,而且你的数据可能并不会马上被写入索引,而是等待要写入的数据达到一定数量之后,批量写入。
+
+这种操作优点类似于我们快递物流的场景,只有当快递数量达到一定量级的时候,比如能装满整个车的时候,快递车才会发车。因为反正是要跑一趟,装的越多,平均成本越低。
+
+这和我们数据写入到磁盘的过程是非常相似的,我们可以把一条文档数据看做是一个快递,而快递车每次发车就是向磁盘写入数据的一个过程,这个过程不宜太多,太多只会降低性能,就是体现在运输成本上面,而对于我们数据写入而言就是体现在我们硬件性能损耗上面。
+
+### 优化手段
+
+以下为常见数据写入的调优手段,写入调优均以提升写入吞吐量和并发能力为目标,而非提升写入实时性。
+
+#### 增加 flush 时间间隔
+
+flush的过程是非常消耗资源的。增加flush的时间间隔目的是减小数据写入磁盘的频率,降低磁盘IO频率。
+
+#### 增加 refresh_interval 参数的值
+
+增加 refresh_interval 参数的值,目的是减少segment文件的创建,降低merge次数,因为merge是发生在jvm中的,有可能导致full GC。
+
+ES的 refresh 行为非常昂贵,并且在正在进行的索引活动时经常调用,会降低索引速度。
+
+默认情况下,Elasticsearch 每秒定期刷新索引,如果没有搜索流量或搜索流量很少(例如每 5 分钟不到一个搜索请求),可以适当调大此参数的值。
+
+#### 增加Buffer大小
+
+本质也是减小refresh的时间间隔,因为导致segment文件创建的原因不仅有时间阈值,还有buffer空间大小,写满了也会创建。 默认值为JVM 空间的10%。
+
+#### 关闭副本
+
+当需要单次写入大量数据的时候,建议关闭副本,暂停搜索服务,或选择在检索请求量谷值区间时间段来完成。
+
+关闭副本可以带来如下好处:
+
+- 减小读写之间的资源抢占,读写分离。
+- 当检索请求数量很少的时候,可以减少甚至完全删除副本分片,关闭segment的自动创建以达到高效利用内存的目的,因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
+
+具体可通过设置`index.number_of_replicas` 为0以加快索引速度。没有副本意味着丢失单个节点可能会导致数据丢失,因此数据保存在其他地方很重要,以便在出现问题时可以重试初始加载。初始加载完成后,可以设置`index.number_of_replicas`改回其原始值。
+
+#### 禁用swap
+
+大多数操作系统尝试将尽可能多的内存用于文件系统缓存,并急切地换掉未使用的应用程序内存。这可能导致部分 JVM 堆甚至其可执行页面被换出到磁盘。
+
+交换对性能和节点稳定性非常不利,应该不惜一切代价避免。它可能导致垃圾收集持续几分钟而不是几毫秒,并且可能导致节点响应缓慢甚至与集群断开连接。在Elastic分布式系统中,让操作系统杀死节点更有效。
+
+#### 使用多个工作线程
+
+发送批量请求的单个线程不太可能最大化 Elasticsearch 集群的索引容量。为了使用集群的所有资源,应该从多个线程或进程发送数据。除了更好地利用集群的资源外,还有助于降低每个 fsync 的成本。
+
+确保注意 `TOO_MANY_REQUESTS` 响应代码:429。(EsRejectedExecutionException使用 Java 客户端),这是 Elasticsearch 告诉我们它无法跟上当前索引速度的方式。发生这种情况时,应该在重试之前暂停索引,最好使用随机指数退避。
+
+与调整批量请求的大小类似,只有测试才能确定最佳工作线程数量是多少。这可以通过逐渐增加线程数量来测试,直到集群上的 I/O 或 CPU 饱和。
+
+#### max_result_window参数
+
+`max_result_window`是分页返回的最大数值,默认值为10000。max_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
+
+设置一个合理的大小是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
+
+## 查询调优
+
+### 读写性能不可兼得
+
+首先要明确一点:鱼和熊掌不可兼得。读写性能调优在很多场景下是只能二选一的。牺牲 A 换 B 的行为非常常见。索引本质上也是通过空间换取时间。牺牲写入实时性就是为了提高检索的性能。
+
+当你在二手平台或者某垂直信息网站发布信息之后,是允许有信息写入的延时性的。但是检索不行,甚至 1 秒的等待时间对用户来说都是无法接受的。满足用户的要求甚至必须做到10 ms以内。
+
+### 优化手段
+
+#### 避免单次召回大量数据
+
+搜索引擎最擅长的事情是从海量数据中查询少量相关文档,而非单次检索大量文档。非常不建议动辄查询上万数据。如果有这样的需求,建议使用滚动查询
+
+#### 避免单个文档过大
+
+鉴于默认`http.max_content_length`设置为 100MB,Elasticsearch 将拒绝索引任何大于该值的文档。您可能决定增加该特定设置,但 Lucene 仍然有大约 2GB 的限制。
+
+即使不考虑硬性限制,大型文档通常也不实用。大型文档对网络、内存使用和磁盘造成了更大的压力,即使对于不请求的搜索请求也是如此。
+
+有时重新考虑信息单元应该是什么是有用的。例如,您想让书籍可搜索的事实并不一定意味着文档应该包含整本书。使用章节甚至段落作为文档可能是一个更好的主意,然后在这些文档中拥有一个属性来标识它们属于哪本书。这不仅避免了大文档的问题,还使搜索体验更好。例如,如果用户搜索两个单词 fooand bar,则不同章节之间的匹配可能很差,而同一段落中的匹配可能很好。
+
+#### 单次查询10条文档 好于 10次查询每次一条
+
+批量请求将产生比单文档索引请求更好的性能。但是每次查询多少文档最佳,不同的集群最佳值可能不同,为了获得批量请求的最佳阈值,建议在具有单个分片的单个节点上运行基准测试。
+
+首先尝试一次索引 100 个文档,然后是 200 个,然后是 400 个等。在每次基准测试运行中,批量请求中的文档数量翻倍。当索引速度开始趋于平稳时,就可以获得已达到数据批量请求的最佳大小。在相同性能的情况下,当大量请求同时发送时,太大的批量请求可能会使集群承受内存压力,因此建议避免每个请求超过几十兆字节。
+
+#### 数据建模
+
+很多人会忽略对 Elasticsearch 数据建模的重要性。
+
+nested属于object类型的一种,是Elasticsearch中用于复杂类型对象数组的索引操作。Elasticsearch没有内部对象的概念,因此,ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表。
+
+特别是,应避免Join连接。Nested 可以使查询慢几倍,Join 会使查询慢数百倍。两种类型的使用场景应该是:Nested针对字段值为非基本数据类型的时候,而Join则用于当子文档数量级非常大的时候。
+
+#### 给系统留足够的内存
+
+Lucene的数据的fsync是发生在OS cache的,要给OS cache预留足够的内存大小。
+
+#### 预索引
+
+利用查询中的模式来优化数据的索引方式。例如,如果所有文档都有一个price字段,并且大多数查询 range 在固定的范围列表上运行聚合,可以通过将范围预先索引到索引中并使用聚合来加快聚合速度。
+
+#### 使用 filter 代替 query
+
+query和filter的主要区别在: filter是结果导向的而query是过程导向。query倾向于“当前文档和查询的语句的相关度”,而filter倾向于“当前文档和查询的条件是不是相符”。即在查询过程中,query是要对查询的每个结果计算相关性得分的,而filter不会。另外filter有相应的缓存机制,可以提高查询效率。
+
+#### 避免深度分页
+
+避免单页数据过大,可以参考百度或者淘宝的做法。es提供两种解决方案 scroll search 和 search after。
+
+#### 使用 Keyword 类型
+
+并非所有数值数据都应映射为数值字段数据类型。Elasticsearch为查询优化数字字段,例如integeror long。如果不需要范围查找,对于 term查询而言,keyword 比 integer 性能更好。
+
+#### 避免使用脚本
+
+Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定义编程的强大的脚本功能。相对于 DSL 而言,脚本的性能更差,DSL能解决 80% 以上的查询需求,如非必须,尽量避免使用 Script。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
similarity index 79%
rename from "docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
rename to "docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
index dccb47f..01aa2dc 100644
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\210\206\350\257\215\345\231\250.md"
@@ -1,18 +1,35 @@
-## 规范化:normalization
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
-在Elasticsearch中,"normalization" 是指将文本数据转化为一种标准形式的步骤。这种处理主要发生在索引时,包括以下操作:
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
-1. **Lowercasing**:将所有字符转换为小写。这是最常见的标准化形式,因为搜索常常是不区分大小写的。
-2. **Removing diacritical marks**:移除重音符号或其他变音记号。例如,将 "résumé" 转换为 "resume"。
-3. **Converting characters to their ASCII equivalent**:将非ASCII字符转换为等效的ASCII字符。例如,将 "ë" 转换为 "e"。
+
+[TOC]
+
+在Elasticsearch中,分词器是用于将文本数据划分为一系列的单词(或称之为词项、tokens)的组件。这个过程是全文搜索中的关键步骤。
+
+一个分词器通常包含以下三个部分:
+
+- **字符过滤器(Character Filters)**:它接收原始文本作为输入,然后可以对这些原始文本进行各种转换,如去除HTML标签,将数字转换为文字等。
+- **分词器(Tokenizer)**:它将经过字符过滤器处理后的文本进行切分,生成一系列词项。例如,标准分词器会按照空格将文本切分成词项。
+- **词项过滤器(Token Filters)**:它对词项进行进一步的处理。比如小写化,停用词过滤(移除常见而无意义的词汇如"and", "the"),同义词处理,stemming(提取词根)等。
+
+Elasticsearch提供了许多内置的分词器,如标准分词器(Standard Tokenizer)、简单分词器(Simple Tokenizer)、空白分词器(Whitespace Tokenizer)、关键字分词器(Keyword Tokenizer)等。每种分词器都有其特定的应用场景,并且用户也可以自定义分词器以满足特殊需求。
+
+## 规范化:Normalization
+
+在Elasticsearch中,"Normalization" 是指将文本数据转化为一种标准形式的步骤。这种处理主要发生在索引时,包括以下操作:
+
+- **Lowercasing**:将所有字符转换为小写。这是最常见的标准化形式,因为搜索常常是不区分大小写的。
+- **Removing diacritical marks**:移除重音符号或其他变音记号。例如,将 "résumé" 转换为 "resume"。
+- **Converting characters to their ASCII equivalent**:将非ASCII字符转换为等效的ASCII字符。例如,将 "ë" 转换为 "e"。
这些转换有助于提高搜索的准确性,因为用户可能以各种不同的方式输入同一个词语。通过将索引和搜索查询都转换为相同的形式,可以更好地匹配相关结果。
-**说白了normalization就是将不通用的词汇变成通用的词汇。文档规范化,提高召回率**。
+**normalization的作用就是将文档规范化,提高召回率**
举个例子:
-假设我们希望在 Elasticsearch 中创建一个新的索引,该索引包含一个自定义分析器,该分析器将文本字段转换为小写并移除变音符号。你可以使用以下的请求:
+假设我们希望在 Elasticsearch 中创建一个新的索引,该索引包含一个自定义分析器,该分析器将文本字段转换为小写并移除变音符号。示例如下:
```JSON
PUT /my_index
@@ -20,7 +37,8 @@ PUT /my_index
"settings": {
"analysis": {
"analyzer": {
- "my_custom_analyzer": { "type": "custom",
+ "my_custom_analyzer": {
+ "type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "asciifolding"]
}
@@ -42,9 +60,9 @@ PUT /my_index
这个分析器包括三部分:
-- `"type": "custom"`: 这表示我们正在创建一个自定义分析器。
-- `"tokenizer": "standard"`: 这设置了标准分词器,它按空格和标点符号将文本拆分为单词。
-- `"filter": ["lowercase", "asciifolding"]`: 这是一个过滤器链,将所有文本转为小写 (lowercasing) 并移除所有的变音符号(如 accented characters)。
+- `"type": "custom"`: 这表示我们正在创建一个自定义分析器。
+- `"tokenizer": "standard"`: 这设置了标准分词器,它按空格和标点符号将文本拆分为单词。
+- `"filter": ["lowercase", "asciifolding"]`: 这是一个过滤器链,将所有文本转为小写 (lowercasing) 并移除所有的变音符号(如 accented characters)。
最后,在 `mappings` 对象中,我们指定 "my_field" 字段要使用这个自定义分析器。
@@ -59,19 +77,19 @@ POST /my_index/_doc
Elasticsearch 在索引这个文档时会将 "Méditerranéen RÉSUMÉ" 转换成 "mediterraneen resume"。这样,无论搜索查询是 "Méditerranéen", "méditerranéen", "MEDITERRANÉEN", "Resume", "résumé" 或 "RESUME",都能找到这个文档。
-## 字符过滤器:character filter
+## 字符过滤器:Character Filter
-Character filters就是在分词之前过滤掉一些无用的字符, 是 Elasticsearch 中的一种文本处理组件,它可以在分词前先对原始文本进行处理。这包括删除HTML标签、转换符号等。
+Character Filters就是在分词之前过滤掉一些无用的字符, 是 Elasticsearch 中的一种文本处理组件,它可以在分词前先对原始文本进行处理。这包括删除HTML标签、转换符号等。
-下面是一些常用的 character filter:
+下面是一些常用的 Character Filter:
-1. **HTML Strip Character Filter**:从输入中去除HTML元素,只保留文本内容。例如,`Hello World
` 被处理为 `"Hello World"`。
-2. **Mapping Character Filter**:通过一个预定义的映射关系,将指定的字符或字符串替换为其他字符或字符串。例如,你可以定义一个规则将 "&" 替换为 "and"。
-3. **Pattern Replace Character Filter**:使用正则表达式匹配和替换字符。
+- **HTML Strip Character Filter**:从输入中去除HTML元素,只保留文本内容。例如,`Hello World
` 被处理为 `"Hello World"`。
+- **Mapping Character Filter**:通过一个预定义的映射关系,将指定的字符或字符串替换为其他字符或字符串。例如,你可以定义一个规则将 "&" 替换为 "and"。
+- **Pattern Replace Character Filter**:使用正则表达式匹配和替换字符。
### HTML Strip Character Filter
-HTML Strip Character Filter 是 Elasticsearch 中的一个 character filter,其功能是从输入的文本中去除 HTML 元素。这对于处理包含 HTML 标签的文本十分有用。
+HTML Strip Character Filter 是 Elasticsearch 中的一种 Character Filter,其功能是从输入的文本中去除 HTML 元素。这对于处理包含 HTML 标签的文本十分有用。
下面的例子展示了如何创建一个使用 HTML Strip Character Filter 的索引:
@@ -175,7 +193,7 @@ Pattern Replace Character Filter 是 Elasticsearch 中一个强大的工具,
例如,假设你需要在索引或搜索时删除所有的数字,可以使用 Pattern Replace Character Filter,并设置一个匹配所有数字的正则表达式 `[0-9]`,然后将其替换为空字符串或其他所需的字符。
-以下是如何配置并使用 Pattern Replace Character Filter 的示例:
+示例如下:
```JSON
PUT /my_index
@@ -210,9 +228,7 @@ PUT /my_index
在这个例子中,我们定义了一个名为 `my_pattern_replace_char_filter` 的字符过滤器,该过滤器将所有数字(匹配正则表达式 `[0-9]`)替换为一个空字符串("")。然后,在我们的分析器 `my_analyzer` 中使用了这个字符过滤器。最后,在映射中我们指定了字段 "text" 使用这个分析器。因此,当你向 "text" 字段存储含有数字的文本时,所有的数字会被移除。
-例如:
-
-当你配置好索引并设定了特定的字符过滤规则后,你可以向这个索引插入文档。以下是一个插入文档的例子:
+当你配置好索引并设定了特定的字符过滤规则后,你可以向这个索引插入文档。例如:
```JSON
PUT /my_index/_doc/1
@@ -225,7 +241,7 @@ PUT /my_index/_doc/1
所以,在Elasticsearch中,无论用户搜索 "I have apples." 还是原始的 "I have 10 apples.",都能找到这条记录。同时,如果你检索这个文档,例如 `GET /my_index/_doc/1`,返回的结果中 `text` 字段仍为原始输入: "I have 10 apples.",因为 character filter 只对搜索和索引过程生效,不会改变实际存储的文档内容。
-Pattern Replace Character Filter有一个常用的场景就是手机号脱敏,比如:假设我们希望将电话号码中的前 7 位数字替换为星号 "*" 来进行脱敏处理。可以使用 Pattern Replace Character Filter 进行配置,如下:
+Pattern Replace Character Filter有一个常用的场景就是手机号脱敏,比如:假设我们希望将电话号码中的某几位数字替换为星号 "*" 来进行脱敏处理。可以使用 Pattern Replace Character Filter 进行配置,如下:
```JSON
PUT /my_index
@@ -269,15 +285,15 @@ PUT /my_index/_doc/1
}
```
-Elasticsearch 在索引这个文档时,会按照我们设置的规则将手机号码脱敏为 "123***\*8901\*\*",所以无论用户搜索 "\*\*My phone number is 12345678901.\*\*" 还是 "\*\*My phone number is 123\****8901." 都能找到这条记录。
+Elasticsearch 在索引这个文档时,会按照我们设置的规则将手机号码脱敏,所以无论用户搜索 "My phone number is 12345678901." 还是 "My phone number is 123\****8901." 都能找到这条记录。
-## 令牌过滤器(token filter)
+## 令牌过滤器(Token Filter)
在 Elasticsearch 中,Token Filter 负责处理 Analyzer 的 Tokenizer 输出的单词或者 tokens。这些处理操作包括:转换为小写、删除停用词、添加同义词等。
### 大小写和停用词
-以下是一个例子,我们创建一个自定义分析器来演示如何使用 `lowercase` 和 `stop` token filter:
+以下是一个例子,我们创建一个自定义分析器来演示如何使用 `lowercase` 和 `stop token filter`:
```JSON
PUT /my_index
@@ -326,11 +342,11 @@ PUT /my_index/_doc/1
### 同义词
-`synonym` token filter 可以帮助我们处理同义词。它可以将某个词或短语映射到其它的同义词。
+`synonym token filter` 可以帮助我们处理同义词。它可以将某个词或短语映射到其它的同义词。
-例如,假设你有一个电子商务网站,并且你想让搜索 "cellphone" 的用户也能看到所有包含 "mobile", "smartphone" 的商品。你可以使用 `synonym` token filter 来实现这一目标。
+例如,假设你有一个电子商务网站,并且你想让搜索 "cellphone" 的用户也能看到所有包含 "mobile", "smartphone" 的商品。你可以使用 `synonym token filter` 来实现这一目标。
-以下是一个使用 `synonym` token filter 的例子:
+以下是一个使用 `synonym token filter` 的例子:
```JSON
PUT /my_index
@@ -423,21 +439,21 @@ PUT /my_index
注意:`synonyms_path` 是相对于 `config` 目录的路径。例如,如果你的 `config` 目录在 `/etc/elasticsearch/`,那么 `synonyms.txt` 文件应该放在 `/etc/elasticsearch/analysis/synonyms.txt`。
-## 分词器(tokenizer)
+## 分词器(Tokenizer)
在 Elasticsearch 中,分词器是用于将文本字段分解成独立的关键词(或称为 token)的组件。这是全文搜索中的一个重要过程。Elasticsearch 提供了多种内建的 tokenizer。
以下是一些常用的 tokenizer:
-1. **Standard Tokenizer**:它根据空白字符和大部分标点符号将文本划分为单词。这是默认的 tokenizer。
-2. **Whitespace Tokenizer**:仅根据空白字符(包括空格,tab,换行等)进行切分。
-3. **Language Tokenizers**:基于特定语言的规则来进行分词,如 `english`、`french` 等。
-4. **Keyword Tokenizer**:它接收任何文本并作为一个整体输出,没有进行任何分词。
-5. **Pattern Tokenizer**:使用正则表达式来进行分词,可以自定义规则。
+- **Standard Tokenizer**:它根据空白字符和大部分标点符号将文本划分为单词。这是默认的 tokenizer。
+- **Whitespace Tokenizer**:仅根据空白字符(包括空格,tab,换行等)进行切分。
+- **Language Tokenizers**:基于特定语言的规则来进行分词,如 `english`、`french` 等。
+- **Keyword Tokenizer**:它接收任何文本并作为一个整体输出,没有进行任何分词。
+- **Pattern Tokenizer**:使用正则表达式来进行分词,可以自定义规则。
你可以根据不同的数据和查询需求,选择适当的 tokenizer。另外,也可以通过定义 custom analyzer 来混合使用 tokenizer 和 filter(比如 lowercase filter,stop words filter 等)以达到更复杂的分词需求。
-### 自定义分词器:custom analyzer
+### 自定义分词器:Custom Analyzer
在 Elasticsearch 中,你可以创建自定义分词器(Custom Analyzer)。一个自定义分词器由一个 tokenizer 和零个或多个 token filters 组成。tokenizer 负责将输入文本划分为一系列 token,然后 token filters 对这些 token 进行处理,比如转换成小写、删除停用词等。
@@ -477,9 +493,9 @@ PUT /my_index
}
```
-在这个配置中,我们首先定义了一个名为 `my_stopwords` 的停用词过滤器,包含两个停用词 "the" 和 "and"。然后我们创建了一个名为 `my_custom_analyzer` 的自定义分析器,其中使用了 `standard` tokenizer 以及 `lowercase` filter 和 `my_stopwords` filter。
+在这个配置中,我们首先定义了一个名为 `my_stopwords` 的停用词过滤器,包含两个停用词 "the" 和 "and"。然后我们创建了一个名为 `my_custom_analyzer` 的自定义分析器,其中使用了 `standard tokenizer `以及 `lowercase filter` 和 `my_stopwords filter`。
-因此,在为字段 `text` 索引文本时,Elasticsearch 会首先使用 `standard` tokenizer 将文本切分为 tokens,然后将这些 tokens 转换为小写,并移除其中的 "the" 和 "and"。对于搜索查询也同样适用此规则。
+因此,在为字段 `text` 索引文本时,Elasticsearch 会首先使用 `standard tokenizer` 将文本切分为 tokens,然后将这些 tokens 转换为小写,并移除其中的 "the" 和 "and"。对于搜索查询也同样适用此规则。
## 中文分词器:ik分词
@@ -506,8 +522,8 @@ IK 分词器是一个开源的中文分词器插件,特别为 Elasticsearch
### ik提供的两种analyzer
-1. ik_max_word会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query。
-2. ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
+- **ik_max_word**:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query。
+- **ik_smart**:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
### ik自定义词库
@@ -539,7 +555,7 @@ IK 分词器是一个开源的中文分词器插件,特别为 Elasticsearch
要修改词库,必须重启ES才能生效,有时我们会频繁更新词库,比较麻烦,更致命的是,es肯定是分布式的,可能有数百个节点,我们不能每次都一个一个节点上面去修改。基于这种场景,我们可以使用热更新功能。
-实现热更新有2种办法:基于远程词库和基于数据库。
+实现热更新有两种办法:基于远程词库和基于数据库。
#### 基于远程词库
@@ -563,8 +579,8 @@ IK 分词器支持从远程 URL 下载扩展字典,这就可以用来实现词
根据官方文档,该请求需要满足下列2点:
-1. 该 http 请求需要返回两个头部(header),一个是 `Last-Modified`,一个是 `ETag`,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
-2. 该 http 请求返回的内容格式是一行一个分词,换行符用 `\n` 即可。
+- 该 http 请求需要返回两个头部(header),一个是 `Last-Modified`,一个是 `ETag`,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
+- 该 http 请求返回的内容格式是一行一个分词,换行符用 `\n` 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
@@ -580,7 +596,7 @@ IK 分词器支持从远程 URL 下载扩展字典,这就可以用来实现词
#### 基于数据库
-另外一种方式是基于数据库,这种方式使用比较多,需要修改ik插件源码。
+另外一种方式是基于数据库,这种方式使用比较多,但需要修改ik插件源码,有一定复杂度。
基本思路是将词库维护在数据库(MySQL,Oracle等),修改ik源码去数据库加载词库,然后将源码重新打包引入到我们的elasticsearch中。
@@ -591,4 +607,4 @@ IK 分词器支持从远程 URL 下载扩展字典,这就可以用来实现词
3. **编写读取数据库词库的函数**:编写一个可以从数据库读取词库数据并转换为 IK 分词器可以使用的格式(比如 ArrayList)的函数。
4. **修改字典加载部分的代码**:找到 IK 源码中负责加载扩展字典的部分,原本这部分代码是将文件内容加载到内存中,现在改为调用你刚才编写的函数,从数据库中加载词库数据。
5. **添加定时任务**:添加一个定时任务,每隔一段时间重新执行一次上述加载操作,以实现词库的热更新。
-6. **编译和安装**:完成上述修改后,按照 IK 插件的构建说明,使用 Maven 或其他工具将其编译成插件,然后安装到 Elasticsearch 中。
\ No newline at end of file
+6. **编译和安装**:完成上述修改后,按照 IK 插件的构建说明,使用 Maven 或其他工具将其编译成插件,然后安装到 Elasticsearch 中。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\271\266\345\217\221\346\216\247\345\210\266.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\271\266\345\217\221\346\216\247\345\210\266.md"
new file mode 100644
index 0000000..a5d74c4
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\345\271\266\345\217\221\346\216\247\345\210\266.md"
@@ -0,0 +1,161 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES的并发控制是一种机制,用于处理多个同时对同一份数据进行读写操作的情况,以确保数据的一致性和正确性。
+
+实现并发控制的方法主要有两种:悲观锁和乐观锁。
+
+## 悲观锁
+
+悲观锁是一种并发控制机制,它基于一种假设:在任何时候都会发生并发冲突。因此,在进行读写操作之前,悲观锁会将数据标记为“被锁定”,以阻止其他操作对其进行修改。
+
+对于一个共享数据,某个线程访问到这个数据的时候,会认为这个数据随时有可能会被其他线程访问而造成数据不安全的情况,因此线程在每次访问的时候都会对数据加一把锁。这样其他线程如果在加锁期间想访问当前数据就只能等待,也就是阻塞线程了。
+
+一个现实中的悲观锁例子是银行柜台排队取款。
+
+假设某个银行只有一个柜台提供服务,多个客户需要办理业务。当第一个客户进入柜台并开始办理业务时,其他客户会悲观地认为自己无法立即获得服务,因此必须在柜台前排队等待。这种情况下,每个客户都悲观地预期自己必须等待一段时间才能办理业务,直到轮到自己。柜台就像是被锁住的资源,只允许一个客户同时使用,其他客户需等待释放才能进行操作。
+
+## 乐观锁
+
+乐观锁基于假设多个事务之间很少发生冲突的思想。在使用乐观锁的情况下,系统默认认为并发操作不会产生冲突,因此不会立即阻塞其他事务的执行。
+
+具体实现乐观锁的方式是,每个事务在读取数据时会获取一个版本号(或时间戳),在提交更新时会检查该版本号是否被其他事务修改过。如果版本号未被修改,意味着没有冲突发生,可以继续提交更新;但如果版本号已经被修改,说明有其他事务已经修改了数据,当前事务则需要重新读取最新数据并重新执行。
+
+乐观锁主要依赖于数据的版本控制来实现并发控制,可以降低锁粒度,提高并发性能。然而,在高并发环境下,如果冲突频繁发生,乐观锁可能会导致大量的回滚和重试操作,影响系统的性能。因此,在选择乐观锁时需要仔细评估并发冲突的概率和代价。
+
+一个现实中的乐观锁例子是电影院的选座系统。当多个用户同时访问选座系统时,系统采用乐观锁机制来处理并发操作。
+
+假设用户A和用户B同时进入选座系统,并选择了相同的座位。系统会首先记录用户A和用户B选择该座位的时间戳或版本号。当用户A提交座位选择后,系统会检查座位的时间戳或版本号是否被修改。如果未被修改,则说明没有冲突发生,系统会将座位分配给用户A。但如果时间戳或版本号已经被修改,说明用户B已经在此期间选择了相同的座位,系统需要重新读取最新数据并通知用户A重新选择座位。
+
+在这个例子中,选座系统默认认为用户之间很少选择相同座位,因此不立即阻塞其他用户的操作。通过乐观锁机制,系统可以减少并发冲突的发生,并提高用户的选择效率和系统的并发性能。
+
+## 如何选择
+
+**首先,悲观锁和乐观锁没有孰优孰劣,它们各自有各自的适用场景**
+
+选择乐观锁还是悲观锁取决于具体的应用场景和需求。下面是一些考虑因素:
+
+1. 并发程度:如果系统中并发冲突较为频繁,多个事务之间经常需要争抢同一个资源,那么悲观锁可能更适合。悲观锁可以确保资源的互斥访问,但会导致其他事务等待锁释放,可能影响系统的性能。
+2. 冲突概率:如果系统中并发冲突较为罕见,多个事务之间很少竞争同一个资源,那么乐观锁可能更适合。乐观锁假设并发操作不会产生冲突,可以提高系统的并发性能。但如果冲突发生频率较高,乐观锁可能会导致大量的回滚和重试,降低系统性能。
+3. 锁粒度:悲观锁通常会对整个资源或数据进行加锁,阻塞其他事务的访问。如果需要细粒度的并发控制,或者希望允许多个事务同时读取数据,那么乐观锁可能更适合。乐观锁可以降低锁粒度,提高并发性能。
+4. 实现复杂度:乐观锁相对而言实现起来更简单,只需要添加版本号或时间戳等机制即可。而悲观锁的实现可能需要借助底层的锁机制,如数据库的行级锁或使用并发控制工具。因此,在实现复杂度方面,乐观锁更容易实现和维护。
+
+总而言之,选择乐观锁还是悲观锁应该根据具体场景和需求进行评估。如果并发冲突较为频繁且需要确保互斥访问,可以选择悲观锁;如果并发冲突较为罕见且需要提高并发性能,可以选择乐观锁。
+
+## ES的并发控制
+
+**ES的并发控制是通过乐观锁机制来实现的**
+
+Elasticsearch 是分布式的。创建、更新或删除文档时,必须将文档的新版本复制到集群中的其他节点。ES 也是异步并行的,所以这些复制请求是并行发送的,并且可能不按顺序执行到每个节点。ES需要一种并发策略来保证数据的安全性,而这种策略就是乐观锁并发控制策略。
+
+为了保证旧文档不会被新文档覆盖,对文档执行的每个操作都由协调该更改的主分片分配一个序列号(_seq_no)。每个操作都会操作序列号递增,因此可以保证较新的操作具有更高的序列号。然后,ES 可以使用操作序列号来确保更新的文档版本永远不会被分配了较小序列号的版本覆盖。
+
+### 版本号:_version
+
+**基本原理**
+
+每个索引文档都有一个版本号。默认情况下,使用从 1 开始的内部版本控制,每次更新都会增加,包括删除。
