From eaf4d46b9c2626f37bdfec157af2ca3f7f99e9c2 Mon Sep 17 00:00:00 2001
From: BookSea <65435519+BookaiCode@users.noreply.github.com>
Date: Sun, 6 Apr 2025 16:52:03 +0800
Subject: [PATCH 01/12] Update README.md
---
README.md | 2 ++
1 file changed, 2 insertions(+)
diff --git a/README.md b/README.md
index af1d7d8..1259b4e 100644
--- a/README.md
+++ b/README.md
@@ -186,6 +186,8 @@
- [实战Arthas:常见命令与最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488559&idx=1&sn=4b5003cb33446ab4a6173285fe9d83d3&chksm=cf8467eaf8f3eefc033de8f63cba9f0d7b2b5eb0ccfb5209f458a9ab447367b34954f296638b#rd)
+- [Maven实战](https://mp.weixin.qq.com/s/ErtWrRNzjJcR2ettUhAxsQ)
+
### :bulb: 资源 ###
- [精品电子书(持续更新)](/docs/md/PDF.md)
From 76ec887d67808cb0e3ca90f1db14bd1b1d340d41 Mon Sep 17 00:00:00 2001
From: BookSea <65435519+BookaiCode@users.noreply.github.com>
Date: Sun, 6 Apr 2025 16:52:46 +0800
Subject: [PATCH 02/12] Add files via upload
---
.../Maven\345\256\236\346\210\230.md" | 672 ++++++++++++++++++
1 file changed, 672 insertions(+)
create mode 100644 "docs/md/\345\205\266\344\273\226/Maven\345\256\236\346\210\230.md"
diff --git "a/docs/md/\345\205\266\344\273\226/Maven\345\256\236\346\210\230.md" "b/docs/md/\345\205\266\344\273\226/Maven\345\256\236\346\210\230.md"
new file mode 100644
index 0000000..272fdb2
--- /dev/null
+++ "b/docs/md/\345\205\266\344\273\226/Maven\345\256\236\346\210\230.md"
@@ -0,0 +1,672 @@
+
+
+# Maven实战
+
+## 一、Maven介绍
+
+### 1.1 现存问题
+
+jar包问题
+
+* jar包需要在本地保存,而且在使用的时候需要将jar复制到项目中,再build才可以生效。
+* jar包的体量不小,一个项目中可能需要上百的jar的支持,这样一个项目就太大了。
+* 如果jar包的版本需要升级,需要重新去搜集新版本的jar包,重新去build,时间成本太高了。
+* 做一些功能时,可能需要因为几个,甚至十几个jar包,才能完成一个功能,都需要自己维护,甚至记住。
+
+项目结构的问题
+
+* 之前开发工具很多,有Eclipse,MyEclipse,IDEA,VSCode等等……不同的开发工具的项目的结构会有一些不同,多人协同开发时,就会造成冲突,甚至还需要统一开发工具。
+
+整体项目的生命流程
+
+* 整个项目从立项开发,到最后的发布上线到生产环境,没有一套统一的流程来控制。
+
+### 1.2 Maven
+
+- Maven可以帮助我们更好地去管理jar包,只需要指定好jar的一些基本的标识,就可以让jar包支持我们的项目。而且Maven可以帮助咱们导入一个jar包后,自动将和它绑定好的其他jar包引入。
+- Maven可以提供一个统一的项目结构。
+- Maven也对整体项目的生命周期有响应的管理,从开始的编译、测试、打包、部署等操作,都提供了相应的支持。
+- Maven还提供了分模块开发的功能。
+
+Maven是apache组织的一个顶级开源项目。 http://maven.apache.org
+
+## 二、Maven安装&环境变量配置
+
+### 2.1 Maven的安装
+
+首先下载Maven,直接去官网即可
+
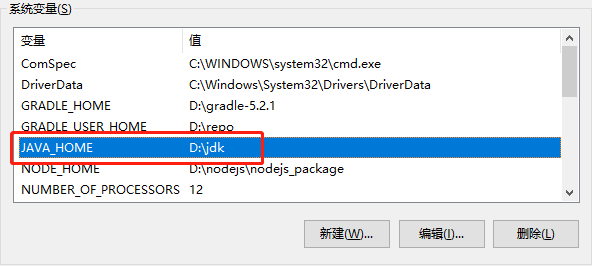
+在点击Download之后,需要注意看一下对JDK版本的支持。
+
+Maven需要JDK的环境变量支持,一定要看一下自己又没有设置上JAVA_HOME
+
+
+
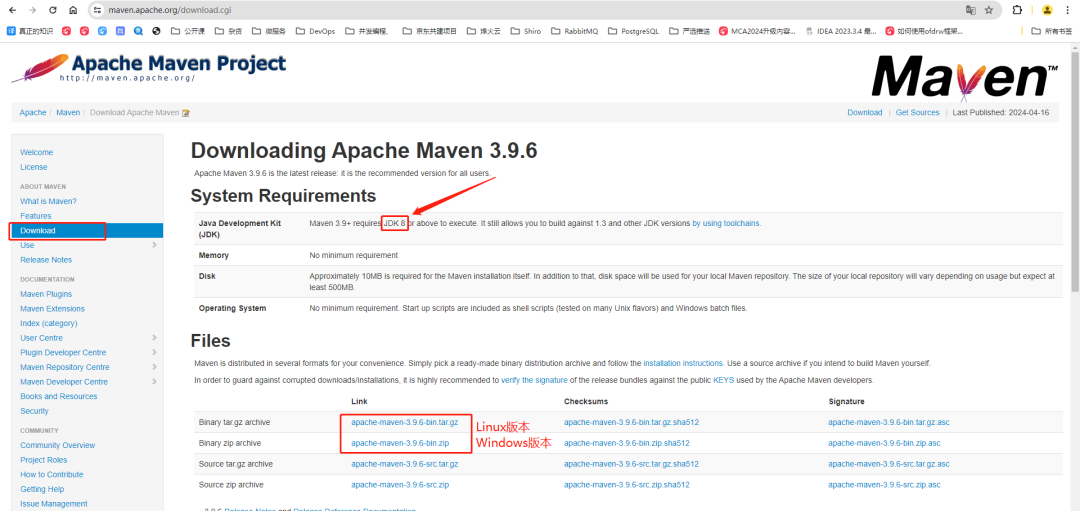
+需要根据自己的环境变量,下载对应的压缩包。
+
+Linux、Mac选择.tar.gz的压缩包
+
+Windows选择zip的压缩包
+
+
+
+下载好之后,得到一个压缩包。
+
+解压的目录最好没有任何的中文和空格等特殊字符。推荐放到磁盘的根目录下即可。
+
+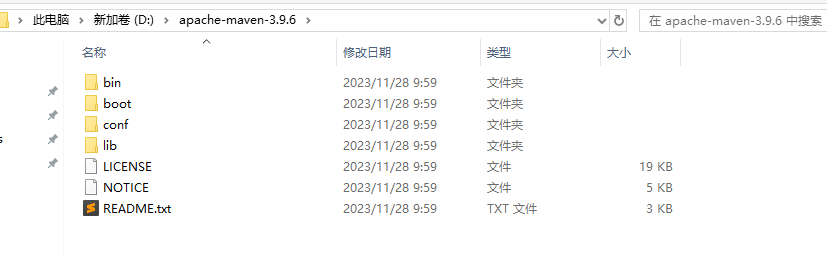
+
+> bin:含有mvn运行的脚本。
+>
+> boot:含有类加载器框架,Maven使用这个框架来加载自己的类库。
+>
+> conf:含有非常核心的settings.xml文件。
+>
+> lib:含有Maven运行时需要的一些类库。
+
+### 2.2 Maven的环境变量的配置
+
+首先配置Maven的环境变量前,必须先查看一下JDK环境变量配置。
+
+
+
+其次,查看一下前面说过的JAVA_HOME。
+
+上述两点都ok的话,直接开始配置环境变量
+
+* 配置MAVEN_HOME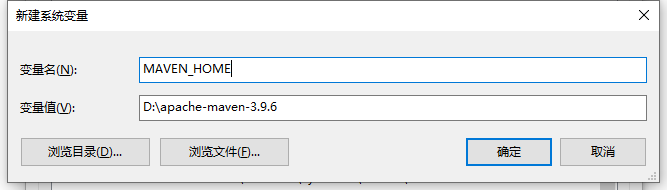
+* 配置到path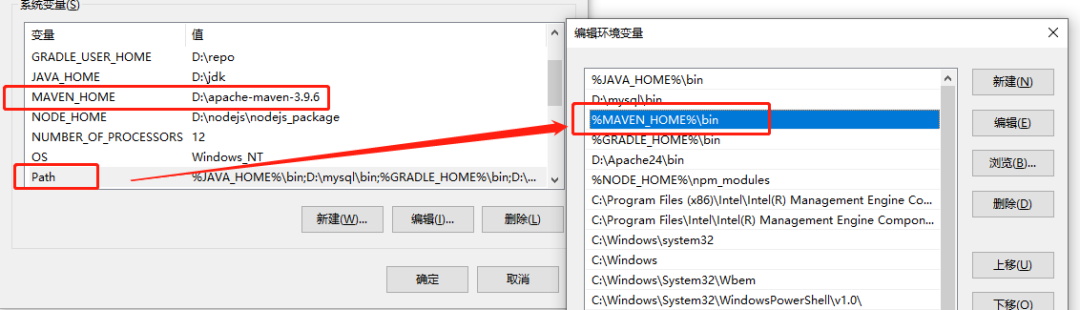
+
+**配置完毕后,记得重新打开一下cmd窗口。别直接在之前的cmd窗口测试**。
+
+在cmd窗口执行mvn -v
