diff --git a/README.md b/README.md
index 11f3a7db..641ebdcf 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,6 @@
-  +
+ 
diff --git a/docs/.vuepress/config.js b/docs/.vuepress/config.js
index 4c6f199d..00d043b5 100644
--- a/docs/.vuepress/config.js
+++ b/docs/.vuepress/config.js
@@ -55,7 +55,7 @@ module.exports = {
},
],
sidebarDepth: 2, // 侧边栏显示深度,默认1,最大2(显示到h3标题)
- logo: 'https://raw.githubusercontent.com/dunwu/images/dev/common/dunwu-logo.png', // 导航栏logo
+ logo: 'https://gitee.com/quyangzhao/images/tree/dev/common/dunwu-logo.png', // 导航栏logo
repo: 'dunwu/java-tutorial', // 导航栏右侧生成Github链接
searchMaxSuggestions: 10, // 搜索结果显示最大数
lastUpdated: '上次更新', // 更新的时间,及前缀文字 string | boolean (取值为git提交时间)
diff --git "a/docs/02.JavaEE/01.JavaWeb/03.JavaWeb\344\271\213Filter\345\222\214Listener.md" "b/docs/02.JavaEE/01.JavaWeb/03.JavaWeb\344\271\213Filter\345\222\214Listener.md"
index f13e99be..909b249a 100644
--- "a/docs/02.JavaEE/01.JavaWeb/03.JavaWeb\344\271\213Filter\345\222\214Listener.md"
