This class also contains methods to use these lists to look up + * classes and resources.
+ */ +/*package*/ final class DexPathList { + private static final String DEX_SUFFIX = ".dex"; + private static final String JAR_SUFFIX = ".jar"; + private static final String ZIP_SUFFIX = ".zip"; + private static final String APK_SUFFIX = ".apk"; + /** class definition context */ + private final ClassLoader definingContext; + /** list of dex/resource (class path) elements */ + // 把dex封装成一个数组,每个Element代表一个dex + private final Element[] dexElements; + /** list of native library directory elements */ + private final File[] nativeLibraryDirectories; + + // ..... + + /** + * Finds the named class in one of the dex files pointed at by + * this instance. This will find the one in the earliest listed + * path element. If the class is found but has not yet been + * defined, then this method will define it in the defining + * context that this instance was constructed with. + * + * @return the named class or {@code null} if the class is not + * found in any of the dex files + */ + public Class findClass(String name) { + for (Element element : dexElements) { + DexFile dex = element.dexFile; + // 遍历数组,拿到第一个就返回 + if (dex != null) { + Class clazz = dex.loadClassBinaryName(name, definingContext); + if (clazz != null) { + return clazz; + } + } + } + return null; + } +} +``` +从上面的源码中分析,我知道系统会把所有相关的`dex`维护到一个数组中,然后在加载类的时候会从该数组中的第一个元素中取,然后返回。那我们只要保证将我们热修复后的`dex`对应的`Element`放到该数组的第一个位置就可以了,这样系统就会加载我们热修复的`dex`中的类。 +所以方案出来了,只要把有问题的类修复后,放到一个单独的`dex`,然后把该`Dex`转换成对应的`Element`后再将该`Element`插入到`dexElements`数组的第一个位置就可以了。那该如何去将其插入到`dexElements`数组的第一个位置呢?-- 暴力反射。 + + + +到这里我感觉初步的思路已经有了: + +- 将补丁作为`dex`发布。 +- 通过反射修改该`dex`所对应的`Element`在数组中的位置。 + +但是我也想到肯定还会有类似下面的问题: + +- 资源文件的处理 +- 四大组件的处理 +- 清单文件的处理 + + +虽然我知道没有这么简单,但是我还是决定抱着不作不死的宗旨继续前行。 + +好了,`demo`走起来。 + + +怎么生成`dex`文件呢? 这要讲过两部分: + +- `.class`-> `.jar` : `jar -cvf test.jar com/charon/instantfix_sample/MainActivity.class` +- `.jar`-> `.dex`: `dx --dex --output=target.jar test.jar` `target.jar`就是包含`.dex`的`jar`包 + + +生成好`dex`后我们为了模拟先将其放到`asset`目录下(实际开发中肯定要从接口中去下载,当然还会有一些版本号的判断等),然后就是将该`dex`转换成 + + +方案中采用的是`MultiDex`,对其进行一部分改造,具体代码: + +- 添加`dex`文件,并执行`install` + +```java +/** +* 添加apk包外的dex文件 +* 自动执行install +* @param dexFile +*/ +public static void addDexFileAutoInstall(Context context, List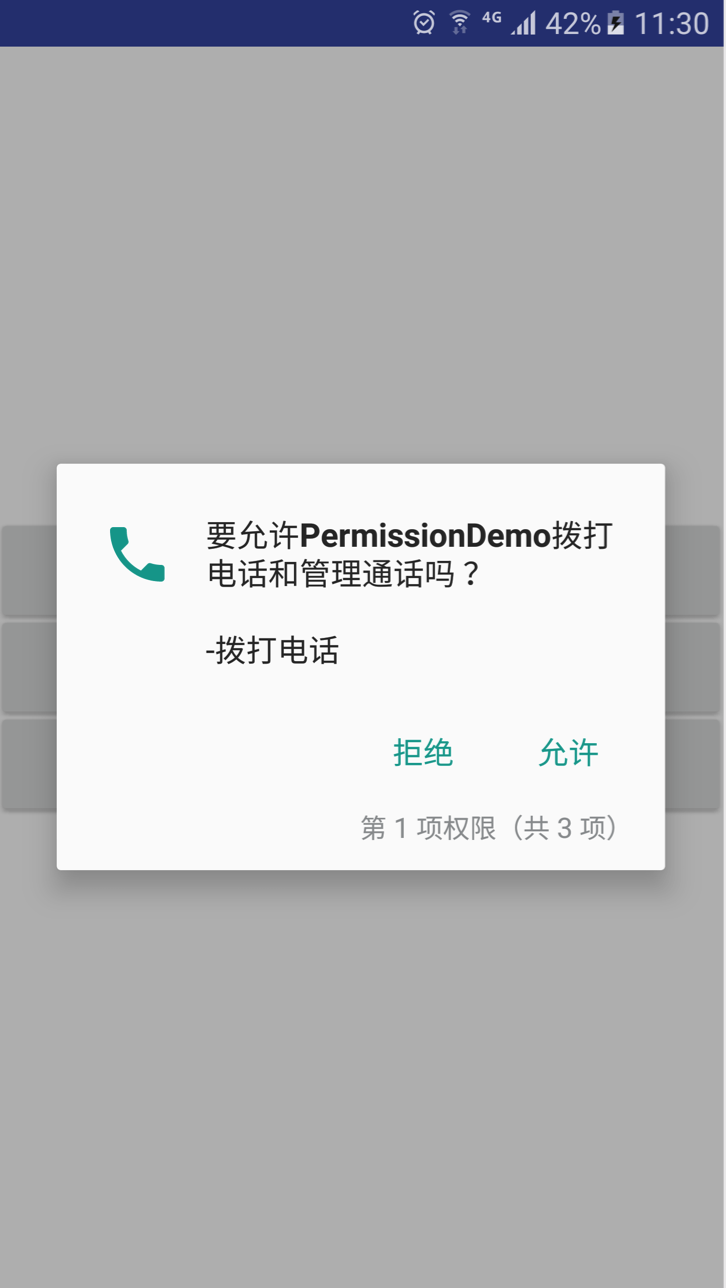 +
+##### 申请需要的权限
+
+如果应用没有所需的权限时,应用必须调用`ActivityCompat.requestPermissions (Activity activity,
+ String[] permissions,
+ int requestCode)`方法来申请对用的权限。参数传递对应所需的权限以及一个整数型的`request code`来标记该权限申请。 该方法是异步的:该方法会立即返回,在用户响应了请求权限的对话框之后,系统会调用对用的回调方法来通知结果,并且会传递在`reqeustPermissions()`方法中的`request code`。(在Android 6.0之前调用的时候会直接去调用`onRequestPermissionsResult()`的回调方法)
+如图:
+
+
+
+下面是检查是否读取联系人权限,并且在必要时申请权限的代码:
+
+```java
+// Here, thisActivity is the current activity
+if (ContextCompat.checkSelfPermission(thisActivity,
+ Manifest.permission.READ_CONTACTS)
+ != PackageManager.PERMISSION_GRANTED) {
+
+ // Should we show an explanation?
+ if (ActivityCompat.shouldShowRequestPermissionRationale(thisActivity,
+ Manifest.permission.READ_CONTACTS)) {
+
+ // Show an expanation to the user *asynchronously* -- don't block
+ // this thread waiting for the user's response! After the user
+ // sees the explanation, try again to request the permission.
+
+ } else {
+
+ // No explanation needed, we can request the permission.
+
+ ActivityCompat.requestPermissions(thisActivity,
+ new String[]{Manifest.permission.READ_CONTACTS},
+ MY_PERMISSIONS_REQUEST_READ_CONTACTS);
+
+ // MY_PERMISSIONS_REQUEST_READ_CONTACTS is an
+ // app-defined int constant. The callback method gets the
+ // result of the request.