+
+
+
+> Ps:常见错误,没有配置正确的JAVA_HOME
+
+
+
+## 三、仓库&settings.xml配置(重要)
+
+### 3.1 仓库
+
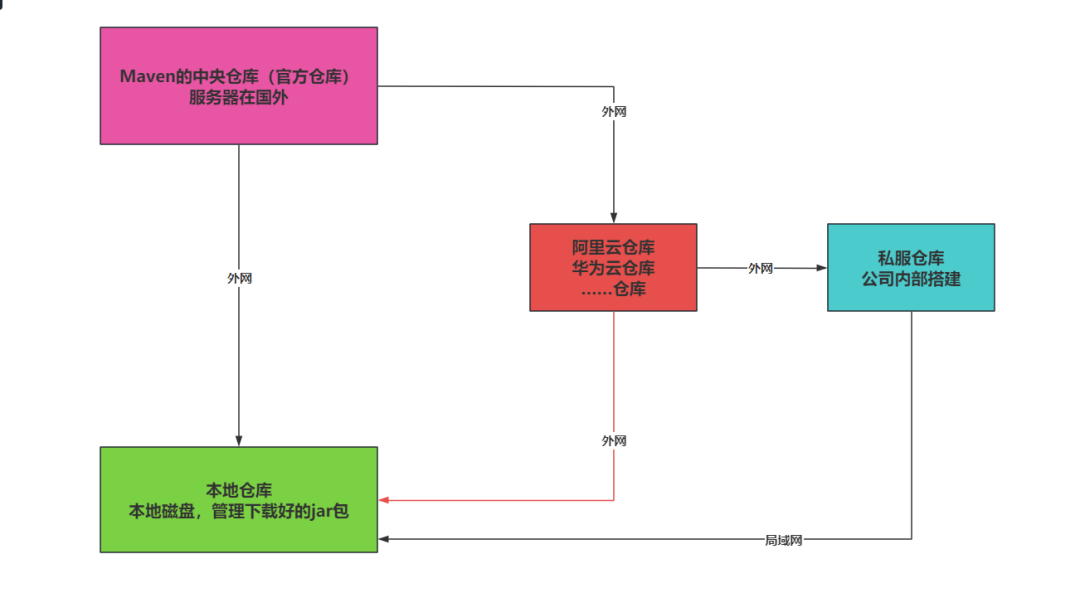
+Maven可以帮助咱们管理jar文件,但是,jar包是需要从网上下载下来的。
+
+仓库很多,有官方的中央仓库,还有国内公司的仓库,还有公司内部会搭建的私服
+
+
+
+咱们后面需要配置好国内公司的一些仓库。
+
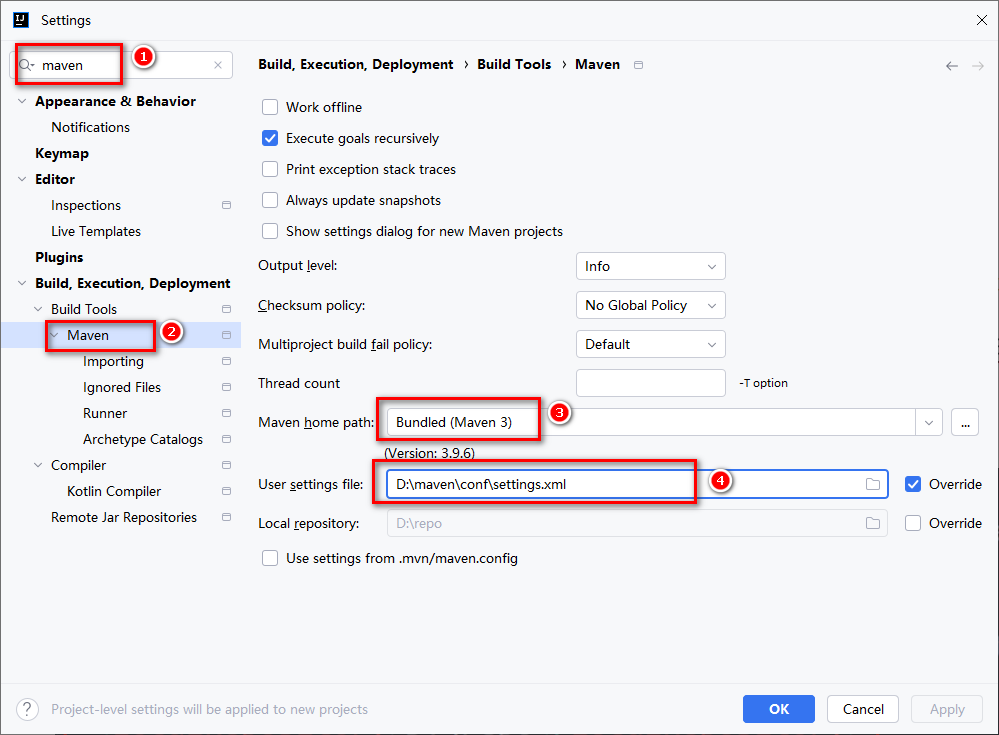
+### 3.2 settings.xml配置(重要)
+
+在MAVEN_HOME目录下,有一个conf目录。在conf目录下就有需要修改的settings.xml文件。
+
+需要修改三点内容
+
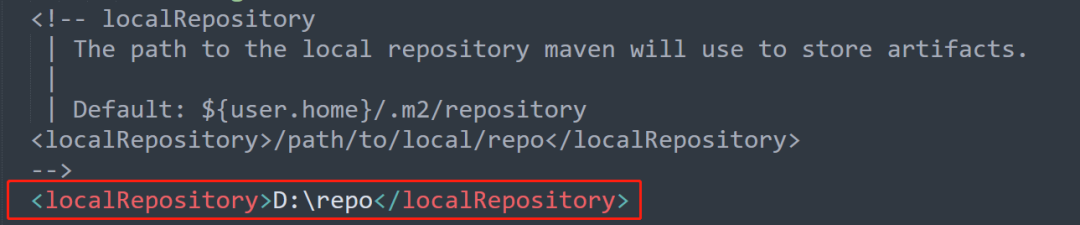
+#### 3.2.1 本地仓库地址
+
+默认情况下,本地仓库在C盘。
+
+> Default: ${user.home}/.m2/repository
+
+根据配置文件中的注释,默认是仍在用户目录下的.m2目录下的repository目录中。
+
+这个本地仓库会随着项目越来越多,这个仓库也会越来越大。可能会占用10多个G,甚至更多。
+
+所以推荐放在系统盘之外。(如果就C盘,那就用默认的吧…………)
+
+
+
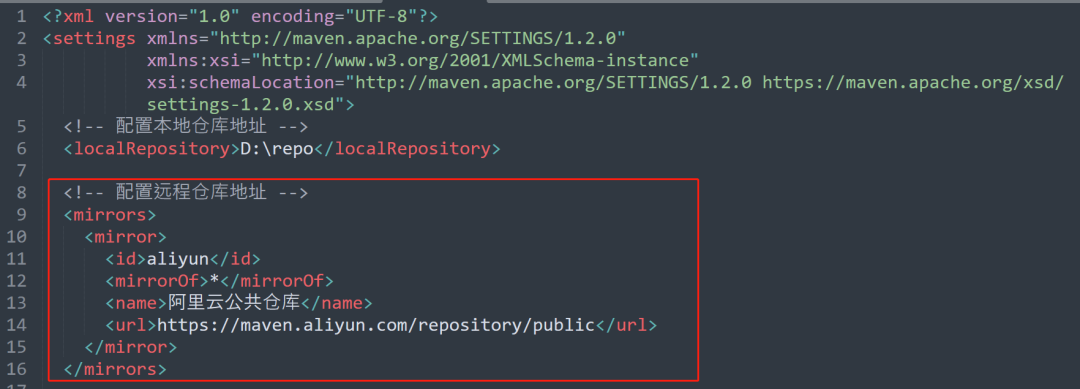
+#### 3.2.2 配置阿里云/华为云……仓库
+
+配置阿里云仓库
+
+
+
+```xml
+
+
+
+ aliyun
+ *
+ 阿里云公共仓库
+ https://maven.aliyun.com/repository/public
+
+
+```
+
+华为云的仓库地址:`https://repo.huaweicloud.com/repository/maven/`
+
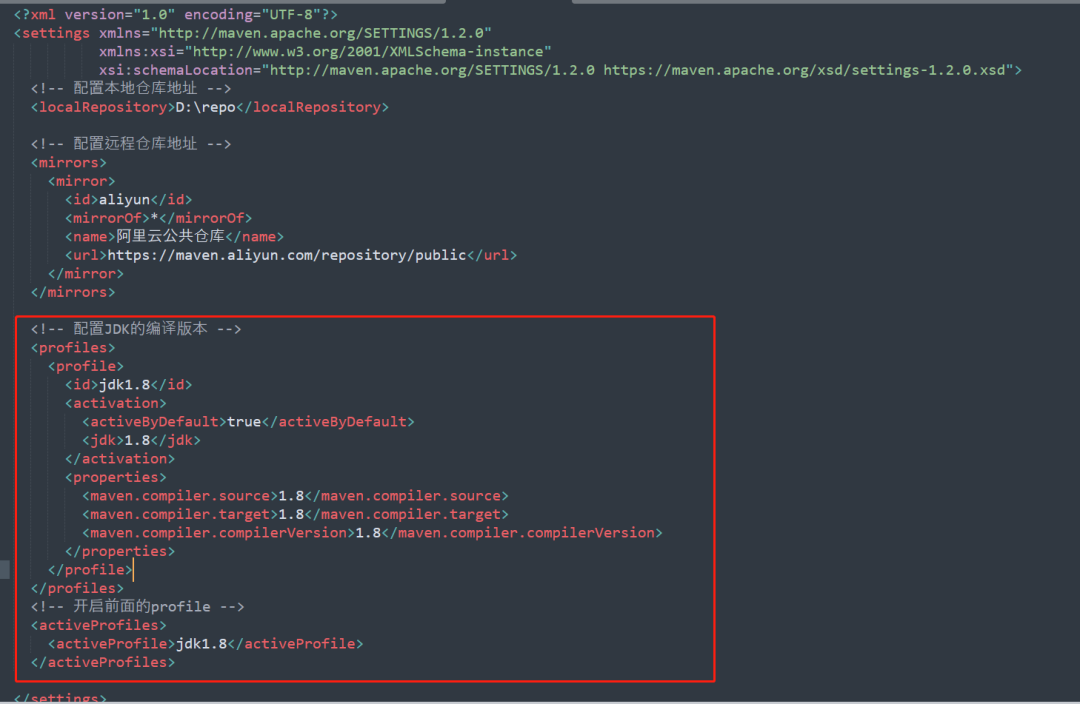
+#### 3.2.3 JDK编译版本配置
+
+Maven默认采用JDK1.5的编译方式去编译项目。
+为了让Maven支持现在JDK的编译版本,可以指定一下现在采用JDK1.8
+
+
+
+```xml
+
+
+
+ jdk1.8
+
+ true
+ 1.8
+
+
+ 1.8
+ 1.8
+ 1.8
+
+
+
+
+
+ jdk1.8
+
+```
+
+## 四、IDEA配置Maven
+
+**先看老版本的,再看新版本的!!!**
+
+### 4.1 2019.1.3 IDEA配置Maven
+
+打开IDEA的初始窗口
+
+
+
+右下角的Configure的位置打开settings,点开后,在左上角可以看到是Settings for New Projects
+
+
+
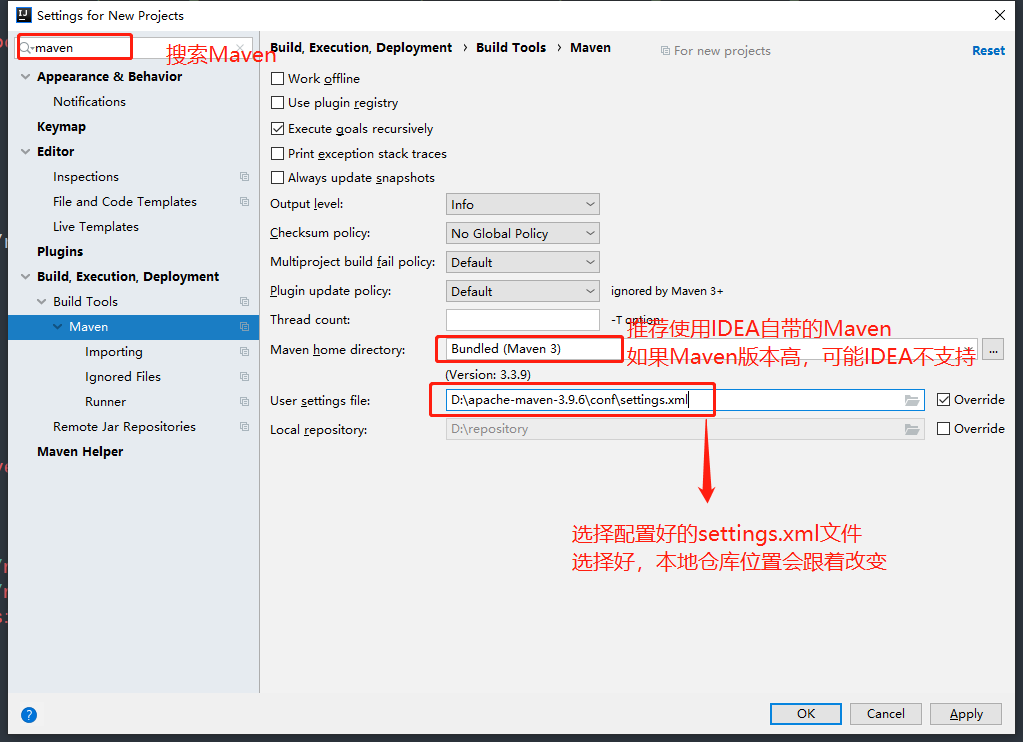
+因为IDEA版本的原因,对Maven的版本也是有要求的。
+
+比如现在的2019.1.3的IDEA版本,无法支撑3.6.1以上的Maven版本
+
+
+
+一定要记得,点击Apply,然后ok,确认生效。
+
+### 4.2 2024.1 IDEA配置Maven
+
+首先一定要记住,选择Settings for new projects
+
+
+
+
+
+
+
+## 五、IDEA构建Maven项目
+
+**先看老版本的,再看新版本的!!!**
+
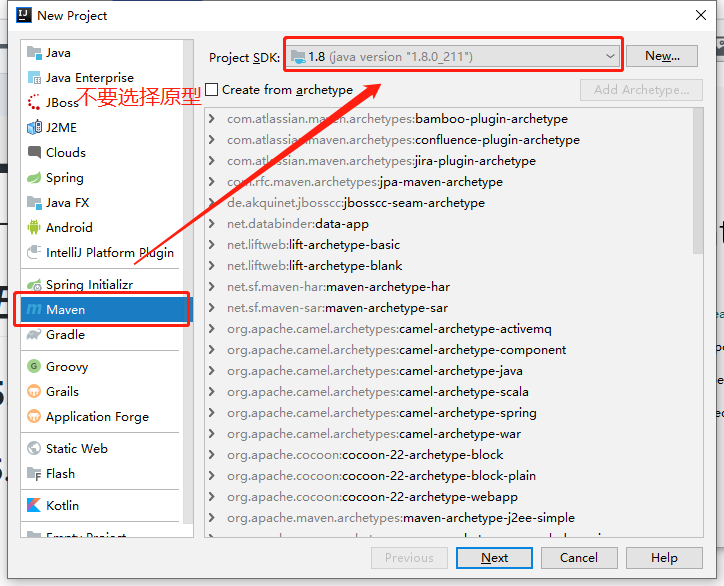
+### 5.1 2019.1.3 IDEA构建Maven项目
+
+点击Create New Project
+
+
+
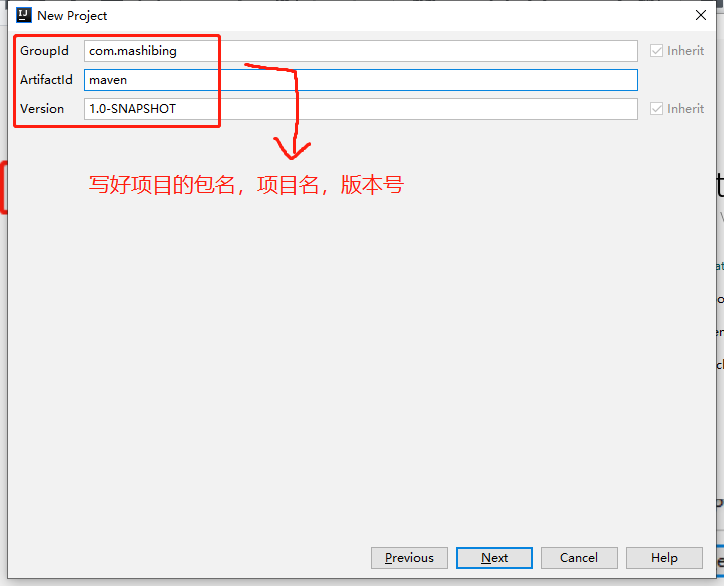
+next后,指定当前项目的三围,包名,项目名,版本号
+
+
+
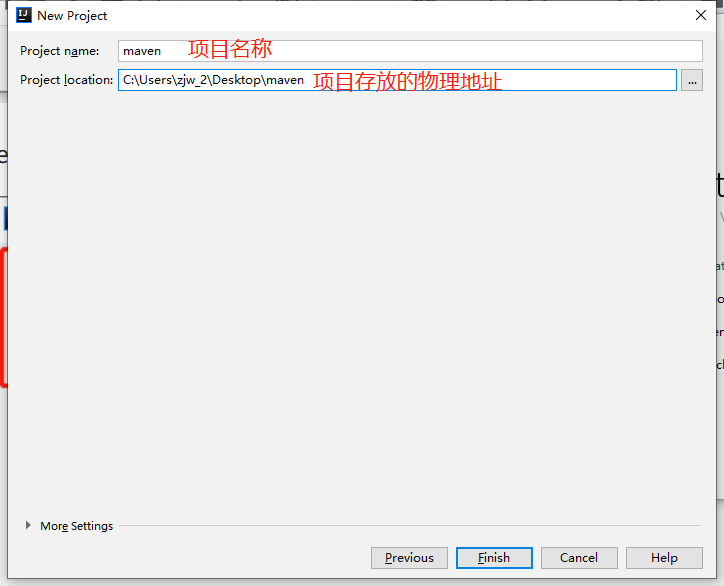
+指定好项目名和存放地址。这里对存放地址修改一下就ok。
+
+
+
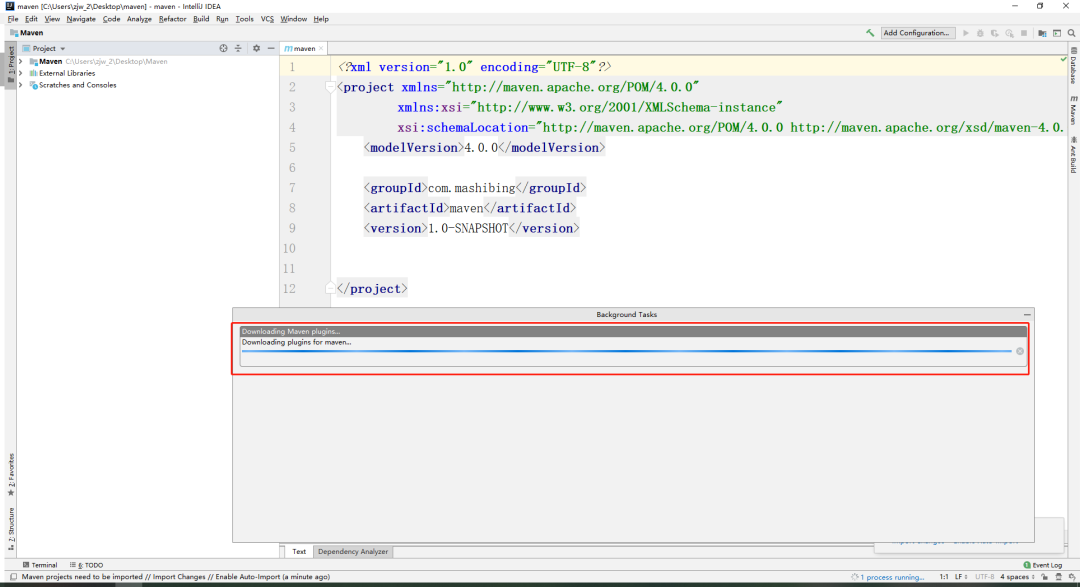
+指定好之后,点击Finish即可。
+
+
+
+进来后,可以看到右下角的进度条,在下载一些Maven必要的插件
+
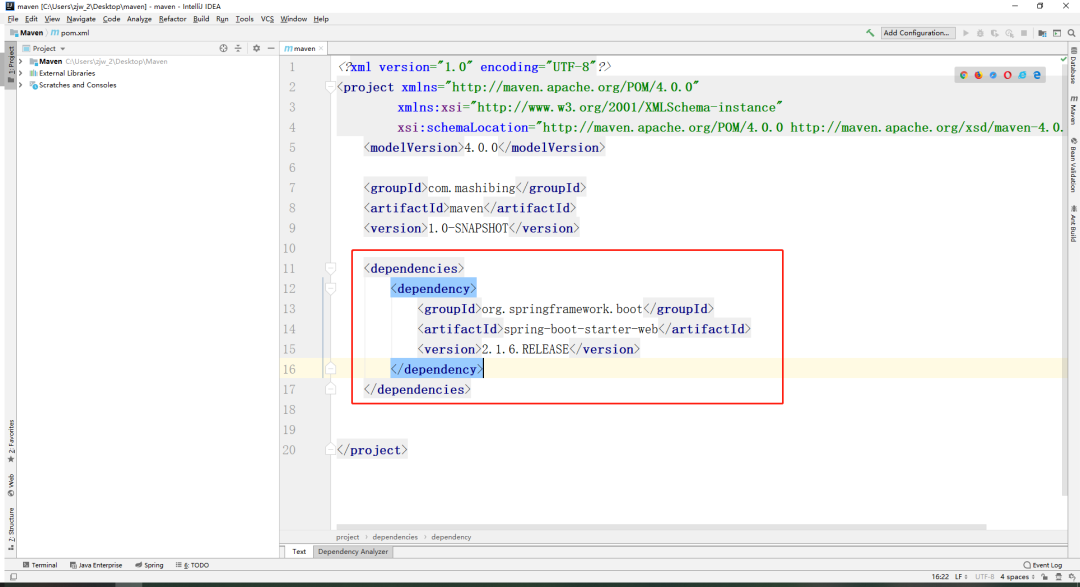
+在下载插件时,可能需要一定的时间,等插件下载好,为了确认咱们阿里云私服的配置是否生效,随便复制下面内容到当前位置。 **一定一定一定记得点击右下角的import Changes**
+
+```xml
+
+
+ org.springframework.boot
+ spring-boot-starter-web
+ 2.1.6.RELEASE
+
+
+```
+
+
+
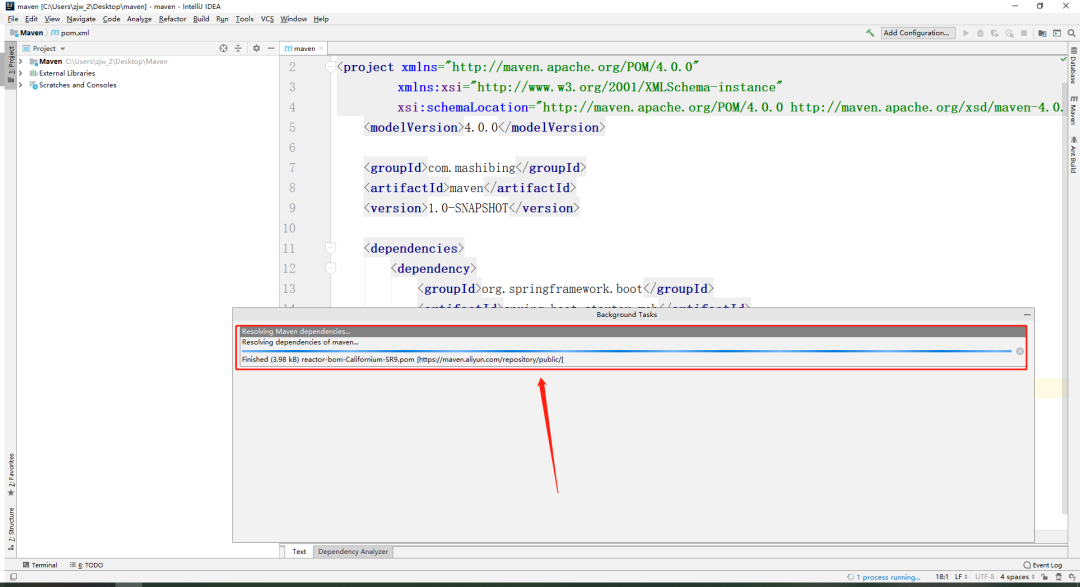
+快速地点击右下角的进度条,查看下载的链接地址,确认一下是否是阿里云的地址
+
+
+
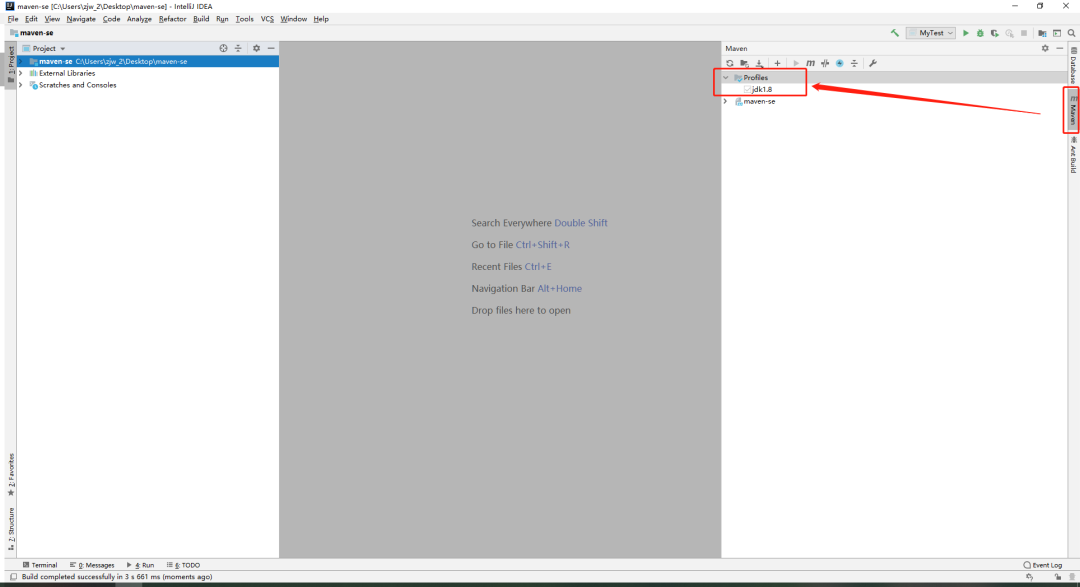
+再次查看右侧的Maven栏,确认profiles中的JDK1.8编译版本已经生效
+
+
+
+最后查看完毕后,要对Maven项目的目录结构有个了解
+
+
+
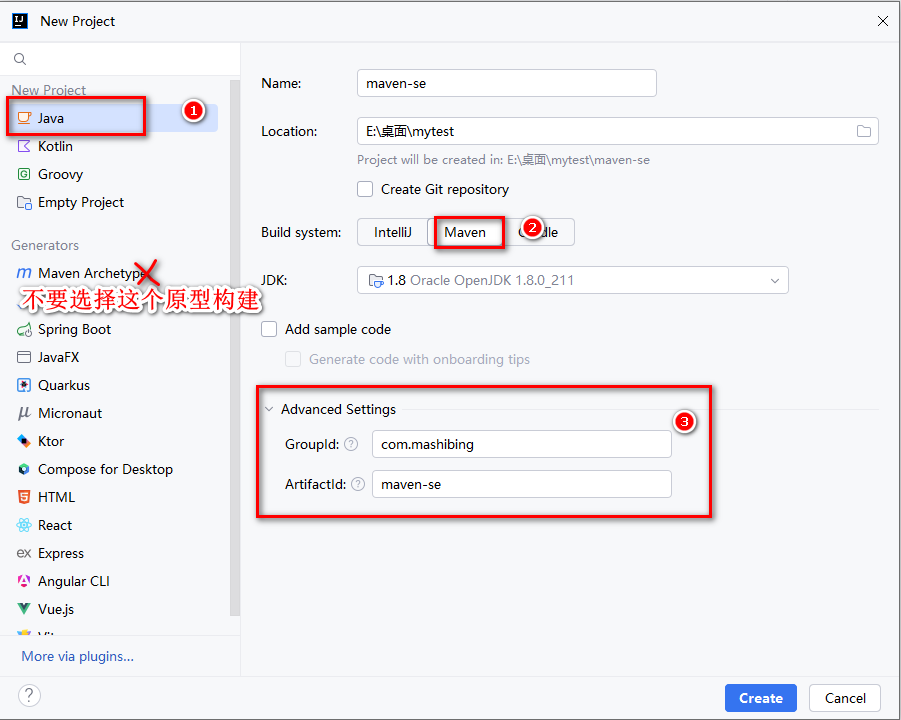
+### 5.2 2014.1 IDEA构建Maven项目
+
+
+
+### 5.3 IDEA构建Maven的Web项目
+
+这个新老版本是一致的!!!
+
+这里是先构建Maven的基础项目,然后将基础项目修改为Web项目。
+
+
+
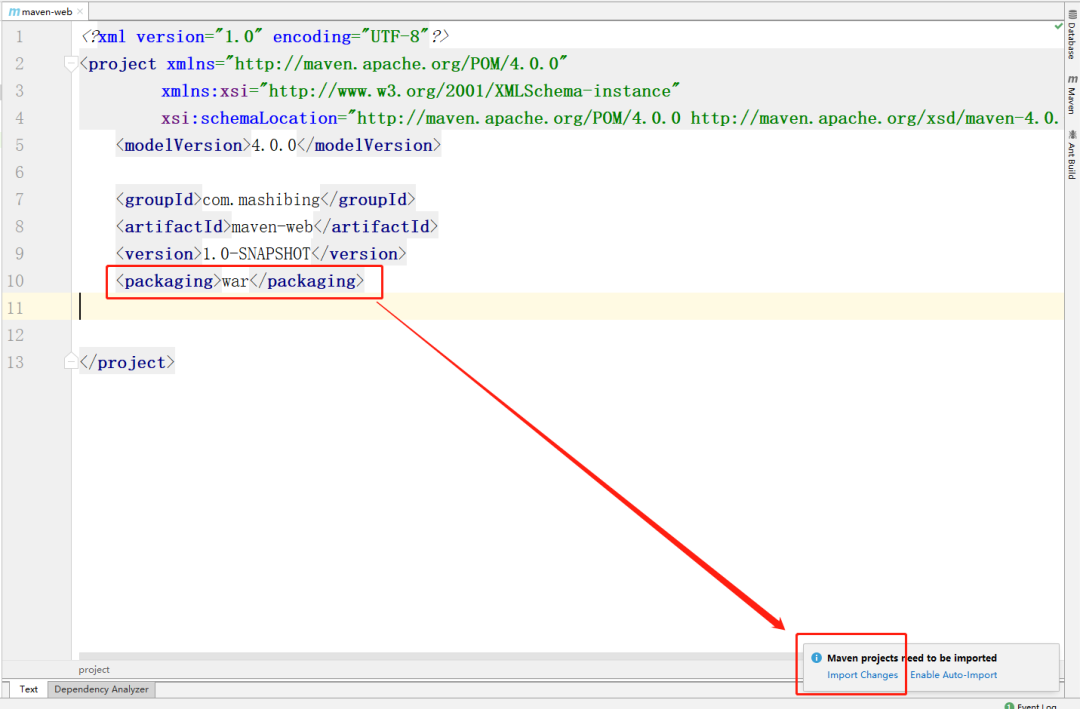
+正常,构建的基础maven项目,打包的方式是jar文件。需要将当前web项目的打包方式修改为war的形式。
+
+需要修改pom.xml文件指定打包方式。
+
+默认情况下,这个packaging是jar的打包形式。需要指定好war的形式,一定一定一定记得import Changes
+
+
+
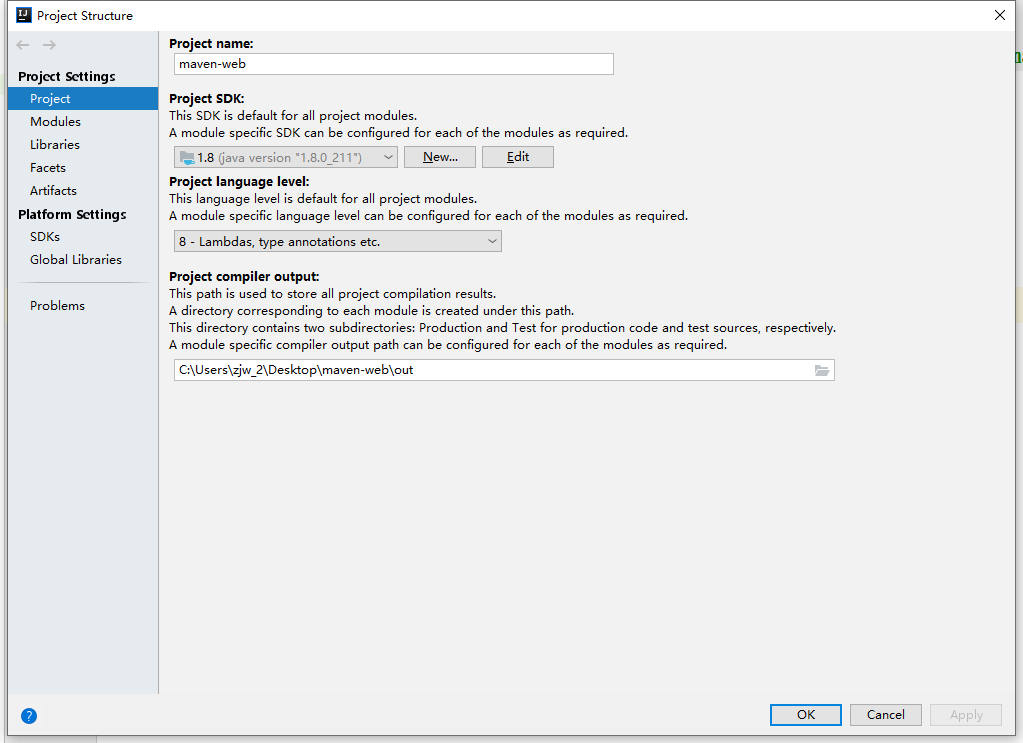
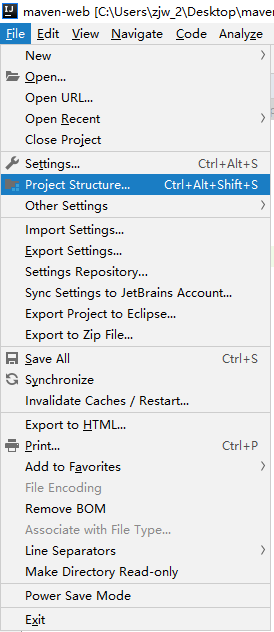
+然后选中项目,点击左上角的file,选择Project Structure
+
+
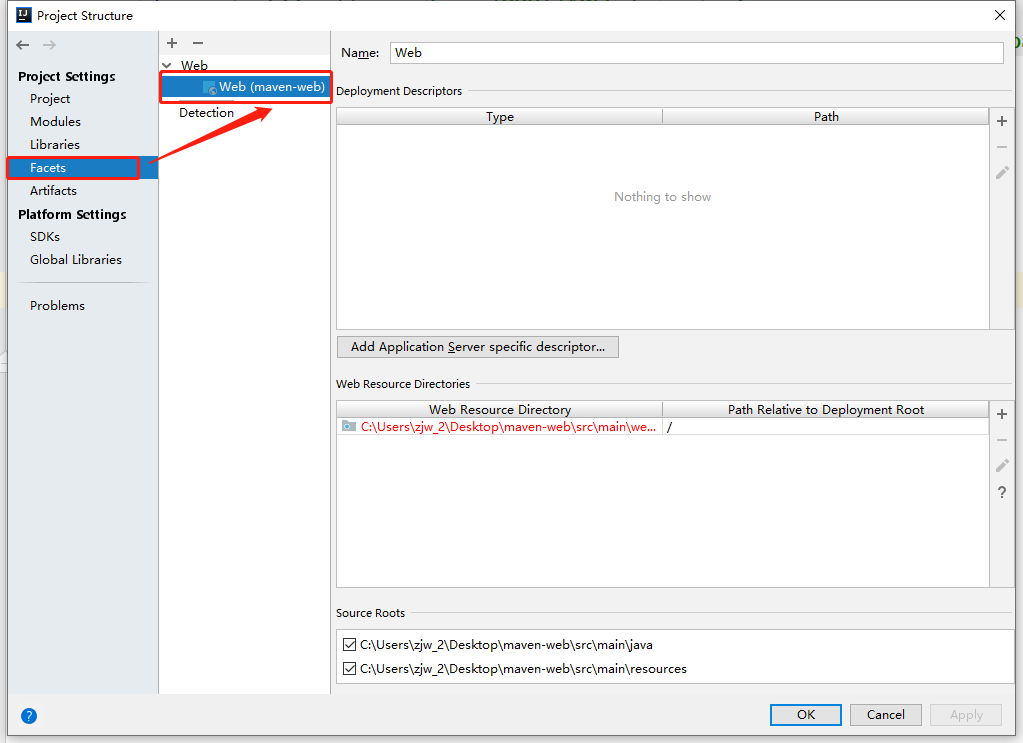
+
+选择左侧导航栏中的facets选项,如果你的Facets界面没有这个Web,说明之前的war没配置好!!
