diff --git a/BaekJoon_Algorithm/1002.py b/BaekJoon_Algorithm/1002.py
new file mode 100644
index 0000000..3dcbba2
--- /dev/null
+++ b/BaekJoon_Algorithm/1002.py
@@ -0,0 +1,30 @@
+# 1002 터렛
+
+"""
+This is about mathematic problem. The conception is the distance between two circle's center.
+"""
+T = int(input())
+pos_info = [list(map(int, input().split())) for _ in range(T)]
+
+for x1, y1, r1, x2, y2, r2 in pos_info:
+ distance_between_centers = ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
+
+ if distance_between_centers == 0 and r1 == r2:
+ print(-1)
+ elif abs(r1 - r2) == distance_between_centers or r1 + r2 == distance_between_centers:
+ print(1)
+ elif abs(r1 - r2) < distance_between_centers < (r1 + r2):
+ print(2)
+ else:
+ print(0)
+
+"""
+3
+0 0 13 40 0 37
+0 0 3 0 7 4
+1 1 1 1 1 5
+=>
+2
+1
+0
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1003.py b/BaekJoon_Algorithm/1003.py
new file mode 100644
index 0000000..7972aae
--- /dev/null
+++ b/BaekJoon_Algorithm/1003.py
@@ -0,0 +1,86 @@
+# 1003. 피보나치 함수
+
+"""
+I solve this problem by myself with Recursion, but I have to consider Time Complexity and Memory Complexity.
+See it again for solving those problems with tricks.
+"""
+
+# 1. My Solution(Use DP, but got Memory exceeded)
+import sys
+input = sys.stdin.readline
+
+# # # Recursion is easy, but it makes Time Exceeded
+# # def Fibonacci(num):
+# # if num == 0:
+# # return "0"
+# # elif num == 1:
+# # return "1"
+# # else:
+# # return Fibonacci(num - 1) + Fibonacci(num - 2)
+
+# 2. Use Dynamic Programming, but Memory Exceeded
+def Fibonacci(num):
+ if num < 0 or num > 40:
+ return
+
+ fib_sequence = ["0", "1"]
+ for i in range(2, num + 1):
+ fib_sequence.append(fib_sequence[i - 1] + fib_sequence[i - 2])
+
+ return fib_sequence[num]
+
+# Same as previous method
+# def Fibonacci(num):
+# if num < 0 or num > 40:
+# return
+#
+# a, b = str("0"), str("1")
+# for _ in range(2, num + 1):
+# a, b = b, a + b
+#
+# return str(b)
+
+T = int(input())
+cases = [int(input()) for _ in range(T)]
+for case in cases:
+ binary_str = Fibonacci(case)
+ zero_cnts, one_cnts = binary_str.count("0"), binary_str.count("1")
+ print(zero_cnts, one_cnts)
+
+# 2. Not my solution
+T = int(input())
+for tc in range(T):
+ N = int(input())
+ zero_cnts = [1, 0]
+ one_cnts = [0, 1]
+
+ for i in range(2, N + 1):
+ zero_cnts.append(zero_cnts[i - 1] + zero_cnts[i - 2])
+ one_cnts.append(one_cnts[i - 1] + one_cnts[i - 2])
+
+ print("{} {}".format(zero_cnts[N], one_cnts[N]))
+
+"""
+3
+0
+1
+3
+=>
+1 0
+0 1
+1 2
+==========
+2
+6
+22
+=>
+5 8
+10946 17711
+===========
+2
+40
+0
+=>
+63245986 102334155
+1 0
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1004.py b/BaekJoon_Algorithm/1004.py
new file mode 100644
index 0000000..5b9998d
--- /dev/null
+++ b/BaekJoon_Algorithm/1004.py
@@ -0,0 +1,91 @@
+# 1004. 어린 왕자
+
+"""
+I was stuck about getting data. I need to study more about Python language.
+And also the solution is unique because it requires mathematical thinking.
+See it again.
+"""
+# 1. My Solution
+T = int(input())
+for _ in range(T):
+ min_cnts = 0
+ x1, y1, x2, y2 = map(int, input().split())
+ planets = int(input())
+ for planet in range(planets):
+ cx, cy, r = map(int, input().split())
+ dist1 = (x1 - cx) ** 2 + (y1 - cy) ** 2
+ dist2 = (x2 - cx) ** 2 + (y2 - cy) ** 2
+ if (dist1 < r ** 2 and dist2 > r ** 2) or (dist1 > r ** 2 and dist2 < r ** 2):
+ min_cnts += 1
+
+ print(min_cnts)
+
+# 2. Not my Solution
+T = int(input())
+for _ in range(T):
+ cnt = 0
+ x1, y1, x2, y2 = map(int, input().split())
+ N = int(input())
+ for i in range(N):
+ cx, cy, r = map(int, input().split())
+ dist1 = (x1 - cx) ** 2 + (y1 - cy) ** 2
+ dist2 = (x2 - cx) ** 2 + (y2 - cy) ** 2
+
+ if (dist1 < r ** 2 and dist2 > r ** 2) or (dist1 > r ** 2 and dist2 < r ** 2):
+ cnt += 1
+
+ print(cnt)
+
+"""
+2
+-5 1 12 1
+7
+1 1 8
+-3 -1 1
+2 2 2
+5 5 1
+-4 5 1
+12 1 1
+12 1 2
+-5 1 5 1
+1
+0 0 2
+=>
+3
+0
+==============
+3
+-5 1 5 1
+3
+0 0 2
+-6 1 2
+6 2 2
+2 3 13 2
+8
+-3 -1 1
+2 2 3
+2 3 1
+0 1 7
+-4 5 1
+12 1 1
+12 1 2
+12 1 3
+102 16 19 -108
+12
+-107 175 135
+-38 -115 42
+140 23 70
+148 -2 39
+-198 -49 89
+172 -151 39
+-179 -52 43
+148 42 150
+176 0 10
+153 68 120
+-56 109 16
+-187 -174 8
+=>
+2
+5
+3
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1009.py b/BaekJoon_Algorithm/1009.py
new file mode 100644
index 0000000..6be6702
--- /dev/null
+++ b/BaekJoon_Algorithm/1009.py
@@ -0,0 +1,76 @@
+# 1009. 분산처리
+
+"""
+I catch this problem is based on rules of end number at decimal numbers.
+But I miss multiply number of 10.
+"""
+# 1. My Solution
+test_cases = int(input())
+for case in range(test_cases):
+ a, b = map(int, input().split())
+ a %= 10
+
+ if a == 0:
+ print(10)
+ elif a in [1, 5, 6]:
+ print(a)
+ elif a in [4, 9]:
+ b %= 2
+ if b == 1:
+ print(a)
+ else:
+ print((a * a) % 10)
+ else:
+ b %= 4
+ if b == 0:
+ print((a ** 4) % 10)
+ else:
+ print((a ** b) % 10)
+
+# 2. Not my Solution
+T = int(input())
+
+for _ in range(T):
+ a, b = map(int, input().split())
+ a = a % 10
+
+ if a == 0:
+ print(10)
+ elif a == 1 or a == 5 or a == 6:
+ print(a)
+ elif a == 4 or a == 9:
+ b = b % 2
+ if b == 1:
+ print(a)
+ else:
+ print((a * a) % 10)
+ else:
+ b = b % 4
+ if b == 0:
+ print((a ** 4) % 10 % 10 % 10)
+ else:
+ print((a ** b) % 10 % 10 % 10)
+
+"""
+5
+1 6
+3 7
+6 2
+7 100
+9 635
+=>
+1
+7
+6
+1
+9
+==========
+3
+19 34
+20 10
+50 100
+=>
+9
+0
+0
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1010.py b/BaekJoon_Algorithm/1010.py
new file mode 100644
index 0000000..105d0bb
--- /dev/null
+++ b/BaekJoon_Algorithm/1010.py
@@ -0,0 +1,50 @@
+# 1010. 다리 놓기
+
+"""
+I didn't solve this problem by myself. I need to find the rule of math at problem.
+This is about DP(Dynamic Programming), but finding math rule is easier to solve it.
+See it again.
+"""
+# 1. My Solution(practice)
+import math
+T = int(input())
+
+for _ in range(T):
+ N, M = map(int, input().split())
+ bridges = math.factorial(M) // (math.factorial(N) * math.factorial(M - N))
+ print(bridges)
+
+# # 1. My Solution
+# import math
+#
+# T = int(input())
+# for _ in range(T):
+# N, M = map(int, input().split())
+# bridges = math.factorial(M) // (math.factorial(N) * math.factorial(M - N))
+# print(bridges)
+
+
+# 2. Not my Solution
+def factorial(N):
+ num = 1
+ for i in range(1, N + 1):
+ num *= i
+
+ return num
+
+t = int(input())
+for _ in range(t):
+ n, m = map(int, input().split())
+ bridges = factorial(m) // (factorial(n) * factorial(m - n))
+ print(bridges)
+
+"""
+3
+2 2
+1 5
+13 29
+=>
+1
+5
+67863915
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1012.py b/BaekJoon_Algorithm/1012.py
new file mode 100644
index 0000000..34ffeda
--- /dev/null
+++ b/BaekJoon_Algorithm/1012.py
@@ -0,0 +1,128 @@
+# 1012. 유기농 배추
+
+"""
+I didn't solve this problem by myself. This is about Search and BFS is better than DFS in this problem.
+This is a basic BFS code, so I have to rewind the flow.
+See it again.
+"""
+# 1. My Solution
+T = int(input())
+
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+
+def BFS(x, y):
+ queue = [(x, y)]
+ ground[x][y] = 0
+
+ while queue:
+ x, y = queue.pop(0)
+
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+
+ if mx < 0 or mx >= M or my < 0 or my >= N:
+ continue
+
+ if ground[mx][my] == 1:
+ queue.append((mx, my))
+ ground[mx][my] = 0
+
+
+for t in range(T):
+ M, N, K = map(int, input().split())
+ ground = [[0] * N for _ in range(M)]
+ min_cnts = 0
+
+ for k in range(K):
+ x, y = map(int, input().split())
+ ground[x][y] = 1
+
+ for row in range(M):
+ for col in range(N):
+ if ground[row][col] == 1:
+ BFS(row, col)
+ min_cnts += 1
+
+ print(min_cnts)
+
+
+# # 2. Not my Solution
+# T = int(input()) #테스트케이스의 개수
+#
+# dx = [-1,1,0,0]
+# dy = [0,0,-1,1]
+#
+# def BFS(x,y):
+# queue = [(x,y)]
+# matrix[x][y] = 0 # 방문처리
+#
+# while queue:
+# x,y = queue.pop(0)
+#
+# for i in range(4):
+# nx = x + dx[i]
+# ny = y + dy[i]
+#
+# if nx < 0 or nx >= M or ny < 0 or ny >= N:
+# continue
+#
+# if matrix[nx][ny] == 1 :
+# queue.append((nx,ny))
+# matrix[nx][ny] = 0
+#
+# # 행렬만들기
+# for i in range(T):
+# M, N, K = map(int, input().split())
+# matrix = [[0] * (N) for _ in range(M)]
+# cnt = 0
+#
+# for j in range(K):
+# x,y = map(int, input().split())
+# matrix[x][y] = 1
+#
+# for a in range(M):
+# for b in range(N):
+# if matrix[a][b] == 1:
+# BFS(a, b)
+# cnt += 1
+#
+# print(cnt)
+
+
+"""
+2
+10 8 17
+0 0
+1 0
+1 1
+4 2
+4 3
+4 5
+2 4
+3 4
+7 4
+8 4
+9 4
+7 5
+8 5
+9 5
+7 6
+8 6
+9 6
+10 10 1
+5 5
+=>
+5
+1
+=======================
+1
+5 3 6
+0 2
+1 2
+2 2
+3 2
+4 2
+4 0
+=>
+2
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1015.py b/BaekJoon_Algorithm/1015.py
new file mode 100644
index 0000000..3fb924f
--- /dev/null
+++ b/BaekJoon_Algorithm/1015.py
@@ -0,0 +1,53 @@
+# 1015. 수열 정렬
+
+"""
+I didn't solve this problem by myself. I didn't catch '비내림수' in this problem.
+Think simple and catch the main point quickly.
+"""
+# 1. My Solution
+P_size = int(input())
+A_sequence = list(map(int, input().split()))
+
+A_sort = sorted(A_sequence)
+B_sequence = []
+for i in range(P_size):
+ B_sequence.append(A_sort.index(A_sequence[i]))
+ A_sort[A_sort.index(A_sequence[i])] = -1
+
+for i in range(P_size):
+ print(str(B_sequence[i]), end=' ')
+
+# 2. Not my Solution
+import sys
+
+input = sys.stdin.readline
+
+N = int(input())
+A = list(map(int, input().split()))
+sortA = sorted(A, reverse=False)
+
+P = []
+for i in range(N):
+ P.append(sortA.index(A[i]))
+ sortA[sortA.index(A[i])] = -1
+
+for i in range(N):
+ print(str(P[i]), end=' ')
+
+
+"""
+3
+2 3 1
+=>
+1 2 0
+=========
+4
+2 1 3 1
+=>
+2 0 3 1
+=========
+8
+4 1 6 1 3 6 1 4
+=>
+4 0 6 1 3 7 2 5
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1026.py b/BaekJoon_Algorithm/1026.py
new file mode 100644
index 0000000..c914c03
--- /dev/null
+++ b/BaekJoon_Algorithm/1026.py
@@ -0,0 +1,36 @@
+# 1026. 보물
+
+# 1. My Solution
+N = int(input())
+A = list(map(int, input().split()))
+B = list(map(int, input().split()))
+A_sort, B_rev_sort = sorted(A), sorted(B, reverse=True)
+answer = 0
+for a_element, b_element in zip(A_sort, B_rev_sort):
+ answer += a_element * b_element
+
+print(answer)
+
+# 2. Not my Solution
+
+
+
+"""
+5
+1 1 1 6 0
+2 7 8 3 1
+=>
+18
+===============
+3
+1 1 3
+10 30 20
+=>
+80
+===============
+9
+5 15 100 31 39 0 0 3 26
+11 12 13 2 3 4 5 9 1
+=>
+528
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1051.py b/BaekJoon_Algorithm/1051.py
new file mode 100644
index 0000000..4630471
--- /dev/null
+++ b/BaekJoon_Algorithm/1051.py
@@ -0,0 +1,87 @@
+# 1051. 숫자 정사각형
+
+"""
+I almost solve this problem by myself. The key of this problem is finding 4 coordinates of square that satisfy same costs.
+I miss the point that the possible length of square.
+See it again.
+"""
+# 1. My Solution
+N, M = map(int, input().split())
+rectangle = [list(map(int, list(input()))) for _ in range(N)]
+max_length = min(N, M)
+
+def find_square(s):
+ for i in range(N - s + 1):
+ for j in range(M - s + 1):
+ if rectangle[i][j] == rectangle[i][j + s - 1] == rectangle[i + s - 1][j] == rectangle[i + s -1][j + s - 1]:
+ return True
+
+ return False
+
+for p_len in range(max_length, 0, -1):
+ if find_square(p_len):
+ print(p_len ** 2)
+ break
+
+# 2. Not my Solution
+def find_squre(s):
+ for i in range(N-s+1):
+ for j in range(M-s+1):
+ if numbers[i][j] == numbers[i][j+s-1] == numbers[i+s-1][j] == numbers[i+s-1][j+s-1]:
+ return True
+
+ return False
+
+
+N, M = map(int, input().split())
+numbers = [list(map(int, list(input()))) for _ in range(N)]
+
+size = min(N,M)
+
+# 최대 크기부터 하나씩 줄여가며 시작
+for k in range(size, 0, -1):
+ # 네 꼭지점의 크기가 같은 정사각형을 찾았으면 True를 받아 넓이를 출력해주고 break
+ if find_squre(k):
+ print(k**2)
+ break
+
+"""
+3 5
+42101
+22100
+22101
+=>
+9
+================
+2 2
+12
+34
+=>
+1
+================
+2 4
+1255
+3455
+=>
+4
+================
+1 10
+1234567890
+=>
+1
+================
+11 10
+9785409507
+2055103694
+0861396761
+3073207669
+1233049493
+2300248968
+9769239548
+7984130001
+1670020095
+8894239889
+4053971072
+=>
+49
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1063.py b/BaekJoon_Algorithm/1063.py
new file mode 100644
index 0000000..f51e313
--- /dev/null
+++ b/BaekJoon_Algorithm/1063.py
@@ -0,0 +1,162 @@
+# 1063. 킹
+
+"""
+I didn't solve this problem by myself. I miss two key points.
+First is the starting position of king and stone(1, 1).
+Last one is the overlapped of king and stone.
+See this again.
+"""
+# 1.My Solution(practice)
+king_pos_str, stone_pos_str, N = input().split()
+king_moving_poses = [input() for _ in range(int(N))]
+
+king_moves_dict = {'R': (1, 0), 'L': (-1, 0), 'B': (0, -1), 'T': (0, 1),
+ 'RT': (1, 1), 'LT': (-1, 1), 'RB': (1, -1),
+ 'LB': (-1, -1)}
+
+king_pos = [int(ord(king_pos_str[0])) - int(ord('A')) + 1, int(king_pos_str[1])]
+stone_pos = [int(ord(stone_pos_str[0])) - int(ord('A')) + 1, int(stone_pos_str[1])]
+
+for king_move in king_moving_poses:
+ move_r, move_c = king_moves_dict[king_move]
+ move_king_x, move_king_y = king_pos[0] + move_r, king_pos[1] + move_c
+ if move_king_x in range(1, 9) and move_king_y in range(1, 9):
+ if move_king_x == stone_pos[0] and move_king_y == stone_pos[1]:
+ move_stone_x, move_stone_y = stone_pos[0] + move_r, stone_pos[1] + move_c
+ if move_stone_x in range(1, 9) and move_stone_y in range(1, 9):
+ king_pos = [move_king_x, move_king_y]
+ stone_pos = [move_stone_x, move_stone_y]
+ else:
+ king_pos = [move_king_x, move_king_y]
+
+print(chr(king_pos[0] + ord('A') - 1) + str(king_pos[1]))
+print(chr(stone_pos[0] + ord('A') - 1) + str(stone_pos[1]))
+
+# 1. My Solution
+
+# A1, A2(string + string)
+king_pos_str, stone_pos_str, move_cnts_str = input().split()
+move_cnts = int(move_cnts_str)
+king_moving_poses = [input() for _ in range(move_cnts)]
+
+king_moves_dict = {'R': (1, 0), 'L': (-1, 0), 'B': (0, -1), 'T': (0, 1),
+ 'RT': (1, 1), 'LT': (-1, 1), 'RB': (1, -1), 'LB': (-1, -1)
+ }
+
+king_pos = [int(ord(king_pos_str[0])) - int(ord('A')) + 1, int(king_pos_str[1])]
+stone_pos = [int(ord(stone_pos_str[0])) - int(ord('A')) + 1, int(stone_pos_str[1])]
+
+for king_move in king_moving_poses:
+ move_r, move_c = king_moves_dict[king_move]
+ moved_king_x, moved_king_y = king_pos[0] + move_r, king_pos[1] + move_c
+ if moved_king_x in range(1, 9) and moved_king_y in range(1, 9):
+ if moved_king_x == stone_pos[0] and moved_king_y == stone_pos[1]:
+ if moved_king_x == stone_pos[0] and moved_king_y == stone_pos[1]:
+ moved_stone_x = stone_pos[0] + move_r
+ moved_stone_y = stone_pos[1] + move_c
+ if moved_stone_x in range(1, 9) and moved_stone_y in range(1, 9):
+ king_pos = [moved_king_x, moved_king_y]
+ stone_pos = [moved_stone_x, moved_stone_y]
+ else:
+ king_pos = [moved_king_x, moved_king_y]
+
+print(chr(king_pos[0] + ord('A') - 1) + str(king_pos[1]))
+print(chr(stone_pos[0] + ord('A') - 1) + str(stone_pos[1]))
+
+# 2. Not my Solution
+king, stone, N = input().split()
+k = list(map(int, [ord(king[0]) - 64, king[1]]))
+s = list(map(int, [ord(stone[0]) - 64, stone[1]]))
+
+# 이때 k와 s는 [1,1] [8,8]
+
+# 딕셔너리 (이동 타입에 따라 dx와 dy 설정)
+move = {'R': [1, 0], 'L': [-1, 0], 'B': [0, -1], 'T': [0, 1], 'RT': [1, 1], 'LT': [-1, 1], 'RB': [1, -1],
+ 'LB': [-1, -1]}
+
+# 움직이는 횟수 만큼 실행
+for _ in range(int(N)):
+ m = input() # 지금 이동
+
+ # 움직였을 경우의 위치 : nx, ny
+ nx = k[0] + move[m][0]
+ ny = k[1] + move[m][1]
+
+ # 킹 조건 검사
+ if 0 < nx <= 8 and 0 < ny <= 8:
+ # 돌 위에 얹히는가?
+ if nx == s[0] and ny == s[1]:
+ sx = s[0] + move[m][0]
+ sy = s[1] + move[m][1]
+ # 돌 조건 검사
+ if 0 < sx <= 8 and 0 < sy <= 8:
+ k = [nx, ny] # 킹 이동
+ s = [sx, sy] # 돌 이동
+ else:
+ k = [nx, ny] # 킹만 이동
+print(f'{chr(k[0] + 64)}{k[1]}')
+print(f'{chr(s[0] + 64)}{s[1]}')
+
+
+
+"""
+A1 A2 5
+B
+L
+LB
+RB
+LT
+=>
+A1
+A2
+===============
+A1 H8 1
+T
+=>
+A2
+H8
+===============
+A1 A2 1
+T
+=>
+A2
+A3
+===============
+A1 A2 2
+T
+R
+=>
+B2
+A3
+===============
+A8 B7 18
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+RB
+=>
+G2
+H1
+==================
+C1 B1 3
+L
+T
+LB
+=>
+B2
+A1
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1080.py b/BaekJoon_Algorithm/1080.py
new file mode 100644
index 0000000..3c99f24
--- /dev/null
+++ b/BaekJoon_Algorithm/1080.py
@@ -0,0 +1,138 @@
+# 1080. 행렬
+
+"""
+I didn't solve this problem by myself. The key of this problem is comparing first element of two marices.
+And the last key is that impossible changes of two matrices.
+See it again.
+"""
+# 1. My Solution(practice)
+N, M = map(int, input().split())
+matrix_A = [list(map(int, list(input()))) for _ in range(N)]
+matrix_B = [list(map(int, list(input()))) for _ in range(N)]
+
+def convert(i, j):
+ for r in range(i, i + 3):
+ for c in range(j, j + 3):
+ if matrix_A[r][c] == 0:
+ matrix_A[r][c] = 1
+ else:
+ matrix_A[r][c] = 0
+
+min_cnts = 0
+if N >= 3 and M >= 3:
+ for row in range(N - 2):
+ for col in range(M - 2):
+ if matrix_A[row][col] != matrix_B[row][col]:
+ min_cnts += 1
+ convert(row, col)
+else:
+ min_cnts = -1
+
+if min_cnts != -1:
+ if matrix_A != matrix_B:
+ min_cnts = -1
+
+print(min_cnts)
+
+# 2. Not my Solution
+n, m = map(int, input().split())
+listA = []
+for _ in range(n): # 리스트A 선언
+ listA.append(list(map(int, list(input()))))
+listB = []
+for _ in range(n): # 리스트B 선언
+ listB.append(list(map(int, list(input()))))
+
+
+def check(i, j): # 뒤집기 함수
+ for x in range(i, i+3):
+ for y in range(j, j+3):
+ if listA[x][y] == 0:
+ listA[x][y] = 1
+ else:
+ listA[x][y] = 0
+
+
+cnt = 0 # 카운트
+if (n < 3 or m < 3) and listA != listB:
+ # 예외 1, 리스트가 작을 때
+ cnt = -1
+else:
+ for r in range(n-2):
+ for c in range(m-2):
+ if listA[r][c] != listB[r][c]:
+ cnt += 1
+ check(r, c)
+
+if cnt != -1:
+ if listA != listB: # A와 B가 같은지 확인
+ cnt = -1
+print(cnt)
+
+"""
+3 4
+0000
+0010
+0000
+1001
+1011
+1001
+=>
+2
+===========
+3 3
+111
+111
+111
+000
+000
+000
+=>
+1
+===========
+1 1
+1
+0
+=>
+-1
+===========
+18 3
+001
+100
+100
+000
+011
+010
+100
+100
+010
+010
+010
+110
+101
+101
+000
+110
+000
+110
+001
+100
+011
+000
+100
+010
+011
+100
+101
+101
+010
+001
+010
+010
+111
+110
+111
+001
+=>
+7
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/10872.py b/BaekJoon_Algorithm/10872.py
new file mode 100644
index 0000000..2e821d6
--- /dev/null
+++ b/BaekJoon_Algorithm/10872.py
@@ -0,0 +1,19 @@
+# 10872. 팩토리얼
+
+N = int(input())
+
+N_facto = 1
+for i in range(1, N + 1):
+ N_facto *= i
+
+print(N_facto)
+
+"""
+10
+=>
+3728800
+==========
+0
+=>
+1
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1094.py b/BaekJoon_Algorithm/1094.py
new file mode 100644
index 0000000..0f57246
--- /dev/null
+++ b/BaekJoon_Algorithm/1094.py
@@ -0,0 +1,23 @@
+# 1094. 막대기
+
+X = int(input())
+
+bin_X = bin(X)[2:]
+print(bin_X.count('1'))
+"""
+23
+=>
+4
+==========
+32
+=>
+1
+==========
+64
+=>
+1
+==========
+48
+=>
+2
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1105.py b/BaekJoon_Algorithm/1105.py
new file mode 100644
index 0000000..e42123a
--- /dev/null
+++ b/BaekJoon_Algorithm/1105.py
@@ -0,0 +1,84 @@
+# 1105. 팔
+
+"""
+I almost solve this problem by myself. But I miss Memory Excess and Time Excess.
+Not using sort function. Try to memorize this problem by Greedy problem.
+See it again.
+"""
+# 1. My Solution(practice, greedy)
+A, B = map(str, input().split())
+
+min_eight_cnts = 0
+if len(A) != len(B):
+ print(0)
+else:
+ for chr_idx in range(len(A)):
+ if A[chr_idx] == B[chr_idx]:
+ if A[chr_idx] == '8':
+ min_eight_cnts += 1
+ else:
+ break
+
+ print(min_eight_cnts)
+
+
+# 2. My Solution(practice, mine)
+L, R = map(int, input().split())
+
+min_eight_cnts = float("inf")
+
+for num in range(L, R + 1):
+ eight_cnts = str(num).count('8')
+ min_eight_cnts = min(min_eight_cnts, eight_cnts)
+ if min_eight_cnts == 0:
+ break
+
+print(min_eight_cnts)
+
+####################################################################
+# 1. My Solution
+L, R = map(int, input().split())
+
+min_cnt = float("inf")
+
+for num in range(L, R + 1):
+ cnt_eight = str(num).count('8')
+ min_cnt = min(min_cnt, cnt_eight)
+ if min_cnt == 0:
+ break
+
+print(min_cnt)
+
+
+# 2. Not my Solution
+A, B = map(str, input().split(' '))
+
+ret = 0
+
+if len(A) != len(B):
+ print(0)
+else:
+ for i in range(len(A)):
+ if A[i] == B[i]:
+ if A[i] == '8':
+ ret += 1
+ else:
+ break
+ print(ret)
+"""
+1 10
+=>
+0
+=============
+88 88
+=>
+2
+=============
+800 899
+=>
+1
+=============
+8808 8880
+=>
+2
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1120.py b/BaekJoon_Algorithm/1120.py
new file mode 100644
index 0000000..277b193
--- /dev/null
+++ b/BaekJoon_Algorithm/1120.py
@@ -0,0 +1,54 @@
+# 1120. 문자열
+
+"""
+I didn't solve this problem by myself. I'm trying to find the rules in two strings.
+But this requires finding all rules in two strings(Brute-Force Algorithm).
+"""
+# 1. My Solution
+strs_lst = input().split()
+diff_lst = []
+A, B = strs_lst
+
+for j in range(len(B) - len(A) + 1):
+ diff_cnt = 0
+ for i in range(len(A)):
+ if A[i] != B[i + j]:
+ diff_cnt += 1
+
+ diff_lst.append(diff_cnt)
+
+print(min(diff_lst))
+
+# # 2. Not my Solution
+# A, B = input().split()
+#
+# answer = []
+# for i in range(len(B) - len(A) + 1):
+# count = 0
+# for j in range(len(A)):
+# if A[j] != B[i + j]:
+# count += 1
+# answer.append(count)
+#
+# print(min(answer))
+"""
+adaabc aababbc
+=>
+2
+==================
+hello xello
+=>
+1
+==================
+koder topcoder
+=>
+1
+==================
+abc topabcoder
+=>
+0
+==================
+giorgi igroig
+=>
+6
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1138.py b/BaekJoon_Algorithm/1138.py
new file mode 100644
index 0000000..c0b4fd7
--- /dev/null
+++ b/BaekJoon_Algorithm/1138.py
@@ -0,0 +1,60 @@
+# 1138. 한 줄로 서기
+
+"""
+This requires Ability to understand text.
+I didn't catch what requires in this problem.
+"""
+# 1. My Solution
+N = int(input())
+memory = list(map(int, input().split()))
+
+answer = [0] * N
+for i in range(N):
+ cnt = 0
+ for j in range(N):
+ if cnt == memory[i] and answer[j] == 0:
+ answer[j] = i + 1
+ break
+ elif answer[j] == 0:
+ cnt += 1
+
+print(*answer)
+
+# # 2. Not my Solution
+# n = int(input())
+#
+# arr = list(map(int, input().split()))
+# answer = [0] * n
+#
+# for i in range(n):
+# cnt = 0
+# for j in range(n):
+# if cnt == arr[i] and answer[j] == 0:
+# answer[j] = i + 1
+# break
+# elif answer[j] == 0:
+# cnt += 1
+#
+# print(' '.join(map(str, answer)))
+
+"""
+4
+2 1 1 0
+=>
+4 2 1 3
+==========
+5
+0 0 0 0 0
+=>
+1 2 3 4 5
+==========
+6
+5 4 3 2 1 0
+=>
+6 5 4 3 2 1
+=============
+7
+6 1 1 1 2 0 0
+=>
+6 2 3 4 7 5 1
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1149.py b/BaekJoon_Algorithm/1149.py
new file mode 100644
index 0000000..2563c18
--- /dev/null
+++ b/BaekJoon_Algorithm/1149.py
@@ -0,0 +1,87 @@
+# 1149. RGB 거리
+
+# 1. My Solution
+N = int(input())
+possible_colors = [list(map(int, input().split())) for _ in range(N)]
+
+dp = [[0] * 3 for _ in range(N)]
+dp[0] = possible_colors[0]
+
+for r_idx in range(1, N):
+ for c_idx in range(3):
+ dp[r_idx][c_idx] = possible_colors[r_idx][c_idx] + min(dp[r_idx - 1][(c_idx + 1) % 3],
+ dp[r_idx - 1][(c_idx + 2) % 3])
+
+print(min(dp[N - 1]))
+
+# # 2. Not my Solution(chatGPT)
+# N = int(input())
+# possible_colors = [list(map(int, input().split())) for _ in range(N)]
+#
+# dp = [[0] * 3 for _ in range(N)]
+# dp[0] = possible_colors[0]
+#
+# for i in range(1, N):
+# for j in range(3):
+# dp[i][j] = possible_colors[i][j] + min(dp[i - 1][(j + 1) % 3],
+# dp[i - 1][(j + 2) % 3])
+#
+# print(min(dp[N - 1]))
+
+# 3. Not my Solution(Blog)
+n = int(input())
+a = [0] * n
+
+for i in range(n):
+ a[i] = list(map(int, input().split()))
+
+for i in range(1, n): # 1부터 시작하는 이유는 다음 입력값이 이전 입력값의 최소값을 사용하기때문이다
+ a[i][0] = min(a[i - 1][1], a[i - 1][2]) + a[i][0]
+ a[i][1] = min(a[i - 1][0], a[i - 1][2]) + a[i][1]
+ a[i][2] = min(a[i - 1][0], a[i - 1][1]) + a[i][2]
+
+print(min(a[n - 1][0], a[n - 1][1], a[n - 1][2]))
+"""
+3
+26 40 83
+49 60 57
+13 89 99
+=>
+96
+==============
+3
+1 100 100
+100 1 100
+100 100 1
+=>
+3
+==============
+3
+1 100 100
+100 100 100
+1 100 100
+=>
+102
+==============
+6
+30 19 5
+64 77 64
+15 19 97
+4 71 57
+90 86 84
+93 32 91
+=>
+208
+==============
+8
+71 39 44
+32 83 55
+51 37 63
+89 29 100
+83 58 11
+65 13 15
+47 25 29
+60 66 19
+=>
+253
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1181.py b/BaekJoon_Algorithm/1181.py
new file mode 100644
index 0000000..8098f05
--- /dev/null
+++ b/BaekJoon_Algorithm/1181.py
@@ -0,0 +1,44 @@
+# 1181. 단어 정렬
+
+"""
+I almost solve this problem by myself. But I miss a little point that Python sort function can sorting with multiple arguments.
+"""
+# 1. My Solution
+N = int(input())
+words_lst = list(set([input() for _ in range(N)]))
+# print(sorted(words_lst, key=lambda x: (len(x), x)))
+for word in sorted(words_lst, key=lambda x: (len(x), x)):
+ print(word)
+
+# 2. Not my Solution
+
+
+
+"""
+13
+but
+i
+wont
+hesitate
+no
+more
+no
+more
+it
+cannot
+wait
+im
+yours
+=>
+i
+im
+it
+no
+but
+more
+wait
+wont
+yours
+cannot
+hesitate
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1189.py b/BaekJoon_Algorithm/1189.py
new file mode 100644
index 0000000..25b5779
--- /dev/null
+++ b/BaekJoon_Algorithm/1189.py
@@ -0,0 +1,103 @@
+# 1189. 컴백홈
+
+"""
+I didn't solve this problem by myself. This is about Back Tracking Algorithm.
+The limitation is moving coordinate is '.'.
+And DFS is better than BFS for applying Back Tracking.
+See it again.
+"""
+# 1. My Solution(practice)
+R, C, K = map(int, input().split())
+road_map = [list(input()) for _ in range(R)]
+
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+answer = 0
+
+def DFS(x, y, distance):
+ global answer
+ if x == 0 and y == C - 1 and distance == K:
+ answer += 1
+ else:
+ road_map[x][y] = 'T'
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+ if mx in range(R) and my in range(C) and road_map[mx][my] == '.':
+ road_map[mx][my] = 'T'
+ DFS(mx, my, distance + 1)
+ road_map[mx][my] = '.'
+
+DFS(R - 1, 0, 1)
+print(answer)
+
+# 1. My Solution
+R, C, K = map(int, input().split())
+road_map = [list(input()) for _ in range(R)]
+
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+
+answer = 0
+def DFS(x, y, distance):
+ global answer
+ if distance == K and x == 0 and y == C - 1:
+ answer += 1
+ else:
+ road_map[x][y] = 'T'
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+
+ if mx in range(R) and my in range(C) and road_map[mx][my] == '.':
+ road_map[mx][my] = 'T'
+ DFS(mx, my, distance + 1)
+ road_map[mx][my] = '.'
+
+DFS(R - 1, 0, 1)
+print(answer)
+
+# 2. Not my Solution
+import sys
+input = sys.stdin.readline
+
+# r X c 맵
+# 거리가 k 인 가짓수 구하기
+r,c,k = map(int, input().split())
+graph = []
+for _ in range(r):
+ graph.append(list(input().rstrip()))
+
+dx = [1,-1,0,0]
+dy = [0,0,1,-1]
+
+answer = 0
+def dfs(x,y,distance):
+ global answer
+ # 목표 도착 지점 : (0,c-1)
+ # 목표 거리 : k
+ if distance == k and y == c-1 and x==0:
+ answer += 1
+ else:
+ # T로 방문처리
+ graph[x][y]='T'
+ for i in range(4):
+ nx = x+dx[i]
+ ny = y+dy[i]
+ # 백트래킹 한정 조건 : graph[nx][ny] == '.'
+ if(0 <= nx < r and 0 <= ny < c and graph[nx][ny] == '.'):
+ graph[nx][ny]='T'
+ dfs(nx,ny,distance+1)
+ # 원래 상태로 돌려 놓아 다른 방향으로 다시 탐색하도록 한다.
+ graph[nx][ny]='.'
+
+# 시작점 : (r-1,0)
+# 초기 distance : 1
+dfs(r-1,0,1)
+# 정답
+print(answer)
+
+"""
+3 4 6
+....
+.T..
+....
+=>
+4
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1193.py b/BaekJoon_Algorithm/1193.py
new file mode 100644
index 0000000..d5c21f4
--- /dev/null
+++ b/BaekJoon_Algorithm/1193.py
@@ -0,0 +1,104 @@
+# 1193. 분수찾기
+
+"""
+I didn't solve this problem by myself. The key of this problem is finding rules for making fraction.
+ZigZag sequence and I need to catch finding rules.
+See it again.
+"""
+# 1. My Solution(practice)
+N = int(input())
+
+N_line = 1
+while N > N_line:
+ N -= N_line
+ N_line += 1
+
+if N_line % 2 == 0:
+ numerator = N
+ denominator = N_line - N + 1
+else:
+ numerator = N_line - N + 1
+ denominator = N
+
+print(f"{numerator}/{denominator}")
+
+# 1193. 분수찾기
+
+# 1. My Solution
+N = int(input())
+
+N_line = 1
+while N > N_line:
+ N -= N_line
+ N_line += 1
+
+if N_line % 2 == 0:
+ numerator = N
+ denominator = N_line - N + 1
+else:
+ numerator = N_line - N + 1
+ denominator = N
+
+print(f"{numerator}/{denominator}")
+
+
+# 2. Not my Solution
+num = int(input())
+line = 1
+
+while num > line:
+ num -= line
+ line += 1
+
+# 짝수일경우
+if line % 2 == 0:
+ a = num
+ b = line - num + 1
+# 홀수일경우
+elif line % 2 == 1:
+ a = line - num + 1
+ b = num
+
+print(f'{a}/{b}')
+
+"""
+1
+=>
+1/1
+=========
+2
+=>
+1/2
+=========
+3
+=>
+2/1
+=========
+4
+=>
+3/1
+=========
+5
+=>
+2/2
+=========
+6
+=>
+1/3
+=========
+7
+=>
+1/4
+=========
+8
+=>
+2/3
+=========
+9
+=>
+3/2
+=========
+14
+=>
+2/4
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1213.py b/BaekJoon_Algorithm/1213.py
new file mode 100644
index 0000000..bc92da2
--- /dev/null
+++ b/BaekJoon_Algorithm/1213.py
@@ -0,0 +1,66 @@
+# 1213. 팰린드롬 만들기
+
+"""
+I didn't solve this problem by myself. The key of this problem is sorting and keep Palindrome.
+The rule of making Palindrome is that there's no odd counts of character in english name.
+"""
+# 1. My Solution
+from collections import Counter
+
+english_name = input()
+check_words = Counter(english_name)
+cnts = 0
+change_results = ""
+mid = ""
+for key, value in check_words.items():
+ if value % 2 == 1:
+ cnts += 1
+ mid = key
+ if cnts >= 2:
+ print("I'm Sorry Hansoo")
+ exit()
+
+for key, value in sorted(check_words.items()):
+ change_results += key * (value // 2)
+
+print(change_results + mid + change_results[::-1])
+
+# 2. Not my Solution
+import collections
+import sys
+
+word = sys.stdin.readline().rstrip()
+check_word = collections.Counter(word)
+cnt = 0
+result = ''
+mid = ''
+for k, v in list(check_word.items()):
+ if v % 2 == 1: #홀수라면
+ cnt += 1
+ mid = k #중간에 들어갈 값으로 저장
+ if cnt >= 2: #홀수가 2개이상이면 팰린드롬이 될 수 없다!!
+ print("I'm Sorry Hansoo")
+ exit()
+
+for k, v in sorted(check_word.items()): #정렬을 통해 사전순으로 for문을 돌게함
+ result += (k * (v // 2)) #정확히 절반으로 나뉜 문자열을 만들어야 하므로 현재 갯수를 2로 나눠줌
+print(result + mid + result[::-1]) # 앞+중간+뒤 를 더해 문자열 출력
+
+
+"""
+AABB
+=>
+ABBA
+========
+AAABB
+=>
+ABABA
+========
+ABACABA
+=>
+
+========
+ABCD
+=>
+I'm Sorry Hansoo
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1260.py b/BaekJoon_Algorithm/1260.py
new file mode 100644
index 0000000..ce3f8bc
--- /dev/null
+++ b/BaekJoon_Algorithm/1260.py
@@ -0,0 +1,146 @@
+# 1260. DFS와 BFS
+
+"""
+I didn't solve this problem by myself. This is a fundamental concept of DFS and BFS.
+And there are two versions of applying BFS and DFS(Bi-directional vertex and vertex).
+See it again.
+"""
+# 1. My Solution(practice)
+from collections import deque
+
+N, M, V = map(int, input().split())
+graph = [[False] * (N + 1) for _ in range(N + 1)]
+for _ in range(M):
+ start, end = map(int, input().split())
+ graph[start][end] = True
+ graph[end][start] = True
+
+dfs_visited = [False] * (N + 1)
+bfs_visited = [False] * (N + 1)
+
+def DFS(moving_v):
+ dfs_visited[moving_v] = True
+ print(moving_v, end=' ')
+
+ for i in range(1, N + 1):
+ if not dfs_visited[i] and graph[moving_v][i]:
+ DFS(i)
+
+def BFS(moving_v):
+ v_que = deque([moving_v])
+ bfs_visited[moving_v] = True
+
+ while v_que:
+ moving_v = v_que.popleft()
+ print(moving_v, end=' ')
+ for i in range(1, N + 1):
+ if not bfs_visited[i] and graph[moving_v][i]:
+ v_que.append(i)
+ bfs_visited[i] = True
+
+DFS(V)
+print()
+BFS(V)
+
+# # 1. My Solution(Reference code)
+# from collections import deque
+# N, M, V = map(int, input().split())
+# graph = [[False] * (N + 1) for _ in range(N + 1)]
+#
+# for _ in range(N):
+# start, end = map(int, input().split())
+# graph[start][end] = True
+# graph[end][start] = True
+#
+# dfs_visited = [False] * (N + 1)
+# bfs_visited = [False] * (N + 1)
+#
+# def DFS(moving_v):
+# dfs_visited[moving_v] = True
+# print(moving_v, end=' ')
+# for i in range(1, N + 1):
+# if not dfs_visited[i] and graph[moving_v][i]:
+# DFS(i)
+#
+# def BFS(moving_v):
+# v_que = deque([moving_v])
+# bfs_visited[moving_v] = True
+#
+# while v_que:
+# moving_v = v_que.popleft()
+# print(moving_v, end=' ')
+# for i in range(1, N + 1):
+# if not bfs_visited[i] and graph[moving_v][i]:
+# v_que.append(i)
+# bfs_visited[i] = True
+#
+# DFS(V)
+# print()
+# BFS(V)
+
+# 2. Not my Solution
+from collections import deque
+N, M, V = map(int, input().split())
+graph = [[] for _ in range(N + 1)]
+
+for _ in range(M):
+ start, end = map(int, input().split())
+ graph[start].append(end)
+ graph[end].append(start)
+
+for i in graph:
+ i.sort()
+
+dfs_visited = [False] * (N + 1)
+bfs_visited = [False] * (N + 1)
+
+def DFS(moving_v):
+ dfs_visited[moving_v] = True
+ print(moving_v, end=' ')
+ for i in graph[moving_v]:
+ if not dfs_visited[i]:
+ DFS(i)
+
+def BFS(moving_v):
+ v_que = deque([moving_v])
+ bfs_visited[moving_v] = True
+
+ while v_que:
+ moving_v = v_que.popleft()
+ print(moving_v, end=' ')
+ for i in graph[moving_v]:
+ if not bfs_visited[i]:
+ bfs_visited[i] = True
+ v_que.append(i)
+
+
+DFS(V)
+print()
+BFS(V)
+"""
+4 5 1
+1 2
+1 3
+1 4
+2 4
+3 4
+=>
+1 2 4 3
+1 2 3 4
+==============
+5 5 3
+5 4
+5 2
+1 2
+3 4
+3 1
+=>
+3 1 2 5 4
+3 1 4 2 5
+==============
+1000 1 1000
+999 1000
+=>
+1000 999
+1000 999
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1269.py b/BaekJoon_Algorithm/1269.py
new file mode 100644
index 0000000..964da7f
--- /dev/null
+++ b/BaekJoon_Algorithm/1269.py
@@ -0,0 +1,20 @@
+# 1269. 대칭 차집합
+
+# 1. My Solution
+A_elements, B_elements = map(int, input().split())
+A = set(map(int, input().split()))
+B = set(map(int, input().split()))
+print(len(A - B) + len(B - A))
+
+# 2. Not my Solution
+
+
+
+"""
+3 5
+1 2 4
+2 3 4 5 6
+=>
+4
+==============
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1271.py b/BaekJoon_Algorithm/1271.py
new file mode 100644
index 0000000..44a0216
--- /dev/null
+++ b/BaekJoon_Algorithm/1271.py
@@ -0,0 +1,17 @@
+# 1271. 엄청난 부자 2
+
+# 1. My Solution
+n, m = map(int, input().split())
+
+div_money, rest = divmod(n, m)
+print(div_money, rest)
+# 2. Not my Solution
+
+
+"""
+1000 100
+=>
+10
+0
+===========
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1312.py b/BaekJoon_Algorithm/1312.py
new file mode 100644
index 0000000..9cd9131
--- /dev/null
+++ b/BaekJoon_Algorithm/1312.py
@@ -0,0 +1,31 @@
+# 1312. 소수
+
+# 1. My Solution
+A, B, N = map(int, input().split())
+answer = 0
+
+for idx in range(N):
+ A = (A % B) * 10
+ answer = A // B
+
+print(answer)
+
+
+# # 2. Not my Solution
+# A, B, N = map(int, input().split())
+#
+# for i in range(N):
+# A = (A % B) * 10
+# result = A // B
+#
+# print(result)
+
+"""
+3 4 1
+=>
+7
+===========
+25 7 5
+=>
+2
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1325.py b/BaekJoon_Algorithm/1325.py
new file mode 100644
index 0000000..c03848d
--- /dev/null
+++ b/BaekJoon_Algorithm/1325.py
@@ -0,0 +1,143 @@
+# 1325. 효율적인 해킹
+
+"""
+I didn't solve this problem by myself. I think this is related with DFS.
+But it's wrong for memory excess. So this is about BFS.
+I need to see more about BFS implementation.
+See it again.
+"""
+# 1. My Solution(practice)
+from collections import deque
+
+N, M = map(int, input().split())
+graph = [[] for _ in range(N + 1)]
+max_conntections = []
+
+for _ in range(M):
+ start, end = map(int, input().split())
+ graph[end].append(start)
+
+def BFS(moving_v):
+ v_que = deque([moving_v])
+ visited = [0] * (N + 1)
+ visited[moving_v] = 1
+ cnt = 1
+
+ while v_que:
+ moving_v = v_que.popleft()
+ for connect in graph[moving_v]:
+ if not visited[connect]:
+ v_que.append(connect)
+ visited[connect] = 1
+ cnt += 1
+
+ return cnt
+
+max_cnt = 1
+for i in range(1, N + 1):
+ cnt = BFS(i)
+
+ if cnt > max_cnt:
+ max_cnt = cnt
+ max_conntections = []
+ max_conntections.append(i)
+ elif cnt == max_cnt:
+ max_conntections.append(i)
+
+print(*max_conntections)
+
+# 1325. 효율적인 해킹
+
+# 1. My Solution
+from collections import deque
+
+N, M = map(int, input().split())
+graph = [[] for _ in range(N + 1)]
+max_connections = []
+
+for _ in range(M):
+ start, end = map(int, input().split())
+ graph[end].append(start)
+
+def BFS(moving_v):
+ v_que = deque([moving_v])
+ visited = [0] * (N + 1)
+ visited[moving_v] = 1
+ cnt = 1
+
+ while v_que:
+ v = v_que.popleft()
+ for j in graph[v]:
+ if not visited[j]:
+ v_que.append(j)
+ visited[j] = 1
+ cnt += 1
+
+ return cnt
+
+max_cnt = 1
+for i in range(1, N + 1):
+ cnt = BFS(i)
+
+ if cnt > max_cnt:
+ max_cnt = cnt
+ max_connections = []
+ max_connections.append(i)
+ elif cnt == max_cnt:
+ max_connections.append(i)
+
+print(*max_connections)
+
+# 2. Not my Solution
+import sys
+from collections import deque
+
+sys.setrecursionlimit(10**6)
+input = sys.stdin.readline
+n, m = map(int, input().split())
+g = [[] for _ in range(n + 1)]
+ret = []
+
+for _ in range(m):
+ a, b = map(int, input().split())
+ g[b].append(a)
+
+def dfs(i):
+ global cnt
+ visit[i] = 1
+ for c in g[i]:
+ if not visit[c]:
+ cnt += 1
+ dfs(c)
+
+max_cnt = 0
+for i in range(1, n + 1):
+ visit = [0] * (n + 1)
+ cnt = 1
+ dfs(i)
+ if cnt > max_cnt:
+ max_cnt = cnt
+ ret = []
+ ret.append(i)
+ elif cnt == max_cnt:
+ ret.append(i)
+
+print(*ret)
+"""
+5 4
+3 1
+3 2
+4 3
+5 3
+=>
+1 2
+"""
+"""
+5 4
+3 1
+3 2
+4 3
+5 3
+=>
+1 2
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1326.py b/BaekJoon_Algorithm/1326.py
new file mode 100644
index 0000000..f7a7159
--- /dev/null
+++ b/BaekJoon_Algorithm/1326.py
@@ -0,0 +1,124 @@
+# 1326. 폴짝폴짝
+
+"""
+I didn't solve this problem by myself. The key of this problem is BFS.
+I need to try implementing BFS even if it's hard.
+See it again.
+"""
+# 1. My Solution(practice)
+from collections import deque
+
+def BFS(start, end, bridge, N):
+ min_cnts = [float("inf")] * N
+ poses_que = deque([start - 1])
+ min_cnts[start - 1] = 0
+
+ while poses_que:
+ cur_pos = poses_que.popleft()
+ for mov_pos in range(N):
+ if (mov_pos - cur_pos) % bridge[cur_pos] == 0 and min_cnts[mov_pos] == float("inf"):
+ poses_que.append(mov_pos)
+ min_cnts[mov_pos] = min_cnts[cur_pos] + 1
+ if mov_pos == end - 1:
+ return min_cnts[mov_pos]
+
+ return -1
+
+N = int(input())
+bridge = list(map(int, input().split()))
+a, b = map(int, input().split())
+
+print(BFS(a, b, bridge, N))
+
+# 1326. 폴짝폴짝
+
+# 1. My Solution
+from collections import deque
+
+def BFS(start, end, bridge, N):
+ poses_que = deque([start - 1])
+ min_cnts = [-1] * N
+ min_cnts[start - 1] = 0
+
+ while poses_que:
+ cur_pos = poses_que.popleft()
+ for mov_pos in range(N):
+ if (mov_pos - cur_pos) % bridge[cur_pos] == 0 and min_cnts[mov_pos] == -1:
+ poses_que.append(mov_pos)
+ min_cnts[mov_pos] = min_cnts[cur_pos] + 1
+ if mov_pos == end - 1:
+ return min_cnts[mov_pos]
+
+ return -1
+
+N = int(input())
+bridge = list(map(int, input().split()))
+a, b = map(int, input().split())
+
+print(BFS(a, b, bridge, N))
+
+# # 1. My Solution(ChatGPT, wrong)
+# from collections import deque
+#
+# def bfs(start, end, graph):
+# visited = [False] * (N + 1)
+# queue = deque([(start, 0)]) # (node, steps)
+# visited[start] = True
+#
+# while queue:
+# node, steps = queue.popleft()
+#
+# if node == end:
+# return steps
+#
+# for neighbor in graph[node]:
+# if not visited[neighbor]:
+# visited[neighbor] = True
+# queue.append((neighbor, steps + 1))
+#
+# return -1 # If destination is unreachable
+#
+# N = int(input())
+# bridge = list(map(int, input().split()))
+# a, b = map(int, input().split())
+#
+# graph = [[] for _ in range(N + 1)]
+# for idx, pos in enumerate(bridge, start=1):
+# time = 1
+# while pos * time <= N:
+# graph[idx].append(pos * time)
+# time += 1
+#
+# min_steps = bfs(a, b, graph)
+# print(min_steps)
+
+# # 2. Not my Solution
+# from collections import deque
+#
+# def bfs(a, b, bridge, N):
+# q = deque()
+# q.append(a-1)
+# check = [-1]*N
+# check[a-1] = 0
+# while q:
+# node = q.popleft()
+# for n in range(N):
+# if (n-node)%bridge[node] == 0 and check[n] == -1:
+# q.append(n)
+# check[n] = check[node] + 1
+# if n == b-1:
+# return check[n]
+# return -1
+#
+# N = int(input())
+# bridge = list(map(int, input().split()))
+# a, b = map(int, input().split())
+# print(bfs(a, b, bridge, N))
+
+"""
+5
+1 2 2 1 2
+1 5
+=>
+1
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1330.py b/BaekJoon_Algorithm/1330.py
new file mode 100644
index 0000000..1bb7e0c
--- /dev/null
+++ b/BaekJoon_Algorithm/1330.py
@@ -0,0 +1,24 @@
+# 1330. 두 수 비교하기
+
+A, B = map(int, input().split())
+
+if A < B:
+ print("<")
+elif A > B:
+ print(">")
+else:
+ print("==")
+
+"""
+1 2
+=>
+<
+========
+10 2
+=>
+>
+========
+5 5
+=>
+==
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1388.py b/BaekJoon_Algorithm/1388.py
new file mode 100644
index 0000000..e75346b
--- /dev/null
+++ b/BaekJoon_Algorithm/1388.py
@@ -0,0 +1,207 @@
+# 1388. 바닥 장식
+
+"""
+I didn't solve this problem by myself. The key of this problem is DFS.
+This is a basic implementation of DFS Algorithm. And this can be solved without using DFS Algorithm.
+See two methods again.
+"""
+# 1. My Solution(practice, DFS)
+N, M = map(int, input().split())
+floor = [list(input()) for _ in range(N)]
+
+def DFS(x, y):
+ if floor[x][y] == '-':
+ floor[x][y] = 1
+ for _y in [-1, 1]:
+ ran_y = y + _y
+ if 0 <= ran_y < M and floor[x][ran_y] == '-':
+ DFS(x, ran_y)
+
+ if floor[x][y] == '|':
+ floor[x][y] = 1
+ for _x in [-1, 1]:
+ ran_x = x + _x
+ if 0 <= ran_x < N and floor[ran_x][y] == '|':
+ DFS(ran_x, y)
+
+cnts = 0
+for row in range(N):
+ for col in range(M):
+ if floor[row][col] == '-' or floor[row][col] == '|':
+ DFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# 2. My Solution(Practice, not DFS)
+N, M = map(int, input().split())
+floor = [list(input()) for _ in range(N)]
+
+cnts = 0
+for row in range(N):
+ a = ""
+ for col in range(M):
+ if floor[row][col] == '-':
+ if floor[row][col] != a:
+ cnts += 1
+
+ a = floor[row][col]
+
+for col in range(M):
+ a = ""
+ for row in range(N):
+ if floor[row][col] == '|':
+ if floor[row][col] != a:
+ cnts += 1
+
+ a = floor[row][col]
+
+print(cnts)
+
+# 1388. 바닥 장식
+
+# 1. My Solution
+N, M = map(int, input().split())
+floor = [list(input()) for _ in range(N)]
+
+def DFS(x, y):
+ if floor[x][y] == '-':
+ floor[x][y] = 1
+ for _y in [-1, 1]:
+ ran_y = y + _y
+ if (0 < ran_y < M) and floor[x][ran_y] == '-':
+ DFS(x, ran_y)
+
+ if floor[x][y] == '|':
+ floor[x][y] = 1
+ for _x in [-1, 1]:
+ ran_x = x + _x
+ if (0 < ran_x < N) and floor[ran_x][y] == '|':
+ DFS(ran_x, y)
+
+cnts = 0
+for row in range(N):
+ for col in range(M):
+ if floor[row][col] == '-' or floor[row][col] == '|':
+ DFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# # 2. Not my Solution(Blog, DFS)
+# # dfs 알고리즘 함수 정의
+# def dfs(x, y):
+# # 바닥 장식 모양이 '-' 일 때
+# if graph[x][y] == '-':
+# graph[x][y] = 1 # 해당 노드 방문처리
+# for _y in [1, -1]: # 양옆(좌우) 확인하기
+# Y = y + _y
+# # 좌우 노드가 주어진 범위를 벗어나지 않고 '-'모양이라면 재귀함수 호출
+# if (Y > 0 and Y < m) and graph[x][Y] == '-':
+# dfs(x, Y)
+# # 바닥 장식 모양이 '|' 일 때
+# if graph[x][y] == '|':
+# graph[x][y] = 1 # 해당 노드 방문처리
+# for _x in [1, -1]: # 상하(위아래) 확인하기
+# X = x + _x
+# # 상하 노드가 주어진 범위를 벗어나지 않고 '|' 모양이라면 재귀함수 호출
+# if (X > 0 and X < n) and graph[X][y] == '|':
+# dfs(X, y)
+#
+#
+# n, m = map(int, input().split()) # 방 바닥의 세로 크기 n, 가로 크기 m
+# graph = [] # 2차원 리스트의 맵 정보 저장할 공간
+# for _ in range(n):
+# graph.append(list(input()))
+#
+# count = 0
+# for i in range(n):
+# for j in range(m):
+# if graph[i][j] == '-' or graph[i][j] == '|':
+# dfs(i, j) # 노드가 '-'이나 '|'일 경우에 재귀함수 호출
+# count += 1
+#
+# print(count)
+
+# # 3. Not my Solution(Blog, not DFS)
+# # 방 바닥의 세로 크기 n, 가로 크기 m
+# n, m = map(int, input().split())
+# graph = [] # 2차원 리스트의 맵 정보 저장할 공간
+# for _ in range(n):
+# graph.append(list(input()))
+#
+# # '-'모양의 나무 판자 개수 계산
+# count = 0
+# for i in range(n):
+# a = ''
+# for j in range(m):
+# if graph[i][j] == '-':
+# if graph[i][j] != a:
+# count += 1
+# a = graph[i][j]
+#
+# # 'ㅣ'모양의 나무 판자 개수 계산
+# for j in range(m):
+# a = ''
+# for i in range(n):
+# if graph[i][j] == '|':
+# if graph[i][j] != a:
+# count += 1
+# a = graph[i][j]
+#
+# print(count)
+
+"""
+4 4
+----
+----
+----
+----
+=>
+4
+============
+6 9
+-||--||--
+--||--||-
+|--||--||
+||--||--|
+-||--||--
+--||--||-
+=>
+31
+============
+7 8
+--------
+|------|
+||----||
+|||--|||
+||----||
+|------|
+--------
+=>
+13
+============
+10 10
+||-||-|||-
+||--||||||
+-|-|||||||
+-|-||-||-|
+||--|-||||
+||||||-||-
+|-||||||||
+||||||||||
+||---|--||
+-||-||||||
+=>
+41
+=============
+6 6
+-||--|
+||||||
+|||-|-
+-||||-
+||||-|
+||-||-
+=>
+19
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1446.py b/BaekJoon_Algorithm/1446.py
new file mode 100644
index 0000000..a4ed167
--- /dev/null
+++ b/BaekJoon_Algorithm/1446.py
@@ -0,0 +1,184 @@
+# 1446. 지름길
+
+"""
+I didn't solve this problem by myself. The key of this problem is Dijkstra Algorithm.