+
+版本号可以设置为外部值(例如,如果在数据库中维护)。要启用此功能,`version_type` 应设置为 `external`。提供的值必须是大于或等于 0 且小于 9.2e+18 左右的数字长整型值。
+
+使用外部版本类型时,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本。如果为真,文档将被索引并使用新的版本号。如果提供的值小于或等于存储文档的版本号,则会发生版本冲突,索引操作将失败。
+
+**作用范围**
+
+_version 的有效范围为当前文档。
+
+**版本类型**
+
+`version_type`字段有以下几种取值:
+
+- `internal`(默认值):使用内部版本号(_version)来检测文档版本冲突。如果两个操作同时修改了相同的文档,后面执行的操作将失败并返回版本冲突的错误。
+- `external`:使用外部版本号来检测文档版本冲突。当执行操作时,必须提供文档的当前版本号,如果提供的版本号与实际版本号不匹配,则操作将失败。
+- `external_gte`:同样使用外部版本号,但提供的版本号大于等于实际版本号时才执行操作。如果提供的版本号小于实际版本号,则操作将失败,external_gte 需要谨慎使用,否则可能会丢失数据。
+
+通过指定适当的`version_type`,可以根据业务需求选择如何处理文档版本冲突。在某些场景下,外部版本号可能更适合,因为它允许应用程序明确控制版本冲突的处理方式。而在其他情况下,可以使用内部版本号来简化版本管理,并自动处理版本冲突。
+
+### _seq_no & _primary_term
+
+_seq_no 和 _primary_term 是用来并发控制,和 `_version`不同,`_version`属于当前文档,而 `_seq_no`属于整个index。
+
+**_seq_no & _primary_term**
+
+- **_seq_no**:索引级别的版本号,索引中所有文档共享一个 `_seq_no` 。
+- **_primary_term**:primary_term是一个整数,每当Primary Shard发生重新分配时,比如节点重启,Primary选举或重新分配等primary_term会递增1。主要作用是用来恢复数据时处理当多个文档的_seq_no 一样时的冲突,避免 Primary Shard 上的数据写入被覆盖。
+
+**if_seq_no & if_primary_term**
+
+在Elasticsearch中,`if_seq_no` 和 `if_primary_term` 是用于乐观锁并发控制的参数,用于确保对文档的操作不会与其他操作产生冲突。
+
+`if_seq_no` 参数用于指定期望的文档序列号(seq_no),而 `if_primary_term` 参数用于指定期望的 primary term。这两个参数一起作为条件,如果提供的条件与实际存储的文档序列号和主要项匹配,则操作成功执行;否则,操作将失败并返回版本冲突的错误。
+
+假设我们有一个名为 `my_index` 的索引,其中包含 `_id` 为 `1` 的文档。当前文档的 `seq_no` 是 `10`,`primary_term` 是 `1`。
+
+示例 1:更新文档
+
+```json
+PUT my_index/_doc/1?if_seq_no=10&if_primary_term=1
+{
+ "foo": "bar"
+}
+```
+
+输出:
+
+```json
+{
+ "_index": "my_index",
+ "_type": "_doc",
+ "_id": "1",
+ "_version": 11,
+ "result": "updated",
+ "_shards": {
+ "total": 2,
+ "successful": 1,
+ "failed": 0
+ }
+}
+```
+
+在这个示例中,通过提供正确的 `if_seq_no` 和 `if_primary_term` 条件,操作成功地更新了文档,并返回了更新后的版本号 `_version`。
+
+示例 2:更新文档,但条件不匹配
+
+```json
+PUT my_index/_doc/1?if_seq_no=11&if_primary_term=1
+{
+ "foo": "bar"
+}
+```
+
+输出:
+
+```json
+{
+ "error": {
+ "root_cause": [
+ {
+ "type": "version_conflict_engine_exception",
+ "reason": "[1]: version conflict, current version [11], provided version [11]",
+ "index_uuid": "xxxxxxxxxxxxx",
+ "shard": "0",
+ "index": "my_index"
+ }
+ ],
+ "type": "version_conflict_engine_exception",
+ "reason": "[1]: version conflict, current version [11], provided version [11]",
+ "index_uuid": "xxxxxxxxxxxxx",
+ "shard": "0",
+ "index": "my_index"
+ },
+ "status": 409
+}
+```
+
+在这个示例中,由于提供的 `if_seq_no` 和 `if_primary_term` 条件与实际存储的文档序列号和主要项不匹配,操作失败并返回版本冲突的错误。
+
+通过使用 `if_seq_no` 和 `if_primary_term` 参数,我们可以精确控制对文档的并发操作,并避免冲突。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\220\234\347\264\242\346\216\250\350\215\220.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\220\234\347\264\242\346\216\250\350\215\220.md"
new file mode 100644
index 0000000..460d567
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\220\234\347\264\242\346\216\250\350\215\220.md"
@@ -0,0 +1,370 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+我们在进行搜索的时候,一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错,以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest。
+
+ES针对不同的应用场景,把Suggester主要分为以下四种:
+
+`Tern Suggester`,`Phrase Suggester`,`Completion Suggester`,`Context Suggester`
+
+## Term Suggester
+
+意如其名,Term Suggester针对单独term的搜索推荐,不考虑搜索短语中多个term的关系。
+
+请求示例模版:
+
+```json
+POST /_search
+{
+ "suggest": {
+ "": {
+ "text": "",
+ "term": {
+ "suggest_mode": "",
+ "field": ""
+ }
+ }
+ }
+}
+```
+
+以下是一个具体的示例,演示如何使用 Term Suggester 进行搜索建议:
+
+```json
+POST my_index/_search
+{
+ "suggest": {
+ "my-suggestion": {
+ "text": "bown",
+ "term": {
+ "suggest_mode": "popular",
+ "field": "title"
+ }
+ }
+ }
+}
+```
+
+在这个示例中,我们发送了一个建议请求,要求根据用户输入的文本 `"bown"` 提供搜索建议。建议器将在 `title` 字段中查找匹配项,并提供最受欢迎的建议结果。
+
+### Options
+
+- **text**:用户搜索的文本。
+- **field**:要从哪个字段选取推荐数据。
+- **analyzer**:使用哪种分词器。
+- **size**:每个建议返回的最大结果数。
+- **sort**:如何按照提示词项排序,参数值只可以是以下两个枚举:
+ - score:分数>词频>词项本身。
+ - frequency:词频>分数>词项本身。
+- **suggest_mode**:搜索推荐的推荐模式,参数值亦是枚举:
+ - missing:默认值,当用户输入的文本在索引中找不到匹配项时,仍然提供建议。如果用户输入的文本在索引中没有匹配项,但有与之相关的建议结果,则这些建议结果将被返回作为搜索建议。这种模式适用于确保即使没有完全匹配的结果,用户仍能获得相关的建议。
+ - popular:根据最受欢迎或最频繁出现的词项来生成建议结果。对于给定的用户输入,Term Suggester 将返回那些在索引中最常出现的词项作为建议结果。这种模式适用于提供与最流行或最常见搜索关键词相关的建议。
+ - always:始终提供建议,即使已经存在完全匹配的结果。无论用户输入的文本是否与索引中的某个词项完全匹配,Term Suggester 都会提供一组建议结果。这种模式适用于用户输入的文本可能只是部分匹配的情况,以便提供更多的补全或纠错建议。
+- **max_edits**:可以具有最大偏移距离候选建议以便被认为是建议。只能是1到2之间的值。任何其他值都将导致引发错误的请求错误。默认为2。
+- **prefix_length**:前缀匹配的时候,必须满足的最少字符。
+- **min_word_length**:最少包含的单词数量,通过设置 `min_word_length` 参数,可以过滤掉那些长度不足的词项,从而得到更具有意义和相关性的建议结果。
+- **min_doc_freq**:最少的文档频率,通过设置 `min_doc_freq` 参数,可以过滤掉那些在文档中出现频率较低的词项,从而得到更具有代表性和相关性的建议结果。
+- **max_term_freq**:最大的词频,通过设置 `max_term_freq` 参数,可以控制建议结果中词项的重复出现程度,以避免过多重复的词项。
+
+## Phrase Suggester
+
+Phrase Suggester 是 Elasticsearch 中用于短语级别建议的功能。它可以根据用户输入的文本生成相关的短语建议,帮助用户补全或纠正输入。
+
+Term Suggester可以对单个term进行建议或者纠错,但是不会考虑多个term之间的关系,Phrase Suggester在Term Suggester的基础上,会去考虑多个term之间的关系,比如是否同时出现在一个索引原文中,相邻程度以及词频等等。
+
+以下是一个使用 Phrase Suggester 的请求示例模板:
+
+```json
+POST /_search
+{
+ "suggest": {
+ "": {
+ "text": "",
+ "phrase": {
+ "field": "",
+ "gram_size": ,
+ "direct_generator": [
+ {
+ "field": "",
+ "suggest_mode": ""
+ }
+ ]
+ }
+ }
+ }
+}
+```
+
+以下是一个具体的示例,演示如何使用 Phrase Suggester 进行短语建议:
+
+```json
+POST my_index/_search
+{
+ "suggest": {
+ "my-suggestion": {
+ "text": "quik brwn",
+ "phrase": {
+ "field": "title",
+ "gram_size": 2,
+ "direct_generator": [
+ {
+ "field": "title",
+ "suggest_mode": "popular"
+ }
+ ]
+ }
+ }
+ }
+}
+```
+
+在这个示例中,我们发送了一个建议请求,要求根据用户输入的文本 `"quik brwn"` 提供短语建议。Phrase Suggester 将在 `title` 字段中查找与短语相关的建议结果。
+
+生成短语时,使用的 gram 大小为 2,表示使用两个连续的词项进行组合。而直接生成器(direct_generator)将根据最受欢迎或最频繁出现的词项生成建议结果。
+
+### Options
+
+- **real_word_error_likelihood**:默认值为 0.95,即告诉 Elasticsearch 索引中有5% 的术语拼写错误。该参数指定了词语在索引中被认为是拼写错误的概率。较低的值将使得更多在索引中出现的词语被视为拼写错误,即使它们实际上是正确的。
+- **max_errors**:最大容忍错误百分比。默认值为 1,表示最多允许 1% 的错误。当建议短语与输入短语匹配时,如果超过该百分比的术语被认为是错误的,则该建议会被排除。
+- **confidence**:默认值为 1.0,取值范围为 [0, 1]。该参数控制建议结果的置信度阈值。只有得分高于此阈值的建议才会返回。较高的值意味着只有得分接近或高于输入短语的建议才会显示。
+- **collate**:该参数用于修剪建议结果,仅保留那些与给定查询匹配的建议。它接受一个匹配查询作为参数,并且只有当建议的文本与该查询匹配时,才会返回该建议。还可以在查询参数的 "params" 对象中添加更多字段。当参数 "prune" 设置为 true 时,响应中会增加一个 "collate_match" 字段,指示建议结果中是否存在匹配所有更正关键词的匹配项。
+- **direct_generator**:该参数控制候选生成器的行为。Phrase Suggester 使用候选生成器生成给定文本中每个项的可能建议项列表。目前,只有一种候选生成器可用,即 direct_generator。它以文本中的每个项单独调用 Term Suggester 来生成候选项,并将生成器的输出与建议结果进行打分。
+
+## Completion Suggester
+
+Completion Suggester 是一种用于实现自动补全功能的建议器。它基于预定义的文本片段,为用户提供与输入文本匹配的建议。
+
+Completion Suggester 支持三种查询:前缀查询(prefix),模糊查询(fuzzy),正则表达式查询(regex)。
+
+Completion Suggester也是最常使用的Suggester。
+
+主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。
+
+因此实现上它和前面两个Suggester采用了不同的数据结构。
+
+**索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放,对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在**
+
+使用Completion Suggester需要注意以下两点:
+
+- 内存代价太大,性能高是通过大量的内存换来的。
+- 只能前缀搜索,假如输入的不是前缀,召回率可能很低。
+
+Completion Suggester 需要对字段进行特定的映射来支持自动补全功能。以下是为使用 Completion Suggester 所需的映射配置:
+
+1. **type**:将字段类型设置为 "completion"。
+2. **analyzer**:为字段指定一个适当的分析器。建议使用 "simple" 分析器,因为它会保留完整的输入字符串作为术语的后缀,并用于生成建议。
+3. **search_analyzer**:对搜索查询应用的分析器。通常,与索引时使用的相同的分析器一起使用。
+
+以下是一个示例映射配置:
+
+```json
+{
+ "mappings": {
+ "properties": {
+ "suggestion_field": {
+ "type": "completion",
+ "analyzer": "simple",
+ "search_analyzer": "simple"
+ }
+ }
+ }
+}
+```
+
+请注意,Completion Suggester 只能在专门为自动补全而设计的字段上使用。它不适用于常规的文本字段。
+
+以下是一个使用 Completion Suggester 的请求示例模板:
+
+```json
+POST /_search
+{
+ "suggest": {
+ "": {
+ "prefix": "",
+ "completion": {
+ "field": ""
+ }
+ }
+ }
+}
+```
+
+以下是一个具体的示例,演示如何使用 Completion Suggester 进行自动完成建议:
+
+```json
+POST my_index/_search
+{
+ "suggest": {
+ "my-suggestion": {
+ "prefix": "th",
+ "completion": {
+ "field": "title_suggest"
+ }
+ }
+ }
+}
+```
+
+在这个示例中,我们发送了一个建议请求,要求根据用户输入的前缀 `"th"` 提供自动完成建议。Completion Suggester 将在 `title_suggest` 字段中查找与前缀匹配的建议结果。
+
+## Context Suggester
+
+Context Suggester允许在生成建议时考虑额外的上下文信息。与 Completion Suggester 不同,Context Suggester 可以根据特定的上下文条件来过滤和排序建议结果。
+
+Context Suggester是建立在Completion Suggester基础之上的,可以看成是Completion Suggester的一种补充。
+
+Context Suggester 支持两种类型的上下文:
+
+- **Category Context**:允许为建议结果定义一个或多个分类标签,并使用这些标签进行过滤。这样可以确保生成的建议结果与特定的类别相关联。例如,如果您正在构建一个电子商务应用程序,可以使用 Category Context 将建议限制为特定的产品类别,如衣物、鞋类等。
+- **Geo Location Context**:允许您基于地理位置信息进行建议。您可以提供经纬度坐标,并根据这些坐标过滤建议结果。这对于需要基于用户当前位置生成建议的应用程序非常有用,比如附近的商铺或景点推荐。
+
+Context Suggester 中,有几个重要的参数可以用来指定上下文条件和设置建议行为。下面是一些常用的参数:
+
+- **name**:上下文名称,用于标识特定的上下文条件。
+- **type**:上下文类型,可以是 `"category"` 或 `"geo"`,分别表示分类标签上下文和地理位置上下文。
+- **path**:对于嵌套对象,用于指定包含上下文条件的字段路径。
+
+**请求示例:**
+
+```json
+POST /my-index/_search
+{
+ "suggest": {
+ "my-suggestion": {
+ "prefix": "Pro",
+ "completion": {
+ "field": "suggestions",
+ "context": {
+ "category": {
+ "path": "category.sub_category"
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们向索引 `my-index` 发送了一个搜索请求,并使用了 Context Suggester。
+
+- `field` 参数设置为 `"suggestions"`,表示要从该字段中获取建议。
+- `context.path` 参数设置为 `"category.sub_category"`,表示要从文档的 `category.sub_category` 字段中提取上下文信息。
+
+这样,Context Suggester 将根据搜索的前缀和上下文信息生成相应的建议结果。
+
+- **context**:上下文值,根据上下文类型和值的数据类型进行指定。可以是文本、数字、布尔值等。
+- **boost**:可选参数,用于调整上下文的重要性。默认情况下,所有上下文都具有相同的权重。
+- **precision**:仅适用于 Geo Location Context,用于指定经纬度坐标的精度。
+- **neighbors**:仅适用于 Geo Location Context,用于指定返回结果时附近的邻居数量。
+
+通过这些参数,可以配置 Context Suggester 来满足特定的需求。例如,可以定义多个不同的上下文条件,并为每个上下文条件指定不同的权重,以影响建议结果的排序顺序。还可以使用 path 参数来处理嵌套对象中的上下文条件。
+
+当使用 Context Suggester 时,可以通过以下请求示例向 Elasticsearch 插入文档:
+
+```
+POST /my-index/_doc/1
+{
+ "title": "Product 1",
+ "suggestions": [
+ {
+ "input": "Product 1",
+ "weight": 10,
+ "contexts": {
+ "category": ["electronics"],
+ "location": ["New York"]
+ }
+ },
+ {
+ "input": "Phone",
+ "weight": 5,
+ "contexts": {
+ "category": ["electronics", "communication"],
+ "location": ["Seattle"]
+ }
+ }
+ ]
+}
+```
+
+这个请求用于向名为 "my-index" 的索引插入一篇文档。该文档的ID是 "1",包含了一个 "title" 字段和一个 "suggestions" 字段。
+
+"suggestions" 字段是一个数组,其中包含了两个建议项。每个建议项都有一个 "input" 属性表示建议的文本,一个可选的 "weight" 属性表示权重值,以及一个 "contexts" 对象表示建议的上下文信息。
+
+具体解释如下:
+
+- "title": "Product 1" 表示这篇文档的标题是 "Product 1"。
+- "suggestions":[...] 是一个包含两个建议项的数组。
+- 第一个建议项:
+ - "input":"Product 1" 表示第一个建议项的文本是 "Product 1"。
+ - "weight":10 表示给予这个建议项的权重是 10。
+ - "contexts":{...} 表示这个建议项的上下文信息。
+ - "category":["electronics"] 表示这个建议项属于 "electronics" 类别。
+ - "location":["New York"] 表示这个建议项的位置是 "New York"。
+- 第二个建议项:
+ - "input":"Phone" 表示第二个建议项的文本是 "Phone"。
+ - "weight":5 表示给予这个建议项的权重是 5。
+ - "contexts":{...} 表示这个建议项的上下文信息。
+ - "category":["electronics", "communication"] 表示这个建议项属于 "electronics" 和 "communication" 类别。
+ - "location":["Seattle"] 表示这个建议项的位置是 "Seattle"。
+
+接下来,让我给出一个关于如何发送请求并获取响应的示例:
+
+**请求:**
+
+```json
+POST /my-index/_search
+{
+ "suggest": {
+ "my-suggestion": {
+ "prefix": "Pro",
+ "completion": {
+ "field": "suggestions",
+ "context": {
+ "category": "electronics",
+ "location": "New York"
+ }
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们发送了一个搜索请求,并指定了一个自定义的建议器名称 `"my-suggestion"`。我们设置了前缀为 `"Pro"`,并在 `completion` 参数中指定了要使用的字段名和上下文信息。
+
+**响应:**
+
+```json
+{
+ "suggest": {
+ "my-suggestion": [
+ {
+ "text": "Pro",
+ "offset": 0,
+ "length": 3,
+ "options": [
+ {
+ "text": "Product 1",
+ "_index": "my-index",
+ "_type": "_doc",
+ "_id": "1",
+ "_score": 10,
+ "_source": {
+ "title": "Product 1"
+ },
+ "contexts": {
+ "category": ["electronics"],
+ "location": ["New York"]
+ }
+ }
+ ]
+ }
+ ]
+ }
+}
+```
+
+在响应结果中,将看到根据输入前缀 `"Pro"` 检索到的一个建议项。该建议项具有文本、偏移量、长度等属性,并包含相关的元数据,如源文档的信息和上下文信息。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md"
new file mode 100644
index 0000000..659c26a
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md"
@@ -0,0 +1,383 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+[TOC]
+
+**开个新的坑,创作关于Elasticsearch的系列文章**
+
+首先,让我们简单的了解一下Elasticsearch:
+
+Elasticsearch是一个开源的搜索和分析引擎,支持近实时的大数据存储、搜索和分析。它基于Apache Lucene项目,提供全文搜索及能力强大的分布式多用户搜索引擎,同时配备RESTful web接口。它不仅能执行复杂查询,还能高效处理复杂的数据分析。
+
+由于其出色的大数据处理能力,Elasticsearch被广泛应用于需要快速搜索和分析大量结构化和非结构化数据的业务场景。
+
+众多公司都广泛使用Elasticsearch,而我们学习它,是因为它是当前最流行的搜索和数据分析解决方案之一。
+
+这是该系列的首篇文章,本章将介绍Elasticsearch的基本概念和相关术语,以帮助您初步理解并熟悉Elasticsearch。
+
+注:所用的Elasticsearch版本为7.4。
+
+## 节点
+
+ElasticSearch 是一种分布式搜索和分析引擎,它的核心是 Lucene。 ES 具有分布式特性,意味着它可以在很多不同的服务器上运行,这些服务器被称为 "节点"。
+
+- 每个Elasticsearch节点实际上就是一个Java进程,就是一个Elasticsearch的实例。
+- 一个节点 ≠一台服务器,意味着一台服务器上可以启动多个Elasticsearch的实例。
+
+集群节点角色可以在配置文件`elasticsearch.yml`中通过`node.roles`配置,如果配置了节点角色,那么该节点将只会执行配置的角色功能。
+
+根据角色的不同,Elasticsearch 的节点可以分为以下几种类型:
+
+### master:候选节点
+
+所谓master节点,就是在主节点down机的时候,可以参与选举,取而代之的节点。
+
+举个例子:
+
+**主节点好比班长,在班长不在的时候(主节点down机了),要选举出一个临时班长(master中选举)**
+
+master节点不仅有选举权还有被选举权,每个master节点主要负责索引创建、索引删除、追踪节点信息和决定分片分配节点等。
+
+配置方法:
+
+```yaml
+node.roles: [ master ]
+```
+
+### data:数据节点
+
+**数据节点顾名思义就是存放数据的节点,数据节点负责存储文档数据和数据的CRUD操作**
+
+因此该节点是CPU和IO密集型,需要实时监控该节点的资源信息,以免过载。
+
+数据节点又可分为:data_content,data_hot,data_warm,data_code。
+
+- **data_content**:数据内容节点,目录节点负责存储常量数据,且不随着时间的推移,改变数据的温层(hot、warm、cold)。且该节点的查询优先级是高于其它IO操作,所以该节点search和aggregations都会较快一些。
+- **data_hot**:热节点,保存热数据,经常会被访问,用于存储最近频繁搜索和修改的时序数据。
+- **data_code**:冷节点,保存冷数据,很少会被访问,当数据不再更新,那么可以将该数据移动到冷数据节点,冷数据节点用于存储只读,且访问频率较低的数据。该节点机器性能可以低一点。
+- **data_warm**:温节点,介于热节点和冷节点之间,当数据访问频率下降,可以将其移动到温节点,温节点用于存储修改较少,但仍然有查询的数据,查询的频率肯定比热点节点要少。
+
+配置方法:
+
+```yaml
+node.roles: [ data ]
+```
+
+### Ingest:预处理节点
+
+Ingest 节点是 Elasticsearch 的一种特殊类型的节点,用于预处理文档。预处理可能包括执行各种转换和修改,例如增加新字段、改变已有字段的值、移除字段、更改字段的数据类型等。
+
+在 Elasticsearch 中,此类预处理操作是由 Ingest Pipeline 来完成的。一个 Ingest Pipeline 是一系列的处理器(processor),每一个处理器完成特定的任务。你可以定义多个处理器,然后按照特定的顺序执行。
+
+要配置 Elasticsearch 使其具有 Ingest 能力,需要在 `elasticsearch.yml` 文件中设置如下:
+
+```yaml
+node.roles: [ ingest ]
+```
+
+以上设置表示该节点将作为 Ingest 节点。
+
+以下是创建 Ingest Pipeline 的简单示例:
+
+```json
+PUT _ingest/pipeline/my_pipeline_id
+{
+ "description" : "my pipeline",
+ "processors" : [
+ {
+ "set" : {
+ "field": "new_field",
+ "value": "new_value"
+ }
+ },
+ {
+ "remove" : {
+ "field": "old_field"
+ }
+ }
+ ]
+}
+```
+
+这个 pipeline 包含两个处理器,第一个处理器在文档中添加了一个新字段,并设置了它的值;第二个处理器删除了一个旧字段。
+
+之后在索引文档时,可以使用这个 pipeline:
+
+```json
+PUT /my_index/_doc/my_id?pipeline=my_pipeline_id
+{
+ "field1" : "value1",
+ "old_field" : "value2"
+}
+```
+
+在这个例子中,被索引的文档将被 Ingest pipeline 提前处理,添加新字段并删除旧字段。
+
+### ml:机器学习节点
+
+Elasticsearch的机器学习(ML)节点用于运行各种机器学习作业,例如异常检测或数据帧分析。这些节点特性在 Elasticsearch 的集群设置中进行配置。
+
+配置 elasticsearch.yml:打开每个节点的 'elasticsearch.yml' 文件,并添加或修改以下设置:
+
+```yaml
+node.roles: [ ml ]
+xpack.ml.enabled: true
+```
+
+这些设置会使节点成为一个机器学习节点。
+
+注意:在生产环境中,你应确保你的机器学习节点有足够的内存和 CPU 来处理你的机器学习工作负载。如果你尝试运行一个过于复杂或者数据量过大的机器学习作业,可能会导致节点崩溃或者过载。
+
+### remote_ cluster_ client:远程候选节点
+
+远程候选节点可以作为远程集群的客户端,其作用在于帮助在本地集群与远程集群之间进行通信。当你希望模拟跨集群搜索或者跨集群复制时,这个节点角色就会派上用场。
+
+配置:
+
+```
+node.roles: [ remote_cluster_client ]
+```
+
+然后,你需要在`elasticsearch.yml`中设置远程集群的信息:
+
+```yaml
+cluster:
+ remote:
+ my_remote_cluster:
+ seeds: 127.0.0.1:9300
+```
+
+在此示例中,“my_remote_cluster”是远程集群的别名,而“seeds”是远程集群中的种子节点的地址列表。你可以根据实际情况来更改这些值。
+
+注意:在某些环境中,可能需要额外的网络配置才能确保节点之间的正常通信。
+
+### transform:转换节点
+
+转换节点(Transform)是一种将 Elasticsearch 索引数据进行统计分析并产生新的索引的功能。它可以用来执行复杂的聚合查询,并将结果持久化到新的 Elasticsearch 索引中。这个过程可以定期运行,也可以根据需求随时启动或停止。
+
+以下是创建一个 Transform 的基本步骤:
+
+1. 使用 Kibana 或者 Elasticsearch API 来创建一个 Transform。你需要指定源索引(source index),目标索引(destination index),以及 Transform 的配置。
+2. 在 Transform 的配置中,你需要指定聚合查询(aggregations)以及群组字段(group by fields)。这些配置决定了怎样对源索引进行统计分析并生成新的索引。
+
+一个简单的 Transform 配置示例如下:
+
+```json
+PUT _transform/my_transform
+{
+ "source": {
+ "index": ["my_source_index"]
+ },
+ "dest": {
+ "index": "my_dest_index"
+ },
+ "pivot": {
+ "group_by": {
+ "user_id": {
+ "terms": {
+ "field": "user_id"
+ }
+ }
+ },
+ "aggregations": {
+ "total_clicks": {
+ "sum": {
+ "field": "clicks"
+ }
+ }
+ }
+ },
+ "frequency": "1m",
+ "sync": {
+ "time": {
+ "field": "timestamp",
+ "delay": "60s"
+ }
+ }
+}
+```
+
+在上面的示例中,Transform 是从 `my_source_index` 中的数据计算每个 `user_id` 的点击次数总和,并将结果保存到 `my_dest_index` 中。这个 Transform 每分钟运行一次,并且在处理含有 `timestamp` 字段的最新数据时会有 60 秒的延迟。
+
+更多关于 Elasticsearch Transform 的详细信息,建议参考 Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/transform-apis.html
+
+### voting_ only:仅投票节点
+
+在master选举过程中,仅投票节点顾名思义就是只参与主节点选举过程,但不会被选为主节点。
+
+**"voting-only"节点主要用来解决"split brain"(脑裂)的问题**
+
+在某些情况下,可能会发生两个或更多节点都认为自己是主节点的情况,这就是所谓的脑裂。通过增加"voting-only"节点,可以增加主节点选举的“选票”,从而降低脑裂的风险。
+
+要将一个节点配置为"voting-only"节点,需要在该节点的`elasticsearch.yml`配置文件中设置以下属性:
+
+```yaml