+++ "b/docs/02.JavaEE/01.JavaWeb/03.JavaWeb\344\271\213Filter\345\222\214Listener.md"
@@ -24,7 +24,7 @@ permalink: /pages/5ecb29/
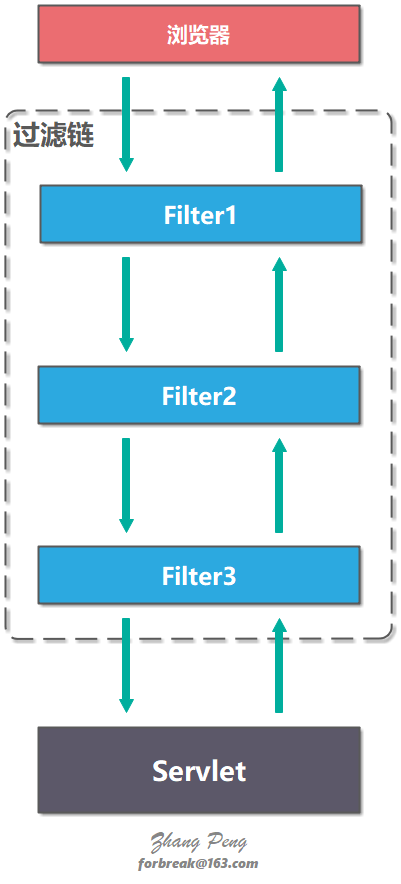
Filter 提供了过滤链(Filter Chain)的概念,一个过滤链包括多个 Filter。客户端请求 request 在抵达 Servlet 之前会经过过滤链的所有 Filter,服务器响应 response 从 Servlet 抵达客户端浏览器之前也会经过过滤链的所有 FIlter。
-
+
### 过滤器方法
diff --git "a/docs/02.JavaEE/02.\346\234\215\345\212\241\345\231\250/01.Tomcat/01.Tomcat\345\277\253\351\200\237\345\205\245\351\227\250.md" "b/docs/02.JavaEE/02.\346\234\215\345\212\241\345\231\250/01.Tomcat/01.Tomcat\345\277\253\351\200\237\345\205\245\351\227\250.md"
index 77264e08..bfa42a7c 100644
--- "a/docs/02.JavaEE/02.\346\234\215\345\212\241\345\231\250/01.Tomcat/01.Tomcat\345\277\253\351\200\237\345\205\245\351\227\250.md"
+++ "b/docs/02.JavaEE/02.\346\234\215\345\212\241\345\231\250/01.Tomcat/01.Tomcat\345\277\253\351\200\237\345\205\245\351\227\250.md"
@@ -111,7 +111,7 @@ tar -zxf apache-tomcat-8.5.24.tar.gz