+
+
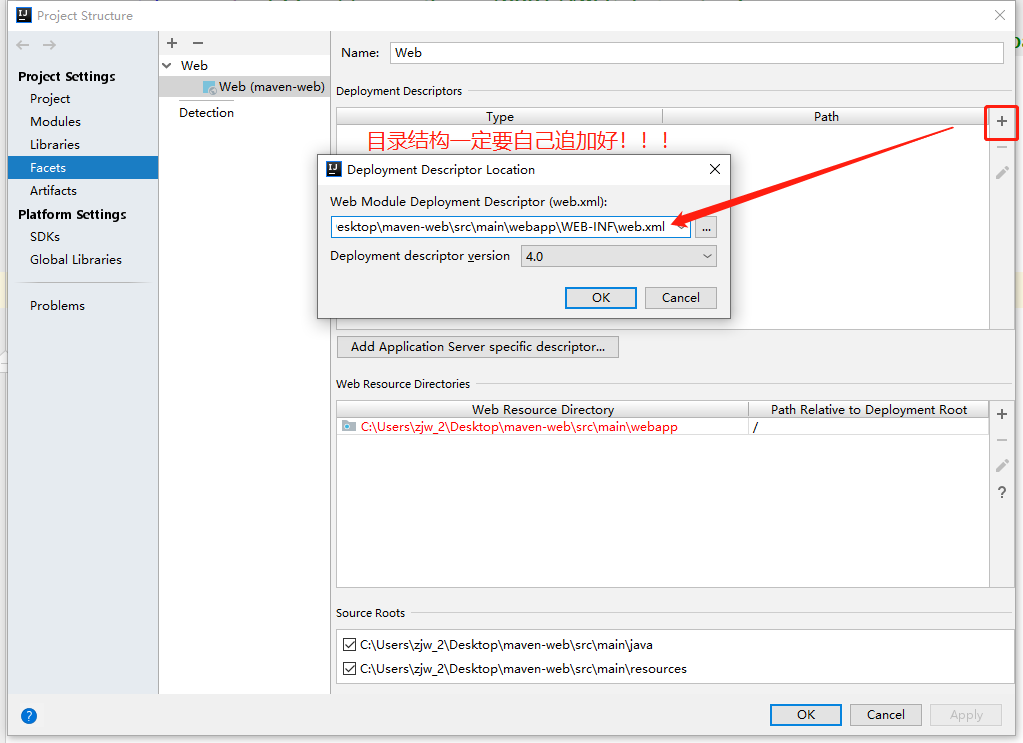
+
+然后点击右上角的+,追加一个web.xml文件,记得一定要放到webapp资源目录下
+
+
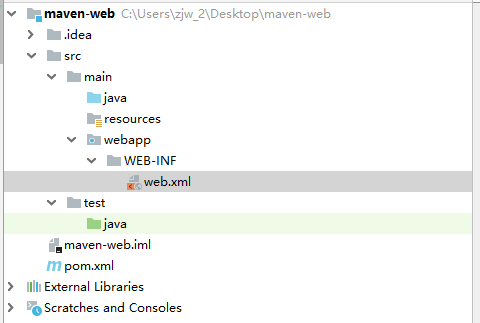
+
+点击ok,就会自动生成webapp目录,以及目录下的web.xml文件
+
+
+
+## 六、导入依赖jar(重要)
+
+创建好Maven项目之后,需要导入具体的jar包时,要通过 **坐标** 导入
+
+* 每个jar都需要三个内容形成一个唯一的坐标,需要groupId + artifactId + version导入一个具体的jar。
+* 在maven项目中,只需要导入配置的坐标,Maven便会自动地去网上下载jar文件,并且添加到项目中。
+
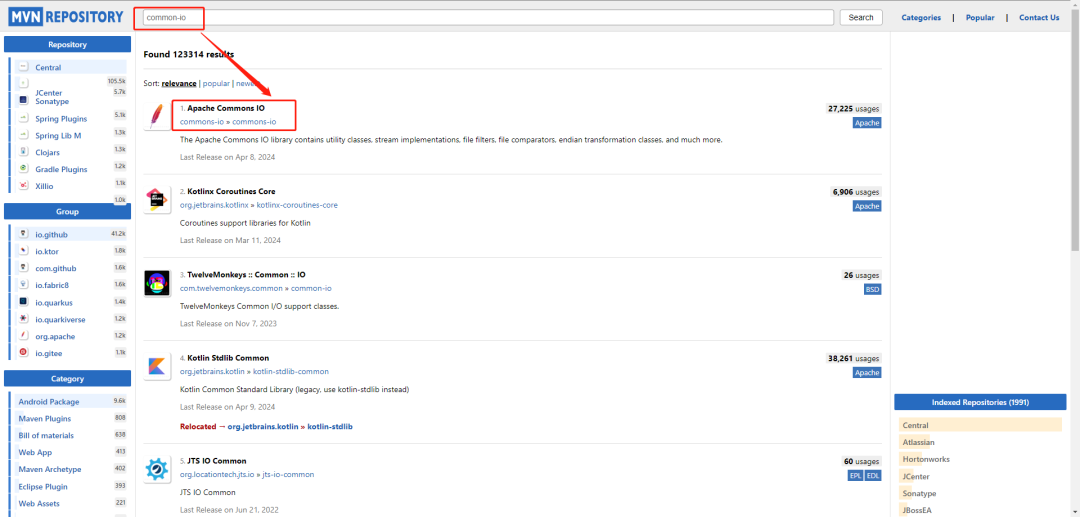
+当需要使用某个jar时,知道大概的名字,但是不会背下来具体的坐标信息,可以去一个地方搜索
+
+[https://mvnrepository.com/](https://mvnrepository.com/)
+
+可以去这个地址搜索具体的jar包坐标
+
+
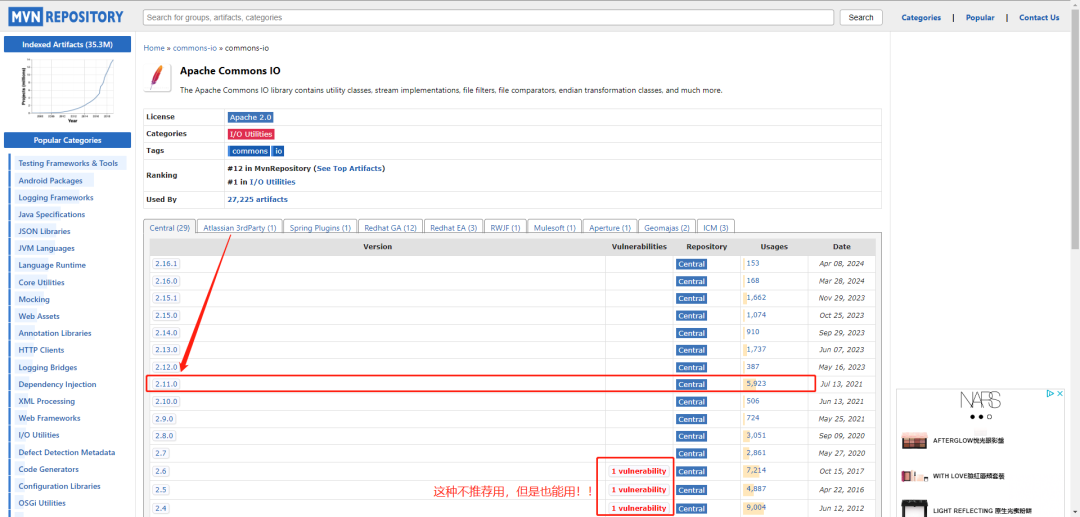
+
+进入具体的依赖内部后,选择对应的版本
+
+
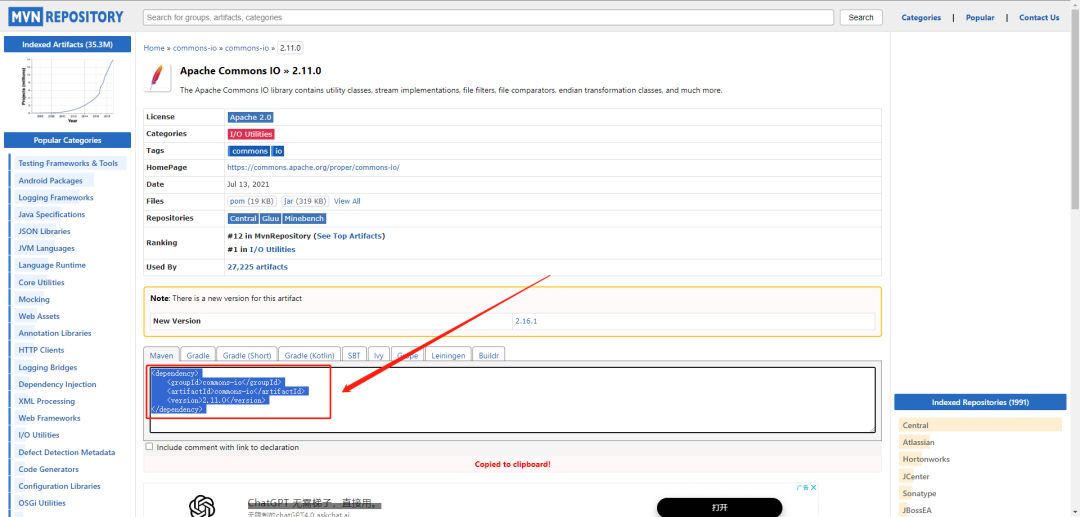
+
+找到需要导入的dependency
+
+
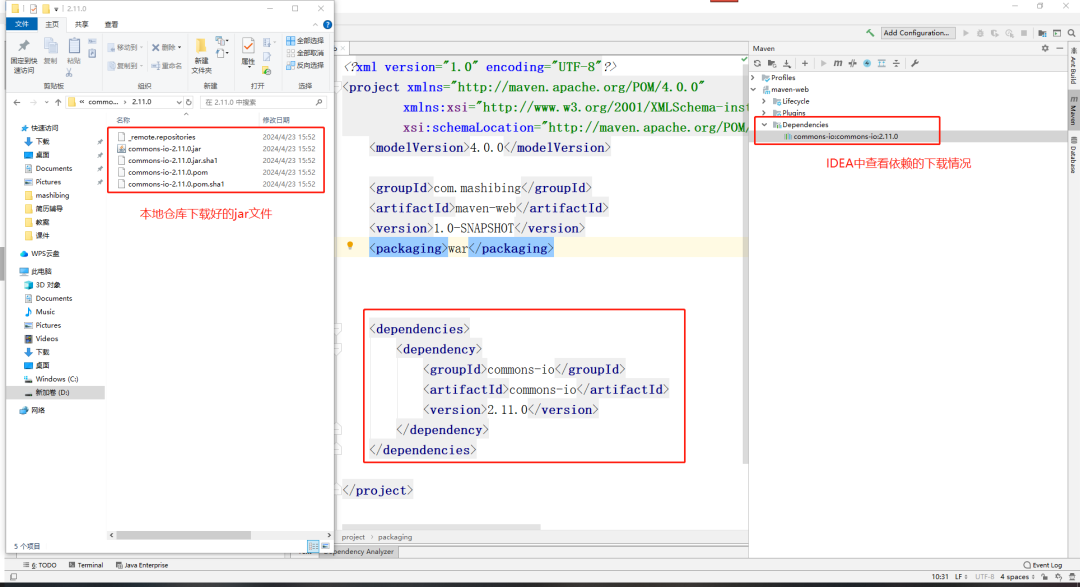
+
+复制好之后,扔到项目的pom.xml文件中
+
+
+
+如果本地仓库出现了.lastUpdated后缀的文件,可能有两个情况
+
+* 这个坐标的jar文件不存在
+* 因为网络原因下载失败了
+
+**这种.lastUpdated后缀的文件,会导致后续依赖下载失败,记得如果出现了依赖失败,检查坐标都没问题,并且也是走阿里云或者华为云去下载的,依然失败。记得去本地仓库看一下,是不是有.lastUpdated后缀的文件导致无法下载成功**!
+
+## 七、依赖的作用域
+
+所谓的依赖作用域就是当前这个jar文件在什么情况下,项目会使用到。
+
+这个所谓的情况,可以分成三点来聊:
+
+* 编译阶段
+* 测试阶段
+* 运行阶段
+
+Maven中给予依赖五种作用域:
+
+* compile(默认作用域):编译,测试,运行都会提供当前依赖的功能
+ ```
+
+ commons-io
+ commons-io
+ 2.11.0
+
+ ```
+* provided:编译,测试会提供当前依赖的功能。 一般Servlet,JSP会涉及。
+ ```
+
+ javax.servlet
+ javax.servlet-api
+ 3.1.0
+ provided
+
+ ```
+* runtime:测试,运行会提供当前依赖的功能。一般MySQL会涉及。
+ ```
+
+ mysql
+ mysql-connector-java
+ 8.0.28
+ runtime
+
+ ```
+* test:测试会提供当前依赖的功能。
+ ```
+
+ junit
+ junit
+ 4.13.2
+ test
+
+ ```
+* system:不是在什么情况下用,这个比较特殊,是将一些本地仓库没有的jar文件,引入到当前项目。
+ ```
+
+ com.oracle.database.jdbc
+ ojdbc10
+ 19.21.0.0
+ system
+ D:/ojdbc10-19.21.0.0.jar
+
+ ```
+
+**system,不推荐用,哪怕一些依赖,本地仓库无法下载,也别用system去引入。这种引入方式会导致后期打包还是更换了环境之后,无法使用。(后面咱们会根据maven的命令,可以将本地的jar包安装到本地仓库)**
+
+```shell
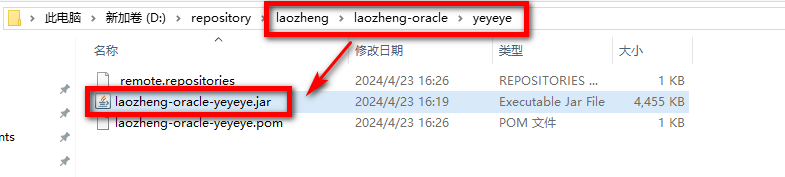
+mvn install:install-file -Dfile=D:/ojdbc10-19.21.0.0.jar -DgroupId=laozheng -DartifactId=laozheng-oracle -Dversion=yeyeye -Dpackaging=jar
+```
+
+搞定后,本地仓库可以看到install的jar文件和路径
+
+
+
+然后就可以在项目中引用了。
+
+```xml
+
+ laozheng
+ laozheng-oracle
+ yeyeye
+
+```
+
+## 八、依赖冲突
+
+首先,咱们要先了解一下Maven依赖的传递特性。
+
+当咱们导入一个jar包后,如果这个jar为了完成一些功能,还需要其他的jar的功能。
+
+比如有A,有B,其中A依赖了B。
+
+咱们只需要导入A包,B会自动被依赖过来。优点大大的:
+
+* 不需要刻意的去记导入A之后,还需要导入什么其他的依赖。
+* 关于某个版本的A需要哪个版本的B也不需要关注。
+
+上面是优点,但是也存在着一些问题。
+
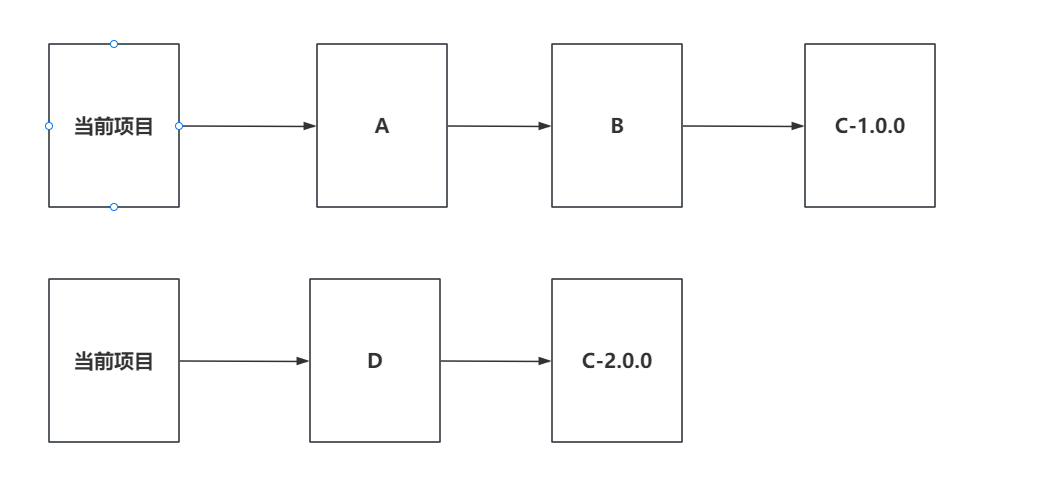
+当前项目 -> A -> B(1.0.0)
+
+当前项目 -> C -> B(2.0.0)
+
+此时,当前项目会出现相同的依赖,有两个,但是版本不一样,此时就会产生依赖冲突问题。
+
+一般依赖冲突会在启动或者测试项目时,直接给你甩异常。而且这个依赖不太好处理。需要解决这种依赖冲突。
+
+### 8.1 就近原则
+
+
+
+明显,当前项目通过D依赖C的路径最近,基于就近原则,会使用2.0.0的版本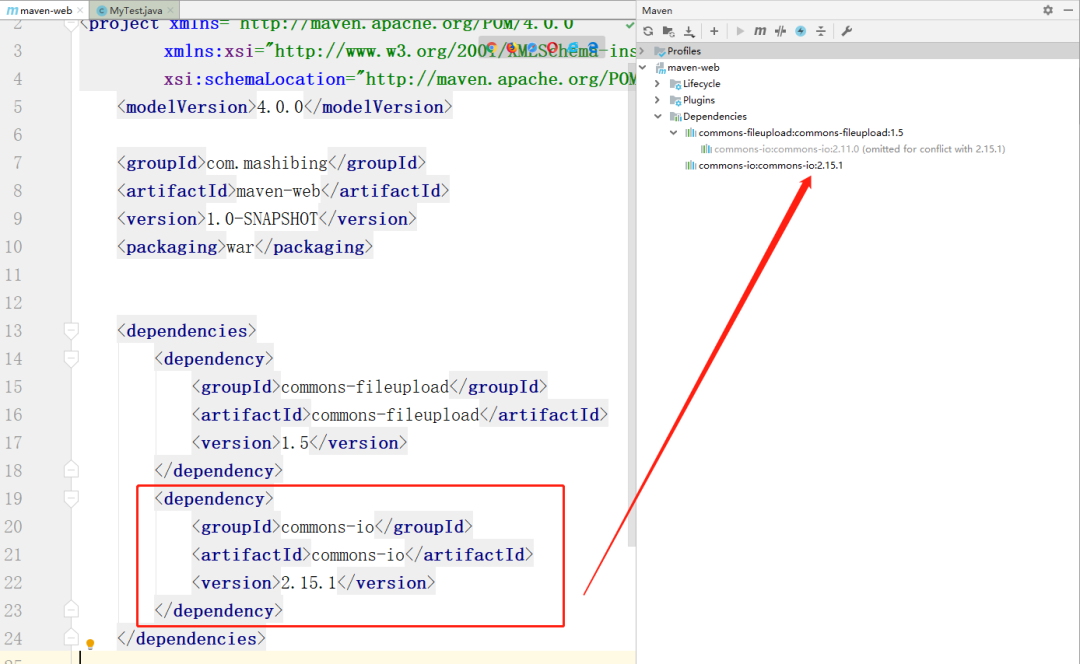
+
+### 8.2 优先声明原则
+
+当出现依赖传递导致相同jar包版本不一致时,此时会根据优先声明原则来决定使用谁。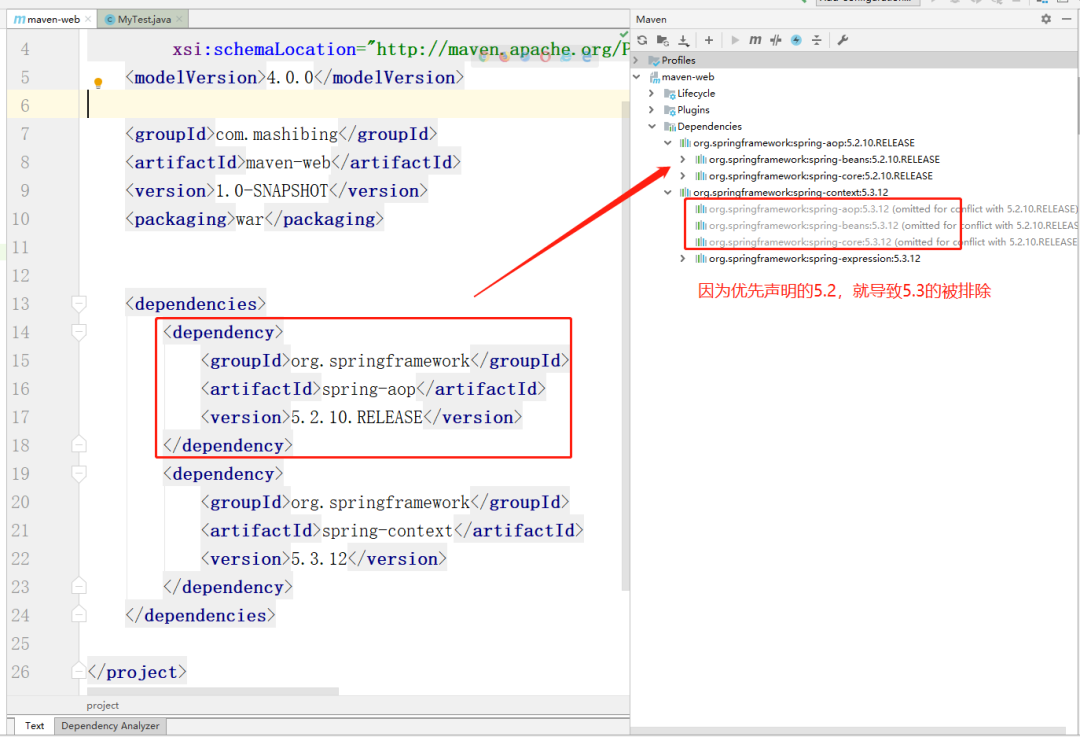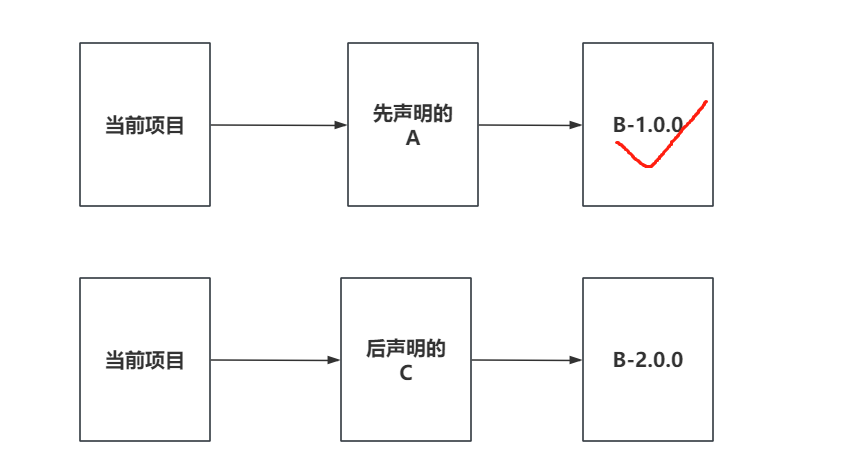
+
+如果是你主动导入的依赖,此时会根据你最后引用的版本决定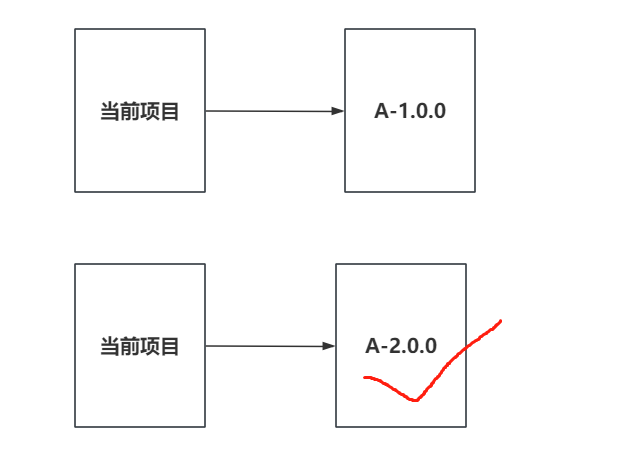
+
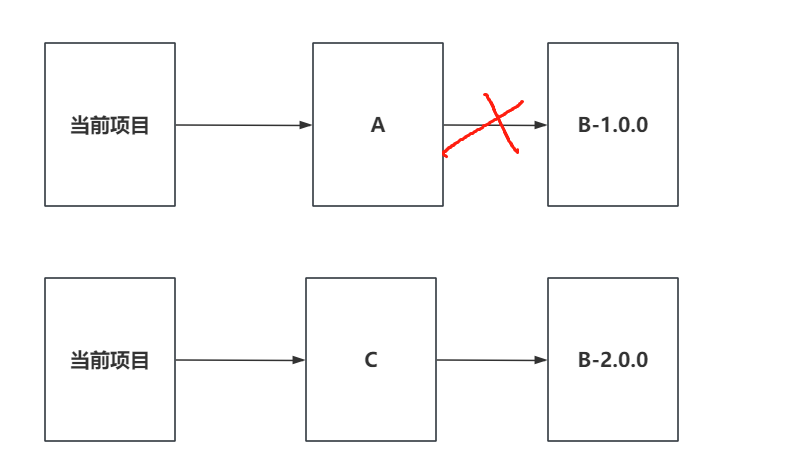
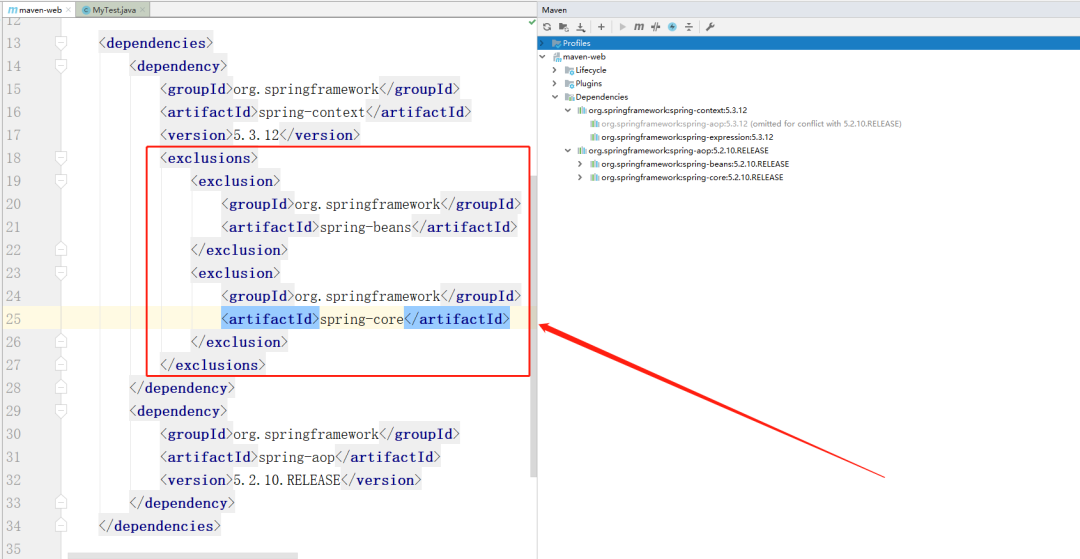
+### 8.3 手动排除依赖
+
+可以手动的形式,在引入A依赖时,将B依赖中A依赖排除掉