+This problem can solve without Dijkstra, So I need to rewind two methods.
+See it again.
+"""
+# 1. My Solution(practice, dijkstra)
+import heapq as hq
+
+def Dijkstra(start):
+ dists_que = []
+ hq.heappush(dists_que, (0, start))
+ distances[start] = 0
+
+ while dists_que:
+ distance, cur_pos = hq.heappop(dists_que)
+
+ if distance > distances[cur_pos]:
+ continue
+
+ for nxt_end, nxt_distance in shortcuts[cur_pos]:
+ cost = distance + nxt_distance
+ if cost < distances[nxt_end]:
+ distances[nxt_end] = cost
+ hq.heappush(dists_que, (cost, nxt_end))
+
+N, D = map(int, input().split())
+shortcuts = [[] for _ in range(D + 1)]
+distances = [float("inf")] * (D + 1)
+
+for pos in range(D):
+ shortcuts[pos].append((pos + 1, 1))
+
+for _ in range(N):
+ start, end, distance = map(int, input().split())
+ if end > D:
+ continue
+
+ shortcuts[start].append((end, distance))
+
+Dijkstra(0)
+print(distances[D])
+
+# 2. My Solution(practice, no dijkstra)
+N, D = map(int, input().split())
+shortcuts = [list(map(int, input().split())) for _ in range(N)]
+
+distances = [dist for dist in range(D + 1)]
+
+for pos in range(D + 1):
+ distances[pos] = min(distances[pos], distances[pos - 1] + 1)
+ for start, end, distance in shortcuts:
+ if pos == start and end <= D and distances[pos] + distance < distances[end]:
+ distances[end] = distances[start] + distance
+
+print(distances[D])
+
+# # 2. Not my Solution(blog, Dijkstra)
+# import heapq as hq
+# INF = int(1e9)
+#
+# def Dijkstra(start):
+# dists_que = []
+# hq.heappush(dists_que, (0, start))
+# distances[start] = 0
+#
+# while dists_que:
+# distance, cur_pos = hq.heappop(dists_que)
+#
+# if distance > distances[cur_pos]:
+# continue
+#
+# for nxt_end, nxt_distance in shortcuts[cur_pos]:
+# cost = distance + nxt_distance
+# if cost < distances[nxt_end]:
+# distances[nxt_end] = cost
+# hq.heappush(dists_que, (cost, nxt_end))
+#
+# N, D = map(int, input().split())
+# shortcuts = [[] for _ in range(D + 1)]
+# distances = [INF] * (D + 1)
+#
+# for pos in range(D):
+# shortcuts[pos].append((pos + 1, 1))
+#
+# for _ in range(N):
+# start, end, distance = map(int, input().split())
+# if end > D:
+# continue
+#
+# shortcuts[start].append((end, distance))
+#
+# Dijkstra(0)
+# print(distances[D])
+
+# # 2. Not my Solution(blog, not Dijkstra)
+# import heapq
+# import sys
+# input = sys.stdin.readline
+#
+# INF = int(1e9)
+#
+# def dijkstra(start):
+# q = []
+# heapq.heappush(q,(0,start))
+# distance[start] = 0
+# while q:
+# dist, now = heapq.heappop(q)
+#
+# #지금 힙큐에서 뺀게 now까지 가는데 최소비용이 아닐수도 있으니 체크
+# if dist > distance[now]:
+# continue
+#
+# for i in graph[now]:
+# cost = dist + i[1]
+# if cost < distance[i[0]]:
+# distance[i[0]] = cost
+# heapq.heappush(q,(cost, i[0]))
+#
+#
+# n , d = map(int,input().split())
+# graph = [[] for _ in range(d+1)]
+# distance = [INF] * (d+1)
+#
+# #일단 거리 1로 초기화.
+# for i in range(d):
+# graph[i].append((i+1, 1))
+#
+# #지름길 있는 경우에 업데이트
+# for _ in range(n):
+# s, e, l = map(int,input().split())
+# if e > d:# 고려 안해도 됨.
+# continue
+# graph[s].append((e,l))
+#
+# dijkstra(0)
+# print(distance[d])
+
+# 3. Not my solution
+n, d = map(int, input().split())
+
+graph = []
+for _ in range(n):
+ graph.append(list(map(int, input().split())))
+
+distances = [i for i in range(d + 1)]
+
+for i in range(d + 1):
+ distances[i] = min(distances[i], distances[i - 1] + 1)
+ for start, end, distance in graph:
+ if i == start and end <= d and distances[i] + distance < distances[end]:
+ distances[end] = distances[start] + distance
+
+print(distances[d])
+
+"""
+5 150
+0 50 10
+0 50 20
+50 100 10
+100 151 10
+110 140 90
+=>
+70
+=====================
+2 100
+10 60 40
+50 90 20
+=>
+80
+=====================
+8 900
+0 10 9
+20 60 45
+80 190 100
+50 70 15
+160 180 14
+140 160 14
+420 901 5
+450 900 0
+=>
+432
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1531.py b/BaekJoon_Algorithm/1531.py
new file mode 100644
index 0000000..9729ebc
--- /dev/null
+++ b/BaekJoon_Algorithm/1531.py
@@ -0,0 +1,48 @@
+# 1531. 투명
+
+"""
+I didn't solve this problem by myself. This is about simple implementation but I think too much.
+See this again for simple implementation.
+"""
+# 1. My Solution
+N, M = map(int, input().split())
+points_info = [list(map(int, input().split())) for _ in range(N)]
+picture = [[0] * 100 for _ in range(100)]
+
+for x1, y1, x2, y2 in points_info:
+ for row in range(x1, x2 + 1):
+ for col in range(y1, y2 + 1):
+ picture[row - 1][col - 1] += 1
+
+picture_cnts = 0
+for row in range(len(picture)):
+ for col in range(len(picture[0])):
+ if picture[row][col] > M:
+ picture_cnts += 1
+
+print(picture_cnts)
+
+# # 2. Not my Solution
+# N, M = map(int, input().split())
+# li = [[0]*100 for _ in range(100)]
+# for _ in range(N):
+# x1, y1, x2, y2 = map(int, input().split())
+# for i in range(x1, x2+1):
+# for j in range(y1, y2+1):
+# li[i-1][j-1] += 1
+# cnt = 0
+# for i in range(100):
+# for j in range(100):
+# if li[i][j] > M:
+# cnt += 1
+# print(cnt)
+
+"""
+3 1
+21 21 80 80
+41 41 60 60
+71 71 90 90
+=>
+500
+
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1543.py b/BaekJoon_Algorithm/1543.py
new file mode 100644
index 0000000..2349c3b
--- /dev/null
+++ b/BaekJoon_Algorithm/1543.py
@@ -0,0 +1,40 @@
+# 1543. 문서 검색
+
+"""
+I solve this problem by myself. I use Python's re module for solving regular expression.
+findall function can find non-overlap searching expression.
+"""
+# 1. My Solution
+import re
+document = input()
+search_word = input()
+
+print(len(re.findall(search_word, document)))
+
+# 2. Not my Solution
+word = input()
+small = input()
+sp_word = word.split(small)
+
+print(len(sp_word) - 1)
+"""
+ababababa
+aba
+=>
+2
+==============
+a a a a a
+a a
+=>
+2
+==============
+ababababa
+ababa
+=>
+1
+==============
+aaaaaaa
+aa
+=>
+3
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1544.py b/BaekJoon_Algorithm/1544.py
new file mode 100644
index 0000000..107a2f1
--- /dev/null
+++ b/BaekJoon_Algorithm/1544.py
@@ -0,0 +1,83 @@
+# 1544. 사이클 단어
+
+"""
+I didn't solve this problem by myself. I catch how to make cycle words not using deque.
+But I didn't catch how to discriminate different words. And I learned Python's deque rotate function.
+"""
+# 1. My Solution
+from collections import deque
+def cycle_word(w1, w2):
+ if len(w1) != len(w2): return w2
+ w2 = deque(w2)
+
+ for _ in range(len(w2)):
+ w2.rotate(1)
+ c_word = "".join(w2)
+ if w1 == c_word: return c_word
+
+ return "".join(w2)
+
+N = int(input())
+words_lst = [input() for _ in range(N)]
+
+for i in range(N):
+ for j in range(1, N):
+ if words_lst[i] != words_lst[j]:
+ words_lst[j] = cycle_word(words_lst[i], words_lst[j])
+
+print(len(set(words_lst)))
+
+# 2. Not my Solution
+from collections import deque
+
+def rotate_word(w1, w2):
+ if len(w1) != len(w2): return w2
+ w2 = deque(w2)
+
+ for _ in range(len(w2)):
+ w2.rotate(1)
+ t = "".join(w2)
+ if w1 == t: return t
+
+ return "".join(w2)
+
+n = int(input())
+l = [input() for _ in range(n)]
+
+for i in range(n):
+ for j in range(i, n):
+ if l[i] != l[j]:
+ l[j] = rotate_word(l[i], l[j])
+
+print(len(set(l)))
+
+"""
+5
+picture
+turepic
+icturep
+word
+ordw
+=>
+2
+===============
+7
+ast
+ats
+tas
+tsa
+sat
+sta
+ttt
+=>
+3
+===============
+5
+aaaa
+aaa
+aa
+aaaa
+aaaaa
+=>
+4
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/16099.py b/BaekJoon_Algorithm/16099.py
new file mode 100644
index 0000000..65c99d3
--- /dev/null
+++ b/BaekJoon_Algorithm/16099.py
@@ -0,0 +1,46 @@
+# 16099. Larger Sport Facility
+
+# 1. My Solution
+Ts = int(input())
+answers = []
+areas_info = [list(map(int, input().split())) for _ in range(Ts)]
+
+for tele_l, tele_w, euro_l, euro_w in areas_info:
+ tele_area, euro_area = tele_l * tele_w, euro_l * euro_w
+ if tele_area < euro_area:
+ answers.append("Eurocom")
+ elif tele_area > euro_area:
+ answers.append("TelecomParisTech")
+ else:
+ answers.append("Tie")
+
+for answer in answers:
+ print(answer)
+
+# 2. Not my Solution
+Ts = int(input())
+results = []
+
+for _ in range(Ts):
+ tele_l, tele_w, euro_l, euro_w = map(int, input().split())
+ tele_area, euro_area = tele_l * tele_w, euro_l * euro_w
+
+ if tele_area < euro_area:
+ results.append("Eurecom")
+ elif tele_area > euro_area:
+ results.append("TelecomParisTech")
+ else:
+ results.append("Tie")
+
+# Print the results
+for result in results:
+ print(result)
+
+"""
+2
+3 2 4 2
+536874368 268792221 598 1204
+=>
+Eurecom
+TelecomParisTech
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1635.py b/BaekJoon_Algorithm/1635.py
new file mode 100644
index 0000000..3b0a809
--- /dev/null
+++ b/BaekJoon_Algorithm/1635.py
@@ -0,0 +1,59 @@
+# 1635. 1 또는 -1
+
+"""
+This code is not passing Baekjoon Server.
+I use Overlapping combination to solve this problem, but I got Mermory Error.
+The error is still going on.
+"""
+# 1. My Solution
+def generate_combinations(length):
+ if length == 0:
+ return [[]]
+ else:
+ previous_combinations = generate_combinations(length - 1)
+ new_combinations = []
+ for combination in previous_combinations:
+ new_combinations.append(combination + [-1])
+ new_combinations.append(combination + [1])
+ return new_combinations
+
+def find_zero_sum_combinations(sequences):
+ zero_sum_combinations = []
+ for sequence in sequences:
+ combinations = generate_combinations(len(sequence))
+ for combination in combinations:
+ if sum(a*b for a, b in zip(sequence, combination)) == 0:
+ zero_sum_combinations.append(combination)
+ break
+ return zero_sum_combinations
+
+# 입력을 받습니다.
+N, M = map(int, input().split())
+sequences = [list(map(int, input().split())) for _ in range(M)]
+
+# 0인 조합을 찾습니다.
+zero_sum_combinations = find_zero_sum_combinations(sequences)
+
+# 결과를 출력합니다.
+for combination in zero_sum_combinations:
+ print(*combination)
+
+# 2. Not my Solution
+
+
+"""
+4 6
+-1 -1 -1 -1
+-1 1 -1 -1
+1 1 1 1
+1 -1 -1 -1
+1 -1 1 1
+1 1 -1 -1
+================
+-1 1 -1 1
+1 -1 -1 -1
+-1 1 -1 1
+1 -1 1 1
+1 -1 -1 -1
+-1 1 -1 1
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1716.py b/BaekJoon_Algorithm/1716.py
new file mode 100644
index 0000000..ef7e8b4
--- /dev/null
+++ b/BaekJoon_Algorithm/1716.py
@@ -0,0 +1,73 @@
+# 1716. Polynomial Remains
+
+"""
+I didn't solve this problem by myself. I didn't catch the key point of this problem(Because of English Explanation).
+First point is that the end condition of this problem.
+And last is that the meaning of remains at Polynomial coefficients.
+"""
+# 1. My Solution
+while True:
+ N, K = map(int, input().split())
+ if N == -1 and K == -1:
+ break
+
+ coefficients = list(map(int, input().split()))
+ for i in range(N, K - 1, -1):
+ coefficients[i - K] -= coefficients[i]
+ coefficients[i] = 0
+
+ rests = []
+ for i in range(N, -1, -1):
+ if coefficients[i]:
+ rests.append(coefficients[i])
+
+ if not rests:
+ rests.append(0)
+
+ print(*rests[::-1])
+
+# 2. Not my Solution(ChatGPT)
+while True:
+ n, k = map(int, input().split())
+ if n == -1 and k == -1:
+ break
+
+ coefs_lst = list(map(int, input().split()))
+ for i in range(n, k - 1, -1):
+ coefs_lst[i - k] -= coefs_lst[i]
+ coefs_lst[i] = 0
+
+ st = []
+ for i in range(n, -1, -1):
+ if coefs_lst[i]:
+ st.append(coefs_lst[i])
+
+ if not st:
+ st.append(0)
+
+ print(*st[::-1])
+"""
+5 2
+6 3 3 2 0 1
+5 2
+0 0 3 2 0 1
+4 1
+1 4 1 1 1
+6 3
+2 3 -3 4 1 0 1
+1 0
+5 1
+0 0
+7
+3 5
+1 2 3 4
+-1 -1
+=>
+3 2
+-3 -1
+-2
+-1 2 -3
+0
+0
+1 2 3 4
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1747.py b/BaekJoon_Algorithm/1747.py
new file mode 100644
index 0000000..c4b84c2
--- /dev/null
+++ b/BaekJoon_Algorithm/1747.py
@@ -0,0 +1,72 @@
+# 1747. 소수 & 팰린드롬
+
+"""
+I almost solve this problem by myself.
+I catch Palindrome and Prime number implementation by my reference code, so see it again for perfect implementation.
+But I miss except conditions that if the number is 1 and number is 1000000.
+"""
+# 1. My Solution
+N = int(input())
+
+def is_prime_number(num):
+ for i in range(2, int(num ** 0.5) + 1):
+ if num % i == 0:
+ return False
+
+ return True
+
+def is_palindrome(num):
+ num_str = str(num)
+ if num_str == num_str[::-1]:
+ return True
+
+ return False
+
+answer = 0
+for num in range(N, 1000001):
+ if num == 1:
+ continue
+ if is_prime_number(num) and is_palindrome(num):
+ answer = num
+ break
+
+if answer == 0:
+ answer = 1003001
+
+print(answer)
+
+# 2. Not my Solution
+import math
+
+def isPrime(x): # 소수인지 판별해주는 함수
+ for i in range(2, int(math.sqrt(x)+1)):
+ if x % i == 0:
+ return False
+ return True
+
+N = int(input())
+result = 0
+
+for i in range(N, 1000001): # 입력값 N 부터 최대값 까지 순환
+ if i == 1: # 1은 소수가 아니기 때문에 예외처리
+ continue
+ if str(i) == str(i)[::-1]: # 팰림드롬 수 일 경우
+ if isPrime(i) == True: # 소수 판별 함수 적용
+ result = i
+ break
+
+if result == 0: # 입력값이 만약 최대 값 100만일 경우
+ result = 1003001 # 100만 이상이면서 팰림드롬 및 소수일 경우를 적용
+
+print(result)
+
+
+"""
+31
+=>
+101
+================
+1000000
+=>
+1003001
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1755.py b/BaekJoon_Algorithm/1755.py
new file mode 100644
index 0000000..accd67b
--- /dev/null
+++ b/BaekJoon_Algorithm/1755.py
@@ -0,0 +1,65 @@
+# 1755. 숫자 놀이
+
+"""
+I solve this problem by myself. But I need to see Other's solution for making code efficient.
+See it again.
+"""
+# 1. My Solution
+M, N = map(int, input().split())
+
+num_to_str = {'1': "one", '2': "two", '3': "three", '4': "four",
+ '5': "five", '6': "six", '7': "seven", '8': "eight",
+ '9': 'nine', '0': "zero"}
+str_to_int = {"one": '1', "two": '2', "three": '3', "four": '4',
+ "five": '5', "six": '6', "seven": '7', "eight": '8',
+ "nine": '9', "zero": '0'}
+
+numbers_str = []
+for num in range(M, N + 1):
+ convert_str = ""
+ num_str = str(num)
+ if len(num_str) >= 2:
+ for chr_idx, num_chr in enumerate(num_str):
+ if chr_idx != len(num_str) - 1:
+ convert_str += num_to_str[num_chr]
+ convert_str += ' '
+ else:
+ convert_str += num_to_str[num_chr]
+
+ numbers_str.append(convert_str)
+ else:
+ numbers_str.append(num_to_str[num_str])
+
+sort_numbers = sorted(numbers_str)
+answer = []
+for s_num in sort_numbers:
+ numbers_str = "".join(str_to_int[s_num_chr] for s_num_chr in s_num.split())
+ answer.append(int(numbers_str))
+
+for num_idx, number in enumerate(answer, 1):
+ if num_idx % 10 == 0:
+ print(number)
+ else:
+ print(number, end=' ')
+
+# 2. Not my Solution
+d = {'1':'one', '2':'two', '3':'three', '4':'four', '5':'five',
+ '6':'six', '7':'seven', '8':'eight', '9':'nine', '0':'zero'}
+M, N = map(int, input().split())
+li = []
+for i in range(M, N+1):
+ s = ' '.join([d[c] for c in str(i)])
+ li.append([i, s])
+li.sort(key=lambda x:x[1])
+for i in range(len(li)):
+ if i % 10 == 0 and i != 0:
+ print()
+ print(li[i][0], end=' ')
+
+"""
+8 28
+=>
+8 9 18 15 14 19 11 17 16 13
+12 10 28 25 24 21 27 26 23 22
+20
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/1789.py b/BaekJoon_Algorithm/1789.py
new file mode 100644
index 0000000..eed3d03
--- /dev/null
+++ b/BaekJoon_Algorithm/1789.py
@@ -0,0 +1,39 @@
+# 1789. 수들의 합
+
+"""
+I didn't solve this problem by myself. I catch that this is related with Sum of Arithmetic Sequences.
+But the key point is making S with many numbers as possible.
+See it again.
+"""
+# 1. My Solution(Blog)
+s = int(input())
+total, count = 0, 0
+
+while True:
+ count += 1
+ total += count
+ if total > s:
+ count -= 1
+ break
+
+print(count)
+
+# 2. Not my Solution(Blog)
+S = int(input())
+i, cnt = 0, 0
+
+while True:
+ if S > i:
+ i += 1
+ S -= i
+ cnt += 1
+ else:
+ print(cnt)
+ break
+
+print(cnt)
+"""
+200
+=>
+19
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/2075.py b/BaekJoon_Algorithm/2075.py
new file mode 100644
index 0000000..c1ad94c
--- /dev/null
+++ b/BaekJoon_Algorithm/2075.py
@@ -0,0 +1,60 @@
+# 2075. N번째 큰 수
+
+"""
+I didn't solve this problem by myself. I have to think about Memory Excess and Time Excess.
+And the key is that using queue data structure for all data is wrong in here.
+See this again.
+"""
+# # 1. My Solution(Wrong, memory excess)
+# N = int(input())
+# graph = [list(map(int, input().split())) for _ in range(N)]
+#
+# graph_sort = sorted(sum(graph, []), reverse=True)
+# print(graph_sort[N - 1])
+
+# 1. My Solution
+import heapq as hq
+
+N = int(input())
+graph = []
+
+for _ in range(N):
+ numbers = map(int, input().split())
+ for number in numbers:
+ if len(graph) < N:
+ hq.heappush(graph, number)
+ else:
+ if graph[0] < number:
+ hq.heappop(graph)
+ hq.heappush(graph, number)
+
+print(graph[0])
+
+
+# 2. Not my Solution
+import heapq
+
+heap = []
+n = int(input())
+
+for _ in range(n):
+ numbers = map(int, input().split())
+ for number in numbers:
+ if len(heap) < n: # heap의 크기를 n개로 유지
+ heapq.heappush(heap, number)
+ else:
+ if heap[0] < number:
+ heapq.heappop(heap)
+ heapq.heappush(heap, number)
+print(heap[0])
+
+"""
+5
+12 7 9 15 5
+13 8 11 19 6
+21 10 26 31 16
+48 14 28 35 25
+52 20 32 41 49
+=>
+35
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/2161.py b/BaekJoon_Algorithm/2161.py
new file mode 100644
index 0000000..2b11fe3
--- /dev/null
+++ b/BaekJoon_Algorithm/2161.py
@@ -0,0 +1,30 @@
+# 2161. 카드1
+
+"""
+I solve this problem by myself. See again for using Python collection's deque.
+The positive value of deque's rotate function means rotate sequence in a right way.
+Negative means rotate sequence in a left way.
+"""
+# 1. My Solution
+from collections import deque
+
+N = int(input())
+cards = deque([num for num in range(1, N + 1)])
+discards = []
+
+while len(cards) >= 1:
+ discards.append(cards.popleft())
+ cards.rotate(-1)
+
+print(*discards)
+
+# 2. Not my Solution
+
+
+
+"""
+7
+=>
+1 3 5 7 4 2 6
+
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/2195.py b/BaekJoon_Algorithm/2195.py
new file mode 100644
index 0000000..ce2ebb3
--- /dev/null
+++ b/BaekJoon_Algorithm/2195.py
@@ -0,0 +1,78 @@
+# 2195. 문자열 복사
+
+"""
+I didn't solve this problem by myself. I think this is a little hard version of simple implementation.
+The key of this problem is finding the longest overlapping words between P and S.
+See it again.
+"""
+# 1. My Solution
+S = input()
+target_P = input()
+index_p = 0
+answer = 0
+
+while index_p < len(target_P):
+ index_s, overlaps, max_value = 0, 0, 0
+ for index_s in range(len(S)):
+ if index_p + overlaps >= len(target_P):
+ break
+
+ if target_P[index_p + overlaps] == S[index_s]:
+ overlaps += 1
+ max_value = max(max_value, overlaps)
+ else:
+ overlaps = 0
+ index_p += max_value
+ answer += 1
+
+print(answer)
+
+# # 2. Not my Solution(Blog 1)
+# import sys
+# input = sys.stdin.readline
+#
+# S = input().strip()
+# P = input().strip()
+# index_p = 0
+# ans = 0
+#
+# while index_p < len(P):
+# max_value, temp, index_s = 0, 0, 0
+# while index_s < len(S) and index_p + temp < len(P):
+# if P[index_p + temp] == S[index_s]:
+# temp += 1
+# max_value = max(max_value, temp)
+# else:
+# temp = 0
+# index_s += 1
+# index_p += max_value
+# ans += 1
+#
+# print(ans)
+
+# 3. Not my Solution(Blog 2)
+fst = input()
+scd = input()
+rst = 0
+start = 0 #문자 시작 인덱싱
+end = 0 #끝 인덱싱
+while True:
+ if start == len(scd): #scd문자열 모두 탐색했다면
+ break
+ for i in range(len(fst) - (end - start)): #길이만큼의 문자열 있는지
+ if fst[i:i + (end - start) + 1] == scd[start:end + 1]: #있다면 길이 1을 늘려서 한번더 탐색
+ end += 1
+ break
+ else: #없다면 결과값, 문자 인덱싱 갱신
+ rst += 1
+ end -= 1
+ start = end + 1
+ end = start
+print(rst)
+"""
+xy0z
+zzz0yyy0xxx
+=>
+10
+
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/2420.py b/BaekJoon_Algorithm/2420.py
new file mode 100644
index 0000000..daa50da
--- /dev/null
+++ b/BaekJoon_Algorithm/2420.py
@@ -0,0 +1,11 @@
+# 2420. 사파리 월드
+
+N, M = map(int, input().split())
+
+print(int(abs(N - M)))
+
+"""
+-2 5
+=>
+7
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/26307.py b/BaekJoon_Algorithm/26307.py
new file mode 100644
index 0000000..ef5a435
--- /dev/null
+++ b/BaekJoon_Algorithm/26307.py
@@ -0,0 +1,17 @@
+# 26307. Correct
+
+# 1. My Solution
+HH, MM = map(int, input().split())
+start_time = 540
+end_time = HH * 60 + MM
+print(end_time - start_time)
+
+"""
+9 0
+=>
+0
+============
+11 59
+=>
+179
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/26489.py b/BaekJoon_Algorithm/26489.py
new file mode 100644
index 0000000..bcb814a
--- /dev/null
+++ b/BaekJoon_Algorithm/26489.py
@@ -0,0 +1,51 @@
+# 26489. Gum Gum for Jay Jay
+
+"""
+I almost solve this problem by myself. But I don't know how to solve RunTimeError.
+The key of this problem is using try except.
+"""
+# 1. My Solution
+answers = 0
+while True:
+ try:
+ line = input()
+ if line == "gum gum for jay jay":
+ answers += 1
+ except EOFError:
+ break
+
+print(answers)
+
+# 2. Not my Solution
+def gum_gum_for_jay_jay():
+ answer = 0
+
+ while True:
+ try:
+ gum_gum = input()
+ answer += 1
+ except EOFError:
+ break
+
+ return answer
+
+
+if __name__ == "__main__":
+ print(gum_gum_for_jay_jay())
+
+
+"""
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+gum gum for jay jay
+=>
+11
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/6186.py b/BaekJoon_Algorithm/6186.py
new file mode 100644
index 0000000..82f5a76
--- /dev/null
+++ b/BaekJoon_Algorithm/6186.py
@@ -0,0 +1,193 @@
+# 6186. Best Grass
+
+"""
+I didn't solve this problem by myself. The key of this problem is BFS and DFS.
+This is a basic problem of solving both BFS and DFS. But BFS is more efficient than using DFS.
+See this again.
+"""
+# 1. My Solution(Practice, BFS)
+from collections import deque
+
+R, C = map(int, input().split())
+field = [list(input()) for _ in range(R)]
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+
+def BFS(x, y):
+ que = deque([(x, y)])
+ field[x][y] = 1
+
+ while que:
+ x, y = que.popleft()
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+ if 0 <= mx < R and 0 <= my < C and field[mx][my] == '#':
+ que.append((mx, my))
+ field[mx][my] = 1
+
+cnts = 0
+for row in range(R):
+ for col in range(C):
+ if field[row][col] == '#':
+ BFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# 2. My Solution(Practice, DFS)
+import sys
+sys.setrecursionlimit(100000)
+
+R, C = map(int, input().split())
+field = [list(input()) for _ in range(R)]
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+visited = [[False] * C for _ in range(R)]
+
+def DFS(x, y):
+ visited[x][y] = True
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+ if 0 <= mx < R and 0 <= my < C and field[mx][my] == '#' and not visited[mx][my]:
+ DFS(mx, my)
+
+cnts = 0
+for row in range(R):
+ for col in range(C):
+ if field[row][col] == '#' and not visited[row][col]:
+ DFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# 6186. Best Grass
+
+# 1. My Solution(BFS)
+from collections import deque
+
+R, C = map(int, input().split())
+field = [list(input()) for _ in range(R)]
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+cnts = 0
+
+def BFS(x, y):
+ que = deque([(x, y)])
+ field[x][y] = 1
+
+ while que:
+ x, y = que.popleft()
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+ if (0 <= mx < R) and (0 <= my < C) and field[mx][my] == '#':
+ que.append((mx, my))
+ field[mx][my] = 1
+
+for row in range(R):
+ for col in range(C):
+ if field[row][col] == '#':
+ BFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# 2. My Solution(DFS)
+import sys
+
+sys.setrecursionlimit(100000)
+
+
+R, C = map(int, input().split())
+field = [list(input()) for _ in range(R)]
+visited = [[False] * C for _ in range(R)]
+ds_dict = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
+
+def DFS(x, y):
+ visited[x][y] = True
+ for dx, dy in ds_dict.values():
+ mx, my = x + dx, y + dy
+ if 0 <= mx < R and 0 <= my < C:
+ if field[mx][my] == '#' and not visited[mx][my]:
+ DFS(mx, my)
+
+cnts = 0
+for row in range(R):
+ for col in range(C):
+ if field[row][col] == '#' and not visited[row][col]:
+ DFS(row, col)
+ cnts += 1
+
+print(cnts)
+
+# # 2. Not my Solution(Blog, BFS)
+# from collections import deque
+#
+# def bfs(y, x):
+# q = deque()
+# q.append((y, x))
+# graph[y][x] = '1'
+# while q:
+# y, x = q.popleft()
+# for dy, dx in d:
+# Y, X = y+dy, x+dx
+# if (0 <= Y < R) and (0 <= X < C) and graph[Y][X] == '#':
+# q.append((Y, X))
+# graph[Y][X] = '1'
+#
+# R, C = map(int, input().split())
+# graph = [list(input()) for _ in range(R)]
+# d = [(-1, 0), (1, 0), (0, -1), (0, 1)]
+# cnt = 0
+# for i in range(R):
+# for j in range(C):
+# if graph[i][j] == '#':
+# bfs(i, j)
+# cnt += 1
+# print(cnt)
+
+# # 3. Not my Solution(Blog, DFS)
+# import sys
+#
+# sys.setrecursionlimit(100000)
+#
+#
+# def read():
+# return sys.stdin.readline().rstrip()
+#
+#
+# vec = [(1, 0), (0, 1), (-1, 0), (0, -1)]
+#
+# r, c = [int(i) for i in read().split(" ")]
+# field = [[0 for _ in range(c)] for _ in range(r)]
+# check = [[0 for _ in range(c)] for _ in range(r)]
+# for i in range(r):
+# for j, char in enumerate(read()):
+# if char == '#':
+# field[i][j] = 1
+#
+#
+# def dfs(y, x):
+# check[y][x] = 1
+# for dv in vec:
+# ny, nx = y + dv[0], x + dv[1]
+# range_chk = 0 <= ny < r and 0 <= nx < c
+# if range_chk:
+# if field[ny][nx] and not check[ny][nx]:
+# dfs(ny, nx)
+#
+#
+# ans = 0
+# for y in range(r):
+# for x in range(c):
+# if field[y][x] and not check[y][x]:
+# dfs(y, x)
+# ans += 1
+#
+# print(ans)
+"""
+5 6
+.#....
+..#...
+..#..#
+...##.
+.#....
+=>
+5
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/DynaimcProgramming/1309.py b/BaekJoon_Algorithm/DynaimcProgramming/1309.py
new file mode 100644
index 0000000..7571386
--- /dev/null
+++ b/BaekJoon_Algorithm/DynaimcProgramming/1309.py
@@ -0,0 +1,50 @@
+# 1309. 동물원
+
+"""
+I didn't solve this problem by myself. The key of this problem is finding math rules.
+Find math rules elaborated(dp[i] = 2 * dp[i - 1] + dp[i - 2]).
+See it again.
+"""
+# 1. My Solution(practice)
+N = int(input())
+
+if N == 1:
+ print(3)
+else:
+ dp = [1 for _ in range(N + 1)]
+ dp[1], dp[2] = 3, 7
+ for i in range(3, N + 1):
+ dp[i] = (2 * dp[i - 1] + dp[i - 2]) % 9901
+
+ print(dp[N])
+
+# 1. My Solution
+N = int(input())
+
+if N == 1:
+ print(3)
+else:
+ dp = [1 for _ in range(N + 1)]
+ dp[1], dp[2] = 3, 7
+ for i in range(3, N + 1):
+ dp[i] = (2 * dp[i - 1] + dp[i - 2]) % 9901
+
+ print(dp[N])
+
+# 2. Not my Solution
+from sys import stdin
+N = int(stdin.readline())
+
+if N == 1:
+ print(3)
+else:
+ dp = [1 for _ in range(N + 1)]
+ dp[1], dp[2] = 3, 7
+ for i in range(3, N + 1):
+ dp[i] = (2 * dp[i - 1] + dp[i - 2]) % 9901
+ print(dp[N])
+"""
+4
+=>
+41
+"""
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/DynaimcProgramming/DeliverySugar.py b/BaekJoon_Algorithm/DynaimcProgramming/DeliverySugar.py
new file mode 100644
index 0000000..2bd48fb
--- /dev/null
+++ b/BaekJoon_Algorithm/DynaimcProgramming/DeliverySugar.py
@@ -0,0 +1,30 @@
+# 1. 설탕 배달
+
+'''C++과 같은 풀이인데 무슨 오류인지 모르겠네... 백준에서 오류남(내 풀이)
+ 입력 받을 때 숫자만 입력받아야하고, -1을 문자열로 출력해야 함'''
+N = int(input())
+bag = 0
+
+while True:
+ if N % 5 == 0:
+ print(N // 5 + bag)
+ break
+ elif N <= 0:
+ print('-1')
+ break
+ N -= 3
+ bag += 1
+
+'''남의 풀이'''
+sugar = int(input())
+
+bag = 0
+while sugar >= 0 :
+ if sugar % 5 == 0 : # 5의 배수이면
+ bag += (sugar // 5) # 5로 나눈 몫을 구해야 정수가 됨
+ print(bag)
+ break
+ sugar -= 3
+ bag += 1 # 5의 배수가 될 때까지 설탕-3, 봉지+1
+else :
+ print(-1)
\ No newline at end of file
diff --git a/BaekJoon_Algorithm/DynaimcProgramming/__init__.py b/BaekJoon_Algorithm/DynaimcProgramming/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/BaekJoon_Algorithm/__init__.py b/BaekJoon_Algorithm/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/CodeUp/100.py b/CodeUp/100.py
new file mode 100644
index 0000000..eb97f0a
--- /dev/null
+++ b/CodeUp/100.py
@@ -0,0 +1,30 @@
+# 코드업 100제 마지막 문제
+
+"""
+I almost solve this problem by myself. But I miss after finding the target coordinate.
+The easiest way is applying infinity loop for finding target coordinate.
+And make some exceptions.
+See it again.
+"""
+miro_box = [list(map(int, input().split())) for _ in range(10)]
+
+start_x, start_y = 1, 1
+while True:
+ if miro_box[start_x][start_y] == 0:
+ miro_box[start_x][start_y] = 9
+ elif miro_box[start_x][start_y] == 2:
+ miro_box[start_x][start_y] = 9
+ break
+
+ if miro_box[start_x][start_y + 1] == 1 and miro_box[start_x + 1][start_y] == 1:
+ break
+
+ if miro_box[start_x][start_y + 1] != 1:
+ start_y += 1
+ elif miro_box[start_x + 1][start_y] != 1:
+ start_x += 1
+
+for row in range(len(miro_box)):
+ for col in range(len(miro_box[0])):
+ print(miro_box[row][col], end=' ')
+ print()
\ No newline at end of file
diff --git a/CodeUp/__init__.py b/CodeUp/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/HCILab_Algorithm/CountsOfRoutes.py b/HCILab_Algorithm/CountsOfRoutes.py
new file mode 100644
index 0000000..7c5d6b4
--- /dev/null
+++ b/HCILab_Algorithm/CountsOfRoutes.py
@@ -0,0 +1,39 @@
+# 10주차 20220523 길갯수
+
+def solution(m, n):
+ answer = 0
+
+ routes = [[1] * n for _ in range(m)]
+ for row in range(1, m):
+ for col in range(1, n):
+ routes[row][col] = routes[row - 1][col] + routes[row][col - 1]
+
+ answer = routes[m - 1][n - 1]
+ return answer
+
+m_1 = 3
+m_2 = 7
+m_3 = 11
+m_4 = 9
+m_5 = 19
+m_6 = 1
+m_7 = 5
+m_8 = 4
+
+n_1 = 2
+n_2 = 3
+n_3 = 5
+n_4 = 11
+n_5 = 13
+n_6 = 1
+n_7 = 5
+n_8 = 7
+
+print(solution(m_1, n_1))
+print(solution(m_2, n_2))
+print(solution(m_3, n_3))
+print(solution(m_4, n_4))
+print(solution(m_5, n_5))
+print(solution(m_6, n_6))
+print(solution(m_7, n_7))
+print(solution(m_8, n_8))
\ No newline at end of file
diff --git a/HCILab_Algorithm/CrossSteppingstone.py b/HCILab_Algorithm/CrossSteppingstone.py
new file mode 100644
index 0000000..c9320dc
--- /dev/null
+++ b/HCILab_Algorithm/CrossSteppingstone.py
@@ -0,0 +1,55 @@
+# 25. 징검다리 건너기
+
+def solution(stones, k):
+ answer = 0
+
+ left, right = 1, 200000000
+ while left <= right:
+ temp = stones.copy()
+ mid = (left + right) // 2
+ cnt = 0
+ for t in temp:
+ if t - mid <= 0:
+ cnt += 1
+ else:
+ cnt = 0
+ if cnt >= k:
+ break
+
+ if cnt >= k:
+ right = mid - 1
+ else:
+ left = mid + 1
+
+ answer = left
+ return answer
+
+stones_1 = [2, 4, 5, 3, 2, 1, 4, 2, 5, 1]
+
+k_1 = 3
+
+print(solution(stones_1, k_1))
+
+def solution_error(stones, k):
+ answer = 0
+
+ while(True):
+ answer += 1
+ for i in range(len(stones)):
+ if stones[i] == 0:
+ continue
+ else:
+ stones[i] -= 1
+
+ count = 0
+ for stone in stones:
+ if stone == 0:
+ count += 1
+ if count == k:
+ return answer
+ else:
+ count = 0
+
+ return answer
+
+print(solution_error(stones_1, k_1))
diff --git a/HCILab_Algorithm/JumpGame.py b/HCILab_Algorithm/JumpGame.py
new file mode 100644
index 0000000..1ec6274
--- /dev/null
+++ b/HCILab_Algorithm/JumpGame.py
@@ -0,0 +1,37 @@
+# 7주차 2번 점프 게임
+
+def solution(nums):
+ answer = False
+
+ for idx, num in enumerate(nums):
+ if num == 0:
+ continue
+
+ if idx - num >= 0 and nums[idx - num] == 0:
+ return True
+ if idx + num < len(nums) and nums[idx + num] == 0:
+ return True
+
+ return answer
+
+nums_1 = [2, 3, 1, 1, 4]
+nums_2 = [3, 2, 1, 0, 4]
+nums_3 = [2, 5, 0, 0]
+nums_4 = [0, 2, 3]
+nums_5 = [5, 9, 3, 2, 1, 0, 2, 3, 3, 1, 0, 0]
+nums_6 = [2, 0]
+nums_7 = [2, 0, 0]
+nums_8 = [0]
+nums_9 = [3, 1, 2, 1, 4]
+nums_10 = [2, 0, 0, 5]
+
+print(solution(nums_1))
+print(solution(nums_2))
+print(solution(nums_3))
+print(solution(nums_4))
+print(solution(nums_5))
+print(solution(nums_6))
+print(solution(nums_7))
+print(solution(nums_8))
+print(solution(nums_9))
+print(solution(nums_10))
\ No newline at end of file
diff --git a/HCILab_Algorithm/MaximumPartArrary.py b/HCILab_Algorithm/MaximumPartArrary.py
new file mode 100644
index 0000000..f23e429
--- /dev/null
+++ b/HCILab_Algorithm/MaximumPartArrary.py
@@ -0,0 +1,30 @@
+# 10주차 20220523 최대 부분 배열
+
+def solution(nums):
+ answer = 0
+
+ max_arr = [nums[0]]
+ for i in range(1, len(nums)):
+ max_arr.append(nums[i] + (max_arr[i - 1] if max_arr[i - 1] > 0 else 0))
+
+ answer = max(max_arr)
+ return answer
+
+nums_1 = [ -2, 1, -3, 4, -1, 2, 1, -5, 4]
+nums_2 = [1, 2]
+nums_3 = [-1]
+nums_4 = [0, 3, -1]
+nums_5 = [-2, -1]
+nums_6 = [-9, 8, -7, 6, -5, 4, -3, 2, -1, 0]
+nums_7 = [-5, -2, 8, 9]
+nums_8 = [-5, 3, 9, -7]
+
+
+print(solution(nums_1))
+print(solution(nums_2))
+print(solution(nums_3))
+print(solution(nums_4))
+print(solution(nums_5))
+print(solution(nums_6))
+print(solution(nums_7))
+print(solution(nums_8))
\ No newline at end of file
diff --git a/HCILab_Algorithm/PonketMon.py b/HCILab_Algorithm/PonketMon.py
new file mode 100644
index 0000000..bec4d15
--- /dev/null
+++ b/HCILab_Algorithm/PonketMon.py
@@ -0,0 +1,47 @@
+# 27. 폰캣몬
+
+def solution(nums):
+ answer = 0
+
+ mine = [nums[0]]
+ for one in nums:
+ if len(mine) != len(nums) // 2:
+ if one not in mine:
+ mine.append(one)
+ else:
+ break
+
+ answer = len(mine)
+ return answer
+
+nums_1 = [3, 1, 2, 3]
+nums_2 = [3, 3, 3, 2, 2, 4]
+nums_3 = [3, 3, 3, 2, 2, 2]
+
+# print(solution(nums_1))
+# print(solution(nums_2))
+# print(solution(nums_3))
+
+'''내 풀이'''
+from itertools import combinations
+def solution_mine(nums):
+ answer = 0
+
+ comb_nums = list(combinations(nums, len(nums) // 2))
+ no_dup_comb_nums = sorted([set(item) for item in comb_nums], key=lambda x: len(x),
+ reverse=True)
+ answer = len(no_dup_comb_nums[0])
+ return answer
+
+# print(solution_mine(nums_1))
+# print(solution_mine(nums_2))
+# print(solution_mine(nums_3))
+
+def solution_best(nums):
+ answer = min(len(nums) // 2, len(set(nums)))
+
+ return answer
+
+print(solution_best(nums_1))
+print(solution_best(nums_2))
+print(solution_best(nums_3))
\ No newline at end of file
diff --git a/HCILab_Algorithm/SumOfPaths.py b/HCILab_Algorithm/SumOfPaths.py
new file mode 100644
index 0000000..d57930b
--- /dev/null
+++ b/HCILab_Algorithm/SumOfPaths.py
@@ -0,0 +1,106 @@
+# 1. 경로 노드들의 합 구하기
+
+class Node:
+ def __init__(self, val):
+ self.val = val
+ self.left = None
+ self.right = None
+
+class BinaryTree:
+ def __init__(self):
+ self.root = None
+
+ def deserialize(self, new_node):
+ if not self.root:
+ self.root = new_node
+ return
+
+ queue = [self.root]
+ while queue:
+ temp = queue.pop(0)
+ if temp.val != 'null':
+ if not temp.left:
+ temp.left = new_node
+ return
+ queue.append(temp.left)
+ if not temp.right:
+ temp.right = new_node
+ return
+ queue.append(temp.right)
+
+ def level_sum(self, root, val = 0, target = 0):
+ cnt = 0
+ val += [int(root.val) if root.val != 'null' else 0][0]
+
+ if root.left:
+ if root.left.val == 'null':
+ if val == target:
+ return 1
+ else:
+ cnt += self.level_sum(root.left, val, target)
+ else:
+ if val == target:
+ return 1
+
+ if root.right and root.right.val != 'null':
+ cnt += self.level_sum(root.right, val, target)
+ return cnt
+
+def solution(tree, k):
+ answer = 0
+
+ t = BinaryTree()
+ for node in tree.split(','):
+ t.deserialize(Node(node))
+
+ answer = t.level_sum(t.root, target = k)
+ return answer
+
+tree_1 = '5,4,8,11,null,13,4,7,2,null,null,5,1'
+tree_2 = '7,3,8,13,4,10,9,2,1,16,null,5,null,null,6'
+tree_3 = '9,2,4,14,null,8,5'
+tree_4 = '3,7,8,4,9,13,17,5,null,12,2,10,14,1,6'
+tree_5 = '10'
+tree_6 = '4,2,5,12,6,5,8,null,null,8,2,null,6,3,1'
+tree_7 = '5,2,4,10,11,15,7,6,8,35,22,16,37,22,24'
+tree_8 = '3,7,2,15,24,13,11'
+tree_9 = '1,7,9,10,11,8,9,17,17,11,14,17,3,16,4'
+tree_10 = '9,2,4,14,null,8,5'
+tree_11 = '3,7,8,4,9,13,17,5,null,12,2,10,14,1,6'
+tree_12 = '7,8,5,3,7,4,null,5,2,9,8,null,7,null,null'
+tree_13 = '5,4,8,11,null,13,4,7,2,null,null,5,1'
+tree_14 = '5,3,9,8,null,2,null'
+tree_15 = '7,1,3,8,5,9,null,4,9,12,2,6,null,null,null'
+
+k_1 = 22
+k_2 = 30
+k_3 = 25
+k_4 = 30
+k_5 = 10
+k_6 = 20
+k_7 = 40
+k_8 = 40
+k_9 = 35
+k_10 = 15
+k_11 = 21
+k_12 = 23
+k_13 = 26
+k_14 = 16
+k_15 = 25
+
+print(solution(tree_1, k_1))
+print(solution(tree_2, k_2))
+print(solution(tree_3, k_3))
+print(solution(tree_4, k_4))
+print(solution(tree_5, k_5))
+print()
+print(solution(tree_6, k_6))
+print(solution(tree_7, k_7))
+print(solution(tree_8, k_8))
+print(solution(tree_9, k_9))
+print(solution(tree_10, k_10))
+print(solution(tree_11, k_11))
+print(solution(tree_12, k_12))
+print(solution(tree_13, k_13))
+print(solution(tree_14, k_14))
+print(solution(tree_15, k_15))
\ No newline at end of file
diff --git a/HCILab_Algorithm/TheLongestPalindrome.py b/HCILab_Algorithm/TheLongestPalindrome.py
new file mode 100644
index 0000000..cd9ca7c
--- /dev/null
+++ b/HCILab_Algorithm/TheLongestPalindrome.py
@@ -0,0 +1,23 @@
+# 31. 가장 긴 펠린드롬
+
+def isPalin(x):
+ if x == x[::-1]:
+ return True
+ return False
+
+def solution(s):
+ answer = 0
+
+ for i in range(len(s)):
+ for j in range(i + 1, len(s) + 1):
+ if isPalin(s[i:j]):
+ if answer < len(s[i:j]):
+ answer = len(s[i:j])
+
+ return answer
+
+s_1 = 'abcdcba'
+s_2 = 'abacde'
+
+print(solution(s_1))
+print(solution(s_2))
\ No newline at end of file
diff --git a/HCILab_Algorithm/WordPuzzle.py b/HCILab_Algorithm/WordPuzzle.py
new file mode 100644
index 0000000..8943adb
--- /dev/null
+++ b/HCILab_Algorithm/WordPuzzle.py
@@ -0,0 +1,19 @@
+# 1. 단어 퍼즐
+
+def solution(strs, t):
+ answer = 0
+
+
+ return answer
+
+strs_1 = ["ba","na","n","a"]
+strs_2 = ["app","ap","p","l","e","ple","pp"]
+strs_3 = ["ba","an","nan","ban","n"]
+
+t_1 = "banana"
+t_2 = "apple"
+t_3 = "banana"
+
+print(solution(strs_1, t_1))
+print(solution(strs_2, t_2))
+print(solution(strs_3, t_3))
\ No newline at end of file
diff --git a/HCILab_Algorithm/__init__.py b/HCILab_Algorithm/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/OneBookCodingTest/Chapter3/RemoveConsecutivecharA.py b/OneBookCodingTest/Chapter3/RemoveConsecutivecharA.py
new file mode 100644
index 0000000..8413acb
--- /dev/null
+++ b/OneBookCodingTest/Chapter3/RemoveConsecutivecharA.py
@@ -0,0 +1,62 @@
+# 1. 연속된 문자 A 제거
+
+S = input()
+
+# 1. Use deque for solving this problem
+from collections import deque
+
+change_str = ""
+s_idx = 0
+S_que = deque(map(str, S))
+while len(S_que) != 1:
+ if S_que[s_idx] in ['a', 'A'] and S_que[s_idx + 1] in ['a', 'A']:
+ S_que.popleft()
+ S_que.popleft()
+ S_que.appendleft('a')
+ else:
+ front_chr = S_que.popleft()
+ change_str += front_chr
+
+change_str += S_que.pop()
+print(change_str)
+
+# 2. Use Python re module(recommend Solution)
+import re
+
+pattern = re.compile("[aA]{2,}")
+result = pattern.findall(S)
+print(re.sub(pattern, 'a', S))
+
+# 3. Book Solution(Too much complicated, not recommend)
+def solution(S):
+ answer = ""
+ i = 0
+
+ while i < len(S):
+ if S[i] != 'a' and S[i] != 'A':
+ answer += S[i]
+ i += 1
+ continue
+
+ j = i + 1
+ while j < len(S):
+ if S[j] != 'a' and S[j] != 'A':
+ break
+ j += 1
+
+ if j - i == 1:
+ answer += S[i]
+ else:
+ answer += S[i].lower()
+ i = j
+
+ return answer
+
+print(solution(S))
+"""
+ZZaAAbBAAA
+=> ZZabBa
+
+ABAaaAAAaab
+=> ABab
+"""
\ No newline at end of file
diff --git a/OneBookCodingTest/Chapter3/__init__.py b/OneBookCodingTest/Chapter3/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/OneBookCodingTest/__init__.py b/OneBookCodingTest/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/KAKAO/MakeTwoQueueSumWithSame.py b/Programmers/KAKAO/MakeTwoQueueSumWithSame.py
new file mode 100644
index 0000000..9069ceb
--- /dev/null
+++ b/Programmers/KAKAO/MakeTwoQueueSumWithSame.py
@@ -0,0 +1,51 @@
+# KAKAO Tech 기출 문제 1. 두 큐 합 같게 만들기
+
+from collections import deque
+'''
+Using Queue but I think in different ways.
+My way is to make queue1 and queue2 with one total queue.
+And multiply 2 for total queue and compare front queue and rear queue
+But I don't know how to implement it.
+So follow queue solution
+'''
+def solution(queue1, queue2):
+ answer = 0
+
+ que1, que2 = deque(queue1), deque(queue2)
+ que1_sum, que2_sum = sum(queue1), sum(queue2)
+ total_sum = que1_sum + que2_sum
+
+ if total_sum % 2 != 0:
+ return -1
+
+ cnt = 0
+ while que1_sum != que2_sum:
+ if answer > len(que1) + len(que2) + 1:
+ return -1
+
+ if que1_sum < que2_sum:
+ que2_num = que2.popleft()
+ que1.append(que2_num)
+ que1_sum += que2_num
+ que2_sum -= que2_num
+ else:
+ que1_num = que1.popleft()
+ que2.append(que1_num)
+ que2_sum += que1_num
+ que1_sum -= que1_num
+
+ answer += 1
+
+ return answer
+
+queue1_1 = [3, 2, 7, 2]
+queue1_2 = [1, 2, 1, 2]
+queue1_3 = [1, 1]
+
+queue2_1 = [4, 6, 5, 1]
+queue2_2 = [1, 10, 1, 2]
+queue2_3 = [1, 5]
+
+print(solution(queue1_1, queue2_1))
+print(solution(queue1_2, queue2_2))
+print(solution(queue1_3, queue2_3))
diff --git a/Programmers/KAKAO/__init__.py b/Programmers/KAKAO/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/LEVEL0/AddPolynomial.py b/Programmers/LEVEL0/AddPolynomial.py
new file mode 100644
index 0000000..fe597db
--- /dev/null
+++ b/Programmers/LEVEL0/AddPolynomial.py
@@ -0,0 +1,56 @@
+# Restart 19. 다항식 더하기
+def solution(polynomial):
+ answer = ''
+
+ x_coef, const = 0, 0
+ polynomial = polynomial.split(' + ')
+ for poly in polynomial:
+ if 'x' in poly:
+ if poly[:-1]:
+ x_coef += int(poly[:-1])
+ else:
+ x_coef += 1
+ else:
+ const += int(poly)
+
+ if x_coef and const:
+ answer = f'{x_coef}x + {const}' if x_coef > 1 else f'x + {const}'
+ elif x_coef and not const:
+ answer = f'{x_coef}x' if x_coef > 1 else f'x'
+ else:
+ answer = f'{const}'
+ return answer
+
+polynomial_1 = "3x + 7 + x"
+polynomial_2 = "x + x + x"
+
+print(solution(polynomial_1))
+print(solution(polynomial_2))
+
+def solution_other(polynomial):
+ answer = ''
+ x_coef, num = 0, 0
+ polynomial = polynomial.split(' + ')
+ for poly in polynomial:
+ if 'x' in poly:
+ if len(poly) == 1:
+ x_coef += 1
+ else:
+ x_coef += int(poly[:-1])
+ else:
+ num += int(poly)
+
+ if x_coef == 0 and num == 0:
+ return '0'
+ if x_coef == 0:
+ return str(num)
+ if x_coef == 1:
+ x_coef = ''
+ if num == 0:
+ return str(x_coef) + 'x'
+
+ answer = str(x_coef) + 'x + ' + str(num)
+ return answer
+
+# print(solution_other(polynomial_1))
+# print(solution_other(polynomial_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/AdditionofHiddenNumber_2.py b/Programmers/LEVEL0/AdditionofHiddenNumber_2.py
new file mode 100644
index 0000000..dfbfb1d
--- /dev/null
+++ b/Programmers/LEVEL0/AdditionofHiddenNumber_2.py
@@ -0,0 +1,36 @@
+# Restart 8. 숨어있는 숫자의 덧셈(2)
+
+# My Solution
+import re
+def solution(my_string):
+ answer = 0
+
+ extract_num = re.findall(r'\d+', my_string)
+ extract_num_process = [extract_n for extract_n in extract_num if len(extract_n) == len(str(int(extract_n)))]
+ answer = sum(list(map(int, extract_num_process)))
+ return answer
+
+my_string_1 = "aAb1B2cC34oOp"
+my_string_2 = "1a2b3c4d123Z"
+
+print(solution(my_string_1))
+print(solution(my_string_2))
+
+import re
+def solution_other(my_string):
+ answer = sum([int(i) for i in re.findall(r'[0-9]+', my_string)])
+
+ return answer
+
+print(solution_other(my_string_1))
+print(solution_other(my_string_2))
+
+# No using re module
+def solution_best(my_string):
+ extract_num_str = ''.join(i if i.isdigit() else ' ' for i in my_string)
+ answer = sum(int(i) for i in extract_num_str.split())
+
+ return answer
+
+print(solution_best(my_string_1))
+print(solution_best(my_string_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/ChickenCoupon.py b/Programmers/LEVEL0/ChickenCoupon.py
new file mode 100644
index 0000000..adde355
--- /dev/null
+++ b/Programmers/LEVEL0/ChickenCoupon.py
@@ -0,0 +1,46 @@
+# Restart 17. 치킨 쿠폰
+
+'''
+Not my solution, key point is coupons operation.
+'''
+def solution(chicken):
+ answer = 0
+ coupons = chicken
+ while coupons >= 10:
+ service = coupons // 10
+ answer += service
+ coupons = coupons % 10 + service
+ return answer
+
+chicken_1 = 100
+chicken_2 = 1081
+
+print(solution(chicken_1))
+print(solution(chicken_2))
+
+'''
+Almost same, but I have to consider coupon rest
+'''
+def solution_mine(chicken):
+ answer = 0
+
+ coupons = 0
+ while chicken >= 10:
+ if chicken != 10:
+ service, coupon = divmod(chicken, 10)
+ answer += service
+ coupons += coupon
+ if coupons >= 10:
+ coup_service, coup_coupon = divmod(coupons, 10)
+ answer += coup_service
+ coupons = coup_coupon
+ else:
+ service, coupon = 1, 1
+ answer += service
+ coupons += coupon
+ chicken //= 10
+
+ return answer
+
+print(solution_mine(chicken_1))
+print(solution_mine(chicken_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/ConditionOfTriangle_2.py b/Programmers/LEVEL0/ConditionOfTriangle_2.py
new file mode 100644
index 0000000..a1cd837
--- /dev/null
+++ b/Programmers/LEVEL0/ConditionOfTriangle_2.py
@@ -0,0 +1,34 @@
+# Restart 11. 삼각형의 완성조건 (2)
+
+# My Solution
+def solution(sides):
+ sides.sort()
+ answer = len(range(sides[1] - sides[0] + 1, sides[1] + 1)) + len(range(sides[1] + 1, sum(sides)))
+
+ return answer
+
+sides_1 = [1, 2]
+sides_2 = [3, 6]
+sides_3 = [11, 7]
+
+print(solution(sides_1))
+print(solution(sides_2))
+print(solution(sides_3))
+
+def solution_other(sides):
+ answer = len(list(range(abs(sides[0] - sides[1]) + 1, sum(sides))))
+
+ return answer
+
+print(solution_other(sides_1))
+print(solution_other(sides_2))
+print(solution_other(sides_3))
+
+def solution_best(sides):
+ answer = sum(sides) - max(sides) + min(sides) - 1
+
+ return answer
+
+print(solution_best(sides_1))
+print(solution_best(sides_2))
+print(solution_best(sides_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/ControlZ.py b/Programmers/LEVEL0/ControlZ.py
new file mode 100644
index 0000000..ec290dd
--- /dev/null
+++ b/Programmers/LEVEL0/ControlZ.py
@@ -0,0 +1,17 @@
+# Restart 14. 컨트롤 제트
+
+# My Solution
+def solution(s):
+ answer = 0
+
+ s_split = s.split()
+ stack = []
+ for str_s in s_split:
+ if str_s != 'Z':
+ stack.append(int(str_s))
+ else:
+ stack.pop()
+
+ answer = sum(stack)
+ return answer
+
diff --git a/Programmers/LEVEL0/DeterminingFiniteDecimalNumber.py b/Programmers/LEVEL0/DeterminingFiniteDecimalNumber.py
new file mode 100644
index 0000000..89ba922
--- /dev/null
+++ b/Programmers/LEVEL0/DeterminingFiniteDecimalNumber.py
@@ -0,0 +1,65 @@
+# Restart 18.유한소수 구하기
+
+'''
+Try to find aliquots in b that are divided by GCD.
