diff --git a/.gitignore b/.gitignore
deleted file mode 100644
index b0b6f3a..0000000
--- a/.gitignore
+++ /dev/null
@@ -1,160 +0,0 @@
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-build/
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-wheels/
-share/python-wheels/
-*.egg-info/
-.installed.cfg
-*.egg
-MANIFEST
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.nox/
-.coverage
-.coverage.*
-.cache
-nosetests.xml
-coverage.xml
-*.cover
-*.py,cover
-.hypothesis/
-.pytest_cache/
-cover/
-
-# Translations
-*.mo
-*.pot
-
-# Django stuff:
-*.log
-local_settings.py
-db.sqlite3
-db.sqlite3-journal
-
-# Flask stuff:
-instance/
-.webassets-cache
-
-# Scrapy stuff:
-.scrapy
-
-# Sphinx documentation
-docs/_build/
-
-# PyBuilder
-.pybuilder/
-target/
-
-# Jupyter Notebook
-.ipynb_checkpoints
-
-# IPython
-profile_default/
-ipython_config.py
-
-# pyenv
-# For a library or package, you might want to ignore these files since the code is
-# intended to run in multiple environments; otherwise, check them in:
-# .python-version
-
-# pipenv
-# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
-# However, in case of collaboration, if having platform-specific dependencies or dependencies
-# having no cross-platform support, pipenv may install dependencies that don't work, or not
-# install all needed dependencies.
-#Pipfile.lock
-
-# poetry
-# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
-# This is especially recommended for binary packages to ensure reproducibility, and is more
-# commonly ignored for libraries.
-# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
-#poetry.lock
-
-# pdm
-# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
-#pdm.lock
-# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
-# in version control.
-# https://pdm.fming.dev/#use-with-ide
-.pdm.toml
-
-# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
-__pypackages__/
-
-# Celery stuff
-celerybeat-schedule
-celerybeat.pid
-
-# SageMath parsed files
-*.sage.py
-
-# Environments
-.env
-.venv
-env/
-venv/
-ENV/
-env.bak/
-venv.bak/
-
-# Spyder project settings
-.spyderproject
-.spyproject
-
-# Rope project settings
-.ropeproject
-
-# mkdocs documentation
-/site
-
-# mypy
-.mypy_cache/
-.dmypy.json
-dmypy.json
-
-# Pyre type checker
-.pyre/
-
-# pytype static type analyzer
-.pytype/
-
-# Cython debug symbols
-cython_debug/
-
-# PyCharm
-# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
-# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
-# and can be added to the global gitignore or merged into this file. For a more nuclear
-# option (not recommended) you can uncomment the following to ignore the entire idea folder.
-.idea/
\ No newline at end of file
diff --git a/0094-binary-tree-inorder-traversal/0094-binary-tree-inorder-traversal.py b/0094-binary-tree-inorder-traversal/0094-binary-tree-inorder-traversal.py
deleted file mode 100644
index f9ee718..0000000
--- a/0094-binary-tree-inorder-traversal/0094-binary-tree-inorder-traversal.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# Definition for a binary tree node.
-# class TreeNode:
-# def __init__(self, val=0, left=None, right=None):
-# self.val = val
-# self.left = left
-# self.right = right
-
-# ⊙ 전위 순회(preorder traverse) : 뿌리(root)를 먼저 방문
-# ⊙ 중위 순회(inorder traverse) : 왼쪽 하위 트리를 방문 후 뿌리(root)를 방문
-# ⊙ 후위 순회(postorder traverse) : 하위 트리 모두 방문 후 뿌리(root)를 방문
-
-class Solution:
- def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
- output = []
- def inorder(root, list):
- if root:
- inorder(root.left,list)
- output.append(root.val)
- inorder(root.right,list)
- return output
-
- # if not root:
- # return None
-
- return inorder(root,output)
-
-
-
-
\ No newline at end of file
diff --git a/0094-binary-tree-inorder-traversal/README.md b/0094-binary-tree-inorder-traversal/README.md
deleted file mode 100644
index 9917c30..0000000
--- a/0094-binary-tree-inorder-traversal/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-Easy
Given the root of a binary tree, return the inorder traversal of its nodes' values.
-
-
-Example 1:
- -
-
-Input: root = [1,null,2,3]
-Output: [1,3,2]
-
-
-Example 2:
-
-
-Input: root = []
-Output: []
-
-
-Example 3:
-
-
-Input: root = [1]
-Output: [1]
-
-
-
-Constraints:
-
-
- - The number of nodes in the tree is in the range
[0, 100].
- -100 <= Node.val <= 100
-
-
-Follow up: Recursive solution is trivial, could you do it iteratively?
\ No newline at end of file
diff --git a/0101-symmetric-tree/0101-symmetric-tree.py b/0101-symmetric-tree/0101-symmetric-tree.py
deleted file mode 100644
index 9a5b19f..0000000
--- a/0101-symmetric-tree/0101-symmetric-tree.py
+++ /dev/null
@@ -1,19 +0,0 @@
-# Definition for a binary tree node.
-# class TreeNode:
-# def __init__(self, val=0, left=None, right=None):
-# self.val = val
-# self.left = left
-# self.right = right
-class Solution:
- def isSymmetric(self, root: Optional[TreeNode]) -> bool:
- def is_mirror(t1,t2):
- if not t1 and not t2:
- return True
- elif not t1 or not t2:
- return False
-
- return (t1.val == t2.val and is_mirror(t1.left, t2.right) and is_mirror(t1.right, t2.left))
-
- if not root:
- return True
- return is_mirror(root.left, root.right)
\ No newline at end of file
diff --git a/0101-symmetric-tree/README.md b/0101-symmetric-tree/README.md
deleted file mode 100644
index 1f21130..0000000
--- a/0101-symmetric-tree/README.md
+++ /dev/null
@@ -1,27 +0,0 @@
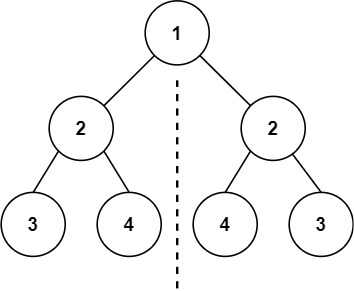
-Easy
Given the root of a binary tree, check whether it is a mirror of itself (i.e., symmetric around its center).
-
-
-Example 1:
- -
-
-Input: root = [1,2,2,3,4,4,3]
-Output: true
-
-
-Example 2:
- -
-
-Input: root = [1,2,2,null,3,null,3]
-Output: false
-
-
-
-Constraints:
-
-
- - The number of nodes in the tree is in the range
[1, 1000].
- -100 <= Node.val <= 100
-
-
-Follow up: Could you solve it both recursively and iteratively?
\ No newline at end of file
diff --git a/0118-pascals-triangle/0118-pascals-triangle.py b/0118-pascals-triangle/0118-pascals-triangle.py
deleted file mode 100644
index 01c2c9b..0000000
--- a/0118-pascals-triangle/0118-pascals-triangle.py
+++ /dev/null
@@ -1,14 +0,0 @@
-class Solution:
- def generate(self, numRows: int) -> List[List[int]]:
- # output = [[0] * numRows]
- output = [[0] * (i + 1) for i in range(numRows)]
-
- for i in range(numRows):
- output[i][0] = 1
- output[i][-1] = 1
-
- for j in range(1,i): # 0에서 1로 수정
- if j != 0 or j != i:
- output[i][j] = output[i-1][j-1] + output[i-1][j]
-
- return output
\ No newline at end of file
diff --git a/0118-pascals-triangle/README.md b/0118-pascals-triangle/README.md
deleted file mode 100644
index 549ce27..0000000
--- a/0118-pascals-triangle/README.md
+++ /dev/null
@@ -1,18 +0,0 @@
-Easy
Given an integer numRows, return the first numRows of Pascal's triangle.
-
-In Pascal's triangle, each number is the sum of the two numbers directly above it as shown:
- -
-
-Example 1:
-Input: numRows = 5
-Output: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
-
Example 2:
-Input: numRows = 1
-Output: [[1]]
-
-
-Constraints:
-
-
diff --git a/0119-pascals-triangle-ii/0119-pascals-triangle-ii.py b/0119-pascals-triangle-ii/0119-pascals-triangle-ii.py
deleted file mode 100644
index 5cb63cf..0000000
--- a/0119-pascals-triangle-ii/0119-pascals-triangle-ii.py
+++ /dev/null
@@ -1,18 +0,0 @@
-class Solution:
- def getRow(self, rowIndex: int) -> List[int]:
- if rowIndex == 0 or rowIndex == 1 :
- output = [1] * (rowIndex + 1)
- return output
-
- output = [1] * (2)
- for i in range(2, rowIndex + 1):
- newList = [1] * (i + 1)
- print(newList)
-
- for j in range(1,i):
- newList[j] = output[j-1] + output[j]
- print(newList)
- output = newList
-
- return output
-
\ No newline at end of file
diff --git a/0119-pascals-triangle-ii/README.md b/0119-pascals-triangle-ii/README.md
deleted file mode 100644
index 1a64158..0000000
--- a/0119-pascals-triangle-ii/README.md
+++ /dev/null
@@ -1,24 +0,0 @@
-Easy
Given an integer rowIndex, return the rowIndexth (0-indexed) row of the Pascal's triangle.
-
-In Pascal's triangle, each number is the sum of the two numbers directly above it as shown:
-
-
-Example 1:
-Input: rowIndex = 3
-Output: [1,3,3,1]
-
Example 2:
-Input: rowIndex = 0
-Output: [1]
-
Example 3:
-Input: rowIndex = 1
-Output: [1,1]
-
-
-Constraints:
-
-
-
-
-Follow up: Could you optimize your algorithm to use only O(rowIndex) extra space?
diff --git a/0121-best-time-to-buy-and-sell-stock/0121-best-time-to-buy-and-sell-stock.py b/0121-best-time-to-buy-and-sell-stock/0121-best-time-to-buy-and-sell-stock.py
deleted file mode 100644
index d9c303a..0000000
--- a/0121-best-time-to-buy-and-sell-stock/0121-best-time-to-buy-and-sell-stock.py
+++ /dev/null
@@ -1,12 +0,0 @@
-class Solution:
- def maxProfit(self, prices: List[int]) -> int:
- min_price = float("inf")
- max_profit = 0
-
- for price in prices:
- if price < min_price :
- min_price = price
- elif max_profit < (price - min_price):
- max_profit = price - min_price
-
- return max_profit
diff --git a/0121-best-time-to-buy-and-sell-stock/README.md b/0121-best-time-to-buy-and-sell-stock/README.md
deleted file mode 100644
index c985d4a..0000000
--- a/0121-best-time-to-buy-and-sell-stock/README.md
+++ /dev/null
@@ -1,31 +0,0 @@
-Easy
You are given an array prices where prices[i] is the price of a given stock on the ith day.
-
-You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
-
-Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
-
-
-Example 1:
-
-
-Input: prices = [7,1,5,3,6,4]
-Output: 5
-Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
-Note that buying on day 2 and selling on day 1 is not allowed because you must buy before you sell.
-
-
-Example 2:
-
-
-Input: prices = [7,6,4,3,1]
-Output: 0
-Explanation: In this case, no transactions are done and the max profit = 0.
-
-
-
-Constraints:
-
-
- 1 <= prices.length <= 1050 <= prices[i] <= 104
diff --git a/0268-missing-number/0268-missing-number.py b/0268-missing-number/0268-missing-number.py
deleted file mode 100644
index 36badbf..0000000
--- a/0268-missing-number/0268-missing-number.py
+++ /dev/null
@@ -1,10 +0,0 @@
-class Solution:
- def missingNumber(self, nums: List[int]) -> int:
- n = len(nums)
- nums.sort()
-
- for index, num in enumerate(nums):
- if index != num:
- return index
-
- return n
\ No newline at end of file
diff --git a/0268-missing-number/README.md b/0268-missing-number/README.md
deleted file mode 100644
index d6ee3af..0000000
--- a/0268-missing-number/README.md
+++ /dev/null
@@ -1,39 +0,0 @@
-Easy
Given an array nums containing n distinct numbers in the range [0, n], return the only number in the range that is missing from the array.
-
-
-Example 1:
-
-
-Input: nums = [3,0,1]
-Output: 2
-Explanation: n = 3 since there are 3 numbers, so all numbers are in the range [0,3]. 2 is the missing number in the range since it does not appear in nums.
-
-
-Example 2:
-
-
-Input: nums = [0,1]
-Output: 2
-Explanation: n = 2 since there are 2 numbers, so all numbers are in the range [0,2]. 2 is the missing number in the range since it does not appear in nums.
-
-
-Example 3:
-
-
-Input: nums = [9,6,4,2,3,5,7,0,1]
-Output: 8
-Explanation: n = 9 since there are 9 numbers, so all numbers are in the range [0,9]. 8 is the missing number in the range since it does not appear in nums.
-
-
-
-Constraints:
-
-
- n == nums.length1 <= n <= 1040 <= nums[i] <= n- All the numbers of
nums are unique.
-
-
-
-Follow up: Could you implement a solution using only O(1) extra space complexity and O(n) runtime complexity?
diff --git a/0409-longest-palindrome/0409-longest-palindrome.py b/0409-longest-palindrome/0409-longest-palindrome.py
deleted file mode 100644
index 51d3500..0000000
--- a/0409-longest-palindrome/0409-longest-palindrome.py
+++ /dev/null
@@ -1,23 +0,0 @@
-from collections import Counter
-
-class Solution:
- def longestPalindrome(self, s: str) -> int:
- output = 0
-
- s_count = Counter(s)
- is_alone = False
-
- for c in s_count.values():
- print(c)
- if (c % 2) == 0: # 짝수면
- output += c
- else : # 홀수면
- output += (c - 1)
- is_alone = True
-
- if is_alone == True:
- output += 1
-
-
- return output
-
\ No newline at end of file
diff --git a/0409-longest-palindrome/README.md b/0409-longest-palindrome/README.md
deleted file mode 100644
index b2f8005..0000000
--- a/0409-longest-palindrome/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
-Easy
Given a string s which consists of lowercase or uppercase letters, return the length of the longest palindrome that can be built with those letters.
-
-Letters are case sensitive, for example, "Aa" is not considered a palindrome.
-
-
-Example 1:
-
-
-Input: s = "abccccdd"
-Output: 7
-Explanation: One longest palindrome that can be built is "dccaccd", whose length is 7.
-
-
-Example 2:
-
-
-Input: s = "a"
-Output: 1
-Explanation: The longest palindrome that can be built is "a", whose length is 1.
-
-
-
-Constraints:
-
-
- 1 <= s.length <= 2000s consists of lowercase and/or uppercase English letters only.
diff --git a/0441-arranging-coins/0441-arranging-coins.py b/0441-arranging-coins/0441-arranging-coins.py
deleted file mode 100644
index 08f96ce..0000000
--- a/0441-arranging-coins/0441-arranging-coins.py
+++ /dev/null
@@ -1,23 +0,0 @@
-class Solution:
- def arrangeCoins(self, n: int) -> int:
- def ap(k):
- return k * (k+1) // 2
- if n == 1 :
- return 1
-
- low, high = 1, n
- mid = 0
- while low <= high :
- mid = (low + high) // 2 # 1
- print(mid)
-
- ap_result = ap(mid)
- print(ap_result)
- if ap_result == n:
- return mid
- elif ap_result > n:
- high = mid - 1
- elif ap_result < n:
- low = mid + 1
-
- return high
\ No newline at end of file
diff --git a/0441-arranging-coins/README.md b/0441-arranging-coins/README.md
deleted file mode 100644
index d770ba0..0000000
--- a/0441-arranging-coins/README.md
+++ /dev/null
@@ -1,27 +0,0 @@
-Easy
You have n coins and you want to build a staircase with these coins. The staircase consists of k rows where the ith row has exactly i coins. The last row of the staircase may be incomplete.
-
-Given the integer n, return the number of complete rows of the staircase you will build.
-
-
-Example 1:
-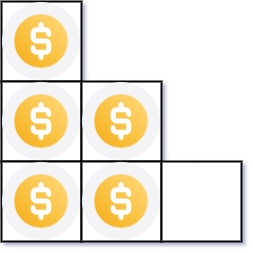 -
-
-Input: n = 5
-Output: 2
-Explanation: Because the 3rd row is incomplete, we return 2.
-
-
-Example 2:
-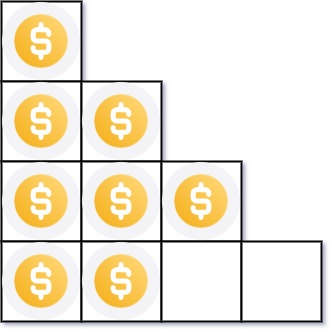 -
-
-Input: n = 8
-Output: 3
-Explanation: Because the 4th row is incomplete, we return 3.
-
-
-
-Constraints:
-
-
diff --git a/0455-assign-cookies/0455-assign-cookies.py b/0455-assign-cookies/0455-assign-cookies.py
deleted file mode 100644
index 3a2e44d..0000000
--- a/0455-assign-cookies/0455-assign-cookies.py
+++ /dev/null
@@ -1,31 +0,0 @@
-class Solution:
- def findContentChildren(self, g: List[int], s: List[int]) -> int:
- g.sort() # kid
- s.sort() # cookie
- print(s)
- print(g)
- output = 0
- g_index = 0
- s_index = 0
-
- while g_index < len(g) and s_index < len(s):
- if s[s_index] >= g[g_index] :
- print(s_index)
- print(g_index)
- s_index += 1
- g_index += 1
- output += 1
- else :
- s_index += 1
- return output
- # for cookie in s :
- # if g is None : return output
- # for kid in g:
- # if cookie >= kid :
- # print(cookie)
- # print(kid)
- # output += 1
- # g = g[1:]
- # continue
- # return output
-
\ No newline at end of file
diff --git a/0455-assign-cookies/README.md b/0455-assign-cookies/README.md
deleted file mode 100644
index 3442881..0000000
--- a/0455-assign-cookies/README.md
+++ /dev/null
@@ -1,36 +0,0 @@
-Easy
Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
-
-Each child i has a greed factor g[i], which is the minimum size of a cookie that the child will be content with; and each cookie j has a size s[j]. If s[j] >= g[i], we can assign the cookie j to the child i, and the child i will be content. Your goal is to maximize the number of your content children and output the maximum number.
-
-
-Example 1:
-
-
-Input: g = [1,2,3], s = [1,1]
-Output: 1
-Explanation: You have 3 children and 2 cookies. The greed factors of 3 children are 1, 2, 3.
-And even though you have 2 cookies, since their size is both 1, you could only make the child whose greed factor is 1 content.
-You need to output 1.
-
-
-Example 2:
-
-
-Input: g = [1,2], s = [1,2,3]
-Output: 2
-Explanation: You have 2 children and 3 cookies. The greed factors of 2 children are 1, 2.
-You have 3 cookies and their sizes are big enough to gratify all of the children,
-You need to output 2.
-
-
-
-Constraints:
-
-
- 1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1
-
-
-Note: This question is the same as 2410: Maximum Matching of Players With Trainers.
diff --git a/0506-relative-ranks/0506-relative-ranks.py b/0506-relative-ranks/0506-relative-ranks.py
deleted file mode 100644
index e9d28a1..0000000
--- a/0506-relative-ranks/0506-relative-ranks.py
+++ /dev/null
@@ -1,24 +0,0 @@
-class Solution:
- def findRelativeRanks(self, score: List[int]) -> List[str]:
- tuple_list = []
- # 1. 메달별 tuple 정렬
- for i in range(len(score)):
- tuple_list.append((i, score[i]))
- tuple_list.sort(key = lambda x : x[1], reverse = True)
-
- # 2. 크기만큼 미리 정렬
- output = [0 for i in range(len(score))]
-
- # 3. tupe 방식에 따라 재정렬
- for i in range(len(score)):
- medal = ""
- if i == 0:
- medal = "Gold Medal"
- elif i == 1:
- medal = "Silver Medal"
- elif i == 2:
- medal = "Bronze Medal"
- else:
- medal = str(i + 1)
- output[tuple_list[i][0]] = medal
- return output
\ No newline at end of file
diff --git a/0506-relative-ranks/README.md b/0506-relative-ranks/README.md
deleted file mode 100644
index 0a1c613..0000000
--- a/0506-relative-ranks/README.md
+++ /dev/null
@@ -1,39 +0,0 @@
-Easy
You are given an integer array score of size n, where score[i] is the score of the ith athlete in a competition. All the scores are guaranteed to be unique.
-
-The athletes are placed based on their scores, where the 1st place athlete has the highest score, the 2nd place athlete has the 2nd highest score, and so on. The placement of each athlete determines their rank:
-
-
- - The
1st place athlete's rank is "Gold Medal".
- - The
2nd place athlete's rank is "Silver Medal".
- - The
3rd place athlete's rank is "Bronze Medal".
- - For the
4th place to the nth place athlete, their rank is their placement number (i.e., the xth place athlete's rank is "x").
-
-
-Return an array answer of size n where answer[i] is the rank of the ith athlete.
-
-
-Example 1:
-
-
-Input: score = [5,4,3,2,1]
-Output: ["Gold Medal","Silver Medal","Bronze Medal","4","5"]
-Explanation: The placements are [1st, 2nd, 3rd, 4th, 5th].
-
-Example 2:
-
-
-Input: score = [10,3,8,9,4]
-Output: ["Gold Medal","5","Bronze Medal","Silver Medal","4"]
-Explanation: The placements are [1st, 5th, 3rd, 2nd, 4th].
-
-
-
-
-Constraints:
-
-
- n == score.length1 <= n <= 1040 <= score[i] <= 106- All the values in
score are unique.
-
diff --git a/0561-array-partition/0561-array-partition.py b/0561-array-partition/0561-array-partition.py
deleted file mode 100644
index 09195ca..0000000
--- a/0561-array-partition/0561-array-partition.py
+++ /dev/null
@@ -1,10 +0,0 @@
-class Solution:
- def arrayPairSum(self, nums: List[int]) -> int:
- total = 0
- nums.sort()
-
- for i in range(0, len(nums) , 2):
- # total += min(nums[i : i + 2])
- total += nums[i]
-
- return total
\ No newline at end of file
diff --git a/0561-array-partition/README.md b/0561-array-partition/README.md
deleted file mode 100644
index babdba7..0000000
--- a/0561-array-partition/README.md
+++ /dev/null
@@ -1,30 +0,0 @@
-Easy
Given an integer array nums of 2n integers, group these integers into n pairs (a1, b1), (a2, b2), ..., (an, bn) such that the sum of min(ai, bi) for all i is maximized. Return the maximized sum.
-
-
-Example 1:
-
-
-Input: nums = [1,4,3,2]
-Output: 4
-Explanation: All possible pairings (ignoring the ordering of elements) are:
-1. (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
-2. (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
-3. (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
-So the maximum possible sum is 4.
-
-Example 2:
-
-
-Input: nums = [6,2,6,5,1,2]
-Output: 9
-Explanation: The optimal pairing is (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9.
-
-
-
-Constraints:
-
-
- 1 <= n <= 104nums.length == 2 * n-104 <= nums[i] <= 104
diff --git a/0747-min-cost-climbing-stairs/0747-min-cost-climbing-stairs.py b/0747-min-cost-climbing-stairs/0747-min-cost-climbing-stairs.py
deleted file mode 100644
index 9083d6c..0000000
--- a/0747-min-cost-climbing-stairs/0747-min-cost-climbing-stairs.py
+++ /dev/null
@@ -1,28 +0,0 @@
-class Solution:
- def minCostClimbingStairs(self, cost: List[int]) -> int:
- # DP 방법 -> 점화식
- output = 0
- dp = [0 for _ in range(len(cost))]
- dp[0] = cost[0]
- dp[1] = cost[1]
-
- i = 2
- while i < len(cost) :
- dp[i] = cost[i] + min(dp[i-1], dp[i-2])
- i += 1
-
- output = min(dp[len(cost) - 1], dp[len(cost) - 2])
- return output
-
- # 그리디 방법
- # 최소 비용 찾기
- # total, i, = 0, (len(cost))
- # while i >= 2:
- # if cost[i - 2] <= cost[i - 1]: # 뒤쪽이 더 크면
- # i -= 2 # 앞에 인덱스로
- # elif cost[i - 2] > cost[i - 1]: # 앞쪽이 더 크면
- # i -= 1
- # print(i)
- # total += cost[i]
-
- # return total
\ No newline at end of file
diff --git a/0747-min-cost-climbing-stairs/README.md b/0747-min-cost-climbing-stairs/README.md
deleted file mode 100644
index be0a33d..0000000
--- a/0747-min-cost-climbing-stairs/README.md
+++ /dev/null
@@ -1,39 +0,0 @@
-Easy
You are given an integer array cost where cost[i] is the cost of ith step on a staircase. Once you pay the cost, you can either climb one or two steps.
-
-You can either start from the step with index 0, or the step with index 1.
-
-Return the minimum cost to reach the top of the floor.
-
-
-Example 1:
-
-
-Input: cost = [10,15,20]
-Output: 15
-Explanation: You will start at index 1.
-- Pay 15 and climb two steps to reach the top.
-The total cost is 15.
-
-
-Example 2:
-
-
-Input: cost = [1,100,1,1,1,100,1,1,100,1]
-Output: 6
-Explanation: You will start at index 0.
-- Pay 1 and climb two steps to reach index 2.
-- Pay 1 and climb two steps to reach index 4.
-- Pay 1 and climb two steps to reach index 6.
-- Pay 1 and climb one step to reach index 7.
-- Pay 1 and climb two steps to reach index 9.
-- Pay 1 and climb one step to reach the top.
-The total cost is 6.
-
-
-
-Constraints:
-
-
- 2 <= cost.length <= 10000 <= cost[i] <= 999
diff --git a/0783-search-in-a-binary-search-tree/0783-search-in-a-binary-search-tree.py b/0783-search-in-a-binary-search-tree/0783-search-in-a-binary-search-tree.py
deleted file mode 100644
index 393decf..0000000
--- a/0783-search-in-a-binary-search-tree/0783-search-in-a-binary-search-tree.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# Definition for a binary tree node.
-# class TreeNode:
-# def __init__(self, val=0, left=None, right=None):
-# self.val = val
-# self.left = left
-# self.right = right
-class Solution:
- def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
- if not root:
- return None
- if root.val == val:
- return root
- elif root.val < val:
- return self.searchBST(root.right, val)
- else:
- return self.searchBST(root.left, val)
- # def searchBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:
- # data = root
-
- # while root is not None:
- # if data == val:
- # return self.subTree(root)
- # elif data < val: #찾으려는 값이 더 크면 오른쪽으로
- # return self.searchBST(root.right, val)
- # elif data > val:
- # return self.searchBST(root.left, val)
-
- # return None
-
- # def subTree(self, root : Optional[TreeNode]) -> Optional[TreeNode]:
- # data = root.val
- # subTree_list = TreeNode(data)
-
- # if data is not None:
- # subTree_list.left = TreeNode(root.left)
- # subTree_list.right = TreeNode(root.right)
-
- # return subTree_list
-
diff --git a/0783-search-in-a-binary-search-tree/README.md b/0783-search-in-a-binary-search-tree/README.md
deleted file mode 100644
index 0ebb87b..0000000
--- a/0783-search-in-a-binary-search-tree/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
-Easy
You are given the root of a binary search tree (BST) and an integer val.
-
-Find the node in the BST that the node's value equals val and return the subtree rooted with that node. If such a node does not exist, return null.
-
-
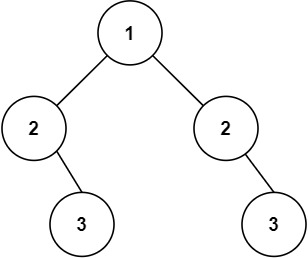
-Example 1:
-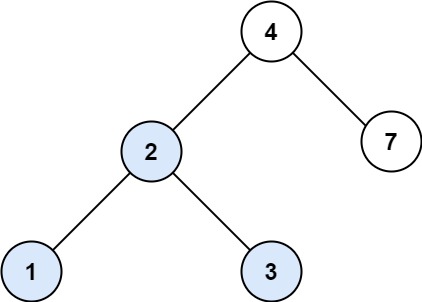 -
-
-Input: root = [4,2,7,1,3], val = 2
-Output: [2,1,3]
-
-
-Example 2:
-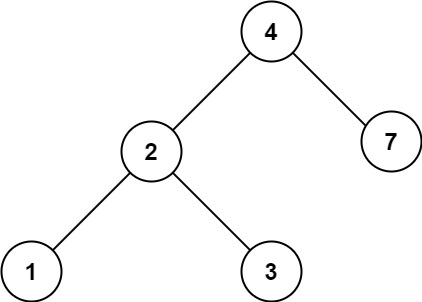 -
-
-Input: root = [4,2,7,1,3], val = 5
-Output: []
-
-
-
-Constraints:
-
-
- - The number of nodes in the tree is in the range
[1, 5000].
- 1 <= Node.val <= 107root is a binary search tree.1 <= val <= 107
diff --git a/0789-kth-largest-element-in-a-stream/0789-kth-largest-element-in-a-stream.py b/0789-kth-largest-element-in-a-stream/0789-kth-largest-element-in-a-stream.py
deleted file mode 100644
index 20db199..0000000
--- a/0789-kth-largest-element-in-a-stream/0789-kth-largest-element-in-a-stream.py
+++ /dev/null
@@ -1,28 +0,0 @@
-import heapq
-class KthLargest:
-
- def __init__(self, k: int, nums: List[int]):
- self.heap = nums
- self.k = k
- heapq.heapify(self.heap)
-
-
- def add(self, val: int) -> int:
- if self.heap:
- heapq.heappush(self.heap, val)
- while self.k < len(self.heap):
- heapq.heappop(self.heap)
- else :
- self.heap.append(val)
- heapq.heapify(self.heap)
- heap_ = self.heap[0]
-
- return heap_
-
-
-# Your KthLargest object will be instantiated and called as such:
-# obj = KthLargest(k, nums)
-# param_1 = obj.add(val)
-
-# 실수1
-# pop 은 없음
\ No newline at end of file
diff --git a/0789-kth-largest-element-in-a-stream/README.md b/0789-kth-largest-element-in-a-stream/README.md
deleted file mode 100644
index f080c21..0000000
--- a/0789-kth-largest-element-in-a-stream/README.md
+++ /dev/null
@@ -1,39 +0,0 @@
-Easy
Design a class to find the kth largest element in a stream. Note that it is the kth largest element in the sorted order, not the kth distinct element.
-
-Implement KthLargest class:
-
-
- KthLargest(int k, int[] nums) Initializes the object with the integer k and the stream of integers nums.int add(int val) Appends the integer val to the stream and returns the element representing the kth largest element in the stream.
-
-
-Example 1:
-
-
-Input
-["KthLargest", "add", "add", "add", "add", "add"]
-[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
-Output
-[null, 4, 5, 5, 8, 8]
-
-Explanation
-KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
-kthLargest.add(3); // return 4
-kthLargest.add(5); // return 5
-kthLargest.add(10); // return 5
-kthLargest.add(9); // return 8
-kthLargest.add(4); // return 8
-
-
-
-Constraints:
-
-
- 1 <= k <= 1040 <= nums.length <= 104-104 <= nums[i] <= 104-104 <= val <= 104- At most
104 calls will be made to add.
- - It is guaranteed that there will be at least
k elements in the array when you search for the kth element.
-
diff --git a/0933-increasing-order-search-tree/0933-increasing-order-search-tree.py b/0933-increasing-order-search-tree/0933-increasing-order-search-tree.py
deleted file mode 100644
index 6051379..0000000
--- a/0933-increasing-order-search-tree/0933-increasing-order-search-tree.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Definition for a binary tree node.
-# class TreeNode:
-# def __init__(self, val=0, left=None, right=None):
-# self.val = val
-# self.left = left
-# self.right = right
-class Solution:
- def increasingBST(self, root: TreeNode) -> TreeNode:
-
- def inorder_tree(root, list):
- if root is not None:
- inorder_tree(root.left, list)
- # list.append(root.val) #node 값이 아니라 node 자체
- list.append(root)
- inorder_tree(root.right, list)
- return list
-
- nodes = inorder_tree(root,[])
-
- # 새로운 트리의 더미 루트 노드 생성
- dummy = TreeNode(0)
- current = dummy
-
- for node in nodes:
- node.left = None # 왼쪽 자식 제거
- current.right = node # 오른쪽 자식으로 설정
- current = node # current를 갱신
-
- return dummy.right
-
- # list.sort(reverse = True) #리스트 정렬 생략
- # print(list)
-
- # 새로 생성 X
- # new_root = TreeNode()
- # new_root.val = list.pop()
- # print(root)
-
- # def right_tree(root: TreeNode, list) -> TreeNode:
- # if root is None:
- # return None
- # # print(root)
- # if root is not None:
- # # print(root)
- # # 왼쪽
- # root.left = None
- # # root 값
- # root.val = list.pop()
- # # 오른쪽
- # # new_root = TreeNode()
- # root.right = right_tree(root, list)
- # return root
-
- # print(root, list)
- # return right_tree(root, list)
\ No newline at end of file
diff --git a/0933-increasing-order-search-tree/README.md b/0933-increasing-order-search-tree/README.md
deleted file mode 100644
index 2a6f39d..0000000
--- a/0933-increasing-order-search-tree/README.md
+++ /dev/null
@@ -1,24 +0,0 @@
-Easy
Given the root of a binary search tree, rearrange the tree in in-order so that the leftmost node in the tree is now the root of the tree, and every node has no left child and only one right child.
-
-
-Example 1:
-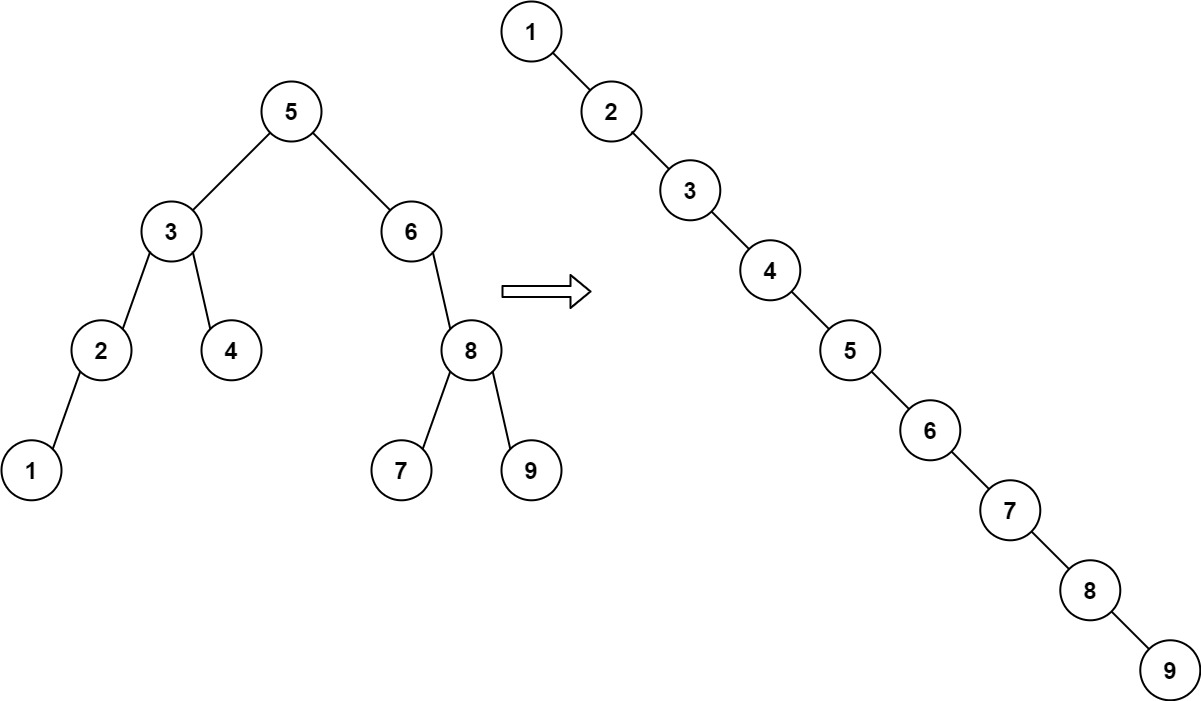 -
-
-Input: root = [5,3,6,2,4,null,8,1,null,null,null,7,9]
-Output: [1,null,2,null,3,null,4,null,5,null,6,null,7,null,8,null,9]
-
-
-Example 2:
-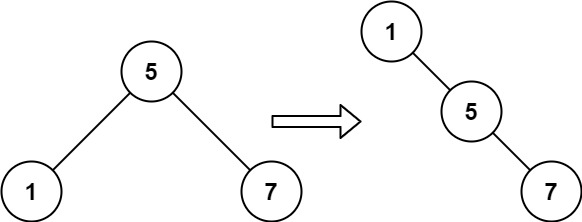 -
-
-Input: root = [5,1,7]
-Output: [1,null,5,null,7]
-
-
-
-Constraints:
-
-
- - The number of nodes in the given tree will be in the range
[1, 100].
- 0 <= Node.val <= 1000
diff --git a/1013-fibonacci-number/1013-fibonacci-number.py b/1013-fibonacci-number/1013-fibonacci-number.py
deleted file mode 100644
index 0b0c845..0000000
--- a/1013-fibonacci-number/1013-fibonacci-number.py
+++ /dev/null
@@ -1,8 +0,0 @@
-class Solution:
- def fib(self, n: int) -> int:
- #base case
- if n < 2 :
- return n
-
- #recursive case
- return self.fib(n - 1) + self.fib(n - 2)
\ No newline at end of file
diff --git a/1013-fibonacci-number/README.md b/1013-fibonacci-number/README.md
deleted file mode 100644
index 2ac4ae5..0000000
--- a/1013-fibonacci-number/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
-Easy
The Fibonacci numbers, commonly denoted F(n) form a sequence, called the Fibonacci sequence, such that each number is the sum of the two preceding ones, starting from 0 and 1. That is,
-
-
-F(0) = 0, F(1) = 1
-F(n) = F(n - 1) + F(n - 2), for n > 1.
-
-
-Given n, calculate F(n).
-
-
-Example 1:
-
-
-Input: n = 2
-Output: 1
-Explanation: F(2) = F(1) + F(0) = 1 + 0 = 1.
-
-
-Example 2:
-
-
-Input: n = 3
-Output: 2
-Explanation: F(3) = F(2) + F(1) = 1 + 1 = 2.
-
-
-Example 3:
-
-
-Input: n = 4
-Output: 3
-Explanation: F(4) = F(3) + F(2) = 2 + 1 = 3.
-
-
-
-Constraints:
-
-
diff --git a/1086-divisor-game/1086-divisor-game.py b/1086-divisor-game/1086-divisor-game.py
deleted file mode 100644
index 2bafd5a..0000000
--- a/1086-divisor-game/1086-divisor-game.py
+++ /dev/null
@@ -1,9 +0,0 @@
-class Solution:
- def divisorGame(self, n: int) -> bool:
- # 짝수이면
- if n % 2 == 0:
- return True
- else :
- return False
-
-
\ No newline at end of file
diff --git a/1086-divisor-game/README.md b/1086-divisor-game/README.md
deleted file mode 100644
index cc8498a..0000000
--- a/1086-divisor-game/README.md
+++ /dev/null
@@ -1,36 +0,0 @@
-Easy
Alice and Bob take turns playing a game, with Alice starting first.
-
-Initially, there is a number n on the chalkboard. On each player's turn, that player makes a move consisting of:
-
-
- - Choosing any
x with 0 < x < n and n % x == 0.
- - Replacing the number
n on the chalkboard with n - x.
-
-
-Also, if a player cannot make a move, they lose the game.
-
-Return true if and only if Alice wins the game, assuming both players play optimally.
-
-
-Example 1:
-
-
-Input: n = 2
-Output: true
-Explanation: Alice chooses 1, and Bob has no more moves.
-
-
-Example 2:
-
-
-Input: n = 3
-Output: false
-Explanation: Alice chooses 1, Bob chooses 1, and Alice has no more moves.
-
-
-
-Constraints:
-
-
diff --git a/1236-n-th-tribonacci-number/1236-n-th-tribonacci-number.py b/1236-n-th-tribonacci-number/1236-n-th-tribonacci-number.py
deleted file mode 100644
index 62a58c9..0000000
--- a/1236-n-th-tribonacci-number/1236-n-th-tribonacci-number.py
+++ /dev/null
@@ -1,16 +0,0 @@
-class Solution:
- def tribonacci(self, n: int) -> int:
- t = [0 for _ in range(n + 1)]
- if n < 1: return t[n]
-
- t[1] = 1
- if n < 2: return t[n]
-
- t[2] = 1
- if n < 3: return t[n]
-
- i = 3
- while i < n + 1:
- t[i] = t[i-3] + t[i-2] + t[i-1]
- i += 1
- return t[-1]
\ No newline at end of file
diff --git a/1236-n-th-tribonacci-number/README.md b/1236-n-th-tribonacci-number/README.md
deleted file mode 100644
index 4179ca0..0000000
--- a/1236-n-th-tribonacci-number/README.md
+++ /dev/null
@@ -1,31 +0,0 @@
-Easy
The Tribonacci sequence Tn is defined as follows:
-
-T0 = 0, T1 = 1, T2 = 1, and Tn+3 = Tn + Tn+1 + Tn+2 for n >= 0.
-
-Given n, return the value of Tn.
-
-
-Example 1:
-
-
-Input: n = 4
-Output: 4
-Explanation:
-T_3 = 0 + 1 + 1 = 2
-T_4 = 1 + 1 + 2 = 4
-
-
-Example 2:
-
-
-Input: n = 25
-Output: 1389537
-
-
-
-Constraints:
-
-
- 0 <= n <= 37- The answer is guaranteed to fit within a 32-bit integer, ie.
answer <= 2^31 - 1.
-
\ No newline at end of file
diff --git a/1572-subrectangle-queries/1572-subrectangle-queries.py b/1572-subrectangle-queries/1572-subrectangle-queries.py
deleted file mode 100644
index 2bc2d95..0000000
--- a/1572-subrectangle-queries/1572-subrectangle-queries.py
+++ /dev/null
@@ -1,18 +0,0 @@
-class SubrectangleQueries:
-
- def __init__(self, rectangle: List[List[int]]):
- self.rectangle = rectangle
-
- def updateSubrectangle(self, row1: int, col1: int, row2: int, col2: int, newValue: int) -> None:
- for row in range(row1, row2 + 1):
- for col in range(col1, col2 + 1):
- self.rectangle[row][col] = newValue
-
-
- def getValue(self, row: int, col: int) -> int:
- return self.rectangle[row][col]
-
-# Your SubrectangleQueries object will be instantiated and called as such:
-# obj = SubrectangleQueries(rectangle)
-# obj.updateSubrectangle(row1,col1,row2,col2,newValue)
-# param_2 = obj.getValue(row,col)
\ No newline at end of file
diff --git a/1572-subrectangle-queries/README.md b/1572-subrectangle-queries/README.md
deleted file mode 100644
index 9357662..0000000
--- a/1572-subrectangle-queries/README.md
+++ /dev/null
@@ -1,81 +0,0 @@
-Medium
Implement the class SubrectangleQueries which receives a rows x cols rectangle as a matrix of integers in the constructor and supports two methods:
-
-1. updateSubrectangle(int row1, int col1, int row2, int col2, int newValue)
-
-
- - Updates all values with
newValue in the subrectangle whose upper left coordinate is (row1,col1) and bottom right coordinate is (row2,col2).
-
-
-2. getValue(int row, int col)
-
-
- - Returns the current value of the coordinate
(row,col) from the rectangle.
-
-
-
-Example 1:
-
-
-Input
-["SubrectangleQueries","getValue","updateSubrectangle","getValue","getValue","updateSubrectangle","getValue","getValue"]
-[[[[1,2,1],[4,3,4],[3,2,1],[1,1,1]]],[0,2],[0,0,3,2,5],[0,2],[3,1],[3,0,3,2,10],[3,1],[0,2]]
-Output
-[null,1,null,5,5,null,10,5]
-Explanation
-SubrectangleQueries subrectangleQueries = new SubrectangleQueries([[1,2,1],[4,3,4],[3,2,1],[1,1,1]]);
-// The initial rectangle (4x3) looks like:
-// 1 2 1
-// 4 3 4
-// 3 2 1
-// 1 1 1
-subrectangleQueries.getValue(0, 2); // return 1
-subrectangleQueries.updateSubrectangle(0, 0, 3, 2, 5);
-// After this update the rectangle looks like:
-// 5 5 5
-// 5 5 5
-// 5 5 5
-// 5 5 5
-subrectangleQueries.getValue(0, 2); // return 5
-subrectangleQueries.getValue(3, 1); // return 5
-subrectangleQueries.updateSubrectangle(3, 0, 3, 2, 10);
-// After this update the rectangle looks like:
-// 5 5 5
-// 5 5 5
-// 5 5 5
-// 10 10 10
-subrectangleQueries.getValue(3, 1); // return 10
-subrectangleQueries.getValue(0, 2); // return 5
-
-
-Example 2:
-
-
-Input
-["SubrectangleQueries","getValue","updateSubrectangle","getValue","getValue","updateSubrectangle","getValue"]
-[[[[1,1,1],[2,2,2],[3,3,3]]],[0,0],[0,0,2,2,100],[0,0],[2,2],[1,1,2,2,20],[2,2]]
-Output
-[null,1,null,100,100,null,20]
-Explanation
-SubrectangleQueries subrectangleQueries = new SubrectangleQueries([[1,1,1],[2,2,2],[3,3,3]]);
-subrectangleQueries.getValue(0, 0); // return 1
-subrectangleQueries.updateSubrectangle(0, 0, 2, 2, 100);
-subrectangleQueries.getValue(0, 0); // return 100
-subrectangleQueries.getValue(2, 2); // return 100
-subrectangleQueries.updateSubrectangle(1, 1, 2, 2, 20);
-subrectangleQueries.getValue(2, 2); // return 20
-
-
-
-Constraints:
-
-
- - There will be at most
500 operations considering both methods: updateSubrectangle and getValue.
- 1 <= rows, cols <= 100rows == rectangle.lengthcols == rectangle[i].length0 <= row1 <= row2 < rows0 <= col1 <= col2 < cols1 <= newValue, rectangle[i][j] <= 10^90 <= row < rows0 <= col < cols
diff --git a/1651-shuffle-string/1651-shuffle-string.py b/1651-shuffle-string/1651-shuffle-string.py
deleted file mode 100644
index d80541a..0000000
--- a/1651-shuffle-string/1651-shuffle-string.py
+++ /dev/null
@@ -1,8 +0,0 @@
-class Solution:
- def restoreString(self, s: str, indices: List[int]) -> str:
- t = [0 for i in range(len(s))]
-
- for i in range(len(s)):
- t[indices[i]] = s[i]
-
- return ''.join(t)
\ No newline at end of file
diff --git a/1651-shuffle-string/README.md b/1651-shuffle-string/README.md
deleted file mode 100644
index 7bba5ab..0000000
--- a/1651-shuffle-string/README.md
+++ /dev/null
@@ -1,31 +0,0 @@
-Easy
You are given a string s and an integer array indices of the same length. The string s will be shuffled such that the character at the ith position moves to indices[i] in the shuffled string.
-
-Return the shuffled string.
-
-
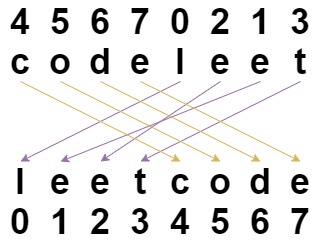
-Example 1:
- -
-
-Input: s = "codeleet", indices = [4,5,6,7,0,2,1,3]
-Output: "leetcode"
-Explanation: As shown, "codeleet" becomes "leetcode" after shuffling.
-
-
-Example 2:
-
-
-Input: s = "abc", indices = [0,1,2]
-Output: "abc"
-Explanation: After shuffling, each character remains in its position.
-
-
-
-Constraints:
-
-
- s.length == indices.length == n1 <= n <= 100s consists of only lowercase English letters.0 <= indices[i] < n- All values of
indices are unique.
-
diff --git a/1653-number-of-good-leaf-nodes-pairs/1653-number-of-good-leaf-nodes-pairs.py b/1653-number-of-good-leaf-nodes-pairs/1653-number-of-good-leaf-nodes-pairs.py
deleted file mode 100644
index 72c0579..0000000
--- a/1653-number-of-good-leaf-nodes-pairs/1653-number-of-good-leaf-nodes-pairs.py
+++ /dev/null
@@ -1,53 +0,0 @@
-# Definition for a binary tree node.
-# class TreeNode:
-# def __init__(self, val=0, left=None, right=None):
-# self.val = val
-# self.left = left
-# self.right = right
-
-# class Solution:
-# def countPairs(self, root: TreeNode, distance: int) -> int:
-# def inorder(root, leaf_list):
-# if root:
-# inorder(root.left, leaf_list)
-# if root.left is None and root.right is None:
-# leaf_list.append(root)
-# inorder(root.right, leaf_list)
-# return leaf_list
-# def dfs(root, leaf_list):
-# # visited = set()
-# distances = -1
-# stack = leaf_list
-# while stack:
-# leaf = stack.pop()
-# leaf_list = []
-# leaf_list = inorder(root, leaf_list)
-# dfs(root, leaf_list)
-
-class Solution:
- def countPairs(self, root: TreeNode, distance: int) -> int:
-
- def dfs(node):
- if not node:
- return []
-
- if not node.left and not node.right : # falsy 처럼 조회
- return [1]
-
- left_distances = dfs(node.left)
- right_distances = dfs(node.right)
-
- for l in left_distances:
- for r in right_distances:
- if l + r <= distance:
- self.result += 1
-
- current_distances = [d + 1 for d in left_distances + right_distances if d + 1 <= distance]
- print(current_distances)
-
- return current_distances
-
- self.result = 0
- dfs(root)
-
- return self.result
\ No newline at end of file
diff --git a/1653-number-of-good-leaf-nodes-pairs/README.md b/1653-number-of-good-leaf-nodes-pairs/README.md
deleted file mode 100644
index 8613ad8..0000000
--- a/1653-number-of-good-leaf-nodes-pairs/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
-Medium
You are given the root of a binary tree and an integer distance. A pair of two different leaf nodes of a binary tree is said to be good if the length of the shortest path between them is less than or equal to distance.
-
-Return the number of good leaf node pairs in the tree.
-
-
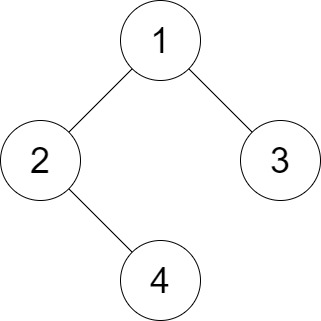
-Example 1:
- -
-
-Input: root = [1,2,3,null,4], distance = 3
-Output: 1
-Explanation: The leaf nodes of the tree are 3 and 4 and the length of the shortest path between them is 3. This is the only good pair.
-
-
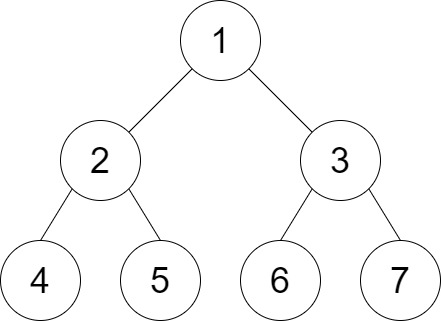
-Example 2:
- -
-
-Input: root = [1,2,3,4,5,6,7], distance = 3
-Output: 2
-Explanation: The good pairs are [4,5] and [6,7] with shortest path = 2. The pair [4,6] is not good because the length of ther shortest path between them is 4.
-
-
-Example 3:
-
-
-Input: root = [7,1,4,6,null,5,3,null,null,null,null,null,2], distance = 3
-Output: 1
-Explanation: The only good pair is [2,5].
-
-
-
-Constraints:
-
-
- - The number of nodes in the
tree is in the range [1, 210].
- 1 <= Node.val <= 1001 <= distance <= 10
diff --git a/1916-find-center-of-star-graph/1916-find-center-of-star-graph.py b/1916-find-center-of-star-graph/1916-find-center-of-star-graph.py
deleted file mode 100644
index 1270ce8..0000000
--- a/1916-find-center-of-star-graph/1916-find-center-of-star-graph.py
+++ /dev/null
@@ -1,9 +0,0 @@
-class Solution:
- def findCenter(self, edges: List[List[int]]) -> int:
- common_value = set(edges[0])
-
- for edge in edges[1:]:
- common_value = common_value.intersection(set(edge))
- print(common_value)
-
- return common_value.pop()
\ No newline at end of file
diff --git a/1916-find-center-of-star-graph/README.md b/1916-find-center-of-star-graph/README.md
deleted file mode 100644
index 784d054..0000000
--- a/1916-find-center-of-star-graph/README.md
+++ /dev/null
@@ -1,31 +0,0 @@
-Easy
There is an undirected star graph consisting of n nodes labeled from 1 to n. A star graph is a graph where there is one center node and exactly n - 1 edges that connect the center node with every other node.
-
-You are given a 2D integer array edges where each edges[i] = [ui, vi] indicates that there is an edge between the nodes ui and vi. Return the center of the given star graph.
-
-
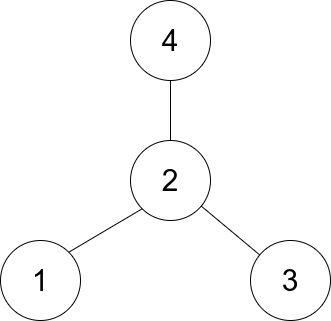
-Example 1:
- -
-
-Input: edges = [[1,2],[2,3],[4,2]]
-Output: 2
-Explanation: As shown in the figure above, node 2 is connected to every other node, so 2 is the center.
-
-
-Example 2:
-
-
-Input: edges = [[1,2],[5,1],[1,3],[1,4]]
-Output: 1
-
-
-
-Constraints:
-
-
- 3 <= n <= 105edges.length == n - 1edges[i].length == 21 <= ui, vi <= nui != vi- The given
edges represent a valid star graph.
-
diff --git a/2121-find-if-path-exists-in-graph/2121-find-if-path-exists-in-graph.py b/2121-find-if-path-exists-in-graph/2121-find-if-path-exists-in-graph.py
deleted file mode 100644
index 29de065..0000000
--- a/2121-find-if-path-exists-in-graph/2121-find-if-path-exists-in-graph.py
+++ /dev/null
@@ -1,36 +0,0 @@
-class Solution:
- def validPath(self, n: int, edges: List[List[int]], source: int, destination: int) -> bool:
- if source == destination : return True
- # 2. DFS 사용
- def dfs(graph, start_node, end_node):
-
- # DFS 위한 스택과 방문관련 set선언
- stack = deque()
- visited = set()
-
- stack.append(start_node)
- visited.add(start_node)
-
- while stack:
- node = stack.pop()
- for val in graph[node]:
- # 이미 방문했는지 체크
- if val in visited:
- continue
-
- # 목적지인지 체크
- if val == end_node:
- return True
- stack.append(val)
- visited.add(val)
-
- return False
-
- # 1. 인접리스트 만들기
- adj_list = {i : [] for i in range(n)}
- for u,v in edges:
- adj_list[u].append(v)
- adj_list[v].append(u)
-
- print(adj_list)
- return dfs(adj_list, source, destination)
\ No newline at end of file
diff --git a/2121-find-if-path-exists-in-graph/README.md b/2121-find-if-path-exists-in-graph/README.md
deleted file mode 100644
index 6e74b14..0000000
--- a/2121-find-if-path-exists-in-graph/README.md
+++ /dev/null
@@ -1,38 +0,0 @@
-Easy
There is a bi-directional graph with n vertices, where each vertex is labeled from 0 to n - 1 (inclusive). The edges in the graph are represented as a 2D integer array edges, where each edges[i] = [ui, vi] denotes a bi-directional edge between vertex ui and vertex vi. Every vertex pair is connected by at most one edge, and no vertex has an edge to itself.
-
-You want to determine if there is a valid path that exists from vertex source to vertex destination.
-
-Given edges and the integers n, source, and destination, return true if there is a valid path from source to destination, or false otherwise.
-
-
-Example 1:
-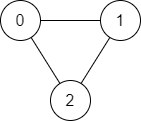 -
-
-Input: n = 3, edges = [[0,1],[1,2],[2,0]], source = 0, destination = 2
-Output: true
-Explanation: There are two paths from vertex 0 to vertex 2:
-- 0 → 1 → 2
-- 0 → 2
-
-
-Example 2:
-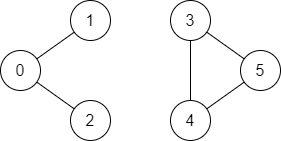 -
-
-Input: n = 6, edges = [[0,1],[0,2],[3,5],[5,4],[4,3]], source = 0, destination = 5
-Output: false
-Explanation: There is no path from vertex 0 to vertex 5.
-
-
-
-Constraints:
-
-
- 1 <= n <= 2 * 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ui, vi <= n - 1ui != vi0 <= source, destination <= n - 1- There are no duplicate edges.
- - There are no self edges.
-
diff --git a/2327-largest-number-after-digit-swaps-by-parity/2327-largest-number-after-digit-swaps-by-parity.py b/2327-largest-number-after-digit-swaps-by-parity/2327-largest-number-after-digit-swaps-by-parity.py
deleted file mode 100644
index b637857..0000000
--- a/2327-largest-number-after-digit-swaps-by-parity/2327-largest-number-after-digit-swaps-by-parity.py
+++ /dev/null
@@ -1,51 +0,0 @@
-class Solution:
- def largestInteger(self, num: int) -> int:
-
- str_num = str(num)
- # 1. 홀수 짝수 자릿수 찾기
- bigger = "even" if int(str_num[0]) % 2 == 0 else "odd"
- even_num_seat = [i for i in range(len(str_num)) if int(str_num[i]) % 2 == 0] #짝수
- odd_num_seat = [i for i in range(len(str_num)) if int(str_num[i]) % 2 == 1] # 홀수
-
- # print(even_num_seat)
- # print(odd_num_seat)
-
- # 2. 자릿수의 수 중에 수 정렬하기
- even_num, odd_num = [], []
- for seat in even_num_seat:
- even_num.append(int(str_num[seat]))
- for seat in odd_num_seat:
- odd_num.append(int(str_num[seat]))
- even_num.sort()
- odd_num.sort()
- # print(even_num)
- # print(odd_num)
-
- # 3. 생성 후 처리하기
- output = [0 for i in range(len(str_num))]
- for v in even_num_seat:
- output[v] = even_num.pop()
- for v in odd_num_seat:
- output[v] = odd_num.pop()
- # print(output)
- return int(''.join(list(map(str, output))))
-
- # 짝수홀수 자릿수로 잘못 이해함
- # 1. 짝수 홀수 분리
- # str_num = str(num)
- # even_num = [int(str_num[i]) for i in range(0,len(str_num), 2)] #짝수
- # odd_num = [int(str_num[i]) for i in range(1,len(str_num), 2)] # 홀수
-
- # odd_num.sort(reverse = True)
- # even_num.sort(reverse = True)
-
- # print(odd_num)
- # print(even_num)
-
- # output = []
- # for i in range(len(str_num)):
- # if i % 2 == 1: #홀수
- # output.append(odd_num[i // 2])
- # elif i % 2 == 0: #짝수
- # output.append(even_num[i // 2])
- # return int(''.join(list(map(str, output))))
\ No newline at end of file
diff --git a/2327-largest-number-after-digit-swaps-by-parity/README.md b/2327-largest-number-after-digit-swaps-by-parity/README.md
deleted file mode 100644
index cb9d3da..0000000
--- a/2327-largest-number-after-digit-swaps-by-parity/README.md
+++ /dev/null
@@ -1,32 +0,0 @@
-Easy
You are given a positive integer num. You may swap any two digits of num that have the same parity (i.e. both odd digits or both even digits).
-
-Return the largest possible value of num after any number of swaps.
-
-
-Example 1:
-
-
-Input: num = 1234
-Output: 3412
-Explanation: Swap the digit 3 with the digit 1, this results in the number 3214.
-Swap the digit 2 with the digit 4, this results in the number 3412.
-Note that there may be other sequences of swaps but it can be shown that 3412 is the largest possible number.
-Also note that we may not swap the digit 4 with the digit 1 since they are of different parities.
-
-
-Example 2:
-
-
-Input: num = 65875
-Output: 87655
-Explanation: Swap the digit 8 with the digit 6, this results in the number 85675.
-Swap the first digit 5 with the digit 7, this results in the number 87655.
-Note that there may be other sequences of swaps but it can be shown that 87655 is the largest possible number.