+
+
+
+
+
+```xml
+
+
+ org.springframework
+ spring-context
+ 5.3.12
+
+
+ org.springframework
+ spring-beans
+
+
+ org.springframework
+ spring-core
+
+
+
+
+ org.springframework
+ spring-aop
+ 5.2.10.RELEASE
+
+
+
+```
+
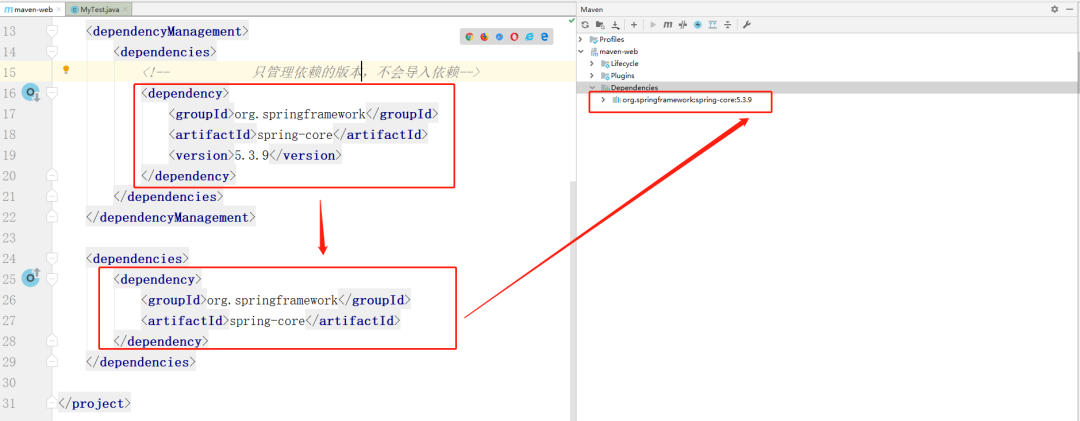
+### 8.4 声明依赖版本
+
+可以通过dependencyManagement标签,提前声明依赖的版本。
+
+dependencyManagement标签只会声明版本,不会将依赖导入,导入依赖依然需要借助dependencies
+
+配置完下面的内容后,再导入spring-beans、spring-core无论什么方式,都使用dependencyManagement中声明的版本。
+
+```xml
+
+
+
+
+ org.springframework
+ spring-beans
+ 5.1.8.RELEASE
+
+
+ org.springframework
+ spring-core
+ 5.3.9
+
+
+
+```
+
+如果前面已经声明好了依赖的版本。
+
+但是你在pom.xml文件中,直接引入了一个具体的版本的依赖,和dependencyManagement不一致,那么会使用你指定好的版本。这种依赖传递的版本会严格遵循dependencyManagement。
+
+其次,如果基于dependencyManagement声明好了版本,在dependencies中导入依赖时,是可以不写版本号的,可以直接基于dependencyManagement中的版本导入。
+
+
+
+## 九、Maven指令
+
+Maven为整个项目生命周期的各个阶段,提供了各种各样的指令。
+
+先了解常用的几个:
+
+```java
+mvn clean:清空target目录。
+mvn compile:编译整个项目,生成到target
+mvn test:专门针对test目录下的内容做测试
+mvn package:会将当前项目打包,jar,war。
+mvn install:将当前项目进行编译,测试,打包,并且将jar包安装到本地仓库。
+// mvn deploy:私服的位置再讲
+```
+
+* compile:这里是将main目录下的内容编译,生成一个target目录,将编译后的内容全部放到target目录下,java和resources都可以称为classpath,因为编译后的内容都是放在classes目录下的。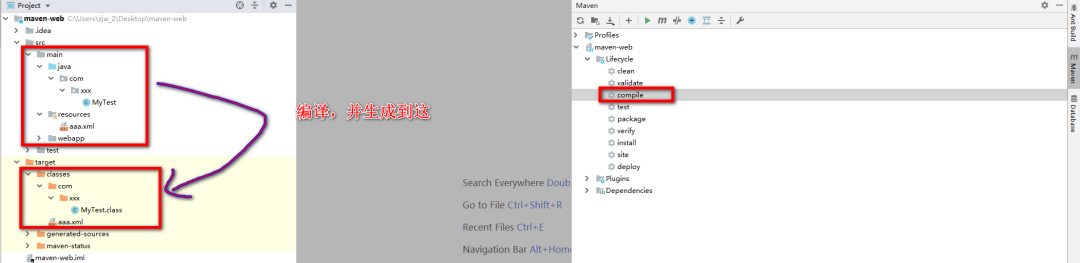
+* clean:就是将编译后的内容全部清除掉。
+* test:测试会优先进行编译,并且会针对test目录下以Test结尾的类中追加了@Test注解的方法运行测试,如果报错,控制台会有显示。直接Build失败。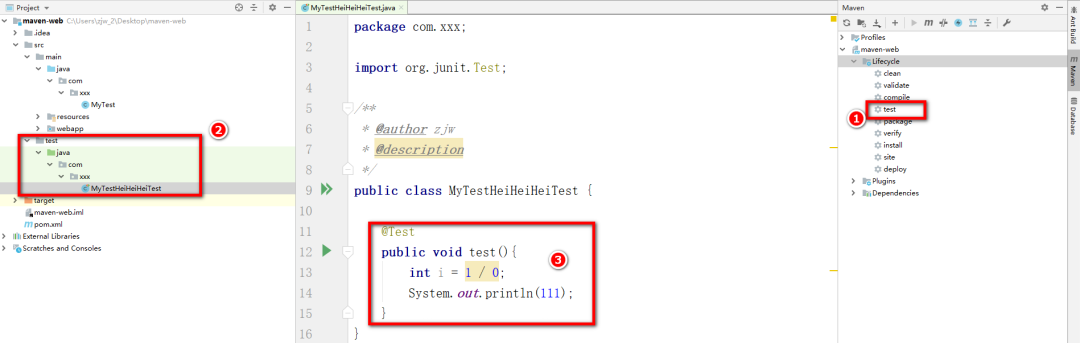
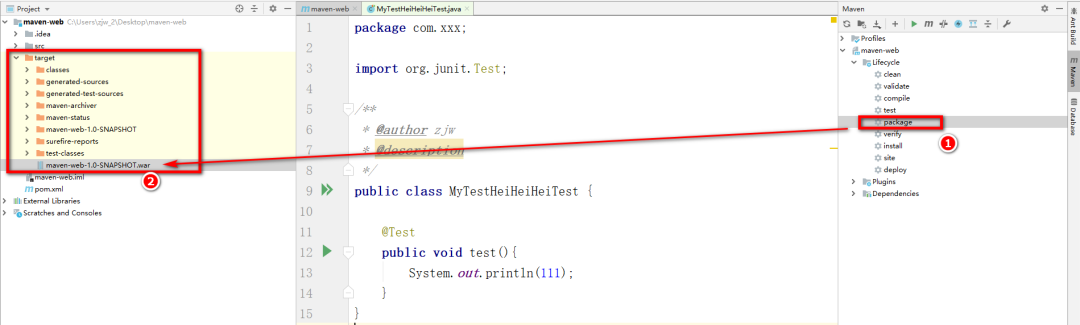
+* package:将项目进行打包,但是打包会经历compile以及test,并且成功后,才会将项目打包成具体的jar或者是war。打包后的具体文件,会存放在target目录下。项目打包无法跳过编译过程的,但是可以跳过测试的过程,需要自行敲命令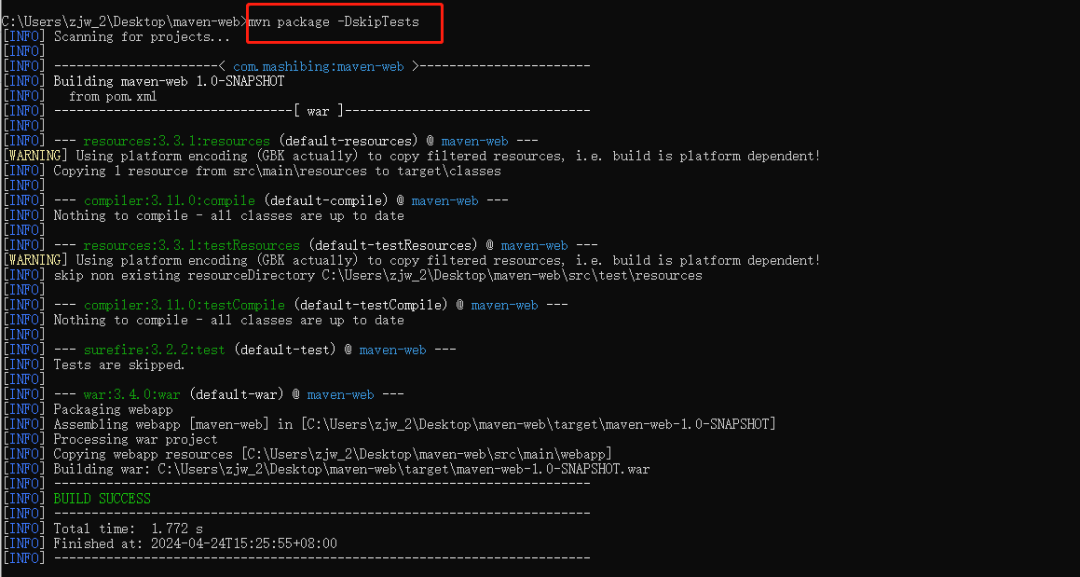
+
+ ```
+ mvn package -DskipTests
+ ```
+
+ 
+* install:将当前项目做好编译,测试,打包,并且将项目安装到本地仓库。如果安装到本地仓库的是一个jar包,其他项目就可以将这个jar依赖过来使用。!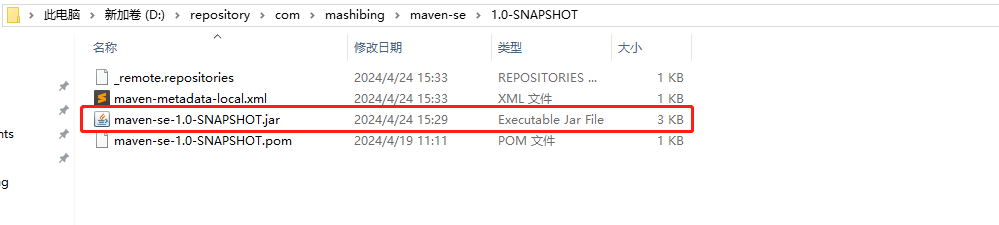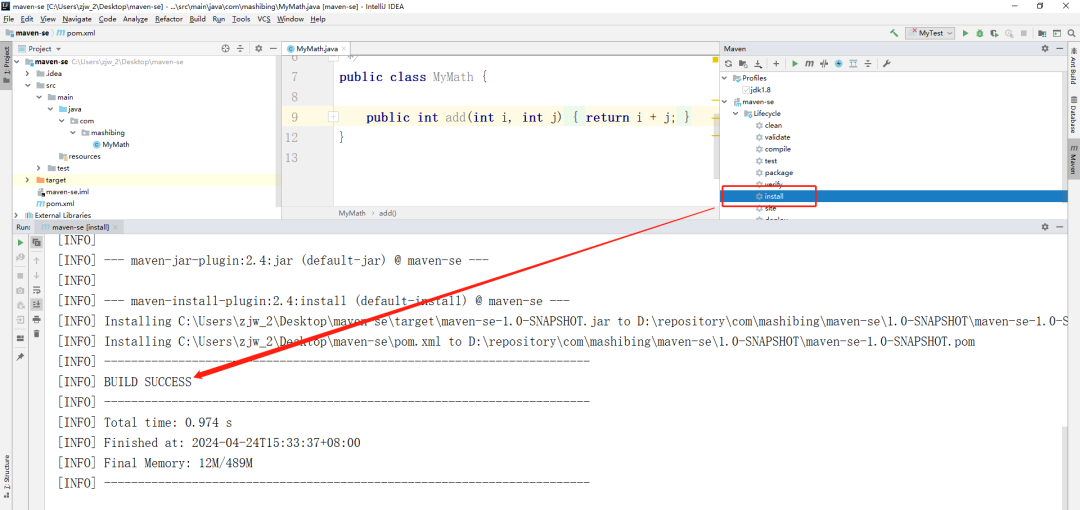
+
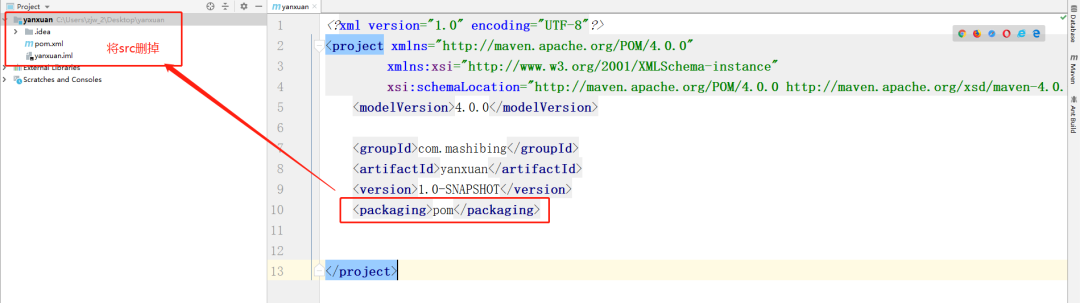
+## 十、聚合工程
+
+在项目打包的方式中,前面聊过jar,还有war的形式。
+
+除此之外,还有一个打包的形式,叫做pom。pom就是所谓的聚合工程。
+
+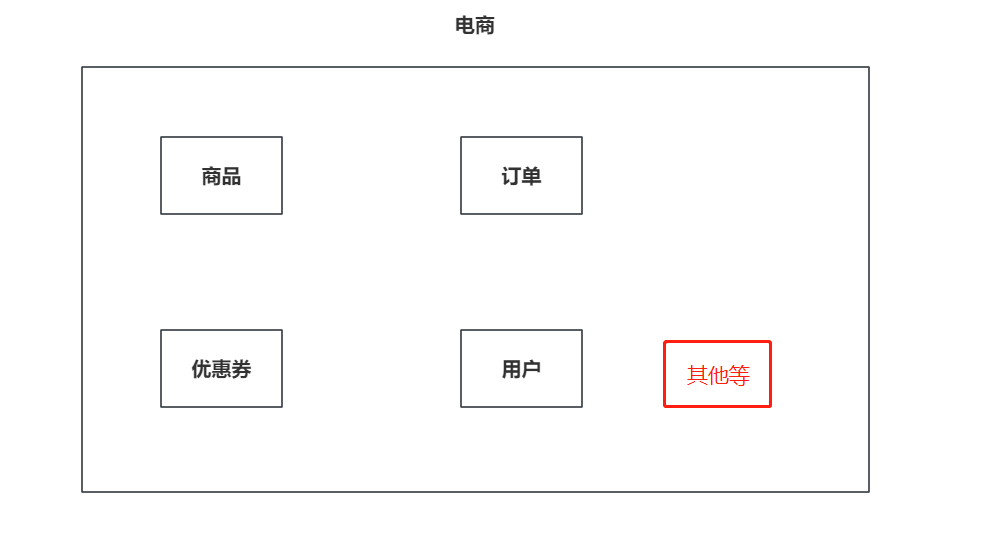
+
+构建最外层的电商聚合工程,聚合工程不需要写任何的业务代码,它的目的就是管理其他的子工程
+
+
+
+构建好聚合工程后,可以再构建子工程,流程如下。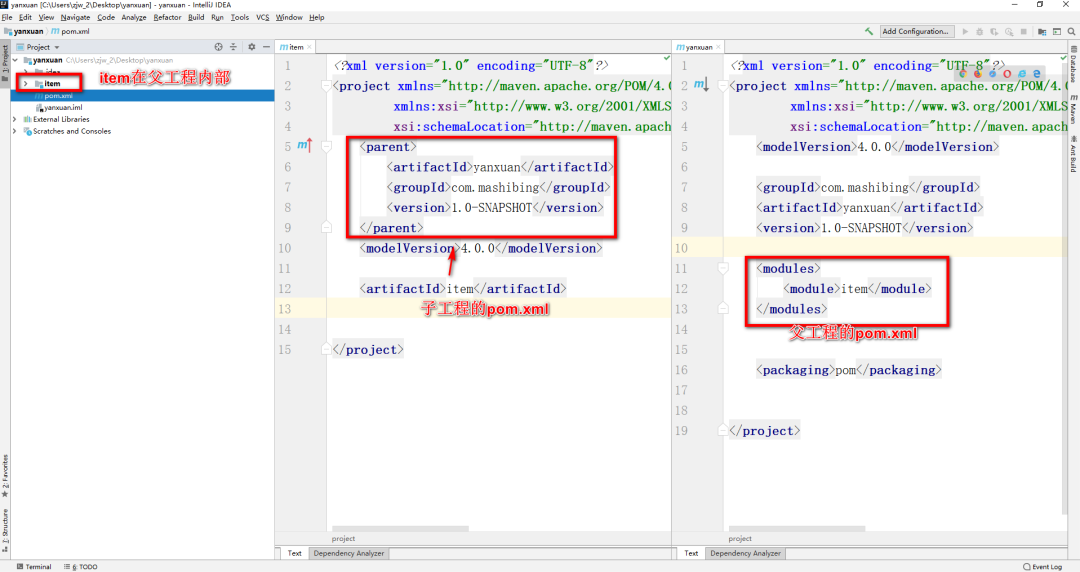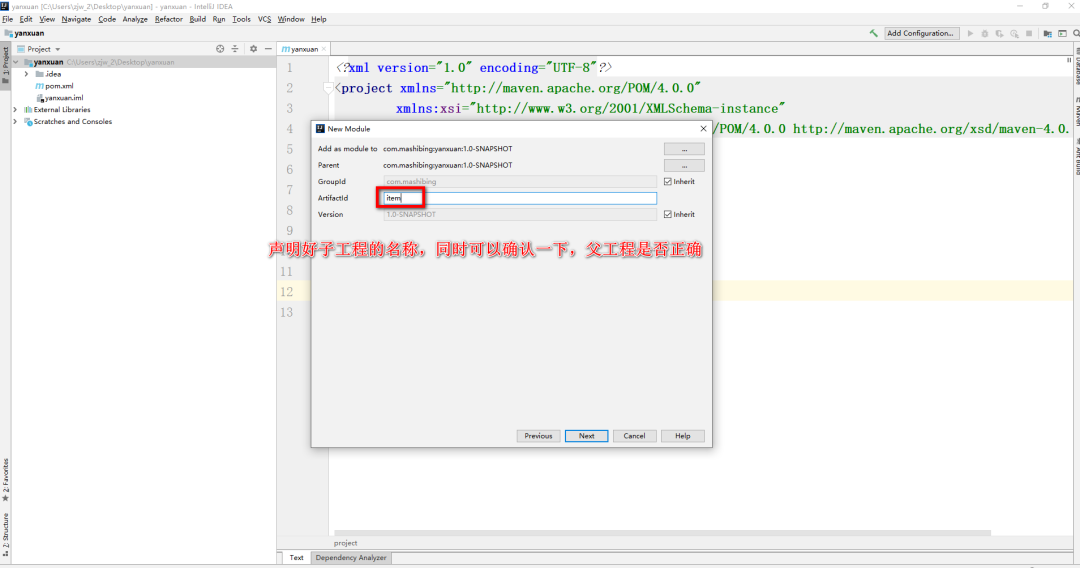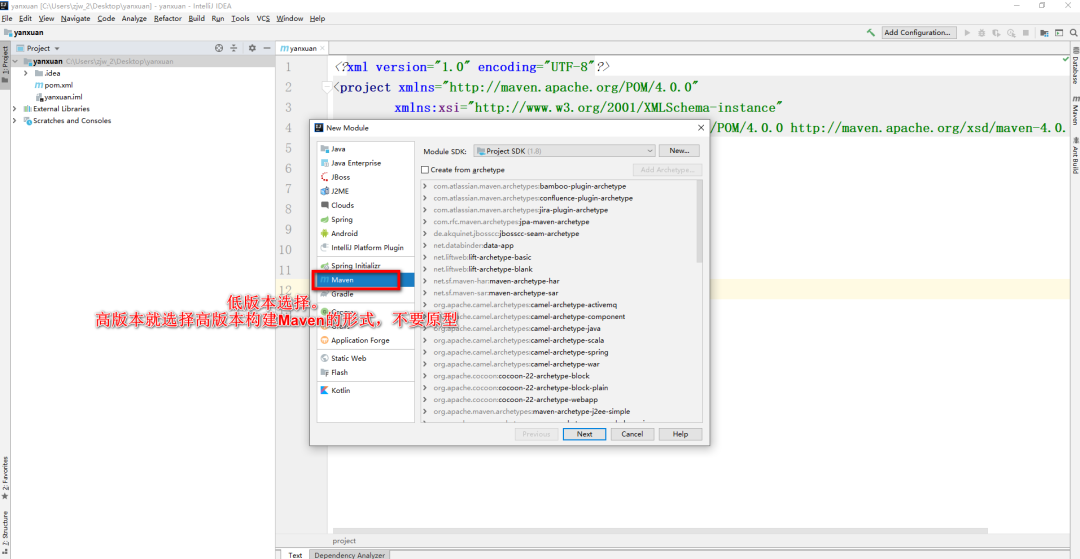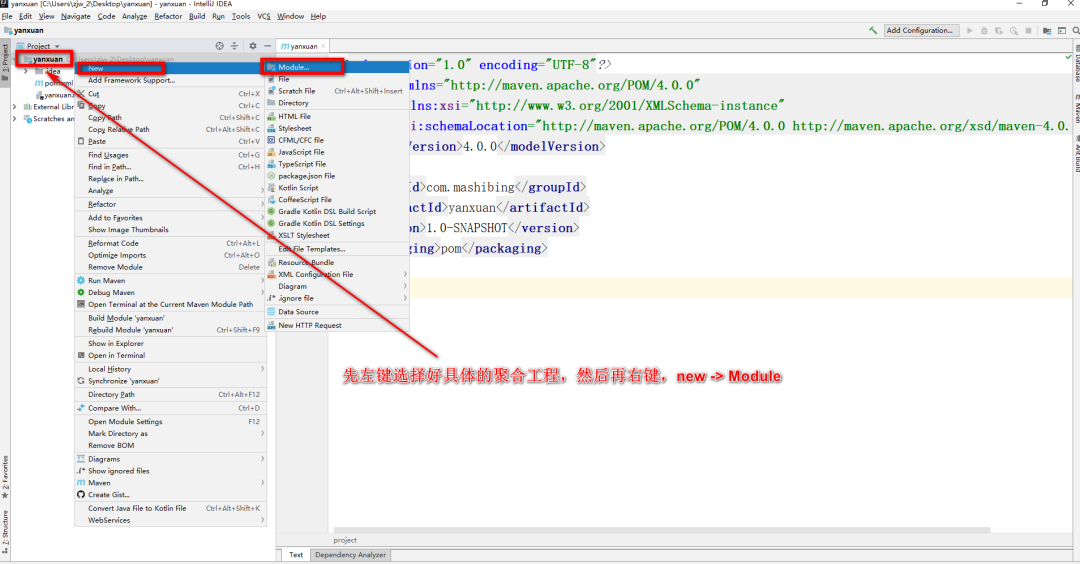
+
+好处是可以在聚合工程内去管理依赖的版本。同时可以基于聚合工程做统一的多个项目的打包或者其他操作。而且拆分模块去写项目。
+
+## 十一、Maven私服
+
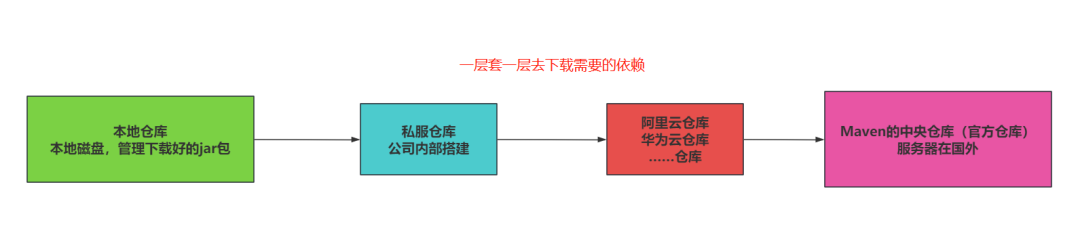
+### 11.1 Maven私服的概念
+
+> * 私服是搭建在局域网的一种特殊的远程仓库,目的是代理远程仓库,让下载依赖的效率更高。
+> * 有了私服之后,使用Maven需要下载依赖时,直接请求私服下载依赖,将私服中的依赖下载到本地仓库中。如果私服中没有具体依赖,私服会去外部的远程仓库下载。
+> * 私服可以解决在业务做开发时,有一些内部的依赖,是中央仓库没有提供的,是公司开发人员自行封装的一些依赖。可以将公司自研的一些框架和依赖上传到私服中,让公司内部人员可以通过私服将这种依赖下载到本地仓库。
+
+
+
+> 搭建私服的方式非常多,Apache Archiva,Sonatype Nexus。 一般都会采用后者。
+
+### 11.2 搭建Nexus私服
+
+去官网下载最新的安装包。
+
+http://www.sonatype.com
+
+但是在官网想找到Download挺麻烦的,下载的话,直接进入到下面这个地址
+
+https://help.sonatype.com/en/download.html
+
+
+
+下载完毕是一个zip的压缩包,最好解压到非系统盘的位置,路径不要带 **中文和空格** !!!!