+node.roles: [voting_only]
+```
+
+保存并重启该节点后,它就会成为一个"voting-only"节点。
+
+### coordinating only:协调节点
+
+协调节点主要负责根据集群状态路由分发搜索,不参与索引和搜索操作,不存储数据,只负责将请求路由到适当的节点(例如数据节点或主节点),并根据结果组织响应返回给客户端。
+
+**此外每个节点都自带协调节点功能,即便没有去专门配置,任何Elasticsearch节点默认都能成为协调节点**
+
+## 分片
+
+分片的思想在很多分布式应用和海量数据处理的场景中都非常常见,通常来说,面对海量数据的存储,单个节点显得力不从心。
+
+**通俗解释,分片就是将数据拆分多份,放到不同的服务器节点**
+
+Elasticsearch里的分片分为两种:
+
+- **主分片(Primary Shard)**:这是最初创建索引时所设定的分片。主要用于数据持久化,可以通过配置文件或者API进行设置。
+- **副本分片(Replica Shard)**:这是从主分片复制出来的分片,用于提高数据的可用性和查询性能。副本不会与其对应的主分片放在同一节点上,以防止单点故障。
+
+### 主分片
+
+ES可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
+
+**分片的数量只能在索引创建前指定,并且索引创建后不能更改**
+
+ES的分片数量在索引创建时设定是因为ES将每个索引的数据分布在多个分片上以实现数据的水平扩展。这种分布是基于数据的哈希值进行的,这样可以保证数据的均匀分布。一旦索引被创建并且数据开始写入,这种数据的分布就已经确定下来了。
+
+当客户端发起创建document的时候,ES需要确定这个document放在该index的哪个shard上。这个过程就是**数据路由**。
+
+**路由算法:shard = hash(routing) % number_of_primary_shards**
+
+这里的`routing`指的就是document的id,如果`number_of_primary_shards`在查询的时候取余发生了变化,则无法获取到该数据。
+
+并且如果在索引创建后改变分片的数量,就需要重新计算所有数据的哈希值并且在分片之间迁移数据。这不仅会消耗大量的计算和IO资源,而且在数据迁移过程中还可能会影响查询的准确性。因此,ES设计决定在索引创建时就确定分片的数量,而且创建后不能更改。
+
+然而,虽然原始分片的数量在创建后不能更改,但是你可以通过**reindex**操作将数据复制到一个新的索引中,这个新的索引可以有不同的分片数量。
+
+### 副本分片
+
+副本分片代表索引的副本,ES可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高ES的查询效率,ES会自动对搜索请求进行负载均衡。
+
+- 每个主分片和其副本分片不能存在于同一个节点上,所以最低的可用配置是两个节点互为主备。
+- 副本分片是不能直接写入数据的,只能通过主分片做数据同步。
+
+以下是如何在创建索引时配置主分片和副本分片的示例:
+
+```json
+PUT /my_index
+{
+ "settings": {
+ "number_of_shards": 3, # 主分片数量
+ "number_of_replicas": 2 # 副本分片数量
+ }
+}
+```
+
+这个设置会创建一个名为`my_index`的新索引,它有3个主分片和2个副本。也就是说,总共有9个分片 (3主 * (1原始 + 2副本))。
+
+你也可以在索引创建后修改其副本分片数:
+
+```json
+PUT /my_index/_settings
+{
+ "number_of_replicas": 1
+}
+```
+
+这将`my_index`索引的副本数从2更改为1。
+
+请注意,虽然你可以在索引创建后更改副本分片的数量,但不能更改主分片的数量。因此,在创建索引时,需要仔细考虑主分片的数量。
+
+## 集群状态
+
+集群健康状态(Cluster Health)描述了集群的总体健康状况,分为 "Green"、"Yellow" 和 "Red"。
+
+- Green:主/副分片都已经分配好且可用,集群处于最健康的状态100%可用。
+- Yellow:主分片可用,但是至少有一个副本是未分配的。这种情况下数据也是完整的,但是集群的高可用性会被弱化。
+- Red:至少有一个不可用的主分片。此时只是部分数据可以查询,已经影响到了整体的读写,需要重点关注。
+
+## 健康值检查
+
+在Elasticsearch中,你可以使用两种主要的API来检查集群的健康状况:`_cat/health`和`_cluster/health`。虽然它们提供了相似的信息,但是它们的输出格式不同。
+
+`_cat/health`:该API以简洁的表格式返回关于集群健康的信息。它易于阅读和理解。
+
+示例:`GET _cat/health?v`
+
+这将返回如下所示的输出:
+
+```
+epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
+1605102382 13:59:42 elasticsearch green 3 3 12 6 0 0 0 0 - 100.0%
+```
+
+返回参数说明:
+
+| 参数 | 含义 |
+| --------------------- | -------------------------- |
+| epoch | 自Unix Epoch以来的秒数 |
+| timestamp | 当前时间戳 |
+| cluster | 集群名称 |
+| status | 集群状态(绿色、黄色或红色) |
+| node.total | 集群中的节点总数 |
+| node.data | 集群中承载数据的节点数 |
+| shards | 集群中的分片总数 |
+| pri | 集群中的主要分片数量 |
+| relo | 正在进行重定位的分片数量 |
+| init | 初始化的分片数量 |
+| unassign | 未分配的分片数量 |
+| pending_tasks | 等待执行的集群级任务数量 |
+| max_task_wait_time | 等待任务的最长时间 |
+| active_shards_percent | 活动分片占总分片的百分比 |
+
+- `_cluster/health`:这个API 以JSON格式返回关于集群健康的详细信息。它提供更丰富的数据,并因此更适合编程访问。
+
+示例:`GET _cluster/health`
+
+这将返回如下所示的输出:
+
+```json
+{
+ "cluster_name" : "elasticsearch",
+ "status" : "yellow",
+ "timed_out" : false,
+ "number_of_nodes" : 1,
+ "number_of_data_nodes" : 1,
+ "active_primary_shards" : 12,
+ "active_shards" : 12,
+ "relocating_shards" : 0,
+ "initializing_shards" : 0,
+ "unassigned_shards" : 2,
+ "delayed_unassigned_shards": 0,
+ "number_of_pending_tasks" : 0,
+ "number_of_in_flight_fetch": 0,
+ "task_max_waiting_in_queue_millis": 0,
+ "active_shards_percent_as_number": 85.7
+}
+```
+
+返回参数说明:
+
+| 参数 | 描述 |
+| ---------------------------------- | ------------------------------------------------------------ |
+| `cluster_name` | 集群的名称。 |
+| `status` | 集群的状态,它可能的值有:`green`、`yellow` 或者 `red`。`green` 表示所有主要和副本分片都是活动的。`yellow` 表示所有主要分片是活动的但不是所有副本都是活动的。`red` 表示至少一个主要分片不是活动的。 |
+| `timed_out` | 如果请求超时,该值为 true。 |
+| `number_of_nodes` | 集群中的节点数。 |
+| `number_of_data_nodes` | 集群中执行数据相关操作的节点数。 |
+| `active_primary_shards` | 当前活动的主分片数。 |
+| `active_shards` | 当前活动的分片数。 |
+| `relocating_shards` | 正在重新定位的分片数。 |
+| `initializing_shards` | 初始化中的分片数。 |
+| `unassigned_shards` | 未分配的分片数。 |
+| `delayed_unassigned_shards` | 延迟未分配的分片数。 |
+| `number_of_pending_tasks` | 等待执行的集群级别更改的数量。 |
+| `number_of_in_flight_fetch` | 当前正在进行的获取操作数。 |
+| `task_max_waiting_in_queue_millis` | 在执行队列中等待的任务的最长时间(以毫秒为单位)。 |
+| `active_shards_percent_as_number` | 活动分片所占的百分比。 |
+
+## 索引和文档
+
+ES中索引可以类比为关系型数据库中的Table,在7.0版本之前index由若干个type组成,type实际上是文档的逻辑分类,而文档是ES存储的最小单元。文档(doc)可以类比为关系型数据库中的行,每个文档都有一个文档id。
+
+**7.0及之后弱化了type的概念,7.x版本index只有一个type:_doc**
+
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\250\241\347\263\212\346\220\234\347\264\242.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\250\241\347\263\212\346\220\234\347\264\242.md"
new file mode 100644
index 0000000..1221ce1
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\250\241\347\263\212\346\220\234\347\264\242.md"
@@ -0,0 +1,302 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+在 Elasticsearch 中,模糊搜索是一种近似匹配的搜索方式。它允许找到与搜索词项相似但不完全相等的文档。
+
+## 前缀匹配:prefix
+
+前缀匹配通过指定一个前缀值,搜索并匹配索引中指定字段的文档,找出那些以该前缀开头的结果。
+
+在 Elasticsearch 中,可以使用 `prefix` 查询来执行前缀搜索。其基本语法如下:
+
+```json
+{
+ "query": {
+ "prefix": {
+ "field_name": {
+ "value": "prefix_value"
+ }
+ }
+ }
+}
+```
+
+其中,`field_name` 是要进行前缀搜索的字段名,`prefix_value` 是要匹配的前缀值。
+
+**注意**:前缀搜索匹配的是term,而不是field,换句话说前缀搜索匹配的是分析之后的词项,并且不计算相关度评分。
+
+**优点:**
+
+- 快速:前缀搜索使用倒排索引加速匹配过程,具有较高的查询性能。
+- 灵活:可以基于不同的字段进行前缀搜索,适用于各种数据模型。
+
+**缺点:**
+
+- 前缀无法通配:前缀搜索只能匹配以指定前缀开始的文档,无法进行通配符匹配。
+- 高内存消耗:如果前缀值过长或前缀匹配的文档数量过多,将占用较大的内存资源,并且前缀搜索是没有缓存的。
+
+### index_prefixes
+
+`index_prefixes`参数允许对词条前缀进行索引,以加速前缀搜索。它接受以下可选设置:
+
+- **min_chars**:索引的最小前缀长度(包含),必须大于0,默认值为2。
+- **max_chars**:索引的最大前缀长度(包含),必须小于20,默认值为5。
+
+index_prefixe可以理解为在索引上又建了层索引,会为词项再创建倒排索引,会加快前缀搜索的时间,但是会浪费大量空间,本质还是空间换时间。
+
+## 通配符匹配:wildcard
+
+通配符匹配允许使用通配符来匹配文档中的字段值,是一种基于模式匹配的搜索方法,它使用通配符字符来匹配文档中的字段值。
+
+通配符字符包括 `*` 和 `?`,其中 `*` 表示匹配任意数量(包括零个)的字符,而 `?` 则表示匹配一个字符。
+
+在通配符搜索中,可以在搜索词中使用通配符字符,将其替换为要匹配的任意字符或字符序列。通配符搜索可以应用于具有文本类型的字段。
+
+**注意**:通配符搜索和前缀搜索一样,匹配的都是分析之后的词项。
+
+**请求示例:** 以下是一个使用通配符搜索的示例请求:
+
+```
+GET /my_index/_search
+{
+ "query": {
+ "wildcard": {
+ "title.keyword": {
+ "value": "elast*"
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们对名为 `my_index` 的索引执行了一个通配符搜索。我们指定了要搜索的字段为 `title.keyword`,并使用 `elast*` 作为通配符搜索词。这将匹配 `title.keyword` 字段中以 `elast` 开头的任意字符序列。
+
+## 正则表达式匹配:regexp
+
+正则表达式匹配(regexp)是一种基于正则表达式模式进行匹配的搜索方法,它允许使用正则表达式来匹配文档中的字段值。
+
+**用途:** 正则表达式匹配在以下情况下非常有用:
+
+- 高级模式匹配:当需要更复杂的模式匹配时,正则表达式匹配提供了更多的灵活性和功能。
+- 模糊搜索:通过使用通配符和限定符,可以进行更精确的模糊匹配。
+
+**优缺点:**
+
+- 优点:
+ - 强大的模式匹配:正则表达式匹配提供了强大且灵活的模式匹配功能,可以满足各种复杂的搜索需求。
+ - 可定制性:通过使用正则表达式,您可以根据具体需求编写自定义的匹配规则。
+- 缺点:
+ - 性能:正则表达式匹配的性能较低,尤其是在大型索引上进行正则表达式匹配可能会导致搜索延迟和资源消耗增加。
+ - 学习成本高:使用正则表达式需要一定的学习和理解,对于不熟悉正则表达式的人来说可能会有一定的难度。
+
+**语法**:
+
+```json
+GET /_search
+{
+ "query": {
+ "regexp": {
+ "": {
+ "value": "",
+ "flags": "ALL",
+ }
+ }
+ }
+}
+```
+
+**请求示例:** 以下是一个使用正则表达式匹配的示例请求:
+
+```
+GET /my_index/_search
+{
+ "query": {
+ "regexp": {
+ "title.keyword": {
+ "value": "elast.*",
+ "flags": "ALL"
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们对名为 `my_index` 的索引执行了一个正则表达式匹配。我们指定要搜索的字段为 `title.keyword`,并使用 `elast.*` 作为正则表达式匹配模式。这将匹配 `title.keyword` 字段中以 `elast` 开头的字符序列,并且后面可以是任意字符。
+
+**注意**:regexp查询的性能可以根据提供的正则表达式而有所不同。为了提高性能,应避免使用通配符模式,如 `.` 或 `.?+` 未经前缀或后缀。
+
+### flags
+
+正则表达式匹配的 `flags` 参数用于指定正则表达式的匹配选项。它可以修改正则表达式的行为以进行更灵活和精确的匹配。
+
+**语法:** 在正则表达式匹配的查询中,`flags` 参数是一个字符串,它可以包含多个选项,并用逗号分隔。每个选项都由一个字母表示。
+
+以下是常用的 `flags` 参数选项及其说明:
+
+- `ALL`:启用所有选项,相当于同时启用了 `ANYSTRING`, `COMPLEMENT`, `EMPTY`, `INTERSECTION`, `INTERVAL`, `NONE`, `NOTEMPTY`, 和 `NOTNONE`。
+- `ANYSTRING`:允许使用 `.` 来匹配任意字符,默认情况下 `.` 不匹配换行符。
+- `COMPLEMENT`:求反操作,匹配除指定模式外的所有内容。
+- `EMPTY`:匹配空字符串。
+- `INTERSECTION`:允许使用 `&&` 运算符来定义交集。
+- `INTERVAL`:允许使用 `{}` 来定义重复数量的区间。
+- `NONE`:禁用所有选项,相当于不设置 `flags` 参数。
+- `NOTEMPTY`:匹配非空字符串。
+- `NOTNONE`:匹配任何内容,包括空字符串。
+
+flags参数用到的场景比较少,做下了解即可。
+
+
+## 模糊匹配:fuzzy
+
+模糊查询(Fuzzy Query)是 Elasticsearch 中一种近似匹配的搜索方式,用于查找与搜索词项相似但不完全相等的文档。基于编辑距离(Levenshtein 距离)计算两个词项之间的差异。
+
+它通过允许最多的差异量来匹配文档,以处理输入错误、拼写错误或轻微变体的情况。
+
+**用途**:纠正拼写错误,模糊查询可用于纠正用户可能犯的拼写错误,可以提供宽松匹配,使搜索结果更加全面。
+
+- 混淆字符 (**b**ox → fox)
+- 缺少字符 (**b**lack → lack)
+- 多出字符 (sic → sic**k**)
+- 颠倒次序 (a**c**t → **c**at)
+
+请求示例:
+
+```json
+GET /my_index/_search
+{
+ "query": {
+ "fuzzy": {
+ "title": {
+ "value": "quick",
+ "fuzziness": "2"
+ }
+ }
+ }
+}
+```
+
+`fuzziness`是编辑距离,即:**编辑成正确字符所需要挪动的字符的数量**
+
+### 参数
+
+- **value**:必须,关键词。
+- **fuzziness**:编辑距离,范围是(0,1,2),并非越大越好,过大召回率高但结果不准确,默认是:AUTO,即自动从0~2取值。
+ - 两段文本之间的Damerau-Levenshtein距离是使一个字符串与另一个字符串匹配所需的插入、删除、替换和调换的数量。
+ - 距离公式:Levenshtein是lucene的概念,ES做了改进,使用的是基于Levenshtein的Damerau-Levenshtein,比如:axe=>aex。 Levenshtein会算作2个距离,而Damerau-Levenshtein只会算成1个距离。
+- **transpositions**:可选,布尔值,指示编辑是否包括两个相邻字符的变位(ab→ba),默认为true,使用的是Damerau-Levenshtein,如果为false,就会使用Levenshtein去计算。
+
+## 短语前缀:match_phrase_prefix
+
+先来了解下match_phrase,match_phrase检索有如下特点:
+
+- match_phrase会分词。
+- 被检索字段必须包含match_phrase中的所有词项并且顺序必须是相同的。
+- 默认被检索字段包含的match_phrase中的词项之间不能有其他词项。
+
+`match_phrase_prefix`与`match_phrase`相同,但是它多了一个特性,就是它允许在文本的最后一个词项(term)上的前缀匹配。
+
+如果是一个单词,比如a,它会匹配文档字段所有以a开头的文档,如果是一个短语,比如 "this is ma" ,他会先在倒排索引中做以ma做前缀搜索,然后在匹配到的doc中以 "this is" 做match_phrase查询。
+
+`match_phrase_prefix` 查询是一种结合了短语匹配和前缀匹配的查询方式。它用于在某个字段中匹配包含指定短语前缀的文档。
+
+具体来说,`match_phrase_prefix` 查询会将查询字符串分成两部分:前缀部分和后缀部分。然后它会先对前缀部分进行短语匹配,找到以该短语开头的文档片段;接下来,针对符合前缀匹配的文档片段,再对后缀部分进行前缀匹配,从而进一步筛选出最终匹配的文档。
+
+以下是 `match_phrase_prefix` 查询的示例:
+
+```
+GET /my_index/_search
+{
+ "query": {
+ "match_phrase_prefix": {
+ "title": {
+ "query": "quick brown f",
+ "max_expansions": 10
+ }
+ }
+ }
+}
+```
+
+解释:
+
+- 在上述示例中,我们执行了一个 `match_phrase_prefix` 查询。
+- 查询字段为 `title`,我们要求匹配的短语是 "quick brown f"。
+- `max_expansions` 参数用于控制扩展的前缀项数量(默认为 50)。这里我们设置为 10,表示最多扩展 10 个前缀项进行匹配。
+
+`match_phrase_prefix` 查询适用于需要同时支持短语匹配和前缀匹配的场景。例如,当用户输入一个搜索短语的前缀时,可以使用该查询来获取相关的文档结果。
+
+### 参数
+
+- **analyzer**:指定何种分析器来对该短语进行分词处理。
+- **max_expansions**:限制匹配的最大词项,有点类似SQL中的limit,默认值是50。
+- **boost**:用于设置该查询的权重。
+- **slop**:允许短语间的词项(term)间隔,slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配,相隔多远意思就是说为了让查询和文档匹配你需要移动词条多少次,默认是0。
+
+## ngram & edge ngram
+
+ngram 和 edge ngram 是两种用于分析和索引文本的字符级别的分词器。
+
+- **ngram**:ngram 分词器将输入的文本按照指定的长度切割成一系列连续的字符片段。例如,对于字符串 "Hello",使用 2-gram(双字符)分词器会生成 ["He", "el", "ll", "lo"]。
+- **edge ngram**:edge ngram 分词器是 ngram 分词器的一种特殊形式,它只会产生从单词开头开始的 ngram 片段。例如,对于字符串 "Hello",使用 2-gram(双字符)edge ngram 分词器会生成 ["He", "el"]。 edge ngram作用类似fuzzy,但是性能要比fuzzy好,当然也更占用磁盘空间,原因是因为edge ngram对更细粒度的token创建了索引。
+
+参数:
+
+- **min_gram**:创建索引所拆分字符的最小阈值。
+- **max_gram**:创建索引所拆分字符的最大阈值。
+
+以下是一个示例来说明如何在 Elasticsearch 中使用 ngram 和 edge ngram 分词器:
+
+```json
+PUT /my_index
+{
+ "settings": {
+ "analysis": {
+ "analyzer": {
+ "my_ngram_analyzer": {
+ "tokenizer": "my_ngram_tokenizer"
+ },
+ "my_edge_ngram_analyzer": {
+ "tokenizer": "my_edge_ngram_tokenizer"
+ }
+ },
+ "tokenizer": {
+ "my_ngram_tokenizer": {
+ "type": "ngram",
+ "min_gram": 2,
+ "max_gram": 4
+ },
+ "my_edge_ngram_tokenizer": {
+ "type": "edge_ngram",
+ "min_gram": 2,
+ "max_gram": 10
+ }
+ }
+ }
+ },
+ "mappings": {
+ "properties": {
+ "title": {
+ "type": "text",
+ "analyzer": "my_ngram_analyzer"
+ },
+ "keyword": {
+ "type": "text",
+ "analyzer": "my_edge_ngram_analyzer"
+ }
+ }
+ }
+}
+```
+
+在上述示例中,我们创建了一个名为 `my_index` 的索引,定义了两个不同的分词器和对应的字段映射:
+
+- `my_ngram_analyzer` 使用了 ngram 分词器,适用于处理 `title` 字段。
+- `my_edge_ngram_analyzer` 使用了 edge ngram 分词器,适用于处理 `keyword` 字段。
+
+通过在查询时指定相应的分析器,可以使用这些分词器来进行文本搜索、前缀搜索等操作。
+
+注意:ngram 作为 tokenizer 的时候会把空格也包含在内,而作为 token filter 时,空格不会作为处理字符。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\267\261\345\272\246\345\210\206\351\241\265\351\227\256\351\242\230.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\267\261\345\272\246\345\210\206\351\241\265\351\227\256\351\242\230.md"
new file mode 100644
index 0000000..00ea092
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\346\267\261\345\272\246\345\210\206\351\241\265\351\227\256\351\242\230.md"
@@ -0,0 +1,370 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+ES的深度分页问题指的是在大数据集和大页数的情况下,通过持续向后翻页来获取查询结果的一种性能问题。当页码非常高时,ES需要遍历大量文档才能找到正确的分页位置,导致性能和查询速度变慢。
+
+## 深度分页(Deep Paging)
+
+分页是Elasticsearch中最常见的查询场景之一,正常情况下分页代码如下所示:
+
+```json
+GET my_index/_search
+{
+ "from": 0,
+ "size": 5
+}
+```
+
+以下是一个示例响应输出,具体结果会根据实际数据而有所不同:
+
+```json
+{
+ "took" : 10,
+ "timed_out" : false,
+ "_shards" : {
+ "total" : 1,
+ "successful" : 1,
+ "skipped" : 0,
+ "failed" : 0
+ },
+ "hits" : {
+ "total" : {
+ "value" : 100,
+ "relation" : "eq"
+ },
+ "max_score" : 1.0,
+ "hits" : [
+ {
+ "_index" : "my_index",
+ "_type" : "_doc",
+ "_id" : "1",
+ "_score" : 1.0,
+ "_source" : {
+ "title" : "Document 1",
+ "content" : "This is the content of document 1."
+ }
+ }
+ ......
+ ]
+ }
+}
+```
+
+在上述示例中,响应包含了以下信息:
+
+- took:执行搜索所花费的时间(以毫秒为单位)。
+- timed_out:指示搜索是否超时。
+- _shards:索引的分片信息。
+- hits:包含了搜索结果的对象。
+ - `total`:匹配到的文档总数。
+ - `max_score`:最高得分的文档的分值。
+ - `hits`:实际匹配到的文档数组。
+
+但是当我们查询的数据页数特别大, `from + size`大于 `10000`的时候,就会出现问题。
+
+```json
+GET my_index/_search
+{
+ "from": 10000,
+ "size": 5
+}
+```
+
+报错信息如下所示:
+
+> "reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10005]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
+
+报错信息的解释为当前查询的结果超过了 `10000`的最大值,这个错误表示请求中的偏移量(`from`)加上大小(`size`)超过了索引级别参数 `index.max_result_window` 所允许的限制。
+
+默认情况下,该限制为10000,由 `max_result_window` 参数控制。在示例中,请求指定的`from`值为10000加上`size`值为5,总计为10005,超过了默认限制。
+
+## 深度分页的性能问题和危害
+
+首先我们要达成一个共识:
+
+分页查询的时候数据肯定是按照某种顺序排列的,ES中如果不人工指定排序字段,那么最终结果将按照相关度评分排序。
+
+**分布式系统都面临着同一个问题,数据的排序不可能在同一个节点完成**
+
+举个例子:比如我想在一个拥有10万名考生的索引中查询成绩排在10001~10100位的100名考生信息。
+
+这个看似简单的查询实际上并不简单。
+
+假设我们有一个名为"exam_info"的索引,其中存放着10万名考生的考试信息。
+
+由于Elasticsearch的分布式特性和数据分片策略,索引数据在写入时无法预知后续业务查询的具体排序规则,因此数据的排序是随机的。
+
+而且,为了提高数据的准确性,在Elasticsearch中,数据会被均匀地分布在多个分片中。
+
+假设现在有5个分片,并且每个分片中有2万条有效数据。根据需求,我们需要查询成绩排在10001到10100位的一百名考生的信息。为了实现这个目标,首先需要按照成绩进行倒序排列,然后查询按照成绩排序的10001到10100位的学生信息。
+
+在单机数据库中,这个查询逻辑相对简单,只需将10万名学生的成绩排序,然后从前10100条数据中取出第10001~10100条数据,即按照每页100名学生的方式查询第101页的数据。
+
+**然而,在分布式数据库中,情况就不同了,考生的成绩被分散保存在每个分片中,无法保证要查询的这一百名考生的成绩都在同一个分片中**
+
+实际上,结果很可能分布在每个分片中。换句话说,从任意一个分片中取出的前10100名考生的成绩,都不一定是总成绩的前10100名。
+
+**为了解决这个问题,唯一的方法是从每个分片中取出当前分片的前10100名考生的成绩,然后进行汇总(合并排序),再从汇总后的数据中查询前10100名的成绩。只有这样才能确保查询到的成绩是整个索引中的前10100名**
+
+要理解这个过程,可以类比为从保存世界所有国家短跑运动员成绩的索引中查询短跑世界前三名。
+
+每个国家对应一个分片的数据,每个国家会选出成绩最好的前三位运动员参加最后的竞争。然后,从每个国家选出的前三名运动员中再次选出全球前三名。只有经过这两个阶段的筛选和排序,才能得到确切的世界前三名。
+
+现在知道为什么深度分页会导致性能问题了吧。
+
+**每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在Heap中的,也就是说当你单次查询的数量越大,那么堆内存中汇总的数据也就越多,对内存的压力也就越大**
+
+这里的单次查询的数据量取决于你查询的是第几条数据而不是查询了几条数据,比如你希望查询的是第 `10001~10100`这一百条数据,但是ES必须将前 `10100`条全部取出进行二次查询。
+
+因此,如果查询的数据排序越靠后,就越容易导致OOM(Out Of Memory)情况的发生,频繁的深分页查询会导致频繁的FGC。
+
+ES为了避免用户在不了解其内部原理的情况下而做出错误的操作,设置了一个阈值,即 `max_result_window`,其默认值为 `10000`,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。其作用是为了保护堆内存不被错误操作导致溢出。
+
+ `max_result_window` 的合理大小是需要通过各项指标参数来衡量确定的,比如用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
+
+## 深度分页解决方案
+
+### 滚动查询:Scroll Search
+
+Scroll Search是一种用于处理大量数据的分批次查询机制。通过使用滚动搜索,可以在不影响性能的情况下逐批次地获取结果集。
+
+假设我们有一个名为"exam_info"的索引,其中存放着10万名考生的考试信息。我们希望按照成绩进行倒序排序,并获取前100名考生的信息。
+
+示例输入:
+
+```json
+GET /exam_info/_search?scroll=5m
+{
+ "size": 100,
+ "sort": [
+ { "score": "desc" }
+ ]
+}
+```
+
+参数解释:
+
+- `scroll`:定义滚动搜索的时间间隔。这里设置为5分钟,在5分钟内完成整个滚动搜索操作。
+- `size`:每个滚动搜索批次返回的文档数量。这里设置为100,表示每次获取100个考生的信息。
+- `sort`:指定按照成绩字段("score")进行倒序排序。
+
+示例输出:
+
+```json
+{
+ "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACsFlRlQjNqSVh0VzIwdXk4UnhOTmdSc2cAAAAAADFLW0xjb3VkT1dHcG9uejZtZURxS3oxMw==",
+ "hits": {
+ "total": 100000,
+ "max_score": null,
+ "hits": [
+ { "name": "John", "score": 98 },
+ { "name": "Alice", "score": 97 },
+ { "name": "Bob", "score": 95 },
+ ...
+ ]
+ }
+}
+```
+
+输出解释:
+
+- `_scroll_id`:滚动搜索的标识符,用于后续获取下一批次结果。
+- `hits.total`:符合查询条件的总文档数。这里为10万。
+- `hits.hits`:当前批次返回的文档列表,每个文档包含考生的姓名("name")和成绩("score")。
+
+在获得第一批结果后,可以使用滚动搜索的Scroll API来获取下一批结果,直到获取完整的结果集。
+
+示例输入:
+
+```json
+GET /_search/scroll
+{
+ "scroll": "5m",
+ "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACsFlRlQjNqSVh0VzIwdXk4UnhOTmdSc2cAAAAAADFLW0xjb3VkT1dHcG9uejZtZURxS3oxMw=="
+}
+```
+
+示例输出:
+
+```json
+{
+ "_scroll_id": "DXF1ZXJ5VGhlbkZldGNoBQAAAAAAAACsFlRlQjNqSVh0VzIwdXk4UnhOTmdSc2cAAAAAADFLW0xjb3VkT1dHcG9uejZtZURxS3oxMw==",
+ "hits": {
+ "total": 100000,
+ "max_score": null,
+ "hits": [
+ { "name": "Eric", "score": 94 },
+ { "name": "Catherine", "score": 93 },
+ { "name": "David", "score": 92 },
+ ...