-
-
-
-Constraints:
-
-
diff --git a/2413-smallest-number-in-infinite-set/2413-smallest-number-in-infinite-set.py b/2413-smallest-number-in-infinite-set/2413-smallest-number-in-infinite-set.py
deleted file mode 100644
index 1583ba8..0000000
--- a/2413-smallest-number-in-infinite-set/2413-smallest-number-in-infinite-set.py
+++ /dev/null
@@ -1,39 +0,0 @@
-import heapq as hq
-
-class SmallestInfiniteSet:
-
- def __init__(self):
- # self.current = 1
- self.min_heap = list(range(1,1001))
- self.set = set(self.min_heap) #set 의 필요성 몰랐음
- hq.heapify(self.min_heap)
-
-
- def popSmallest(self) -> int:
- try:
- pop_data = hq.heappop(self.min_heap)
- # if pop_data in self.set:
- self.set.remove(pop_data)
- return pop_data
-
- except IndexError:
- return None
- except KeyError:
- return None
-
- def addBack(self, num: int) -> None:
- if num < 1 or num > 1000:
- return None
- else :
- if num in self.set:
- return
- else :
- hq.heappush(self.min_heap, num)
- self.set.add(num)
- return None
-
-
-# Your SmallestInfiniteSet object will be instantiated and called as such:
-# obj = SmallestInfiniteSet()
-# param_1 = obj.popSmallest()
-# obj.addBack(num)
\ No newline at end of file
diff --git a/2413-smallest-number-in-infinite-set/README.md b/2413-smallest-number-in-infinite-set/README.md
deleted file mode 100644
index cc5671a..0000000
--- a/2413-smallest-number-in-infinite-set/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
-Medium
You have a set which contains all positive integers [1, 2, 3, 4, 5, ...].
-
-Implement the SmallestInfiniteSet class:
-
-
- SmallestInfiniteSet() Initializes the SmallestInfiniteSet object to contain all positive integers.int popSmallest() Removes and returns the smallest integer contained in the infinite set.void addBack(int num) Adds a positive integer num back into the infinite set, if it is not already in the infinite set.
-
-
-Example 1:
-
-
-Input
-["SmallestInfiniteSet", "addBack", "popSmallest", "popSmallest", "popSmallest", "addBack", "popSmallest", "popSmallest", "popSmallest"]
-[[], [2], [], [], [], [1], [], [], []]
-Output
-[null, null, 1, 2, 3, null, 1, 4, 5]
-
-Explanation
-SmallestInfiniteSet smallestInfiniteSet = new SmallestInfiniteSet();
-smallestInfiniteSet.addBack(2); // 2 is already in the set, so no change is made.
-smallestInfiniteSet.popSmallest(); // return 1, since 1 is the smallest number, and remove it from the set.
-smallestInfiniteSet.popSmallest(); // return 2, and remove it from the set.
-smallestInfiniteSet.popSmallest(); // return 3, and remove it from the set.
-smallestInfiniteSet.addBack(1); // 1 is added back to the set.
-smallestInfiniteSet.popSmallest(); // return 1, since 1 was added back to the set and
- // is the smallest number, and remove it from the set.
-smallestInfiniteSet.popSmallest(); // return 4, and remove it from the set.
-smallestInfiniteSet.popSmallest(); // return 5, and remove it from the set.
-
-
-
-Constraints:
-
-
- 1 <= num <= 1000- At most
1000 calls will be made in total to popSmallest and addBack.
-
diff --git a/2585-delete-greatest-value-in-each-row/2585-delete-greatest-value-in-each-row.py b/2585-delete-greatest-value-in-each-row/2585-delete-greatest-value-in-each-row.py
deleted file mode 100644
index 0beb4dd..0000000
--- a/2585-delete-greatest-value-in-each-row/2585-delete-greatest-value-in-each-row.py
+++ /dev/null
@@ -1,21 +0,0 @@
-import heapq
-class Solution:
- def deleteGreatestValue(self, grid: List[List[int]]) -> int:
-
- # 1. row 수에 따라서 list 생성, answer 생성
- answer = []
- max_heaps = [[-y for y in x] for x in grid]
-
- # 2. grid 에서 각 row list에 대해서 max_heap 정렬
- for i in range(len(max_heaps)):
- heapq.heapify(max_heaps[i])
-
-
- # 3. 각 list 에서 pop 하고나서 answer에 누적연산
- while any(max_heaps):
- tmp_list = []
- for _ in range(len(max_heaps)):
- tmp_list.append(- heapq.heappop(max_heaps[_]))
- answer.append(max(tmp_list))
-
- return sum(answer)
\ No newline at end of file
diff --git a/2585-delete-greatest-value-in-each-row/README.md b/2585-delete-greatest-value-in-each-row/README.md
deleted file mode 100644
index 7f4761b..0000000
--- a/2585-delete-greatest-value-in-each-row/README.md
+++ /dev/null
@@ -1,45 +0,0 @@
-Easy
You are given an m x n matrix grid consisting of positive integers.
-
-Perform the following operation until grid becomes empty:
-
-
- - Delete the element with the greatest value from each row. If multiple such elements exist, delete any of them.
- - Add the maximum of deleted elements to the answer.
-
-
-Note that the number of columns decreases by one after each operation.
-
-Return the answer after performing the operations described above.
-
-
-Example 1:
-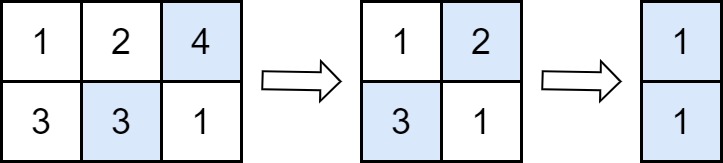 -
-
-Input: grid = [[1,2,4],[3,3,1]]
-Output: 8
-Explanation: The diagram above shows the removed values in each step.
-- In the first operation, we remove 4 from the first row and 3 from the second row (notice that, there are two cells with value 3 and we can remove any of them). We add 4 to the answer.
-- In the second operation, we remove 2 from the first row and 3 from the second row. We add 3 to the answer.
-- In the third operation, we remove 1 from the first row and 1 from the second row. We add 1 to the answer.
-The final answer = 4 + 3 + 1 = 8.
-
-
-Example 2:
- -
-
-Input: grid = [[10]]
-Output: 10
-Explanation: The diagram above shows the removed values in each step.
-- In the first operation, we remove 10 from the first row. We add 10 to the answer.
-The final answer = 10.
-
-
-
-Constraints:
-
-
- m == grid.lengthn == grid[i].length1 <= m, n <= 501 <= grid[i][j] <= 100
diff --git a/2692-take-gifts-from-the-richest-pile/2692-take-gifts-from-the-richest-pile.py b/2692-take-gifts-from-the-richest-pile/2692-take-gifts-from-the-richest-pile.py
deleted file mode 100644
index 82e02ee..0000000
--- a/2692-take-gifts-from-the-richest-pile/2692-take-gifts-from-the-richest-pile.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import heapq
-import math
-
-class Solution:
- def pickGifts(self, gifts: List[int], k: int) -> int:
- answer = 0
-
- # 1. gits 를 maxheap 으로 변환
- max_heap = [-x for x in gifts]
- heapq.heapify(max_heap)
-
- # 2. K 번 반복하기
- for _ in range(k):
- # (1) heapop 후 제곱근 (내림)
- if not max_heap:
- break
- piles = - heapq.heappop(max_heap)
- print(piles)
-
- # 1) 만약 1이라면 제곱근 안하기
- if piles == 1:
- answer += 1
- continue
- # 2) 제곱근
- squ_pile = int(math.sqrt(piles))
- # (2) heappush
- heapq.heappush(max_heap, -squ_pile)
-
- # 3. list 의 값 더하기
- answer += (-sum(max_heap))
-
- return answer
\ No newline at end of file
diff --git a/2692-take-gifts-from-the-richest-pile/README.md b/2692-take-gifts-from-the-richest-pile/README.md
deleted file mode 100644
index dec8744..0000000
--- a/2692-take-gifts-from-the-richest-pile/README.md
+++ /dev/null
@@ -1,44 +0,0 @@
-Easy
You are given an integer array gifts denoting the number of gifts in various piles. Every second, you do the following:
-
-
- - Choose the pile with the maximum number of gifts.
- - If there is more than one pile with the maximum number of gifts, choose any.
- - Leave behind the floor of the square root of the number of gifts in the pile. Take the rest of the gifts.
-
-
-Return the number of gifts remaining after k seconds.
-
-
-Example 1:
-
-
-Input: gifts = [25,64,9,4,100], k = 4
-Output: 29
-Explanation:
-The gifts are taken in the following way:
-- In the first second, the last pile is chosen and 10 gifts are left behind.
-- Then the second pile is chosen and 8 gifts are left behind.
-- After that the first pile is chosen and 5 gifts are left behind.
-- Finally, the last pile is chosen again and 3 gifts are left behind.
-The final remaining gifts are [5,8,9,4,3], so the total number of gifts remaining is 29.
-
-
-Example 2:
-
-
-Input: gifts = [1,1,1,1], k = 4
-Output: 4
-Explanation:
-In this case, regardless which pile you choose, you have to leave behind 1 gift in each pile.
-That is, you can't take any pile with you.
-So, the total gifts remaining are 4.
-
-
-
-Constraints:
-
-
- 1 <= gifts.length <= 1031 <= gifts[i] <= 1091 <= k <= 103
diff --git a/README.md b/README.md
index 1dc2a2f..32c96db 100644
--- a/README.md
+++ b/README.md
@@ -1,196 +1 @@
-# Algorithm
-
-- 차근차근 근육기르기
-
-
-# Array
-| |
-| ------- |
-| [0118-pascals-triangle](https://github.com/Mo-bile/python_Algorithm/tree/master/0118-pascals-triangle) |
-| [1572-subrectangle-queries](https://github.com/Mo-bile/python_Algorithm/tree/master/1572-subrectangle-queries) |
-| [1651-shuffle-string](https://github.com/Mo-bile/python_Algorithm/tree/master/1651-shuffle-string) |
-# Dynamic Programming
-| |
-| ------- |
-| [0118-pascals-triangle](https://github.com/Mo-bile/python_Algorithm/tree/master/0118-pascals-triangle) |
-| [1013-fibonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1013-fibonacci-number) |
-| [1086-divisor-game](https://github.com/Mo-bile/python_Algorithm/tree/master/1086-divisor-game) |
-# Math
-| |
-| ------- |
-| [1013-fibonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1013-fibonacci-number) |
-| [1086-divisor-game](https://github.com/Mo-bile/python_Algorithm/tree/master/1086-divisor-game) |
-# Recursion
-| |
-| ------- |
-| [1013-fibonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1013-fibonacci-number) |
-# Memoization
-| |
-| ------- |
-| [1013-fibonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1013-fibonacci-number) |
-# Brainteaser
-| |
-| ------- |
-| [1086-divisor-game](https://github.com/Mo-bile/python_Algorithm/tree/master/1086-divisor-game) |
-# Game Theory
-| |
-| ------- |
-| [1086-divisor-game](https://github.com/Mo-bile/python_Algorithm/tree/master/1086-divisor-game) |
-# Design
-| |
-| ------- |
-| [1572-subrectangle-queries](https://github.com/Mo-bile/python_Algorithm/tree/master/1572-subrectangle-queries) |
-# Matrix
-| |
-| ------- |
-| [1572-subrectangle-queries](https://github.com/Mo-bile/python_Algorithm/tree/master/1572-subrectangle-queries) |
-# String
-| |
-| ------- |
-| [1651-shuffle-string](https://github.com/Mo-bile/python_Algorithm/tree/master/1651-shuffle-string) |
-
-# LeetCode Topics
-## Array
-| |
-| ------- |
-| [0119-pascals-triangle-ii](https://github.com/Mo-bile/python_Algorithm/tree/master/0119-pascals-triangle-ii) |
-| [0121-best-time-to-buy-and-sell-stock](https://github.com/Mo-bile/python_Algorithm/tree/master/0121-best-time-to-buy-and-sell-stock) |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-| [0455-assign-cookies](https://github.com/Mo-bile/python_Algorithm/tree/master/0455-assign-cookies) |
-| [0506-relative-ranks](https://github.com/Mo-bile/python_Algorithm/tree/master/0506-relative-ranks) |
-| [0561-array-partition](https://github.com/Mo-bile/python_Algorithm/tree/master/0561-array-partition) |
-| [0747-min-cost-climbing-stairs](https://github.com/Mo-bile/python_Algorithm/tree/master/0747-min-cost-climbing-stairs) |
-| [2585-delete-greatest-value-in-each-row](https://github.com/Mo-bile/python_Algorithm/tree/master/2585-delete-greatest-value-in-each-row) |
-| [2692-take-gifts-from-the-richest-pile](https://github.com/Mo-bile/python_Algorithm/tree/master/2692-take-gifts-from-the-richest-pile) |
-## Sorting
-| |
-| ------- |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-| [0455-assign-cookies](https://github.com/Mo-bile/python_Algorithm/tree/master/0455-assign-cookies) |
-| [0506-relative-ranks](https://github.com/Mo-bile/python_Algorithm/tree/master/0506-relative-ranks) |
-| [0561-array-partition](https://github.com/Mo-bile/python_Algorithm/tree/master/0561-array-partition) |
-| [2327-largest-number-after-digit-swaps-by-parity](https://github.com/Mo-bile/python_Algorithm/tree/master/2327-largest-number-after-digit-swaps-by-parity) |
-| [2585-delete-greatest-value-in-each-row](https://github.com/Mo-bile/python_Algorithm/tree/master/2585-delete-greatest-value-in-each-row) |
-## Heap (Priority Queue)
-| |
-| ------- |
-| [0506-relative-ranks](https://github.com/Mo-bile/python_Algorithm/tree/master/0506-relative-ranks) |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-| [2327-largest-number-after-digit-swaps-by-parity](https://github.com/Mo-bile/python_Algorithm/tree/master/2327-largest-number-after-digit-swaps-by-parity) |
-| [2585-delete-greatest-value-in-each-row](https://github.com/Mo-bile/python_Algorithm/tree/master/2585-delete-greatest-value-in-each-row) |
-| [2692-take-gifts-from-the-richest-pile](https://github.com/Mo-bile/python_Algorithm/tree/master/2692-take-gifts-from-the-richest-pile) |
-## Tree
-| |
-| ------- |
-| [0094-binary-tree-inorder-traversal](https://github.com/Mo-bile/python_Algorithm/tree/master/0094-binary-tree-inorder-traversal) |
-| [0101-symmetric-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0101-symmetric-tree) |
-| [0783-search-in-a-binary-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0783-search-in-a-binary-search-tree) |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-| [0933-increasing-order-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0933-increasing-order-search-tree) |
-| [1653-number-of-good-leaf-nodes-pairs](https://github.com/Mo-bile/python_Algorithm/tree/master/1653-number-of-good-leaf-nodes-pairs) |
-## Design
-| |
-| ------- |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-## Binary Search Tree
-| |
-| ------- |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-| [0441-arranging-coins](https://github.com/Mo-bile/python_Algorithm/tree/master/0441-arranging-coins) |
-| [0783-search-in-a-binary-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0783-search-in-a-binary-search-tree) |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-| [0933-increasing-order-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0933-increasing-order-search-tree) |
-## Binary Tree
-| |
-| ------- |
-| [0094-binary-tree-inorder-traversal](https://github.com/Mo-bile/python_Algorithm/tree/master/0094-binary-tree-inorder-traversal) |
-| [0101-symmetric-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0101-symmetric-tree) |
-| [0783-search-in-a-binary-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0783-search-in-a-binary-search-tree) |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-| [0933-increasing-order-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0933-increasing-order-search-tree) |
-| [1653-number-of-good-leaf-nodes-pairs](https://github.com/Mo-bile/python_Algorithm/tree/master/1653-number-of-good-leaf-nodes-pairs) |
-## Data Stream
-| |
-| ------- |
-| [0789-kth-largest-element-in-a-stream](https://github.com/Mo-bile/python_Algorithm/tree/master/0789-kth-largest-element-in-a-stream) |
-## Depth-First Search
-| |
-| ------- |
-| [0094-binary-tree-inorder-traversal](https://github.com/Mo-bile/python_Algorithm/tree/master/0094-binary-tree-inorder-traversal) |
-| [0101-symmetric-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0101-symmetric-tree) |
-| [0933-increasing-order-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0933-increasing-order-search-tree) |
-| [1653-number-of-good-leaf-nodes-pairs](https://github.com/Mo-bile/python_Algorithm/tree/master/1653-number-of-good-leaf-nodes-pairs) |
-| [2121-find-if-path-exists-in-graph](https://github.com/Mo-bile/python_Algorithm/tree/master/2121-find-if-path-exists-in-graph) |
-## Breadth-First Search
-| |
-| ------- |
-| [0101-symmetric-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0101-symmetric-tree) |
-| [2121-find-if-path-exists-in-graph](https://github.com/Mo-bile/python_Algorithm/tree/master/2121-find-if-path-exists-in-graph) |
-## Stack
-| |
-| ------- |
-| [0094-binary-tree-inorder-traversal](https://github.com/Mo-bile/python_Algorithm/tree/master/0094-binary-tree-inorder-traversal) |
-| [0933-increasing-order-search-tree](https://github.com/Mo-bile/python_Algorithm/tree/master/0933-increasing-order-search-tree) |
-## Dynamic Programming
-| |
-| ------- |
-| [0119-pascals-triangle-ii](https://github.com/Mo-bile/python_Algorithm/tree/master/0119-pascals-triangle-ii) |
-| [0121-best-time-to-buy-and-sell-stock](https://github.com/Mo-bile/python_Algorithm/tree/master/0121-best-time-to-buy-and-sell-stock) |
-| [0747-min-cost-climbing-stairs](https://github.com/Mo-bile/python_Algorithm/tree/master/0747-min-cost-climbing-stairs) |
-| [1236-n-th-tribonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1236-n-th-tribonacci-number) |
-## Greedy
-| |
-| ------- |
-| [0409-longest-palindrome](https://github.com/Mo-bile/python_Algorithm/tree/master/0409-longest-palindrome) |
-| [0455-assign-cookies](https://github.com/Mo-bile/python_Algorithm/tree/master/0455-assign-cookies) |
-| [0561-array-partition](https://github.com/Mo-bile/python_Algorithm/tree/master/0561-array-partition) |
-## Counting Sort
-| |
-| ------- |
-| [0561-array-partition](https://github.com/Mo-bile/python_Algorithm/tree/master/0561-array-partition) |
-## Graph
-| |
-| ------- |
-| [1916-find-center-of-star-graph](https://github.com/Mo-bile/python_Algorithm/tree/master/1916-find-center-of-star-graph) |
-| [2121-find-if-path-exists-in-graph](https://github.com/Mo-bile/python_Algorithm/tree/master/2121-find-if-path-exists-in-graph) |
-## Union Find
-| |
-| ------- |
-| [2121-find-if-path-exists-in-graph](https://github.com/Mo-bile/python_Algorithm/tree/master/2121-find-if-path-exists-in-graph) |
-## Hash Table
-| |
-| ------- |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-| [0409-longest-palindrome](https://github.com/Mo-bile/python_Algorithm/tree/master/0409-longest-palindrome) |
-## Math
-| |
-| ------- |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-| [0441-arranging-coins](https://github.com/Mo-bile/python_Algorithm/tree/master/0441-arranging-coins) |
-| [1236-n-th-tribonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1236-n-th-tribonacci-number) |
-## Bit Manipulation
-| |
-| ------- |
-| [0268-missing-number](https://github.com/Mo-bile/python_Algorithm/tree/master/0268-missing-number) |
-## String
-| |
-| ------- |
-| [0409-longest-palindrome](https://github.com/Mo-bile/python_Algorithm/tree/master/0409-longest-palindrome) |
-## Two Pointers
-| |
-| ------- |
-| [0455-assign-cookies](https://github.com/Mo-bile/python_Algorithm/tree/master/0455-assign-cookies) |
-## Memoization
-| |
-| ------- |
-| [1236-n-th-tribonacci-number](https://github.com/Mo-bile/python_Algorithm/tree/master/1236-n-th-tribonacci-number) |
-## Simulation
-| |
-| ------- |
-| [2585-delete-greatest-value-in-each-row](https://github.com/Mo-bile/python_Algorithm/tree/master/2585-delete-greatest-value-in-each-row) |
-| [2692-take-gifts-from-the-richest-pile](https://github.com/Mo-bile/python_Algorithm/tree/master/2692-take-gifts-from-the-richest-pile) |
-## Matrix
-| |
-| ------- |
-| [2585-delete-greatest-value-in-each-row](https://github.com/Mo-bile/python_Algorithm/tree/master/2585-delete-greatest-value-in-each-row) |
-
\ No newline at end of file
+# python_Algorithm
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/10.fib_optimized.md b/algorithm_paradaim/DynamicProgramming/10.fib_optimized.md
deleted file mode 100644
index 6f5bbed..0000000
--- a/algorithm_paradaim/DynamicProgramming/10.fib_optimized.md
+++ /dev/null
@@ -1,52 +0,0 @@
-영상에서 보셨듯,
-n 번째 피보나치 수를 계산하기 위해서는 가장 최근에 계산한 두 값만 알면 됩니다.
-
-공간 복잡도 O(1)로 fib_optimized 함수를 작성하세요.
-
-```python
-print(fib_optimized(1)) # 1을 출력
-print(fib_optimized(2)) # 1을 출력
-print(fib_optimized(3)) # 2을 출력
-print(fib_optimized(4)) # 3을 출력
-print(fib_optimized(5)) # 5을 출력
-```
-
-```python
-# 모's 방식
-def fib_optimized(n):
- previous = 0
- current = 1
- temp = 0
- for i in range(1, n):
- temp = current
- current += previous
- previous = temp
-
- return current
-
-def fib_optimized2(n):
- current = 1
- previous = 0
-
- # 반복적으로 위 변수들을 업데이트한다.
- for i in range(1, n):
- current, previous = current + previous, current
-
- # n번재 피보나치 수를 리턴한다.
- return current
-
-
-# 테스트 코드
-print(fib_optimized(16))
-print(fib_optimized(53))
-print(fib_optimized(213))
-```
-
-> GPT 선생 첨삭
->1. 간결성!
-
-모's 방식은 n - 1을 반환하는데, 이는 일반적인 피보나치 수열의 n번째 항과 혼동을 줄 수 있습니다. 명확한 인덱싱과 주석을 통해 이해하기 쉬운 코드 작성이 중요합니다.이고, 코드를 간결하게 유지하는 것이 좋습니다.
-
->개인적 반성
->- 반복문에서 i가 2부터 시작하는것으로 처음에 뒀었다. 하지만 공간 최적화 방식은 i가 1인 경우부터 공간을 다시 재배치 해야한다.즉 접근을 필요로하는 인덱스 순간이 다름
->- ```current, previous = current + previous, current``` 이 방식도 가능하다는 점이 흥미로움
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/10.fib_optimized.py b/algorithm_paradaim/DynamicProgramming/10.fib_optimized.py
deleted file mode 100644
index 49b0ac1..0000000
--- a/algorithm_paradaim/DynamicProgramming/10.fib_optimized.py
+++ /dev/null
@@ -1,15 +0,0 @@
-def fib_optimized(n):
- previous = 0
- current = 1
- temp = 0
- for i in range(1, n):
- temp = current
- current += previous
- previous = temp
-
- return current
-
-# 테스트 코드
-print(fib_optimized(16))
-print(fib_optimized(53))
-print(fib_optimized(213))
diff --git a/algorithm_paradaim/DynamicProgramming/11.max_profit.md b/algorithm_paradaim/DynamicProgramming/11.max_profit.md
deleted file mode 100644
index de596eb..0000000
--- a/algorithm_paradaim/DynamicProgramming/11.max_profit.md
+++ /dev/null
@@ -1,62 +0,0 @@
->문제
-> 솔희는 학원 쉬는 시간에 친구들을 상대로 새꼼달꼼 장사를 합니다.
-> 그러다 문뜩, 갖고 있는 새꼼달꼼으로 벌어들일 수 있는 최대 수익이 궁금해졌는데요...
-> 가능한 최대 수익을 리턴시켜 주는 함수 max_profit을 작성해 보세요.
-> max_profit은 파라미터로 개수별 가격이 정리되어 있는 리스트 price_list와 판매할 새꼼달꼼 개수 count를 받습니다.
-> 예를 들어 price_list가 [100, 400, 800, 900, 1000]이라면,
->- 새꼼달꼼 1개에 100원
->- 새꼼달꼼 2개에 400원
->- 새꼼달꼼 3개에 800원
->- 새꼼달꼼 4개에 900원
->- 새꼼달꼼 5개에 1000원
->이렇게 가격이 책정된 건데요.
->만약 오늘 솔희가 새꼼달꼼 5개를 판매한다면 최대로 얼마를 벌 수 있을까요?
-한 친구에게 3개 팔고 다른 친구에게 2개를 팔면, 800+ 400 800+ 400 을 해서 총 1200원의 수익을 낼 수 있겠죠.
-
-```python
-def max_profit(price_list, count):
- # 코드를 작성하세요.
-# 테스트
-print(max_profit([100, 400, 800, 900, 1000], 5))
-1200
-```
-
-```python
-# 모's 방식
-def fib_optimized(n):
- previous = 0
- current = 1
- temp = 0
- for i in range(1, n):
- temp = current
- current += previous
- previous = temp
-
- return current
-
-def fib_optimized2(n):
- current = 1
- previous = 0
-
- # 반복적으로 위 변수들을 업데이트한다.
- for i in range(1, n):
- current, previous = current + previous, current
-
- # n번재 피보나치 수를 리턴한다.
- return current
-
-
-# 테스트 코드
-print(fib_optimized(16))
-print(fib_optimized(53))
-print(fib_optimized(213))
-```
-
-> GPT 선생 첨삭
->1. 간결성!
-
-모's 방식은 n - 1을 반환하는데, 이는 일반적인 피보나치 수열의 n번째 항과 혼동을 줄 수 있습니다. 명확한 인덱싱과 주석을 통해 이해하기 쉬운 코드 작성이 중요합니다.이고, 코드를 간결하게 유지하는 것이 좋습니다.
-
->개인적 반성
->- 반복문에서 i가 2부터 시작하는것으로 처음에 뒀었다. 하지만 공간 최적화 방식은 i가 1인 경우부터 공간을 다시 재배치 해야한다.즉 접근을 필요로하는 인덱스 순간이 다름
->- ```current, previous = current + previous, current``` 이 방식도 가능하다는 점이 흥미로움
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/11.max_profit.py b/algorithm_paradaim/DynamicProgramming/11.max_profit.py
deleted file mode 100644
index 2935a1f..0000000
--- a/algorithm_paradaim/DynamicProgramming/11.max_profit.py
+++ /dev/null
@@ -1,5 +0,0 @@
-def max_profit(price_list, count):
-
-
-# 테스트
-print(max_profit([100, 400, 800, 900, 1000], 5))
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/12.max_profit.md b/algorithm_paradaim/DynamicProgramming/12.max_profit.md
deleted file mode 100644
index d5e4239..0000000
--- a/algorithm_paradaim/DynamicProgramming/12.max_profit.md
+++ /dev/null
@@ -1,38 +0,0 @@
->문제
-
-솔희는 학원 쉬는 시간에 친구들을 상대로 새꼼달꼼 장사를 합니다. 그러다 문뜩, 갖고 있는 새꼼달꼼으로 벌어들일 수 있는 최대 수익이 궁금해졌습니다.
-
-가능한 최대 수익을 리턴시켜 주는 함수 max_profit_memo를 Memoization 방식으로 작성해 보세요. max_profit_memo는 파라미터 세 개를 받습니다.
-
-- `price_list`: 개수별 가격이 정리되어 있는 리스트
-- `count`: 판매할 새꼼달꼼 개수
-- `cache`: 개수별 최대 수익이 저장되어 있는 사전
-
-예를 들어 price_list가 [0, 100, 400, 800, 900, 1000]이라면, 아래처럼 가격이 책정된 거예요.
-
-새꼼달꼼 0개에 0원
-새꼼달꼼 1개에 100원
-새꼼달꼼 2개에 400원
-새꼼달꼼 3개에 800원
-새꼼달꼼 4개에 900원
-새꼼달꼼 5개에 1000원
-만약 솔희가 새꼼달꼼 5개를 판매한다면 최대로 얼마를 벌 수 있을까요?
-
-한 친구에게 3개 팔고 다른 친구에게 2개를 팔면,
-800 + 400 을 해서 총 1200원의 수익을 낼 수 있겠죠.
-```python
-def max_profit(price_list, count):
- # 코드를 작성하세요.
-# 테스트
-print(max_profit([100, 400, 800, 900, 1000], 5))
-1200
-```
-
-
->개인적 반성
->- 그래도 다행인점은 count를 두개로 나누려고 함
-> - 여기서 내가 놓친것?
-> 1. 몫, 나머지로 할 필요없이 i 와 count - i 로 나누면 됨
-> 2. count를 2로 나눈 몫까지만 반복하면 됨 -> 대칭되기 때문에
-> 3. max() 메소드 사용에 안익숙함
-> - 반복적 사용에 익숙해지자
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/12.max_profit_memo.py b/algorithm_paradaim/DynamicProgramming/12.max_profit_memo.py
deleted file mode 100644
index d3b8da0..0000000
--- a/algorithm_paradaim/DynamicProgramming/12.max_profit_memo.py
+++ /dev/null
@@ -1,38 +0,0 @@
-def max_profit_memo(price_list, count, cache):
- #base case
- # count 1개는 그 가격 그대로 원으로 return
- if count < 2:
- cache[count] = price_list[count]
- return cache[count]
-
- # cache 내에 존재하는 경우
- if count in cache:
- # count 개를 팔때 저장된 최대 값
- return cache[count]
-
- if count < len(price_list):
- profit = price_list[count]
- else:
- profit = 0
-
- # cache 내에 존재하지 않는 경우
- # 반복문 목적 : 나누는 경우의 수 각 만들어서 더하기
- for i in range(1, count // 2 + 1):
- profit = max(profit,
- max_profit_memo(price_list, i, cache) +
- max_profit_memo(price_list, count - i, cache)
- )
- cache[count] = profit
- return profit
-
-
-def max_profit(price_list, count):
- max_profit_cache = {}
-
- return max_profit_memo(price_list, count, max_profit_cache)
-
-
-# 테스트 코드
-print(max_profit([0, 100, 400, 800, 900, 1000], 5))
-print(max_profit([0, 100, 400, 800, 900, 1000], 10))
-print(max_profit([0, 100, 400, 800, 900, 1000, 1400, 1600, 2100, 2200], 9))
diff --git a/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.md b/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.md
deleted file mode 100644
index febbb88..0000000
--- a/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.md
+++ /dev/null
@@ -1,28 +0,0 @@
->문제
-
-솔희는 학원 쉬는 시간에 친구들을 상대로 새꼼달꼼 장사를 합니다. 그러다 문뜩, 갖고 있는 새꼼달꼼으로 벌어들일 수 있는 최대 수익이 궁금해졌는데요...
-
-가능한 최대 수익을 리턴시켜 주는 함수 max_profit을 Tabulation 방식으로 작성해 보세요. max_profit은 파라미터 두 개를 받습니다.
-
-- price_list: 개수별 가격이 정리되어 있는 리스트
-- count: 판매할 새꼼달꼼 개수
-예를 들어 price_list가 [0, 100, 400, 800, 900, 1000]이라면,
-
-새꼼달꼼 0개에 0원
-새꼼달꼼 1개에 100원
-새꼼달꼼 2개에 400원
-새꼼달꼼 3개에 800원
-새꼼달꼼 4개에 900원
-새꼼달꼼 5개에 1000원
-이렇게 가격이 책정된 건데요. 만약 솔희가 새꼼달꼼 5개를 판매한다면 최대로 얼마를 벌 수 있을까요?
-
-한 친구에게 3개 팔고 다른 친구에게 2개를 팔면,
-800+ 400 을 해서 총 1200원의 수익을 낼 수 있겠죠.
-
-
->개인적 반성
->- 다행인점 : 이중반복문 아이디어를 생각해냄
->- 아쉬운점 :
-> 1. tabulation 용 table에 값은 0번인덱스만 넣으면됨
-> 2. (b) 부분에 count하면 아예 count가 리스트 범위 넘으면 늘 0임
-> 3. (c) 대칭적구조는 이렇게 접근하는것이 바람직
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.py b/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.py
deleted file mode 100644
index ec163ae..0000000
--- a/algorithm_paradaim/DynamicProgramming/13.max_profit_tap.py
+++ /dev/null
@@ -1,24 +0,0 @@
-def max_profit(price_list, count):
- # profit_table = [price_list[0], price_list[1]] # 그냥 0만 너을 때와 어떤차이?
- profit_table = [price_list[0]] #같은 값이 두번 들어가버림 (a)
- # profit_table = [0]
-
- for i in range(1, count + 1):
- if i < len(price_list): # count -> i 로 변경 (b)
- profit = price_list[i]
- else:
- profit = 0
-
- for j in range(1, i // 2 + 1): # i // 2 + 1 로 변경 (c)
- tmp = profit_table[j] + profit_table[i - j]
- profit = max(profit, tmp)
- profit_table.append(profit)
-
- return profit_table[count]
-
-
-
-# 테스트 코드
-print(max_profit([0, 200, 600, 900, 1200, 2000], 5))
-print(max_profit([0, 300, 600, 700, 1100, 1400], 8))
-print(max_profit([0, 100, 200, 400, 600, 900, 1200, 1300, 1500, 1800], 9))
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/5._fib.md b/algorithm_paradaim/DynamicProgramming/5._fib.md
deleted file mode 100644
index 08ad945..0000000
--- a/algorithm_paradaim/DynamicProgramming/5._fib.md
+++ /dev/null
@@ -1,62 +0,0 @@
-```python
-
-# 모's 방식
-def fib_memo(n, cache):
- # baseCase
- if n < 2:
- # return n
- cache[n] = n
- return cache.get(n)
-
- # cache[n]이 존재하지 않는 경우
- if cache.get(n) is None:
- value = fib_memo(n - 1, cache) + fib_memo(n - 2, cache)
- cache[n] = value
- return value
- # cache[n]이 존재하는 경우
- else:
- return cache.get(n)
-
-# 모범답안
-def fib_memo2(n, cache):
- # base case
- if n < 3:
- return 1
-
- # 이미 n번째 피보나치를 계산했으면:
- # 저장된 값을 바로 리턴한다
- if n in cache:
- return cache[n]
-
- # 아직 n번째 피보나치 수를 계산하지 않았으면:
- # 계산을 한 후 cache에 저장
- cache[n] = fib_memo(n - 1, cache) + fib_memo(n - 2, cache)
-
- # 계산한 값을 리턴한다
- return cache[n]
-
-
-def fib(n):
- # n번째 피보나치 수를 담는 사전
- fib_cache = {}
- return fib_memo(n, fib_cache)
-
-# 테스트 코드
-print(fib(10))
-print(fib(50))
-print(fib(100))
-```
-
-
-> GPT 선생 첨삭
->- Base Case의 정확한 처리: 피보나치 수열의 정의에 맞게 base case를 처리하는 것이 중요합니다.
->- 캐시 접근의 명확성: 캐시에 값이 있는지 확인하는 방법을 명확하게 하여 코드의 가독성을 높이세요.
->- 코드 간결성: 불필요한 조건문과 복잡성을 줄이고, 코드를 간결하게 유지하는 것이 좋습니다.
-
->개인적 반성
->- in 키워드 사용으로 딕셔너리 내 ```키``` 중에서 존재 유무 boolean 으로 return 하는 것 몰랐음
->- 먼저 cache[n] 이 존재하는 경우 부터 먼저 조건으로 따지면 중복으로 조건을 안거침
->- 의문은 피보나치 수열 인덱스 3 미만의 경우 1을 리턴하는데 이것이 바람직한것임?
-> - 왜냐하면 이 부분은 어차피 인덱스 0,1,2 는 연산 보조용임
-> - 그리고 가장 중요한것은 각 각 피보나치 항마다 캐싱된 ```결과값이 저장```됨
-> - 즉 모든 값이 저장 될 필요가 없음!
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/5.fib.py b/algorithm_paradaim/DynamicProgramming/5.fib.py
deleted file mode 100644
index cb627a5..0000000
--- a/algorithm_paradaim/DynamicProgramming/5.fib.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# 모's 방식
-def fib_memo(n, cache):
- # baseCase
- if n < 2:
- # return n
- cache[n] = n
- return cache.get(n)
-
- # cache[n]이 존재하지 않는 경우
- if cache.get(n) is None:
- value = fib_memo(n - 1, cache) + fib_memo(n - 2, cache)
- cache[n] = value
- return value
- # cache[n]이 존재하는 경우
- else:
- return cache.get(n)
-
-# 모범답안
-def fib_memo2(n, cache):
- # base case
- if n < 3:
- return 1
-
- # 이미 n번째 피보나치를 계산했으면:
- # 저장된 값을 바로 리턴한다
- if n in cache:
- return cache[n]
-
- # 아직 n번째 피보나치 수를 계산하지 않았으면:
- # 계산을 한 후 cache에 저장
- cache[n] = fib_memo2(n - 1, cache) + fib_memo2(n - 2, cache)
-
- # 계산한 값을 리턴한다
- return cache[n]
-
-
-def fib(n):
- # n번째 피보나치 수를 담는 사전
- fib_cache = {}
- return fib_memo2(n, fib_cache)
-
-# 테스트 코드
-print(fib(10))
-print(fib(50))
-# print(fib(100))
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/7._fib_tap.md b/algorithm_paradaim/DynamicProgramming/7._fib_tap.md
deleted file mode 100644
index 0269f34..0000000
--- a/algorithm_paradaim/DynamicProgramming/7._fib_tap.md
+++ /dev/null
@@ -1,46 +0,0 @@
-- n 번째 피보나치 수를 찾아주는 함수 fib_tab을 작성해 보세요.
-- fib_tab는 꼭 tabulation 방식으로 구현하셔야 합니다!
-
-
-```python
-
-# 모's 방식
-def fib_tab(n):
- fib_table = dict()
- fib_table[0] = 1
- fib_table[1] = 1
- for i in range(2, n):
- fib_table[i] = fib_table[i - 1] + fib_table[i - 2]
- return fib_table[n - 1]
-
-# 모범답안
-def fib_tab2(n):
- # 이미 계산된 피보나치 수를 담는 리스트
- fib_table = [0, 1, 1]
-
- # n번째 피보나치 수까지 리스트를 하나씩 채워 나간다
- for i in range(3, n + 1):
- fib_table.append(fib_table[i - 1] + fib_table[i - 2])
-
- # 피보나치 n번째 수를 리턴한다
- return fib_table[n]
-
-# 테스트 코드
-print(fib_tab(10))
-print(fib_tab(56))
-print(fib_tab(132))
-```
-
-
-> GPT 선생 첨삭
->1. 피보나치 수열의 정의 불일치:
->2. 피보나치 수열은 일반적으로 F(0) = 0, F(1) = 1로 시작합니다. 모's 방식은 이를 F(0) = 1, F(1) = 1로 잘못 초기화하여 정의에 부합하지 않습니다.
->3. 자료 구조 선택:dict 대신 list를 사용하는 것이 이 경우 더 효율적입니다. list는 연속적인 메모리 할당과 인덱스를 통한 빠른 접근이 가능하여, 순차적인 데이터 접근에 더 적합합니다.
-코드의 명확성:
-
-모's 방식은 n - 1을 반환하는데, 이는 일반적인 피보나치 수열의 n번째 항과 혼동을 줄 수 있습니다. 명확한 인덱싱과 주석을 통해 이해하기 쉬운 코드 작성이 중요합니다.이고, 코드를 간결하게 유지하는 것이 좋습니다.
-
->개인적 반성
->- 딕셔너리를 쓰더라도, Key 가 0부터 시작하는 정수에 불과하다면, 이에 더 바람직한 자료구조는 리스트임
->- 피보나치의 0번인덱스 시작은 0임
->- 쉬운 코드 작성을 위해 n - 1반환이 아니라, n반환하게끔하는것이 바람직함
\ No newline at end of file
diff --git a/algorithm_paradaim/DynamicProgramming/7.fib_tap.py b/algorithm_paradaim/DynamicProgramming/7.fib_tap.py
deleted file mode 100644
index 52df7e8..0000000
--- a/algorithm_paradaim/DynamicProgramming/7.fib_tap.py
+++ /dev/null
@@ -1,12 +0,0 @@
-def fib_tab(n):
- fib_table = dict()
- fib_table[0] = 1
- fib_table[1] = 1
- for i in range(2, n):
- fib_table[i] = fib_table[i - 1] + fib_table[i - 2]
- return fib_table[n - 1]
-
-# 테스트 코드
-print(fib_tab(10))
-print(fib_tab(56))
-print(fib_tab(132))
\ No newline at end of file
diff --git "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.56.05.png" "b/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.56.05.png"
deleted file mode 100644
index 292d6f9..0000000
Binary files "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.56.05.png" and /dev/null differ
diff --git "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.57.57.png" "b/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.57.57.png"
deleted file mode 100644
index 4f2ec76..0000000
Binary files "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 7.57.57.png" and /dev/null differ
diff --git "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.00.35.png" "b/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.00.35.png"
deleted file mode 100644
index d720098..0000000
Binary files "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.00.35.png" and /dev/null differ
diff --git "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.01.26.png" "b/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.01.26.png"
deleted file mode 100644
index 1cacc6c..0000000
Binary files "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.01.26.png" and /dev/null differ
diff --git "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.15.29.png" "b/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.15.29.png"
deleted file mode 100644
index 70db899..0000000
Binary files "a/algorithm_paradaim/DynamicProgramming/image/\354\212\244\355\201\254\353\246\260\354\203\267 2023-10-19 \354\230\244\355\233\204 8.15.29.png" and /dev/null differ
diff --git a/algorithm_paradaim/DynamicProgramming/readme.md b/algorithm_paradaim/DynamicProgramming/readme.md
deleted file mode 100644
index c97d1e1..0000000
--- a/algorithm_paradaim/DynamicProgramming/readme.md
+++ /dev/null
@@ -1,87 +0,0 @@
-최적부분구조와 중복되는 부분구조 두가지로 대별됨
-
-## 1. 최적 부분구조
-
-- 최적부분구조가 있다는것은, "부분 문제들의 최적의 답을 이용해서, 기존 문제의 최적의 답을 구할 수있다는 것"
-
-
-- 예 : 피보나치 수열, 서울에서 부산까지의 최단거리
-> 
-> 서울에서 H,I,J 로가는 최단경로를 풀어야함
-> 이 상황에서 각각 4,6,8 더한것을 비교하면 서울에서 부산까지 최적거리 알 수있음
-
-
-## 2. 중복되는 부분문제
-
-- 피보나치 예시
-> 5를 해결위해서는 4,3 을해결하고....그런데 중복되는 문제 3,2,1 이 있음
-> **중복되는 부분문제**
-
-
-- 합병정렬의 경우
-> 
-> 왼쪽 오른쪽 해결은 완전히 독립적임
-> 이것은 결국 **중복되지 않는 부분문제**임
-
-## 3. Danamic programming
-
-- 최적 부분구조가 있다 -> 기존문제를 부분문제로 나눠서 풀 수 있다. -> 중복되는 부분 문제들이 있을 수있다
-> 비효율이 있을 수있음
-> 그런데 이런 비효율을 해결위한것이 DP임
-> 
-> 정리하면 DP는 이럴때 해결하는 것
-
-- DP 란
-> 한 번 계산한 결과를 **재활용하는 방식**
-> 
-> ```fib(7)``` 을 풀기위한 중복문제가 많음
-> 이 중복을 한번씩만 딱 풀자는게 그 취지임
-
-- DP 구현 방법은 2가지임
-> 1. Memorization
-> 2. Tabulation
-
-## 4. Memoization
-
-- 카페 알바때 커피,케익,와플 같이 많이 시키는데, 매번 때마다 하기 번거로워 그래서 하나로 묶자 -> 메모
-- *중복되는 계산은 한번만 계산 후 메모* -> 메모리제이션
-
-- 피보나치수열에서!
-> 보통 다시 쓸 값을 cache 라고함
->
-> fib(2) 는 base case 이므로 곧바로 답을 알 수 있음
-> 
-> 메모라이제이션으로 DP로 중복되는 부분문제의 중복되는 비효율성 해결함
-
-
-## 5. 피보나치 수열
-> 실습 설명
->
->
-> n 번째 피보나치 수를 찾아주는 함수 fib_memo을 작성해 보세요.
-> fib_memo는 꼭 memoization 방식으로 구현하셔야 합니다!
->
-
-> - 힌트 1
-> Memoization 방식으로 문제를 풀면 재귀 함수를 사용하는데요. 재귀 함수를 작성할 때 가장 먼저 생각해야 하는 두 가지가 무엇인지 기억하시나요?
-
-> - 힌트 2
-> 재귀 함수를 작성할 때에는 base case와 recursive case에 대해 생각해야 합니다.
-> - Recursive case: 현 문제가 너무 커서, 같은 형태의 더 작은 부분 문제를 재귀적으로 푸는 경우
-> - Base case: 이미 문제가 충분히 작아서, 더 작은 부분 문제로 나누지 않고도 바로 답을 알 수 있는 경우
-우선 base case가 무엇인지 생각해 볼까요?
-
-
-> - 힌트 3
-> - Recursive case에는 두 가지 경우가 있습니다.
-> - fib_memo(n, cache)를 호출했다고 가정했을 때…
-> - 이미 n 번째 피보나치 수를 계산한 경우, 즉 cache[n]이 존재하는 경우
-> - 아직 n 번째 피보나치 수를 계산하지 않은 경우, 즉 cache[n]이 존재하지 않는 경우
-두 경우를 고려해서 코드를 작성해 보세요.
-
-
-
-
-
-
-
diff --git a/algorithm_paradaim/GreedyAlgorithm/10.course_selection.md b/algorithm_paradaim/GreedyAlgorithm/10.course_selection.md
deleted file mode 100644
index 0c662bd..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/10.course_selection.md
+++ /dev/null
@@ -1,84 +0,0 @@
-## 문제
-
-대학교의 수업 리스트가 나왔습니다.
-```python
-[(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 6), (13, 16), (9, 11), (1, 8)]
-```
-리스트에 담겨있는 튜플들은 각각 하나의 수업을 나타냅니다. 각 튜플의 0번째 항목은 해당 수업의 시작 교시, 그리고 1 번 항목은 해당 수업이 끝나는 교시입니다. 예를 들어서 0번 인덱스에 있는 튜플값은 (4, 7)이니까, 해당 수업은 4교시에 시작해서 7교시에 끝나는 거죠.
-
-(2, 5)를 듣는다고 가정합시다. (4, 7) 수업은 (2, 5)가 끝나기 전에 시작하기 때문에, 두 수업은 같이 들을 수 없습니다. 반면, 수업 (1, 3)과 (4, 7)은 시간이 겹치지 않기 때문에 동시에 들을 수 있습니다.
-
-(단, (2, 5), (5, 7)과 같이 5교시에 끝나는 수업과 5교시에 시작하는 수업은 서로 같이 듣지 못한다고 가정합니다)
-
-열정이 불타오르는 신입생 지웅이는 최대한 많은 수업을 들을 수 있는 수업 조합을 찾아주는 함수 course_selection 함수를 작성하려고 합니다.
-
-course_selection은 파라미터로 전체 수업 리스트를 받고 가능한 많은 수업을 담은 리스트를 리턴합니다.
-
-```python
-# 테스트
-print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 6), (13, 16), (9, 11), (1, 8)]))
-
-# [(1, 3), (4, 7), (8, 10), (13, 16)]
-```
-
-## 답안
-```python
-
-# mo's 답
-def course_selection(course_list):
- selected_list = list()
-
- for i in range(len(course_list)):
- earliest_end_course = 100
- earliest_end_index = -1
- for j, val in enumerate(course_list):
- end_time = val[1]
- if end_time < earliest_end_course:
- earliest_end_course = end_time
- earliest_end_index = j
-
- if earliest_end_index != -1:
- selected_list.append(course_list[earliest_end_index])
- course_list.remove(course_list[earliest_end_index])
-
- for k, val2 in enumerate(course_list):
- start_time = val2[0]
- end_time = val2[1]
- if earliest_end_course >= start_time or earliest_end_course >= end_time:
- course_list.remove(course_list[k])
-
- return selected_list
-
-print(course_selection([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
-print(course_selection([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
-print(course_selection([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))
-
-
-```
-
-```python
-# 모범답안
-
-def course_selection2(course_list):
- # 수업 끝나는 순서로 정렬
- # key 는 정렬기준 정해주는 것임
- sorted_list = sorted(course_list, key=lambda x : x[1])
- # print(sorted_list) # [(2, 3), (4, 5), (1, 7), (6, 8), (6, 10), (9, 10)]
-
- my_selection = [sorted_list[0]]
-
- for course in sorted_list:
- if course[0] > my_selection[-1][1]:
- my_selection.append(course)
-
- return my_selection
-
-print(course_selection2([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
-print(course_selection2([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
-print(course_selection2([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))
-```
-
-# 개인적 반성
-> - 정렬이 key 를 기준으로 가능하다는 것을 전혀 몰랐음
-> - enumerate 로 index, key가 가능하다는것을 알게됐음
-> - 이중 for문으로 하고 조건문안에 또 for문에 들어가게 해서 아쉬움
\ No newline at end of file
diff --git a/algorithm_paradaim/GreedyAlgorithm/10.course_selection.py b/algorithm_paradaim/GreedyAlgorithm/10.course_selection.py
deleted file mode 100644
index 6e46dfb..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/10.course_selection.py
+++ /dev/null
@@ -1,38 +0,0 @@
-def course_selection(course_list):
- selected_list = list()
-
- for i in range(len(course_list)):
- earliest_end_course = 100
- earliest_end_index = -1
- for j, val in enumerate(course_list):
- end_time = val[1]
- if end_time < earliest_end_course:
- earliest_end_course = end_time
- earliest_end_index = j
-
- if earliest_end_index != -1:
- selected_list.append(course_list[earliest_end_index])
- course_list.remove(course_list[earliest_end_index])
-
- for k, val2 in enumerate(course_list):
- start_time = val2[0]
- end_time = val2[1]
- if earliest_end_course >= start_time or earliest_end_course >= end_time:
- course_list.remove(course_list[k])
-
- return selected_list
-
-def course_selection2(course_list):
- sorted_list = sorted(course_list, key=lambda x : x[1]) #key를 기준으로 정렬가능함
- my_selection = [sorted_list[0]]
-
- for course in sorted_list:
- if course[0] > my_selection[-1][1]: #이렇게 리스트안, 리스트는 이렇게 접근가능 함
- my_selection.append(course)
-
- return my_selection
-
-# 테스트 코드
-print(course_selection2([(6, 10), (2, 3), (4, 5), (1, 7), (6, 8), (9, 10)]))
-print(course_selection2([(1, 2), (3, 4), (0, 6), (5, 7), (8, 9), (5, 9)]))
-print(course_selection2([(4, 7), (2, 5), (1, 3), (8, 10), (5, 9), (2, 5), (13, 16), (9, 11), (1, 8)]))
diff --git a/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.md b/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.md
deleted file mode 100644
index 173b16a..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.md
+++ /dev/null
@@ -1,14 +0,0 @@
-## 문제
-
-최소 동전으로 돈을 거슬러 주는 함수를 Greedy Algorithm으로 구현해 보겠습니다.
-
-우리가 작성할 함수 min_coin_count는 `거슬러 줘야 하는 총액 value`와 `동전 리스트 coin_list`를 파라미터로 받고, 거슬러 주기 위해 필요한 최소 동전 개수를 리턴합니다.
-
-예를 들어 1170원을 거슬러 주기 위해서는 500원 2개, 100원 1개, 50원 1개, 10원 2개를 줄 수 있기 때문에 6을 리턴하면 되겠죠?
-
-동전의 조합은 항상 500원, 100원, 50원, 10원이라고 가정합시다.
-
-
-
-# 개인적 반성
-> - 나머지는 모두 일치함 다만 sorted를 for문 list에다가 바로 할 수있음
\ No newline at end of file
diff --git a/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.py b/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.py
deleted file mode 100644
index fcc4ddc..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/4.min_coin_count.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# 모's way
-def min_coin_count(value, coin_list):
- coin_list.sort(reverse=True)
- count_coin = 0
-
- for coin in coin_list:
- count_coin += value // coin
- value %= coin
- if value <= 0:
- break
- return count_coin
-
-# 모범답안
-def min_coin_count2(value, coin_list):
- # 누적 동전 개수
- count = 0
-
- # coin_list의 값들을 큰 순서대로 본다
- for coin in sorted(coin_list, reverse=True):
- # 현재 동전으로 몇 개 거슬러 줄 수 있는지 확인한다
- count += (value // coin)
-
- # 잔액을 계산한다
- value %= coin
-
- return count
-
-# 테스트 코드
-default_coin_list = [100, 500, 10, 50]
-print(min_coin_count(1440, default_coin_list))
-print(min_coin_count(1700, default_coin_list))
-print(min_coin_count(23520, default_coin_list))
-print(min_coin_count(32590, default_coin_list))
\ No newline at end of file
diff --git a/algorithm_paradaim/GreedyAlgorithm/6.max_product.md b/algorithm_paradaim/GreedyAlgorithm/6.max_product.md
deleted file mode 100644
index ddd8692..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/6.max_product.md
+++ /dev/null
@@ -1,19 +0,0 @@
-## 문제
-```python
-def max_product(card_lists):
- # 여기에 코드를 작성하세요
-
-# 테스트 코드
-test_cards = [[1, 2, 3], [4, 6, 1], [8, 2, 4], [3, 2, 5], [5, 2, 3], [3, 2, 1]]
-print(max_product(test_cards))
-```
-여럿이서 카드 게임을 하고 있는데, 각 플레이어는 3장의 카드를 들고 있습니다. 위의 경우 첫 번째 플레이어는
-1 , 2 , 3 을 들고 있고, 두 번째 플레이어는
-4 , 6 , 1 을 들고 있고, 세 번째 플레이어는
-8 , 2 , 4 를 들고 있는 거죠.
-
-함수 max_product는 한 사람당 카드를 하나씩 뽑아서 모두 곱했을 때 가능한 최대 곱을 리턴합니다. max_product를 Greedy Algorithm 방식으로 구현해 보세요.
-
-# 개인적 반성
-> - max()메소드는 list에다가 곧바로 이용가능함
-> -
\ No newline at end of file
diff --git a/algorithm_paradaim/GreedyAlgorithm/6.max_product.py b/algorithm_paradaim/GreedyAlgorithm/6.max_product.py
deleted file mode 100644
index 4070a7b..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/6.max_product.py
+++ /dev/null
@@ -1,35 +0,0 @@
-def max_product(card_lists):
- value = 1
-
- for cards in card_lists:
- greedy = 0
- for card in cards:
- greedy = max(greedy, card)
- value *= greedy
-
- return value
-
-def max_product2(card_lists):
- # 누적된 곱을 저장하는 변수
- product = 1
-
- # 반복문을 돌면서 카드 뭉치를 하나씩 본다
- for card_list in card_lists:
- # product에 각 뭉치의 최댓값을 곱해 준다
- product *= max(card_list)
-
- return product
-
-
-# 테스트 코드
-test_cards1 = [[1, 6, 5], [4, 2, 3]]
-print(max_product(test_cards1))
-
-test_cards2 = [[9, 7, 8], [9, 2, 3], [9, 8, 1], [2, 8, 3], [1, 3, 6], [7, 7, 4]]
-print(max_product(test_cards2))
-
-test_cards3 = [[1, 2, 3], [4, 6, 1], [8, 2, 4], [3, 2, 5], [5, 2, 3], [3, 2, 1]]
-print(max_product(test_cards3))
-
-test_cards4 = [[5, 5, 5], [4, 3, 5], [1, 1, 1], [9, 8, 3], [2, 8, 4], [5, 7, 4]]
-print(max_product(test_cards4))
diff --git a/algorithm_paradaim/GreedyAlgorithm/7.min_fee.md b/algorithm_paradaim/GreedyAlgorithm/7.min_fee.md
deleted file mode 100644
index 940fa55..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/7.min_fee.md
+++ /dev/null
@@ -1,19 +0,0 @@
-## 문제
-```python
-def max_product(card_lists):
- # 여기에 코드를 작성하세요
-
-# 테스트 코드
-test_cards = [[1, 2, 3], [4, 6, 1], [8, 2, 4], [3, 2, 5], [5, 2, 3], [3, 2, 1]]
-print(max_product(test_cards))
-```
-여럿이서 카드 게임을 하고 있는데, 각 플레이어는 3장의 카드를 들고 있습니다. 위의 경우 첫 번째 플레이어는
-1 , 2 , 3 을 들고 있고, 두 번째 플레이어는
-4 , 6 , 1 을 들고 있고, 세 번째 플레이어는
-8 , 2 , 4 를 들고 있는 거죠.
-
-함수 max_product는 한 사람당 카드를 하나씩 뽑아서 모두 곱했을 때 가능한 최대 곱을 리턴합니다. max_product를 Greedy Algorithm 방식으로 구현해 보세요.
-
-# 개인적 반성
-> - max()메소드는 list에다가 곧바로 이용가능함
-> - 직렬방식보다는 병렬방식으로 생각할수도 있음
\ No newline at end of file
diff --git a/algorithm_paradaim/GreedyAlgorithm/7.min_fee.py b/algorithm_paradaim/GreedyAlgorithm/7.min_fee.py
deleted file mode 100644
index 8dc3ee7..0000000
--- a/algorithm_paradaim/GreedyAlgorithm/7.min_fee.py
+++ /dev/null
@@ -1,22 +0,0 @@
-def min_fee(pages_to_print):
- late_min = 0
- late_list = list()
-
- for page in sorted(pages_to_print):
- late_min += page
- late_list.append(late_min)
-
- return sum(late_list)
-
-def min_fee2(pages_to_print):
- sorted_page = sorted(pages_to_print)
- amount = 0
- for i in range(len(sorted_page)):
- amount += sorted_page[i] * (len(sorted_page) - i)
- return amount
-
-# 테스트 코드
-print(min_fee2([6, 11, 4, 1]))
-print(min_fee2([3, 2, 1]))
-print(min_fee2([3, 1, 4, 3, 2]))
-print(min_fee2([8, 4, 2, 3, 9, 23, 6, 8]))
\ No newline at end of file
diff --git a/algorithm_paradaim/brute_force/5_distance.md b/algorithm_paradaim/brute_force/5_distance.md
deleted file mode 100644
index e10f25a..0000000
--- a/algorithm_paradaim/brute_force/5_distance.md
+++ /dev/null
@@ -1,34 +0,0 @@
-## 실습 설명
-스다벅스는 줄어든 매출 때문에 지점 하나를 닫아야 하는 위기에 처해 있습니다. 어떤 지점을 닫는 게 회사에 타격이 적을지 고민이 되는데요. 서로 가까이 붙어 있는 매장이 있으면, 그 중 하나는 없어져도 괜찮지 않을까 싶습니다.
-
-사장님은 비서 태호에게, 직선 거리가 가장 가까운 두 매장을 찾아서 보고하라는 임무를 주셨습니다.
-
-태호는 영업팀에서 매장들 좌표 위치를 튜플 리스트로 받아 왔습니다.
-
-```python
-# 예시 tuple 리스트
-test_coordinates = [(2, 3), (12, 30), (40, 50), (5, 1), (12, 10), (3, 4)]
-
-```
-튜플은 각 매장의 위치를
-x,y
-
- 좌표로 나타낸 것입니다. 0번 매장은 (2, 3)에, 그리고 1번 매장은 (12, 30) 위치에 있는 거죠.
-
-태호가 사용하려는 함수 closest_pair는 이 좌표 리스트를 파라미터로 받고, 리스트 안에서 가장 가까운 두 매장을 [(x1, y1), (x2, y2)] 형식으로 리턴합니다.
-
-참고로 태호는 이미 두 좌표 사이의 거리를 계산해 주는 함수 distance를 써 놨는데요, 함수 distance는 인풋으로 두 튜플을 받아서 그 사이의 직선 거리를 리턴합니다.
-```python
-print(distance((2, 5), (5, 9))) # => 두 지점 사이의 거리 5.0이 출력됨
-```
-실습 결과
-- 테스트
-
-```python
-test_coordinates = [(2, 3), (12, 30), (40, 50), (5, 1), (12, 10), (3, 4)]
-print(closest_pair(test_coordinates))
-```
-
-```python
-[(2, 3), (3, 4)]
-```
diff --git a/algorithm_paradaim/brute_force/5_distance.py b/algorithm_paradaim/brute_force/5_distance.py
deleted file mode 100644
index 79fe2ef..0000000
--- a/algorithm_paradaim/brute_force/5_distance.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# [(2, 3), (3, 4)]
-
-# 제곱근 사용을 위한 sqrt 함수
-from math import sqrt
-
-# 두 매장의 직선 거리를 계산해 주는 함수
-def distance(store1, store2):
- return sqrt((store1[0] - store2[0]) ** 2 + (store1[1] - store2[1]) ** 2)
-
-# 가장 가까운 두 매장을 찾아주는 함수
-def closest_pair(coordinates):
- tuple_list = [coordinates[0], coordinates[1]]
- min_product = distance(coordinates[0], coordinates[1])
- tmp = min_product
-
- for coordinate in coordinates:
- for coordinate2 in coordinates:
- if(coordinate == coordinate2):
- continue
- min_product = min(min_product, distance(coordinate, coordinate2))
- if min_product != tmp:
- tuple_list = [coordinate, coordinate2]
- tmp = min_product
-
- return tuple_list
-
-# 모범답안 케이스 -> 코드 길이가 더 짧음
-
-# 1. len 인덱스 조작 서툼
-# 2. 문제에서 요구하는건 최소길이가 없음 그냥 그 좌표 쌍만 찾으면 됨
-def closest_pair2(coordinates):
- pair = [coordinates[0], coordinates[1]]
-
- for i in range(len(coordinates) - 1): # 0 ~ 끝 -1 까지
- for j in range(i + 1, len(coordinates)): # 1 ~ 끝까지
- store1, store2 = coordinates[i], coordinates[j]
-
- # 굳이 최소길이 구할 필요 없음
- if distance(pair[0], pair[1]) > distance(store1, store2):
- pair = [store1, store2]
- return pair
-
-
-# 테스트 코드
-test_coordinates = [(2, 3), (12, 30), (40, 50), (5, 1), (12, 10), (3, 4)]
-print(closest_pair(test_coordinates))
-print(closest_pair2(test_coordinates))
\ No newline at end of file
diff --git a/algorithm_paradaim/brute_force/6_lodon_rainfall.md b/algorithm_paradaim/brute_force/6_lodon_rainfall.md
deleted file mode 100644
index 38dc21f..0000000
--- a/algorithm_paradaim/brute_force/6_lodon_rainfall.md
+++ /dev/null
@@ -1,30 +0,0 @@
-## 실습 설명
-런던에 엄청난 폭우가 쏟아진다고 가정합시다. 정말 재난 영화에서나 나올 법한 양의 비가 내려서, 고층 건물이 비에 잠길 정도입니다.