启动后,访问 `http://localhost:8080` ,可以看到 Tomcat 安装成功的测试页面。
-
+
### 2.2. 配置
@@ -364,7 +364,7 @@ public class SimpleTomcatServer {
- 设置启动应用的端口、JVM 参数、启动浏览器等。
- 成功后,可以访问 `http://localhost:8080/`(当然,你也可以在 url 中设置上下文名称)。
-
+
> **说明**
>
@@ -374,7 +374,7 @@ public class SimpleTomcatServer {
## 3. Tomcat 架构
-
+
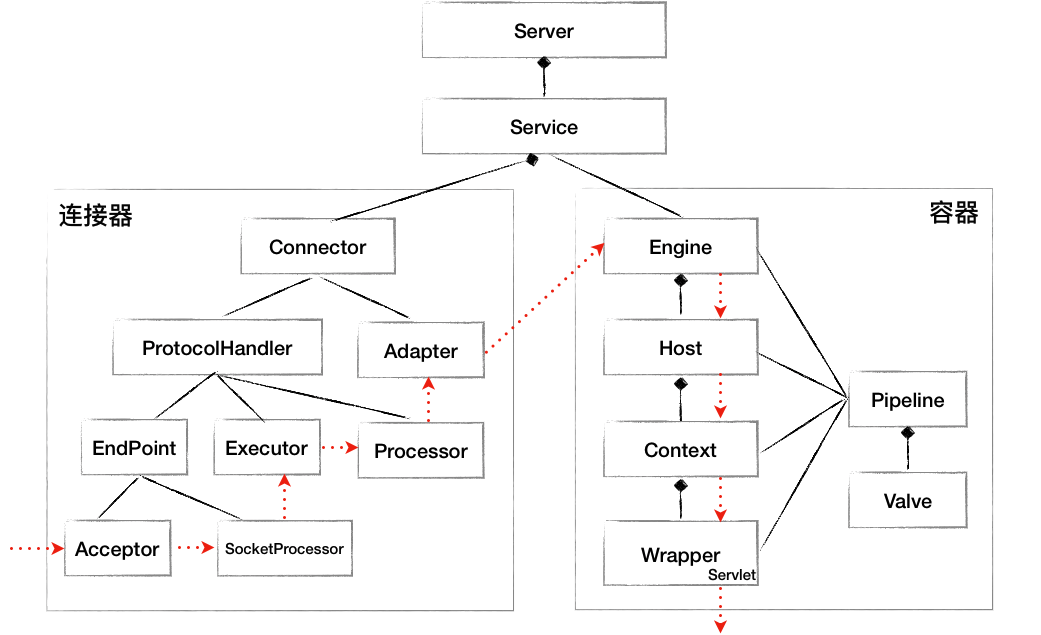
Tomcat 要实现 2 个核心功能:
@@ -402,7 +402,7 @@ Tomcat 支持的应用层协议有:
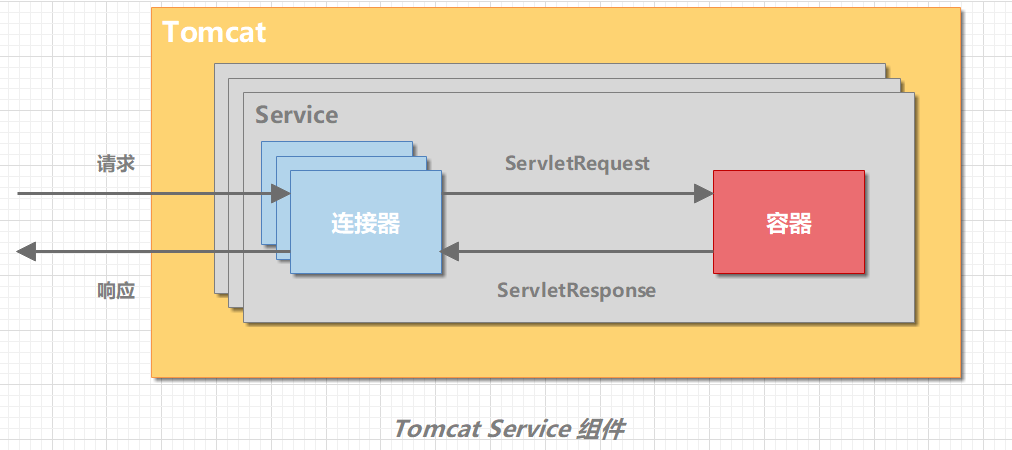
Tomcat 支持多种 I/O 模型和应用层协议。为了实现这点,一个容器可能对接多个连接器。但是,单独的连接器或容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作 Service 组件。Tomcat 内可能有多个 Service,通过在 Tomcat 中配置多个 Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。
-
+
**一个 Tomcat 实例有一个或多个 Service;一个 Service 有多个 Connector 和 Container**。Connector 和 Container 之间通过标准的 ServletRequest 和 ServletResponse 通信。
@@ -418,13 +418,13 @@ Tomcat 支持多种 I/O 模型和应用层协议。为了实现这点,一个
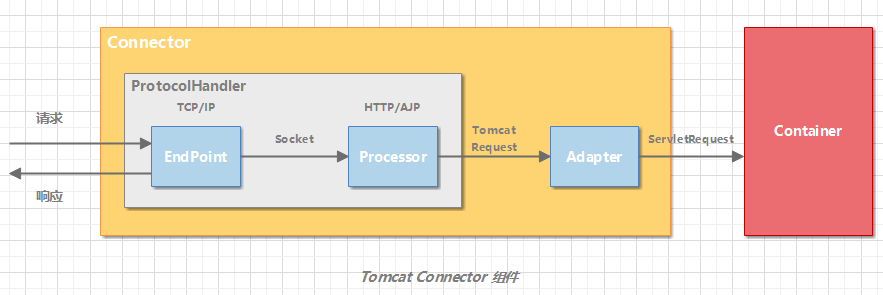
Tomcat 设计了 3 个组件来实现这 3 个功能,分别是 **`EndPoint`**、**`Processor`** 和 **`Adapter`**。
-
+