+ ]
+ }
+}
+```
+
+继续使用Scroll API获取后续批次的结果,直到滚动搜索结束。
+
+相关参数的含义:
+
+- `scroll`:定义滚动搜索的时间间隔。指定一个合适的时间段,确保在这个时间内能够完成整个滚动搜索操作。默认为1分钟,时间单位应越小越好,够当前查询使用即可。
+
+时间单位:
+
+| `d` | Days |
+| -------- | ------------ |
+| `h` | Hours |
+| `m` | Minutes |
+| `s` | Seconds |
+| `ms` | Milliseconds |
+| `micros` | Microseconds |
+| `nanos` | Nanoseconds |
+
+- `size`:每个滚动搜索批次返回的文档数量。
+
+
+
+Scroll Search 无法保存索引状态,原因是滚动搜索是一种临时的、游标式的查询机制,仅用于获取大量数据的分批次结果。它并不会保留索引状态或缓存查询结果。
+
+当执行滚动搜索时,Elasticsearch会创建一个滚动上下文(scroll context),该上下文存储了关于初始查询的一些信息,包括查询条件、排序方式等。然后,每次使用滚动上下文来获取下一批结果时,Elasticsearch都会根据该上下文重新执行查询以返回新的结果。这样可以确保在整个滚动搜索过程中,能够按顺序逐步获取完整的结果集。
+
+然而,滚动搜索并不会保存查询结果或索引的快照。一旦滚动上下文被使用完毕(超过滚动时间间隔或已经遍历完所有结果),它就会被丢弃,并且之前返回的结果将不能再重现。如果需要持久化查询结果或经常使用相同的滚动上下文进行查询,可能需要考虑其他方法,如将结果存储在自定义的数据结构中或使用游标分页等技术。
+
+注意:
+
+- Scroll上下文的存活时间是滚动的,下次执行查询会刷新,也就是说,不需要足够长来处理所有数据,它只需要足够长来处理前一批结果。保持旧段处于活动状态意味着需要更多的磁盘空间和文件句柄。确保您已将节点配置为具有充足的空闲文件句柄。
+- 为防止因打开过多Scrolls而导致的问题,ES不允许用户打开超过一定限制的Scrolls。默认情况下,打开Scrolls的最大数量为 500。此限制可以通过 `search.max_open_scroll_context`集群设置进行更新 。
+
+Scroll 超时后,搜索上下文会自动删除。然而,保持Scrolls打开是有代价的,因此一旦不再使用就应明确清除Scroll上下文。
+
+```json
+#清除单个
+DELETE /_search/scroll
+{
+ "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
+}
+
+#清除多个
+DELETE /_search/scroll
+{
+ "scroll_id" : [
+ "scroll_id1",
+ "scroll_id2"
+ ]
+}
+
+#清除所有
+DELETE /_search/scroll/_all
+```
+
+总而言之,滚动搜索是一种方便的分批次查询机制,但不适合长期保存查询结果或索引状态。它主要用于处理大量数据的查询,以提高性能和效率。
+
+### Search After
+
+Search After 是一种基于游标的分页查询机制,用于获取大量数据的连续结果。与滚动搜索不同,Search After适用于持久化保存查询状态,并支持随时获取下一页结果。
+
+假设我们有一个名为"exam_info"的索引,其中存放着10万名考生的考试信息。我们希望按照成绩进行倒序排序,并获取前100名考生的信息。
+
+示例输入:
+
+```json
+GET /exam_info/_search
+{
+ "size": 100,
+ "sort": [
+ { "score": "desc" }
+ ]
+}
+```
+
+参数解释:
+
+- `size`:每页返回的文档数量。这里设置为100,表示每次获取100个考生的信息。
+- `sort`:指定按照成绩字段("score")进行倒序排序。
+
+示例输出:
+
+```json
+{
+ "took": 5,
+ "timed_out": false,
+ "_shards": {
+ "total": 1,
+ "successful": 1,
+ "skipped": 0,
+ "failed": 0
+ },
+ "hits": {
+ "total": 100000,
+ "max_score": null,
+ "hits": [
+ { "name": "John", "score": 98 },
+ { "name": "Alice", "score": 97 },
+ { "name": "Bob", "score": 95 },
+ ...
+ ]
+ }
+}
+```
+
+输出解释:
+
+- `took`:查询所花费的时间,单位为毫秒。
+- `hits.total`:符合查询条件的总文档数。这里为10万。
+- `hits.hits`:当前页返回的文档列表,每个文档包含考生的姓名("name")和成绩("score")。
+
+在获得第一页结果后,可以使用Search After来获取下一页的结果。
+
+示例输入:
+
+```json
+GET /exam_info/_search
+{
+ "size": 100,
+ "sort": [
+ { "score": "desc" }
+ ],
+ "search_after": [97]
+}
+```
+
+参数解释:
+
+- `size`:每页返回的文档数量。与初始请求保持一致。
+- `sort`:指定按照成绩字段进行倒序排序。与初始请求保持一致。
+- `search_after`:指定上一页最后一条数据的排序值,以此作为游标进行下一页查询。
+
+示例输出:
+
+```json
+{
+ "took": 2,
+ "timed_out": false,
+ "_shards": {
+ "total": 1,
+ "successful": 1,
+ "skipped": 0,
+ "failed": 0
+ },
+ "hits": {
+ "total": 100000,
+ "max_score": null,
+ "hits": [
+ { "name": "Eva", "score": 94 },
+ { "name": "Daniel", "score": 93 },
+ { "name": "Catherine", "score": 92 },
+ ...
+ ]
+ }
+}
+```
+
+Search After 和 Scroll Search 的主要区别如下:
+
+- 结果排序:Search After依赖排序字段进行分页,需要指定相应的排序方式。而Scroll Search可以根据查询条件对结果进行排序。
+- 时间限制:Search After没有时间限制,可按需获取结果。而Scroll Search需要设置滚动时间间隔,超过该时间将失去滚动上下文。
+
+总结起来,ES的深度分页在处理大规模数据集时是一项非常有用的功能,深度分页查询可能会面临一些性能和可靠性方面的挑战,需要根据具体情况进行权衡和优化。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md"
new file mode 100644
index 0000000..2102c25
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md"
@@ -0,0 +1,326 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+[TOC]
+
+本篇主要是介绍Elasticsearch中索引的基本操作API,即增删改查(CRUD)。
+
+## 创建索引
+
+```JSON
+PUT /my_index?pretty
+```
+
+`?pretty`是一个可选参数,如果加上,Elasticsearch 将返回格式化(即缩进、换行等使结果更易读)过的 JSON。
+
+输出示例:
+
+```json
+{
+ "acknowledged" : true,
+ "shards_acknowledged" : true,
+ "index" : "my_index"
+}
+```
+
+这个输出表示索引已成功创建。`"acknowledged": true` 表示请求已被接受,`"shards_acknowledged": true` 表示所有的分片都已经准备就绪,`"index": "my_index"` 是你刚才创建的索引名称。
+
+## 删除索引
+
+```JSON
+DELETE /my_index?pretty
+```
+
+假设 `my_index` 索引存在并已成功删除,则输出如下:
+
+```json
+{
+ "acknowledged" : true
+}
+```
+
+这个响应表示Elasticsearch已确认删除请求。
+
+**注意:该操作是不可逆的,一旦删除,所有存储在索引中的数据都将被永久移除,因此在执行此操作时务必谨慎**
+
+## 查询数据
+
+请求:
+
+```json
+GET /my_index/_search
+{
+ "query": {
+ "match": {
+ "field_name": "my_value"
+ }
+ }
+}
+```
+
+在此示例中,我们在名为 `my_index` 的索引上进行搜索,查找字段 `field_name` 中值为 `my_value` 的文档。
+
+响应:
+Elasticsearch返回的响应包括一系列关于查询的信息,例如查询所花费的时间、是否超时、命中的文档数等。同时,返回的结果也会包括所有匹配的文档。
+
+```json
+{
+ "took": 30,
+ "timed_out": false,
+ "_shards": {
+ "total": 5,
+ "successful": 5,
+ "skipped": 0,
+ "failed": 0
+ },
+ "hits": {
+ "total": {
+ "value": 1,
+ "relation": "eq"
+ },
+ "max_score": 1.0,
+ "hits": [
+ {
+ "_index": "my_index",
+ "_type": "_doc",
+ "_id": "1",
+ "_score": 1.0,
+ "_source": {
+ "field_name": "my_value"
+ }
+ }
+ ]
+ }
+}
+```
+
+请注意,以上只是基本的示例,实际ES查询可能会复杂得多,包含过滤、聚合、排序等多种操作。
+
+获取所有索引数据的信息
+
+```JSON
+GET _cat/indices?v
+```
+
+示例输出:
+
+```
+health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
+green open .kibana_task_manager_1 C9SW_Y7cQ8-TJQGArKRcDA 1 0 2 0 31.8kb 31.8kb
+yellow open my_index 7V75Rtf1QBCslQvWWPOS2A 1 1 0 0 283b 283b
+green open .apm-agent-configuration en6N1awvRZSLySqh0yjleA 1 0 0 0 283b 283b
+green open .kibana_1 9-gHntOQTCeM8RqViBAaog 1 0 8 1 19.1kb 19.1kb
+```
+
+返回的结果会包含以下列:
+
+- `health`:索引的健康状态。它可以是"green"(一切正常),"yellow"(至少所有主分片都是可用的,但不是所有副本分片都可用)或者"red"(有主分片无法使用)。
+- `status`:索引的状态。通常情况下,可能的值是"open"或"close"。
+- `index`:索引的名称。
+- `uuid`:代表索引的唯一标识符。
+- `pri`:主分片的数量。
+- `rep`:每个主分片的副本数。
+- `docs.count`:存储在索引中的文档数量。
+- `docs.deleted`:已删除但尚未完全从存储中移除的文档数量。
+- `store.size`:索引当前占用的总物理存储空间。
+- `pri.store.size`:主分片占用的物理存储空间。
+
+查询指定文档id
+
+```JSON
+GET /my_index/_doc/doc_id
+```
+
+返回如下:
+
+```json
+{
+ "_index": "my_index",
+ "_type": "_doc",
+ "_id": "1",
+ "_version": 3,
+ "_seq_no": 2,
+ "_primary_term": 2,
+ "found": true,
+ "_source": {
+ "field1": "123",
+ "field2": "456"
+ }
+}
+```
+
+这个命令会返回一个包含以下字段的 JSON 响应:
+
+- `_index`:文档所在的索引。
+- `_type`:文档的类型。在 7.x 版本中,这通常是 `_doc`。
+- `_id`:文档的 ID。
+- `_version`: 文档的版本号。每当文档更新时,此数字都会增加。
+- `_seq_no`:序列号,每次对文档进行操作时此数字会增加。
+- `_primary_term`: 主要期限数,主要用于处理并发控制。
+- `found`:如果找到了文档,则此值为 true;否则,为 false。
+- `_source`: 文档的原始内容。
+
+如果没有找到与给定 ID 匹配的文档,Elasticsearch 会返回一个状态码为 404 的响应,并且 `found` 字段的值将为 false。
+
+## 添加 & 更新数据
+
+```JSON
+PUT /index/_doc/doc_id
+{
+ JSON数据
+}
+
+//例如:PUT /my_index/_doc/1
+//{
+// "field1": "123",
+// "field2": "456"
+//}
+```
+
+PUT既可以用于添加数据,也可以用于更新数据,比如我想更新文档 1 的name字段为:小明,可以这么写:
+
+```JSON
+PUT /my_index/_doc/1
+{
+"name": "小明"
+}
+```
+
+**注意:PUT既可以用于插入,也可以用于更新,所以PUT的更新是全量更新,而不是部分更新。也就是上面的语句执行之后,文档会被直接替换,只会有name字段,字段值为小明**
+
+如果我们只想部分更新文档中的字段,可以使用POST,示例如下:
+
+```JSON
+POST /index/_update/1
+{
+ "doc": {
+ "name": "小明"
+ }
+}
+```
+
+这个命令只会更新文档中的 name 字段为小明。其他字段还是保留原样。
+
+## cat命令
+
+cat命令在ES中会经常使用,下面介绍cat命令中常用的几个命令。
+
+### 参数
+
+cat命令组成形式是:`GET /_cat/indices?format=json&pretty`, `?`之前是命令,之后是参数,多个参数用`&`分隔。
+
+参数有下:
+
+```JSON
+//v 显示更加详细的信息
+GET /_cat/master?v
+//help 显示命令结果字段说明
+GET /_cat/master?help
+//h 显示命令结果想要展示的字段
+GET /_cat/master?h=ip,node
+GET /_cat/master?h=i*,node
+//format 显示命令结果展示格式,支持格式类型:text json smile yaml cbor
+GET /_cat/indices?format=json&pretty
+//s 显示命令结果按照指定字段排序
+GET _cat/indices?v&s=index:desc,docs.count:desc
+```
+
+### 常用命令
+
+**aliases :显示别名**
+
+```JSON
+GET /_cat/aliases
+```
+
+获取所有索引别名,如果想获得某个索引的别名可以使用:`GET index/alias`。
+
+**allocation :显示每个节点的分片数和磁盘使用情况**
+
+```JSON
+GET /_cat/allocation
+```
+
+**count :显示整个集群或者索引的文档个数**
+
+```JSON
+GET /_cat/count
+GET /_cat/count/index
+```
+
+**fielddata :显示每个节点字段所占的堆空间**
+
+```JSON
+GET /_cat/fielddata
+GET /_cat/fielddata?fields=name,addr
+```
+
+**health :显示集群是否健康**
+
+```JSON
+GET /_cat/health
+```
+
+**indices :显示索引的情况**
+
+```JSON
+GET /_cat/indices
+GET /_cat/indices/index
+```
+
+**master: 显示master节点信息**
+
+```JSON
+GET /_cat/master
+```
+
+**nodes :显示所有node节点信息**
+
+```JSON
+GET /_cat/nodes
+```
+
+**recovery :显示索引恢复情况**
+
+当索引迁移的任何时候都可能会出现恢复情况,例如,快照恢复、复制更改、节点故障或节点启动期间。
+
+```JSON
+GET /_cat/recovery
+```
+
+**thread_pool :显示每个节点线程运行情况**
+
+```JSON
+GET /_cat/thread_pool
+GET /_cat/thread_pool/bulk
+GET /_cat/thread_pool/bulk?h=id,name,active,rejected,completed
+```
+
+**shards :显示每个索引各个分片的情况**
+
+展示索引的各个分片,主副分片,文档个数,所属节点,占存储空间大小等信息。
+
+```JSON
+GET /_cat/shards
+GET /_cat/shards/index
+GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
+```
+
+分片的状态:`INITIALIZING`初始化;`STARTED`分配完成;`UNASSIGNED`不能分配;可以通过`unassigned.reason`属性查看不能分配的原因。
+
+**segments :显示每个segment的情况**
+
+包括属于索引,节点,主副,文档数等
+
+```JSON
+GET /_cat/segments
+GET /_cat/segments/index
+```
+
+**templates :显示每个template的情况**
+
+```JSON
+GET /_cat/templates
+GET /_cat/templates/mytempla*
+```
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md"
new file mode 100644
index 0000000..70f6b1e
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md"
@@ -0,0 +1,211 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+Elasticsearch 提供了 `_mget` 和 `_bulk` API 来执行批量操作,它允许你在单个 HTTP 请求中进行多个索引获取/删除/更新/创建操作。这种方法比发送大量的单个请求更有效率。
+
+## 基于 mget 的批量查询
+
+mget(multi-get) API用于批量检索多个文档。它可以通过一次请求获取多个文档的内容,并提供了一些参数来控制检索行为。下面是mget API的请求示例、响应示例以及一些常用参数的含义:
+
+请求示例:
+
+```json
+POST /_mget
+{
+ "docs": [
+ {
+ "_index": "my_index",
+ "_id": "1"
+ },
+ {
+ "_index": "my_index",
+ "_id": "2"
+ }
+ ]
+}
+```
+
+上述示例中,我们向`my_index`索引发出一个mget请求,要求检索id为1和2的两个文档。
+
+响应示例:
+
+```json
+{
+ "docs": [
+ {
+ "_index": "my_index",
+ "_id": "1",
+ "_source": {
+ "field1": "value1",
+ "field2": "value2"
+ },
+ "found": true
+ },
+ {
+ "_index": "my_index",
+ "_id": "2",
+ "_source": {
+ "field1": "value3",
+ "field2": "value4"
+ },
+ "found": true
+ }
+ ]
+}
+```
+
+上述示例中,响应结果中包含了每个请求文档的结果。每个结果都有`_source`字段,其中包含了文档的实际内容。同时,还有一个`found`字段指示是否找到了对应的文档。
+
+以下是一些常用的mget参数及其含义:
+
+- `_index`:指定索引名称,表示要检索的文档所在的索引。
+- `_id`:指定文档的唯一标识符,用于唯一确定要检索的文档。
+- `_source`:设置为false可以禁用返回文档的内容,只返回元数据信息。默认为true,返回完整的文档内容。
+- `stored_fields`:指定要返回的存储字段(stored fields),用逗号分隔多个字段名。这些字段必须在映射中设置了`store`属性才能被返回。
+- `_source_includes`和`_source_excludes`:允许选择性地包含或排除返回文档中的特定字段,以控制返回结果的内容。
+- `routing`:指定文档的路由值,用于决定将文档存储在哪个分片上。如果索引设置了自定义路由策略,必须提供正确的路由值。
+
+这些参数可以通过请求体中的每个文档对象进行设置,例如:
+
+```json
+{
+ "_index": "my_index",
+ "_id": "1",
+ "_source": false,
+ "stored_fields": "field1"
+}
+```
+
+## 基于 bulk 的批量增删改
+
+bulk API允许执行批量的索引、删除和更新操作。它可以通过一次请求同时处理多个操作,提高数据的写入效率。
+
+bulk API中,请求是通过一行一行的JSON数据进行定义的。每个操作(索引、删除、更新)都需要按照特定格式写在一行中。
+
+格式要求如下:
+
+1. 每个操作必须以一个操作描述符开始,例如`index`、`delete`、`update`。
+2. 操作描述符后面必须跟着一个JSON对象,该对象包含操作所需的参数和数据。
+3. 每个操作及其对应的JSON数据必须用换行符分隔。
+
+示例:
+
+```
+{操作描述符}
+{JSON数据}
+{操作描述符}
+{JSON数据}
+...
+```
+
+注意以下几点:
+
+- 请求数据中的每一行都必须是有效的JSON格式,且不能有多余的空格或换行符。
+- 在一个bulk请求中,可以包含任意数量的操作。
+- bulk请求可以一次性执行多个操作,提高效率,但也会增加单个请求的复杂性和长度。
+
+下面是bulk API的请求示例、响应示例以及一些常用参数的含义。
+
+请求示例:
+
+```json
+POST /_bulk
+{"index":{"_index":"my_index","_id":"1"}}
+{"field1":"value1","field2":"value2"}
+{"delete":{"_index":"my_index","_id":"2"}}
+{"update":{"_index":"my_index","_id":"3"}}
+{"doc":{"field1":"updated_value"}}
+```
+
+上述示例展示了一个包含三个操作的bulk请求:
+
+1. 索引(index)操作:将一个新文档插入到`my_index`索引中,指定唯一标识符为1。
+2. 删除(delete)操作:从`my_index`索引中删除唯一标识符为2的文档。
+3. 更新(update)操作:将`my_index`索引中唯一标识符为3的文档进行更新。
+
+响应示例:
+
+```json
+{
+ "took": 15,
+ "errors": false,
+ "items": [
+ {
+ "index": {
+ "_index": "my_index",
+ "_id": "1",
+ "_version": 1,
+ "result": "created",
+ "status": 201
+ }
+ },
+ {
+ "delete": {
+ "_index": "my_index",
+ "_id": "2",
+ "_version": 2,
+ "result": "deleted",
+ "status": 200
+ }
+ },
+ {
+ "update": {
+ "_index": "my_index",
+ "_id": "3",
+ "_version": 2,
+ "result": "updated",
+ "status": 200
+ }
+ }
+ ]
+}
+```
+
+上述示例展示了每个操作的响应结果。每个结果都包含了与对应操作相关的元数据信息,如索引名称、文档ID、版本号、操作结果(如创建、删除、更新)以及HTTP状态码。
+
+以下是一些常用的bulk参数及其含义:
+
+- `index`:指定要执行索引操作的索引名称和文档ID。
+- `delete`:指定要执行删除操作的索引名称和文档ID。
+- `update`:指定要执行更新操作的索引名称和文档ID。
+- `doc`:在更新操作中,用于指定要更新的字段和值。
+- `retry_on_conflict`:在并发更新时,设置重试次数以处理冲突,默认为0,表示不进行重试。
+- `pipeline`:指定在索引操作期间使用的管道ID,用于预处理文档。
+
+这些参数需要在每个操作的请求行中进行设置,例如:
+
+```json
+{"index":{"_index":"my_index","_id":"1","pipeline":"my_pipeline"}}
+```
+
+## filter_path
+
+在 Elasticsearch 中,`filter_path`参数用于过滤返回的响应内容,可以用于减小 Elasticsearch 返回的数据量。当你指明一个或多个路径时,返回的 JSON 对象就只会包含这些路径下的键,它接收一个逗号分隔的列表,其中包含了你想要返回的 JSON 对象内的路径。这个参数支持通配符(`*`)匹配和数组元素(`[]`)匹配。列如:
+
+```
+POST /_bulk?filter_path=items.*.error
+```
+
+上述请求中的 `filter_path=items.*.error` 会让 Elasticsearch 仅返回 `_bulk` API 调用结果中的错误信息。`items.*.error` 这个路径表示,在返回的响应中,匹配到所有存在 `error` 字段的 `items`。
+
+这样做有两个主要好处:
+
+1. 它可以提升 Elasticsearch 的性能,因为少量的数据意味着更快的序列化和反序列化。
+2. 它可帮助你聚焦于感兴趣的部分,不必处理无关的数据。
+
+请注意,`*` 是通配符,代表任何值。
+
+以下是一些其他 `filter_path` 的示例:
+
+- `filter_path=took`: 这个请求仅返回执行请求所花费的时间(以毫秒为单位)。
+- `filter_path=items._id,items._index`: 这个请求仅返回每个 item 的 `_id` 和 `_index` 字段。
+- `filter_path=items.*.error`: 这个请求会返回所有包含 `error` 字段的 items。
+- `filter_path=hits.hits._source`: 这个请求仅返回搜索结果中的原始文档内容。
+- `filter_path=_shards, hits.total`: 这个请求返回关于 `shards` 的信息和命中的总数。
+- `filter_path=aggregations.*.value`: 这个请求仅返回每个聚合的值。
+
+请注意,如果你在 `filter_path` 中指定了多个字段,你需要使用逗号将它们分隔开。
\ No newline at end of file
diff --git "a/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\256\241\347\220\206.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\256\241\347\220\206.md"
new file mode 100644
index 0000000..b82b4ad
--- /dev/null
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\256\241\347\220\206.md"
@@ -0,0 +1,444 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+
+[TOC]
+
+在Elasticsearch中,索引是对数据进行组织和存储的基本单元。索引管理涉及创建、配置、更新和删除索引,以及与索引相关的操作,如数据导入、搜索和聚合等。这些关键任务直接影响着系统性能、数据可用性和查询效率。
+
+本文将深入探讨ES索引管理的重要性和最佳实践。我们将介绍索引模板的概念及其用途,了解如何通过索引别名实现无缝切换和版本控制。我们还将探讨滚动索引的概念,它可以帮助应对长期运行的查询和保持数据的时效性。
+
+## 常用索引API
+
+### _cat
+
+通过使用 `_cat API`,可以快速查看和监控集群的状态、索引的健康情况、节点间分片的分配情况等。这些接口提供了轻量级和易于使用的方式来获取集群信息,为管理员和开发人员提供了便利。
+
+| API | 描述 |
+| ----------------------------- | ------------------------------------ |
+| `_cat/allocation` | 获取分片分配信息 |
+| `_cat/count` | 获取索引文档计数信息 |
+| `_cat/fielddata` | 获取字段数据缓存信息 |
+| `_cat/health` | 获取集群健康状态信息 |
+| `_cat/indices` | 获取索引信息 |
+| `_cat/master` | 获取主节点信息 |
+| `_cat/nodeattrs` | 获取节点属性信息 |
+| `_cat/nodes` | 获取节点信息 |
+| `_cat/pending_tasks` | 获取挂起任务信息 |
+| `_cat/plugins` | 获取插件信息 |
+| `_cat/recovery` | 获取分片恢复信息 |
+| `_cat/repositories` | 获取仓库信息 |
+| `_cat/thread_pool` | 获取线程池信息 |
+| `_cat/shards` | 获取分片信息 |
+| `_cat/snapshots` | 获取快照信息 |
+| `_cat/tasks` | 获取任务信息 |
+| `_cat/templates` | 获取索引模板信息 |
+| `_cat/segments` | 获取段信息 |
+| `_cat/aliases/{alias}` | 根据别名获取指定索引的别名信息 |
+| `_cat/indices/{index}` | 根据索引名称获取指定索引的详细信息 |
+| `_cat/shards/{index}` | 根据索引名称获取指定索引的分片信息 |
+| `_cat/recovery/{index}` | 根据索引名称获取指定索引的恢复信息 |
+| `_cat/segments/{index}` | 根据索引名称获取指定索引的段信息 |
+| `_cat/tasks/{task_id}` | 根据任务ID获取指定任务的详细信息 |
+| `_cat/snapshots/{repository}` | 根据仓库名称获取指定仓库中的快照信息 |
+| `_cat/nodeattrs/{node_id}` | 根据节点ID获取指定节点的属性信息 |
+
+### _cluster
+
+通过使用 `_cluster API`,可以获得集群的健康状况、资源使用情况,进行集群级别的配置和管理操作。这些接口提供了对集群的细粒度控制和监控能力,帮助您保持集群的稳定性、优化性能,并进行故障排除和调试。
+
+请注意,访问 `_cluster API` 需要具有适当的权限。使用这些接口时,请确保遵循 Elasticsearch 的安全最佳实践,并谨慎处理敏感信息。
+
+| API | 描述 |
+| --------------------------------------- | -------------------------- |
+| `_cluster/allocation/explain` | 解释分片分配相关信息 |
+| `_cluster/health` | 获取集群健康状态信息 |
+| `_cluster/pending_tasks` | 获取挂起任务信息 |
+| `_cluster/reroute` | 重新路由分片 |
+| `_cluster/state` | 获取集群状态信息 |
+| `_cluster/stats` | 获取集群统计信息 |
+| `_cluster/settings` | 获取或更改集群级别的设置 |
+| `_cluster/recovery` | 获取正在进行的分片恢复信息 |
+| `_cluster/nodes/hot_threads` | 获取热线程信息 |
+| `_cluster/nodes/info` | 获取节点信息 |
+| `_cluster/nodes/reload_secure_settings` | 重新加载安全设置 |
+| `_cluster/nodes/stats` | 获取节点统计信息 |
+| `_cluster/pending_tasks` | 获取待处理的任务列表 |
+| `_cluster/remote/info` | 获取远程集群连接信息 |
+
+### 判断索引是否存在
+
+```JSON
+HEAD
+```
+
+### 打开和关闭索引
+
+在生产环境有时要禁止索引做读写操作,此时可以对索引执行关闭。
+
+**打开索引**
+
+```JSON
+POST /_open
+```
+
+**关闭索引**
+
+```JSON
+POST /_close
+```
+
+## 索引压缩
+
+索引压缩并不是指压缩索引的大小,而是压缩索引的分片。
+
+例如:有一个名为 `my_index`的索引有6个主分片,压缩为只有2个主分片,称之为索引压缩。
+
+### 前提条件
+
+- 进行压缩的时候,索引必须是只读状态。
+- 目标索引的所有主分片必须位于同一节点(因为创建目标索引时会将段从源索引硬链接到目标索引,而硬链接是不支持跨节点的。如果文件系统不支持硬链接,则会将所有segment file都复制到新索引中,复制过程很耗时)。
+- 索引的健康状态必须为Green。
+- 目标索引不能已存在,避免重名。
+- 目标索引的分片数量必须为源索引的约数,比如我源索引分片数为6,那么目标索引的分片数只能为:1,2,3,6。
+- 目标节点所在的服务器确保有足够大的磁盘空间。
+
+### 操作步骤
+
+1. **备份数据,以防数据丢失,不做强制要求**
+
+```json
+POST _reindex
+{
+ "source": {
+ "index": "source_index"
+ },
+ "dest": {
+ "index": "target_index"
+ }
+}
+```
+
+注意:索引比较大的情况下,`_reindex` 操作可能耗时会比较久。
+
+2. **设置副本数为0**
+
+```json
+"index.number_of_replicas": 0
+```
+
+关闭副本数主要是为了只做一份数据的压缩,重复数据没必要同步两次。
+
+3. **设置只读**
+
+设置索引为只读状态,在索引压缩的时候,数据是不可写的。
+
+```json
+"index.blocks.write": true
+```
+
+4. **迁移数据**
+