+ }
+}
+```
+
+> 注意:当调用`requestPermissions()`方法时,系统会显示一个标准的对话框。应用不能指定或者改变该对话框。如果你想提供一些信息或者说明给用户,你需要在调用`requestPermissions()`之前处理。
+
+##### 处理请求权限的的结果
+
+如果应用申请权限,系统会显示一个对话框。当用户相应后,系统会调用应用中的`onRequestPermissionsResult (int requestCode,
+ String[] permissions,
+ int[] grantResults)`方法并传递用户的操作结果。在应用中必须要重写该方法来查找授权了什么权限。该回调方法会传递你在`requestPermisssions()`方法中传递的`request code`。直接在`Activity`或者`Fragment`中重写`onRequestPermissionsResult()`方法即可。例如,申请`READ_CONTACTS`的权限可能会有下面的回到方法:
+
+```java
+@Override
+public void onRequestPermissionsResult(int requestCode,
+ String permissions[], int[] grantResults) {
+ switch (requestCode) {
+ case MY_PERMISSIONS_REQUEST_READ_CONTACTS: {
+ // If request is cancelled, the result arrays are empty.
+ if (grantResults.length > 0
+ && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
+
+ // permission was granted, yay! Do the
+ // contacts-related task you need to do.
+
+ } else {
+
+ // permission denied, boo! Disable the
+ // functionality that depends on this permission.
+ }
+ return;
+ }
+
+ // other 'case' lines to check for other
+ // permissions this app might request
+ }
+}
+
+```
+
+系统提示的对话框会描述应用所需的`permission groud`。它不会列出特定的权限。例如,如果你申请了`READ_CONTACTS`权限,系统的对话框只会说你的应用需要获取设备的联系人信息。用户只需要授权每个`permission group`一次。如果你应用需要申请其他任何一个在该`permission group`中的权限时,系统会自动授权。在申请这些授权时,系统会像用户明确通过系统对话框统一授权时一样去调用`onRequestPermissionsResult()`方法并且传递`PERMISSION_GRANTED`参数。
+
+> 注意:虽然用户已经授权了同一`permission group`中其他的任何权限,但是应用仍然需要明确申请每个需要的权限。例外,`permission group`中的权限在以后可能会发生变化。
+
+例如,假设在应用的`manifest`文件中同时声明了`READ_CONTACTS`和`WRITE_CONTACTS`权限。如果你申请`READ_CONTACTS`权限而且用户同意了该权限,如果你想继续申请`WRITE_CONTACTS`权限,系统不会与用户有任何交互就会直接进行授权。
+
+如果用户拒绝了一个权限申请,你的应用进行合适的处理。例如,你的应用可能显示一个对话框来表明无法执行用户请求的需要该权限的操作。
+
+如果系统向用户申请权限授权,用户选择了让系统以后不要再申请该权限。 在这种情况下,应用在任何时间调用`reqeustPermissions()`方法来再次申请权限时,系统都会直接拒绝该请求。系统会直接调用`onRequestPermissionResult()`回调方法并且传递`PERMISSION_DENIED`参数,和用户明确拒绝应用申请该权限时一样。 这就意味着在你调用`requestPermissions()`方法是,你无法确定是否会和用户有直接的交互操作。
+
+
+示例代码:
+```java
+
+final private int REQUEST_CODE_ASK_MULTIPLE_PERMISSIONS = 124;
+
+private void insertDummyContactWrapper() {
+ List
+
+##### 申请需要的权限
+
+如果应用没有所需的权限时,应用必须调用`ActivityCompat.requestPermissions (Activity activity,
+ String[] permissions,
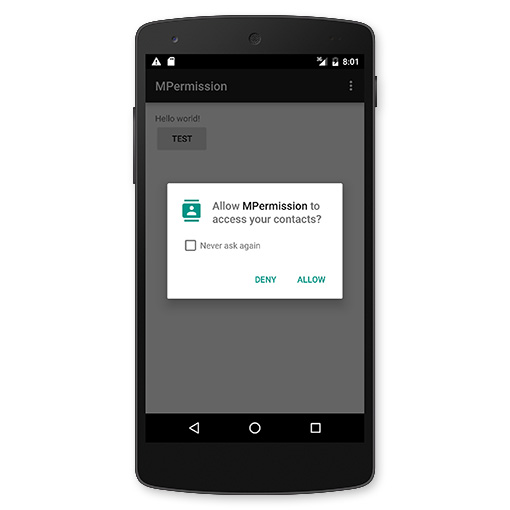
+ int requestCode)`方法来申请对用的权限。参数传递对应所需的权限以及一个整数型的`request code`来标记该权限申请。 该方法是异步的:该方法会立即返回,在用户响应了请求权限的对话框之后,系统会调用对用的回调方法来通知结果,并且会传递在`reqeustPermissions()`方法中的`request code`。(在Android 6.0之前调用的时候会直接去调用`onRequestPermissionsResult()`的回调方法)
+如图:
+
+
+
+下面是检查是否读取联系人权限,并且在必要时申请权限的代码:
+
+```java
+// Here, thisActivity is the current activity
+if (ContextCompat.checkSelfPermission(thisActivity,
+ Manifest.permission.READ_CONTACTS)
+ != PackageManager.PERMISSION_GRANTED) {
+
+ // Should we show an explanation?
+ if (ActivityCompat.shouldShowRequestPermissionRationale(thisActivity,
+ Manifest.permission.READ_CONTACTS)) {
+
+ // Show an expanation to the user *asynchronously* -- don't block
+ // this thread waiting for the user's response! After the user
+ // sees the explanation, try again to request the permission.
+
+ } else {
+
+ // No explanation needed, we can request the permission.
+
+ ActivityCompat.requestPermissions(thisActivity,
+ new String[]{Manifest.permission.READ_CONTACTS},
+ MY_PERMISSIONS_REQUEST_READ_CONTACTS);
+
+ // MY_PERMISSIONS_REQUEST_READ_CONTACTS is an
+ // app-defined int constant. The callback method gets the
+ // result of the request.
+ }
+}
+```
+
+> 注意:当调用`requestPermissions()`方法时,系统会显示一个标准的对话框。应用不能指定或者改变该对话框。如果你想提供一些信息或者说明给用户,你需要在调用`requestPermissions()`之前处理。
+
+##### 处理请求权限的的结果
+
+如果应用申请权限,系统会显示一个对话框。当用户相应后,系统会调用应用中的`onRequestPermissionsResult (int requestCode,
+ String[] permissions,
+ int[] grantResults)`方法并传递用户的操作结果。在应用中必须要重写该方法来查找授权了什么权限。该回调方法会传递你在`requestPermisssions()`方法中传递的`request code`。直接在`Activity`或者`Fragment`中重写`onRequestPermissionsResult()`方法即可。例如,申请`READ_CONTACTS`的权限可能会有下面的回到方法:
+
+```java
+@Override
+public void onRequestPermissionsResult(int requestCode,
+ String permissions[], int[] grantResults) {
+ switch (requestCode) {
+ case MY_PERMISSIONS_REQUEST_READ_CONTACTS: {
+ // If request is cancelled, the result arrays are empty.
+ if (grantResults.length > 0
+ && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
+
+ // permission was granted, yay! Do the
+ // contacts-related task you need to do.
+
+ } else {
+
+ // permission denied, boo! Disable the
+ // functionality that depends on this permission.