组件间通过抽象接口交互。这样做还有一个好处是**封装变化。**这是面向对象设计的精髓,将系统中经常变化的部分和稳定的部分隔离,有助于增加复用性,并降低系统耦合度。网络通信的 I/O 模型是变化的,可能是非阻塞 I/O、异步 I/O 或者 APR。应用层协议也是变化的,可能是 HTTP、HTTPS、AJP。浏览器端发送的请求信息也是变化的。但是整体的处理逻辑是不变的,EndPoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。
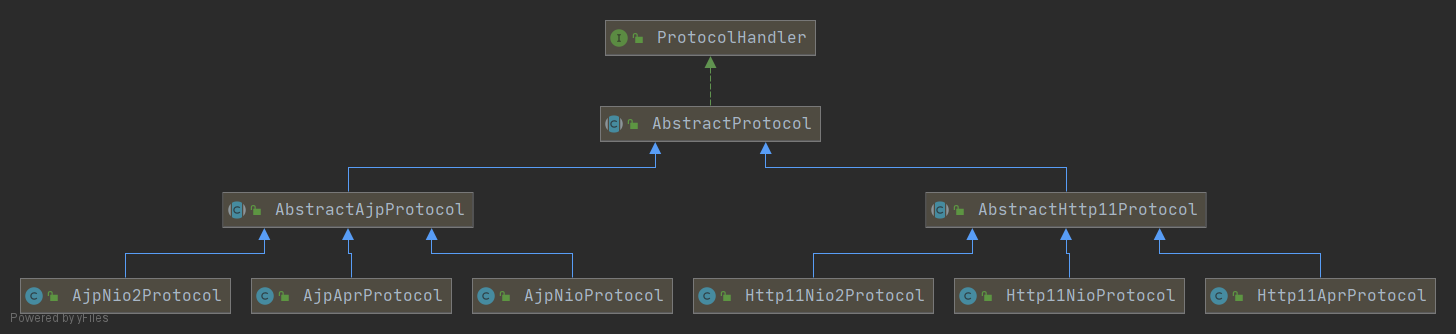
如果要支持新的 I/O 方案、新的应用层协议,只需要实现相关的具体子类,上层通用的处理逻辑是不变的。由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO2 + AJP。Tomcat 的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点。各种协议和通信模型的组合有相应的具体实现类。比如:Http11NioProtocol 和 AjpNioProtocol。
-
+
#### 3.2.1. ProtocolHandler 组件
@@ -444,7 +444,7 @@ EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 Ab
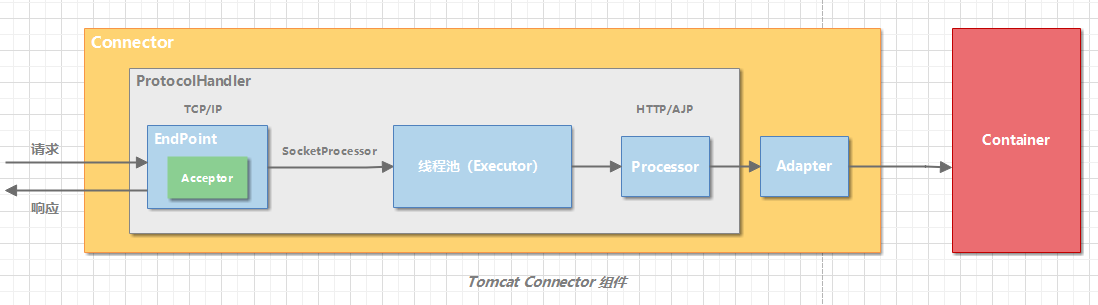
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、HTTP11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式。
-
+
从图中我们看到,EndPoint 接收到 Socket 连接后,生成一个 SocketProcessor 任务提交到线程池去处理,SocketProcessor 的 Run 方法会调用 Processor 组件去解析应用层协议,Processor 通过解析生成 Request 对象后,会调用 Adapter 的 Service 方法。