+'''
+from math import gcd, sqrt
+def is_prime(num):
+ for i in range(2, int(sqrt(num)) + 1):
+ if num % i == 0:
+ return False
+
+ return True
+
+def solution(a, b):
+ answer = 0
+
+ a, b = a // gcd(a, b), b // gcd(a, b)
+
+ b_aliquots = [b_aliq for b_aliq in range(2, b + 1) if b % b_aliq == 0]
+ b_aliquot_primes = [b_aliquot for b_aliquot in b_aliquots if is_prime(b_aliquot)]
+ answer_lst = [b_aliquot_prime for b_aliquot_prime in b_aliquot_primes if b_aliquot_prime != 2 and
+ b_aliquot_prime != 5]
+
+ answer = 1 if len(answer_lst) == 0 else 2
+ return answer
+
+a_1 = 7
+a_2 = 11
+a_3 = 12
+
+b_1 = 20
+b_2 = 22
+b_3 = 21
+
+print(solution(a_1, b_1))
+print(solution(a_2, b_2))
+print(solution(a_3, b_3))
+
+'''
+Best idea : just divide 2 and 5 and if there exist rest, judge it.
+'''
+def solution_best(a, b):
+ answer = 0
+
+ b //= gcd(a, b)
+ while b % 2 == 0:
+ b //= 2
+
+ while b % 5 == 0:
+ b //= 5
+ answer = 1 if b == 1 else 2
+
+ return answer
+
+a_1 = 7
+a_2 = 11
+a_3 = 12
+
+b_1 = 20
+b_2 = 22
+b_3 = 21
+
+print(solution_best(a_1, b_1))
+print(solution_best(a_2, b_2))
+print(solution_best(a_3, b_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/FindAreaofRectangle.py b/Programmers/LEVEL0/FindAreaofRectangle.py
new file mode 100644
index 0000000..47b1087
--- /dev/null
+++ b/Programmers/LEVEL0/FindAreaofRectangle.py
@@ -0,0 +1,21 @@
+# Restart 12. 직사각형 넓이 구하기
+
+def solution(dots):
+ dots.sort()
+ answer = abs(dots[3][0] - dots[0][0]) * abs(dots[3][1] - dots[0][1])
+
+ return answer
+
+dots_1 = [[1, 1], [2, 1], [2, 2], [1, 2]]
+dots_2 = [[-1, -1], [1, 1], [1, -1], [-1, 1]]
+
+print(solution(dots_1))
+print(solution(dots_2))
+
+def solution_best(dots):
+ answer = (max(dots)[0] - min(dots)[0]) * (max(dots)[1] - min(dots)[1])
+
+ return answer
+
+print(solution_best(dots_1))
+print(solution_best(dots_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/FindMode.py b/Programmers/LEVEL0/FindMode.py
new file mode 100644
index 0000000..07055da
--- /dev/null
+++ b/Programmers/LEVEL0/FindMode.py
@@ -0,0 +1,41 @@
+# Restart 20. 최빈값 구하기
+'''
+My Solution : use Counter object to find most common values
+'''
+from collections import Counter
+def solution(array):
+ answer = 0
+
+ arr_counter = Counter(array)
+ arr_cntr_sort = arr_counter.most_common()
+ count_lst = [arr_cntr[1] for arr_cntr in arr_cntr_sort]
+ if count_lst[0] in count_lst[1:]:
+ answer = -1
+ else:
+ answer = arr_cntr_sort[0][0]
+
+ return answer
+
+array_1 = [1, 2, 3, 3, 3, 4]
+array_2 = [1, 1, 2, 2]
+array_3 = [1]
+
+print(solution(array_1))
+print(solution(array_2))
+print(solution(array_3))
+
+'''
+Not using Counter object, but see this method.
+'''
+def solution_best(array):
+ answer = -1
+
+ while len(array) != 0:
+ for idx, value in enumerate(set(array)):
+ array.remove(value)
+ if idx == 0: return value
+ return answer
+
+print(solution_best(array_1))
+print(solution_best(array_2))
+print(solution_best(array_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/ForeignLanguageDictionary.py b/Programmers/LEVEL0/ForeignLanguageDictionary.py
new file mode 100644
index 0000000..bd30060
--- /dev/null
+++ b/Programmers/LEVEL0/ForeignLanguageDictionary.py
@@ -0,0 +1,38 @@
+# Restart 9. 외계어 사전
+
+# My Solution
+from itertools import permutations
+def solution(spell, dic):
+ answer = 2
+
+ comb_spell = [''.join(spell_comb) for spell_comb in list(permutations(spell, len(spell)))]
+
+ for word in dic:
+ if word in comb_spell:
+ answer = 1
+
+ return answer
+
+spell_1 = ["p", "o", "s"]
+spell_2 = ["z", "d", "x"]
+spell_3 = ["s", "o", "m", "d"]
+
+dic_1 = ["sod", "eocd", "qixm", "adio", "soo"]
+dic_2 = ["def", "dww", "dzx", "loveaw"]
+dic_3 = ["moos", "dzx", "smm", "sunmmo", "som"]
+
+print(solution(spell_1, dic_1))
+print(solution(spell_2, dic_2))
+print(solution(spell_3, dic_3))
+
+def solution_other(spell, dic):
+ answer = 2
+
+ spell = set(spell)
+ for s in dic:
+ if not spell - set(s):
+ answer = 1
+ return answer
+
+print(solution_other(spell_1, dic_1))
+print(solution_other())
\ No newline at end of file
diff --git a/Programmers/LEVEL0/FractionSum.py b/Programmers/LEVEL0/FractionSum.py
new file mode 100644
index 0000000..1f04f6b
--- /dev/null
+++ b/Programmers/LEVEL0/FractionSum.py
@@ -0,0 +1,30 @@
+# Restart 22. 분수의 덧셈
+
+'''
+Python Fraction module for operating Fraction
+'''
+from fractions import Fraction
+def solution(numer1, denom1, numer2, denom2):
+ answer = []
+
+ frac_1 = Fraction(numer1, denom1)
+ frac_2 = Fraction(numer2, denom2)
+ frac_sum = frac_1 + frac_2
+ for num in [frac_sum.numerator, frac_sum.denominator]:
+ answer.append(num)
+ return answer
+
+numer1_1 = 1
+numer2_1 = 3
+
+denom1_1 = 2
+denom2_1 = 4
+
+numer1_2 = 9
+numer2_2 = 1
+
+denom1_2 = 2
+denom2_2 = 3
+
+print(solution(numer1_1, denom1_1, numer2_1, denom2_1))
+print(solution(numer1_2, denom1_2, numer2_2, denom2_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/HateEnglish.py b/Programmers/LEVEL0/HateEnglish.py
new file mode 100644
index 0000000..b9e48aa
--- /dev/null
+++ b/Programmers/LEVEL0/HateEnglish.py
@@ -0,0 +1,41 @@
+# Restart 8. 영어가 싫어요
+
+# My Solution
+import re
+def solution(numbers):
+ answer = 0
+
+ numbers = re.sub(r'zero', '0', numbers)
+ numbers = re.sub(r'one', '1', numbers)
+ numbers = re.sub(r'two', '2', numbers)
+ numbers = re.sub(r'three', '3', numbers)
+ numbers = re.sub(r'four', '4', numbers)
+ numbers = re.sub(r'five', '5', numbers)
+ numbers = re.sub(r'six', '6', numbers)
+ numbers = re.sub(r'seven', '7', numbers)
+ numbers = re.sub(r'eight', '8', numbers)
+ numbers = re.sub(r'nine', '9', numbers)
+
+ answer = int(numbers)
+ return answer
+
+numbers_1 = "onetwothreefourfivesixseveneightnine"
+numbers_2 = "onefourzerosixseven"
+
+print(solution(numbers_1))
+print(solution(numbers_2))
+
+def solution_other(numbers):
+ answer = 0
+
+ for num, eng in enumerate(['zero', 'one', 'two',
+ 'three', 'four', 'five',
+ 'six', 'seven', 'eight',
+ 'nine']):
+ numbers = numbers.replace(eng, str(num))
+
+ answer = int(numbers)
+ return answer
+
+print(solution_other(numbers_1))
+print(solution_other(numbers_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/IceAmericano.py b/Programmers/LEVEL0/IceAmericano.py
new file mode 100644
index 0000000..6d515e4
--- /dev/null
+++ b/Programmers/LEVEL0/IceAmericano.py
@@ -0,0 +1,23 @@
+# Restart 1. 아이스 아메리카노
+
+def solution(money):
+ answer = []
+
+ americano = 5500
+ answer += divmod(money, americano)
+
+ return answer
+
+money_1 = 5500
+money_2 = 15000
+
+print(solution(money_1))
+print(solution(money_2))
+
+def solution_other(money):
+ answer = [money // 5500, money % 5500]
+
+ return answer
+
+print(solution_other(money_1))
+print(solution_other(money_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/LengthofOverlapSegments.py b/Programmers/LEVEL0/LengthofOverlapSegments.py
new file mode 100644
index 0000000..b21eb11
--- /dev/null
+++ b/Programmers/LEVEL0/LengthofOverlapSegments.py
@@ -0,0 +1,34 @@
+# Restart 25. 겹치는 선분의 길이
+
+def solution(lines):
+ answer = 0
+
+ table = [set([]) for _ in range(200)]
+ for index, line in enumerate(lines):
+ x1, x2 = line
+ for x in range(x1, x2):
+ table[x + 100].add(index)
+
+ for line in table:
+ if len(line) > 1:
+ answer += 1
+ return answer
+
+lines_1 = [[0, 1], [2, 5], [3, 9]]
+lines_2 = [[-1, 1], [1, 3], [3, 9]]
+lines_3 = [[0, 5], [3, 9], [1, 10]]
+
+print(solution(lines_1))
+print(solution(lines_2))
+print(solution(lines_3))
+
+def solution_best(lines):
+ answer = 0
+
+ sets = [set(range(min(line), max(line))) for line in lines]
+ answer = len(sets[0] & sets[1] | sets[0] & sets[2] | sets[1] & sets[2])
+ return answer
+
+print(solution_best(lines_1))
+print(solution_best(lines_2))
+print(solution_best(lines_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/LoginSuccess.py b/Programmers/LEVEL0/LoginSuccess.py
new file mode 100644
index 0000000..c6ba174
--- /dev/null
+++ b/Programmers/LEVEL0/LoginSuccess.py
@@ -0,0 +1,56 @@
+# Restart 15. 로그인 성공?
+
+# My Wrong Solution
+'''
+조건문 만으로 처리할 수 없음
+id와 password 모두 다 고려하는 조건이어야 하기 때문에
+'''
+def solution_wrong(id_pw, db):
+ answer = 'login' if id_pw[0] in [data[0] for data in db] and id_pw[1] in [data[1] for data in db] \
+ else 'wrong pw' if id_pw[0] in [data[0] for data in db] and id_pw[1] not in [data[1] for data in db] else 'fail'
+
+ return answer
+
+id_pw_1 = ["meosseugi", "1234"]
+id_pw_2 = ["programmer01", "15789"]
+id_pw_3 = ["rabbit04", "98761"]
+
+db_1 = [["rardss", "123"], ["yyoom", "1234"], ["meosseugi", "1234"]]
+db_2 = [["programmer02", "111111"], ["programmer00", "134"], ["programmer01", "1145"]]
+db_3 = [["jaja11", "98761"], ["krong0313", "29440"], ["rabbit00", "111333"]]
+
+# print(solution_wrong(id_pw_1, db_1))
+# print(solution_wrong(id_pw_2, db_2))
+# print(solution_wrong(id_pw_3, db_3))
+
+# Use for loop
+def solution(id_pw, db):
+ answer = 'fail'
+
+ for data in db:
+ if id_pw[0] in data:
+ if id_pw[1] == data[1]:
+ answer = 'login'
+ else:
+ answer = 'wrong pw'
+ return answer
+
+print(solution(id_pw_1, db_1))
+print(solution(id_pw_2, db_2))
+print(solution(id_pw_3, db_3))
+
+# Use Hash
+def solution_best(id_pw, db):
+ answer = 'fail'
+ db_dict = {data[0] : data[1] for data in db}
+
+ if id_pw[0] in db_dict:
+ if id_pw[1] == db_dict[id_pw[0]]:
+ answer = 'login'
+ else:
+ answer = 'wrong pw'
+ return answer
+
+print(solution_best(id_pw_1, db_1))
+print(solution_best(id_pw_2, db_2))
+print(solution_best(id_pw_3, db_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/MakeBbyA.py b/Programmers/LEVEL0/MakeBbyA.py
new file mode 100644
index 0000000..78f914a
--- /dev/null
+++ b/Programmers/LEVEL0/MakeBbyA.py
@@ -0,0 +1,28 @@
+# Restart 2. A로 B 만들기
+
+# My Solution
+from collections import Counter
+def solution(before, after):
+ bef_counter = Counter(before)
+ aft_counter = Counter(after)
+
+ answer = 1 if bef_counter.items() == aft_counter.items() else 0
+ return answer
+
+before_1 = "olleh"
+before_2 = "allpe"
+
+after_1 = "hello"
+after_2 = "apple"
+
+print(solution(before_1, after_1))
+print(solution(before_2, after_2))
+
+# Best Solution that I thought
+def solution_best(before, after):
+ answer = 1 if sorted(before) == sorted(after) else 0
+
+ return answer
+
+print(solution_best(before_1, after_1))
+print(solution_best(before_2, after_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/MakeTwoDimension.py b/Programmers/LEVEL0/MakeTwoDimension.py
new file mode 100644
index 0000000..f71cc71
--- /dev/null
+++ b/Programmers/LEVEL0/MakeTwoDimension.py
@@ -0,0 +1,27 @@
+# Restart 3. 2차원으로 만들기
+
+# My Solution
+def solution(num_list, n):
+ answer = [num_list[num_idx:num_idx + n] for num_idx in range(0, len(num_list), n)]
+
+ return answer
+
+num_list_1 = [1, 2, 3, 4, 5, 6, 7, 8]
+num_list_2 = [100, 95, 2, 4, 5, 6, 18, 33, 948]
+
+n_1 = 2
+n_2 = 3
+
+print(solution(num_list_1, n_1))
+print(solution(num_list_2, n_2))
+
+import numpy as np
+def solution_other(num_list, n):
+ answer = 0
+
+ arr = np.array(num_list).reshape(-1, n)
+ answer = arr.tolist()
+ return answer
+
+print(solution_other(num_list_1, n_1))
+print(solution_other(num_list_2, n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/NearestNumber.py b/Programmers/LEVEL0/NearestNumber.py
new file mode 100644
index 0000000..9e14245
--- /dev/null
+++ b/Programmers/LEVEL0/NearestNumber.py
@@ -0,0 +1,53 @@
+# Restart 5. 가장 가까운 수
+
+# My Solution
+'''
+이렇게 풀면 [8, 6], 7과 같이 순서가 바뀐 경우에는 해결되지 않음
+'''
+def solution(array, n):
+ answer = 0
+
+ dif_arr = [arr - n if arr > n else n - arr for arr in array]
+ min_arr_idx = dif_arr.index(min(dif_arr))
+ answer = array[min_arr_idx]
+
+ return answer
+
+array_1 = [3, 10, 28]
+array_2 = [10, 11, 12]
+
+n_1 = 20
+n_2 = 13
+
+# print(solution(array_1, n_1))
+# print(solution(array_2, n_2))
+
+# Unique Solution
+solution_unique = lambda a, n:sorted(a, key = lambda x : (abs(x - n), x))[0]
+
+# print(solution_unique(array_1, n_1))
+# print(solution_unique(array_2, n_2))
+
+# Other Solution
+def solution_other(array, n):
+ answer = 0
+
+ array.sort(key = lambda x : (abs(x - n), x - n))
+ answer = array[0]
+ return answer
+
+# print(solution_other(array_1, n_1))
+# print(solution_other(array_2, n_2))
+
+# Best Solution
+def solution_best(array, n):
+ # print(sorted([index, abs(n - num), num] for index, num in enumerate(array)))
+ # print(sorted([[index, abs(n - num), num] for index, num in enumerate(array)], key=lambda x: (x[1], x[-1])))
+ # print(sorted([[index, abs(n - num), num] for index, num in enumerate(array)], key=lambda x: (x[1], x[-1]))[0])
+ # print(sorted([[index, abs(n - num), num] for index, num in enumerate(array)], key=lambda x: (x[1], x[-1]))[0][0])
+ answer = array[sorted([[index, abs(n-num), num] for index, num in enumerate(array)], key=lambda x: (x[1], x[-1]))[0][0]]
+
+ return answer
+
+# print(solution_best(array_1, n_1))
+# print(solution_best(array_2, n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/NextNumber.py b/Programmers/LEVEL0/NextNumber.py
new file mode 100644
index 0000000..df88794
--- /dev/null
+++ b/Programmers/LEVEL0/NextNumber.py
@@ -0,0 +1,43 @@
+# Restart 21. 다음에 올 숫자
+
+'''
+Consider that common difference or common ratio be able to get a minus cost.
+'''
+def solution(common):
+ answer = 0
+
+ two_overlap_lst = []
+ for idx in range(0, len(common) - 1):
+ two_overlap_lst.append(common[idx:idx + 2])
+
+ diff_lst = []
+ for first, second in two_overlap_lst:
+ diff_lst.append(second - first)
+
+ if len(set(diff_lst)) == 1:
+ answer = common[-1] + diff_lst[0]
+ else:
+ first, second = two_overlap_lst[0]
+ common_ratio = second // first
+ answer = common[-1] * common_ratio
+
+ return answer
+
+common_1 = [1, 2, 3, 4]
+common_2 = [2, 4, 8]
+
+print(solution(common_1))
+print(solution(common_2))
+
+def solution_best(common):
+ answer = 0
+
+ a, b, c = common[:3]
+ if (b - a) == (c - b):
+ answer = common[-1] + (b - a)
+ else:
+ answer = common[-1] * (b // a)
+ return answer
+
+print(solution_best(common_1))
+print(solution_best(common_2))
diff --git a/Programmers/LEVEL0/NumberofBeadSplit.py b/Programmers/LEVEL0/NumberofBeadSplit.py
new file mode 100644
index 0000000..16a83a3
--- /dev/null
+++ b/Programmers/LEVEL0/NumberofBeadSplit.py
@@ -0,0 +1,36 @@
+# Restart 9. 구슬 나누는 경우의 수
+
+# My Solution
+def solution(balls, share):
+ answer = 0
+
+ n_factorial, m_factorial, n_diff_m_factorial = 1, 1, 1
+ for n_facto in range(1, balls + 1):
+ n_factorial *= n_facto
+
+ for m_facto in range(1, share + 1):
+ m_factorial *= m_facto
+
+ for n_dif_m_facto in range(1, balls - share + 1):
+ n_diff_m_factorial *= n_dif_m_facto
+
+ answer = n_factorial / ((n_diff_m_factorial) * m_factorial)
+ return answer
+
+balls_1 = 3
+balls_2 = 5
+
+share_1 = 2
+share_2 = 3
+
+print(solution(balls_1, share_1))
+print(solution(balls_2, share_2))
+
+import math
+def solution_other(balls, share):
+ answer = math.comb(balls, share)
+
+ return answer
+
+print(solution_other(balls_1, share_1))
+print(solution_other(balls_2, share_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/Parallel.py b/Programmers/LEVEL0/Parallel.py
new file mode 100644
index 0000000..025dad7
--- /dev/null
+++ b/Programmers/LEVEL0/Parallel.py
@@ -0,0 +1,68 @@
+# Restart 26. 평행
+
+from itertools import combinations
+def solution(dots):
+ answer = 0
+
+ # Find 4 dots combination
+ dots_comb = list(combinations(dots, 2))
+
+ # Find line combination that satisfy [a-b, c-d], [a-c, b-d], [a-d, b-c]
+ lines_comb = [(dots_comb[line_idx], dots_comb[-line_idx - 1]) for line_idx in range(len(dots_comb) // 2)]
+
+ for two_lines in lines_comb:
+ first_line, second_line = two_lines
+ (first_front_x, first_front_y), (first_rear_x, first_rear_y) = first_line
+ (second_front_x, second_front_y), (second_rear_x, second_rear_y) = second_line
+ first_grad = (first_rear_y - first_front_y) / (first_rear_x - first_front_x)
+ second_grad = (second_rear_y - second_front_y) / (second_rear_x - second_front_x)
+
+ if first_grad == second_grad:
+ answer = 1
+
+
+ return answer
+
+dots_1 = [[1, 4], [9, 2], [3, 8], [11, 6]]
+dots_2 = [[3, 5], [4, 1], [2, 4], [5, 10]]
+
+print(solution(dots_1))
+print(solution(dots_2))
+
+'''
+Weird about confusing Problem's explanation
+a, b, c, d
+[a-b], [a-c], [a-d], [b-c], [b-d], [c-d] -> not apply combination 2
+'''
+def solution_mine(dots):
+ answer = 0
+
+ dots_comb = list(combinations(dots, 2))
+ print(dots_comb)
+ grad_lst = []
+ for two_points in dots_comb:
+ (first_x, first_y), (last_x, last_y) = two_points
+ gradient = (last_y - first_y) / (last_x - first_x)
+ grad_lst.append(gradient)
+
+ if len(grad_lst) != len(set(grad_lst)):
+ answer = 1
+ else:
+ answer = 0
+
+ return answer
+
+# print(solution_mine(dots_1))
+# print(solution_mine(dots_2))
+
+def solution_other(dots):
+ [[x1, y1], [x2, y2], [x3, y3], [x4, y4]] = dots
+ answer1 = ((y1 - y2) * (x3 - x4) == (y3 - y4) * (x1 - x2))
+ answer2 = ((y1 - y3) * (x2 - x4) == (y2 - y4) * (x1 - x3))
+ answer3 = ((y1 - y4) * (x2 - x3) == (y2 - y3) * (x1 - x4))
+
+ return 1 if answer1 or answer2 or answer3 else 0
+
+from functools import reduce
+def solution_best(dots):
+ return int(max(reduce(lambda dict, x: dict.update({x: dict.get(x, 0)+1}) or dict,[(d1[1] - d2[1]) / (d1[0] - d2[0]) if d1[0] - d2[0] else "x" for d1 in dots for d2 in dots if not d1 == d2], {}).values()) > 2)
diff --git a/Programmers/LEVEL0/PushString.py b/Programmers/LEVEL0/PushString.py
new file mode 100644
index 0000000..5ee7c67
--- /dev/null
+++ b/Programmers/LEVEL0/PushString.py
@@ -0,0 +1,35 @@
+# Restart 13. 문자열 밀기
+
+# My Solution
+from collections import deque
+def solution(A, B):
+ answer = 0
+
+ A_deq = deque(A)
+ push_cases = []
+ for idx in range(len(A)):
+ last_char = A_deq.pop()
+ A_deq.appendleft(last_char)
+ push_cases.append(''.join(A_deq))
+
+ if B in push_cases:
+ answer = push_cases.index(B) + 1
+
+ # 이 부분도 고려했어야 함!!!
+ if A == B:
+ answer = 0
+ return answer
+
+A_1 = 'hello'
+A_2 = 'apple'
+
+B_1 = 'ohell'
+B_2 = 'elppa'
+
+# print(solution(A_1, B_1))
+# print(solution(A_2, B_2))
+
+solution_best = lambda a, b:(b * 2).find(a)
+
+print(solution_best(A_1, B_1))
+print(solution_best(A_2, B_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/Ranking.py b/Programmers/LEVEL0/Ranking.py
new file mode 100644
index 0000000..350da17
--- /dev/null
+++ b/Programmers/LEVEL0/Ranking.py
@@ -0,0 +1,21 @@
+# Restart 16. 등수 매기기
+
+# My Solution
+'''
+Use one more list that sort average score
+and iterate average list and find index at sorting average score
+'''
+def solution(score):
+ answer = []
+
+ avg_score = [sum(sc) / len(sc) for sc in score]
+ avg_score_sort = sorted(avg_score, reverse = True)
+ for avg in avg_score:
+ answer.append(avg_score_sort.index(avg) + 1)
+ return answer
+
+score_1 = [[80, 70], [90, 50], [40, 70], [50, 80]]
+score_2 = [[80, 70], [70, 80], [30, 50], [90, 100], [100, 90], [100, 100], [10, 30]]
+
+print(solution(score_1))
+print(solution(score_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/SafetyArea.py b/Programmers/LEVEL0/SafetyArea.py
new file mode 100644
index 0000000..f74c422
--- /dev/null
+++ b/Programmers/LEVEL0/SafetyArea.py
@@ -0,0 +1,112 @@
+# Restart 24. 안전지대
+
+'''
+My Solution : didn`t solve this problem by myself, but I change something
+'''
+def solution(board):
+ answer = 0
+
+ # 8 directions
+ move_coords = [(-1, 0), (-1, -1), (0, -1), (1, -1), (1, 0), (1, 1), (0, 1), (-1, 1)]
+ booms = []
+ for row in range(len(board)):
+ for col in range(len(board[0])):
+ if board[row][col] == 1:
+ booms.append((row, col))
+
+ # Re-initialize booms nearby areas to booms areas
+ for boom_row, boom_col in booms:
+ for dx, dy in move_coords:
+ mx, my = boom_row + dx, boom_col + dy
+ if 0 <= mx < len(board) and 0 <= my < len(board):
+ board[mx][my] = 1
+
+ # Count non-boom areas
+ for row in range(len(board)):
+ for col in range(len(board[0])):
+ if board[row][col] == 0:
+ answer += 1
+ return answer
+
+board_1 = [[0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0],
+ [0, 0, 1, 0, 0],
+ [0, 0, 0, 0, 0]]
+board_2 = [[0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0],
+ [0, 0, 1, 1, 0],
+ [0, 0, 0, 0, 0]]
+board_3 = [[1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1]]
+
+print(solution(board_1))
+print(solution(board_2))
+print(solution(board_3))
+
+'''
+Using set for excepting boom areas
+'''
+def solution_other(board):
+ answer = 0
+
+ danger = set()
+ for row_idx, row in enumerate(board):
+ for col_idx, col in enumerate(row):
+ if not col:
+ continue
+ danger.update((row_idx + di, col_idx + dj) for di in [-1, 0, 1] for dj in [-1, 0, 1])
+
+ answer = len(board) * len(board) - sum(0 <= i < len(board) and 0 <= j < len(board) for i, j in danger)
+ return answer
+
+print(solution_other(board_1))
+print(solution_other(board_2))
+print(solution_other(board_3))
+
+'''
+Use numpy ndarray and apply ndarray`s padding
+'''
+import numpy as np
+from collections import Counter
+def solution_best(board):
+ answer = 0
+
+ board_padded = np.pad(board, ((1, 1), (1, 1)), constant_values = -1)
+ danger_array = np.pad(board, ((1, 1), (1, 1)), constant_values = -1)
+ for row in range(1, len(board) - 1):
+ for col in range(1, len(board[0]) - 1):
+ if board_padded[row][col] == 1:
+ for x in range(row - 1, row + 2):
+ for y in range(col - 1, col + 2):
+ danger_array[x][y] = 1
+
+ danger_list = danger_array.reshape(1, -1).squeeze()
+ answer = Counter(danger_list)[0]
+ return answer
+
+# print(solution_best(board_1))
+# print(solution_best(board_2))
+# print(solution_best(board_3))
+
+'''
+Use numpy ndarray different and it`s good.
+'''
+def solution_best_1(board):
+ answer = 0
+
+ board = np.array(board)
+ for row, col in zip(*np.where(board == 1)):
+ board[row - 1 if row else 0:row + 2, col - 1 if col else 0:col + 2] = 1
+
+ answer = len(board[board == 0])
+ return answer
+
+# print(solution_best_1(board_1))
+# print(solution_best_1(board_2))
+# print(solution_best_1(board_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/SetTreatmentOrder.py b/Programmers/LEVEL0/SetTreatmentOrder.py
new file mode 100644
index 0000000..401ea89
--- /dev/null
+++ b/Programmers/LEVEL0/SetTreatmentOrder.py
@@ -0,0 +1,26 @@
+# Restart 6. 진료 순서 정하기
+
+# My Solution
+def solution(emergency):
+ answer = []
+
+ rank_dict = {emer: idx + 1 for idx, emer in enumerate(sorted(emergency, reverse=True))}
+ answer = [rank_dict[emer] for emer in emergency]
+ return answer
+
+emergency_1 = [3, 76, 24]
+emergency_2 = [1, 2, 3, 4, 5, 6, 7]
+emergency_3 = [30, 10, 23, 6, 100]
+
+print(solution(emergency_1))
+print(solution(emergency_2))
+print(solution(emergency_3))
+
+def solution_best(emergency):
+ answer = [sorted(emergency, reverse = True).index(emer) + 1 for emer in emergency]
+
+ return answer
+
+print(solution_best(emergency_1))
+print(solution_best(emergency_2))
+print(solution_best(emergency_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/SumofConsecutiveNumbers.py b/Programmers/LEVEL0/SumofConsecutiveNumbers.py
new file mode 100644
index 0000000..db11014
--- /dev/null
+++ b/Programmers/LEVEL0/SumofConsecutiveNumbers.py
@@ -0,0 +1,33 @@
+# Restart 23. 연속된 수의 합
+
+def solution(num, total):
+ answer = []
+
+ x = (total - sum(range(1, num))) // num
+ answer = [x + i for i in range(num)]
+ return answer
+
+num_1 = 3
+num_2 = 5
+num_3 = 4
+num_4 = 5
+
+total_1 = 12
+total_2 = 15
+total_3 = 14
+total_4 = 5
+
+print(solution(num_1, total_1))
+print(solution(num_2, total_2))
+print(solution(num_3, total_3))
+print(solution(num_4, total_4))
+
+def solution_best(num, total):
+ answer = [(total - (num * (num - 1) // 2)) // num + i for i in range(num)]
+
+ return answer
+
+print(solution_best(num_1, total_1))
+print(solution_best(num_2, total_2))
+print(solution_best(num_3, total_3))
+print(solution_best(num_4, total_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/ThrowBall.py b/Programmers/LEVEL0/ThrowBall.py
new file mode 100644
index 0000000..841b259
--- /dev/null
+++ b/Programmers/LEVEL0/ThrowBall.py
@@ -0,0 +1,38 @@
+# Restart 7. 공 던지기
+
+# My Solution
+def solution(numbers, k):
+ answer = 0
+
+ quote = 0
+ if len(numbers) < k * 2:
+ quote = (k * 2) // len(numbers)
+ else:
+ answer = numbers[0::2][k - 1]
+ return answer
+
+ numbers *= (1 + quote)
+ answer = numbers[0::2][k - 1]
+ return answer
+
+numbers_1 = [1, 2, 3]
+numbers_2 = [1, 2, 3, 4, 5, 6]
+numbers_3 = [1, 2, 3]
+
+k_1 = 2
+k_2 = 5
+k_3 = 3
+
+print(solution(numbers_1, k_1))
+print(solution(numbers_2, k_2))
+print(solution(numbers_3, k_3))
+
+# Solution Best by using math
+def solution_best(numbers, k):
+ answer = 2 * (k - 1) % numbers[-1] + 1
+
+ return answer
+
+print(solution_best(numbers_1, k_1))
+print(solution_best(numbers_2, k_2))
+print(solution_best(numbers_3, k_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL0/__init__.py b/Programmers/LEVEL0/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/LEVEL0/babble.py b/Programmers/LEVEL0/babble.py
new file mode 100644
index 0000000..4509b83
--- /dev/null
+++ b/Programmers/LEVEL0/babble.py
@@ -0,0 +1,40 @@
+# Restart 27. 옹알이
+
+
+from itertools import permutations
+def solution(babbling):
+ answer = 0
+
+ possible_pron = ['aya', 'ye', 'woo', 'ma']
+ possible_word = []
+ for i in range(1, len(possible_pron) + 1):
+ for j in permutations(possible_pron, i):
+ possible_word.append(''.join(j))
+
+ for babb in babbling:
+ if babb in possible_word:
+ answer += 1
+ return answer
+
+babbling_1 = ["aya", "yee", "u", "maa", "wyeoo"]
+babbling_2 = ["ayaye", "uuuma", "ye", "yemawoo", "ayaa"]
+
+print(solution(babbling_1))
+print(solution(babbling_2))
+
+'''
+Using re module
+'''
+import re
+def solution_best(babbling):
+ answer = 0
+
+ regex = re.compile('^(aya|ye|woo|ma)+$')
+ for babb in babbling:
+ if regex.match(babb):
+ answer += 1
+
+ return answer
+
+print(solution_best(babbling_1))
+print(solution_best(babbling_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/AddMissingNumbers.py b/Programmers/LEVEL1/AddMissingNumbers.py
new file mode 100644
index 0000000..dbe13ae
--- /dev/null
+++ b/Programmers/LEVEL1/AddMissingNumbers.py
@@ -0,0 +1,25 @@
+# 49. 없는 숫자 더하기
+
+def solution(numbers):
+ answer = 0
+
+ all_num = [i for i in range(10)]
+ for number in all_num:
+ if number not in numbers:
+ answer += number
+
+ return answer
+
+numbers_1 = [1, 2, 3, 4, 6, 7, 8, 0]
+numbers_2 = [5, 8, 4, 0, 6, 7, 9]
+
+print(solution(numbers_1))
+print(solution(numbers_2))
+
+def solution_best(numbers):
+ answer = 45 - sum(numbers)
+
+ return answer
+
+print(solution_best(numbers_1))
+print(solution_best(numbers_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/ApplyMorePaint.py b/Programmers/LEVEL1/ApplyMorePaint.py
new file mode 100644
index 0000000..68f73fd
--- /dev/null
+++ b/Programmers/LEVEL1/ApplyMorePaint.py
@@ -0,0 +1,69 @@
+# Restart 39. 덧칠하기
+
+# Solve by relationship between m and section list
+def solution(n, m, section):
+ answer = 1
+ start_colored = section[0]
+
+ for colored in range(1, len(section)):
+ if section[colored] - start_colored >= m:
+ answer += 1
+ start_colored = section[colored]
+
+ return answer
+
+# Solve by using deque
+from collections import deque
+def solution_other(n, m, section):
+ answer = 0
+ section = deque(section)
+
+ while section:
+ start_colored = section.popleft()
+ while section:
+ if section[0] >= start_colored + m:
+ break
+ section.popleft()
+ answer += 1
+ return answer
+
+n_1 = 8
+n_2 = 5
+n_3 = 4
+
+m_1 = 4
+m_2 = 4
+m_3 = 1
+
+section_1 = [2, 3, 6]
+section_2 = [1, 3]
+section_3 = [1, 2, 3, 4]
+
+print(solution(n_1, m_1, section_1))
+print(solution(n_2, m_2, section_2))
+print(solution(n_3, m_3, section_3))
+print()
+print(solution_other(n_1, m_1, section_1))
+print(solution_other(n_2, m_2, section_2))
+print(solution_other(n_3, m_3, section_3))
+
+
+# Find how to remove list element that overlapped specific contents
+def solution_mine(n, m, section):
+ answer = 0
+
+ # Complete Search
+ # If colored, cost is 1 else 0(need to be colored)
+ wall_sections = [(wall_section, 0) if wall_section in section else (wall_section, 1)
+ for wall_section in list(range(1, n + 1))]
+
+ # Possible cases of colored areas by considering m
+ # 8, 4 -> 5 / 5, 4 -> 2 / 4, 1 -> 4
+ color_possibles = [wall_sections[start_wall:start_wall + m] for start_wall in range(len(wall_sections) - m + 1)]
+
+ # How to remove cases that are overlapped at specific elements
+ # [(1, 1), (2, 0), (3, 0), (4, 1)], [(2, 0), (3, 0), (4, 1), (5, 1)]
+
+ return answer
+
+
diff --git a/Programmers/LEVEL1/Babbling2.py b/Programmers/LEVEL1/Babbling2.py
new file mode 100644
index 0000000..8bd9724
--- /dev/null
+++ b/Programmers/LEVEL1/Babbling2.py
@@ -0,0 +1,26 @@
+# 옹알이2
+
+"""
+I didn't solve this problem by myself. The key of this problem is a simple implementation.
+Think problem simple, not complicated.
+See it again.
+"""
+def solution(babbling):
+ answer = 0
+
+ possibles = ["aya", "ye", "woo", "ma"]
+ for babble in babbling:
+ for possible in possibles:
+ if possible * 2 not in babble:
+ babble = babble.replace(possible, ' ')
+
+ if babble.isspace():
+ answer += 1
+
+ return answer
+
+babbling_1 = ["aya", "yee", "u", "maa"]
+babbling_2 = ["ayaye", "uuu", "yeye", "yemawoo", "ayaayaa"]
+
+print(solution(babbling_1))
+print(solution(babbling_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/Bandage.py b/Programmers/LEVEL1/Bandage.py
new file mode 100644
index 0000000..d1e0737
--- /dev/null
+++ b/Programmers/LEVEL1/Bandage.py
@@ -0,0 +1,94 @@
+# PCCP 기출문제 1번 붕대 감기
+
+"""
+I solve this problem by myself. But it is not efficient method.
+I follow the table in problem, but it requires efficient arrangement.
+See other solution and try to solve like that.
+See it again.
+"""
+# 1. My Solution
+def solution(bandage, health, attacks):
+ answer = 0
+
+ cast_time, second_restore, extra_restore = bandage
+ start_attack_times, damages = list(list(zip(*attacks))[0]), list(list(zip(*attacks))[1])
+ table = [[health, 0, False]]
+ for time in range(1, attacks[-1][0] + 1):
+ cur_health, consecutive_success, attack = table[-1]
+
+ if cur_health >= health:
+ cur_health = health
+
+ if time in start_attack_times:
+ cur_health -= damages[start_attack_times.index(time)]
+ consecutive_success = 0
+ attack = True
+ table.append([cur_health, consecutive_success, attack])
+ continue
+
+ consecutive_success += 1
+ cur_health += second_restore
+
+ if consecutive_success == cast_time:
+ cur_health += extra_restore
+ consecutive_success = 0
+
+ if attack == True:
+ attack = False
+
+ if cur_health >= health:
+ cur_health = health
+
+ if cur_health <= 0:
+ break
+
+ table.append([cur_health, consecutive_success, attack])
+
+ answer = table[-1][0]
+ if answer <= 0:
+ answer = -1
+
+ return answer
+
+def solution_other(bandage, health, attacks):
+ answer = 0
+
+ max_health = health
+ start = 1
+ for start_time, damage in attacks:
+ max_health += ((start_time - start) // bandage[0]) * bandage[2] + (start_time - start) * bandage[1]
+ start = start_time + 1
+ if max_health >= health:
+ max_health = health
+
+ max_health -= damage
+ if max_health <= 0:
+ return -1
+
+ answer = max_health
+ return answer
+
+bandage_1 = [5, 1, 5]
+bandage_2 = [3, 2, 7]
+bandage_3 = [4, 2, 7]
+bandage_4 = [1, 1, 1]
+
+health_1 = 30
+health_2 = 20
+health_3 = 20
+health_4 = 5
+
+attacks_1 = [[2, 10], [9, 15], [10, 5], [11, 5]]
+attacks_2 = [[1, 15], [5, 16], [8, 6]]
+attacks_3 = [[1, 15], [5, 16], [8, 6]]
+attacks_4 = [[1, 2], [3, 2]]
+
+# print(solution(bandage_1, health_1, attacks_1))
+# print(solution(bandage_2, health_2, attacks_2))
+# print(solution(bandage_3, health_3, attacks_3))
+# print(solution(bandage_4, health_4, attacks_4))
+
+print(solution_other(bandage_1, health_1, attacks_1))
+# print(solution_other(bandage_2, health_2, attacks_2))
+# print(solution_other(bandage_3, health_3, attacks_3))
+# print(solution_other(bandage_4, health_4, attacks_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/CalculatingInsufficientAmount.py b/Programmers/LEVEL1/CalculatingInsufficientAmount.py
new file mode 100644
index 0000000..257c629
--- /dev/null
+++ b/Programmers/LEVEL1/CalculatingInsufficientAmount.py
@@ -0,0 +1,24 @@
+# 52. 부족한 금액 계산하기
+
+def solution(price, money, count):
+ answer = sum([cnt * price for cnt in range(1, count + 1)]) - money
+
+ if money > sum([cnt * price for cnt in range(1, count + 1)]):
+ answer = 0
+
+ return answer
+
+price_1 = 3
+
+money_1 = 20
+
+count_1 = 4
+
+print(solution(price_1, money_1, count_1))
+
+def solution_best(price, money, count):
+ answer = max(0, price * (count + 1) * count // 2 - money)
+
+ return answer
+
+print(solution_best(price_1, money_1, count_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/CardPacks.py b/Programmers/LEVEL1/CardPacks.py
new file mode 100644
index 0000000..80d27c5
--- /dev/null
+++ b/Programmers/LEVEL1/CardPacks.py
@@ -0,0 +1,56 @@
+# Restart 41. 카드 뭉치
+
+'''
+Consider the order of cards1 list and cards2 list that can make goal list.
+It's important to think different when this kind of problems are coming out.
+'''
+def solution(cards1, cards2, goal):
+ answer = 'Yes'
+
+ for goal_str in goal:
+ if cards1 and goal_str == cards1[0]:
+ del cards1[0]
+ elif cards2 and goal_str == cards2[0]:
+ del cards2[0]
+ else:
+ answer = 'No'
+
+ return answer
+
+# Same as Previous solution but this is using list pop function. And consider conditions about list length and element is in list or not.
+def solution_other(cards1, cards2, goal):
+ answer = 'Yes'
+
+ for goal_str in goal:
+ if len(cards1) > 0 and goal_str == cards1[0]:
+ cards1.pop(0)
+ elif len(cards2) > 0 and goal_str == cards2[0]:
+ cards2.pop(0)
+ else:
+ answer = 'No'
+
+ return answer
+
+cards1_1 = ["i", "drink", "water"]
+cards1_2 = ["i", "water", "drink"]
+
+cards2_1 = ["want", "to"]
+cards2_2 = ["want", "to"]
+
+goal_1 = ["i", "want", "to", "drink", "water"]
+goal_2 = ["i", "want", "to", "drink", "water"]
+
+print(solution(cards1_1, cards2_1, goal_1))
+print(solution(cards1_2, cards2_2, goal_2))
+
+cards1_1 = ["i", "drink", "water"]
+cards1_2 = ["i", "water", "drink"]
+
+cards2_1 = ["want", "to"]
+cards2_2 = ["want", "to"]
+
+goal_1 = ["i", "want", "to", "drink", "water"]
+goal_2 = ["i", "want", "to", "drink", "water"]
+
+print(solution_other(cards1_1, cards2_1, goal_1))
+print(solution_other(cards1_2, cards2_2, goal_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/ColaProblem.py b/Programmers/LEVEL1/ColaProblem.py
new file mode 100644
index 0000000..d32d5de
--- /dev/null
+++ b/Programmers/LEVEL1/ColaProblem.py
@@ -0,0 +1,26 @@
+# Restart 45. 콜라 문제
+
+'''
+Keypoint of this problem is thinking Mathmetically.
+Catch the rule of Math formula.
+'''
+def solution(a, b, n):
+ answer = 0
+
+ rest_lst = [rest for rest in range(a)]
+ while n not in rest_lst:
+ answer += (n // a) * b
+ n = (n // a) * b + (n % a)
+ return answer
+
+a_1 = 2
+a_2 = 3
+
+b_1 = 1
+b_2 = 1
+
+n_1 = 20
+n_2 = 20
+
+print(solution(a_1, b_1, n_1))
+print(solution(a_2, b_2, n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/CountOfAliquotAndSum.py b/Programmers/LEVEL1/CountOfAliquotAndSum.py
new file mode 100644
index 0000000..5f1ec12
--- /dev/null
+++ b/Programmers/LEVEL1/CountOfAliquotAndSum.py
@@ -0,0 +1,55 @@
+# 45. 약수의 개수와 덧셈
+
+def solution(left, right):
+ answer = 0
+
+ for cost in range(left, right + 1):
+ aliquot_cnt = 0
+ for aliquot in range(1, cost + 1):
+ if cost % aliquot == 0:
+ aliquot_cnt += 1
+
+ if aliquot_cnt % 2 == 0:
+ answer += cost
+ else:
+ answer -= cost
+ return answer
+
+left_1 = 13
+left_2 = 24
+
+right_1 = 17
+right_2 = 27
+
+print(solution(left_1, right_1))
+print(solution(left_2, right_2))
+
+import math
+def solution_other(left, right):
+ answer = 0
+
+ for cost in range(left, right + 1):
+ sqrt = math.sqrt(cost)
+ if int(sqrt) == sqrt:
+ answer -= cost
+ else:
+ answer += cost
+
+ return answer
+
+print(solution_other(left_1, right_1))
+print(solution_other(left_2, right_2))
+
+def solution_best(left, right):
+ answer = 0
+
+ for cst in range(left, right + 1):
+ if int(cst ** 0.5) == cst ** 0.5:
+ answer -= cst
+ else:
+ answer += cst
+
+ return answer
+
+print(solution_best(left_1, right_1))
+print(solution_best(left_2, right_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/CountSpecificString.py b/Programmers/LEVEL1/CountSpecificString.py
new file mode 100644
index 0000000..d9e0dc0
--- /dev/null
+++ b/Programmers/LEVEL1/CountSpecificString.py
@@ -0,0 +1,27 @@
+# Restart 29. 문자열이 몇 번 등장하는지 세기
+
+def solution(myString, pat):
+ answer = 0
+
+ for idx, chr in enumerate(myString):
+ if myString[idx:].startswith(pat):
+ answer += 1
+
+ return answer
+
+myString_1 = 'banana'
+myString_2 = 'aaaa'
+
+pat_1 = 'ana'
+pat_2 = 'aa'
+
+print(solution(myString_1, pat_1))
+print(solution(myString_2, pat_2))
+
+def solution_best(myString, pat):
+ answer = sum(myString[i:i + len(pat)] == pat for i in range(len(myString)))
+
+ return answer
+
+print(solution_best(myString_1, pat_1))
+print(solution_best(myString_2, pat_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/DartGame.py b/Programmers/LEVEL1/DartGame.py
index bce8e13..f56df3b 100644
--- a/Programmers/LEVEL1/DartGame.py
+++ b/Programmers/LEVEL1/DartGame.py
@@ -1,74 +1,107 @@
-# 39. 다트 게임
-
-# 내 풀이 X ... 뭔가 복잡해
-def solution(dartResult):
- answer = 0
-
- bonus = {'S' : 1, 'D' : 2, 'T' : 3}
- option = {'*' : 2, '#' : -1}
-
- Third_period = [0, 0, 0]
- flag = -1
-
- for idx, dart in enumerate(dartResult):
- if dart.isdigit():
- flag += 1
- if dart == '0':
- continue
- elif dartResult[idx + 1].isdigit(): # 10 이상일 때
- Third_period[flag] = int(dart) * 10
- flag -= 1
- else:
- Third_period[flag] = int(dart)
- elif dart in 'SDT': # SDT
- Third_period[flag] **= bonus[dart]
- else:
- if dart == '*':
- Third_period[flag - 1] *= 2
-
- Third_period[flag] *= option[dart]
-
- answer = sum(Third_period)
- return answer
-
-dartResult_1 = '1S2D*3T'
-dartResult_2 = '1D2S#10S'
-dartResult_3 = '1D2S0T'
-dartResult_4 = '1S*2T*3S'
-dartResult_5 = '1D#2S*3S'
-dartResult_6 = '1T2D3D#'
-dartResult_7 = '1D2S3T*'
-
-print(solution(dartResult_1))
-print(solution(dartResult_2))
-print(solution(dartResult_3))
-print(solution(dartResult_4))
-print(solution(dartResult_5))
-print(solution(dartResult_6))
-print(solution(dartResult_7))
-
-import re
-
-def solution_best(dartResult):
- answer = 0
-
- bonus = {'S' : 1, 'D' : 2, 'T' : 3}
- option = {'' : 1, '*' : 2, '#' : -1}
-
- p = re.compile('(\d+)([SDT])([*#]?)')
- dart = p.findall(dartResult)
- for i in range(len(dart)):
- if dart[i][2] == '*' and i > 0:
- dart[i - 1] *= 2
- dart[i] = int(dart[i][0]) ** bonus[dart[i][1]] * option[dart[i][2]]
-
- answer = sum(dart)
- return answer
-
-print(solution_best(dartResult_1))
-print(solution_best(dartResult_2))
-print(solution_best(dartResult_3))
-print(solution_best(dartResult_4))
-print(solution_best(dartResult_5))
-print(solution_best(dartResult_6))
-print(solution_best(dartResult_7))
\ No newline at end of file
+# 39. 다트 게임
+
+# 내 풀이 X ... 뭔가 복잡해
+def solution(dartResult):
+ answer = 0
+
+ bonus = {'S': 1, 'D': 2, 'T': 3}
+ option = {'*': 2, '#': -1}
+
+ chances = [0, 0, 0]
+ number_cnt = -1
+ for idx, dart in enumerate(dartResult):
+ if dart.isdigit():
+ number_cnt += 1
+ if dart == '0':
+ continue
+ # 10일 때
+ elif dartResult[idx + 1].isdigit():
+ chances[number_cnt] = int(dart) * 10
+ number_cnt -= 1
+ else:
+ chances[number_cnt] = int(dart)
+ elif dart in 'SDT':
+ chances[number_cnt] **= bonus[dart]
+ else:
+ if dart == '*':
+ chances[number_cnt - 1] *= 2
+ else:
+ chances[number_cnt - 1] *= -1
+
+ answer = sum(chances)
+ return answer
+
+dartResult_1 = '1S2D*3T'
+dartResult_2 = '1D2S#10S'
+dartResult_3 = '1D2S0T'
+dartResult_4 = '1S*2T*3S'
+dartResult_5 = '1D#2S*3S'
+dartResult_6 = '1T2D3D#'
+dartResult_7 = '1D2S3T*'
+
+# print(solution(dartResult_1))
+# print(solution(dartResult_2))
+# print(solution(dartResult_3))
+# print(solution(dartResult_4))
+# print(solution(dartResult_5))
+# print(solution(dartResult_6))
+# print(solution(dartResult_7))
+
+def solution_other(dartResult):
+ answer = []
+
+ dartResult = dartResult.replace('10', 'k')
+ point = ['10' if i == 'k' else i for i in dartResult]
+
+ i = -1
+ sdt = ['S', 'D', 'T']
+ for j in point:
+ if j in sdt:
+ answer[i] = answer[i] ** (sdt.index(j) + 1)
+ elif j == '*':
+ answer[i] = answer[i] * 2
+ if i != 0:
+ answer[i - 1] = answer[i - 1] * 2
+ elif j == '#':
+ answer[i] = answer[i] * (-1)
+ else:
+ answer.append(int(j))
+ i += 1
+
+ return sum(answer)
+
+# print(solution_other(dartResult_1))
+# print(solution_other(dartResult_2))
+# print(solution_other(dartResult_3))
+# print(solution_other(dartResult_4))
+# print(solution_other(dartResult_5))
+# print(solution_other(dartResult_6))
+# print(solution_other(dartResult_7))
+
+import re
+
+def solution_best(dartResult):
+ answer = 0
+
+ bonus = {'S' : 1, 'D' : 2, 'T' : 3}
+ option = {'' : 1, '*' : 2, '#' : -1}
+
+ p = re.compile('(\d+)([SDT])([*#]?)')
+ dart = p.findall(dartResult)
+ print(dart)
+ for i in range(len(dart)):
+ if dart[i][2] == '*' and i > 0:
+ dart[i - 1] *= 2
+ dart[i] = int(dart[i][0]) ** bonus[dart[i][1]] * option[dart[i][2]]
+
+ answer = sum(dart)
+ return answer
+
+# print(solution_best(dartResult_1))
+# print(solution_best(dartResult_2))
+# print(solution_best(dartResult_3))
+# print(solution_best(dartResult_4))
+# print(solution_best(dartResult_5))
+# print(solution_best(dartResult_6))
+# print(solution_best(dartResult_7))
+
diff --git a/Programmers/LEVEL1/DesktopCleanup.py b/Programmers/LEVEL1/DesktopCleanup.py
new file mode 100644
index 0000000..79035d0
--- /dev/null
+++ b/Programmers/LEVEL1/DesktopCleanup.py
@@ -0,0 +1,33 @@
+# Restart 39. 바탕화면 정리
+
+def solution(wallpaper):
+ answer = []
+
+ board = [[elem for elem in row] for row in wallpaper]
+ board_row, board_col = len(board), len(board[0])
+
+ files_loc_lst = []
+ for row_idx in range(board_row):
+ for col_idx in range(board_col):
+ if board[row_idx][col_idx] == '#':
+ files_loc_lst.append((row_idx, col_idx))
+
+ row_lst, col_lst = [], []
+ for row, col in files_loc_lst:
+ row_lst.append(row)
+ col_lst.append(col)
+
+ row_min, row_max = min(row_lst), max(row_lst) + 1
+ col_min, col_max = min(col_lst), max(col_lst) + 1
+ answer = [row_min, col_min, row_max, col_max]
+ return answer
+
+wallpaper_1 = [".#...", "..#..", "...#."]
+wallpaper_2 = ["..........", ".....#....", "......##..", "...##.....", "....#....."]
+wallpaper_3 = [".##...##.", "#..#.#..#", "#...#...#", ".#.....#.", "..#...#..", "...#.#...", "....#...."]
+wallpaper_4 = ["..", "#."]
+
+print(solution(wallpaper_1))
+print(solution(wallpaper_2))
+print(solution(wallpaper_3))
+print(solution(wallpaper_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/FailRate.py b/Programmers/LEVEL1/FailRate.py
index 0047743..8826d23 100644
--- a/Programmers/LEVEL1/FailRate.py
+++ b/Programmers/LEVEL1/FailRate.py
@@ -1,74 +1,116 @@
-# 38. 실패율
-
-# 내 풀이 X ... 뭔가 어렵네...
-def solution(N, stages):
- answer = []
-
- # 스테이지 도달한 플레이어 수 ... k
- success_players = len(stages)
-
- # 실패율 리스트
- failing_rate_lst = []
-
- for i in range(1, N + 1):
- # 스테이지 도달했으나 클리어하지 못한 플레이어 수
- failing_cnt = 0
- for j in range(len(stages)):
- if stages[j] == i:
- failing_cnt += 1
-
- if failing_cnt == 0:
- failing_rate_lst.append(0)
- else:
- failing_rate_lst.append(failing_cnt / success_players)
- success_players = success_players - failing_cnt
-
- failing_rate_reverse_sort = sorted(failing_rate_lst, reverse = True)
- # print(failing_rate_reverse_sort)
-
- for i in range(len(failing_rate_reverse_sort)):
- answer.append(failing_rate_lst.index(failing_rate_reverse_sort[i]) + 1)
- failing_rate_lst[failing_rate_lst.index(failing_rate_reverse_sort[i])] = 2
-
- return answer
-
-N_1 = 5
-N_2 = 4
-
-stages_1 = [2, 1, 2, 6, 2, 4, 3, 3]
-stages_2 = [4, 4, 4, 4, 4]
-
-# print(solution(N_1, stages_1))
-# print(solution(N_2, stages_2))
-
-# 이중 리스트 풀이 ... [2, 1, 2, 6, 2, 4, 3, 3] -> [[1], [2, 2, 2], [3, 3], [4], [6]]
-def solution_mine(N, stages):
- answer = []
-
-
- return answer
-
-# print(solution_mine(N_1, stages_1))
-# print(solution_mine(N_2, stages_2))
-
-def solution_best(N, stages):
- answer = []
-
- # 실패율 딕셔너리
- result = {}
-
- # 스테이지에 도달한 플레이어 수 = success_players / denominator : 분모
- denominator = len(stages)
-
- for stage in range(1, N + 1):
- if denominator != 0:
- failing_count = stages.count(stage)
- result[stage] = failing_count / denominator
- denominator -= failing_count
- else:
- result[stage] = 0
- answer = sorted(result, key=lambda x: result[x], reverse=True)
- return answer
-
-print(solution_best(N_1, stages_1))
+# 38. 실패율
+
+# 내 풀이
+def solution(N, stages):
+ answer = []
+
+ # 실패율 딕셔너리
+ result = {}
+
+ # 도달한 플레이어 수 ... 매 단계마다 바뀔 수 있다
+ denominator = len(stages)
+
+ for stage in range(1, N + 1):
+ if denominator != 0:
+ fail_cnt = stages.count(stage)
+ result[stage] = fail_cnt / denominator
+ denominator -= fail_cnt
+ else:
+ result[stage] = 0
+
+ answer = sorted(result, key=lambda x: result[x],
+ reverse = True)
+ return answer
+
+N_1 = 5
+N_2 = 4
+
+stages_1 = [2, 1, 2, 6, 2, 4, 3, 3]
+stages_2 = [4, 4, 4, 4, 4]
+
+# print(solution(N_1, stages_1))
+# print(solution(N_2, stages_2))
+
+# 이중 리스트 풀이 ... [2, 1, 2, 6, 2, 4, 3, 3] -> [[1], [2, 2, 2], [3, 3], [4], [6]]
+from collections import Counter
+def solution_mine(N, stages):
+ answer = []
+
+ # {'1' : 2, '2' : 3, ... }
+ result = {str(i): 0 for i in range(N + 1)}
+ for i in stages:
+ if str(i) in result.keys():
+ result[str(i)] += 1
+ else:
+ if i == N + 1:
+ result[str(0)] += 1
+
+ # 마지막까지 성공한 사람
+ success = {'0': result['0']}
+ del (result['0'])
+
+ denominator = len(stages)
+ failing_rate_lst = []
+ for stage, cnt in result.items():
+ failing_rate = 0
+ if cnt != 0:
+ failing_rate = cnt / denominator
+ failing_rate_lst.append(failing_rate)
+ denominator -= cnt
+ else:
+ failing_rate = 0
+ failing_rate_lst.append(failing_rate)
+
+ sort_failing_rate_lst = sorted(failing_rate_lst,
+ reverse=True)
+ answer = [sort_failing_rate_lst.index(i) + 1
+ for i in failing_rate_lst]
+ return answer
+
+# print(solution_mine(N_1, stages_1))
+# print(solution_mine(N_2, stages_2))
+
+def solution_best(N, stages):
+ answer = []
+
+ # 실패율 딕셔너리
+ result = {}
+
+ # 스테이지에 도달한 플레이어 수 = success_players / denominator : 분모
+ denominator = len(stages)
+
+ for stage in range(1, N + 1):
+ if denominator != 0:
+ failing_count = stages.count(stage)
+ result[stage] = failing_count / denominator
+ denominator -= failing_count
+ else:
+ result[stage] = 0
+ answer = sorted(result, key=lambda x: result[x], reverse=True)
+ return answer
+#
+# print(solution_best(N_1, stages_1))
+# print(solution_best(N_2, stages_2))
+
+
+def solution_other(N, stages):
+ answer = []
+ _len = len(stages)
+ _num = 0
+
+ for x in range(1, N + 1):
+ for y in stages:
+ if x == y:
+ _num += 1
+ if _num > 0:
+ answer.append(_num / _len)
+ _len = _len - _num
+ _num = 0
+ else:
+ answer.append(0)
+ answer = sorted(range(len(answer)), key=lambda k: answer[k], reverse=True)
+ answer = [x + 1 for x in answer]
+ return answer
+
+print(solution_other(N_1, stages_1))
print(solution_best(N_2, stages_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/FindLongestSubstringEndingSpecifigString.py b/Programmers/LEVEL1/FindLongestSubstringEndingSpecifigString.py
new file mode 100644
index 0000000..4fb185c
--- /dev/null
+++ b/Programmers/LEVEL1/FindLongestSubstringEndingSpecifigString.py
@@ -0,0 +1,36 @@
+# Restart 28. 특정 문자열로 끝나는 가장 긴 부분 문자열 찾기
+
+'''
+Not solve this problem by myself.