+ }
+ return;
+ }
+
+ // other 'case' lines to check for other
+ // permissions this app might request
+ }
+}
+
+```
+
+系统提示的对话框会描述应用所需的`permission groud`。它不会列出特定的权限。例如,如果你申请了`READ_CONTACTS`权限,系统的对话框只会说你的应用需要获取设备的联系人信息。用户只需要授权每个`permission group`一次。如果你应用需要申请其他任何一个在该`permission group`中的权限时,系统会自动授权。在申请这些授权时,系统会像用户明确通过系统对话框统一授权时一样去调用`onRequestPermissionsResult()`方法并且传递`PERMISSION_GRANTED`参数。
+
+> 注意:虽然用户已经授权了同一`permission group`中其他的任何权限,但是应用仍然需要明确申请每个需要的权限。例外,`permission group`中的权限在以后可能会发生变化。
+
+例如,假设在应用的`manifest`文件中同时声明了`READ_CONTACTS`和`WRITE_CONTACTS`权限。如果你申请`READ_CONTACTS`权限而且用户同意了该权限,如果你想继续申请`WRITE_CONTACTS`权限,系统不会与用户有任何交互就会直接进行授权。
+
+如果用户拒绝了一个权限申请,你的应用进行合适的处理。例如,你的应用可能显示一个对话框来表明无法执行用户请求的需要该权限的操作。
+
+如果系统向用户申请权限授权,用户选择了让系统以后不要再申请该权限。 在这种情况下,应用在任何时间调用`reqeustPermissions()`方法来再次申请权限时,系统都会直接拒绝该请求。系统会直接调用`onRequestPermissionResult()`回调方法并且传递`PERMISSION_DENIED`参数,和用户明确拒绝应用申请该权限时一样。 这就意味着在你调用`requestPermissions()`方法是,你无法确定是否会和用户有直接的交互操作。
+
+
+示例代码:
+```java
+
+final private int REQUEST_CODE_ASK_MULTIPLE_PERMISSIONS = 124;
+
+private void insertDummyContactWrapper() {
+ List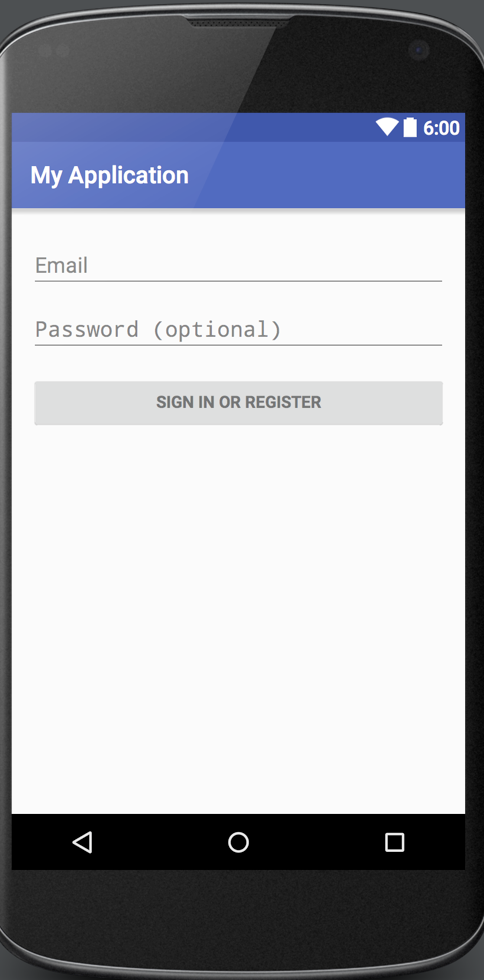 +
+不得不说,`Material Design`的效果真是美美哒!
+
+好,那我们就用用户登录页来按照`MVP`的模式实现一下:
+
+- M: 很显然Model应该是`User`类。
+- V: `View`就是`LoginActivity`。
+- P: P那我们一会就创建一个`LoginPresenter`类。
+
+齐了,那接下来就详细分析下他们这三部分:
+
+- `User`: 应该有`email`, `password`, `boolean login(email, password)`。
+- `LoginActivity`:点击登录应该要出`loading`页。登录成功后要进入下一个页面。如果登录失败应该弹`toast`提示。那就需要`void showLoading()`,`void hideLoading()`,`void showErrorTip()`,`void doLoginSuccess()`这四个方法。
+- `LoginPresenter`:这是`Model`和`View`的桥梁。他需要做的处理业务逻辑,直接与`Model`打交道,然后将`UI`的逻辑交给`LoginActivity`处理。
+那怎么做呢? 按照我上面总结的那一句话,、`MVP`其实就是面向接口编程,`V`实现接口,`P`使用接口。很显然我们需要提供一个接口。那就新建一个`ILoginView`的接口。这里面有哪些方法呢? 当然是上面我们在分析`LoginActiity`时提出的那四个方法。这样`LoginActivity`直接实现`ILoginView`接口就好。
+
+
+开始做:
+
+- 先把`Model`做好吧,创建`User`类。
+
+ ```java
+ public class User {
+ private String email;
+ private String password;
+ public User(String email, String password) {
+ this.email = email;
+ this.password = password;
+ }
+
+ public boolean login() {
+ // do login request..
+ return true;
+ }
+ }
+ ```
+
+- 创建`ILoginView`接口,定义登录所需要的`ui`逻辑。
+
+ ```java
+ public interface ILoginView {
+ void showLoading();
+ void hideLoading();
+ void showErrorTip();
+ void doLoginSuccess();
+ }
+ ```
+
+- 创建`LoginPresenter`类,使用`ILoginView`接口,那该类主要有什么功能呢? 它主要是处理业务逻辑的,
+ 对于登录的话,当然是用户在`UI`页面输入邮箱和密码,然后`Presenter`去开线程、请求接口。然后得到登录结果再去让`UI`显示对应的视图。那自然就是有一个`void login(String email, String passowrd)`的方法了
+
+ ```java
+ public class LoginPresenter {
+ private ILoginView mLoginView;
+
+ public LoginPresenter(ILoginView loginView) {
+ mLoginView = loginView;
+ }
+
+ public void login(String email, String password) {
+ if (TextUtils.isEmpty(email) || TextUtils.isEmpty(password)) {
+ //
+ mLoginView.showErrorTip();
+ return;
+ }
+ mLoginView.showLoading();
+ User user = new User(email, password);
+
+ // do network request....
+ // ....
+ onSuccess() {
+ boolean login = user.login();
+ if (login) {
+ mLoginView.doLoginSuccess();
+ } else {
+ mLoginView.showErrorTip();
+ }
+ mLoginView.hideLoading();
+ }
+
+ onFailde() {
+ mLoginView.showErrorTip();
+ mLoginView.hideLoading();
+ }
+ }
+ }
+ ```
+- 创建`LoginActivity`,实现`ILoginView`的接口,然后内部调用`LoginPresenter`来处理业务逻辑。
+
+ ```java
+ public class LoginActivity extends AppCompatActivity implements ILoginView {
+ private LoginPresenter mLoginPresenter;
+
+ private AutoCompleteTextView mEmailView;
+ private EditText mPasswordView;
+ private View mProgressView;
+ private View mLoginButton;
+
+ @Override
+ protected void onCreate(Bundle savedInstanceState) {
+ super.onCreate(savedInstanceState);
+ setContentView(R.layout.activity_login);
+ mEmailView = (AutoCompleteTextView) findViewById(R.id.email);
+ mPasswordView = (EditText) findViewById(R.id.password);
+ mLoginButton = findViewById(R.id.email_sign_in_button);
+ mProgressView = findViewById(R.id.login_progress);
+
+ mLoginPresenter = new LoginPresenter(this);
+
+ mLoginButton.setOnClickListener(new View.OnClickListener() {
+ @Override
+ public void onClick(View v) {
+ mLoginPresenter.login(mEmailView.getText().toString().trim(), mPasswordView.getText().toString().trim());
+ }
+ });
+ }
+
+ @Override
+ public void showLoading() {
+ mProgressView.setVisibility(View.VISIBLE);
+ }
+
+ @Override
+ public void hideLoading() {
+ mProgressView.setVisibility(View.GONE);
+ }
+
+ @Override
+ public void showErrorTip() {
+ Toast.makeText(this, "login faled", Toast.LENGTH_SHORT).show();
+ }
+
+ @Override
+ public void doLoginSuccess() {
+ Toast.makeText(this, "login success", Toast.LENGTH_SHORT).show();
+ }
+ }
+ ```
+
+---
+
+
+上面只是抛砖引玉。`MVP`的优点十分明显,就是代码解耦、可以让逻辑清晰,但是同样它也会有缺点,它的缺点就是项目的复杂程度会增加,项目中会多出很多类。
+之前很多人都在讨论该如何去正确的设计使用`MVP`来避免它的缺点,众说纷纭,很多人讨论的你死我活。直到`Google`发布了`MVP架构蓝图`,大家才意识到这才是规范。
+
+项目地址:[android-architecture](https://github.com/googlesamples/android-architecture)
+`Google`将该项目命名为`Android`的架构蓝图,我想从名字上已可以看穿一切。
+
+在它的官方介绍中是这样说的:
+
+> The Android framework offers a lot of flexibility when it comes to defining how to organize and architect an Android app. This freedom, whilst very valuable, can also result in apps with large classes, inconsistent naming and architectures (or lack of) that can make testing, maintaining and extending difficult.
+
+> Android Architecture Blueprints is meant to demonstrate possible ways to help with these common problems. In this project we offer the same application implemented using different architectural concepts and tools.