@@ -471,7 +471,7 @@ Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 Servlet 来处理
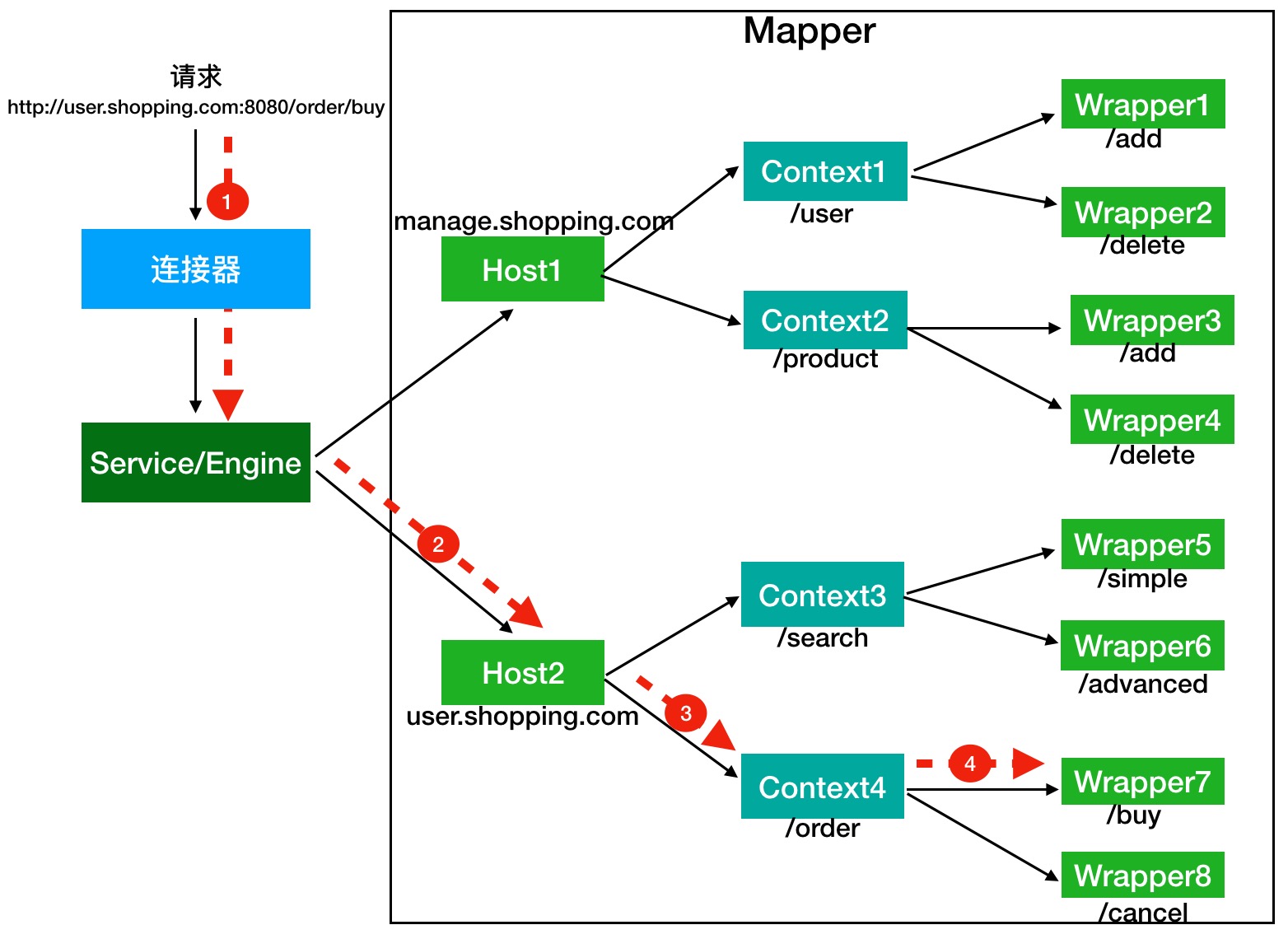
举例来说,假如有一个网购系统,有面向网站管理人员的后台管理系统,还有面向终端客户的在线购物系统。这两个系统跑在同一个 Tomcat 上,为了隔离它们的访问域名,配置了两个虚拟域名:`manage.shopping.com`和`user.shopping.com`,网站管理人员通过`manage.shopping.com`域名访问 Tomcat 去管理用户和商品,而用户管理和商品管理是两个单独的 Web 应用。终端客户通过`user.shopping.com`域名去搜索商品和下订单,搜索功能和订单管理也是两个独立的 Web 应用。如下所示,演示了 url 应声 Servlet 的处理流程。
-
+
假如有用户访问一个 URL,比如图中的`http://user.shopping.com:8080/order/buy`,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?
@@ -490,7 +490,7 @@ Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理
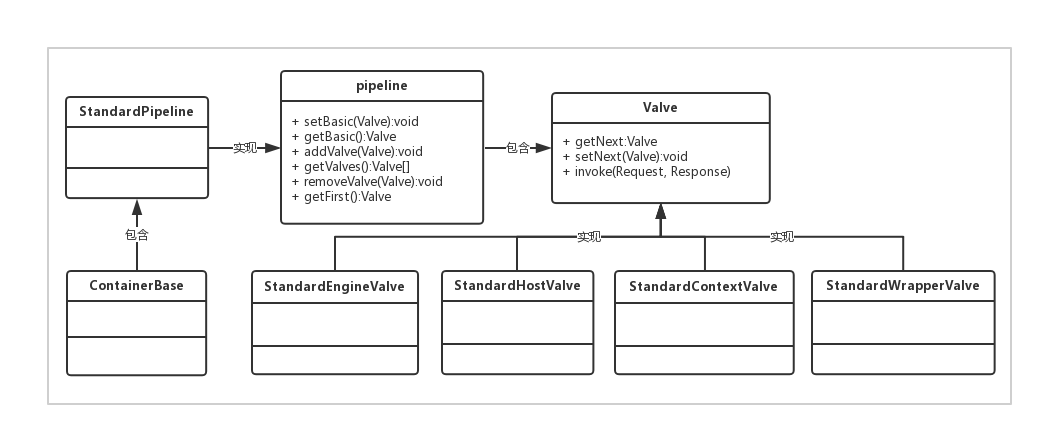
先来了解一下 Valve 和 Pipeline 接口的设计:
-
+
- 每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。但是,不同容器的 Pipeline 是怎么链式触发的呢,比如 Engine 中 Pipeline 需要调用下层容器 Host 中的 Pipeline。
- 这是因为 Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。
@@ -499,7 +499,7 @@ Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理
- 各层容器对应的 basic valve 分别是 `StandardEngineValve`、`StandardHostValve`、 `StandardContextValve`、`StandardWrapperValve`。