-
-그렇게 되었을 때, 건물과 건물 사이에 얼마큼의 빗물이 담길 수 있는지 알고 싶은데요. 그것을 계산해 주는 함수 trapping_rain을 작성해 보려고 합니다.
-
-함수 ```trapping_rain```은 건물 높이 정보를 보관하는 리스트 buildings를 파라미터로 받고, 담기는 빗물의 총량을 리턴해 줍니다.
-
-예를 들어서 파라미터 buildings로 ```[3, 0, 0, 2, 0, 4]```가 들어왔다고 합시다. 그러면 0번 인덱스에 높이
-3
-의 건물이, 3번 인덱스에 높이
-2
-의 건물이, 5번 인덱스에 높이
-4
-의 건물이 있다는 뜻입니다. 1번, 2번, 4번 인덱스에는 건물이 없습니다.
-
-그러면 총 10 만큼의 빗물이 담길 수 있습니다. 따라서 trapping_rain 함수는 10을 리턴하는 거죠.
-
-이번에는 파라미터 buildings로 [0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1]가 들어왔다고 합시다. 그러면 아래의 사진에 따라 총
-6 만큼의 빗물이 담길 수 있습니다. 따라서 trapping_rain 함수는 6을 리턴하는 거죠
-
-
-
-이 정보를 기반으로, trapping_rain 함수를 작성해 보세요!
-
-# 실습 결과
-### 테스트 코드
-print(trapping_rain([3, 0, 0, 2, 0, 4]))
-print(trapping_rain([0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1]))
-10
-6
\ No newline at end of file
diff --git a/algorithm_paradaim/brute_force/6_london_rainfall.py b/algorithm_paradaim/brute_force/6_london_rainfall.py
deleted file mode 100644
index ff00d34..0000000
--- a/algorithm_paradaim/brute_force/6_london_rainfall.py
+++ /dev/null
@@ -1,78 +0,0 @@
-# 10
-# 6
-
-# def trapping_rain(buildings):
-# building_set = [buildings[0], buildings[1]]
-# index = [0, 1]
-# # 1. 현재 나 보다 큰 값 찾기
-# for i in range(len(buildings) - 1):
-# for j in range(i + 1, len(buildings)):
-# if building_set[0] < buildings[j]:
-# building_set[0] = buildings[j]
-# index[0] = j
-#
-# if building_set[1] < buildings[i]:
-# building_set[1] = buildings[i]
-# index[1] = i
-#
-# index[0] += 1
-# index[1] += 1
-# real_index = abs(index[0] - index[1] - 1)
-# print(real_index)
-# print(index, buildings, "확인용")
-# print(index)
-# print(building_set)
-#
-# differ = building_set[0] * building_set[1] * real_index
-# print("differ은",differ)
-# return building_set
-
- # 2. 0 전후에 가장 큰 값 두가지 받아오기
-
- # 3. 두가지 값 중 작은 값 기준으로 count 하기
-
-# 모재영 방법
-def trapping_rain(buildings):
- rainfall_total = 0
- rainfall = [0] * len(buildings)
- max_left = 0
- max_right = 0
- for i in range(0, len(buildings)):
- # 현재 인덱스 기준 왼쪽 가장 높은 건물 높이
- for j in range(i, -1, -1):
- max_left = max(buildings[j], max_left)
- # 현재 인덱스 기준 오른쪽 가장 높은 건물 높이
- for j in range(i, len(buildings), +1):
- max_right = max(buildings[j], max_right)
-
- rainfaill_element = min(max_left, max_right) - buildings[i]
- if(rainfaill_element < 0): rainfaill_element = 0
-
- rainfall[i] = rainfaill_element
- max_left = 0
- max_right = 0
-
- # max_right 로 다시 i 로 현재위치 재조정
-
- for rain in rainfall:
- rainfall_total += rain
- print(rainfall)
- return rainfall_total
-
-# code it 방법
-def trapping_rain2(buildings):
- total_height = 0
-
- for i in range(1, len(buildings)-1 ):
- #슬라이싱으로 가볍게 가능함
- max_left = max(buildings[:i])
- max_right = max(buildings[i:])
-
- # max_left, max_right 초기화 필요없음 -> 슬라이싱 함
- upper_bound = min(max_left, max_right)
- total_height += max(0, upper_bound - buildings[i])
- return total_height
-
-# 테스트
-print(trapping_rain2([3, 0, 0, 2, 0, 4]))
-print(trapping_rain2([0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1]))
diff --git a/algorithm_paradaim/brute_force/card_product.py b/algorithm_paradaim/brute_force/card_product.py
deleted file mode 100644
index 1f81d26..0000000
--- a/algorithm_paradaim/brute_force/card_product.py
+++ /dev/null
@@ -1,26 +0,0 @@
-# 24
-# 32
-# 28
-
-def max_product(left_cards, right_cards):
- # max = 0
- product = left_cards[0] * right_cards[0]
- for left_card in left_cards:
- for right_card in right_cards:
-
- # max() 로 아래 3줄코드를 모두 해결이 가능함
- product = max(product, left_card * right_card)
- # max() 를 쓰지 않은 경우
- # result = left_card * right_card
- # if(result > max):
- # max = result
- return product
-
-
-
-# 여기에 코드를 작성하세요
-
-# 테스트 코드
-print(max_product([1, 6, 5], [4, 2, 3]))
-print(max_product([1, -9, 3, 4], [2, 8, 3, 1]))
-print(max_product([-1, -7, 3], [-4, 3, 6]))
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/11.partition.md b/algorithm_paradaim/divide_and_conquer/11.partition.md
deleted file mode 100644
index 4e65493..0000000
--- a/algorithm_paradaim/divide_and_conquer/11.partition.md
+++ /dev/null
@@ -1,82 +0,0 @@
-### 실습 설명
-- partition 함수 설명 영상을 토대로 partition 함수를 작성하세요.
-
-- partition 함수는 리스트 my_list, 그리고 partition할 범위를 나타내는 인덱스 start와 인덱스 end를 파라미터로 받습니다. my_list의 값들을 pivot 기준으로 재배치한 후, pivot의 최종 위치 인덱스를 리턴해야 합니다.
-
-> 예시 1
-Pivot(기준점)은 마지막 인덱스에 있는 5.
-
-```python
-list1 = [4, 3, 6, 2, 7, 1, 5]
-pivot_index1 = partition(list1, 0, len(list1) - 1)
-print(list1)
-print(pivot_index1)
-# [4, 3, 2, 1, 5, 6, 7]
-# 4
-```
-5보다 작은 값들은 왼쪽에, 5보다 큰 값들은 오른쪽에 배치됩니다.
-
-> 예시 2
-Pivot(기준점)은 마지막 인덱스에 있는 4.
-```python
-list2 = [6, 1, 2, 6, 3, 5, 4]
-pivot_index2 = partition(list2, 0, len(list2) - 1)
-print(list2)
-print(pivot_index2)
-# [1, 2, 3, 4, 6, 5, 6]
-# 3
-```
-4보다 작은 값들은 왼쪽에, 4보다 큰 값들은 오른쪽에 배치됩니다.
-
-> 팁
-partition 함수를 작성하다 보면 코드가 꽤나 지저분해질 수 있습니다. 특히 리스트에서 값들의 위치를 바꿔주는 경우가 많은데요. 코드가 지저분해지는 걸 방지하기 위해서 swap_elements라는 함수를 먼저 작성하는게 좋습니다.
-
-```python
-list1 = [1, 2, 3, 4, 5, 6]
-swap_elements(list1, 2, 5) # 2번 인덱스 값과 5번 인덱스 값 위치 바꿈
-print(list1) # => [1, 2, 6, 4, 5, 3]
-```
-swap_elements 함수가 제대로 작동하는지 확인하고 나서 partition 함수를 작성해 주세요.
-
-### 문제풀이 반성
-> 1. swap_elements 에서 자바나 C 처럼 list 가 전역적으로 이용된다는것 생각을 못함
-> - 혹은 temp 를 이용한다는 아이디어를 곧바로 생각하지 못함
-> - 그래서 swap 함수에서 list에 대한 특별한 함수를 써야한다는것에 잡혀있음
->
-> 2. partition 함수에서 문제점
-> - start, end 각각 지점 판단못함 (특히 start!!)
-> - for 로 i 가 순회하게끔 하려고 함
-> - 통일감있게 p 와 (i,b)는 index값으로 유지하자
-
-### 해답
-```python
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p:
- # 여기서 등호 누락
- if my_list[i] <= my_list[p]:
- swap_elements(my_list, i, b)
- b += 1
- i += 1
-
- swap_elements(my_list, b, p)
- p = b
- return p
-
-
-
-# 테스트 코드 1
-list1 = [4, 3, 6, 2, 7, 1, 5]
-pivot_index1 = partition(list1, 0, len(list1) - 1)
-print(list1)
-print(pivot_index1)
-
-# 테스트 코드 2
-list2 = [6, 1, 2, 6, 3, 5, 4]
-pivot_index2 = partition(list2, 0, len(list2) - 1)
-print(list2)
-print(pivot_index2)
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/11.partition.py b/algorithm_paradaim/divide_and_conquer/11.partition.py
deleted file mode 100644
index 5c90cbb..0000000
--- a/algorithm_paradaim/divide_and_conquer/11.partition.py
+++ /dev/null
@@ -1,132 +0,0 @@
-# 두 요소의 위치를 바꿔주는 helper function
-def swap_elements(my_list, index1, index2):
- # index1_element = my_list[index1]
- # index2_element = my_list[index2]
- # my_list.remove(index1_element)
- # my_list.remove(index2_element)
- # my_list.insert(index1,index2_element)
- # my_list.insert(index2,index1_element)
- temp = my_list[index1]
- my_list[index1] = my_list[index2]
- my_list[index2] = temp
-
-# 퀵 정렬에서 사용되는 partition 함수
-# def partition(my_list, start, end):
- # pivot = my_list[end]
- # small = list()
- # big = list()
- # big_index = 0
- #
- # for i in range(len(my_list) - 2):
- # # pivot 이 더 클 때
- #
- # # swap 한다 => b++ =>
- #
- # # 1) small 에 (리스트 앞부분에) 넣어준다
- #
- # # 2) small_index 를 받아준다
- #
- # # 3) small 과 big 의 위치를 바꾼다.
- #
- # # 3) big_index 를 밀어낸다.
- # print(i , big_index)
- # print(my_list[i] < pivot)
- # if my_list[i] < pivot:
- # swap_elements(my_list, i, big_index)
- # big_index += 1
- # small.append(my_list[i])
- # # pivot 이 더 작을 때
- # else:
- # print("아무것도")
- # big.append(my_list[i])
- # print(i+1,"순회", my_list)
- #
- #
- # if i == 4:
- # print("옴")
- # print(big_index)
- # swap_elements(my_list, pivot, big_index - 1)
- # print("최종",my_list)
-
-
- # my_list.clear()
- # my_list += small + pivot + big
-
-
-# 힌트 보고 푼 방법
-# def partition(my_list, start, end):
-# pivot = my_list[end]
-# i = start
-# b_index = 0
-#
-# for _ in range(len(my_list)):
-#
-# if my_list[i] < pivot:
-# swap_elements(my_list, i , b_index)
-# i += 1
-# b_index += 1
-# else:
-# i += 1
-# swap_elements(my_list, b_index, end)
-#
-# return my_list.index(pivot)
-
-# 해답을 보고 푼 방법
-# def partition(my_list, start, end):
-# # 리스트 값 확인과 기준점 이하 값들의 위치 확인을 위한 변수 정의
-#
-# # * start, end 의 용도 생각못함
-# i = start
-# b = start
-# # * pivot 값을 굳이 뺄 필요없음
-# p = end
-#
-# # 범위안의 모든 값들을 볼 때까지 반복문을 돌린다
-# while i < p:
-# # i 인덱스의 값이 기준점보다 작으면
-# # i와 b 인덱스에 있는 값들을 교환하고
-# # b를 1 증가 시킨다
-# if my_list[i] <= my_list[p]:
-# swap_elements(my_list, i, b)
-# b += 1
-# # * i는 이렇게 외부로 두면 충분함
-# i += 1
-#
-# # b와 기준점인 p 인덱스에 있는 값들을 바꿔준다
-# swap_elements(my_list, b, p)
-# p = b
-#
-# # pivot의 최종 인덱스를 리턴해 준다
-# return p
-
-
-# 한번더 안보고 풀어보기
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p:
- # 여기서 등호 누락
- if my_list[i] <= my_list[p]:
- swap_elements(my_list, i, b)
- b += 1
- i += 1
-
- swap_elements(my_list, b, p)
- p = b
- return p
-
-
-
-# 테스트 코드 1
-list1 = [4, 3, 6, 2, 7, 1, 5]
-pivot_index1 = partition(list1, 0, len(list1) - 1)
-print(list1)
-print(pivot_index1)
-
-# 테스트 코드 2
-list2 = [6, 1, 2, 6, 3, 5, 4]
-pivot_index2 = partition(list2, 0, len(list2) - 1)
-print(list2)
-print(pivot_index2)
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/12.quicksort.md b/algorithm_paradaim/divide_and_conquer/12.quicksort.md
deleted file mode 100644
index 7ecfacb..0000000
--- a/algorithm_paradaim/divide_and_conquer/12.quicksort.md
+++ /dev/null
@@ -1,70 +0,0 @@
-### 실습 설명
-- Divide and Conquer 방식으로 quicksort 함수를 써 보세요. quicksort는 파라미터로 리스트 하나와 리스트 내에서 정렬시킬 범위를 나타내는 인덱스 start와 인덱스 end를 받습니다.
-
-
-- merge_sort 함수와 달리 quicksort 함수는 정렬된 새로운 리스트를 리턴하는 게 아니라, 파라미터로 받는 리스트 자체를 정렬시키는 것입니다.
-- **모's 중요** : 이러한 방식을 ```In-plcae 정렬방식 : In-place Algorithm은 추가 메모리를 사용하지 않고 입력 데이터를 직접 조작하여 정렬하는 알고리즘```이라고 함
-
-- swap_elements와 partition 함수는 이전 과제에서 작성한 그대로 사용하면 됩니다!
-
-### 문제풀이 반성
-> 1. 우선 긍정적인 부분은 답 도출은 성공함
-> 2. 다만 아쉬운 부분은?
-> - 퀵정렬의 경우 return 은 '***새로운리스트***' 를 리턴하는것이 아니라는 점
-> - -> 일단 call by reference 라는것 기억하기
-> - recurisve case 에서 pivot 값을 기준으로 +- 1을 해 주는것이 바람직
-
-
-```python
-def swap_elements(my_list, index1, index2):
- my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
-
-# 퀵 정렬에서 사용되는 partition 함수
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p :
- if my_list[i] <= my_list[p]:
- swap_elements(my_list,i,b)
- b += 1
- i += 1
-
- swap_elements(my_list, p, b)
- p = b
- return p
-
-def quicksort(my_list, start, end):
- # base case
- # * 연산으로 return 하는 것이 바람직함
- # * 추가로 list 를 반환하는 것이 아니라는 점
- if end - start < 1:
- return
-
- # my_list를 두 부분으로 나누어주고,
- # partition 이후 pivot의 인덱스를 리턴받는다
- pivot = partition(my_list, start, end)
-
- # * 두부분 다 pivot -1 혹은 +1을 해야함
- # pivot의 왼쪽 부분 정렬
- quicksort(my_list, start, pivot - 1)
-
- # pivot의 오른쪽 부분 정렬
- quicksort(my_list, pivot + 1, end)
-
-# 테스트 코드 1
-list1 = [1, 3, 5, 7, 9, 11, 13, 11]
-quicksort(list1, 0, len(list1) - 1)
-print(list1)
-
-# 테스트 코드 2
-list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
-quicksort(list2, 0, len(list2) - 1)
-print(list2)
-
-# 테스트 코드 3
-list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
-quicksort(list3, 0, len(list3) - 1)
-print(list3)
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/12.quicksort.py b/algorithm_paradaim/divide_and_conquer/12.quicksort.py
deleted file mode 100644
index 9fdf085..0000000
--- a/algorithm_paradaim/divide_and_conquer/12.quicksort.py
+++ /dev/null
@@ -1,62 +0,0 @@
-def swap_elements(my_list, index1, index2):
- my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
-
-# 퀵 정렬에서 사용되는 partition 함수
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p :
- if my_list[i] <= my_list[p]:
- swap_elements(my_list,i,b)
- b += 1
- i += 1
-
- swap_elements(my_list, p, b)
- p = b
- return p
-
-# 퀵 정렬
-# 내가 직접 풀어본 경우
-# def quicksort(my_list, start, end):
-# #base_case
-# if start == end:
-# return my_list
-#
-# #recursive case
-# pivot = partition(my_list, start, end)
-# return quicksort(my_list, start, pivot - 1) + quicksort(my_list, pivot, end)
-
-def quicksort(my_list, start, end):
- # base case
- # * 연산으로 return 하는 것이 바람직함
- # * 추가로 list 를 반환하는 것이 아니라는 점
- if end - start < 1:
- return
-
- # my_list를 두 부분으로 나누어주고,
- # partition 이후 pivot의 인덱스를 리턴받는다
- pivot = partition(my_list, start, end)
-
- # * 두부분 다 pivot -1 혹은 +1을 해야함
- # pivot의 왼쪽 부분 정렬
- quicksort(my_list, start, pivot - 1)
-
- # pivot의 오른쪽 부분 정렬
- quicksort(my_list, pivot + 1, end)
-
-# 테스트 코드 1
-list1 = [1, 3, 5, 7, 9, 11, 13, 11]
-quicksort(list1, 0, len(list1) - 1)
-print(list1)
-
-# 테스트 코드 2
-list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
-quicksort(list2, 0, len(list2) - 1)
-print(list2)
-
-# 테스트 코드 3
-list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
-quicksort(list3, 0, len(list3) - 1)
-print(list3)
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/13.better_quicksort.md b/algorithm_paradaim/divide_and_conquer/13.better_quicksort.md
deleted file mode 100644
index 2cabc55..0000000
--- a/algorithm_paradaim/divide_and_conquer/13.better_quicksort.md
+++ /dev/null
@@ -1,80 +0,0 @@
-### 실습 설명
-- 이전 과제에서 quicksort 함수를 작성했습니다.
-
-
-#### 테스트 코드
-```python
-test_list = [9, 5, 1, 5, 2, 8, 2, 7, 1, 3, 6, 2, 4, 7, 10, 11, 4, 6]
-quicksort(test_list, 0, len(test_list) - 1)
-print(test_list)
-```
-- 그런데 quicksort 함수에 필수로 start와 end 파라미터를 넘겨줘야 한다는 게 조금 거슬리네요. 테스트를 할 때 만큼은 아래처럼 깔끔하게 작성하고 싶은데요.
-
-#### 테스트 코드
-```python
-test_list = [9, 5, 1, 5, 2, 8, 2, 7, 1, 3, 6, 2, 4, 7, 10, 11, 4, 6]
-quicksort(test_list) # start, end 파라미터 없이 호출
-print(test_list)
-```
-- 어떻게 할 수 있을까요?
-
-- swap_elements와 partition와 quicksort 함수는 이전 과제에서 작성한 그대로 사용하면 됩니다!
-
-### 문제풀이 반성
-> 1. 다만 아쉬운 부분은?
-> - 옵셔널 파라미터에 JS의 undefinde 도 가능한점
-> - return 조건문에 end - start 임 , start - end가 아니라
-> - 왜냐 start - end 하면 늘 음수임
-
-### 해답
-```python
-
-# 두 요소의 위치를 바꿔주는 helper function
-def swap_elements(my_list, index1, index2):
- my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
-
-# 퀵 정렬에서 사용되는 partition 함수
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p:
- if my_list[i] <= my_list[p]:
- swap_elements(my_list, i, b)
- b += 1
- i += 1
-
- swap_elements(my_list, p, b)
- p = b
- return p
-
-# 퀵 정렬 (start, end 파라미터 없이도 호출이 가능하도록 수정해보세요!)
-# start 와 end 별도 선언 및 pivot 으로 renew 해주기가 쟁점
-def quicksort(my_list, start = 0, end = None):
- if end == None:
- end = len(my_list) - 1
-
- if end - start < 1:
- return
- pivot = partition(my_list, start, end)
-
- quicksort(my_list, start, pivot - 1)
- quicksort(my_list, pivot + 1, end)
-
-# 테스트 코드 1
-list1 = [1, 3, 5, 7, 9, 11, 13, 11]
-quicksort(list1) # start, end 파라미터 없이 호출
-print(list1)
-
-# 테스트 코드 2
-list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
-quicksort(list2) # start, end 파라미터 없이 호출
-print(list2)
-
-# 테스트 코드 3
-list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
-quicksort(list3) # start, end 파라미터 없이 호출
-print(list3)
-
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/13.better_quicksort.py b/algorithm_paradaim/divide_and_conquer/13.better_quicksort.py
deleted file mode 100644
index 3ca5034..0000000
--- a/algorithm_paradaim/divide_and_conquer/13.better_quicksort.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# 두 요소의 위치를 바꿔주는 helper function
-def swap_elements(my_list, index1, index2):
- my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
-
-# 퀵 정렬에서 사용되는 partition 함수
-def partition(my_list, start, end):
- i = start
- b = start
- p = end
-
- while i < p:
- if my_list[i] <= my_list[p]:
- swap_elements(my_list, i, b)
- b += 1
- i += 1
-
- swap_elements(my_list, p, b)
- p = b
- return p
-
-# 퀵 정렬 (start, end 파라미터 없이도 호출이 가능하도록 수정해보세요!)
-# start 와 end 별도 선언 및 pivot 으로 renew 해주기가 쟁점
-def quicksort(my_list, start = 0, end = None):
- if end == None:
- end = len(my_list) - 1
-
- if end - start < 1:
- return
- pivot = partition(my_list, start, end)
-
- quicksort(my_list, start, pivot - 1)
- quicksort(my_list, pivot + 1, end)
-
-# 테스트 코드 1
-list1 = [1, 3, 5, 7, 9, 11, 13, 11]
-quicksort(list1) # start, end 파라미터 없이 호출
-print(list1)
-
-# 테스트 코드 2
-list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
-quicksort(list2) # start, end 파라미터 없이 호출
-print(list2)
-
-# 테스트 코드 3
-list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
-quicksort(list3) # start, end 파라미터 없이 호출
-print(list3)
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/4.1toN_sum.md b/algorithm_paradaim/divide_and_conquer/4.1toN_sum.md
deleted file mode 100644
index ea1f38f..0000000
--- a/algorithm_paradaim/divide_and_conquer/4.1toN_sum.md
+++ /dev/null
@@ -1,30 +0,0 @@
-# 1부터 n까지의 합
-
-Divide and Conquer를 이용해서
-1 부터 n 까지 더하는 예시를 보았는데요. 코드로 한 번 구현해 봅시다.
-
-우리가 작성할 함수 consecutive_sum은 두 개의 정수 인풋 start와 end를 받고, start부터 end까지의 합을 리턴합니다. end는 start보다 크다고 가정합니다
-
-
-
-### 해답
-
-```python
-def consecutive_sum(start, end):
- # base case : 문제가 작아서 바로 풀 수있는 경우
- if end == start:
- return start
-
- # divide
- mid = (start + end) // 2
-
- # conquer, combine
- return consecutive_sum(start, mid) + consecutive_sum(mid + 1, end)
-
-
-# 테스트 코드
-print(consecutive_sum(1, 10))
-print(consecutive_sum(1, 100))
-print(consecutive_sum(1, 253))
-print(consecutive_sum(1, 388))
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/4.1toN_sum.py b/algorithm_paradaim/divide_and_conquer/4.1toN_sum.py
deleted file mode 100644
index 9c5fe91..0000000
--- a/algorithm_paradaim/divide_and_conquer/4.1toN_sum.py
+++ /dev/null
@@ -1,36 +0,0 @@
-# def consecutive_sum(start, end):
-# total = 0
-# # 재귀 구간
-# # 먼저 두개로 분할한다 (divide)
-# divide_number = (start + end) // 2
-# # 분할은 자기 분할할 수 없을 만큼(자기자신) 나눈다. (conquer)
-# # print(divide_number)
-# if start == end:
-# return divide_number
-#
-# left_divide = consecutive_sum(start, divide_number)
-# right_divde = consecutive_sum(divide_number+1, end)
-# # 함수탈출 구간
-# # 끝까지 나눈것에서 부터 합을 구한다
-# total += (left_divide + right_divde)
-# # 구한 합에서 옆에 나눈것과 조합한다
-# return total
-
-# 풀이
-def consecutive_sum(start, end):
- # base case : 문제가 작아서 바로 풀 수있는 경우
- if end == start:
- return start
-
- # divide
- mid = (start + end) // 2
-
- # conquer, combine
- return consecutive_sum(start, mid) + consecutive_sum(mid + 1, end)
-
-
-# 테스트 코드
-print(consecutive_sum(1, 10))
-print(consecutive_sum(1, 100))
-print(consecutive_sum(1, 253))
-print(consecutive_sum(1, 388))
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/7.merge_sort.md b/algorithm_paradaim/divide_and_conquer/7.merge_sort.md
deleted file mode 100644
index 7fcd4ce..0000000
--- a/algorithm_paradaim/divide_and_conquer/7.merge_sort.md
+++ /dev/null
@@ -1,54 +0,0 @@
-합병 정렬 알고리즘 중 사용되는 merge 함수를 작성해 보세요.
-
-merge 함수는 정렬된 두 리스트 list1과 list2를 받아서, 하나의 정렬된 리스트를 리턴합니다.
-
-
-### 알아둘 점
-> 1. 합병정렬은 양쪽 리스트는 각각 정렬이 되어 있음
-> 2. 처음부터 빈 리스트인경우 고려
-> 3. 두개는 하나의 반복문에서 동시에
-> 4. 한쪽이 다 끝나면 나머지는 한번에 넣어버리기 (1번 연결)
-
-
-#### 문제 풀이반성
-> 1. 슬라이싱 += 방식으로 하면 엘리먼트 하나씩 꺼내기 가능함
-> 2. 조건문은 등호 보다는 부등호 방식이 나을 수있음
-> 3. 문제 풀기 전 해당 알고리즘, 자료구조의 특징에 대해서 한번 더 생각! -> 시간 아끼는 길임
-> 4. 추가 ***매우중요*** : 비교는 elif가 아니라 else를 해야함
-> - 이유 : 같은 값인 경우에 어떤 조건도 만족하지 못함
-
-
-### 해답
-```python
-
-# 모법답안
-def merge(list1, list2):
- i = 0
- j = 0
-
- merged_list = []
-
- while i < len(list1) and j < len(list2):
- if list1[i] > list2[j]:
- merged_list.append(list2[j])
- j += 1
- else:
- merged_list.append(list1[i])
- i += 1
-
-
- if i == len(list1):
- merged_list += list2[j:]
- elif j == len(list2):
- merged_list += list1[i:]
-
- return merged_list
-
-# 테스트 코드
-print(merge([1], []))
-print(merge([], [1]))
-print(merge([2], [1]))
-print(merge([1, 2, 3, 4], [5, 6, 7, 8]))
-print(merge([5, 6, 7, 8], [1, 2, 3, 4]))
-print(merge([4, 7, 8, 9], [1, 3, 6, 10]))
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/7.merge_sort.py b/algorithm_paradaim/divide_and_conquer/7.merge_sort.py
deleted file mode 100644
index 79240ab..0000000
--- a/algorithm_paradaim/divide_and_conquer/7.merge_sort.py
+++ /dev/null
@@ -1,107 +0,0 @@
-
-# 모재영 풀이
-# def merge(list1, list2):
-# merge_list = []
-# if not list1:
-# merge_list.append(list2[0])
-# return merge_list
-# if not list2:
-# merge_list.append(list1[0])
-# return merge_list
-#
-# i = 0
-# j = 0
-# while(i != len(list1) and len(list2) != j):
-# if(list1[i] > list2[j]):
-# merge_list.append(list2[j])
-# j += 1
-# elif(list1[i] < list2[j]):
-# merge_list.append(list1[i])
-# i += 1
-#
-# if i != len(list1):
-# for i in range (i, len(list1)):
-# merge_list.append(list1[i])
-#
-# if j != len(list2):
-# for j in range (j, len(list2)):
-# merge_list.append(list2[j])
-#
-#
-# return merge_list
-
-
- # 테스트 풀이
-
- # list1_min = 0
- # list2_min = 0
- # #base case
- # if len(list1) == 1 :
- # list1_min = (min(list1[:len(list1)]))
- # if len(list2) == 1 :
- # list2_min = (min(list2[:len(list2)]))
- #
- # merge_list = min(list1_min, list2_min)
- #
- # return merge_list
- #
- # # divide
- # list1_mid = len(list1) // 2
- # list2_mid = len(list2) // 2
- #
- # # conquer # combine
- # return (merge(list1[:list1_mid], list1[list1_mid + 1:])
- # + merge(list2[:list2_mid], list2[list2_mid + 1:]))
-
-
-# 모법답안
-def merge(list1, list2):
- i = 0
- j = 0
-
- merged_list = []
-
- while i < len(list1) and j < len(list2):
- if list1[i] > list2[j]:
- merged_list.append(list2[j])
- j += 1
- else:
- merged_list.append(list1[i])
- i += 1
-
-
- if i == len(list1):
- merged_list += list2[j:]
- elif j == len(list2):
- merged_list += list1[i:]
-
- return merged_list
-
-# 재작성 (0926) -> 틀림
-# merge_list = []
-#
-# i, j = 0, 0
-# while i < len(list1) and j < len(list2):
-# if list1[i] > list2[j]:
-# merge_list.append(list2[j])
-# j += 1
-# elif list1[i] < list2[j]:
-# merge_list.append(list1[i])
-# i += 1
-#
-# if i == len(list1):
-# merge_list += list2[j:]
-# if j == len(list2):
-# merge_list += list1[i:]
-#
-# return merge_list
-
-
-
-# 테스트 코드
-print(merge([1], []))
-print(merge([], [1]))
-print(merge([2], [1]))
-print(merge([1, 2, 3, 4], [5, 6, 7, 8]))
-print(merge([5, 6, 7, 8], [1, 2, 3, 4]))
-print(merge([4, 7, 8, 9], [1, 3, 6, 10]))
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.md b/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.md
deleted file mode 100644
index 3be76c3..0000000
--- a/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.md
+++ /dev/null
@@ -1,56 +0,0 @@
-### 실습 설명
-- Divide and Conquer 방식으로 merge_sort 함수를 써 보세요. merge_sort는 파라미터로 리스트 하나를 받고, 정렬된 새로운 리스트를 리턴합니다.
-
-- merge 함수는 이전 과제에서 작성한 그대로 사용하면 됩니다!
-
-
-### 알아둘 점
-> 1. 앞 merge 는 combine용이라는 점!!
-> 2. basecase 를 먼저 두고 생각하기
-
-
-#### 문제 풀이반성
-> 1. 추가 ***매우중요*** : 비교는 elif가 아니라 else를 해야함
-> - 이유 : 같은 값인 경우에 어떤 조건도 만족하지 못함
-> 2. combine 의 경우 merge() 함수로 해결하는것임
-> 3. 전반적인 앞서 본 1 to N 까지와 논리는 동일함
-
-
-### 해답
-```python
-def merge(list1, list2):
- merge_list = []
- i, j = 0, 0
- while i < len(list1) and j < len(list2):
- if list1[i] > list2[j]:
- merge_list.append(list2[j])
- j += 1
- # elif (list1[i] < list2[j]):
- else:
- merge_list.append(list1[i])
- i += 1
-
- if i == len(list1):
- merge_list += list2[j:]
- if j == len(list2):
- merge_list += list1[i:]
-
- return merge_list
-
-# 합병 정렬
-def merge_sort(my_list):
- merged_list = []
- if len(my_list) < 2:
- return my_list
-
- divide_list_left = merge_sort(my_list[:len(my_list)//2])
- divide_list_right = merge_sort(my_list[len(my_list)//2:])
-
- return merge(divide_list_left, divide_list_right)
-
-# 테스트 코드
-print(merge_sort([1, 3, 5, 7, 9, 11, 13, 11]))
-print(merge_sort([28, 13, 9, 30, 1, 48, 5, 7, 15]))
-print(merge_sort([2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]))
-
-```
\ No newline at end of file
diff --git a/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.py b/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.py
deleted file mode 100644
index ca50884..0000000
--- a/algorithm_paradaim/divide_and_conquer/8.merge_sort_2.py
+++ /dev/null
@@ -1,47 +0,0 @@
-def merge(list1, list2):
- merge_list = []
- i, j = 0, 0
- while i < len(list1) and j < len(list2):
- if list1[i] > list2[j]:
- merge_list.append(list2[j])
- j += 1
- # elif (list1[i] < list2[j]):
- else:
- merge_list.append(list1[i])
- i += 1
-
- if i == len(list1):
- merge_list += list2[j:]
- if j == len(list2):
- merge_list += list1[i:]
-
- return merge_list
-
-# 합병 정렬
-def merge_sort(my_list):
- merged_list = []
- if len(my_list) < 2:
- return my_list
-
- divide_list_left = merge_sort(my_list[:len(my_list)//2])
- divide_list_right = merge_sort(my_list[len(my_list)//2:])
-
- return merge(divide_list_left, divide_list_right)
-
- # if len(divide_list_left) < 2:
- # merged_list.append(merge(divide_list_left, divide_list_right))
- # return merged_list
- #
- # if len(divide_list_right) < 2:
- # merged_list.append(merge(divide_list_left, divide_list_right))
- # return merged_list
-
- # sorted_list_left = (merge_sort(divide_list_left))
- # sorted_list_right = (merge_sort(divide_list_right))
- # merged_list += sorted_list_left[:len(sorted_list_left)]
- # merged_list += sorted_list_right[:len(sorted_list_right)]
-
-# 테스트 코드
-print(merge_sort([1, 3, 5, 7, 9, 11, 13, 11]))
-print(merge_sort([28, 13, 9, 30, 1, 48, 5, 7, 15]))
-print(merge_sort([2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]))
diff --git a/data_structure/basic_data_structure/abstract_data/queue_service_center.py b/data_structure/basic_data_structure/abstract_data/queue_service_center.py
deleted file mode 100644
index 908ad3c..0000000
--- a/data_structure/basic_data_structure/abstract_data/queue_service_center.py
+++ /dev/null
@@ -1,50 +0,0 @@
-from collections import deque
-""""문제 : 서비스 센터 문의 처리"""
-
-class CustomerComplaint:
- """고객 센터 문의를 나타내는 클래스"""
- def __init__(self, name, email, content):
- self.name = name
- self.email = email
- self.content = content
-
-
-class CustomerServiceCenter:
- """고조선 호텔 서비스 센터 클래스"""
- def __init__(self):
- self.queue = deque() # 대기 중인 문의를 저장할 큐 생성
-
- def process_complaint(self):
- """접수된 고객 센터 문의 내용 처리하는 메소드"""
- if len(self.queue) == 0 :
- print("더 이상 대기 중인 문의가 없습니다!")
- return
-
- complaint = self.queue.popleft()
- print("{0}님의 {1} 문의 내용 접수 되었습니다. 담당자가 배정되면 {2}로 연락드리겠습니다!"
- .format(complaint.name, complaint.content, complaint.email))
- # print(f"{complaint.name}님의 {complaint.content} 문의 내용 접수 되었습니다. 담당자가 배정되면 {complaint.email}로 연락드리겠습니다!")
-
- def add_complaint(self, name, email, content):
- """새로운 문의를 큐에 추가 시켜주는 메소드"""
- self.queue.append(CustomerComplaint(name,email,content))
-
-
-# 고객 문의 센터 인스턴스 생성
-center = CustomerServiceCenter()
-
-# 문의 접수한다
-center.add_complaint("강영훈", "younghoon@codeit.com", "음식이 너무 맛이 없어요")
-
-# 문의를 처리한다
-center.process_complaint()
-center.process_complaint()
-
-# 문의 세 개를 더 접수한다
-center.add_complaint("이윤수", "yoonsoo@codeit.kr", "에어컨이 안 들어와요...")
-center.add_complaint("손동욱", "dongwook@codeit.us", "결제가 제대로 안 되는 거 같군요")
-center.add_complaint("김현승", "hyunseung@codeit.ca", "방을 교체해주세요")
-
-# 문의를 처리한다
-center.process_complaint()
-center.process_complaint()
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/abstract_data/stack_pair.py b/data_structure/basic_data_structure/abstract_data/stack_pair.py
deleted file mode 100644
index d1cac9b..0000000
--- a/data_structure/basic_data_structure/abstract_data/stack_pair.py
+++ /dev/null
@@ -1,50 +0,0 @@
-"""" 문제 : 괄호 짝 확인하기"""
-
-from collections import deque
-
-def parentheses_checker(string):
- """주어진 문자열 인풋의 모든 괄호가 짝이 있는지 확인해주는 메소드"""
-
- print(f"테스트하는 문자열: {string}")
- stack = deque() # 사용할 스택 정의
- # index = []
- for i in range(len(string)):
- char = string[i]
- if char == "(":
- stack.append(i)
- # index.append(i)
- elif char == ")":
- if stack :
- stack.pop()
- # index.pop()
- else :
- print(f"문자열 {i} 번째 위치에 있는 괄호에 맞는 열리는 괄호가 없습니다")
-
- while stack:
- print(f"문자열 {stack.pop()} 번째 위치에 있는 괄호가 닫히지 않았습니다")
-
- # 잘못생각함
- # for char in string:
- # stack.append(char)
- #
- # parentheses = {}
- # for i in range(len(string)):
- # stack_pop = stack.pop()
- #
- # if stack_pop == "(" or stack_pop == ")":
- # parentheses[len(string) - i] = stack_pop
-
-
-case1 = "(1+2)*(3+5)"
-case2 = "((3*12)/(41-31))"
-case3 = "((1+4)-(3*12)/3"
-case4 = "(12-3)*(56/3))"
-case5 = ")1+14)/3"
-case6 = "(3+15(*3"
-
-# parentheses_checker(case1)
-# parentheses_checker(case2)
-# parentheses_checker(case3)
-parentheses_checker(case4)
-# parentheses_checker(case5)
-# parentheses_checker(case6)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/doubly_linked_list/Insert_after.py b/data_structure/basic_data_structure/doubly_linked_list/Insert_after.py
deleted file mode 100644
index d894912..0000000
--- a/data_structure/basic_data_structure/doubly_linked_list/Insert_after.py
+++ /dev/null
@@ -1,134 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, data):
- self.data = data # 실제 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
- self.prev = None # 전 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
-
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
- def insert_after(self, previous_node, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data)
-
- if previous_node is self.tail:
- new_node.prev = self.tail
- self.tail.next = new_node
- self.tail = new_node
-
- else:
- new_node.prev = previous_node
- new_node.next = previous_node.next
-
- previous_node.next = new_node
- previous_node.next.prev = new_node
-
- def prepend(self, data):
- """링크드 리스트 가장 앞에 데이터를 추가시켜주는 메소드"""
- new_node = Node(data)
-
- if self.head is None:
- self.head = new_node
- self.tail = new_node
- else:
- self.head.prev = new_node
- new_node.next = self.head
- self.head = new_node
-
- def find_node_at(self, index):
- """링크드 리스트 접근 연산 메소드. 파라미터 인덱스는 항상 있다고 가정한다"""
-
- iterator = self.head # 링크드 리스트를 돌기 위해 필요한 노드 변수
-
- # index 번째 있는 노드로 간다
- for _ in range(index):
- iterator = iterator.next
-
- return iterator
-
- def append(self, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data) # 새로운 노드 생성
-
- # 빈 링크드 리스트라면 head와 tail을 새로 만든 노드로 지정
- if self.head is None:
- self.head = new_node
- self.tail = new_node
- # 이미 노드가 있으면
- else:
- self.tail.next = new_node # 마지막 노드의 다음 노드로 추가
- new_node.prev = self.tail
- self.tail = new_node # 마지막 노드 업데이
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += " {} |".format(iterator.data)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-
-# # 새로운 링크드 리스트 생성
-# my_list = LinkedList()
-#
-# # 새로운 노드 5개 추가
-# my_list.append(2)
-# my_list.append(3)
-# my_list.append(5)
-# my_list.append(7)
-# my_list.append(11)
-#
-# print(my_list)
-#
-# print("--------")
-#
-# # tail 노드 뒤에 노드 삽입
-# tail_node = my_list.tail # 4 번째(마지막)노드를 찾는다
-# my_list.insert_after(tail_node, 5) # 4 번째(마지막)노드 뒤에 노드 추가
-# print(my_list)
-# print(my_list.tail.data) # 새로운 tail 노드 데이터 출력
-#
-# print("--------")
-# # 링크드 리스트 중간에 데이터 삽입
-# node_at_index_3 = my_list.find_node_at(3) # 노드 접근
-# my_list.insert_after(node_at_index_3, 3)
-# print(my_list)
-#
-# print("--------")
-# # 링크드 리스트 중간에 데이터 삽입
-# node_at_index_2 = my_list.find_node_at(2) # 노드 접근
-# my_list.insert_after(node_at_index_2, 2)
-# print(my_list)
-#
-# print("----가장 앞 삽입----")
-
-# 새로운 링크드 리스트 생성
-my_list = LinkedList()
-
-# 여러 데이터를 링크드 리스트 앞에 추가
-my_list.prepend(11)
-my_list.prepend(7)
-my_list.prepend(5)
-my_list.prepend(3)
-my_list.prepend(2)
-
-print(my_list) # 링크드 리스트 출력
-
-# head, tail 노드가 제대로 설정됐는지 확인
-print(my_list.head.data)
-print(my_list.tail.data)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/doubly_linked_list/delete.py b/data_structure/basic_data_structure/doubly_linked_list/delete.py
deleted file mode 100644
index df9f0aa..0000000
--- a/data_structure/basic_data_structure/doubly_linked_list/delete.py
+++ /dev/null
@@ -1,89 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, data):
- self.data = data # 실제 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
- self.prev = None # 전 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
-
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
-
-
- def find_node_at(self, index):
- """링크드 리스트 접근 연산 메소드. 파라미터 인덱스는 항상 있다고 가정한다"""
-
- iterator = self.head # 링크드 리스트를 돌기 위해 필요한 노드 변수
-
- # index 번째 있는 노드로 간다
- for _ in range(index):
- iterator = iterator.next
-
- return iterator
-
- def append(self, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data) # 새로운 노드 생성
-
- # 빈 링크드 리스트라면 head와 tail을 새로 만든 노드로 지정
- if self.head is None:
- self.head = new_node
- self.tail = new_node
- # 이미 노드가 있으면
- else:
- self.tail.next = new_node # 마지막 노드의 다음 노드로 추가
- new_node.prev = self.tail
- self.tail = new_node # 마지막 노드 업데이
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += " {} |".format(iterator.data)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-
-# 새로운 링크드 리스트 생성
-my_list = LinkedList()
-
-# 새로운 노드 4개 추가
-my_list.append(2)
-my_list.append(3)
-my_list.append(5)
-my_list.append(7)
-
-print(my_list)
-
-# 두 노드 사이에 있는 노드 삭제
-node_at_index_2 = my_list.find_node_at(2)
-my_list.delete(node_at_index_2)
-print(my_list)
-
-# 가장 앞 노드 삭제
-head_node = my_list.head
-print(my_list.delete(head_node))
-print(my_list)
-
-# 가장 뒤 노드 삭제
-tail_node = my_list.tail
-my_list.delete(tail_node)
-print(my_list)
-
-# 마지막 노드 삭제
-last_node = my_list.head
-my_list.delete(last_node)
-print(my_list)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/doubly_linked_list/doubly_linked_list.py b/data_structure/basic_data_structure/doubly_linked_list/doubly_linked_list.py
deleted file mode 100644
index 7801c53..0000000
--- a/data_structure/basic_data_structure/doubly_linked_list/doubly_linked_list.py
+++ /dev/null
@@ -1,121 +0,0 @@
-class Node:
- """ 링크드 리스트의 노드 클리스"""
- def __init__(self, data):
- self.data = data # 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
- self.prev = None
-
-# 데이터가 2,3,5,7,11 을 담는 노드 인스턴스들 생성
-head_node = Node(2)
-node_1 = Node(3)
-node_2 = Node(5)
-node_3 = Node(7)
-tail_node = Node(11)
-
-# 노드들을 연결
-head_node.next = node_1
-node_1.next = node_2
-node_2.next = node_3
-node_3.next = tail_node
-
-# 노드 순서대로 출력
-iterator = head_node #반복문으로 리스트 볼 때 도움주는 역할
-
-# iterator 가 none이 아닌동안 반복함
-while iterator is not None:
- print(iterator.data)
- iterator = iterator.next
-
-print("-----------")
-class LikedList:
- """ 링크드 리스트 클래스 """
- def __init__(self):
- self.head = None
- self.tail = None
-
- def find_node_at(self, index):
- """ 링크드 리스트 접근연산 메소드. 파라미터 인덱스는 항상 있다고 가정"""
- iterator = self.head
-
- for _ in range(index):
- iterator = iterator.next
-
- return iterator
-
- def append(self, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data)
-
- # if는 싱글과 동일함
- if self.head is None: # 링크드 리스트가 비어 있는 경우
- self.head = new_node
- self.tail = new_node
- else: # 링크드 리스트가 비어 있지 않은 경우
- self.tail.next = new_node
- new_node.prev = self.tail
- self.tail = new_node
-
-
- def insert_after(self, previous_node, data):
- """링크드 리스트 주어진 노드 뒤 삽입 연산 메소드"""
- new_node = Node(data)
-
- # 가장 마지막 순서 삽입
- if previous_node is self.tail:
- self.tail.next = new_node
- self.tail = new_node
-
- else: # 두 노드 사이에 삽입
- new_node.next = previous_node.next
- previous_node.next = new_node
-
- def delete_after(self, previous_node):
- """링크드 리스트 삭제연산. 주어진 노드 뒤 노드를 삭제한다"""
- data = previous_node.next.data
-
- # 지우려는 노드가 tail 일때
- if previous_node.next is self.tail:
- previous_node.next = None
- self.tail = previous_node
- # 두 노드 사이를 노드를 지울 떄
- else:
- previous_node.next = previous_node.next.next
-
- return data
-
- def prepend(self, data):
- """링크드 리스트의 가장 앞에 데이터 삽입"""
- new_node = Node(data)
- if self.head is None:
- self.tail = new_node
- else:
- new_node.next = self.head
-
- self.head = new_node
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += " {} |".format(iterator.data)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-# 새로운 링크드 리스트 생성
-my_list = LikedList()
-
-# 링크드 리스트에 데이터 추가
-my_list.append(2)
-my_list.append(3)
-my_list.append(5)
-my_list.append(7)
-my_list.append(11)
-
-print(my_list)
diff --git a/data_structure/basic_data_structure/hash_table/HDLL.py b/data_structure/basic_data_structure/hash_table/HDLL.py
deleted file mode 100644
index 1516c68..0000000
--- a/data_structure/basic_data_structure/hash_table/HDLL.py
+++ /dev/null
@@ -1,83 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, key, value):
- self.key = key
- self.value = value
- self.next = None # 다음 노드에 대한 레퍼런스
- self.prev = None # 전 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
-
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
- def find_node_with_key(self, key):
- """링크드 리스트에서 주어진 데이터를 갖고있는 노드를 리턴한다. 단, 해당 노드가 없으면 None을 리턴한다"""
- iterator = self.head # 링크드 리스트를 돌기 위해 필요한 노드 변수
-
- while iterator is not None:
- if iterator.key == key:
- return iterator
-
- iterator = iterator.next
-
- return None
-
- def append(self, key, value):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(key, value)
-
- # 빈 링크드 리스트라면 head와 tail을 새로 만든 노드로 지정
- if self.head is None:
- self.head = new_node
- self.tail = new_node
- # 이미 노드가 있으면
- else:
- self.tail.next = new_node # 마지막 노드의 다음 노드로 추가
- new_node.prev = self.tail
- self.tail = new_node # 마지막 노드 업데이
-
- def delete(self, node_to_delete):
- """더블리 링크드 리스트 삭제 연산 메소드"""
-
- # 링크드 리스트에서 마지막 남은 데이터를 삭제할 때
- if node_to_delete is self.head and node_to_delete is self.tail:
- self.tail = None
- self.head = None
-
- # 링크드 리스트 가장 앞 데이터 삭제할 때
- elif node_to_delete is self.head:
- self.head = self.head.next
- self.head.prev = None
-
- # 링크드 리스트 가장 뒤 데이터 삭제할 떄
- elif node_to_delete is self.tail:
- self.tail = self.tail.prev
- self.tail.next = None
-
- # 두 노드 사이에 있는 데이터 삭제할 때
- else:
- node_to_delete.prev.next = node_to_delete.next
- node_to_delete.next.prev = node_to_delete.prev
-
- return node_to_delete.value
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = ""
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += "{}: {}\n".format(iterator.key, iterator.value)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
diff --git a/data_structure/basic_data_structure/hash_table/main.py b/data_structure/basic_data_structure/hash_table/main.py
deleted file mode 100644
index 3ea881c..0000000
--- a/data_structure/basic_data_structure/hash_table/main.py
+++ /dev/null
@@ -1,184 +0,0 @@
-from HDLL import LinkedList # 해시 테이블에서 사용할 링크드 리스트 임포트
-
-class HashTable:
- """해시 테이블 클래스"""
-
- def __init__(self, capacity):
- self._capacity = capacity # 파이썬 리스트 수용 크기 저장
- self._table = [LinkedList() for _ in range(self._capacity)] # 파이썬 리스트 인덱스에 반 링크드 리스트 저장
-
- def _hash_function(self, key):
- """
- 주어진 key에 나누기 방법을 사용해서 해시된 값을 리턴하는 메소드
- 주의: key는 파이썬 불변 타입이여야 한다.
- """
- return hash(key) % self._capacity
-
- def look_up_value(self, key):
- """
- 주어진 key에 해당하는 데이터를 리턴하는 메소드
- """
- # 코드를 쓰세요
- hash = self._hash_function(key)
- find = self._table[hash].find_node_with_key(key)
- return find.value
-
- def insert(self, key, value):
- """
- 새로운 key - value 쌍을 삽입시켜주는 메소드
- 이미 해당 key에 저장된 데이터가 있으면 해당 key에 해당하는 데이터를 바꿔준다
- """
- # 코드를 쓰세요
- hash = self._hash_function(key)
-
- node_with_key = self._table[hash].find_node_with_key(key)
-
- if node_with_key is not None:
- self._table[hash].delete(node_with_key)
- else:
- self._table[hash].append(key,value)
-
-
- def __str__(self):
- """해시 테이블 문자열 메소드"""
- res_str = ""
-
- for linked_list in self._table:
- res_str += str(linked_list)
-
- return res_str[:-1]
-
-
-# test_scores = HashTable(50) # 시험 점수를 담을 해시 테이블 인스턴스 생성
-#
-# # 여러 학생들 이름과 시험 점수 삽입
-# test_scores.insert("현승", 85)
-# test_scores.insert("영훈", 90)
-# test_scores.insert("동욱", 87)
-# test_scores.insert("지웅", 99)
-# test_scores.insert("신의", 88)
-# test_scores.insert("규식", 97)
-# test_scores.insert("태호", 90)
-#
-# print(test_scores)
-#
-# # key인 이름으로 특정 학생 시험 점수 검색
-# print(test_scores.look_up_value("현승"))
-# print(test_scores.look_up_value("태호"))
-# print(test_scores.look_up_value("영훈"))
-#
-# # 학생들 시험 점수 수정
-# test_scores.insert("현승", 10)
-# test_scores.insert("태호", 20)
-# test_scores.insert("영훈", 30)
-
-print("-------------------------")
-
-# 모범답안
-class HashTable_best:
- def __init__(self, capacity):
- self._capacity = capacity # 파이썬 리스트 수용 크기 저장
- self._table = [LinkedList() for _ in range(self._capacity)] # 파이썬 리스트 인덱스에 반 링크드 리스트 저장
-
- def _hash_function(self, key):
- """
- 주어진 key에 나누기 방법을 사용해서 해시된 값을 리턴하는 메소드
- 주의 사항: key는 파이썬 불변 타입이어야 한다.
- """
- return hash(key) % self._capacity
-
- def _get_linked_list_for_key(self, key):
- """주어진 key에 대응하는 인덱스에 저장된 링크드 리스트를 리턴하는 메소드"""
- hashed_index = self._hash_function(key)
- return self._table[hashed_index]
-
- def _look_up_node(self, key):
- """파라미터로 받은 key를 갖고 있는 노드를 리턴하는 메소드"""
- linked_list = self._get_linked_list_for_key(key)
- return linked_list.find_node_with_key(key)
-
- def look_up_value(self, key):
- """
- 주어진 key에 해당하는 데이터를 리턴하는 메소드
- """
- return self._look_up_node(key).value
-
- def insert(self, key, value):
- """
- 새로운 key - 데이터 쌍을 삽입시켜주는 메소드
- 이미 해당 key에 저장된 데이터가 있으면 해당 key에 대응하는 데이터를 바꿔준다
- """
- existing_node = self._look_up_node(key) # 이미 저장된 key인지 확인한다
-
- if existing_node is not None:
- existing_node.value = value # 이미 저장된 key면 데이터만 바꿔주고
- else:
- # 없는 키면 새롭게 삽입시켜준다
- linked_list = self._get_linked_list_for_key(key)
- linked_list.append(key, value)
-
- def delete_by_key(self, key):
-
- node = self._look_up_node(key) # 예와 처리 신경쓰자!!
-
- """주어진 key에 해당하는 key - value 쌍을 삭제하는 메소드"""
- if node is not None:
- self._get_linked_list_for_key(key).delete(node)
-
- def __str__(self):
- """해시 테이블 문자열 메소드"""
- res_str = ""
-
- for linked_list in self._table:
- res_str += str(linked_list)
-
- return res_str[:-1]
-
-
-# print(test_scores)
-# test_scores = HashTable_best(50) # 시험 점수를 담을 해시 테이블 인스턴스 생성
-
-# 여러 학생들 이름과 시험 점수 삽입
-# test_scores.insert("현승", 85)
-# test_scores.insert("영훈", 90)
-# test_scores.insert("동욱", 87)
-# test_scores.insert("지웅", 99)
-# test_scores.insert("신의", 88)
-# test_scores.insert("규식", 97)
-# test_scores.insert("태호", 90)
-#
-# print(test_scores)
-#
-# # key인 이름으로 특정 학생 시험 점수 검색
-# print(test_scores.look_up_value("현승"))
-# print(test_scores.look_up_value("태호"))
-# print(test_scores.look_up_value("영훈"))
-#
-# # 학생들 시험 점수 수정
-# test_scores.insert("현승", 10)
-# test_scores.insert("태호", 20)
-# test_scores.insert("영훈", 30)
-#
-# print(test_scores)
-
-print("-------------------------")
-
-test_scores3 = HashTable_best(50) # 시험 점수를 담을 해시 테이블 인스턴스 생성
-
-# 여러 학생들 이름과 시험 점수 삽입
-test_scores3.insert("현승", 85)
-test_scores3.insert("영훈", 90)
-test_scores3.insert("동욱", 87)
-test_scores3.insert("지웅", 99)
-test_scores3.insert("신의", 88)
-test_scores3.insert("규식", 97)
-test_scores3.insert("태호", 90)
-
-# 학생들 시험 점수 삭제
-test_scores3.delete_by_key("태호")
-test_scores3.delete_by_key("지웅")
-test_scores3.delete_by_key("신의")
-test_scores3.delete_by_key("현승")
-test_scores3.delete_by_key("규식")
-
-print(test_scores3)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/linked_list/LinedList.py b/data_structure/basic_data_structure/linked_list/LinedList.py
deleted file mode 100644
index 612d79b..0000000
--- a/data_structure/basic_data_structure/linked_list/LinedList.py
+++ /dev/null
@@ -1,166 +0,0 @@
-class Node:
- """ 링크드 리스트의 노드 클리스"""
- def __init__(self, data):
- self.data = data # 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
-
-# 데이터가 2,3,5,7,11 을 담는 노드 인스턴스들 생성
-head_node = Node(2)
-node_1 = Node(3)
-node_2 = Node(5)
-node_3 = Node(7)
-tail_node = Node(11)
-
-# 노드들을 연결
-head_node.next = node_1
-node_1.next = node_2
-node_2.next = node_3
-node_3.next = tail_node
-
-# 노드 순서대로 출력
-iterator = head_node #반복문으로 리스트 볼 때 도움주는 역할
-
-# iterator 가 none이 아닌동안 반복함
-while iterator is not None:
- print(iterator.data)
- iterator = iterator.next
-
-print("-----------")
-class LikedList:
- """ 링크드 리스트 클래스 """
- def __init__(self):
- self.head = None
- self.tail = None
-
- def find_node_at(self, index):
- """ 링크드 리스트 접근연산 메소드. 파라미터 인덱스는 항상 있다고 가정"""
- iterator = self.head
-
- for _ in range(index):
- iterator = iterator.next
-
- return iterator
-
- def append(self, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data)
-
- if self.head is None: # 링크드 리스트가 비어 있는 경우
- self.head = new_node
- self.tail = new_node
- else: # 링크드 리스트가 비어 있지 않은 경우
- self.tail.next = new_node
- self.tail = new_node
-
- def delete(self, node_to_delete):
- """더블리 링크드 리스트 삭제 연산 메소드"""
- # 하나만 있을 경우
- # if self.head is self.tail:
- if node_to_delete is self.head and node_to_delete is self.tail:
- self.head = None
- self.tail = None
- # 가장 앞 노드 선택 -> head 제거
- elif node_to_delete.prev is None:
- self.head = self.head.next
- self.head.prev = None
- # 가장 끝 노드 선택 -> tail 제거
- elif node_to_delete.next is None:
- self.tail = self.tail.prev
- self.tail.next = None
- else:
- node_to_delete.prev.next = node_to_delete.next
- node_to_delete.next.prev = node_to_delete.prev
-
- return node_to_delete.data
-
- def insert_after(self, previous_node, data):
- """링크드 리스트 주어진 노드 뒤 삽입 연산 메소드"""
- new_node = Node(data)
-
- # 가장 마지막 순서 삽입
- if previous_node is self.tail:
- self.tail.next = new_node
- self.tail = new_node
-
- else: # 두 노드 사이에 삽입
- new_node.next = previous_node.next
- previous_node.next = new_node
-
- def delete_after(self, previous_node):
- """링크드 리스트 삭제연산. 주어진 노드 뒤 노드를 삭제한다"""
- data = previous_node.next.data
-
- # 지우려는 노드가 tail 일때
- if previous_node.next is self.tail:
- previous_node.next = None
- self.tail = previous_node
- # 두 노드 사이를 노드를 지울 떄
- else:
- previous_node.next = previous_node.next.next
-
- return data
-
- def prepend(self, data):
- """링크드 리스트의 가장 앞에 데이터 삽입"""
- new_node = Node(data)
- if self.head is None:
- self.tail = new_node
- else:
- new_node.next = self.head
-
- self.head = new_node
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += " {} |".format(iterator.data)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-# 새로운 링크드 리스트 생성
-my_list = LikedList()
-
-# 링크드 리스트에 데이터 추가
-my_list.append(2)
-my_list.append(3)
-my_list.append(5)
-my_list.append(7)
-my_list.append(11)
-
-# 링크드 리스트 출력
-iterator = head_node
-while iterator is not None:
- print(iterator.data)
- iterator = iterator.next
-
-print("-----------")
-# 링크드 리스트 노드에 접근 (데이터 가지고 오기)
-print(my_list.find_node_at(3).data)
-# 링크드 리스트 노드에 접근 (데이터 바꾸기)
-my_list.find_node_at(2).data = 13
-
-print(my_list) # 전체 링크드 리스트 출력
-
-print("----- 삭 제 ------")
-my_list2 = LikedList()
-
-my_list2.append(2)
-my_list2.append(3)
-my_list2.append(5)
-my_list2.append(7)
-my_list2.append(11)
-
-print(my_list2)
-
-node2 = my_list2.find_node_at(2)
-print(my_list2.delete_after(node2))
-
-print(my_list2)
diff --git a/data_structure/basic_data_structure/linked_list/find_linked_list.py b/data_structure/basic_data_structure/linked_list/find_linked_list.py
deleted file mode 100644
index c887ef8..0000000
--- a/data_structure/basic_data_structure/linked_list/find_linked_list.py
+++ /dev/null
@@ -1,117 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, data):
- self.data = data # 실제 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
-
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
- def find_node_with_data(self, data):
- """링크드 리스트에서 탐색 연산 메소드. 단, 해당 노드가 없으면 None을 리턴한다"""
- iterator = self.head
- while iterator is not None:
- if iterator.data == data:
- return iterator
- iterator = iterator.next
-
- return None
-
- def insert_after(self, previous_node, data):
- """링크드 리스트 주어진 노드 뒤 삽입 연산 메소드"""
- new_node = Node(data)
-
- # 가장 마지막 순서 삽입
- if previous_node is self.tail:
- self.tail.next = new_node
- self.tail = new_node
-
- else: # 두 노드 사이에 삽입
- new_node.next = previous_node.next
- previous_node.next = new_node
-
- def append(self, data):
- """링크드 리스트 추가 연산 메소드"""
- new_node = Node(data)
-
- # 링크드 리스트가 비어 있으면 새로운 노드가 링크드 리스트의 처음이자 마지막 노드다
- if self.head is None:
- self.head = new_node
- self.tail = new_node
- # 링크드 리스트가 비어 있지 않으면
- else:
- self.tail.next = new_node # 가장 마지막 노드 뒤에 새로운 노드를 추가하고
- self.tail = new_node # 마지막 노드를 추가한 노드로 바꿔준다
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += " {} |".format(iterator.data)
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-
-# 새로운 링크드 리스트 생성
-linked_list = LinkedList()
-
-# 여러 데이터를 링크드 리스트 마지막에 추가
-linked_list.append(2)
-linked_list.append(3)
-linked_list.append(5)
-linked_list.append(7)
-linked_list.append(11)
-
-# 데이터 2를 갖는 노드 탐색
-node_with_2 = linked_list.find_node_with_data(2)
-
-if not node_with_2 is None:
- print(node_with_2.data)
-else:
- print("2를 갖는 노드는 없습니다")
-
-# 데이터 11을 갖는 노드 탐색
-node_with_11 = linked_list.find_node_with_data(11)
-
-if not node_with_11 is None:
- print(node_with_11.data)
-else:
- print("11을 갖는 노드는 없습니다")
-
-# 데이터 6 갖는 노드 탐색
-node_with_6 = linked_list.find_node_with_data(6)
-
-if not node_with_6 is None:
- print(node_with_6.data)
-else:
- print("6을 갖는 노드는 없습니다")
-
-# 삽입연산 수행
-# 새로운 링크드 리스트 생성
-print("-----------")
-linked_list2 = LinkedList()
-
-# 여러 데이터를 링크드 리스트 마지막에 추가
-linked_list2.append(2)
-linked_list2.append(3)
-linked_list2.append(5)
-linked_list2.append(7)
-linked_list2.append(11)
-
-print(linked_list2)
-node2 = linked_list2.find_node_with_data(2)
-linked_list2.insert_after(node2, 6)
-print(linked_list2)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/linked_list/pop_left.py b/data_structure/basic_data_structure/linked_list/pop_left.py
deleted file mode 100644
index 6b84857..0000000
--- a/data_structure/basic_data_structure/linked_list/pop_left.py
+++ /dev/null
@@ -1,75 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, data):
- self.data = data # 실제 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
- def pop_left(self):
- """링크드 리스트의 가장 앞 노드 삭제 메소드. 단, 링크드 리스트에 항상 노드가 있다고 가정한다"""
- data = self.head.data
-
- # if self.head is None:
- # self.tail = None
- if self.head is self.tail:
- self.head = None
- self.tail = None
- else:
- self.head = self.head.next
- return data
-
- def prepend(self, data):
- """링크드 리스트의 가장 앞에 데이터 삽입"""
- new_node = Node(data) # 새로운 노드를 만든다
-
- # 링크드 리스트가 비었는지 확인
- if self.head is None:
- self.tail = new_node
- else:
- new_node.next = self.head # 새로운 노드의 다음 노드를 head 노드로 정해주고
-
- self.head = new_node # 리스트의 head_node를 새롭게 삽입한 노드로 정해준다
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += f" {iterator.data} |"
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-
-# 새로운 링크드 리스트 생성
-linked_list = LinkedList()
-
-# 여러 데이터를 링크드 리스트 앞에 추가
-linked_list.prepend(11)
-linked_list.prepend(7)
-linked_list.prepend(5)
-linked_list.prepend(3)
-linked_list.prepend(2)
-
-# 가장 앞 노드 계속 삭제
-print(linked_list.pop_left())
-print(linked_list.pop_left())
-print(linked_list.pop_left())
-print(linked_list.pop_left())
-print(linked_list.pop_left())
-
-print(linked_list) # 링크드 리스트 출력
-print(linked_list.head)
-print(linked_list.tail)
\ No newline at end of file
diff --git a/data_structure/basic_data_structure/linked_list/prepend.py b/data_structure/basic_data_structure/linked_list/prepend.py
deleted file mode 100644
index 8689917..0000000
--- a/data_structure/basic_data_structure/linked_list/prepend.py
+++ /dev/null
@@ -1,58 +0,0 @@
-class Node:
- """링크드 리스트의 노드 클래스"""
-
- def __init__(self, data):
- self.data = data # 실제 노드가 저장하는 데이터
- self.next = None # 다음 노드에 대한 레퍼런스
-
-
-class LinkedList:
- """링크드 리스트 클래스"""
-
- def __init__(self):
- self.head = None # 링크드 리스트의 가장 앞 노드
- self.tail = None # 링크드 리스트의 가장 뒤 노드
-
- def prepend(self, data):
- """링크드 리스트의 가장 앞에 데이터 삽입"""
- new_node = Node(data)
- if self.head is None:
- self.tail = new_node
- else:
- new_node.next = self.head
-
- self.head = new_node
-
-
- def __str__(self):
- """링크드 리스트를 문자열로 표현해서 리턴하는 메소드"""
- res_str = "|"
-
- # 링크드 리스트 안에 모든 노드를 돌기 위한 변수. 일단 가장 앞 노드로 정의한다.