+
+> You can use these samples as a reference or as a starting point for creating your own apps. The focus here is on code structure, architecture, testing and maintainability. However, bear in mind that there are many ways to build apps with these architectures and tools, depending on your priorities, so these shouldn't be considered canonical examples. The UI is deliberately kept simple.
+
+
+
+已完成的示例:
+
+- todo-mvp/ - Basic Model-View-Presenter architecture.
+- todo-mvp-loaders/ - Based on todo-mvp, fetches data using Loaders.
+- todo-mvp-databinding/ - Based on todo-mvp, uses the Data Binding Library.
+- todo-mvp-clean/ - Based on todo-mvp, uses concepts from Clean Architecture.
+- todo-mvp-dagger/ - Based on todo-mvp, uses Dagger2 for Dependency Injection
+- todo-mvp-contentproviders/ - Based on todo-mvp-loaders, fetches data using Loaders and uses Content Providers
+- todo-mvp-rxjava/ - Based on todo-mvp, uses RxJava for concurrency and data layer abstraction.
+
+
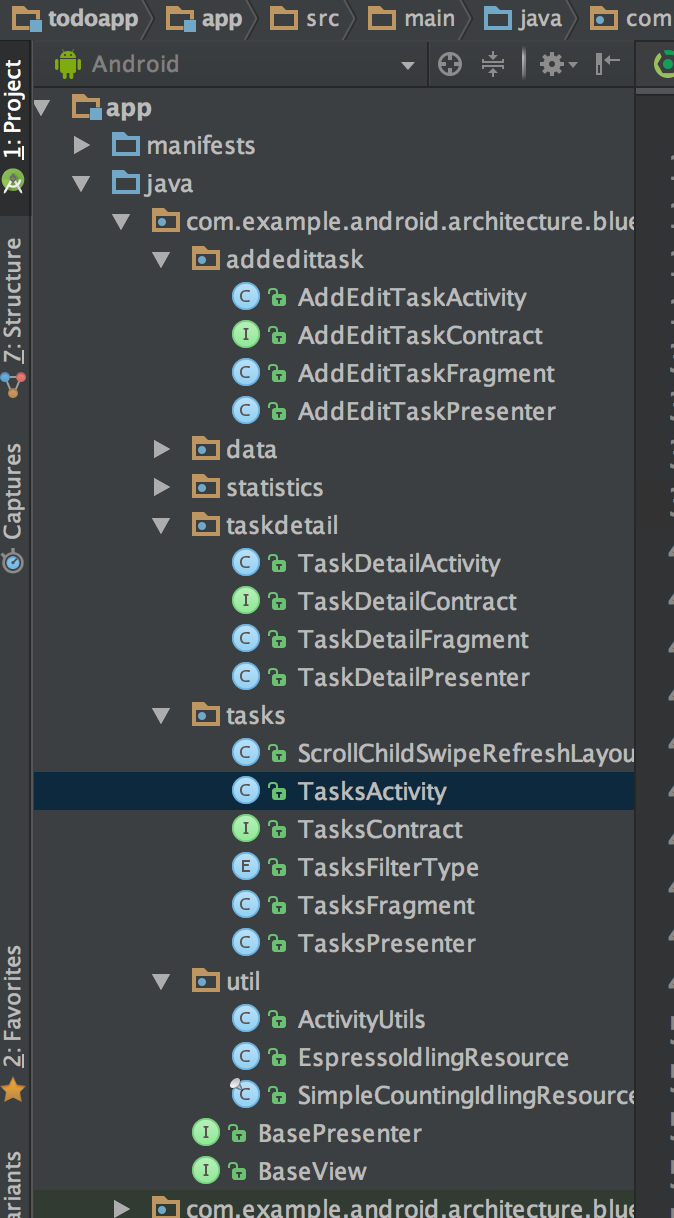
+我们接下来就用`todo-mvp`来进行分析,这个应用非常简单,主要有以下几个功能:
+
+- 列表页:展示所有的`todo`项
+- 添加页:添加`todo`项
+- 详情页:查看`todo`项的详情
+- 统计页:查看当前所有已完成`todo`及未完成项的统计数据
+
+代码并不多:
+
+
+
+
+不得不说,`Material Design`的效果真是美美哒!
+
+好,那我们就用用户登录页来按照`MVP`的模式实现一下:
+
+- M: 很显然Model应该是`User`类。
+- V: `View`就是`LoginActivity`。
+- P: P那我们一会就创建一个`LoginPresenter`类。
+
+齐了,那接下来就详细分析下他们这三部分:
+
+- `User`: 应该有`email`, `password`, `boolean login(email, password)`。
+- `LoginActivity`:点击登录应该要出`loading`页。登录成功后要进入下一个页面。如果登录失败应该弹`toast`提示。那就需要`void showLoading()`,`void hideLoading()`,`void showErrorTip()`,`void doLoginSuccess()`这四个方法。
+- `LoginPresenter`:这是`Model`和`View`的桥梁。他需要做的处理业务逻辑,直接与`Model`打交道,然后将`UI`的逻辑交给`LoginActivity`处理。
+那怎么做呢? 按照我上面总结的那一句话,、`MVP`其实就是面向接口编程,`V`实现接口,`P`使用接口。很显然我们需要提供一个接口。那就新建一个`ILoginView`的接口。这里面有哪些方法呢? 当然是上面我们在分析`LoginActiity`时提出的那四个方法。这样`LoginActivity`直接实现`ILoginView`接口就好。
+
+
+开始做:
+
+- 先把`Model`做好吧,创建`User`类。
+
+ ```java
+ public class User {
+ private String email;
+ private String password;
+ public User(String email, String password) {
+ this.email = email;
+ this.password = password;
+ }
+
+ public boolean login() {
+ // do login request..
+ return true;
+ }
+ }
+ ```
+
+- 创建`ILoginView`接口,定义登录所需要的`ui`逻辑。
+
+ ```java
+ public interface ILoginView {
+ void showLoading();
+ void hideLoading();
+ void showErrorTip();
+ void doLoginSuccess();
+ }
+ ```
+
+- 创建`LoginPresenter`类,使用`ILoginView`接口,那该类主要有什么功能呢? 它主要是处理业务逻辑的,
+ 对于登录的话,当然是用户在`UI`页面输入邮箱和密码,然后`Presenter`去开线程、请求接口。然后得到登录结果再去让`UI`显示对应的视图。那自然就是有一个`void login(String email, String passowrd)`的方法了
+
+ ```java
+ public class LoginPresenter {
+ private ILoginView mLoginView;
+
+ public LoginPresenter(ILoginView loginView) {
+ mLoginView = loginView;
+ }
+
+ public void login(String email, String password) {
+ if (TextUtils.isEmpty(email) || TextUtils.isEmpty(password)) {
+ //
+ mLoginView.showErrorTip();
+ return;
+ }
+ mLoginView.showLoading();
+ User user = new User(email, password);
+
+ // do network request....
+ // ....