+```json
+"index.routing.allocation.require._name": "target_node"
+```
+
+`index.routing.allocation.require`是Elasticsearch中的索引级别设置,用于指定分配索引分片的要求条件。通过设置该参数,可以控制分配策略,将索引的分片分配到特定的节点或节点标签。
+
+具体使用方式如下:
+
+设置分片的要求条件:
+
+```json
+PUT /my_index/_settings
+{
+ "index.routing.allocation.require.node_type": "hot"
+}
+```
+
+上述示例将索引`my_index`的分片要求分配到拥有`node_type=hot`标签的节点上。
+
+5. **执行压缩命令**
+
+```json
+POST /my_index/_shrink/target_index
+{
+ "settings": {
+ "index.number_of_replicas": 1,
+ "index.number_of_shards": 3,
+ //索引压缩算法
+ "index.codec": "best_compression"
+ }
+}
+```
+
+`reindex`和`shrink`是Elasticsearch中用于重新索引和缩减索引的两个不同操作,它们具有以下区别:
+
+Reindex(重新索引):
+
+- `reindex`操作用于将数据从一个索引复制到另一个索引,并可以在此过程中进行转换、筛选或重塑数据。
+- 通过`reindex`操作,可以更改索引的映射、调整分片设置、修改文档内容等。
+- `reindex`操作是非破坏性的,原始索引和目标索引同时存在,可以逐步迁移数据。
+
+Shrink(缩减索引):
+
+- `shrink`操作用于减少索引的分片数量,将一个大的索引缩减为更小的索引。
+- 通过`shrink`操作,可以将原始索引的分片合并为较少数量的目标索引分片。
+- `shrink`操作通常用于优化索引性能、减少资源占用、提高查询效率等。注意,缩减索引会导致一定的数据迁移开销。
+
+关键区别:
+
+- `reindex`是复制数据并对其进行转换的过程,可以在任何时候执行,并且不需要目标索引事先存在。它允许更灵活地处理数据,并且可以应用各种转换逻辑。
+- `shrink`是减少索引分片数量的操作,只能在满足特定条件的情况下执行。它主要用于优化索引性能和资源利用。
+
+总结来说,`reindex`用于数据的复制和转换,而`shrink`用于缩减索引的分片数量以提高性能。具体选择哪个操作取决于需求和目标。
+
+6. **恢复索引**
+
+```json
+PUT target_index/_settings
+{
+ //允许分配到任意节点
+ "index.routing.allocation.require._name": null,
+ "index.blocks.write": false
+}
+```
+
+索引压缩完成,此时可以逐步将业务从源索引切流到目标索引上,可以使用alias来完成切流过程。
+
+## 索引别名
+
+索引别名是个非常重要并且非常实用的功能
+
+### 别名作用
+
+**官方描述**
+
+索引别名是用于引用一个或多个现有索引的辅助名称,大多数 Elasticsearch API 接受索引别名来代替索引。
+
+Elasticsearch 的所有 API 都会自动将别名转换为实际的索引名称。一个别名也可以映射到多个索引,当指定它时,别名会自动扩展为别名索引。别名也可以与搜索时自动应用的过滤器和路由值相关联。别名不能与索引同名。
+
+**保护索引**
+
+索引相对于调用者是隐藏的。
+
+### 使用场景
+
+索引别名在Elasticsearch中具有以下用途和使用场景:
+
+- 通过使用别名,可以为不同版本的索引创建不同的别名,并在切换版本时轻松进行索引升级和回滚。
+- 可以先创建一个新的索引并将别名指向新索引,然后平滑地将读写操作从旧索引切换到新索引。
+- 通过别名,可以将多个索引组合成一个逻辑集合,并对集合进行查询或操作。这样做可以方便地处理大量数据,实现数据分片和分布式搜索。
+- 使用别名可以为不同的用户、应用程序或租户创建独立的别名,以实现数据的隔离和多租户支持。
+- 别名还可以用于按照特定规则将请求路由到不同的索引,以实现负载均衡或按时间范围进行数据分片。
+
+这些只是一些使用场景的例子,实际上别名功能非常灵活,可以根据具体需求进行定制。索引别名为用户提供了更大的灵活性和可管理性,使得在进行索引维护、升级或数据操作时更加方便和安全。
+
+### 使用
+
+**语法**
+
+```json
+POST /_aliases
+```
+
+下面是一个使用`_aliases` API 创建和删除别名的示例,以及相应的输入和输出:
+
+**创建别名**
+
+- 输入:
+
+ ```json
+ POST /_aliases
+ {
+ "actions": [
+ { "add": { "index": "my_index", "alias": "my_alias" } }
+ ]
+ }
+ ```
+
+- 输出:
+
+ ```json
+ {
+ "acknowledged": true
+ }
+ ```
+
+ 解释:通过以上输入,将索引`my_index`与别名`my_alias`进行关联。输出中的`acknowledged`字段为`true`表示操作已成功。
+
+**删除别名**
+
+- 输入:
+
+ ```json
+ POST /_aliases
+ {
+ "actions": [
+ { "remove": { "index": "my_index", "alias": "my_alias" } }
+ ]
+ }
+ ```
+
+- 输出:
+
+ ```json
+ {
+ "acknowledged": true
+ }
+ ```
+
+ 解释:通过以上输入,解除索引`my_index`与别名`my_alias`的关联。输出中的`acknowledged`字段为`true`表示操作已成功。
+
+
+注意:
+
+- 一个索引可以绑定多个别名,一个别名也可以绑定多个索引。
+- 别名不能和索引名相同。
+
+## 索引模版
+
+索引模板(Index Template)是在Elasticsearch中用于自动创建和配置索引的一种机制。它允许你定义索引的设置、映射和别名等,并在新索引满足特定条件时自动应用这些配置。
+
+索引模板的主要目的是为了简化索引管理和维护工作,并确保新创建的索引具有一致的结构和配置。
+
+索引模板在企业生产实践中常配合滚动索引(Rollover Index)、索引的生命周期管理(ILM:Index lifecycle management)、数据流一起使用。
+
+以下是索引模板的核心概念和用法:
+
+- 索引名称模式(index_patterns):
+ - 索引模板通过`index_patterns`参数定义一个或多个与索引名称匹配的模式。
+ - 模式通常包含一个固定的前缀和一个通配符,如`my_index-*`,其中`*`表示通配符部分。
+ - 当新索引的名称与模式匹配时,该模板将被应用到新索引上。
+- 设置和配置(settings):
+ - 索引模板可以定义新索引的各种设置和配置,例如分片数量、副本数量、刷新间隔等。
+ - 这些设置将自动应用到新索引上,确保新索引的行为与模板定义的一致。
+- 映射(mappings):
+ - 通过索引模板,您可以定义新索引的字段映射、属性和数据类型等。
+ - 索引模板中的映射配置将自动应用到新索引上,确保新索引的结构与模板定义的一致。
+- 别名(aliases):
+ - 索引模板可以定义一个或多个别名,用于管理和访问新创建的索引。
+ - 别名可以被用作查询、索引操作等,而不需要直接指定特定的索引名称。
+
+通过使用索引模板,可以根据业务需求和索引管理的最佳实践来定义一套统一的索引创建和配置规则。当创建新的满足模式匹配条件的索引时,Elasticsearch会自动应用该模板,并创建带有预定义设置、映射和别名的索引。
+
+下面是一个示例请求,用于创建名为`my_index_template`的索引模板:
+
+```json
+PUT _index_template/my_index_template
+{
+ "index_patterns": ["my_index-*"],
+ "template": {
+ "settings": {
+ "number_of_shards": 5,
+ "number_of_replicas": 1
+ },
+ "mappings": {
+ "properties": {
+ "field1": {
+ "type": "text"
+ },
+ "field2": {
+ "type": "keyword"
+ }
+ }
+ },
+ "aliases": {
+ "my_alias": {}
+ }
+ }
+}
+```
+
+在上述示例中:
+
+- `_index_template/my_index_template`表示要创建的索引模板的名称。
+- `index_patterns`参数设置了匹配的索引名称模式,这里使用了通配符`*`来适配任意后缀。
+- `template`字段指定了要应用于新索引的设置、映射和别名等配置。
+- `settings`定义了新索引的分片数为5,副本数为1。
+- `mappings`指定了新索引的字段映射配置,其中`field1`为文本类型,`field2`为关键字类型。
+- `aliases`定义了一个别名`my_alias`,用于访问该索引。
+
+通过发送以上请求,您可以创建一个名为`my_index_template`的索引模板。当新创建的索引名称满足`my_index-*`的模式时,该模板将自动应用到新索引上,并使新索引具有预定义的设置、映射和别名。
+
+## 滚动索引
+
+滚动索引(Rollover Index)是Elasticsearch中用于管理索引自动切换和维护的一种机制。它允许在索引达到预定义条件时,自动创建新的索引并将写入流量切换到新索引上,以实现索引的平滑滚动和分片维护。
+
+使用滚动索引的主要场景是处理大容量和高吞吐量的数据,并确保索引的性能和可伸缩性。
+
+下面是滚动索引(Rollover Index)的基本工作流程:
+
+1. 创建索引模板(Index Template):
+ - 首先,你需要创建一个索引模板,其中包含指定条件以触发滚动操作的设置。这些条件可以是基于时间、文档数量、索引大小等来定义。
+2. 创建初始索引(Initial Index):
+ - 使用索引模板创建初始索引,该索引将用于接收初始的数据写入流量。
+3. 监控索引状态:
+ - 持续监控当前索引的状态和指标,如文档数量、索引大小等。
+ - 当索引达到预定义的条件时,即满足了滚动的触发条件,就会开始进行滚动操作。
+4. 触发滚动操作:
+ - 当索引满足触发条件时,Elasticsearch将自动创建新的索引,同时将写入流量切换到新索引上。
+ - 新索引可以具有更高的分片数、新的配置参数和优化设置,以确保整个系统的性能和可用性。
+5. 后续维护和操作:
+ - 一旦滚动操作完成,你可以对旧索引进行必要的维护操作,如关闭、删除或备份。
+ - 您还可以使用滚动名称(Alias)来管理所有滚动的索引,以便于查询和操作。
+
+通过使用滚动索引(Rollover Index),可以实现自动化的索引管理和平滑的索引切换,同时为数据处理和存储提供了更好的可伸缩性和性能。它特别适用于需要处理大量数据并保证系统稳定性的场景,如日志记录、时间序列数据等。
+
+### 触发条件
+
+滚动索引(Rollover Index)的触发条件是通过索引模板中的一些参数来定义的。以下是常用的触发条件及其参数:
+
+- 文档数量触发条件:
+ - `max_docs`:指定索引中的文档数量上限,达到该值时触发滚动操作。
+- 索引大小触发条件:
+ - `max_size`:指定索引的大小上限,达到该值时触发滚动操作。
+ - `max_size_bytes`:与`max_size`类似,但使用字节数表示索引大小上限。
+- 时间触发条件:
+ - `max_age`:指定索引的最大存储时间,超过该时间时触发滚动操作。
+ - `max_age_seconds`:与`max_age`类似,但以秒为单位表示存储时间上限。
+- 自定义触发条件:
+ - `conditions`:允许您自定义其他触发条件,例如基于字段的特定规则或复杂逻辑判断。
+
+这些触发条件参数可以在索引模板中进行配置,以根据具体需求定义何时触发滚动操作。可以同时使用多个触发条件,也可以选择仅使用其中部分来触发滚动操作。
+
+例如,以下是一个示例索引模板的定义,其中包含了文档数量和时间两个触发条件:
+
+```json
+PUT _template/my_template
+{
+ "index_patterns": ["my_index*"],
+ "settings": {
+ "number_of_shards": 5
+ },
+ "mappings": {
+ "_source": {
+ "enabled": true
+ }
+ },
+ "aliases": {
+ "my_alias": {}
+ },
+ "rollover": {
+ "max_docs": 100000,
+ "max_age": "7d"
+ }
+}
+```
+
+以上示例中,当索引满足文档数量达到10万或存储时间超过7天的条件之一时,将触发滚动操作。
+
+或者也可以直接调用 `_rollover` API:
+
+```json
+# index_alias 必须是别名 而不能是索引的本名
+POST /index_alias/_rollover
+{
+ "conditions": {
+ "max_age": "7d",
+ "max_docs": 2,
+ "max_size": "5gb"
+ }
+}
+```
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md"
similarity index 65%
rename from "docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md"
rename to "docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md"
index 0dc2100..e639203 100644
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md"
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\201\232\345\220\210\346\237\245\350\257\242.md"
@@ -1,28 +1,44 @@
-## 概念
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
-聚合(aggs)不同于普通查询,是目前学到的第二种大的查询分类,第一种即“query”,因此在代码中的第一层嵌
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
-套由“query”变为了“aggs”。**用于进行聚合的字段必须是exact value,分词字段不可进行聚合**,对于text字段如
+[TOC]
-果需要使用聚合,需要开启fielddata,但是通常不建议,因为fielddata是将聚合使用的数据结构由磁盘
+聚合查询是 Elasticsearch 中一种强大的数据分析工具,用于从索引中提取和计算有关数据的统计信息。聚合查询可以执行各种聚合操作,如计数、求和、平均值、最小值、最大值、分组等,以便进行数据汇总和分析。
-(doc_values)变为了堆内存(field_data),大数据的聚合操作很容易导致OOM。
+下面是一些常见的聚合查询类型:
-## doc values 和 fielddata
+- **Metric Aggregations(指标聚合)**:这些聚合操作返回基于字段值的度量结果,如求和、平均值、最小值、最大值等。常见的指标聚合包括 Sum、Avg、Min、Max、Stats 等。
+- **Bucket Aggregations(桶聚合)**:类比SQL中的group by,主要用于统计不同类型数据的数量,这些聚合操作将文档划分为不同的桶(buckets),并对每个桶中的文档进行聚合计算。常见的桶聚合包括 Terms(按字段值分组)、Date Histogram(按时间间隔分组)、Range(按范围分组)等。
+- **Pipeline Aggregations(管道聚合)**:这些聚合操作通过在其他聚合结果上执行额外的计算来产生新的聚合结果。例如,使用 Moving Average 聚合可以计算出移动平均值。
-在 Elasticsearch 中,聚合操作主要依赖于 doc values 或 fielddata 来进行。
+聚合查询通常与查询语句结合使用,可以在查询结果的基础上进行进一步的数据分析和统计。聚合查询语法使用 JSON 格式,可以通过 Elasticsearch 的 REST API 或各种客户端库进行发送和解析。
-1. **Doc values**:对于大多数字段类型,Elasticsearch 使用 doc values 进行排序和聚合。doc values 是一种在磁盘上的、列式存储的数据结构,适用于稀疏字段,也就是字段中有很多不同的值。它们默认开启,并且不能被禁用。
-2. **Fielddata**:对于TEXT字段,doc values 默认是关闭的,因为文本字段通常包含很多不同的值,使用 doc values 会消耗大量内存。这时候,如果需要对文本字段进行聚合或排序,Elasticsearch 使用 fielddata。fielddata 是一个将所有文档的字段值加载到内存的数据结构,使用它可以使得聚合、排序和脚本运行更快,但代价是消耗更多的内存。
+聚合查询支持嵌套,即一个聚合内部可以包含别的子聚合,从而实现非常复杂的数据挖掘和统计需求。
-当执行聚合操作时,Elasticsearch 需要访问所有匹配文档的字段值。对于非文本字段,默认情况下
+在ES中,用于进行聚合的字段可以是exact value也可以是分词字段,对于分词字段,可以使用特定的聚合操作来进行分组聚合,例如Terms Aggregation、Date Histogram Aggregation等。
-Elasticsearch 使用 doc values 来实现。对于文本字段,必须首先启用 fielddata。然而,由于 fielddata 占用大量内存,Elasticsearch 默认禁用了它。
+对于text字段的聚合,可以通过开启fielddata来实现,但通常不建议这样做,因为fielddata会将聚合使用的数据结构从磁盘(doc_values)转换为堆内存(field_data),在处理大量数据时容易导致内存溢出(OOM)问题。
-对于文本字段,fielddata 默认是禁用的。如果你确实需要对一个文本字段启用 fielddata(虽然大多数场景下不推荐这么做,因为可能导致内存消耗过大),你可以通过更新映射(mapping)来实现。以下是如何在 `my_field` 字段上启用 fielddata 的示例:
+如果需要在text字段上执行聚合,可以考虑在该字段上添加.keyword子字段,并使用该子字段进行聚合操作,以获得更准确的结果。
+
+## doc_values & fielddata
+
+在 Elasticsearch 中,聚合操作主要依赖于 doc_values 或 fielddata 来进行。
+
+- **Doc Values(文档值)**:Doc Values 是一种以列式存储格式保存字段值的数据结构,它用于支持快速的聚合、排序和统计操作。Doc Values 在磁盘上存储,并被加载到 JVM 堆内存中进行计算。它们适用于精确值(如 keyword 类型)和数字类型的字段,在大多数情况下是默认启用的。
+- **Fielddata(字段数据)**:Fielddata 是一种将字段值加载到堆内存中的数据结构,它用于支持复杂的文本分析和聚合操作。Fielddata 适用于文本类型的字段,例如 text 类型,因为它们需要进行分词和分析。但是,由于 Fielddata 需要大量的堆内存资源,特别是在处理大数据集时,容易导致内存溢出(OOM)的问题,因此不建议随意启用。
+
+在设计索引时,需要根据字段类型和使用场景的不同,合理选择是否启用 Doc Values 或 Fielddata,以平衡性能和资源消耗的需求。
+
+当执行聚合操作时,Elasticsearch 需要访问所有匹配文档的字段值。对于非文本字段,默认情况下Elasticsearch 使用 doc values 来实现。对于文本字段,必须首先启用 fielddata。然而,由于 fielddata 占用大量内存,Elasticsearch 默认禁用了它。
+
+如果你确实需要对一个文本字段启用 fielddata(虽然大多数场景下不推荐这么做,因为可能导致内存消耗过大),你可以通过更新映射(mapping)来实现。
+
+以下是如何在 `my_field` 字段上启用 fielddata 的示例:
```JSON
-PUT my-index/_mapping
+PUT my_index/_mapping
{
"properties": {
@@ -34,11 +50,11 @@ PUT my-index/_mapping
}
```
-注意,更改 fielddata 设置只会影响新的数据,已经索引的数据不会受到更改。如果你想让更改生效,需要重新索引(reindex)你的数据。
+**注意:更改 fielddata 设置只会影响新的数据,已经索引的数据不会受到更改。如果你想让更改生效,需要重新索引(reindex)你的数据**
-另外,一般情况下,建议你使用 mapping 中的 `keyword` 类型来进行聚合、排序或脚本,而不是启用 `text` 类型的 fielddata。这是因为 `keyword` 类型字段默认开启了 doc values,比在 `text` 上启用 fielddata 更加高效且节省内存。
+另外,一般情况下,建议使用 mapping 中的 `keyword` 类型来进行聚合、排序或脚本,而不是启用 `text` 类型的 fielddata。这是因为 `keyword` 类型字段默认开启了 doc values,比在 `text` 上启用 fielddata 更加高效且节省内存。
-## multi-fields(多字段)类型
+## multi-fields
在 Elasticsearch 中,一个字段有可能是 multi-fields(多字段)类型,这意味着同一份数据可以被索引为不同类型的字段。常见的情况就是,一个字段既被索引为 `text` 类型用于全文搜索,又被索引为 `keyword` 类型用于精确值搜索、排序和聚合。
@@ -48,15 +64,9 @@ PUT my-index/_mapping
如果你的字段没有 `.keyword` 子字段,那可能是在定义 mapping 时没有包含这一部分,或者这个字段的类型本身就是 `keyword`。
-## 聚合分类
+## 分桶聚合
-- 分桶聚合(Bucket agregations):类比SQL中的group by的作用,主要用于统计不同类型数据的数量。
-- 指标聚合(Metrics agregations):主要用于最大值、最小值、平均值、字段之和等指标的统计。
-- 管道聚合(Pipeline agregations):用于对聚合的结果进行二次聚合,如要统计绑定数量最多的标签bucket,就是要先按照标签进行分桶,再在分桶的结果上计算最大值。
-
-### 分桶聚合
-
-分桶(bucketing)聚合是一种特殊类型的聚合,它将输入文档集合中的文档分配到一个或多个桶中,每个桶都对应于一个键(key)。
+分桶(Bucket)聚合是一种特殊类型的聚合,它将输入文档集合中的文档分配到一个或多个桶中,每个桶都对应于一个键(key)。
下面是一些常用的分桶聚合类型:
@@ -90,7 +100,30 @@ GET /blog/_search
Elasticsearch 将返回一个包含每个作者以及他们所写的文章数量的列表。注意,由于 Elasticsearch 默认只返回前十个桶,如果你的数据中有更多的作者,可能需要设置 `size` 参数来获取更多的结果。
-### 指标聚合
+### Histogram
+
+`histogram` 是桶聚合的一种类型,它可以按照指定的间隔将数字字段的值划分为一系列桶。每个桶代表了这个区间内的所有文档。
+
+以下是一个例子,我们根据价格字段创建一个间隔为 50 的直方图:
+
+```JSON
+GET /products/_search
+{
+ "size": 0,
+ "aggs" : {
+ "prices" : {
+ "histogram" : {
+ "field" : "price",
+ "interval" : 50
+ }
+ }
+ }
+}
+```
+
+在这个例子中,“prices” 是一个 histogram 聚合,它以 50 为间隔将产品的价格划分为一系列的桶。
+
+## 指标聚合
在 Elasticsearch 中,指标聚合是对数据进行统计计算的一种方式,例如求和、平均值、最小值、最大值等。以下是一些常用的指标聚合类型:
@@ -115,14 +148,32 @@ GET /sales/_search
}
```
-在这个查询中:
+### Percentiles
-- `"size": 0` 表示我们只对聚合结果感兴趣,不需要返回任何具体的搜索结果。
-- `"aggs"` (或者 `"aggregations"`) 块定义了我们的聚合。
-- `"average_price"` 是我们自己为这个聚合命名的标签,可以用任何你喜欢的标签名。
-- `"avg": { "field": "price" }` 定义了我们执行的聚合类型以及对哪个字段进行聚合。在这里,我们告诉 Elasticsearch 使用 `avg` 聚合,并且对 `price` 字段的值进行计算。Elasticsearch 将返回一个包含所有销售记录平均价格的结果。
+`percentiles` 是指标聚合的一种,它用于计算数值字段的百分位数。给定一个列表百分比,Elasticsearch 可以计算每个百分比下的数值。
+
+以下是一个例子,我们计算价格字段的 1st, 5th, 25th, 50th, 75th, 95th, and 99th 百分位数:
+
+```JSON
+GET /products/_search
+{
+ "size": 0,
+ "aggs" : {
+ "price_percentiles" : {
+ "percentiles" : {
+ "field" : "price",
+ "percents" : [1, 5, 25, 50, 75, 95, 99]
+ }
+ }
+ }
+}
+```
+
+在这个例子中,“price_percentiles” 是一个 percentiles 聚合,它计算了价格在各个百分位点的数值。
-#### 去重
+注意,对于大数据集,计算精确的百分位数可能需要消耗大量资源。因此,Elasticsearch 默认使用一个名为 `TDigest` 的算法来提供近似的计算结果,同时还能保持内存使用的可控性。
+
+### cardinality
如果你想在 Elasticsearch 中进行去重操作,可以使用 `terms` 聚合加上 `cardinality` 聚合。这是一个示例,假设我们有一个包含user_id的 "users" 索引,并且我们想要知道有多少唯一的 user_id:
@@ -145,11 +196,13 @@ GET /users/_search
- `"distinct_user_ids"` 是我们自己为这个聚合命名的标签。
- `"cardinality": { "field": "user_id.keyword" }` 使用了 `cardinality` 聚合,该聚合会返回指定字段(在这里是 `user_id.keyword`)的不同值的数量。
-Elasticsearch 将返回一个结果,告诉我们有多少个不同的 user_id。请注意,`cardinality` 聚合可能并不总是完全精确,特别是对于大型数据集,因为它在内部使用了一种叫做 HyperLogLog 的算法来近似计算基数,这种算法会在保持内存消耗相对较小的情况下提供接近准确的结果。如果你需要完全精确的结果,可能需要考虑其他方法,例如使用脚本或者将数据导出到外部系统进行处理。
+Elasticsearch 将返回一个结果,告诉我们有多少个不同的 user_id。请注意,`cardinality` 聚合可能并不总是完全精确,特别是对于大型数据集,因为它在内部使用了一种叫做 `HyperLogLog` 的算法来近似计算基数,这种算法会在保持内存消耗相对较小的情况下提供接近准确的结果。如果你需要完全精确的结果,可能需要考虑其他方法,例如使用脚本或者将数据导出到外部系统进行处理。
+
+## 管道聚合
-### 管道聚合
+在 Elasticsearch 中,管道聚合(pipeline aggregations)是指这样一种聚合:它以其他聚合的结果作为输入,并进行进一步处理。
-在 Elasticsearch 中,管道聚合(pipeline aggregations)是指这样一种聚合:它以其他聚合的结果作为输入,并进行进一步处理。常见的管道聚合包括:
+常见的管道聚合包括:
- `avg_bucket`
- `sum_bucket`
@@ -198,7 +251,7 @@ GET /sales/_search
返回的结果中会包含每个月的平均销售价格,以及所有月份中平均销售价格的最大值。
-### 嵌套聚合
+## 嵌套聚合
嵌套聚合就是在聚合内使用聚合,在 Elasticsearch 中,嵌套聚合通常用于处理 nested 类型的字段。nested 类型允许你将一个文档中的一组对象作为独立的文档进行索引和查询,这对于拥有复杂数据结构(例如数组或列表中的对象)的场景非常有用。
@@ -236,9 +289,11 @@ GET /users/_search
请注意,在处理 nested 数据时,你需要确保 mapping 中相应的字段已经被设置为 nested 类型,否则该查询可能无法按预期工作。
-## 基于查询结果和聚合 & 基于聚合结果的查询
+## 基于查询结果的聚合 & 基于聚合结果的查询
-基于查询结果的聚合: 在这种情况下,我们首先执行一个查询,然后对查询结果进行聚合。例如,如果我们要查询所有包含某关键字的文档,并计算它们的平均价格,可以这样做:
+基于查询结果的聚合:在这种情况下,我们首先执行一个查询,然后对查询结果进行聚合。
+
+例如,如果我们要查询所有包含某关键字的文档,并计算它们的平均价格,可以这样做:
```JSON
GET /products/_search
@@ -260,7 +315,9 @@ GET /products/_search
在上述例子中,我们首先通过 `match` 查询找到描述中包含 "laptop" 的所有产品,然后对这些产品的价格进行平均值聚合。
-基于聚合结果的查询(Post-Filter): 这种情况下,我们先执行聚合,然后基于聚合的结果执行过滤操作。这通常用于在聚合结果中应用一些额外的过滤条件。例如,如果我们想对所有产品进行销售数量聚合,然后从结果中过滤出销售数量大于10的产品,可以这样做:
+基于聚合结果的查询:这种情况下,我们先执行聚合,然后基于聚合的结果执行过滤操作。
+
+这通常用于在聚合结果中应用一些额外的过滤条件。例如,如果我们想对所有产品进行销售数量聚合,然后从结果中过滤出销售数量大于10的产品,可以这样做:
```JSON
GET /sales/_search
@@ -290,6 +347,8 @@ GET /sales/_search
## 聚合排序
+### count
+
在 Elasticsearch 中,聚合排序允许你基于某一聚合的结果来对桶进行排序。例如,你可能希望查看销售量最高的10个产品,可以使用 `terms` 聚合以及其 `size` 和 `order` 参数来实现:
```JSON
@@ -316,7 +375,7 @@ GET /sales/_search
返回的结果将包含销售量最高的前10个产品的 ID 列表。
-需要注意的是,由于 Elasticsearch 默认会对桶进行优化,所以在使用 `size` 参数时可能无法得到完全准确的结果。如果需要更精确的结果,可以在请求中设置 `"size": 0` ,然后使用 `composite` 聚合来分页获取所有结果。
+### term
`_term` 在 Elasticsearch 的聚合排序中用来指定按照词条(即桶的键)来排序。
@@ -336,7 +395,7 @@ GET /sales/_search
}
```
-在这个例子中,`products` 是一个 `terms` 聚合,用于按 `product_id` 对销售记录进行分组,然后通过 `"order": { "_term": "asc" }` 指定了按照 `product_id` 的值升序排序这些桶。
+在这个例子中,通过 `"order": { "_term": "asc" }` 指定了按照 `product_id` 的值升序排序这些桶。
返回的结果将包含按照 `product_id` 升序排列的产品 ID 列表,每个产品 ID 对应一个桶,并且每个桶内包含对应产品的销售记录。
@@ -356,54 +415,4 @@ GET /sales/_search
}
}
}
-```
-
-## **Histogram & Percentiles **
-
-### **Histogram 聚合**
-
-`histogram` 是一个类型的桶聚合,它可以按照指定的间隔将数字字段的值划分为一系列桶。每个桶代表了这个区间内的所有文档。
-
-以下是一个例子,我们根据价格字段创建一个间隔为 50 的直方图:
-
-```JSON
-GET /products/_search
-{
- "size": 0,
- "aggs" : {
- "prices" : {
- "histogram" : {
- "field" : "price",
- "interval" : 50
- }
- }
- }
-}
-```
-
-在这个例子中,“prices” 是一个 histogram 聚合,它以 50 为间隔将产品的价格划分为一系列的桶。
-
-### **Percentiles 聚合**
-
-`percentiles` 是一种度量聚合,它用于计算数值字段的百分位数。给定一个列表百分比,Elasticsearch 可以计算每个百分比下的数值。
-
-以下是一个例子,我们计算价格字段的 1st, 5th, 25th, 50th, 75th, 95th, and 99th 百分位数:
-
-```JSON
-GET /products/_search
-{
- "size": 0,
- "aggs" : {
- "price_percentiles" : {
- "percentiles" : {
- "field" : "price",
- "percents" : [1, 5, 25, 50, 75, 95, 99]
- }
- }
- }
-}
-```
-
-在这个例子中,“price_percentiles” 是一个 percentiles 聚合,它计算了价格在各个百分位点的数值。
-
-注意,对于大数据集,计算精确的百分位数可能需要消耗大量资源。因此,Elasticsearch 默认使用一个名为 `TDigest` 的算法来提供近似的计算结果,同时还能保持内存使用的可控性。
\ No newline at end of file
+```
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md" "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md"
similarity index 76%
rename from "docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md"
rename to "docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md"
index 10c32c3..5e4d2e3 100644
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md"
+++ "b/docs/md/es/\344\270\200\350\265\267\345\255\246Elasticsearch\347\263\273\345\210\227-\350\204\232\346\234\254\346\237\245\350\257\242.md"
@@ -1,3 +1,7 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
[TOC]
Elasticsearch的 Scripting 是一种允许你使用脚本来评估自定义表达式的功能。通过它,你可以实现更复杂的查询、数据处理以及柔性调整索引结构等。