- iterator = self.head
-
- # 링크드 리스트 끝까지 돈다
- while iterator is not None:
- # 각 노드의 데이터를 리턴하는 문자열에 더해준다
- res_str += f" {iterator.data} |"
- iterator = iterator.next # 다음 노드로 넘어간다
-
- return res_str
-
-
-# 새로운 링크드 리스트 생성
-linked_list = LinkedList()
-
-# 여러 데이터를 링크드 리스트 앞에 추가
-linked_list.prepend(11)
-linked_list.prepend(7)
-linked_list.prepend(5)
-linked_list.prepend(3)
-linked_list.prepend(2)
-
-print(linked_list) # 링크드 리스트 출력
-
-# head, tail 노드가 제대로 설정됐는지 확인
-print(linked_list.head.data)
-print(linked_list.tail.data)
-
diff --git a/data_structure/graph/adjacency.py b/data_structure/graph/adjacency.py
deleted file mode 100644
index a07290d..0000000
--- a/data_structure/graph/adjacency.py
+++ /dev/null
@@ -1,34 +0,0 @@
-# 모든 요소를 0으로 초기화시킨 크기 6 x 6 인접 행렬
-adjacency_matrix = [[0 for i in range(6)] for i in range(6)]
-
-# 여기에 코드를 작성하세요
-
-# 영훈 0
-adjacency_matrix[0][1] = 1
-adjacency_matrix[1][0] = 1
-adjacency_matrix[0][2] = 1
-adjacency_matrix[2][0] = 1
-
-# 현승 1
-adjacency_matrix[1][3] = 1
-adjacency_matrix[3][1] = 1
-adjacency_matrix[1][5] = 1
-adjacency_matrix[5][1] = 1
-
-# 동욱 2
-adjacency_matrix[2][5] = 1
-adjacency_matrix[5][2] = 1
-
-# 지웅 3
-adjacency_matrix[3][4] = 1
-adjacency_matrix[4][3] = 1
-adjacency_matrix[3][5] = 1
-adjacency_matrix[5][3] = 1
-
-# 규리 4
-adjacency_matrix[4][5] = 1
-adjacency_matrix[5][4] = 1
-
-
-
-print(adjacency_matrix)
\ No newline at end of file
diff --git a/data_structure/graph/adjacency_list/StationNode.py b/data_structure/graph/adjacency_list/StationNode.py
deleted file mode 100644
index 0ecf4f3..0000000
--- a/data_structure/graph/adjacency_list/StationNode.py
+++ /dev/null
@@ -1,22 +0,0 @@
-class StationNode:
- """간단한 지하철 역 노드 클래스"""
- def __init__(self, station_name):
- self.station_name = station_name
- self.adjacent_stations = [] # 인접 리스트
-
-
- def add_connection(self, other_station):
- """지하철 역 노드 사이 엣지 저장하기"""
- self.adjacent_stations.append(other_station)
- other_station.adjacent_stations.append(self)
-
-
- def __str__(self):
- """지하철 노드 문자열 메소드. 지하철 역 이름과 연결된 역들을 모두 출력해준다"""
- res_str = f"{self.station_name}: " # 리턴할 문자열
-
- # 리턴할 문자열에 인접한 역 이름들 저장
- for station in self.adjacent_stations:
- res_str += f"{station.station_name} "
-
- return res_str
\ No newline at end of file
diff --git a/data_structure/graph/adjacency_list/main.py b/data_structure/graph/adjacency_list/main.py
deleted file mode 100644
index 0695d5c..0000000
--- a/data_structure/graph/adjacency_list/main.py
+++ /dev/null
@@ -1,40 +0,0 @@
-from StationNode import *
-
-# 코드를 추가하세요
-def create_subway_graph(input_file):
- """input_file에서 데이터를 읽어 와서 지하철 그래프를 리턴하는 함수"""
- stations = {} # 지하철 역 노드들을 담을 딕셔너리
-
- # 파라미터로 받은 input_file 파일을 연다
- with open(input_file) as stations_raw_file:
- for line in stations_raw_file: # 파일을 한 줄씩 받아온다
- previous_station = None # 엣지를 저장하기 위한 도우미 변수. 현재 보고 있는 역 전 역을 저장한다
- subway_line = line.strip().split("-") # 앞 뒤 띄어쓰기를 없애고 "-"를 기준점으로 데이터를 나눈다
-
- for name in subway_line:
- station_name = name.strip() # 앞 뒤 띄어쓰기 없애기
-
- # 지하철 역 이름이 이미 저장한 key 인지 확인
- if station_name not in stations:
- current_station = StationNode(station_name) # 새로운 인스턴스를 생성하고
- stations[station_name] = current_station # dictionary에 역 이름은 key로, 역 노드 인스턴스를 value로 저장한다
-
- else:
- current_station = stations[station_name] # 이미 저장한 역이면 stations 에서 역 인스턴스 가져옴
-
- if previous_station is not None:
- current_station.add_connection(previous_station) # 현재 역과 전 역의 엣지를 연결한다
-
- previous_station = current_station
-
-
-
-
- return stations
-
-
-stations = create_subway_graph("./stations.txt") # stations.txt 파일로 그래프를 만든다
-
-# stations에 저장한 역 인접 역들 출력 (채점을 위해 역 이름 순서대로 출력)
-for station in sorted(stations.keys()):
- print(stations[station])
\ No newline at end of file
diff --git a/data_structure/graph/adjacency_list/stations.txt b/data_structure/graph/adjacency_list/stations.txt
deleted file mode 100644
index 5068618..0000000
--- a/data_structure/graph/adjacency_list/stations.txt
+++ /dev/null
@@ -1,18 +0,0 @@
-소요산 - 동두천 - 보산 - 동두천중앙 - 지행 - 덕정 - 덕계 - 양주 - 녹양 - 가능 - 의정부 - 회룡 - 망월사 - 도봉산 - 도봉 - 방학 - 창동 - 녹천 - 월계 - 성북 - 석계 - 신이문 - 외대앞 - 회기 - 청량리 - 제기동 - 신설동 - 동묘앞 - 동대문 - 종로5가 - 종로3가 - 종각 - 시청 - 서울역 - 남영 - 용산 - 노량진 - 대방 - 신길 - 영등포 - 신도림 - 구로 - 구일 - 개봉 - 오류동 - 온수 - 역곡 - 소사 - 부천 - 중동 - 송내 - 부개 - 부평 - 백운 - 동암 - 간석 - 주안 - 도화 - 제물포 - 도원 - 동인천 - 인천 - 광명 - 가산디지털단지 - 독산 - 금천구청 - 석수 - 관악 - 안양 - 명학 - 금정 - 군포 - 당정 - 의왕 - 성균관대 - 화서 - 수원 - 세류 - 병점 - 세마 - 오산대 - 오산 - 진위 - 송탄 - 서정리 - 지제 - 평택 - 성환 - 직산 - 두정 - 천안 - 봉명 - 쌍용 - 아산 - 배방 - 온양온천 - 신창 - 서동탄
-시청 - 을지로입구 - 을지로3가 - 을지로4가 - 동대문역사문화공원 - 신당 - 상왕십리 - 왕십리 - 한양대 - 뚝섬 - 성수 - 건대입구 - 구의 - 강변 - 잠실나루 - 잠실 - 신천 - 종합운동장 - 삼성 - 선릉 - 역삼 - 강남 - 교대 - 서초 - 방배 - 사당 - 낙성대 - 서울대입구 - 봉천 - 신림 - 신대방 - 구로디지털단지 - 대림 - 신도림 - 문래 - 영등포구청 - 당산 - 합정 - 홍대입구 - 신촌 - 이대 - 아현 - 충정로 - 시청
-신도림 - 도림천 - 양천구청 - 신정네거리 - 까치산
-신설동 - 용두 - 신답 - 용답 - 성수
-대화 - 주엽 - 정발산 - 마두 - 백석 - 대곡 - 화정 - 원당 - 삼송 - 지축 - 구파발 - 연신내 - 불광 - 녹번 - 홍제 - 무악재 - 독립문 - 경복궁 - 안국 - 종로3가 - 을지로3가 - 충무로 - 동대입구 - 약수 - 금호 - 옥수 - 압구정 - 신사 - 잠원 - 고속터미널 - 교대 - 남부터미널 - 양재 - 매봉 - 도곡 - 대치 - 학여울 - 대청 - 일원 - 수서 - 가락시장 - 경찰병원 - 오금
-당고개 - 상계 - 노원 - 창동 - 쌍문 - 수유 - 미아 - 미아삼거리 - 길음 - 성신여대입구 - 한성대입구 - 혜화 - 동대문 - 동대문역사문화공원 - 충무로 - 명동 - 회현 - 서울역 - 숙대입구 - 삼각지 - 신용산 - 이촌 - 동작 - 이수 - 사당 - 남태령 - 선바위 - 경마공원 - 대공원 - 과천 - 정부과천청사 - 인덕원 - 평촌 - 범계 - 금정 - 산본 - 수리산 - 대야미 - 반월 - 상록수 - 한대앞 - 중앙 - 고잔 - 공단 - 안산 - 신길온천 - 정왕 - 오이도
-방화 - 개화산 - 김포공항 - 송정 - 마곡 - 발산 - 우장산 - 화곡 - 까치산 - 신정 - 목동 - 오목교 - 양평 - 영등포구청 - 영등포시장 - 신길 - 여의도 - 여의나루 - 마포 - 공덕 - 애오개 - 충정로 - 서대문 - 광화문 - 종로3가 - 을지로4가 - 동대문역사문화공원 - 청구 - 신금호 - 행당 - 왕십리 - 마장 - 답십리 - 장한평 - 군자 - 아차산 - 광나루 - 천호 - 강동 - 길동 - 굽은다리 - 명일 - 고덕 - 상일동 - 둔촌동 - 올림픽공원 - 방이 - 오금 - 개롱 - 거여 - 마천
-응암 - 역촌 - 불광 - 독바위 - 연신내 - 구산 - 응암 - 새절 - 증산 - 디지털미디어시티 - 월드컵경기장 - 마포구청 - 망원 - 합정 - 상수 - 광흥창 - 대흥 - 공덕 - 효창공원앞 - 삼각지 - 녹사평 - 이태원 - 한강진 - 버티고개 - 약수 - 청구 - 신당 - 동묘앞 - 창신 - 보문 - 안암 - 고려대 - 월곡 - 상월곡 - 돌곶이 - 석계 - 태릉입구 - 화랑대 - 봉화산
-장암 - 도봉산 - 수락산 - 마들 - 노원 - 중계 - 하계 - 공릉 - 태릉입구 - 먹골 - 중화 - 상봉 - 면목 - 사가정 - 용마산 - 중곡 - 군자 - 어린이대공원 - 건대입구 - 뚝섬유원지 - 청담 - 강남구청 - 학동 - 논현 - 반포 - 고속터미널 - 내방 - 이수 - 남성 - 숭실대입구 - 상도 - 장승배기 - 신대방삼거리 - 보라매 - 신풍 - 대림 - 남구로 - 가산디지털단지 - 철산 - 광명사거리 - 천왕 - 온수 - 까치울 - 부천종합운동장 - 춘의 - 신중동 - 부천시청 - 상동 - 삼산체육관 - 굴포천 - 부평구청
-암사 - 천호 - 강동구청 - 몽촌토성 - 잠실 - 석촌 - 송파 - 가락시장 - 문정 - 장지 - 복정 - 산성 - 남한산성입구 - 단대오거리 - 신흥 - 수진 - 모란
-개화 - 김포공항 - 공항시장 - 신방화 - 양천향교 - 가양 - 증미 - 등촌 - 염창 - 신목동 - 선유도 - 당산 - 국회의사당 - 여의도 - 샛강 - 노량진 - 노들 - 흑석 - 동작 - 구반포 - 신반포 - 고속터미널 - 사평 - 신논현 - 언주 - 선정릉 - 삼성중앙 - 봉은사 - 종합운동장
-왕십리 - 서울숲 - 압구정로데오 - 강남구청 - 선정릉 - 선릉 - 한티 - 도곡 - 구룡 - 개포동 - 대모산입구 - 수서 - 복정 - 경원대 - 태평 - 모란 - 야탑 - 이매 - 서현 - 수내 - 정자 - 미금 - 오리 - 죽전 - 보정 - 구성 - 신갈 - 기흥 - 상갈 - 청명 - 영통 - 망포
-용문 - 원덕 - 양평 - 오빈 - 아신 - 국수 - 신원 - 양수 - 운길산 - 팔당 - 도심 - 덕소 - 양정 - 도농 - 구리 - 양원 - 망우 - 상봉 - 중랑 - 회기 - 청량리 - 왕십리 - 응봉 - 옥수 - 한남 - 서빙고 - 이촌 - 용산 - 서울역 - 신촌 (경의중앙선) - 공덕 - 서강 - 홍대입구 - 가좌 - 디지털미디어시티 - 수색 - 화전 - 행신 - 능곡 - 대곡 - 곡산 - 백마 - 풍산 - 일산 - 탄현 - 운정 - 금릉 - 금촌 - 월롱 - 파주 - 문산
-서울역 - 공덕 - 홍대입구 - 디지털미디어시티 - 김포공항 - 계양 - 검암 - 운서 - 공항화물청사 - 인천국제공항
-계양 - 귤현 - 박촌 - 임학 - 계산 - 경인교대입구 - 작전 - 갈산 - 부평구청 - 부평시장 - 부평 - 동수 - 부평삼거리 - 간석오거리 - 인천시청 - 예술회관 - 인천터미널 - 문학경기장 - 선학 - 신연수 - 원인재 - 동춘 - 동막 - 캠퍼스타운 - 테크노파크 - 지식정보단지 - 인천대입구 - 센트럴파크 - 국제업무지구
-상봉 - 망우 - 갈매 - 별내역 - 퇴계원 - 사릉 - 금곡 - 평내호평 - 마석 - 대성리 - 청평 - 상천 - 가평 - 굴봉산 - 백양리 - 강촌 - 김유정 - 남춘천 - 춘천
-오이도 - 월곶 - 소래포구 - 인천논현 - 호구포 - 남동인더스파크 - 원인재 - 연수 - 송도
-강남 - 양재 - 양재시민의숲 - 청계산입구 - 판교 - 정자
\ No newline at end of file
diff --git a/data_structure/graph/bfs/main.py b/data_structure/graph/bfs/main.py
deleted file mode 100644
index 33f87ee..0000000
--- a/data_structure/graph/bfs/main.py
+++ /dev/null
@@ -1,39 +0,0 @@
-from collections import deque
-from subway_graph import create_station_graph
-
-def bfs(graph, start_node):
- """시작 노드에서 bfs를 실행하는 함수"""
- queue = deque() # 빈 큐 생성
-
- # 일단 모든 노드를 방문하지 않은 노드로 표시
- for station_node in graph.values():
- station_node.visited = False
-
- # 시작점 노드를 방문 표시한 후 큐에 넣어준다
- start_node.visited = True
- queue.append(start_node)
-
- while queue:
- current_station = queue.popleft()
- for neighbor in current_station.adjacent_stations:
- if neighbor.visited == False: # if not neighbor.visited:
- neighbor.visited = True
- queue.append(neighbor)
-
-stations = create_station_graph("./new_stations.txt") # stations.txt 파일로 그래프를 만든다
-gangnam_station = stations["강남"]
-
-# 강남역과 경로를 통해 연결된 모든 노드를 탐색
-bfs(stations, gangnam_station)
-
-# 강남역과 서울 지하철 역들이 연결됐는지 확인
-print(stations["강동구청"].visited)
-print(stations["평촌"].visited)
-print(stations["송도"].visited)
-print(stations["개화산"].visited)
-
-# 강남역과 대전 지하철 역들이 연결됐는지 확인
-print(stations["반석"].visited)
-print(stations["지족"].visited)
-print(stations["노은"].visited)
-print(stations["(대전)신흥"].visited)
\ No newline at end of file
diff --git a/data_structure/graph/bfs/new_stations.txt b/data_structure/graph/bfs/new_stations.txt
deleted file mode 100644
index 9f5c82f..0000000
--- a/data_structure/graph/bfs/new_stations.txt
+++ /dev/null
@@ -1,19 +0,0 @@
-소요산 - 동두천 - 보산 - 동두천중앙 - 지행 - 덕정 - 덕계 - 양주 - 녹양 - 가능 - 의정부 - 회룡 - 망월사 - 도봉산 - 도봉 - 방학 - 창동 - 녹천 - 월계 - 성북 - 석계 - 신이문 - 외대앞 - 회기 - 청량리 - 제기동 - 신설동 - 동묘앞 - 동대문 - 종로5가 - 종로3가 - 종각 - 시청 - 서울역 - 남영 - 용산 - 노량진 - 대방 - 신길 - 영등포 - 신도림 - 구로 - 구일 - 개봉 - 오류동 - 온수 - 역곡 - 소사 - 부천 - 중동 - 송내 - 부개 - 부평 - 백운 - 동암 - 간석 - 주안 - 도화 - 제물포 - 도원 - 동인천 - 인천 - 광명 - 가산디지털단지 - 독산 - 금천구청 - 석수 - 관악 - 안양 - 명학 - 금정 - 군포 - 당정 - 의왕 - 성균관대 - 화서 - 수원 - 세류 - 병점 - 세마 - 오산대 - 오산 - 진위 - 송탄 - 서정리 - 지제 - 평택 - 성환 - 직산 - 두정 - 천안 - 봉명 - 쌍용 - 아산 - 배방 - 온양온천 - 신창 - 서동탄
-시청 - 을지로입구 - 을지로3가 - 을지로4가 - 동대문역사문화공원 - 신당 - 상왕십리 - 왕십리 - 한양대 - 뚝섬 - 성수 - 건대입구 - 구의 - 강변 - 잠실나루 - 잠실 - 신천 - 종합운동장 - 삼성 - 선릉 - 역삼 - 강남 - 교대 - 서초 - 방배 - 사당 - 낙성대 - 서울대입구 - 봉천 - 신림 - 신대방 - 구로디지털단지 - 대림 - 신도림 - 문래 - 영등포구청 - 당산 - 합정 - 홍대입구 - 신촌 - 이대 - 아현 - 충정로 - 시청
-신도림 - 도림천 - 양천구청 - 신정네거리 - 까치산
-신설동 - 용두 - 신답 - 용답 - 성수
-대화 - 주엽 - 정발산 - 마두 - 백석 - 대곡 - 화정 - 원당 - 삼송 - 지축 - 구파발 - 연신내 - 불광 - 녹번 - 홍제 - 무악재 - 독립문 - 경복궁 - 안국 - 종로3가 - 을지로3가 - 충무로 - 동대입구 - 약수 - 금호 - 옥수 - 압구정 - 신사 - 잠원 - 고속터미널 - 교대 - 남부터미널 - 양재 - 매봉 - 도곡 - 대치 - 학여울 - 대청 - 일원 - 수서 - 가락시장 - 경찰병원 - 오금
-당고개 - 상계 - 노원 - 창동 - 쌍문 - 수유 - 미아 - 미아삼거리 - 길음 - 성신여대입구 - 한성대입구 - 혜화 - 동대문 - 동대문역사문화공원 - 충무로 - 명동 - 회현 - 서울역 - 숙대입구 - 삼각지 - 신용산 - 이촌 - 동작 - 이수 - 사당 - 남태령 - 선바위 - 경마공원 - 대공원 - 과천 - 정부과천청사 - 인덕원 - 평촌 - 범계 - 금정 - 산본 - 수리산 - 대야미 - 반월 - 상록수 - 한대앞 - 중앙 - 고잔 - 공단 - 안산 - 신길온천 - 정왕 - 오이도
-방화 - 개화산 - 김포공항 - 송정 - 마곡 - 발산 - 우장산 - 화곡 - 까치산 - 신정 - 목동 - 오목교 - 양평 - 영등포구청 - 영등포시장 - 신길 - 여의도 - 여의나루 - 마포 - 공덕 - 애오개 - 충정로 - 서대문 - 광화문 - 종로3가 - 을지로4가 - 동대문역사문화공원 - 청구 - 신금호 - 행당 - 왕십리 - 마장 - 답십리 - 장한평 - 군자 - 아차산 - 광나루 - 천호 - 강동 - 길동 - 굽은다리 - 명일 - 고덕 - 상일동 - 둔촌동 - 올림픽공원 - 방이 - 오금 - 개롱 - 거여 - 마천
-응암 - 역촌 - 불광 - 독바위 - 연신내 - 구산 - 응암 - 새절 - 증산 - 디지털미디어시티 - 월드컵경기장 - 마포구청 - 망원 - 합정 - 상수 - 광흥창 - 대흥 - 공덕 - 효창공원앞 - 삼각지 - 녹사평 - 이태원 - 한강진 - 버티고개 - 약수 - 청구 - 신당 - 동묘앞 - 창신 - 보문 - 안암 - 고려대 - 월곡 - 상월곡 - 돌곶이 - 석계 - 태릉입구 - 화랑대 - 봉화산
-장암 - 도봉산 - 수락산 - 마들 - 노원 - 중계 - 하계 - 공릉 - 태릉입구 - 먹골 - 중화 - 상봉 - 면목 - 사가정 - 용마산 - 중곡 - 군자 - 어린이대공원 - 건대입구 - 뚝섬유원지 - 청담 - 강남구청 - 학동 - 논현 - 반포 - 고속터미널 - 내방 - 이수 - 남성 - 숭실대입구 - 상도 - 장승배기 - 신대방삼거리 - 보라매 - 신풍 - 대림 - 남구로 - 가산디지털단지 - 철산 - 광명사거리 - 천왕 - 온수 - 까치울 - 부천종합운동장 - 춘의 - 신중동 - 부천시청 - 상동 - 삼산체육관 - 굴포천 - 부평구청
-암사 - 천호 - 강동구청 - 몽촌토성 - 잠실 - 석촌 - 송파 - 가락시장 - 문정 - 장지 - 복정 - 산성 - 남한산성입구 - 단대오거리 - 신흥 - 수진 - 모란
-개화 - 김포공항 - 공항시장 - 신방화 - 양천향교 - 가양 - 증미 - 등촌 - 염창 - 신목동 - 선유도 - 당산 - 국회의사당 - 여의도 - 샛강 - 노량진 - 노들 - 흑석 - 동작 - 구반포 - 신반포 - 고속터미널 - 사평 - 신논현 - 언주 - 선정릉 - 삼성중앙 - 봉은사 - 종합운동장
-왕십리 - 서울숲 - 압구정로데오 - 강남구청 - 선정릉 - 선릉 - 한티 - 도곡 - 구룡 - 개포동 - 대모산입구 - 수서 - 복정 - 경원대 - 태평 - 모란 - 야탑 - 이매 - 서현 - 수내 - 정자 - 미금 - 오리 - 죽전 - 보정 - 구성 - 신갈 - 기흥 - 상갈 - 청명 - 영통 - 망포
-용문 - 원덕 - 양평 - 오빈 - 아신 - 국수 - 신원 - 양수 - 운길산 - 팔당 - 도심 - 덕소 - 양정 - 도농 - 구리 - 양원 - 망우 - 상봉 - 중랑 - 회기 - 청량리 - 왕십리 - 응봉 - 옥수 - 한남 - 서빙고 - 이촌 - 용산 - 서울역 - 신촌 (경의중앙선) - 공덕 - 서강 - 홍대입구 - 가좌 - 디지털미디어시티 - 수색 - 화전 - 행신 - 능곡 - 대곡 - 곡산 - 백마 - 풍산 - 일산 - 탄현 - 운정 - 금릉 - 금촌 - 월롱 - 파주 - 문산
-서울역 - 공덕 - 홍대입구 - 디지털미디어시티 - 김포공항 - 계양 - 검암 - 운서 - 공항화물청사 - 인천국제공항
-계양 - 귤현 - 박촌 - 임학 - 계산 - 경인교대입구 - 작전 - 갈산 - 부평구청 - 부평시장 - 부평 - 동수 - 부평삼거리 - 간석오거리 - 인천시청 - 예술회관 - 인천터미널 - 문학경기장 - 선학 - 신연수 - 원인재 - 동춘 - 동막 - 캠퍼스타운 - 테크노파크 - 지식정보단지 - 인천대입구 - 센트럴파크 - 국제업무지구
-상봉 - 망우 - 갈매 - 별내역 - 퇴계원 - 사릉 - 금곡 - 평내호평 - 마석 - 대성리 - 청평 - 상천 - 가평 - 굴봉산 - 백양리 - 강촌 - 김유정 - 남춘천 - 춘천
-오이도 - 월곶 - 소래포구 - 인천논현 - 호구포 - 남동인더스파크 - 원인재 - 연수 - 송도
-강남 - 양재 - 양재시민의숲 - 청계산입구 - 판교 - 정자
-반석 - 지족 - 노은 - (대전)월드컵경기장 - (대전)현충원 - 구암 - 유성온천 - 갑천 - 월평 - 갈마 - 정부청사 - (대전)시청 - 탄방 - (대전)용문 - 오룡 - 서대전네거리 - 중구청 - 중앙로 - 대전역 - 대동 - (대전)신흥 - 판암
\ No newline at end of file
diff --git a/data_structure/graph/bfs/subway_graph.py b/data_structure/graph/bfs/subway_graph.py
deleted file mode 100644
index 747b9d2..0000000
--- a/data_structure/graph/bfs/subway_graph.py
+++ /dev/null
@@ -1,38 +0,0 @@
-class StationNode:
- """지하철 역을 나타내는 역"""
- def __init__(self, station_name):
- self.station_name = station_name
- self.adjacent_stations = []
- self.visited = False
-
- def add_connection(self, station):
- """파라미터로 받은 역과 엣지를 만들어주는 메소드"""
- self.adjacent_stations.append(station)
- station.adjacent_stations.append(self)
-
-
-def create_station_graph(input_file):
- stations = {}
-
- # 일반 텍스트 파일을 여는 코드
- with open(input_file) as stations_raw_file:
- for line in stations_raw_file: # 파일을 한 줄씩 받아온다
- previous_station = None # 엣지를 저장하기 위한 변수
- raw_data = line.strip().split("-")
-
- for name in raw_data:
- station_name = name.strip()
-
- if station_name not in stations:
- current_station = StationNode(station_name)
- stations[station_name] = current_station
-
- else:
- current_station = stations[station_name]
-
- if previous_station is not None:
- current_station.add_connection(previous_station)
-
- previous_station = current_station
-
- return stations
\ No newline at end of file
diff --git a/data_structure/graph/dfs/main.py b/data_structure/graph/dfs/main.py
deleted file mode 100644
index 4b66355..0000000
--- a/data_structure/graph/dfs/main.py
+++ /dev/null
@@ -1,45 +0,0 @@
-from collections import deque
-from subway_graph import *
-
-def dfs(graph, start_node):
- """dfs 함수"""
- stack = deque() # 빈 스택 생성
-
- # 모든 노드를 처음 보는 노드로 초기화
- for station_node in graph.values():
- station_node.visited = 0
-
- # 테스트 코드
- start_node.visited = 1 # 착각해서 station_node로 했음
- stack.append(start_node) # 착각해서 station_node로 했음
-
- while stack:
- current_node = stack.pop()
- current_node.visited = 2
-
- for neighbor in current_node.adjacent_stations:
- if neighbor.visited == 0:
- neighbor.visited = 1
- stack.append(neighbor)
-
-
-
-stations = create_station_graph("./new_stations.txt") # stations.txt 파일로 그래프를 만든다
-
-gangnam_station = stations["강남"]
-
-# 강남역과 경로를 통해 연결된 모든 노드를 탐색
-dfs(stations, gangnam_station)
-
-# 강남역과 서울 지하철 역들 연결됐는지 확인
-print(stations["강동구청"].visited)
-print(stations["평촌"].visited)
-print(stations["송도"].visited)
-print(stations["개화산"].visited)
-
-# 강남역과 대전 지하철 역들 연결됐는지 확인
-print(stations["반석"].visited)
-print(stations["지족"].visited)
-print(stations["노은"].visited)
-print(stations["(대전)신흥"].visited)
-
diff --git a/data_structure/graph/dfs/new_stations.txt b/data_structure/graph/dfs/new_stations.txt
deleted file mode 100644
index 9f5c82f..0000000
--- a/data_structure/graph/dfs/new_stations.txt
+++ /dev/null
@@ -1,19 +0,0 @@
-소요산 - 동두천 - 보산 - 동두천중앙 - 지행 - 덕정 - 덕계 - 양주 - 녹양 - 가능 - 의정부 - 회룡 - 망월사 - 도봉산 - 도봉 - 방학 - 창동 - 녹천 - 월계 - 성북 - 석계 - 신이문 - 외대앞 - 회기 - 청량리 - 제기동 - 신설동 - 동묘앞 - 동대문 - 종로5가 - 종로3가 - 종각 - 시청 - 서울역 - 남영 - 용산 - 노량진 - 대방 - 신길 - 영등포 - 신도림 - 구로 - 구일 - 개봉 - 오류동 - 온수 - 역곡 - 소사 - 부천 - 중동 - 송내 - 부개 - 부평 - 백운 - 동암 - 간석 - 주안 - 도화 - 제물포 - 도원 - 동인천 - 인천 - 광명 - 가산디지털단지 - 독산 - 금천구청 - 석수 - 관악 - 안양 - 명학 - 금정 - 군포 - 당정 - 의왕 - 성균관대 - 화서 - 수원 - 세류 - 병점 - 세마 - 오산대 - 오산 - 진위 - 송탄 - 서정리 - 지제 - 평택 - 성환 - 직산 - 두정 - 천안 - 봉명 - 쌍용 - 아산 - 배방 - 온양온천 - 신창 - 서동탄
-시청 - 을지로입구 - 을지로3가 - 을지로4가 - 동대문역사문화공원 - 신당 - 상왕십리 - 왕십리 - 한양대 - 뚝섬 - 성수 - 건대입구 - 구의 - 강변 - 잠실나루 - 잠실 - 신천 - 종합운동장 - 삼성 - 선릉 - 역삼 - 강남 - 교대 - 서초 - 방배 - 사당 - 낙성대 - 서울대입구 - 봉천 - 신림 - 신대방 - 구로디지털단지 - 대림 - 신도림 - 문래 - 영등포구청 - 당산 - 합정 - 홍대입구 - 신촌 - 이대 - 아현 - 충정로 - 시청
-신도림 - 도림천 - 양천구청 - 신정네거리 - 까치산
-신설동 - 용두 - 신답 - 용답 - 성수
-대화 - 주엽 - 정발산 - 마두 - 백석 - 대곡 - 화정 - 원당 - 삼송 - 지축 - 구파발 - 연신내 - 불광 - 녹번 - 홍제 - 무악재 - 독립문 - 경복궁 - 안국 - 종로3가 - 을지로3가 - 충무로 - 동대입구 - 약수 - 금호 - 옥수 - 압구정 - 신사 - 잠원 - 고속터미널 - 교대 - 남부터미널 - 양재 - 매봉 - 도곡 - 대치 - 학여울 - 대청 - 일원 - 수서 - 가락시장 - 경찰병원 - 오금
-당고개 - 상계 - 노원 - 창동 - 쌍문 - 수유 - 미아 - 미아삼거리 - 길음 - 성신여대입구 - 한성대입구 - 혜화 - 동대문 - 동대문역사문화공원 - 충무로 - 명동 - 회현 - 서울역 - 숙대입구 - 삼각지 - 신용산 - 이촌 - 동작 - 이수 - 사당 - 남태령 - 선바위 - 경마공원 - 대공원 - 과천 - 정부과천청사 - 인덕원 - 평촌 - 범계 - 금정 - 산본 - 수리산 - 대야미 - 반월 - 상록수 - 한대앞 - 중앙 - 고잔 - 공단 - 안산 - 신길온천 - 정왕 - 오이도
-방화 - 개화산 - 김포공항 - 송정 - 마곡 - 발산 - 우장산 - 화곡 - 까치산 - 신정 - 목동 - 오목교 - 양평 - 영등포구청 - 영등포시장 - 신길 - 여의도 - 여의나루 - 마포 - 공덕 - 애오개 - 충정로 - 서대문 - 광화문 - 종로3가 - 을지로4가 - 동대문역사문화공원 - 청구 - 신금호 - 행당 - 왕십리 - 마장 - 답십리 - 장한평 - 군자 - 아차산 - 광나루 - 천호 - 강동 - 길동 - 굽은다리 - 명일 - 고덕 - 상일동 - 둔촌동 - 올림픽공원 - 방이 - 오금 - 개롱 - 거여 - 마천
-응암 - 역촌 - 불광 - 독바위 - 연신내 - 구산 - 응암 - 새절 - 증산 - 디지털미디어시티 - 월드컵경기장 - 마포구청 - 망원 - 합정 - 상수 - 광흥창 - 대흥 - 공덕 - 효창공원앞 - 삼각지 - 녹사평 - 이태원 - 한강진 - 버티고개 - 약수 - 청구 - 신당 - 동묘앞 - 창신 - 보문 - 안암 - 고려대 - 월곡 - 상월곡 - 돌곶이 - 석계 - 태릉입구 - 화랑대 - 봉화산
-장암 - 도봉산 - 수락산 - 마들 - 노원 - 중계 - 하계 - 공릉 - 태릉입구 - 먹골 - 중화 - 상봉 - 면목 - 사가정 - 용마산 - 중곡 - 군자 - 어린이대공원 - 건대입구 - 뚝섬유원지 - 청담 - 강남구청 - 학동 - 논현 - 반포 - 고속터미널 - 내방 - 이수 - 남성 - 숭실대입구 - 상도 - 장승배기 - 신대방삼거리 - 보라매 - 신풍 - 대림 - 남구로 - 가산디지털단지 - 철산 - 광명사거리 - 천왕 - 온수 - 까치울 - 부천종합운동장 - 춘의 - 신중동 - 부천시청 - 상동 - 삼산체육관 - 굴포천 - 부평구청
-암사 - 천호 - 강동구청 - 몽촌토성 - 잠실 - 석촌 - 송파 - 가락시장 - 문정 - 장지 - 복정 - 산성 - 남한산성입구 - 단대오거리 - 신흥 - 수진 - 모란
-개화 - 김포공항 - 공항시장 - 신방화 - 양천향교 - 가양 - 증미 - 등촌 - 염창 - 신목동 - 선유도 - 당산 - 국회의사당 - 여의도 - 샛강 - 노량진 - 노들 - 흑석 - 동작 - 구반포 - 신반포 - 고속터미널 - 사평 - 신논현 - 언주 - 선정릉 - 삼성중앙 - 봉은사 - 종합운동장
-왕십리 - 서울숲 - 압구정로데오 - 강남구청 - 선정릉 - 선릉 - 한티 - 도곡 - 구룡 - 개포동 - 대모산입구 - 수서 - 복정 - 경원대 - 태평 - 모란 - 야탑 - 이매 - 서현 - 수내 - 정자 - 미금 - 오리 - 죽전 - 보정 - 구성 - 신갈 - 기흥 - 상갈 - 청명 - 영통 - 망포
-용문 - 원덕 - 양평 - 오빈 - 아신 - 국수 - 신원 - 양수 - 운길산 - 팔당 - 도심 - 덕소 - 양정 - 도농 - 구리 - 양원 - 망우 - 상봉 - 중랑 - 회기 - 청량리 - 왕십리 - 응봉 - 옥수 - 한남 - 서빙고 - 이촌 - 용산 - 서울역 - 신촌 (경의중앙선) - 공덕 - 서강 - 홍대입구 - 가좌 - 디지털미디어시티 - 수색 - 화전 - 행신 - 능곡 - 대곡 - 곡산 - 백마 - 풍산 - 일산 - 탄현 - 운정 - 금릉 - 금촌 - 월롱 - 파주 - 문산
-서울역 - 공덕 - 홍대입구 - 디지털미디어시티 - 김포공항 - 계양 - 검암 - 운서 - 공항화물청사 - 인천국제공항
-계양 - 귤현 - 박촌 - 임학 - 계산 - 경인교대입구 - 작전 - 갈산 - 부평구청 - 부평시장 - 부평 - 동수 - 부평삼거리 - 간석오거리 - 인천시청 - 예술회관 - 인천터미널 - 문학경기장 - 선학 - 신연수 - 원인재 - 동춘 - 동막 - 캠퍼스타운 - 테크노파크 - 지식정보단지 - 인천대입구 - 센트럴파크 - 국제업무지구
-상봉 - 망우 - 갈매 - 별내역 - 퇴계원 - 사릉 - 금곡 - 평내호평 - 마석 - 대성리 - 청평 - 상천 - 가평 - 굴봉산 - 백양리 - 강촌 - 김유정 - 남춘천 - 춘천
-오이도 - 월곶 - 소래포구 - 인천논현 - 호구포 - 남동인더스파크 - 원인재 - 연수 - 송도
-강남 - 양재 - 양재시민의숲 - 청계산입구 - 판교 - 정자
-반석 - 지족 - 노은 - (대전)월드컵경기장 - (대전)현충원 - 구암 - 유성온천 - 갑천 - 월평 - 갈마 - 정부청사 - (대전)시청 - 탄방 - (대전)용문 - 오룡 - 서대전네거리 - 중구청 - 중앙로 - 대전역 - 대동 - (대전)신흥 - 판암
\ No newline at end of file
diff --git a/data_structure/graph/dfs/subway_graph.py b/data_structure/graph/dfs/subway_graph.py
deleted file mode 100644
index 43d2302..0000000
--- a/data_structure/graph/dfs/subway_graph.py
+++ /dev/null
@@ -1,42 +0,0 @@
-class StationNode:
- """간단한 지하철 역 노드 클래스"""
- def __init__(self, station_name):
- self.station_name = station_name
- self.visited = 0 # 한 번도 본적 없을 때: 0, 스택에 있을 때: 1, 발견된 상태: 2
- self.adjacent_stations = []
-
-
- def add_connection(self, other_station):
- """지하철 역 노드 사이 엣지 저장하기"""
- self.adjacent_stations.append(other_station)
- other_station.adjacent_stations.append(self)
-
-
-def create_station_graph(input_file):
- """input_file에서 데이터를 읽어 와서 지하철 그래프 노드들을 리턴하는 함수"""
- stations = {} # 지하철 역 노드들을 담을 딕셔너리
-
- # 파라미터로 받은 input_file 파일을 연다
- with open(input_file) as stations_raw_file:
- for line in stations_raw_file: # 파일을 한 줄씩 받아온다
- previous_station = None # 엣지를 저장하기 위한 도우미 변수. 현재 보고 있는 역 전 역을 저장한다
- subway_line = line.strip().split("-") # 앞 뒤 띄어쓰기를 없애고 "-"를 기준점으로 데이터를 나눈다
-
- for name in subway_line:
- station_name = name.strip() # 앞 뒤 띄어쓰기 없애기
-
- # 지하철 역 이름이 이미 저장한 key 인지 확인
- if station_name not in stations:
- current_station = StationNode(station_name) # 새로운 인스턴스를 생성하고
- stations[station_name] = current_station # dictionary에 역 이름은 key로, 역 인스턴스를 value로 저장한다
-
- else:
- current_station = stations[station_name] # 이미 저장한 역이면 stations에서 역 인스턴스를 갖고 온다
-
- if previous_station is not None:
- current_station.add_connection(previous_station) # 현재 역과 전 역의 엣지를 연결한다
-
- previous_station = current_station # 현재 역을 전 역으로 저장
-
- return stations
-
diff --git a/data_structure/graph/graph/main.py b/data_structure/graph/graph/main.py
deleted file mode 100644
index 4fc18d8..0000000
--- a/data_structure/graph/graph/main.py
+++ /dev/null
@@ -1,33 +0,0 @@
-class StationNode:
- """간단한 지하철 역 노드 클래스"""
-
- def __init__(self, station_name):
- self.station_name = station_name
-
-
-def create_station_nodes(input_file):
- """input_file에서 데이터를 읽어 와서 지하철 그래프 노드들을 리턴하는 함수"""
- stations = {} # 지하철 역 노드들을 담을 딕셔너리
-
- # 파라미터로 받은 input_file 파일을 연다
- with open(input_file) as stations_raw_file:
- for line in stations_raw_file: # 파일을 한 줄씩 받아온다
- subway_line = line.strip().split("-") # 앞 뒤 띄어쓰기를 없애고 "-"를 기준점으로 데이터를 나눈다
-
- for name in subway_line:
- station_name = name.strip() # 앞 뒤 띄어쓰기 없애기
-
- # 지하철 역 이름이 이미 저장한 key 인지 확인
- if station_name not in stations:
- current_station = StationNode(station_name) # 새로운 인스턴스를 생성하고
- stations[station_name] = current_station # dictionary에 역 이름은 key로, 역 노드 인스턴스를 value로 저장한다
-
- return stations
-
-
-stations = create_station_nodes("stations.txt") # stations.txt 파일로 그래프 노드들을 만든다
-
-# 테스트 코드
-# stations에 저장한 역들 이름 출력 (채점을 위해 역 이름 순서대로 출력)
-for station in sorted(stations.keys()):
- print(stations[station].station_name)
\ No newline at end of file
diff --git a/data_structure/graph/graph/stations.txt b/data_structure/graph/graph/stations.txt
deleted file mode 100644
index 5068618..0000000
--- a/data_structure/graph/graph/stations.txt
+++ /dev/null
@@ -1,18 +0,0 @@
-소요산 - 동두천 - 보산 - 동두천중앙 - 지행 - 덕정 - 덕계 - 양주 - 녹양 - 가능 - 의정부 - 회룡 - 망월사 - 도봉산 - 도봉 - 방학 - 창동 - 녹천 - 월계 - 성북 - 석계 - 신이문 - 외대앞 - 회기 - 청량리 - 제기동 - 신설동 - 동묘앞 - 동대문 - 종로5가 - 종로3가 - 종각 - 시청 - 서울역 - 남영 - 용산 - 노량진 - 대방 - 신길 - 영등포 - 신도림 - 구로 - 구일 - 개봉 - 오류동 - 온수 - 역곡 - 소사 - 부천 - 중동 - 송내 - 부개 - 부평 - 백운 - 동암 - 간석 - 주안 - 도화 - 제물포 - 도원 - 동인천 - 인천 - 광명 - 가산디지털단지 - 독산 - 금천구청 - 석수 - 관악 - 안양 - 명학 - 금정 - 군포 - 당정 - 의왕 - 성균관대 - 화서 - 수원 - 세류 - 병점 - 세마 - 오산대 - 오산 - 진위 - 송탄 - 서정리 - 지제 - 평택 - 성환 - 직산 - 두정 - 천안 - 봉명 - 쌍용 - 아산 - 배방 - 온양온천 - 신창 - 서동탄
-시청 - 을지로입구 - 을지로3가 - 을지로4가 - 동대문역사문화공원 - 신당 - 상왕십리 - 왕십리 - 한양대 - 뚝섬 - 성수 - 건대입구 - 구의 - 강변 - 잠실나루 - 잠실 - 신천 - 종합운동장 - 삼성 - 선릉 - 역삼 - 강남 - 교대 - 서초 - 방배 - 사당 - 낙성대 - 서울대입구 - 봉천 - 신림 - 신대방 - 구로디지털단지 - 대림 - 신도림 - 문래 - 영등포구청 - 당산 - 합정 - 홍대입구 - 신촌 - 이대 - 아현 - 충정로 - 시청
-신도림 - 도림천 - 양천구청 - 신정네거리 - 까치산
-신설동 - 용두 - 신답 - 용답 - 성수
-대화 - 주엽 - 정발산 - 마두 - 백석 - 대곡 - 화정 - 원당 - 삼송 - 지축 - 구파발 - 연신내 - 불광 - 녹번 - 홍제 - 무악재 - 독립문 - 경복궁 - 안국 - 종로3가 - 을지로3가 - 충무로 - 동대입구 - 약수 - 금호 - 옥수 - 압구정 - 신사 - 잠원 - 고속터미널 - 교대 - 남부터미널 - 양재 - 매봉 - 도곡 - 대치 - 학여울 - 대청 - 일원 - 수서 - 가락시장 - 경찰병원 - 오금
-당고개 - 상계 - 노원 - 창동 - 쌍문 - 수유 - 미아 - 미아삼거리 - 길음 - 성신여대입구 - 한성대입구 - 혜화 - 동대문 - 동대문역사문화공원 - 충무로 - 명동 - 회현 - 서울역 - 숙대입구 - 삼각지 - 신용산 - 이촌 - 동작 - 이수 - 사당 - 남태령 - 선바위 - 경마공원 - 대공원 - 과천 - 정부과천청사 - 인덕원 - 평촌 - 범계 - 금정 - 산본 - 수리산 - 대야미 - 반월 - 상록수 - 한대앞 - 중앙 - 고잔 - 공단 - 안산 - 신길온천 - 정왕 - 오이도
-방화 - 개화산 - 김포공항 - 송정 - 마곡 - 발산 - 우장산 - 화곡 - 까치산 - 신정 - 목동 - 오목교 - 양평 - 영등포구청 - 영등포시장 - 신길 - 여의도 - 여의나루 - 마포 - 공덕 - 애오개 - 충정로 - 서대문 - 광화문 - 종로3가 - 을지로4가 - 동대문역사문화공원 - 청구 - 신금호 - 행당 - 왕십리 - 마장 - 답십리 - 장한평 - 군자 - 아차산 - 광나루 - 천호 - 강동 - 길동 - 굽은다리 - 명일 - 고덕 - 상일동 - 둔촌동 - 올림픽공원 - 방이 - 오금 - 개롱 - 거여 - 마천
-응암 - 역촌 - 불광 - 독바위 - 연신내 - 구산 - 응암 - 새절 - 증산 - 디지털미디어시티 - 월드컵경기장 - 마포구청 - 망원 - 합정 - 상수 - 광흥창 - 대흥 - 공덕 - 효창공원앞 - 삼각지 - 녹사평 - 이태원 - 한강진 - 버티고개 - 약수 - 청구 - 신당 - 동묘앞 - 창신 - 보문 - 안암 - 고려대 - 월곡 - 상월곡 - 돌곶이 - 석계 - 태릉입구 - 화랑대 - 봉화산
-장암 - 도봉산 - 수락산 - 마들 - 노원 - 중계 - 하계 - 공릉 - 태릉입구 - 먹골 - 중화 - 상봉 - 면목 - 사가정 - 용마산 - 중곡 - 군자 - 어린이대공원 - 건대입구 - 뚝섬유원지 - 청담 - 강남구청 - 학동 - 논현 - 반포 - 고속터미널 - 내방 - 이수 - 남성 - 숭실대입구 - 상도 - 장승배기 - 신대방삼거리 - 보라매 - 신풍 - 대림 - 남구로 - 가산디지털단지 - 철산 - 광명사거리 - 천왕 - 온수 - 까치울 - 부천종합운동장 - 춘의 - 신중동 - 부천시청 - 상동 - 삼산체육관 - 굴포천 - 부평구청
-암사 - 천호 - 강동구청 - 몽촌토성 - 잠실 - 석촌 - 송파 - 가락시장 - 문정 - 장지 - 복정 - 산성 - 남한산성입구 - 단대오거리 - 신흥 - 수진 - 모란
-개화 - 김포공항 - 공항시장 - 신방화 - 양천향교 - 가양 - 증미 - 등촌 - 염창 - 신목동 - 선유도 - 당산 - 국회의사당 - 여의도 - 샛강 - 노량진 - 노들 - 흑석 - 동작 - 구반포 - 신반포 - 고속터미널 - 사평 - 신논현 - 언주 - 선정릉 - 삼성중앙 - 봉은사 - 종합운동장
-왕십리 - 서울숲 - 압구정로데오 - 강남구청 - 선정릉 - 선릉 - 한티 - 도곡 - 구룡 - 개포동 - 대모산입구 - 수서 - 복정 - 경원대 - 태평 - 모란 - 야탑 - 이매 - 서현 - 수내 - 정자 - 미금 - 오리 - 죽전 - 보정 - 구성 - 신갈 - 기흥 - 상갈 - 청명 - 영통 - 망포
-용문 - 원덕 - 양평 - 오빈 - 아신 - 국수 - 신원 - 양수 - 운길산 - 팔당 - 도심 - 덕소 - 양정 - 도농 - 구리 - 양원 - 망우 - 상봉 - 중랑 - 회기 - 청량리 - 왕십리 - 응봉 - 옥수 - 한남 - 서빙고 - 이촌 - 용산 - 서울역 - 신촌 (경의중앙선) - 공덕 - 서강 - 홍대입구 - 가좌 - 디지털미디어시티 - 수색 - 화전 - 행신 - 능곡 - 대곡 - 곡산 - 백마 - 풍산 - 일산 - 탄현 - 운정 - 금릉 - 금촌 - 월롱 - 파주 - 문산
-서울역 - 공덕 - 홍대입구 - 디지털미디어시티 - 김포공항 - 계양 - 검암 - 운서 - 공항화물청사 - 인천국제공항
-계양 - 귤현 - 박촌 - 임학 - 계산 - 경인교대입구 - 작전 - 갈산 - 부평구청 - 부평시장 - 부평 - 동수 - 부평삼거리 - 간석오거리 - 인천시청 - 예술회관 - 인천터미널 - 문학경기장 - 선학 - 신연수 - 원인재 - 동춘 - 동막 - 캠퍼스타운 - 테크노파크 - 지식정보단지 - 인천대입구 - 센트럴파크 - 국제업무지구
-상봉 - 망우 - 갈매 - 별내역 - 퇴계원 - 사릉 - 금곡 - 평내호평 - 마석 - 대성리 - 청평 - 상천 - 가평 - 굴봉산 - 백양리 - 강촌 - 김유정 - 남춘천 - 춘천
-오이도 - 월곶 - 소래포구 - 인천논현 - 호구포 - 남동인더스파크 - 원인재 - 연수 - 송도
-강남 - 양재 - 양재시민의숲 - 청계산입구 - 판교 - 정자
\ No newline at end of file
diff --git a/data_structure/tree/heap/PriorityQueue_Insert.py b/data_structure/tree/heap/PriorityQueue_Insert.py
deleted file mode 100644
index 1c8d9c9..0000000
--- a/data_structure/tree/heap/PriorityQueue_Insert.py
+++ /dev/null
@@ -1,45 +0,0 @@
-def swap(tree, index_1, index_2):
- """완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
- temp = tree[index_1]
- tree[index_1] = tree[index_2]
- tree[index_2] = temp
-
-
-def reverse_heapify(tree, index):
- """삽입된 노드를 힙 속성을 지키는 위치로 이동시키는 함수"""
- parent_index = index // 2 # 삽입된 노드의 부모 노드의 인덱스 계산
-
- # 왼쪽 자식 노드의 값과 비교
- if 0 < parent_index < len(tree) and tree[index] > tree[parent_index]:
- swap(tree, index, parent_index)
- reverse_heapify(tree, parent_index)
-
-
-
-class PriorityQueue:
- """힙으로 구현한 우선순위 큐"""
- def __init__(self):
- self.heap = [None] # 파이썬 리스트로 구현한 힙
-
-
- def insert(self, data):
- """삽입 메소드"""
- self.heap.append(data)
- reverse_heapify(self.heap, len(self.heap) - 1)
-
- def __str__(self):
- return str(self.heap)
-
-
-# 테스트 코드
-priority_queue = PriorityQueue()
-
-priority_queue.insert(6)
-priority_queue.insert(9)
-priority_queue.insert(1)
-priority_queue.insert(3)
-priority_queue.insert(10)
-priority_queue.insert(11)
-priority_queue.insert(13)
-
-print(priority_queue)
\ No newline at end of file
diff --git a/data_structure/tree/heap/PriorityQueue_extractMax/heapify_code.py b/data_structure/tree/heap/PriorityQueue_extractMax/heapify_code.py
deleted file mode 100644
index a619c55..0000000
--- a/data_structure/tree/heap/PriorityQueue_extractMax/heapify_code.py
+++ /dev/null
@@ -1,38 +0,0 @@
-def swap(tree, index_1, index_2):
- """완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
- temp = tree[index_1]
- tree[index_1] = tree[index_2]
- tree[index_2] = temp
-
-
-def heapify(tree, index, tree_size):
- """heapify 함수"""
-
- # 왼쪽 자식 노드의 인덱스와 오른쪽 자식 노드의 인덱스를 계산
- left_child_index = 2 * index
- right_child_index = 2 * index + 1
-
- largest = index # 일단 부모 노드의 값이 가장 크다고 설정
-
- # 왼쪽 자식 노드의 값과 비교
- if 0 < left_child_index < tree_size and tree[largest] < tree[left_child_index]:
- largest = left_child_index
-
- # 오른쪽 자식 노드의 값과 비교
- if 0 < right_child_index < tree_size and tree[largest] < tree[right_child_index]:
- largest = right_child_index
-
- if largest != index: # 부모 노드의 값이 자식 노드의 값보다 작으면
- swap(tree, index, largest) # 부모 노드와 최댓값을 가진 자식 노드의 위치를 바꿔 준다
- heapify(tree, largest, tree_size) # 자리가 바뀌어 자식 노드가 된 기존의 부모 노드를대상으로 또 heapify 함수를 호출한다
-
-
-def reverse_heapify(tree, index):
- """삽입된 노드를 힙 속성을 지키는 위치로 이동시키는 함수"""
- parent_index = index // 2 # 삽입된 노드의 부모 노드의 인덱스 계산
-
- # 부모 노드가 존재하고, 부모 노드의 값이 삽입된 노드의 값보다 작을 때
- if 0 < parent_index < len(tree) and tree[index] > tree[parent_index]:
- swap(tree, index, parent_index) # 부모 노드와 삽입된 노드의 위치 교환
- reverse_heapify(tree, parent_index) # 삽입된 노드를 대상으로 다시 reverse_heapify 호출
-
diff --git a/data_structure/tree/heap/PriorityQueue_extractMax/main.py b/data_structure/tree/heap/PriorityQueue_extractMax/main.py
deleted file mode 100644
index a0cd7ab..0000000
--- a/data_structure/tree/heap/PriorityQueue_extractMax/main.py
+++ /dev/null
@@ -1,48 +0,0 @@
-from heapify_code import *
-
-class PriorityQueue:
- """힙으로 구현한 우선순위 큐"""
- def __init__(self):
- self.heap = [None] # 파이썬 리스트로 구현한 힙
-
- def insert(self, data):
- """삽입 메소드"""
- self.heap.append(data) # 힙의 마지막에 데이터 추가
- reverse_heapify(self.heap, len(self.heap)-1) # 삽입된 노드(추가된 데이터)의 위치를 재배치
-
- def extract_max(self):
- """최우선순위 데이터 추출 메소드"""
-
- # 1. root노드와 마지막 노드 위치 바꾸기
- swap(self.heap, 1, len(self.heap) - 1)
-
- # 2. 마지막 위치로 간 root 노드 데이터 별도 변수 저장, 노드 힙에서 제거
- root_node = self.heap.pop()
-
- # 3. 새로운 root 노드 대상으로 히피파이 하여 힙속성 복원
- heapify(self.heap, 1, len(self.heap))
-
- # 4. 리턴
- return root_node
-
- def __str__(self):
- return str(self.heap)
-
-# 출력 코드
-priority_queue = PriorityQueue()
-
-priority_queue.insert(6)
-priority_queue.insert(9)
-priority_queue.insert(1)
-priority_queue.insert(3)
-priority_queue.insert(10)
-priority_queue.insert(11)
-priority_queue.insert(13)
-
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
-print(priority_queue.extract_max())
\ No newline at end of file
diff --git a/data_structure/tree/heap/heapify.py b/data_structure/tree/heap/heapify.py
deleted file mode 100644
index a71eb2a..0000000
--- a/data_structure/tree/heap/heapify.py
+++ /dev/null
@@ -1,34 +0,0 @@
-def swap(tree, index_1, index_2):
- """완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
- temp = tree[index_1]
- tree[index_1] = tree[index_2]
- tree[index_2] = temp
-
-
-def heapify(tree, index, tree_size):
- # print("tree_size is ",tree_size)
- """heapify 함수"""
-
- # 왼쪽 자식 노드의 인덱스와 오른쪽 자식 노드의 인덱스를 계산
- left_child_index = 2 * index
- right_child_index = 2 * index + 1
-
- # 여기에 코드를 작성하세요
- # 1. 3가지 값 중 가장 큰 값은?