+So see this again
+'''
+def solution(myString, pat):
+ answer = myString[:len(myString) - myString[::-1].index(pat[::-1])]
+ # print(myString[:len(myString)])
+ # print(myString[::-1])
+ # print(myString[::-1].index(pat[::-1]))
+ # print(myString[myString[::-1].index(pat[::-1])])
+ # print(myString[:len(myString) - myString[::-1].index(pat[::-1])])
+
+ return answer
+
+myString_1 = "AbCdEFG"
+myString_2 = "AAAAaaaa"
+
+pat_1 = "dE"
+pat_2 = "a"
+
+print(solution(myString_1, pat_1))
+print(solution(myString_2, pat_2))
+
+def solution_other(myString, pat):
+ answer = myString[::-1][myString[::-1].index(pat[::-1]):][::-1]
+
+ return answer
+
+# print(solution_other(myString_1, pat_1))
+# print(solution_other(myString_2, pat_2))
+
+solution_best = lambda x, y:x[:x.rindex(y) + len(y)]
+# print(solution_best(myString_1, pat_1))
+# print(solution_best(myString_2, pat_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/FindNumberRemainder1.py b/Programmers/LEVEL1/FindNumberRemainder1.py
new file mode 100644
index 0000000..c900cf3
--- /dev/null
+++ b/Programmers/LEVEL1/FindNumberRemainder1.py
@@ -0,0 +1,41 @@
+# 51. 나머지가 1이 되는 수 찾기
+
+def solution(n):
+ answer = 0
+
+ res_lst = [n % i for i in range(1, n + 1)]
+ for rest in res_lst:
+ if rest == 1:
+ answer = res_lst.index(rest) + 1
+ break
+
+ return answer
+
+n_1 = 10
+n_2 = 12
+
+# print(solution(n_1))
+# print(solution(n_2))
+
+def solution_other(n):
+ answer = 0
+
+ for divisor in range(2, (n - 1 // 2) + 1):
+ if (n - 1) % divisor == 0:
+ answer = divisor
+ break
+ else:
+ answer = n - 1
+
+ return answer
+
+# print(solution_other(n_1))
+# print(solution_other(n_2))
+
+def solution_best(n):
+ answer = min([x for x in range(1, n + 1) if n % x == 1])
+
+ return answer
+
+# print(solution_best(n_1))
+# print(solution_best(n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/FruitSeller.py b/Programmers/LEVEL1/FruitSeller.py
new file mode 100644
index 0000000..faa5476
--- /dev/null
+++ b/Programmers/LEVEL1/FruitSeller.py
@@ -0,0 +1,32 @@
+# Restart 1. 과일장수
+
+def solution(k, m, score):
+ answer = 0
+
+ score_sort = sorted(score, reverse = True)
+ for box_cnt in range(0, len(score_sort), m):
+ one_box = score_sort[box_cnt:box_cnt + m]
+ if len(one_box) == m:
+ answer += min(one_box) * m
+
+ return answer
+
+k_1 = 3
+k_2 = 4
+
+m_1 = 4
+m_2 = 3
+
+score_1 = [1, 2, 3, 1, 2, 3, 1]
+score_2 = [4, 1, 2, 2, 4, 4, 4, 4, 1, 2, 4, 2]
+
+print(solution(k_1, m_1, score_1))
+print(solution(k_2, m_2, score_2))
+
+def solution_best(k, m, score):
+ answer = sum(sorted(score)[len(score) % m::m]) * m
+
+ return answer
+
+print(solution_best(k_1, m_1, score_1))
+print(solution_best(k_2, m_2, score_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/HallOfFame.py b/Programmers/LEVEL1/HallOfFame.py
new file mode 100644
index 0000000..60defaa
--- /dev/null
+++ b/Programmers/LEVEL1/HallOfFame.py
@@ -0,0 +1,25 @@
+# Restart 46. 명예의 전당(1)
+
+def solution(k, score):
+ answer = []
+
+ k_scores = []
+ for sc in score:
+ k_scores.append(sc)
+ k_scores.sort(reverse = True)
+
+ if len(k_scores) > k:
+ k_scores.pop()
+
+ answer.append(min(k_scores))
+
+ return answer
+
+k_1 = 3
+k_2 = 4
+
+score_1 = [10, 100, 20, 150, 1, 100, 200]
+score_2 = [0, 300, 40, 300, 20, 70, 150, 50, 500, 1000]
+
+print(solution(k_1, score_1))
+print(solution(k_2, score_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/LeftRight.py b/Programmers/LEVEL1/LeftRight.py
new file mode 100644
index 0000000..52a5dfd
--- /dev/null
+++ b/Programmers/LEVEL1/LeftRight.py
@@ -0,0 +1,33 @@
+# Restart 31. 왼쪽 오른쪽
+
+'''
+Error
+There's not any mention about if 'l' or 'r' in str_list.
+Then follow the same rule that was mentioned at previous state.
+'''
+def solution(str_list):
+ answer = []
+
+ for i in range(len(str_list)):
+ if str_list[i] == 'l':
+ answer = str_list[:i]
+ return answer
+ elif str_list[i] == 'r':
+ answer = str_list[i + 1:]
+ return answer
+
+ return answer
+
+str_list_1 = ["u", "u", "l", "r"]
+str_list_2 = ["l"]
+
+print(solution(str_list_1))
+print(solution(str_list_2))
+
+'''
+I didn't consider if 'l' and 'r' in str_list
+'''
+def solution_wrong(str_list):
+ answer = str_list[:str_list.index('l')] if 'l' in str_list else str_list[str_list.index('r') + 1:] if 'r' in str_list else []
+
+ return answer
\ No newline at end of file
diff --git a/Programmers/LEVEL1/MakeArray2.py b/Programmers/LEVEL1/MakeArray2.py
new file mode 100644
index 0000000..dafe5fb
--- /dev/null
+++ b/Programmers/LEVEL1/MakeArray2.py
@@ -0,0 +1,33 @@
+# Restart 33. 배열 만들기 2
+
+def solution(l, r):
+ answer = []
+
+ for int_num in range(l, r + 1):
+ if all(num in ['0', '5'] for num in str(int_num)):
+ answer.append(int_num)
+
+ if len(answer) == 0:
+ answer.append(-1)
+ return answer
+
+l_1 = 5
+l_2 = 10
+
+r_1 = 555
+r_2 = 20
+
+print(solution(l_1, r_1))
+print(solution(l_2, r_2))
+
+def solution_best(l, r):
+ answer = []
+
+ for num in range(l, r + 1):
+ if not set(str(num)) - set(['0', '5']):
+ answer.append(num)
+
+ return answer if answer else [-1]
+
+print(solution_best(l_1, r_1))
+print(solution_best(l_2, r_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/MakeArrayLengthToSquareOfTwo.py b/Programmers/LEVEL1/MakeArrayLengthToSquareOfTwo.py
new file mode 100644
index 0000000..cd2c9c5
--- /dev/null
+++ b/Programmers/LEVEL1/MakeArrayLengthToSquareOfTwo.py
@@ -0,0 +1,36 @@
+# Restart 30. 배열의 길이를 2의 거븓제곱으로 만들기
+
+def solution(arr):
+ answer = arr
+
+ zero_cnts = 0
+ while len(answer) != 2 ** zero_cnts:
+ if len(answer) == 2 ** zero_cnts:
+ break
+
+ if len(answer) > 2 ** zero_cnts:
+ zero_cnts += 1
+ else:
+ chan = (2 ** zero_cnts) - len(answer)
+ for _ in range(chan):
+ answer.append(0)
+
+ return answer
+
+arr_1 = [1, 2, 3, 4, 5, 6]
+arr_2 = [58, 172, 746, 89]
+
+print(solution(arr_1))
+print(solution(arr_2))
+
+def solution_best(arr):
+ zero_cnts = 1
+ arr_len = len(arr)
+ while zero_cnts < arr_len:
+ zero_cnts *= 2
+
+ answer = arr + [0] * (zero_cnts - arr_len)
+ return answer
+
+print(solution_best(arr_1))
+print(solution_best(arr_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/MakingHamburger.py b/Programmers/LEVEL1/MakingHamburger.py
new file mode 100644
index 0000000..cf84ac4
--- /dev/null
+++ b/Programmers/LEVEL1/MakingHamburger.py
@@ -0,0 +1,25 @@
+# 햄버거 만들기
+
+"""
+I didn't solve this problem by myself. The key of this problem is Stack.
+But I didn't catch how to solve this with stack Data Structure.
+See it again.
+"""
+def solution(ingredient):
+ answer = 0
+
+ hamburgers = []
+ for material in ingredient:
+ hamburgers.append(material)
+ if hamburgers[-4:] == [1, 2, 3, 1]:
+ answer += 1
+ for _ in range(4):
+ hamburgers.pop()
+
+ return answer
+
+ingredient_1 = [2, 1, 1, 2, 3, 1, 2, 3, 1]
+ingredient_2 = [1, 3, 2, 1, 2, 1, 3, 1, 2]
+
+print(solution(ingredient_1))
+print(solution(ingredient_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/MemoriesScore.py b/Programmers/LEVEL1/MemoriesScore.py
new file mode 100644
index 0000000..0c447d5
--- /dev/null
+++ b/Programmers/LEVEL1/MemoriesScore.py
@@ -0,0 +1,31 @@
+# Restart 37. 추억 점수
+
+def solution(name, yearning, photo):
+ answer = []
+
+ name_year_dict = {n : ye for n, ye in zip(name, yearning)}
+ for pho in photo:
+ missing_score = 0
+ for person in pho:
+ if person in name_year_dict.keys():
+ missing_score += name_year_dict[person]
+
+ answer.append(missing_score)
+ return answer
+
+name_1 = ["may", "kein", "kain", "radi"]
+name_2 = ["kali", "mari", "don"]
+name_3 = ["may", "kein", "kain", "radi"]
+
+yearning_1 = [5, 10, 1, 3]
+yearning_2 = [11, 1, 55]
+yearning_3 = [5, 10, 1, 3]
+
+photo_1 = [["may", "kein", "kain", "radi"],["may", "kein", "brin", "deny"], ["kon", "kain", "may", "coni"]]
+photo_2 = [["kali", "mari", "don"], ["pony", "tom", "teddy"], ["con", "mona", "don"]]
+photo_3 = [["may"],["kein", "deny", "may"], ["kon", "coni"]]
+
+print(solution(name_1, yearning_1, photo_1))
+print(solution(name_2, yearning_2, photo_2))
+print(solution(name_3, yearning_3, photo_3))
+
diff --git a/Programmers/LEVEL1/MinimumRectangle.py b/Programmers/LEVEL1/MinimumRectangle.py
new file mode 100644
index 0000000..63da1bd
--- /dev/null
+++ b/Programmers/LEVEL1/MinimumRectangle.py
@@ -0,0 +1,41 @@
+# 50. 최소 직사각형
+
+def solution(sizes):
+ answer = 0
+
+ width = list(zip(*sizes))[0]
+ height = list(zip(*sizes))[1]
+ w_lst, h_lst = [], []
+ if max(width) < max(height):
+ for w, h in sizes:
+ if h < w:
+ w, h = h, w
+ w_lst.append(w)
+ h_lst.append(h)
+ else:
+ for w, h in sizes:
+ if w < h:
+ w, h = h, w
+ w_lst.append(w)
+ h_lst.append(h)
+
+
+ answer = max(w_lst) * max(h_lst)
+ return answer
+
+sizes_1 = [[60, 50], [30, 70], [60, 30], [80, 40]]
+sizes_2 = [[10, 7], [12, 3], [8, 15], [14, 7], [5, 15]]
+sizes_3 = [[14, 4], [19, 6], [6, 16], [18, 7], [7, 11]]
+
+print(solution(sizes_1))
+print(solution(sizes_2))
+print(solution(sizes_3))
+
+def solution_best(sizes):
+ answer = max(max(x) for x in sizes) * max(min(x) for x in sizes)
+
+ return answer
+
+# print(solution_best(sizes_1))
+# print(solution_best(sizes_2))
+# print(solution_best(sizes_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/NumberStringAndEnglishword.py b/Programmers/LEVEL1/NumberStringAndEnglishword.py
new file mode 100644
index 0000000..8a4af76
--- /dev/null
+++ b/Programmers/LEVEL1/NumberStringAndEnglishword.py
@@ -0,0 +1,54 @@
+# 47. 숫자 문자열과 영단어
+
+def solution(s):
+ answer = 0
+
+ digit_to_num_dict = {'zero' : 0, 'one' : 1,
+ 'two' : 2, 'three' : 3,
+ 'four' : 4, 'five' : 5,
+ 'six' : 6, 'seven' : 7,
+ 'eight' : 8, 'nine' : 9
+ }
+
+ answer_str = ''
+ num_str = ''
+ for ch in s:
+ if ch.isalpha():
+ num_str += ch
+ if num_str in digit_to_num_dict.keys():
+ answer_str += str(digit_to_num_dict[num_str])
+ num_str = ''
+ else:
+ answer_str += ch
+ answer = int(answer_str)
+
+ return answer
+
+s_1 = "one4seveneight"
+s_2 = "23four5six7"
+s_3 = "2three45sixseven"
+s_4 = "123"
+
+# print(solution(s_1))
+# print(solution(s_2))
+# print(solution(s_3))
+# print(solution(s_4))
+
+def solution_best(s):
+ answer = s
+ num_dict = {'zero' : '0', 'one' : '1',
+ 'two' : '2', 'three' : '3',
+ 'four' : '4', 'five' : '5',
+ 'six' : '6', 'seven' : '7',
+ 'eight' : '8', 'nine' : '9'}
+
+ for key, value in num_dict.items():
+ answer = answer.replace(key, value)
+
+ answer = int(answer)
+ return answer
+
+print(solution_best(s_1))
+print(solution_best(s_2))
+print(solution_best(s_3))
+print(solution_best(s_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/OurPassword.py b/Programmers/LEVEL1/OurPassword.py
new file mode 100644
index 0000000..39a1f70
--- /dev/null
+++ b/Programmers/LEVEL1/OurPassword.py
@@ -0,0 +1,94 @@
+# Restart 42. 둘만의 암호
+
+'''
+This problem also requires the reversal of thoughts.
+I didn't solve this problem by myself.
+My Solution is wrong at test case 2.
+'''
+def solution(s, skip, index):
+ answer = ""
+
+ alphabets = "abcdefghijklmnopqrstuvwxyz"
+ alps = sorted(set(alphabets) - set(skip))
+ alp_cnts = len(alps)
+
+ for sub_s in s:
+ answer += alps[(alps.index(sub_s) + index) % alp_cnts]
+ return answer
+
+'''
+This Solution can't solve test case 2.
+'''
+def solution_mine(s, skip, index):
+ answer = ''
+
+ alphabets_lst = [chr(97 + alp_idx) for alp_idx in range(26)]
+ changed_str = ''
+ for sub_s in s:
+ sub_s_idx_lst = [chr(ord(sub_s) + idx) for idx in range(1, index + 1)]
+ remove_sub_s_idx_lst = sorted(list(set(sub_s_idx_lst).difference(skip)))
+ if len(remove_sub_s_idx_lst) != index:
+ diff_cnts = int(abs(index - len(remove_sub_s_idx_lst)))
+ last_remove_sub_s = remove_sub_s_idx_lst[-1]
+ for diff_cnt in range(1, diff_cnts + 1):
+ remove_sub_s_idx_lst.append(chr(ord(last_remove_sub_s) + diff_cnt))
+ changed_str += remove_sub_s_idx_lst[-1]
+ else:
+ changed_str += remove_sub_s_idx_lst[-1]
+
+ for chgd_idx in range(len(changed_str)):
+ if changed_str[chgd_idx] not in alphabets_lst:
+ return_cnts = ord(changed_str[chgd_idx]) - ord('z') - 1
+ answer += alphabets_lst[return_cnts]
+ else:
+ answer += changed_str[chgd_idx]
+
+ return answer
+
+'''
+Same as solution, but it's a little bit simple.
+'''
+def solution_other(s, skip, index):
+ answer = ''
+
+ alps = [chr(alp) for alp in range(ord('a'), ord('z') + 1)
+ if chr(alp) not in skip]
+ answer = ''.join([alps[(alps.index(sub_s) + index) % len(alps)]
+ for sub_s in s])
+ return answer
+
+'''
+Similar with solution, but it's the best.
+'''
+from string import ascii_lowercase
+def solution_best(s, skip, index):
+ answer = ''
+
+ alps = set(ascii_lowercase)
+ alps -= set(skip)
+ alps = sorted(alps)
+ alps_len = len(alps)
+
+ alps_dict = {alpha : idx for idx, alpha in enumerate(alps)}
+
+ for sub_s in s:
+ answer += alps[(alps_dict[sub_s] + index) % alps_len]
+ return answer
+
+s_1 = "aukks"
+s_2 = "zzzz"
+
+skip_1 = "wbqd"
+skip_2 = "abcd"
+
+index_1 = 5
+index_2 = 1
+
+print(solution(s_1, skip_1, index_1))
+print(solution(s_2, skip_2, index_2))
+
+print(solution_other(s_1, skip_1, index_1))
+print(solution_other(s_2, skip_2, index_2))
+
+print(solution_best(s_1, skip_1, index_1))
+print(solution_best(s_2, skip_2, index_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/ParkWalking.py b/Programmers/LEVEL1/ParkWalking.py
new file mode 100644
index 0000000..dca6381
--- /dev/null
+++ b/Programmers/LEVEL1/ParkWalking.py
@@ -0,0 +1,112 @@
+# Restart 38. 공원 산책
+
+import copy
+# My solution can't solve if obstacle is on my route
+def solution_mine(park, routes):
+ answer = []
+
+ move_directions = {'E': [0, 1], 'W': [0, -1], 'S': [1, 0], 'N': [-1, 0]}
+ board = [[elem for elem in row] for row in park]
+ board_row, board_col = len(board), len(board[0])
+ start_pos = [0, board[0].index('S')]
+
+ for route in routes:
+ direction, distance = route.split()[0], int(route.split()[1])
+ moving_pos = [elem * distance for elem in move_directions[direction]]
+ print('moving_pos :', moving_pos)
+ if moving_pos[0] >= board_row - 1 or moving_pos[1] >= board_col - 1:
+ continue
+
+ changed_pos = [st_p + mo_p for st_p, mo_p in zip(start_pos, moving_pos)]
+ print('changed_pos :', changed_pos)
+ print(board[changed_pos[0]][changed_pos[1]])
+ if board[changed_pos[0]][changed_pos[1]] == 'X':
+ continue
+ start_pos = copy.deepcopy(changed_pos)
+
+ return answer
+
+# This is wrong just only 4 test case.
+def solution_other(park, routes):
+ answer = []
+
+ move_directions = {'E': (0, 1), 'W': (0, -1), 'S': (1, 0), 'N': (-1, 0)}
+ board = [[elem for elem in row] for row in park]
+ board_row, board_col = len(board) - 1, len(board[0]) - 1
+ start_pos_x, start_pos_y = 0, 0
+ for row in range(board_row):
+ for col in range(board_col):
+ if board[row][col] == 'S':
+ start_pos_x, start_pos_y = row, col
+ break
+ # start_pos = (0, board[0].index('S'))
+
+ for route in routes:
+ direction, cnts = route.split()[0], int(route.split()[1])
+ dx, dy = start_pos_x, start_pos_y
+
+ for cnt in range(cnts):
+ changed_pos_x, changed_pos_y = start_pos_x + move_directions[direction][0], start_pos_y + \
+ move_directions[direction][1]
+
+ if 0 <= changed_pos_x <= board_row and 0 <= changed_pos_y <= board_col and board[changed_pos_x][
+ changed_pos_y] != 'X':
+ start_pos_x, start_pos_y = changed_pos_x, changed_pos_y
+ else:
+ start_pos_x, start_pos_y = dx, dy
+ break
+
+ answer = [start_pos_x, start_pos_y]
+ return answer
+
+# Solve this problem not by myself
+def solution(park, routes):
+ move_directions = {'E': (0, 1), 'W': (0, -1),
+ 'S': (1, 0), 'N': (-1, 0)}
+ park_row, park_col = len(park), len(park[0])
+ x, y = 0, 0
+ for row in range(park_row):
+ for col in range(park_col):
+ if park[row][col] == 'S':
+ x, y = row, col
+ break
+ # start_pos = (0, board[0].index('S'))
+
+ for route in routes:
+ direction, cnts = route.split()[0], int(route.split()[1])
+ dx, dy = x, y
+
+ for cnt in range(cnts):
+ changed_pos_x, changed_pos_y = x + move_directions[direction][0], y + move_directions[direction][1]
+
+ if 0 <= changed_pos_x <= park_row - 1 and 0 <= changed_pos_y <= park_col - 1 and park[changed_pos_x][
+ changed_pos_y] != 'X':
+ x, y = changed_pos_x, changed_pos_y
+ else:
+ x, y = dx, dy
+ break
+
+ return [x, y]
+
+
+park_1 = ["SOO","OOO","OOO"]
+park_2 = ["SOO","OXX","OOO"]
+park_3 = ["OSO","OOO","OXO","OOO"]
+
+routes_1 = ["E 2","S 2","W 1"]
+routes_2 = ["E 2","S 2","W 1"]
+routes_3 = ["E 2","S 3","W 1"]
+
+# print(solution_mine(park_1, routes_1))
+# print(solution_mine(park_2, routes_2))
+# print(solution_mine(park_3, routes_3))
+#
+# print(solution_other(park_1, routes_1))
+# print(solution_other(park_2, routes_2))
+# print(solution_other(park_3, routes_3))
+
+print(solution(park_1, routes_1))
+print(solution(park_2, routes_2))
+print(solution(park_3, routes_3))
+
+
diff --git a/Programmers/LEVEL1/PersonalInformationCollectionValidityPeriod.py b/Programmers/LEVEL1/PersonalInformationCollectionValidityPeriod.py
new file mode 100644
index 0000000..b48bc0b
--- /dev/null
+++ b/Programmers/LEVEL1/PersonalInformationCollectionValidityPeriod.py
@@ -0,0 +1,114 @@
+# Restart 43. 개인정보 수집 유효기간
+
+'''
+This is Kakao Blind Recruitment problem.
+I can rewind using Python's datetime library. This problem calculate month, so 28days for one month doens't matter.
+See this again for studying datetime library. This is the best solution I think.
+'''
+from datetime import datetime
+from dateutil.relativedelta import relativedelta
+def solution(today, terms, privacies):
+ answer = []
+
+ today = datetime.strptime(today, "%Y.%m.%d")
+ today = today.strftime("%Y.%m.%d")
+ terms_dict = {term.split()[0] : int(term.split()[1]) for term in terms}
+ end_dates_lst = []
+ for privacy in privacies:
+ start_date, p_term = privacy.split()
+ start_date = datetime.strptime(start_date, "%Y.%m.%d")
+ add_month = terms_dict[p_term]
+
+ end_date = start_date + relativedelta(months = add_month)
+ end_date = end_date.strftime("%Y.%m.%d")
+ end_dates_lst.append(end_date)
+
+ # print(end_dates_lst)
+ for dt_idx in range(1, len(end_dates_lst) + 1):
+ if today >= end_dates_lst[dt_idx - 1]:
+ answer.append(dt_idx)
+
+ return answer
+
+'''
+Compare today and calculated privacy date and terms
+'''
+# If valid, True
+def date_comparison(expiration_date, today):
+ # Compare year
+ if expiration_date[0] > today[0]:
+ return True
+
+ # Compare Month
+ if expiration_date[0] == today[0] and expiration_date[1] > today[1]:
+ return True
+
+ # Compare Day
+ if expiration_date[0] == today[0] and expiration_date[1] == today[1] and expiration_date[2] > today[2]:
+ return True
+
+ return False
+
+def solution_other(today, terms, privacies):
+ answer = []
+
+ idx = 1
+ today = list(map(int, today.split('.')))
+ expiration = {term[0] : int(term[2:]) for term in terms}
+
+ for privacy in privacies:
+ privacy = privacy.split()
+ privacy_date = list(map(int, privacy[0].split(".")))
+ privacy_date[1] += expiration[privacy[1]]
+
+ # If month is over 12
+ if privacy_date[1] > 12:
+ if privacy_date[1] % 12 == 0:
+ privacy_date[0] += (privacy_date[1] // 12) - 1
+ privacy_date[1] = 12
+ else:
+ privacy_date[0] += privacy_date[1] // 12
+ privacy_date[1] %= 12
+
+ if date_comparison(privacy_date, today) == False:
+ answer.append(idx)
+
+ idx += 1
+ return answer
+
+'''
+Calculate all times with small unit(in here day)
+This is easy for understanding.
+'''
+def to_days(date):
+ year, month, day = map(int, date.split('.'))
+ return year * 28 * 12 + month * 28 + day
+
+def solution_other_easy(today, terms, privacies):
+ answer = []
+
+ month_to_days = {term[0] : int(term[2:]) * 28 for term in terms}
+ today = to_days(today)
+ answer = [
+ pri_idx for pri_idx, privacy in enumerate(privacies, 1)
+ if to_days(privacy[:-2]) + month_to_days[privacy[-1]] <= today
+ ]
+ return answer
+
+today_1 = "2022.05.19"
+today_2 = "2020.01.01"
+
+terms_1 = ["A 6", "B 12", "C 3"]
+terms_2 = ["Z 3", "D 5"]
+
+privacies_1 = ["2021.05.02 A", "2021.07.01 B", "2022.02.19 C", "2022.02.20 C"]
+privacies_2 = ["2019.01.01 D", "2019.11.15 Z", "2019.08.02 D", "2019.07.01 D", "2018.12.28 Z"]
+
+print(solution(today_1, terms_1, privacies_1))
+print(solution(today_2, terms_2, privacies_2))
+
+print(solution_other(today_1, terms_1, privacies_1))
+print(solution_other(today_2, terms_2, privacies_2))
+
+print(solution_other_easy(today_1, terms_1, privacies_1))
+print(solution_other_easy(today_2, terms_2, privacies_2))
diff --git a/Programmers/LEVEL1/ProcessCode.py b/Programmers/LEVEL1/ProcessCode.py
new file mode 100644
index 0000000..bb59f49
--- /dev/null
+++ b/Programmers/LEVEL1/ProcessCode.py
@@ -0,0 +1,41 @@
+# Restart 34. 코드 처리하기
+
+'''
+I solve this problem by myself, but I don't understand best solution. So check it again.
+'''
+def solution(code):
+ answer = ''
+
+ for code_idx in range(len(code)):
+ mode = 0 if code_idx == 0 else mode
+ if mode == 0:
+ if code[code_idx] != '1':
+ if code_idx % 2 == 0:
+ answer += code[code_idx]
+ else:
+ mode = 1
+ elif mode == 1:
+ if code[code_idx] != '1':
+ if code_idx % 2 == 1:
+ answer += code[code_idx]
+ else:
+ mode = 0
+
+ if len(answer) == 0:
+ answer = 'EMPTY'
+
+ return answer
+
+code_1 = "abc1abc1abc"
+
+# print(solution(code_1))
+
+def solution_best(code):
+ answer = ''.join(code.split('1'))[::2] or 'EMPTY'
+
+ # print(code.split('1'))
+ # print(''.join(code.split('1'))[::2])
+ # print(''.join(code.split('1'))[::2] or 'EMPTY')
+ return answer
+
+print(solution_best(code_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/ReceiveNotificationResult.py b/Programmers/LEVEL1/ReceiveNotificationResult.py
new file mode 100644
index 0000000..598f494
--- /dev/null
+++ b/Programmers/LEVEL1/ReceiveNotificationResult.py
@@ -0,0 +1,48 @@
+# 53. 신고 결과 받기
+
+from collections import Counter
+def solution(id_list, report, k):
+ answer = []
+
+ check_list = []
+ report_dict = {id : [] for id in id_list}
+ for rep in report:
+ reporter, reported = rep.split()
+ if reported not in report_dict[reporter]:
+ report_dict[reporter].append(reported)
+ check_list.append(reported)
+
+ cnt_dict = Counter(check_list)
+ for id in id_list:
+ answer.append(len([check for check in report_dict[id]
+ if cnt_dict[check] >= k]))
+ return answer
+
+id_list_1 = ["muzi", "frodo", "apeach", "neo"]
+id_list_2 = ["con", "ryan"]
+
+report_1 = ["muzi frodo", "apeach frodo", "frodo neo",
+ "muzi neo", "apeach muzi"]
+report_2 = ["ryan con", "ryan con",
+ "ryan con", "ryan con"]
+
+k_1 = 2
+k_2 = 3
+
+print(solution(id_list_1, report_1, k_1))
+print(solution(id_list_2, report_2, k_2))
+
+def solution_best(id_list, report, k):
+ answer = [0] * len(id_list)
+
+ reports = {id : 0 for id in id_list}
+ for rep in set(report):
+ reports[rep.split()[1]] += 1
+
+ for rep in set(report):
+ if reports[rep.split()[1]] >= k:
+ answer[id_list.index(rep.split()[0])] += 1
+ return answer
+
+print(solution_best(id_list_1, report_1, k_1))
+print(solution_best(id_list_2, report_2, k_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/RoughlyMakeKeyboard.py b/Programmers/LEVEL1/RoughlyMakeKeyboard.py
new file mode 100644
index 0000000..112b078
--- /dev/null
+++ b/Programmers/LEVEL1/RoughlyMakeKeyboard.py
@@ -0,0 +1,52 @@
+# Restart 40. 대충 만든 자판
+
+# Solve this problem by myself. I catched that using dictionary for solving this problem.
+# I solve this by finding minimum target character counts to dictionary
+def solution(keymap, targets):
+ answer = [0] * len(targets)
+
+ minimum_keymap_dict = {}
+ keymap_target_idx_lst = sorted([(keym_chr, keym_idx) for keym in keymap for keym_idx, keym_chr in enumerate(keym, 1)],
+ key = lambda x : x[0])
+
+ for keym_chr, keym_idx in keymap_target_idx_lst:
+ if keym_chr not in minimum_keymap_dict:
+ minimum_keymap_dict[keym_chr] = keym_idx
+ else:
+ min_key_value = minimum_keymap_dict[keym_chr]
+ if keym_idx < min_key_value:
+ minimum_keymap_dict[keym_chr] = keym_idx
+
+ for target_idx in range(len(targets)):
+ target = targets[target_idx]
+ for target_chr in target:
+ if target_chr in minimum_keymap_dict:
+ answer[target_idx] += minimum_keymap_dict[target_chr]
+ else:
+ answer[target_idx] = -1
+ break
+
+ return answer
+
+keymap_1 = ["ABACD", "BCEFD"]
+keymap_2 = ["AA"]
+keymap_3 = ["AGZ", "BSSS"]
+
+targets_1 = ["ABCD","AABB"]
+targets_2 = ["B"]
+targets_3 = ["ASA","BGZ"]
+
+# Same as other's solution. So I didn't rewind it.
+def solution_other(keymap, targets):
+ answer = []
+
+
+ return answer
+
+print(solution(keymap_1, targets_1))
+print(solution(keymap_2, targets_2))
+print(solution(keymap_3, targets_3))
+
+print(solution_other(keymap_1, targets_1))
+print(solution_other(keymap_2, targets_2))
+print(solution_other(keymap_3, targets_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/RunningRace.py b/Programmers/LEVEL1/RunningRace.py
new file mode 100644
index 0000000..27444fd
--- /dev/null
+++ b/Programmers/LEVEL1/RunningRace.py
@@ -0,0 +1,20 @@
+# Restart 36. 달리기 경주
+
+def solution(players, callings):
+ answer = players
+
+ players_ranking = {player : int(player_rank) for player_rank, player in enumerate(players)}
+
+ for call_player in callings:
+ passing_player_rank = players_ranking[call_player]
+ players_ranking[call_player] -= 1
+ players_ranking[answer[passing_player_rank - 1]] += 1
+
+ answer[passing_player_rank - 1], answer[passing_player_rank] = call_player, answer[passing_player_rank - 1]
+ return answer
+
+players_1 = ['mumu', 'soe', 'poe', 'kai', 'mine']
+
+callings_1 = ['kai', 'kai', 'mine', 'mine']
+
+print(solution(players_1, callings_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/SculptArray.py b/Programmers/LEVEL1/SculptArray.py
new file mode 100644
index 0000000..0fca898
--- /dev/null
+++ b/Programmers/LEVEL1/SculptArray.py
@@ -0,0 +1,56 @@
+# Restart 35. 배열 조각하기
+
+'''
+I solve it, but it didn't satisfy time efficiency.
+See how to satisfy time complex.
+'''
+def solution(arr, query):
+ answer = arr
+
+ for q_idx in range(len(query)):
+ if q_idx % 2 == 0:
+ answer = answer[:query[q_idx] + 1]
+ else:
+ answer = answer[query[q_idx]:]
+ return answer
+
+arr_1 = [0, 1, 2, 3, 4, 5]
+
+query_1 = [4, 1, 2]
+
+print(solution(arr_1, query_1))
+
+def solution_similar(arr, query):
+ answer = arr
+
+ for q_idx, q in enumerate(query):
+ if q_idx % 2 == 0:
+ answer = answer[:query[q_idx] + 1]
+ else:
+ answer = answer[query[q_idx]:]
+ return answer
+
+print(solution_similar(arr_1, query_1))
+
+'''
+This is my method.
+
+'''
+def solution_error(arr, query):
+ answer = []
+
+ for q_idx in range(len(query)):
+ # print('arr :', arr)
+ arr_q_idx = arr.index(query[q_idx])
+ if q_idx != 0:
+ if q_idx % 2 == 0:
+ answer = answer[:arr_q_idx + 1]
+ else:
+ answer = answer[arr_q_idx:]
+ else:
+ answer = arr[:arr_q_idx + 1]
+ # print('answer :', answer)
+ return answer
+
+# print(solution_error(arr_1, query_1))
+
diff --git a/Programmers/LEVEL1/SequenceAndIntervalQueries2.py b/Programmers/LEVEL1/SequenceAndIntervalQueries2.py
new file mode 100644
index 0000000..5b1a346
--- /dev/null
+++ b/Programmers/LEVEL1/SequenceAndIntervalQueries2.py
@@ -0,0 +1,37 @@
+# Restart 32. 수열과 구간 쿼리 2
+
+'''
+I have to think about the initialization of possible list(poss_lst).
+See again
+'''
+def solution(arr, queries):
+ answer = []
+
+ # for s, e, k in queries:
+ # sub_arr = arr[s:e + 1]
+ # poss_lst = [num for num in sub_arr if num > k]
+ #
+ # try:
+ # answer.append(min(poss_lst))
+ # except:
+ # answer.append(-1)
+
+ for s, e, k in queries:
+ poss_lst = [num for num in arr[s:e + 1] if num > k]
+ answer.append(-1 if len(poss_lst) == 0 else min(poss_lst))
+ return answer
+
+arr_1 = [0, 1, 2, 4, 3]
+
+queries_1 = [[0, 4, 2],[0, 3, 2],[0, 2, 2]]
+
+# print(solution(arr_1, queries_1))
+
+def solution_best(arr, queries):
+ answer = list(map(lambda x: -1 if x == 10 ** 6 else x,
+ [min(list(filter(lambda x : x > k, arr[s:e + 1])) +
+ [10 ** 6]) for s, e, k in queries]))
+
+ return answer
+
+print(solution_best(arr_1, queries_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/StringSplit.py b/Programmers/LEVEL1/StringSplit.py
new file mode 100644
index 0000000..e0c491c
--- /dev/null
+++ b/Programmers/LEVEL1/StringSplit.py
@@ -0,0 +1,62 @@
+# Restart 44. 문자열 나누기
+
+'''
+Solve this problem by following the statements of problem.
+But it's hard to implement for me. See this again.
+Last condition is important.
+'''
+def solution(s):
+ answer = 0
+
+ first_alp = ''
+ fir_alp_same_cnt = 0
+ diff_cnt = 0
+ for sub_s in s:
+ if first_alp == '':
+ first_alp = sub_s
+ fir_alp_same_cnt = 1
+ continue
+
+ if first_alp == sub_s:
+ fir_alp_same_cnt += 1
+ else:
+ diff_cnt += 1
+
+ if fir_alp_same_cnt == diff_cnt:
+ first_alp = ''
+ fir_alp_same_cnt = 0
+ diff_cnt = 0
+ answer += 1
+
+ if first_alp != '':
+ answer += 1
+ return answer
+
+'''
+This is completely different with Solution.
+pointer index is the keypoint and last condition is important in here.
+'''
+def solution_best(s):
+ answer = 0
+
+ pointer = 0
+ first_same_cnt = 0
+ for sub_s_idx, sub_s in enumerate(s):
+ first_same_cnt += 1 if s[pointer] == sub_s else -1
+ if first_same_cnt == 0:
+ answer += 1
+ pointer = sub_s_idx + 1
+
+ return answer + 1 if first_same_cnt else answer
+
+s_1 = "banana"
+s_2 = "abracadabra"
+s_3 = "aaabbaccccabba"
+
+print(solution(s_1))
+print(solution(s_2))
+print(solution(s_3))
+
+print(solution_best(s_1))
+print(solution_best(s_2))
+print(solution_best(s_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/SumOfPlusMinus.py b/Programmers/LEVEL1/SumOfPlusMinus.py
new file mode 100644
index 0000000..36092e2
--- /dev/null
+++ b/Programmers/LEVEL1/SumOfPlusMinus.py
@@ -0,0 +1,25 @@
+# 43. 음양 더하기
+
+def solution(absolutes, signs):
+ answer = 0
+
+ sum_lst = [absolutes[i] if signs[i] == True else -absolutes[i]
+ for i in range(len(signs))]
+
+ answer = sum(sum_lst)
+ return answer
+
+absolutes_1 = [4, 7, 12]
+absolutes_2 = [1, 2, 3]
+
+signs_1 = [True, False, True]
+signs_2 = [False, False, True]
+
+print(solution(absolutes_1, signs_1))
+print(solution(absolutes_2, signs_2))
+
+def solution_best(absolutes, signs):
+ return sum(absolutes if sign else -absolutes for absolutes, sign in zip(absolutes, signs))
+
+print(solution_best(absolutes_1, signs_1))
+print(solution_best(absolutes_2, signs_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/TemplarWeapon.py b/Programmers/LEVEL1/TemplarWeapon.py
new file mode 100644
index 0000000..1a52a32
--- /dev/null
+++ b/Programmers/LEVEL1/TemplarWeapon.py
@@ -0,0 +1,66 @@
+# 기사단원의 무기
+
+"""
+I almost solve this problem by myself. The key of this problem is finding counts of divisors.
+Here's the code of Searching Divisors in Efficient ways.
+See it again.
+"""
+def solution(number, limit, power):
+ answer = 0
+
+ numbers = [num for num in range(1, number + 1)]
+ divisors_cnt = []
+ for num in numbers:
+ divisors = []
+ for i in range(1, int(num ** 0.5) + 1):
+ if num % i == 0:
+ divisors.append(i)
+ if i < num // i:
+ divisors.append(num // i)
+ divisors.sort()
+
+ divisors_cnt.append(len(divisors))
+
+ for divisor_cnt in divisors_cnt:
+ if divisor_cnt <= limit:
+ answer += divisor_cnt
+ else:
+ answer += power
+
+ return answer
+
+def solution_other(number, limit, power):
+ answer = 0
+
+ numbers = [num for num in range(1, number + 1)]
+ divisors_cnt = []
+ for num in numbers:
+ divisors = []
+ for i in range(1, int(num ** 0.5) + 1):
+ if num % i == 0:
+ divisors.append(i)
+ if i < num // i:
+ divisors.append(num // i)
+ divisors.sort()
+
+ divisors_cnt.append(len(set(divisors)))
+
+ for divisor_cnt in divisors_cnt:
+ if divisor_cnt <= limit:
+ answer += divisor_cnt
+ else:
+ answer += power
+
+ return answer
+
+number_1 = 5
+number_2 = 10
+
+limit_1 = 3
+limit_2 = 3
+
+power_1 = 2
+power_2 = 2
+
+print(solution(number_1, limit_1, power_1))
+print(solution(number_2, limit_2, power_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL1/__init__.py b/Programmers/LEVEL1/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/LEVEL2/BestAndWorstOfLotto.py b/Programmers/LEVEL2/BestAndWorstOfLotto.py
new file mode 100644
index 0000000..52b2aa8
--- /dev/null
+++ b/Programmers/LEVEL2/BestAndWorstOfLotto.py
@@ -0,0 +1,66 @@
+# 30. 로또의 최고 순위와 최저 순위
+
+'''스스로 풀었지만 비효율적인 풀이'''
+def solution(lottos, win_nums):
+ answer = [7, 7]
+
+ lottos.sort()
+ win_nums.sort()
+
+ for i in lottos:
+ if i == 0:
+ answer[0] -= 1
+ else:
+ for j in win_nums:
+ if i == j:
+ answer[0] -= 1
+ answer[1] -= 1
+
+ if answer[0] == 7:
+ answer[0] -= 1
+ if answer[1] == 7:
+ answer[1] -= 1
+
+ return answer
+
+lottos_1 = [44, 1, 0, 0, 31, 25]
+lottos_2 = [0, 0, 0, 0, 0, 0]
+lottos_3 = [45, 4, 35, 20, 3, 9]
+
+win_nums_1 = [31, 10, 45, 1, 6, 19]
+win_nums_2 = [38, 19, 20, 40, 15, 25]
+win_nums_3 = [20, 9, 3, 45, 4, 35]
+
+# print(solution(lottos_1, win_nums_1))
+# print(solution(lottos_2, win_nums_2))
+# print(solution(lottos_3, win_nums_3))
+
+def solution_best(lottos, win_nums):
+ answer = [6, 6, 5, 4, 3, 2, 1]
+
+ cnt_0 = lottos.count(0)
+ match = 0
+ for x in win_nums:
+ if x in lottos:
+ match += 1
+ return [answer[cnt_0 + match], answer[match]]
+
+# print(solution_best(lottos_1, win_nums_1))
+# print(solution_best(lottos_2, win_nums_2))
+# print(solution_best(lottos_3, win_nums_3))
+
+from collections import Counter
+def solution_other(lottos, win_nums):
+ lotto = {6: 1, 5: 2, 4: 3, 3: 4, 2: 5, 1: 6, 0: 6}
+
+ c = Counter(lottos) - Counter(win_nums)
+ print(Counter(lottos))
+ print(Counter(win_nums))
+ print(c)
+
+ cnt = 6 - sum([v for k, v in c.items()])
+ return [lotto[cnt + c[0]], lotto[cnt]]
+
+print(solution_other(lottos_1, win_nums_1))
+# print(solution_other(lottos_2, win_nums_2))
+# print(solution_other(lottos_3, win_nums_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/BracketTransformation.py b/Programmers/LEVEL2/BracketTransformation.py
new file mode 100644
index 0000000..b860180
--- /dev/null
+++ b/Programmers/LEVEL2/BracketTransformation.py
@@ -0,0 +1,132 @@
+# 61. 괄호 변환
+
+def balanced(p):
+ num = 0
+ tmp = []
+
+ for idx, value in enumerate(p):
+ if value == '(':
+ num += 1
+ elif value == ')':
+ num -= 1
+
+ if num == 0:
+ return idx
+
+def correct(string):
+ tmp = []
+
+ for i in string:
+ if i == '(':
+ tmp.append(i)
+ else:
+ if len(tmp) == 0:
+ return False
+ tmp.pop()
+
+ if len(tmp) == 0:
+ return True
+ else:
+ return False
+
+def solution(p):
+ answer = ''
+
+ if p == '' or correct(p):
+ return p
+
+ u, v = p[:balanced(p) + 1], p[balanced(p) + 1:]
+ if correct(u):
+ string = solution(v)
+ return u + string
+ else:
+ answer += '('
+ answer += solution(v)
+ answer += ')'
+ u = list(u[1:-1])
+
+ for i in range(len(u)):
+ if u[i] == '(':
+ u[i] = ')'
+ elif u[i] == ')':
+ u[i] = '('
+
+ answer += ''.join(u)
+
+ return answer
+
+p_1 = "(()())()"
+p_2 = ")("
+p_3 = "()))((()"
+
+# print(solution(p_1))
+# print(solution(p_2))
+# print(solution(p_3))
+
+'''
+비슷한 풀이, 좀 더 좋은 풀이
+'''
+from collections import Counter
+def is_balanced(p):
+ bracket_counter = Counter(p)
+ bal = bracket_counter['('] - bracket_counter[')']
+
+ return not(bool(bal))
+
+def is_right(p):
+ if is_balanced(p) == False:
+ return False
+
+ bracket_counter = Counter(p)
+ bal = bracket_counter['('] - bracket_counter[')']
+ if bal < 0:
+ return False
+
+ return True
+
+def solution_other(p):
+ answer = ''
+
+ if is_right(p) == True:
+ return p
+
+ for i in range(2, len(p) + 1, 2):
+ if is_balanced(p[:i]) == True:
+ u, v = p[:i], p[i:]
+ break
+
+ if is_right(u) == True:
+ return u + solution_other(v)
+ else:
+ answer = '(' + solution_other(v) + ')'
+ for i in u[1:-1]:
+ if i == '(':
+ if i == '(':
+ answer += ')'
+ else:
+ answer += '('
+
+ return answer
+
+# print(solution_other(p_1))
+# print(solution_other(p_2))
+# print(solution_other(p_3))
+
+def solution_best(p):
+ if p == '': return p
+ r = True
+ c = 0
+ for i in range(len(p)):
+ if p[i] == '(': c -= 1
+ else: c += 1
+ if c > 0: r = False
+ if c == 0:
+ if r:
+ return p[:i + 1] + solution_best(p[i + 1:])
+ else:
+ return '(' + solution_best(p[i + 1:]) + ')' + ''.join(list(
+ map(lambda x:'(' if x==')' else ')',p[1:i])))
+
+# print(solution_best(p_1))
+# print(solution_best(p_2))
+# print(solution_best(p_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/Cache.py b/Programmers/LEVEL2/Cache.py
new file mode 100644
index 0000000..c2919ff
--- /dev/null
+++ b/Programmers/LEVEL2/Cache.py
@@ -0,0 +1,155 @@
+# 45. 캐시
+
+'''
+LRU(Least Recently Used)알고리즘 : 가장 최근에 사용되지 않은 것 즉, 가장 오래전에 사용한 것을 제거하는 알고리즘
+오랫동안 사용하지 않았던 데이터는 앞으로도 사용할 확률이 적다.
+'''
+def solution(cacheSize, cities):
+ answer = 0
+
+ cache = []
+ cities = [city.lower() for city in cities]
+ if cacheSize != 0:
+ for city in cities:
+ if city in cache:
+ cache.pop(cache.index(city))
+ cache.append(city)
+ answer += 1
+ else:
+ if len(cache) < cacheSize:
+ cache.append(city)
+ answer += 5
+ else:
+ cache.pop(0)
+ cache.append(city)
+ answer += 5
+ else:
+ answer += len(cities) * 5
+
+ return answer
+
+cacheSize_1 = 3
+cacheSize_2 = 3
+cacheSize_3 = 2
+cacheSize_4 = 5
+cacheSize_5 = 2
+cacheSize_6 = 0
+
+cities_1 = ["Jeju", "Pangyo", "Seoul", "NewYork", "LA",
+ "Jeju", "Pangyo", "Seoul", "NewYork", "LA"
+ ]
+cities_2 = ["Jeju", "Pangyo", "Seoul", "Jeju", "Pangyo",
+ "Seoul", "Jeju", "Pangyo", "Seoul"
+ ]
+cities_3 = ["Jeju", "Pangyo", "Seoul", "NewYork", "LA",
+ "SanFrancisco", "Seoul", "Rome", "Paris",
+ "Jeju", "NewYork", "Rome"
+ ]
+cities_4 = ["Jeju", "Pangyo", "Seoul", "NewYork", "LA",
+ "SanFrancisco", "Seoul", "Rome", "Paris",
+ "Jeju", "NewYork", "Rome"
+ ]
+cities_5 = ["Jeju", "Pangyo", "NewYork", "newyork"]
+cities_6 = ["Jeju", "Pangyo", "Seoul", "NewYork", "LA"]
+
+print(solution(cacheSize_1, cities_1))
+print(solution(cacheSize_2, cities_2))
+print(solution(cacheSize_3, cities_3))
+print(solution(cacheSize_4, cities_4))
+print(solution(cacheSize_5, cities_5))
+print(solution(cacheSize_6, cities_6))
+
+from collections import deque
+
+def solution_other(cacheSize, cities):
+ answer = 0
+ buffer = deque()
+
+ # cacheSize가 0인 경우에는 참조하는 값이 없으므로 전부 5를 곱함
+ if cacheSize == 0:
+ return len(cities) * 5
+
+ # 그렇지 않은경우에는, 모든 city에 대해서 확인
+ # 1. city가 buffer에 있으면 +1, 그렇지 않으면 +5
+ # 2. city가 buffer에 있으면 삭제하고 가장 먼저 참조된 값으로 변경 `buffer.remove(i) -> buffer.append(i)`
+ # city가 buffer에 없으면, buffer의 크기와 cacheSize의 크기를 비교
+ # cacheSize 보다 크기가 크면 가장 오래전 참조된 값을 삭제 `buffer.popleft()`
+ # cacheSize 보다 작으면, 단순 삽입 `buffer.append(i)`
+ else:
+ for i in cities:
+ # 대소문자는 구분하지 않으므로 lower으로 변경
+ i = i.lower()
+ if i in buffer:
+ answer += 1
+ else:
+ answer += 5
+
+ if i in buffer:
+ buffer.remove(i)
+ else:
+ if len(buffer) >= cacheSize:
+ buffer.popleft()
+
+ buffer.append(i)
+ return answer
+
+print(solution_other(cacheSize_1, cities_1))
+print(solution_other(cacheSize_2, cities_2))
+print(solution_other(cacheSize_3, cities_3))
+print(solution_other(cacheSize_4, cities_4))
+print(solution_other(cacheSize_5, cities_5))
+print(solution_other(cacheSize_6, cities_6))
+
+def solution_good(cacheSize, cities):
+ answer = 0
+ buffer = deque()
+
+ if cacheSize == 0:
+ return 5 * len(cities)
+
+ for city in cities:
+ city = city.lower()
+ if city not in buffer:
+ if len(buffer) == cacheSize:
+ buffer.popleft()
+ buffer.append(city)
+ answer += 5
+ else:
+ buffer.remove(city)
+ buffer.append(city)
+ answer += 1
+
+ return answer
+
+print(solution_good(cacheSize_1, cities_1))
+print(solution_good(cacheSize_2, cities_2))
+print(solution_good(cacheSize_3, cities_3))
+print(solution_good(cacheSize_4, cities_4))
+print(solution_good(cacheSize_5, cities_5))
+print(solution_good(cacheSize_6, cities_6))
+
+'''
+deque의 maxlen인자를 사용하여 불필요한 과정 줄임
+queue가 꽉 찬 상태에서 새 아이템을 넣으면 첫 아이템이 자동으로 삭제됨.
+'''
+def solution_best(cacheSize, cities):
+ answer = 0
+ cache = deque(maxlen = cacheSize)
+
+ for city in cities:
+ city = city.lower()
+ if city in cache:
+ cache.remove(city)
+ cache.append(city)
+ answer += 1
+ else:
+ cache.append(city)
+ answer += 5
+ return answer
+
+print(solution_best(cacheSize_1, cities_1))
+print(solution_best(cacheSize_2, cities_2))
+print(solution_best(cacheSize_3, cities_3))
+print(solution_best(cacheSize_4, cities_4))
+print(solution_best(cacheSize_5, cities_5))
+print(solution_best(cacheSize_6, cities_6))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/CandidateKey.py b/Programmers/LEVEL2/CandidateKey.py
new file mode 100644
index 0000000..376d8c9
--- /dev/null
+++ b/Programmers/LEVEL2/CandidateKey.py
@@ -0,0 +1,73 @@
+# 41. 후보키
+
+'''
+범위가 4개로만 국한되는건가? 아니다
+전체 조합에서 조건에 만족하지 않는 조건들을 빼는 방식으로 푼다
+'''
+from itertools import combinations
+def solution(relation):
+ answer = 0
+
+ cand_keys = []
+ n_row, n_col = len(relation), len(relation[0])
+
+ # 전체 조합
+ candidates = []
+ for i in range(1, n_col + 1):
+ candidates.extend(combinations(range(n_col), i))
+
+ # 유일성
+ unique = []
+ for keys in candidates:
+ tmp = [tuple(item[key] for key in keys)
+ for item in relation]
+ if len(set(tmp)) == n_row:
+ unique.append(keys)
+
+ cand_keys = set(unique)
+ for i in range(len(unique)):
+ for j in range(i + 1, len(unique)):
+ if len(unique[i]) == len(set(unique[i]).intersection(set(unique[j]))):
+ cand_keys.discard(unique[j])
+
+ answer = len(cand_keys)
+ return answer
+
+relation_1 = [["100", "ryan", "music", "2"],
+ ["200", "apeach", "math", "2"],
+ ["300", "tube", "computer", "3"],
+ ["400", "con", "computer", "4"],
+ ["500", "muzi", "music", "3"],
+ ["600", "apeach", "music", "2"]
+ ]
+
+print(solution(relation_1))
+
+def solution_other(relation):
+ answer = 0
+ cand_keys = []
+
+ for i in range(1, 1 << len(relation[0])):
+ tmp_set = set()
+ for j in range(len(relation)):
+ tmp = ''
+ for k in range(len(relation[0])):
+ if i & (1 << k):
+ tmp += str(relation[j][k])
+ tmp_set.add(tmp)
+
+ if len(tmp_set) == len(relation):
+ not_duplicate = True
+ for num in cand_keys:
+ if (num & i) == num:
+ not_duplicate = False
+ break
+ if not_duplicate:
+ cand_keys.append(i)
+
+ answer = len(cand_keys)
+ return answer
+
+print(solution_other(relation_1))
+
+
diff --git a/Programmers/LEVEL2/Compression.py b/Programmers/LEVEL2/Compression.py
new file mode 100644
index 0000000..0e8949b
--- /dev/null
+++ b/Programmers/LEVEL2/Compression.py
@@ -0,0 +1,81 @@
+# 47. 압축
+
+def solution(msg):
+ answer = []
+
+ dict = {chr(65 + i) : i + 1 for i in range(26)}
+ w, c = 0, 0
+ while True:
+ c += 1
+ if c == len(msg):
+ answer.append(dict[msg[w:c]])
+ break
+
+ if msg[w:c + 1] not in dict:
+ dict[msg[w:c + 1]] = len(dict) + 1
+ answer.append(dict[msg[w:c]])
+ w = c
+
+ return answer
+
+msg_1 = 'KAKAO'
+msg_2 = 'TOBEORNOTTOBEORTOBEORNOT'
+msg_3 = 'ABABABABABABABAB'
+
+print(solution(msg_1))
+print(solution(msg_2))
+print(solution(msg_3))
+
+'''
+먼저 대문자 알파벳 별로 값을 가지는 dictionary 만든 후
+msg의 첫 번째 문자열 값을 compress_str변수에 저장한 후
+'KAKAO'의 경우
+'K' ... dictionary에 있으니 answer list에 'K' value값 추가 후
+'KA' ... dictionary에 없으므로 dictionary에 27
+'A'... dictionary에 있으니 answer list에 'A' value값 추가
+이런 식으로 생각
+----------------------------------------------------------
+현재 글자 + 다음 글자가 dictionary에 있는지 없는지로 나눠서
+풀어야 한다.