- 由于 Valve 是一个处理点,因此 invoke 方法就是来处理请求的。注意到 Valve 中有 getNext 和 setNext 方法,因此我们大概可以猜到有一个链表将 Valve 链起来了。
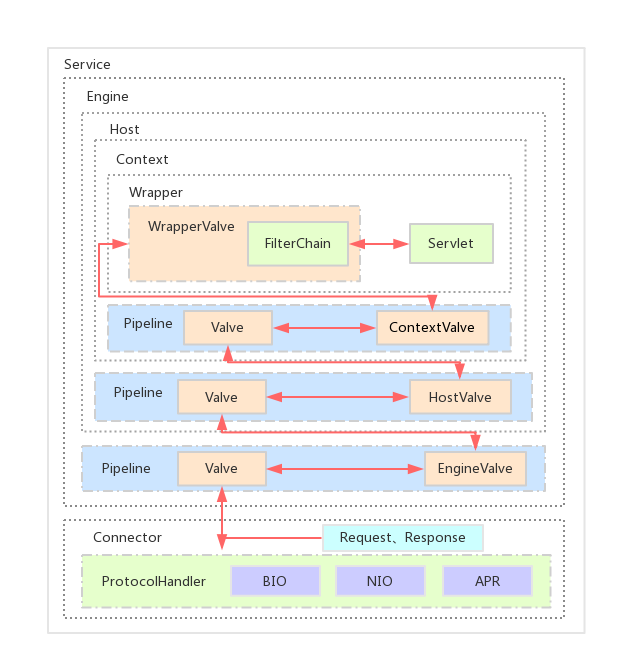
-
+
整个调用过程由连接器中的 Adapter 触发的,它会调用 Engine 的第一个 Valve:
@@ -511,7 +511,7 @@ connector.getService().getContainer().getPipeline().getFirst().invoke(request, r
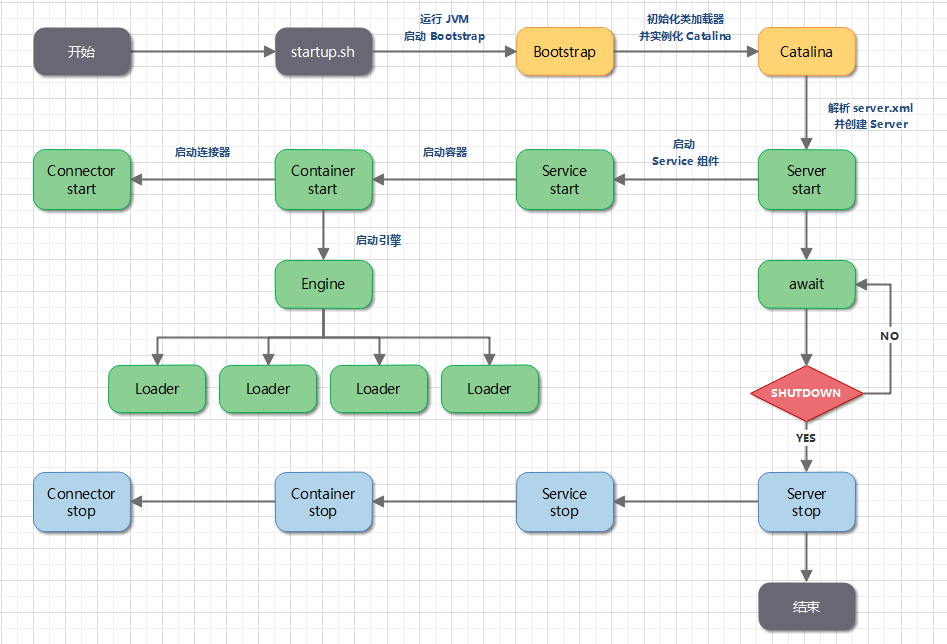
### 4.1. Tomcat 的启动过程
-
+
1. Tomcat 是一个 Java 程序,它的运行从执行 `startup.sh` 脚本开始。`startup.sh` 会启动一个 JVM 来运行 Tomcat 的启动类 `Bootstrap`。
2. `Bootstrap` 会初始化 Tomcat 的类加载器并实例化 `Catalina`。
@@ -731,12 +731,12 @@ ContextConfig 解析 web.xml 顺序:
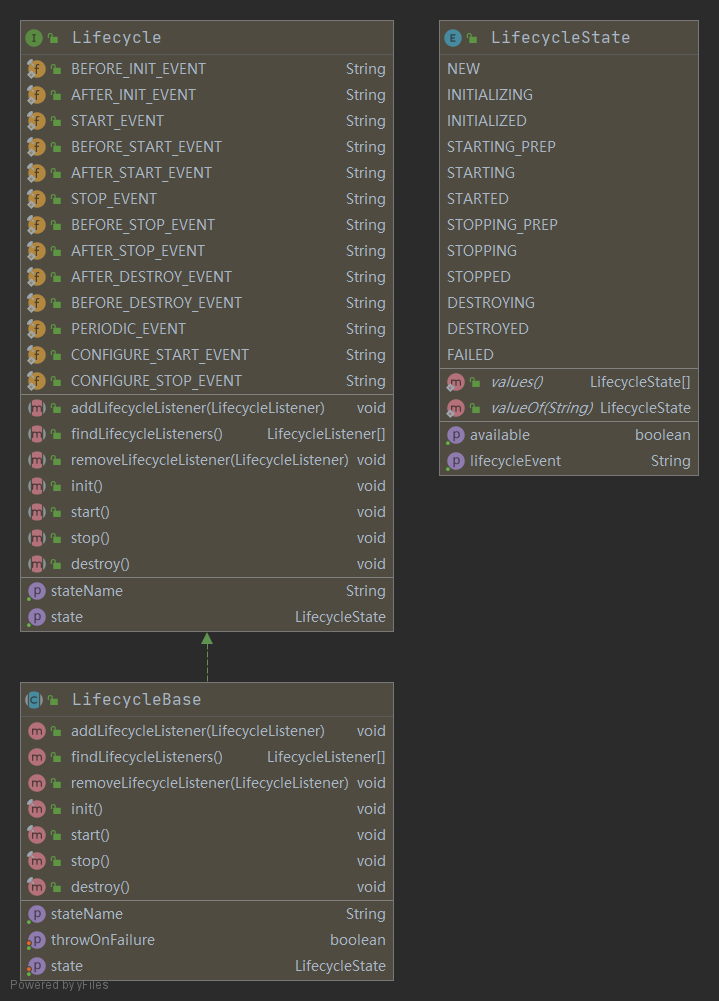
### 4.3. LifeCycle
-
+
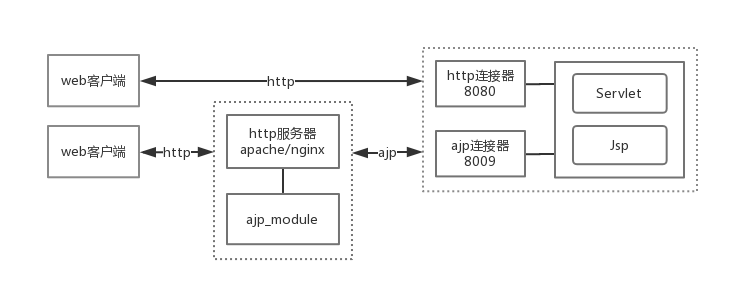
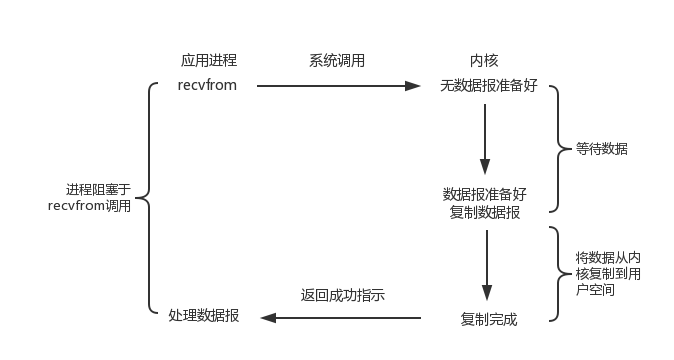
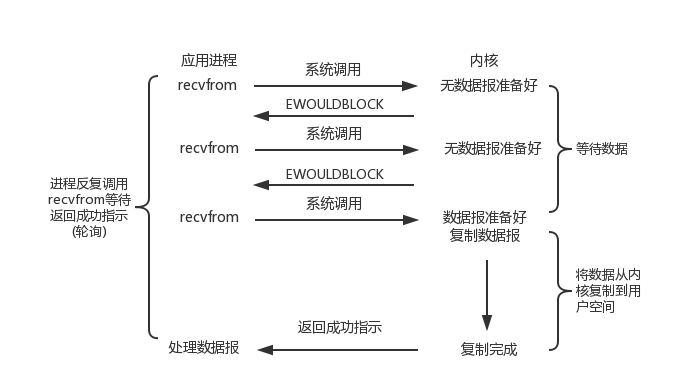
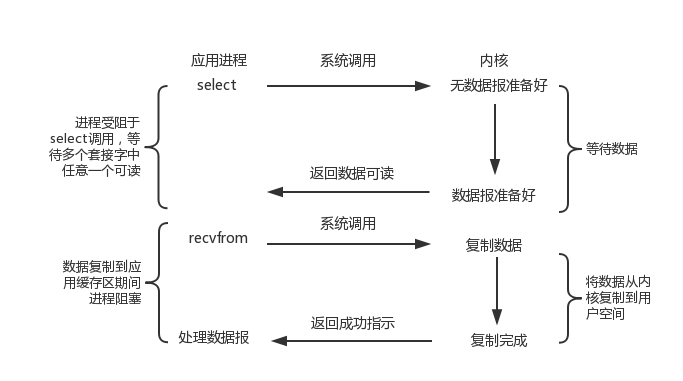
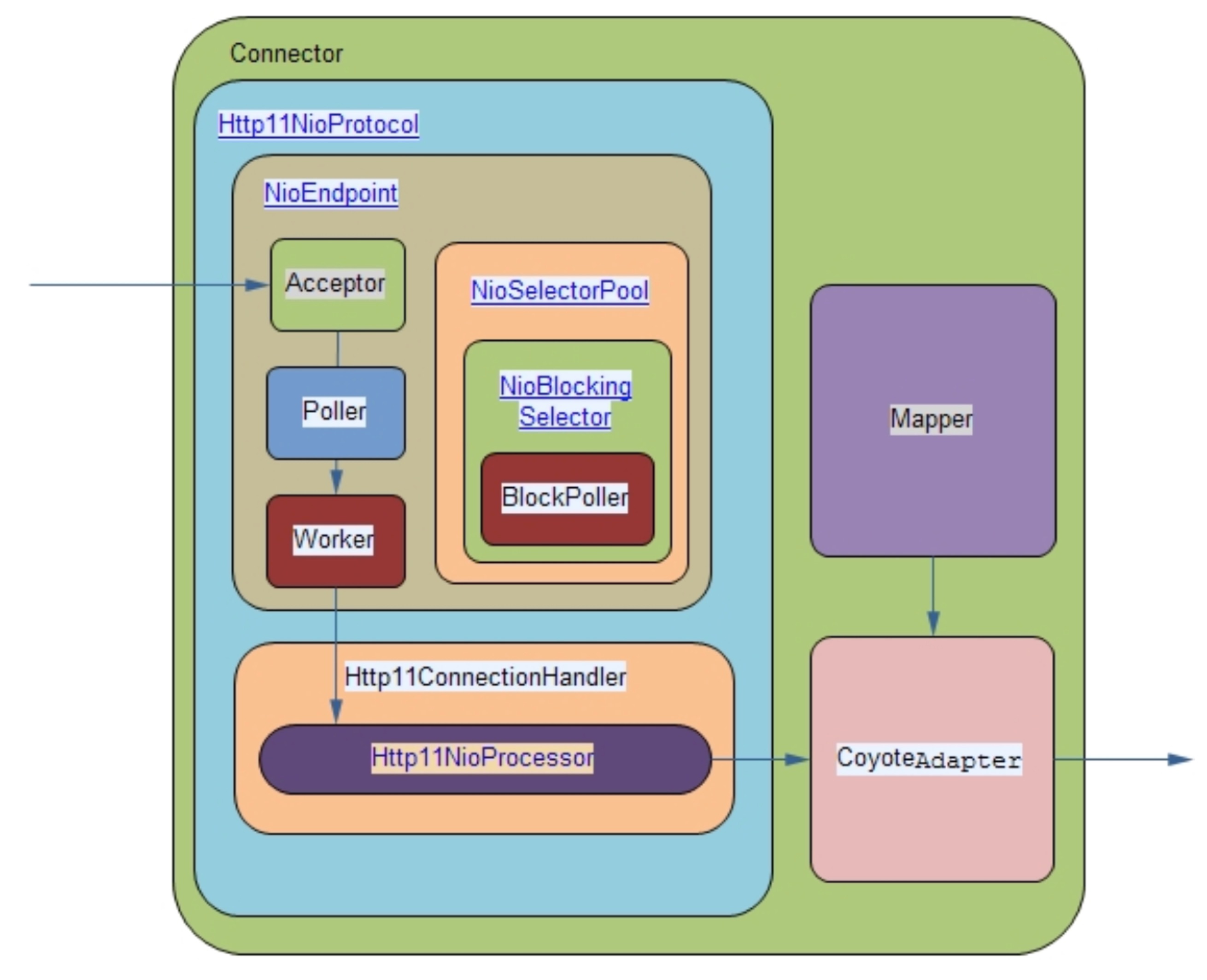
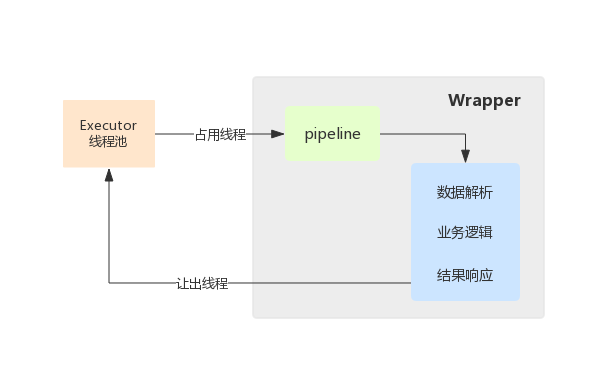
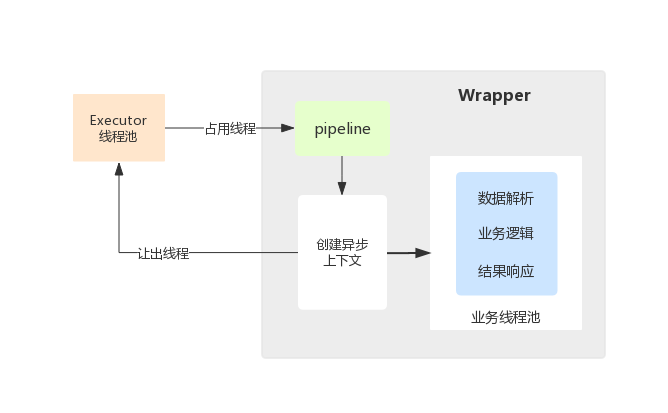
#### 4.3.1. 请求处理过程
-