+
+解压后,有两个目录
+
+
+
+进入到nexus-3.67.1-01目录下,再进入bin目录下。
+
+
+
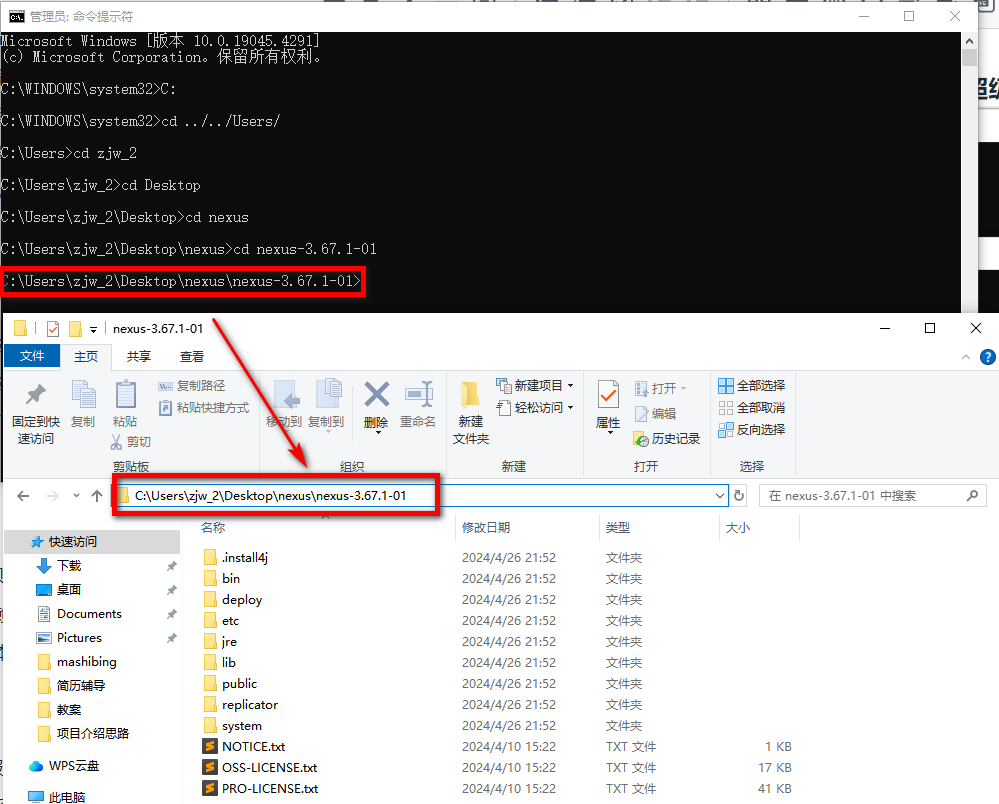
+启动时,需要基于doc窗口去运行Nexus私服,但是一定要以 **超级管理员** 的身份打开cmd。
+
+
+
+在bin目录下执行指定,访问外网慢的话,可能需要至少9~10分钟左右甚至更多。
+
+```shell
+nexus.exe /run
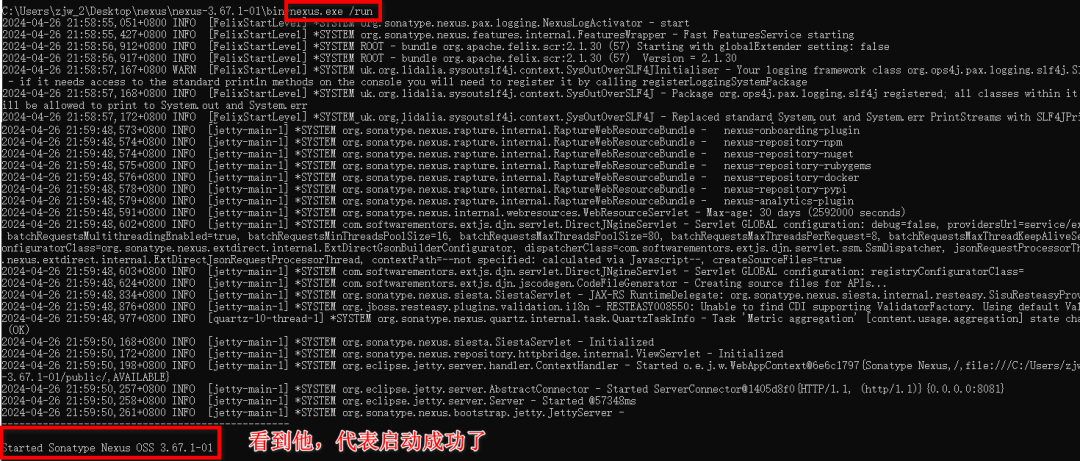
+```
+
+
+
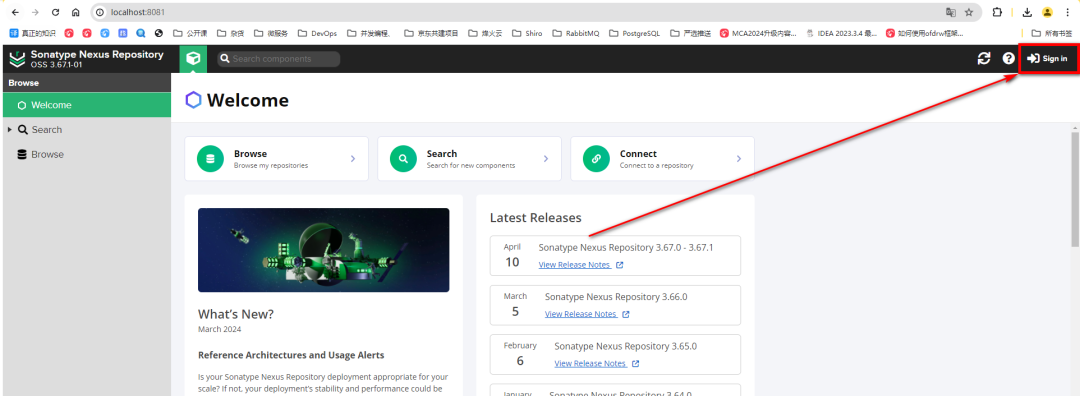
+启动成功后,直接访问http://localhost:8081/
+
+进入首页后,需要加载一小会,可以访问到首页,第一个要做的事情是登录
+
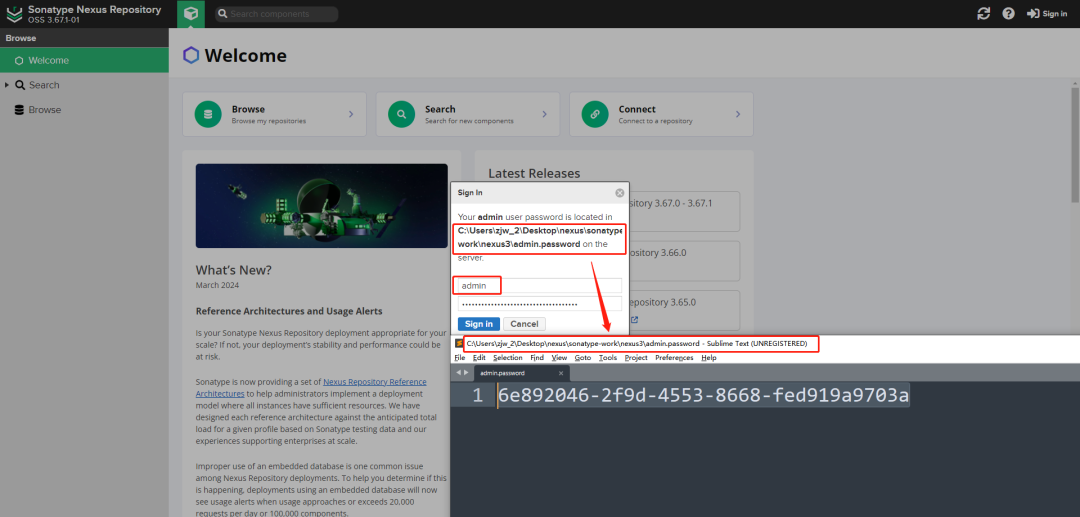
+
+
+登录即可,默认用户名是admin,密码在下面图中的文件里
+
+
+
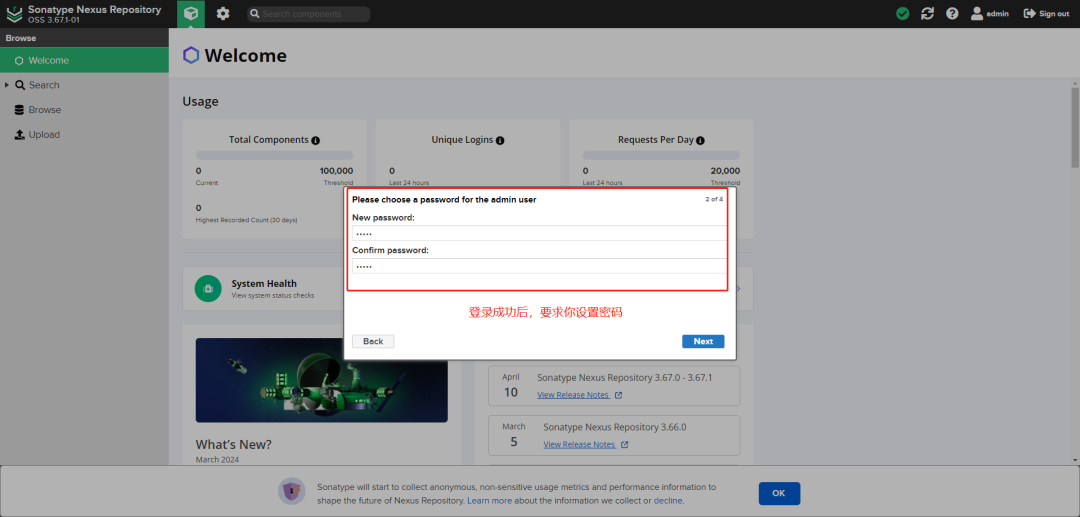
+登录成功后,第二步需要重新设置密码
+
+
+
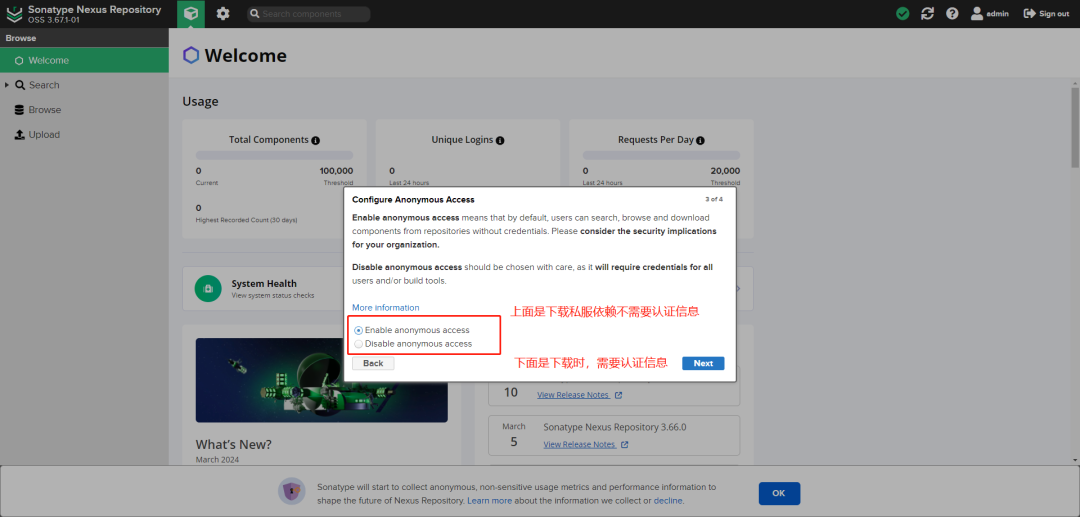
+设置私服下载依赖的权限信息
+
+
+
+关注前四个即可
+
+
+
+### 11.3 Nexus私服配置&下载依赖
+
+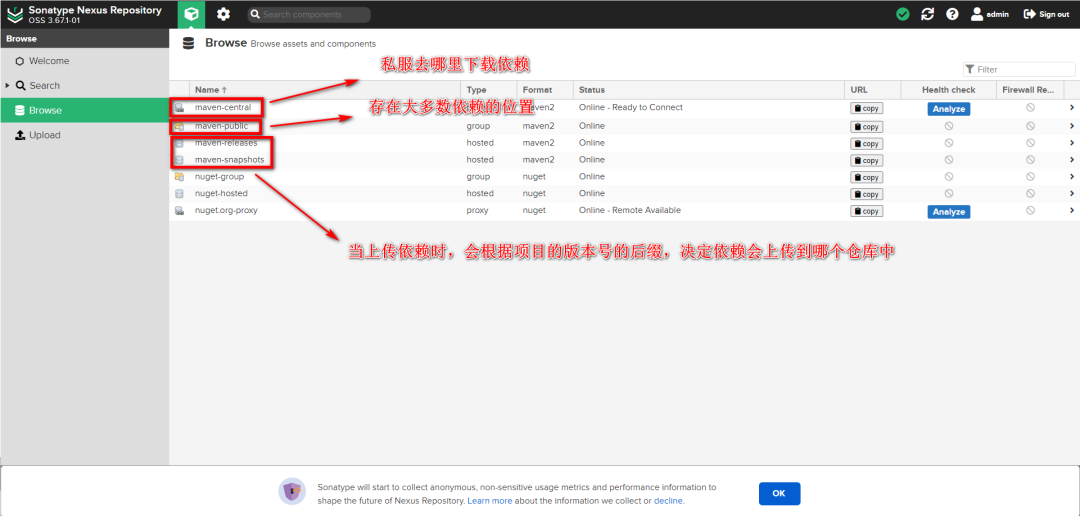
+
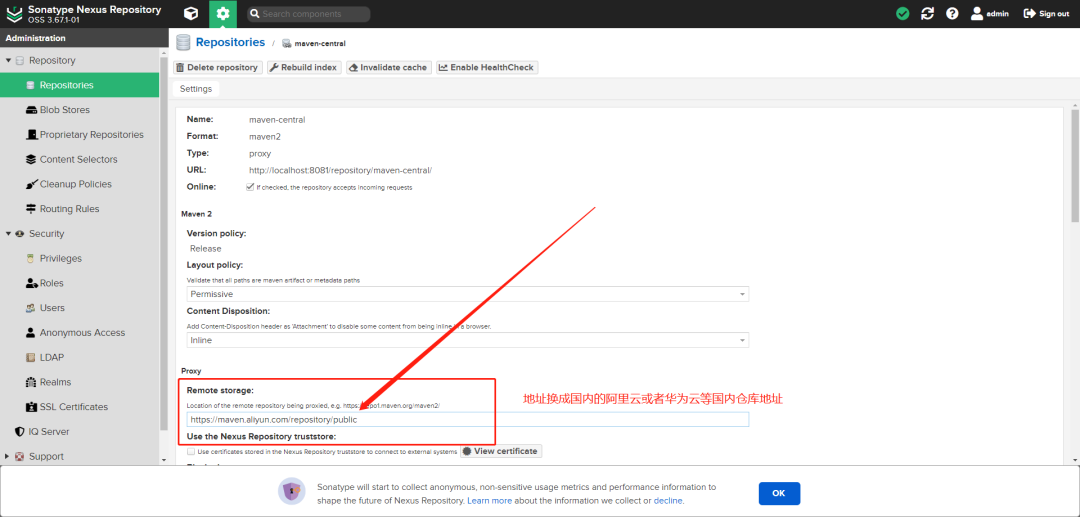
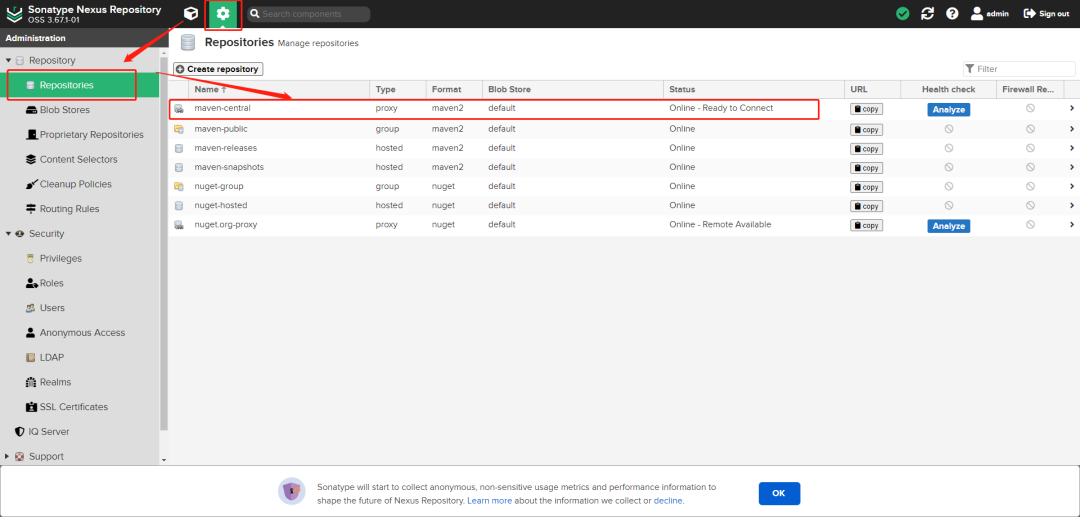
+将私服仓库的代理,设置为国内的仓库镜像源
+
+
+
+配置完,拉到最下面,记得Save保存一下。
+
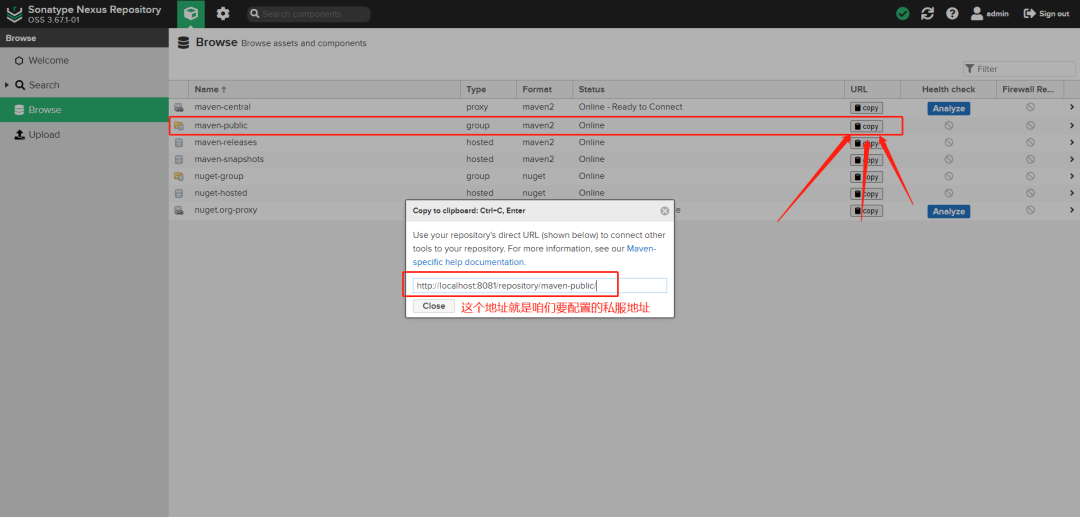
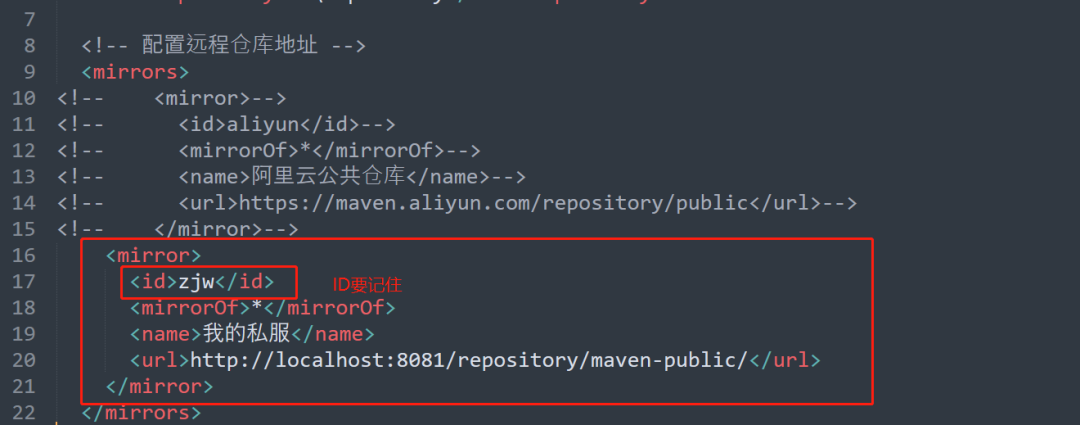
+接下来配置好私服的地址,让项目基于私服下载依赖
+
+
+
+
+
+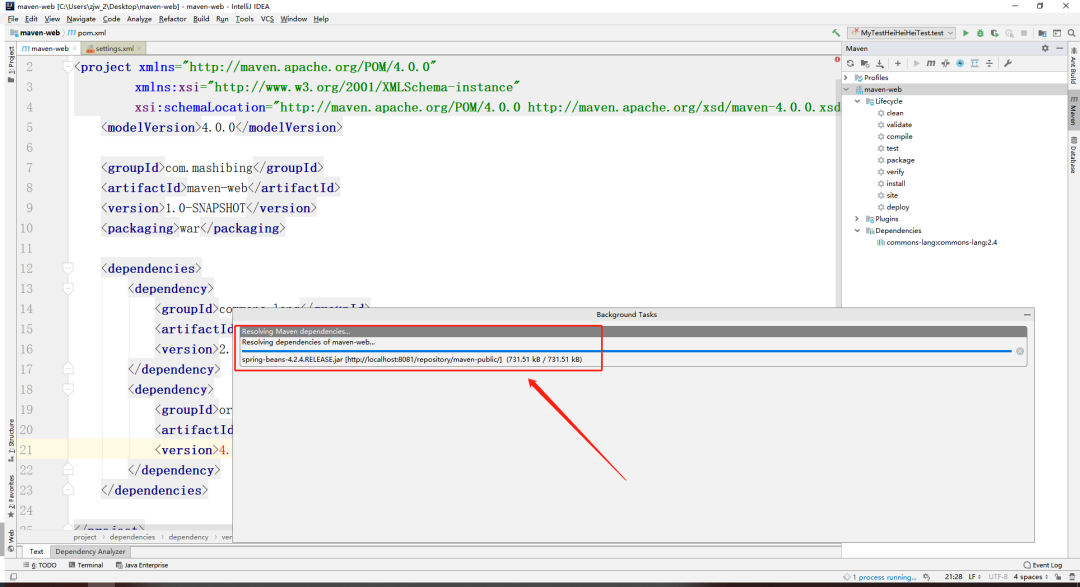
+
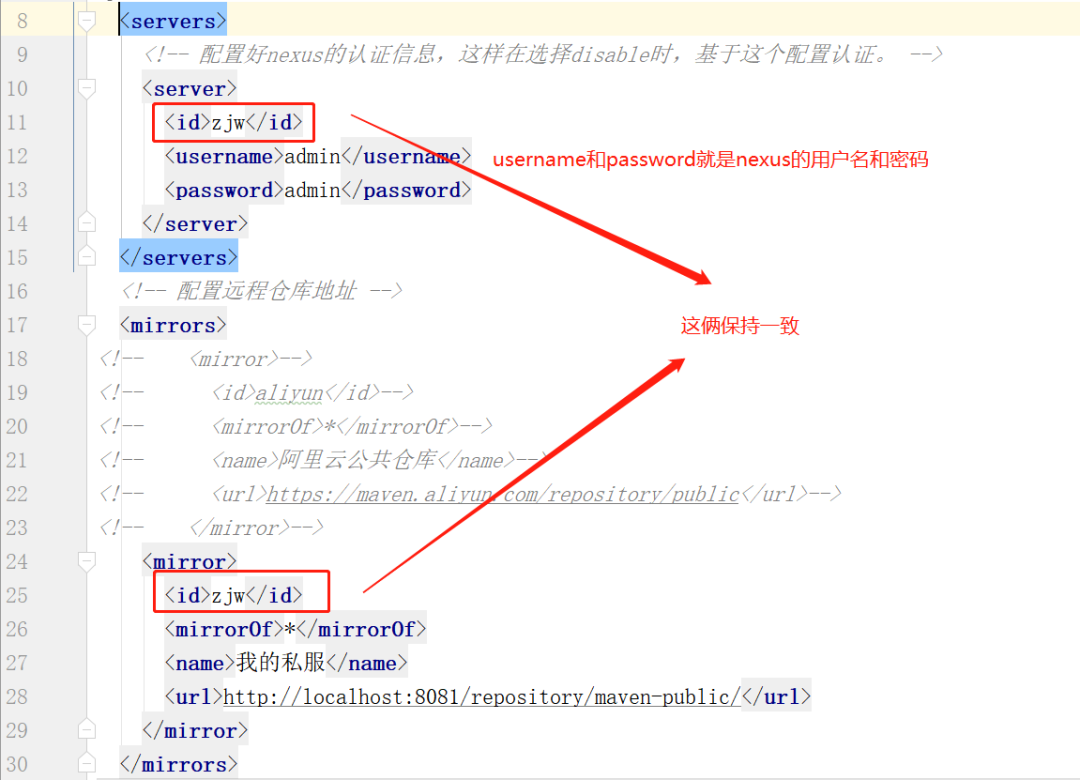
+因为初始化Nexus时,选择的是下载依赖不需要认证信息。
+
+如果选择的是需要,要如何配置。
+
+
+
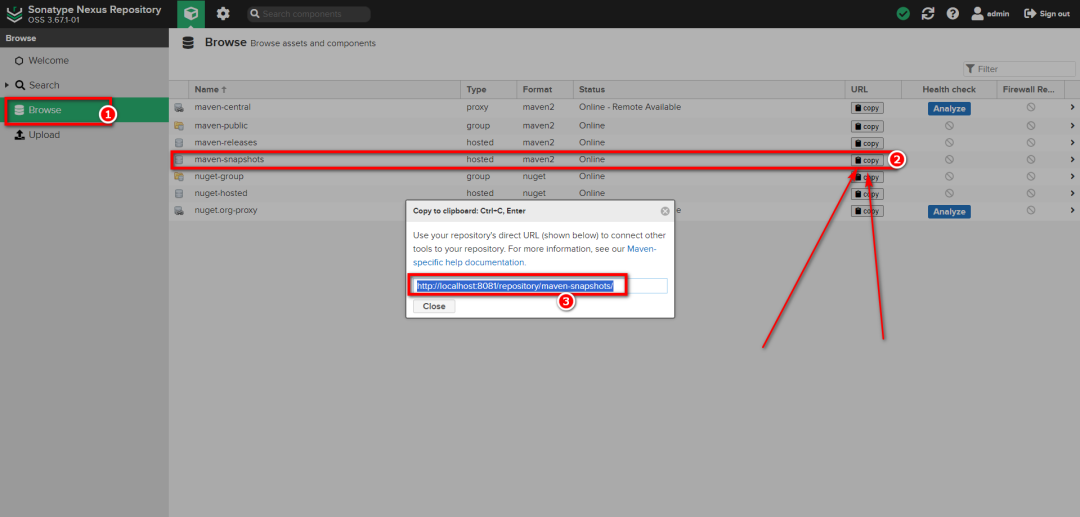
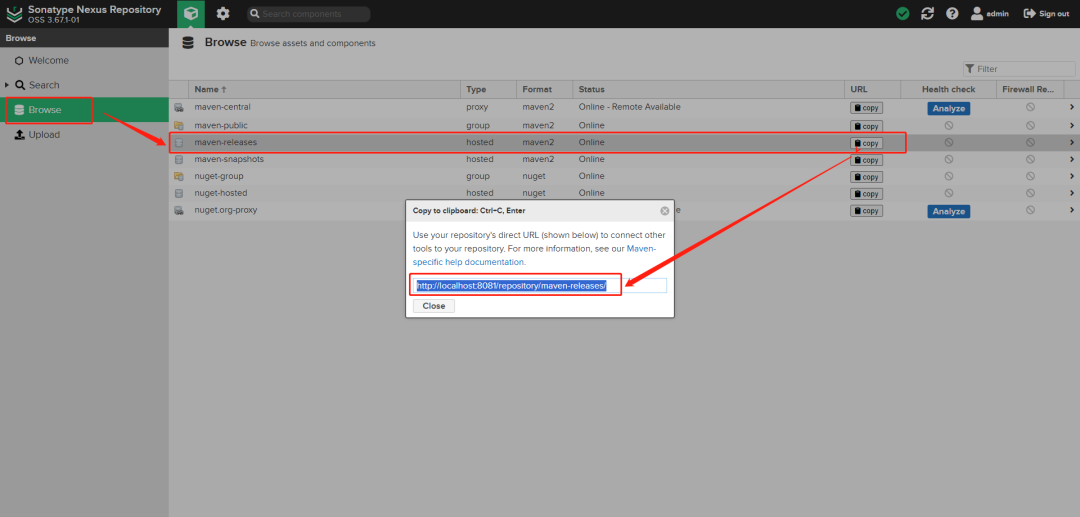
+### 11.4 上传依赖到私服
+
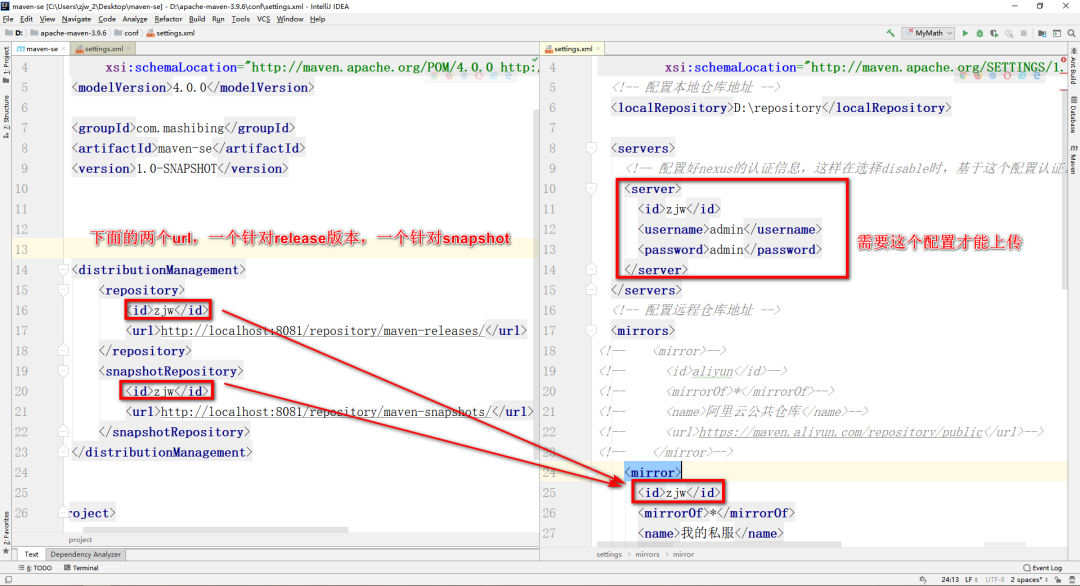
+首先在Maven私服的位置,找到release和snapshot的仓库地址
+
+
+
+
+
+然后在pom.xml文件中配置相应的信息
+
+```xml
+
+
+ zjw
+ http://localhost:8081/repository/maven-releases/
+
+
+ zjw
+ http://localhost:8081/repository/maven-snapshots/
+
+
+```
+
+
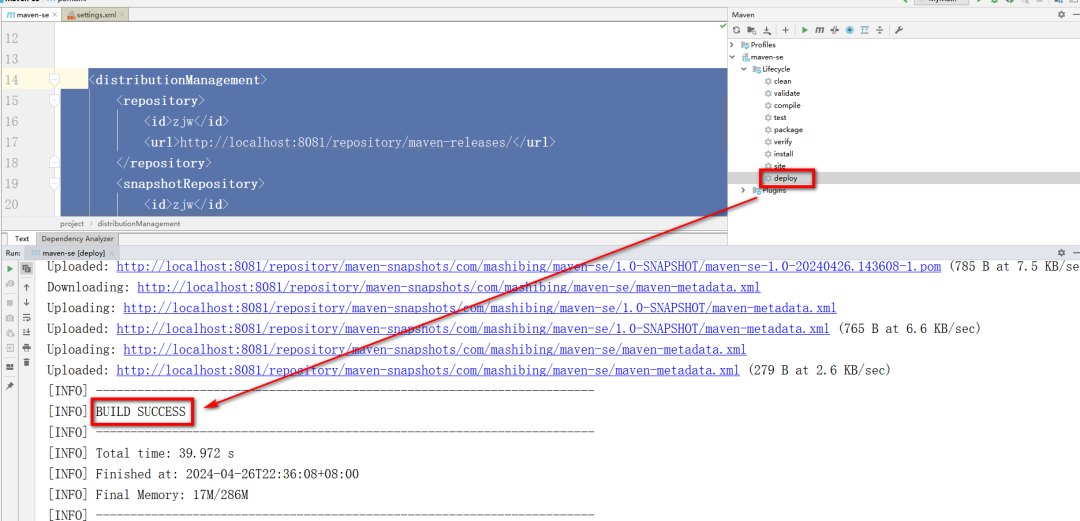
+
+准备好之后,直接在项目右侧,点击deploy上传当前项目的jar到私服
+
+
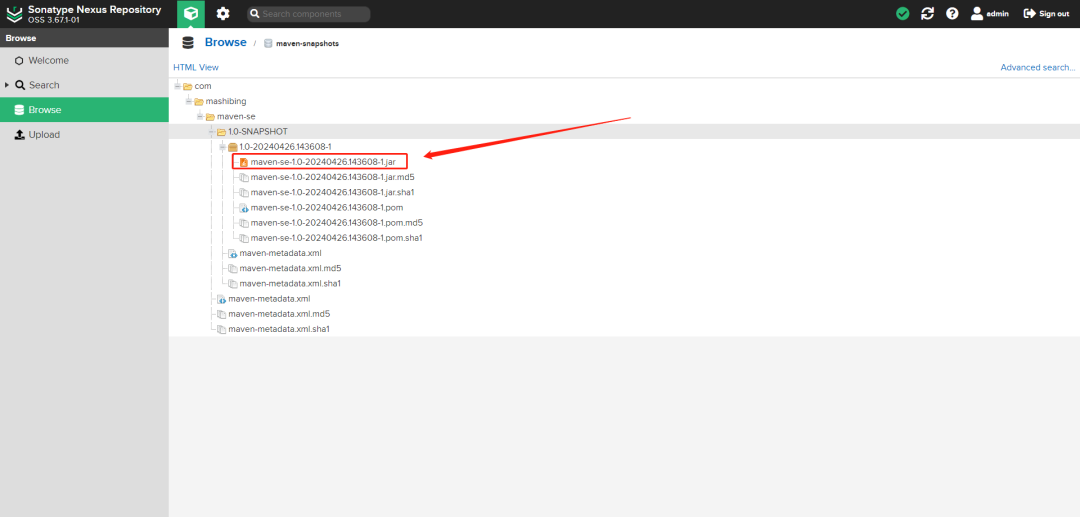
+
+上传成功后,可以在私服中找到
+
+
+
+其他的项目在配置没问题的情况下,就可以使用私服中的各种依赖了。
From 11463b695993a4d7230869d6ead5edc82f0b3877 Mon Sep 17 00:00:00 2001
From: zhengshuhai <1242909896@qq.com>
Date: Wed, 30 Apr 2025 20:57:06 +0800
Subject: [PATCH 03/12] Mockito
---
README.md | 3 +-
...345\215\212\346\227\266\351\227\264(1).md" | 532 ++++++++++++++++++
2 files changed, 533 insertions(+), 2 deletions(-)
create mode 100644 "docs/md/\345\205\266\344\273\226/\344\270\215\347\224\250Mockito\345\206\231\345\215\225\345\205\203\346\265\213\350\257\225\357\274\237\344\275\240\345\217\257\350\203\275\345\234\250\346\265\252\350\264\271\344\270\200\345\215\212\346\227\266\351\227\264(1).md"
diff --git a/README.md b/README.md
index 1259b4e..e1278f7 100644
--- a/README.md
+++ b/README.md
@@ -183,10 +183,9 @@
### :jack_o_lantern: 其他 ###
- [良心推荐!几款收藏的神级IDEA插件分享](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488457&idx=1&sn=f771ccebb84f226e7302b89caa5c056b&chksm=cf84600cf8f3e91aab4564d91feacb8822b53a2b3a79547439d64d2c0b7b293435a1ae79f994#rd)
-
- [实战Arthas:常见命令与最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247488559&idx=1&sn=4b5003cb33446ab4a6173285fe9d83d3&chksm=cf8467eaf8f3eefc033de8f63cba9f0d7b2b5eb0ccfb5209f458a9ab447367b34954f296638b#rd)
-
- [Maven实战](https://mp.weixin.qq.com/s/ErtWrRNzjJcR2ettUhAxsQ)
+- [不用Mockito写单元测试?你可能在浪费一半时间](https://mp.weixin.qq.com/s/NICubD9Yq0pn6qwpVIznfg)
### :bulb: 资源 ###
diff --git "a/docs/md/\345\205\266\344\273\226/\344\270\215\347\224\250Mockito\345\206\231\345\215\225\345\205\203\346\265\213\350\257\225\357\274\237\344\275\240\345\217\257\350\203\275\345\234\250\346\265\252\350\264\271\344\270\200\345\215\212\346\227\266\351\227\264(1).md" "b/docs/md/\345\205\266\344\273\226/\344\270\215\347\224\250Mockito\345\206\231\345\215\225\345\205\203\346\265\213\350\257\225\357\274\237\344\275\240\345\217\257\350\203\275\345\234\250\346\265\252\350\264\271\344\270\200\345\215\212\346\227\266\351\227\264(1).md"
new file mode 100644
index 0000000..597c1ea
--- /dev/null
+++ "b/docs/md/\345\205\266\344\273\226/\344\270\215\347\224\250Mockito\345\206\231\345\215\225\345\205\203\346\265\213\350\257\225\357\274\237\344\275\240\345\217\257\350\203\275\345\234\250\346\265\252\350\264\271\344\270\200\345\215\212\346\227\266\351\227\264(1).md"
@@ -0,0 +1,532 @@
+你是不是也经常在写单元测试时,被数据库连接、第三方接口这些折腾得头疼?明明只是想验证自己的业务逻辑,却不得不花半天时间处理各种外部依赖——这种体验就像是想喝杯咖啡却发现要自己种咖啡豆。
+
+好在Mockito这个神器能让你的测试飞起来!它帮你模拟复杂依赖,让测试回归到代码逻辑本身。无论是验证某个方法是否被正确调用,还是模拟异常来测试程序的健壮性,Mockito 都能让测试变得专注而高效。
+
+# 简介
+
+Mockito是一个用于Java单元测试的mock框架,用于创建**模拟对象**(mock object)来替代真实对象,帮助开发者隔离外部依赖,从而专注于单元测试的逻辑,Mockito通常配合单元测试框架(如JUnit)使用。
+
+- 官方网站:https://site.mockito.org/
+- 官方文档:https://javadoc.io/doc/org.mockito/mockito-core/latest/org/mockito/Mockito.html
+
+# 依赖
+
+```xml
+
+
+ org.mockito
+ mockito-core
+ 4.11.0
+ test
+
+```
+
+如果使用Spring Boot Test 则不需要引入,Spring Boot Test 默认集成了 Mockito。
+
+# 常见用法
+
+Mockito的核心功能包括:
+
+- **创建mock对象**:使用`mock()`创建mock对象。
+- **打桩**:使用`when()`和`thenReturn()`等方法指定mock对象的特定方法被调用时的行为(如返回值或抛出异常)。
+- **验证行为**:使用`verify()`检查mock对象的特定方法是否被调用,参数和调用次数是否符合预期。
+
+下面通过示例展开介绍Mockito的用法。
+
+## 验证行为
+
+Mockito 的 `verify()` 用于验证**模拟对象的方法是否按预期被调用**,包括调用次数、参数匹配等。它支持精确验证(如 `times(2)`)、最少/最多次数(`atLeast()`/`atMost()`)、未调用(`never()`)及顺序验证(结合 `InOrder`)等,确保代码执行逻辑正确。
+
+```java
+public class MockTest {
+
+ @Test
+ public void testBasicVerification() {
+ List mockList = mock(List.class);
+
+ // 模拟调用
+ mockList.add("apple");
+ mockList.add("banana");
+ mockList.add("apple");
+ mockList.add("orange");
+
+ // 1. 验证方法被调用【恰好一次】(默认行为)
+ verify(mockList).add("banana");
+
+ // 2. 验证方法被调用【指定次数】
+ verify(mockList, times(2)).add("apple"); // 精确2次
+
+ // 3. 验证方法【从未调用】
+ verify(mockList, never()).clear();
+
+ // 4. 验证【调用顺序】
+ InOrder inOrder = inOrder(mockList);
+ inOrder.verify(mockList).add("apple");
+ inOrder.verify(mockList).add("banana");
+ inOrder.verify(mockList).add("apple");
+
+ verifyNoMoreInteractions(mockList);
+ }
+
+}
+```
+
+`org.mockito.Mockito`类的`mock()`方法用于创建指定类或接口的mock对象。一旦创建,mock对象就会记住所有的方法调用。之后可以选择性地验证感兴趣的方法调用。
+
+- **验证单次调用**:`verify(mockList).add("banana");`→ 检查 `add("banana")` 被调用 1 次。
+
+- **验证精确次数**:`verify(mockList, times(2)).add("apple");`→ 检查 `add("apple")` 被调用 2 次。
+
+- **验证禁止调用**:`verify(mockList, never()).clear();`→ 确保 `clear()` 从未调用。
+
+- **验证调用顺序**:
+
+ ```java
+ InOrder inOrder = inOrder(mockList);
+ inOrder.verify(mockList).add("apple");
+ inOrder.verify(mockList).add("banana");
+ inOrder.verify(mockList).add("apple");
+ ```
+
+ 严格按顺序验证调用链。
+
+- **未验证的调用**:`verifyNoMoreInteractions()` 用来检查mock对象没有未验证的调用。由于`mockList.add("orange")`被调用过,但没有验证,因此最后的测试将会失败。
+
+## 打桩
+
+**打桩**是为模拟对象(Mock)的方法调用预设返回值或行为,使得测试代码可以**隔离外部依赖**,并控制方法的输出或异常,一旦被打桩,方法将返回指定的值,无论调用多少次。通过打桩,可以模拟数据库、网络请求等复杂或不可控的操作。
+
+```java
+ @Test
+ public void testStubbing() {
+ // 1. 创建模拟对象
+ List mockList = mock(List.class);
+
+ // 2. 基础打桩:返回固定值
+ when(mockList.get(0)).thenReturn("apple");
+ assertEquals("apple", mockList.get(0));
+
+ // 3. 抛出异常
+ when(mockList.get(1)).thenThrow(new RuntimeException("索引错误"));
+ assertThrows(RuntimeException.class, () -> mockList.get(1));
+
+ // 4. 多次调用不同返回值
+ when(mockList.size())
+ .thenReturn(1)
+ .thenReturn(2);
+ assertEquals(1, mockList.size());
+ assertEquals(2, mockList.size());
+
+ // 5. 参数匹配器(如 anyInt())
+ when(mockList.get(anyInt())).thenReturn("default");
+ assertEquals("default", mockList.get(999));
+
+ // 6. Void 方法打桩(如抛出异常)
+ doThrow(new IllegalStateException("清空失败")).when(mockList).clear();
+ assertThrows(IllegalStateException.class, mockList::clear);
+ }
+```
+
+**语法优先级**:
+
+- `when(...).thenX()` 适用于有返回值的方法。
+- `doX().when(mock).method()` 适用于 void 方法。
+
+**参数匹配器**:使用 `any()`、`eq()` 等灵活匹配参数,但需注意参数一致性(不能混用具体值和匹配器)。
+
+**覆盖规则**:最后一次打桩会覆盖之前的定义(例如多次对 `mock.get(0)` 打桩,以最后一次为准)。
+
+**默认情况下,对于所有返回值的方法,mock对象将返回适当的默认值**。例如,对于`int`或`Integer`返回0,对于`boolean`或`Boolean`返回`false`,对于集合类型返回空集合,对于其他对象类型(例如字符串)返回`null`。
+
+## 连续打桩和回调打桩
+
+**连续打桩(Chained Stubbing)**:为同一个方法的连续多次调用定义不同的返回值或行为,常用于模拟多次调用时的动态响应。
+
+```java
+ @Test
+ public void testChainedStubbing() {
+ List mockList = mock(List.class);
+
+ // 定义连续打桩:第一次调用返回 "A",第二次返回 "B",第三次抛出异常
+ when(mockList.get(0))
+ .thenReturn("A")
+ .thenReturn("B")
+ .thenThrow(new RuntimeException("No more elements"));
+
+ // 验证
+ assertEquals("A", mockList.get(0)); // 第一次返回 "A"
+ assertEquals("B", mockList.get(0)); // 第二次返回 "B"
+ assertThrows(RuntimeException.class, () -> mockList.get(0)); // 第三次抛出异常
+ }
+```
+
+超出定义的调用次数后,最后一次行为会持续生效(例如第三次后继续调用会一直抛异常)。
+
+**回调打桩(Callback Stubbing)**:`thenAnswer()` 可以实现动态返回值逻辑,根据方法参数或外部条件生成响应。
+
+```java
+ @Test
+ public void testChainedStubbing() {
+ List mockList = mock(List.class);
+
+ // 根据参数动态返回:参数是偶数时返回 "even",奇数返回 "odd"
+ when(mockList.get(anyInt())).thenAnswer(invocation -> {
+ int index = invocation.getArgument(0); // 获取第一个参数
+ return (index % 2 == 0) ? "even" : "odd";
+ });
+
+ // 验证
+ assertEquals("even", mockList.get(0)); // 0是偶数
+ assertEquals("odd", mockList.get(1)); // 1是奇数
+ }
+```
+
+- **灵活控制**:可在 `thenAnswer()` 中编写任意 Java 代码,甚至访问外部变量。
+- **参数获取**:通过 `invocation.getArgument(n)` 获取第 `n` 个参数(从 0 开始)。
+
+## 参数匹配器
+