+ onSuccess() {
+ boolean login = user.login();
+ if (login) {
+ mLoginView.doLoginSuccess();
+ } else {
+ mLoginView.showErrorTip();
+ }
+ mLoginView.hideLoading();
+ }
+
+ onFailde() {
+ mLoginView.showErrorTip();
+ mLoginView.hideLoading();
+ }
+ }
+ }
+ ```
+- 创建`LoginActivity`,实现`ILoginView`的接口,然后内部调用`LoginPresenter`来处理业务逻辑。
+
+ ```java
+ public class LoginActivity extends AppCompatActivity implements ILoginView {
+ private LoginPresenter mLoginPresenter;
+
+ private AutoCompleteTextView mEmailView;
+ private EditText mPasswordView;
+ private View mProgressView;
+ private View mLoginButton;
+
+ @Override
+ protected void onCreate(Bundle savedInstanceState) {
+ super.onCreate(savedInstanceState);
+ setContentView(R.layout.activity_login);
+ mEmailView = (AutoCompleteTextView) findViewById(R.id.email);
+ mPasswordView = (EditText) findViewById(R.id.password);
+ mLoginButton = findViewById(R.id.email_sign_in_button);
+ mProgressView = findViewById(R.id.login_progress);
+
+ mLoginPresenter = new LoginPresenter(this);
+
+ mLoginButton.setOnClickListener(new View.OnClickListener() {
+ @Override
+ public void onClick(View v) {
+ mLoginPresenter.login(mEmailView.getText().toString().trim(), mPasswordView.getText().toString().trim());
+ }
+ });
+ }
+
+ @Override
+ public void showLoading() {
+ mProgressView.setVisibility(View.VISIBLE);
+ }
+
+ @Override
+ public void hideLoading() {
+ mProgressView.setVisibility(View.GONE);
+ }
+
+ @Override
+ public void showErrorTip() {
+ Toast.makeText(this, "login faled", Toast.LENGTH_SHORT).show();
+ }
+
+ @Override
+ public void doLoginSuccess() {
+ Toast.makeText(this, "login success", Toast.LENGTH_SHORT).show();
+ }
+ }
+ ```
+
+---
+
+
+上面只是抛砖引玉。`MVP`的优点十分明显,就是代码解耦、可以让逻辑清晰,但是同样它也会有缺点,它的缺点就是项目的复杂程度会增加,项目中会多出很多类。
+之前很多人都在讨论该如何去正确的设计使用`MVP`来避免它的缺点,众说纷纭,很多人讨论的你死我活。直到`Google`发布了`MVP架构蓝图`,大家才意识到这才是规范。
+
+项目地址:[android-architecture](https://github.com/googlesamples/android-architecture)
+`Google`将该项目命名为`Android`的架构蓝图,我想从名字上已可以看穿一切。
+
+在它的官方介绍中是这样说的:
+