- max_value = max(tree[index], tree[left_child_index], tree[right_child_index])
-
- # 2. 부모라면 그대로, 자식이라면 위치 바꾸기
- max_index = tree.index(max_value)
- # print(max_index)
- if tree[index] != max_value:
- swap(tree, index, max_index)
-
- # 3. 다음 인덱스로 이동 (자식)
- if(max_index * 2 < tree_size + 1):
- heapify(tree, max_index, tree_size)
-
-
-# 테스트 코드
-tree = [None, 15, 5, 12, 14, 9, 10, 6, 2, 11, 1] # heapify하려고 하는 완전 이진 트리
-heapify(tree, 2, len(tree)) # 노드 2에 heapify 호출
-print(tree)
\ No newline at end of file
diff --git a/data_structure/tree/heap/heapsort.py b/data_structure/tree/heap/heapsort.py
deleted file mode 100644
index 02ffc99..0000000
--- a/data_structure/tree/heap/heapsort.py
+++ /dev/null
@@ -1,76 +0,0 @@
-def swap(tree, index_1, index_2):
- """완전 이진 트리의 노드 index_1과 노드 index_2의 위치를 바꿔준다"""
- temp = tree[index_1]
- tree[index_1] = tree[index_2]
- tree[index_2] = temp
-
-
-def heapify(tree, index, tree_size):
- """heapify 함수"""
-
- # 왼쪽 자식 노드의 인덱스와 오른쪽 자식 노드의 인덱스를 계산
- left_child_index = 2 * index
- right_child_index = 2 * index + 1
-
- largest = index # 일단 부모 노드의 값이 가장 크다고 설정
-
- # 왼쪽 자식 노드의 값과 비교
- if 0 < left_child_index < tree_size and tree[largest] < tree[left_child_index]:
- largest = left_child_index
-
- # 오른쪽 자식 노드의 값과 비교
- if 0 < right_child_index < tree_size and tree[largest] < tree[right_child_index]:
- largest = right_child_index
-
- if largest != index: # 부모 노드의 값이 자식 노드의 값보다 작으면
- swap(tree, index, largest) # 부모 노드와 최댓값을 가진 자식 노드의 위치를 바꿔준다
- heapify(tree, largest, tree_size) # 자리가 바뀌어 자식 노드가 된 기존의 부모 노드를대상으로 또 heapify 함수를 호출한다
-
-
-# mo's solution
-# def heapsort(tree):
-# """힙 정렬 함수"""
-# tree_size = len(tree) # 15
-#
-# # 여기에 코드를 작성하세요
-# # 1. 리스트를 힙으로 만듬
-# for i in range(tree_size):
-# index = tree_size - i
-# heapify(tree, index, tree_size)
-#
-# # 4. 힙에 남아엤는 노드 없도록 2 ~ 3 반복
-# for j in range(tree_size):
-# size_j = tree_size - j - 1
-# # 3. 새로운 root노드가 힙 속성 지키게 heapify 함
-# for i in range(tree_size):
-# # 2. root 노드와 마지막 노드 위치 바꿈 -> 힙에서 없어졌다고 가정
-# if(size_j < 1):
-# return
-# swap(tree, 1, size_j)
-# index = tree_size - i
-# heapify(tree, index, size_j)
-
-# 모범답안
-def heapsort(tree):
- """힙 정렬 함수"""
- tree_size = len(tree)
-
- # 마지막 인덱스부터 처음 인덱스까지 heapify를 호출한다
- for index in range(tree_size-1, 0, -1):
- heapify(tree, index, tree_size)
-
- # 마지막 인덱스부터 처음 인덱스까지
- for i in range(tree_size-1, 0, -1):
- swap(tree, 1, i) # root 노드와 마지막 인덱스를 바꿔준 후
- heapify(tree, 1, i) # root 노드에 heapify를 호출한다
-
-# 이중 for 문 이유
-# 1. range() 에 대한 이유가 부족했음
-# range(start, stop, step)
-
-
-
-# 테스트 코드
-data_to_sort = [None, 6, 1, 4, 7, 10, 3, 8, 5, 1, 5, 7, 4, 2, 1]
-heapsort(data_to_sort)
-print(data_to_sort)
\ No newline at end of file
diff --git a/data_structure/tree/tree/append.py b/data_structure/tree/tree/append.py
deleted file mode 100644
index c1af701..0000000
--- a/data_structure/tree/tree/append.py
+++ /dev/null
@@ -1,75 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- def insert(self, data):
- new_node = Node(data) # 삽입할 데이터를 갖는 새 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수, root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드의 데이터보다 크다면
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- else :
- temp = temp.right_child
-
- else: # 삽입하려는 데이터가 현재 노드의 데이터보다 작다면
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-# 이진 탐색 트리 출력
-bst.print_sorted_tree()
\ No newline at end of file
diff --git a/data_structure/tree/tree/binary_tree.py b/data_structure/tree/tree/binary_tree.py
deleted file mode 100644
index 1729e3e..0000000
--- a/data_structure/tree/tree/binary_tree.py
+++ /dev/null
@@ -1,37 +0,0 @@
-class Node:
- """이진 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.left_child = None
- self.right_child = None
-
-
-# root 노드 생성
-root_node = Node("A")
-node_B = Node("B")
-node_C = Node("C")
-node_D = Node("D")
-node_E = Node("E")
-node_F = Node("F")
-node_G = Node("G")
-node_H = Node("H")
-
-# 여기에 코드를 작성하세요
-root_node.left_child = node_B
-root_node.right_child = node_C
-node_B.left_child = node_D
-node_B.right_child = node_E
-node_E.left_child = node_G
-node_E.right_child = node_H
-node_C.right_child = node_F
-
-
-# 테스트 코드
-test_node = root_node.right_child.right_child
-print(test_node.data)
-
-test_node = root_node.left_child.right_child.left_child
-print(test_node.data)
-
-test_node = root_node.left_child.right_child.right_child
-print(test_node.data)
\ No newline at end of file
diff --git a/data_structure/tree/tree/complete_binary_tree.py b/data_structure/tree/tree/complete_binary_tree.py
deleted file mode 100644
index e52c5ca..0000000
--- a/data_structure/tree/tree/complete_binary_tree.py
+++ /dev/null
@@ -1,49 +0,0 @@
-def get_parent_index(complete_binary_tree, index):
- """배열로 구현한 완전 이진 트리에서 index번째 노드의 부모 노드의 인덱스를 리턴하는 함수"""
- index_ = index // 2
- if index_ < 1:
- return None
- return index_
-
-
-def get_left_child_index(complete_binary_tree, index):
- """배열로 구현한 완전 이진 트리에서 index번째 노드의 왼쪽 자식 노드의 인덱스를 리턴하는 함수"""
- index_ = index * 2
- if index_ > len(complete_binary_tree):
- return None
-
- return index_
-
-
-def get_right_child_index(complete_binary_tree, index):
- """배열로 구현한 완전 이진 트리에서 index번째 노드의 오른쪽 자식 노드의 인덱스를 리턴하는 함수"""
- index_ = index * 2 + 1
- if index_ > len(complete_binary_tree):
- return None
- return index_
-
-# 테스트 코드
-root_node_index = 1 # root 노드
-
-tree = [None, 1, 5, 12, 11, 9, 10, 14, 2, 10] # 과제 이미지에 있는 완전 이진 트리
-
-# root 노드의 왼쪽과 오른쪽 자식 노드의 인덱스를 받아온다
-left_child_index = get_left_child_index(tree, root_node_index)
-right_child_index = get_right_child_index(tree,root_node_index)
-
-print(tree[left_child_index])
-print(tree[right_child_index])
-
-# 9번째 노드의 부모 노드의 인덱스를 받아온다
-parent_index = get_parent_index(tree, 9)
-print(tree[parent_index])
-
-# 부모나 자식 노드들이 없는 경우들
-parent_index = get_parent_index(tree, 1) # root 노드의 부모 노드의 인덱스를 받아온다
-print(parent_index)
-
-left_child_index = get_left_child_index(tree, 6) # 6번째 노드의 왼쪽 자식 노드의 인덱스를 받아온다
-print(left_child_index)
-
-right_child_index = get_right_child_index(tree, 8) # 8번째 노드의 오른쪽 자식 노드의 인덱스를 받아온다
-print(right_child_index)
\ No newline at end of file
diff --git a/data_structure/tree/tree/delete.py b/data_structure/tree/tree/delete.py
deleted file mode 100644
index 157b0c1..0000000
--- a/data_structure/tree/tree/delete.py
+++ /dev/null
@@ -1,139 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- def delete(self, data):
- """이진 탐색 트리 삭제 메소드"""
- node_to_delete = self.search(data) # 삭제할 노드를 가지고 온다
- parent_node = node_to_delete.parent # 삭제할 노드의 부모 노드
-
- # 경우 1: 지우려는 노드가 leaf 노드일 때
- if node_to_delete.left_child is None and node_to_delete.right_child is None:
- if self.root is node_to_delete:
- self.root = None
- else: # 일반적인 경우
- if node_to_delete is parent_node.left_child:
- parent_node.left_child = None
- else :
- parent_node.right_child = None
-
-
- # # 삭제하려는 노드가 부모 노드의 왼쪽 자식이면
- # if parent_node.left_child.data == node_to_delete.data:
- # parent_node.left_child = None
-
- # # 삭제하려는 노드가 부모 노드의 오쪽 자식이면
- # else :
- # parent_node.right_child = None
-
- @staticmethod
- def find_min(node):
- """(부분)이진 탐색 트리의 가장 작은 노드 리턴"""
- # 여기에 코드를 작성하세요
- temp = node # 탐색용 변수, 파라미터 node로 초기화
-
- # temp가 node를 뿌리로 갖는 부분 트리에서 가장 작은 노드일 때까지 왼쪽 자식 노드로 간다
- while temp.left_child is not None:
- temp = temp.left_child
-
- return temp
-
-
- def search(self, data):
- """이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
- temp = self.root # 탐색용 변수, root 노드로 초기화
-
- # 원하는 데이터를 갖는 노드를 찾을 때까지 돈다
- while temp is not None:
- # 원하는 데이터를 갖는 노드를 찾으면 리턴
- if data == temp.data:
- return temp
- # 원하는 데이터가 노드의 데이터보다 크면 오른쪽 자식 노드로 간다
- if data > temp.data:
- temp = temp.right_child
- # 원하는 데이터가 노드의 데이터보다 작으면 왼쪽 자식 노드로 간다
- else:
- temp = temp.left_child
-
- return None # 원하는 데이터가 트리에 없으면 None 리턴
-
-
- def insert(self, data):
- """이진 탐색 트리 삽입 메소드"""
- new_node = Node(data) # 삽입할 데이터를 갖는 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- # 여기에 코드를 작성하세요
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수. root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드 데이터보다 크다면
- # 오른쪽 자식이 없으면 새로운 노드를 현재 노드 오른쪽 자식으로 만듦
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- # 오른쪽 자식이 있으면 오른쪽 자식으로 간다
- else:
- temp = temp.right_child
- else: # 삽입하려는 데이터가 현재 노드 데이터보다 작다면
- # 왼쪽 자식이 없으면 새로운 노드를 현재 노드 왼쪽 자식으로 만듦
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- # 왼쪽 자식이 있다면 왼쪽 자식으로 간다
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-# leaf 노드 삭제
-bst.delete(2)
-bst.delete(4)
-
-bst.print_sorted_tree()
\ No newline at end of file
diff --git a/data_structure/tree/tree/delete2.py b/data_structure/tree/tree/delete2.py
deleted file mode 100644
index 0bec6b2..0000000
--- a/data_structure/tree/tree/delete2.py
+++ /dev/null
@@ -1,156 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- def delete(self, data):
- """이진 탐색 트리 삭제 메소드"""
- node_to_delete = self.search(data) # 삭제할 노드를 가지고 온다
- parent_node = node_to_delete.parent # 삭제할 노드의 부모 노드
-
- # 경우 1: 지우려는 노드가 leaf 노드일 때
- if node_to_delete.left_child is None and node_to_delete.right_child is None:
- if self.root is node_to_delete:
- self.root = None
- else: # 일반적인 경우
- if node_to_delete is parent_node.left_child:
- parent_node.left_child = None
- else:
- parent_node.right_child = None
-
- # 경우 2: 지우려는 노드가 자식이 하나인 노드일 때:
- elif node_to_delete.left_child is None:
- if node_to_delete is self.root:
- self.root = node_to_delete.right_child
- self.root.parent = None
- elif node_to_delete is parent_node.left_child:
- parent_node.left_child = node_to_delete.right_child
- node_to_delete.right_child.parent = parent_node
- else:
- parent_node.right_child = node_to_delete.right_child
- node_to_delete.right_child.parent = parent_node
-
- elif node_to_delete.right_child is None: # 지우려는 노드가 왼쪽 자식만 있을 때:
- # 지우려는 노드가 root 노드일 때
- if node_to_delete is self.root:
- self.root = node_to_delete.left_child
- self.root.parent = None
- # 지우려는 노드가 부모의 왼쪽 자식일 때
- elif node_to_delete is parent_node.left_child:
- parent_node.left_child = node_to_delete.left_child
- node_to_delete.left_child.parent = parent_node
- # 지우려는 노드가 부모의 오른쪽 자식일 때
- else:
- parent_node.right_child = node_to_delete.left_child
- node_to_delete.left_child.parent = parent_node
-
- @staticmethod
- def find_min(node):
- """(부분)이진 탐색 트리의 가장 작은 노드 리턴"""
- # 여기에 코드를 작성하세요
- temp = node # 탐색 변수. 파라미터 node로 초기화
-
- # temp가 node를 뿌리로 갖는 부분 트리에서 가장 작은 노드일 때까지 왼쪽 자식 노드로 간다
- while temp.left_child is not None:
- temp = temp.left_child
-
- return temp
-
-
- def search(self, data):
- """이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
- temp = self.root # 탐색 변수. root 노드로 초기화
-
- # 원하는 데이터를 갖는 노드를 찾을 때까지 돈다
- while temp is not None:
- # 원하는 데이터를 갖는 노드를 찾으면 리턴
- if data == temp.data:
- return temp
- # 원하는 데이터가 노드의 데이터보다 크면 오른쪽 자식 노드로 간다
- if data > temp.data:
- temp = temp.right_child
- # 원하는 데이터가 노드의 데이터보다 작으면 왼쪽 자식 노드로 간다
- else:
- temp = temp.left_child
-
- return None # 원하는 데이터가 트리에 없으면 None 리턴
-
-
- def insert(self, data):
- """이진 탐색 트리 삽입 메소드"""
- new_node = Node(data) # 삽입할 데이터를 갖는 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- # 여기에 코드를 작성하세요
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수. root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드 데이터보다 크다면
- # 오른쪽 자식이 없으면 새로운 노드를 현재 노드 오른쪽 자식으로 만듦
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- # 오른쪽 자식이 있으면 오른쪽 자식으로 간다
- else:
- temp = temp.right_child
- else: # 삽입하려는 데이터가 현재 노드 데이터보다 작다면
- # 왼쪽 자식이 없으면 새로운 노드를 현재 노드 왼쪽 자식으로 만듦
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- # 왼쪽 자식이 있다면 왼쪽 자식으로 간다
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-# 자식이 하나만 있는 노드 삭제
-bst.delete(5)
-bst.delete(9)
-
-bst.print_sorted_tree()
\ No newline at end of file
diff --git a/data_structure/tree/tree/delete3.py b/data_structure/tree/tree/delete3.py
deleted file mode 100644
index 1acf887..0000000
--- a/data_structure/tree/tree/delete3.py
+++ /dev/null
@@ -1,177 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- def delete(self, data):
- """이진 탐색 트리 삭제 메소드"""
- node_to_delete = self.search(data) # 삭제할 노드를 가지고 온다
- parent_node = node_to_delete.parent # 삭제할 노드의 부모 노드
-
- # 경우 1: 지우려는 노드가 leaf 노드일 때
- if node_to_delete.left_child is None and node_to_delete.right_child is None:
- if self.root is node_to_delete:
- self.root = None
- else: # 일반적인 경우
- if node_to_delete is parent_node.left_child:
- parent_node.left_child = None
- else:
- parent_node.right_child = None
-
- # 경우 2: 지우려는 노드가 자식이 하나인 노드일 때:
- elif node_to_delete.left_child is None: # 지우려는 노드가 오른쪽 자식만 있을 때:
- # 지우려는 노드가 root 노드일 때
- if node_to_delete is self.root:
- self.root = node_to_delete.right_child
- self.root.parent = None
- # 지우려는 노드가 부모의 왼쪽 자식일 때
- elif node_to_delete is parent_node.left_child:
- parent_node.left_child = node_to_delete.right_child
- node_to_delete.right_child.parent = parent_node
- # 지우려는 노드가 부모의 오른쪽 자식일 때
- else:
- parent_node.right_child = node_to_delete.right_child
- node_to_delete.right_child.parent = parent_node
-
- elif node_to_delete.right_child is None: # 지우려는 노드가 왼쪽 자식만 있을 때:
- # 지우려는 노드가 root 노드일 때
- if node_to_delete is self.root:
- self.root = node_to_delete.left_child
- self.root.parent = None
- # 지우려는 노드가 부모의 왼쪽 자식일 때
- elif node_to_delete is parent_node.left_child:
- parent_node.left_child = node_to_delete.left_child
- node_to_delete.left_child.parent = parent_node
- # 지우려는 노드가 부모의 오른쪽 자식일 때
- else:
- parent_node.right_child = node_to_delete.left_child
- node_to_delete.left_child.parent = parent_node
-
- # 경우 3: 지우려는 노드가 2개의 자식이 있을 때
- else:
- successor = self.find_min(node_to_delete.right_child) # 삭제하려는 노드의 successor 노드 받아오기
-
- node_to_delete.data = successor.data # 삭제하려는 노드의 데이터에 successor의 데이터 저장
-
- # successor 노드 트리에서 삭제
- if successor is successor.parent.left_child: # successor 노드가 오른쪽 자식일 때
- successor.parent.left_child = successor.right_child
- else: # successor 노드가 왼쪽 자식일 때
- successor.parent.right_child = successor.right_child
-
- if successor.right_child is not None: # successor 노드가 오른쪽 자식이 있을 떄
- successor.right_child.parent = successor.parent
-
- # 여기에 코드를 작성하세요
-
-
- @staticmethod
- def find_min(node):
- """(부분)이진 탐색 트리의 가장 작은 노드 리턴"""
- # 여기에 코드를 작성하세요
- temp = node # 탐색 변수. 파라미터 node로 초기화
-
- # temp가 node를 뿌리로 갖는 부분 트리에서 가장 작은 노드일 때까지 왼쪽 자식 노드로 간다
- while temp.left_child is not None:
- temp = temp.left_child
-
- return temp
-
-
- def search(self, data):
- """이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
- temp = self.root # 탐색 변수. root 노드로 초기화
-
- # 원하는 데이터를 갖는 노드를 찾을 때까지 돈다
- while temp is not None:
- # 원하는 데이터를 갖는 노드를 찾으면 리턴
- if data == temp.data:
- return temp
- # 원하는 데이터가 노드의 데이터보다 크면 오른쪽 자식 노드로 간다
- if data > temp.data:
- temp = temp.right_child
- # 원하는 데이터가 노드의 데이터보다 작으면 왼쪽 자식 노드로 간다
- else:
- temp = temp.left_child
-
- return None # 원하는 데이터가 트리에 없으면 None 리턴
-
-
- def insert(self, data):
- """이진 탐색 트리 삽입 메소드"""
- new_node = Node(data) # 삽입할 데이터를 갖는 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- # 여기에 코드를 작성하세요
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수. root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드 데이터보다 크다면
- # 오른쪽 자식이 없으면 새로운 노드를 현재 노드 오른쪽 자식으로 만듦
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- # 오른쪽 자식이 있으면 오른쪽 자식으로 간다
- else:
- temp = temp.right_child
- else: # 삽입하려는 데이터가 현재 노드 데이터보다 작다면
- # 왼쪽 자식이 없으면 새로운 노드를 현재 노드 왼쪽 자식으로 만듦
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- # 왼쪽 자식이 있다면 왼쪽 자식으로 간다
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-# 자식이 두 개 다 있는 노드 삭제
-bst.delete(7)
-bst.delete(11)
-
-bst.print_sorted_tree()
\ No newline at end of file
diff --git a/data_structure/tree/tree/find_min.py b/data_structure/tree/tree/find_min.py
deleted file mode 100644
index 8848896..0000000
--- a/data_structure/tree/tree/find_min.py
+++ /dev/null
@@ -1,112 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- @staticmethod
- def find_min(node):
- """(부분)이진 탐색 트리의 가장 작은 노드 리턴"""
- # 코드를 쓰세요
- temp = node # 도우미 변수. 파라미터 node로 초기화
-
- # temp가 node를 뿌리로 갖는 부분 트리에서 가장 작은 노드일 때까지 왼쪽 자식 노드로 간다
- while temp.left_child is not None:
- temp = temp.left_child
-
- return temp
-
-
- def search(self, data):
- """이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
- temp = self.root # 탐색용 변수, root 노드로 초기화
-
- # 원하는 데이터를 갖는 노드를 찾을 때까지 돈다
- while temp is not None:
- # 원하는 데이터를 갖는 노드를 찾으면 리턴
- if data == temp.data:
- return temp
- # 원하는 데이터가 노드의 데이터보다 크면 오른쪽 자식 노드로 간다
- if data > temp.data:
- temp = temp.right_child
- # 원하는 데이터가 노드의 데이터보다 작으면 왼쪽 자식 노드로 간다
- else:
- temp = temp.left_child
-
- return None # 원하는 데이터가 트리에 없으면 None 리턴
-
-
- def insert(self, data):
- """이진 탐색 트리 삽입 메소드"""
- new_node = Node(data) # 삽입할 데이터를 갖는 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- # 여기에 코드를 작성하세요
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수. root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드 데이터보다 크다면
- # 오른쪽 자식이 없으면 새로운 노드를 현재 노드 오른쪽 자식으로 만듦
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- # 오른쪽 자식이 있으면 오른쪽 자식으로 간다
- else:
- temp = temp.right_child
- else: # 삽입하려는 데이터가 현재 노드 데이터보다 작다면
- # 왼쪽 자식이 없으면 새로운 노드를 현재 노드 왼쪽 자식으로 만듦
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- # 왼쪽 자식이 있다면 왼쪽 자식으로 간다
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-print(bst.find_min(bst.root).data) # 전체 이진 탐색 트리에서 가장 작은 노드
-print(bst.find_min(bst.root.right_child).data) # root 노드의 오른쪽 부분 트리에서 가장 작은 노드
\ No newline at end of file
diff --git a/data_structure/tree/tree/in_order_tree.py b/data_structure/tree/tree/in_order_tree.py
deleted file mode 100644
index 1a2df53..0000000
--- a/data_structure/tree/tree/in_order_tree.py
+++ /dev/null
@@ -1,47 +0,0 @@
-class Node:
- """이진 트리 노드를 나타내는 클래스"""
-
- def __init__(self, data):
- """이진 트리 노드는 데이터와 두 자식 노드에 대한 레퍼런스를 갖는다"""
- self.data = data
- self.left_child = None
- self.right_child = None
-
-def traverse_inorder(node):
- """in-order 순회 함수"""
- if node is not None: # 받은 인자 노드가 None이면 자식이 더이상 존재하지 않는것임
- traverse_inorder(node.left_child)
- print(node.data)
- traverse_inorder(node.right_child)
-
-
-# 여러 노드 인스턴스 생성
-node_A = Node("A")
-node_B = Node("B")
-node_C = Node("C")
-node_D = Node("D")
-node_E = Node("E")
-node_F = Node("F")
-node_G = Node("G")
-node_H = Node("H")
-node_I = Node("I")
-
-# 생성한 노드 인스턴스들 연결
-node_F.left_child = node_B
-node_F.right_child = node_G
-
-node_B.left_child = node_A
-node_B.right_child = node_D
-
-node_D.left_child = node_C
-node_D.right_child = node_E
-
-node_G.right_child = node_I
-
-node_I.left_child = node_H
-
-# 노드 F를 root 노드로 만든다
-root_node = node_F
-
-# 만들어 놓은 트리를 in-order로 순회한다
-traverse_inorder(root_node)
\ No newline at end of file
diff --git a/data_structure/tree/tree/search.py b/data_structure/tree/tree/search.py
deleted file mode 100644
index ad3a92b..0000000
--- a/data_structure/tree/tree/search.py
+++ /dev/null
@@ -1,101 +0,0 @@
-class Node:
- """이진 탐색 트리 노드 클래스"""
- def __init__(self, data):
- self.data = data
- self.parent = None
- self.right_child = None
- self.left_child = None
-
-
-def print_inorder(node):
- """주어진 노드를 in-order로 출력해주는 함수"""
- if node is not None:
- print_inorder(node.left_child)
- print(node.data)
- print_inorder(node.right_child)
-
-
-class BinarySearchTree:
- """이진 탐색 트리 클래스"""
- def __init__(self):
- self.root = None
-
-
- def search(self, data):
- """이진 탐색 트리 탐색 메소드, 찾는 데이터를 갖는 노드가 없으면 None을 리턴한다"""
- temp = self.root
- while temp is not None:
- if data > temp.data: # 자식 데이터가 더 크면
- temp = temp.right_child
-
- elif data == temp.data:
- return temp
-
- elif data < temp.data: # 자식데이터가 작으면
- temp = temp.left_child
-
- return None
-
-
-
- def insert(self, data):
- """이진 탐색 트리 삽입 메소드"""
- new_node = Node(data) # 삽입할 데이터를 갖는 노드 생성
-
- # 트리가 비었으면 새로운 노드를 root 노드로 만든다
- if self.root is None:
- self.root = new_node
- return
-
- # 여기에 코드를 작성하세요
- temp = self.root # 저장하려는 위치를 찾기 위해 사용할 변수. root 노드로 초기화한다
-
- # 원하는 위치를 찾아간다
- while temp is not None:
- if data > temp.data: # 삽입하려는 데이터가 현재 노드 데이터보다 크다면
- # 오른쪽 자식이 없으면 새로운 노드를 현재 노드 오른쪽 자식으로 만듦
- if temp.right_child is None:
- new_node.parent = temp
- temp.right_child = new_node
- return
- # 오른쪽 자식이 있으면 오른쪽 자식으로 간다
- else:
- temp = temp.right_child
- else: # 삽입하려는 데이터가 현재 노드 데이터보다 작다면
- # 왼쪽 자식이 없으면 새로운 노드를 현재 노드 왼쪽 자식으로 만듦
- if temp.left_child is None:
- new_node.parent = temp
- temp.left_child = new_node
- return
- # 왼쪽 자식이 있다면 왼쪽 자식으로 간다
- else:
- temp = temp.left_child
-
-
- def print_sorted_tree(self):
- """이진 탐색 트리 내의 데이터를 정렬된 순서로 출력해주는 메소드"""
- print_inorder(self.root) # root 노드를 in-order로 출력한다
-
-
-# 빈 이진 탐색 트리 생성
-bst = BinarySearchTree()
-
-# 데이터 삽입
-bst.insert(7)
-bst.insert(11)
-bst.insert(9)
-bst.insert(17)
-bst.insert(8)
-bst.insert(5)
-bst.insert(19)
-bst.insert(3)
-bst.insert(2)
-bst.insert(4)
-bst.insert(14)
-
-
-# 노드 탐색과 출력
-print(bst.search(7).data)
-print(bst.search(19).data)
-print(bst.search(2).data)
-print(bst.search(20))
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.md" "b/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.md"
deleted file mode 100644
index 0917b6b..0000000
--- "a/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.md"
+++ /dev/null
@@ -1,96 +0,0 @@
-
-## 일지
-- 1회 시도한 날 : 2024-01-30 ~ 2024-02-05 (1시간)
-- 2회 시도한 날 :
-- 3회 시도한 날 :
-
-## 문제 보기
-
-### 실습 설명
-규식이는 친구들 사이에서 투자의 귀재로 알려져 있습니다. 페이수북과 인수타그램에 자신의 성과를 과시하기 때문인데요. 사실 규식이가 그 정도의 실력자는 아닙니다. 성과가 좋을 때에만 SNS에 공유해서 그렇게 비춰질 뿐이죠.
-
-계속해서 멋진 모습을 보여주기 위해, 특정 기간 중 수익이 가장 큰 구간을 찾아내는 함수 `sublist_max()`를 작성해 보려고 합니다.
-
-***Brute Force*** 방법을 이용해서 이 문제를 한번 풀어 봅시다!
-
-### 함수 설명
-우선 함수 `sublist_max()`는 파라미터로 리스트 profits를 받는데요. profits에는 며칠 동안의 수익이 담겨 있습니다. 예를 들어서 profits가 `[7, -3, 4, -8]`이라면 첫 날에는 7달러를 벌었고, 둘째 날에는 3달러를 잃었고, 셋째 날에는 4달러를 벌었고, 마지막 날에는 8달러를 잃은 거죠.
-
-`sublist_max()` 함수는 profits에서 최대 수익을 내는 구간의 수익을 리턴합니다.
-
-profits가 `[7, -3, 4, -8]`이라면 무엇을 리턴해야 할까요? profits에서 가장 많은 수익을 낸 구간은 `[7, -3, 4]`입니다. 이 구간에서 낸 수익은 8달러이니, 8을 리턴하면 되겠죠!
-
-만약 profits가 `[-2, -3, 4, -1, -2, 1, 5, -3]`이라면? profits에서 수익이 가장 큰 구간은 `[4, -1, -2, 1, 5]`입니다. 이 구간에서 낸 수익은 7달러이니, 7을 리턴하겠죠?
-
-### 실습 코드
-
-```python
-def sublist_max(profits):
- # 여기에 코드를 작성하세요
-
-
-# 테스트 코드
-print(sublist_max([4, 3, 8, -2, -5, -3, -5, -3]))
-print(sublist_max([2, 3, 1, -1, -2, 5, -1, -1]))
-print(sublist_max([7, -3, 14, -8, -5, 6, 8, -5, -4, 10, -1, 8]))
-```
-
-## 문제풀이
-
-#### 모's 풀이
-```python
-def sublist_max(profits):
- max_value = -100
- # pre_value = 0
- sum_list = list()
-
- for i in range(len(profits)):
- sum_list = profits[i:]
- # j = 0
- for j in range(len(sum_list)):
- # pre_value = max_value # 아래 break 필요가 없어짐
- new_list = sum_list[:j + 1] # 수월한 디버깅 위해서 변수를 따로 둠
- max_value = max(max_value, sum(new_list))
- # if pre_value == max_value: # *중간끼인 + 값 생략되는 우려 존재
- # break
- return max_value
-
-# 테스트 코드
-print(sublist_max([4, 3, 8, -2, -5, -3, -5, -3]))
-print(sublist_max([2, 3, 1, -1, -2, 5, -1, -1]))
-print(sublist_max([7, -3, 14, -8, -5, 6, 8, -5, -4, 10, -1, 8])) # 6, 8, -5, -4, 10, -1, 8 => 22
-```
-
-#### 모범답안 풀이
-```python
-def sublist_max(profits):
- max_profit = profits[0] # 최대 수익
-
- for i in range(len(profits)):
- # 인덱스 i부터 j까지 수익의 합을 보관하는 변수
- total = 0
-
- for j in range(i, len(profits)):
- # i부터 j까지 수익의 합을 계산
- total += profits[j]
-
- # i부터 j까지 수익의 합이 최대 수익이라면, max_profit 업데이트
- max_profit = max(max_profit, total)
-
- return max_profit
-
-
-# 테스트 코드
-print(sublist_max([4, 3, 8, -2, -5, -3, -5, -3]))
-print(sublist_max([2, 3, 1, -1, -2, 5, -1, -1]))
-print(sublist_max([7, -3, 14, -8, -5, 6, 8, -5, -4, 10, -1, 8]))
-
-```
-
-
-## 반성
-1. `max_profit` 는 최대수익 [0] 기준으로 해도 좋음
-2. 별도 list 새로 만들기 보다 `total += profits[j]` 로 가능함
-3. 시작과 끝 값에 대한 주의를 좀 더 가지기
-4. Edge Case 를 좀 더 생각하기
-5. 순서도를 좀 더 명확히 그리기
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.py" "b/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.py"
deleted file mode 100644
index 91e7beb..0000000
--- "a/dev_problem_soving_abilty/Level1/1_\355\210\254\354\236\220\352\267\200\354\236\254_\354\213\235_I.py"
+++ /dev/null
@@ -1,22 +0,0 @@
-# 의문 1. 어떻게 해결하지?
-
-def sublist_max(profits):
- max_value = -100
- # pre_value = 0
- sum_list = list()
-
- for i in range(len(profits)):
- sum_list = profits[i:]
- # j = 0
- for j in range(len(sum_list)):
- # pre_value = max_value # 아래 break 필요가 없어짐
- new_list = sum_list[:j + 1] # 수월한 디버깅 위해서 변수를 따로 둠
- max_value = max(max_value, sum(new_list))
- # if pre_value == max_value: # *중간끼인 + 값 생략되는 우려 존재
- # break
- return max_value
-
-# 테스트 코드
-print(sublist_max([4, 3, 8, -2, -5, -3, -5, -3]))
-print(sublist_max([2, 3, 1, -1, -2, 5, -1, -1]))
-print(sublist_max([7, -3, 14, -8, -5, 6, 8, -5, -4, 10, -1, 8])) # 6, 8, -5, -4, 10, -1, 8 => 22
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.md" "b/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.md"
deleted file mode 100644
index a2e2de4..0000000
--- "a/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.md"
+++ /dev/null
@@ -1,100 +0,0 @@
-
-## 일지
-- 1회 시도한 날 : 2024-02-05 ~ 2024-02-15 (2시간)
-- 2회 시도한 날 :
-- 3회 시도한 날 :
-
-## 문제 보기
-
-### 실습 설명
-거듭 제곱을 계산하는 함수 power()를 작성하고 싶습니다. power()는 파라미터로 자연수 x와 자연수 y를 받고, x^y 를 리턴합니다.
-
-가장 쉽게 생각할 수 있는 방법은 반복문으로 단순하게 x를 y번 곱해 주는 방법입니다.
-
-```python
-def power(x, y):
- total = 1
-
- # x를 y번 곱해 준다
- for i in range(y):
- total *= x
-
- return total
-```
-이 알고리즘의 시간 복잡도는 O(y)인데요. O(lg y) 로 더 빠르게 할 수는 없을까요?
-
-
-
-### 주의사항
-`return x ** y`는 답이 아닙니다. 우리는 거듭 제곱을 구하는 원리를 파악하여 효율적인 ‘알고리즘’을 구현하고 싶은 것입니다.
-### 실습 코드
-
-```python
-def power(x, y):
- # 여기에 코드를 작성하세요
-
-
-# 테스트 코드
-print(power(3, 5))
-print(power(5, 6))
-print(power(7, 9))
-```
-
-## 문제풀이
-
-#### 모's 풀이
-```python
-
-# y == 0 일 떄는 return 이 1임
-def power(x, y):
- #base case
- if y == 0:
- return 1
-
- #recursive case
- x *= power(x , y - 1)
-
- return x
-# 하지만 위 코드는 O(N)임 문제목적은 O(lg N) 임
-
-
-```
-
-#### 모범답안 풀이
-```python
-
-def power(x, y):
- x_table = list()
- #base case
- if y < 1:
- return 1
-
- if y % 2 == 0 :
- return power(x, y // 2) * power(x, y // 2)
- else:
- return x * power(x, y // 2) * power(x, y // 2)
-# 그럼에도 불구하고 이 코드는 O(N)이다. 중복된 연산이 있는데 DP방식을 이용하면 해결하면 가능함
-
-def power(x, y):
- if y == 0:
- return 1
-
- # 계산을 한 번만 하기 위해서 변수에 저장
- subresult = power(x, y // 2)
-
- # 문제를 최대한 똑같은 크기의 문제 두 개로 나눠준다 (짝수, 홀수 경우 따로)
- if y % 2 == 0:
- return subresult * subresult
- else:
- return x * subresult * subresult
-
-
-# 테스트 코드
-print(power(3, 5))
-print(power(5, 6))
-print(power(7, 9))
-
-```
-
-
-## 반성
diff --git "a/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.py" "b/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.py"
deleted file mode 100644
index 4da55d9..0000000
--- "a/dev_problem_soving_abilty/Level1/2_\352\261\260\353\223\255\354\240\234\352\263\261_\353\271\240\353\245\264\352\262\214_\352\263\204\354\202\260.py"
+++ /dev/null
@@ -1,16 +0,0 @@
-def power(x, y):
- x_table = list()
- #base case
- if y < 1:
- return 1
-
- if y % 2 == 0 :
- return power(x, y // 2) * power(x, y // 2)
- else:
- return x * power(x, y // 2) * power(x, y // 2)
-
-
-# 테스트 코드
-print(power(3, 5))
-print(power(5, 6))
-print(power(7, 9))
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.md" "b/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.md"
deleted file mode 100644
index acf6edf..0000000
--- "a/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.md"
+++ /dev/null
@@ -1,142 +0,0 @@
-
-## 일지
-- 1회 시도한 날 : 2024-02-15 ~ 2024-02-18 (2.3시간)
-- 2회 시도한 날 :
-- 3회 시도한 날 :
-
-## 문제 보기
-
-### 실습 설명
-신입 사원 장그래는 마부장님을 따라 등산을 가게 되었습니다.
-
-탈수를 방지하기 위해서 1km당 1L의 물을 반드시 마셔야 하는데요. 다행히 등산길 곳곳에는 물통을 채울 수 있는 약수터가 마련되어 있습니다. 다만 매번 줄서 기다려야 한다는 번거로움이 있기 때문에, 시간을 아끼기 위해서는 최대한 적은 약수터를 들르고 싶습니다.
-
-함수 `select_stops()`는 파라미터로 약수터 위치 리스트 `water_stops`와 물통 용량 `capacity`를 받고, 장그래가 들를 약수터 위치 리스트를 리턴합니다. 앞서 설명한 대로 약수터는 최대한 적게 들러야겠죠.
-
-(탈수로 인해서 정상에 도달 하지 못하는 경우는 없다고 가정합니다.)
-
-참고로 모든 위치는 km 단위이고 용량은 L 단위입니다. 그리고 등산하기 전에는 이미 물통이 가득 채워져 있으며, 약수터에 들르면 늘 물통을 가득 채운다고 가정합시다.
-
-예시를 하나 볼게요.
-
-```python
-# 약수터 위치: [1km, 4km, 5km, 7km, 11km, 12km, 13km, 16km, 18km, 20km, 22km, 24km, 26km]
-# 물통 용량: 4L
-select_stops([1, 4, 5, 7, 11, 12, 13, 16, 18, 20, 22, 24, 26], 4)
-
-```
-처음에 4L의 물통이 채워져 있기 때문에, 장그래는 약수터에 들르지 않고 최대 4km 지점까지 올라갈 수 있습니다. 탈수 없이 계속 올라가기 위해서는 1km 지점이나 4km 지점에서 물통을 채워야겠죠?
-
-최대한 적은 약수터를 들르면서 올라가야 하고, **마지막에 산 정상인 26km 지점의 약수터를 들르면 성공**적인 등산입니다.
-
-
-### 실습 결과
-
-```python
-[4, 7, 11, 13, 16, 20, 24, 26]
-[5, 8, 12, 17, 23, 28, 32, 38, 44, 47]
-```
-
-### 핵심 아이디어
-- 최적 부분구조로 약수터 도착가능한 약수터는 두개(22, 24)인데, 두개 중 선택은 이전 부분문제들의 방법에 따라 변경됨
-- 그리디 방법으로는 출발할 때 항상 가장 먼 약수터 선택이 바람직한지 결정하면됨 -> 이 경우 가장먼 약수터 선택이 가장 좋은선택임
- - 즉 1km 지점 약수터가 갈수 있는 거리는, 4km 지점 약수터에서도 갈 수있음, 반대로는 어려움
-
-
-## 문제풀이
-
-#### 모's 풀이
-```python
-
-def select_stops(water_stops, capacity):
- select_list = list()
- select_list.append(water_stops[-1]) # 26
- # limit_stop = capacity
-
- for i in range(len(water_stops)):
- now_stop = select_list[i] # 26
- compare_list = list()
- for j in range(len(water_stops) - 1):
- next_stop_range = now_stop - capacity
- # 26 - 4 = 22
-
- stop_candidate = water_stops[-(j + 2)]
- if stop_candidate >= next_stop_range:
- compare_list.append(stop_candidate)
-
- compare_list.sort()
- if compare_list[0] == select_list[-1]:
- break
- if select_list[-1] - capacity <= 0:
- break
-
- select_list.append(compare_list[0])
-
- return sorted(select_list)
-
-# 테스트 코드
-list1 = [1, 4, 5, 7, 11, 12, 13, 16, 18, 20, 22, 24, 26]
-print(select_stops(list1, 4))
-
-list2 = [5, 8, 12, 17, 20, 22, 23, 24, 28, 32, 38, 42, 44, 47]
-print(select_stops(list2, 6))
-
-# 결과
-# [4, 7, 11, 12, 16, 18, 22, 26]
-# [5, 8, 12, 17, 22, 28, 32, 38, 42, 47]
-
-
-```
-
-- 위 풀이에서 GPT 센세는 브루트포스가 아니라 그리디 알고리즘이라고 하였음
-
-
-#### 모범답안 풀이
-```python
-
-def select_stops(water_stops, capacity):
- # 약수터 위치 리스트
- stop_list = []
-
- # 마지막 들른 약수터 위치
- prev_stop = 0
-
- for i in range(len(water_stops)):
- # i 지점까지 갈 수 없으면, i - 1 지점 약수터를 들른다
- if water_stops[i] - prev_stop > capacity:
- stop_list.append(water_stops[i - 1])
- prev_stop = water_stops[i - 1]
-
- # 마지막 약수터는 무조건 간다
- stop_list.append(water_stops[-1])
-
- return stop_list
-
-
-# 테스트 코드
-list1 = [1, 4, 5, 7, 11, 12, 13, 16, 18, 20, 22, 24, 26]
-print(select_stops(list1, 4))
-
-list2 = [5, 8, 12, 17, 20, 22, 23, 24, 28, 32, 38, 42, 44, 47]
-print(select_stops(list2, 6))
-
-#결과
-#[4, 7, 11, 13, 16, 20, 24, 26]
-#[5, 8, 12, 17, 23, 28, 32, 38, 44, 47]
-
-
-
-```
-
-
-## 반성
-```python
-
-if water_stops[i] - prev_stop > capacity:
- stop_list.append(water_stops[i - 1])
- prev_stop = water_stops[i - 1]
-
-```
-- 위 조건문이 핵심 로직임
- - 그리디 알고리즘에 이용되는 핵심로직임
- - 거리를 초과하면 물 못채움 (why : 그리디 알고리즘으로 최대 범위) -> 그 직전으로 돌아가서 범위 계산
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.py" "b/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.py"
deleted file mode 100644
index bf6c481..0000000
--- "a/dev_problem_soving_abilty/Level1/3_\353\271\240\353\245\270\353\223\261\354\202\260.py"
+++ /dev/null
@@ -1,46 +0,0 @@
-def select_stops(water_stops, capacity):
- sorted_list = []
- current_stop = 0
- for i in range(len(water_stops)):
- stop_capacity = water_stops[i] - capacity
- if stop_capacity > current_stop:
- sorted_list.append(water_stops[i - 1])
- current_stop = water_stops[i - 1]
-
- sorted_list.append(water_stops[-1])
-
- return sorted_list
-
- # select_list = list()
- # select_list.append(water_stops[-1]) # 26
- # # limit_stop = capacity
- #
- # for i in range(len(water_stops)):
- # now_stop = select_list[i] # 26
- # compare_list = list()
- # for j in range(len(water_stops) - 1):
- # next_stop_range = now_stop - capacity
- # # 26 - 4 = 22
- #
- # stop_candidate = water_stops[-(j + 2)]
- # if stop_candidate >= next_stop_range:
- # compare_list.append(stop_candidate)
- #
- # compare_list.sort()
- # if compare_list[0] == select_list[-1]:
- # break
- # if select_list[-1] - capacity <= 0:
- # break
- #
- # select_list.append(compare_list[0])
- #
- # return sorted(select_list)
-
-
-
-# 테스트 코드
-list1 = [1, 4, 5, 7, 11, 12, 13, 16, 18, 20, 22, 24, 26]
-print(select_stops(list1, 4))
-
-list2 = [5, 8, 12, 17, 20, 22, 23, 24, 28, 32, 38, 42, 44, 47]
-print(select_stops(list2, 6))
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.md" "b/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.md"
deleted file mode 100644
index 92a546d..0000000
--- "a/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.md"
+++ /dev/null
@@ -1,111 +0,0 @@
-
-## 일지
-- 1회 시도한 날 : 2024-02-20 ~ 2024-02- (_시간)
-- 2회 시도한 날 :
-- 3회 시도한 날 :
-
-## 문제 보기
-
-### 실습 설명
-(N + 1)의 크기인 리스트에, 1부터 N까지의 임의의 자연수가 요소로 할당되어 있습니다. 그렇다면 어떤 수는 꼭 한 번은 반복되겠지요.
-
-예를 들어 `[1, 3, 4, 2, 5, 4]`와 같은 리스트 있을 수도 있고, `[1, 1, 1, 6, 2, 2, 3]`과 같은 리스트가 있을 수도 있습니다. (몇 개의 수가 여러 번 중복되어 있을 수도 있습니다.)
-
-이런 리스트에서 반복되는 요소를 찾아내려고 합니다.
-
-중복되는 어떠한 수 ‘하나’만 찾아내도 됩니다. 즉 `[1, 1, 1, 6, 2, 2, 3]` 예시에서 1, 2를 모두 리턴하지 않고, 1 또는 2 하나만 리턴하게 하면 됩니다.
-
-중복되는 수를 찾는 시간 효율적인 함수를 설계해 보세요.
-
-### 실습 결과
-```python
-3
-5
-3
-```
-
-### 핵심 아이디어
-- 딕셔너리를 이용해서 이미 방문했는지 확인하기
-- 이 경우 저장됐는지 찾는 방법은 Key 로 확
-
-## 문제풀이
-
-#### 모's 풀이
-```python
-
-def find_same_number(some_list):
- some_list.sort() # O(n log n)
-
- for i in range(len(some_list) - 1): # O(n)
- if some_list[i] == some_list[i+1]:
- return some_list[i + 1]
- return None
-# => O(n log n)
-
-```
-- O(n log n) 이지만 복잡도는 O(n)으로 해야함
-- sort 는 퀵소트, 머지소트 이기 때문에 사용 불가
-
-- 개선한 풀이
-```python
-def find_same_number(some_list):
- elements_seen_so_far = dict()
-
- for i in range(len(some_list)):
- elements_seen_so_far[some_list[i]] = False
-
- for i in range(len(some_list)):
- if elements_seen_so_far[some_list[i]] == True:
- return some_list[i]
- else :
- elements_seen_so_far[some_list[i]] = True
- return None
-
-# 중복되는 수 ‘하나’만 리턴합니다.
-print(find_same_number([1, 4, 3, 5, 3, 2]))
-print(find_same_number([4, 1, 5, 2, 3, 5]))
-print(find_same_number([5, 2, 3, 4, 1, 6, 7, 8, 9, 3]))
-```
-
-- 모답 본 후 본 풀이
-```python
-
-def find_same_number(some_list):
- elements_seen_so_far = dict()
-
- for some in some_list:
- if some in elements_seen_so_far :
- return some
- else :
- elements_seen_so_far[some] = True
- return None
-```
-
-#### 모범답안 풀이
-```python
-def find_same_number(some_list):
- # 이미 나온 요소를 저장시켜줄 사전
- elements_seen_so_far = {}
-
- for element in some_list:
- # 이미 나온 요소인지 확인하고 맞으면 요소를 리턴한다
- if element in elements_seen_so_far:
- return element
-
- # 해당 요소를 사전에 저장시킨다
- elements_seen_so_far[element] = True
-
-print(find_same_number([1, 4, 3, 5, 3, 2]))
-print(find_same_number([4, 1, 5, 2, 3, 5]))
-print(find_same_number([5, 2, 3, 4, 1, 6, 7, 8, 9, 3]))
-```
-
-- 아래 방식을 이해하지 못해서 key로 딕셔너리에 존재하는지 여부에 대한 조건문 작성하지 못함
-```python
-if '사과' in data:
- print("yes")
-```
-
-## 반성
-- dict() 가 익숙하지 않아서 사용을 회피했는데, 이번 기회에 좀 더 잘 활용해보자
-- for 를 쓸 때 range()를 고민하지 않고 사용했는데, 그로인해서 딕셔너리 key 확인에 지체가 있었다.
\ No newline at end of file
diff --git "a/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.py" "b/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.py"
deleted file mode 100644
index fb61284..0000000
--- "a/dev_problem_soving_abilty/Level1/4_\354\244\221\353\263\265\355\225\255\353\252\251.py"
+++ /dev/null
@@ -1,13 +0,0 @@
-def find_same_number(some_list):
- elements_seen_so_far = dict()
- for some in some_list:
- if some in elements_seen_so_far :
- return some
- else :
- elements_seen_so_far[some] = True
- return None
-
-# 중복되는 수 ‘하나’만 리턴합니다.
-print(find_same_number([1, 4, 3, 5, 3, 2]))
-print(find_same_number([4, 1, 5, 2, 3, 5]))
-print(find_same_number([5, 2, 3, 4, 1, 6, 7, 8, 9, 3]))
diff --git a/pythonInit/conditional/__init__.py b/pythonInit/conditional/__init__.py
deleted file mode 100644
index 9dbe218..0000000
--- a/pythonInit/conditional/__init__.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# in, not in 연산자
-data = [i for i in range(0,101, 10)]
-print(data)
-
-# 인라인 조건문
-if data in [0,10]: print("true")
-
-# 조건부 표현식
-score = 85
-result = "success" if score == 85 else "false"
-print(result)
-
-# 조건부 표현식 심화
-a = [i for i in range(1,5)]
-a.append(3)
-a.append(5)
-a.append(5)
-a.append(5)
-print(a)
-
-remove_set = {3,5}
-
-result = []
-for i in a:
- if i not in remove_set:
- result.append(i)
-
-print(result)
-
-# -> 간소화
-b = [i for i in range(1,5)]
-b.append(3)
-b.append(5)
-b.append(5)
-b.append(5)
-print(b)
-
-result2 = [j for j in b if j not in remove_set]
-print(result2)
diff --git a/pythonInit/data_type/dictionary.py b/pythonInit/data_type/dictionary.py
deleted file mode 100644
index 4073dbd..0000000
--- a/pythonInit/data_type/dictionary.py
+++ /dev/null
@@ -1,13 +0,0 @@
-# 해시테이블 이용함
-
-data = dict()
-data['사과'] = 'APPLE'
-data['바나나'] = 'banana'
-
-print(data)
-
-if '사과' in data:
- print("oo")
-
-print(data.keys())
-print(data.values())
\ No newline at end of file
diff --git a/pythonInit/data_type/list.py b/pythonInit/data_type/list.py
deleted file mode 100644
index a47fa7f..0000000
--- a/pythonInit/data_type/list.py
+++ /dev/null
@@ -1,54 +0,0 @@
-a = [1,2,3,4,5,6,7,8,9]
-print(a)
-print(a[4])
-
-# 초기화 방법 2가지
-b = list()
-print(b)
-
-c = []
-print(c)
-
-# 크기가 N 인 1차원리스트 초기화
-n = 10
-a = [0] * n
-print(a)
-
-a.clear()
-print("클리어")
-print(a)
-# 인덱싱, 슬라이싱
-
-
-# 초기회
-for i in range(1,10):
- a.append(i)
-print(a)
-
-# 인덱싱 : 특정 인덱스로 원소접근
-print(a[3])
-print(a[-1])
-# 슬라이싱 : 연속적인 위치 가지는 원소접근
-print(a[5:9])
-
-# 리스트 컨프리헨션
-array = [i for i in range(20) if i % 2 == 1]
-print(array)
-
- # 위 리스트 초기화 코드 컨프리헨션으로 바꾸기
-array2 = [i for i in range(1,10)]
-print(array2)
-
-# 2차원 리스트 초기화에 유용
-# 3 X 4 초기화
-n = 3
-m = 4
-
-# '_' 는 반복 변수값 불필요 일시
-array3 = [[0] * m for _ in range(n)]
-print(array3)
-
-# insert( O(1) ) append( O(NlogN) ) remove( O(N) ) 주의
-
-
-
diff --git a/pythonInit/data_type/number.py b/pythonInit/data_type/number.py
deleted file mode 100644
index 4ec0318..0000000
--- a/pythonInit/data_type/number.py
+++ /dev/null
@@ -1,43 +0,0 @@
-# 정수형 실수형
-
-a = 1000
-print(a)
-
-a = 158.93
-print(a)
-
-a = -5.
-print(a)
-
-a = -.7
-print(a)
-
-# 제곱
-b = 1e9 #10의 9승
-print(b)
-
-c = 82e5
-print(c)
-
-d = 89e-3
-print(d)
-
-# round 함수
-A = 0.3 + 0.6
-print(A)
-
-if A == 0.9:
- print(True)
-else:
- print(False)
-#round -> 4 + 1 번째 자리에서 반올림
-print(round(A,4))
-
-q = 7
-w = 3
-print(q/w)
-print(q//w) #몫 연산
-print(q%w) #나머지 연산
-print(q ** w) # 거듭제곱 연산
-
-
diff --git a/pythonInit/data_type/set.py b/pythonInit/data_type/set.py
deleted file mode 100644
index 179769f..0000000
--- a/pythonInit/data_type/set.py
+++ /dev/null
@@ -1,9 +0,0 @@
-data = set([i for i in range(10)])
-
-print(data)
-
-data.add(20)
-print(data)
-
-data.update([15,30])
-print(data)
diff --git a/pythonInit/data_type/string.py b/pythonInit/data_type/string.py
deleted file mode 100644
index 6393892..0000000
--- a/pythonInit/data_type/string.py
+++ /dev/null
@@ -1,10 +0,0 @@
-data = "hello"
-print(data)
-
-data2 = ' hello \'you\''
-print(data2)
-
-data3 = data + data2
-print(data3)
-
-print((data + " ") * 10)
\ No newline at end of file
diff --git a/pythonInit/data_type/tuple.py b/pythonInit/data_type/tuple.py
deleted file mode 100644
index a9d3296..0000000
--- a/pythonInit/data_type/tuple.py
+++ /dev/null
@@ -1,5 +0,0 @@
-a = (1,2,3,4)
-print(a)
-
-# a[2] = 7 #에러 발생 tuple 은 변경 불가
-# 그래프 알고리즘(다익스트라) & 공간효율적이며 & 원소간 성질 다를 때 이용
\ No newline at end of file
diff --git a/pythonInit/function/__init__.py b/pythonInit/function/__init__.py
deleted file mode 100644
index ed56b92..0000000
--- a/pythonInit/function/__init__.py
+++ /dev/null
@@ -1,28 +0,0 @@
-def add(a,b):
- return a + b
-
-print('함수의 결과: ',add(3,8))
-
-# global
-
-q = 0
-def func():
- global q
- q += 5
-
-for i in range(10):
- func()
-
-print(q)
-
-
-# 람다 익스프레션
-result = (lambda a, b : a + b)(3,7)
-print(result)
-
-list = [i for i in range(1,50)]
-print(list)
-
-
-sorted_false_ = (lambda a: sorted(a,None,False))(list)
-print(sorted_false_)
\ No newline at end of file
diff --git a/pythonInit/input_output/__init__.py b/pythonInit/input_output/__init__.py
deleted file mode 100644
index e02e2f8..0000000
--- a/pythonInit/input_output/__init__.py
+++ /dev/null
@@ -1,23 +0,0 @@
-# 여러 수 입력 받기
-
-# n, m, z = map(int,input("몇개? ").split())
-# print(n)
-#
-# data = list(map(int,input().split()))
-# print(data)
-#
-# data2 = list(input("테스트").split())
-# print(data2)
-#
-# for i in data2: print(type(i))
-# print(type[da])
-
-# 입력 속도 향상
-import sys
-tmp = sys.stdin.readline().rstrip()
-print(tmp)
-
-
-# 출력시 타입오류 관련
-answer = 7
-print("정답은" + str(answer) + "입니다.")