+현재 글자 + 다음 글자가 dictionary에 없으면 w = c, c = c + 1
+현재 글자 + 다음 글자가 dictionary에 없으면 w는 변화없음, c = c + 1
+'''
+def solution_mine(msg):
+ answer = []
+
+ dict = {chr(64 + i): i for i in range(1, 26)}
+ compress_str = msg[0]
+ if compress_str in dict.keys():
+ answer.append(dict[compress_str])
+
+ for i in range(1, len(msg)):
+ compress_str += msg[i]
+ if msg[i] in dict.keys():
+ answer.append(dict[msg[i]])
+
+ if compress_str not in dict.keys():
+ dict[compress_str] = len(dict.keys()) + 2
+ compress_str = compress_str[1:]
+
+ return answer
+
+def solution_other(msg):
+ answer = []
+
+ tmp = {chr(e + 64) : e for e in range(1, 27)}
+ num = 27
+ while msg:
+ tt = 1
+ while msg[:tt] in tmp.keys() and tt <= msg.__len__():
+ tt += 1
+ tt -= 1
+ if msg[:tt] in tmp.keys():
+ answer.append(tmp[msg[:tt]])
+ tmp[msg[:tt + 1]] = num
+ num += 1
+ msg = msg[tt:]
+ return answer
+
+print(solution_other(msg_1))
+print(solution_other(msg_2))
+print(solution_other(msg_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/ConfirmDistance.py b/Programmers/LEVEL2/ConfirmDistance.py
new file mode 100644
index 0000000..4385285
--- /dev/null
+++ b/Programmers/LEVEL2/ConfirmDistance.py
@@ -0,0 +1,185 @@
+# 54. 거리두기 확인하기
+
+
+size = 5
+def valid(r, c):
+ return -1 < r < size and -1 < c < size
+
+
+def BFS_check(x, y, place):
+ dist = [(1, 0), (0, 1), (-1, 0), (0, -1)]
+ for dx, dy in dist:
+ nx, ny = x + dx, y + dy
+ if valid(nx, ny) and place[nx][ny] == 'P':
+ return False
+
+ dist = [(-1, -1), (-1, 1), (1, -1), (1, 1)]
+ for dx, dy in dist:
+ nx, ny = x + dx, y + dy
+ if valid(nx, ny) and place[nx][ny] == 'P' \
+ and (place[x][ny] != 'X' or place[nx][y] != 'X'):
+ return False
+
+ dist = [(2, 0), (0, 2), (-2, 0), (0, -2)]
+ for dx, dy in dist:
+ nx, ny = x + dx, y + dy
+ if valid(nx, ny) and place[nx][ny] == 'P' and place[x + dx // 2][y + dy // 2] != 'X':
+ return False
+
+ return True
+
+def solution(places):
+ answer = []
+
+ for place in places:
+ flag = False
+ for r, c in [(i, j) for i in range(5) for j in range(5)]:
+ if place[r][c] == 'P':
+ result = BFS_check(r, c, place)
+ if not result:
+ answer.append(0)
+ flag = True
+ break
+
+ if not flag:
+ answer.append(1)
+
+ return answer
+
+places_1 = [
+ ["POOOP", "OXXOX", "OPXPX", "OOXOX", "POXXP"],
+ ["POOPX", "OXPXP", "PXXXO", "OXXXO", "OOOPP"],
+ ["PXOPX", "OXOXP", "OXPOX", "OXXOP", "PXPOX"],
+ ["OOOXX", "XOOOX", "OOOXX", "OXOOX", "OOOOO"],
+ ["PXPXP", "XPXPX", "PXPXP", "XPXPX", "PXPXP"]
+ ]
+
+# print(solution(places_1))
+
+def solution_other(places):
+ answer = []
+
+ # place를 하나씩 확인
+ for place in places:
+
+ # 거리두기가 지켜지지 않음을 확인하면 바로 반복을 멈추기 위한 key
+ key = False
+ nowArr = []
+
+ # 이번 place를 nowArr에 담아줍니다.
+ for n in place:
+ nowArr.append(list(n))
+
+ # 이중 for문을 이용해 하나씩 확인합니다.
+ for i in range(5):
+ if key:
+ break
+
+ for j in range(5):
+ if key:
+ break
+
+ # 사람을 찾아내면 판단을 시작합니다.
+ if nowArr[i][j] == "P":
+
+ if i + 1 < 5:
+ # 만약 바로 아랫부분에 사람이 존재하면 break
+ if nowArr[i + 1][j] == "P":
+ key = True
+ break
+ # 만약 아랫부분이 빈테이블이고 그 다음에 바로 사람이 있다면 한칸 떨어져 있더라도 맨허튼 거리는 2이므로 break
+ if nowArr[i + 1][j] == "O":
+ if i + 2 < 5:
+ if nowArr[i + 2][j] == "P":
+ key = True
+ break
+ # 바로 오른쪽 부분에 사람이 존재하면 break
+ if j + 1 < 5:
+ if nowArr[i][j + 1] == "P":
+ key = True
+ break
+ # 만약 오른쪽 부분이 빈테이블이고 그 다음에 바로 사람이 있다면 한칸 떨어져 있더라도 맨허튼 거리는 2이므로 break
+ if nowArr[i][j + 1] == "O":
+ if j + 2 < 5:
+ if nowArr[i][j + 2] == "P":
+ key = True
+ break
+ # 우측 아래 부분입니다.
+ if i + 1 < 5 and j + 1 < 5:
+ # 만약 우측 아래가 사람이고, 오른 쪽 또는 아랫부분중 하나라도 빈테이블이면 break
+ if nowArr[i + 1][j + 1] == "P" and (nowArr[i + 1][j] == "O" or nowArr[i][j + 1] == "O"):
+ key = True
+ break
+
+ # 좌측 아래부분입니다.
+ if i + 1 < 5 and j - 1 >= 0:
+ # 만약 좌측 아래가 사람이고, 왼쪽 또는 아랫부분중 하나라도 빈테이블이면 break
+ if nowArr[i + 1][j - 1] == "P" and (nowArr[i + 1][j] == "O" or nowArr[i][j - 1] == "O"):
+ key = True
+ break
+
+ # 위의 for문동안 key가 True로 변경되었다면 거리두가기 지켜지지 않은것 이므로 0을 answer에 추가
+ if key:
+ answer.append(0)
+ else:
+ # key가 false로 끝났다면 거리두기가 지켜졌으므로 1 추가
+ answer.append(1)
+ return answer
+
+# print(solution_other(places_1))
+
+from collections import deque
+
+move_x = [1, 0, -1, 0]
+move_y = [0, -1, 0, 1]
+
+def BFS(place, x, y):
+ visited = [[0 for y in range(5)] for x in range(5)]
+ deq = deque()
+ deq.append([x, y, 0])
+ visited[x][y] = 1
+
+ while deq:
+ now = deq.popleft()
+
+ if 1 <= now[2] <= 2 and place[now[0]][now[1]] == 'P':
+ return False
+
+ if 3 <= now[2]:
+ break
+
+ for move in range(4):
+ nxt = [0, 0, 0]
+ nxt[0] = now[0] + move_x[move]
+ nxt[1] = now[1] + move_y[move]
+ nxt[2] = now[2] + 1
+
+ if 0 <= nxt[0] < 5 and 0 <= nxt[1] < 5:
+ if place[nxt[0]][nxt[1]] != 'X' and visited[nxt[0]][nxt[1]] == 0:
+ deq.append(nxt)
+ visited[nxt[0]][nxt[1]] = 1
+
+ return True
+
+def solution_best(places):
+ answer = []
+
+ for place in places:
+ false_place = True
+ for x in range(len(place)):
+ for y in range(len(place[0])):
+ if place[x][y] == 'P':
+ if BFS(place, x, y) == False:
+ false_place = False
+ break
+ if false_place == False:
+ break
+
+ if false_place == False:
+ answer.append(0)
+ else:
+ answer.append(1)
+
+ return answer
+
+print(solution_best(places_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/ConvertNumber.py b/Programmers/LEVEL2/ConvertNumber.py
new file mode 100644
index 0000000..14d4f39
--- /dev/null
+++ b/Programmers/LEVEL2/ConvertNumber.py
@@ -0,0 +1,82 @@
+# 숫자 변환하기
+
+"""
+I didn't solve this problem by myself. I miss the key that this is about Search and BFS is appropriate for this problem.
+But using Python's set is more efficient than using Python deque.
+See it again.
+"""
+from collections import deque
+
+def solution(x, y, n):
+ answer = 0
+ distances = [0 for _ in range(y + 1)]
+
+ que = deque([x])
+ if x == y:
+ return 0
+
+ while que:
+ mx = que.popleft()
+ for m_dir in range(3):
+ if m_dir == 0:
+ cur_x = mx + n
+ if m_dir == 1:
+ cur_x = mx * 2
+ if m_dir == 2:
+ cur_x = mx * 3
+
+ if cur_x > y or distances[cur_x]:
+ continue
+
+ if cur_x == y:
+ return distances[mx] + 1
+
+ que.append(cur_x)
+ distances[cur_x] = distances[mx] + 1
+
+ return -1
+
+
+x_1 = 10
+x_2 = 10
+x_3 = 2
+
+y_1 = 40
+y_2 = 40
+y_3 = 5
+
+n_1 = 5
+n_2 = 30
+n_3 = 4
+
+print(solution(x_1, y_1, n_1))
+print(solution(x_2, y_2, n_2))
+print(solution(x_3, y_3, n_3))
+
+
+def solution_best(x, y, n):
+ answer = 0
+
+ s = set()
+ s.add(x)
+ while s:
+ if y in s:
+ return answer
+
+ nxt = set()
+ for i in s:
+ if i + n <= y:
+ nxt.add(i + n)
+ if i * 2 <= y:
+ nxt.add(i * 2)
+ if i * 3 <= y:
+ nxt.add(i * 3)
+ s = nxt
+ answer += 1
+
+ return answer
+
+
+print(solution_best(x_1, y_1, n_1))
+print(solution_best(x_2, y_2, n_2))
+print(solution_best(x_3, y_3, n_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/DifferentBitBelowTwoCounts.py b/Programmers/LEVEL2/DifferentBitBelowTwoCounts.py
new file mode 100644
index 0000000..412ce83
--- /dev/null
+++ b/Programmers/LEVEL2/DifferentBitBelowTwoCounts.py
@@ -0,0 +1,62 @@
+# 43. 2개 이하로 다른 비트
+
+def solution(numbers):
+ answer = []
+
+ for number in numbers:
+ bin_number = list('0' + bin(number)[2:])
+ idx = ''.join(bin_number).rfind('0')
+ bin_number[idx] = '1'
+
+ if number % 2 == 1:
+ bin_number[idx + 1] = '0'
+
+ answer.append(int(''.join(bin_number), 2))
+ return answer
+
+numbers_1 = [2, 7]
+
+print(solution(numbers_1))
+
+'''
+numbers 리스트 안에 값을 기준으로 이진수로 바꿨을 때 한 자리를 더 추가한 값들 중 가장 큰 값
+ex) 2 -> 010(2) -> 111(2) -> 7값을 기준으로
+3 ~ 7까지의 수를 이진수로 바꿔서 비교
+ex) 3 -> 011(2) -> 010(2)와 011(2) 각 자리별로 비교
+비트가 다른 것들의 개수를 bit_checks변수에 저장
+bit_checks가 2보다 작은 수들 중에 값이 제일 작은 수 반환(여기가 안 됨)
+그리고 만약에 이게 해결이 되더라도 시간 초과로 걸릴 듯...
+'''
+def solution_mine(numbers):
+ answer = 0
+
+ bin_number_lst = []
+ for number in numbers:
+ bin_number = bin(number)[2:]
+ max_num = int((len(bin_number) + 1) * '1', 2)
+ bit_checks = 0
+ for num in range(number + 1, max_num + 1):
+ b_num = bin(num)[2:]
+ for bit1, bit2 in zip(bin_number, b_num):
+ if bit_checks <= 2:
+ if bit1 != bit2:
+ bit_checks += 1
+ else:
+ break
+
+ if bit_checks <= 2:
+ bin_number_lst.append(num)
+
+ bit_checks = 0
+
+ print(bin_number_lst)
+ return answer
+
+def solution_best(numbers):
+ answer = []
+
+ for idx, val in enumerate(numbers):
+ answer.append(((val ^ (val + 1)) >> 2) + val + 1)
+ return answer
+
+print(solution_best(numbers_1))
diff --git a/Programmers/LEVEL2/EfficientHacking.py b/Programmers/LEVEL2/EfficientHacking.py
new file mode 100644
index 0000000..d0c1e6f
--- /dev/null
+++ b/Programmers/LEVEL2/EfficientHacking.py
@@ -0,0 +1,41 @@
+# 효율적인 해킹
+
+"""
+I didn't solve this problem by myself. The key of this problem is sorting column and ascending sorting.
+And get S_i with easy method. Think simple, not complicated.
+See it again.
+"""
+def solution(data, col, row_begin, row_end):
+ answer = 0
+
+ table = sorted(data, key=lambda row: [row[col - 1], -row[0]])
+ for i in range(row_begin, row_end + 1):
+ result = 0
+ for j in table[i - 1]:
+ result += j % i
+
+ answer = answer ^ result
+
+ return answer
+
+data_1 = [[2, 2, 6],
+ [1, 5, 10],
+ [4, 2, 9],
+ [3, 8, 3]]
+
+col_1 = 2
+
+row_begin_1 = 2
+
+row_end_1 = 3
+
+print(solution(data_1, col_1, row_begin_1, row_end_1))
+
+from functools import reduce
+
+def solution_best(data, col, row_begin, row_end):
+ data.sort(key=lambda x: (x[col - 1], -x[0]))
+ return reduce(lambda x, y: x ^ y,
+ [sum(map(lambda x: x % (i + 1), data[i])) for i in range(row_begin - 1, row_end)])
+
+print(solution_best(data_1, col_1, row_begin_1, row_end_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/ExpressionOfNumber.py b/Programmers/LEVEL2/ExpressionOfNumber.py
new file mode 100644
index 0000000..06182d2
--- /dev/null
+++ b/Programmers/LEVEL2/ExpressionOfNumber.py
@@ -0,0 +1,29 @@
+# 54. 숫자의 표현
+
+def solution(n):
+ answer = 0
+
+ for i in range(1, n + 1):
+ sum = 0
+ for j in range(i, n + 1):
+ sum += j
+ if sum == n:
+ answer += 1
+ break
+ elif sum > n:
+ break
+
+ return answer
+
+n_1 = 15
+
+print(solution(n_1))
+
+# 등차수열의 합 공식
+def solution_best(n):
+ # n % i is 0으로 나와있는데 is문법은 보통 같은 객체를 가리킬 때 사용
+ answer = len([i for i in range(1, n + 1, 2) if n % i == 0])
+
+ return answer
+
+print(solution_best(n_1))
diff --git a/Programmers/LEVEL2/FatigureDegree.py b/Programmers/LEVEL2/FatigureDegree.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/LEVEL2/FibonacciNumber.py b/Programmers/LEVEL2/FibonacciNumber.py
new file mode 100644
index 0000000..f4d7a5c
--- /dev/null
+++ b/Programmers/LEVEL2/FibonacciNumber.py
@@ -0,0 +1,31 @@
+# 58. 피보나치 수
+
+def solution(n):
+ answer = 0
+
+ fibo_lst = [0, 1]
+ while len(fibo_lst) <= n:
+ first, second = fibo_lst[-2], fibo_lst[-1]
+ fibo_lst.append(first + second)
+
+ answer = fibo_lst[-1] % 1234567
+ return answer
+
+n_1 = 3
+n_2 = 5
+
+print(solution(n_1))
+print(solution(n_2))
+
+def solution_other(n):
+ answer = 0
+
+ a, b = 0, 1
+ for i in range(n):
+ a, b = b, a + b
+
+ answer = a % 1234567
+ return answer
+
+print(solution_other(n_1))
+print(solution_other(n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/FilenameSort.py b/Programmers/LEVEL2/FilenameSort.py
new file mode 100644
index 0000000..703ad76
--- /dev/null
+++ b/Programmers/LEVEL2/FilenameSort.py
@@ -0,0 +1,82 @@
+# 50. 파일명 정렬
+
+def solution(files):
+ answer = []
+
+ divide_files = []
+ for file_idx, file in enumerate(files):
+ head = ''
+ number = ''
+ tail = ''
+ file_idx += 1
+ for ch in file:
+ if not ch.isdigit():
+ if len(number) == 0:
+ head += ch
+ else:
+ tail += ch
+ else:
+ if 0 <= len(number) <= 5:
+ if len(tail) != 0:
+ tail += ch
+ else:
+ number += ch
+ else:
+ tail += ch
+ divide_files.append([head, number, tail])
+
+ '''
+ 정렬을 하는 부분 ... 해결 못함
+ '''
+ divide_files = sorted(divide_files, key = lambda x : (x[0].lower(), int(x[1])))
+ answer = [''.join(file) for file in divide_files]
+ return answer
+
+files_1 = ["img12.png", "img10.png", "img02.png", "img1.png", "IMG01.GIF", "img2.JPG"]
+files_2 = ["F-5 Freedom Fighter", "B-50 Superfortress", "A-10 Thunderbolt II", "F-14 Tomcat"]
+files_3 = ["foo010bar020.zip"]
+
+# print(solution(files_1))
+# print(solution(files_2))
+# print(solution(files_3))
+
+'''
+내 풀이보다는 더 좋은 풀이
+정규식으로 중간에 숫자값 찾고 그걸 기준으로 문자열을 나눈다
+-------------------------------------------------------------
+3번째 경우에는 적용이 안 되는데... 왜 이게 답이 되는 건지??
+'''
+import re
+def solution_other(files):
+ a = sorted(files, key = lambda file : int(re.findall('\d+', file)[0]))
+ answer = sorted(a, key = lambda file : re.split('\d+', file.lower())[0])
+
+ return answer
+
+print(solution_other(files_1))
+print(solution_other(files_2))
+print(solution_other(files_3))
+
+'''
+1. head/number/tail을 구분한다. 숫자를 반영해서 정렬해야 하므로,
+ 숫자 기준으로 split하면 된다. 정규식으로 숫자만 잘라낸 방법은 아래와 같다.
+2. 숫자 기준으로 split하면 문제에서 제공한 조건에 맞게 정렬한다. 문자열
+ 대소문자 구분을 할 필요가 없으므로 문자열은 정렬 기준에서 통일하고,
+ 문자열로 되어 있는 숫자를 숫자 값에 맞춰 정렬한다.
+3. 정렬된 리스트 안에 있는 split된 리스트값을 문자열로 바꿔서 출력
+-------------------------------------------------------------
+3번째 경우에는 적용이 안 되는데... 왜 이게 답이 되는 건지??
+'''
+import re
+def solution_best(files):
+ answer = []
+
+ divide_files = [re.split(r'([0-9]+)', file) for file in files]
+ sort = sorted(divide_files, key = lambda x: (x[0].lower(), int(x[1])))
+
+ answer = [''.join(s) for s in sort]
+ return answer
+
+# print(solution_best(files_1))
+# print(solution_best(files_2))
+# print(solution_best(files_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/FriendsFourBlock.py b/Programmers/LEVEL2/FriendsFourBlock.py
new file mode 100644
index 0000000..306bdb2
--- /dev/null
+++ b/Programmers/LEVEL2/FriendsFourBlock.py
@@ -0,0 +1,189 @@
+# 41. 프렌즈4블록
+
+# Not solve by myself.
+def pop_num(b, m, n):
+ pop_set = set()
+
+ # search
+ for i in range(1, n):
+ for j in range(1, m):
+ if b[i][j] == b[i - 1][j - 1] == b[i - 1][j] == b[i][j - 1] != '_':
+ pop_set |= set([(i, j), (i-1, j-1), (i-1, j), (i, j-1)])
+
+ # set board
+ for i, j in pop_set:
+ b[i][j] = 0
+
+ for row_idx, row in enumerate(b):
+ empty = ['_'] * row.count(0)
+ b[row_idx] = empty + [block for block in row if block != 0]
+
+ return len(pop_set)
+
+def solution(m, n, board):
+ answer = 0
+
+ game_board = list(map(list, zip(*board)))
+ while True:
+ pop = pop_num(game_board, m, n)
+ if pop == 0: return answer
+ answer += pop
+
+ return answer
+
+m_1 = 4
+m_2 = 6
+
+n_1 = 5
+n_2 = 6
+
+board_1 = ["CCBDE",
+ "AAADE",
+ "AAABF",
+ "CCBBF"
+ ]
+board_2 = ["TTTANT",
+ "RRFACC",
+ "RRRFCC",
+ "TRRRAA",
+ "TTMMMF",
+ "TMMTTJ"
+ ]
+
+print(solution(m_1, n_1, board_1))
+print(solution(m_2, n_2, board_2))
+
+'''
+board를 3차원 리스트로 만들고
+[ [['C'], ['C'], ['B'], ['D'], ['E']],
+ [['A'], ['A'], ['A'], ['D'], ['E']],
+ ...(이렇게 하면 안 됨)
+
+len(board) - 1, len(board[0]) -1만큼 반복하면서
+겹치는 부분을 0으로 초기화한 후
+
+다시 반복하면서 값이 0인 경우 pop을 하는 방식으로 생각했는데
+그럴 경우 pop이 안된다.
+'''
+def solution_mine(m, n, board):
+ answer = 0
+
+ game_board = [[[ch] for ch in row] for row in board]
+ print(game_board)
+ for row in range(len(game_board) - 1):
+ for col in range(len(game_board[0]) - 1):
+ if game_board[row][col] == game_board[row][col + 1] == \
+ game_board[row + 1][col] == game_board[row + 1][col + 1]:
+ game_board[row][col], game_board[row][col + 1], \
+ game_board[row + 1][col], game_board[row + 1][col + 1] \
+ = 0, 0, 0, 0
+
+ for row in range(len(game_board) - 1):
+ for col in range(len(game_board[0]) - 1):
+ if row != 0 and col != 0:
+ game_board[row][col], game_board[row][col + 1] = game_board[row - 1][col], game_board[row - 1][col + 1]
+ else:
+ game_board[row].pop(col)
+ game_board[row].pop(col + 1)
+ answer += 2
+ return answer
+
+# print(solution_mine(m_1, n_1, board_1))
+# print(solution_mine(m_2, n_2, board_2))
+
+def solution_other(m, n, board):
+ answer = 0
+
+ # board 배열로 만들기
+ for i in range(len(board)):
+ popped = board.pop(0)
+ board.append([p for p in popped])
+
+ # 터진 블록이 없을 때까지 반복
+ while True:
+ # 이번 턴에 터져야 할 블록들 모음
+ checked = []
+ for i in range(m - 1):
+ for j in range(n - 1):
+ if board[i][j] == '0':
+ continue
+
+ # 연속으로 두 개가 동일한 블록이면, 밑에 두 개도 동일한지 확인
+ if board[i][j] == board[i][j + 1]:
+ if board[i][j] == board[i + 1][j] and board[i][j + 1] == board[i + 1][j + 1]:
+ # 터져야 할 블록들 전부 저장
+ checked.append((i, j))
+ checked.append((i, j + 1))
+ checked.append((i + 1, j))
+ checked.append((i + 1, j + 1))
+
+ # 이번에 터진 블록 없으면 종료
+ if len(checked) == 0:
+ break
+ else:
+ # 모아둔 블록 다 터뜨리기
+ answer += len(set(checked))
+ for c in checked:
+ board[c[0]][c[1]] = '0'
+
+ # 블록들 내리기
+ for c in reversed(checked):
+ check_n = c[0] - 1
+ put_n = c[0]
+
+ # 터진 자리 위에 있는 블록들 다 내린다다
+ while check_n >= 0:
+ if board[put_n][c[1]] == '0' and board[check_n][c[1]] != "0":
+ board[put_n][c[1]] = board[check_n][c[1]]
+ board[check_n][c[1]] = "0"
+ put_n -= 1
+
+ check_n -= 1
+
+ return answer
+
+# print(solution_other(m_1, n_1, board_1))
+# print(solution_other(m_2, n_2, board_2))
+
+import numpy as np
+def solution_best(m, n, board):
+ list = []
+
+ for i in board:
+ for j in i:
+ list.append(j)
+
+ list = np.array(list).reshape(m, n)
+ test = np.zeros((m, n))
+ a = []
+
+ while 1: # 전체 코드 돌리는 for문
+ for i in range(m):
+ if i + 1 != len(list):
+ for j in range(1, n):
+ if list[i][j - 1] == list[i][j] == list[i + 1][j] == list[i + 1][j - 1]:
+ if list[i][j - 1] == ' ' or list[i][j - 1] == '':
+ test[i][j - 1], test[i][j], test[i + 1][j], test[i + 1][j - 1] = '0' * 4
+ else:
+ test[i][j - 1], test[i][j], test[i + 1][j], test[i + 1][j - 1] = '1' * 4
+
+ a.append(np.sum(test))
+ r = np.sum(test)
+
+ testwhere = np.where(test == 1)
+ list[testwhere] = "@"
+
+ for g in range(max(m, n)):
+ for i in range(m):
+ if i - 1 != -1:
+ for j in range(0, n):
+ if list[i][j] == '@' or list[i][j] == '':
+ if list[i - 1][j] is not None:
+ list[i][j] = list[i - 1][j]
+ list[i - 1][j] = ''
+
+ test[testwhere] = 0
+
+ if r == 0:
+ answer = sum(a)
+ return answer
\ No newline at end of file
diff --git a/Programmers/LEVEL2/FunctionDevelop.py b/Programmers/LEVEL2/FunctionDevelop.py
new file mode 100644
index 0000000..eac0f52
--- /dev/null
+++ b/Programmers/LEVEL2/FunctionDevelop.py
@@ -0,0 +1,47 @@
+# 40. 기능 개발
+
+def solution(progresses, speeds):
+ answer = []
+
+ release_day = 0
+ finished_time = []
+ for progress, speed in zip(progresses, speeds):
+ release_day += 1
+ course_rate = progress + speed * release_day
+ while course_rate < 100:
+ release_day += 1
+ course_rate = progress + speed * release_day
+ finished_time.append(release_day)
+ release_day = 0
+
+ front = 0
+ for index in range(len(finished_time)):
+ if finished_time[front] < finished_time[index]:
+ answer.append(index - front)
+ front = index
+ answer.append(len(finished_time) - front)
+ return answer
+
+progresses_1 = [93, 30, 55]
+progresses_2 = [95, 90, 99, 99, 80, 99]
+
+speeds_1 = [1, 30, 5]
+speeds_2 = [1, 1, 1, 1, 1, 1]
+
+# print(solution(progresses_1, speeds_1))
+# print(solution(progresses_2, speeds_2))
+
+def solution_best(progresses, speeds):
+ answer = []
+
+ for progress, speed in zip(progresses, speeds):
+ if len(answer) == 0 or answer[-1][0] < -((progress - 100) // speed):
+ answer.append([-((progress - 100) // speed), 1])
+ else:
+ answer[-1][1] += 1
+
+ answer = [ans[1] for ans in answer]
+ return answer
+
+print(solution_best(progresses_1, speeds_1))
+print(solution_best(progresses_2, speeds_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/GameMapShortestDistance.py b/Programmers/LEVEL2/GameMapShortestDistance.py
new file mode 100644
index 0000000..8ed4fa7
--- /dev/null
+++ b/Programmers/LEVEL2/GameMapShortestDistance.py
@@ -0,0 +1,147 @@
+# 44. 게임 맵 최단 거리
+
+def solution(maps):
+ # 상대 팀 진영에 도착할 수 없는 경우
+ answer = -1
+
+ # 게임 맵 크기
+ game_map_size = len(maps) - 1
+ # 사용자 맵의 크기
+ map_size = len(maps[0]) - 1
+ # 이동방향
+ directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
+
+ # 경로 저장 리스트
+ path_lst = []
+
+ # 게임 시작 위치, 1부터 시작
+ path_lst.append([0, 0, 1])
+
+ while path_lst:
+ # 현재 위치
+ x, y, cnt = path_lst.pop(0)
+ # 지나온 길 벽으로 없애기
+ maps[x][y] = 0
+ # 너비 우선 탐색, 상하좌우
+ for dx, dy in directions:
+ mx, my = x + dx, y + dy
+ # 마지막 지점 먼저 도달하면 경로 출력
+ if mx == game_map_size and my == map_size:
+ answer = cnt + 1
+ return answer
+
+ if 0 <= mx <= game_map_size and 0 <= my <= map_size and maps[mx][my] == 1:
+ maps[mx][my] = 0
+ path_lst.append([mx, my, cnt + 1])
+
+ return answer
+
+maps_1 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 1],
+ [0, 0, 0, 0, 1]
+ ]
+maps_2 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 0],
+ [0, 0, 0, 0, 1]
+ ]
+
+print(solution(maps_1))
+print(solution(maps_2))
+
+'''
+deque 사용하여 BFS로 해결하기
+'''
+from collections import deque
+
+d = [[1, 0], [0, 1], [-1, 0], [0, -1]]
+def solution_other(maps):
+ rows = len(maps)
+ cols = len(maps[0])
+ table = [[-1 for _ in range(cols)] for _ in range(rows)]
+ queue = deque()
+ queue.append([0, 0])
+ table[0][0] = 1
+
+ while queue:
+ y, x = queue.popleft()
+
+ for i in range(4):
+ ny = y + d[i][0]
+ nx = x + d[i][1]
+
+ if -1 < ny < rows and -1 < nx < cols:
+ if maps[ny][nx] == 1:
+ if table[ny][nx] == -1:
+ table[ny][nx] = table[y][x] + 1
+ queue.append([ny, nx])
+
+ answer = table[-1][-1]
+ return answer
+
+maps_1 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 1],
+ [0, 0, 0, 0, 1]
+ ]
+maps_2 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 0],
+ [0, 0, 0, 0, 1]
+ ]
+# print(solution_other(maps_1))
+# print(solution_other(maps_2))
+
+'''
+위의 solution풀이와 비슷, deque 사용
+'''
+def solution_good(maps):
+ dx = [-1, 1, 0, 0]
+ dy = [0, 0, -1, 1]
+
+ rows = len(maps)
+ cols = len(maps[0])
+
+ graph = [[-1 for _ in range(cols)] for _ in range(rows)]
+
+ queue = deque()
+ queue.append([0, 0])
+
+ graph[0][0] = 1
+
+ while queue:
+ y, x = queue.popleft()
+
+ # 현재 위치에서 4가지 방향으로 위치 확인
+ for i in range(4):
+ mx = x + dx[i]
+ my = y + dy[i]
+
+ if 0 <= my < rows and 0 <= mx < cols and maps[my][mx] == 1:
+ if graph[my][mx] == -1:
+ graph[my][mx] = graph[y][x] + 1
+ queue.append([my, mx])
+
+ answer = graph[-1][-1]
+
+ return answer
+
+maps_1 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 1],
+ [0, 0, 0, 0, 1]
+ ]
+maps_2 = [[1, 0, 1, 1, 1],
+ [1, 0, 1, 0, 1],
+ [1, 0, 1, 1, 1],
+ [1, 1, 1, 0, 0],
+ [0, 0, 0, 0, 1]
+ ]
+# print(solution_good(maps_1))
+# print(solution_good(maps_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/GetGround.py b/Programmers/LEVEL2/GetGround.py
new file mode 100644
index 0000000..91d1c3c
--- /dev/null
+++ b/Programmers/LEVEL2/GetGround.py
@@ -0,0 +1,33 @@
+# 53. 땅따먹기
+
+def solution(land):
+ answer = 0
+
+ for i in range(1, len(land)):
+ for j in range(len(land[0])):
+ land[i][j] += max(land[i - 1][:j] + land[i - 1][j + 1:])
+
+ answer = max(land[len(land) - 1])
+ return answer
+
+land_1 = [[1, 2, 3, 5],
+ [5, 6, 7, 8],
+ [4, 3, 2, 1]
+ ]
+
+print(solution(land_1))
+
+def solution_other(land):
+ for i in range(len(land) - 1):
+ land[i + 1][0] += max(land[i][1], land[i][2], land[i][3])
+ land[i + 1][1] += max(land[i][0], land[i][2], land[i][3])
+ land[i + 1][2] += max(land[i][0], land[i][1], land[i][3])
+ land[i + 1][3] += max(land[i][0], land[i][1], land[i][2])
+
+ return max(land[-1])
+
+land_1 = [[1, 2, 3, 5],
+ [5, 6, 7, 8],
+ [4, 3, 2, 1]
+ ]
+print(solution_other(land_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/IterateBinaryConvert.py b/Programmers/LEVEL2/IterateBinaryConvert.py
new file mode 100644
index 0000000..73e3912
--- /dev/null
+++ b/Programmers/LEVEL2/IterateBinaryConvert.py
@@ -0,0 +1,67 @@
+# 42. 이진 변환 반복하기
+
+def solution(s):
+ answer = []
+
+ erase_cnt, bin_cnt = 0, 0
+ while True:
+ if s == '1':
+ break
+
+ erase_cnt += s.count('0')
+ s = s.replace('0', '')
+
+ s = bin(len(s))[2:]
+ bin_cnt += 1
+
+ answer = [bin_cnt, erase_cnt]
+ return answer
+
+s_1 = '110010101001'
+s_2 = '01110'
+s_3 = '1111111'
+
+print(solution(s_1))
+print(solution(s_2))
+print(solution(s_3))
+
+'''
+list로 풀려고 했는데 '0'을 지우는 부분에서 막힘
+문자열 그대로로 풀어야 함.
+'''
+def solution_mine(s):
+ answer = []
+
+ s = [ch for ch in s]
+ bin_cnt = 0
+ trans_s = []
+ while s.count('0') != 0:
+ for ch in s:
+ if ch == '0':
+ s.remove(ch)
+ trans_s.append(ch)
+ len_trans_s = len(trans_s)
+ bin_trans_s = bin(len_trans_s)
+ bin_cnt += 1
+ bin_trans_s = int(bin(len(s)), 2)
+
+ answer.append([bin_cnt, bin_trans_s])
+ return answer
+
+# print(solution_mine(s_1))
+# print(solution_mine(s_2))
+# print(solution_mine(s_3))
+
+def solution_best(s):
+ bin_cnt, erase_cnt = 0, 0
+ while s != '1':
+ bin_cnt += 1
+ num = s.count('1')
+ erase_cnt += len(s) - num
+ s = bin(num)[2:]
+
+ return [bin_cnt, erase_cnt]
+
+print(solution_best(s_1))
+print(solution_best(s_2))
+print(solution_best(s_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/JumpAndTeleport.py b/Programmers/LEVEL2/JumpAndTeleport.py
new file mode 100644
index 0000000..2881bb0
--- /dev/null
+++ b/Programmers/LEVEL2/JumpAndTeleport.py
@@ -0,0 +1,35 @@
+# 46. 점프와 순간이동
+
+'''
+가장 가까운 거리에 있으면서 n값보다 작은 2의 거듭제곱 수만큼 빼고
+2500 -> 2500 - 2048
+2로 안 나눠질 경우 1씩 더하는 방식
+------------------------------------------------------------
+입력받은 n값이 0이 될 때까지 n을 2로 나눈 몫과 나머지 구하고
+나머지 1일 경우만 count
+'''
+def solution(n):
+ answer = 0
+
+ while n > 0:
+ quote, rest = divmod(n, 2)
+ n = quote
+ if rest != 0:
+ answer += 1
+
+ return answer
+
+n_1 = 5
+n_2 = 6
+n_3 = 5000
+
+print(solution(n_1))
+print(solution(n_2))
+print(solution(n_3))
+
+def solution_best(n):
+ return bin(n).count('1')
+
+print(solution_best(n_1))
+print(solution_best(n_2))
+print(solution_best(n_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/MakeJadenCaseString.py b/Programmers/LEVEL2/MakeJadenCaseString.py
new file mode 100644
index 0000000..91377e2
--- /dev/null
+++ b/Programmers/LEVEL2/MakeJadenCaseString.py
@@ -0,0 +1,33 @@
+# 59. JadenCase 문자열 만들기
+
+'''
+공백문자가 반복되어 나올 수 있으며 반복 되어 나온 공백은 문자열로 취급하지 않습니다
+라는 조건이 명시되어 있지 않아 틀렸던 문제, 거의 다 맞춤.
+'''
+def solution(s):
+ answer = ' '.join([word.title() if word.isalpha() else word.lower() for word in s.split(' ')])
+
+ return answer
+
+s_1 = "3people unFollowed me"
+s_2 = "for the last week"
+
+print(solution(s_1))
+print(solution(s_2))
+
+def solution_mine(s):
+ answer = ' '.join([word.title() if word.isalpha() else word
+ for word in s.split()])
+
+ return answer
+
+print(solution_mine(s_1))
+print(solution_mine(s_2))
+
+def solution_good(s):
+ answer = ' '.join([word.capitalize() for word in s.split(' ')])
+
+ return answer
+
+print(solution_good(s_1))
+print(solution_good(s_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/MakeMinimum.py b/Programmers/LEVEL2/MakeMinimum.py
new file mode 100644
index 0000000..6ccc830
--- /dev/null
+++ b/Programmers/LEVEL2/MakeMinimum.py
@@ -0,0 +1,33 @@
+# 57. 최솟값 만들기
+
+
+def solution(A, B):
+ answer = 0
+
+ A.sort()
+ B.sort(reverse = True)
+
+ sum_lst = []
+ for a, b in zip(A, B):
+ multiply = a * b
+ sum_lst.append(multiply)
+
+ answer = sum(sum_lst)
+ return answer
+
+A_1 = [1, 4, 2]
+A_2 = [1, 2]
+
+B_1 = [5, 4, 4]
+B_2 = [3, 4]
+
+print(solution(A_1, B_1))
+print(solution(A_2, B_2))
+
+def solution_best(A, B):
+ answer = sum(a * b for a, b in zip(sorted(A), sorted(B, reverse = True)))
+
+ return answer
+
+print(solution_best(A_1, B_1))
+print(solution_best(A_2, B_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/MaximizeFormula.py b/Programmers/LEVEL2/MaximizeFormula.py
new file mode 100644
index 0000000..fd68d34
--- /dev/null
+++ b/Programmers/LEVEL2/MaximizeFormula.py
@@ -0,0 +1,119 @@
+# 39. 수식 최대화
+
+'''
+Not solve this problem by myself. I think 80% I did, but I don`t know
+how to calculate formula.
+'''
+import re
+from itertools import permutations
+def solution(expression):
+ answer = 0
+ operators = [x for x in ['-', '+', '*'] if x in expression]
+ operators_perm = list(permutations(operators))
+
+ expression = re.split('([^0-9])', expression)
+ for order in operators_perm:
+ expression_cpy = expression[:]
+ for operator in order:
+ # 이 부분 주목
+ while operator in expression_cpy:
+ operator_idx = expression_cpy.index(operator)
+ formula_cost = str(eval(expression_cpy[operator_idx - 1] +
+ expression_cpy[operator_idx] +
+ expression_cpy[operator_idx + 1]))
+ expression_cpy[operator_idx - 1] = formula_cost
+ expression_cpy = expression_cpy[:operator_idx] + expression_cpy[operator_idx + 2:]
+ answer = max(answer, abs((int(expression_cpy[-1]))))
+ return answer
+
+expression_1 = '100-200*300-500+20'
+expression_2 = '50*6-3*2'
+
+# print(solution(expression_1))
+# print(solution(expression_2))
+
+'''
+100-200*300-500+20 이 예의 경우
+['100', '-', '200], ['200', '*', '300'], ... , ['500', '+', '20']
+형태로 만드는 것은 성공하였고, 각 연산자 별로 우선순위를 조합으로 만드는 것까지
+성공하였으나,
+계산을 수행할 때 바뀌는 과정을 어떻게 구현해야할지 감이 안 잡힘.
+'''
+import re
+from itertools import permutations
+def solution_mine(expression):
+ answer = 0
+
+ # [('100', '-'), '200], [('200', '*'), '300], ...
+ p = re.compile('(\d+)([-+*]?)')
+ expression = p.findall(expression)
+ formula_lst = []
+ for (express1_num, operator), express2 in zip(expression, expression[1:]):
+ formula_lst.append([express1_num, operator, express2[0]])
+ print(formula_lst)
+
+ # 연산자 우선순위 순열
+ operators = set([i[1] for i in formula_lst if i[1] in ['-', '+', '*']])
+ operators_perm = list(permutations(operators, len(operators)))
+ print(operators_perm)
+
+ answer_lst = []
+ for order in operators_perm:
+ formula_cost = 0
+ for operator in order:
+ for formula in formula_lst:
+ if operator in formula:
+ formula_cost += eval(''.join(formula))
+ del formula_lst[formula_lst.index(formula)]
+ answer_lst.append(formula_cost)
+
+ print(answer_lst)
+ return answer
+
+# 다른 풀이(재귀)
+def calculate(priority, n, expression):
+ if n == 2:
+ return str(eval(expression))
+
+ if priority[n] == '*':
+ result = eval('*'.join([calculate(priority, n + 1, e)
+ for e in expression.split('*')]))
+ if priority[n] == '+':
+ result = eval('+'.join([calculate(priority, n + 1, e)
+ for e in expression.split('+')]))
+ if priority[n] == '-':
+ result = eval('-'.join([calculate(priority, n + 1, e)
+ for e in expression.split('-')]))
+ return str(result)
+
+def solution_other(expression):
+ answer = 0
+
+ priorities = (list(permutations(['+', '-', '*'], 3)))
+ for priority in priorities:
+ result = int(calculate(priority, 0, expression))
+ answer = max(answer, abs(result))
+
+ return answer
+
+# print(solution_other(expression_1))
+# print(solution_other(expression_2))
+
+# 제일 좋다고 생각되는 풀이(재귀랑 거의 비슷한 구조)
+def solution_best(expression):
+ answer = []
+
+ operations = [('+', '-', '*'),('+', '*', '-'),('-', '+', '*'),('-', '*', '+'),('*', '+', '-'),('*', '-', '+')]
+ for operator in operations:
+ first = operator[0]
+ second = operator[1]
+ temp_list = []
+ for e in expression.split(first):
+ temp = [f'({i})' for i in e.split(second)]
+ temp_list.append(f'{second.join(temp)}')
+ answer.append(abs(eval(first.join(temp_list))))
+ return max(answer)
+
+print(solution_best(expression_1))
+print(solution_best(expression_2))
+
diff --git a/Programmers/LEVEL2/MaximumAndMinimum.py b/Programmers/LEVEL2/MaximumAndMinimum.py
new file mode 100644
index 0000000..2d94ef2
--- /dev/null
+++ b/Programmers/LEVEL2/MaximumAndMinimum.py
@@ -0,0 +1,16 @@
+# 56. 최댓값과 최솟값
+
+def solution(s):
+ answer = ''
+
+ s_split = list(map(int, s.split()))
+ answer += str(min(s_split)) + ' ' + str(max(s_split))
+ return answer
+
+s_1 = "1 2 3 4"
+s_2 = "-1 -2 -3 -4"
+s_3 = "-1 -1"
+
+print(solution(s_1))
+print(solution(s_2))
+print(solution(s_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/MoreSpicy.py b/Programmers/LEVEL2/MoreSpicy.py
index 6c73341..9bf6578 100644
--- a/Programmers/LEVEL2/MoreSpicy.py
+++ b/Programmers/LEVEL2/MoreSpicy.py
@@ -3,10 +3,21 @@
def solution(scovile, K):
answer = 0
+ hq.heapify(scovile)
+ while scovile[0] < K:
+ mix_scov = hq.heappop(scovile) + hq.heappop(scovile) * 2
+ hq.heappush(scovile, mix_scov)
+ answer += 1
+ if len(scovile) == 1 and scovile[0] < K:
+ return -1
return answer
+scovile_1 = [1, 2, 3, 9, 10, 12]
+K_1 = 7
+print(solution(scovile_1, K_1))
+
# 가장 작은 값을 생각하자!! ... 힙 안 쓰면 초과 걸리네
def solution_error(scovile, K):
answer = 0
@@ -22,12 +33,12 @@ def solution_error(scovile, K):
answer += 1
return answer
-scovile_1 = [1, 2, 3, 9, 10, 12]
-K_1 = 7
+# print(solution_error(scovile_1, K_1))
-print(solution_error(scovile_1, K_1))
+'''
-def solution_best(scovile, K):
+'''
+def solution_other(scovile, K):
answer = 0
heap = []
@@ -44,4 +55,5 @@ def solution_best(scovile, K):
return answer
-# print(solution_best(scovile_1, K_1))
\ No newline at end of file
+# print(solution_other(scovile_1, K_1))
+
diff --git a/Programmers/LEVEL2/MultiplyOfMatrix.py b/Programmers/LEVEL2/MultiplyOfMatrix.py
new file mode 100644
index 0000000..6bfd761
--- /dev/null
+++ b/Programmers/LEVEL2/MultiplyOfMatrix.py
@@ -0,0 +1,30 @@
+# 52. 행렬의 곱셈
+
+def solution(arr1, arr2):
+ answer = [[]]
+
+ answer = [[sum(r * c for r, c in zip(row, col))
+ for col in zip(*arr2)] for row in arr1]
+ return answer
+
+arr1_1 = [[1, 4], [3, 2], [4, 1]]
+arr1_2 = [[2, 3, 2], [4, 2, 4], [3, 1, 4]]
+
+arr2_1 = [[3, 3], [3, 3]]
+arr2_2 = [[5, 4, 3], [2, 4, 1], [3, 1, 1]]
+
+print(solution(arr1_1, arr2_1))
+print(solution(arr1_2, arr2_2))
+
+import numpy as np
+
+def solution_best(arr1, arr2):
+ answer = [[]]
+
+ ar1 = np.array(arr1)
+ ar2 = np.array(arr2)
+ answer = np.dot(ar1, ar2).tolist()
+ return answer
+
+# print(solution_best(arr1_1, arr2_1))
+# print(solution_best(arr1_2, arr2_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/NCountsLCM.py b/Programmers/LEVEL2/NCountsLCM.py
new file mode 100644
index 0000000..6b2e4aa
--- /dev/null
+++ b/Programmers/LEVEL2/NCountsLCM.py
@@ -0,0 +1,55 @@
+# 60. N개의 최소공배수
+
+def solution(arr):
+ answer = 0
+
+ arr.sort(reverse = True)
+ a, b = arr.pop(), arr.pop()
+ while arr:
+ n, m = max(a, b), min(a, b)
+ while m > 0:
+ n, m = m, n % m
+ LCM = int(a * b / n)
+ cst = arr.pop()
+ a, b = max(LCM, cst), min(LCM, cst)
+ n, m = max(a, b), min(a, b)
+ while m > 0:
+ n, m = m, n % m
+ answer = int(a * b / n)
+
+ return answer
+
+arr_1 = [2, 6, 8, 14]
+arr_2 = [1, 2, 3]
+
+# print(solution(arr_1))
+# print(solution(arr_2))
+
+'''
+math 모듈 사용하여 풀기
+'''
+import math
+def solution_other(arr):
+ answer = 0
+
+ first = arr[0]
+ for cst in arr[1:]:
+ LCM = abs(first * cst) // math.gcd(first, cst)
+ first = LCM
+
+ answer = first
+ return answer
+
+# print(solution_other(arr_1))
+# print(solution_other(arr_2))
+
+'''
+python 3.9 이상의 버전에서는 math모듈에서 lcm함수 지원
+'''
+# def solution_best(arr):
+# answer = math.lcm(3, 5)
+#
+# return answer
+#
+# print(solution_best(arr_1))
+# print(solution_best(arr_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/NewsClustering.py b/Programmers/LEVEL2/NewsClustering.py
new file mode 100644
index 0000000..67d2ff0
--- /dev/null
+++ b/Programmers/LEVEL2/NewsClustering.py
@@ -0,0 +1,114 @@
+# 36. 뉴스 클러스터링
+
+# 집합으로 생각하면 안 되는 문제 ... 3번째 case
+def solution(str1, str2):
+ answer = 0
+
+ str1_lst = []
+ str2_lst = []
+
+ # 'FR', 'RA', ...
+ for s1, slice_s1 in zip(str1, str1[1:]):
+ two_str = ''.join([s1, slice_s1])
+ # '+' 기호 제거
+ if two_str.isalpha():
+ str1_lst.append(two_str.lower())
+
+ for s2, slice_s2 in zip(str2, str2[1:]):
+ two_str_1 = ''.join([s2, slice_s2])
+ if two_str_1.isalpha():
+ str2_lst.append(two_str_1.lower())
+
+ if len(str1_lst) > len(str2_lst):
+ intersection_sets = [str1_lst.remove(x) for x in str2_lst
+ if x in str1_lst]
+ else:
+ intersection_sets = [str2_lst.remove(x) for x in str1_lst
+ if x in str2_lst]
+
+ union_sets = str1_lst + str2_lst
+ union = len(union_sets)
+
+ if union == 0:
+ return 65536
+
+ answer = int(len(intersection_sets) / union * 65536)
+ return answer
+
+str1_1 = 'FRANCE'
+str1_2 = 'handshake'
+str1_3 = 'aa1+aa2'
+str1_4 = 'E=M*C^2'
+
+str2_1 = 'french'
+str2_2 = 'shake hands'
+str2_3 = 'AAAA12'
+str2_4 = 'e=m*c^2'
+
+print(solution(str1_1, str2_1))
+print(solution(str1_2, str2_2))
+print(solution(str1_3, str2_3))
+print(solution(str1_4, str2_4))
+
+def solution_other(str1, str2):
+ list_str1 = []
+ list_str2 = []
+
+ for s1, slice_s1 in zip(str1, str1[1:]): # str1 문자만 2글자씩 뽑기
+ join_str = "".join([s1, slice_s1])
+ if join_str.isalpha():
+ list_str1.append(join_str.lower())
+
+ for s2, slice_s2 in zip(str2, str2[1:]): # str2 문자만 2글자씩 뽑기
+ join_str = "".join([s2, slice_s2])
+ if join_str.isalpha():
+ list_str2.append(join_str.lower())
+
+ # print(list_str1)
+ # print(list_str2)
+ if len(list_str1) > len(list_str2):
+ # 교집합의 개수를 구함
+ inter = [list_str1.remove(x) for x in list_str2 if x in list_str1]
+ else:
+ inter = [list_str2.remove(x) for x in list_str1 if x in list_str2]
+
+ # print(inter)
+ # 합집합은 교집합 + 나머지 원소들
+ list_uni = list_str1 + list_str2
+ uni = len(list_uni)
+
+ if uni == 0:
+ return 65536
+
+ return int(len(inter) / uni * 65536)
+
+# print(solution_other(str1_1, str2_1))
+# print(solution_other(str1_2, str2_2))
+# print(solution_other(str1_3, str2_3))
+# print(solution_other(str1_4, str2_4))
+
+def solution_best(str1, str2):
+ answer = 0
+
+ str1_lst = [str1[i:i + 2].lower() for i in range(len(str1) - 1)
+ if str1[i:i + 2].isalpha()]
+ str2_lst = [str2[i:i + 2].lower() for i in range(len(str2) - 1)
+ if str2[i:i + 2].isalpha()]
+
+ intersections = 0
+ unions = 0
+
+ for s in set(str1_lst + str2_lst):
+ unions += max(str1_lst.count(s), str2_lst.count(s))
+ intersections += min(str1_lst.count(s), str2_lst.count(s))
+
+ if unions == 0:
+ return 65536
+
+ answer = int(intersections / unions * 65536)
+ return answer
+
+# print(solution_best(str1_1, str2_1))
+# print(solution_best(str1_2, str2_2))
+# print(solution_best(str1_3, str2_3))
+# print(solution_best(str1_4, str2_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/NoChangeSquare.py b/Programmers/LEVEL2/NoChangeSquare.py
index a681134..c405401 100644
--- a/Programmers/LEVEL2/NoChangeSquare.py
+++ b/Programmers/LEVEL2/NoChangeSquare.py
@@ -1,32 +1,33 @@
-# 1. 멀쩡한 사각형
-
-def gcd(x, y):
- if x < y:
- x, y = y, x
- else:
- while y:
- x, y = y, x % y
- return x
-
-def lcm(x, y):
- return x * y // gcd(x, y)
-
-import math
-
-def solution(w, h):
- answer = w * h - (w + h - math.gcd(w, h))
-
- return answer
-
-w_1 = 8
-h_1 = 12
-
-print(solution(w_1, h_1))
-
-def GCD(x, y): return y if x == 0 else GCD(y % x, x)
-def solution_best(w, h):
- answer = w * h - (w + h - GCD(w, h))
-
- return answer
-
-print(solution_best(w_1, h_1))
+# 1. 멀쩡한 사각형
+
+def gcd(x, y):
+ if x < y:
+ x, y = y, x
+ else:
+ while y:
+ x, y = y, x % y
+ return x
+
+def lcm(x, y):
+ return x * y // gcd(x, y)
+
+import math
+
+def solution(w, h):
+ answer = w * h - (w + h - math.gcd(w, h))
+
+ return answer
+
+w_1 = 8
+h_1 = 12
+
+print(solution(w_1, h_1))
+
+
+def GCD(x, y): return y if x == 0 else GCD(y % x, x)
+def solution_best(w, h):
+ answer = w * h - (w + h - GCD(w, h))
+
+ return answer
+
+print(solution_best(w_1, h_1))
diff --git a/Programmers/LEVEL2/NowThatSong.py b/Programmers/LEVEL2/NowThatSong.py
new file mode 100644
index 0000000..3817564
--- /dev/null
+++ b/Programmers/LEVEL2/NowThatSong.py
@@ -0,0 +1,176 @@
+# 49. 방금그곡
+
+# '#'을 변환해주는 함수
+def change_sharp(sheet):
+ sheet = sheet.replace('C#', 'c')
+ sheet = sheet.replace('D#', 'd')
+ sheet = sheet.replace('F#', 'f')
+ sheet = sheet.replace('G#', 'g')
+ sheet = sheet.replace('A#', 'a')
+
+ return sheet
+
+def caltime(musicinfo):
+ start_time = musicinfo[0]
+ end_time = musicinfo[1]
+ hour = 1 * (int(end_time.split(':')[0]) - int(start_time.split(':')[0]))
+ if hour == 0:
+ total_time = int(end_time.split(':')[1]) - int(start_time.split(':')[1])
+ else:
+ total_time = 60 * hour + int(end_time.split(':')[1]) - int(start_time.split(':')[1])
+
+ return total_time
+
+def solution(m, musicinfos):
+ answer = []
+
+ m = change_sharp(m)
+ for idx, music_info in enumerate(musicinfos):
+ music_info = change_sharp(music_info)
+ music_info = music_info.split(',')
+ playing_time = caltime(music_info)
+
+ if len(music_info[3]) >= playing_time:
+ melody = music_info[3][:playing_time]
+ else:
+ q, r = divmod(playing_time, len(music_info[3]))
+ melody = music_info[3] * q + music_info[3][:r]
+
+ if m in melody:
+ answer.append([idx, playing_time, music_info[2]])
+
+ if len(answer) != 0:
+ answer = sorted(answer, key = lambda x: (-x[1], x[0]))
+ return answer[0][2]
+
+ return '(None)'
+
+m_1 = "ABCDEFG"
+m_2 = "CC#BCC#BCC#BCC#B"
+m_3 = "ABC"
+
+musicinfos_1 = ["12:00,12:14,HELLO,CDEFGAB",
+ "13:00,13:05,WORLD,ABCDEF"]
+musicinfos_2 = ["03:00,03:30,FOO,CC#B",
+ "04:00,04:08,BAR,CC#BCC#BCC#B"]
+musicinfos_3 = ["12:00,12:14,HELLO,C#DEFGAB",
+ "13:00,13:05,WORLD,ABCDEF"]
+
+print(solution(m_1, musicinfos_1))
+print(solution(m_2, musicinfos_2))
+print(solution(m_3, musicinfos_3))
+
+'''
+내 풀이(datetime 모듈을 이용해서 풀어보기)
+'#' 문자 바꾸는 과정 필요함
+마지막에 (None)을 return해야 함.
+해결함
+'''
+
+def change(sheet):
+ sheet = sheet.replace('A#', 'a')
+ sheet = sheet.replace('C#', 'c')
+ sheet = sheet.replace('D#', 'd')
+ sheet = sheet.replace('F#', 'f')
+ sheet = sheet.replace('G#', 'g')
+
+
+ return sheet
+
+from datetime import datetime
+def solution_mine(m, musicinfos):
+ answer = ''
+
+ m = change(m)
+ timeformat = '%H:%M'
+ real_sheet_music_lst = []
+ for idx, music_info in enumerate(musicinfos):
+ music = music_info.split(',')
+ start_time, end_time = datetime.strptime(music[0], timeformat), \
+ datetime.strptime(music[1], timeformat)
+ playing_time = int((end_time - start_time).seconds / 60)
+ music_name = music[2]
+ sheet_music = change(music[3])
+
+ if len(sheet_music) < playing_time:
+ q, r = divmod(playing_time, len(sheet_music))
+ real_sheet_music = sheet_music * q + sheet_music[:r]
+ else:
+ real_sheet_music = sheet_music[:playing_time]
+
+ if m in real_sheet_music:
+ real_sheet_music_lst.append([idx, playing_time, music_name])
+
+ if len(real_sheet_music_lst) != 0:
+ real_sheet_music_lst = sorted(real_sheet_music_lst, key=lambda x: (-x[1], x[0]))
+ answer = real_sheet_music_lst[0][2]
+ return answer
+
+ if len(answer) == 0:
+ answer = '(None)'
+
+ return answer
+
+# print(solution_mine(m_1, musicinfos_1))
+# print(solution_mine(m_2, musicinfos_2))
+# print(solution_mine(m_3, musicinfos_3))
+
+'''
+다른 사람 풀이
+거의 똑같음.