+> The Android framework offers a lot of flexibility when it comes to defining how to organize and architect an Android app. This freedom, whilst very valuable, can also result in apps with large classes, inconsistent naming and architectures (or lack of) that can make testing, maintaining and extending difficult.
+
+> Android Architecture Blueprints is meant to demonstrate possible ways to help with these common problems. In this project we offer the same application implemented using different architectural concepts and tools.
+
+> You can use these samples as a reference or as a starting point for creating your own apps. The focus here is on code structure, architecture, testing and maintainability. However, bear in mind that there are many ways to build apps with these architectures and tools, depending on your priorities, so these shouldn't be considered canonical examples. The UI is deliberately kept simple.
+
+
+
+已完成的示例:
+
+- todo-mvp/ - Basic Model-View-Presenter architecture.
+- todo-mvp-loaders/ - Based on todo-mvp, fetches data using Loaders.
+- todo-mvp-databinding/ - Based on todo-mvp, uses the Data Binding Library.
+- todo-mvp-clean/ - Based on todo-mvp, uses concepts from Clean Architecture.
+- todo-mvp-dagger/ - Based on todo-mvp, uses Dagger2 for Dependency Injection
+- todo-mvp-contentproviders/ - Based on todo-mvp-loaders, fetches data using Loaders and uses Content Providers
+- todo-mvp-rxjava/ - Based on todo-mvp, uses RxJava for concurrency and data layer abstraction.
+
+
+我们接下来就用`todo-mvp`来进行分析,这个应用非常简单,主要有以下几个功能:
+
+- 列表页:展示所有的`todo`项
+- 添加页:添加`todo`项
+- 详情页:查看`todo`项的详情
+- 统计页:查看当前所有已完成`todo`及未完成项的统计数据
+
+代码并不多:
+
+
+ +
+功能也比较简单:
+
+
+
+功能也比较简单:
+
+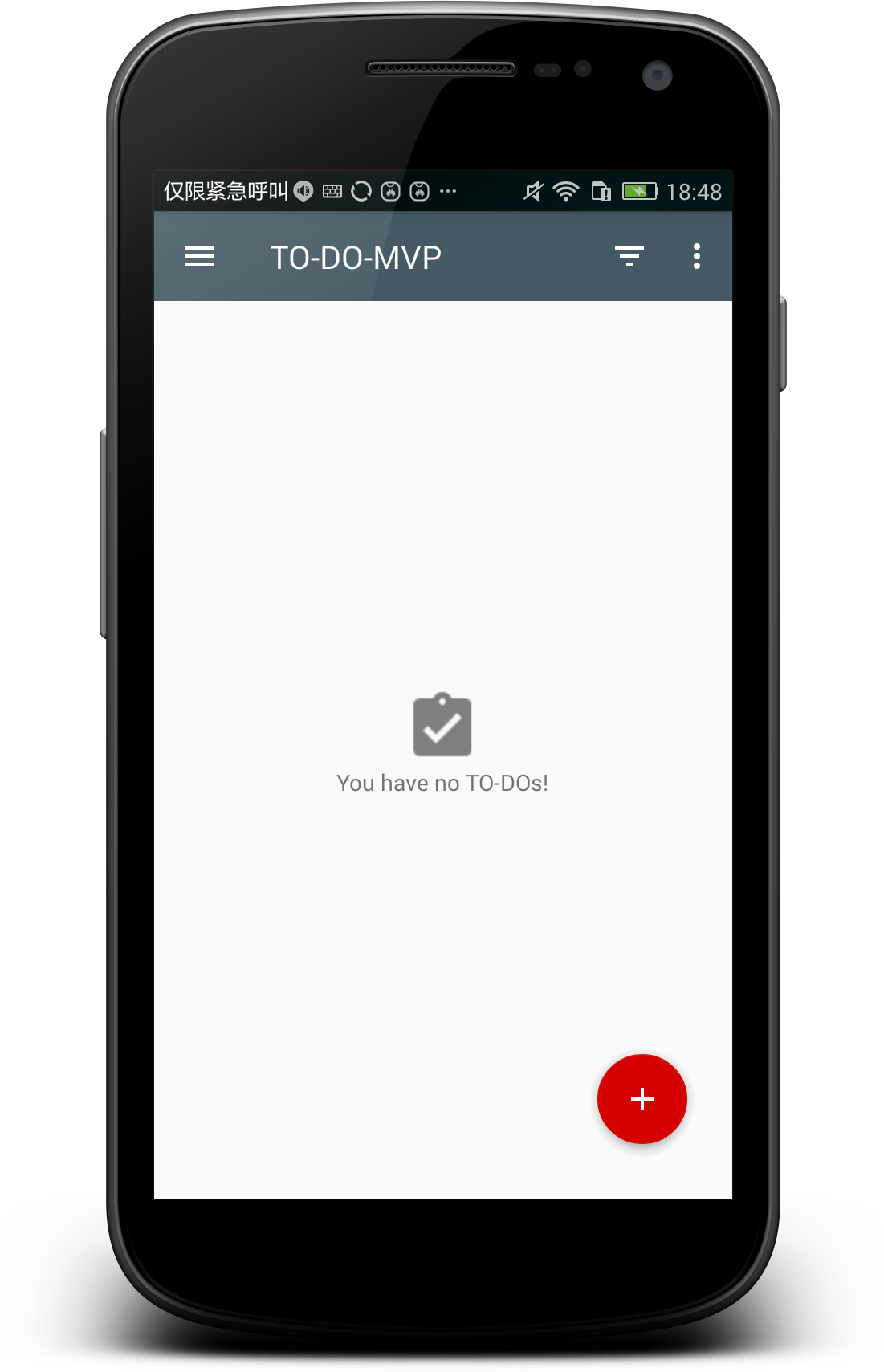
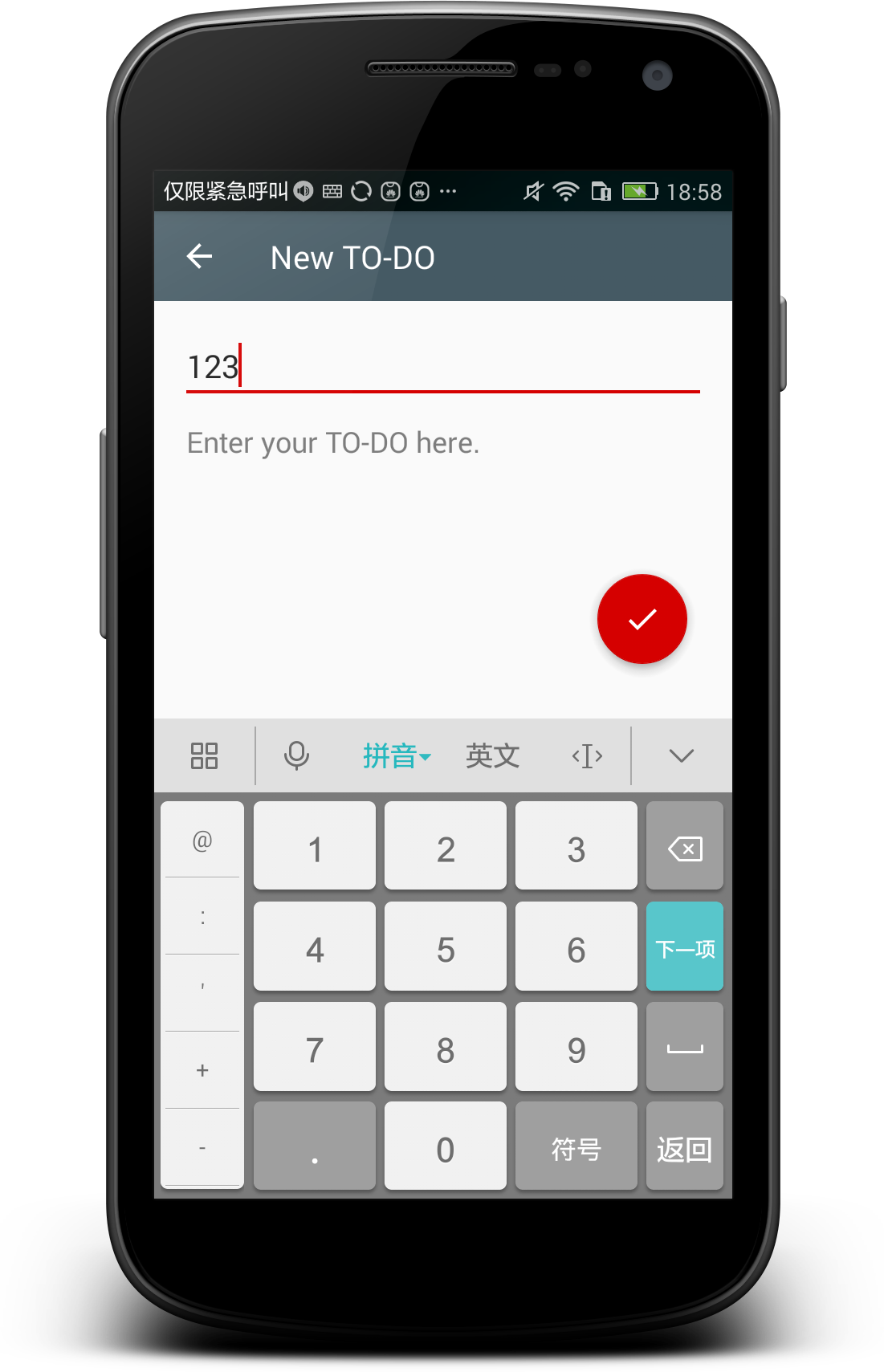 +
+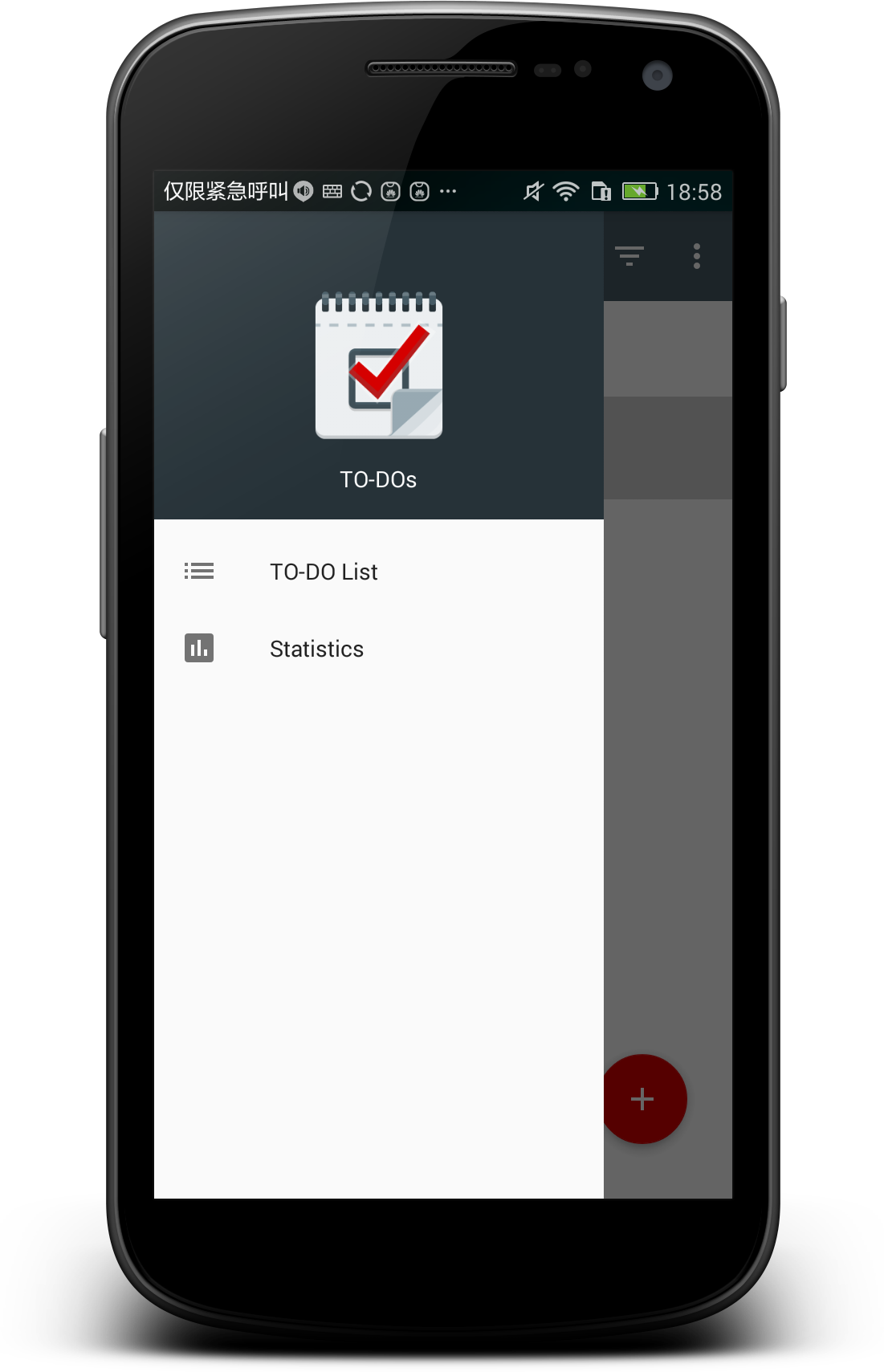
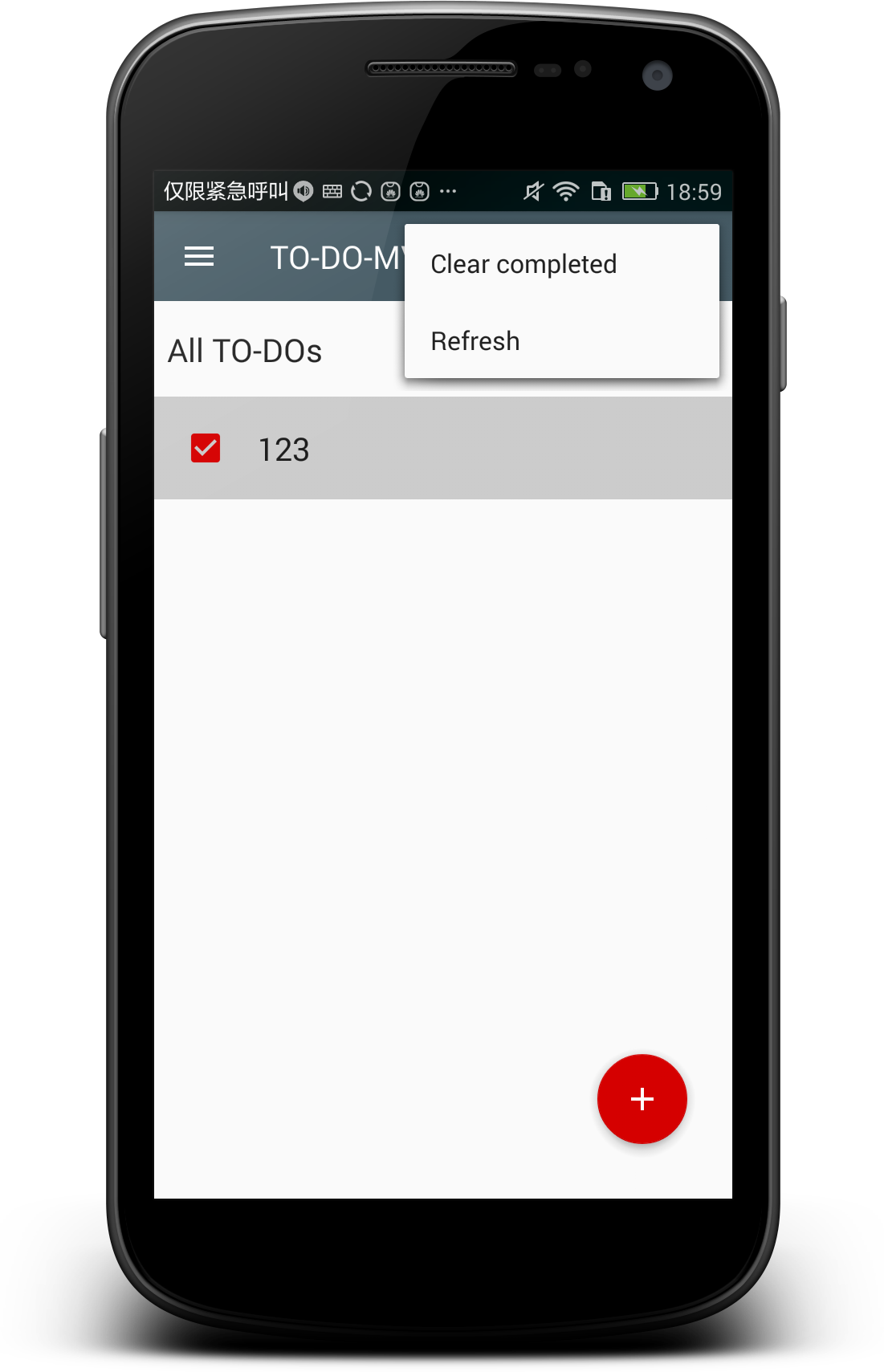 +
+我们先从两个`Base`类开始看,分别是`BaseView`以及`BasePresenter`类。
+
+`BaseView`类:
+
+```java
+public interface BaseView
+
+我们先从两个`Base`类开始看,分别是`BaseView`以及`BasePresenter`类。
+
+`BaseView`类:
+
+```java