\ No newline at end of file
diff --git a/pythonInit/library/inner_function.py b/pythonInit/library/inner_function.py
deleted file mode 100644
index 431b26c..0000000
--- a/pythonInit/library/inner_function.py
+++ /dev/null
@@ -1,28 +0,0 @@
-# 기본 연산
-result = sum([1,2,3,45])
-print(result)
-
-result2 = min([1,4,6,4,2,1])
-print(result2)
-
-# 정렬
-list = [2,5,6,1,23,57,341,533,51,65,9,4]
-result3 = sorted(list, reverse=True)
-print(result3)
-
-# 튜플정렬 (key)
-tuple_list = [(3,"김"), (5,"이"),(1,"박"),(9,"최")]
-print(tuple_list)
-tuple_list_sort= sorted(tuple_list,key = lambda x : x[1])
-print(tuple_list_sort)
-
-# 딕셔너리 정렬 안됨 -> list 로 특정 요소만 반환이 됨
-dic_list = dict()
-dic_list['3'] = '김'
-dic_list['5'] = '이'
-dic_list['1'] = '박'
-dic_list['7'] = '최'
-print(dic_list)
-dic_list_sort = sorted(dic_list, key= lambda x : x[0])
-print(type(dic_list_sort))
-print(dic_list_sort)
\ No newline at end of file
diff --git a/pythonInit/library/itertools_lib.py b/pythonInit/library/itertools_lib.py
deleted file mode 100644
index 26a465c..0000000
--- a/pythonInit/library/itertools_lib.py
+++ /dev/null
@@ -1,11 +0,0 @@
-from itertools import permutations, combinations
-
-date = ['A','B','C','D','E']
-result = list(permutations(date,2))
-print(result)
-
-result2 = list(combinations(date,2))
-print(result2)
-
-
-# 그외 heapq, bisect, collections 는 아직 안함
\ No newline at end of file
diff --git a/pythonInit/library/math.py b/pythonInit/library/math.py
deleted file mode 100644
index a2d3cc3..0000000
--- a/pythonInit/library/math.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import math
-
-print(math.factorial(5))
\ No newline at end of file
diff --git a/pythonTest/binary_search.py b/pythonTest/binary_search.py
deleted file mode 100644
index 7969d1e..0000000
--- a/pythonTest/binary_search.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# 0
-# None
-# 2
-# 4
-# 1
-
-def binary_search(element, some_list):
- start = 0
- # end = len(some_list)
- end = len(some_list) - 1 # X -1을 안붙여줌
-
- for data in range(len(some_list)):
- mid = (start + end) // 2
- if some_list[mid] == element:
- return mid
- # element 가 클 때
- elif some_list[mid] < element:
- start = mid + 1
- # element 가 작을 때
- elif some_list[mid] > element:
- end = mid - 1
- return None # V : 이거도 안넣어줌
-
-
-print(binary_search(2, [2, 3, 5, 7, 11]))
-print(binary_search(0, [2, 3, 5, 7, 11]))
-print(binary_search(5, [2, 3, 5, 7, 11]))
-print(binary_search(3, [2, 3, 5, 7, 11]))
-print(binary_search(11, [2, 3, 5, 7, 11]))
\ No newline at end of file
diff --git a/pythonTest/linear_search.py b/pythonTest/linear_search.py
deleted file mode 100644
index 655355d..0000000
--- a/pythonTest/linear_search.py
+++ /dev/null
@@ -1,16 +0,0 @@
-# 0
-# None
-# 2
-# 1
-# 4
-
-def linear_search(element, some_list):
- for index in range(len(some_list)):
- if element == some_list[index]: return index
- return None
-
-print(linear_search(2, [2, 3, 5, 7, 11]))
-print(linear_search(0, [2, 3, 5, 7, 11]))
-print(linear_search(5, [2, 3, 5, 7, 11]))
-print(linear_search(3, [2, 3, 5, 7, 11]))
-print(linear_search(11, [2, 3, 5, 7, 11]))
\ No newline at end of file
diff --git a/pythonTest/test.py b/pythonTest/test.py
deleted file mode 100644
index f6e1473..0000000
--- a/pythonTest/test.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# True
-# False
-# True
-# True
-# False
-
-def is_palindrome(word):
- for i in range(len(word) // 2):
- if(word[i] != word[-i-1]):
- return False;
- return True;
-
-# 테스트 코드
-print(is_palindrome("racecar"))
-print(is_palindrome("stars"))
-print(is_palindrome("토마토"))
-print(is_palindrome("kayak"))
-print(is_palindrome("hello"))
\ No newline at end of file
diff --git a/stats.json b/stats.json
deleted file mode 100644
index 81c9913..0000000
--- a/stats.json
+++ /dev/null
@@ -1 +0,0 @@
-{"leetcode":{"easy":20,"hard":0,"medium":1,"shas":{"0506-relative-ranks":{"0506-relative-ranks.py":"e9d28a1ca3735d06e7aae08e0f719c0d572c4b9e","README.md":"0a1c61317480f02f75fe348defc77ecab245e3a3","difficulty":"easy"},"README.md":{"":"1dc2a2f81712fda928d5c2e6d4b1c7172ca528f1"},"0789-kth-largest-element-in-a-stream":{"0789-kth-largest-element-in-a-stream.py":"20db19981c727f2960209c1a8f82c4ed46a56aba","README.md":"f080c21c1adf3cfffa878ffe9379f35ff52002b2","difficulty":"easy"},"stats.json":{"":"bdfea5e6c2304bc3005f9ccf9b51bf7038c7e88e"},"0118-pascals-triangle":{"0118-pascals-triangle.py":"01c2c9b5420336ad677bdcb8e42b0e57fd329f33","README.md":"549ce276ec0d25402deff66cf41209e7589d123d"},"0783-search-in-a-binary-search-tree":{"0783-search-in-a-binary-search-tree.py":"393decfa85c3b31fb13d9ea8036cfc526d0ff2bf","README.md":"0ebb87b67c966c7015765bd0dd9990eb6353574f","difficulty":"easy"},"1013-fibonacci-number":{"1013-fibonacci-number.py":"0b0c84588eb4af9d11dc04f00a462cb27617b3e1","README.md":"2ac4ae56a3b012f1cae799cadcf8d8465aa0c385"},"1086-divisor-game":{"1086-divisor-game.py":"2bafd5aee689f1af275f80ce09f709cfa3f80fcc","README.md":"cc8498a624d9885fd9eaff5666187311e6c958a3"},"1572-subrectangle-queries":{"1572-subrectangle-queries.py":"2bc2d95c8c547fe5784805701705c340c6a7d20e","README.md":"9357662674bdebe61e2c36bc04269bd757df9075"},"1651-shuffle-string":{"1651-shuffle-string.py":"d80541aa2b5b4fb62a66105e6cb0074e39fb90ea","README.md":"7bba5ab5286f4b385d6530cc553b36ea3a0fc73b"},"2413-smallest-number-in-infinite-set":{"2413-smallest-number-in-infinite-set.py":"1583ba8164a7cfdab7da098b85c5a7108f463338","README.md":"cc5671ac1018b121b8cd00fc70a6f5b33968ba78"},"0101-symmetric-tree":{"0101-symmetric-tree.py":"9a5b19fe0d925c7b203011c02c406c8a99be1a5f","README.md":"1f2113012a39cfbad1ebdddb1b47cba18e5fa452","difficulty":"easy"},"0094-binary-tree-inorder-traversal":{"0094-binary-tree-inorder-traversal.py":"f9ee718899bca997aaa2364d3672c03a5a722d02","README.md":"9917c3063b6843bf0d5bc242d506276c6cbf513b","difficulty":"easy"},"0933-increasing-order-search-tree":{"0933-increasing-order-search-tree.py":"60513792739e346b66107b74920ae5e39e029131","README.md":"2a6f39d6cf6873b3fe696c6edd0bf267f8db1435","difficulty":"easy"},"0119-pascals-triangle-ii":{"0119-pascals-triangle-ii.py":"5cb63cf767cdc1f103ef2b8641c2947a8745494d","README.md":"1a64158a4091f668fba1de2b1e9de2a61d02b2a1","difficulty":"easy"},"0561-array-partition":{"0561-array-partition.py":"09195cac4ad6bcd86cd74c56e12af725126dc582","README.md":"babdba7c3e28b260904756395eb694fc4db71165","difficulty":"easy"},"1916-find-center-of-star-graph":{"1916-find-center-of-star-graph.py":"1270ce8385db3d1d0d5b61d048015a0e84840dc6","README.md":"784d054f74bdd3a44e5020d53b21593739472472","difficulty":"easy"},"2121-find-if-path-exists-in-graph":{"2121-find-if-path-exists-in-graph.py":"29de065b7b37a5b43bb97f88761c1237a37d12c6","README.md":"6e74b14e557cb61cc4175bd9ce63fdf484c88bd7","difficulty":"easy"},"0268-missing-number":{"0268-missing-number.py":"36badbf52109551b6d0b18f0f713fb522a5d1105","README.md":"d6ee3afb48242fe188a8add0fc4019b6ecd58b25","difficulty":"easy"},"0441-arranging-coins":{"0441-arranging-coins.py":"08f96ced74cd3cf69671c1f592d1f5d5f2f0d666","README.md":"d770ba06e6226fecebbbbafd408e9f20562c31de","difficulty":"easy"},"1653-number-of-good-leaf-nodes-pairs":{"1653-number-of-good-leaf-nodes-pairs.py":"72c057987903f8a10845e59b7b203adc9b6b0826","README.md":"8613ad8142cf1fd6a1fab2380451aa7c079cc24d","difficulty":"medium"},"0409-longest-palindrome":{"0409-longest-palindrome.py":"ff21678c642a265beff5dfdd1f1c4315e94bbfab","README.md":"b2f8005d6c833406aa39cb58aa78f68d1f326ec5","difficulty":"easy"},"0455-assign-cookies":{"0455-assign-cookies.py":"3a2e44dfe8e0965ed5a64e0cce468a6ee211c81d","README.md":"344288168c6c926a0c18007637479cbbee6513b2","difficulty":"easy"},"0747-min-cost-climbing-stairs":{"0747-min-cost-climbing-stairs.py":"9083d6c2103a46380b3531319c38aa05bb16502d","README.md":"be0a33d8d0a7615b46a6edb8d8543d1d9dfa59af","difficulty":"easy"},"1236-n-th-tribonacci-number":{"1236-n-th-tribonacci-number.py":"ae76e57e6c4a2cf5732fadd7a33880de04a3658f","README.md":"4179ca091ccbcf2708a751df75bfe85f68b90220","difficulty":"easy"},"0121-best-time-to-buy-and-sell-stock":{"0121-best-time-to-buy-and-sell-stock.py":"d9c303abbd9b453f26c46d6e1f06d1f677a11ca6","README.md":"c985d4a7bb22bad48ddd48f971d6376a9b0b8e9b","difficulty":"easy"},"2692-take-gifts-from-the-richest-pile":{"2692-take-gifts-from-the-richest-pile.py":"82e02eee558bfe17a7b7e1757c669547917e37e5","README.md":"dec87447513c2debbd86d3aaf54ff99863ff2ac9","difficulty":"easy"},"2585-delete-greatest-value-in-each-row":{"2585-delete-greatest-value-in-each-row.py":"0beb4dda7ea4e2ceda36f096bd9cd25febd6b4fc","README.md":"7f4761b4163ddd33627581b5223865a1a00e8710","difficulty":"easy"},"2327-largest-number-after-digit-swaps-by-parity":{"2327-largest-number-after-digit-swaps-by-parity.py":"b637857504603c6abd626302443c5db8c3e0a800","README.md":"cb9d3da5e6b6501cdf20e72926669b9a2fafe70e","difficulty":"easy"}},"solved":21}}
\ No newline at end of file
diff --git a/template_md/template.md b/template_md/template.md
deleted file mode 100644
index 5a9b86c..0000000
--- a/template_md/template.md
+++ /dev/null
@@ -1,38 +0,0 @@
-
-## 일지
-- 1회 시도한 날 : 2024-02-05 ~ (_시간)
-- 2회 시도한 날 :
-- 3회 시도한 날 :
-
-## 문제 보기
-
-### 실습 설명
-
-
-```python
-
-```
-### 주의사항
-
-
-### 실습 코드
-
-```python
-```
-
-## 문제풀이
-
-#### 모's 풀이
-```python
-
-```
-
-#### 모범답안 풀이
-```python
-
-
-```
-
-
-## 반성
-1.
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/README.md" "b/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/README.md"
deleted file mode 100644
index 9f0daf0..0000000
--- "a/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/README.md"
+++ /dev/null
@@ -1,30 +0,0 @@
-# [Bronze I] 적어도 대부분의 배수 - 1145
-
-[문제 링크](https://www.acmicpc.net/problem/1145)
-
-### 성능 요약
-
-메모리: 33240 KB, 시간: 32 ms
-
-### 분류
-
-브루트포스 알고리즘
-
-### 제출 일자
-
-2024년 8월 26일 22:52:31
-
-### 문제 설명
-
-다섯 개의 자연수가 있다. 이 수의 적어도 대부분의 배수는 위의 수 중 적어도 세 개로 나누어 지는 가장 작은 자연수이다.
-
-서로 다른 다섯 개의 자연수가 주어질 때, 적어도 대부분의 배수를 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 다섯 개의 자연수가 주어진다. 100보다 작거나 같은 자연수이고, 서로 다른 수이다.
-
-### 출력
-
- 첫째 줄에 적어도 대부분의 배수를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230.py" "b/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230.py"
deleted file mode 100644
index b2b8323..0000000
--- "a/\353\260\261\354\244\200/Bronze/1145.\342\200\205\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230/\354\240\201\354\226\264\353\217\204\342\200\205\353\214\200\353\266\200\353\266\204\354\235\230\342\200\205\353\260\260\354\210\230.py"
+++ /dev/null
@@ -1,34 +0,0 @@
-from itertools import combinations
-from math import gcd
-
-if __name__ == "__main__":
- input_list = list(map(int, input().split()))
-
- # 최대공약수 구하기인것을 몰랐을 때
- # set 으로 해서 공집합 방식으로 하려고 함
-
- # set_list = []
- # for _ in range(len(input_list)):
- # value = input_list.pop()
- #
- # multi = 1
- # set_value = set()
- # multiple_value = 0
- # while multiple_value < 101:
- # multiple_value = multi * value
- # multi += 1
- # set_value.add(multiple_value)
- # set_list.append(set_value)
- # print(set_list)
-
-
- def lcm(a,b):
- # 최소공배수로 최대공약수 구하기
- return a * b // gcd(a,b)
-
- min_lcm = float('inf')
- for combo in combinations(input_list, 3):
- lcm_value = lcm(lcm(combo[0], combo[1]), combo[2])
- min_lcm = min(min_lcm, lcm_value)
-
- print(min_lcm)
diff --git "a/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/README.md" "b/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/README.md"
deleted file mode 100644
index c99280d..0000000
--- "a/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/README.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# [Bronze I] Yangjojang of The Year - 11557
-
-[문제 링크](https://www.acmicpc.net/problem/11557)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 32 ms
-
-### 분류
-
-구현, 정렬
-
-### 제출 일자
-
-2024년 11월 23일 11:29:53
-
-### 문제 설명
-
-입학 OT때 누구보다도 남다르게 놀았던 당신은 자연스럽게 1학년 과대를 역임하게 되었다.
-
-타교와의 조인트 엠티를 기획하려는 당신은 근처에 있는 학교 중 어느 학교가 술을 가장 많이 먹는지 궁금해졌다.
-
-학교별로 한 해동안 술 소비량이 주어질 때, 가장 술 소비가 많은 학교 이름을 출력하여라.
-
-### 입력
-
- 입력의 첫 줄에는 테스트 케이스의 숫자 T가 주어진다.
-
-매 입력의 첫 줄에는 학교의 숫자 정수 N(1 ≤ N ≤ 100)이 주어진다.
-
-이어서 N줄에 걸쳐 학교 이름 S(1 ≤ |S| ≤ 20, S는 공백없는 대소문자 알파벳 문자열)와 해당 학교가 지난 한 해동안 소비한 술의 양 L(0 ≤ L ≤ 10,000,000)이 공백으로 구분되어 정수로 주어진다.
-
-같은 테스트 케이스 안에서 소비한 술의 양이 같은 학교는 없다고 가정한다.
-
-### 출력
-
- 각 테스트 케이스마다 한 줄에 걸쳐 술 소비가 가장 많은 학교의 이름을 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/Yangjojang\342\200\205of\342\200\205The\342\200\205Year.py" "b/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/Yangjojang\342\200\205of\342\200\205The\342\200\205Year.py"
deleted file mode 100644
index 635446f..0000000
--- "a/\353\260\261\354\244\200/Bronze/11557.\342\200\205Yangjojang\342\200\205of\342\200\205The\342\200\205Year/Yangjojang\342\200\205of\342\200\205The\342\200\205Year.py"
+++ /dev/null
@@ -1,12 +0,0 @@
-import sys
-
-T = int(sys.stdin.readline())
-
-for t in range(T):
- N = int(sys.stdin.readline())
- univ = []
- for n in range(N):
- s, a = sys.stdin.readline().split()
- univ.append((s, int(a)))
- univ.sort(key= lambda x : x[1], reverse=True)
- sys.stdout.write(univ[0][0] + '\n')
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/README.md" "b/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/README.md"
deleted file mode 100644
index 0154a2e..0000000
--- "a/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/README.md"
+++ /dev/null
@@ -1,35 +0,0 @@
-# [Bronze II] 단어순서 뒤집기 - 12605
-
-[문제 링크](https://www.acmicpc.net/problem/12605)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 32 ms
-
-### 분류
-
-자료 구조, 파싱, 스택, 문자열
-
-### 제출 일자
-
-2024년 11월 10일 09:27:37
-
-### 문제 설명
-
-스페이스로 띄어쓰기 된 단어들의 리스트가 주어질때, 단어들을 반대 순서로 뒤집어라. 각 라인은 w개의 영단어로 이루어져 있으며, 총 L개의 알파벳을 가진다. 각 행은 알파벳과 스페이스로만 이루어져 있다. 단어 사이에는 하나의 스페이스만 들어간다.
-
-### 입력
-
- 첫 행은 N이며, 전체 케이스의 개수이다.
-
-N개의 케이스들이 이어지는데, 각 케이스는 스페이스로 띄어진 단어들이다. 스페이스는 라인의 처음과 끝에는 나타나지 않는다. N과 L은 다음 범위를 가진다.
-
-
-
-### 출력
-
- 각 케이스에 대해서, 케이스 번호가 x일때 "Case #x: " 를 출력한 후 그 후에 이어서 단어들을 반대 순서로 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260.py" "b/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260.py"
deleted file mode 100644
index bfd9e92..0000000
--- "a/\353\260\261\354\244\200/Bronze/12605.\342\200\205\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260/\353\213\250\354\226\264\354\210\234\354\204\234\342\200\205\353\222\244\354\247\221\352\270\260.py"
+++ /dev/null
@@ -1,7 +0,0 @@
-import sys
-N = int(sys.stdin.readline())
-for _ in range(N):
- words = sys.stdin.readline().split()
- reverse_words = words[::-1]
- answer = " ".join(reverse_words)
- sys.stdout.write("Case #" + str(_+1) +": " + answer + "\n")
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/README.md" "b/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/README.md"
deleted file mode 100644
index 238d1df..0000000
--- "a/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/README.md"
+++ /dev/null
@@ -1,44 +0,0 @@
-# [Bronze II] 탕수육 - 13419
-
-[문제 링크](https://www.acmicpc.net/problem/13419)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 32 ms
-
-### 분류
-
-구현, 시뮬레이션, 문자열
-
-### 제출 일자
-
-2024년 11월 30일 10:53:21
-
-### 문제 설명
-
-환규와 태욱이는 둘이서 즐길 수 있는 간단한 게임인 탕수육 게임을 하기로 했다. 게임의 규칙은 다음과 같다.
-
-
- - 누가 먼저 시작할지 순서를 정한다.
- - 먼저 시작하는 사람이 단어의 가장 첫 글자를 말한다.
- - 이후 두 사람이 번갈아 가며 자신의 차례에 이전 사람이 말한 글자의 다음 글자를 말한다.
- - 만약 이전 사람이 단어의 가장 마지막 글자를 말했다면 자신의 차례에 단어의 가장 첫 글자를 말한다.
- - 만약 자신의 차례에 잘못된 글자를 말하면 게임에서 지게 된다.
-
-
-위 규칙을 이용해 탕수육이란 단어를 가지고 게임을 진행하면 다음과 같다.
-
-탕 수 육 탕 수 육 탕 수 육 탕 수 육 …
-
-위 예시에서 밑줄 친 부분은 첫 번째 사람이, 밑줄이 없는 부분은 두 번째 사람이 말하게 되는 부분이다. 이때 밑줄 그어진 부분만 따로 살펴보면 “탕육수탕육수…”가 됨을 알 수 있는데, 따라서 먼저 시작하는 사람은 게임을 시작하기 전에 “탕육수” 만을 기억한 후 상대방이 어떤 단어를 말하든 “탕육수” 순서로 계속 반복해서 말하면 절대로 틀리지 않는다. 만약 “탕육”이나 “탕육수탕”을 기억한다면 기억한 문자열을 처음부터 하나씩 순서대로 말했을 때 자신의 차례에 올바르지 않은 문자를 말하게 되어 게임에서 지게 된다. “탕육수탕육수”를 기억한다고 하더라도 자신의 차례에 틀린 문자를 말하게 되지는 않지만, “탕육수” 만을 기억해도 게임을 진행할 수 있으므로 이 경우 항상 기억해야 할 최소한의 글자만을 기억한다고 가정한다. 또한, 나중에 시작하는 사람도 게임을 시작하기 전에 “수탕육”만을 기억한 다음 “수탕육” 순서대로 반복해서 말하면 절대로 틀리지 않는다.
-
-환규와 태욱이는 이번에는 한글 대신 알파벳을 사용해서 게임을 해보기로 했다. 만약 주어진 단어가 “ABC”이고, 환규가 먼저 시작한다면 환규는 “ACB”를, 태욱이는 “BAC” 만을 기억하면 게임을 지지 않게 된다. 게임에 사용할 알파벳으로 된 문자열이 주어질 때, 두 사람이 미리 기억하고 있어야 되는 문자열 중 가장 짧은 것을 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 입력 데이터는 표준 입력을 사용한다. 입력은 T개의 테스트 데이터로 구성된다. 입력의 첫 번째 줄에 테스트 케이스의 개수를 나타내는 자연수 T가 주어진다. 각각의 테스트 케이스의 첫째 줄에 게임에 사용할 문자열이 주어진다. 문자열의 길이는 1보다 크거나 같고 26보다 작거나 같다. 게임에 사용할 문자열은 알파벳 대문자로만 이루어져 있으며 같은 알파벳을 두 개 이상 포함하지 않는다.
-
-### 출력
-
- 출력은 표준 출력을 사용한다. 입력받은 데이터에 대해, 각 테스트 케이스의 답을 순서대로 출력한다. 각 테스트 케이스마다 첫 번째 줄에 먼저 시작한 사람이 기억해야 될 문자열 중 가장 짧은 것을 알파벳 대문자로 출력한다. 두 번째 줄에는 나중에 시작한 사람이 기억해야 될 문자열중 가장 짧은 것을 알파벳 대문자로 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/\355\203\225\354\210\230\354\234\241.py" "b/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/\355\203\225\354\210\230\354\234\241.py"
deleted file mode 100644
index ba1a7ad..0000000
--- "a/\353\260\261\354\244\200/Bronze/13419.\342\200\205\355\203\225\354\210\230\354\234\241/\355\203\225\354\210\230\354\234\241.py"
+++ /dev/null
@@ -1,64 +0,0 @@
-import sys
-
-def minimal_period(s):
- n = len(s)
- for p in range(1, n + 1):
- if n % p == 0 and s == s[:p] * (n // p):
- return s[:p]
- return s
-
-def get_player_sequence(s, start):
- n = len(s)
- letters = []
- for i in range(n):
- index = (i * 2 + start) % n
- letters.append(s[index])
- sequence = ''.join(letters)
- return minimal_period(sequence)
-
-T = int(sys.stdin.readline().strip())
-
-for _ in range(T):
- s = sys.stdin.readline().strip()
- hwan = get_player_sequence(s, 0) # 첫 번째 사람은 0부터 시작
- tae = get_player_sequence(s, 1) # 두 번째 사람은 1부터 시작
-
- print(hwan)
- print(tae)
-
-
-# import sys
-#
-# def find_min_rotation(s):
-# n = len(s)
-# double_s = s + s
-# return min(double_s[i : i + n] for i in range(n))
-#
-# # 무조건 이기기 위한 값?
-# T = int(sys.stdin.readline().strip())
-#
-# # 어떻게 하면 기억해야할 문자열 중 가장 짧은 것을 출력할 수 있을까?
-# for _ in range(T):
-# s = sys.stdin.readline().strip()
-# hwan = find_min_rotation(s) # 먼저
-# tae = find_min_rotation(s[::-1]) # 다음
-#
-# print(hwan)
-# print(tae)
-#
-#
-#
-# # # 우선 해당 문자열을 최대한 나열하고, 반복되는 지점을 찾는다.
-# # # 반복되는 직전까지를 가장 짧은 문자열로 뽑아낸다.
-# # i = 0
-# # while True :
-# # turn_index = i % len(s)
-# # if len(hwan) <= len(tae):
-# # hwan.append(s[turn_index])
-# # else :
-# # tae.append(s[turn_index])
-# #
-# # if i == 20:
-# # break
-# #
-# # i += 1
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/README.md" "b/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/README.md"
deleted file mode 100644
index 4596b94..0000000
--- "a/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/README.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# [Bronze I] 세준세비 - 1524
-
-[문제 링크](https://www.acmicpc.net/problem/1524)
-
-### 성능 요약
-
-메모리: 40036 KB, 시간: 228 ms
-
-### 분류
-
-구현, 정렬
-
-### 제출 일자
-
-2024년 11월 26일 21:35:43
-
-### 문제 설명
-
-세준이와 세비는 온라인 게임을 즐겨한다. 이 온라인 게임에서는 군대를 서로 키울 수 있다. 세준이는 N명의 병사를 키웠고, 세비는 M명의 병사를 키웠다.
-
-이제 서로 전쟁을 하려고 한다.
-
-전쟁은 여러 번의 전투로 이루어진다. 각 전투에서 살아있는 병사중 제일 약한 병사가 죽는다. 만약 제일 약한 병사가 여러 명이고, 제일 약한 병사가 모두 같은 편에 있다면, 그 중에 한 명이 임의로 선택되어 죽는다. 하지만, 제일 약한 병사가 여러 명이고, 양 편에 모두 있다면, 세비의 제일 약한 병사 중 한 명이 임의로 선택되어 죽는다.
-
-전쟁은 한 명의 병사를 제외하고 모두 죽었을 때 끝난다. 전쟁의 승자를 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 테스트 케이스의 개수 T가 주어진다. T는 100보다 작거나 같다. 각 테스트 케이스는 다음과 같이 이루어져 있다. 첫째 줄에 N과 M이 들어오고, 둘째 줄에는 세준이의 병사들의 힘이 들어오고, 셋째 줄에는 세비의 병사들의 힘이 들어온다. 힘은 정수이고, 이 값이 클수록 강하고, 작을수록 약하다.
-
-각 테스트 케이스는 줄 바꿈으로 구분되어 있다.
-
-### 출력
-
- 각 테스트 케이스에 대해서 한 줄에 하나씩 차례대로 승자를 출력한다. 세준이가 이기면 S를 세비가 이기면 B를 둘다 아닐 경우에는 C를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/\354\204\270\354\244\200\354\204\270\353\271\204.py" "b/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/\354\204\270\354\244\200\354\204\270\353\271\204.py"
deleted file mode 100644
index 47f641a..0000000
--- "a/\353\260\261\354\244\200/Bronze/1524.\342\200\205\354\204\270\354\244\200\354\204\270\353\271\204/\354\204\270\354\244\200\354\204\270\353\271\204.py"
+++ /dev/null
@@ -1,24 +0,0 @@
-import sys
-
-# 1-1. 게임 횟수 입력
-games = int(sys.stdin.readline())
-# 1-2. 세준 N, 세비 M 명 병사 (같을 경우 세바 병사 사망)
-for _ in range(games):
- sys.stdin.readline().strip()
- NM = list(map(int,sys.stdin.readline().split()))
- # 1-3. 세준 병사의 힘들, 세바 병사 들의 힘들 입력 & 정렬
- Jn_armies = sorted(list(map(int, sys.stdin.readline().split())), reverse=True)
- Bm_armies = sorted(list(map(int, sys.stdin.readline().split())), reverse=True)
- # 2. 게임 진행
- while Jn_armies and Bm_armies:
- if Jn_armies[-1] < Bm_armies[-1]:
- n_army = Jn_armies.pop()
- else:
- m_army = Bm_armies.pop()
-
- if Jn_armies:
- sys.stdout.write("S\n")
- # print("S")
- elif Bm_armies:
- sys.stdout.write("B\n")
- # print("B")
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/README.md" "b/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/README.md"
deleted file mode 100644
index cc42012..0000000
--- "a/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/README.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# [Bronze I] 근무 지옥에 빠진 푸앙이 (Small) - 25593
-
-[문제 링크](https://www.acmicpc.net/problem/25593)
-
-### 성능 요약
-
-메모리: 34060 KB, 시간: 52 ms
-
-### 분류
-
-자료 구조, 해시를 사용한 집합과 맵, 구현, 문자열
-
-### 제출 일자
-
-2024년 11월 5일 00:23:25
-
-### 문제 설명
-
-군대에 간 푸앙이는 4교대 근무를 서게 된다. 근무 시간대는 08:00~12:00, 12:00~18:00, 18:00~22:00, 22:00~08:00 으로 각각 4, 6, 4, 10시간의 근무로 구성되어 있다.
-
-푸앙이와 동기들은 근무 시간이 최대한 공평하게 배분되기를 원한다. 그래서 근무표 전체에서 각 인원의 근무 시간이 12시간 이하로 차이 나게 해서 최대 50주 치 근무표를 짜려고 한다.
-
-푸앙이는 원래 똑똑해서 이 정도는 한눈에 계산이 가능했지만 어째서인지 푸앙이는 계산이 불가능해졌다. 푸앙이를 위해서 대신 근무표가 공평한지 계산해주자.
-
-### 입력
-
- 첫 번째 줄에 주의 개수인 $N$이 입력된다. $(1 \leq N \leq 50)$
-
-둘째 줄부터 근무표가 주어진다. 각 주는 4개의 줄로 표현되며, 그중 첫째 줄은 각 날의 08:00~12:00에 근무하는 사람의 이름 또는 '-', 둘째 줄은 12:00~18:00, 셋째 줄은 18:00~22:00, 넷째 줄은 22:00~08:00을 나타낸다. '-'는 근무자가 없음을 의미한다. 근무자의 이름은 모두 알파벳 소문자로 이루어져 있고 20글자를 넘지 않는다.
-
-각 날에는 4개의 시간대에 모두 근무자가 있거나 모두 근무자가 없다. 예를 들어 12:00~18:00에만 근무자가 있는 날은 없다.
-
-근무표에 적히지 않은 근무자는 없으며, 근무자 수는 최대 $100$명이다.
-
-### 출력
-
- 근무표가 공평하면 “Yes”를 아니면 “No”를 출력한다. 단, 아무도 근무하지 않을 경우 공평한 것으로 간주한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211.py" "b/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211.py"
deleted file mode 100644
index c64b2c2..0000000
--- "a/\353\260\261\354\244\200/Bronze/25593.\342\200\205\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211/\352\267\274\353\254\264\342\200\205\354\247\200\354\230\245\354\227\220\342\200\205\353\271\240\354\247\204\342\200\205\355\221\270\354\225\231\354\235\264\342\200\205\357\274\210Small\357\274\211.py"
+++ /dev/null
@@ -1,51 +0,0 @@
-import sys
-from collections import defaultdict
-
-# 1. 입력
-N = int(sys.stdin.readline())
-
-work_dict = defaultdict(int)
-for i in range(4 * N):
- count = i % 4
-
- daily_workers = sys.stdin.readline().split()
- daily_workers_ = [worker for worker in daily_workers if worker != '-']
- # print(daily_workers_)
-
- if count == 0 or count == 2:
- for worker in daily_workers_:
- work_dict[worker] += 4
- elif count == 1 :
- for worker in daily_workers_:
- work_dict[worker] += 6
- elif count == 3:
- for worker in daily_workers_:
- work_dict[worker] += 10
-
-
-# 2. dict 비교
-# sorted_work_dict = sorted(work_dict.items(), key = lambda item:item[1]) -> 필요없음
-# print(sorted_work_dict)
-
-# min = sorted_work_dict[0][1]
-# max = sorted_work_dict[-1][1]
-
-# min_hours = min(work_dict.values())
-# max_hours = max(work_dict.values())
-
-# differ = max_hours - min_hours
-# print(differ)
-
-if work_dict:
- min_hours = min(work_dict.values())
- max_hours = max(work_dict.values())
- differ = max_hours - min_hours
- if differ <= 12:
- sys.stdout.write("Yes")
- # print("Yes")
- else :
- sys.stdout.write("No")
- # print("No")
-else :
- sys.stdout.write("Yes")
- # print("Yes")
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/README.md" "b/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/README.md"
deleted file mode 100644
index 58cea8c..0000000
--- "a/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/README.md"
+++ /dev/null
@@ -1,48 +0,0 @@
-# [Bronze II] 할리갈리 - 27160
-
-[문제 링크](https://www.acmicpc.net/problem/27160)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 104 ms
-
-### 분류
-
-자료 구조, 해시를 사용한 집합과 맵, 구현, 문자열
-
-### 제출 일자
-
-2024년 11월 3일 10:01:04
-
-### 문제 설명
-
-
-
-그림 B.1: 할리갈리
-
-《할리갈리》는 단추가 달린 종 하나와 과일이 그려진 카드들로 구성된 보드게임입니다.
-
-카드에는 총 $4$종류의 과일이 최대 $5$개까지 그려져 있습니다. 그려진 과일의 종류는 딸기, 바나나, 라임, 그리고 자두입니다.
-
-게임을 시작할 때 플레이어들은 카드 뭉치를 공평하게 나눠가지며 자신이 가진 카드를 전부 소모하면 패배합니다.
-
-게임은 시작 플레이어가 본인의 카드 뭉치에서 카드 한 장을 공개하는 것으로 시작합니다. 이후 반시계 방향으로 돌아가며 본인의 카드를 한 장씩 공개합니다.
-
-펼쳐진 카드들 중 한 종류 이상의 과일이 정확히 $5$개 있는 경우 종을 눌러야 하며 가장 먼저 종을 누른 플레이어가 모든 카드를 모아 자신의 카드 뭉치 아래에 놓습니다. 종을 잘못 누른 경우 다른 모든 플레이어에게 카드를 한 장씩 나누어줘야 합니다.
-
-《할리갈리》를 처음 해보는 한별이는 할리갈리 고수인 히나에게 이기기 위해 여러분에게 도움을 청했습니다. 한별이를 도와 펼쳐진 카드들의 목록이 주어졌을 때, 한별이가 종을 쳐야 하는지 알려주세요.
-
-### 입력
-
- 첫 번째 줄에 펼쳐진 카드의 개수 $N$이 주어집니다.
-
-두 번째 줄부터 $N$개의 줄에 걸쳐 한 줄에 하나씩 펼쳐진 카드의 정보가 주어집니다.
-
-카드의 정보는 공백으로 구분된, 과일의 종류를 나타내는 문자열 $S$와 과일의 개수를 나타내는 양의 정수 $X$로 이루어져 있습니다.
-
- $S$는 STRAWBERRY, BANANA, LIME, PLUM 중 하나입니다.
-
-### 출력
-
- 한별이가 종을 쳐야 하면 YES을, 아니면 NO를 출력해주세요.
-
diff --git "a/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/\355\225\240\353\246\254\352\260\210\353\246\254.py" "b/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/\355\225\240\353\246\254\352\260\210\353\246\254.py"
deleted file mode 100644
index 6aafeea..0000000
--- "a/\353\260\261\354\244\200/Bronze/27160.\342\200\205\355\225\240\353\246\254\352\260\210\353\246\254/\355\225\240\353\246\254\352\260\210\353\246\254.py"
+++ /dev/null
@@ -1,21 +0,0 @@
-import sys
-
-N = int(sys.stdin.readline())
-dict = {}
-answer = "NO"
-
-for i in range(N):
- S = sys.stdin.readline()
- fruit, count = S.split()
- c = int(count)
-
- if fruit in dict:
- dict[fruit] += c
- else :
- dict[fruit] = c
-
-for k, v in dict.items():
- if v == 5:
- answer = "YES"
-
-print(answer)
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/README.md" "b/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/README.md"
deleted file mode 100644
index 6456195..0000000
--- "a/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/README.md"
+++ /dev/null
@@ -1,167 +0,0 @@
-# [Bronze II] 모스 부호 - 29701
-
-[문제 링크](https://www.acmicpc.net/problem/29701)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 32 ms
-
-### 분류
-
-자료 구조, 해시를 사용한 집합과 맵, 구현, 문자열
-
-### 제출 일자
-
-2024년 11월 1일 20:56:07
-
-### 문제 설명
-
-혜민이는 요즘 모스 부호에 관심이 많아졌다. 모스 부호는 짧은 신호와 긴 신호를 적절히 조합하여 문자 기호를 표기하는 방식이다. 각 문자를 나타내는 방식은 미리 정해져 있는데, 예를 들어, 짧은 신호를 '.', 긴 신호를 '-'로 나타낸다면, 모스 부호로 알파벳 'A'는 '.-', 숫자 1은 '.----'와 같이 표기할 수 있다. 모스 부호를 알고 있으면 위험한 상황에서 구조 요청을 하는 데 유용할 것 같아, 혜민이는 평상시에 친구들과 연락을 주고받을 때도 모스 부호를 사용하려고 한다. 혜민이는 친구들이 보내온 모스 부호를 올바르게 해독했는지 바로바로 확인하고 싶어졌다. 알파벳 A-Z, 숫자 0-9, 기호 ',', '.', '?', ':', '-', '@'로 이루어진 길이 $N$인 문자열을 변환한 모스 부호가 주어질 때, 주어진 모스 부호를 해독하여 원래의 문자열을 출력하는 프로그램을 작성해 보자.
-
-각 문자를 모스 부호로 나타내는 방법은 아래 표에 정리되어 있다. (단, 표의 둘째, 넷째 열은 첫째, 셋째 열의 문자를 모스 부호로 변환한 결과를 나타내며, '.'는 짧은 신호를, '-'는 긴 신호를 의미한다.)
-
-
-
-
- | A |
- .- |
- B |
- -... |
-
-
- | C |
- -.-. |
- D |
- -.. |
-
-
- | E |
- . |
- F |
- ..-. |
-
-
- | G |
- --. |
- H |
- .... |
-
-
- | I |
- .. |
- J |
- .--- |
-
-
- | K |
- -.- |
- L |
- .-.. |
-
-
- | M |
- -- |
- N |
- -. |
-
-
- | O |
- --- |
- P |
- .--. |
-
-
- | Q |
- --.- |
- R |
- .-. |
-
-
- | S |
- ... |
- T |
- - |
-
-
- | U |
- ..- |
- V |
- ...- |
-
-
- | W |
- .-- |
- X |
- -..- |
-
-
- | Y |
- -.-- |
- Z |
- --.. |
-
-
- | 1 |
- .---- |
- 2 |
- ..--- |
-
-
- | 3 |
- ...-- |
- 4 |
- ....- |
-
-
- | 5 |
- ..... |
- 6 |
- -.... |
-
-
- | 7 |
- --... |
- 8 |
- ---.. |
-
-
- | 9 |
- ----. |
- 0 |
- ----- |
-
-
- | , |
- --..-- |
- . |
- .-.-.- |
-
-
- | ? |
- ..--.. |
- : |
- ---... |
-
-
- | - |
- -....- |
- @ |
- .--.-. |
-
-
-
-
-### 입력
-
- 첫째 줄에 모스 부호로 변환하기 전 문자열의 길이를 나타내는 정수 $N(1 \leq N \leq 100)$이 주어진다.
-
-둘째 줄에 원래의 문자열을 모스 부호로 변환한 메시지가 주어진다. 이 메시지에서 짧은 신호는 '.', 긴 신호는 '-'로 나타내며, 원래의 문자열을 구성하는 각각의 문자를 모스 부호로 변환한 결과는 공백으로 구분되어 있다.
-
-위 표를 이용해 해독할 수 없는 메시지는 주어지지 않는다.
-
-### 출력
-
- 주어진 모스 부호를 해독하여 길이 $N$인 문자열을 공백 없이 출력한다.
-
-알파벳의 경우, 반드시 대문자로 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270.py" "b/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270.py"
deleted file mode 100644
index f7992cd..0000000
--- "a/\353\260\261\354\244\200/Bronze/29701.\342\200\205\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270/\353\252\250\354\212\244\342\200\205\353\266\200\355\230\270.py"
+++ /dev/null
@@ -1,15 +0,0 @@
-import sys
-
-mos_dict = {
-"A" :".-", "B" :"-...", "C" :"-.-.", "D" :"-..", "E" :".","F":"..-.", "G" : "--.","H":"....", "I":"..","J":".---"
-,"K" : "-.-", "L" :".-.." ,"M":"--", "N" :"-.", "O":"---","P":".--.", "Q":"--.-", "R":".-.", "S":"...", "T":"-"
-,"U":"..-", "V":"...-", "W" :".--", "X" :"-..-", "Y":"-.--", "Z" :"--..", "1":".----", "2":"..---",
-"3": "...--", "4": "....-","5":".....", "6":"-...." ,"7":"--...","8":"---..", "9": "----.","0":"-----",
-",": "--..--", ".":".-.-.-", "?":"..--..", ":" :"---...", "-": "-....-", "@":".--.-."}
-
-mos_dict_inverse= {v : k for k , v in mos_dict.items()}
-T = int(sys.stdin.readline())
-list = list(map(str, sys.stdin.readline().split()))
-for i in range(T):
- list[i] = mos_dict_inverse[list[i]]
-print("".join(list))
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/README.md" "b/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/README.md"
deleted file mode 100644
index f692b0e..0000000
--- "a/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/README.md"
+++ /dev/null
@@ -1,42 +0,0 @@
-# [Bronze I] 전주 듣고 노래 맞히기 - 31562
-
-[문제 링크](https://www.acmicpc.net/problem/31562)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 36 ms
-
-### 분류
-
-브루트포스 알고리즘, 자료 구조, 해시를 사용한 집합과 맵, 구현, 문자열
-
-### 제출 일자
-
-2024년 11월 3일 16:13:58
-
-### 문제 설명
-
-윤수와 정환은 「전주 듣고 노래 맞히기」라는 게임을 할 예정이다. 「전주 듣고 노래 맞히기」는 주어진 노래의 전주를 듣고 먼저 제목을 맞히는 사람이 점수를 얻어 최종적으로 점수가 더 많은 사람이 이기는 게임이다. 절대 음감을 가진 윤수는 노래의 첫 네 음만 듣고도 어떤 노래든 바로 맞힐 수 있다. 따라서, 정환은 윤수를 이기기 위해 첫 세 음만으로 노래를 맞히게 해주는 프로그램을 만들려고 한다. 우선 정환이 알고 있는 노래 제목, 음이름 등을 데이터로 만든 뒤 프로그램을 구현하기 시작했다. 예를 들어, 다음은 TwinkleStar(반짝반짝 작은 별)의 악보 중 일부이다.
-
-
-
-위 악보를 박자와 관계없이 음이름으로 표현하면 CCGGAAG가 된다.
-
-윤수를 이기기 위해서는 이 프로그램이 첫 세 음인 CCG만으로 노래 제목인 TwinkleStar를 출력할 수 있어야 한다. 또한, 세상의 모든 노래를 아는 윤수와 다르게 정환은 음을 아는 노래가 $N$개뿐이다. 그래서 프로그램에 $N$개의 노래의 정보를 저장해 놓을 것이다. 만약 저장된 노래 중 입력한 첫 세 음으로 시작하는 노래가 여러 개 있어 무슨 노래인지 정확히 알 수 없는 경우 ?를 출력하고, 입력한 첫 세 음에 맞는 저장된 노래가 없을 경우 !를 출력한다.
-
-정환을 도와서 첫 세 음만으로 본인이 음을 아는 노래를 맞히는 프로그램을 완성하자. 이 프로그램은 대문자와 소문자를 구분한다.
-
-### 입력
-
- 첫 번째 줄에 정환이 음을 아는 노래의 개수 $N$, 정환이 맞히기를 시도할 노래의 개수 $M$이 공백으로 구분되어 주어진다.
-
-두 번째 줄부터 $N$개의 줄에 걸쳐 노래 제목의 길이 $T$, 영어 대소문자로 이루어진 문자열 노래 제목 $S$, 해당 노래에서 처음 등장하는 일곱 개의 음이름 $a_1, a_2, a_3, a_4, a_5, a_6, a_7$이 공백으로 구분되어 주어진다.
-
- $N+2$번째 줄부터 $M$개의 줄에 걸쳐 정환이 맞히기를 시도할 노래의 첫 세 음의 음이름 $b_1, b_2, b_3$가 공백으로 구분되어 주어진다.
-
-주어지는 음이름은 각각 C, D, E, F, G, A, B 중 하나이다. 같은 제목이 두 번 이상 주어지지 않는다.
-
-### 출력
-
- 정환이 맞히기를 시도할 각 노래에 대하여 프로그램에 저장된 노래와 첫 세 음이 동일한 노래가 하나만 있다면 해당 노래의 제목을, 두 개 이상이면 ?을, 없다면 !을 한 줄에 하나씩 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260.py" "b/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260.py"
deleted file mode 100644
index 58f8ab8..0000000
--- "a/\353\260\261\354\244\200/Bronze/31562.\342\200\205\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260/\354\240\204\354\243\274\342\200\205\353\223\243\352\263\240\342\200\205\353\205\270\353\236\230\342\200\205\353\247\236\355\236\210\352\270\260.py"
+++ /dev/null
@@ -1,30 +0,0 @@
-import sys
-
-# N, M 입력
-N, M = sys.stdin.readline().split()
-a_dict = {}
-b_count = {}
-count = 0
-# N 입력
-for i in range(int(N)):
- T, S, *a = sys.stdin.readline().split()
- a = "".join(a)[:3]
-
- if a in a_dict:
- a_dict[a].append(S)
- else :
- a_dict[a] = [S]
-
-
-# M 입력
-for j in range(int(M)):
- b_list = sys.stdin.readline().split()
- b = "".join(b_list)
-
- if b in a_dict:
- if len(a_dict[b]) > 1:
- print("?")
- else :
- print(a_dict[b][0])
- else :
- print("!")
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/README.md" "b/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/README.md"
deleted file mode 100644
index 89ae7c5..0000000
--- "a/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/README.md"
+++ /dev/null
@@ -1,28 +0,0 @@
-# [Bronze III] 수학적 호기심 - 9094
-
-[문제 링크](https://www.acmicpc.net/problem/9094)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 3160 ms
-
-### 분류
-
-브루트포스 알고리즘, 수학
-
-### 제출 일자
-
-2024년 9월 1일 11:00:39
-
-### 문제 설명
-
-두 정수 n과 m이 주어졌을 때, 0 < a < b < n인 정수 쌍 (a, b) 중에서 (a2+b2+m)/(ab)가 정수인 쌍의 개수를 구하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 테스트 케이스의 개수 T가 주어진다. 각 테스트 케이스는 한 줄로 이루어져 있으며, n과 m이 주어진다. 두 수는 0보다 크고, 100보다 작거나 같다.
-
-### 출력
-
- 각 테스트 케이스마다 문제의 조건을 만족하는 (a, b)쌍의 개수를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254.py" "b/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254.py"
deleted file mode 100644
index 4c6bb32..0000000
--- "a/\353\260\261\354\244\200/Bronze/9094.\342\200\205\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254/\354\210\230\355\225\231\354\240\201\342\200\205\355\230\270\352\270\260\354\213\254.py"
+++ /dev/null
@@ -1,18 +0,0 @@
-import sys
-from itertools import combinations
-
-def integer_count(n,m):
- count = 0
- for combo in combinations(range(1, n),2):
- if (combo[0]**2 + combo[1]**2 + m) % (combo[0]*combo[1]) == 0:
- count += 1
- return count
-
-
-T = int(sys.stdin.readline())
-
-for _ in range(T):
- n, m = map(int,sys.stdin.readline().split())
- count = integer_count(n, m)
- print(count)
-
diff --git "a/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/README.md" "b/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/README.md"
deleted file mode 100644
index 0139b4a..0000000
--- "a/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/README.md"
+++ /dev/null
@@ -1,34 +0,0 @@
-# [Bronze I] 민균이의 비밀번호 - 9933
-
-[문제 링크](https://www.acmicpc.net/problem/9933)
-
-### 성능 요약
-
-메모리: 34028 KB, 시간: 52 ms
-
-### 분류
-
-자료 구조, 해시를 사용한 집합과 맵, 구현, 문자열
-
-### 제출 일자
-
-2024년 11월 5일 20:25:14
-
-### 문제 설명
-
-창영이는 민균이의 컴퓨터를 해킹해 텍스트 파일 하나를 자신의 메일로 전송했다. 파일에는 단어가 한 줄에 하나씩 적혀있었고, 이 중 하나는 민균이가 온라인 저지에서 사용하는 비밀번호이다.
-
-파일을 살펴보던 창영이는 모든 단어의 길이가 홀수라는 사실을 알아내었다. 그리고 언젠가 민균이가 이 목록에 대해서 얘기했던 것을 생각해냈다. 민균이의 비밀번호는 목록에 포함되어 있으며, 비밀번호를 뒤집어서 쓴 문자열도 포함되어 있다.
-
-예를 들어, 민균이의 비밀번호가 "tulipan"인 경우에 목록에는 "napilut"도 존재해야 한다. 알 수 없는 이유에 의해 모두 비밀번호로 사용 가능하다고 한다.
-
-민균이의 파일에 적혀있는 단어가 모두 주어졌을 때, 비밀번호의 길이와 가운데 글자를 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 단어의 수 N (2 ≤ N ≤ 100)이 주어진다. 다음 N개 줄에는 파일에 적혀있는 단어가 한 줄에 하나씩 주어진다. 단어는 알파벳 소문자로만 이루어져 있으며, 길이는 2보다 크고 14보다 작은 홀수이다.
-
-### 출력
-
- 첫째 줄에 비밀번호의 길이와 가운데 글자를 출력한다. 항상 답이 유일한 경우만 입력으로 주어진다.
-
diff --git "a/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270.py" "b/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270.py"
deleted file mode 100644
index 92f3fbc..0000000
--- "a/\353\260\261\354\244\200/Bronze/9933.\342\200\205\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270/\353\257\274\352\267\240\354\235\264\354\235\230\342\200\205\353\271\204\353\260\200\353\262\210\355\230\270.py"
+++ /dev/null
@@ -1,19 +0,0 @@
-import sys
-from collections import defaultdict
-
-N = int(sys.stdin.readline())
-pws_dict = defaultdict(str)
-answer = ""
-
-for _ in range(N):
- s = sys.stdin.readline().strip()
- if len(s) % 2 == 0 :
- continue
- pws_dict[s] = s[::-1]
-
-for k in pws_dict.keys():
- if pws_dict[k] in pws_dict:
- answer = k
-
-sys.stdout.write(str(len(answer)))
-sys.stdout.write(" "+answer[len(answer)//2])
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/README.md" "b/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/README.md"
deleted file mode 100644
index 408653d..0000000
--- "a/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/README.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# [Silver IV] 스택 - 10828
-
-[문제 링크](https://www.acmicpc.net/problem/10828)
-
-### 성능 요약
-
-메모리: 31252 KB, 시간: 40 ms
-
-### 분류
-
-자료 구조, 구현, 스택
-
-### 제출 일자
-
-2024년 11월 9일 09:35:51
-
-### 문제 설명
-
-정수를 저장하는 스택을 구현한 다음, 입력으로 주어지는 명령을 처리하는 프로그램을 작성하시오.
-
-명령은 총 다섯 가지이다.
-
-
- - push X: 정수 X를 스택에 넣는 연산이다.
- - pop: 스택에서 가장 위에 있는 정수를 빼고, 그 수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
- - size: 스택에 들어있는 정수의 개수를 출력한다.
- - empty: 스택이 비어있으면 1, 아니면 0을 출력한다.
- - top: 스택의 가장 위에 있는 정수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
-
-
-### 입력
-
- 첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지 않은 명령이 주어지는 경우는 없다.
-
-### 출력
-
- 출력해야하는 명령이 주어질 때마다, 한 줄에 하나씩 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/\354\212\244\355\203\235.py" "b/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/\354\212\244\355\203\235.py"
deleted file mode 100644
index 2e2895a..0000000
--- "a/\353\260\261\354\244\200/Silver/10828.\342\200\205\354\212\244\355\203\235/\354\212\244\355\203\235.py"
+++ /dev/null
@@ -1,33 +0,0 @@
-import sys
-
-def sysPrint(s):
- sys.stdout.write(str(s) + "\n")
-N = int(sys.stdin.readline())
-
-stack = list()
-
-for _ in range(N):
- sysInput = list(sys.stdin.readline().split())
- opp = sysInput[0]
-
- if opp == "push":
- stack.append(sysInput[1])
- elif opp == "pop":
- if len(stack) == 0 :
- sysPrint(-1)
- continue
- sysPrint(stack.pop())
- elif opp == "size":
- sysPrint(len(stack))
- elif opp == "empty":
- if len(stack) == 0 :
- sysPrint(1)
- else:
- sysPrint(0)
- elif opp == "top":
- if len(stack) == 0 :
- sysPrint(-1)
- continue
- sysPrint(stack[-1])
- else:
- sysPrint("error")
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/K\353\262\210\354\247\270\342\200\205\354\210\230.py" "b/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/K\353\262\210\354\247\270\342\200\205\354\210\230.py"
deleted file mode 100644
index 3966ac2..0000000
--- "a/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/K\353\262\210\354\247\270\342\200\205\354\210\230.py"
+++ /dev/null
@@ -1,8 +0,0 @@
-import sys
-
-N, K = map(int,(sys.stdin.readline().split()))
-A = list(map(int,sys.stdin.readline().split()))
-A = A[:N]
-A.sort()
-
-sys.stdout.write(str(A[K - 1]))
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/README.md" "b/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/README.md"
deleted file mode 100644
index f7a0f4b..0000000
--- "a/\353\260\261\354\244\200/Silver/11004.\342\200\205K\353\262\210\354\247\270\342\200\205\354\210\230/README.md"
+++ /dev/null
@@ -1,30 +0,0 @@
-# [Silver V] K번째 수 - 11004
-
-[문제 링크](https://www.acmicpc.net/problem/11004)
-
-### 성능 요약
-
-메모리: 623196 KB, 시간: 3732 ms
-
-### 분류
-
-정렬
-
-### 제출 일자
-
-2024년 11월 23일 10:48:19
-
-### 문제 설명
-
-수 N개 A1, A2, ..., AN이 주어진다. A를 오름차순 정렬했을 때, 앞에서부터 K번째 있는 수를 구하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 N(1 ≤ N ≤ 5,000,000)과 K (1 ≤ K ≤ N)이 주어진다.
-
-둘째에는 A1, A2, ..., AN이 주어진다. (-109 ≤ Ai ≤ 109)
-
-### 출력
-
- A를 정렬했을 때, 앞에서부터 K번째 있는 수를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/README.md" "b/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/README.md"
deleted file mode 100644
index b35bae6..0000000
--- "a/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/README.md"
+++ /dev/null
@@ -1,39 +0,0 @@
-# [Silver II] 양 한마리... 양 두마리... - 11123
-
-[문제 링크](https://www.acmicpc.net/problem/11123)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 264 ms
-
-### 분류
-
-너비 우선 탐색, 깊이 우선 탐색, 그래프 이론, 그래프 탐색
-
-### 제출 일자
-
-2024년 8월 24일 18:18:09
-
-### 문제 설명
-
-얼마전에 나는 불면증에 시달렸지... 천장이 뚫어져라 뜬 눈으로 밤을 지새우곤 했었지. 그러던 어느 날 내 친구 광민이에게 나의 불면증에 대해 말했더니 이렇게 말하더군. "양이라도 세봐!" 정말 도움이 안되는 친구라고 생각했었지. 그런데 막상 또 다시 잠을 청해보려고 침대에 눕고 보니 양을 세고 있더군... 그런데 양을 세다보니 이걸로 프로그램을 하나 짜볼 수 있겠단 생각이 들더군 후후후... 그렇게 나는 침대에서 일어나 컴퓨터 앞으로 향했지.
-
-양을 # 으로 나타내고 . 으로 풀을 표현하는 거야. 서로 다른 # 두 개 이상이 붙어있다면 한 무리의 양들이 있는거지. 그래... 좋았어..! 이걸로 초원에서 풀을 뜯고 있는 양들을 그리드로 표현해 보는거야!
-
-그렇게 나는 양들을 그리드로 표현하고 나니까 갑자기 졸렵기 시작했어. 하지만 난 너무 궁금했지. 내가 표현한 그 그리드 위에 몇 개의 양무리가 있었는지! 그래서 나는 동이 트기 전까지 이 프로그램을 작성하고 장렬히 전사했지. 다음날 내가 잠에서 깨어났을 때 내 모니터에는 몇 개의 양무리가 있었는지 출력되어 있었지.
-
-### 입력
-
- 첫 번째 줄은 테스트 케이스의 수를 나타나는 T를 입력받는다.
-
-이후 각 테스트 케이스의 첫 번째 줄에서는 H,W 를 입력받는다. H는 그리드의 높이이고, W는 그리드의 너비이다. 이후 그리드의 높이 H 에 걸쳐서 W개의 문자로 이루어진 문자열 하나를 입력받는다.
-
-
- - 0 < T ≤ 100
- - 0 < H, W ≤ 100
-
-
-### 출력
-
- 각 테스트 케이스마다, 양의 몇 개의 무리로 이루어져 있었는지를 한 줄에 출력하면 된다.
-
diff --git "a/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216.py" "b/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216.py"
deleted file mode 100644
index 928669b..0000000
--- "a/\353\260\261\354\244\200/Silver/11123.\342\200\205\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216/\354\226\221\342\200\205\355\225\234\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216\342\200\205\354\226\221\342\200\205\353\221\220\353\247\210\353\246\254\357\274\216\357\274\216\357\274\216.py"
+++ /dev/null
@@ -1,49 +0,0 @@
-def find_is_lamb_by_dfs(grid, row, column):
-
- directins = [(0,-1),(0,1),(1,0),(-1,0)]
-
- def dfs(x, y):
- stack = [(x, y)]
-
- while stack:
- cx,cy = stack.pop()
-
- if grid[cx][cy] == ".":
- continue
-
- grid[cx][cy] = "."
-
- for dx,dy in directins:
- nx, ny = cx + dx, cy + dy
-
- #for loop 밖에 있었음
- if (0 <= nx < row) and (0 <= ny < column) and (grid[nx][ny] == "#"):
- stack.append((nx,ny))
-
- lamb_count = 0
- for i in range(row):
- for j in range(column):
- if grid[i][j] == "#":
- dfs(i, j)
- lamb_count += 1
-
- return lamb_count
-
-
-if __name__ == "__main__":
-
- test_case = int(input())
-
- for _ in range(test_case):
- # row, colum 갯수 입력 받음
- R, C = map(int, input().split())
-
- grid = []
-
- # row 수만큼 반복문으로 입력을 받음
- # 각 row 마다 리스트 입력을 받음
- for __ in range(R):
- grid.append(list(input()))
-
- result = find_is_lamb_by_dfs(grid, R, C)
- print(result)
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/DFS\354\231\200\342\200\205BFS.java" "b/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/DFS\354\231\200\342\200\205BFS.java"
deleted file mode 100644
index a7f29c7..0000000
--- "a/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/DFS\354\231\200\342\200\205BFS.java"
+++ /dev/null
@@ -1,126 +0,0 @@
-import java.io.*;
-import java.util.*;
-
-public class Main {
-
- private static ArrayList[] A;
- private static boolean[] visited;
-
- public static void main(String[] args) throws IOException {
-
- BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
-
- StringTokenizer st = new StringTokenizer(br.readLine());
- //입력
- int N = Integer.parseInt(st.nextToken()); // 노드
- int M = Integer.parseInt(st.nextToken()); //에지
- int V = Integer.parseInt(st.nextToken()); //시작노드
-
- A = new ArrayList[N + 1];
- visited = new boolean[N + 1];
- int a = 0;
- int b = 0;
-
- //초기화
- for(int i = 1 ; i < N + 1 ; i++){ //노드 갯수만큼 반복
- A[i] = new ArrayList();
- }
-
- //
- for(int i = 1 ; i < M+1 ; i ++){ //에지 갯수만큼 반복
- st = new StringTokenizer(br.readLine());
- a = Integer.parseInt(st.nextToken());
- b = Integer.parseInt(st.nextToken());
-
- //양쪽에 연결완료
- A[a].add(b);
- A[b].add(a);
- }
-
-//boolean 초기화 하면 false가 기본인줄 몰랐음
- // 각 노드별 탐색시작
- // for(int i = 1 ; i < N + 1 ; i++) {
-
- // visited[i] = false; //초기화
-
- // }
-
- //순서대비 (오름차순 정렬)
- for(int i = 1 ; i < N + 1 ; i++){
- Collections.sort(A[i]);
- }
-
- visited = new boolean[N+1];
-
-// 연결요소 처럼 그래프가 여러개인 경우 이용하는 것임
-// for(int i = 1 ; i < N + 1 ; i++){
-
-// if(! visited[i])
- dfs(V);
-// }
- System.out.println();
-
- visited = new boolean[N+1];
- bfs(V);
- System.out.println();
-
- }
-
- private static void dfs(int v) {
- System.out.print(v + " ");
-
-// //방문확인
- if(visited[v]) return ;
-
-//
-//
-// //인접노드들의 방문체크
-// visited[v + 1] = true;
-//
-//
-// for(int i = 1 ; i < A.length + 1 ; i++)
-// dfs(i);
-//
-// return v;
-// if(visited[v+1]) return;
-
- visited[v] = true;
-
- for(int i : A[v])
- if(!visited[i]) dfs(i);
-
- }
-
- private static void bfs(int v) {
- //큐 선언
- Queue queue = new LinkedList();
-
- //1
- //큐에 삽입 시 // 방문배열에 남기기
- queue.add(v); visited[v] = true;
-
- //2
- //while 쓰는 이유는 재귀함수가 아니라 queue를 쓰기 때문
- //큐가 빌 때 까지 반복
- while (!queue.isEmpty()){
-
- //3
- //큐에서 꺼낸다. // 방문순서 출력하
- int now_Node = queue.poll(); System.out.print(now_Node + " ");
-
- //4
- //꺼내느 노드의 인접노드를 탐색한다.
- for(int i : A[now_Node]){
-
- //5
- //인접노드가 방문하지 않았으면
- if(!visited[i]) {
- //방문배열에 남기고
- //큐에 넣는다./
- queue.add(i);
- visited[i] = true;
- }
- }
- }
- }
-}
diff --git "a/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/README.md" "b/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/README.md"
deleted file mode 100644
index 6a73663..0000000
--- "a/\353\260\261\354\244\200/Silver/1260.\342\200\205DFS\354\231\200\342\200\205BFS/README.md"
+++ /dev/null
@@ -1,28 +0,0 @@
-# [Silver II] DFS와 BFS - 1260
-
-[문제 링크](https://www.acmicpc.net/problem/1260)
-
-### 성능 요약
-
-메모리: 22228 KB, 시간: 388 ms
-
-### 분류
-
-그래프 이론, 그래프 탐색, 너비 우선 탐색, 깊이 우선 탐색
-
-### 제출 일자
-
-2023년 3월 25일 23:35:17
-
-### 문제 설명
-
-그래프를 DFS로 탐색한 결과와 BFS로 탐색한 결과를 출력하는 프로그램을 작성하시오. 단, 방문할 수 있는 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문하고, 더 이상 방문할 수 있는 점이 없는 경우 종료한다. 정점 번호는 1번부터 N번까지이다.
-
-### 입력
-
- 첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000), 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다. 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
-
-### 출력
-
- 첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다. V부터 방문된 점을 순서대로 출력하면 된다.
-
diff --git "a/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/README.md" "b/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/README.md"
deleted file mode 100644
index 092c574..0000000
--- "a/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/README.md"
+++ /dev/null
@@ -1,40 +0,0 @@
-# [Silver V] 국회의원 선거 - 1417
-
-[문제 링크](https://www.acmicpc.net/problem/1417)
-
-### 성능 요약
-
-메모리: 33188 KB, 시간: 44 ms
-
-### 분류
-
-자료 구조, 그리디 알고리즘, 구현, 우선순위 큐, 시뮬레이션
-
-### 제출 일자
-
-2024년 11월 21일 10:20:18
-
-### 문제 설명
-
-다솜이는 사람의 마음을 읽을 수 있는 기계를 가지고 있다. 다솜이는 이 기계를 이용해서 2008년 4월 9일 국회의원 선거를 조작하려고 한다.
-
-다솜이의 기계는 각 사람들이 누구를 찍을 지 미리 읽을 수 있다. 어떤 사람이 누구를 찍을 지 정했으면, 반드시 선거때 그 사람을 찍는다.
-
-현재 형택구에 나온 국회의원 후보는 N명이다. 다솜이는 이 기계를 이용해서 그 마을의 주민 M명의 마음을 모두 읽었다.
-
-다솜이는 기호 1번이다. 다솜이는 사람들의 마음을 읽어서 자신을 찍지 않으려는 사람을 돈으로 매수해서 국회의원에 당선이 되게 하려고 한다. 다른 모든 사람의 득표수 보다 많은 득표수를 가질 때, 그 사람이 국회의원에 당선된다.
-
-예를 들어서, 마음을 읽은 결과 기호 1번이 5표, 기호 2번이 7표, 기호 3번이 7표 라고 한다면, 다솜이는 2번 후보를 찍으려고 하던 사람 1명과, 3번 후보를 찍으려고 하던 사람 1명을 돈으로 매수하면, 국회의원에 당선이 된다.
-
-돈으로 매수한 사람은 반드시 다솜이를 찍는다고 가정한다.
-
-다솜이가 매수해야하는 사람의 최솟값을 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 후보의 수 N이 주어진다. 둘째 줄부터 차례대로 기호 1번을 찍으려고 하는 사람의 수, 기호 2번을 찍으려고 하는 수, 이렇게 총 N개의 줄에 걸쳐 입력이 들어온다. N은 50보다 작거나 같은 자연수이고, 득표수는 100보다 작거나 같은 자연수이다.