+

-
+

-
+

-
+

-
+

-

+

-
+

-
+

-
+

-  +
+ 
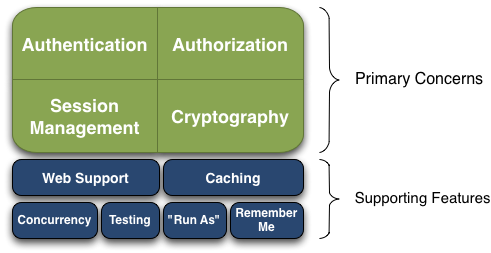
核心功能:
@@ -48,7 +48,7 @@ permalink: /pages/cd25bf/
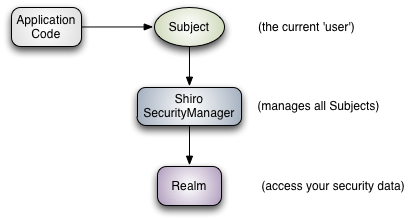
### Shiro 架构概述
-  +
+ 
- **Subject** - **主题**。它代表当前用户,`Subject` 可以是一个人,但也可以是第三方服务、守护进程帐户、时钟守护任务或者其它——当前和软件交互的任何事件。`Subject` 是 Shiro 的入口。
@@ -63,7 +63,7 @@ permalink: /pages/cd25bf/
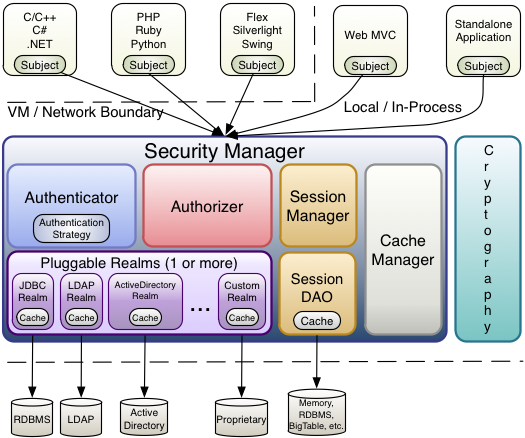
`SecurityManager` 是 Shiro 框架核心中的核心,它相当于 Shiro 的总指挥,负责调度所有行为,包括:认证、授权、获取安全数据(调用 `Realm`)、会话管理等。
-
+
`SecurityManager` 聚合了以下组件:
@@ -128,7 +128,7 @@ currentUser.logout();
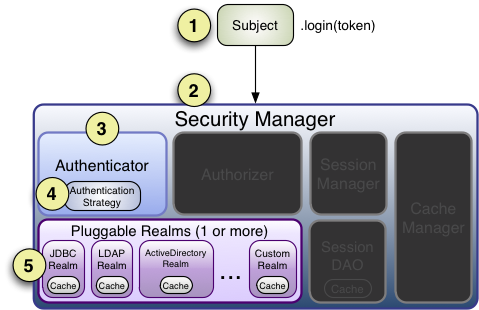
### 认证流程
-
+
1. 应用程序代码调用 `Subject.login` 方法,传入构造的 `AuthenticationToken` 实例,该实例代表最终用户的 `Principals` 和 `Credentials`。
@@ -282,7 +282,7 @@ public void updateAccount(Account userAccount) {
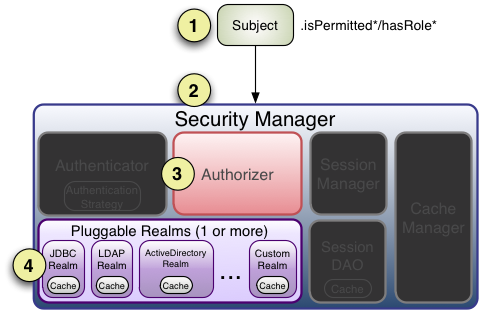
### 授权流程
-
+
1. 应用程序或框架代码调用任何 `Subject` 的 `hasRole*`,`checkRole*`,`isPermitted*` 或 `checkPermission*` 方法,并传入所需的权限或角色。
diff --git "a/docs/13.\346\241\206\346\236\266/12.\345\256\211\345\205\250/02.SpringSecurity.md" "b/docs/13.\346\241\206\346\236\266/12.\345\256\211\345\205\250/02.SpringSecurity.md"
index 4c136eb7..179d7c88 100644
--- "a/docs/13.\346\241\206\346\236\266/12.\345\256\211\345\205\250/02.SpringSecurity.md"