+public interface BaseView+ * For simplicity, this implements a dumb synchronisation between locally persisted data and data + * obtained from the server, by using the remote data source only if the local database doesn't + * exist or is empty. + */ +public class TasksRepository implements TasksDataSource { + .... +} +``` + +先看一下`TasksDataSource`接口: + +```java +/** + * Main entry point for accessing tasks data. + *
+ * For simplicity, only getTasks() and getTask() have callbacks. Consider adding callbacks to other
+ * methods to inform the user of network/database errors or successful operations.
+ * For example, when a new task is created, it's synchronously stored in cache but usually every
+ * operation on database or network should be executed in a different thread.
+ */
+public interface TasksDataSource {
+
+ interface LoadTasksCallback {
+
+ void onTasksLoaded(List This can be useful for applications that wish to implement various forms of gestural
+ * manipulation of item views within the RecyclerView. OnItemTouchListeners may intercept
+ * a touch interaction already in progress even if the RecyclerView is already handling that
+ * gesture stream itself for the purposes of scrolling.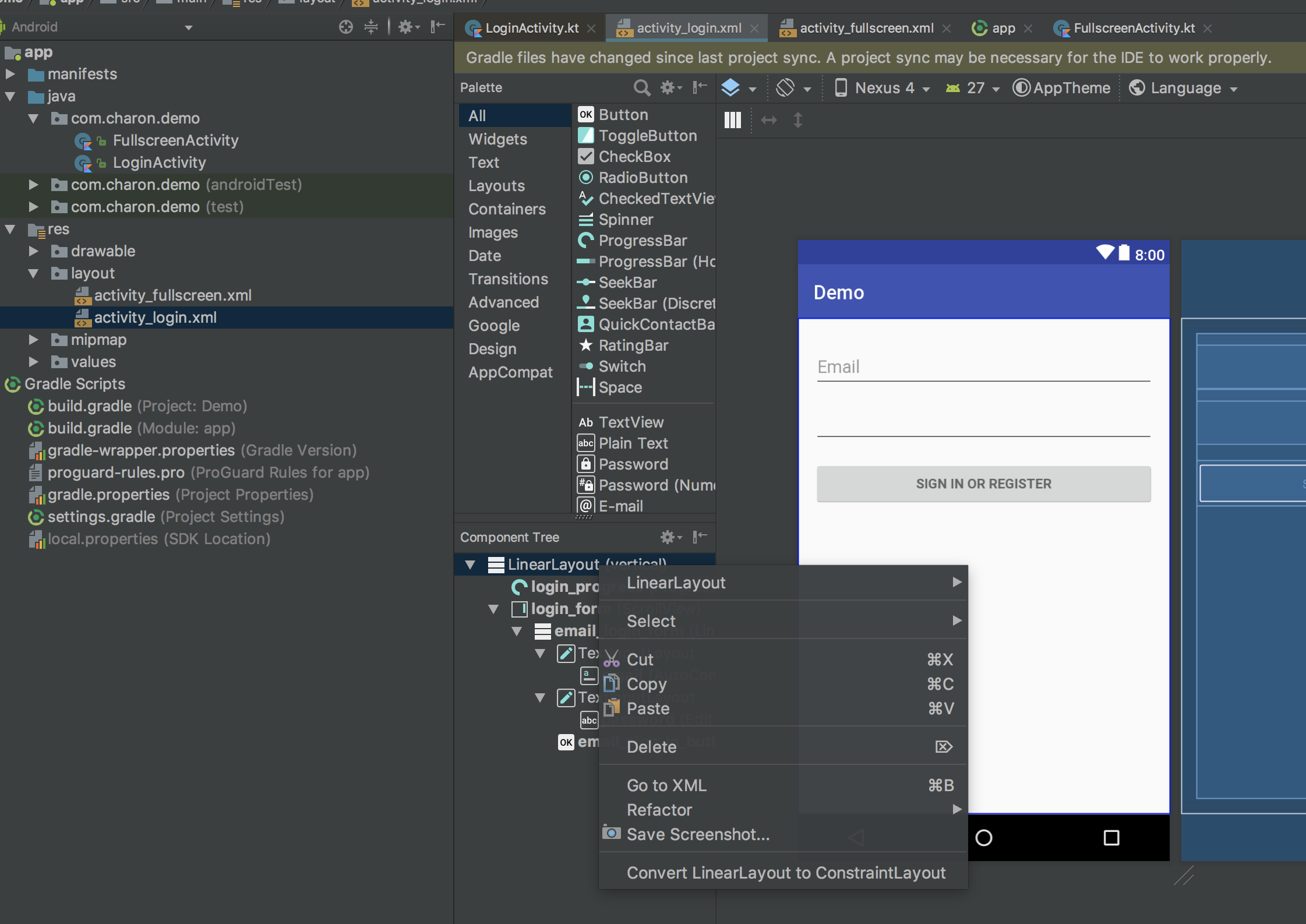 +
+然后会提示添加`ConstraintLayout`支持库。
+
+
+然后会提示添加`ConstraintLayout`支持库。
+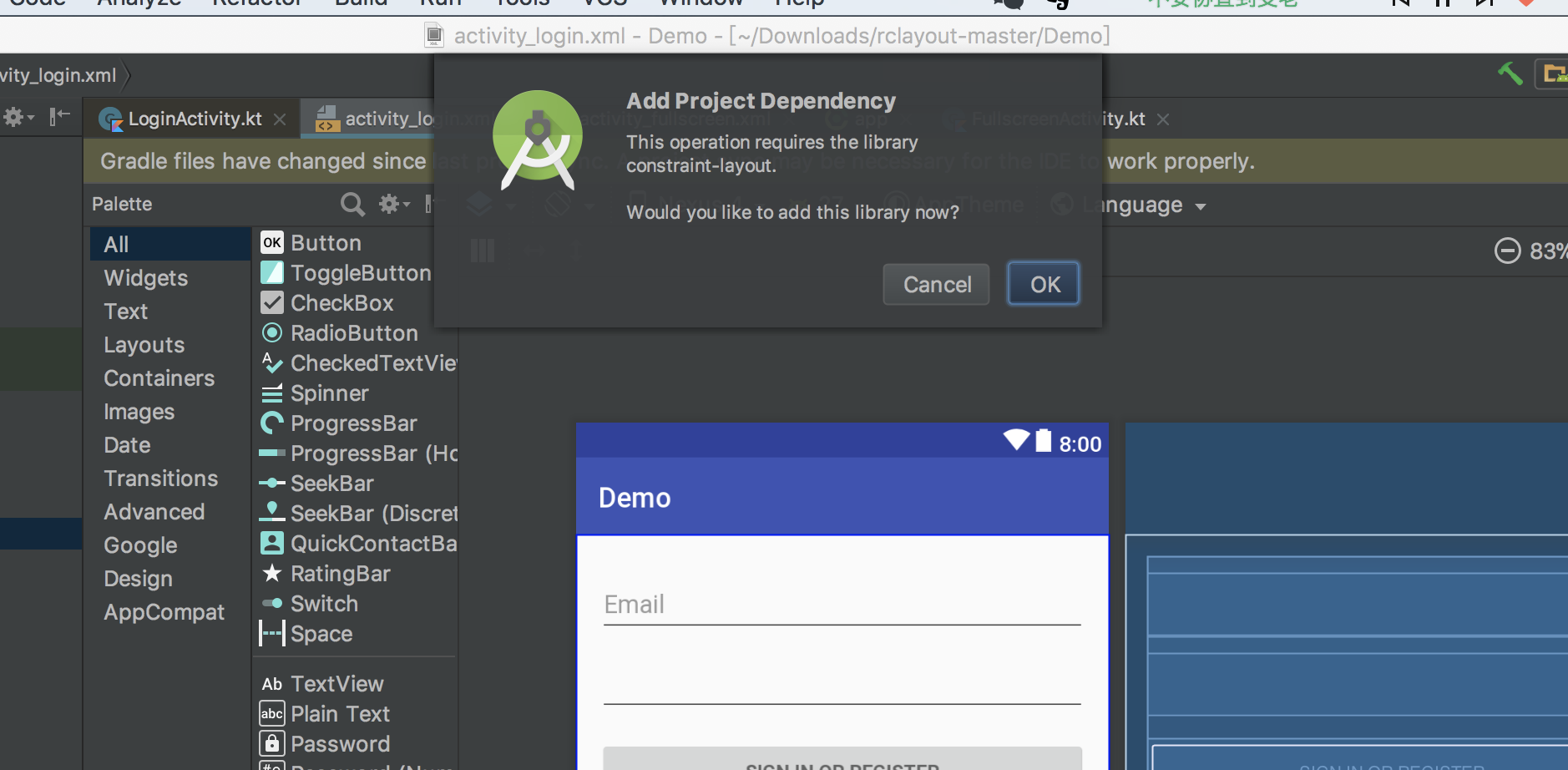 +
+
+相对于传统布局`ConstraintLayout`在以下方面提供了一些新的特性:
+
+- 相对定位
+
+ 这个和`RelativeLayout`比较像,就是一个控件相对于另一个控件的位置约束关系:
+
+ - 横向:`Left、Right、Start、End`
+ - 纵向:`Top、Bottom、Baseline(文本底部的基准线)`
+
+ ```xml
+
+
+ ```
+ 常用的有:
+ ```xml
+ * layout_constraintLeft_toLeftOf // 左边左对齐
+ * layout_constraintLeft_toRightOf // 左边右对齐
+ * layout_constraintRight_toLeftOf // 右边左对齐
+ * layout_constraintRight_toRightOf // 右边右对齐
+ * layout_constraintTop_toTopOf // 上边顶部对齐
+ * layout_constraintTop_toBottomOf // 上边底部对齐
+ * layout_constraintBottom_toTopOf // 下边顶部对齐
+ * layout_constraintBottom_toBottomOf // 下边底部对齐
+ * layout_constraintBaseline_toBaselineOf // 文本内容基准线对齐
+ * layout_constraintStart_toEndOf // 起始边向尾部对齐
+ * layout_constraintStart_toStartOf // 起始边向起始边对齐
+ * layout_constraintEnd_toStartOf // 尾部向起始边对齐
+ * layout_constraintEnd_toEndOf // 尾部向尾部对齐
+
+ ```
+