-
-### 출력
-
- 첫째 줄에 다솜이가 매수해야 하는 사람의 최솟값을 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260.py" "b/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260.py"
deleted file mode 100644
index cd8c6fe..0000000
--- "a/\353\260\261\354\244\200/Silver/1417.\342\200\205\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260/\352\265\255\355\232\214\354\235\230\354\233\220\342\200\205\354\204\240\352\261\260.py"
+++ /dev/null
@@ -1,42 +0,0 @@
-import sys
-from heapq import heappush, heappop
-
-# 1. N 후보 입력, N만큼 M 반복입력
-N = int(sys.stdin.readline())
-candidates = []
-
-# 1-1. 다솜입력
-dasom = int(sys.stdin.readline())
-
-for _ in range(N - 1):
- # 최대힙으로 - 붙임
- M = (-int(sys.stdin.readline()))
- heappush(candidates, M)
-
-answer = 0
-while True:
- if len(candidates) == 0:
- break
-
- max_votes = (-heappop(candidates))
- if dasom <= max_votes:
- answer += 1
- dasom += 1
- max_votes -= 1
- heappush(candidates, -max_votes)
- else:
- break
-
-sys.stdout.write(str(answer))
-
-# # 튜플 방식으로 생각 했을 때
-# # 2. maxheap 으로 tuple로 저장
-# for _ in range(N):
-# M = int(sys.stdin.readline())
-# heappush(candidates, (_,M))
-#
-# print(candidates)
-#
-# # 3. 1순위 후보가 최대값 인지 검증 후 아니면 다른 1등 에서 1을 빼고, 1순위에 1추가
-# for i in range(1, len(candidates)):
-# if candidates[0][1] < candidates[i][1]:
diff --git "a/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/README.md" "b/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/README.md"
deleted file mode 100644
index 5c1d922..0000000
--- "a/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/README.md"
+++ /dev/null
@@ -1,30 +0,0 @@
-# [Silver IV] 숫자놀이 - 1755
-
-[문제 링크](https://www.acmicpc.net/problem/1755)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 32 ms
-
-### 분류
-
-정렬, 문자열
-
-### 제출 일자
-
-2024년 11월 28일 10:42:05
-
-### 문제 설명
-
-79를 영어로 읽되 숫자 단위로 하나씩 읽는다면 "seven nine"이 된다. 80은 마찬가지로 "eight zero"라고 읽는다. 79는 80보다 작지만, 영어로 숫자 하나씩 읽는다면 "eight zero"가 "seven nine"보다 사전순으로 먼저 온다.
-
-문제는 정수 M, N(1 ≤ M ≤ N ≤ 99)이 주어지면 M 이상 N 이하의 정수를 숫자 하나씩 읽었을 때를 기준으로 사전순으로 정렬하여 출력하는 것이다.
-
-### 입력
-
- 첫째 줄에 M과 N이 주어진다.
-
-### 출력
-
- M 이상 N 이하의 정수를 문제 조건에 맞게 정렬하여 한 줄에 10개씩 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/\354\210\253\354\236\220\353\206\200\354\235\264.py" "b/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/\354\210\253\354\236\220\353\206\200\354\235\264.py"
deleted file mode 100644
index 91332b9..0000000
--- "a/\353\260\261\354\244\200/Silver/1755.\342\200\205\354\210\253\354\236\220\353\206\200\354\235\264/\354\210\253\354\236\220\353\206\200\354\235\264.py"
+++ /dev/null
@@ -1,35 +0,0 @@
-import sys
-# 1. 값 두개 입력받음 (정수)
-M, N = sys.stdin.readline().strip().split()
-
-# 1-1 입력 받은 값 (정수로 나열)
-numbers = [str(i) for i in range(int(M), int(N) + 1)]
-
-# 2. 정렬 기준 만듬
-number_standard = {0 : 'zero', 1: 'one', 2: 'two', 3: 'three', 4:'four', 5:'five', 6:'six', 7:'seven', 8:'eight', 9:'nine'}
-number_standard_sort = dict(sorted(number_standard.items(), key=lambda x: x[1]))
-
-# 원래 숫자와 우선순위 정렬
-number_dict = {str(n) : i for i, n in enumerate(number_standard_sort)}
-
-# 2. 값들 정렬
-# for _ in range(len(numbers)):
-# # 1순위 : 자리 갯수 (한자리, 두자리)
-# if len(numbers[i]) == 1:
-
-# numbers.sort(key = lambda x : (len(x), number_dict[x]))
-numbers.sort(key=lambda x: [number_dict[digit] for digit in x])
-i = 1
-for num in numbers:
- sys.stdout.write(str(num) + " ")
- if i % 10 == 0:
- sys.stdout.write("\n")
- i += 1
-
-# 비람다 방식
-# def sort_key(x):
-# # 각 자릿수를 number_dict의 순서로 매핑
-# mapped_digits = [number_dict[digit] for digit in x]
-# return mapped_digits
-# # 두 자릿수 이상의 숫자도 처리
-# numbers.sort(key=sort_key)
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/README.md" "b/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/README.md"
deleted file mode 100644
index 2a8e747..0000000
--- "a/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/README.md"
+++ /dev/null
@@ -1,35 +0,0 @@
-# [Silver II] 최소 힙 - 1927
-
-[문제 링크](https://www.acmicpc.net/problem/1927)
-
-### 성능 요약
-
-메모리: 37044 KB, 시간: 96 ms
-
-### 분류
-
-자료 구조, 우선순위 큐
-
-### 제출 일자
-
-2024년 11월 16일 10:43:58
-
-### 문제 설명
-
-널리 잘 알려진 자료구조 중 최소 힙이 있다. 최소 힙을 이용하여 다음과 같은 연산을 지원하는 프로그램을 작성하시오.
-
-
- - 배열에 자연수 x를 넣는다.
- - 배열에서 가장 작은 값을 출력하고, 그 값을 배열에서 제거한다.
-
-
-프로그램은 처음에 비어있는 배열에서 시작하게 된다.
-
-### 입력
-
- 첫째 줄에 연산의 개수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 N개의 줄에는 연산에 대한 정보를 나타내는 정수 x가 주어진다. 만약 x가 자연수라면 배열에 x라는 값을 넣는(추가하는) 연산이고, x가 0이라면 배열에서 가장 작은 값을 출력하고 그 값을 배열에서 제거하는 경우이다. x는 231보다 작은 자연수 또는 0이고, 음의 정수는 입력으로 주어지지 않는다.
-
-### 출력
-
- 입력에서 0이 주어진 횟수만큼 답을 출력한다. 만약 배열이 비어 있는 경우인데 가장 작은 값을 출력하라고 한 경우에는 0을 출력하면 된다.
-
diff --git "a/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/\354\265\234\354\206\214\342\200\205\355\236\231.py" "b/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/\354\265\234\354\206\214\342\200\205\355\236\231.py"
deleted file mode 100644
index 8d1ec61..0000000
--- "a/\353\260\261\354\244\200/Silver/1927.\342\200\205\354\265\234\354\206\214\342\200\205\355\236\231/\354\265\234\354\206\214\342\200\205\355\236\231.py"
+++ /dev/null
@@ -1,16 +0,0 @@
-import heapq
-import sys
-
-N = int(sys.stdin.readline())
-heap = []
-
-for _ in range(N):
- X = int(sys.stdin.readline())
-
- if X == 0 :
- if not heap:
- sys.stdout.write("0\n")
- continue
- sys.stdout.write(str(heapq.heappop(heap))+"\n")
- continue
- heapq.heappush(heap, X)
diff --git "a/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/README.md" "b/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/README.md"
deleted file mode 100644
index 1cc8cca..0000000
--- "a/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/README.md"
+++ /dev/null
@@ -1,40 +0,0 @@
-# [Silver I] 센티와 마법의 뿅망치 - 19638
-
-[문제 링크](https://www.acmicpc.net/problem/19638)
-
-### 성능 요약
-
-메모리: 40900 KB, 시간: 156 ms
-
-### 분류
-
-자료 구조, 구현, 우선순위 큐
-
-### 제출 일자
-
-2024년 11월 18일 12:15:28
-
-### 문제 설명
-
-센티는 마법 도구들을 지니고 여행을 떠나는 것이 취미인 악당이다.
-
-거인의 나라에 도착한 센티는 자신보다 키가 크거나 같은 거인들이 있다는 사실이 마음에 들지 않았다.
-
-센티가 꺼내 들은 마법 도구는 바로 마법의 뿅망치로, 이 뿅망치에 맞은 사람의 키가 ⌊ 뿅망치에 맞은 사람의 키 / 2 ⌋로 변하는 마법 도구이다. 단, 키가 1인 경우 더 줄어들 수가 없어 뿅망치의 영향을 받지 않는다.
-
-하지만 마법의 뿅망치는 횟수 제한이 있다. 그래서 센티는 마법의 뿅망치를 효율적으로 사용하기 위한 전략을 수립했다. 바로 매번 가장 키가 큰 거인 가운데 하나를 때리는 것이다.
-
-과연 센티가 수립한 전략에 맞게 마법의 뿅망치를 이용한다면 거인의 나라의 모든 거인이 센티보다 키가 작도록 할 수 있을까?
-
-### 입력
-
- 첫 번째 줄에는 센티를 제외한 거인의 나라의 인구수 N (1 ≤ N ≤ 105)과 센티의 키를 나타내는 정수 Hcenti (1 ≤ Hcenti ≤ 2 × 109), 마법의 뿅망치의 횟수 제한 T (1 ≤ T ≤ 105)가 빈칸을 사이에 두고 주어진다.
-
-두 번째 줄부터 N개의 줄에 각 거인의 키를 나타내는 정수 H (1 ≤ H ≤ 2 × 109)가 주어진다.
-
-### 출력
-
- 마법의 뿅망치를 센티의 전략대로 이용하여 거인의 나라의 모든 거인이 센티보다 키가 작도록 할 수 있는 경우, 첫 번째 줄에 YES를 출력하고, 두 번째 줄에 마법의 뿅망치를 최소로 사용한 횟수를 출력한다.
-
-마법의 뿅망치를 센티의 전략대로 남은 횟수 전부 이용하고도 거인의 나라에서 센티보다 키가 크거나 같은 거인이 있는 경우, 첫 번째 줄에 NO를 출력하고, 두 번째 줄에 마법의 뿅망치 사용 이후 거인의 나라에서 키가 가장 큰 거인의 키를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230.py" "b/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230.py"
deleted file mode 100644
index b4259a1..0000000
--- "a/\353\260\261\354\244\200/Silver/19638.\342\200\205\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230/\354\204\274\355\213\260\354\231\200\342\200\205\353\247\210\353\262\225\354\235\230\342\200\205\353\277\205\353\247\235\354\271\230.py"
+++ /dev/null
@@ -1,40 +0,0 @@
-import sys
-import heapq
-
-# 1. N, H, T 입력 /
-N, H, T = map(int,sys.stdin.readline().split()) # map 으로 가능함
-giants = []
-
-# N. append
-for _ in range(N):
- giants.append(int(sys.stdin.readline().strip()))
-
-# 2. maxheap 정렬
-max_heap = [-x for x in giants]
-heapq.heapify(max_heap)
-
-# 뿅망치 횟수
-count = 0
-for _ in range(T):
- # maxheap 의 1/2 로 줄이기
- max_value = - heapq.heappop(max_heap)
- if max_value < H:
- sys.stdout.write("YES\n"+str(count))
- sys.exit(0)
- if max_value == 1:
- heapq.heappush(max_heap, -max_value)
- break
-
- # heappush
- half_giant = max_value // 2
- heapq.heappush(max_heap, -half_giant)
- count += 1
-
-# 판별
-
-max_giant = -heapq.heappop(max_heap)
-if H > max_giant:
- sys.stdout.write("YES\n"+str(count))
-else:
- sys.stdout.write("NO\n" + str(max_giant))
-
diff --git "a/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/README.md" "b/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/README.md"
deleted file mode 100644
index 5d8a8fe..0000000
--- "a/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/README.md"
+++ /dev/null
@@ -1,34 +0,0 @@
-# [Silver V] 카드1 - 2161
-
-[문제 링크](https://www.acmicpc.net/problem/2161)
-
-### 성능 요약
-
-메모리: 34008 KB, 시간: 56 ms
-
-### 분류
-
-자료 구조, 구현, 큐
-
-### 제출 일자
-
-2024년 11월 12일 15:17:45
-
-### 문제 설명
-
-N장의 카드가 있다. 각각의 카드는 차례로 1부터 N까지의 번호가 붙어 있으며, 1번 카드가 제일 위에, N번 카드가 제일 아래인 상태로 순서대로 카드가 놓여 있다.
-
-이제 다음과 같은 동작을 카드가 한 장 남을 때까지 반복하게 된다. 우선, 제일 위에 있는 카드를 바닥에 버린다. 그 다음, 제일 위에 있는 카드를 제일 아래에 있는 카드 밑으로 옮긴다.
-
-예를 들어 N=4인 경우를 생각해 보자. 카드는 제일 위에서부터 1234 의 순서로 놓여있다. 1을 버리면 234가 남는다. 여기서 2를 제일 아래로 옮기면 342가 된다. 3을 버리면 42가 되고, 4를 밑으로 옮기면 24가 된다. 마지막으로 2를 버리고 나면, 버린 카드들은 순서대로 1 3 2가 되고, 남는 카드는 4가 된다.
-
-N이 주어졌을 때, 버린 카드들을 순서대로 출력하고, 마지막에 남게 되는 카드를 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 정수 N(1 ≤ N ≤ 1,000)이 주어진다.
-
-### 출력
-
- 첫째 줄에 버리는 카드들을 순서대로 출력한다. 제일 마지막에는 남게 되는 카드의 번호를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/\354\271\264\353\223\2341.py" "b/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/\354\271\264\353\223\2341.py"
deleted file mode 100644
index 9757c02..0000000
--- "a/\353\260\261\354\244\200/Silver/2161.\342\200\205\354\271\264\353\223\2341/\354\271\264\353\223\2341.py"
+++ /dev/null
@@ -1,17 +0,0 @@
-import sys
-from collections import deque
-
-N = int(sys.stdin.readline().strip())
-
-queue = deque(str(_) for _ in range(1, N + 1))
-
-while queue:
- dump_card = queue.popleft()
- sys.stdout.write(f"{dump_card} ")
- # sys.stdout.write(dump_card)
- # sys.stdout.write(" ")
-
- if not queue:
- break
- store = queue.popleft()
- queue.append(store)
\ No newline at end of file
diff --git "a/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/README.md" "b/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/README.md"
deleted file mode 100644
index 282cc94..0000000
--- "a/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/README.md"
+++ /dev/null
@@ -1,38 +0,0 @@
-# [Silver V] 기술 연계마스터 임스 - 25497
-
-[문제 링크](https://www.acmicpc.net/problem/25497)
-
-### 성능 요약
-
-메모리: 33464 KB, 시간: 864 ms
-
-### 분류
-
-자료 구조, 구현, 스택
-
-### 제출 일자
-
-2024년 11월 14일 09:15:42
-
-### 문제 설명
-
-임스는 연계 기술을 사용하는 게임을 플레이 중에 있다. 연계 기술은 사전 기술과 본 기술의 두 개의 개별 기술을 순서대로 사용해야만 정상적으로 사용 가능한 기술을 말한다.
-
-하나의 사전 기술은 하나의 본 기술과만 연계해서 사용할 수 있으며, 연계할 사전 기술 없이 본 기술을 사용했을 경우에는 게임의 스크립트가 꼬여서 이후 사용하는 기술들이 정상적으로 발동되지 않는다. 그렇지만 반드시 사전 기술을 사용한 직후에 본 기술을 사용할 필요는 없으며, 중간에 다른 기술을 사용하여도 연계는 정상적으로 이루어진다.
-
-임스가 사용할 수 있는 기술에는 $1$~$9$, $L$, $R$, $S$, $K$가 있다. $1$~$9$는 연계 없이 사용할 수 있는 기술이고, $L$은 $R$의 사전 기술, $S$은 $K$의 사전 기술이다.
-
-임스가 정해진 순서대로 $N$개의 기술을 사용할 때, 기술이 몇 번이나 정상적으로 발동하는지를 구해보자.
-
-단, 연계 기술은 사전 기술과 본 기술 모두 정상적으로 발동되었을 때만 하나의 기술이 발동된 것으로 친다.
-
-### 입력
-
- 첫 번째 줄에는 총 기술 사용 횟수 $N$이 주어진다. ($1 \le N \le 200\,000$)
-
-두 번째 줄에는 임스가 사용할 $N$개의 기술이 공백 없이 주어진다.
-
-### 출력
-
- 임스가 정상적으로 기술을 사용한 총 횟수를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244.py" "b/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244.py"
deleted file mode 100644
index 4458d1d..0000000
--- "a/\353\260\261\354\244\200/Silver/25497.\342\200\205\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244/\352\270\260\354\210\240\342\200\205\354\227\260\352\263\204\353\247\210\354\212\244\355\204\260\342\200\205\354\236\204\354\212\244.py"
+++ /dev/null
@@ -1,34 +0,0 @@
-import sys
-
-N = int(sys.stdin.readline())
-count = 0
-
-values = list(sys.stdin.readline())
-# has_L = False
-# has_S = False
-buffer = []
-i = 0
-while i < N :
- value = values[i]
-
- if value in "123456789":
- count += 1
- elif value in "LS":
- buffer.append(value)
- elif value == "R":
- if "L" in buffer:
- buffer.remove("L")
- count += 1
- else:
- break
- elif value == "K":
- if "S" in buffer:
- buffer.remove("S")
- count += 1
- else:
- break
- else :
- break
- i += 1
-
-sys.stdout.write(str(count))
diff --git "a/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/README.md" "b/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/README.md"
deleted file mode 100644
index 0604932..0000000
--- "a/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/README.md"
+++ /dev/null
@@ -1,36 +0,0 @@
-# [Silver I] 영역 구하기 - 2583
-
-[문제 링크](https://www.acmicpc.net/problem/2583)
-
-### 성능 요약
-
-메모리: 31120 KB, 시간: 40 ms
-
-### 분류
-
-너비 우선 탐색, 깊이 우선 탐색, 그래프 이론, 그래프 탐색
-
-### 제출 일자
-
-2024년 8월 26일 10:07:13
-
-### 문제 설명
-
-눈금의 간격이 1인 M×N(M,N≤100)크기의 모눈종이가 있다. 이 모눈종이 위에 눈금에 맞추어 K개의 직사각형을 그릴 때, 이들 K개의 직사각형의 내부를 제외한 나머지 부분이 몇 개의 분리된 영역으로 나누어진다.
-
-예를 들어 M=5, N=7 인 모눈종이 위에 <그림 1>과 같이 직사각형 3개를 그렸다면, 그 나머지 영역은 <그림 2>와 같이 3개의 분리된 영역으로 나누어지게 된다.
-
-![]()
-
-<그림 2>와 같이 분리된 세 영역의 넓이는 각각 1, 7, 13이 된다.
-
-M, N과 K 그리고 K개의 직사각형의 좌표가 주어질 때, K개의 직사각형 내부를 제외한 나머지 부분이 몇 개의 분리된 영역으로 나누어지는지, 그리고 분리된 각 영역의 넓이가 얼마인지를 구하여 이를 출력하는 프로그램을 작성하시오.
-
-### 입력
-
- 첫째 줄에 M과 N, 그리고 K가 빈칸을 사이에 두고 차례로 주어진다. M, N, K는 모두 100 이하의 자연수이다. 둘째 줄부터 K개의 줄에는 한 줄에 하나씩 직사각형의 왼쪽 아래 꼭짓점의 x, y좌표값과 오른쪽 위 꼭짓점의 x, y좌표값이 빈칸을 사이에 두고 차례로 주어진다. 모눈종이의 왼쪽 아래 꼭짓점의 좌표는 (0,0)이고, 오른쪽 위 꼭짓점의 좌표는(N,M)이다. 입력되는 K개의 직사각형들이 모눈종이 전체를 채우는 경우는 없다.
-
-### 출력
-
- 첫째 줄에 분리되어 나누어지는 영역의 개수를 출력한다. 둘째 줄에는 각 영역의 넓이를 오름차순으로 정렬하여 빈칸을 사이에 두고 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260.py" "b/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260.py"
deleted file mode 100644
index 4f80b48..0000000
--- "a/\353\260\261\354\244\200/Silver/2583.\342\200\205\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260/\354\230\201\354\227\255\342\200\205\352\265\254\355\225\230\352\270\260.py"
+++ /dev/null
@@ -1,74 +0,0 @@
-# 복습용 버전 2
-# 입력
-# 첫째 줄에 M과 N, 그리고 K가 빈칸을 사이에 두고 차례로 주어진다. M, N, K는 모두 100 이하의 자연수이다.
-# 둘째 줄부터 K개의 줄에는 한 줄에 하나씩 직사각형의 왼쪽 아래 꼭짓점의 x, y좌표값과 오른쪽 위 꼭짓점의 x, y좌표값이
-# 빈칸을 사이에 두고 차례로 주어진다. 모눈종이의 왼쪽 아래 꼭짓점의 좌표는 (0,0)이고, 오른쪽 위 꼭짓점의 좌표는(N,M)이다.
-# 입력되는 K개의 직사각형들이 모눈종이 전체를 채우는 경우는 없다.
-#
-# 5 7 3
-# 0 2 4 4
-# 1 1 2 5
-# 4 0 6 2
-#
-# 출력
-# 첫째 줄에 분리되어 나누어지는 영역의 개수를 출력한다.
-# 둘째 줄에는 각 영역의 넓이를 오름차순으로 정렬하여 빈칸을 사이에 두고 출력한다.
-def fill_square(M, N, square):
-
- area = [[0 for x in range(N)] for y in range(M)]
-
- for x1,y1,x2,y2 in square:
- for y in range(y1, y2):
- for x in range(x1, x2):
- area[y][x] = 1
-
- return area
-
-def find_area(M, N, adj_list):
- directions = [(0,1),(0,-1),(1,0),(-1,0)]
-
- def dfs(y,x,grid):
- size = 0
- stack = [(y,x)]
-
- while stack:
- cy, cx = stack.pop()
-
- if grid[cy][cx] == 1:
- continue
- grid[cy][cx] = 1
- size += 1
-
- for dy, dx in directions:
- ny, nx = cy + dy, cx + dx
- # 아래 조건문 부분 빠트림
- if (0 <= ny < M) and (0 <= nx < N) and (grid[ny][nx] == 0):
- stack.append((ny,nx))
-
- return size
-
- result = []
- for y in range(M):
- for x in range(N):
- if adj_list[y][x] == 0:
- size = dfs(y, x, adj_list)
- result.append(size)
- result.sort()
- return len(result), result
-
-
-if __name__ == "__main__":
- # M 은 y / N 은 x
- M, N, K = map(int, input().split())
-
- square = []
- for _ in range(K):
- square.append(list(map(int, input().split())))
-
- adj_list = fill_square(M,N,square)
-
- count, sizes = find_area(M,N,adj_list)
- print(count)
- result = map(str, sizes)
- a = ' '.join(result)
- print(a)
diff --git "a/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/README.md" "b/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/README.md"
deleted file mode 100644
index 36b8d1b..0000000
--- "a/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/README.md"
+++ /dev/null
@@ -1,41 +0,0 @@
-# [Silver V] 식당 입구 대기 줄 - 26042
-
-[문제 링크](https://www.acmicpc.net/problem/26042)
-
-### 성능 요약
-
-메모리: 34324 KB, 시간: 104 ms
-
-### 분류
-
-자료 구조, 구현, 큐
-
-### 제출 일자
-
-2024년 11월 15일 10:30:34
-
-### 문제 설명
-
-여러 명의 학생이 식사하기 위하여 학교 식당을 향해 달려가고 있다. 학교 식당에 도착한 학생은 식당 입구에 줄을 서서 대기한다. 학교 식당에 먼저 도착한 학생이 나중에 도착한 학생보다 식당 입구의 앞쪽에서 대기한다. 식사는 1인분씩 준비된다. 식사 1인분이 준비되면 식당 입구의 맨 앞에서 대기 중인 학생 1명이 식당으로 들어가서 식사를 시작한다. 식사를 시작한 학생은 항상 식사를 마친다.
-
-학생이 학교 식당에 도착하고 식사가 준비되는 n개의 정보가 저장된 A가 주어진다. A에 저장된 첫 번째 정보부터 n번째 정보까지 순서대로 처리한 다음, 식당 입구에 줄을 서서 대기하는 학생 수가 최대가 되었던 순간의 학생 수와 이때 식당 입구의 맨 뒤에 대기 중인 학생의 번호를 출력하자. 대기하는 학생 수가 최대인 경우가 여러 번이라면 맨 뒤에 줄 서 있는 학생의 번호가 가장 작은 경우를 출력하자.
-
-A에 저장된 n개의 정보는 아래 두 가지 유형으로 구분된다. 첫 번째가 유형 1, 두 번째가 유형 2이다.
-
-
- - 1 a: 학생 번호가 양의 정수 a인 학생 1명이 학교 식당에 도착하여 식당 입구의 맨 뒤에 줄을 서기 시작한다.
- - 2: 식사 1인분이 준비되어 식당 입구의 맨 앞에서 대기 중인 학생 1명이 식사를 시작한다.
-
-
-식사 1인분이 준비될 때는 식당 입구에서 대기 중인 학생이 항상 존재한다. 식당 입구에 줄을 서서 대기하였으나 식사가 준비 안 된 학생은 식사를 못 한다.
-
-### 입력
-
- 첫 번째 줄에 n이 주어진다.
-
-다음 줄부터 n개의 줄에 걸쳐 한 줄에 하나의 정보가 주어진다. 주어지는 정보는 유형 1, 2중 하나이다.
-
-### 출력
-
- 첫 번째 정보부터 n번째 정보까지 순서대로 처리한 다음, 식당 입구에 줄을 서서 대기하는 학생 수가 최대가 되었던 순간의 학생 수와 이때 식당 입구의 맨 뒤에 대기 중인 학생의 번호를 빈칸을 사이에 두고 순서대로 출력한다. 대기하는 학생 수가 최대인 경우가 여러 번이라면 맨 뒤에 줄 서 있는 학생의 번호가 가장 작은 경우를 출력한다.
-
diff --git "a/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204.py" "b/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204.py"
deleted file mode 100644
index f442b88..0000000
--- "a/\353\260\261\354\244\200/Silver/26042.\342\200\205\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204/\354\213\235\353\213\271\342\200\205\354\236\205\352\265\254\342\200\205\353\214\200\352\270\260\342\200\205\354\244\204.py"
+++ /dev/null
@@ -1,34 +0,0 @@
-from collections import deque
-import sys
-
-input = sys.stdin.readline # 빠른 입력을 위해 sys.stdin.readline 사용
-
-
-def find_max_queue_info():
- n = int(input().strip())
- queue = deque()
- max_count = 0
- min_last_student = None
-
- for _ in range(n):
- command = input().strip().split()
- if command[0] == '1': # 학생이 줄을 섬
- student_num = int(command[1])
- queue.append(student_num)
-
- # 대기 학생 수와 마지막 학생 갱신 조건을 단순화
- if len(queue) > max_count:
- max_count = len(queue)
- min_last_student = student_num
- elif len(queue) == max_count and (min_last_student is None or student_num < min_last_student):
- min_last_student = student_num
-
- elif command[0] == '2': # 식사가 준비되어 대기 중인 학생이 식사를 시작함
- queue.popleft()
-
- # 최종 결과 출력
- print(max_count, min_last_student)
-
-
-# 함수 호출
-find_max_queue_info()
diff --git "a/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/Bad\342\200\205Grass.py" "b/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/Bad\342\200\205Grass.py"
deleted file mode 100644
index 34f9c87..0000000
--- "a/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/Bad\342\200\205Grass.py"
+++ /dev/null
@@ -1,34 +0,0 @@
-def find_is_islands(grid, R, C):
- def iterative_dfs(x, y):
- stack = [(x, y)]
- while stack:
- cx, cy = stack.pop()
- if grid[cx][cy] == 0:
- continue
- grid[cx][cy] = 0
- for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1), (-1, -1), (-1, 1), (1, -1), (1, 1)]:
- nx, ny = cx + dx, cy + dy
- if 0 <= nx < R and 0 <= ny < C and grid[nx][ny] > 0:
- stack.append((nx, ny))
-
- island_count = 0
-
- for i in range(R):
- for j in range(C):
- if grid[i][j] > 0:
- iterative_dfs(i, j)
- island_count += 1
-
- return island_count
-
-if __name__ == "__main__":
- R, C = map(int, input().split())
-
- grid = []
-
- for _ in range(R):
- grid.append(list(map(int, input().split())))
-
- result = find_is_islands(grid, R, C)
-
- print(result)
diff --git "a/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/README.md" "b/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/README.md"
deleted file mode 100644
index 50ce8b4..0000000
--- "a/\353\260\261\354\244\200/Silver/6080.\342\200\205Bad\342\200\205Grass/README.md"
+++ /dev/null
@@ -1,45 +0,0 @@
-# [Silver II] Bad Grass - 6080
-
-[문제 링크](https://www.acmicpc.net/problem/6080)
-
-### 성능 요약
-
-메모리: 196500 KB, 시간: 904 ms
-
-### 분류
-
-너비 우선 탐색, 깊이 우선 탐색, 그래프 이론, 그래프 탐색
-
-### 제출 일자
-
-2024년 8월 22일 19:41:02
-
-### 문제 설명
-
-Bessie was munching on tender shoots of grass and, as cows do, contemplating the state of the universe. She noticed that she only enjoys the grass on the wide expanses of pasture whose elevation is at the base level of the farm. Grass from elevations just 1 meter higher is tougher and not so appetizing. The bad grass gets worse as the elevation increases.
-
-Continuing to chew, she realized that this unappetizing food grows the sides of hills that form a set of 'islands' of bad grass among the sea of tender, verdant, delicious, abundant grass.
-
-Bessie donned her lab coat and vowed to determine just how many islands of bad grass her pasture had. She created a map in which she divided the pasture into R (1 < R <= 1,000) rows and C (1 < C <= 1,000) columns of 1 meter x 1 meter squares. She measured the elevation above the base level for each square and rounded it to a non-negative integer. She noted hungrily that the tasty grass all had elevation 0.
-
-She commenced counting the islands. If two squares are neighbors in any of the horizontal, vertical or diagonal directions then they are considered to be part of the same island.
-
-How many islands of bad grass did she count for each of the supplied maps?
-
-### 입력
-
-
- - Line 1: Two space-separated integers: R and C
- - Lines 2..R+1: Line i+1 describes row i of the map with C space separated integers
-
-
-
-
-### 출력
-
-
- - Line 1: A single integer that specifies the number of islands.
-
-
-
-
diff --git "a/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/Clear\342\200\205Cold\342\200\205Water.py" "b/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/Clear\342\200\205Cold\342\200\205Water.py"
deleted file mode 100644
index 0dcd123..0000000
--- "a/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/Clear\342\200\205Cold\342\200\205Water.py"
+++ /dev/null
@@ -1,50 +0,0 @@
-from collections import deque
-
-
-def read_input():
- """입력을 처리하고 트리 구조를 반환하는 함수"""
- # N 파이프 갯수, C 가짓점 갯수
- N, C = map(int, input().split())
-
- tree = {i: [] for i in range(1, N + 1)}
- for _ in range(C):
- E_i, B1_i, B2_i = map(int, input().split())
- tree[E_i].append(B1_i)
- tree[E_i].append(B2_i)
- # 양방향 연결을 위해 추가
- tree[B1_i].append(E_i)
- tree[B2_i].append(E_i)
-
- return N, tree
-
-def calculate_distances(N, tree):
- """BFS 또는 DFS를 사용하여 각 파이프의 거리를 계산하는 함수"""
- distances = [-1] * (N + 1) # 인덱스 1부터 사용하기 위해 N + 1크기
-
- queue = deque([1])
- distances[1] = 1
-
- while queue:
- current = queue.popleft()
-
- for neighbor in tree[current]:
- if distances[neighbor] == -1:
- distances[neighbor] = distances[current] + 1
- queue.append(neighbor)
-
- return distances
-
-def print_distances(distances):
- """계산된 거리를 출력하는 함수"""
- for i in range(1, len(distances)):
- print(distances[i])
-
-if __name__ == "__main__":
- # 1. 입력을 받아 트리 구조 생성
- N, tree = read_input()
-
- # 2. 각 파이프의 거리를 계산
- distances = calculate_distances(N, tree)
-
- # 3. 계산된 거리를 출력
- print_distances(distances)
diff --git "a/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/README.md" "b/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/README.md"
deleted file mode 100644
index ee35fb6..0000000
--- "a/\353\260\261\354\244\200/Silver/6188.\342\200\205Clear\342\200\205Cold\342\200\205Water/README.md"
+++ /dev/null
@@ -1,41 +0,0 @@
-# [Silver II] Clear Cold Water - 6188
-
-[문제 링크](https://www.acmicpc.net/problem/6188)
-
-### 성능 요약
-
-메모리: 55140 KB, 시간: 1464 ms
-
-### 분류
-
-너비 우선 탐색, 깊이 우선 탐색, 그래프 이론, 그래프 탐색, 트리
-
-### 제출 일자
-
-2024년 8월 21일 21:38:45
-
-### 문제 설명
-
-The steamy, sweltering summers of Wisconsin's dairy district stimulate the cows to slake their thirst. Farmer John pipes clear cold water into a set of N (3 <= N <= 99999; N odd) branching pipes conveniently numbered 1..N from a pump located at the barn. As the water flows through the pipes, the summer heat warms it. Bessie wants to find the coldest water so she can enjoy the weather more than any other cow.
-
-She has mapped the entire set of branching pipes and noted that they form a tree with its root at the farm and furthermore that every branch point has exactly two pipes exiting from it. Surprisingly, every pipe is exactly one unit in length; of course, all N pipes connect up in one way or another to the pipe-tree.
-
-Given the map of all the pipe connections, make a list of the distance from the barn for every branching point and endpoint. Bessie will use the list to find the very coldest water.
-
-The endpoint of a pipe, which might enter a branching point or might be a spigot, is named by the pipe's number. The map contains C (1 <= C <= N) connections, each of which specifies three integers: the endpoint E_i (1 <= E_i <= N) of a pipe and two branching pipes B1_i and B2_i (2 <= B1_i <= N; 2 <= B2_i <= N). Pipe number 1 connects to the barn; the distance from its endpoint to the barn is 1.
-
-### 입력
-
-
- - Line 1: Two space-separated integers: N and C
- - Lines 2..C+1: Line i+1 describes branching point i with three space-separated integers: E_i, B1_i, and B2_i
-
-
-
-
-### 출력
-
-
- - Lines 1..N: Line i of the output contains a single integer that is the distance from the barn to the endpoint of pipe i
-
-
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/README.md"
deleted file mode 100644
index 02a2ad7..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/README.md"
+++ /dev/null
@@ -1,64 +0,0 @@
-# [level 1] 같은 숫자는 싫어 - 12906
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12906)
-
-### 성능 요약
-
-메모리: 27.9 MB, 시간: 57.70 ms
-
-### 구분
-
-코딩테스트 연습 > 스택/큐
-
-### 채점결과
-
-정확성: 71.9
효율성: 28.1
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 11월 12일 10:32:20
-
-### 문제 설명
-
-배열 arr가 주어집니다. 배열 arr의 각 원소는 숫자 0부터 9까지로 이루어져 있습니다. 이때, 배열 arr에서 연속적으로 나타나는 숫자는 하나만 남기고 전부 제거하려고 합니다. 단, 제거된 후 남은 수들을 반환할 때는 배열 arr의 원소들의 순서를 유지해야 합니다. 예를 들면,
-
-
-- arr = [1, 1, 3, 3, 0, 1, 1] 이면 [1, 3, 0, 1] 을 return 합니다.
-- arr = [4, 4, 4, 3, 3] 이면 [4, 3] 을 return 합니다.
-
-
-배열 arr에서 연속적으로 나타나는 숫자는 제거하고 남은 수들을 return 하는 solution 함수를 완성해 주세요.
-
-제한사항
-
-
-- 배열 arr의 크기 : 1,000,000 이하의 자연수
-- 배열 arr의 원소의 크기 : 0보다 크거나 같고 9보다 작거나 같은 정수
-
-
-
-
-입출력 예
-
-
-| arr |
-answer |
-
-
-
-| [1,1,3,3,0,1,1] |
-[1,3,0,1] |
-
-
-| [4,4,4,3,3] |
-[4,3] |
-
-
-
-입출력 예 설명
-
-입출력 예 #1,2
-문제의 예시와 같습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264.py"
deleted file mode 100644
index dbff13e..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12906.\342\200\205\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264/\352\260\231\354\235\200\342\200\205\354\210\253\354\236\220\353\212\224\342\200\205\354\213\253\354\226\264.py"
+++ /dev/null
@@ -1,8 +0,0 @@
-def solution(arr):
- answer = []
- answer.append(arr[0])
- for a in arr:
- if answer[-1] != a:
- answer.append(a)
-
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/README.md"
deleted file mode 100644
index eaac9f4..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/README.md"
+++ /dev/null
@@ -1,64 +0,0 @@
-# [level 1] 문자열 내 p와 y의 개수 - 12916
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12916?language=python3)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 0.06 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 10월 28일 15:02:01
-
-### 문제 설명
-
-대문자와 소문자가 섞여있는 문자열 s가 주어집니다. s에 'p'의 개수와 'y'의 개수를 비교해 같으면 True, 다르면 False를 return 하는 solution를 완성하세요. 'p', 'y' 모두 하나도 없는 경우는 항상 True를 리턴합니다. 단, 개수를 비교할 때 대문자와 소문자는 구별하지 않습니다.
-
-예를 들어 s가 "pPoooyY"면 true를 return하고 "Pyy"라면 false를 return합니다.
-
-제한사항
-
-
-- 문자열 s의 길이 : 50 이하의 자연수
-- 문자열 s는 알파벳으로만 이루어져 있습니다.
-
-
-
-
-입출력 예
-
-
-| s |
-answer |
-
-
-
-| "pPoooyY" |
-true |
-
-
-| "Pyy" |
-false |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-'p'의 개수 2개, 'y'의 개수 2개로 같으므로 true를 return 합니다.
-
-입출력 예 #2
-'p'의 개수 1개, 'y'의 개수 2개로 다르므로 false를 return 합니다.
-
-※ 공지 - 2021년 8월 23일 테스트케이스가 추가되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230.py"
deleted file mode 100644
index b5f8d31..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12916.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\342\200\205p\354\231\200\342\200\205y\354\235\230\342\200\205\352\260\234\354\210\230.py"
+++ /dev/null
@@ -1,12 +0,0 @@
-from collections import Counter
-
-def solution(s):
- l = s.lower()
- counter = Counter(l)
-
- if counter['p'] == counter['y']:
- return True
- else :
- return False
-
-
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md"
deleted file mode 100644
index 01a68af..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md"
+++ /dev/null
@@ -1,46 +0,0 @@
-# [level 1] 문자열 내림차순으로 배치하기 - 12917
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12917)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.05 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 02일 11:30:11
-
-### 문제 설명
-
-문자열 s에 나타나는 문자를 큰것부터 작은 순으로 정렬해 새로운 문자열을 리턴하는 함수, solution을 완성해주세요.
-s는 영문 대소문자로만 구성되어 있으며, 대문자는 소문자보다 작은 것으로 간주합니다.
-
-제한 사항
-
-
-
-입출력 예
-
-
-| s |
-return |
-
-
-
-| "Zbcdefg" |
-"gfedcbZ" |
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py"
deleted file mode 100644
index 93043b3..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12917.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py"
+++ /dev/null
@@ -1,4 +0,0 @@
-def solution(s):
- result = sorted(s, reverse=True)
- answer = ''.join(result)
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/README.md"
deleted file mode 100644
index 6bb6289..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/README.md"
+++ /dev/null
@@ -1,40 +0,0 @@
-# [level 1] 문자열을 정수로 바꾸기 - 12925
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12925)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 0.02 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 07월 25일 12:25:11
-
-### 문제 설명
-
-문자열 s를 숫자로 변환한 결과를 반환하는 함수, solution을 완성하세요.
-
-제한 조건
-
-
-- s의 길이는 1 이상 5이하입니다.
-- s의 맨앞에는 부호(+, -)가 올 수 있습니다.
-- s는 부호와 숫자로만 이루어져있습니다.
-- s는 "0"으로 시작하지 않습니다.
-
-
-입출력 예
-
-예를들어 str이 "1234"이면 1234를 반환하고, "-1234"이면 -1234를 반환하면 됩니다.
-str은 부호(+,-)와 숫자로만 구성되어 있고, 잘못된 값이 입력되는 경우는 없습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260.py"
deleted file mode 100644
index f4eb625..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12925.\342\200\205\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260/\353\254\270\354\236\220\354\227\264\354\235\204\342\200\205\354\240\225\354\210\230\353\241\234\342\200\205\353\260\224\352\276\270\352\270\260.py"
+++ /dev/null
@@ -1,8 +0,0 @@
-def solution(s):
-
- # if s.count('-') == 1:
- # return -int(s[1:])
- # else :
- # return int(s)
- return int(s)
-
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/README.md"
deleted file mode 100644
index 9df15f5..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/README.md"
+++ /dev/null
@@ -1,45 +0,0 @@
-# [level 1] 자연수 뒤집어 배열로 만들기 - 12932
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12932?language=python3)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.01 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 07월 22일 15:32:51
-
-### 문제 설명
-
-자연수 n을 뒤집어 각 자리 숫자를 원소로 가지는 배열 형태로 리턴해주세요. 예를들어 n이 12345이면 [5,4,3,2,1]을 리턴합니다.
-
-제한 조건
-
-
-- n은 10,000,000,000이하인 자연수입니다.
-
-
-입출력 예
-
-
-| n |
-return |
-
-
-
-| 12345 |
-[5,4,3,2,1] |
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260.py"
deleted file mode 100644
index b18a6df..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12932.\342\200\205\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260/\354\236\220\354\227\260\354\210\230\342\200\205\353\222\244\354\247\221\354\226\264\342\200\205\353\260\260\354\227\264\353\241\234\342\200\205\353\247\214\353\223\244\352\270\260.py"
+++ /dev/null
@@ -1,29 +0,0 @@
-def solution(n):
- # ten = 10
- # while(True):
- # if n / ten == 1:
- # break
- # else :
- # ten = ten * 10
- # return ten
- answer = []
-
-
-
- size = 10 ** (len(str(n)) - 1)
- while(True):
- value = n // size
- new_n = n % size
- answer.append(value)
-
- if size != 1:
- size = size // 10
- n = new_n
- else :
- break
-
- answer.reverse()
-
- return answer
-
-
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md"
deleted file mode 100644
index e8b1984..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/README.md"
+++ /dev/null
@@ -1,45 +0,0 @@
-# [level 1] 정수 내림차순으로 배치하기 - 12933
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12933)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 0.66 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 01일 14:39:29
-
-### 문제 설명
-
-함수 solution은 정수 n을 매개변수로 입력받습니다. n의 각 자릿수를 큰것부터 작은 순으로 정렬한 새로운 정수를 리턴해주세요. 예를들어 n이 118372면 873211을 리턴하면 됩니다.
-
-제한 조건
-
-
-n은 1이상 8000000000 이하인 자연수입니다.
-
-입출력 예
-
-
-| n |
-return |
-
-
-
-| 118372 |
-873211 |
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py"
deleted file mode 100644
index d309cc1..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12933.\342\200\205\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260/\354\240\225\354\210\230\342\200\205\353\202\264\353\246\274\354\260\250\354\210\234\354\234\274\353\241\234\342\200\205\353\260\260\354\271\230\355\225\230\352\270\260.py"
+++ /dev/null
@@ -1,6 +0,0 @@
-def solution(n):
- list_n = list(map(int, str(n)))
- sorted_n = sorted(list_n, reverse=True)
- str_n = list(map(str,sorted_n))
- result = ''.join(str_n)
- return int(result)
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/README.md"
deleted file mode 100644
index bed013a..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/README.md"
+++ /dev/null
@@ -1,50 +0,0 @@
-# [level 1] 평균 구하기 - 12944
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12944)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.02 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 07월 23일 14:23:14
-
-### 문제 설명
-
-정수를 담고 있는 배열 arr의 평균값을 return하는 함수, solution을 완성해보세요.
-
-제한사항
-
-
-- arr은 길이 1 이상, 100 이하인 배열입니다.
-- arr의 원소는 -10,000 이상 10,000 이하인 정수입니다.
-
-
-입출력 예
-
-
-| arr |
-return |
-
-
-
-| [1,2,3,4] |
-2.5 |
-
-
-| [5,5] |
-5 |
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260.py"
deleted file mode 100644
index 82f876d..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/12944.\342\200\205\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260/\355\217\211\352\267\240\342\200\205\352\265\254\355\225\230\352\270\260.py"
+++ /dev/null
@@ -1,4 +0,0 @@
-def solution(arr):
-
-
- return sum(arr) / len(arr)
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/README.md"
deleted file mode 100644
index d4d196d..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/README.md"
+++ /dev/null
@@ -1,120 +0,0 @@
-# [level 1] 과일 장수 - 135808
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/135808)
-
-### 성능 요약
-
-메모리: 21.6 MB, 시간: 337.56 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 09일 18:11:18
-
-### 문제 설명
-
-과일 장수가 사과 상자를 포장하고 있습니다. 사과는 상태에 따라 1점부터 k점까지의 점수로 분류하며, k점이 최상품의 사과이고 1점이 최하품의 사과입니다. 사과 한 상자의 가격은 다음과 같이 결정됩니다.
-
-
-- 한 상자에 사과를 m개씩 담아 포장합니다.
-- 상자에 담긴 사과 중 가장 낮은 점수가 p (1 ≤ p ≤ k)점인 경우, 사과 한 상자의 가격은 p * m 입니다.
-
-
-과일 장수가 가능한 많은 사과를 팔았을 때, 얻을 수 있는 최대 이익을 계산하고자 합니다.(사과는 상자 단위로만 판매하며, 남는 사과는 버립니다)
-
-예를 들어, k = 3, m = 4, 사과 7개의 점수가 [1, 2, 3, 1, 2, 3, 1]이라면, 다음과 같이 [2, 3, 2, 3]으로 구성된 사과 상자 1개를 만들어 판매하여 최대 이익을 얻을 수 있습니다.
-
-
-- (최저 사과 점수) x (한 상자에 담긴 사과 개수) x (상자의 개수) = 2 x 4 x 1 = 8
-
-
-사과의 최대 점수 k, 한 상자에 들어가는 사과의 수 m, 사과들의 점수 score가 주어졌을 때, 과일 장수가 얻을 수 있는 최대 이익을 return하는 solution 함수를 완성해주세요.
-
-제한사항
-
-
-- 3 ≤
k ≤ 9
-- 3 ≤
m ≤ 10
-- 7 ≤
score의 길이 ≤ 1,000,000
-
-
-- 이익이 발생하지 않는 경우에는 0을 return 해주세요.
-
-
-
-
-입출력 예
-
-
-| k |
-m |
-score |
-result |
-
-
-
-| 3 |
-4 |
-[1, 2, 3, 1, 2, 3, 1] |
-8 |
-
-
-| 4 |
-3 |
-[4, 1, 2, 2, 4, 4, 4, 4, 1, 2, 4, 2] |
-33 |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-
-
-입출력 예 #2
-
-
-- 다음과 같이 사과 상자를 포장하여 모두 팔면 최대 이익을 낼 수 있습니다.
-
-
-
-| 사과 상자 |
-가격 |
-
-
-
-| [1, 1, 2] |
-1 x 3 = 3 |
-
-
-| [2, 2, 2] |
-2 x 3 = 6 |
-
-
-| [4, 4, 4] |
-4 x 3 = 12 |
-
-
-| [4, 4, 4] |
-4 x 3 = 12 |
-
-
-
-따라서 (1 x 3 x 1) + (2 x 3 x 1) + (4 x 3 x 2) = 33을 return합니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230.py"
deleted file mode 100644
index dabe205..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/135808.\342\200\205\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230/\352\263\274\354\235\274\342\200\205\354\236\245\354\210\230.py"
+++ /dev/null
@@ -1,3 +0,0 @@
-def solution(k, m, score):
- answer = 0
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/README.md"
deleted file mode 100644
index 92ca9ac..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/README.md"
+++ /dev/null
@@ -1,80 +0,0 @@
-# [level 1] 문자열 나누기 - 140108
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/140108)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 2.80 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 10월 30일 14:19:05
-
-### 문제 설명
-
-문자열 s가 입력되었을 때 다음 규칙을 따라서 이 문자열을 여러 문자열로 분해하려고 합니다.
-
-
-- 먼저 첫 글자를 읽습니다. 이 글자를 x라고 합시다.
-- 이제 이 문자열을 왼쪽에서 오른쪽으로 읽어나가면서, x와 x가 아닌 다른 글자들이 나온 횟수를 각각 셉니다. 처음으로 두 횟수가 같아지는 순간 멈추고, 지금까지 읽은 문자열을 분리합니다.
-s에서 분리한 문자열을 빼고 남은 부분에 대해서 이 과정을 반복합니다. 남은 부분이 없다면 종료합니다.- 만약 두 횟수가 다른 상태에서 더 이상 읽을 글자가 없다면, 역시 지금까지 읽은 문자열을 분리하고, 종료합니다.
-
-
-문자열 s가 매개변수로 주어질 때, 위 과정과 같이 문자열들로 분해하고, 분해한 문자열의 개수를 return 하는 함수 solution을 완성하세요.
-
-
-
-제한사항
-
-
-- 1 ≤
s의 길이 ≤ 10,000
-s는 영어 소문자로만 이루어져 있습니다.
-
-
-
-입출력 예
-
-
-| s |
-result |
-
-
-
-| "banana" |
-3 |
-
-
-| "abracadabra" |
-6 |
-
-
-| "aaabbaccccabba" |
-3 |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-s="banana"인 경우 ba - na - na와 같이 분해됩니다.
-
-입출력 예 #2
-s="abracadabra"인 경우 ab - ra - ca - da - br - a와 같이 분해됩니다.
-
-입출력 예 #3
-s="aaabbaccccabba"인 경우 aaabbacc - ccab - ba와 같이 분해됩니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260.py"
deleted file mode 100644
index 9f0f4d5..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/140108.\342\200\205\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260/\353\254\270\354\236\220\354\227\264\342\200\205\353\202\230\353\210\204\352\270\260.py"
+++ /dev/null
@@ -1,16 +0,0 @@
-def solution(s):
- result = 0
- while s:
- count = 0
- move = 0
- for c in s :
- if c == s[0] :
- count += 1
- else :
- count -= 1
- move += 1
- if count == 0 :
- break
- result += 1
- s = s[move:]
- return result
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/README.md"
deleted file mode 100644
index a4784a7..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/README.md"
+++ /dev/null
@@ -1,78 +0,0 @@
-# [level 1] 크기가 작은 부분문자열 - 147355
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/147355)
-
-### 성능 요약
-
-메모리: 10.5 MB, 시간: 10.99 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 10월 30일 10:54:52
-
-### 문제 설명
-
-숫자로 이루어진 문자열 t와 p가 주어질 때, t에서 p와 길이가 같은 부분문자열 중에서, 이 부분문자열이 나타내는 수가 p가 나타내는 수보다 작거나 같은 것이 나오는 횟수를 return하는 함수 solution을 완성하세요.
-
-예를 들어, t="3141592"이고 p="271" 인 경우, t의 길이가 3인 부분 문자열은 314, 141, 415, 159, 592입니다. 이 문자열이 나타내는 수 중 271보다 작거나 같은 수는 141, 159 2개 입니다.
-
-
-
-제한사항
-
-
-- 1 ≤
p의 길이 ≤ 18
-p의 길이 ≤ t의 길이 ≤ 10,000t와 p는 숫자로만 이루어진 문자열이며, 0으로 시작하지 않습니다.
-
-
-
-입출력 예
-
-
-| t |
-p |
-result |
-
-
-
-| "3141592" |
-"271" |
-2 |
-
-
-| "500220839878" |
-"7" |
-8 |
-
-
-| "10203" |
-"15" |
-3 |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-본문과 같습니다.
-
-입출력 예 #2
-p의 길이가 1이므로 t의 부분문자열은 "5", "0", 0", "2", "2", "0", "8", "3", "9", "8", "7", "8"이며 이중 7보다 작거나 같은 숫자는 "5", "0", "0", "2", "2", "0", "3", "7" 이렇게 8개가 있습니다.
-
-입출력 예 #3
-p의 길이가 2이므로 t의 부분문자열은 "10", "02", "20", "03"이며, 이중 15보다 작거나 같은 숫자는 "10", "02", "03" 이렇게 3개입니다. "02"와 "03"은 각각 2, 3에 해당한다는 점에 주의하세요
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264.py"
deleted file mode 100644
index a330a7c..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/147355.\342\200\205\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264/\355\201\254\352\270\260\352\260\200\342\200\205\354\236\221\354\235\200\342\200\205\353\266\200\353\266\204\353\254\270\354\236\220\354\227\264.py"
+++ /dev/null
@@ -1,19 +0,0 @@
-def solution(t, p):
- p_length = int(len(p)) # 3
- p_value = int(p) # 271
- result = 0
-
- for i in range(len(t)):
- if len(t) + 1 <= i + p_length :
- break
- else :
- sub = int(t[i : i + p_length])
- print(sub)
- if p_value >= sub :
- result += 1
-
-
- return result
-
-
-
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/README.md"
deleted file mode 100644
index d14fb5d..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/README.md"
+++ /dev/null
@@ -1,126 +0,0 @@
-# [level 1] 바탕화면 정리 - 161990
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/161990)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.04 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 16일 15:34:31
-
-### 문제 설명
-
-코딩테스트를 준비하는 머쓱이는 프로그래머스에서 문제를 풀고 나중에 다시 코드를 보면서 공부하려고 작성한 코드를 컴퓨터 바탕화면에 아무 위치에나 저장해 둡니다. 저장한 코드가 많아지면서 머쓱이는 본인의 컴퓨터 바탕화면이 너무 지저분하다고 생각했습니다. 프로그래머스에서 작성했던 코드는 그 문제에 가서 다시 볼 수 있기 때문에 저장해 둔 파일들을 전부 삭제하기로 했습니다.
-
-컴퓨터 바탕화면은 각 칸이 정사각형인 격자판입니다. 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어집니다. 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현합니다. 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가집니다. 드래그를 하면 파일들을 선택할 수 있고, 선택된 파일들을 삭제할 수 있습니다. 머쓱이는 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 하며 드래그로 파일들을 선택하는 방법은 다음과 같습니다.
-
-
-드래그는 바탕화면의 격자점 S(lux, luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx, rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동입니다. 이때, "점 S에서 점 E로 드래그한다"고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현합니다.
점 S(lux, luy)에서 점 E(rdx, rdy)로 드래그를 할 때, "드래그 한 거리"는 |rdx - lux| + |rdy - luy|로 정의합니다.
점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됩니다.
-
-예를 들어 wallpaper = [".#...", "..#..", "...#."]인 바탕화면을 그림으로 나타내면 다음과 같습니다.
-
-이러한 바탕화면에서 다음 그림과 같이 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그 한 거리 (3 - 0) + (4 - 1) = 6을 최솟값으로 모든 파일을 선택 가능합니다.
-
-(0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어납니다.
-
-머쓱이의 컴퓨터 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝점을 담은 정수 배열을 return하는 solution 함수를 작성해 주세요. 드래그의 시작점이 (lux, luy), 끝점이 (rdx, rdy)라면 정수 배열 [lux, luy, rdx, rdy]를 return하면 됩니다.
-
-
-
-제한사항
-
-
-- 1 ≤
wallpaper의 길이 ≤ 50
-- 1 ≤
wallpaper[i]의 길이 ≤ 50
-
-
-wallpaper의 모든 원소의 길이는 동일합니다.
-wallpaper[i][j]는 바탕화면에서 i + 1행 j + 1열에 해당하는 칸의 상태를 나타냅니다.wallpaper[i][j]는 "#" 또는 "."의 값만 가집니다.- 바탕화면에는 적어도 하나의 파일이 있습니다.
-- 드래그 시작점 (
lux, luy)와 끝점 (rdx, rdy)는 lux < rdx, luy < rdy를 만족해야 합니다.
-
-
-
-
-입출력 예
-
-
-| wallpaper |
-result |
-
-
-
-| [".#...", "..#..", "...#."] |
-[0, 1, 3, 4] |
-
-
-| ["..........", ".....#....", "......##..", "...##.....", "....#....."] |
-[1, 3, 5, 8] |
-
-
-| [".##...##.", "#..#.#..#", "#...#...#", ".#.....#.", "..#...#..", "...#.#...", "....#...."] |
-[0, 0, 7, 9] |
-
-
-| ["..", "#."] |
-[1, 0, 2, 1] |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-
-- 문제 설명의 예시와 같은 예제입니다. (0, 1)에서 (3, 4)로 드래그 하면 모든 파일을 선택할 수 있고 드래그 한 거리는 6이었고, 6보다 적은 거리로 모든 파일을 선택하는 방법은 없습니다. 따라서 [0, 1, 3, 4]를 return합니다.
-
-
-입출력 예 #2
-
-
-예제 2번의 바탕화면은 다음과 같습니다.
-
-
-
-(1, 3)에서 (5, 8)로 드래그하면 모든 파일을 선택할 수 있고 이보다 적은 이동거리로 모든 파일을 선택하는 방법은 없습니다. 따라서 가장 적은 이동의 드래그로 모든 파일을 선택하는 방법인 [1, 3, 5, 8]을 return합니다.
-
-입출력 예 #3
-
-
-예제 3번의 바탕화면은 다음과 같습니다.
-
-
-
-모든 파일을 선택하기 위해선 바탕화면의 가장 왼쪽 위 (0, 0)에서 가장 오른쪽 아래 (7, 9)로 드래그 해야만 합니다. 따라서 [0, 0, 7, 9]를 return합니다.
-
-입출력 예 #4
-
-
-예제 4번의 바탕화면은 다음과 같이 2행 1열에만 아이콘이 있습니다.
-
-
-
-이를 드래그로 선택하기 위해서는 그 칸의 왼쪽 위 (1, 0)에서 오른쪽 아래 (2, 1)로 드래그 하면 됩니다. (1, 0)에서 (2, 2)로 드래그 해도 아이콘을 선택할 수 있지만 이전보다 이동거리가 늘어납니다. 따라서 [1, 0, 2, 1]을 return합니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254.py"
deleted file mode 100644
index ba5371a..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/161990.\342\200\205\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254/\353\260\224\355\203\225\355\231\224\353\251\264\342\200\205\354\240\225\353\246\254.py"
+++ /dev/null
@@ -1,22 +0,0 @@
-def solution(wallpaper):
- top, down,left, right = None, None, float('inf'), -float('inf')
-
- for i in range(len(wallpaper)):
- row = wallpaper[i]
-
- loc = row.find('#')
- rloc = row.rfind('#')
-
- if loc != -1: # find 성공했을 때
- if top == None : # top 을 아직 찾은적이 없을 때
- top = i
- down = i
-
- left = min(left, loc)
- right = max(right, rloc)
-
- # answer.append(top)
- # answer.append(left)
- # answer.append(down + 1)
- # answer.append(right + 1)
- return [top, left, down + 1, right + 1]
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/README.md"
deleted file mode 100644
index 6512f12..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/README.md"
+++ /dev/null
@@ -1,129 +0,0 @@
-# [level 1] 공원 산책 - 172928
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/172928)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 0.47 ms
-
-### 구분
-
-코딩테스트 연습 > 연습문제
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 17일 15:51:12
-
-### 문제 설명
-
-지나다니는 길을 'O', 장애물을 'X'로 나타낸 직사각형 격자 모양의 공원에서 로봇 강아지가 산책을 하려합니다. 산책은 로봇 강아지에 미리 입력된 명령에 따라 진행하며, 명령은 다음과 같은 형식으로 주어집니다.
-
-
-
-예를 들어 "E 5"는 로봇 강아지가 현재 위치에서 동쪽으로 5칸 이동했다는 의미입니다. 로봇 강아지는 명령을 수행하기 전에 다음 두 가지를 먼저 확인합니다.
-
-
-- 주어진 방향으로 이동할 때 공원을 벗어나는지 확인합니다.
-- 주어진 방향으로 이동 중 장애물을 만나는지 확인합니다.
-
-
-위 두 가지중 어느 하나라도 해당된다면, 로봇 강아지는 해당 명령을 무시하고 다음 명령을 수행합니다.
-공원의 가로 길이가 W, 세로 길이가 H라고 할 때, 공원의 좌측 상단의 좌표는 (0, 0), 우측 하단의 좌표는 (H - 1, W - 1) 입니다.
-
-
-
-공원을 나타내는 문자열 배열 park, 로봇 강아지가 수행할 명령이 담긴 문자열 배열 routes가 매개변수로 주어질 때, 로봇 강아지가 모든 명령을 수행 후 놓인 위치를 [세로 방향 좌표, 가로 방향 좌표] 순으로 배열에 담아 return 하도록 solution 함수를 완성해주세요.
-
-
-
-제한사항
-
-
-- 3 ≤
park의 길이 ≤ 50
-
-
-- 3 ≤
park[i]의 길이 ≤ 50
-
-
-park[i]는 다음 문자들로 이루어져 있으며 시작지점은 하나만 주어집니다.