+'''
+def change_signature(music):
+ if 'A#' in music:
+ music = music.replace('A#', 'a')
+ if 'F#' in music:
+ music = music.replace('F#', 'f')
+ if 'C#' in music:
+ music = music.replace('C#', 'c')
+ if 'G#' in music:
+ music = music.replace('G#', 'g')
+ if 'D#' in music:
+ music = music.replace('D#', 'd')
+
+ return music
+
+def solution_other(m, musicinfos):
+ answer = []
+ index = 0 # 먼저 입력된 음악을 판단하기 위해 index 추가
+ for info in musicinfos:
+ index += 1
+ music = info.split(',')
+ start = music[0].split(':') # 시작 시간
+ end = music[1].split(':') # 종료 시간
+ # 재생시간 계산
+ time = (int(end[0]) * 60 + int(end[1])) - (int(start[0]) * 60 + int(start[1]))
+
+ # 악보에 #이 붙은 음을 소문자로 변환
+ changed = change(music[3])
+
+ # 음악 길이
+ a = len(changed)
+
+ # 재생시간에 재생된 음
+ b = changed * (time // a) + changed[:time % a]
+
+ # 기억한 멜로디도 #을 제거
+ m = change(m)
+
+ # 기억한 멜로디가 재생된 음에 있다면 결과배열에 [시간, index, 제목]을 추가
+ if m in b:
+ answer.append([time, index, music[2]])
+
+ # 결과배열이 비어있다면 "None" 리턴
+ if not answer:
+ return "(None)"
+ # 결과배열의 크기가 1이라면 제목 리턴
+ elif len(answer) == 1:
+ return answer[0][2]
+ # 결과 배열의 크기가 2보다 크다면 재생된 시간이 긴 음악, 먼저 입력된 음악순으로 정렬
+ else:
+ answer = sorted(answer, key=lambda x: (-x[0], x[1]))
+ return answer[0][2] # 첫번째 제목을 리턴
+
+# print(solution_other(m_1, musicinfos_1))
+# print(solution_other(m_2, musicinfos_2))
+# print(solution_other(m_3, musicinfos_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/NthNumbericalSystemGame.py b/Programmers/LEVEL2/NthNumbericalSystemGame.py
new file mode 100644
index 0000000..1ec5987
--- /dev/null
+++ b/Programmers/LEVEL2/NthNumbericalSystemGame.py
@@ -0,0 +1,73 @@
+# 51. N진수 게임
+
+'''
+진법 변환 어떻게 하는지 파악하는 것이 관건
+'''
+def convert(base, cost):
+ rest = '0123456789ABCDEF'
+ trans_str = ''
+
+ if cost == 0:
+ return '0'
+ while cost > 0:
+ trans_str = rest[cost % base] + trans_str
+ cost = cost // base
+
+ return trans_str
+
+def solution(n, t, m, p):
+ answer = ''
+
+ total_trans_str = ''
+ for i in range(t * m):
+ total_trans_str += convert(n, i)
+
+ for ch in range(p -1 , t * m, m):
+ answer += total_trans_str[ch]
+
+ return answer
+
+n_1 = 2
+n_2 = 16
+n_3 = 16
+
+t_1 = 4
+t_2 = 16
+t_3 = 16
+
+m_1 = 2
+m_2 = 2
+m_3 = 2
+
+p_1 = 1
+p_2 = 1
+p_3 = 2
+
+print(solution(n_1, t_1, m_1, p_1))
+print(solution(n_2, t_2, m_2, p_2))
+print(solution(n_3, t_3, m_3, p_3))
+
+def convert_recursive(num, base):
+ T = '0123456789ABCDEF'
+ q, r = divmod(num, base)
+
+ if q == 0:
+ return T[r]
+ else:
+ return convert_recursive(q, base) + T[r]
+
+def solution_other(n, t, m, p):
+ answer = ''
+
+ total_str = ''
+ for i in range(t * m):
+ total_str += convert_recursive(i, n)
+
+ for _ in range(t):
+ answer += total_str[p - 1]
+ p += m
+
+ return answer
+
+# print(solution_other(n_1, t_1, m_1, p_1))
+# print(solution_other(n_2, t_2, m_2, p_2))
diff --git a/Programmers/LEVEL2/OneTwoFourCountryNumber.py b/Programmers/LEVEL2/OneTwoFourCountryNumber.py
index ac01a8e..f2c60b7 100644
--- a/Programmers/LEVEL2/OneTwoFourCountryNumber.py
+++ b/Programmers/LEVEL2/OneTwoFourCountryNumber.py
@@ -1,37 +1,38 @@
-# 5. 124 나라의 숫자
-
-def solution(n):
- answer = ''
-
- if n <= 3:
- answer = '124'[n - 1]
- else:
- q, r = divmod(n - 1, 3)
- answer = solution(q) + '124'[r]
- return answer
-
-n_1 = 1
-n_2 = 2
-n_3 = 3
-n_4 = 4
-
-# print(solution(n_1))
-# print(solution(n_2))
-# print(solution(n_3))
-# print(solution(n_4))
-
-def solution_other(n):
- answer = ''
- num = ['1', '2', '4']
-
- while n > 0:
- n -= 1
- answer = num[n % 3] + answer
- n //= 3
-
- return answer
-
-print(solution_other(n_1))
-print(solution_other(n_2))
-print(solution_other(n_3))
-print(solution_other(n_4))
\ No newline at end of file
+# 5. 124 나라의 숫자
+
+def solution(n):
+ answer = ''
+
+ if n <= 3:
+ answer = '124'[n - 1]
+ else:
+ q, r = divmod(n - 1, 3)
+ answer = solution(q) + '124'[r]
+ return answer
+
+n_1 = 1
+n_2 = 2
+n_3 = 3
+n_4 = 4
+
+print(solution(n_1))
+print(solution(n_2))
+print(solution(n_3))
+print(solution(n_4))
+
+def solution_other(n):
+ answer = ''
+ num = ['1', '2', '4']
+
+ while n > 0:
+ n -= 1
+ answer = num[n % 3] + answer
+ n //= 3
+
+ return answer
+
+print(solution_other(n_1))
+print(solution_other(n_2))
+print(solution_other(n_3))
+print(solution_other(n_4))
+
diff --git a/Programmers/LEVEL2/OpenChattingRoom.py b/Programmers/LEVEL2/OpenChattingRoom.py
new file mode 100644
index 0000000..7eb7c3f
--- /dev/null
+++ b/Programmers/LEVEL2/OpenChattingRoom.py
@@ -0,0 +1,91 @@
+# 31. 오픈 채팅방
+
+def solution(record):
+ answer = []
+
+ user_dict = {}
+ for message in record:
+ if (message.split()[0] == 'Enter') or (message.split()[0] == 'Change'):
+ user_dict[message.split()[1]] = message.split()[2]
+
+ for message in record:
+ if message.split()[0] == 'Enter':
+ answer.append('{}님이 들어왔습니다.'.format(user_dict[message.split()[1]]))
+ elif message.split()[0] == 'Leave':
+ answer.append('{}님이 나갔습니다.'.format(user_dict[message.split()[1]]))
+ else:
+ pass
+
+ return answer
+
+record_1 = ["Enter uid1234 Muzi",
+ "Enter uid4567 Prodo",
+ "Leave uid1234",
+ "Enter uid1234 Prodo",
+ "Change uid4567 Ryan"]
+
+print(solution(record_1))
+
+'''
+어떤 경우에 딕셔너리에 추가를 해야 하는지 생각을 잘못함. 한 번에 다 생각하려고 하지 않기
+'''
+def solution_mine(record):
+ answer = []
+
+ message = [[reco.split()] for reco in record]
+ message_dict = {}
+ for person in message:
+ if person[0][0] == 'Enter':
+ if person[0][1] not in message_dict.keys():
+ message_dict[person[0][1]] = person[0][2]
+ else:
+ message_dict[person[0][1]] = person[0][2]
+ answer.append(str(person[0][2]) + '님이 들어왔습니다.')
+ elif person[0][0] == 'Leave':
+ if person[0][1] in message_dict.keys():
+ answer.append(str(message_dict[person[0][1]]) + '님이 나갔습니다.')
+ else:
+ if person[0][1] in message_dict.keys():
+ message_dict[person[0][1]] = person[0][2]
+ answer.append(str(person[0][2]) + '님이 들어왔습니다.')
+
+ return answer
+
+# print(solution_mine(record_1))
+
+def solution_other(record):
+ answer = []
+
+ namespace = {}
+ printer = {'Enter': '님이 들어왔습니다.', 'Leave': '님이 나갔습니다.'}
+ for r in record:
+ rr = r.split(' ')
+ if rr[0] in ['Enter', 'Change']:
+ namespace[rr[1]] = rr[2]
+
+ for r in record:
+ if r.split(' ')[0] != 'Change':
+ answer.append(namespace[r.split(' ')[1]] + printer[r.split(' ')[0]])
+ return answer
+
+# print(solution_other(record_1))
+
+def solution_best(records):
+ user_id = {EC.split()[1]: EC.split()[-1] for EC in records if EC.startswith('Enter') or EC.startswith('Change')}
+ return [f'{user_id[E_L.split()[1]]}님이 들어왔습니다.' if E_L.startswith('Enter') else f'{user_id[E_L.split()[1]]}님이 나갔습니다.'
+ for E_L in records if not E_L.startswith('Change')]
+
+# print(solution_best(record_1))
+'''
+처음 풀이하는데 있어서 Enter에 대해 먼저 dict를 만들고 Change에 대해 dict를 만들어서 에러가 발생
+다음 반례를 생각해보길,
+1.prodo 입장 ->
+2.prodo에서 ryan으로 Change ->
+3.prodo 퇴장 ->
+4.prodo로 재입장
+
+return ['prodo 입장','prodo 퇴장','prodo 입장']
+
+Change가 최종적인 닉네임이 아님,,
+재입장시에도 닉네임변경이 가능하다는 것을 배제하고 풀어서 틀린 것.
+'''
diff --git a/Programmers/LEVEL2/PlusMinusAdd.py b/Programmers/LEVEL2/PlusMinusAdd.py
index ecbf0c9..7e04c17 100644
--- a/Programmers/LEVEL2/PlusMinusAdd.py
+++ b/Programmers/LEVEL2/PlusMinusAdd.py
@@ -1,19 +1,19 @@
-# 25. 음양 더하기
-
-def solution(absolutes, signs):
- answer = 0
-
- sum_lst = [absolutes[i] if signs[i] == True else -absolutes[i]
- for i in range(len(signs))]
-
- answer = sum(sum_lst)
- return answer
-
-absolutes_1 = [4, 7, 12]
-absolutes_2 = [1, 2, 3]
-
-signs_1 = [True, False, True]
-signs_2 = [False, False, True]
-
-print(solution(absolutes_1, signs_1))
+# 25. 음양 더하기
+
+def solution(absolutes, signs):
+ answer = 0
+
+ sum_lst = [absolutes[i] if signs[i] == True else -absolutes[i]
+ for i in range(len(signs))]
+
+ answer = sum(sum_lst)
+ return answer
+
+absolutes_1 = [4, 7, 12]
+absolutes_2 = [1, 2, 3]
+
+signs_1 = [True, False, True]
+signs_2 = [False, False, True]
+
+print(solution(absolutes_1, signs_1))
print(solution(absolutes_2, signs_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/PonketMon.py b/Programmers/LEVEL2/PonketMon.py
index 847deef..bec4d15 100644
--- a/Programmers/LEVEL2/PonketMon.py
+++ b/Programmers/LEVEL2/PonketMon.py
@@ -1,47 +1,47 @@
-# 27. 폰캣몬
-
-def solution(nums):
- answer = 0
-
- mine = [nums[0]]
- for one in nums:
- if len(mine) != len(nums) // 2:
- if one not in mine:
- mine.append(one)
- else:
- break
-
- answer = len(mine)
- return answer
-
-nums_1 = [3, 1, 2, 3]
-nums_2 = [3, 3, 3, 2, 2, 4]
-nums_3 = [3, 3, 3, 2, 2, 2]
-
-# print(solution(nums_1))
-# print(solution(nums_2))
-# print(solution(nums_3))
-
-'''내 풀이'''
-from itertools import combinations
-def solution_mine(nums):
- answer = 0
-
- comb_nums = list(combinations(nums, len(nums) // 2))
- no_dup_comb_nums = sorted([set(item) for item in comb_nums], key=lambda x: len(x),
- reverse=True)
- answer = len(no_dup_comb_nums[0])
- return answer
-
-# print(solution_mine(nums_1))
-# print(solution_mine(nums_2))
-# print(solution_mine(nums_3))
-
-def solution_best(nums):
- answer = min(len(nums) // 2, len(set(nums)))
-
- return answer
-
-print(solution_best(nums_1))
-print(solution_best(nums_2))
+# 27. 폰캣몬
+
+def solution(nums):
+ answer = 0
+
+ mine = [nums[0]]
+ for one in nums:
+ if len(mine) != len(nums) // 2:
+ if one not in mine:
+ mine.append(one)
+ else:
+ break
+
+ answer = len(mine)
+ return answer
+
+nums_1 = [3, 1, 2, 3]
+nums_2 = [3, 3, 3, 2, 2, 4]
+nums_3 = [3, 3, 3, 2, 2, 2]
+
+# print(solution(nums_1))
+# print(solution(nums_2))
+# print(solution(nums_3))
+
+'''내 풀이'''
+from itertools import combinations
+def solution_mine(nums):
+ answer = 0
+
+ comb_nums = list(combinations(nums, len(nums) // 2))
+ no_dup_comb_nums = sorted([set(item) for item in comb_nums], key=lambda x: len(x),
+ reverse=True)
+ answer = len(no_dup_comb_nums[0])
+ return answer
+
+# print(solution_mine(nums_1))
+# print(solution_mine(nums_2))
+# print(solution_mine(nums_3))
+
+def solution_best(nums):
+ answer = min(len(nums) // 2, len(set(nums)))
+
+ return answer
+
+print(solution_best(nums_1))
+print(solution_best(nums_2))
print(solution_best(nums_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/PredictOfConfrontationTable.py b/Programmers/LEVEL2/PredictOfConfrontationTable.py
new file mode 100644
index 0000000..0a5fefa
--- /dev/null
+++ b/Programmers/LEVEL2/PredictOfConfrontationTable.py
@@ -0,0 +1,25 @@
+# 37. 예상 대진표
+
+def solution(n, a, b):
+ answer = 0
+
+ while a != b:
+ answer += 1
+ a, b = (a + 1) // 2, (b + 1) // 2
+
+ return answer
+
+n_1 = 8
+
+a_1 = 4
+
+b_1 = 7
+
+print(solution(n_1, a_1, b_1))
+
+def solution_best(n, a, b):
+ answer = ((a - 1) ^ (b - 1)).bit_length()
+
+ return answer
+
+print(solution_best(n_1, a_1, b_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/Printer.py b/Programmers/LEVEL2/Printer.py
new file mode 100644
index 0000000..f50fe29
--- /dev/null
+++ b/Programmers/LEVEL2/Printer.py
@@ -0,0 +1,86 @@
+# 55. 프린터
+
+'''
+큰 값 순서대로 정렬을 하더라도 우선순위가 같은 것들의 경우가 문제
+가장 큰 값 뒤에 나온 것들을 먼저 뽑고 그 다음에 이전에 못 뽑은 것들을
+뽑아야 함
+'''
+def solution(priorities, location):
+ answer = 0
+
+ print_lst = [(chr(65 + idx), priority) for idx, priority in enumerate(priorities)]
+ waiting_q = []
+ max_p = 0
+
+ while print_lst:
+ front = print_lst.pop(0)
+ priority = front[1]
+ rest_lst = [priority for name, priority in print_lst]
+
+ if rest_lst:
+ max_p = max(rest_lst)
+
+ if priority >= max_p:
+ waiting_q.append(front)
+ else:
+ print_lst.append(front)
+
+ for print_idx, item in enumerate(waiting_q):
+ if item[0] == chr(65 + location):
+ answer += 1
+ break
+ answer += 1
+ return answer
+
+priorities_1 = [2, 1, 3, 2]
+priorities_2 = [1, 1, 9, 1, 1, 1]
+
+location_1 = 2
+location_2 = 0
+
+print(solution(priorities_1, location_1))
+print(solution(priorities_2, location_2))
+
+def solution_other(priorities, location):
+ pi_list = [(p, i) for i, p in enumerate(priorities)]
+ waiting_q = []
+ max_p = 0
+ answer = 0
+
+ while pi_list:
+ pi = pi_list.pop(0)
+ priority = pi[0]
+ p_list = [priority for priority, idx in pi_list]
+ if p_list:
+ max_p = max(p_list)
+
+ if priority >= max_p:
+ waiting_q.append(pi)
+ else:
+ pi_list.append(pi)
+
+ for i, item in enumerate(waiting_q):
+ if item[1] == location:
+ answer = i + 1
+ break
+
+ return answer
+
+# print(solution_other(priorities_1, location_1))
+# print(solution_other(priorities_2, location_2))
+
+def solution_best(priorities, location):
+ answer = 0
+ queue = [(i, p) for i, p in enumerate(priorities)]
+
+ while True:
+ cur = queue.pop(0)
+ if any(cur[1] < q[1] for q in queue):
+ queue.append(cur)
+ else:
+ answer += 1
+ if cur[0] == location:
+ return answer
+
+# print(solution_best(priorities_1, location_1))
+# print(solution_best(priorities_2, location_2))
diff --git a/Programmers/LEVEL2/RemoveWithPair.py b/Programmers/LEVEL2/RemoveWithPair.py
new file mode 100644
index 0000000..c171a95
--- /dev/null
+++ b/Programmers/LEVEL2/RemoveWithPair.py
@@ -0,0 +1,61 @@
+# 33. 짝지어 제거하기
+
+# 자료구조 stack을 사용해야한다는 것까지는 갔으나...
+def solution(s):
+ answer = 0
+
+ stack = []
+ for ch in s:
+ if len(stack) == 0:
+ stack.append(ch)
+ elif stack[-1] == ch:
+ stack.pop()
+ else:
+ stack.append(ch)
+
+ if len(stack) == 0:
+ answer = 1
+ else:
+ answer = 0
+ return answer
+
+s_1 = 'baabaa'
+s_2 = 'cdcd'
+
+# print(solution(s_1))
+# print(solution(s_2))
+
+def solution_other(s):
+ answer = []
+
+ for ch in s:
+ if not answer:
+ answer.append(ch)
+ else:
+ if answer[-1] == ch:
+ answer.pop()
+ else:
+ answer.append(ch)
+
+ return int(not(answer))
+
+# print(solution_other(s_1))
+# print(solution_other(s_2))
+
+def solution_best(s):
+ answer = 0
+
+ stack = []
+ for ch in s:
+ if stack[-1:] == [ch]:
+ stack.pop()
+ else:
+ stack.append(ch)
+
+ if len(stack) == 0:
+ answer = 1
+ return answer
+
+# print(solution_best(s_1))
+# print(solution_best(s_2))
+
diff --git a/Programmers/LEVEL2/RotateBracket.py b/Programmers/LEVEL2/RotateBracket.py
new file mode 100644
index 0000000..2609387
--- /dev/null
+++ b/Programmers/LEVEL2/RotateBracket.py
@@ -0,0 +1,117 @@
+# 40. 괄호 회전하기
+
+# 쉽게 생각하기(stack으로 구현해서 푼다는 idea
+def solution(s):
+ answer = 0
+
+ dic = {'(' : ')', '{' : '}', '[' : ']'}
+ for i in range(len(s)):
+ rotate_s = list(s[i:] + s[:i])
+ stack = []
+ # 여기 부분을 구현 못함.
+ while rotate_s:
+ ch = rotate_s.pop(0)
+ if not stack:
+ stack.append(ch)
+ else:
+ if stack[-1] in [')', '}', ']']:
+ break
+
+ if dic[stack[-1]] == ch:
+ stack.pop()
+ else:
+ stack.append(ch)
+ if not stack:
+ answer += 1
+
+ return answer
+
+s_1 = '[](){}'
+s_2 = '}]()[{'
+s_3 = '[)(]'
+s_4 = '}}}'
+
+print(solution(s_1))
+print(solution(s_2))
+print(solution(s_3))
+print(solution(s_4))
+
+'''
+stack으로 푼다는 것 인지하고 얼추 구현했으나 마지막 부분을 못함.
+괄호 개수로 먼저 비교한 후 회전하였을 때 비교하려고 했으나
+개수를 생각할 필요 없이 회전만 고려하면 해결되었던 문제...
+'''
+from collections import Counter
+def solution_mine(s):
+ answer = 0
+
+ # 사실 필요없던 부분(갯수 세는 부분)
+ bracket_counter = Counter(s)
+ left_cnts, right_cnts = 0, 0
+ for key, value in bracket_counter.items():
+ if key in ['(', '{', '[']:
+ left_cnts += value
+ else:
+ right_cnts += value
+
+ if left_cnts != right_cnts:
+ answer = 0
+ return answer
+
+ dic = {'(' : ')', '{' : '}', '[' : ']'}
+ for i in range(len(s)):
+ rotate_s = list(s[i:] + s[:i])
+ stack = []
+ while rotate_s:
+ ch = rotate_s.pop(0)
+ if not stack:
+ stack.append(ch)
+ else:
+ if stack[-1] in [')', '}', ']']:
+ break
+
+ if dic[stack[-1]] == ch:
+ stack.pop()
+ else:
+ stack.append(ch)
+
+ if not stack:
+ answer += 1
+
+ return answer
+
+print(solution_mine(s_1))
+print(solution_mine(s_2))
+print(solution_mine(s_3))
+print(solution_mine(s_4))
+
+# 다른 풀이
+def is_valid(s):
+ stack = []
+ for ch in s:
+ if not stack:
+ stack.append(ch)
+ elif stack[-1] == '(':
+ if ch==')': stack.pop()
+ else: stack.append(ch)
+ elif stack[-1] == '{':
+ if ch=='}': stack.pop()
+ else: stack.append(ch)
+ elif stack[-1] == '[':
+ if ch==']': stack.pop()
+ else: stack.append(ch)
+
+ return False if stack else True
+
+def solution_other(s):
+ answer = 0
+
+ for i in range(len(s)):
+ answer += is_valid(s[i:]+s[:i])
+
+ return answer
+
+print(solution_other(s_1))
+print(solution_other(s_2))
+print(solution_other(s_3))
+print(solution_other(s_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/RotateMatrixBorder.py b/Programmers/LEVEL2/RotateMatrixBorder.py
new file mode 100644
index 0000000..091e70e
--- /dev/null
+++ b/Programmers/LEVEL2/RotateMatrixBorder.py
@@ -0,0 +1,132 @@
+# 38. 행렬 테두리 회전하기
+
+def solution(rows, columns, queries):
+ answer = []
+
+ # 행렬 만들기
+ board = [[] for _ in range(rows)]
+ for i in range(1, rows + 1):
+ for j in range(1, columns + 1):
+ board[i - 1].append((i - 1) * columns + j)
+
+ for x1, y1, x2, y2 in queries:
+ temp = board[x1 - 1][y2 - 1]
+ min_value = 10001
+
+ # 북쪽 테두리
+ min_value = min(min(board[x1 - 1][y1 - 1: y2 - 1]), min_value)
+ board[x1 - 1][y1:y2] = board[x1 - 1][y1 - 1: y2 - 1]
+
+ # 서쪽 테두리
+ for i in range(x1, x2):
+ min_value = min(board[i][y1 - 1], min_value)
+ board[i - 1][y1 - 1] = board[i][y1 - 1]
+
+ # 남쪽 테두리
+ min_value = min(min(board[x2 - 1][y1:y2]), min_value)
+ board[x2 - 1][y1 - 1:y2 - 1] = board[x2 - 1][y1:y2]
+
+ # 동쪽 테두리
+ for i in range(x2 - 2, x1 - 2, -1):
+ min_value = min(board[i][y2 - 1], min_value)
+ board[i + 1][y2 - 1] = board[i][y2 - 1]
+
+ board[x1][y2 - 1] = temp
+ min_value = min(min_value, temp)
+
+ answer.append(min_value)
+ return answer
+
+rows_1 = 6
+rows_2 = 3
+rows_3 = 100
+
+columns_1 = 6
+columns_2 = 3
+columns_3 = 97
+
+queries_1 = [[2, 2, 5, 4],
+ [3, 3, 6, 6],
+ [5, 1, 6, 3]
+ ]
+queries_2 = [[1, 1, 2, 2],
+ [1, 2, 2, 3],
+ [2, 1, 3, 2],
+ [2, 2, 3, 3]
+ ]
+queries_3 = [[1, 1, 100, 97]]
+
+# print(solution(rows_1, columns_1, queries_1))
+# print(solution(rows_2, columns_2, queries_2))
+# print(solution(rows_3, columns_3, queries_3))
+
+import numpy as np
+def solution_mine(rows, columns, queries):
+ answer = []
+
+ '''
+ [[1, 2, 3, 4, 5, 6],
+ [7, 8, 9, 10, 11, 12],
+ ...
+ 만들기 성공
+ '''
+ matrix = []
+ for i in range(1, rows * columns - rows + 2, rows):
+ tmp = []
+ for j in range(i, columns + i):
+ tmp.append(j)
+ matrix.append(tmp)
+ matrix_np = np.array(matrix)
+
+ # 회전을 어떻게 시켜야할지 구현이 안 됨.
+ for query in queries:
+ x1, y1, x2, y2 = query
+ mid_x = round((x2 - x1) / 2)
+ mid_y = round((y2 - y1) / 2)
+ change_matrix = matrix_np[x1 - 1:x2 - x1][y1 - 1:y2 - y1]
+ print(change_matrix)
+ return answer
+
+def solution_other(rows, columns, queries):
+ answer = []
+
+ # 행렬 만들기
+ array = [[0 for col in range(columns)] for row in range(rows)]
+ t = 1
+ for row in range(rows):
+ for col in range(columns):
+ array[row][col] = t
+ t += 1
+
+ for x1, y1, x2, y2 in queries:
+ tmp = array[x1 - 1][y1 - 1]
+ mini = tmp
+
+ for k in range(x1 - 1, x2 - 1):
+ test = array[k + 1][y1 - 1]
+ array[k][y1 - 1] = test
+ mini = min(mini, test)
+
+ for k in range(y1 - 1, y2 - 1):
+ test = array[x2 - 1][k + 1]
+ array[x2 - 1][k] = test
+ mini = min(mini, test)
+
+ for k in range(x2 - 1, x1 - 1, -1):
+ test = array[k - 1][y2 - 1]
+ array[k][y2 - 1] = test
+ mini = min(mini, test)
+
+ for k in range(y2 - 1, y1 - 1, -1):
+ test = array[x1 - 1][k - 1]
+ array[x1 - 1][k] = test
+ mini = min(mini, test)
+
+ array[x1 - 1][y1] = tmp
+ answer.append(mini)
+
+ return answer
+
+print(solution_other(rows_1, columns_1, queries_1))
+print(solution_other(rows_2, columns_2, queries_2))
+print(solution_other(rows_3, columns_3, queries_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/SisoPartner.py b/Programmers/LEVEL2/SisoPartner.py
new file mode 100644
index 0000000..33dae74
--- /dev/null
+++ b/Programmers/LEVEL2/SisoPartner.py
@@ -0,0 +1,30 @@
+# 시소 짝궁
+
+"""
+I didn't solve this problem by myself. The key of this problem is not using 2 loop.
+And divide pairs and possibles of balanced position.
+See it again.
+"""
+from collections import Counter
+def solution(weights):
+ answer = 0
+
+ cntr = Counter(weights)
+ for weight, weight_cnts in cntr.items():
+ if weight_cnts >= 2:
+ answer += weight_cnts * (weight_cnts - 1) // 2
+
+ weights = set(weights)
+ for weight in weights:
+ if weight * (2/3) in weights:
+ answer += cntr[weight * (2/3)] * cntr[weight]
+ if weight * (2/4) in weights:
+ answer += cntr[weight * (2/4)] * cntr[weight]
+ if weight * (3/4) in weights:
+ answer += cntr[weight * (3/4)] * cntr[weight]
+
+ return answer
+
+weights_1 = [100, 180, 360, 100, 270]
+
+print(solution(weights_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/StringCompression.py b/Programmers/LEVEL2/StringCompression.py
index 5d30920..5a4473b 100644
--- a/Programmers/LEVEL2/StringCompression.py
+++ b/Programmers/LEVEL2/StringCompression.py
@@ -74,11 +74,11 @@ def solution_best(s):
answer = min(pattern)
return answer
-print(solution_best(s_1))
-print(solution_best(s_2))
-print(solution_best(s_3))
-print(solution_best(s_4))
-print(solution_best(s_5))
+# print(solution_best(s_1))
+# print(solution_best(s_2))
+# print(solution_best(s_3))
+# print(solution_best(s_4))
+# print(solution_best(s_5))
def solution_other(s):
length = []
@@ -112,4 +112,5 @@ def solution_other(s):
# print(solution_other(s_2))
# print(solution_other(s_3))
# print(solution_other(s_4))
-# print(solution_other(s_5))
\ No newline at end of file
+# print(solution_other(s_5))
+
diff --git a/Programmers/LEVEL2/TargetNumber.py b/Programmers/LEVEL2/TargetNumber.py
index b7aefc2..9503fa5 100644
--- a/Programmers/LEVEL2/TargetNumber.py
+++ b/Programmers/LEVEL2/TargetNumber.py
@@ -43,12 +43,13 @@ def solution(numbers, target):
answer = 0
lst = [(x, -x) for x in numbers]
+
s = list(map(sum, product(*lst)))
answer = s.count(target)
return answer
-# print(solution(numbers_1, target_1))
+print(solution(numbers_1, target_1))
'''
3. BFS(넓이 우선 탐색) 풀이
diff --git a/Programmers/LEVEL2/VisitDistance.py b/Programmers/LEVEL2/VisitDistance.py
new file mode 100644
index 0000000..2977d5c
--- /dev/null
+++ b/Programmers/LEVEL2/VisitDistance.py
@@ -0,0 +1,86 @@
+# 48. 방문 길이
+
+def solution(dirs):
+ answer = 0
+
+ move = {'R' : (1, 0), 'L' : (-1, 0), 'D' : (0, -1), 'U' : (0, 1)}
+ visited = set()
+ current_x , current_y = 0, 0
+ for dir in dirs:
+ move_x, move_y = current_x + move[dir][0], current_y + move[dir][1]
+ if -5 <= move_x <= 5 and -5 <= move_y <= 5:
+ visited.add((current_x, current_y, move_x, move_y))
+ visited.add((move_x, move_y, current_x, current_y))
+ current_x, current_y = move_x, move_y
+
+ answer = len(visited) // 2
+ return answer
+
+dirs_1 = "ULURRDLLU"
+dirs_2 = "LULLLLLLU"
+
+print(solution(dirs_1))
+print(solution(dirs_2))
+
+'''
+25점
+현재 좌표를 나타내는 currents list에
+지났던 경로가 있는지 없는지 저장하는 visited list로
+각 문자에 맞게 동,서,남,북 값에 맞게 currents list의 값을 초기화해준다
+만약에 -5 <= x <= 5, -5 <= y <= 5 사이에 있으면 위 같이 풀고
+아니면 그냥 넘어가면 됨
+----------------------------------------------------------------
+가는 길만 표시하면 될 것 같았는데 오는 길이 안 겹칠 수도 있겠네
+그래서 set자료형을 사용해서 풀어야
+'''
+def solution_mine(dirs):
+ answer = []
+
+ currents = [0, 0]
+ visited = []
+ for dir in dirs:
+ x, y, = currents[0], currents[1]
+ if -5 <= x and x <= 5 and -5 <= y and y <= 5:
+ if dir == 'R':
+ x += 1
+ elif dir == 'L':
+ x -= 1
+ elif dir == 'D':
+ y -= 1
+ elif dir == 'U':
+ y += 1
+
+ if [x, y] not in visited:
+ visited.append([x, y])
+ answer += 1
+ currents[0], currents[1] = x, y
+ else:
+ answer += 1
+ break
+ else:
+ continue
+
+ return answer
+
+def solution_other(dirs):
+ dxs, dys = [-1, 0, 1, 0], [0, -1, 0, 1]
+ d = {"U": 0, "L": 1, "D": 2, "R": 3}
+
+ visited = set()
+ answer = 0
+ x, y = 0, 0
+ for dir in dirs:
+ i = d[dir]
+ nx, ny = x + dxs[i], y + dys[i]
+ if nx < -5 or nx > 5 or ny < -5 or ny > 5:
+ continue
+ if (x, y, nx, ny) not in visited:
+ visited.add((x, y, nx, ny))
+ visited.add((nx, ny, x, y)) # 길은 '양방향' 임을 빼먹으면 안됨!
+ answer += 1
+ x, y = nx, ny
+
+ return answer
+
+print(solution_other(dirs_1))
+print(solution_other(dirs_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL2/__init__.py b/Programmers/LEVEL2/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/LEVEL3/2XNtiling.py b/Programmers/LEVEL3/2XNtiling.py
new file mode 100644
index 0000000..f68ce63
--- /dev/null
+++ b/Programmers/LEVEL3/2XNtiling.py
@@ -0,0 +1,37 @@
+# 12. 2 x n 타일링
+
+'''
+피보나치 수열
+'''
+def solution(n):
+ answer = 0
+
+ cases = [1, 2]
+ for i in range(2, n):
+ cases.append((cases[-1] + cases[-2]) % 1000000007)
+
+ answer = cases[-1]
+ return answer
+
+n_1 = 4
+
+print(solution(n_1))
+
+def solution_other(n):
+ answer = 0
+
+ a, b = 1, 1
+ for i in range(1, n):
+ a, b = b, (a + b) % 1000000007
+
+ answer = b
+ return answer
+
+# print(solution_other(n_1))
+
+from functools import reduce
+
+solution_best = lambda n : reduce(lambda a, _ : (a[1] % 1000000007, sum(a) % 1000000007),
+ range(1, n), [1, 1])[1]
+
+# print(solution_best(n_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/BestOfSet.py b/Programmers/LEVEL3/BestOfSet.py
new file mode 100644
index 0000000..94127b5
--- /dev/null
+++ b/Programmers/LEVEL3/BestOfSet.py
@@ -0,0 +1,125 @@
+# 2. 최고의 집합
+
+'''
+숫자 s를 자연수 n개로 표현하면서 '곱이 가장 큰 수'가 되도록 하려면, n개의 자연수 간에 차이가
+적어야 한다.
+ex) 7을 3개의 자연수로 표현?? -> (7 // 3 = 2) ... [2, 2, 2]
+s를 n으로 나눈 나머지가 있을 수 있으니 문제에서 오름차순 정렬 만족시키기 위해 맨 뒷자리 수부터
+1씩 더해준다.
+'''
+def solution(n, s):
+ if n > s: return [-1]
+
+ answer = []
+ # s를 n으로 나눈 몫이 n개가 되도록 초기값 설정
+ initial = s // n
+ for _ in range(n):
+ answer.append(initial)
+ idx = -1
+ for _ in range(s % n):
+ answer[idx] += 1
+ idx -= 1
+
+ return answer
+
+n_1 = 2
+n_2 = 2
+n_3 = 2
+
+s_1 = 9
+s_2 = 1
+s_3 = 8
+
+print(solution(n_1, s_1))
+print(solution(n_2, s_2))
+print(solution(n_3, s_3))
+
+'''
+시간 초과 ... 조합 개수가 3개 이상이면 아마 안 될 듯
+'''
+def solution_mine(n, s):
+ answer = []
+
+ multi_lst = [i for i in range(1, s)]
+ multi_set = []
+ if len(multi_lst) < 2:
+ answer.append(-1)
+ return answer
+ else:
+ if len(multi_lst) % 2 == 1:
+ for i in range(len(multi_lst) // 2):
+ two_set = [multi_lst[i], multi_lst[-1 - i]]
+ multi_set.append(two_set)
+ multi_set.append([multi_lst[len(multi_lst) // 2],
+ multi_lst[len(multi_lst) // 2]])
+ else:
+ for i in range(len(multi_lst) // 2):
+ two_set = [multi_lst[i], multi_lst[-1 - i]]
+ multi_set.append(two_set)
+
+ multiply_lst = []
+ for x, y in multi_set:
+ multiply = x * y
+ multiply_lst.append(multiply)
+ answer = multi_set[multiply_lst.index(max(multiply_lst))]
+ return answer
+
+# print(solution_mine(n_1, s_1))
+# print(solution_mine(n_2, s_2))
+# print(solution_mine(n_3, s_3))
+
+'''
+중복조합을 이용해서 풀어본 풀이 ... 시간 초과(범위가 10,000 이상이면 조합 X
+'''
+from itertools import combinations_with_replacement
+def solution_mine2(n, s):
+ answer = []
+
+ num_lst = [i for i in range(1, s)]
+ if len(num_lst) < 2:
+ answer.append(-1)
+ return answer
+
+ comb_lst = list(combinations_with_replacement(num_lst, n))
+ multi_set = []
+ for one_set in comb_lst:
+ if sum(one_set) == s:
+ multi_set.append(one_set)
+
+ biggest_multiply = multi_set[0][0] * multi_set[0][1]
+ answer = list(multi_set[0])
+ for one_set in multi_set:
+ if biggest_multiply < one_set[0] * one_set[1]:
+ if len(answer) == 0:
+ answer = list(one_set)
+ else:
+ answer.clear()
+ answer = list(one_set)
+
+ return answer
+
+# print(solution_mine2(n_1, s_1))
+# print(solution_mine2(n_2, s_2))
+# print(solution_mine2(n_3, s_3))
+
+'''
+다른 사람 풀이
+'''
+def solution_other(n, s):
+ answer = []
+
+ a = int(s / n)
+ if a == 0:
+ return [-1]
+
+ b = s % n
+ for i in range(n - b):
+ answer.append(a)
+ for i in range(b):
+ answer.append(a + 1)
+
+ return answer
+
+# print(solution_other(n_1, s_1))
+# print(solution_other(n_2, s_2))
+# print(solution_other(n_3, s_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/CarpoolTaxiFare.py b/Programmers/LEVEL3/CarpoolTaxiFare.py
new file mode 100644
index 0000000..97f9d53
--- /dev/null
+++ b/Programmers/LEVEL3/CarpoolTaxiFare.py
@@ -0,0 +1,146 @@
+# 23. 합승 택시 요금
+
+# Dijkstra
+from math import inf
+import heapq
+def dijkstra(n, graph, start):
+ dist = [inf for _ in range(n)]
+ dist[start] = 0
+
+ q = []
+ heapq.heappush(q, [dist[start], start])
+ while q:
+ cur_dist, cur_dest = heapq.heappop(q)
+ if dist[cur_dest] >= cur_dist:
+ for i in range(n):
+ new_dist = cur_dist + graph[cur_dest][i]
+ if new_dist < dist[i]:
+ dist[i] = new_dist
+ heapq.heappush(q, [new_dist, i])
+
+ return dist
+
+def solution(n, s, a, b, fares):
+ answer = inf
+
+ s, a, b = s - 1, a - 1, b - 1
+ graph = [[inf] * n for _ in range(n)]
+ for fare in fares:
+ u, v, w = fare
+ graph[u - 1][v - 1] = graph[v - 1][u - 1] = w
+
+ min_graph = []
+ for i in range(n):
+ min_graph.append(dijkstra(n, graph, i))
+
+ for k in range(n):
+ answer = min(answer, min_graph[s][k] + min_graph[k][a] + min_graph[k][b])
+
+ return answer
+
+n_1 = 6
+n_2 = 7
+n_3 = 6
+
+s_1 = 4
+s_2 = 3
+s_3 = 4
+
+a_1 = 6
+a_2 = 4
+a_3 = 5
+
+b_1 = 2
+b_2 = 1
+b_3 = 6
+
+fares_1 = [[4, 1, 10],
+ [3, 5, 24],
+ [5, 6, 2],
+ [3, 1, 41],
+ [5, 1, 24],
+ [4, 6, 50],
+ [2, 4, 66],
+ [2, 3, 22],
+ [1, 6, 25]]
+fares_2 = [[5, 7, 9],
+ [4, 6, 4],
+ [3, 6, 1],
+ [3, 2, 3],
+ [2, 1, 6]]
+fares_3 = [[2, 6, 6],
+ [6, 3, 7],
+ [4, 6, 7],
+ [6, 5, 11],
+ [2, 5, 12],
+ [5, 3, 20],
+ [2, 4, 8],
+ [4, 3, 9]]
+
+print(solution(n_1, s_1, a_1, b_1, fares_1))
+print(solution(n_2, s_2, a_2, b_2, fares_2))
+print(solution(n_3, s_3, a_3, b_3, fares_3))
+
+# Floyd warshall
+def solution_other(n, s, a, b, fares):
+ answer = inf
+
+ s, a, b = s - 1, a - 1, b - 1
+ graph = [[inf] * n for _ in range(n)]
+ for i in range(n):
+ graph[i][i] = 0
+
+ for fare in fares:
+ u, v, w = fare
+ graph[u - 1][v - 1] = graph[v - 1][u - 1] = w
+
+ for k in range(n):
+ for i in range(n):
+ for j in range(n):
+ if graph[i][j] > graph[i][k] + graph[k][j]:
+ graph[i][j] = graph[i][k] + graph[k][j]
+
+ for k in range(n):
+ answer = min(answer, graph[s][k] + graph[k][a] + graph[k][b])
+
+ return answer
+
+print(solution_other(n_1, s_1, a_1, b_1, fares_1))
+print(solution_other(n_2, s_2, a_2, b_2, fares_2))
+print(solution_other(n_3, s_3, a_3, b_3, fares_3))
+
+def solution_best(n, s, a, b, fares):
+ answer = 987654321
+
+ link = [[] for _ in range(n + 1)]
+ for x, y, z in fares:
+ link[x].append((z, y))
+ link[y].append((z, x))
+
+ def dijkstra(start):
+ dist = [987654321] * (n + 1)
+ dist[start] = 0
+ heap = []
+ heapq.heappush(heap, (0, start))
+ while heap:
+ value, destination = heapq.heappop(heap)
+ if dist[destination] < value:
+ continue
+
+ for v, d in link[destination]:
+ next_value = value + v
+ if dist[d] > next_value:
+ dist[d] = next_value
+ heapq.heappush(heap, (next_value, d))
+
+ return dist
+
+ dp = [[]] + [dijkstra(i) for i in range(1, n + 1)]
+ for i in range(1, n + 1):
+ answer = min(dp[i][a] + dp[i][b] + dp[i][s], answer)
+
+ return answer
+
+print(solution_best(n_1, s_1, a_1, b_1, fares_1))
+print(solution_best(n_2, s_2, a_2, b_2, fares_2))
+print(solution_best(n_3, s_3, a_3, b_3, fares_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/ChartEditing.py b/Programmers/LEVEL3/ChartEditing.py
new file mode 100644
index 0000000..f74b5a7
--- /dev/null
+++ b/Programmers/LEVEL3/ChartEditing.py
@@ -0,0 +1,126 @@
+# 19. 표 편집
+
+def solution(n, k, cmd):
+ answer = ''
+
+ linked_list = {i : [i - 1, i + 1] for i in range(1, n + 1)}
+ OX = ['O' for i in range(1, n + 1)]
+ stack = []
+
+ k += 1
+
+ for c in cmd:
+ if c[0] == 'U':
+ for _ in range(int(c[2:])):
+ k = linked_list[k][0]
+ elif c[0] == 'D':
+ for _ in range(int(c[2:])):
+ k = linked_list[k][1]
+ elif c[0] == 'C':
+ prev, next = linked_list[k]
+ stack.append([prev, next, k])
+ OX[k - 1] = 'X'
+
+ if next == n + 1:
+ k = linked_list[k][0]
+ else:
+ k = linked_list[k][1]
+
+ if prev == 0:
+ linked_list[next][0] = prev
+ elif next == n + 1:
+ linked_list[prev][1] = next
+ else:
+ linked_list[next][0] = prev
+ linked_list[prev][1] = next
+ elif c[0] == 'Z':
+ prev, next, now = stack.pop()
+ OX[now - 1] = 'O'
+
+ if prev == 0:
+ linked_list[next][0] = now
+ elif next == n + 1:
+ linked_list[prev][1] = now
+ else:
+ linked_list[prev][1] = now
+ linked_list[next][0] = now
+
+ answer = ''.join(OX)
+ return answer
+
+n_1 = 8
+n_2 = 8
+
+k_1 = 2
+k_2 = 2
+
+cmd_1 = ["D 2",
+ "C",
+ "U 3",
+ "C",
+ "D 4",
+ "C",
+ "U 2",
+ "Z",
+ "Z"]
+
+cmd_2 = ["D 2",
+ "C",
+ "U 3",
+ "C",
+ "D 4",
+ "C",
+ "U 2",
+ "Z",
+ "Z",
+ "U 1",
+ "C"]
+
+# print(solution(n_1, k_1, cmd_1))
+# print(solution(n_2, k_2, cmd_2))
+
+import heapq
+def solution_best(n, k, cmds):
+ answer = ''
+
+ def inverse(num):
+ return -num
+
+ max_heap = list(map(inverse, range(k)))
+ min_heap = list(range(k, n))
+ deleted = ['O' for _ in range(n)]
+ deleted_stack = []
+ heapq.heapify(max_heap)
+ heapq.heapify(min_heap)
+ for cmd in cmds:
+ command = cmd.split()
+ if len(command) > 1:
+ num = command[1]
+ command = command[0]
+ num = int(num)
+ if command == 'D':
+ for _ in range(num):
+ heapq.heappush(max_heap, -heapq.heappop(min_heap))
+ else:
+ for _ in range(num):
+ heapq.heappush(min_heap, -heapq.heappop(max_heap))
+ else:
+ command = command[0]
+ if command == 'C':
+ delete_num = heapq.heappop(min_heap)
+ deleted_stack.append(delete_num)
+ deleted[delete_num] = 'X'
+ if len(min_heap) == 0:
+ heapq.heappush(min_heap, -heapq.heappop(max_heap))
+ else:
+ restore_num = deleted_stack.pop()
+ deleted[restore_num] = 'O'
+ if min_heap[0] > restore_num:
+ heapq.heappush(max_heap, -restore_num)
+ else:
+ heapq.heappush(min_heap, restore_num)
+ answer = ''.join(deleted)
+ return answer
+
+# print(solution_best(n_1, k_1, cmd_1))
+# print(solution_best(n_2, k_2, cmd_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/ChuseokTraffic.py b/Programmers/LEVEL3/ChuseokTraffic.py
new file mode 100644
index 0000000..2873160
--- /dev/null
+++ b/Programmers/LEVEL3/ChuseokTraffic.py
@@ -0,0 +1,188 @@
+# 1. 추석 트래픽
+
+'''
+초당 최대 처리량 : 어떤 특정 초 사이(에를 들면 2 ~ 3초 사이)에 처리량이 가장 많을 때의 값
+처리시간은 시작시간과 끝시간 포함, 밀리세컨드까지 나오기 때문에 값을 다 초로 바꾸고 X 1000
+'''
+# 초당 최대 처리량
+def check_traffic(time, li):
+ c = 0
+ start = time
+ end = time + 1000
+
+ for i in li:
+ if i[1] >= start and i[0] < end:
+ c += 1
+
+ return c
+
+
+def solution(lines):
+ answer = 1
+
+ lst = []
+
+ for line in lines:
+ day, end_time, dispose_time = line.split()
+ end_time = end_time.split(':')
+ dispose_time = float(dispose_time.replace('s', '')) * 1000
+ end = (int(end_time[0]) * 3600 + int(end_time[1]) * 60 + float(end_time[2])) * 1000
+ start = end - dispose_time + 1
+ lst.append([start, end])
+
+ for i in lst:
+ answer = max(answer, check_traffic(i[0], lst), check_traffic(i[1], lst))
+
+ return answer
+
+lines_1 = [
+"2016-09-15 01:00:04.001 2.0s",
+"2016-09-15 01:00:07.000 2s"
+]
+lines_2 = [
+"2016-09-15 01:00:04.002 2.0s",
+"2016-09-15 01:00:07.000 2s"
+]
+lines_3 = [
+"2016-09-15 20:59:57.421 0.351s",
+"2016-09-15 20:59:58.233 1.181s",
+"2016-09-15 20:59:58.299 0.8s",
+"2016-09-15 20:59:58.688 1.041s",
+"2016-09-15 20:59:59.591 1.412s",
+"2016-09-15 21:00:00.464 1.466s",
+"2016-09-15 21:00:00.741 1.581s",
+"2016-09-15 21:00:00.748 2.31s",
+"2016-09-15 21:00:00.966 0.381s",
+"2016-09-15 21:00:02.066 2.62s"
+]
+
+print(solution(lines_1))
+print(solution(lines_2))
+print(solution(lines_3))
+
+def get_times(log):
+ log_str = log.split()
+ end_time = log_str[1].split(':')
+ end_time = int(end_time[0]) * 3600000 + int(end_time[1]) * 60000 + \
+ int(end_time[2].replace('.', ''))
+ start_time = end_time - int(float(log_str[2].replace('s', '')) * 1000) + 1
+
+ return (start_time, end_time) if start_time > 0 else (0, end_time)
+
+def solution_other(lines):
+ answer = 0
+ total_times = []
+ for i in range(len(lines)):
+ start_time, end_time = get_times(lines[i])
+ total_times.append((start_time, end_time, i))
+
+ for i in range(len(total_times)):
+ count = 1
+ end_time = total_times[i][1]
+ for j in range(len(total_times)):
+ if i == j:
+ continue
+ t_start_time = total_times[j][0]
+ t_end_time = total_times[j][1]
+ if t_start_time >= end_time and t_start_time < end_time + 1000:
+ count += 1
+ elif t_end_time >= end_time and t_end_time < end_time + 1000:
+ count += 1
+ elif end_time >= t_start_time and end_time + 1000 <= t_end_time:
+ count += 1
+
+ if count > answer:
+ answer = count
+
+ return answer
+
+# print(solution_other(lines_1))
+# print(solution_other(lines_2))
+# print(solution_other(lines_3))
+
+'''
+시간 계산에 있어서 유용한 datetime 모듈 이용하여 풀기
+'''
+from datetime import datetime
+def solution_best(lines):
+ answer = 0
+
+ range_list = []
+ pointer_list = []
+
+ for line in lines:
+ # ex) "2016-09-15 01:00:04.001 2.0s",
+ # dt = 2016-09-15 01:00:04.001
+ # dr = 2.0s
+ dt = line.split()[0] + ' ' + line.split()[1]
+ dr = line.split()[2]
+
+ # strptime을 통한 dt 형식 변환 : 문자열(기존) >> 날짜(변경)
+ dt = datetime.strptime(dt, '%Y-%m-%d %H:%M:%S.%f')
+
+ # dr[:-1]을 통해 맨 뒤 문자열 "s" 제거,
+ # float()함수를 통해 타입 변경 : 문자열(기존) >> 실수(변경)
+ # * 1000을 통해 단위 변경 : 초(기존) >> 밀리초(변경)
+ # int()를 통해서 타입 변경 : 실수(기존) >> 정수(변경)
+ # ex) dr = 2.0s(기존) >> 2000(변경)
+ dr = int(float(dr[:-1]) * 1000)
+
+ # line의 dt는 처리가 끝난 시각이 기록되어있고, 끝난 시각을 밀리초로 환산하여 end 변수에 할당.
+ # 1. hour, minute, second를 각각 단위에 맞게 계산하여 초로 변환 후 * 1000 = millisecond로 변환
+ # 2. microsecond를 구하고 //1000을 통해서 millisecond를 구해서 더해줌
+ end = (dt.second + dt.minute * 60 + dt.hour * 3600) * 1000 + dt.microsecond // 1000
+
+ # end = dt = 처리가 끝난 시각
+ # start = 처리가 끝난 시각 - 걸린 시각 + 1 = 처리 시작 시각
+ # ex) 2016-09-15 03:10:33.020 0.011s
+ # "2016년 9월 15일 오전 3시 10분 33.010초"부터
+ # "2016년 9월 15일 오전 3시 10분 33.020초"까지 "0.011초"
+ start = end - dr + 1
+
+ # pointer_list에 start, end 포인트를 각각 넣어주고,
+ # range_list에는 start, end를 묶은 범위 tuple을 넣어줌.
+ pointer_list.append(start)
+ pointer_list.append(end)
+ range_list.append((start, end))
+
+ # 여기서부터 잘 생각해야하는게,
+ # 문제에서 원하는 답은 최대 처리량을 갖는 "1초" 구간임.
+ # 최대 값은 start나 end 포인트를 기점으로 나옴.
+ # why? 그 외에 범위에서는 변화가 없기 때문.
+
+ # 따라서, start, end 포인트를 시작으로 1초 즉, point + 999 의 범위 내에
+ # range_list에 넣은 놈들이 포함되냐 안되냐를 count하고 그 max 값을 찾으면 됨.
+
+ # pointer_list를 돌면서 각 pointer로부터 +999의 범위 내에 range_list의 놈들이 포함되려면,
+ # 아래 첨부한 사진을 참조해서
+ # 1. range의 end가 point보다 작거나(앞이거나)
+ # 2. range의 start가 point+999보다 크거나(뒤거나)
+ # 위의 두 경우는 우리가 구하고 싶은 범위에 포함되지 않으니 "넘어가고"
+ # 그 경우들을 제외한 나머지 경우에 대해서 count+1을 해줄거다.
+
+ # 이 내용이 바로 아래 for 문 중에
+ # if not(range_item[1] < pointer) and not(range_item[0] > pointer + 999):
+ # count += 1
+
+ # 각 변수 세팅
+ max_count = 0
+ count = 0
+
+ for pointer in pointer_list:
+ count = 0
+ # pointer_list를 돌면서 start 혹은 end 포인트를 꺼내오고
+ # 새 pointer를 가져올 때, count = 0 초기화
+ for range_item in range_list:
+ if not (range_item[1] < pointer) and not (range_item[0] > pointer + 999):
+ count += 1
+
+ # 각 pointer와 range를 돌면서 새로운 최고값이 나오면 max_count를 갱신
+ if count > max_count:
+ max_count = count
+
+ answer = max_count
+ return answer
+
+# print(solution_best(lines_1))
+# print(solution_best(lines_2))
+# print(solution_best(lines_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/CollectingSticker2.py b/Programmers/LEVEL3/CollectingSticker2.py
new file mode 100644
index 0000000..5e7a26d
--- /dev/null
+++ b/Programmers/LEVEL3/CollectingSticker2.py
@@ -0,0 +1,89 @@
+# 8. 스티커 모으기(2)
+
+'''
+점화식을 이용한 풀이
+맨 앞 스티커 떼는 경우와 아닌 경우로 나눠서 푼다
+'''
+def solution(sticker):
+ answer = 0
+
+ if len(sticker) == 1:
+ return sticker[0]
+
+ # 맨 앞 스티커 떼는 경우
+ table = [0 for _ in range(len(sticker))]
+ table[0] = sticker[0]
+ table[1] = table[0]
+ for i in range(2, len(sticker) - 1):
+ table[i] = max(table[i - 1], table[i - 2] + sticker[i])
+ value = max(table)
+
+ # 맨 앞 스티커 떼지 않는 경우
+ table1 = [0 for _ in range(len(sticker))]
+ table1[0] = 0
+ table1[1] = sticker[1]
+ for i in range(2, len(sticker)):
+ table1[i] = max(table1[i - 1], table1[i - 2] + sticker[i])
+
+ answer = max(value, max(table1))
+ return answer
+
+sticker_1 = [14, 6, 5, 11, 3, 9, 2, 10]
+sticker_2 = [1, 3, 2, 5, 4]
+
+print(solution(sticker_1))
+print(solution(sticker_2))
+
+'''
+내 풀이 너무 쉽게 2개씩 건너뛰어서만 생각했음, 오히려 처음 점화식 풀이가
+답에 더 근접함.