+++ "b/docs/13.\346\241\206\346\236\266/12.\345\256\211\345\205\250/02.SpringSecurity.md"
@@ -70,7 +70,7 @@ try {
Spring Security 框架中的认证数据模型如下:
-
+
- `Authentication` - 认证信息实体。
- `principal` - 用户标识。如:用户名、账户名等。通常是 `UserDetails` 的实例(后面详细讲解)。
diff --git "a/docs/13.\346\241\206\346\236\266/14.\345\276\256\346\234\215\345\212\241/01.Dubbo.md" "b/docs/13.\346\241\206\346\236\266/14.\345\276\256\346\234\215\345\212\241/01.Dubbo.md"
index ec3281ff..cdf7b861 100644
--- "a/docs/13.\346\241\206\346\236\266/14.\345\276\256\346\234\215\345\212\241/01.Dubbo.md"
+++ "b/docs/13.\346\241\206\346\236\266/14.\345\276\256\346\234\215\345\212\241/01.Dubbo.md"
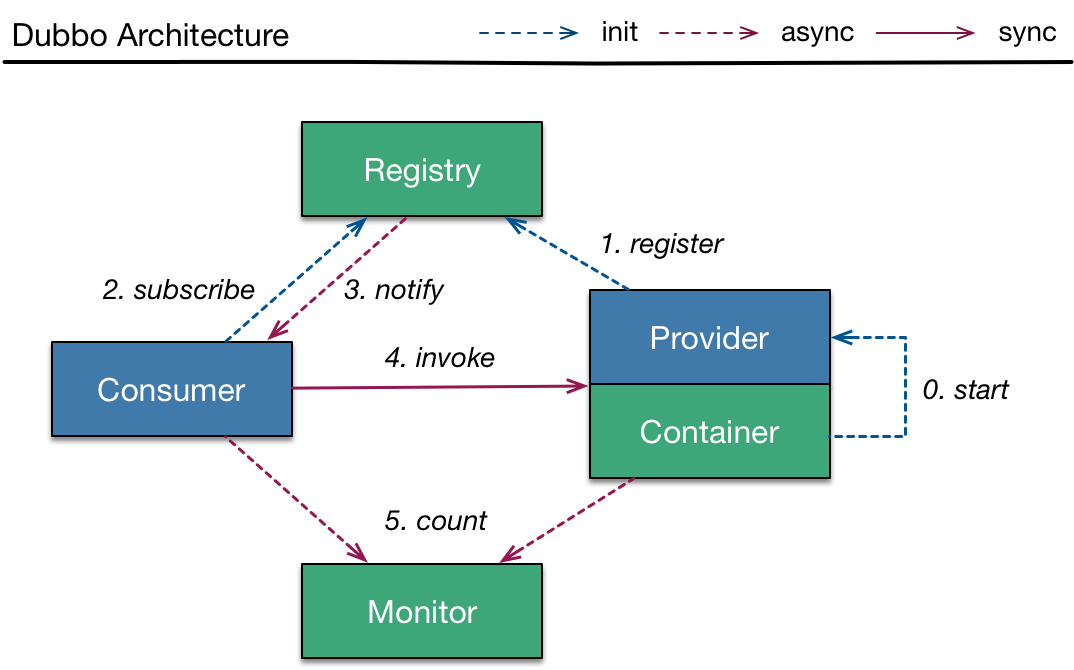
@@ -37,7 +37,7 @@ RPC(Remote Procedure Call),即远程过程调用,它是一种通过网
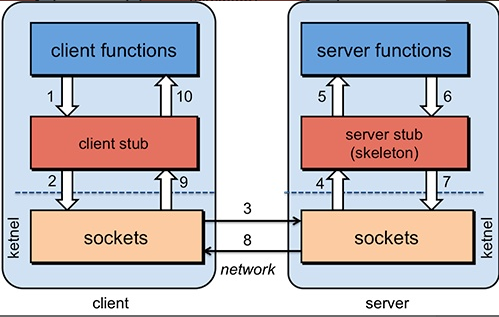
#### RPC 工作流程
-
+
1. 服务消费方(client)调用以本地调用方式调用服务;
2. client stub 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
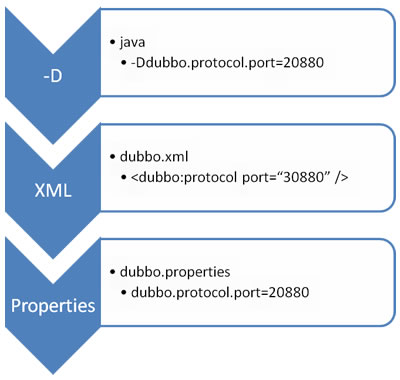
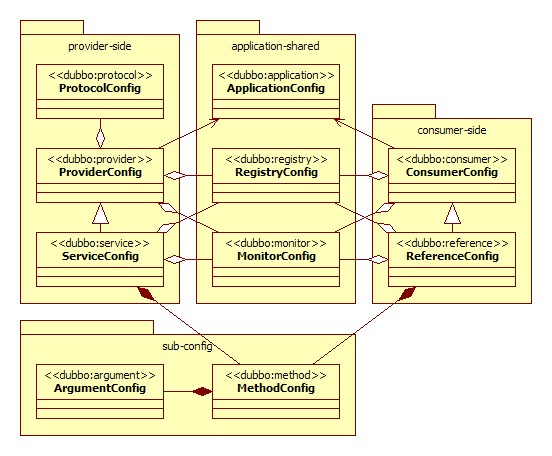
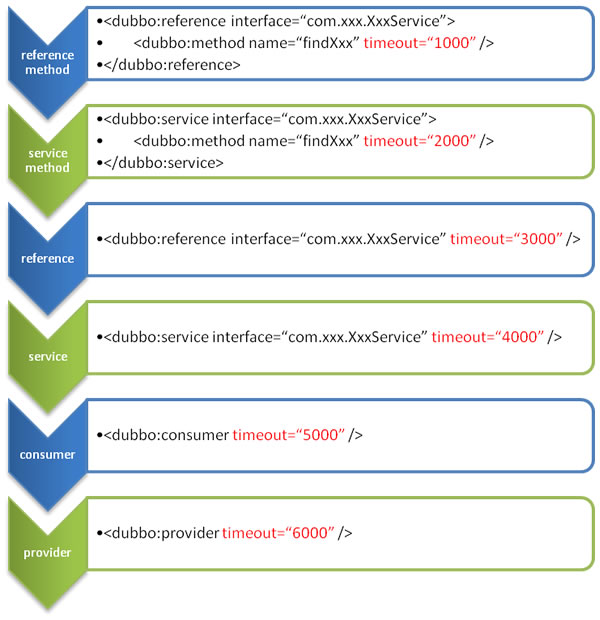
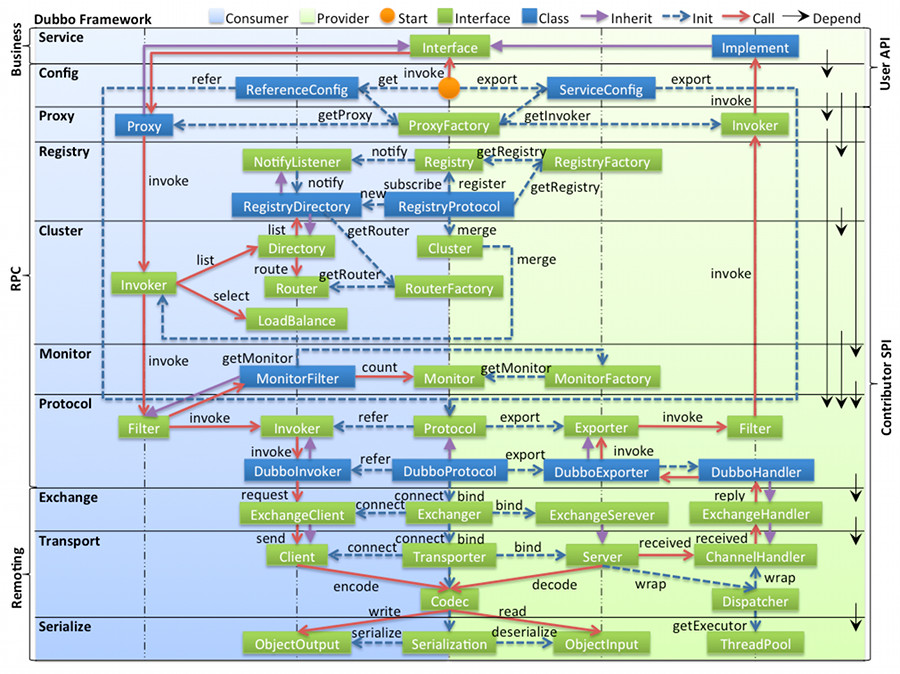
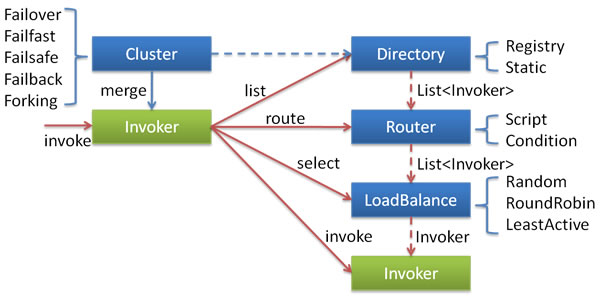
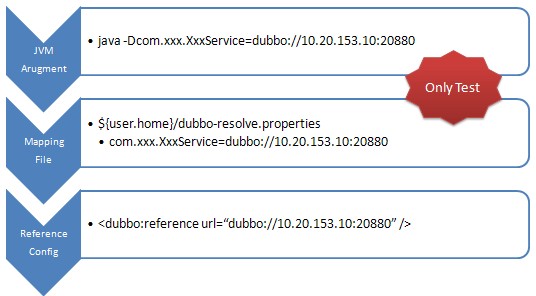
@@ -188,7 +188,7 @@ Dubbo 支持多种配置方式:
- Properties 最后,相当于缺省值,只有 XML 没有配置时,dubbo.properties 的相应配置项才会生效,通常用于共享公共配置,比如应用名。
-
+

-
+

-
+

-
+

-
+

-
+

-
+