+Mockito默认使用`equals()`方法验证参数值。当需要额外的灵活性时,可以使用参数匹配器。
+
+参数匹配器是 Mockito 提供的一种灵活的参数验证机制,允许开发者通过匹配器来匹配方法参数,而无需指定具体值。
+
+参数匹配器广泛用于 `when()` 打桩和 `verify()` 验证中。
+
+```java
+ @Test
+ public void testMatchers() {
+ List mockList = mock(List.class);
+
+ // 1. 通用匹配器:anyInt(), anyString()
+ when(mockList.get(anyInt())).thenReturn("default");
+ assertEquals("default", mockList.get(999));
+
+ // 2. 条件匹配器:startsWith(), endsWith()
+ when(mockList.add(startsWith("app"))).thenReturn(true);
+ assertTrue(mockList.add("apple"));
+ assertFalse(mockList.add("banana"));
+
+ // 3. 混合使用具体值和匹配器(必须用 eq() 包裹具体值)
+ when(mockList.set(eq(0), anyString())).thenReturn("old_value");
+ assertEquals("old_value", mockList.set(0, "new_value"));
+ }
+```
+
+**通用匹配器**
+
+- **作用**:匹配任意参数或特定类型参数。
+
+- **常见方法**:
+- `any()`:匹配任意对象(包括 `null`)。
+
+- `anyInt()`, `anyString()`, `anyList()`:匹配特定类型参数。
+
+- `isNull()`, `isNotNull()`:匹配 `null` 或非 `null` 参数。
+
+**条件匹配器**
+
+- **作用**:根据逻辑条件匹配参数。
+
+- **常见方法**:
+
+ - `eq(value)`:严格匹配具体值(等同于直接写值)。
+
+ - `startsWith("prefix")`:匹配以指定前缀开头的字符串。
+
+ - `endsWith("suffix")`, `contains("substr")`:匹配字符串后缀或子串。
+
+ - `argThat(condition)`:自定义条件(如集合大小、对象属性)。
+
+**混合使用规则**
+
+- **强制要求**:若方法参数中至少有一个匹配器,则所有参数必须用匹配器。
+
+ 错误示例:
+
+ ```java
+ // 错误:混合具体值和匹配器
+ when(mock.method("value", anyInt())).thenReturn(true);
+ ```
+
+ 修复方法:将具体值用 `eq()`包裹:
+
+ ```java
+ when(mock.method(eq("value"), anyInt())).thenReturn(true);
+ ```
+
+ **自定义匹配器**
+
+通过 `argThat()` 实现复杂条件:
+
+```java
+// 自定义匹配器:验证集合大小大于2
+when(mockList.addAll(argThat(list -> list.size() > 2))).thenReturn(true);
+assertTrue(mockList.addAll(List.of("A", "B", "C")));
+```
+
+更多的内置参数匹配器参考:
+
+- https://javadoc.io/static/org.mockito/mockito-core/4.11.0/org/mockito/ArgumentMatchers.html
+
+- https://javadoc.io/static/org.mockito/mockito-core/4.11.0/org/mockito/hamcrest/MockitoHamcrest.html
+
+## 间谍(spy)
+
+`spy()` 可以创建部分真实对象的代理(保留原有行为,可选择性地对某些方法打桩),适合需要混合真实逻辑与模拟行为的场景。
+
+对比 `mock()`:
+
+| 特性 | `mock()` | `spy()` |
+| :----------: | :----------------------------------: | :------------------------: |
+| **默认行为** | 所有方法返回默认值(如 `null`、`0`) | 调用真实方法,除非显式打桩 |
+| **适用场景** | 完全隔离被测对象依赖 | 需保留部分真实逻辑的测试 |
+
+```java
+ @Test
+ public void testSpyBasic() {
+ // 1. 创建一个 ArrayList 的 spy 对象
+ List spyList = spy(new ArrayList<>());
+
+ // 2. 调用真实方法
+ spyList.add("apple");
+ spyList.add("banana");
+
+ // 3. 验证真实行为
+ assertEquals(2, spyList.size()); // 实际调用了 add 和 size 方法
+
+ // 4. 对某个方法打桩
+ when(spyList.size()).thenReturn(100);
+ assertEquals(100, spyList.size()); // 打桩生效
+
+ // 5. 验证方法调用次数
+ verify(spyList, times(2)).add(anyString()); // 验证 add 被调用两次
+ }
+```
+
+当对 `spy` 对象的方法打桩时,若直接使用 `when(...)` 会触发真实方法调用,可能导致异常。
+
+错误示例:
+
+```java
+List spyList = spy(new ArrayList<>());
+// 会被真实执行,但此时列表为空,导致 IndexOutOfBoundsException
+when(spyList.get(0)).thenReturn("mock-value");
+```
+
+正确方式:使用 `doReturn().when()` 语法避免真实调用
+
+```java
+ List spyList = spy(new ArrayList<>());
+ // 正确:不会触发 get(0) 的真实调用
+ doReturn("mock-value").when(spyList).get(0);
+ assertEquals("mock-value", spyList.get(0));
+```
+
+**最佳实践**:
+
+1. **优先使用 `mock()`**:除非需要保留部分真实行为,否则优先用 `mock()` 隔离依赖。
+2. **谨慎打桩**:使用 `doReturn().when()` 替代 `when().thenReturn()`,避免意外触发真实方法。
+3. **避免复杂间谍**:不要对复杂对象(如 Spring Bean)滥用 `spy()`,可能导致测试不可控。
+
+## 参数捕获(ArgumentCaptor)
+
+ArgumentCaptor 用于在测试中捕获方法调用时传递的参数,便于后续对参数值进行详细验证(如对象属性、集合内容等)。
+
+完整示例:
+
+```java
+ @Test
+ public void testCaptureArgument() {
+ // 1. 创建 Mock 对象
+ UserService mockService = mock(UserService.class);
+
+ // 2. 调用被测试方法
+ User user = new User("Alice", 30);
+ mockService.processUser(user);
+
+ // 3. 创建 ArgumentCaptor
+ ArgumentCaptor userCaptor = ArgumentCaptor.forClass(User.class);
+
+ // 4. 验证方法调用并捕获参数
+ verify(mockService).processUser(userCaptor.capture());
+
+ // 5. 获取捕获的参数并验证
+ User capturedUser = userCaptor.getValue();
+ assertEquals("Alice", capturedUser.getName());
+ assertEquals(30, capturedUser.getAge());
+ }
+
+ @Data
+ static class User {
+ private String name;
+ private int age;
+
+ public User(String name, int age) {
+ this.name = name;
+ this.age = age;
+ }
+ }
+
+ static class UserService {
+ public void processUser(User user) {
+ // 实际业务逻辑(在测试中被 Mock)
+ }
+ }
+```
+
+## 静态方法Mock
+
+`Mockito.mockStatic(Class)` 可以创建静态类的 Mock 作用域,并在其中定义行为。
+
+```java
+ @Test
+ public void testMockStaticMethod() {
+ // 1. 创建静态类(如 LocalDate)的 Mock 作用域
+ try (MockedStatic mockedLocalDate = mockStatic(LocalDate.class)) {
+
+ // 2. 定义静态方法 now() 的行为
+ LocalDate fixedDate = LocalDate.of(2023, 10, 1);
+ mockedLocalDate.when(LocalDate::now).thenReturn(fixedDate);
+
+ // 3. 验证静态方法调用
+ assertEquals(fixedDate, LocalDate.now()); // 返回固定日期
+ mockedLocalDate.verify(LocalDate::now); // 验证 now() 被调用
+ }
+
+ // 4. 作用域结束后,静态方法恢复原始行为
+ assertNotEquals("2023-10-01", LocalDate.now().toString());
+ }
+```
+
+**作用域限制**:
+
+- 静态 Mock 仅在 `try-with-resources` 或 `MockedStatic.close()` 前有效。
+- 必须关闭:确保使用 `try-with-resources` 或手动 `close()`,避免影响其他测试。
+
+# 注解
+
+## @Mock
+
+@Mock用于快速创建 Mock 对象,替代 `Mockito.mock(Class)` 方法。
+
+**方式 1:通过 `MockitoJUnitRunner` 自动初始化**
+
+```java
+// 自动初始化 @Mock 注解
+@RunWith(MockitoJUnitRunner.class)
+public class MockTest {
+
+ @Mock // 自动创建 List 的 Mock 对象
+ private List mockList;
+
+ @Test
+ public void testMockAnnotation() {
+ mockList.add("test");
+ verify(mockList).add("test");
+ }
+
+
+}
+```
+
+**JUnit 5 适配**:需使用`@ExtendWith(MockitoExtension.class)`。
+
+**方式 2:手动调用 `MockitoAnnotations.openMocks()`**
+
+```java
+public class MockTest {
+ @Mock
+ private List mockList;
+
+ @Before
+ public void init() {
+ MockitoAnnotations.openMocks(this); // 手动初始化 @Mock 注解
+ }
+
+ @Test
+ public void testMockAnnotation() {
+ mockList.add("test");
+ verify(mockList).add("test");
+ }
+}
+```
+
+## @MockBean
+
+在Spring Boot 集成测试中,@MockBean用于向 ApplicationContext 注入一个Mock 对象,替换原有 Bean。适用于需要隔离外部依赖(如数据库、第三方服务)的集成测试。
+
+示例场景:测试 `UserService` 时,Mock 其依赖的 `UserRepository`,避免真实数据库操作。
+
+```java
+@SpringBootTest // 启动 Spring 上下文
+public class UserServiceTest {
+
+ @Autowired
+ private UserService userService; // 被测服务
+
+ @MockBean // 自动替换 Spring 容器中的 UserRepository Bean
+ private UserRepository userRepository;
+
+ @Test
+ public void testGetUserById() {
+ // 1. 定义 Mock 行为
+ when(userRepository.findById(1L)).thenReturn(new User("Alice"));
+
+ // 2. 调用被测方法
+ User user = userService.getUserById(1L);
+
+ // 3. 验证结果和交互
+ assertEquals("Alice", user.getName());
+ verify(userRepository).findById(1L); // 确保方法被调用
+ }
+}
+```
+
+- **替换规则**:若 Spring 上下文中已存在同名 Bean,`@MockBean` 会覆盖它;若不存在,则新增 Mock Bean。
+- **多 Bean 类型冲突**:若同一类型有多个 Bean,需结合 `@Qualifier` 指定名称。
+
+## @InjectMock
+
+- **核心功能**:自动将 `@Mock` 或 `@Spy` 创建的依赖对象注入到被测试类中,简化依赖管理。
+
+- **适用场景**:单元测试中,快速构建被测试类(如 Service 层),并自动注入其依赖的 Mock 对象(如 Repository)。
+
+示例场景:测试 `UserService`,其依赖 `UserRepository`(需要 Mock)。
+
+```java
+@ExtendWith(MockitoExtension.class)
+public class MockTest {
+
+
+ @Mock // 创建 UserRepository 的 Mock 对象
+ private UserRepository userRepository;
+
+ @InjectMocks // 自动将 userRepository 注入 UserService
+ private UserService userService;
+
+ @Test
+ public void testGetUserById() {
+ // 1. 定义 Mock 行为
+ when(userRepository.findById(1L)).thenReturn(new User("Alice"));
+
+ // 2. 调用被测试方法
+ User user = userService.getUserById(1L);
+
+ // 3. 验证结果和交互
+ assertEquals("Alice", user.getName());
+ verify(userRepository).findById(1L); // 确保方法被调用
+ }
+}
+```
+
+`@InjectMocks` 按以下顺序尝试注入依赖:
+
+1. **构造函数注入**(优先选择参数最多的构造函数)。
+2. **Setter 方法注入**(按方法名匹配,如 `setUserRepository()`)。
+3. **字段注入**(直接注入到 `private` 字段,需匹配名称和类型)。
+
+# 结尾
+
+Mockito 的魅力在于它用简单的语法解决了测试中的复杂问题。通过模拟对象、打桩预设行为、验证调用细节,开发者可以轻松隔离外部依赖,像搭积木一样构造测试场景。无论是新手还是经验丰富的工程师,Mockito 的直观设计都能让人快速上手。
+
+下次当你面对一个难以测试的方法时,不妨试试 Mockito——让它帮你把“不确定”变成“可控”,把“复杂依赖”变成“精准验证”。毕竟,好的测试不是为了证明代码完美,而是为了让它足够可靠,而 Mockito 正是这条路上值得信赖的工具。
From 535dd5b7877127e91ff8a916c3cdad47b94ce0ba Mon Sep 17 00:00:00 2001
From: zhengshuhai <1242909896@qq.com>
Date: Sun, 3 Aug 2025 16:29:07 +0800
Subject: [PATCH 04/12] ANTLR
---
README.md | 2 +-
...30\347\272\247\345\272\224\347\224\250.md" | 872 ++++++++++++++++++
2 files changed, 873 insertions(+), 1 deletion(-)
create mode 100644 "docs/md/\347\274\226\347\250\213\350\257\255\350\250\200/\350\207\252\347\240\224 DSL \347\245\236\345\231\250\357\274\232\344\270\207\345\255\227\346\213\206\350\247\243 ANTLR 4 \346\240\270\345\277\203\345\216\237\347\220\206\344\270\216\351\253\230\347\272\247\345\272\224\347\224\250.md"
diff --git a/README.md b/README.md
index e1278f7..c09df6c 100644
--- a/README.md
+++ b/README.md
@@ -141,8 +141,8 @@
### :dash: 编程语言 ###
- [Scala语言入门:初学者的基础语法指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487245&idx=1&sn=d089e22890f1f7449b7cf34e3cf2f6ed&chksm=cf847cc8f8f3f5deb39556f4229bafb6f1498906dc1d75040f90817bf0396117a7c2cdb498f9#rd)