-
-
-- S : 시작 지점
-- O : 이동 가능한 통로
-- X : 장애물
-
-park는 직사각형 모양입니다.
-- 1 ≤
routes의 길이 ≤ 50
-
-
-routes의 각 원소는 로봇 강아지가 수행할 명령어를 나타냅니다.- 로봇 강아지는
routes의 첫 번째 원소부터 순서대로 명령을 수행합니다.
-routes의 원소는 "op n"과 같은 구조로 이루어져 있으며, op는 이동할 방향, n은 이동할 칸의 수를 의미합니다.
-
-
-- op는 다음 네 가지중 하나로 이루어져 있습니다.
-
-
-- N : 북쪽으로 주어진 칸만큼 이동합니다.
-- S : 남쪽으로 주어진 칸만큼 이동합니다.
-- W : 서쪽으로 주어진 칸만큼 이동합니다.
-- E : 동쪽으로 주어진 칸만큼 이동합니다.
-
-- 1 ≤ n ≤ 9
-
-
-
-
-
-입출력 예
-
-
-| park |
-routes |
-result |
-
-
-
-| ["SOO","OOO","OOO"] |
-["E 2","S 2","W 1"] |
-[2,1] |
-
-
-| ["SOO","OXX","OOO"] |
-["E 2","S 2","W 1"] |
-[0,1] |
-
-
-| ["OSO","OOO","OXO","OOO"] |
-["E 2","S 3","W 1"] |
-[0,0] |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-입력된 명령대로 동쪽으로 2칸, 남쪽으로 2칸, 서쪽으로 1칸 이동하면 [0,0] -> [0,2] -> [2,2] -> [2,1]이 됩니다.
-
-입출력 예 #2
-
-입력된 명령대로라면 동쪽으로 2칸, 남쪽으로 2칸, 서쪽으로 1칸 이동해야하지만 남쪽으로 2칸 이동할 때 장애물이 있는 칸을 지나기 때문에 해당 명령을 제외한 명령들만 따릅니다. 결과적으로는 [0,0] -> [0,2] -> [0,1]이 됩니다.
-
-입출력 예 #3
-
-처음 입력된 명령은 공원을 나가게 되고 두 번째로 입력된 명령 또한 장애물을 지나가게 되므로 두 입력은 제외한 세 번째 명령만 따르므로 결과는 다음과 같습니다. [0,1] -> [0,0]
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205.py"
deleted file mode 100644
index 9ac85fd..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/172928.\342\200\205\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205/\352\263\265\354\233\220\342\200\205\354\202\260\354\261\205.py"
+++ /dev/null
@@ -1,106 +0,0 @@
-# def solution(park, routes):
-# init = []
-# # command = {}
-# # 1. 초기 위치 설정
-# for i in range(len(park)):
-# for j in range(len(park[i])):
-# if park[i][j] == 'S':
-# init.append(i)
-# init.append(j)
-# print(init)
-
-# move = []
-# for i in range(len(routes)):
-# # 2. 명령어 파싱
-# move = [routes[i][0], routes[i][2]]
-# how = int(move[1])
-
-# # 3. 이동 가능 여부 체크
-# if move[0] == 'E' :
-# row = park[init[0]]
-# # slicing = row[init[0] : how + 1]
-# slicing = row[init[1] + 1 : init[1] + how + 1]
-# if slicing in 'X' or len(slicing) < how:
-# continue
-# init[1] += how
-
-# elif move[0] == 'W':
-# row = park[init[0]]
-# # slicing = row[how : init[0] + 1 ]
-# slicing = row[init[1] - how : init[1]]
-# if slicing in 'X' or len(slicing) < how:
-# continue
-# init[1] -= how
-
-
-# elif move[0] == 'S':
-# print(init[0] + how)
-# # if len(park) - init[0] < init[0] + how :
-# if init[0] + how >= len(park):
-# print("넘음")
-# continue
-
-# col = [park[i][init[1]] for i in range(init[0] , init[0] + how)]
-# if 'X' in col or len(col) < how:
-# continue
-# init[0] += how
-
-
-# elif move[0] == 'N':
-# if init[0] - how < 0: # 북쪽으로 이동할 때 공원의 경계를 넘는지 확인
-# continue
-
-# col = [park[i][init[1]] for i in range(init[0] - how, init[0])]
-# if 'X' in col or len(col) < how:
-# continue
-# init[0] -= how
-
-
-
-
-
-
-# # 4. 이동
-
-# # 5. 최종 위치 반환
-# answer = []
-# return init
-
-def solution(park, routes):
- # 1. 초기 위치 찾기
- h, w = len(park), len(park[0])
- for i in range(h):
- for j in range(w):
- if park[i][j] == 'S':
- x, y = i, j
-
- # 2. 명령어 처리
- for route in routes:
- direction, distance = route.split()
- distance = int(distance)
-
- # 임시 위치 설정
- nx, ny = x, y
-
- # 이동 방향에 따른 좌표 변화 계산
- for _ in range(distance):
- if direction == 'E':
- ny += 1
- elif direction == 'W':
- ny -= 1
- elif direction == 'S':
- nx += 1
- elif direction == 'N':
- nx -= 1
-
- # 경계 초과 시 이동 중지
- if nx < 0 or ny < 0 or nx >= h or ny >= w or park[nx][ny] == 'X':
- nx, ny = x, y
- break
-
- # 이동이 가능한 경우 위치 업데이트
- if (nx, ny) != (x, y):
- x, y = nx, ny
-
- # 최종 위치 반환
- return [x, y]
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/README.md"
deleted file mode 100644
index 1aedf0c..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/README.md"
+++ /dev/null
@@ -1,84 +0,0 @@
-# [level 1] 폰켓몬 - 1845
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/1845)
-
-### 성능 요약
-
-메모리: 10.7 MB, 시간: 0.98 ms
-
-### 구분
-
-코딩테스트 연습 > 해시
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 11월 07일 09:11:16
-
-### 문제 설명
-
-당신은 폰켓몬을 잡기 위한 오랜 여행 끝에, 홍 박사님의 연구실에 도착했습니다. 홍 박사님은 당신에게 자신의 연구실에 있는 총 N 마리의 폰켓몬 중에서 N/2마리를 가져가도 좋다고 했습니다.
-홍 박사님 연구실의 폰켓몬은 종류에 따라 번호를 붙여 구분합니다. 따라서 같은 종류의 폰켓몬은 같은 번호를 가지고 있습니다. 예를 들어 연구실에 총 4마리의 폰켓몬이 있고, 각 폰켓몬의 종류 번호가 [3번, 1번, 2번, 3번]이라면 이는 3번 폰켓몬 두 마리, 1번 폰켓몬 한 마리, 2번 폰켓몬 한 마리가 있음을 나타냅니다. 이때, 4마리의 폰켓몬 중 2마리를 고르는 방법은 다음과 같이 6가지가 있습니다.
-
-
-- 첫 번째(3번), 두 번째(1번) 폰켓몬을 선택
-- 첫 번째(3번), 세 번째(2번) 폰켓몬을 선택
-- 첫 번째(3번), 네 번째(3번) 폰켓몬을 선택
-- 두 번째(1번), 세 번째(2번) 폰켓몬을 선택
-- 두 번째(1번), 네 번째(3번) 폰켓몬을 선택
-- 세 번째(2번), 네 번째(3번) 폰켓몬을 선택
-
-
-이때, 첫 번째(3번) 폰켓몬과 네 번째(3번) 폰켓몬을 선택하는 방법은 한 종류(3번 폰켓몬 두 마리)의 폰켓몬만 가질 수 있지만, 다른 방법들은 모두 두 종류의 폰켓몬을 가질 수 있습니다. 따라서 위 예시에서 가질 수 있는 폰켓몬 종류 수의 최댓값은 2가 됩니다.
-당신은 최대한 다양한 종류의 폰켓몬을 가지길 원하기 때문에, 최대한 많은 종류의 폰켓몬을 포함해서 N/2마리를 선택하려 합니다. N마리 폰켓몬의 종류 번호가 담긴 배열 nums가 매개변수로 주어질 때, N/2마리의 폰켓몬을 선택하는 방법 중, 가장 많은 종류의 폰켓몬을 선택하는 방법을 찾아, 그때의 폰켓몬 종류 번호의 개수를 return 하도록 solution 함수를 완성해주세요.
-
-제한사항
-
-
-- nums는 폰켓몬의 종류 번호가 담긴 1차원 배열입니다.
-- nums의 길이(N)는 1 이상 10,000 이하의 자연수이며, 항상 짝수로 주어집니다.
-- 폰켓몬의 종류 번호는 1 이상 200,000 이하의 자연수로 나타냅니다.
-- 가장 많은 종류의 폰켓몬을 선택하는 방법이 여러 가지인 경우에도, 선택할 수 있는 폰켓몬 종류 개수의 최댓값 하나만 return 하면 됩니다.
-
-
-
-
-입출력 예
-
-
-| nums |
-result |
-
-
-
-| [3,1,2,3] |
-2 |
-
-
-| [3,3,3,2,2,4] |
-3 |
-
-
-| [3,3,3,2,2,2] |
-2 |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-문제의 예시와 같습니다.
-
-입출력 예 #2
-6마리의 폰켓몬이 있으므로, 3마리의 폰켓몬을 골라야 합니다.
-가장 많은 종류의 폰켓몬을 고르기 위해서는 3번 폰켓몬 한 마리, 2번 폰켓몬 한 마리, 4번 폰켓몬 한 마리를 고르면 되며, 따라서 3을 return 합니다.
-
-입출력 예 #3
-6마리의 폰켓몬이 있으므로, 3마리의 폰켓몬을 골라야 합니다.
-가장 많은 종류의 폰켓몬을 고르기 위해서는 3번 폰켓몬 한 마리와 2번 폰켓몬 두 마리를 고르거나, 혹은 3번 폰켓몬 두 마리와 2번 폰켓몬 한 마리를 고르면 됩니다. 따라서 최대 고를 수 있는 폰켓몬 종류의 수는 2입니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/\355\217\260\354\274\223\353\252\254.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/\355\217\260\354\274\223\353\252\254.py"
deleted file mode 100644
index 98710c1..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/1845.\342\200\205\355\217\260\354\274\223\353\252\254/\355\217\260\354\274\223\353\252\254.py"
+++ /dev/null
@@ -1,8 +0,0 @@
-from collections import Counter
-
-def solution(nums):
- counter = Counter(nums)
- answer = min(len(counter), len(nums) // 2)
-
-
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/README.md"
deleted file mode 100644
index d4b34cf..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/README.md"
+++ /dev/null
@@ -1,77 +0,0 @@
-# [level 1] 완주하지 못한 선수 - 42576
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42576)
-
-### 성능 요약
-
-메모리: 39 MB, 시간: 66.19 ms
-
-### 구분
-
-코딩테스트 연습 > 해시
-
-### 채점결과
-
-정확성: 58.3
효율성: 41.7
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 11월 08일 10:02:51
-
-### 문제 설명
-
-수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다.
-
-마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수들의 이름이 담긴 배열 completion이 주어질 때, 완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성해주세요.
-
-제한사항
-
-
-- 마라톤 경기에 참여한 선수의 수는 1명 이상 100,000명 이하입니다.
-- completion의 길이는 participant의 길이보다 1 작습니다.
-- 참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있습니다.
-- 참가자 중에는 동명이인이 있을 수 있습니다.
-
-
-입출력 예
-
-
-| participant |
-completion |
-return |
-
-
-
-| ["leo", "kiki", "eden"] |
-["eden", "kiki"] |
-"leo" |
-
-
-| ["marina", "josipa", "nikola", "vinko", "filipa"] |
-["josipa", "filipa", "marina", "nikola"] |
-"vinko" |
-
-
-| ["mislav", "stanko", "mislav", "ana"] |
-["stanko", "ana", "mislav"] |
-"mislav" |
-
-
-
-입출력 예 설명
-
-예제 #1
-"leo"는 참여자 명단에는 있지만, 완주자 명단에는 없기 때문에 완주하지 못했습니다.
-
-예제 #2
-"vinko"는 참여자 명단에는 있지만, 완주자 명단에는 없기 때문에 완주하지 못했습니다.
-
-예제 #3
-"mislav"는 참여자 명단에는 두 명이 있지만, 완주자 명단에는 한 명밖에 없기 때문에 한명은 완주하지 못했습니다.
-
-
-
-※ 공지 - 2023년 01월 25일 테스트케이스가 추가되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230.py"
deleted file mode 100644
index 67f4a56..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42576.\342\200\205\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230/\354\231\204\354\243\274\355\225\230\354\247\200\342\200\205\353\252\273\355\225\234\342\200\205\354\204\240\354\210\230.py"
+++ /dev/null
@@ -1,18 +0,0 @@
-from collections import Counter
-
-def solution(participant, completion):
-
- remaining = Counter(participant) - Counter(completion)
- # print(list(remaining.keys())[0])
- answer = str(list(remaining.keys())[0])
- return answer
-# ps = Counter(participant)
-# cs = Counter(completion)
-
-# for p in ps:
-# if p in cs:
-# ps[p] -= 1
-
-# for k, v in ps.items():
-# if v != 0 :
-# return k
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/README.md"
deleted file mode 100644
index 77994be..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/README.md"
+++ /dev/null
@@ -1,75 +0,0 @@
-# [level 1] 모의고사 - 42840
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42840)
-
-### 성능 요약
-
-메모리: 10.5 MB, 시간: 12.02 ms
-
-### 구분
-
-코딩테스트 연습 > 완전탐색
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 05일 12:18:23
-
-### 문제 설명
-
-수포자는 수학을 포기한 사람의 준말입니다. 수포자 삼인방은 모의고사에 수학 문제를 전부 찍으려 합니다. 수포자는 1번 문제부터 마지막 문제까지 다음과 같이 찍습니다.
-
-1번 수포자가 찍는 방식: 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, ...
-2번 수포자가 찍는 방식: 2, 1, 2, 3, 2, 4, 2, 5, 2, 1, 2, 3, 2, 4, 2, 5, ...
-3번 수포자가 찍는 방식: 3, 3, 1, 1, 2, 2, 4, 4, 5, 5, 3, 3, 1, 1, 2, 2, 4, 4, 5, 5, ...
-
-1번 문제부터 마지막 문제까지의 정답이 순서대로 들은 배열 answers가 주어졌을 때, 가장 많은 문제를 맞힌 사람이 누구인지 배열에 담아 return 하도록 solution 함수를 작성해주세요.
-
-제한 조건
-
-
-- 시험은 최대 10,000 문제로 구성되어있습니다.
-- 문제의 정답은 1, 2, 3, 4, 5중 하나입니다.
-- 가장 높은 점수를 받은 사람이 여럿일 경우, return하는 값을 오름차순 정렬해주세요.
-
-
-입출력 예
-
-
-| answers |
-return |
-
-
-
-| [1,2,3,4,5] |
-[1] |
-
-
-| [1,3,2,4,2] |
-[1,2,3] |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-
-- 수포자 1은 모든 문제를 맞혔습니다.
-- 수포자 2는 모든 문제를 틀렸습니다.
-- 수포자 3은 모든 문제를 틀렸습니다.
-
-
-따라서 가장 문제를 많이 맞힌 사람은 수포자 1입니다.
-
-입출력 예 #2
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/\353\252\250\354\235\230\352\263\240\354\202\254.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/\353\252\250\354\235\230\352\263\240\354\202\254.py"
deleted file mode 100644
index 3fa572b..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/42840.\342\200\205\353\252\250\354\235\230\352\263\240\354\202\254/\353\252\250\354\235\230\352\263\240\354\202\254.py"
+++ /dev/null
@@ -1,51 +0,0 @@
-def solution(answers):
- first, second, third = [], [], []
-
- first_pattern = [1, 2, 3, 4, 5]
- second_pattern = [2, 1, 2, 3, 2, 4, 2, 5]
- third_pattern = [3, 3, 1, 1, 2, 2, 4, 4, 5, 5]
-
- i = 0
- f = 0
- s = 0
- t = 0
- while len(answers) > i:
- first.append(first_pattern[f])
- if len(first_pattern) -1 > f:
- f += 1
- else:
- f = 0
-
- second.append(second_pattern[s])
- if len(second_pattern) -1 > s:
- s += 1
- else:
- s = 0
-
- third.append(third_pattern[t])
- if len(third_pattern) -1 > t:
- t += 1
- else:
- t = 0
- i += 1
-
- correct_f = 0
- correct_s = 0
- correct_t = 0
- for i in range(len(answers) ):
- if first[i] == answers[i]:
- correct_f += 1
- if second[i] == answers[i]:
- correct_s += 1
- if third[i] == answers[i]:
- correct_t += 1
-
- answer = []
- max_value = max(correct_f,correct_s,correct_t)
- if max_value == correct_f:
- answer.append(1)
- if max_value == correct_s:
- answer.append(2)
- if max_value == correct_t:
- answer.append(3)
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/README.md"
deleted file mode 100644
index a9fbf2c..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/README.md"
+++ /dev/null
@@ -1,160 +0,0 @@
-# [level 1] 숫자 문자열과 영단어 - 81301
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/81301?language=python3)
-
-### 성능 요약
-
-메모리: 10.3 MB, 시간: 0.03 ms
-
-### 구분
-
-코딩테스트 연습 > 2021 카카오 채용연계형 인턴십
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 10월 31일 21:02:24
-
-### 문제 설명
-
-
-
-네오와 프로도가 숫자놀이를 하고 있습니다. 네오가 프로도에게 숫자를 건넬 때 일부 자릿수를 영단어로 바꾼 카드를 건네주면 프로도는 원래 숫자를 찾는 게임입니다.
-다음은 숫자의 일부 자릿수를 영단어로 바꾸는 예시입니다.
-
-
-- 1478 → "one4seveneight"
-- 234567 → "23four5six7"
-- 10203 → "1zerotwozero3"
-
-
-이렇게 숫자의 일부 자릿수가 영단어로 바뀌어졌거나, 혹은 바뀌지 않고 그대로인 문자열 s가 매개변수로 주어집니다. s가 의미하는 원래 숫자를 return 하도록 solution 함수를 완성해주세요.
-
-참고로 각 숫자에 대응되는 영단어는 다음 표와 같습니다.
-
-
-| 숫자 |
-영단어 |
-
-
-
-| 0 |
-zero |
-
-
-| 1 |
-one |
-
-
-| 2 |
-two |
-
-
-| 3 |
-three |
-
-
-| 4 |
-four |
-
-
-| 5 |
-five |
-
-
-| 6 |
-six |
-
-
-| 7 |
-seven |
-
-
-| 8 |
-eight |
-
-
-| 9 |
-nine |
-
-
-
-
-
-제한사항
-
-
-- 1 ≤
s의 길이 ≤ 50
-s가 "zero" 또는 "0"으로 시작하는 경우는 주어지지 않습니다.- return 값이 1 이상 2,000,000,000 이하의 정수가 되는 올바른 입력만
s로 주어집니다.
-
-
-
-
-입출력 예
-
-
-| s |
-result |
-
-
-
-"one4seveneight" |
-1478 |
-
-
-"23four5six7" |
-234567 |
-
-
-"2three45sixseven" |
-234567 |
-
-
-"123" |
-123 |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-
-
-입출력 예 #2
-
-
-
-입출력 예 #3
-
-
-- "three"는 3, "six"는 6, "seven"은 7에 대응되기 때문에 정답은 입출력 예 #2와 같은 234567이 됩니다.
-- 입출력 예 #2와 #3과 같이 같은 정답을 가리키는 문자열이 여러 가지가 나올 수 있습니다.
-
-
-입출력 예 #4
-
-
-
-
-
-제한시간 안내
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264.py"
deleted file mode 100644
index 197c255..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/81301.\342\200\205\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264/\354\210\253\354\236\220\342\200\205\353\254\270\354\236\220\354\227\264\352\263\274\342\200\205\354\230\201\353\213\250\354\226\264.py"
+++ /dev/null
@@ -1,24 +0,0 @@
-def solution(s):
- dict = {"zero" : "0", "one" : "1", "two" : "2", "three" : "3", "four" : "4", "five" : "5", "six" : "6", "seven" : "7", "eight" : "8", "nine" : "9" }
- result = ""
- word = ""
-
- for i, c in enumerate(s):
- if c.isdigit() : #숫자라면
- # print(c)
- result += c
- continue
- else : # 문자라면
- word += c
- # print(c)
- # print(word)
- if word in dict:
- # print(dict[word])
- result += dict[word]
- word = ""
- return int(result)
-
-
-# 1. 이 문제는 운이좋겠도 인덱스와 숫자가 동일해서 list로 해도 충분이 가능함
-# 2. replace()로 충분히 가능함
-# 3. defaultdict 도 한번 살펴보자!
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/README.md"
deleted file mode 100644
index 894f2df..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/README.md"
+++ /dev/null
@@ -1,111 +0,0 @@
-# [level 1] 최소직사각형 - 86491
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/86491)
-
-### 성능 요약
-
-메모리: 11.6 MB, 시간: 4.21 ms
-
-### 구분
-
-코딩테스트 연습 > 완전탐색
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 07일 08:44:27
-
-### 문제 설명
-
-명함 지갑을 만드는 회사에서 지갑의 크기를 정하려고 합니다. 다양한 모양과 크기의 명함들을 모두 수납할 수 있으면서, 작아서 들고 다니기 편한 지갑을 만들어야 합니다. 이러한 요건을 만족하는 지갑을 만들기 위해 디자인팀은 모든 명함의 가로 길이와 세로 길이를 조사했습니다.
-
-아래 표는 4가지 명함의 가로 길이와 세로 길이를 나타냅니다.
-
-
-| 명함 번호 |
-가로 길이 |
-세로 길이 |
-
-
-
-| 1 |
-60 |
-50 |
-
-
-| 2 |
-30 |
-70 |
-
-
-| 3 |
-60 |
-30 |
-
-
-| 4 |
-80 |
-40 |
-
-
-
-가장 긴 가로 길이와 세로 길이가 각각 80, 70이기 때문에 80(가로) x 70(세로) 크기의 지갑을 만들면 모든 명함들을 수납할 수 있습니다. 하지만 2번 명함을 가로로 눕혀 수납한다면 80(가로) x 50(세로) 크기의 지갑으로 모든 명함들을 수납할 수 있습니다. 이때의 지갑 크기는 4000(=80 x 50)입니다.
-
-모든 명함의 가로 길이와 세로 길이를 나타내는 2차원 배열 sizes가 매개변수로 주어집니다. 모든 명함을 수납할 수 있는 가장 작은 지갑을 만들 때, 지갑의 크기를 return 하도록 solution 함수를 완성해주세요.
-
-
-
-제한사항
-
-
-- sizes의 길이는 1 이상 10,000 이하입니다.
-
-
-- sizes의 원소는 [w, h] 형식입니다.
-- w는 명함의 가로 길이를 나타냅니다.
-- h는 명함의 세로 길이를 나타냅니다.
-- w와 h는 1 이상 1,000 이하인 자연수입니다.
-
-
-
-
-
-입출력 예
-
-
-| sizes |
-result |
-
-
-
-| [[60, 50], [30, 70], [60, 30], [80, 40]] |
-4000 |
-
-
-| [[10, 7], [12, 3], [8, 15], [14, 7], [5, 15]] |
-120 |
-
-
-| [[14, 4], [19, 6], [6, 16], [18, 7], [7, 11]] |
-133 |
-
-
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-문제 예시와 같습니다.
-
-입출력 예 #2
-명함들을 적절히 회전시켜 겹쳤을 때, 3번째 명함(가로: 8, 세로: 15)이 다른 모든 명함보다 크기가 큽니다. 따라서 지갑의 크기는 3번째 명함의 크기와 같으며, 120(=8 x 15)을 return 합니다.
-
-입출력 예 #3
-명함들을 적절히 회전시켜 겹쳤을 때, 모든 명함을 포함하는 가장 작은 지갑의 크기는 133(=19 x 7)입니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225.py"
deleted file mode 100644
index 40feb2b..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/1/86491.\342\200\205\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225/\354\265\234\354\206\214\354\247\201\354\202\254\352\260\201\355\230\225.py"
+++ /dev/null
@@ -1,12 +0,0 @@
-def solution(sizes):
- big, small = [], []
-
- for size in sizes:
- # for i in range(len(size)):
- big.append(max(size))
- small.append(min(size))
-
- # 큰값과 작은 값 각각 도출하기
- bob = max(big)
- sob = max(small)
- return bob * sob
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/README.md"
deleted file mode 100644
index fa127a8..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/README.md"
+++ /dev/null
@@ -1,72 +0,0 @@
-# [level 2] 올바른 괄호 - 12909
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/12909)
-
-### 성능 요약
-
-메모리: 10.4 MB, 시간: 13.23 ms
-
-### 구분
-
-코딩테스트 연습 > 스택/큐
-
-### 채점결과
-
-정확성: 69.5
효율성: 30.5
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 07월 29일 15:44:39
-
-### 문제 설명
-
-괄호가 바르게 짝지어졌다는 것은 '(' 문자로 열렸으면 반드시 짝지어서 ')' 문자로 닫혀야 한다는 뜻입니다. 예를 들어
-
-
-- "()()" 또는 "(())()" 는 올바른 괄호입니다.
-- ")()(" 또는 "(()(" 는 올바르지 않은 괄호입니다.
-
-
-'(' 또는 ')' 로만 이루어진 문자열 s가 주어졌을 때, 문자열 s가 올바른 괄호이면 true를 return 하고, 올바르지 않은 괄호이면 false를 return 하는 solution 함수를 완성해 주세요.
-
-제한사항
-
-
-- 문자열 s의 길이 : 100,000 이하의 자연수
-- 문자열 s는 '(' 또는 ')' 로만 이루어져 있습니다.
-
-
-
-
-입출력 예
-
-
-| s |
-answer |
-
-
-
-| "()()" |
-true |
-
-
-| "(())()" |
-true |
-
-
-| ")()(" |
-false |
-
-
-| "(()(" |
-false |
-
-
-
-입출력 예 설명
-
-입출력 예 #1,2,3,4
-문제의 예시와 같습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270.py"
deleted file mode 100644
index 402f24d..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/12909.\342\200\205\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270/\354\230\254\353\260\224\353\245\270\342\200\205\352\264\204\355\230\270.py"
+++ /dev/null
@@ -1,22 +0,0 @@
-def solution(s):
- buffer = []
-
- for i in range(len(s)):
- if i == 0 and s[i] == ')':
- return False
-
- if s[i] == '(' :
- buffer.append('(')
- else :
- if len(buffer) == 0:
- return False
- else:
- buffer.pop()
-
- if len(buffer) == 0:
- return True
- else :
- return False
-
-
-
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/README.md"
deleted file mode 100644
index 527e485..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/README.md"
+++ /dev/null
@@ -1,84 +0,0 @@
-# [level 2] 전화번호 목록 - 42577
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42577)
-
-### 성능 요약
-
-메모리: 28 MB, 시간: 98.12 ms
-
-### 구분
-
-코딩테스트 연습 > 해시
-
-### 채점결과
-
-정확성: 83.3
효율성: 16.7
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 20일 22:09:33
-
-### 문제 설명
-
-전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.
-전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.
-
-
-- 구조대 : 119
-- 박준영 : 97 674 223
-- 지영석 : 11 9552 4421
-
-
-전화번호부에 적힌 전화번호를 담은 배열 phone_book 이 solution 함수의 매개변수로 주어질 때, 어떤 번호가 다른 번호의 접두어인 경우가 있으면 false를 그렇지 않으면 true를 return 하도록 solution 함수를 작성해주세요.
-
-제한 사항
-
-
-- phone_book의 길이는 1 이상 1,000,000 이하입니다.
-
-
-- 각 전화번호의 길이는 1 이상 20 이하입니다.
-- 같은 전화번호가 중복해서 들어있지 않습니다.
-
-
-
-입출력 예제
-
-
-| phone_book |
-return |
-
-
-
-| ["119", "97674223", "1195524421"] |
-false |
-
-
-| ["123","456","789"] |
-true |
-
-
-| ["12","123","1235","567","88"] |
-false |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-앞에서 설명한 예와 같습니다.
-
-입출력 예 #2
-한 번호가 다른 번호의 접두사인 경우가 없으므로, 답은 true입니다.
-
-입출력 예 #3
-첫 번째 전화번호, “12”가 두 번째 전화번호 “123”의 접두사입니다. 따라서 답은 false입니다.
-
-
-
-알림
-
-2021년 3월 4일, 테스트 케이스가 변경되었습니다. 이로 인해 이전에 통과하던 코드가 더 이상 통과하지 않을 수 있습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235.py"
deleted file mode 100644
index 202e010..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42577.\342\200\205\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235/\354\240\204\355\231\224\353\262\210\355\230\270\342\200\205\353\252\251\353\241\235.py"
+++ /dev/null
@@ -1,14 +0,0 @@
-def solution(phone_book):
- phone_book.sort()
- result = True
-
- # for phone in phone_book:
- # for phone_v in phone_book:
- # if (phone != phone_v) and (len(phone) < len(phone_v)):
- # return phone_v.startswith(phone)
-
- for i in range(len(phone_book) - 1):
- if phone_book[i+1].startswith(phone_book[i]):
- return False
-
- return result
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/README.md"
deleted file mode 100644
index 2519710..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/README.md"
+++ /dev/null
@@ -1,108 +0,0 @@
-# [level 2] 의상 - 42578
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42578)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.01 ms
-
-### 구분
-
-코딩테스트 연습 > 해시
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 21일 23:53:35
-
-### 문제 설명
-
-코니는 매일 다른 옷을 조합하여 입는것을 좋아합니다.
-
-예를 들어 코니가 가진 옷이 아래와 같고, 오늘 코니가 동그란 안경, 긴 코트, 파란색 티셔츠를 입었다면 다음날은 청바지를 추가로 입거나 동그란 안경 대신 검정 선글라스를 착용하거나 해야합니다.
-
-
-| 종류 |
-이름 |
-
-
-
-| 얼굴 |
-동그란 안경, 검정 선글라스 |
-
-
-| 상의 |
-파란색 티셔츠 |
-
-
-| 하의 |
-청바지 |
-
-
-| 겉옷 |
-긴 코트 |
-
-
-
-
-- 코니는 각 종류별로 최대 1가지 의상만 착용할 수 있습니다. 예를 들어 위 예시의 경우 동그란 안경과 검정 선글라스를 동시에 착용할 수는 없습니다.
-- 착용한 의상의 일부가 겹치더라도, 다른 의상이 겹치지 않거나, 혹은 의상을 추가로 더 착용한 경우에는 서로 다른 방법으로 옷을 착용한 것으로 계산합니다.
-- 코니는 하루에 최소 한 개의 의상은 입습니다.
-
-
-코니가 가진 의상들이 담긴 2차원 배열 clothes가 주어질 때 서로 다른 옷의 조합의 수를 return 하도록 solution 함수를 작성해주세요.
-
-
-
-제한사항
-
-
-- clothes의 각 행은 [의상의 이름, 의상의 종류]로 이루어져 있습니다.
-- 코니가 가진 의상의 수는 1개 이상 30개 이하입니다.
-- 같은 이름을 가진 의상은 존재하지 않습니다.
-- clothes의 모든 원소는 문자열로 이루어져 있습니다.
-- 모든 문자열의 길이는 1 이상 20 이하인 자연수이고 알파벳 소문자 또는 '_' 로만 이루어져 있습니다.
-
-
-입출력 예
-
-
-| clothes |
-return |
-
-
-
-| [["yellow_hat", "headgear"], ["blue_sunglasses", "eyewear"], ["green_turban", "headgear"]] |
-5 |
-
-
-| [["crow_mask", "face"], ["blue_sunglasses", "face"], ["smoky_makeup", "face"]] |
-3 |
-
-
-
-입출력 예 설명
-
-예제 #1
-headgear에 해당하는 의상이 yellow_hat, green_turban이고 eyewear에 해당하는 의상이 blue_sunglasses이므로 아래와 같이 5개의 조합이 가능합니다.
-1. yellow_hat
-2. blue_sunglasses
-3. green_turban
-4. yellow_hat + blue_sunglasses
-5. green_turban + blue_sunglasses
-
예제 #2
-face에 해당하는 의상이 crow_mask, blue_sunglasses, smoky_makeup이므로 아래와 같이 3개의 조합이 가능합니다.
-1. crow_mask
-2. blue_sunglasses
-3. smoky_makeup
-
-
-※ 공지 - 2023년 4월 21일 문제 지문이 리뉴얼되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/\354\235\230\354\203\201.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/\354\235\230\354\203\201.py"
deleted file mode 100644
index 310a63c..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42578.\342\200\205\354\235\230\354\203\201/\354\235\230\354\203\201.py"
+++ /dev/null
@@ -1,22 +0,0 @@
-def solution(clothes):
- answer = 0
-
- dict = {}
- for clothe in clothes:
- kind = clothe[1]
-
- # 조건문으로 분기 시켜주어야함
- if kind in dict:
- dict[kind] += 1
- else:
- dict[kind] = 1
-
-
- comb = 1
- for count in dict.values():
- comb *= (count + 1) # 종류별 옷 선택 X 경우도 포함 + 1
-
- answer = comb - 1 # 아무것도 선택하지 않은경우 제외
-
-
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/README.md"
deleted file mode 100644
index d0fe059..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/README.md"
+++ /dev/null
@@ -1,75 +0,0 @@
-# [level 2] 기능개발 - 42586
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42586)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.01 ms
-
-### 구분
-
-코딩테스트 연습 > 스택/큐
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 23일 00:01:04
-
-### 문제 설명
-
-프로그래머스 팀에서는 기능 개선 작업을 수행 중입니다. 각 기능은 진도가 100%일 때 서비스에 반영할 수 있습니다.
-
-또, 각 기능의 개발속도는 모두 다르기 때문에 뒤에 있는 기능이 앞에 있는 기능보다 먼저 개발될 수 있고, 이때 뒤에 있는 기능은 앞에 있는 기능이 배포될 때 함께 배포됩니다.
-
-먼저 배포되어야 하는 순서대로 작업의 진도가 적힌 정수 배열 progresses와 각 작업의 개발 속도가 적힌 정수 배열 speeds가 주어질 때 각 배포마다 몇 개의 기능이 배포되는지를 return 하도록 solution 함수를 완성하세요.
-
-제한 사항
-
-
-- 작업의 개수(progresses, speeds배열의 길이)는 100개 이하입니다.
-- 작업 진도는 100 미만의 자연수입니다.
-- 작업 속도는 100 이하의 자연수입니다.
-- 배포는 하루에 한 번만 할 수 있으며, 하루의 끝에 이루어진다고 가정합니다. 예를 들어 진도율이 95%인 작업의 개발 속도가 하루에 4%라면 배포는 2일 뒤에 이루어집니다.
-
-
-입출력 예
-
-
-| progresses |
-speeds |
-return |
-
-
-
-| [93, 30, 55] |
-[1, 30, 5] |
-[2, 1] |
-
-
-| [95, 90, 99, 99, 80, 99] |
-[1, 1, 1, 1, 1, 1] |
-[1, 3, 2] |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-첫 번째 기능은 93% 완료되어 있고 하루에 1%씩 작업이 가능하므로 7일간 작업 후 배포가 가능합니다.
-두 번째 기능은 30%가 완료되어 있고 하루에 30%씩 작업이 가능하므로 3일간 작업 후 배포가 가능합니다. 하지만 이전 첫 번째 기능이 아직 완성된 상태가 아니기 때문에 첫 번째 기능이 배포되는 7일째 배포됩니다.
-세 번째 기능은 55%가 완료되어 있고 하루에 5%씩 작업이 가능하므로 9일간 작업 후 배포가 가능합니다.
-
-따라서 7일째에 2개의 기능, 9일째에 1개의 기능이 배포됩니다.
-
-입출력 예 #2
-모든 기능이 하루에 1%씩 작업이 가능하므로, 작업이 끝나기까지 남은 일수는 각각 5일, 10일, 1일, 1일, 20일, 1일입니다. 어떤 기능이 먼저 완성되었더라도 앞에 있는 모든 기능이 완성되지 않으면 배포가 불가능합니다.
-
-따라서 5일째에 1개의 기능, 10일째에 3개의 기능, 20일째에 2개의 기능이 배포됩니다.
-
-※ 공지 - 2020년 7월 14일 테스트케이스가 추가되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/\352\270\260\353\212\245\352\260\234\353\260\234.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/\352\270\260\353\212\245\352\260\234\353\260\234.py"
deleted file mode 100644
index 8cbf159..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42586.\342\200\205\352\270\260\353\212\245\352\260\234\353\260\234/\352\270\260\353\212\245\352\260\234\353\260\234.py"
+++ /dev/null
@@ -1,26 +0,0 @@
-def solution(progresses, speeds):
- answer = []
-
- left_days = []
- for progress, speed in zip(progresses, speeds):
- for i in range(100):
- left_day = progress + (i * speed)
- if left_day >= 100:
- left_days.append(i) # 변수 제대로 넣자
- break
-
- tmp = left_days[0] # 처음 것
- count = 1
- for day in left_days[1:]:
-
- # max_value = max(day, tmp) #완료 날짜될 날짜와 앞 날짜 비교
- if day <= tmp: # 앞날짜가 여전히 더 클 때
- count += 1
- else : # 앞 날짜가 더 적을 때
- answer.append(count)
- tmp = day
- count = 1
-
- answer.append(count)
-
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/README.md"
deleted file mode 100644
index 5d2c6c5..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/README.md"
+++ /dev/null
@@ -1,86 +0,0 @@
-# [level 2] 프로세스 - 42587
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42587)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.64 ms
-
-### 구분
-
-코딩테스트 연습 > 스택/큐
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 08월 18일 21:52:43
-
-### 문제 설명
-
-운영체제의 역할 중 하나는 컴퓨터 시스템의 자원을 효율적으로 관리하는 것입니다. 이 문제에서는 운영체제가 다음 규칙에 따라 프로세스를 관리할 경우 특정 프로세스가 몇 번째로 실행되는지 알아내면 됩니다.
-1. 실행 대기 큐(Queue)에서 대기중인 프로세스 하나를 꺼냅니다.
-2. 큐에 대기중인 프로세스 중 우선순위가 더 높은 프로세스가 있다면 방금 꺼낸 프로세스를 다시 큐에 넣습니다.
-3. 만약 그런 프로세스가 없다면 방금 꺼낸 프로세스를 실행합니다.
- 3.1 한 번 실행한 프로세스는 다시 큐에 넣지 않고 그대로 종료됩니다.
-
예를 들어 프로세스 4개 [A, B, C, D]가 순서대로 실행 대기 큐에 들어있고, 우선순위가 [2, 1, 3, 2]라면 [C, D, A, B] 순으로 실행하게 됩니다.
-
-현재 실행 대기 큐(Queue)에 있는 프로세스의 중요도가 순서대로 담긴 배열 priorities와, 몇 번째로 실행되는지 알고싶은 프로세스의 위치를 알려주는 location이 매개변수로 주어질 때, 해당 프로세스가 몇 번째로 실행되는지 return 하도록 solution 함수를 작성해주세요.
-
-
-
-제한사항
-
-
-priorities의 길이는 1 이상 100 이하입니다.
-
-
-priorities의 원소는 1 이상 9 이하의 정수입니다.priorities의 원소는 우선순위를 나타내며 숫자가 클 수록 우선순위가 높습니다.
location은 0 이상 (대기 큐에 있는 프로세스 수 - 1) 이하의 값을 가집니다.
-
-
-priorities의 가장 앞에 있으면 0, 두 번째에 있으면 1 … 과 같이 표현합니다.
-
-입출력 예
-
-
-| priorities |
-location |
-return |
-
-
-
-| [2, 1, 3, 2] |
-2 |
-1 |
-
-
-| [1, 1, 9, 1, 1, 1] |
-0 |
-5 |
-
-
-
-입출력 예 설명
-
-예제 #1
-
-문제에 나온 예와 같습니다.
-
-예제 #2
-
-6개의 프로세스 [A, B, C, D, E, F]가 대기 큐에 있고 중요도가 [1, 1, 9, 1, 1, 1] 이므로 [C, D, E, F, A, B] 순으로 실행됩니다. 따라서 A는 5번째로 실행됩니다.
-
-
-
-※ 공지 - 2023년 4월 21일 문제 지문이 리뉴얼되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/\355\224\204\353\241\234\354\204\270\354\212\244.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/\355\224\204\353\241\234\354\204\270\354\212\244.py"
deleted file mode 100644
index 75d1416..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42587.\342\200\205\355\224\204\353\241\234\354\204\270\354\212\244/\355\224\204\353\241\234\354\204\270\354\212\244.py"
+++ /dev/null
@@ -1,37 +0,0 @@
-from collections import deque
-
-def solution(priorities, location):
- answer = 0
- queue = deque()
-
- p = 0
- for prioritie in priorities:
- queue.append((p,prioritie))
- p += 1
-
- while queue :
- ps = queue.popleft()
-
- # 우선순위가 더 높은 프로세스가 있는지 확인
- if any(ps[1] < q[1] for q in queue):
- queue.append(ps)
- else :
- answer += 1
- if ps[0] == location:
- return answer
-
- # while queue :
- # ps = queue.popleft()
- # for i in range(len(queue)):
- # # if ps[1] >= queue[i][1]: # 내가 가장 크면
- # if ps[1] >= queue[i][1]: # 내가 가장 크면
- # print(i)
- # print(ps[1], queue[i][1])
- # answer += 1
- # if ps[0] == location:
- # return answer
- # continue # 프로세스 실행
- # # 다른게 더 크면
- # queue.append(ps) # 큐에 다시 넣기
-
- return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/README.md"
deleted file mode 100644
index 10ac333..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/README.md"
+++ /dev/null
@@ -1,72 +0,0 @@
-# [level 2] 더 맵게 - 42626
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42626)
-
-### 성능 요약
-
-메모리: 51.7 MB, 시간: 1748.42 ms
-
-### 구분
-
-코딩테스트 연습 > 힙(Heap)
-
-### 채점결과
-
-정확성: 83.9
효율성: 16.1
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 11월 22일 08:55:30
-
-### 문제 설명
-
-매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같이 특별한 방법으로 섞어 새로운 음식을 만듭니다.
-섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
-
Leo는 모든 음식의 스코빌 지수가 K 이상이 될 때까지 반복하여 섞습니다.
-Leo가 가진 음식의 스코빌 지수를 담은 배열 scoville과 원하는 스코빌 지수 K가 주어질 때, 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 섞어야 하는 최소 횟수를 return 하도록 solution 함수를 작성해주세요.
-
-제한 사항
-
-
-- scoville의 길이는 2 이상 1,000,000 이하입니다.
-- K는 0 이상 1,000,000,000 이하입니다.
-- scoville의 원소는 각각 0 이상 1,000,000 이하입니다.
-- 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다.
-
-
-입출력 예
-
-
-| scoville |
-K |
-return |
-
-
-
-| [1, 2, 3, 9, 10, 12] |
-7 |
-2 |
-
-
-
-입출력 예 설명
-
-
-스코빌 지수가 1인 음식과 2인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
-새로운 음식의 스코빌 지수 = 1 + (2 * 2) = 5
-가진 음식의 스코빌 지수 = [5, 3, 9, 10, 12]
스코빌 지수가 3인 음식과 5인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다.
-새로운 음식의 스코빌 지수 = 3 + (5 * 2) = 13
-가진 음식의 스코빌 지수 = [13, 9, 10, 12]
-
-모든 음식의 스코빌 지수가 7 이상이 되었고 이때 섞은 횟수는 2회입니다.
-
-
-
-※ 공지 - 2022년 12월 23일 테스트 케이스가 추가되었습니다. 기존에 제출한 코드가 통과하지 못할 수도 있습니다.
-※ 공지 - 2023년 03월 23일 테스트 케이스가 추가되었습니다. 기존에 제출한 코드가 통과하지 못할 수도 있습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/\353\215\224\342\200\205\353\247\265\352\262\214.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/\353\215\224\342\200\205\353\247\265\352\262\214.py"
deleted file mode 100644
index c20fc5d..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42626.\342\200\205\353\215\224\342\200\205\353\247\265\352\262\214/\353\215\224\342\200\205\353\247\265\352\262\214.py"
+++ /dev/null
@@ -1,21 +0,0 @@
-import heapq
-def solution(scoville, K):
- count = 0
- # 1. scoville 을 heapify
- heapq.heapify(scoville)
-
- # 2. while 반복문 "scoville최솟값[0]" <= "K" 일때 True
- while scoville[0] < K:
- if len(scoville) <= 1:
- count = -1
- break
- # 2-1. heappop 두번
- least = heapq.heappop(scoville)
- pre_least = heapq.heappop(scoville)
- # 2-2. 두개 값 연산 (최저 + (두번째 최저 * 2))
- new_scoville = least + (pre_least * 2)
- # 2-3. heappush
- heapq.heappush(scoville, new_scoville) # 늘 무조건 push 되어야함
- count += 1
-
- return count
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/README.md"
deleted file mode 100644
index 86eafaa..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/README.md"
+++ /dev/null
@@ -1,59 +0,0 @@
-# [level 2] 가장 큰 수 - 42746
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42746)
-
-### 성능 요약
-
-메모리: 10.2 MB, 시간: 0.02 ms
-
-### 구분
-
-코딩테스트 연습 > 정렬
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 26일 23:42:19
-
-### 문제 설명
-
-0 또는 양의 정수가 주어졌을 때, 정수를 이어 붙여 만들 수 있는 가장 큰 수를 알아내 주세요.
-
-예를 들어, 주어진 정수가 [6, 10, 2]라면 [6102, 6210, 1062, 1026, 2610, 2106]를 만들 수 있고, 이중 가장 큰 수는 6210입니다.
-
-0 또는 양의 정수가 담긴 배열 numbers가 매개변수로 주어질 때, 순서를 재배치하여 만들 수 있는 가장 큰 수를 문자열로 바꾸어 return 하도록 solution 함수를 작성해주세요.
-
-제한 사항
-
-
-- numbers의 길이는 1 이상 100,000 이하입니다.
-- numbers의 원소는 0 이상 1,000 이하입니다.
-- 정답이 너무 클 수 있으니 문자열로 바꾸어 return 합니다.
-
-
-입출력 예
-
-
-| numbers |
-return |
-
-
-
-| [6, 10, 2] |
-"6210" |
-
-
-| [3, 30, 34, 5, 9] |
-"9534330" |
-
-
-
-
-
-※ 공지 - 2021년 10월 20일 테스트케이스가 추가되었습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230.py"
deleted file mode 100644
index a214200..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42746.\342\200\205\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230/\352\260\200\354\236\245\342\200\205\355\201\260\342\200\205\354\210\230.py"
+++ /dev/null
@@ -1,15 +0,0 @@
-from functools import cmp_to_key
-
-def solution(numbers):
- numbers = list(map(str, numbers))
-
- numbers.sort(key=cmp_to_key
- (lambda a, b :
- (1 if a + b < b + a else
- -1 if a + b > b + a else 0)))
-
- return str(int(''.join(numbers)))
-
-
- # answer = ''
- # return answer
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/H\357\274\215Index.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/H\357\274\215Index.py"
deleted file mode 100644
index de68c24..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/H\357\274\215Index.py"
+++ /dev/null
@@ -1,14 +0,0 @@
-# key 해당 value 보다 뒤에 남은 인자의 갯수비교
-
-def solution(citations):
- # 1. 정렬
- citations.sort(reverse = True)
- h = 0
- # 2. 현재 citation 의 값과 자기 포함 뒤에 남은 것보다 큰지 비교
- for i, c in enumerate(citations):
- # 2-1 크다면 answer 에 담고, 다음인덱스로 이동
- if c >= i + 1:
- h = i + 1
- else :
- break
- return h
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/README.md"
deleted file mode 100644
index b969320..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42747.\342\200\205H\357\274\215Index/README.md"
+++ /dev/null
@@ -1,71 +0,0 @@
-# [level 2] H-Index - 42747
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42747)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 0.18 ms
-
-### 구분
-
-코딩테스트 연습 > 정렬
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 11월 29일 09:47:54
-
-### 문제 설명
-
-H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다. 위키백과1에 따르면, H-Index는 다음과 같이 구합니다.
-
-어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h의 최댓값이 이 과학자의 H-Index입니다.
-
-어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요.
-
-제한사항
-
-
-- 과학자가 발표한 논문의 수는 1편 이상 1,000편 이하입니다.
-- 논문별 인용 횟수는 0회 이상 10,000회 이하입니다.
-
-
-입출력 예
-
-
-| citations |
-return |
-
-
-
-| [3, 0, 6, 1, 5] |
-3 |
-
-
-
-입출력 예 설명
-
-이 과학자가 발표한 논문의 수는 5편이고, 그중 3편의 논문은 3회 이상 인용되었습니다. 그리고 나머지 2편의 논문은 3회 이하 인용되었기 때문에 이 과학자의 H-Index는 3입니다.
-
-문제가 잘 안풀린다면😢
-
-힌트가 필요한가요? [코딩테스트 연습 힌트 모음집]으로 오세요! → 클릭
-
-※ 공지 - 2019년 2월 28일 테스트 케이스가 추가되었습니다.
-
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/README.md"
deleted file mode 100644
index 446cc62..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/README.md"
+++ /dev/null
@@ -1,65 +0,0 @@
-# [level 2] 소수 찾기 - 42839
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42839)
-
-### 성능 요약
-
-메모리: 10.4 MB, 시간: 0.18 ms
-
-### 구분
-
-코딩테스트 연습 > 완전탐색
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 30일 09:50:19
-
-### 문제 설명
-
-한자리 숫자가 적힌 종이 조각이 흩어져있습니다. 흩어진 종이 조각을 붙여 소수를 몇 개 만들 수 있는지 알아내려 합니다.
-
-각 종이 조각에 적힌 숫자가 적힌 문자열 numbers가 주어졌을 때, 종이 조각으로 만들 수 있는 소수가 몇 개인지 return 하도록 solution 함수를 완성해주세요.
-
-제한사항
-
-
-- numbers는 길이 1 이상 7 이하인 문자열입니다.
-- numbers는 0~9까지 숫자만으로 이루어져 있습니다.
-- "013"은 0, 1, 3 숫자가 적힌 종이 조각이 흩어져있다는 의미입니다.
-
-
-입출력 예
-
-
-| numbers |
-return |
-
-
-
-| "17" |
-3 |
-
-
-| "011" |
-2 |
-
-
-
-입출력 예 설명
-
-예제 #1
-[1, 7]으로는 소수 [7, 17, 71]를 만들 수 있습니다.
-
-예제 #2
-[0, 1, 1]으로는 소수 [11, 101]를 만들 수 있습니다.
-
-
-- 11과 011은 같은 숫자로 취급합니다.
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260.py"
deleted file mode 100644
index f679705..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42839.\342\200\205\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260/\354\206\214\354\210\230\342\200\205\354\260\276\352\270\260.py"
+++ /dev/null
@@ -1,53 +0,0 @@
-from math import sqrt
-# 조합대신 순열로 (순서가 중요)
-# from itertools import combinations
-from itertools import permutations
-
-def is_prime_number(n):
- if n <= 1:
- return False
- # 2부터 시작해야함
- for i in range(2, int(sqrt(n)) + 1):
- if n % i == 0:
- return False;
- return True;
-
-def solution(numbers):
- number_set = set() # set으로 중복 해결함
-
- for length in range(1, len(numbers) + 1):
- for perm in permutations(numbers,length):
- num = int(''.join(perm))
- number_set.add(num)
-
- prime_count = sum(1 for num in number_set
- if is_prime_number(num))
-
- return prime_count
-
-
-
-# def solution(numbers):
-# count = 0
-# numbers_list = list(numbers)
-# for i in range(1 ,len(numbers_list) + 1):
-# for com in combinations(numbers_list, i):
-
-# new_com = int (list(com))
-# # com_list = list(com)
-# # for v in com_list:
-# if is_prime_number(new_com):
-# count += 1
-
-# return count
-
-
-
-
-
-# 소수 판별에 3가지 방법
-# I-1. 나누어 떨어지는것 하나라도 있으면 O(N)
-# I-2. 절반만 검사하기
-# I-3. 제곱근 -> 대칭된다는 점
-
-# II-1
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/README.md"
deleted file mode 100644
index 18cbfb1..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/README.md"
+++ /dev/null
@@ -1,70 +0,0 @@
-# [level 2] 카펫 - 42842
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/42842)
-
-### 성능 요약
-
-메모리: 10.2 MB, 시간: 0.00 ms
-
-### 구분
-
-코딩테스트 연습 > 완전탐색
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 29일 09:25:26
-
-### 문제 설명
-
-Leo는 카펫을 사러 갔다가 아래 그림과 같이 중앙에는 노란색으로 칠해져 있고 테두리 1줄은 갈색으로 칠해져 있는 격자 모양 카펫을 봤습니다.
-
-
-
-Leo는 집으로 돌아와서 아까 본 카펫의 노란색과 갈색으로 색칠된 격자의 개수는 기억했지만, 전체 카펫의 크기는 기억하지 못했습니다.
-
-Leo가 본 카펫에서 갈색 격자의 수 brown, 노란색 격자의 수 yellow가 매개변수로 주어질 때 카펫의 가로, 세로 크기를 순서대로 배열에 담아 return 하도록 solution 함수를 작성해주세요.
-
-제한사항
-
-
-- 갈색 격자의 수 brown은 8 이상 5,000 이하인 자연수입니다.
-- 노란색 격자의 수 yellow는 1 이상 2,000,000 이하인 자연수입니다.
-- 카펫의 가로 길이는 세로 길이와 같거나, 세로 길이보다 깁니다.
-
-
-입출력 예
-
-
-| brown |
-yellow |
-return |
-
-
-
-| 10 |
-2 |
-[4, 3] |
-
-
-| 8 |
-1 |
-[3, 3] |
-
-
-| 24 |
-24 |
-[8, 6] |
-
-
-
-출처
-
-※ 공지 - 2020년 2월 3일 테스트케이스가 추가되었습니다.
-※ 공지 - 2020년 5월 11일 웹접근성을 고려하여 빨간색을 노란색으로 수정하였습니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/\354\271\264\355\216\253.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/\354\271\264\355\216\253.py"
deleted file mode 100644
index 0a89001..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/42842.\342\200\205\354\271\264\355\216\253/\354\271\264\355\216\253.py"
+++ /dev/null
@@ -1,17 +0,0 @@
-# def solution(brown, yellow):
-# answer = []
-# if brown == (yellow + 3) * 2:
-# answer.append(yellow + 2)
-# answer.append(3)
-
-
-# return answer
-
-def solution(brown, yellow):
- total = brown + yellow
-
- for height in range(1, total + 1):
- if total % height == 0:
- width = total // height
- if width >= height and (width - 2) * (height - 2) == yellow:
- return [width, height]
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/README.md"
deleted file mode 100644
index d309f97..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/README.md"
+++ /dev/null
@@ -1,75 +0,0 @@
-# [level 2] 타겟 넘버 - 43165
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/43165)
-
-### 성능 요약
-
-메모리: 10.1 MB, 시간: 2.85 ms
-
-### 구분
-
-코딩테스트 연습 > 깊이/너비 우선 탐색(DFS/BFS)
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 05월 31일 10:27:56
-
-### 문제 설명
-
-n개의 음이 아닌 정수들이 있습니다. 이 정수들을 순서를 바꾸지 않고 적절히 더하거나 빼서 타겟 넘버를 만들려고 합니다. 예를 들어 [1, 1, 1, 1, 1]로 숫자 3을 만들려면 다음 다섯 방법을 쓸 수 있습니다.
--1+1+1+1+1 = 3
-+1-1+1+1+1 = 3
-+1+1-1+1+1 = 3
-+1+1+1-1+1 = 3
-+1+1+1+1-1 = 3
-
사용할 수 있는 숫자가 담긴 배열 numbers, 타겟 넘버 target이 매개변수로 주어질 때 숫자를 적절히 더하고 빼서 타겟 넘버를 만드는 방법의 수를 return 하도록 solution 함수를 작성해주세요.
-
-제한사항
-
-
-- 주어지는 숫자의 개수는 2개 이상 20개 이하입니다.
-- 각 숫자는 1 이상 50 이하인 자연수입니다.
-- 타겟 넘버는 1 이상 1000 이하인 자연수입니다.
-
-
-입출력 예
-
-
-| numbers |
-target |
-return |
-
-
-
-| [1, 1, 1, 1, 1] |
-3 |
-5 |
-
-
-| [4, 1, 2, 1] |
-4 |
-2 |
-
-
-
-입출력 예 설명
-
-입출력 예 #1
-
-문제 예시와 같습니다.
-
-입출력 예 #2
-+4+1-2+1 = 4
-+4-1+2-1 = 4
-
-- 총 2가지 방법이 있으므로, 2를 return 합니다.
-
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204.py"
deleted file mode 100644
index 7fca938..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/2/43165.\342\200\205\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204/\355\203\200\352\262\237\342\200\205\353\204\230\353\262\204.py"
+++ /dev/null
@@ -1,17 +0,0 @@
-def solution(numbers, target):
-
- def dfs(index, current_sum):
- # 배열의 끝에 도달한 경우
- if index == len(numbers):
- # 현재까지의 합이 타겟 넘버와 같은지 확인
- return 1 if current_sum == target else 0
-
- # 현재 숫자를 더하거나 빼는 두 가지 경우에 대해 재귀적으로 호출
- return dfs(index + 1, current_sum + numbers[index]) + dfs(index + 1, current_sum - numbers[index])
-
- return dfs(0, 0)
-
-
-
-
-
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/README.md" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/README.md"
deleted file mode 100644
index b239f7a..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/README.md"
+++ /dev/null
@@ -1,73 +0,0 @@
-# [level 3] 입국심사 - 43238
-
-[문제 링크](https://school.programmers.co.kr/learn/courses/30/lessons/43238)
-
-### 성능 요약
-
-메모리: 10.2 MB, 시간: 0.03 ms
-
-### 구분
-
-코딩테스트 연습 > 이분탐색
-
-### 채점결과
-
-정확성: 100.0
합계: 100.0 / 100.0
-
-### 제출 일자
-
-2024년 06월 10일 23:21:39
-
-### 문제 설명
-
-n명이 입국심사를 위해 줄을 서서 기다리고 있습니다. 각 입국심사대에 있는 심사관마다 심사하는데 걸리는 시간은 다릅니다.
-
-처음에 모든 심사대는 비어있습니다. 한 심사대에서는 동시에 한 명만 심사를 할 수 있습니다. 가장 앞에 서 있는 사람은 비어 있는 심사대로 가서 심사를 받을 수 있습니다. 하지만 더 빨리 끝나는 심사대가 있으면 기다렸다가 그곳으로 가서 심사를 받을 수도 있습니다.
-
-모든 사람이 심사를 받는데 걸리는 시간을 최소로 하고 싶습니다.
-
-입국심사를 기다리는 사람 수 n, 각 심사관이 한 명을 심사하는데 걸리는 시간이 담긴 배열 times가 매개변수로 주어질 때, 모든 사람이 심사를 받는데 걸리는 시간의 최솟값을 return 하도록 solution 함수를 작성해주세요.
-
-제한사항
-
-
-- 입국심사를 기다리는 사람은 1명 이상 1,000,000,000명 이하입니다.
-- 각 심사관이 한 명을 심사하는데 걸리는 시간은 1분 이상 1,000,000,000분 이하입니다.
-- 심사관은 1명 이상 100,000명 이하입니다.
-
-
-입출력 예
-
-
-| n |
-times |
-return |
-
-
-
-| 6 |
-[7, 10] |
-28 |
-
-
-
-입출력 예 설명
-
-가장 첫 두 사람은 바로 심사를 받으러 갑니다.
-
-7분이 되었을 때, 첫 번째 심사대가 비고 3번째 사람이 심사를 받습니다.
-
-10분이 되었을 때, 두 번째 심사대가 비고 4번째 사람이 심사를 받습니다.
-
-14분이 되었을 때, 첫 번째 심사대가 비고 5번째 사람이 심사를 받습니다.
-
-20분이 되었을 때, 두 번째 심사대가 비지만 6번째 사람이 그곳에서 심사를 받지 않고 1분을 더 기다린 후에 첫 번째 심사대에서 심사를 받으면 28분에 모든 사람의 심사가 끝납니다.
-
-문제가 잘 안풀린다면😢
-
-힌트가 필요한가요? [코딩테스트 연습 힌트 모음집]으로 오세요! → 클릭
-
-※ 공지 - 2019년 9월 4일 문제에 새로운 테스트 케이스를 추가하였습니다. 도움을 주신 weaver9651 님께 감사드립니다.
-
-
-> 출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
\ No newline at end of file
diff --git "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/\354\236\205\352\265\255\354\213\254\354\202\254.py" "b/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/\354\236\205\352\265\255\354\213\254\354\202\254.py"
deleted file mode 100644
index 7162182..0000000
--- "a/\355\224\204\353\241\234\352\267\270\353\236\230\353\250\270\354\212\244/3/43238.\342\200\205\354\236\205\352\265\255\354\213\254\354\202\254/\354\236\205\352\265\255\354\213\254\354\202\254.py"
+++ /dev/null
@@ -1,16 +0,0 @@
-def solution(n, times):
- left, right = min(times), max(times) * n
-
- while left < right: # 이분탐색은 다음과 같이 종료 조건을 두어야함
- sum = 0
- mid = (left + right) // 2
-
- for time in times:
- sum += mid // time
-
- if sum >= n :
- right = mid
- else:
- left = mid + 1 # mid 보다 + 1이 되게 해야함
-
- return left #left가 right 보다 크거나 같으면 left return
\ No newline at end of file