@@ -6,24 +10,13 @@ Elasticsearch支持多种脚本语言。在 ES 中,脚本语言主要是 Painl
以下是一些常见的使用脚本的场景:
-1. **计算字段(Field Calculations)**:你可以使用脚本在查询时动态地改变或添加字段的值。
-2. **脚本查询(Script Queries)**:在查询中使用脚本进行复杂的条件判断。
-3. **脚本聚合(Script Aggregations)**:使用脚本进行更复杂的聚合计算。
+- **计算字段**:你可以使用脚本在查询时动态地改变或添加字段的值。
+- **脚本查询**:在查询中使用脚本进行复杂的条件判断。
+- **脚本聚合**:使用脚本进行更复杂的聚合计算。
使用脚本时需要注意的是,由于涉及到运行时的计算,过度或者不恰当的使用脚本可能会对性能造成影响。另外,由于脚本具有执行任意代码的能力,因此需要确保脚本的使用在一个安全的环境中,并且只运行信任的脚本。
-## 概念
-
-Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定义编程的强大的脚本功能,ES支持多种脚本语言,如painless,其语法类似于Java,也有注释、关键字、类型、变量、函数等,其就要相对于其他脚本高出几倍的性能,并且安全可靠,可以用于内联和存储脚本。
-
-### 支持的语言
-
-- **groovy**:ES 1.4.x-5.0的默认脚本语言。
-- **painless**:JavaEE使用java语言开发,.Net使用C#/F#语言开发,Flutter使用Dart语言开发,同样,ES 5.0+版本后的Scripting使用的语言默认就是painless,painless是一种专门用于Elasticsearch的简单语言,用于内联和存储脚本,是ES 5.0+的默认脚本语言。
-- expression:每个文档的开销较低,表达式的作用更多,可以非常快速地执行,甚至比编写native脚本还要快,支持javascript语法的子集。缺点:只能访问数字,布尔值,日期和geo_point字段,存储的字段不可用。
-- mustache:提供模板参数化查询。
-
-### Painless特点
+## Painless特点
优点:
@@ -37,7 +30,7 @@ Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定
- 相较于DSL性能低
- 不适用于复杂的业务场景
-### 简单例子
+
以下是一个在 Elasticsearch 查询中使用脚本的简单例子。这个例子将会搜索名为 "my_index" 的索引,寻找字段 "price" 和 "tax" 之和大于 100 的文档。
@@ -65,11 +58,11 @@ GET /my_index/_search
这个查询将返回所有 "price" 和 "tax" 之和大于 100 的文档。
-## Scripting的CRUD
+## CRUD
以下是一些使用 Painless 脚本进行的 Elasticsearch CRUD 操作实例:
-### insert(新增)
+**insert(新增)**
```Java
POST product/_update/6 {
@@ -87,7 +80,7 @@ POST product/_update/6 {
因此,整个请求的意思是,在 "product" 索引中,找到 ID 为 6 的文档,并在其 "tags" 字段中添加一个新的元素 '无线充电'。
-### update(更新)
+**update(更新)**
```Java
POST product/_update/2 {
@@ -100,7 +93,7 @@ POST product/_update/2 {
- `POST product/_update/2` 是 HTTP 请求的一部分,它告诉 Elasticsearch 在 "product" 索引中更新 ID 为 2 的文档。
- `"script": "ctx._source.price-=1"` 是请求体,其中的脚本用于执行实际的更新操作。在这个例子中,脚本将当前文档(由 `_source` 指定)的 "price" 字段减去 1。
-### delete(删除)
+**delete(删除)**
```Java
POST product/_update/10 {
@@ -117,7 +110,7 @@ POST product/_update/10 {
- `"script"` 部分中的 `"lang": "painless"` 指定了脚本的语言为 Painless。
- `"source": "ctx.op='delete'"` 是脚本的主体内容。这里,`ctx.op` 是一个特殊变量,表示待执行的操作。当它被设置为 'delete' 时,指示 Elasticsearch 删除当前操作中的文档。
-### upsert(更新插入)
+**upsert(更新插入)**
```Java
POST product/_update/15 {
@@ -141,7 +134,7 @@ POST product/_update/15 {
整个请求的意思是在 "product" 索引中查找 ID 为 15 的文档并使其 "price" 字段增加 100。如果该文档不存在,则会插入一个新的文档,其 "name"、"desc" 和 "price" 字段的值分别为 "小米手机10"、"充电贼快掉电更快" 和 1999。
-### search(查询)
+**search(查询)**
```Java
GET product/_search {
@@ -167,7 +160,7 @@ GET product/_search {
Elasticsearch 会把编译过的脚本储存在缓存中,以提高重复执行同一脚本的性能。当你再次运行相同的脚本时,Elasticsearch 可以直接从缓存中获取已编译的脚本,而不需要再次编译。但是频繁编译脚本会到来性能问题。可以使用参数化脚本动态传参,解决脚本编译的性能问题。
-**参数化脚本在 Elasticsearch 中,是指在编写脚本时使用占位符,并在执行脚本时为这些占位符提供实际值。参数化脚本可以增加脚本的灵活性,并能防止脚本注入攻击**。
+**参数化脚本在 Elasticsearch 中,是指在编写脚本时使用占位符,并在执行脚本时为这些占位符提供实际值。参数化脚本可以增加脚本的灵活性,并能防止脚本注入攻击**
在脚本中,你可以通过 `params` 对象访问到传递的参数。
@@ -229,65 +222,12 @@ GET product / _search {
- `GET product/_search` 是 HTTP 请求的一部分,告诉 Elasticsearch 在 "product" 索引中进行搜索。
-- ```
- "script_fields"
- ```
-
- 部分定义了两个脚本字段:"price" 和 "discount_price"。
-
+- `"script_fields"`部分定义了两个脚本字段:"price" 和 "discount_price"。
- "price" 脚本字段返回每个文档的原始 "price" 字段值;
- "discount_price" 脚本字段返回一个由四个元素组成的数组。数组中的每个元素都是 "price" 字段值与不同折扣率的乘积。这个脚本字段使用了参数化脚本,参数包括四个不同的折扣率:"discount_8", "discount_7", "discount_6" 和 "discount_5"。
因此,整个请求的意思是,在 "product" 索引中搜索所有的文档,并为每个文档计算原始价格和不同折扣率下的价格,然后将这些计算结果作为 "price" 和 "discount_price" 字段返回。
-## 脚本模版
-
-在 Elasticsearch 中,脚本模板就是将脚本的源代码作为字符串存储,在运行时使用参数替换占位符以创建实际的脚本。脚本模板使得你可以重用相同的脚本逻辑,并通过提供不同的参数值来改变其行为。
-
-这种方式与参数化脚本略有不同,参数化脚本只在已经定义的脚本中替换参数。而脚本模板则更加灵活,可以在整个脚本中替换参数,甚至可以改变脚本的结构。
-
-脚本模板的一个主要应用场景是搜索请求。你可能希望根据用户的输入来调整查询的某部分,但又不希望每次都重写整个查询。在这种情况下,你可以创建一个脚本模板,并在其中使用占位符来代表可变的部分。然后,你只需要提供必要的参数就可以执行查询,而无需每次都手动修改查询的源码。
-
-这种做法可以简化代码,增强代码的可读性和可维护性,并且降低了因为拼接字符串导致的错误风险。
-
-下面是一个例子:
-
-```Java
-POST _scripts / calculate_discount {
- "script": {
- "lang": "painless",
- "source": "doc.price.value * params.discount"
- }
-}
-```
-
-这个 Elasticsearch 请求创建了一个名为 `calculate_discount` 的脚本模板。该模板包含一个简单的脚本,用于计算一个文档字段(假设为 "price")的折扣价。"price" 字段值与参数 `params.discount` 相乘,得到折扣后的价格。
-
-这个模板可以在许多不同的地方使用,例如在搜索请求中作为脚本字段或者在更新请求中。只需要提供不同的 `discount` 参数就可以得到不同的折扣价,而无需每次都修改整个脚本源码。
-
-以下是如何在搜索请求中使用这个模板的示例:
-
-```Java
-GET /products/_search
-{
- "query": {
- "match_all": {}
- },
- "script_fields": {
- "discounted_price": {
- "script": {
- "id": "calculate_discount",
- "params": {
- "discount": 0.9
- }
- }
- }
- }
-}
-```
-
-在这个搜索请求中,我们使用了 `calculate_discount` 模板,并提供了一个折扣参数 `0.9`。这个请求会返回所有 "products" 索引中的文档,并且每个文档都会包含一个新的字段 "discounted_price",它的值是原始 "price" 字段值的 90%。
-
## 函数式编程
Elasticsearch 的脚本语言 Painless 支持函数式编程。函数式编程是一种编程范式,它让你能够编写出更加简洁清晰的代码。函数可以作为参数传递给其他函数,也可以从其他函数中返回。
@@ -325,7 +265,7 @@ POST _scripts/calculate_total
如果你需要启用这个功能,可以在 Elasticsearch 的配置文件(`elasticsearch.yml`)里加入以下行:
-```
+```yaml
script.painless.regex.enabled: true
```
@@ -355,10 +295,10 @@ GET /_search
注意正则表达式需要两个反斜杠进行转义,因为 JSON 语法本身也需要对反斜杠进行转义。如果没有 JSON 语法的转义需求,在 Painless 中写正则表达式时只需要一个反斜杠即可。
-## 聚合中使用script
+## 聚合查询中使用Script
```Java
-GET product / _search {
+GET product/_search {
"query": {
"constant_score": {
"filter": {
@@ -396,7 +336,7 @@ GET product / _search {
这样执行之后,你将得到价格小于或等于1000的所有产品,以及每个产品的标签数量。
-## doc 和params
+## doc & params
### doc和params的用法
@@ -460,7 +400,7 @@ GET product / _search {
}
```
-1. `doc['field'].value` 是从Lucene索引中读取字段值,这种方式速度快,效率高。然而,它把数据加载到内存中,可能会增加内存使用。此外,它只能用于简单类型字段,无法处理复杂类型(如object或nested)。
-2. `params['_source']['field']` 是从原始的 `_source` 字段获取数据。这种方式可以访问所有类型的字段,包括复杂类型。但是,这要求加载和解析整个原始JSON文档,因此执行效率较低。
+- `doc['field'].value` 是从Lucene索引中读取字段值,这种方式速度快,效率高。然而,它把数据加载到内存中,可能会增加内存使用。此外,它只能用于简单类型字段,无法处理复杂类型(如object或nested)。
+- `params['_source']['field']` 是从原始的 `_source` 字段获取数据。这种方式可以访问所有类型的字段,包括复杂类型。但是,这要求加载和解析整个原始JSON文档,因此执行效率较低。
所以,如果你的字段是简单类型,并且你关心查询的性能,那么优先使用 `doc['field'].value`。如果你需要处理复杂类型字段或者未索引的字段,那么可以使用 `params['_source']['field']`。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Mapping.md" "b/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Mapping.md"
deleted file mode 100644
index de34686..0000000
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Mapping.md"
+++ /dev/null
@@ -1,290 +0,0 @@
-[TOC]
-
-这篇讲解Elasticsearch中非常重要的一个概念Mapping,Mapping是索引必不可少的组成部分。
-
-## Mapping 的基本概念
-
-**Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分**。
-
-ES 中的 mapping 有点类似与关系型数据库中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
-
-### 查看索引 Mapping
-
-```JSON
-//查看索引完整的mapping
-GET /index/_mappings
-//查看索引指定字段的mapping
-GET /index/_mappings/field/
-```
-
-## 字段数据类型
-
-映射的数据类型也就是 ES 索引支持的数据类型,其概念和 MySQL 中的字段类型相似,但是具体的类型和 MySQL 中有所区别,最主要的区别就在于 ES 中支持可分词的数据类型,如:Text 类型,可分词类型是用以支持全文检索的,这也是 ES 生态最核心的功能。
-
-### 数字类型
-
-- **long**:64 位有符号整形。
-- **integer**:32 位有符号整形。
-- **short**:16 位有符号整形。
-- **byte**:8位有符号整形。
-- **double**:双精度 64位浮点类型。
-- **float**:单精度 64位浮点类型。
-- **half_float**:半精度 64位浮点类型。
-- **scaled_float**:缩放类型浮点数,按固定 double 比例因子缩放。
-- **unsigned_long**:无符号 64 位整数。
-
-### 基本数据类型
-
-- **binary**:Base64 字符串二进制值。
-- **boolean**:布尔类型,接收 ture 和 false 两个值。
-- **alias**:字段别名。
-
-### Keywords 类型
-
-- **keyword**:适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能通过精确值搜索到。如 Id、姓名这类字段应使用 keyword。
-- **constant_keyword**:始终包含相同值的关键字字段。
-- **wildcard**:可针对类似 grep 的场景。
-
-### Dates(时间类型)
-
-- **date**:JSON 没有日期数据类型,因此 Elasticsearch 中的日期可以是以下三种:
- - 包含格式化日期的字符串:例如 "2015-01-01"、 "2015/01/01 12:10:30"。
- - 时间戳:表示自"1970年 1 月 1 日"以来的毫秒数/秒数。
- - date_nanos:此数据类型是对 date 类型的补充。但是有一个重要区别。date 类型存储最高精度为毫秒,而date_nanos 类型存储日期最高精度是纳秒,但是高精度意味着可存储的日期范围小,即:从大约 1970 到 2262。
-
-### 对象类型
-
-- **object**:非基本数据类型之外,默认的 json 对象为 object 类型。
-- **flattened**:单映射对象类型,其值为 json 对象。
-- **nested** :嵌套类型。
-- **join**:父子级关系类型。
-
-### 空间数据类型
-
-- **geo_point**:纬度和经度点。
-- **geo_shape**:复杂的形状,例如多边形。
-- **point**:任意笛卡尔点。
-- **shape**:任意笛卡尔几何。
-
-### 文档排名类型
-
-- **dense_vector**:记录浮点值的密集向量。
-- **rank_feature**:记录数字特征以提高查询时的命中率。
-- **rank_features**:记录数字特征以提高查询时的命中率。
-
-### 文本搜索类型
-
-- **text**:文本类型。
-- **annotated-text:**包含特殊文本标记,用于标识命名实体。
-- **completion** :用于自动补全,即搜索推荐。
-- **search_as_you_type:** 类似文本的字段,经过优化为提供按类型完成的查询提供现成支持。
-- **token_count**:文本中的标记计数。
-
-## 两种映射类型
-
-### 自动映射:Dynamic Field Mapping
-
-| **field type** | **dynamic** |
-| -------------- | ---------------------------------- |
-| true/false | boolean |
-| 小数 | float |
-| 数字 | long |
-| object | object |
-| 数组 | 取决于数组中的第一个非空元素的类型 |
-| 日期格式字符串 | date |
-| 数字类型字符串 | float/long |
-| 其他字符串 | text + keyword |
-
-除了上述字段类型之外,其他类型都必须显式映射,也就是必须手工指定,因为其他类型ES无法自动识别。
-
-### 显式映射 Expllcit Field Mapping
-
-例如:
-
-```JSON
-PUT test_mapping
-{
- "mappings": {
- "properties": {
- "title": {
- "type": "text"
- },
- "name": {
- "type": "text",
- "fields": {
- "name2": {
- "type": "keyword",
- "ignore_ above": 256
- }
- }
- },
- "age": "byte"
- }
- }
-}
-```
-
-## 映射参数
-
-- **index**:是否对创建对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。
-- **analyzer**:指定分析器(character filter、tokenizer、Token filters)。
-- **boost**:对当前字段相关度的评分权重,默认1。
-- **coerce**:是否允许强制类型转换,为 true的话 “1”能被转为 1, false则转不了。
-- **copy_to**:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询。
-- **doc_values**:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持text和annotated_text)。
-- **dynamic**:控制是否可以动态添加新字段
- - **true** 新检测到的字段将添加到映射中(默认)。
- - **false** 新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
- - **strict** 如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映。
-- **eager_global_ordinals**:用于聚合的字段上,优化聚合性能,但不适用于 Frozen indices。
- - **Frozen indices**(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices 的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。
-- **enable**:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。**enable的作用和index类似,区别就是enable可以对全局进行设置**。例如:
-
-```JSON
-PUT my_index
-{
- "mappings": {
- "enabled": false
- }
-}
-```
-
-- **fielddata**:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。
-- **fields**:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)。
-- **format**:格式化。例如:
-
-```JSON
-"date": {
- "type": "date",
- "format": "yyyy-MM-dd"
-}
-```
-
-- **ignore_above**:超过长度将被忽略。
-- **ignore_malformed**:忽略类型错误。
-- **index_options**:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段。
-- **Index_phrases**:提升 exact_value 查询速度,但是要消耗更多磁盘空间。
-- **Index_prefixes**:前缀搜索。
- - **min_chars**:前缀最小长度> 0,默认 2(包含)
- - **max_chars**:前缀最大长度< 20,默认 5(包含)
-- **meta**:附加元数据。
-- **normalizer**:normalizer 参数用于解析前(索引或者查询时)的标准化配置。
-- **norms**:是否禁用评分(在 filter 和聚合字段上应该禁用)。
-- **null_value**:为 null 值设置默认值。
-- **position_increment_gap**:参考:https://blog.csdn.net/wlei0618/article/details/128189190
-- **properties**:除了mapping还可用于object的属性设置。
-- **search_analyzer**:设置单独的查询时分析器,**如果定义了analyzer而没有定义search_analyzer,则search_analyzer的值默认会和analyzer保持一致,如果两个都没有定义,则默认是:"standard"。analyzer针对的是元数据,而search_analyzer针对的是传入的搜索词**。
-- **similarity**:为字段设置相关度算法,和评分有关。支持BM25、classic(TF-IDF)、boolean。
-- **store**:设置字段是否仅查询。
-- **term_vector**:运维参数。
-
-## Text 和 Keyword 类型
-
-### Text 类型
-
-#### 概述
-
-当一个字段是要被全文搜索的,比如 Email 内容、产品描述,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
-
-#### 注意事项
-
-- 适用于全文检索:如 match 查询。
-- 文本字段会被分词。
-- 默认情况下,会创建倒排索引。
-- 自动映射器会为 Text 类型创建 Keyword 字段。
-
-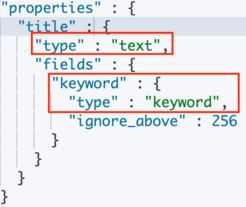
-
-### Keyword 类型
-
-#### 概述
-
-Keyword 类型适用于不分词的字段,如姓名、Id、数字等。如果数字类型不用于范围查找,用 Keyword 的性能要高于数值类型。
-
-#### 语法和语义
-
-如当使用 keyword 类型查询时,其字段值会被作为一个整体,并保留字段值的原始属性。
-
-```JSON
-GET index/_search
-{
- "query": {
- "match": {
- "title.keyword": "测试文本值"
- }
- }
-}
-```
-
-#### 注意事项
-
-- Keyword 不会对文本分词,会保留字段的原有属性,包括大小写等。
-- Keyword 仅仅是字段类型,而不会对搜索词产生任何影响。
-- Keyword 一般用于需要精确查找的字段,或者聚合排序字段。
-- Keyword 通常和 Term 搜索一起用。
-- Keyword 字段的 ignore_above 参数代表其截断长度,默认 256,**如果超出长度,字段值会被忽略,而不是截断,忽略指的是会忽略这个字段的索引,搜索不到,但数据还是存在的**。
-
-## 映射模板
-
-### 简介
-
-之前讲过的映射类型或者字段参数,都是为确定的某个字段而声明的,如果希望对符合某类要求的特定字段制定映射,就需要用到映射模板:Dynamic templates。映射模板有时候也被称作:自动映射模板、动态模板等。
-
-**之前设置mapping的时候,我们明确知道字段名字,但是当我们不确定字段名字的时候该怎么设置mapping?映射模板就是用来解决这种场景的**。
-
-### 用法
-
-#### 基本语法
-
-```JSON
-"dynamic_templates": [
- {
- "my_template_name": {
- ... match conditions ...
- "mapping": { ... }
- }
- },
- ...
-]
-```
-
-#### Conditions参数
-
-- **match_mapping_type** :主要用于对数据类型的匹配。
-- **match 和 unmatch**:用于对字段名称的匹配。
-
-### 案例
-
-```JSON
-PUT test_dynamic_template
-
-{
- "mappings": {
- "dynamic_templates": [
- {
- "integers": {
- "match_mapping_type": "long",
- "mapping": {
- "type": "integer"
- }
- }
- },
- {
- "longs_as_strings": {
- "match_mapping_type": "string",
- "match": "num_*",
- "unmatch": "*_text",
- "mapping": {
- "type": "keyword"
- }
- }
- }
- ]
- }
-}
-```
-
-以上代码会产生以下效果:
-
-- 所有 long 类型字段会默认映射为 integer。
-- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Query DSL.md" "b/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Query DSL.md"
deleted file mode 100644
index feaace6..0000000
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-Query DSL.md"
+++ /dev/null
@@ -1,486 +0,0 @@
-[TOC]
-
-DSL是Domain Specific Language的缩写,指的是为特定问题领域设计的计算机语言。这种语言专注于某特定领域的问题解决,因而比通用编程语言更有效率。
-
-在Elasticsearch(ES)中,DSL指的是Elasticsearch Query DSL,一种以JSON形式表示的查询语言。通过这种语言,用户可以构建复杂的查询、排序和过滤数据等操作。这些查询可以是全文搜索、分面/聚合搜索,也可以是结构化的搜索。
-
-## 查询上下文
-
-使用query关键字进行检索,倾向于相关度搜索,故需要计算评分。搜索是Elasticsearch最关键和重要的部分。
-
-在查询上下文中,一个查询语句表示一个文档和查询语句的匹配程度。无论文档匹配与否,查询语句总能计算出一个相关性分数在`_score`字段上。
-
-## 相关度评分:_score
-
-相关度评分用于对搜索结果排序,评分越高则认为其结果和搜索的预期值相关度越高,即越符合搜索预期值,默认情况下评分越高,则结果越靠前。在7.x之前相关度评分默认使用TF/IDF算法计算而来,7.x之后默认为BM25。
-
-## 源数据:_source
-
-source字段包含索引时原始的JSON文档内容,字段本身不建立索引(因此无法进行搜索),但是会被存储,所以当执行获取请求是可以返回source字段。
-
-虽然很方便,但是source字段的确会对索引产生存储开销,因此可以禁用source字段,达到节省存储开销的目的。可以通过以下接口进行关闭。
-
-```JSON
-PUT my_index
-{
- "mappings": {
- "_source": {
- "enabled": false
- }
- }
-}
-```
-
-但是需要注意的是这么做会带来一些弊端,_source禁用会导致如下功能无法使用:
-
-- 不支持update、update_by_query和reindex API。
-- 不支持高亮。
-- 不支持reindex、更改mapping分析器和版本升级。
-
-**总结:在禁用source之前,应该仔细考虑是否需要进行此操作。如果只是希望降低存储的开销,可以压缩索引比禁用source更好。**
-
-## 数据源过滤器
-
-例如,假设你的应用只需要获取部分字段(如"name"和"price"),而其他字段(如"desc"和"tags")不经常使用或者数据量较大,导致传输和处理这些额外的数据会增加网络开销和处理时间。在这种情况下,通过设置includes和excludes可以有效地减少每次请求返回的数据量,提高效率。例如:
-
-```JSON
-PUT product
-{
- "mappings": {
- "_source": {
- "includes": ["name", "price"],
- "excludes": ["desc", "tags"]
- }
- }
-}
-```
-
-**Including:**结果中返回哪些field。
-
-**Excluding:**结果中不要返回哪些field,不返回的field不代表不能通过该字段进行检索,因为元数据不存在不代表索引不存在,Excluding优先级比Including更高。
-
-> 需要注意的是,尽管这些设置会影响搜索结果中_source字段的内容,但并不会改变实际存储在Elasticsearch中的数据。也就是说,"desc"和"tags"字段仍然会被索引和存储,只是在获取源数据时不会被返回。
-
-在mapping中定义这种方式不推荐,因为mapping不可变。我们可以在查询过程中使用_source指定返回的字段,如下:
-
-```JSON
-GET product/_search
-{
- "_source": {
- "includes": ["owner.*", "name"],
- "excludes": ["name", "desc", "price"]
- },
- "query": {
- "match_all": {}
- }
-}
-```
-
-Elasticsearch的`_source`字段在查询时支持使用通配符(wildcards)来包含或排除特定字段。使得能够更灵活地操纵返回的数据。
-
-关于规则,可以参考以下几点:
-
-- *:匹配任意字符序列,包括空序列。
-- ?:匹配任意单个字符。
-- [abc]: 匹配方括号内列出的任意单个字符。例如,[abc]将匹配"a", "b", 或 "c"。
-
-请注意,通配符表达式可能会导致查询性能下降,特别是在大型索引中,因此应谨慎使用。
-
-## 全文检索
-
-全文检索是Elasticsearch的核心功能之一,它可以高效地在大量文本数据中寻找特定关键词。
-
-在Elasticsearch中,全文检索主要依靠两个步骤:"分析"(Analysis)和"查询"(Search)。
-
-1. 分析: 当你向Elasticsearch索引一个文档时,会进行"分析"处理,将原始文本数据转换成称为"tokens"或"terms"的小片段。这个过程可能包括如下操作:
- - 切分文本(Tokenization)
- - 将所有字符转换为小写(Lowercasing)
- - 删除常见但无重要含义的单词(Stopwords)
- - 提取词根(Stemming)
-2. 查询: 当执行全文搜索时,查询字符串也会经过类似的分析过程,然后再与已经分析过的索引进行比对,找出匹配的结果并返回。
-
-Elasticsearch提供了许多种全文搜索的查询类型,例如:
-
-- Match Query: 最基本的全文搜索查询。
-- Match Phrase Query: 用于查找包含特定短语的文档。
-- Multi-Match Query: 类似Match Query,但可以在多个字段上进行搜索。
-- Query String Query: 提供了丰富的搜索语法,可以执行复杂的、灵活的全文搜索。
-
-### match:匹配包含某个term的子句
-
-```JSON
-GET product/_search
-{
- "query": {
- "match": {
- "name": "xiaomi nfc phone"
- }
- }
-}
-```
-
-上面的搜索语句,只要文档的"name"字段包含"xiaomi"、"nfc"或者"phone"中的任何一个词,就会被视为匹配。
-
-### match_all:匹配所有结果的子句
-
-`match_all` 是 Elasticsearch 中的一个查询类型,它匹配所有文档,不需要任何参数。
-
-```JSON
-GET product/_search
-{
- "query": {
- "match_all": {}
- }
-}
-```
-
-上面的语句等价于:
-
-```JSON
-GET /product/_search
-```
-
-这个查询将会返回索引中的所有文档。这通常用于在没有特定搜索条件时获取所有的文档,或者与其他查询结合使用(如过滤器)。
-
-需要注意,由于 `match_all` 查询可能返回大量的数据,所以一般在使用时都会与分页(pagination)功能结合起来,这样可以控制返回结果的数量,避免一次性加载过多数据导致的性能问题。例如,你可以使用 `from` 和 `size` 参数来限制返回结果:
-
-```JSON
-GET /_search
-{
- "query": {
- "match_all": {}
- },
- "from": 10,
- "size": 10
-}
-```
-
-### multi_match:多字段条件
-
-`multi_match` 查询是 Elasticsearch 中用来在多个字段上执行全文查询的功能。它接受一个查询字符串和一组需要在其中执行查询的字段列表。例如:
-
-```JSON
-GET /_search
-{
- "query": {
- "multi_match" : {
- "query": "xiaomi nfc phone",
- "fields": [ "name", "description" ]
- }
- }
-}`
-```
-
-这个查询会在 "name" 和 "description" 两个字段中查找包含 "xiaomi nfc phone" 的文档。
-
-`multi_match` 还支持多种类型的匹配模式,如:`best_fields`, `most_fields`, `cross_fields`, `phrase`, `phrase_prefix`等。这些类型的行为略有不同,可以按照实际需求进行选择。