-
- [Groovy 初学者指南](https://mp.weixin.qq.com/s?__biz=Mzg4Nzc3NjkzOA==&mid=2247487066&idx=1&sn=da9e3a9aff377d383e34e537e2f55666&chksm=cf847d9ff8f3f489011f26a784302ee68b9c1d7d57d52bc2c924a7c9b1a5f528ef2a417114c0#rd)
+- [自研 DSL 神器:万字拆解 ANTLR 4 核心原理与高级应用]()
### :satellite: 设计模式 ###
diff --git "a/docs/md/\347\274\226\347\250\213\350\257\255\350\250\200/\350\207\252\347\240\224 DSL \347\245\236\345\231\250\357\274\232\344\270\207\345\255\227\346\213\206\350\247\243 ANTLR 4 \346\240\270\345\277\203\345\216\237\347\220\206\344\270\216\351\253\230\347\272\247\345\272\224\347\224\250.md" "b/docs/md/\347\274\226\347\250\213\350\257\255\350\250\200/\350\207\252\347\240\224 DSL \347\245\236\345\231\250\357\274\232\344\270\207\345\255\227\346\213\206\350\247\243 ANTLR 4 \346\240\270\345\277\203\345\216\237\347\220\206\344\270\216\351\253\230\347\272\247\345\272\224\347\224\250.md"
new file mode 100644
index 0000000..3afc345
--- /dev/null
+++ "b/docs/md/\347\274\226\347\250\213\350\257\255\350\250\200/\350\207\252\347\240\224 DSL \347\245\236\345\231\250\357\274\232\344\270\207\345\255\227\346\213\206\350\247\243 ANTLR 4 \346\240\270\345\277\203\345\216\237\347\220\206\344\270\216\351\253\230\347\272\247\345\272\224\347\224\250.md"
@@ -0,0 +1,872 @@
+DSL(领域特定语言) 是一种为解决特定领域的问题而专门设计的计算机语言,它不同于通用编程语言(如 Python、Java)。它通常具有高度定制化的语法和结构,聚焦于某个特定任务或领域(如数据库查询、硬件配置、报表生成),通过提供更简洁、直观且贴近领域术语的表达方式,大幅提升该领域人员的工作效率和生产力,降低复杂性。
+
+**通俗来说,DSL 就像是为某个专业领域量身定做的“行话”工具。**
+
+说到构建自定义 DSL,高效且灵活的语法解析至关重要,**ANTLR 正是解决这一核心挑战的利器。**
+
+# 简介
+
+- 官方地址:https://www.antlr.org/
+- GitHub:https://github.com/antlr/antlr4
+- 在线调试:http://lab.antlr.org/
+- IDEA插件:ANTLR V4
+
+ANTLR 4(**AN**other **T**ool for **L**anguage **R**ecognition,版本4)是一个开源的解析器生成器工具,用于构建语言识别程序。它能够根据用户定义的语法规则,自动生成词法分析器(Lexer)和语法分析器(Parser),从而实现对结构化文本(如编程语言、配置文件、数据格式等)的解析、转换或翻译。
+
+ANTLR 4 最大的核心价值就是降低语言处理的门槛。在ANTRL 4没有出现之前,语言处理主要依赖正则表达式、手工编写解析器以及早期的解析器生成工具(如Lex/Yacc)。
+
+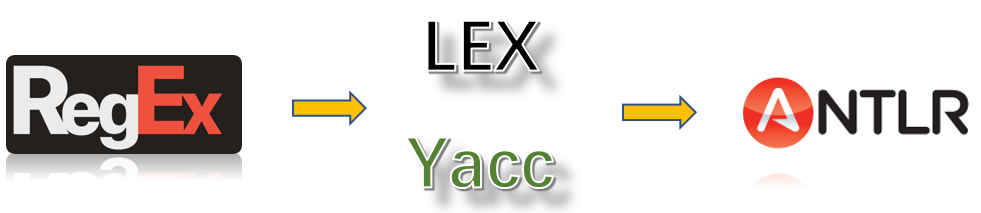
+
+ANTLR 4 的使用很简单,因为其存在的本身的意义就是为了加快语言类应用程序的编写速度,就是为了非专业人员对语言类应用程序快速开发而生的。
+
+首先我们要进行ANTLR 4元语言的编写,也就是需要我们根据我们自己的需要来编写一份语法文件,一份后缀为 **.g4** 的文件,这份文件是我们构建ANTLR 4语言类应用程序的基础,目前ANTLR 4已经支持了数十种编程语言的生成,可以满足不同语言的开发需求。
+
+官方也提供了相关的文件,GitHub:https://github.com/antlr/grammars-v4。
+
+有了这些 Java 文件,语言类应用程序的开发人员就不需要再去思考如何手动编写解析语法树的程序,因为ANTLR 4已经帮我们把这些事情都做了,ANTLR 4自带的jar 包和自动生成的这些语法分析器以及之后所提到的监听器 Listener 和访问器 Visitor 都能够完美的帮我们来处理任何语言类应用程序的自定义需求,从而真正达到即使你没学过编译原理也能自己开发应用程序的效果。
+
+ANTLR 是用 Java 编写的,因此你需要首先安装 Java,哪怕你的目标是使用 ANTLR 来生成其他语言(如C#和C++)的解析器。
+
+下图是我使用 IDEA 中的 ANTLR 4 插件,以及我自己编写的语法,自动生成的语法解析树,这一切都是ANTLR 4帮我们自动完成的。
+
+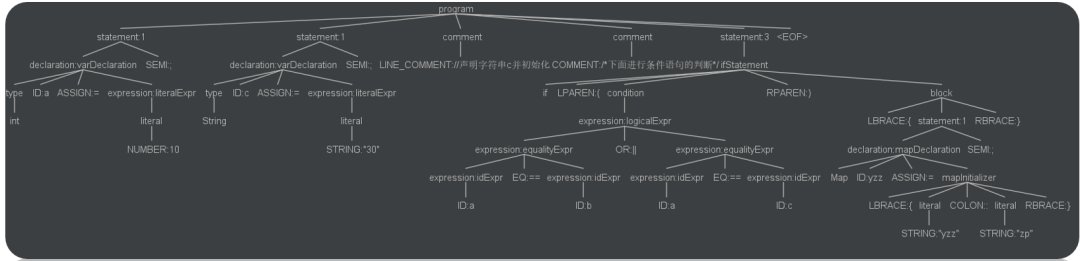
+
+
+
+简而言之,ANTLR 工具将语法文件转换成可以识别该语法文件所描述的语言的程序。例如,给定一个识别 JSON 的语法,ANTLR工具将会根据该语法生成一个程序,此程序可以通过 ANTLR 运行库来识别输入的 JSON。
+
+# 基础概念
+
+## 文件声明
+
+以下是一个包含完整头部声明的 ANTLR 4 语法文件示例,涵盖所有关键字的解释:
+
+```java
+// =========== ANTLR4 语法文件头部声明示例 ===========
+grammar MathParser; // [1] 主声明
+
+// [2] 导入声明(组合语法)
+import TrigParser, VectorParser; // 导入其他语法模块
+
+// [3] 选项配置
+options {
+ language = Java; // 目标生成语言
+ tokenVocab = CoreTokens; // 从外部语法导入词法符号
+ superClass = MathBase; // 自定义基类
+ contextSuperClass = MyCtx; // 自定义上下文基类
+}
+
+// [4] 辅助符号声明
+tokens {
+ // 显式定义新token
+ PI = 'π'; // 带字面量的token
+ FUNCTION_CALL, // 无字面量的抽象token
+ VECTOR_DOT_PRODUCT // 用于语法树节点的标签
+}
+
+// [5] 头部注入 (生成文件顶部的代码)
+@header {
+ package com.company.math;
+ import static com.company.math.TrigUtil.*;
+}
+
+// [6] 成员注入 (向解析器类添加代码)
+@members {
+ private boolean debug = true;
+ private int errorCount = 0;
+
+ @Override
+ public void reportError(RecognitionException e) {
+ errorCount++;
+ super.reportError(e);
+ }
+
+ public int getErrorCount() {
+ return errorCount;
+ }
+}
+
+// [7] 规则定义区
+expression: /* 规则内容 */;
+// ========================================
+```
+
+- **grammar**:定义语法名称(必须匹配文件名),声明完整/词法/解析语法类型。
+- **import**:导入外部语法文件实现规则复用,支持模块化开发。语法导入允许你将语法分解成可复用的逻辑单元。ANTLR 处理被导入的语法的方式和面向对象语言中的父类非常相似。一个语法会从其导入的语法中继承所有的规则、词法符号声明和具名的动作。位于“主语法”中的规则将会覆盖其导入的语法中的规则,以此来实现继承机制。ANTLR将被导入的规则放置在主语法的词法规则列表末尾。这意味着,主语法中的词法规则具有比被导入语法中的规则更高的优先级。
+- **options**:配置代码生成选项(目标语言/基类/符号表等)。
+- **tokens**:声明辅助符号(抽象Token/别名/语法树标签)。tokens 区域存在的意义在于,它定义了一份语法所需,但却未在本语法中列出对应规则的词法符号。大多数情况下,tokens 区域用于定义本语法中动作所需的词法符号类型。
+- **@header**:向生成文件顶部注入代码(包声明/导入语句)。用于将代码注入生成的识别类中的类声明之前。用于将代码注入为识别类的字段和方法。
+- **@members**:向解析器类添加自定义成员(字段/方法/状态管理)。
+
+关于 @header 和 @members,其中 @header 用于当 ANTLR 4 工具生成词法分析器和语法分析器时,将 @header 中的内容原封不动的复制到生成的 Java 文件的顶部,而 @members 用于将代码插入到生成的 Java 类当中,其中可以包含字段声明,自定义方法等内容。
+
+
+
+从图中我们可以看到我们预先在语法文件中进行了 @header 和 @members 的定义和编写,然后利用 ANTLR 4 工具自动生成我们所需要的词法解析器和语法分析器等相关的 Java 文件,后续生成的这些 Java 文件中的相关位置包含了我们在 @header 和 @members 中所定义的相关内容。
+
+不带前缀的语法声明是混合语法,可以同时包含词法规则和语法规则。欲创建一份只允许语法规则出现的文件,使用如下声明:
+
+```java
+parser grammar Name;
+```
+
+同理,纯词法的文件如下所示:
+
+```java
+lexer grammar Name;
+```
+
+## 词法规则
+
+词法文件的规则以大写字母开头。
+
+将字符聚集为单词或者符号(词法符号,token)的过程称为词法分析(lexicalanalysis)或者词法符号化(tokenizing)。我们把可以将输入文本转换为词法符号的程序称为词法分析器(lexer)。词法分析器可以将相关的词法符号归类,例如INT(整数)、ID(标识符)、FLOAT(浮点数)等。当语法分析器不关心单个符号,而仅关心符号的类型时,词法分析器就需要将词汇符号归类。词法符号包含至少两部分信息:词法符号的类型(从而能够通过类型来识别词法结构)和该词法符号对应的文本。
+
+
+
+Java 词法规则示例:
+
+
+
+接下来介绍一下词法规则是如何编写的。
+
+
+
+如上图所示词法规则以大写的字母开头,或者以冒号开头后跟大写字母,这样做是为了与之后所要介绍的语法规则做区分。例如上图中我们就给出了一些示例的规则,定义了INT,ID,STRING类型的词法单元,冒号后面是对这些词法单元的描述。
+
+这种词法规则的类型被称之为标准词法符号类型,这一类词法规则必须用大写字母开头,经过ANTLR 4工具处理会生成可直接在解析器中引用的符号,其规则匹配的优先级由在语法文件中声明词法规则的顺序和词法规则的长度来决定。
+
+其中有很多符号,比如“+”代表着 INTEGER 这一词法规则使用出现至少一次的自然数组成的,而 IDENTIFIER 这一规则中的“*”则代表着 IDENTIFIER 这一词法规则是由大小写字母或下划线加上至少出现0次的单词字符组成的。而 STRING 词法规则中单引号中间的内容则代表着中间的内容直接匹配,是固定的。
+
+
+
+第二类词法规则被称之为片段规则,通过关键字 **fragment** 来定义。
+
+片段规则具有以下特点:首先片段规则是不能独立匹配的,fragment 规则不能直接用于匹配输入文本。它们只能被其他非片段的词法规则所引用。
+
+将一条规则声明为 fragment 可以告诉 ANTLR,该规则本身不是一个词法符号,它只会被其他的词法规则使用。这意味着我们不能在文法规则中引用 HEX_DIGIT。
+
+通常使用片段规则是为了提高可读性和重用性,通过将常用的字符模式提取为片段规则,可以使词法规则更加简洁和易于维护。例如,可以将字母或数字的模式定义为片段规则,然后在多个词法规则中引用它们。
+
+
+
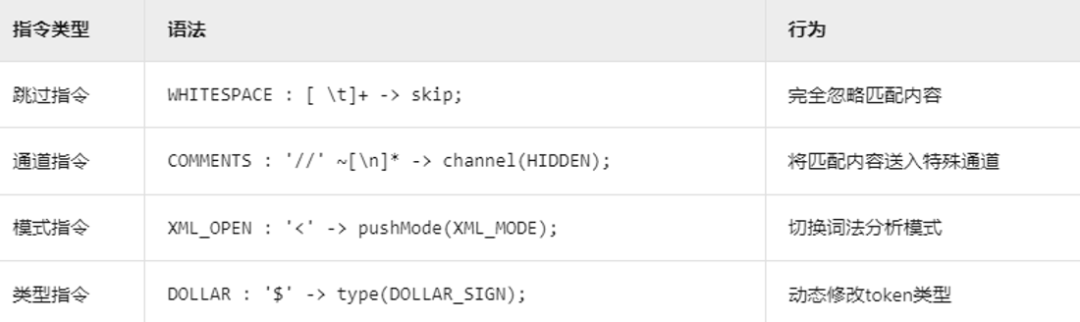
+第三类词法规则被称之为**指令规则**。
+
+- 第一种被称之为跳过指令,ANTLR 4在词法分析过程中会忽略这些匹配的空白字符,不会将它们作为(token)传递给语法分析器;
+- 第二种被称之为通道指令,使用 -> channel(HIDDEN) 指令,ANTLR 将这些注释标记发送到一个隐藏通道,使得它们不会被默认的语法分析器处理,但仍然可以在需要时访问;
+- 第三种被称之为模式指令,使用 -> pushMode(XML_MODE) 指令,ANTLR 会切换到 XML_MODE 模式,这允许在不同的上下文中使用不同的词法规则集;
+- 最后一种被称之为类型指令,使用 -> type(DOLLAR_SIGN) 指令,ANTLR 会将匹配的标记类型动态设置为 DOLLAR_SIGN,这可以用于在语法分析中对不同类型的标记进行区分和处理。
+
+## 语法规则
+
+语法文件的规则以小写字母开头。
+
+首先我们来介绍语法规则的规则组成元素。
+
+
+
+以上名为 assignment 的语法规则中所包含的大写字母序列 IDENTIFIER 被称之终结符,它来自词法分析器,我们在词法规则中会对其进行定义。
+
+
+
+与此相对的是非终结符,比如以上 expression 语法规则中的 term,这些非终结符,由小写字母命名,并且由其他规则所定义。
+
+
+
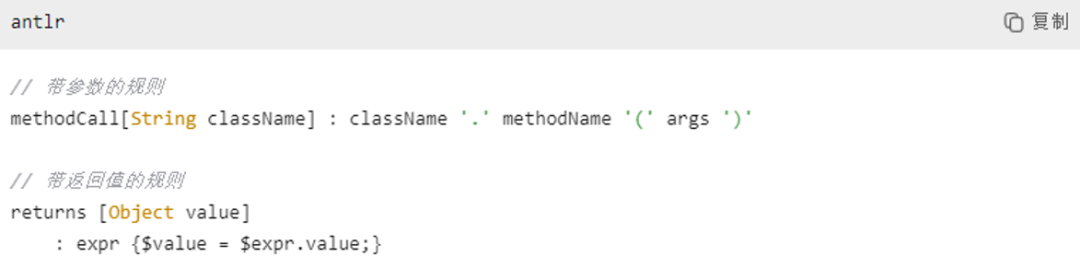
+除了之前介绍的终结符和非终结符两种元素之外,还有带参数的规则和带返回值的规则。因此,参数和返回值也是语法规则的重要元素。
+
+[String className],表示这个规则接受一个参数 className,类型为 String。在解析过程中,可以将外部传入的类名用于匹配。[Object value],表示这个规则在匹配成功后会返回一个 Object 类型的值,存储在 value 中。
+
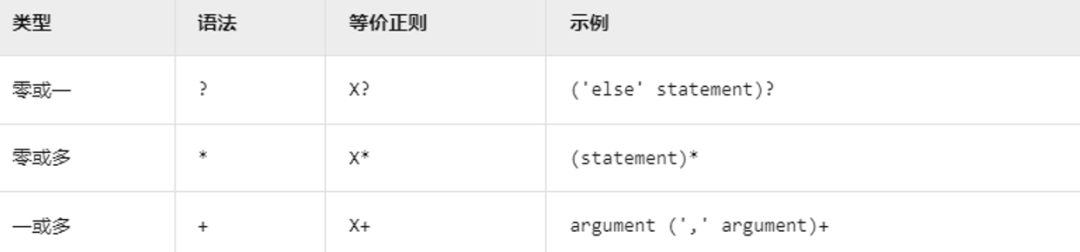
+ANTLR 4的语法规则的核心语法构造分为四种模式,分别是序列模式、选择模式、分组模式、循环模式。
+
+**序列模式**
+
+```java
+sqlSelect : SELECT column FROM table WHERE condition;
+```
+
+元素必须严格按顺序出现(如 SQL 语句结构)。
+
+**选择模式**
+
+```java
+dataType : INT | STRING | BOOL;
+```
+
+多选一匹配(如数据类型只能为三者之一)。
+
+**分组模式**
+
+```java
+functionCall : ID '(' (arg (',' arg)*)? ')';
+```
+
+括号强制组合子规则(如函数参数列表的逗号分隔结构)。
+
+**循环模式**
+
+```java
+emailList : address (',' address)+;
+```
+
+
+
+后缀运算符控制重复次数(如至少一个邮箱地址的逗号分隔列表)。
+
+### 规则标签
+
+在 ANTLR 4 中,规则标签(Rule Labels)是提升语法可读性、精确控制解析树生成的关键机制,我们可以使用 # 给最外层的备选分支添加标签,以获得更加精确的语法分析器监听器事件。一条规则中的备选分支要么全部带上标签,要么全部不带标签。标签主要有两种应用形式:
+
+------
+
+**分支备选标签(Alternative Labels)**
+
+在规则的选择分支(`|`)中标注备选项:
+
+```java
+expression
+ : left=expr '+' right=expr # AddExpr // # 定义标签
+ | left=expr '*' right=expr # MulExpr
+ | NUMBER # NumLiteral
+ ;
+```
+
+**作用**:
+
+> 为每个分支生成独立的上下文类(如`AddExprContext`),在监听器/访问器中提供类型精确的访问方法
+
+**生成代码优势**:
+
+```
+// 自动生成精确的进入/退出方法
+@Override
+public void enterAddExpr(MyParser.AddExprContext ctx) {
+ // 直接访问带标签的元素
+ ExprContext left = ctx.left; // 无需遍历子节点
+ ExprContext right = ctx.right;
+}
+```
+
+------
+
+**元素标签(Element Labels)**
+
+在规则中标记特定子元素:
+
+```
+funcCall : func=ID '(' args+=expr (',' args+=expr)* ')';
+```
+
+**三种标记方式**:
+
+| 标签语法 | 适用对象 | 返回值类型 | 访问示例 |
+| :--------------: | :------: | :---------------: | :------------------------------: |
+| `label=TOKEN` | 词法符号 | `TerminalNode` | `ctx.ID().getText()` |
+| `label=rule` | 规则引用 | `RuleContext`子类 | `ctx.expr().value` |
+| `labelList+=...` | 重复元素 | `List` | `for (exprContext e : ctx.args)` |
+
+**实战应用场景**
+
+- 场景1:四则运算精确解析
+
+```java
+expr
+ : left=expr op=('*'|'/') right=expr # MulDiv
+ | left=expr op=('+'|'-') right=expr # AddSub
+ | NUM # Number
+ | '(' expr ')' # Parens
+ ;
+```
+
+**生成的监听器接口**:
+
+```java
+void enterMulDiv(ExprParser.MulDivContext ctx);
+void enterAddSub(ExprParser.AddSubContext ctx);
+void exitMulDiv(ExprParser.MulDivContext ctx);
+// ...