+'''
+def solution_error(sticker):
+ answer = 0
+
+ cases = []
+ for i in range(len(sticker) % 3):
+ case = []
+ for cost in sticker[i::2]:
+ case.append(cost)
+ cases.append(sum(case))
+ answer = max(cases)
+ return answer
+
+def solution_other(sticker):
+ n = len(sticker)
+
+ # 맨 처음 스티커를 떼었을 때
+ dp = [0] * n
+ dp[0] = sticker[0]
+ if n == 1:
+ return max(dp)
+
+ dp[1] = sticker[1]
+ if n == 2:
+ return max(dp)
+
+ dp[2] = max(sticker[1], sticker[0] + sticker[2])
+ if n == 3:
+ return max(dp)
+
+ for i in range(3, n - 1):
+ dp[i] = max(dp[i - 3] + sticker[i], dp[i - 2] + sticker[i], dp[i - 1])
+
+ # 맨 처음 스티커를 떼지 않을 때
+ dp2 = [0] * n
+ dp2[0] = 0
+ dp2[1] = sticker[1]
+ dp2[2] = max(sticker[1], sticker[2])
+
+ for i in range(3, n):
+ dp2[i] = max(dp2[i - 3] + sticker[i], dp2[i - 2] + sticker[i], dp2[i - 1])
+
+ return max(max(dp), max(dp2))
+
+# print(solution_other(sticker_1))
+# print(solution_other(sticker_2))
+
+
+
+
diff --git a/Programmers/LEVEL3/ExpressToN.py b/Programmers/LEVEL3/ExpressToN.py
new file mode 100644
index 0000000..0ac724f
--- /dev/null
+++ b/Programmers/LEVEL3/ExpressToN.py
@@ -0,0 +1,95 @@
+# 13. N으로 표현
+
+def solution(N, number):
+ answer = -1
+
+ possible_set = [0, [N]]
+ if N == number:
+ return 1
+
+ for i in range(2, 9):
+ case_set = []
+ basic_num = int(str(N) * i)
+ case_set.append(basic_num)
+ for i_half in range(1, i // 2 + 1):
+ for x in possible_set[i_half]:
+ for y in possible_set[i - i_half]:
+ case_set.append(x + y)
+ case_set.append(x - y)
+ case_set.append(y - x)
+ case_set.append(x * y)
+
+ if y != 0:
+ case_set.append(x / y)
+ if x != 0:
+ case_set.append(y / x)
+
+ if number in case_set:
+ return i
+ possible_set.append(case_set)
+
+ return answer
+
+N_1 = 5
+N_2 = 2
+
+number_1 = 12
+number_2 = 11
+
+print(solution(N_1, number_1))
+print(solution(N_2, number_2))
+
+answer = -1
+
+def DFS(n, pos, num, number, s):
+ global answer
+ if pos > 8:
+ return
+ if num == number:
+ if pos < answer or answer == -1:
+ # print(s)
+ answer = pos
+ return
+
+ nn = 0
+ for i in range(8):
+ nn = nn * 10 + n
+ DFS(n, pos + 1 + i, num + nn, number, s + '+')
+ DFS(n, pos + 1 + i, num - nn, number, s + '-')
+ DFS(n, pos + 1 + i, num * nn, number, s + '*')
+ DFS(n, pos + 1 + i, num / nn, number, s + '/')
+
+def solution_other(N, number):
+ DFS(N, 0, 0, number, '')
+
+ return answer
+
+# print(solution_other(N_1, number_1))
+# print(solution_other(N_2, number_2))
+
+def solution_best(N, number):
+ answer = -1
+
+ DP = []
+ for i in range(1, 9):
+ numbers = set()
+ numbers.add(int(str(N) * i))
+
+ for j in range(i - 1):
+ for x in DP[j]:
+ for y in DP[-j - 1]:
+ numbers.add(x + y)
+ numbers.add(x - y)
+ numbers.add(x * y)
+
+ if y != 0:
+ numbers.add(x // y)
+ if number in numbers:
+ answer = i
+ break
+
+ DP.append(numbers)
+ return answer
+
+# print(solution_best(N_1, number_1))
+# print(solution_best(N_2, number_2))
diff --git a/Programmers/LEVEL3/FaultyUser.py b/Programmers/LEVEL3/FaultyUser.py
new file mode 100644
index 0000000..27bf64f
--- /dev/null
+++ b/Programmers/LEVEL3/FaultyUser.py
@@ -0,0 +1,97 @@
+# 21. 불량 사용자
+
+from itertools import permutations
+def compare(users, banned_id):
+ for ban_idx in range(len(banned_id)):
+ if len(users[ban_idx]) != len(banned_id[ban_idx]):
+ return False
+
+ for usr_idx in range(len(users[ban_idx])):
+ if banned_id[ban_idx][usr_idx] == '*':
+ continue
+ if banned_id[ban_idx][usr_idx] != users[ban_idx][usr_idx]:
+ return False
+
+ return True
+
+def solution(user_id, banned_id):
+ answer = 0
+ user_permutation = list(permutations(user_id, len(banned_id)))
+ banned_set = []
+
+ for users in user_permutation:
+ if not compare(users, banned_id):
+ continue
+ else:
+ users = set(users)
+ if users not in banned_set:
+ banned_set.append(users)
+
+ answer = len(banned_set)
+ return answer
+
+user_id_1 = ["frodo", "fradi", "crodo", "abc123", "frodoc"]
+user_id_2 = ["frodo", "fradi", "crodo", "abc123", "frodoc"]
+user_id_3 = ["frodo", "fradi", "crodo", "abc123", "frodoc"]
+
+banned_id_1 = ["fr*d*", "abc1**"]
+banned_id_2 = ["*rodo", "*rodo", "******"]
+banned_id_3 = ["fr*d*", "*rodo", "******", "******"]
+
+# print(solution(user_id_1, banned_id_1))
+# print(solution(user_id_2, banned_id_2))
+# print(solution(user_id_3, banned_id_3))
+
+from itertools import permutations
+def check(user, ban):
+ if len(user) != len(ban):
+ return False
+ else:
+ for i, j in zip(user, ban):
+ if j == '*':
+ continue
+ if i != j:
+ return False
+ return True
+
+def solution_other(user_id, banned_id):
+ answer = 0
+
+ banned_set = []
+ for user in permutations(user_id, len(banned_id)):
+ count = 0
+ for a, b in zip(user, banned_id):
+ if check(a, b):
+ count += 1
+
+ if count == len(banned_id):
+ if set(user) not in banned_set:
+ banned_set.append(set(user))
+
+ answer = len(banned_set)
+ return answer
+
+# print(solution_other(user_id_1, banned_id_1))
+# print(solution_other(user_id_2, banned_id_2))
+# print(solution_other(user_id_3, banned_id_3))
+
+import re
+import itertools
+def solution_best(user_id, banned_id):
+ answer = 0
+
+ banned_id = ["'" + ban.replace('*', '\w') + "'"
+ for ban in banned_id]
+ possible_list = [re.findall(ban, str(user_id)) for ban in banned_id]
+ possible_list = list(itertools.product(*possible_list))
+
+ possible_list = [frozenset(p) for p in possible_list
+ if len(set(p)) == len(banned_id)]
+ possible_list = set(possible_list)
+
+ answer = len(possible_list)
+ return answer
+
+print(solution_best(user_id_1, banned_id_1))
+print(solution_best(user_id_2, banned_id_2))
+print(solution_best(user_id_3, banned_id_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/FindRouteGame.py b/Programmers/LEVEL3/FindRouteGame.py
new file mode 100644
index 0000000..ca153ec
--- /dev/null
+++ b/Programmers/LEVEL3/FindRouteGame.py
@@ -0,0 +1,129 @@
+# 27. 길 찾기 게임
+
+import sys
+sys.setrecursionlimit(10 ** 6)
+
+def preorder(arrY, arrX, answer):
+ node = arrY[0]
+ idx = arrX.index(node)
+ arrY1, arrY2 = [], []
+
+ for i in range(1, len(arrY)):
+ if node[0] > arrY[i][0]:
+ arrY1.append(arrY[i])
+ else:
+ arrY2.append(arrY[i])
+
+ answer.append(node[2])
+ if len(arrY1) > 0:
+ preorder(arrY1, arrX[:idx], answer)
+ if len(arrY2) > 0:
+ preorder(arrY2, arrX[idx + 1:], answer)
+
+ return
+
+def postorder(arrY, arrX, answer):
+ node = arrY[0]
+ idx = arrX.index(node)
+ arrY1, arrY2 = [], []
+
+ for i in range(1, len(arrY)):
+ if node[0] > arrY[i][0]:
+ arrY1.append(arrY[i])
+ else:
+ arrY2.append(arrY[i])
+
+ if len(arrY1) > 0:
+ postorder(arrY1, arrX[:idx], answer)
+ if len(arrY2) > 0:
+ postorder(arrY2, arrX[idx + 1:], answer)
+ answer.append(node[2])
+
+ return
+
+def solution(nodeinfo):
+ answer = []
+ preanswer, postanswer = [], []
+
+ for i in range(len(nodeinfo)):
+ nodeinfo[i].append(i + 1)
+
+ arrY = sorted(nodeinfo, key = lambda x : (-x[1], x[0]))
+ arrX = sorted(nodeinfo)
+
+ preorder(arrY, arrX, preanswer)
+ postorder(arrY, arrX, postanswer)
+
+ answer = [preanswer, postanswer]
+ return answer
+
+nodeinfo_1 = [[5, 3],
+ [11, 5],
+ [13, 3],
+ [3, 5],
+ [6, 1],
+ [1, 3],
+ [8, 6],
+ [7, 2],
+ [2, 2]
+ ]
+
+print(solution(nodeinfo_1))
+
+class Tree:
+ def __init__(self, data, left = None, right = None):
+ self.data = data
+ self.left = left
+ self.right = right
+
+preorderList = []
+postorderList = []
+
+def preorder_1(node, nodeinfo):
+ preorderList.append(nodeinfo.index(node.data) + 1)
+ if node.left:
+ preorder_1(node.left, nodeinfo)
+ if node.right:
+ preorder_1(node.right, nodeinfo)
+
+def postorder_1(node, nodeinfo):
+ if node.left:
+ postorder_1(node.left, nodeinfo)
+ if node.right:
+ postorder_1(node.right, nodeinfo)
+ postorderList.append(nodeinfo.index(node.data) + 1)
+
+def solution_other(nodeinfo):
+ answer = []
+
+ sortedNodeinfo = sorted(nodeinfo, key = lambda x : (-x[1], x[0]))
+
+ root = None
+ for node in sortedNodeinfo:
+ if not root:
+ root = Tree(node)
+ else:
+ current = root
+ while True:
+ if node[0] < current.data[0]:
+ if current.left:
+ current = current.left
+ continue
+ else:
+ current.left = Tree(node)
+ if node[0] > current.data[0]:
+ if current.right:
+ current = current.right
+ continue
+ else:
+ current.right = Tree(node)
+ break
+ break
+
+ preorder_1(root, nodeinfo)
+ postorder_1(root, nodeinfo)
+ answer.append(preorderList)
+ answer.append(postorderList)
+ return answer
+
+print(solution_other(nodeinfo_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/FindtheNumberofDecimalsinKnumber.py b/Programmers/LEVEL3/FindtheNumberofDecimalsinKnumber.py
new file mode 100644
index 0000000..f522b31
--- /dev/null
+++ b/Programmers/LEVEL3/FindtheNumberofDecimalsinKnumber.py
@@ -0,0 +1,79 @@
+# 31. k진수에서 소수 개수 구하기
+
+def change_k_num(n, k):
+ change = ''
+
+ while n > 0:
+ n, mod = divmod(n, k)
+ change += str(mod)
+
+ return change[::-1]
+
+def solution(n, k):
+ answer = 0
+
+ change_k = change_k_num(n, k)
+ change_k = change_k.split('0')
+
+ for num in change_k:
+ if len(num) == 0:
+ continue
+ if int(num) < 2:
+ continue
+
+ # 에라토스테네스의 체
+ prime_number = True
+ for i in range(2, int(int(num) ** 0.5) + 1):
+ if int(num) % i == 0:
+ prime_number = False
+ break
+
+ if prime_number:
+ answer += 1
+
+ return answer
+
+n_1 = 437674
+n_2 = 110011
+
+k_1 = 3
+k_2 = 10
+
+print(solution(n_1, k_1))
+print(solution(n_2, k_2))
+
+def solution_other(n, k):
+ answer = 0
+
+ change_k = ''
+ while n:
+ change_k = str(n % k) + change_k
+ n //= k
+
+ change_k = change_k.split('0')
+
+ for num in change_k:
+ if len(num) == 0:
+ continue
+ if int(num) < 2:
+ continue
+
+ prime_number = True
+ for i in range(2, int(int(num) ** 0.5) + 1):
+ if int(num) % i == 0:
+ prime_number = False
+ break
+
+ if prime_number:
+ answer += 1
+
+ return answer
+
+n_1 = 437674
+n_2 = 110011
+
+k_1 = 3
+k_2 = 10
+
+print(solution_other(n_1, k_1))
+print(solution_other(n_2, k_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/HanoiTower.py b/Programmers/LEVEL3/HanoiTower.py
new file mode 100644
index 0000000..2a89167
--- /dev/null
+++ b/Programmers/LEVEL3/HanoiTower.py
@@ -0,0 +1,42 @@
+# 3. 하노이의 탑
+
+def hanoi(n, start, end, mid, answer):
+ if n == 1:
+ answer.append([start, end])
+ return
+
+ hanoi(n - 1, start, mid, end, answer)
+ answer.append([start, end])
+ hanoi(n - 1, mid, end, start, answer)
+
+def solution(n):
+ answer = []
+
+ hanoi(n, 1, 3, 2, answer)
+ return answer
+
+n_1 = 2
+
+print(solution(n_1))
+
+'''
+런타임 오류
+'''
+from itertools import combinations
+def solution_mine(n):
+ answer = [[]]
+
+ hanoi_cases = 2 ** n - 1
+ for x, y in list(combinations(range(1, hanoi_cases + 1), n)):
+ answer.append([x, y])
+ return answer
+
+# print(solution_mine(n_1))
+
+def solution_best(n, start = 1, end = 3, mid = 2):
+ if n == 1:
+ return ([[start, end]])
+
+ return solution_best(n - 1, start, mid, end) + [[start, end]] + solution_best(n - 1, mid, end, start)
+
+# print(solution_best(n_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/Immigration.py b/Programmers/LEVEL3/Immigration.py
new file mode 100644
index 0000000..c6391ba
--- /dev/null
+++ b/Programmers/LEVEL3/Immigration.py
@@ -0,0 +1,26 @@
+# 22. 입국심사
+
+def solution(n, times):
+ answer = 0
+
+ left, right = 1, max(times) * n
+ while left <= right:
+ mid = (left + right) // 2
+ people = 0
+ for time in times:
+ people += mid // time
+ if people >= n:
+ break
+
+ if people >= n:
+ answer = mid
+ right = mid - 1
+ elif people < n:
+ left = mid + 1
+ return answer
+
+n_1 = 6
+
+times_1 = [7, 10]
+
+print(solution(n_1, times_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/InsertAdvertisement.py b/Programmers/LEVEL3/InsertAdvertisement.py
new file mode 100644
index 0000000..a7a1d19
--- /dev/null
+++ b/Programmers/LEVEL3/InsertAdvertisement.py
@@ -0,0 +1,188 @@
+# 29. 광고 삽입
+
+def str_to_seconds(time):
+ h, m, s = time.split(':')
+
+ return int(h) * 3600 + int(m) * 60 + int(s)
+
+def seconds_to_str(time):
+ h = str(time // 3600).zfill(2)
+ time %= 3600
+ m = str(time // 60).zfill(2)
+ s = str(time % 60).zfill(2)
+
+ return ':'.join([h, m, s])
+
+def solution(play_time, adv_time, logs):
+ answer = ''
+
+ play_time = str_to_seconds(play_time)
+ adv_time = str_to_seconds(adv_time)
+ all_time = [0 for i in range(play_time + 1)]
+
+ for log in logs:
+ start, end = log.split('-')
+ start = str_to_seconds(start)
+ end = str_to_seconds(end)
+ all_time[start] += 1
+ all_time[end] -= 1
+
+ for i in range(1, len(all_time)):
+ all_time[i] = all_time[i] + all_time[i - 1]
+
+ for i in range(1, len(all_time)):
+ all_time[i] = all_time[i] + all_time[i - 1]
+
+ most_view = 0
+ max_time = 0
+ for i in range(adv_time - 1, play_time):
+ if i >= adv_time:
+ if most_view < all_time[i] - all_time[i - adv_time]:
+ most_view = all_time[i] - all_time[i - adv_time]
+ max_time = i - adv_time + 1
+ else:
+ if most_view < all_time[i]:
+ most_view = all_time[i]
+ max_time = i - adv_time + 1
+
+ answer += seconds_to_str(max_time)
+ return answer
+
+play_time_1 = "02:03:55"
+play_time_2 = "99:59:59"
+play_time_3 = "50:00:00"
+
+adv_time_1 = "00:14:15"
+adv_time_2 = "25:00:00"
+adv_time_3 = "50:00:00"
+
+logs_1 = ["01:20:15-01:45:14",
+ "00:40:31-01:00:00",
+ "00:25:50-00:48:29",
+ "01:30:59-01:53:29",
+ "01:37:44-02:02:30"]
+logs_2 = ["69:59:59-89:59:59",
+ "01:00:00-21:00:00",
+ "79:59:59-99:59:59",
+ "11:00:00-31:00:00"]
+logs_3 = ["15:36:51-38:21:49",
+ "10:14:18-15:36:51",
+ "38:21:49-42:51:45"]
+
+print(solution(play_time_1, adv_time_1, logs_1))
+print(solution(play_time_2, adv_time_2, logs_2))
+print(solution(play_time_3, adv_time_3, logs_3))
+
+'''
+다른 풀이
+'''
+def solution_other(play_time, adv_time, logs):
+ answer = ''
+
+ play_time = str_to_int(play_time)
+ adv_time = str_to_int(adv_time)
+ all_time = [0 for i in range(play_time + 1)]
+
+ for log in logs:
+ start, end = log.split('-')
+ start = str_to_int(start)
+ end = str_to_int(end)
+ all_time[start] += 1
+ all_time[end] -= 1
+
+ for i in range(1, len(all_time)):
+ all_time[i] = all_time[i] + all_time[i - 1]
+
+ for i in range(1, len(all_time)):
+ all_time[i] = all_time[i] + all_time[i - 1]
+
+ most_view = 0
+ max_time = 0
+ for i in range(adv_time - 1, play_time):
+ if i >= adv_time:
+ if most_view < all_time[i] - all_time[i - adv_time]:
+ most_view = all_time[i] - all_time[i - adv_time]
+ max_time = i - adv_time + 1
+ else:
+ if most_view < all_time[i]:
+ most_view = all_time[i]
+ max_time = i - adv_time + 1
+
+ answer += int_to_str(max_time)
+ return answer
+
+def str_to_int(time):
+ h, m, s = time.split(':')
+
+ return int(h) * 3600 + int(m) * 60 + int(s)
+
+def int_to_str(time):
+ h = time // 3600
+ h = '0' + str(h) if h < 10 else str(h)
+ time %= 3600
+ m = time // 60
+ m = '0' + str(m) if m < 10 else str(m)
+ time %= 60
+ s = '0' + str(time) if time < 10 else str(time)
+
+ return h + ':' + m + ':' + s
+
+# print(solution_other(play_time_1, adv_time_1, logs_1))
+# print(solution_other(play_time_2, adv_time_2, logs_2))
+# print(solution_other(play_time_3, adv_time_3, logs_3))
+
+'''
+zfill함수(0으로 채우기)
+str.zfill(n) : str의 길이가 n보다 작으면 길이가 n이 되도록 앞에 '0'을 채움.
+'''
+def to_seconds(time):
+ h, m, s = map(int, time.split(':'))
+
+ return h * 3600 + m * 60 + s
+
+def to_time(time):
+ h = str(time // 3600).zfill(2)
+ time %= 3600
+ m = str(time // 60).zfill(2)
+ s = str(time % 60).zfill(2)
+
+ return ':'.join([h, m, s])
+
+def solution_best(play_time, adv_time, logs):
+ answer = ''
+
+ play_time = to_seconds(play_time)
+ adv_time = to_seconds(adv_time)
+
+ memo = [0 for _ in range(play_time + 1)]
+
+ for log in logs:
+ start, end = map(str, log.split('-'))
+ start = to_seconds(start)
+ end = to_seconds(end)
+
+ memo[start] += 1
+ memo[end] += -1
+
+ for i in range(1, play_time + 1):
+ memo[i] = memo[i] + memo[i - 1]
+
+ for i in range(1, play_time + 1):
+ memo[i] = memo[i] + memo[i - 1]
+
+ max_play = memo[adv_time - 1]
+ start = 0
+
+ for i in range(adv_time, play_time):
+ play = memo[i] - memo[i - adv_time]
+
+ if play > max_play:
+ max_play = play
+ start = i - adv_time + 1
+
+ answer = to_time(start)
+ return answer
+
+# print(solution_best(play_time_1, adv_time_1, logs_1))
+# print(solution_best(play_time_2, adv_time_2, logs_2))
+# print(solution_best(play_time_3, adv_time_3, logs_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/InstallOfPillowAndBarrage.py b/Programmers/LEVEL3/InstallOfPillowAndBarrage.py
new file mode 100644
index 0000000..72ec9fc
--- /dev/null
+++ b/Programmers/LEVEL3/InstallOfPillowAndBarrage.py
@@ -0,0 +1,102 @@
+# 26. 기둥과 보 설치
+
+def impossible(result):
+ COL, ROW = 0, 1
+ for x, y, a in result:
+ if a == COL:
+ if y != 0 and (x, y - 1, COL) not in result and \
+ (x - 1, y, ROW) not in result and (x, y, ROW) not in result:
+ return True
+ else:
+ if (x, y - 1, COL) not in result and (x + 1, y - 1, COL) not in result and \
+ not ((x - 1, y, ROW) in result and (x + 1, y, ROW) in result):
+ return True
+ return False
+
+def solution(n, build_frame):
+ result = set()
+
+ for x, y, a, build in build_frame:
+ item = (x, y, a)
+ if build: # 추가일 때
+ result.add(item)
+ if impossible(result):
+ result.remove(item)
+ elif item in result: # 삭제할 때
+ result.remove(item)
+ if impossible(result):
+ result.add(item)
+
+ answer = map(list, result)
+ answer = sorted(answer, key=lambda x: (x[0], x[1], x[2]))
+ return answer
+
+n_1 = 5
+n_2 = 5
+
+build_frame_1 = [[1, 0, 0, 1],
+ [1, 1, 1, 1],
+ [2, 1, 0, 1],
+ [2, 2, 1, 1],
+ [5, 0, 0, 1],
+ [5, 1, 0, 1],
+ [4, 2, 1, 1],
+ [3, 2, 1, 1]
+ ]
+build_frame_2 = [[0, 0, 0, 1],
+ [2, 0, 0, 1],
+ [4, 0, 0, 1],
+ [0, 1, 1, 1],
+ [1, 1, 1, 1],
+ [2, 1, 1, 1],
+ [3, 1, 1, 1],
+ [2, 0, 0, 0],
+ [1, 1, 1, 0],
+ [2, 2, 0, 1]
+ ]
+
+print(solution(n_1, build_frame_1))
+print(solution(n_2, build_frame_2))
+
+def check(ans):
+ for x, y, what in ans:
+ # 기둥
+ # 1. 바닥 위에 있어야댐
+ # 2. 보의 한쪽 끝 부분 위에 있어야댐
+ # 3. 다른 기둥 위에 있어야댐
+ if what == 0:
+ if y == 0 or [x-1, y, 1] in ans or [x, y, 1] in ans or [x, y-1, 0] in ans:
+ continue
+ else:
+ return False
+ # 보
+ # 1. 한쪽 끝 부분이 기둥 위에 있어야댐
+ # 2. 양쪽 끝 부분이 다른 보와 동시에 연결
+ elif what == 1:
+ if [x, y-1, 0] in ans or [x+1, y-1, 0] in ans or ([x-1, y, 1] in ans and [x+1, y, 1] in ans):
+ continue
+ else:
+ return False
+ return True
+
+
+def solution_other(n, build_frame):
+ answer = []
+
+ for f in build_frame:
+ x, y, what, how = f
+
+ if how == 1: # 설치
+ answer.append([x, y, what])
+ if check(answer) is False:
+ answer.remove([x, y, what])
+ else: # 삭제
+ answer.remove([x, y, what])
+ if check(answer) is False:
+ answer.append([x, y, what])
+
+ answer.sort()
+ return answer
+
+print(solution_other(n_1, build_frame_1))
+print(solution_other(n_2, build_frame_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/IntegerTriangle.py b/Programmers/LEVEL3/IntegerTriangle.py
new file mode 100644
index 0000000..7da160f
--- /dev/null
+++ b/Programmers/LEVEL3/IntegerTriangle.py
@@ -0,0 +1,47 @@
+# 14. 정수 삼각형
+
+def solution(triangle):
+ answer = 0
+
+ for rows in range(1, len(triangle)):
+ for idx in range(rows + 1):
+ if idx == 0:
+ triangle[rows][idx] += triangle[rows - 1][idx]
+ elif idx == rows:
+ triangle[rows][idx] += triangle[rows - 1][-1]
+ else:
+ triangle[rows][idx] += max(triangle[rows - 1][idx - 1],
+ triangle[rows - 1][idx])
+
+ answer = max(triangle[-1])
+ return answer
+
+triangle_1 = [[7], [3, 8], [8, 1, 0], [2, 7, 4, 4], [4, 5, 2, 6, 5]]
+
+print(solution(triangle_1))
+
+def solution_other(triangle):
+ answer = 0
+
+ height = len(triangle)
+
+ while height > 1:
+ for i in range(height - 1):
+ triangle[height - 2][i] += max([triangle[height - 1][i],
+ triangle[height - 1][i + 1]])
+ height -= 1
+
+ answer = triangle[0][0]
+ return answer
+
+triangle_1 = [[7], [3, 8], [8, 1, 0], [2, 7, 4, 4], [4, 5, 2, 6, 5]]
+
+print(solution_other(triangle_1))
+
+solution_best = lambda t, l = []: max(l) if not t \
+ else solution_best(t[1:], [max(x, y) + z for x, y, z in zip([0] + l,
+ l + [0],
+ t[0])])
+
+triangle_1 = [[7], [3, 8], [8, 1, 0], [2, 7, 4, 4], [4, 5, 2, 6, 5]]
+print(solution_best(triangle_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/JewelShopping.py b/Programmers/LEVEL3/JewelShopping.py
new file mode 100644
index 0000000..4a4d6fb
--- /dev/null
+++ b/Programmers/LEVEL3/JewelShopping.py
@@ -0,0 +1,119 @@
+# 20. 보석 쇼핑
+
+'''
+두 개의 변수를 이용하여 최종적으로 종류가 다 찼을 때, 시작 변수를 움직여서 조건에 맞는 범위 찾기
+'''
+from collections import Counter
+def solution(gems):
+ answer = []
+
+ shortest = len(gems) + 1
+ start_p, end_p = 0, 0
+ contained = {}
+ counter_gems = Counter(gems)
+
+ while end_p < len(gems):
+ if gems[end_p] not in contained:
+ contained[gems[end_p]] = 1
+ else:
+ contained[gems[end_p]] += 1
+
+ end_p += 1
+
+ if len(contained) == len(counter_gems):
+ while start_p < end_p:
+ if contained[gems[start_p]] > 1:
+ contained[gems[start_p]] -= 1
+ start_p += 1
+ elif shortest > end_p - start_p:
+ shortest = end_p - start_p
+ answer = [start_p + 1, end_p]
+ break
+ else:
+ break
+ return answer
+
+gems_1 = ["DIA", "RUBY", "RUBY", "DIA", "DIA", "EMERALD", "SAPPHIRE", "DIA"]
+gems_2 = ["AA", "AB", "AC", "AA", "AC"]
+gems_3 = ["XYZ", "XYZ", "XYZ"]
+gems_4 = ["ZZZ", "YYY", "NNNN", "YYY", "BBB"]
+
+# print(solution(gems_1))
+# print(solution(gems_2))
+# print(solution(gems_3))
+# print(solution(gems_4))
+
+'''
+Counter객체에 비해 Set이 속도 측면에서 더 빠름
+'''
+def solution_other(gems):
+ answer = []
+
+ start_p, end_p = 0, 0
+ shortest = len(gems) + 1
+ contained = {}
+ check_len = len(set(gems))
+
+ while end_p < len(gems):
+ if gems[end_p] not in contained:
+ contained[gems[end_p]] = 1
+ else:
+ contained[gems[end_p]] += 1
+
+ end_p += 1
+
+ if len(contained) == check_len:
+ while start_p < end_p:
+ if contained[gems[start_p]] > 1:
+ contained[gems[start_p]] -= 1
+ start_p += 1
+ elif shortest > end_p - start_p:
+ shortest = end_p - start_p
+ answer = [start_p + 1, end_p]
+ break
+ else:
+ break
+
+ return answer
+
+print(solution_other(gems_1))
+print(solution_other(gems_2))
+print(solution_other(gems_3))
+print(solution_other(gems_4))
+
+
+def solution_best(gems):
+ answer = []
+
+ size = len(set(gems))
+ dic = {gems[0]:1}
+ temp = [0, len(gems) - 1]
+ start, end = 0, 0
+
+ while (start < len(gems) and end < len(gems)):
+ if len(dic) == size:
+ if end - start < temp[1] - temp[0]:
+ temp = [start, end]
+
+ if dic[gems[start]] == 1:
+ del dic[gems[start]]
+ else:
+ dic[gems[start]] -= 1
+ start += 1
+ else:
+ end += 1
+ if end == len(gems):
+ break
+
+ if gems[end] in dic.keys():
+ dic[gems[end]] += 1
+ else:
+ dic[gems[end]] = 1
+
+ answer = [temp[0] + 1, temp[1] + 1]
+ return answer
+
+# print(solution_best(gems_1))
+# print(solution_best(gems_2))
+# print(solution_best(gems_3))
+# print(solution_best(gems_4))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/LockAndKey.py b/Programmers/LEVEL3/LockAndKey.py
new file mode 100644
index 0000000..cf02ed3
--- /dev/null
+++ b/Programmers/LEVEL3/LockAndKey.py
@@ -0,0 +1,118 @@
+# 17. 자물쇠와 열쇠
+
+def rotation(arr):
+ length = len(arr)
+ rotate_key = [[0] * length for _ in range(length)]
+
+ for i in range(length):
+ for j in range(length):
+ rotate_key[j][length - 1 - i] = arr[i][j]
+
+ return rotate_key
+
+def check(startX, startY, key, lock, p_size, start, end):
+ pad = [[0] * p_size for _ in range(p_size)]
+
+ # 패딩 초기화
+ for i in range(len(key)):
+ for j in range(len(key)):
+ pad[startX + i][startY + j] += key[i][j]
+
+ for i in range(start, end):
+ for j in range(start, end):
+ pad[i][j] += lock[i - start][j - start]
+ if pad[i][j] != 1:
+ return False
+
+ return True
+
+def solution(key, lock):
+ answer = False
+
+ # lock의 시작점과 끝나는 지점
+ start = len(key) - 1
+ end = start + len(lock)
+
+ # padding이 추가된 배열의 행, 열의 크기
+ pad_size = len(lock) + start * 2
+
+ # 4가지만 비교 0, 90, 180, 270
+ for angle in range(4):
+ for i in range(end):
+ for j in range(end):
+ if check(i, j, key, lock, pad_size, start, end):
+ return True
+ key = rotation(key)
+ return answer
+
+key_1 = [
+ [0, 0, 0],
+ [1, 0, 0],
+ [0, 1, 1]
+ ]
+
+lock_1 = [
+ [1, 1, 1],
+ [1, 1, 0],
+ [1, 0, 1]
+ ]
+
+print(solution(key_1, lock_1))
+
+# 행렬 회전 90도
+import numpy as np
+def rotation_np(arr, angle):
+ rotate_key = np.rot90(arr, 3 - angle)
+
+ return rotate_key
+
+def rotate90(arr):
+ return list(zip(*arr[::-1]))
+
+def attach(x, y, M, key, board):
+ for i in range(M):
+ for j in range(M):
+ board[x + i][y + j] += key[i][j]
+
+def detach(x, y, M, key, board):
+ for i in range(M):
+ for j in range(M):
+ board[x + i][y + j] -= key[i][j]
+
+def check_other(board, M, N):
+ for i in range(N):
+ for j in range(N):
+ if board[M + i][M + j] != 1:
+ return False
+
+ return True
+
+def solution_other(key, lock):
+ M, N = len(key), len(lock)
+
+ board = [[0] * (M * 2 + N) for _ in range(M * 2 + N)]
+
+ # 자물쇠 중앙 배치
+ for i in range(N):
+ for j in range(N):
+ board[M + i][M + j] = lock[i][j]
+
+ rotated_key = key
+ # 모든 방향(0, 90, 180, 270)
+ for _ in range(4):
+ rotated_key = rotate90(rotated_key)
+ for x in range(1, M + N):
+ for y in range(1, M + N):
+ # 열쇠 넣어보기
+ attach(x, y, M, rotated_key, board)
+
+ # lock 가능 check
+ if check_other(board, M, N):
+ return True
+
+ # 열쇠 빼기
+ detach(x, y, M, rotated_key, board)
+
+ return False
+
+print(solution_other(key_1, lock_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/Move110.py b/Programmers/LEVEL3/Move110.py
new file mode 100644
index 0000000..7d980d9
--- /dev/null
+++ b/Programmers/LEVEL3/Move110.py
@@ -0,0 +1,114 @@
+# 11. 110 옮기기
+
+'''
+사전 순으로 앞으로 배열 -> 문자열 내에서 모든 '110' 다 뽑아내기
+110 의 경우는 이미 사전순서로 배열이 잘 이루어진 문자열이므로
+0을 만나면 그 0의 뒤에
+1을 만나면 그 1의 앞에
+위치시켜준다.
+'''
+def move(string):
+ p = list('110')
+ size_s = len(string)
+
+ count, stack = 0, []
+ for i in range(size_s):
+ stack.append(string[i])
+ if stack[-3:] == p:
+ stack.pop()
+ stack.pop()
+ stack.pop()
+
+ size_stack = len(stack)
+ count = int((size_s - size_stack) / 3)
+
+ for i in range(size_stack + 1):
+ temp = (stack[i:i + 3] * 3)[:3]
+ if temp > p: break
+
+ new_s = stack[:i] + p * count + stack[i:]
+
+ return ''.join(new_s)
+
+def solution(s):
+ answer = [move(string) for string in s]
+
+ return answer
+
+s_1 = ["1110","100111100","0111111010"]
+
+print(solution(s_1))
+
+def solution_other(s):
+ answer = []
+
+ def extract(s):
+ count, stack = 0, []
+ for _s in s:
+ if _s == '0' and stack[-2:] == ['1', '1']:
+ stack.pop()
+ stack.pop()
+ count += 1
+ else:
+ stack.append(_s)
+
+ return ''.join(stack), count
+
+ def rearrange(s):
+ for i in range(-1, -len(s) - 1, -1):
+ pointer = len(s) + (i + 1)
+ if s[i] == '0':
+ return s[:pointer] + '110' + s[pointer:]
+
+ return '110' + s
+
+ for _s in s:
+ _s, count = extract(_s)
+ for _ in range(count):
+ _s = rearrange(_s)
+ answer.append(_s)
+ return answer
+
+# print(solution_other(s_1))
+
+from collections import deque
+def solution_best(s):
+ answer = []
+
+ for string in s:
+ count, stack = 0, []
+ for ch in string:
+ if ch == '0':
+ if stack[-2:] == ['1', '1']:
+ count += 1
+ stack.pop()
+ stack.pop()
+ else:
+ stack.append(ch)
+ else:
+ stack.append(ch)
+
+ if count == 0:
+ answer.append(string)
+ else:
+ final = deque()
+
+ while stack:
+ if stack[-1] == '1':
+ final.appendleft(stack.pop())
+ elif stack[-1] == '0':
+ break
+
+ while count > 0:
+ final.appendleft('0')
+ final.appendleft('1')
+ final.appendleft('1')
+ count -= 1
+
+ while stack:
+ final.appendleft(stack.pop())
+
+ answer.append(''.join(final))
+ return answer
+
+# print(solution_best(s_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/MoveBlock.py b/Programmers/LEVEL3/MoveBlock.py
new file mode 100644
index 0000000..7f7b045
--- /dev/null
+++ b/Programmers/LEVEL3/MoveBlock.py
@@ -0,0 +1,121 @@
+# 28. 블록 이동하기
+
+from collections import deque
+def move_possible(cur1, cur2, new_board):
+ Y, X = 0, 1
+ cand = []
+ # 평행이동
+ DELTAS = [(-1, 0), (1, 0), (0, -1), (0, 1)]
+ for dy, dx in DELTAS:
+ nxt1 = (cur1[Y] + dy, cur1[X] + dx)
+ nxt2 = (cur2[Y] + dy, cur2[X] + dx)
+ if new_board[nxt1[Y]][nxt1[X]] == 0 and \
+ new_board[nxt2[Y]][nxt2[X]] == 0:
+ cand.append((nxt1, nxt2))
+
+ # 회전
+ # 가로 방향일 떄
+ if cur1[Y] == cur2[Y]:
+ UP, DOWN = -1, 1
+ for d in [UP, DOWN]:
+ if new_board[cur1[Y] + d][cur1[X]] == 0 and \
+ new_board[cur2[Y] + d][cur2[X]] == 0:
+ cand.append((cur1, (cur1[Y] + d, cur1[X])))
+ cand.append((cur2, (cur2[Y] + d, cur2[X])))
+ # 새로 방향일 때
+ else:
+ LEFT, RIGHT = -1, 1
+ for d in [LEFT, RIGHT]:
+ if new_board[cur1[Y]][cur1[X] + d] == 0 and \
+ new_board[cur2[Y]][cur2[X] + d] == 0:
+ cand.append(((cur1[Y], cur1[X] + d), cur1))
+ cand.append(((cur2[Y], cur2[X] + d), cur2))
+
+ return cand
+
+def solution(board):
+ answer = -1
+
+ N = len(board)
+ new_board = [[1] * (N + 2) for _ in range(N + 2)]
+ for i in range(N):
+ for j in range(N):
+ new_board[i + 1][j + 1] = board[i][j]
+
+ # 현재 좌표 위치 큐 삽입, 확인용 set
+ que = deque([((1, 1), (1, 2), 0)])
+ confirm = {((1, 1), (1, 2))}
+
+ while que:
+ cur1, cur2, count = que.popleft()
+ if cur1 == (N, N) or cur2 == (N, N):
+ answer = count
+ return answer
+ for nxt in move_possible(cur1, cur2, new_board):
+ if nxt not in confirm:
+ que.append((*nxt, count + 1))
+ confirm.add(nxt)
+
+ return answer
+
+board_1 = [
+ [0, 0, 0, 1, 1],
+ [0, 0, 0, 1, 0],
+ [0, 1, 0, 1, 1],
+ [1, 1, 0, 0, 1],
+ [0, 0, 0, 0, 0]
+ ]
+
+# print(solution(board_1))
+
+'''
+두 번째 풀이 ... 첫번째와 비슷함
+'''
+from collections import deque
+def getNewPos(pos, board):
+ dir = [[0, 1], [1, 0], [0, -1], [-1, 0]]
+ newPos = []
+ y1, x1 = pos[0]
+ y2, x2 = pos[1]
+ # 상하좌우 이동
+ for dy, dx in dir:
+ if board[y1 + dy][x1 + dx] == 0 and board[y2 + dy][x2 + dx] == 0:
+ newPos.append({(y1 + dy, x1 + dx), (y2 + dy, x2 + dx)})
+ # 가로 -> 세로
+ if y1 == y2:
+ for dy, dx in dir[1::2]:
+ if board[y1 + dy][x1 + dx] == 0 and board[y2 + dy][x2 + dx] == 0:
+ newPos.append({(y1, x1), (y1 + dy, x1)})
+ newPos.append({(y2, x2), (y2 + dy, x2)})
+ # 세로 -> 가로
+ else:
+ for dy, dx in dir[::2]:
+ if board[y1 + dy][x1 + dx] == 0 and board[y2 + dy][x2 + dx] == 0:
+ newPos.append({(y1, x1), (y1, x1 + dx)})
+ newPos.append({(y2, x2), (y2, x2 + dx)})
+ return newPos
+
+def solution_other(board):
+ answer = -1
+
+ n = len(board)
+ board = [[1] + b + [1] for b in board]
+ board = [[1] * (n + 2)] + board + [[1] * (n + 2)]
+ pos = {(1, 1), (1, 2)}
+ q = deque()
+ visited = []
+ q.append([pos, 0])
+ visited.append(pos)
+ while q:
+ pos, distance = q.popleft()
+ distance += 1
+ for newPos in getNewPos(list(pos), board):
+ if (n, n) in newPos:
+ answer = distance
+ return answer
+ if newPos not in visited:
+ q.append([newPos, distance])
+ visited.append(newPos)
+ return answer
+
+print(solution_other(board_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/N_Queen.py b/Programmers/LEVEL3/N_Queen.py
new file mode 100644
index 0000000..d91e12a
--- /dev/null
+++ b/Programmers/LEVEL3/N_Queen.py
@@ -0,0 +1,78 @@
+# 9. N-Queen
+
+def possible(x, y, n, col):
+ for i in range(x):
+ if y == col[i] or abs(y - col[i]) == x - i:
+ return False
+ return True
+
+def queen(x, n, col):
+ if x == n:
+ return 1
+
+ count = 0
+
+ for y in range(n):
+ if possible(x, y, n, col):
+ col[x] = y
+ count += queen(x + 1, n, col)
+
+ return count
+
+def solution(n):
+ answer = 0
+
+ col = [0] * n
+ answer = queen(0, n, col)
+ return answer
+
+n_1 = 4
+
+print(solution(n_1))
+
+def DFS(queen, row, n):
+ count = 0
+ if n == row:
+ return 1
+ for col in range(n):
+ queen[row] = col
+ for i in range(row):
+ if queen[i] == queen[row]:
+ break
+ if abs(queen[i] - queen[row]) == row - i:
+ break
+ else:
+ count += DFS(queen, row + 1, n)
+ return count
+
+def solution_good(n):
+ return DFS([0] * n, 0, n)
+
+# print(solution_good(n_1))
+
+def solution_other(n):
+ cases = [0]
+ def dfs(queens, next_queen):
+ if next_queen in queens:
+ return
+
+ for row, column in enumerate(queens):
+ h = len(queens) - row
+ if next_queen == column + h or next_queen == column - h:
+ return
+
+ queens.append(next_queen)
+ if len(queens) == n:
+ cases[0] += 1
+ return
+
+ for next_queen in range(n):
+ dfs(queens[:], next_queen)
+
+ for next_queen in range(n):
+ queens = []
+ dfs(queens, next_queen)
+
+ return cases[0]
+
+# print(solution_other(n_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/Network.py b/Programmers/LEVEL3/Network.py
new file mode 100644
index 0000000..cb19216
--- /dev/null
+++ b/Programmers/LEVEL3/Network.py
@@ -0,0 +1,88 @@
+# 15. 네트워크
+
+'''
+BFS(Breath-First Search를 이용한 그래프 탐색
+'''
+def solution(n, computers):
+ answer = 0
+
+ bfs = []
+ visited = [0] * n
+
+ while 0 in visited:
+ x = visited.index(0)
+ bfs.append(x)
+ visited[x] = 1
+
+ while bfs:
+ first = bfs.pop(0)
+ visited[first] = 1
+
+ for i in range(n):
+ if visited[i] == 0 and computers[first][i] == 1:
+ bfs.append(i)
+ visited[i] = 1
+ answer += 1
+ return answer
+
+n_1 = 3
+n_2 = 3
+
+computers_1 = [[1, 1, 0], [1, 1, 0], [0, 0, 1]]
+computers_2 = [[1, 1, 0], [1, 1, 1], [0, 1, 1]]
+
+# print(solution(n_1, computers_1))
+# print(solution(n_2, computers_2))
+
+'''
+DFS를 이용한 그래프 탐색
+'''
+def solution_other(n, computers):
+ answer = 0
+
+ visited = [False for i in range(n)]
+ for com in range(n):
+ if visited[com] == False:
+ DFS(n, computers, com, visited)
+ answer += 1
+
+ return answer
+
+def DFS(n, computers, com, visited):
+ visited[com] = True
+ for connect in range(n):
+ if connect != com and computers[com][connect] == 1:
+ if visited[connect] == False:
+ DFS(n, computers, connect, visited)
+
+# print(solution_other(n_1, computers_1))
+# print(solution_other(n_2, computers_2))
+
+'''
+BFS 이용한 풀이
+'''
+from collections import deque
+
+def solution_best(n, computers):
+ def BFS(i):
+ q = deque()
+ q.append(i)
+
+ while q:
+ cst = q.popleft()
+ visited[cst] = 1
+ for a in range(n):
+ if computers[cst][a] and not visited[a]:
+ q.append(a)
+
+ answer = 0
+ visited = [0 for i in range(len(computers))]
+ for i in range(n):
+ if not visited[i]:
+ BFS(i)
+ answer += 1
+
+ return answer
+
+# print(solution_best(n_1, computers_1))
+# print(solution_best(n_2, computers_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/NumberGame.py b/Programmers/LEVEL3/NumberGame.py
new file mode 100644
index 0000000..58c1c73
--- /dev/null
+++ b/Programmers/LEVEL3/NumberGame.py
@@ -0,0 +1,51 @@
+# 10. 숫자 게임
+
+'''
+규칙을 어느 정도 파악했으나 한끗 차이로... j변수
+'''
+def solution(A, B):
+ answer = 0
+
+ A.sort()
+ B.sort()
+ j = 0
+
+ for i in range(len(A)):
+ if A[j] < B[i]:
+ answer += 1
+ j += 1
+
+ return answer
+
+A_1 = [5, 1, 3, 7]
+A_2 = [2, 2, 2, 2]
+
+B_1 = [2, 2, 6, 8]
+B_2 = [1, 1, 1, 1]
+
+print(solution(A_1, B_1))
+print(solution(A_2, B_2))
+
+def solution_other(A, B):
+ answer = 0
+
+ A.sort(reverse = True)
+ B.sort(reverse = True)
+
+ for num_A in A:
+ Min = num_A
+ for i in range(len(B)):
+ if Min < B[i]:
+ Min = B[i]
+ else:
+ break
+
+ if Min == num_A:
+ continue
+ else:
+ B.remove(Min)
+ answer += 1
+ return answer
+
+print(solution_other(A_1, B_1))
+print(solution_other(A_2, B_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/OvertimeDegree.py b/Programmers/LEVEL3/OvertimeDegree.py
new file mode 100644
index 0000000..e1ae1a4
--- /dev/null
+++ b/Programmers/LEVEL3/OvertimeDegree.py
@@ -0,0 +1,107 @@
+# 6. 야근 지수
+
+'''
+효율성 때문에 heap으로 풀어야 함.
+'''
+import heapq as hq
+def solution(n, works):
+ answer = 0
+
+ if sum(works) <= n:
+ return 0
+
+ works = [-i for i in works]
+ hq.heapify(works)
+ for _ in range(n):
+ w = hq.heappop(works) + 1
+ hq.heappush(works, w)
+
+ answer = sum([i ** 2 for i in works])
+ return answer
+
+n_1 = 4
+n_2 = 1
+n_3 = 3
+
+works_1 = [4, 3, 3]
+works_2 = [2, 1, 2]
+works_3 = [1, 1]
+
+print(solution(n_1, works_1))
+print(solution(n_2, works_2))
+print(solution(n_3, works_3))
+
+'''
+accuracy도 틀리고, 효율성도 틀린 풀이
+'''
+def solution_mine(n, works):
+ answer = 0
+
+ if sum(works) < n:
+ answer = 0
+ else:
+ if len(works) < n:
+ diff = n - len(works)
+ for i in range(len(works)):
+ works[i] -= 1
+
+ for i in range(diff):
+ works[i] -= 1
+ else:
+ for i in range(n):
+ works[i] -= 1
+
+ answer = sum([i ** 2 for i in works])
+ return answer
+
+# print(solution_mine(n_1, works_1))
+# print(solution_mine(n_2, works_2))
+# print(solution_mine(n_3, works_3))
+
+'''
+정렬해서 풀어봤자 26점 정도...
+'''
+def solution_mine2(n, works):
+ answer = 0
+
+ if sum(works) < n:
+ answer = 0
+ else:
+ works.sort(reverse=True)
+ if len(works) < n:
+ diff = n - len(works)
+ for i in range(len(works)):
+ works[i] -= 1
+
+ for i in range(diff):
+ works[i] -= 1
+ else:
+ for i in range(n):
+ works[i] -= 1
+
+ answer = sum([i ** 2 for i in works])
+ return answer
+
+# print(solution_mine2(n_1, works_1))
+# print(solution_mine2(n_2, works_2))
+# print(solution_mine2(n_3, works_3))
+
+'''
+이렇게 풀면 안 됨... 효율성 탈락
+'''
+def solution_bad(n, works):
+ answer = 0
+
+ if sum(works) < n:
+ return 0
+
+ while n > 0:
+ works[works.index(max(works))] -= 1
+ n -= 1
+ answer = sum([w ** 2 for w in works])
+ return answer
+
+# print(solution_bad(n_1, works_1))
+# print(solution_bad(n_2, works_2))
+# print(solution_bad(n_3, works_3))
+
diff --git a/Programmers/LEVEL3/ParkingFeeCalculation.py b/Programmers/LEVEL3/ParkingFeeCalculation.py
new file mode 100644
index 0000000..ffe5876
--- /dev/null
+++ b/Programmers/LEVEL3/ParkingFeeCalculation.py
@@ -0,0 +1,103 @@
+# 32. 주차 요금 계산
+
+import math
+def TimeToMinutes(time):
+ hours, minutes = map(int, time.split(':'))
+
+ return hours * 60 + minutes
+
+def solution(fees, records):
+ answer = []
+
+ default_time, default_fee, unint_time, unit_fee = fees
+
+ record_dict = dict()
+ for record in records:
+ time, car_number, history = record.split()
+ car_number = int(car_number)
+ if car_number in record_dict:
+ record_dict[car_number].append([TimeToMinutes(time), history])
+ else:
+ record_dict[car_number] = [[TimeToMinutes(time), history]]
+
+ request_lst = list(record_dict.items())
+ request_lst.sort(key=lambda x: x[0])
+
+
+ for request in request_lst:
+ total_time = 0
+
+ for case in request[1]:
+ if case[1] == 'IN':
+ total_time -= case[0]
+ else:
+ total_time += case[0]
+
+ if request[1][-1][1] == 'IN':
+ total_time += TimeToMinutes('23:59')
+
+ if total_time <= default_time:
+ answer.append(default_fee)
+ else:
+ answer.append(default_fee + math.ceil((total_time - default_time) / unint_time) * unit_fee)
+ return answer
+
+fees_1 = [180, 5000, 10, 600]
+fees_2 = [120, 0, 60, 591]
+fees_3 = [1, 461, 1, 10]
+
+records_1 = ["05:34 5961 IN",
+ "06:00 0000 IN",
+ "06:34 0000 OUT",
+ "07:59 5961 OUT",
+ "07:59 0148 IN",
+ "18:59 0000 IN",
+ "19:09 0148 OUT",
+ "22:59 5961 IN",
+ "23:00 5961 OUT"]
+records_2 = ["16:00 3961 IN",
+ "16:00 0202 IN",
+ "18:00 3961 OUT",
+ "18:00 0202 OUT",
+ "23:58 3961 IN"]
+records_3 = ["00:00 1234 IN"]
+
+print(solution(fees_1, records_1))
+print(solution(fees_2, records_2))
+print(solution(fees_3, records_3))
+
+from collections import defaultdict
+from math import ceil
+
+class Parking:
+ def __init__(self, fees):
+ self.fees = fees
+ self.in_flag = False
+ self.in_time = 0
+ self.total = 0
+
+ def update(self, t, inout):
+ self.in_flag = True if inout == 'IN' else False
+ if self.in_flag:
+ self.in_time = str2int(t)
+ else:
+ self.total += (str2int(t)-self.in_time)
+
+ def calc_fee(self):
+ if self.in_flag: self.update('23:59', 'out')
+ add_t = self.total - self.fees[0]
+ return self.fees[1] + ceil(add_t/self.fees[2]) * self.fees[3] if add_t >= 0 else self.fees[1]
+
+def str2int(string):
+ return int(string[:2])*60 + int(string[3:])
+
+def solution_other(fees, records):
+ recordsDict = defaultdict(lambda:Parking(fees))
+ for rcd in records:
+ t, car, inout = rcd.split()
+ recordsDict[car].update(t, inout)
+ return [v.calc_fee() for k, v in sorted(recordsDict.items())]
+
+print(solution_other(fees_1, records_1))
+print(solution_other(fees_2, records_2))
+print(solution_other(fees_3, records_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/README.md b/Programmers/LEVEL3/README.md
new file mode 100644
index 0000000..8dfc75a
--- /dev/null
+++ b/Programmers/LEVEL3/README.md
@@ -0,0 +1 @@
+All problems at Programmers site's Level3 section.
diff --git a/Programmers/LEVEL3/RestMoney.py b/Programmers/LEVEL3/RestMoney.py
new file mode 100644
index 0000000..6a3505b
--- /dev/null
+++ b/Programmers/LEVEL3/RestMoney.py
@@ -0,0 +1,19 @@
+# 7. 거스름돈
+
+def solution(n, money):
+ answer = 0
+
+ dp = [1] + [0] * n
+ for coin in money:
+ for price in range(coin, n + 1):
+ if price >= coin:
+ dp[price] += dp[price - coin]
+
+ answer = dp[n] % 1000000007
+ return answer
+
+n_1 = 5
+
+money_1 = [1, 2, 5]
+
+print(solution(n_1, money_1))
diff --git a/Programmers/LEVEL3/SheepAndWolf.py b/Programmers/LEVEL3/SheepAndWolf.py
new file mode 100644
index 0000000..b22e25a
--- /dev/null
+++ b/Programmers/LEVEL3/SheepAndWolf.py
@@ -0,0 +1,81 @@
+# 33. 양과 늑대
+
+def solution(info, edges):
+ def NextNodes(v):
+ tmp = []
+ for edge in edges:
+ parent, child = edge
+
+ if v == parent:
+ tmp.append(child)
+ return tmp
+
+ def DFS(sheep, wolf, current, path):
+ if info[current]:
+ wolf += 1
+ else:
+ sheep += 1
+
+
+ return answer
+
+info_1 = [0,0,1,1,1,0,1,0,1,0,1,1]
+info_2 = [0,1,0,1,1,0,1,0,0,1,0]
+
+edges_1 = [[0,1],[1,2],[1,4],[0,8],[8,7],[9,10],[9,11],[4,3],[6,5],[4,6],[8,9]]
+edges_2 = [[0,1],[0,2],[1,3],[1,4],[2,5],[2,6],[3,7],[4,8],[6,9],[9,10]]
+
+print(solution(info_1, edges_1))
+print(solution(info_2, edges_2))
+
+
+def DFS(sheep, wolf, current, path):
+ if info[current]:
+ wolf += 1
+ else:
+ sheep += 1
+
+ if sheep <= wolf:
+ return 0
+
+ max_sheep = sheep
+
+ for p in path:
+ for n in NextNodes(p):
+ if n not in path:
+ path.append(n)
+ max_sheep = max(max_sheep, DFS(sheep, wolf, n, path))
+ path.pop()
+
+ return max_sheep
+
+
+answer = DFS(0, 0, 0, [0])
+
+def solution_other(info, edges):
+ answer = []
+ visited = [0] * len(info)
+ visited[0] = 1
+
+ def DFS(sheep, wolf):
+ if sheep > wolf:
+ answer.append(sheep)
+ else:
+ return
+
+ for i in range(len(edges)):
+ parent = edges[i][0]
+ child = edges[i][1]
+ isWolf = info[child]
+ if visited[parent] and not visited[child]:
+ visited[child] = 1
+ DFS(sheep + (isWolf == 0), wolf + (isWolf == 1))
+ visited[child] = 0
+
+ DFS(1, 0)
+ answer = max(answer)
+ return answer
+
+print(solution_other(info_1, edges_1))
+print(solution_other(info_2, edges_2))
+
diff --git a/Programmers/LEVEL3/StarSequence.py b/Programmers/LEVEL3/StarSequence.py
new file mode 100644
index 0000000..cefa8ad
--- /dev/null
+++ b/Programmers/LEVEL3/StarSequence.py
@@ -0,0 +1,102 @@
+# 18. 스타 수열
+
+'''
+원소의 개수가 가장 많은 것이 모든 부분 수열 중 가장 길이가 긴 스타 수열
+만들 수 있음
+x[0] != x[1], x[2] != x[3], ..., x[2n-2] != x[2n-1]와
+{1,2}, {1,3}, {4,1}, {1,3} 의 교집합은 {1} 이고,
+각 집합 내의 숫자들이 서로 다른 것 주의!!!