+ 上面的这些属性需要结合`id`才能进行约束,这些id可以指向控件也可以指向父容器(也就是`ConstraintLayout`),比如:
+ ```xml
+
+ ```
+
+- 外边距
+
+ ```xml
+ * android:layout_marginStart
+ * android:layout_marginEnd
+ * android:layout_marginLeft
+ * android:layout_marginTop
+ * android:layout_marginRight
+ * android:layout_marginBottom
+ // 这里的gone margin指的是B向A添加约束后,如果A的可见性变为GONE,这时候B的外边距可以改变,也就是B的外边距根据A的可见性分为两种状态。
+ * layout_goneMarginStart
+ * layout_goneMarginEnd
+ * layout_goneMarginLeft
+ * layout_goneMarginTop
+ * layout_goneMarginRight
+ * layout_goneMarginBottom
+
+ ```
+
+- 居中和倾向
+ - 居中
+ 在`RelativeLayout`中我们可以`centerHorizontal`等来进行居中操作,但是在`ConstraintLayout`中没有类似的方法。
+ ```xml
+
+
+
+相对于传统布局`ConstraintLayout`在以下方面提供了一些新的特性:
+
+- 相对定位
+
+ 这个和`RelativeLayout`比较像,就是一个控件相对于另一个控件的位置约束关系:
+
+ - 横向:`Left、Right、Start、End`
+ - 纵向:`Top、Bottom、Baseline(文本底部的基准线)`
+
+ ```xml
+
+
+ ```
+ 常用的有:
+ ```xml
+ * layout_constraintLeft_toLeftOf // 左边左对齐
+ * layout_constraintLeft_toRightOf // 左边右对齐
+ * layout_constraintRight_toLeftOf // 右边左对齐
+ * layout_constraintRight_toRightOf // 右边右对齐
+ * layout_constraintTop_toTopOf // 上边顶部对齐
+ * layout_constraintTop_toBottomOf // 上边底部对齐
+ * layout_constraintBottom_toTopOf // 下边顶部对齐
+ * layout_constraintBottom_toBottomOf // 下边底部对齐
+ * layout_constraintBaseline_toBaselineOf // 文本内容基准线对齐
+ * layout_constraintStart_toEndOf // 起始边向尾部对齐
+ * layout_constraintStart_toStartOf // 起始边向起始边对齐
+ * layout_constraintEnd_toStartOf // 尾部向起始边对齐
+ * layout_constraintEnd_toEndOf // 尾部向尾部对齐
+
+ ```
+
+ 上面的这些属性需要结合`id`才能进行约束,这些id可以指向控件也可以指向父容器(也就是`ConstraintLayout`),比如:
+ ```xml
+
+ ```
+
+- 外边距
+
+ ```xml
+ * android:layout_marginStart
+ * android:layout_marginEnd
+ * android:layout_marginLeft
+ * android:layout_marginTop
+ * android:layout_marginRight
+ * android:layout_marginBottom
+ // 这里的gone margin指的是B向A添加约束后,如果A的可见性变为GONE,这时候B的外边距可以改变,也就是B的外边距根据A的可见性分为两种状态。
+ * layout_goneMarginStart
+ * layout_goneMarginEnd
+ * layout_goneMarginLeft
+ * layout_goneMarginTop
+ * layout_goneMarginRight
+ * layout_goneMarginBottom
+
+ ```
+
+- 居中和倾向
+ - 居中
+ 在`RelativeLayout`中我们可以`centerHorizontal`等来进行居中操作,但是在`ConstraintLayout`中没有类似的方法。
+ ```xml
+