+```
+
+- 场景2:函数调用语义分析
+
+```java
+functionCall
+ : func=ID '('
+ (firstArg=expr (',' otherArgs+=expr)*)?
+ ')' # FuncCall
+ ;
+```
+
+**在访问器中直接获取元素**:
+
+```java
+public Object visitFuncCall(FuncCallContext ctx) {
+ String funcName = ctx.func.getText();
+ List args = new ArrayList<>();
+ if(ctx.firstArg != null) {
+ args.add(ctx.firstArg);
+ args.addAll(ctx.otherArgs);
+ }
+ // ...处理函数调用
+}
+```
+
+# TokenStream
+
+词法分析器处理字符序列并将生成的词法符号提供给语法分析器,语法分析器随即根据这些信息来检查语法的正确性并建造出一棵语法分析树。这个过程对应的ANTLR 类是 CharStream、Lexer、Token、Parser,以及 ParseTree。连接词法分析器和语法分析器的“管道”就是 TokenStream。下图展示了这些类型的对象在内存中的交互方式。
+
+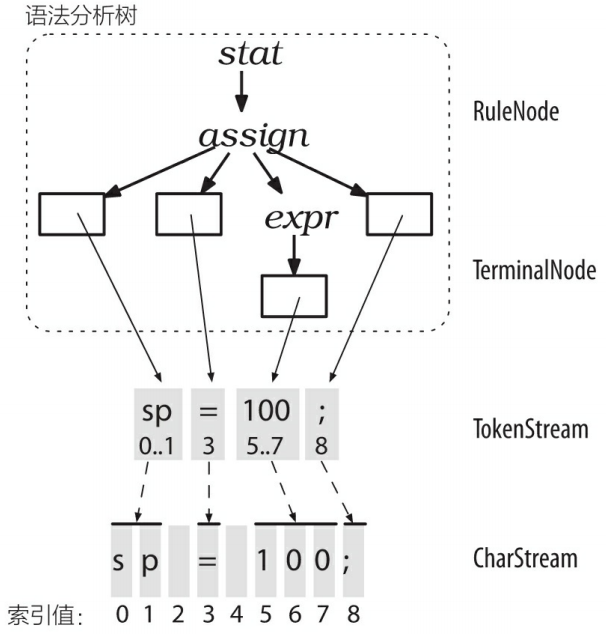
+
+ParseTree 的子类 RuleNode 和 TerminalNode ,二者分别是子树的根节点和叶子节点。RuleNode 有一些令人熟悉的方法,例如 getChild() 和 getParent() ,但是,对于一个特定的语法,RuleNode 并不是确定不变的。为了更好地支持对特定节点的元素的访问,ANTLR 会为每条规则生成一个 RuleNode 的子类。如下图所示,在我们的赋值语句的例子中,子树根节点的类型实际上是:StatContext、AssignContext 以及 ExprContext。
+
+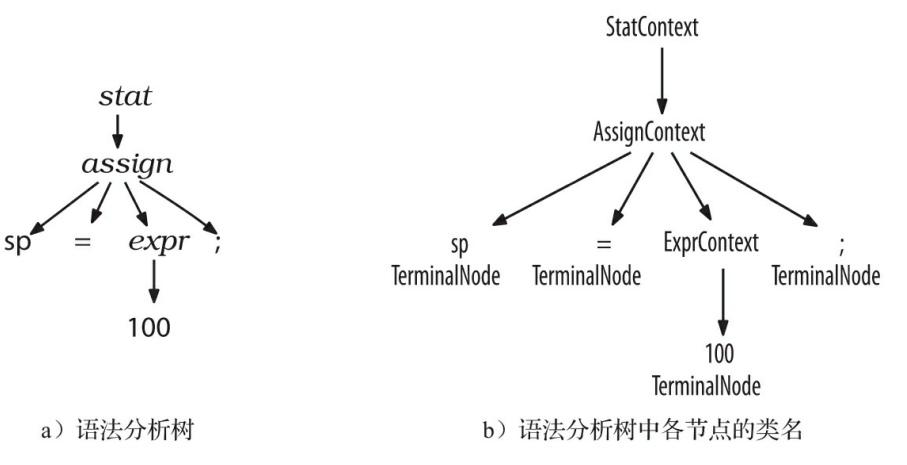
+
+因为这些根节点包含了使用规则识别词组过程中的全部信息,它们被称为上下文(context)对象。每个上下文对象都知道自己识别出的词组中,开始和结束位置处的词法符号,同时提供访问该词组全部元素的途径。例如,AssignContext 类提供了方法 ID() 和方法 expr() 来访问标识符节点和代表表达式的子树。
+
+# 监听器和访问器
+
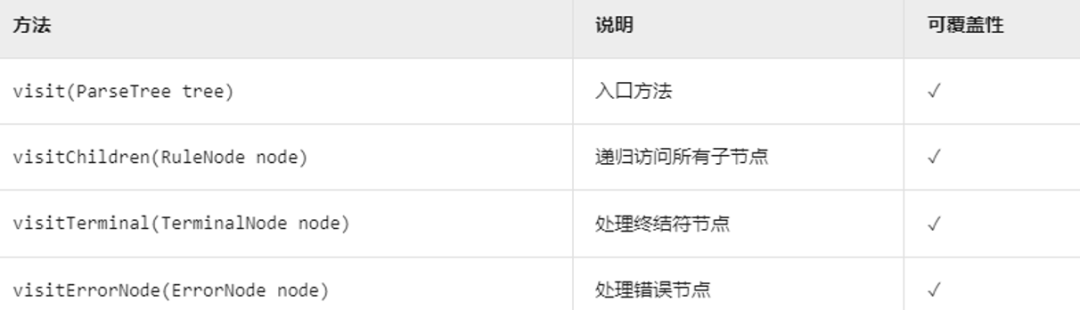
+ANTLR 的运行库提供了两种遍历树的机制。默认情况下,ANTLR 使用内建的遍历器访问生成的语法分析树,并为每个遍历时可能触发的事件生成一个语法分析树监听器接口(parse-tree listener interface)。监听器非常类似于 XML 解析器生成的 SAX 文档对象。SAX 监听器接收类似 startDocument() 和 endDocument() 的事件通知。一个监听器的方法实际上就是回调函数,正如我们在图形界面程序中响应复选框点击事件一样。除了监听器的方式,我们还将介绍另外一种遍历语法分析树的方式:访问者模式(vistor pattern)。
+
+## 监听器
+
+为了将遍历树时触发的事件转化为监听器的调用,ANTLR 运行库提供了 ParseTreeWalker 类。我们可以自行实现 ParseTreeListener 接口,在其中填充自己的逻辑代码(通常是调用程序的其他部分),从而构建出我们自己的语言类应用程序。ANTLR 为每个语法文件生成一个 ParseTreeListener 的子类,在该类中,语法中的每条规则都有对应的 enter 方法和 exit 方法。例如,当遍历器访问到 assign 规则对应的节点时,它就会调用 enterAssign() 方法,然后将对应的语法分析树节点——AssignContext 的实例——当作参数传递给它。在遍历器访问了 assign 节点的全部子节点之后,它会调用 exitAssign() 。下图用粗虚线标识了 ParseTreeWalker对语法分析树进行深度优先遍历的过程。
+
+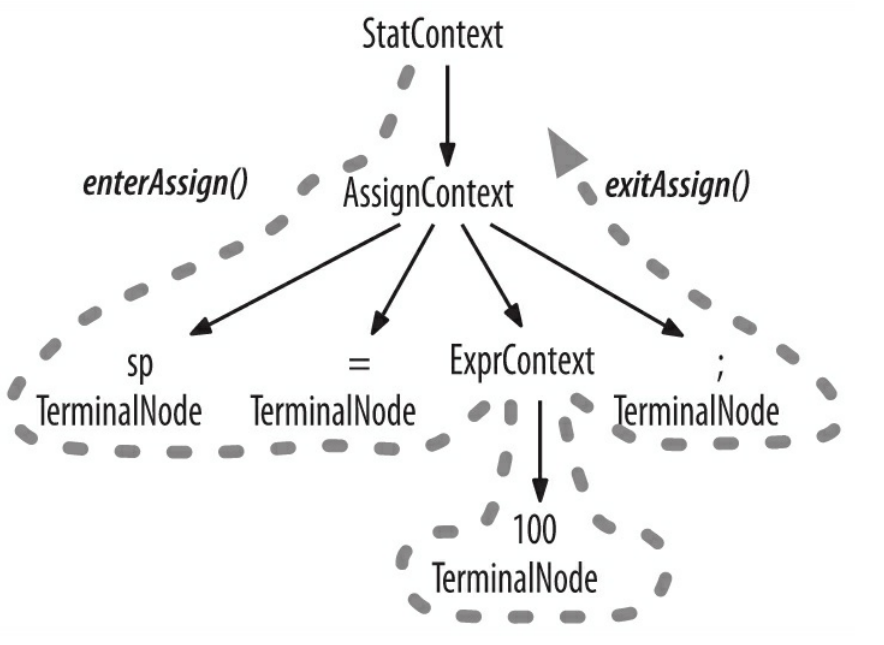
+
+下图显示了在我们的赋值语句生成的语法分析树中,ParseTreeWalker 对监听器方法的完整的调用顺序。
+
+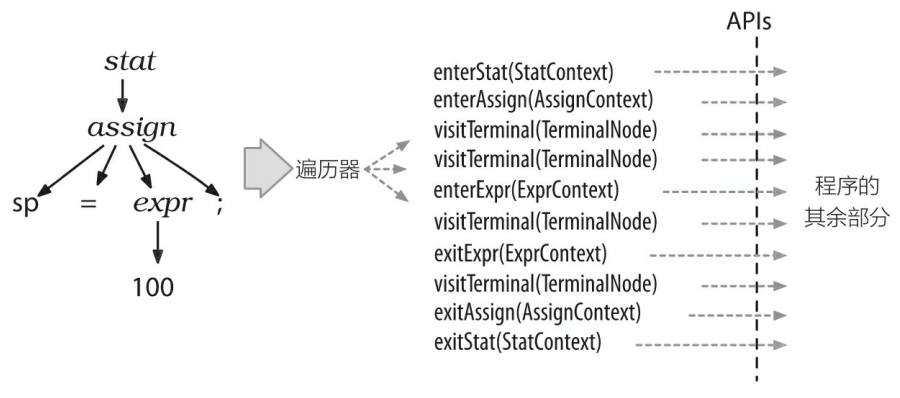
+
+监听器机制的优秀之处在于,这一切都是自动进行的。我们不需要编写对语法分析树的遍历代码,也不需要让我们的监听器显式地访问子节点。
+
+## 访问器
+
+有时候,我们希望控制遍历语法分析树的过程,通过显式的方法调用来访问子节点。下图是是使用常见的访问者模式对我们的语法分析树进行操作的过程。
+
+
+
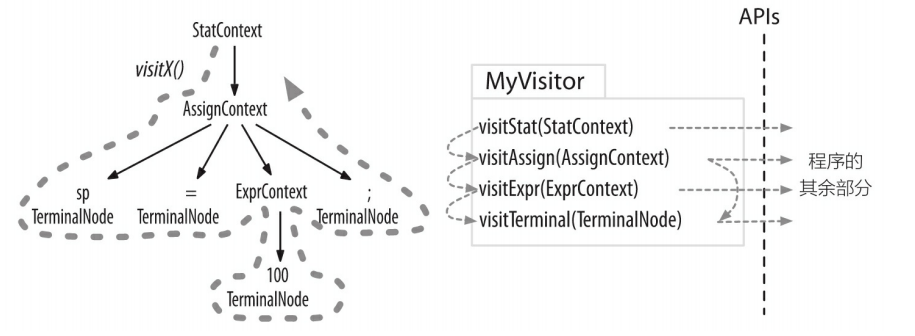
+其中,粗虚线显示了对语法分析树进行深度优先遍历的过程。细虚线标示出访问器方法的调用顺序。我们可以在自己的程序代码中实现这个访问器接口,然后调用visit() 方法来开始对语法分析树的一次遍历。
+
+```java
+ParseTree tree=...; // tree是语法分析得到的结果
+MyVisitor v = new MyVisitor();
+v.visit(tree);
+```
+
+ANTLR 内部为访问者模式提供的支持代码会在根节点处调用 visitStat() 方法。接下来,visitStat() 方法的实现将会调用 visit() 方法,并将所有子节点当作参数传递给它,从而继续遍历的过程。或者,visitMethod() 方法可以显式调用 visitAssign() 方法等。ANTLR会提供访问器接口和一个默认实现类,免去我们一切都要自行实现的麻烦。这样,我们就可以专注于那些我们感兴趣的方法,而无须覆盖接口中的方法。
+
+同时访问者机制支持泛型返回值,可以实现数据聚合。
+
+
+
+**访问器机制和监听器机制的最大的区别在于,监听器的方法会被 ANTLR 提供的遍历器对象自动调用,而在访问器的方法中,必须显式调用 visit 方法来访问子节点。忘记调用visit() 的后果就是对应的子树将不会被访问。**
+
+# 语义判定
+
+语义判定(Semantic Predicates)允许在语法规则中嵌入布尔表达式,从而在运行时动态控制解析过程。这使得 ANTLR4 能够处理上下文相关的语法结构。
+
+基本语法:
+
+```
+ruleName
+ : {布尔表达式}? 规则元素 // 验证型判定
+ | {布尔表达式}?=> 规则元素 // 门控型判定
+ ;
+```
+
+## 判定类型
+
+**验证型判定**
+
+- 语法:`{布尔表达式}?`
+- 行为:
+ - 尝试匹配规则元素
+ - 如果匹配成功,评估布尔表达式
+ - 如果表达式为 `false`,放弃当前分支并尝试其他备选分支
+
+```
+expr
+ : {isType("int")}? ID // 只有当 isType("int") 为 true 时才匹配
+ | INT
+ ;
+```
+
+**门控型判定**
+
+- 语法:`{布尔表达式}?=>`
+- 行为:
+ - 在尝试匹配规则元素前评估布尔表达式
+ - 如果表达式为 `false`,立即放弃整个分支
+ - 不会尝试匹配规则元素
+
+```
+statement
+ : {inLoop()}?=> 'break' ';' // 只有在循环中才允许 break
+ | 'continue' ';'
+ ;
+```
+
+## 实现机制
+
+**在语法文件中声明**:
+
+```java
+grammar ContextSensitive;
+
+@parser::members {
+ private SymbolTable symbolTable = new SymbolTable();
+
+ private boolean isType(String id) {
+ return symbolTable.isType(id);
+ }
+}
+
+expr
+ : {isType($ID.text)}? ID // 使用语义判定
+ | INT
+ ;
+```
+
+ANTLR 会将语义判定转换为解析器代码:
+
+```java
+public class ContextSensitiveParser extends Parser {
+ // ...
+
+ public final ExprContext expr() {
+ // 尝试第一个备选分支
+ if (isType(input.LT(1).getText())) {
+ // 创建上下文对象
+ // 匹配 ID
+ }
+ // 否则尝试第二个分支
+ else {
+ // 匹配 INT
+ }
+ }
+}
+```
+
+# Channel
+
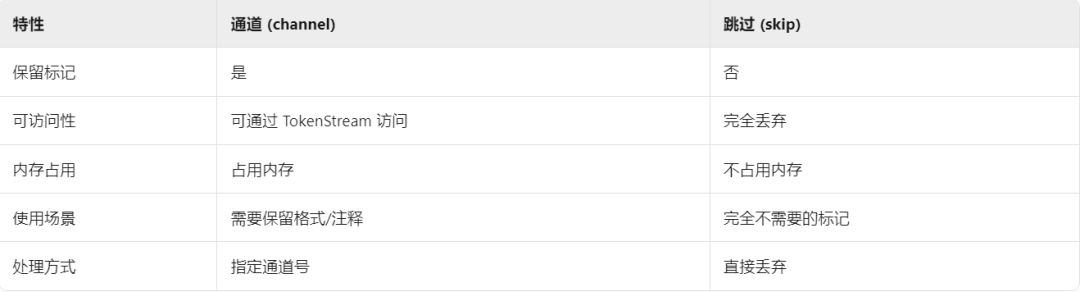
+在 ANTLR 4 中,通道(channels)是一种强大的机制,用于将词法标记(tokens)分类处理。ANTLR 4 有两个预定义通道:
+
+- 默认通道 (Token.DEFAULT_CHANNEL),通道号: 0,包含所有需要被解析器处理的标记。
+- 隐藏通道 (Token.HIDDEN_CHANNEL),通道号: 1,包含所有不需要被解析器直接处理的标记。
+
+**通道与 skip 的区别**
+
+
+
+**自定义通道**
+
+```
+// ===== 1. 声明通道 =====
+channels {
+ ERROR_CHANNEL, // 自定义错误信息通道
+ HIDDEN_COMMENTS // 隐藏注释通道
+}
+
+// ===== 2. 将词法规则定向到通道 =====
+ERROR_TOKEN : '' -> channel(ERROR_CHANNEL); // 捕获错误标记
+LINE_COMMENT : '//' ~[\r\n]* -> channel(HIDDEN_COMMENTS); // 隐藏注释
+BLOCK_COMMENT : '/*' .*? '*/' -> channel(HIDDEN_COMMENTS);
+
+// ===== 3. 保留传统空白符处理 =====
+WS : [ \t\r\n]+ -> skip; // 完全跳过空白符
+```
+
+ANTLR 4 通过 `channels{}` 声明自定义通道,并用 `-> channel(NAME) `将词法规则输出定向到指定通道,保留但隔离特殊内容。
+
+# 嵌入动作
+
+ANTLR 的嵌入动作(Embedded Actions)是在语法规则中**直接插入目标语言代码**的机制,它允许开发者在解析过程的关键节点执行自定义逻辑。
+
+```
+语法规则 { 代码块 }
+```
+
+ANTLR 在解析时会在对应位置**实时执行这些代码**
+
+**执行时机**
+
+1. **元素匹配前**:`{代码} 规则元素`
+2. **元素匹配后**:`规则元素 {代码}`
+3. **规则匹配完成**:`规则元素 @after {代码}`
+
+------
+
+**动作类型与代码示例**
+
+- **简单打印动作**(调试追踪)
+
+```
+expression
+ : left=expression '+' { System.out.println("检测到加号"); }
+ right=expression
+ { System.out.println("完成加法: "+$left.value+"+"+$right.value); }
+ ;
+```
+
+**输出示例**:
+
+```
+检测到加号
+完成加法: 5+3
+```
+
+- **条件拦截动作**(语义检查)
+
+```
+vectorOperation
+ : ID '=' (vec1=vector '×' vec2=vector
+ {
+ if($vec1.dimension != $vec2.dimension)
+ throw new RuntimeException("维度不匹配");
+ })
+ { System.out.println("叉积运算完成"); }
+ ;
+```
+
+- **动态计算动作**(属性传递)
+
+```
+number returns [int value]
+ : digits=INT { $value = Integer.parseInt($digits.text); }
+ | hex='0x' hexDigits=HEX
+ { $value = Integer.parseInt($hexDigits.text,16); }
+ ;
+```
+
+- **集合构造动作**(数据聚合)
+
+```
+jsonArray returns [List