-
-例如,“best_fields” 类型会从指定的字段中挑选分数最高的匹配结果计算最终得分,而“most_fields” 类型则会在每个字段中都寻找匹配项并将其分数累加起来。
-
-需要注意的是,当使用 `multi_match` 查询时,如果字段不同,其权重可能也会不同。你可以通过在字段名后面添加尖括号(^)和权重值来调整特定字段的权重。例如,`"fields": [ "name^3", "description" ]`表示在"name"字段中的匹配结果权重是"description"字段的三倍。
-
-### match_phrase:短语查询
-
-`match_phrase` 是 Elasticsearch 中的一种全文查询类型,它用于精确匹配包含指定短语的文档。match_phrase 查询需要字段值中的单词顺序与查询字符串中的单词顺序完全一致。
-
-例如:
-
-```JSON
-GET /_search
-{
- "query": {
- "match_phrase": {
- "message": "this is a test"
- }
- }
-}
-```
-
-这个查询将会找到"message"字段中包含完整短语"this is a test"的所有文档。
-
-此外,`match_phrase` 查询还有一个 `slop` 参数,可以定义词组中的词语可能存在的位置偏移量。例如,如果将 `slop` 设置为 1,则查询 "this is a test" 也可匹配 "this is test a",因为 "a" 和 "test" 只需移动一个位置即可匹配。
-
-## Query String
-
-Query String Query是Elasticsearch中的一种查询方式,它允许你使用特定的搜索语法来进行复杂的、灵活的查询。
-
-Query String Query是基于Lucene Query Parser解析器的,因此支持丰富的搜索语法,包括但不限于:
-
-- 基本文本查询: "quick brown fox"
-- 逻辑操作符 (AND, OR, NOT): "quick AND brown"
-- 范围查询: "age:[18 TO 30]"
-- 通配符查询: "qu?ck br*wn"
-- 分组: "(quick OR brown) AND fox"
-- 字段指定查询: "title:quick"
-
-下面是几个例子:
-
-### 查询所有
-
-```JSON
-GET /product/_search
-```
-
-### 分页
-
-```JSON
-GET /product/_search?from=0&size=2&sort=price:asc
-```
-
-### 精准匹配 exact value
-
-```JSON
-GET /product/_search?q=date:2021-06-01
-```
-
-### _all搜索 相当于在所有有索引的字段中检索
-
-all搜索与精准匹配就是带不带字段参数的区别,如果把index索引禁用,则all搜索不会去该字段上查询。
-
-```JSON
-GET /product/_search?q=2021-06-01
-```
-
-## 精准查询-Term query
-
-精确查询用于查找包含指定精确值的文档,而不是执行全文搜索。
-
-### term:匹配和搜索词项完全相等的结果
-
-举个例子:
-
-```JSON
-GET /_search
-{
- "query": {
- "term": {
- "user": "kimchy"
- }
- }
-}
-```
-
-这个查询会找到"user"字段精确匹配"kimchy"的所有文档。
-
-需要注意的是,`term` 查询对大小写敏感,并且不会进行分词处理。也就是说,如果你在使用 `term` 查询时输入了一个完整的句子,它将尝试查找与这个完整句子精确匹配的文档,而不是把句子拆分成单词进行匹配。
-
-#### term和match_phrase的区别
-
-`term` 查询和 `match_phrase` 查询是 Elasticsearch 提供的两种查询方式,它们都用于查找文档,但主要的区别在于如何解析查询字符串以及匹配的精确度。
-
-1. `term` 查询:这种查询对待查询字符串为一个完整的单位,不进行分词处理,并且大小写敏感。它可以在文本、数值或布尔类型字段上使用,通常用于精确匹配某个字段的确切值。
-2. `match_phrase` 查询:这种查询把查询字符串当作一种短语来匹配。查询字符串会被分词器拆分成单独的词项,然后按照词项在查询字符串中的顺序去匹配文档。只有当文档中的词项顺序与查询字符串中的顺序完全一致时才能匹配成功,match_phrase 查询通常对大小写不敏感,除非你的字段映射或索引设置更改了这个行为。
-
-简单来说,`term` 查询更多的是做精确的、字面的匹配,而 `match_phrase` 则是做短语匹配,在搜索结果的精确度上,`term` 查询比 `match_phrase` 更高。
-
-### terms:匹配和搜索词项列表中任意项匹配的结果
-
-`terms` 查询用于匹配指定字段中包含一个或多个值的文档。这是一个精确匹配查询,不会像全文查询那样对查询字符串进行分析。
-
-假设你有一个 "user" 的字段,并且你想找到该字段值为 "John" 或者 "Jane" 的所有文档,你可以使用 `terms` 查询:
-
-```JSON
-GET /_search
-{
- "query": {
- "terms" : {
- "user" : ["John", "Jane"],
- "boost" : 1.0
- }
- }
-}
-```
-
-上面的查询将返回所有"user" 字段等于 "John" 或者 "Jane" 的文档。
-
-其中`boost` 参数用于增加或减少特定查询的相对权重。它将改变查询结果的相关性分数(_score),以影响最终结果的排名。
-
-例如,在上述 `terms` 查询中,`boost` 参数被设置为 1.0。这意味着如果字段 "user" 的值包含 "John" 或 "Jane",那么其相关性分数(_score)就会乘以 1.0。因此,这个设置实际上并没有改变任何东西,因为乘以 1 不会改变原始分数。但是,如果你将 `boost` 参数设置为大于 1 的数,那么匹配的文档的 _score 将会提高,反之则会降低。
-
-### range:范围查找
-
-range 查询允许你查找位于特定范围内的值。这对于日期、数字或其他可排序类型的字段非常有用。
-
-下面的语句会查询出age字段大于等于10,小于等于20的文档。
-
-例子1:假设你有一些表示博客文章的文档,每个文档都有一个发表日期,并且你想找出在特定日期范围内发布的所有文章,你可以使用 `range` 查询来实现这一目标
-
-```JSON
-GET /_search
-{
- "query": {
- "range" : {
- "date" : {
- "gte" : "2020-01-01",
- "lte" : "2020-12-31",
- "format": "yyyy-MM-dd"
- }
- }
- }
-}
-```
-
-在上面的查询中,`range` 查询被用来查找字段 "date" 的值在 "2020-01-01" 和 "2020-12-31"(包含)之间的所有文档。
-
-`range` 查询支持以下运算符:
-
-- `gt`:大于 (greater than)
-- `gte`:大于等于 (greater than or equal to)
-- `lt`:小于 (less than)
-- `lte`:小于等于 (less than or equal to)
-
-例子2:下面的语句会查询出date字段1天前的文档,其中now表示当前时间。
-
-```JSON
-GET product/_search
-{
- "query": {
- "range": {
- "date": {
- "gte": "now-1d/d",
- "lt": "now/d"
- }
- }
- }
-}
-```
-
-例子3:下面的语句会查询出date字段小于当前时间,大于2021-04-15T08:00:00的文档。time_zone表示时区,意思就是原文档中的数据会被+8小时再去搜索,例如原文档有条数据是:2021-04-15。则该数据能被查询出来。
-
-```JSON
-GET product/_search
-{
- "query": {
- "range": {
- "date": {
- "time_zone": "+08:00",
- "gte": "2021-04-15T08:00:00",
- "lt": "now"
- }
- }
- }
-}
-```
-
-## 过滤器-Filter
-
-过滤器(Filter)是一种特殊类型的查询,它不关心评分 (_score),只关心是否匹配。基于这个原因,过滤器比标准的全文查询更快并且能被缓存。
-
-一个典型的使用场景是布尔查询 (`bool`), 它有两个重要的部分:`must` 和 `filter`。`must` 部分用于全文搜索,`filter` 部分用于过滤结果。看一个例子:
-
-```JSON
-GET /_search
-{
- "query": {
- "bool": {
- "must": [
- { "match": { "title": "quick" }}
- ],
- "filter": [
- { "term": { "published": true }}
- ]
- }
- }
-}
-```
-
-在这个查询中,`bool` 查询包含了一个 `must` 子句和一个 `filter` 子句。`must` 子句会执行全文搜索并对结果进行评分。在这个例子中,它会找出所有标题包含"quick"的文章。
-
-`filter` 子句则会在 `must` 子句的基础上进一步过滤结果。在这个例子中,它会筛选出那些已经发布的文章。这个过滤操作不会影响到评分,因为它只关心是否匹配。
-
-总的来说,过滤器非常适合用于分类、范围查询或者确认某个字段是否存在等场景。过滤器的效率高并且可以被缓存,所以在大型数据集上性能表现良好。
-
-### Filter缓存机制
-
-在 Elasticsearch 中,过滤查询结果的缓存机制是非常重要的一个性能优化手段。由于过滤器(filter)只关心是否匹配,而不关心评分 (_score),因此它们的结果可以被缓存以提高性能。
-
-每次 filter 查询执行时,Elasticsearch 都会生成一个名为 "bitset" 的数据结构,其中每个文档都对应一个位(0 或 1),表示这个文档是否与 filter 匹配。这个 bitset 就是被存储在缓存中的部分。
-
-如果相同的 filter 查询再次执行,Elasticsearch 可以直接从缓存中获取这个 bitset,而不需要再次遍历所有的文档来找出哪些文档符合这个 filter。这大大提高了查询速度,并减少了 CPU 使用。
-
-这种缓存策略特别适合那些重复查询的场景,例如用户界面的过滤器和类似的功能,因为他们通常会产生很多相同的 filter 查询。
-
-然而,值得注意的是,虽然这种缓存可以显著改善查询性能,但也会占用内存空间。如果你有很多唯一的过滤条件,那么过滤器缓存可能会变得很大,从而导致内存问题。这就需要你对使用的过滤器进行适当的管理和限制。
-
-另外,Elasticsearch 默认情况下会自动选择哪些过滤器进行缓存,考虑到查询频率和成本等因素。你也可以手动配置某个特定的 filter 是否需要进行缓存。
-
-## 组合查询-Bool query
-
-组合查询可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
-
-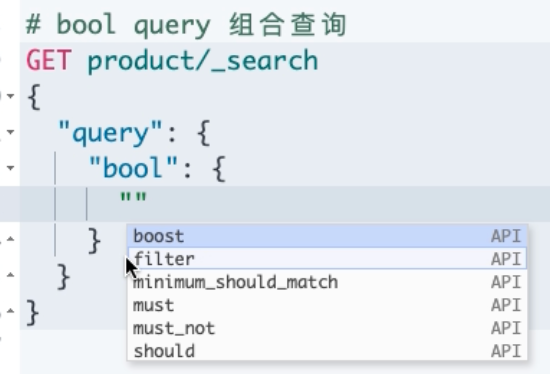
-
-boot和minumum_should_match是参数,其他四个都是查询子句。
-
-- **must**:必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分。
-- **filter**:过滤器不计算相关度分数。
-- **should**:满足 or子句(查询)应出现在匹配的文档中。
-- **must_not**:必须不满足,不计算相关度分数 ,not子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。
-
-例子1:下面的语句表示:包含"xiaomi"或"phone" 并且包含"shouji"的文档例子:
-
-```JSON
-GET product/_search
-{
- "query": {
- "bool": {
- "must": [
- {
- "match": {
- "name": "xiaomi phone"
- }
- },
- {
- "match_phrase": {
- "desc": "shouji"
- }
- }
- ]
- }
- }
-}
-```
-
-### should与must或filter一起使用
-
-当 `should` 子句与 `must` 或 `filter` 子句一起使用时,这时候需要注意了!只要满足了 `must` 或 `filter` 的条件,`should` 子句就不再是必须的。换句话说,如果存在一个或者多个 `must` 或 `filter` 子句,那么 `should` 子句的条件会被视为可选。
-
-然而,如果 `should` 子句与 `must_not` 子句单独使用(也就是没有 `must` 或 `filter`),则至少需要满足一个 `should` 子句的条件。
-
-这里有一个例子来说明:
-
-```JSON
-GET /_search
-{
- "query": {
- "bool": {
- "must": [
- { "term": { "user": "kimchy" }}
- ],
- "filter": [
- { "term": { "tag": "tech" }}
- ],
- "should": [
- { "term": { "tag": "wow" }},
- { "term": { "tag": "elasticsearch" }}
- ]
- }
- }
-}
-```
-
-在这个查询中,`must` 和 `filter` 子句的条件是必须满足的,而 `should` 子句的条件则是可选的。如果匹配的文档同时满足 `should` 子句的条件,那么它们的得分将会更高。
-
-那如果我们一起使用的时候想让should满足该怎么办?这时候`minimum_should_match` 参数就派上用场了。
-
-### minimum_should_match
-
-minimum_should_match参数定义了在 `should` 子句中至少需要满足多少条件。
-
-例如,如果你有5个 `should` 子句并且设置了 `"minimum_should_match": 3`,那么任何匹配至少三个 `should` 子句的文档都会被返回。
-
-这个参数可以接收绝对数值(如 `2`)、百分比(如 `30%`)、和组合(如 `3<90%` 表示至少匹配3个或者90%,取其中较大的那个)等不同类型的值。
-
-注意:如果 `bool` 查询中只有 `should` 子句(没有 `must` 或 `filter`),那么默认情况下至少需要匹配一个 `should` 条件,也就是`minimum_should_match`默认值是1,除非 `minimum_should_match` 明确设定为其他值。如果包含 `must` 或 `filter`的情况下`minimum_should_match`默认值 0。
-
-所以我们可以在包含`must` 或 `filter`的情况下,设置`minimum_should_match`值来满足`should`子句中的条件。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md" "b/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md"
deleted file mode 100644
index d3f0ab3..0000000
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\346\240\270\345\277\203\346\246\202\345\277\265.md"
+++ /dev/null
@@ -1,127 +0,0 @@
-[TOC]
-
-这章主要是对Elasticsearch中的基本概念以及涉及到的一些名词做下讲解,能够对Elasticsearch有一个初步的认识。
-
-## 节点
-
-- 每个Elasticsearch节点实际上就是一个Java进程,就是一个Elasticsearch的实例。
-- 一个节点 ≠一台服务器,也就是说我可以在一台服务器上启动多个Elasticsearch实例。
-
-## 角色
-
-集群节点角色可以在配置文件`elasticsearch.yml`中通过`node.roles`配置,如果配置了节点角色,那么该节点将只会执行配置的角色功能。
-
-### master:候选节点
-
-所谓master节点,就是在主节点down机的时候,可以参与选举,取而代之的节点。**举个例子:主节点好比班长,在班长不在的时候(主节点down机了),要选举出一个临时班长(master中选举)**。master节点不仅有选举权还有被选举权。每个master节点主要负责索引创建、索引删除、追踪节点信息和决定分片分配节点等。
-
-配置节点(下面节点配置方法同):
-
-```text
-node.roles: [ master ]
-```
-
-### data:数据节点
-
-数据节点顾名思义就是存放数据的节点,数据节点负责存储文档数据和数据的CRUD操作。因此该节点是CPU和IO密集型,需要实时监控该节点资源信息,以免过载。数据节点又分为:**data_content,data_hot,data_warm,data_code**。
-
-- data_content:数据内容节点,目录节点负责存储常量数据,且不随着时间的推移,改变数据的温层(hot、warm、cold)。且该节点的查询优先级是高于其它IO操作,所以该节点search和aggregations都会较快一些。
-- data_hot:热节点,保存热数据,经常会被访问,用于存储最近频繁搜索和修改的时序数据。
-- data_code:冷节点,保存冷数据,很少会被访问,当数据不再更新,那么可以将该数据移动到冷数据节点;冷数据节点用于存储只读,且访问频率较低的数据。该节点机器性能可以低一点。
-- data_warm:温节点,介于热节点和冷节点之间(温节点是我自己翻译的),当数据访问频率下降,可以将其移动到温节点,温节点用于存储修改较少,但仍然有查询的数据。查询的频率肯定比热点节点要少。
-
-### Ingest:预处理节点
-
-作用类似于Logstash中的Filter,Ingest其实就是管道的入口节点,比如说我们在做日志分析的时候,可以把日志输出的数据交给预处理节点做预处理。
-
-### ml:机器学习节点
-
-机器学习节点负责处理机器学习相关请求。
-
-### remote_ cluster_ client:候选客户端节点
-
-远程候选节点可以作为远程集群的客户端,主要负责搜索远程集群数据和同步两个集群间数据。
-
-### transform:转换节点
-
-转换节点会进行一种特殊操作,通过特定聚集语句计算,然后将结果写到新的索引中。
-
-### voting_ only:仅投票节点
-
-在master选举过程中,仅投票节点顾名思义就是仅仅投票,不会被选举为master。
-
-### Coordinating only node:协调节点
-
-协调节点主要负责根据集群状态路由分发搜索,路由分发bulk操作。**此外每个节点都是自带协调节点功能**。
-
-## 分片
-
-分片的思想在很多分布式应用和海量数据处理的场所非常常见,通常来说,面对海量数据的存储,单个节点显得力不从心。通俗解释,分片就是将数据拆分多份,放到不同的服务器节点。
-
-Elasticsearch里的分片为为2种:**主分片和副本分片**。
-
-### Shards主分片
-
-es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。**分片的数量只能在索引创建前指定,并且索引创建后不能更改**。这里和索引分片的算法有关,因为是通过取模算法去判断分到哪,如果改变了就无法正常查询之前的索引。
-
-当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。**路由算法:shard = hash(routing) % number_of_primary_shards**。这里的routing指的就是document的id,如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据。
-
-### Replicas副本分片
-
-代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
-
-- 一个索引包含一个或多个分片,在7.0之前默认五个主分片,每个主分片一个副本;在7.0之后默认一个主分片。副本可以在索引创建之后修改数量,但是主分片的数量一旦确定不可修改,只能创建索引。
-- 每个分片都是一个Lucene实例,有完整的创建索引和处理请求的能力。
-- ES会自动在nodes上做分片均衡。
-- 一个doc不可能同时存在于多个主分片中,但是当每个主分片的副本数量不为一时,可以同时存在于多个副本中。
-- 每个主分片和其副本分片不能同时存在于同一个节点上,所以最低的可用配置是两个节点互为主备。
-- 副本分片是不能直接写入数据的,只能通过主分片做数据同步。
-- 增减节点时,shard会自动在nodes中负载均衡。
-
-## 集群
-
-上面所说的节点角色构成了整个集群。
-
-### 集群状态
-
-- Green:主/副分片都已经分配好且可用,集群处于最健康的状态100%可用。
-- Yellow:主分片可用,但是至少有一个副本是未分配的。这种情况下数据也是完整的,但是集群的高可用性会被弱化。
-- Red:至少有一个不可用的主分片。此时只是部分数据可以查询,已经影响到了整体的读写,需要重点关注。
-
-### 健康值检查
-
-```java
-//查看集群健康状况
-_cat/health
-_cluster/health
-```
-
-#### 返回参数说明
-
-示例:
-
-```JSON
-{
- "cluster_name" : "elastic-log-xxx",
- "status" : "green",
- "timed_out" : false,
- "number_of_nodes" : 24,
- "number_of_data_nodes" : 21,
- "active_primary_shards" : 27777,
- "active_shards" : 27804,
- "relocating_shards" : 0,
- "initializing_shards" : 0,
- "unassigned_shards" : 0,
- "delayed_unassigned_shards" : 0,
- "number_of_pending_tasks" : 0,
- "number_of_in_flight_fetch" : 0,
- "task_max_waiting_in_queue_millis" : 0,
- "active_shards_percent_as_number" : 100.0
-}
-```
-
-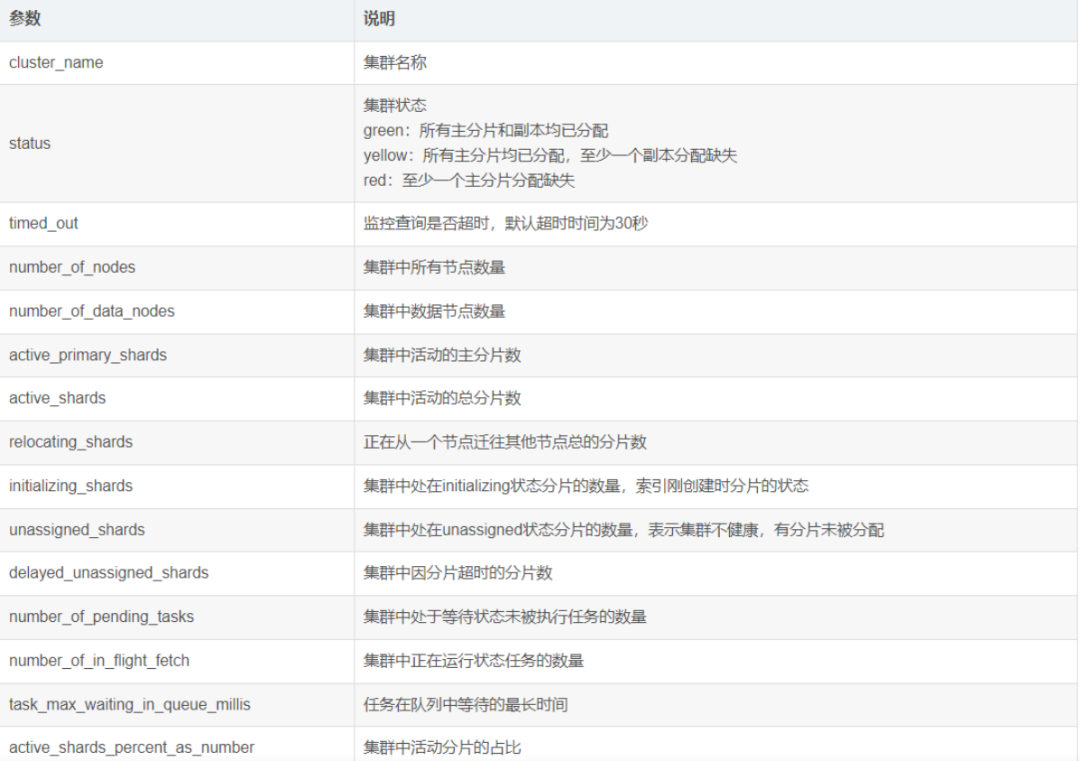
-
-## 索引和文档
-
-**es中索引类比为关系型数据库中的Table,在7.0版本之前index由若干个type组成,type实际上是文档的逻辑分类,而文档是es存储的最小单元。7.0及之后弱化了type的概念,7.x版本index只有一个type:_doc。文档(doc)可以类比为关系型数据库中的行,每个文档都有一个文档id**。
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md" "b/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md"
deleted file mode 100644
index ec2ca63..0000000
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204CRUD.md"
+++ /dev/null
@@ -1,231 +0,0 @@
-[TOC]
-
-这章主要是介绍Elasticsearch中索引的基本操作API,即增删改查(CRUD)。
-
-## 创建索引
-
-```JSON
-PUT /index?pretty
-```
-
-?pretty可加可不加,主要就是对输出进行格式化,更加好看点。
-
-## 删除索引
-
-```JSON
-DELETE /index?pretty
-```
-
-## 查询数据
-
-查询当前索引的信息
-
-```JSON
-GET /index/_search
-//_search:查询 index 索引下的所有信息。
-```
-
-输出示例如下:
-
-```JSON
-{
- //消耗时间
- "took": 11,
- "timed_out": false,
- "_shards" : {
- "total": 1,
- "successful" : 1,
- "skipped": 0,
- "failed": 0
-},
-"hits": {
- "total": {
- "value": 0,
- "relation": "eq"
- },
- "max_ score": null,
- "hits": []
-}
-}
-```
-
-获取所有索引数据的信息
-
-```JSON
-GET _cat/indices?v
-```
-
-查询指定文档id
-
-```JSON
-GET /index/_doc/doc_id
-```
-
-## 添加 & 更新数据
-
-```JSON
-PUT /index/_doc/doc_id
-{
- JSON数据
-}
-
-//例如:PUT /index/_doc/1
-//{
-// "field1": "value1",
-// "field2": 123
-//}
-```
-
-PUT也可以用于更新数据,比如我有一个文档有两个字段:name和age。我想更新name为:小明,可以这么写:
-
-```JSON
-PUT /index/_doc/1
-{
-"name": "小明"
-}
-```
-
-**需要注意的是PUT既可以用于插入,也可以用于更新,所以PUT的更新是全量更新,而不是部分更新。也就是上面的语句执行之后,文档会被直接替换,只会有name字段,字段值为小明**。
-
-如果我们想要部分更新的话,可以使用POST,示例如下:
-
-```JSON
-POST /index/_doc/id/_update
-{
- "doc": {
- "name": "小明"
- }
-}
-```
-
-把PUT换位POST,并把更新的字段包进doc里,就能实现更新部分字段。除了上面那种写法外,还可以使用下面这种写法,更推荐使用下面这种写法:
-
-```JSON
-POST /index/_update/1
-{
-"doc": {
-"name": "小明"
-}
-}
-```
-
-## cat命令
-
-cat命令在es中会经常使用,下面介绍cat命令中常用的几个命令。
-
-### 公共参数
-
-cat命令组成形式是:`GET /_cat/indices?format=json&pretty`, `?`之前是命令,之后是参数,多个参数用`&`分隔。公共参数有下:
-
-```JSON
-//v 显示更加详细的信息
-GET /_cat/master?v
-//help 显示命令结果字段说明
-GET /_cat/master?help
-//h 显示命令结果想要展示的字段
-GET /_cat/master?h=ip,node
-GET /_cat/master?h=i*,node
-//format 显示命令结果展示格式,支持格式类型:text json smile yaml cbor
-GET /_cat/indices?format=json&pretty
-//s 显示命令结果按照指定字段排序
-GET _cat/indices?v&s=index:desc,docs.count:desc
-```
-
-## 常用命令
-
-### aliases 显示别名
-
-```JSON
-GET /_cat/aliases
-```
-
-GET /_cat/aliases是获取所有别名,如果想获得某个索引的别名可以使用:`GET index/alias`。
-
-### allocation 显示每个节点的分片数和磁盘使用情况
-
-```JSON
-GET /_cat/allocation
-```
-
-### count 显示整个集群或者索引的文档个数
-
-```JSON
-GET /_cat/count
-GET /_cat/count/index
-```
-
-### fielddata 显示每个节点字段所占的堆空间
-
-```JSON
-GET /_cat/fielddata
-GET /_cat/fielddata?fields=name,addr
-```
-
-### health 显示集群是否健康
-
-```JSON
-GET /_cat/health
-```
-
-### indices 显示索引的情况
-
-```JSON
-GET /_cat/indices
-GET /_cat/indices/index
-```
-
-### master 显示master节点信息
-
-```JSON
-GET /_cat/master
-```
-
-### nodes 显示所有node节点信息
-
-```JSON
-GET /_cat/nodes
-```
-
-### recovery 显示索引恢复情况
-
-当索引迁移的任何时候都可能会出现恢复情况,例如,快照恢复、复制更改、节点故障或节点启动期间。
-
-```JSON
-GET /_cat/recovery
-```
-
-### thread_pool 显示每个节点线程运行情况。
-
-```JSON
-GET /_cat/thread_pool
-GET /_cat/thread_pool/bulk
-GET /_cat/thread_pool/bulk?h=id,name,active,rejected,completed
-```
-
-### shards 显示每个索引各个分片的情况
-
-展示索引的各个分片,主副分片,文档个数,所属节点,占存储空间大小
-
-```JSON
-GET /_cat/shards
-GET /_cat/shards/index
-GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
-```
-
-分片的状态:`INITIALIZING`初始化;`STARTED`分配完成;`UNASSIGNED`不能分配;可以通过`unassigned.reason`属性查看不能分配的原因。
-
-### segments 显示每个segment的情况
-
-包括属于索引,节点,主副,文档数等
-
-```JSON
-GET /_cat/segments
-GET /_cat/segments/index
-```
-
-### templates 显示每个template的情况
-
-```JSON
-GET /_cat/templates
-GET /_cat/templates/mytempla*
-```
\ No newline at end of file
diff --git "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md" "b/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md"
deleted file mode 100644
index f6a4ed4..0000000
--- "a/docs/md/es/\345\255\246\345\245\275Elasticsearch\347\263\273\345\210\227-\347\264\242\345\274\225\347\232\204\346\211\271\351\207\217\346\223\215\344\275\234.md"
+++ /dev/null
@@ -1,151 +0,0 @@
-[TOC]
-
-Elasticsearch 提供了 _bulk API 来执行批量操作,它允许你在单个 HTTP 请求中进行多个索引/删除/更新/创建操作。这种方法比发送大量的单个请求更有效率。
-
-## 基于mget的批量查询
-
-mget(多文档获取)是Elasticsearch中提供的一个API,用于一次性从同一个索引或者不同索引中检索多个文档。
-
-例子一:
-
-以下是一个Elasticsearch的`mget`(多文档获取)操作示例。在这个示例中,我们将获取索引 `test-index` 中具有特定ID的多个文档。
-
-```Java
-GET /test-index/_mget
-{
- "ids": ["1", "2"]
-}
-```
-
-在上述请求中,我们正在获取ID为 "1" 和 "2" 的文档。
-
-例子二:
-
-你也可以在不同的索引中获取文档,只需指定每个文档的 `_index` 和 `_id`:
-
-```Java
-GET /_mget
-{
- "docs": [
- {
- "_index": "test-index",
- "_id": "1"
- },
- {
- "_index": "another-index",
- "_id": "2"
- }
- ]
-}
-```
-
-在这个请求中,我们从 "test-index" 索引获取ID为 "1" 的文档,并从 "another-index" 索引获取ID为 "2" 的文档。
-
-例子三:
-
-在以下的Elasticsearch `mget`(多文档获取)例子中,我们将从两个不同的索引获取文档,并且只返回特定的字段:
-
-```Java
-GET /_mget
-{
- "docs": [
- {
- "_index": "test-index-1",
- "_id": "1",
- "_source": ["field1", "field2"]
- },
- {
- "_index": "test-index-2",
- "_id": "2",
- "_source": "field3"
- }
- ]
-}
-```
-
-在这个请求中,我们从 "test-index-1" 索引获取ID为 "1" 的文档,并只返回 "field1" 和 "field2" 字段。同时,我们从 "test-index-2" 索引获取ID为 "2" 的文档,并只返回 "field3" 字段。
-
-源过滤 (`_source`) 可以用来限制返回的字段。你可以提供一个字段的列表,或者一个单独的字段。注意,如果你请求的字段不存在,它将不会出现在响应中。
-
-## 基于bulk的批量增删改
-
-bulk基本格式如下:
-
-```Java
-POST //_bulk
-{"action": {"metadata"}}
-{"data"}
-```
-
-bulk api对json的语法有严格的要求,除了delete外,每一个操作都要两个json串(metadata和business data),且每个json串内不能换行,非同一个json串必须换行,否则会报错。
-
-bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志。
-
-### 增加
-
-```Java
-POST /_bulk
-{ "create" : { "_index" : "product2", "_id" : "2" } }
-{ "field1" : "value1", "field2" : "value2" }
-```
-
-在这个请求中,我们创建了一个新的文档,其在 "product2" 索引中的ID为 "2",并且包含两个字段 "field1" 和 "field2"。
-
-请注意,这个操作都由两行组成:第一行包含操作类型(在这个示例中为 "create")和元数据;第二行包含要创建或索引的实际文档数据。
-
-### 删除
-
-删除文档,ES对文档的删除是懒删除机制,即标记删除(lazy delete原理)。
-
-```Java
-POST /_bulk
-{ "delete" : { "_index" : "test-index", "_id" : "1" } }
-{ "delete" : { "_index" : "test-index", "_id" : "2" } }
-```
-
-在这个请求中,我们从 "test-index" 索引中删除了ID为 "1" 和 "2" 的两个文档。
-
-注意,每个 `delete` 操作仅由一行组成,这一行包含操作类型(在这个示例中为 "delete")以及元数据。
-
-### 修改
-
-```Java
-POST /_bulk
-{ "update" : { "_index" : "test-index", "_id" : "1" } }
-{ "doc" : { "field1" : "new_value1", "field2" : "new_value2" }}
-{ "update" : { "_index" : "test-index", "_id" : "2" } }
-{ "doc" : { "field1" : "new_value3", "field2" : "new_value4" }}
-```
-
-在这个请求中,我们在 "test-index" 索引中更新了两个文档:
-
-- 我们更新了ID为 "1" 的文档,设置 "field1" 和 "field2" 字段的值为 "new_value1" 和 "new_value2"。
-- 我们也更新了ID为 "2" 的文档,设置 "field1" 和 "field2" 字段的值为 "new_value3" 和 "new_value4"。
-
-## filter_path
-
-在Elasticsearch中,`filter_path`参数用于过滤返回的响应内容,可以用于减小 Elasticsearch 返回的数据量。当你指明一个或多个路径时,返回的JSON对象就只会包含这些路径下的键,它接收一个逗号分隔的列表,其中包含了你想要返回的 JSON 对象内的路径。这个参数支持通配符(`*`)匹配和数组元素(`[]`)匹配。列如:
-
-```
-POST /_bulk?filter_path=items.*.error
-```
-
-上述请求中的 `filter_path=items.*.error` 会让Elasticsearch仅返回 `_bulk` API调用结果中的错误信息。`items.*.error` 这个路径表示,在返回的响应中,匹配到所有存在 `error` 字段的 `items`。
-
-这样做有两个主要好处:
-
-1. 它可以提升Elasticsearch的性能,因为少量的数据意味着更快的序列化和反序列化。
-2. 它可帮助你聚焦于感兴趣的部分,不必处理无关的数据。
-
-请注意,`*` 是通配符,代表任何值。
-
-以下是一些其他 `filter_path` 的示例:
-
-1. `filter_path=took`: 这个请求仅返回执行请求所花费的时间(以毫秒为单位)。
-2. `filter_path=items._id,items._index`: 这个请求仅返回每个 item 的 `_id` 和 `_index` 字段。
-3. `filter_path=items.*.error`: 这个请求会返回所有包含 `error` 字段的 items。
-4. `filter_path=hits.hits._source`: 这个请求仅返回搜索结果中的原始文档内容。
-5. `filter_path=_shards, hits.total`: 这个请求返回关于 `shards` 的信息和命中的总数。
-6. `filter_path=aggregations.*.value`: 这个请求仅返回每个聚合的值。
-
-请注意,如果你在 `filter_path` 中指定了多个字段,你需要使用逗号将它们分隔开。
\ No newline at end of file
diff --git "a/docs/md/java/ExecutorCompletionService\350\257\246\350\247\243.md" "b/docs/md/java/ExecutorCompletionService\350\257\246\350\247\243.md"
new file mode 100644
index 0000000..55c7c07
--- /dev/null
+++ "b/docs/md/java/ExecutorCompletionService\350\257\246\350\247\243.md"
@@ -0,0 +1,153 @@
+本文已收录至Github,推荐阅读 👉 [Java随想录](https://github.com/ZhengShuHai/JavaRecord)
+
+微信公众号:[Java随想录](https://mmbiz.qpic.cn/mmbiz_jpg/jC8rtGdWScMuzzTENRgicfnr91C5Bg9QNgMZrxFGlGXnTlXIGAKfKAibKRGJ2QrWoVBXhxpibTQxptf8MsPTyHvSg/0?wx_fmt=jpeg)
+
+[TOC]
+
+## 摘要
+
+ExecutorCompletionService 是Java并发编程中的一个有用的工具类,它实现了 CompletionService 接口。ExecutorCompletionService 将 Executor 和BlockingQueue 功能融合在一起,使用它可以提交我们的任务。这个任务委托给 Executor 执行,可以使用 ExecutorCompletionService 对象的 take() 和 poll() 方法获取结果。
+
+本文将深入讲解 ExecutorCompletionService 的使用以及源码解析。
+
+## ExecutorCompletionService适用场景
+
+ExecutorCompletionService在以下场景中特别有用:
+
+- **并行任务处理**:当需要同时执行多个任务,并按照完成的顺序获取它们的结果时,可以使用ExecutorCompletionService来简化任务提交和结果获取的流程。
+- **高性能计算**:在需要进行大规模计算或复杂计算的场景中,可以将任务拆分成多个子任务,并使用ExecutorCompletionService来管理和获取子任务的结果。
+
+假设现在有一批需要进行计算的任务,为了提高整批任务的执行效率,我们可以使用线程池来异步计算这些任务。通过向线程池中不断提交任务并保留与每个任务关联的Future对象。最后,我们可以遍历这些Future对象,并通过调用 get() 方法获取每个任务的计算结果。
+
+**Future的不足**
+
+Future 没有办法回调,只能手动去调用,当通过 get() 方法获取线程的返回值时,会导致阻塞,也就是和当前这个 Future 关联的计算任务执行完成的时候才返回结果,新任务必须等待已完成任务的结果才能继续进行处理。
+
+这样会浪费很多时间,因为我们不知道哪个线程先执行完了,只能挨个去获取结果,这样已经完成的线程会因为前面未完成的线程的耗时而无法提前进行汇总,最好是谁先执行完成,谁先返回。
+
+而 ExecutorCompletionService 可以实现这样的效果,节省获取完成结果的时间,它的内部有一个先进先出的阻塞队列,用于保存已经执行完成的 Future,通过调用它的 take() 方法或 poll() 方法可以获取到一个已经执行完成的 Future,进而通过调用 Future 接口实现类的 get() 方法获取最终的结果。
+
+**CompletionService的目标是任务谁先完成谁先获取,即结果按照完成先后顺序排序**
+
+## ExecutorCompletionService使用
+
+ExecutorCompletionService 提供了一种方便的方式来处理一组异步任务,并按照完成的顺序获取它们的结果。它内部使用了Executor框架来执行任务,并且内部管理着一个已完成任务的阻塞队列,在结果获取上提供了更加灵活和高效的机制。
+
+下面是一个简单的例子来演示ExecutorCompletionService的基本使用:
+
+```java
+public class ExecutorCompletionServiceExample {
+ public static void main(String[] args) throws InterruptedException, ExecutionException {
+ ExecutorService executor = Executors.newFixedThreadPool(5);
+ CompletionService completionService = new ExecutorCompletionService<>(executor);
+
+ // 提交任务
+ for (int i = 0; i < 10; i++) {
+ final int taskId = i;
+ completionService.submit(() -> {
+ double sleepTime = Math.random() * 1000;
+ Thread.sleep((long) sleepTime); // 模拟耗时操作
+ return "Task " + taskId + " completed,cost time: " + sleepTime;
+ });
+ }
+
+ // 获取结果
+ for (int i = 0; i < 10; i++) {
+ Future future = completionService.take();
+ String result = future.get();
+ System.out.println(result);
+ }
+
+ executor.shutdown();
+ }
+}
+```
+
+输出:
+
+```java
+Task 2 completed,cost time: 170.01927312611775
+Task 3 completed,cost time: 460.9622858036789
+Task 1 completed,cost time: 563.24738180643
+Task 0 completed,cost time: 595.938819219159
+Task 5 completed,cost time: 480.4473056068137
+Task 4 completed,cost time: 748.2343208613524
+Task 6 completed,cost time: 370.4679098376097
+Task 7 completed,cost time: 270.45945981324905
+Task 9 completed,cost time: 336.5536570760892
+Task 8 completed,cost time: 577.5774464801026
+```
+
+在上述代码中,我们创建了一个固定大小的线程池,并使用 ExecutorCompletionService 来提交和获取任务的结果。通过调用`completionService.submit()`方法来提交任务,并随机指定睡眠时间,来模拟任务执行的耗时,然后通过`completionService.take()`方法来获取已完成的任务结果。
+
+可以看到是按照任务的执行耗时顺序去获取结果的。
+
+## ExecutorCompletionService原理解析
+
+ExecutorCompletionService 提供了两个构造函数,一个可以指定阻塞队列,另一个使用内部默认的阻塞队列,两个构造函数都需要传进线程池参数。
+
+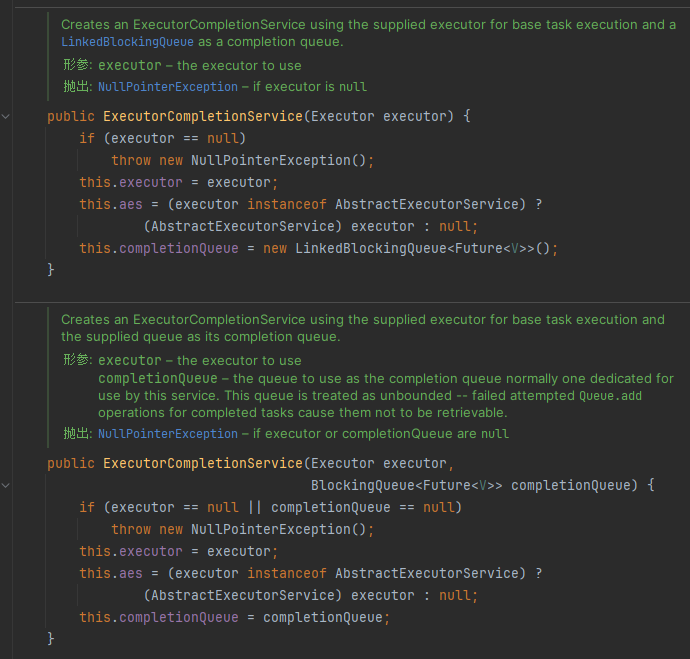
+
+提供了三个获取方法,可以看到都是从队列中获取。
+
+- take()/poll() 方法的工作都委托给内部的已完成任务队列 completionQueue。
+- 如果队列中有已完成的任务, take() 方法就返回任务的结果,否则阻塞等待任务完成。
+- poll() 与 take() 方法不同,poll() 有两个版本:
+ - 无参的 poll() 方法:如果完成队列中有数据就返回,否则返回null。
+ - 有参数的 poll() 方法:如果完成队列中有数据就直接返回,否则等待指定的时间,到时间后如果还是没有数据就返回null。
+
+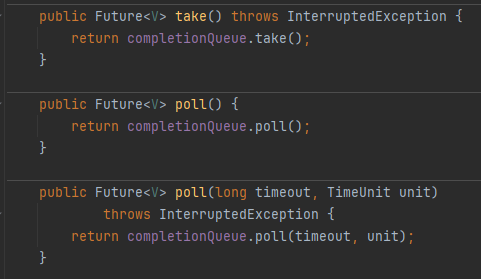
+
+两个提交任务方法,可以看到 submit() 方法最终会委托给内部的 executor 去执行任务,提交任务的时候会将任务封装成 QueueingFuture 对象。
+
+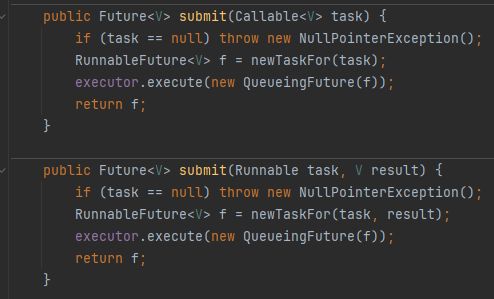
+
+ExecutorCompletionService内部维护了 `QueueingFuture` 类,`QueueingFuture` 继承了 `FutureTask`,并重写了 `done(`) 方法,
+
+可以看到 done() 方法在任务完成的时候会将结果存进 已完成任务队列 completionQueue 中。
+
+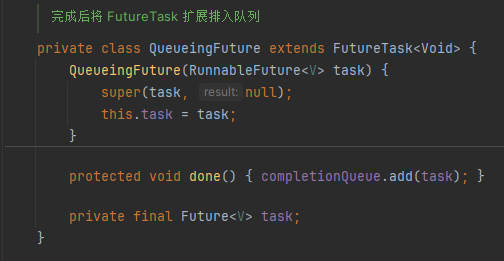
+
+Futuretask 的 done() 方法是用来标记一个任务已经完成的方法。当一个 Futuretask 中的任务完成后,就会调用 done() 方法通知。
+
+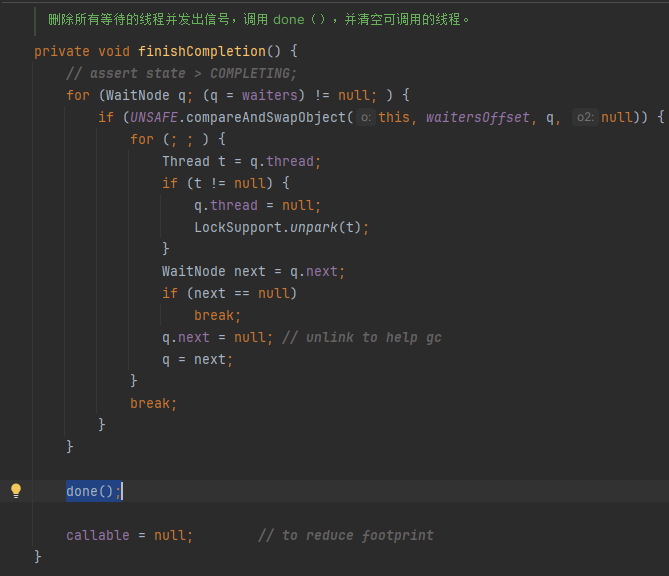
+
+默认是空方法,不会执行任何动作。
+
+
+
+
+
+**执行流程**
+
+当我们使用ExecutorCompletionService类时,它能够按照任务完成的顺序获取它们的结果,这是因为ExecutorCompletionService类内部结合了QueueingFuture类和done()方法的机制。以下是源码流程步骤解释:
+
+1. 提交任务:
+ - 我们通过submit方法将任务提交给ExecutorCompletionService。在提交任务时,ExecutorCompletionService会使用自定义的QueueingFuture类来包装任务,并将其交给底层线程池执行。
+2. QueueingFuture类:
+ - QueueingFuture类是ExecutorCompletionService的内部类,继承自FutureTask。它的构造方法接收一个Callable对象作为参数。
+ - 在QueueingFuture类中,它重写了done()方法。done()方法会在任务执行完成后被调用。
+3. 任务执行完成时的处理:
+ - 当任务执行完成后,在底层线程池的Worker线程中,会调用QueueingFuture的done()方法。
+ - 在done()方法中,QueueingFuture会首先调用父类FutureTask的done()方法,以触发对计算结果的获取。然后,它会将任务的结果存储到一个内部的BlockingQueue队列中(即completionQueue)。
+4. 获取任务结果:
+ - 当我们调用take方法获取任务结果时,它会从completionQueue队列中取出已完成的任务结果,并返回该结果。如果队列为空,则会阻塞等待,直到有任务完成并返回结果。
+ - take方法内部会调用QueueingFuture的get()方法,从而触发对应任务的计算结果的获取。
+5. 保证按顺序获取结果:
+ - 由于completionQueue是一个阻塞队列,并且在done()方法中将任务结果按照完成的顺序放入队列中,因此我们可以通过按顺序获取队列中的任务结果,来保证按照任务完成的顺序获取它们的结果。
+
+通过以上源码流程步骤,ExecutorCompletionService类能够按照任务完成的顺序获取结果。它利用QueueingFuture类包装任务并存储结果到阻塞队列中,在任务执行完成后,按照完成的顺序将结果放入队列,从而实现了按顺序获取结果的功能。
+
+## 注意事项
+
+在使用ExecutorCompletionService时,需要注意以下事项:
+
+- **合理选择线程池大小**:根据任务的数量和复杂性,合理选择线程池的大小,以充分利用系统资源并避免资源浪费。
+- **及时处理异常**:在任务执行过程中,如果发生异常,需要及时处理和记录异常信息,以保证程序的稳定性和可靠性。
+- **使用Future对象进行任务取消和超时控制**:通过使用Future对象的cancel方法,可以取消正在执行的任务。同时,可以通过调整 poll 方法的参数来设置超时时间,避免长时间等待任务结果而导致阻塞。
+
+## 总结
+
+ExecutorCompletionService是一个强大且灵活的工具类,能够简化异步任务的处理和结果获取过程。通过使用ExecutorCompletionService,我们可以更加高效地处理一组异步任务,并按照完成的顺序获取它们的结果。
+
+本文介绍了ExecutorCompletionService的基本使用方法,并对其源码进行了解析。希望通过这篇文章能够帮助读者更好地理解和应用ExecutorCompletionService。
\ No newline at end of file
diff --git "a/docs/md/java/\345\274\202\346\255\245\347\274\226\347\250\213\345\210\251\345\231\250\357\274\232CompletableFuture\346\267\261\345\272\246\350\247\243\346\236\220.md" "b/docs/md/java/\345\274\202\346\255\245\347\274\226\347\250\213\345\210\251\345\231\250\357\274\232CompletableFuture\346\267\261\345\272\246\350\247\243\346\236\220.md"
new file mode 100644
index 0000000..dcddf56
--- /dev/null
+++ "b/docs/md/java/\345\274\202\346\255\245\347\274\226\347\250\213\345\210\251\345\231\250\357\274\232CompletableFuture\346\267\261\345\272\246\350\247\243\346\236\220.md"
@@ -0,0 +1,605 @@
+## 摘要
+
+在异步编程中,我们经常需要处理各种异步任务和操作。Java 8引入的 CompletableFuture 类为我们提供了一种强大而灵活的方式来处理异步编程需求。CompletableFuture 类提供了丰富的方法和功能,能够简化异步任务的处理和组合。
+
+本文将深入解析 CompletableFuture,希望对各位读者能有所帮助。
+
+**CompletableFuture 适用于以下场景**
+
+- 并发执行多个异步任务,等待它们全部完成或获取其中任意一个的结果。
+- 对已有的异步任务进行进一步的转换、组合和操作。
+- 异步任务之间存在依赖关系,需要按照一定的顺序进行串行执行。
+- 需要对异步任务的结果进行异常处理、超时控制或取消操作。
+
+## 如何使用
+
+下面是一个演示 CompletableFuture 如何使用的代码示例:
+
+```java
+public class CompletableFutureExample {
+
+ public static void main(String[] args) {
+ // 创建CompletableFuture对象,并定义异步任务
+ CompletableFuture future = CompletableFuture.supplyAsync(() -> {
+ // 异步任务的逻辑代码
+ // 在这里执行耗时操作或其他需要异步执行的任务
+ try {
+ TimeUnit.SECONDS.sleep(2); // 模拟耗时操作
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ return "Hello, ";
+ });
+
+ // 添加任务完成后的回调方法
+ CompletableFuture resultFuture = future.thenApplyAsync(result -> {
+ // 任务完成后的处理逻辑
+ // result为上一步任务的结果
+ return result + "World!";
+ });
+
+ // 组合多个CompletableFuture对象
+ CompletableFuture combinedFuture = future.thenCombine(resultFuture, (result1, result2) -> {
+ // 对多个CompletableFuture的结果进行组合处理
+ return result1 + result2 + " Welcome to the CompletableFuture world!";
+ });
+
+ // 异常处理
+ CompletableFuture exceptionHandledFuture = combinedFuture.exceptionally(ex -> {
+ // 异常处理逻辑
+ System.out.println("任务执行出现异常:" + ex.getMessage());
+ return "Fallback Result";
+ });
+
+ // 等待并获取任务的结果
+ try {
+ String result = exceptionHandledFuture.get();
+ System.out.println("任务的最终结果为:" + result);
+ } catch (InterruptedException | ExecutionException e) {
+ // 处理异常情况
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+结果输出:
+
+```java
+任务的最终结果为:Hello, Hello, World! Welcome to the CompletableFuture world!
+```
+
+首先,我们创建了一个`CompletableFuture`对象`future`。在`future`中,我们使用`supplyAsync`方法定义了一个异步任务,其中 lambda表达式 中的代码会在另一个线程中执行。在这个例子中,我们模拟了一个耗时操作,通过`TimeUnit.SECONDS.sleep(2)`暂停了2秒钟。
+
+然后,我们添加了一个回调方法`resultFuture`。在这个回调方法中,将前一个异步任务的结果作为参数进行处理,并返回处理后的新结果。在这个例子中,我们将前一个任务的结果与字符串 "World!" 连接起来,形成新的结果。
+
+接下来,我们使用`thenCombine`方法组合了两个`CompletableFuture`对象:`future`和`resultFuture`。在这个组合任务中,我们将两个任务的结果进行组合处理,返回最终的结果。在这个例子中,我们将前两个任务的结果与字符串 " Welcome to the CompletableFuture world!" 连接起来。
+
+此外,我们还处理了异常情况。通过`exceptionally`方法,我们定义了一个异常处理回调方法。如果在任务执行过程中发生了异常,我们可以在这里对异常进行处理,并返回一个默认值作为结果。
+
+最后,我们使用`get`方法等待并获取最终的任务结果。需要注意的是,`get`方法可能会阻塞当前线程,直到任务完成并返回结果。在这个例子中,我们使用`try-catch`块捕获可能的异常情况,并打印出最终的任务结果。
+
+这个例子只是部分展示了`CompletableFuture`的功能,实际上它比你想象的还要强大!
+
+## 源码解析
+
+CompletableFuture 的源码非常庞大和复杂,涉及到并发、线程池、同步机制等多方面的知识。在这里,我们只重点介绍 CompletableFuture 的核心实现原理。
+
+### 基本结构
+
+
+
+CompletableFuture 的作者是大名鼎鼎的 Doug Lea。CompletableFuture 类是实现了 Future 和 CompletionStage 接口的一个关键类。它可以表示异步计算的结果,并提供了一系列方法来操作和处理这些结果。
+
+CompletableFuture 内部使用了一个属性`result`来保存计算结果,以及若干个属性`waiters`来保存等待结果的任务。当计算完成后,CompletableFuture将会通知所有等待结果的任务,并将结果传递给它们。
+
+为了实现链式操作,CompletableFuture还定义了内部类:`Completion`, `UniCompletion`, 和 `BiCompletion`。
+
+`Completion`, `UniCompletion`, 和 `BiCompletion` 是 `CompletableFuture` 内部用于处理异步任务完成的辅助类。
+
+- `Completion` 是一个通用的辅助类,它包含了任务完成后的回调方法,以及处理异常的方法。
+- `UniCompletion` 是 `Completion` 的子类,是一元依赖的基类,用于处理单个任务的完成情况,并提供了更多的方法来处理结果和异常。
+- `BiCompletion` 是 `UniCompletion` 的子类,是二元依赖的基类,同时也是多元依赖的基类,用于处理两个任务的完成情况,并提供了更多的方法来组合和处理这两个任务的结果和异常。
+
+这些辅助类在 `CompletableFuture` 的内部被使用,以实现异步任务的执行、结果的处理和组合等操作。它们提供了一种灵活的方式来处理异步任务的完成情况,并通过回调方法或其他一些方法来处理任务的结果和异常。
+
+### 内部原理
+
+
+
+CompletableFuture中包含两个字段:**result** 和 **stack**。result 用于存储当前CF的结果,stack (Completion)表示当前CF完成后需要触发的依赖动作(Dependency Actions),去触发依赖它的CF的计算,依赖动作可以有多个(表示有多个依赖它的CF),以栈(Treiber stack)的形式存储,stack表示栈顶元素。
+
+CompletableFuture 在设计思想上类似 “观察者模式,每个 CompletableFuture 都可以被看作一个被观察者,其内部有一个Completion类型的链表成员变量stack,用来存储注册到其中的所有观察者。当被观察者执行完成后会弹栈stack属性,依次通知注册到其中的观察者。
+
+### 执行流程
+
+CompletableFuture 的执行流程如下:
+
+1. 创建CompletableFuture对象:通过调用`CompletableFuture`类的构造方法或静态工厂方法创建一个新的CompletableFuture对象。
+2. 定义异步任务:使用`supplyAsync()`、`runAsync()`等方法定义需要在后台线程中执行的异步任务,这些方法接受一个 lambda表达式 或 Supplier/Runnable 接口作为参数。
+3. 启动异步任务:一旦CompletableFuture对象创建并定义了异步任务,任务会立即在后台线程中开始执行,并返回一个代表异步计算结果的CompletableFuture对象。
+4. 异步任务执行过程:
+ - 当异步任务完成时,它会设置自己的结果值,将状态标记为已完成。
+ - 如果有其他线程在此之前调用了`complete()`、`completeExceptionally()`、`cancel()`等方法,可能会影响任务的最终状态。
+5. 注册回调方法:
+ - 使用`thenApply()`, `thenAccept()`, `thenRun()`等方法来注册回调函数,当异步任务完成或异常时,这些回调函数会被触发。
+ - 回调函数也可以是异步的,通过`thenApplyAsync()`, `thenAcceptAsync()`, `thenRunAsync()`等方法注册。
+6. 组合多个CompletableFuture:
+ - 使用`thenCompose()`, `thenCombine()`, `allOf()`, `anyOf()`等方法,可以将多个CompletableFuture对象进行组合,形成更复杂的异步任务处理流程。
+7. 处理异常:
+ - 通过使用`exceptionally()`, `handle()`, `whenComplete()`等方法,可以注册异常处理函数,当异步任务出现异常时,这些处理函数会被触发。
+8. 等待结果:
+ - 使用`get()`或`join()`方法来阻塞当前线程,并等待CompletableFuture对象的完成并获取最终的结果。
+ - `get()`方法会抛出可能的异常(InterruptedException, ExecutionException)。
+ - `join()`方法与`get()`类似,但不会抛出 checked 异常。
+9. 取消任务:通过调用CompletableFuture对象的`cancel()`方法取消异步任务的执行。
+
+请注意,以上步骤的顺序和具体实现可能略有不同,但大致上反映了CompletableFuture的执行流程。在实际应用中,我们可以根据需求选择适合的方法来处理异步任务的完成情况、结果、异常以及任务之间的关系。
+
+## 方法介绍
+
+CompletableFuture类提供了一系列用于处理和组合异步任务的方法。以下是这些方法的介绍:
+
+### 创建对象
+
+创建一个 `CompletableFuture` 对象有以下几种方法:
+
+- 使用 `CompletableFuture` 的构造方法
+
+```java
+CompletableFuture future = new CompletableFuture<>();
+```
+
+- 使用 `CompletableFuture` 的静态工厂方法
+
+```java
+CompletableFuture future = CompletableFuture.supplyAsync(() -> {
+ // 异步任务逻辑
+ return "Result";
+});
+
+CompletableFuture future = CompletableFuture.runAsync(() -> {
+ // 异步任务逻辑
+});
+```
+
+- 使用转换方法
+
+```java
+
+CompletableFuture transformedFuture = originalFuture.thenApply(result -> {
+ // 转换逻辑
+ return result.length();
+});
+
+originalFuture.thenAccept(result -> {
+ // 处理结果逻辑
+ System.out.println("Result: " + result);
+});
+
+CompletableFuture runnableFuture = originalFuture.thenRun(() -> {
+ // 在结果完成后执行的操作
+});
+```
+
+- 直接创建一个已完成状态的CompletableFuture
+
+```java
+//CompletableFuture.completedFuture()直接创建一个已完成状态的CompletableFuture
+CompletableFuture cf2 = CompletableFuture.completedFuture("result");
+
+//先初始化一个未完成的CompletableFuture,然后通过complete()、completeExceptionally(),也完成该CompletableFuture
+CompletableFuture cf = new CompletableFuture<>();
+cf.complete("success");
+```
+
+- toCompletableFuture
+
+```JAVA
+CompletionStage stage = CompletableFuture.supplyAsync(() -> 42);
+
+CompletableFuture future = stage.toCompletableFuture();
+```
+
+用于将当前的 `CompletionStage` 对象转换为一个 `CompletableFuture` 对象。
+
+### 异步执行任务
+
+以下是在 `CompletableFuture` 对象上异步执行任务的一些方法示例:
+
+- `supplyAsync(Supplier supplier)`:异步执行一个有返回值的供应商(Supplier)任务。
+
+```java
+CompletableFuture future = CompletableFuture.supplyAsync(() -> {
+ // 异步任务逻辑
+ return "Result";
+});
+```
+
+- `runAsync(Runnable runnable)`:异步执行一个没有返回值的任务。
+
+```java
+CompletableFuture future = CompletableFuture.runAsync(() -> {
+ // 异步任务逻辑
+});
+```
+
+### 链式操作
+
+CompletableFuture提供了不同的方式来对异步任务进行链式操作。
+
+- thenRun
+
+```java
+CompletableFuture executedFuture = future.thenRun(() -> executeTask());
+```
+
+`thenRun`方法用于在CompletableFuture完成后执行一个Runnable任务。它返回一个新的CompletableFuture对象,该对象没有返回值。
+
+- thenAccept
+
+```java
+CompletableFuture acceptedFuture = future.thenAccept(result -> processResult(result));
+```
+
+`thenAccept`方法用于在CompletableFuture完成后对结果进行处理。它接收一个Consumer函数作为参数,并返回一个新的CompletableFuture对象。
+
+- thenApply
+
+```java
+CompletableFuture appliedFuture = future.thenApply(result -> transformResult(result));
+```
+
+`thenApply`方法用于在CompletableFuture完成后对结果进行转换。它接收一个Function函数作为参数,并返回一个新的CompletableFuture对象。
+
+- thenCompose
+
+```java
+CompletableFuture composedFuture = future.thenCompose(result -> executeAnotherTask(result));
+```
+
+用于对异步任务的结果进行处理,并返回一个新的异步任务。
+
+- whenComplete
+
+```java
+CompletableFuture future = CompletableFuture.supplyAsync(() -> 42);
+
+CompletableFuture whenCompleteFuture = future.whenComplete((result, exception) -> {
+ if (exception != null) {
+ System.out.println("Exception occurred: " + exception.getMessage());
+ } else {
+ System.out.println("Result: " + result);
+ }
+});
+
+whenCompleteFuture.join();
+```
+
+用于在异步任务完成后执行指定的动作。它允许你在任务完成时处理结果或处理异常。
+
+- `thenCompose()` 用于对异步任务的结果进行处理,并返回一个新的异步任务。它接受一个函数式接口参数,根据原始任务的结果创建并返回一个新的 `CompletionStage` 对象。
+- `whenComplete()` 用于在异步任务完成后执行指定的动作。它接受一个消费者函数式接口参数,用于处理任务的结果或异常,但没有返回值。
+
+### 异步任务组合
+
+CompletableFuture还提供了一系列方法来组合和处理多个异步任务的结果。
+
+- allOf
+
+```java
+CompletableFuture allFuture = CompletableFuture.allOf(future1, future2, future3);
+```
+
+`allOf`方法接收一组CompletableFuture对象作为参数,并返回一个新的CompletableFuture对象,该对象在所有给定的CompletableFuture都完成时完成。这样我们可以等待所有任务都完成后再进行下一步操作。
+
+- anyOf
+
+```java
+CompletableFuture