+'''
+from collections import Counter
+def solution(a):
+ answer = -1
+
+ elements = Counter(a)
+ for k in elements.keys():
+ if elements[k] <= answer:
+ continue
+
+ common_cnt = 0
+ idx = 0
+ while idx < len(a) - 1:
+ if (a[idx] != k and a[idx + 1] != k) or (a[idx] == a[idx + 1]):
+ idx += 1
+ continue
+ common_cnt += 1
+ idx += 2
+ answer = max(common_cnt, answer)
+
+ if answer == -1:
+ answer = 0
+ else:
+ answer *= 2
+
+ return answer
+
+a_1 = [0]
+a_2 = [5, 2, 3, 3, 5, 3]
+a_3 = [0, 3, 3, 0, 7, 2, 0, 2, 2, 0]
+
+# print(solution(a_1))
+# print(solution(a_2))
+# print(solution(a_3))
+
+def solution_other(a):
+ answer = -1
+
+ if len(a) % 2 != 0 or len(a) < 2:
+ answer = 0
+
+ counter = Counter(a)
+ for key, val in counter.items():
+ if counter[key] * 2 < answer:
+ continue
+
+ max_val, idx = key, 0
+ length = 0
+ while idx < len(a) - 1:
+ if (a[idx] != max_val and a[idx + 1] != max_val) or a[idx] == a[idx + 1]:
+ idx += 1
+ continue
+
+ length += 2
+ idx += 2
+
+ answer = max(answer, length)
+
+ return answer
+
+# print(solution_other(a_1))
+# print(solution_other(a_2))
+# print(solution_other(a_3))
+
+# 유사 딕셔너리
+from collections import defaultdict
+def solution_best(a):
+ answer = 0
+
+ dic = defaultdict(list)
+ for i, v in enumerate(a):
+ dic[v].append(i)
+
+ l = len(a)
+ for k, v in dic.items():
+ if len(v) <= answer // 2:
+ continue
+ else:
+ now = a.copy()
+ cnt = 0
+ for j in v:
+ if j > 0 and now[j - 1] != k:
+ now[j - 1] = k
+ cnt += 2
+ elif j < l - 1 and now[j + 1] != k:
+ now[j + 1] = k
+ cnt += 2
+ answer = max(answer, cnt)
+
+ return answer
+
+# print(solution_best(a_1))
+# print(solution_best(a_2))
+# print(solution_best(a_3))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/TheLongJump.py b/Programmers/LEVEL3/TheLongJump.py
new file mode 100644
index 0000000..8fe2363
--- /dev/null
+++ b/Programmers/LEVEL3/TheLongJump.py
@@ -0,0 +1,54 @@
+# 5. 멀리 뛰기
+
+
+def solution(n):
+ answer = 0
+
+ if n < 3:
+ return n
+
+ cases = [0] * (n + 1)
+ cases[1], cases[2] = 1, 2
+ for i in range(3, n + 1):
+ cases[i] = cases[i - 1] + cases[i - 2]
+
+ answer = cases[n] % 1234567
+ return answer
+
+n_1 = 4
+n_2 = 3
+
+print(solution(n_1))
+print(solution(n_2))
+
+'''
+2000이하의 정수여도 각 case 하나에 대해 permutation을 사용
+'''
+from itertools import permutations
+def solution_mine(n):
+ answer = 1
+
+ q, r = divmod(n, 2)
+ cases = [[1] * n]
+ two_cnts = q
+ for two_cnt in range(1, two_cnts + 1):
+ one_cnts = n - (2 * two_cnt)
+ case = [2] * two_cnt + [1] * one_cnts
+ cases.append(case)
+
+ for case in cases[1:]:
+ perm_case = len(list(set(list(permutations(case, len(case))))))
+ answer += perm_case
+ return answer
+
+# print(solution_mine(n_1))
+# print(solution_mine(n_2))
+
+'''
+같은 피보나치수열인데 한 줄만에 품
+'''
+def solution_best(n):
+ return 1 if n < 2 else solution_best(n - 1) + solution_best(n - 2)
+
+print(solution_best(n_1))
+print(solution_best(n_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/TheLongestPalindrome.py b/Programmers/LEVEL3/TheLongestPalindrome.py
new file mode 100644
index 0000000..5ef6675
--- /dev/null
+++ b/Programmers/LEVEL3/TheLongestPalindrome.py
@@ -0,0 +1,22 @@
+# 30. 가장 긴 펠린드롬
+
+def isPalindrome(st):
+ if st == st[::-1]:
+ return True
+ return False
+
+def solution(s):
+ answer = 0
+
+ for i in range(len(s)):
+ for j in range(i + 1, len(s) + 1):
+ if isPalindrome(s[i:j]):
+ if answer < len(s[i:j]):
+ answer = len(s[i:j])
+ return answer
+
+s_1 = 'abcdcba'
+s_2 = 'abacde'
+
+print(solution(s_1))
+print(solution(s_2))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/TrackConstruction.py b/Programmers/LEVEL3/TrackConstruction.py
new file mode 100644
index 0000000..5ab9686
--- /dev/null
+++ b/Programmers/LEVEL3/TrackConstruction.py
@@ -0,0 +1,65 @@
+# 24. 경주로 건설
+
+import sys
+from collections import deque
+
+def solution(board):
+ def bfs(start):
+ answer = sys.maxsize
+ dic = {0: [-1, 0], 1: [0, 1], 2: [1, 0], 3: [0, -1]} # 북동남서
+ length = len(board)
+ visited = [[sys.maxsize] * length for _ in range(length)]
+ visited[0][0] = 0
+
+ q = deque([start]) # x, y, cost, dir
+ while q:
+ x, y, c, d = q.popleft()
+ for i in range(4):
+ nx = x + dic[i][0]
+ ny = y + dic[i][1]
+
+ # 범위안에 들어오는지 확인
+ if 0 <= nx < length and 0 <= ny < length and board[nx][ny] == 0:
+ # 진행방향에 따른 비용 추가
+ nc = c + 100 if i == d else c + 600
+ if nc < visited[nx][ny]:
+ visited[nx][ny] = nc
+ q.append([nx, ny, nc, i])
+
+ return visited[-1][-1]
+
+ return min([bfs((0, 0, 0, 1)), bfs((0, 0, 0, 2))])
+
+board_1 = [[0, 0, 0],
+ [0, 0, 0],
+ [0, 0, 0]
+ ]
+
+board_2 = [[0, 0, 0, 0, 0, 0, 0, 1],
+ [0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 1, 0, 0],
+ [0, 0, 0, 0, 1, 0, 0, 0],
+ [0, 0, 0, 1, 0, 0, 0, 1],
+ [0, 0, 1, 0, 0, 0, 1, 0],
+ [0, 1, 0, 0, 0, 1, 0, 0],
+ [1, 0, 0, 0, 0, 0, 0, 0]
+ ]
+
+board_3 = [[0, 0, 1, 0],
+ [0, 0, 0, 0],
+ [0, 1, 0, 1],
+ [1, 0, 0, 0]
+ ]
+
+board_4 = [[0, 0, 0, 0, 0, 0],
+ [0, 1, 1, 1, 1, 0],
+ [0, 0, 1, 0, 0, 0],
+ [1, 0, 0, 1, 0, 1],
+ [0, 1, 0, 0, 0, 1],
+ [0, 0, 0, 0, 0, 0]
+ ]
+
+print(solution(board_1))
+print(solution(board_2))
+print(solution(board_3))
+print(solution(board_4))
diff --git a/Programmers/LEVEL3/WayToMakeLine.py b/Programmers/LEVEL3/WayToMakeLine.py
new file mode 100644
index 0000000..840ccc6
--- /dev/null
+++ b/Programmers/LEVEL3/WayToMakeLine.py
@@ -0,0 +1,53 @@
+# 4. 줄 서는 방법
+
+import math
+def solution(n, k):
+ answer = []
+
+ num_lst = [i for i in range(1, n + 1)]
+ while n != 0:
+ temp = math.factorial(n) // n
+ idx = k // temp
+ k = k % temp
+ if k == 0:
+ answer.append(num_lst.pop(idx - 1))
+ else:
+ answer.append(num_lst.pop(idx))
+
+ n -= 1
+ return answer
+
+n_1 = 3
+
+k_1 = 5
+
+print(solution(n_1, k_1))
+
+'''
+accuracy : 63.2, efficiency : 0
+n이 20이하의 자연수라서 permutations 사용 시 시간초과 발생
+'''
+from itertools import permutations
+def solution_mine(n, k):
+ answer = []
+
+ line_cases = list(permutations(range(1, n + 1), n))
+ for i in range(len(line_cases)):
+ if i == k - 1:
+ answer += line_cases[i]
+ return answer
+
+print(solution_mine(n_1, k_1))
+
+def solution_best(n, k):
+ answer = []
+
+ order = list(range(1, n + 1))
+ while n != 0:
+ fact = math.factorial(n - 1)
+ answer.append(order.pop((k - 1) // fact))
+ n, k = n - 1, k % fact
+
+ return answer
+
+print(solution_best(n_1, k_1))
\ No newline at end of file
diff --git a/Programmers/LEVEL3/WordTransformation.py b/Programmers/LEVEL3/WordTransformation.py
new file mode 100644
index 0000000..1d9df2d
--- /dev/null
+++ b/Programmers/LEVEL3/WordTransformation.py
@@ -0,0 +1,130 @@
+# 16. 단어 변환
+
+# BFS를 이용한 풀
+def solution(begin, target, words):
+ answer = 0
+
+ change_lst = [begin]
+ if target not in words:
+ answer = 0
+ else:
+ while len(words) != 0:
+ for item in change_lst:
+ possible_words = []
+ for word in words:
+ check = 0
+ for one in range(len(item)):
+ if item[one] != word[one]:
+ check += 1
+ if check == 2:
+ break
+
+ if check == 1:
+ possible_words.append(word)
+ words.remove(word)
+ answer += 1
+ if target in possible_words:
+ return answer
+ else:
+ change_lst = possible_words
+ return answer
+
+begin_1 = 'hit'
+begin_2 = 'hit'
+
+target_1 = 'cog'
+target_2 = 'cog'
+
+words_1 = ['hot', 'dot', 'dog', 'lot', 'log', 'cog']
+words_2 = ['hot', 'dot', 'dog', 'lot', 'log']
+
+print(solution(begin_1, target_1, words_1))
+print(solution(begin_2, target_2, words_2))
+
+def BFS(begin, target, words, visited):
+ count = 0
+ stack = [(begin, 0)]
+
+ while stack:
+ cur, depth = stack.pop()
+ if cur == target:
+ return depth
+
+ for i in range(len(words)):
+ if visited[i] == True:
+ continue
+ cnt = 0
+ for a, b in zip(cur, words[i]):
+ if a != b:
+ cnt += 1
+ if cnt == 1:
+ visited[i] = True
+ stack.append((words[i], depth + 1))
+
+def solution_bfs(begin, target, words):
+ answer = 0
+
+ if target not in words:
+ return answer
+
+ visited = [False] * len(words)
+
+ answer = BFS(begin, target, words, visited)
+ return answer
+
+begin_1 = 'hit'
+begin_2 = 'hit'
+
+target_1 = 'cog'
+target_2 = 'cog'
+
+words_1 = ['hot', 'dot', 'dog', 'lot', 'log', 'cog']
+words_2 = ['hot', 'dot', 'dog', 'lot', 'log']
+
+# print(solution_bfs(begin_1, target_1, words_1))
+# print(solution_bfs(begin_2, target_2, words_2))
+
+def DFS(current, word):
+ match_count = 0
+ for c, w in zip(current, word):
+ if c == w:
+ match_count += 1
+
+ if match_count == len(word) - 1:
+ return True
+ else:
+ return False
+
+def solution_dfs(begin, target, words):
+ if target not in words:
+ return 0
+
+ answer = 0
+ visited = [0] * len(words)
+ current_lst = [begin]
+
+ while current_lst:
+ current = current_lst.pop()
+ if current == target:
+ return answer
+
+ for i in range(len(words)):
+ if not visited[i]:
+ if DFS(current, words[i]):
+ visited[i] = 1
+ current_lst.append(words[i])
+ answer += 1
+ return answer
+
+begin_1 = 'hit'
+begin_2 = 'hit'
+
+target_1 = 'cog'
+target_2 = 'cog'
+
+words_1 = ['hot', 'dot', 'dog', 'lot', 'log', 'cog']
+words_2 = ['hot', 'dot', 'dog', 'lot', 'log']
+
+# print(solution_dfs(begin_1, target_1, words_1))
+# print(solution_dfs(begin_2, target_2, words_2))
+
diff --git a/Programmers/LEVEL4/WordPuzzle.py b/Programmers/LEVEL4/WordPuzzle.py
new file mode 100644
index 0000000..3ddf620
--- /dev/null
+++ b/Programmers/LEVEL4/WordPuzzle.py
@@ -0,0 +1,86 @@
+# 1. 단어 퍼즐
+
+def solution(strs, t):
+ answer = 0
+
+ n = len(t)
+ dp = [0] * (n + 1)
+
+ for i in range(1, n + 1):
+ dp[i] = float('inf')
+ for k in range(1, 6):
+ if i - k < 0:
+ s = 0
+ else:
+ s = i - k
+
+ if t[s:i] in strs:
+ dp[i] = min(dp[i], dp[i - k] + 1)
+
+ if dp[-1] == float('inf'):
+ answer = -1
+ else:
+ answer = dp[-1]
+
+ return answer
+
+strs_1 = ["ba","na","n","a"]
+strs_2 = ["app","ap","p","l","e","ple","pp"]
+strs_3 = ["ba","an","nan","ban","n"]
+strs_4 = ["ab", "na", "n", "a", "bn"]
+strs_5 = ["H", "e", "o", "He", "ll"]
+strs_6 = ["Py", "t", "h", "tho", "on", "thon"]
+
+t_1 = "banana"
+t_2 = "apple"
+t_3 = "banana"
+t_4 = "nabnabn"
+t_5 = "Hello"
+t_6 = "Python"
+
+print(solution(strs_1, t_1))
+print(solution(strs_2, t_2))
+print(solution(strs_3, t_3))
+print(solution(strs_4, t_4))
+print(solution(strs_5, t_5))
+print(solution(strs_6, t_6))
+
+print()
+import math
+def solution_other(strs, t):
+ answer = 0
+
+ default = math.inf
+ dp = [default for i in range(len(t) + 1)]
+ dp[0] = 0
+
+ for i in range(1, len(t) + 1):
+ j = i - 5 if i > 5 else 0
+ while j < i:
+ if dp[j] + 1 < dp[i] and t[j:i] in strs:
+ dp[i] = dp[j] + 1
+ j += 1
+
+ answer = dp[-1] if dp[-1] != default else -1
+ return answer
+
+strs_1 = ["ba","na","n","a"]
+strs_2 = ["app","ap","p","l","e","ple","pp"]
+strs_3 = ["ba","an","nan","ban","n"]
+strs_4 = ["ab", "na", "n", "a", "bn"]
+strs_5 = ["H", "e", "o", "He", "ll"]
+strs_6 = ["Py", "t", "h", "tho", "on", "thon"]
+
+t_1 = "banana"
+t_2 = "apple"
+t_3 = "banana"
+t_4 = "nabnabn"
+t_5 = "Hello"
+t_6 = "Python"
+
+print(solution_other(strs_1, t_1))
+print(solution_other(strs_2, t_2))
+print(solution_other(strs_3, t_3))
+print(solution_other(strs_4, t_4))
+print(solution_other(strs_5, t_5))
+print(solution_other(strs_6, t_6))
\ No newline at end of file
diff --git a/Programmers/LEVEL4/__init__.py b/Programmers/LEVEL4/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Programmers/__init__.py b/Programmers/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Samsung_SW/2048Game_Easy.py b/Samsung_SW/2048Game_Easy.py
new file mode 100644
index 0000000..4bff762
--- /dev/null
+++ b/Samsung_SW/2048Game_Easy.py
@@ -0,0 +1,76 @@
+# 삼성 SW 역량 기출문제 2. 2048(Easy)
+from collections import deque
+
+board_size = int(input())
+board = [list(map(int, input().split())) for _ in range(board_size)]
+# print(board)
+
+answer, que = 0, deque()
+
+def get(row, column):
+ # print('get function')
+ # print(board[row][column])
+ if board[row][column]:
+ que.append(board[row][column])
+ board[row][column] = 0
+ # print('que :', que)
+
+def merge(row, col, d_row, d_col):
+ while que:
+ # FIFO
+ x = que.popleft()
+ if not board[row][col]:
+ board[row][col] = x
+ elif board[row][col] == x:
+ board[row][col] = x * 2
+ row, col = row + d_row, col + d_col
+ else:
+ row, col = row + d_row, col + d_col
+ board[row][col] = x
+
+def move(one_dir):
+ # Go up
+ if one_dir == 0:
+ for col in range(board_size):
+ for row in range(board_size):
+ get(row, col)
+ merge(0, col, 1, 0)
+ # Go down
+ elif one_dir == 1:
+ for col in range(board_size):
+ for row in range(board_size - 1, -1, -1):
+ get(row, col)
+ merge(board_size - 1, col, -1, 0)
+ # Go Right
+ elif one_dir == 2:
+ for row in range(board_size):
+ for col in range(board_size):
+ get(row, col)
+ merge(row, 0, 0, 1)
+ else:
+ for row in range(board_size):
+ for col in range(board_size - 1, -1, -1):
+ get(row, col)
+ merge(row, board_size - 1, 0, -1)
+
+def solve_main(count):
+ global board, answer
+
+ if count == 5:
+ for b_size in range(board_size):
+ answer = max(answer, max(board[b_size]))
+
+ return
+
+ bef_board = [x[:] for x in board]
+
+ # Move for Four Directions
+ for four_dirs in range(4):
+ move(four_dirs)
+ solve_main(count + 1)
+ board = [b_x[:] for b_x in bef_board]
+
+ # print(board)
+
+solve_main(0)
+print(answer)
\ No newline at end of file
diff --git a/Samsung_SW/BladeEscape2.py b/Samsung_SW/BladeEscape2.py
new file mode 100644
index 0000000..c7b0cdd
--- /dev/null
+++ b/Samsung_SW/BladeEscape2.py
@@ -0,0 +1,140 @@
+# 삼성 SW 역량 기출문제 1. 구슬 탈출 2
+from collections import deque
+
+import sys
+# Fast input Output
+input = sys.stdin.readline
+
+board_row, board_col = map(int, input().split())
+
+board = [[elem for elem in input()] for row in range(board_row)]
+# print(board)
+
+visited = [[[[False] * board_col for _ in range(board_row)] for _ in range(board_col)] for _ in range(board_row)]
+# print(visited)
+dx, dy = (-1, 0, 1, 0), (0, 1, 0, -1)
+que = deque()
+
+# Save Red Marble position and Blue Marble position
+def init():
+ rx, ry, bx, by = [0] * 4
+ for row in range(board_row):
+ for col in range(board_col):
+ if board[row][col] == 'R':
+ rx, ry = row, col
+ elif board[row][col] == 'B':
+ bx, by = row, col
+
+ que.append((rx, ry, bx, by, 1))
+ visited[rx][ry][bx][by] = True
+
+# Move function that if next movement is wall or hole
+def move(x, y, dx, dy):
+ move_cnts = 0
+ while board[x + dx][y + dy] != '#' and board[x][y] != 'O':
+ x += dx
+ y += dy
+ move_cnts += 1
+
+ return x, y, move_cnts
+
+# Use BFS(Breath-First Search) to find the answer
+def BFS():
+ init()
+ while que:
+ rx, ry, bx, by, depth = que.popleft()
+ if depth > 10:
+ break
+
+ # Search for Four directions
+ for four_dir in range(len(dx)):
+ next_rx, next_ry, r_cnt = move(rx, ry, dx[four_dir], dy[four_dir])
+ next_bx, next_by, b_cnt = move(bx, by, dx[four_dir], dy[four_dir])
+
+ # If Blue Marble in hole, it's not the end(failure)
+ if board[next_bx][next_by] == 'O':
+ continue
+
+ if board[next_rx][next_ry] == 'O':
+ print(depth)
+ return
+
+ # Except cases that Red Marble and Blue Marble are in same position
+ if next_rx == next_bx and next_ry == next_by:
+ # Move Marble back that move counts are more than another one
+ if r_cnt > b_cnt:
+ next_rx -= dx[four_dir]
+ next_ry -= dy[four_dir]
+ else:
+ next_bx -= dx[four_dir]
+ next_by -= dy[four_dir]
+
+ # Finished BFS and check visited
+ if not visited[next_rx][next_ry][next_bx][next_by]:
+ visited[next_rx][next_ry][next_bx][next_by] = True
+ que.append((next_rx, next_ry, next_bx, next_by, depth + 1))
+
+ print(-1)
+
+BFS()
+
+'''
+board_1 :
+#####
+#..B#
+#.#.#
+#RO.#
+#####
+
+board_2 :
+#######
+#...RB#
+#.#####
+#.....#
+#####.#
+#O....#
+#######
+
+board_3 :
+#######
+#..R#B#
+#.#####
+#.....#
+#####.#
+#O....#
+#######
+
+board_4 :
+##########
+#R#...##B#
+#...#.##.#
+#####.##.#
+#......#.#
+#.######.#
+#.#....#.#
+#.#.#.#..#
+#...#.O#.#
+##########
+
+board_5 :
+#######
+#R.O.B#
+#######
+
+board_6 :
+##########
+#R#...##B#
+#...#.##.#
+#####.##.#
+#......#.#
+#.######.#
+#.#....#.#
+#.#.##...#
+#O..#....#
+##########
+
+board_7 :
+##########
+#.O....RB#
+##########
+'''
\ No newline at end of file
diff --git a/Samsung_SW/__init__.py b/Samsung_SW/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Softeer/MapAutoConstruct.py b/Softeer/MapAutoConstruct.py
new file mode 100644
index 0000000..1b6a842
--- /dev/null
+++ b/Softeer/MapAutoConstruct.py
@@ -0,0 +1,9 @@
+# 1. 지도 자동 구축
+
+N = int(input('점의 개수 : '))
+
+k, total = 2, 0
+for i in range(N):
+ total += (2 ** i)
+
+print((k + total) * (k + total))
\ No newline at end of file
diff --git a/Softeer/__init__.py b/Softeer/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/ThisIsCodingTest/Greedy/RestMoney.py b/ThisIsCodingTest/Greedy/RestMoney.py
new file mode 100644
index 0000000..5917f17
--- /dev/null
+++ b/ThisIsCodingTest/Greedy/RestMoney.py
@@ -0,0 +1,31 @@
+# 3-1. 거스름돈
+
+# N = int(input('Total Money : '))
+#
+# coins_type = [50, 10, 500, 100]
+#
+# counts = 0
+# coins_type.sort(reverse = True)
+# for coin in coins_type:
+# counts += N // coin
+# N %= coin
+#
+# print(counts)
+
+# Programmers style
+
+def solution(money):
+ answer = 0
+
+ coins_type = [10, 50, 100, 500]
+ coins_type.sort(reverse = True)
+ coin_cnts = 0
+ for coin in coins_type:
+ coin_cnts += money // coin
+ money %= coin
+
+ answer = coin_cnts
+ return answer
+
+money_1 = 1260
+print(solution(money_1))
\ No newline at end of file
diff --git a/ThisIsCodingTest/Greedy/__init__.py b/ThisIsCodingTest/Greedy/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/ThisIsCodingTest/__init__.py b/ThisIsCodingTest/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/gemini/multimodal-live-api/real_time_rag_retail_gemini_2_0.ipynb b/gemini/multimodal-live-api/real_time_rag_retail_gemini_2_0.ipynb
new file mode 100644
index 0000000..63eb995
--- /dev/null
+++ b/gemini/multimodal-live-api/real_time_rag_retail_gemini_2_0.ipynb
@@ -0,0 +1,1890 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "id": "ur8xi4C7S06n"
+ },
+ "outputs": [],
+ "source": [
+ "# Copyright 2024 Google LLC\n",
+ "#\n",
+ "# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
+ "# you may not use this file except in compliance with the License.\n",
+ "# You may obtain a copy of the License at\n",
+ "#\n",
+ "# https://www.apache.org/licenses/LICENSE-2.0\n",
+ "#\n",
+ "# Unless required by applicable law or agreed to in writing, software\n",
+ "# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
+ "# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
+ "# See the License for the specific language governing permissions and\n",
+ "# limitations under the License."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JAPoU8Sm5E6e"
+ },
+ "source": [
+ "# Real-time Retrieval Augmented Generation (RAG) using the Multimodal Live API with Gemini 2.0\n",
+ "\n",
+ "\n",
+ " \n",
+ " \n",
+ " 
Open in Colab\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ " 
Open in Colab Enterprise\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ " 
Open in Vertex AI Workbench\n",
+ " \n",
+ " | \n",
+ " \n",
+ " \n",
+ " 
View on GitHub\n",
+ " \n",
+ " | \n",
+ "
\n",
+ "\n",
+ "
\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "
\n",
+ "Share to:\n",
+ "\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "  \n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "  \n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "84f0f73a0f76"
+ },
+ "source": [
+ "| | |\n",
+ "|-|-|\n",
+ "| Author(s) | [Deepak Moonat](https://github.com/dmoonat/) |"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-MDW_A-nBksi"
+ },
+ "source": [
+ "
\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "84f0f73a0f76"
+ },
+ "source": [
+ "| | |\n",
+ "|-|-|\n",
+ "| Author(s) | [Deepak Moonat](https://github.com/dmoonat/) |"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-MDW_A-nBksi"
+ },
+ "source": [
+ "\n",
+ "\n",
+ "⚠️ Gemini 2.0 Flash (Model ID: gemini-2.0-flash-live-preview-04-09) and the Google Gen AI SDK are currently experimental and output can vary ⚠️\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tvgnzT1CKxrO"
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "This notebook provides a comprehensive demonstration of the Vertex AI Gemini and Multimodal Live APIs, showcasing text and audio generation capabilities. Users will learn to develop a real-time Retrieval Augmented Generation (RAG) system leveraging the Multimodal Live API for a retail use-case. This system will generate audio and text responses grounded in provided documents. The tutorial covers the following:\n",
+ "\n",
+ "- **Gemini API:** Text output generation.\n",
+ "- **Multimodal Live API:** Text and audio output generation.\n",
+ "- **Retrieval Augmented Generation (RAG):** Text and audio output generation grounded in provided documents for a retail use-case."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xKVzRJhgJ4EZ"
+ },
+ "source": [
+ "### Gemini 2.0\n",
+ "\n",
+ "[Gemini 2.0 Flash](https://cloud.google.com/vertex-ai/generative-ai/docs/gemini-v2) is a new multimodal generative ai model from the Gemini family developed by [Google DeepMind](https://deepmind.google/). It now available as an experimental preview release through the Gemini API in Vertex AI and Vertex AI Studio. The model introduces new features and enhanced core capabilities:\n",
+ "\n",
+ "- Multimodal Live API: This new API helps you create real-time vision and audio streaming applications with tool use.\n",
+ "- Speed and performance: Gemini 2.0 Flash is the fastest model in the industry, with a 3x improvement in time to first token (TTFT) over 1.5 Flash.\n",
+ "- Quality: The model maintains quality comparable to larger models like Gemini 2.0 and GPT-4o.\n",
+ "- Improved agentic experiences: Gemini 2.0 delivers improvements to multimodal understanding, coding, complex instruction following, and function calling.\n",
+ "- New Modalities: Gemini 2.0 introduces native image generation and controllable text-to-speech capabilities, enabling image editing, localized artwork creation, and expressive storytelling.\n",
+ "- To support the new model, we're also shipping an all new SDK that supports simple migration between the Gemini Developer API and the Gemini API in Vertex AI.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "61RBz8LLbxCR"
+ },
+ "source": [
+ "## Get started"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "No17Cw5hgx12"
+ },
+ "source": [
+ "### Install Dependencies\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ue_G9ZU80ON0"
+ },
+ "source": [
+ "- `google-genai`: Google Gen AI python library\n",
+ "- `PyPDF2`: To read PDFs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "id": "tFy3H3aPgx12"
+ },
+ "outputs": [],
+ "source": [
+ "%%capture\n",
+ "\n",
+ "%pip install --upgrade --quiet google-genai PyPDF2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "R5Xep4W9lq-Z"
+ },
+ "source": [
+ "### Restart runtime\n",
+ "\n",
+ "To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which restarts the current kernel.\n",
+ "\n",
+ "The restart might take a minute or longer. After it's restarted, continue to the next step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "id": "XRvKdaPDTznN",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "40bb6a57-4766-4182-f79d-33677d9f34ad"
+ },
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ "{'status': 'ok', 'restart': True}"
+ ]
+ },
+ "metadata": {},
+ "execution_count": 1
+ }
+ ],
+ "source": [
+ "import IPython\n",
+ "\n",
+ "app = IPython.Application.instance()\n",
+ "app.kernel.do_shutdown(True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SbmM4z7FOBpM"
+ },
+ "source": [
+ "\n",
+ "⚠️ The kernel is going to restart. Wait until it's finished before continuing to the next step. ⚠️\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dmWOrTJ3gx13"
+ },
+ "source": [
+ "### Authenticate your notebook environment (Colab only)\n",
+ "\n",
+ "If you're running this notebook on Google Colab, run the cell below to authenticate your environment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "id": "NyKGtVQjgx13"
+ },
+ "outputs": [],
+ "source": [
+ "import sys\n",
+ "\n",
+ "if \"google.colab\" in sys.modules:\n",
+ " from google.colab import auth\n",
+ "\n",
+ " auth.authenticate_user()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DF4l8DTdWgPY"
+ },
+ "source": [
+ "### Set Google Cloud project information\n",
+ "\n",
+ "To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).\n",
+ "\n",
+ "Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "id": "Nqwi-5ufWp_B"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "PROJECT_ID = \"mindful-phalanx-457200-f5\" # @param {type: \"string\", placeholder: \"[your-project-id]\", isTemplate: true}\n",
+ "if not PROJECT_ID or PROJECT_ID == \"mindful-phalanx-457200-f5\":\n",
+ " PROJECT_ID = str(os.environ.get(\"GOOGLE_CLOUD_PROJECT\"))\n",
+ "\n",
+ "LOCATION = os.environ.get(\"GOOGLE_CLOUD_REGION\", \"us-central1\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5303c05f7aa6"
+ },
+ "source": [
+ "### Import libraries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "id": "6fc324893334"
+ },
+ "outputs": [],
+ "source": [
+ "# For asynchronous operations\n",
+ "import asyncio\n",
+ "\n",
+ "# For data processing\n",
+ "import glob\n",
+ "from typing import Any\n",
+ "\n",
+ "from IPython.display import Audio, Markdown, display\n",
+ "import PyPDF2\n",
+ "\n",
+ "# For GenerativeAI\n",
+ "from google import genai\n",
+ "from google.genai import types\n",
+ "from google.genai.types import LiveConnectConfig\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "\n",
+ "# For similarity score\n",
+ "from sklearn.metrics.pairwise import cosine_similarity\n",
+ "\n",
+ "# For retry mechanism\n",
+ "from tenacity import retry, stop_after_attempt, wait_random_exponential"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "OV5bFDTVE3oX"
+ },
+ "source": [
+ "#### Initialize Gen AI client"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3pjBP_V7JqhD"
+ },
+ "source": [
+ "- Client for calling the Gemini API in Vertex AI\n",
+ "- `vertexai=True`, indicates the client should communicate with the Vertex AI API endpoints."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {
+ "id": "bEhq_4GBEW2a"
+ },
+ "outputs": [],
+ "source": [
+ "# Vertex AI API\n",
+ "client = genai.Client(\n",
+ " vertexai=True,\n",
+ " project=PROJECT_ID,\n",
+ " location=LOCATION,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "e43229f3ad4f"
+ },
+ "source": [
+ "### Initialize model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {
+ "id": "cf93d5f0ce00"
+ },
+ "outputs": [],
+ "source": [
+ "MODEL_ID = (\n",
+ " \"gemini-2.0-flash-live-preview-04-09\"\n",
+ ")\n",
+ "MODEL = (\n",
+ " f\"projects/{PROJECT_ID}/locations/{LOCATION}/publishers/google/models/{MODEL_ID}\"\n",
+ ")\n",
+ "\n",
+ "text_embedding_model = \"text-embedding-005\" # @param {type:\"string\", isTemplate: true}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "H4TDOc3aqwuz"
+ },
+ "source": [
+ "## Sample Use Case - Retail Customer Support Assistance"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "cH6zJeecq6SU"
+ },
+ "source": [
+ "Let's imagine a bicycle shop called `Cymbal Bikes` that offers various services like brake repair, chain replacement, and more. Our goal is to create a straightforward support system that can answer customer questions based on the shop's policies and service offerings."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uA3X24j86uE7"
+ },
+ "source": [
+ "Having a customer support assistance offers numerous advantages for businesses, ultimately leading to improved customer satisfaction and loyalty, as well as increased profitability. Here are some key benefits:\n",
+ "\n",
+ "- Faster Resolution of Issues: Users can quickly find answers to their questions without having to search through store's website.\n",
+ "- Improved Efficiency: The assistant can handle simple, repetitive questions, freeing up human agents to focus on more complex or strategic tasks.\n",
+ "- 24/7 Availability: Unlike human colleagues, the assistant is available around the clock, providing immediate support regardless of time zones or working hours.\n",
+ "- Consistent Information: The assistant provides standardized answers, ensuring consistency and accuracy."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mZZLuCecsp0e"
+ },
+ "source": [
+ "#### Context Documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nWrK7HHjssqB"
+ },
+ "source": [
+ "- Download the documents from Google Cloud Storage bucket\n",
+ "- These documents are specific to `Cymbal Bikes` store\n",
+ " - [`Cymbal Bikes Return Policy`](https://storage.googleapis.com/github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesReturnPolicy.pdf): Contains information about return policy\n",
+ " - [`Cymbal Bikes Services`](https://storage.googleapis.com/github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesServices.pdf): Contains information about services provided by Cymbal Bikes"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {
+ "id": "iLhNfYfYspnC",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "c4be97bf-0e0d-4769-80fd-8080930daddc"
+ },
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Copying gs://github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesReturnPolicy.pdf...\n",
+ "/ [1 files][ 1.7 KiB/ 1.7 KiB] \n",
+ "Operation completed over 1 objects/1.7 KiB. \n",
+ "Copying gs://github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesServices.pdf...\n",
+ "/ [1 files][ 1.5 KiB/ 1.5 KiB] \n",
+ "Operation completed over 1 objects/1.5 KiB. \n"
+ ]
+ }
+ ],
+ "source": [
+ "!gsutil cp \"gs://github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesReturnPolicy.pdf\" \"documents/CymbalBikesReturnPolicy.pdf\"\n",
+ "!gsutil cp \"gs://github-repo/generative-ai/gemini2/use-cases/retail_rag/documents/CymbalBikesServices.pdf\" \"documents/CymbalBikesServices.pdf\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GOFNGNGjjEzD"
+ },
+ "source": [
+ "### Text"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QlcEVrUtP9TI"
+ },
+ "source": [
+ "- Let's check a specific query to our retail use-case"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "metadata": {
+ "id": "eLqbaZjoCzng",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 442
+ },
+ "outputId": "ec0a2e60-b933-4f2b-d820-ef86a20d58d4"
+ },
+ "outputs": [
+ {
+ "output_type": "error",
+ "ename": "ClientError",
+ "evalue": "403 PERMISSION_DENIED. {'error': {'code': 403, 'message': 'Permission denied on resource project None.', 'status': 'PERMISSION_DENIED', 'details': [{'@type': 'type.googleapis.com/google.rpc.ErrorInfo', 'reason': 'CONSUMER_INVALID', 'domain': 'googleapis.com', 'metadata': {'service': 'aiplatform.googleapis.com', 'containerInfo': 'None', 'consumer': 'projects/None'}}, {'@type': 'type.googleapis.com/google.rpc.LocalizedMessage', 'locale': 'en-US', 'message': 'Permission denied on resource project None.'}, {'@type': 'type.googleapis.com/google.rpc.Help', 'links': [{'description': 'Google developers console', 'url': 'https://console.developers.google.com'}]}]}}",
+ "traceback": [
+ "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
+ "\u001b[0;31mClientError\u001b[0m Traceback (most recent call last)",
+ "\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0mquery\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m\"What is the price of a basic tune-up at Cymbal Bikes?\"\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 3\u001b[0;31m response = client.models.generate_content(\n\u001b[0m\u001b[1;32m 4\u001b[0m \u001b[0mmodel\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mMODEL_ID\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0mcontents\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mquery\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.11/dist-packages/google/genai/models.py\u001b[0m in \u001b[0;36mgenerate_content\u001b[0;34m(self, model, contents, config)\u001b[0m\n\u001b[1;32m 5017\u001b[0m \u001b[0;32mwhile\u001b[0m \u001b[0mremaining_remote_calls_afc\u001b[0m \u001b[0;34m>\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5018\u001b[0m \u001b[0mi\u001b[0m \u001b[0;34m+=\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 5019\u001b[0;31m response = self._generate_content(\n\u001b[0m\u001b[1;32m 5020\u001b[0m \u001b[0mmodel\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mmodel\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mcontents\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mcontents\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mconfig\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mconfig\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5021\u001b[0m )\n",
+ "\u001b[0;32m/usr/local/lib/python3.11/dist-packages/google/genai/models.py\u001b[0m in \u001b[0;36m_generate_content\u001b[0;34m(self, model, contents, config)\u001b[0m\n\u001b[1;32m 3993\u001b[0m \u001b[0mrequest_dict\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0m_common\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mencode_unserializable_types\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mrequest_dict\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3994\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 3995\u001b[0;31m response_dict = self._api_client.request(\n\u001b[0m\u001b[1;32m 3996\u001b[0m \u001b[0;34m'post'\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpath\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrequest_dict\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mhttp_options\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3997\u001b[0m )\n",
+ "\u001b[0;32m/usr/local/lib/python3.11/dist-packages/google/genai/_api_client.py\u001b[0m in \u001b[0;36mrequest\u001b[0;34m(self, http_method, path, request_dict, http_options)\u001b[0m\n\u001b[1;32m 740\u001b[0m \u001b[0mhttp_method\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpath\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mrequest_dict\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mhttp_options\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 741\u001b[0m )\n\u001b[0;32m--> 742\u001b[0;31m \u001b[0mresponse\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0m_request\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mhttp_request\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mstream\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0;32mFalse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 743\u001b[0m \u001b[0mjson_response\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mresponse\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mjson\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 744\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0mjson_response\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.11/dist-packages/google/genai/_api_client.py\u001b[0m in \u001b[0;36m_request\u001b[0;34m(self, http_request, stream)\u001b[0m\n\u001b[1;32m 669\u001b[0m \u001b[0mtimeout\u001b[0m\u001b[0;34m=\u001b[0m\u001b[0mhttp_request\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtimeout\u001b[0m\u001b[0;34m,\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 670\u001b[0m )\n\u001b[0;32m--> 671\u001b[0;31m \u001b[0merrors\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mAPIError\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mraise_for_response\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mresponse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 672\u001b[0m return HttpResponse(\n\u001b[1;32m 673\u001b[0m \u001b[0mresponse\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mheaders\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mresponse\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mstream\u001b[0m \u001b[0;32melse\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0mresponse\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtext\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.11/dist-packages/google/genai/errors.py\u001b[0m in \u001b[0;36mraise_for_response\u001b[0;34m(cls, response)\u001b[0m\n\u001b[1;32m 99\u001b[0m \u001b[0mstatus_code\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mresponse\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mstatus_code\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 100\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;36m400\u001b[0m \u001b[0;34m<=\u001b[0m \u001b[0mstatus_code\u001b[0m \u001b[0;34m<\u001b[0m \u001b[0;36m500\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 101\u001b[0;31m \u001b[0;32mraise\u001b[0m \u001b[0mClientError\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mstatus_code\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mresponse_json\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mresponse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 102\u001b[0m \u001b[0;32melif\u001b[0m \u001b[0;36m500\u001b[0m \u001b[0;34m<=\u001b[0m \u001b[0mstatus_code\u001b[0m \u001b[0;34m<\u001b[0m \u001b[0;36m600\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 103\u001b[0m \u001b[0;32mraise\u001b[0m \u001b[0mServerError\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mstatus_code\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mresponse_json\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mresponse\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;31mClientError\u001b[0m: 403 PERMISSION_DENIED. {'error': {'code': 403, 'message': 'Permission denied on resource project None.', 'status': 'PERMISSION_DENIED', 'details': [{'@type': 'type.googleapis.com/google.rpc.ErrorInfo', 'reason': 'CONSUMER_INVALID', 'domain': 'googleapis.com', 'metadata': {'service': 'aiplatform.googleapis.com', 'containerInfo': 'None', 'consumer': 'projects/None'}}, {'@type': 'type.googleapis.com/google.rpc.LocalizedMessage', 'locale': 'en-US', 'message': 'Permission denied on resource project None.'}, {'@type': 'type.googleapis.com/google.rpc.Help', 'links': [{'description': 'Google developers console', 'url': 'https://console.developers.google.com'}]}]}}"
+ ]
+ }
+ ],
+ "source": [
+ "query = \"What is the price of a basic tune-up at Cymbal Bikes?\"\n",
+ "\n",
+ "response = client.models.generate_content(\n",
+ " model=MODEL_ID,\n",
+ " contents=query,\n",
+ ")\n",
+ "\n",
+ "display(Markdown(response.text))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-D6q7KUDuH-E"
+ },
+ "source": [
+ "> The correct answer to the query is `A basic tune-up costs $100.`\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "uoigEKWkQjwi"
+ },
+ "source": [
+ "- You can see, the model is unable to answer it correctly, as it's very specific to our hypothetical use-case. However, it does provide some details to get the answer from the internet.\n",
+ "\n",
+ "- Without the necessary context, the model's response is essentially a guess and may not align with the desired information.\n",
+ "\n",
+ "- LLM is trained on vast amount of data, which leads to hallucinations. To overcome this challenge, in coming sections we'll look into how to ground the answers using Retrieval Augmented Generation (RAG)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nhzKqZdunwYJ"
+ },
+ "source": [
+ "## Grounding"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kzNcDkRevJi3"
+ },
+ "source": [
+ "Grounding is crucial in this scenario because the model needs to access and process relevant information from external sources (the \"Cymbal Bikes Return Policy\" and \"Cymbal Bikes Services\" documents) to answer specific queries accurately. Without grounding, the model relies solely on its pre-trained knowledge, which may not contain the specific details about the bike store's policies.\n",
+ "\n",
+ "In the example, the question about the return policy for bike helmets at Cymbal Bikes cannot be answered correctly without accessing the provided documents. The model's general knowledge of return policies is insufficient. Grounding allows the model to:\n",
+ "\n",
+ "1. **Retrieve relevant information:** The system must first locate the pertinent sections within the provided documents that address the user's question about bike helmet returns.\n",
+ "\n",
+ "2. **Process and synthesize information:** After retrieving relevant passages, the model must then understand and synthesize the information to construct an accurate answer.\n",
+ "\n",
+ "3. **Generate a grounded response:** Finally, the response needs to be directly derived from the factual content of the documents. This ensures accuracy and avoids hallucinations – generating incorrect or nonsensical information not present in the source documents.\n",
+ "\n",
+ "Without grounding, the model is forced to guess or extrapolate from its general knowledge, which can lead to inaccurate or misleading responses. The grounding process makes the model's responses more reliable and trustworthy, especially for domain-specific knowledge like store policies or procedures.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-SyokS1pUR9O"
+ },
+ "source": [
+ "## Multimodal Live API"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pwZeOc5-UXKD"
+ },
+ "source": [
+ "The multimodal live API enables you to build low-latency, multi-modal applications. It currently supports text as input and text & audio as output.\n",
+ "\n",
+ "- Low Latency, where audio output is required, where the Text-to-Speech step can be skipped\n",
+ "- Provides a more interactive user experience.\n",
+ "- Suitable for applications requiring immediate audio feedback"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ad9d532aab36"
+ },
+ "source": [
+ "See the [Multimodal Live API](https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/multimodal-live) page for more details."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aS1zTjSMcij2"
+ },
+ "source": [
+ "#### Asynchronous (async) operation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iH9CBOpncnK8"
+ },
+ "source": [
+ "When to use async calls:\n",
+ "1. **I/O-bound operations**: When your code spends a significant amount of time waiting for external resources\n",
+ " (e.g., network requests, file operations, database queries). Async allows other tasks to run while waiting. \n",
+ " This is especially beneficial for real-time applications or when dealing with multiple concurrent requests.\n",
+ " \n",
+ " Example:\n",
+ " - Fetching data from a remote server.\n",
+ "\n",
+ "2. **Parallel tasks**: When you have independent tasks that can run concurrently without blocking each other. Async\n",
+ " allows you to efficiently utilize multiple CPU cores or network connections.\n",
+ " \n",
+ " Example:\n",
+ " - Processing a large number of prompts and generating audio for each.\n",
+ "\n",
+ "\n",
+ "3. **User interfaces**: In applications with graphical user interfaces (GUIs), async operations prevent the UI from\n",
+ " freezing while performing long-running tasks. Users can interact with the interface even when background\n",
+ " operations are active.\n",
+ " \n",
+ " Example: \n",
+ " - A chatbot interacting in real time, where an audio response is generated in the background.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aB4U6s1-UlFw"
+ },
+ "source": [
+ "### Text"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YvUJzbgPM26m"
+ },
+ "source": [
+ "For text generation, you need to set the `response_modalities` to `TEXT`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "YQOurRs5UU9p"
+ },
+ "outputs": [],
+ "source": [
+ "async def generate_content(query: str) -> str:\n",
+ " \"\"\"Function to generate text content using Gemini live API.\n",
+ "\n",
+ " Args:\n",
+ " query: The query to generate content for.\n",
+ "\n",
+ " Returns:\n",
+ " The generated content.\n",
+ " \"\"\"\n",
+ " config = LiveConnectConfig(response_modalities=[\"TEXT\"])\n",
+ "\n",
+ " async with client.aio.live.connect(model=MODEL, config=config) as session:\n",
+ "\n",
+ " await session.send(input=query, end_of_turn=True)\n",
+ "\n",
+ " response = []\n",
+ " async for message in session.receive():\n",
+ " try:\n",
+ " if message.text:\n",
+ " response.append(message.text)\n",
+ " except AttributeError:\n",
+ " pass\n",
+ "\n",
+ " if message.server_content.turn_complete:\n",
+ " response = \"\".join(str(x) for x in response)\n",
+ " return response"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ye1TwWVaVSxF"
+ },
+ "source": [
+ "- Try a specific query"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "gGqsp6nFDNsG"
+ },
+ "outputs": [],
+ "source": [
+ "query = \"What is the price of a basic tune-up at Cymbal Bikes?\"\n",
+ "\n",
+ "response = await generate_content(query)\n",
+ "display(Markdown(response))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "roXuCp_cXE9q"
+ },
+ "source": [
+ "### Audio"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lBnz34QaakVM"
+ },
+ "source": [
+ "- For audio generation, you need to set the `response_modalities` to `AUDIO`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "BmLuvxnFbC4Z"
+ },
+ "outputs": [],
+ "source": [
+ "async def generate_audio_content(query: str):\n",
+ " \"\"\"Function to generate audio response for provided query using Gemini Multimodal Live API.\n",
+ "\n",
+ " Args:\n",
+ " query: The query to generate audio response for.\n",
+ "\n",
+ " Returns:\n",
+ " The audio response.\n",
+ " \"\"\"\n",
+ " config = LiveConnectConfig(response_modalities=[\"AUDIO\"])\n",
+ " async with client.aio.live.connect(model=MODEL, config=config) as session:\n",
+ "\n",
+ " await session.send(input=query, end_of_turn=True)\n",
+ "\n",
+ " audio_parts = []\n",
+ " async for message in session.receive():\n",
+ " if message.server_content.model_turn:\n",
+ " for part in message.server_content.model_turn.parts:\n",
+ " if part.inline_data:\n",
+ " audio_parts.append(\n",
+ " np.frombuffer(part.inline_data.data, dtype=np.int16)\n",
+ " )\n",
+ "\n",
+ " if message.server_content.turn_complete:\n",
+ " if audio_parts:\n",
+ " audio_data = np.concatenate(audio_parts, axis=0)\n",
+ " await asyncio.sleep(0.4)\n",
+ " display(Audio(audio_data, rate=24000, autoplay=True))\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "xKQ_l6wiLH_w"
+ },
+ "source": [
+ "In this example, you send a text prompt and request the model response in audio."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rXJRoxUAcFVB"
+ },
+ "source": [
+ "- Let's check the same query as before"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "CfZy_XZeDUtS"
+ },
+ "outputs": [],
+ "source": [
+ "query = \"What is the price of a basic tune-up at Cymbal Bikes?\"\n",
+ "\n",
+ "await generate_audio_content(query)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "clfXp2PZmxDZ"
+ },
+ "source": [
+ "- Model is unable to answer the query, but with the Multimodal Live API, it doesn't hallucinate, which is pretty good!!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wT2oB1BOqDYP"
+ },
+ "source": [
+ "### Continuous Audio Interaction (Not multiturn)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T4iAJCstqR5s"
+ },
+ "source": [
+ " - Below function generates audio output based on the provided text prompt.\n",
+ " - The generated audio is displayed using `IPython.display.Audio`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bZntNTPiYLA8"
+ },
+ "source": [
+ "- Input your prompts (type `q` or `quit` or `exit` to exit).\n",
+ "- Example prompts:\n",
+ " - Hello\n",
+ " - Who are you?\n",
+ " - What's the largest planet in our solar system?\n",
+ " - Tell me 3 fun facts about the universe?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "7M0zkHNrOBQf"
+ },
+ "outputs": [],
+ "source": [
+ "async def continuous_audio_generation():\n",
+ " \"\"\"Continuously generates audio responses for the asked queries.\"\"\"\n",
+ " while True:\n",
+ " query = input(\"Your query > \")\n",
+ " if any(query.lower() in s for s in [\"q\", \"quit\", \"exit\"]):\n",
+ " break\n",
+ " await generate_audio_content(query)\n",
+ "\n",
+ "\n",
+ "await continuous_audio_generation()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QX9k92TlJ864"
+ },
+ "source": [
+ "## Enhancing LLM Accuracy with RAG"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "oOJ-Wx18hpju"
+ },
+ "source": [
+ "We'll be showcasing the design pattern for how to implement Real-time Retrieval Augmented Generation (RAG) using Gemini 2.0 multimodal live API.\n",
+ "\n",
+ "- Multimodal live API uses websockets to communicate over the internet\n",
+ "- It maintains a continuous connection\n",
+ "- Ideal for real-time applications which require persistent communication\n",
+ "\n",
+ "\n",
+ "> Note: Replicating real-life scenarios with Python can be challenging within the constraints of a Colab environment.\n",
+ "\n",
+ "\n",
+ "However, the flow shown in this section can be modified for streaming audio input and output.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "We'll build the RAG pipeline from scratch to help you understand each and every components of the pipeline.\n",
+ "\n",
+ "There are other ways to build the RAG pipeline using open source tools such as [LangChain](https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/multimodal_rag_langchain.ipynb), [LlamaIndex](https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/llamaindex_rag.ipynb) etc."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u5CXTtsPEyJ0"
+ },
+ "source": [
+ "### Context Documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vvdcw1AOg4se"
+ },
+ "source": [
+ "- Documents are the building blocks of any RAG pipeline, as it provides the relevant context needed to ground the LLM responses\n",
+ "- We'll be using the documents already downloaded at the start of the notebook\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "M22BSDb2Xxpb"
+ },
+ "outputs": [],
+ "source": [
+ "documents = glob.glob(\"documents/*\")\n",
+ "documents"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zNpUL7t0e054"
+ },
+ "source": [
+ "### Retrieval Augmented Generation Architecture"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vV5Et4YHbqqE"
+ },
+ "source": [
+ "In general, RAG architecture consists of the following components\n",
+ "\n",
+ "**Data Preparation**\n",
+ "1. Chunking: Dividing the document into smaller, manageable pieces for processing.\n",
+ "2. Embedding: Transforming text chunks into numerical vectors representing semantic meaning.\n",
+ "3. Indexing: Organizing embeddings for efficient similarity search."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "563756fa3b7f"
+ },
+ "source": [
+ "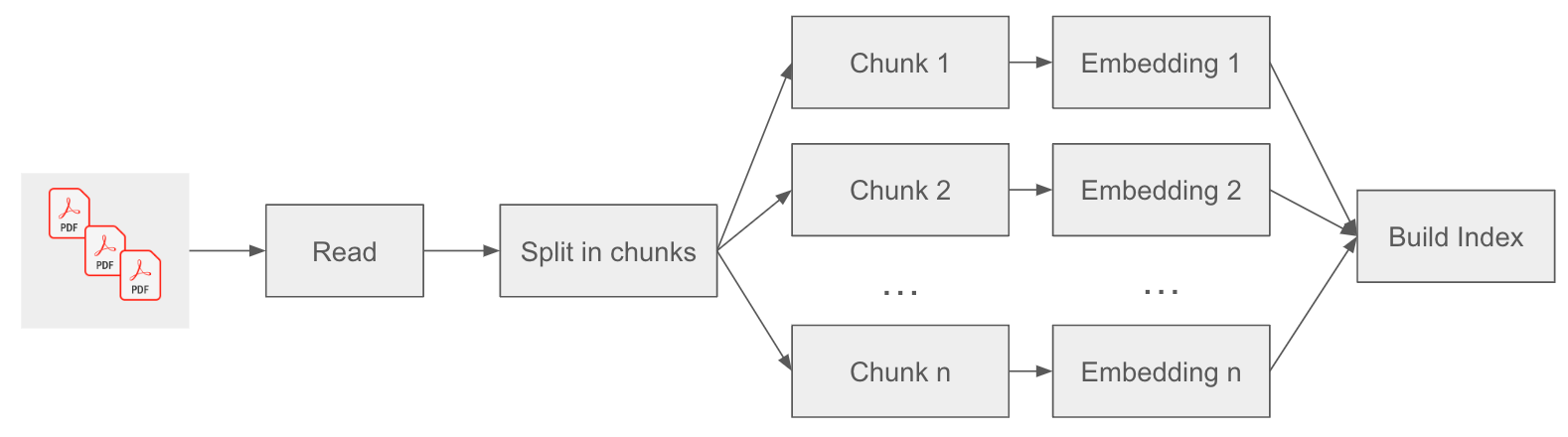"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pf4sXzYUby57"
+ },
+ "source": [
+ "**Inference**\n",
+ "1. Retrieval: Finding the most relevant chunks based on the query embedding.\n",
+ "2. Query Augmentation: Enhancing the query with retrieved context for improved generation.\n",
+ "3. Generation: Synthesizing a coherent and informative answer based on the augmented query."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1a30b41b63f1"
+ },
+ "source": [
+ "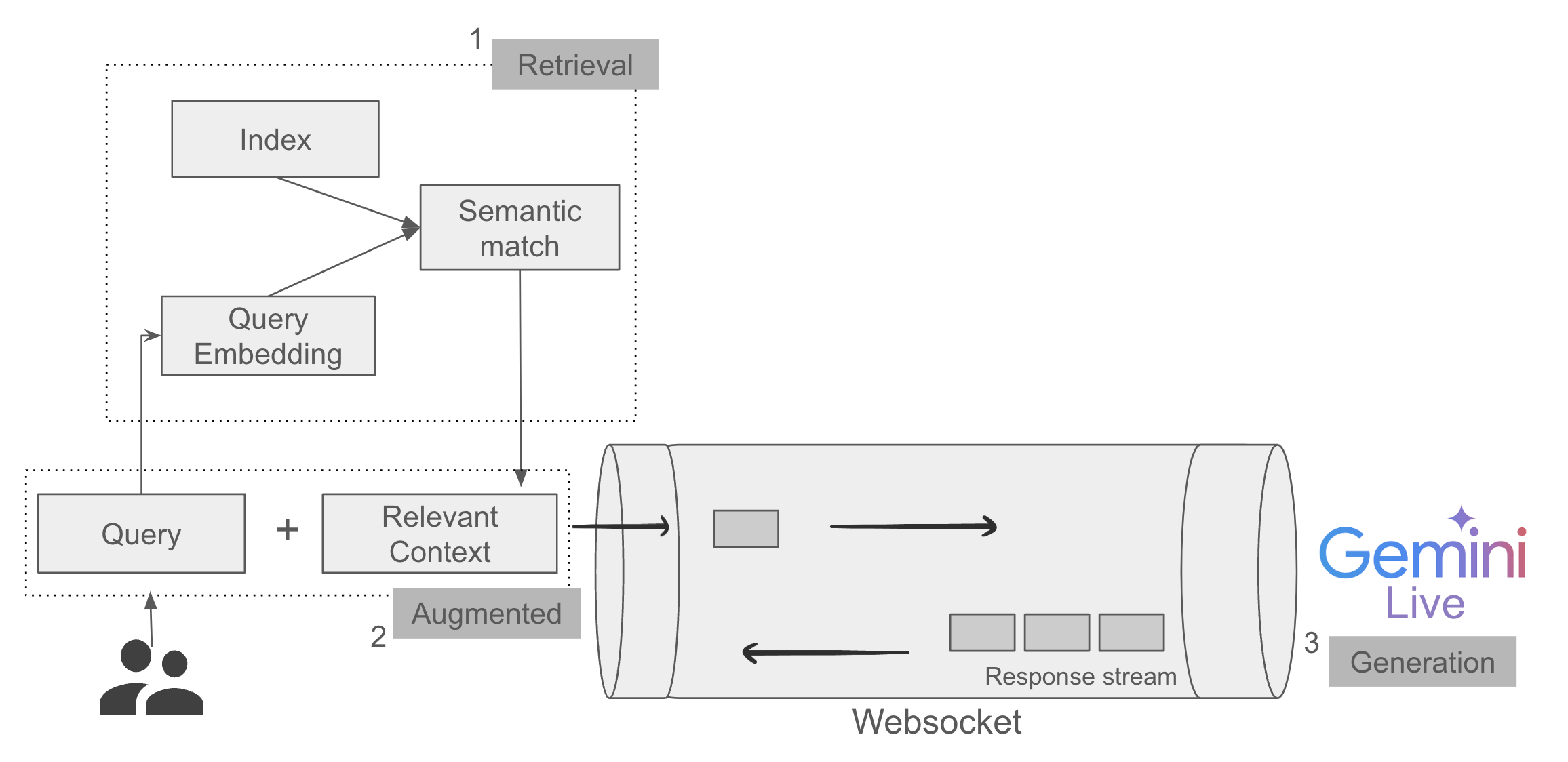"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "M-0zlJ3_FRfa"
+ },
+ "source": [
+ "#### Document Embedding and Indexing"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0fY3xLaFKBIS"
+ },
+ "source": [
+ "Following blocks of code shows how to process unstructured data(PDFs), extract text, and divide them into smaller chunks for efficient embedding and retrieval."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JTTOQ35Ia-V2"
+ },
+ "source": [
+ "- Embeddings:\n",
+ " - Numerical representations of text\n",
+ " - It capture the semantic meaning and context of the text\n",
+ " - We'll use Vertex AI's text embedding model to generate embeddings\n",
+ " - Error handling (like the retry mechanism) during embedding generation due to potential API quota limits.\n",
+ "\n",
+ "- Indexing:\n",
+ " - Build a searchable index from embeddings, enabling efficient similarity search.\n",
+ " - For example, the index is like a detailed table of contents for a massive reference book.\n",
+ "\n",
+ "\n",
+ "Check out the Google Cloud Platform [documentation](https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings) for detailed understanding and example use-cases."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Vun69x23FWiw"
+ },
+ "outputs": [],
+ "source": [
+ "@retry(wait=wait_random_exponential(multiplier=1, max=120), stop=stop_after_attempt(4))\n",
+ "def get_embeddings(\n",
+ " embedding_client: Any, embedding_model: str, text: str, output_dim: int = 768\n",
+ ") -> list[float]:\n",
+ " \"\"\"\n",
+ " Generate embeddings for text with retry logic for API quota management.\n",
+ "\n",
+ " Args:\n",
+ " embedding_client: The client object used to generate embeddings.\n",
+ " embedding_model: The name of the embedding model to use.\n",
+ " text: The text for which to generate embeddings.\n",
+ " output_dim: The desired dimensionality of the output embeddings (default is 768).\n",
+ "\n",
+ " Returns:\n",
+ " A list of floats representing the generated embeddings. Returns None if a \"RESOURCE_EXHAUSTED\" error occurs.\n",
+ "\n",
+ " Raises:\n",
+ " Exception: Any exception encountered during embedding generation, excluding \"RESOURCE_EXHAUSTED\" errors.\n",
+ " \"\"\"\n",
+ " try:\n",
+ " response = embedding_client.models.embed_content(\n",
+ " model=embedding_model,\n",
+ " contents=[text],\n",
+ " config=types.EmbedContentConfig(output_dimensionality=output_dim),\n",
+ " )\n",
+ " return [response.embeddings[0].values]\n",
+ " except Exception as e:\n",
+ " if \"RESOURCE_EXHAUSTED\" in str(e):\n",
+ " return None\n",
+ " print(f\"Error generating embeddings: {str(e)}\")\n",
+ " raise"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2csDY5NsswwJ"
+ },
+ "source": [
+ "- The code block executes the following steps:\n",
+ "\n",
+ " - Extracts text from PDF documents and segments it into smaller chunks for processing.\n",
+ " - Employs a Vertex AI model to transform each text chunk into a numerical embedding vector, facilitating semantic representation and search.\n",
+ " - Constructs a Pandas DataFrame to store the embeddings, enriched with metadata such as document name and page number, effectively creating a searchable index for efficient retrieval.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "9TJlvdIsRfmX"
+ },
+ "outputs": [],
+ "source": [
+ "def build_index(\n",
+ " document_paths: list[str],\n",
+ " embedding_client: Any,\n",
+ " embedding_model: str,\n",
+ " chunk_size: int = 512,\n",
+ ") -> pd.DataFrame:\n",
+ " \"\"\"\n",
+ " Build searchable index from a list of PDF documents with page-wise processing.\n",
+ "\n",
+ " Args:\n",
+ " document_paths: A list of file paths to PDF documents.\n",
+ " embedding_client: The client object used to generate embeddings.\n",
+ " embedding_model: The name of the embedding model to use.\n",
+ " chunk_size: The maximum size (in characters) of each text chunk. Defaults to 512.\n",
+ "\n",
+ " Returns:\n",
+ " A Pandas DataFrame where each row represents a text chunk. The DataFrame includes columns for:\n",
+ " - 'document_name': The path to the source PDF document.\n",
+ " - 'page_number': The page number within the document.\n",
+ " - 'page_text': The full text of the page.\n",
+ " - 'chunk_number': The chunk number within the page.\n",
+ " - 'chunk_text': The text content of the chunk.\n",
+ " - 'embeddings': The embedding vector for the chunk.\n",
+ "\n",
+ " Raises:\n",
+ " ValueError: If no chunks are created from the input documents.\n",
+ " Exception: Any exceptions encountered during file processing are printed to the console and the function continues to the next document.\n",
+ " \"\"\"\n",
+ " all_chunks = []\n",
+ "\n",
+ " for doc_path in document_paths:\n",
+ " try:\n",
+ " with open(doc_path, \"rb\") as file:\n",
+ " pdf_reader = PyPDF2.PdfReader(file)\n",
+ "\n",
+ " for page_num in range(len(pdf_reader.pages)):\n",
+ " page = pdf_reader.pages[page_num]\n",
+ " page_text = page.extract_text()\n",
+ "\n",
+ " chunks = [\n",
+ " page_text[i : i + chunk_size]\n",
+ " for i in range(0, len(page_text), chunk_size)\n",
+ " ]\n",
+ "\n",
+ " for chunk_num, chunk_text in enumerate(chunks):\n",
+ " embeddings = get_embeddings(\n",
+ " embedding_client, embedding_model, chunk_text\n",
+ " )\n",
+ "\n",
+ " if embeddings is None:\n",
+ " print(\n",
+ " f\"Warning: Could not generate embeddings for chunk {chunk_num} on page {page_num + 1}\"\n",
+ " )\n",
+ " continue\n",
+ "\n",
+ " chunk_info = {\n",
+ " \"document_name\": doc_path,\n",
+ " \"page_number\": page_num + 1,\n",
+ " \"page_text\": page_text,\n",
+ " \"chunk_number\": chunk_num,\n",
+ " \"chunk_text\": chunk_text,\n",
+ " \"embeddings\": embeddings,\n",
+ " }\n",
+ " all_chunks.append(chunk_info)\n",
+ "\n",
+ " except Exception as e:\n",
+ " print(f\"Error processing document {doc_path}: {str(e)}\")\n",
+ " continue\n",
+ "\n",
+ " if not all_chunks:\n",
+ " raise ValueError(\"No chunks were created from the documents\")\n",
+ "\n",
+ " return pd.DataFrame(all_chunks)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yFGsl-Zvlej6"
+ },
+ "source": [
+ "Let's create embeddings and an index using the provided documents"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "hjl5FDQckDcO"
+ },
+ "outputs": [],
+ "source": [
+ "vector_db_mini_vertex = build_index(\n",
+ " documents, embedding_client=client, embedding_model=text_embedding_model\n",
+ ")\n",
+ "vector_db_mini_vertex"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "pZLX5ozMlxTX"
+ },
+ "outputs": [],
+ "source": [
+ "# Index size\n",
+ "vector_db_mini_vertex.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "cvNVn3kT9FiB"
+ },
+ "outputs": [],
+ "source": [
+ "# Example of how a chunk looks like\n",
+ "vector_db_mini_vertex.loc[0, \"chunk_text\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Hul4bjAkBkg0"
+ },
+ "source": [
+ "To enhance the performance of retrieval systems, consider the following:\n",
+ "\n",
+ "- Optimize chunk size selection to balance granularity and context.\n",
+ "- Evaluate various chunking strategies to identify the most effective approach for your data.\n",
+ "- Explore managed services and scalable indexing solutions, such as [Vertex AI Search](https://cloud.google.com/generative-ai-app-builder/docs/create-datastore-ingest), to enhance performance and efficiency."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "43txjyVlHT6v"
+ },
+ "source": [
+ "#### Retrieval"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y92jM-v8KBfV"
+ },
+ "source": [
+ "The below code demonstrates how to query the index and uses a cosine similarity measure for comparing query vectors against the index. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bI1YsFoKtyxY"
+ },
+ "source": [
+ "* **Input:** Accepts a query string and parameters like the number of relevant chunks to return.\n",
+ "* **Embedding Generation:** Generates an embedding for the input query using the same model used to embed the document chunks.\n",
+ "* **Similarity Search:** Compares the query embedding to the embeddings of all indexed document chunks, using cosine similarity. Could use other distance metrics as well.\n",
+ "* **Ranking:** Ranks the chunks based on their similarity scores to the query.\n",
+ "* **Top-k Retrieval:** Returns the top *k* most similar chunks, where *k* is specified by the input parameters. This could be configurable.\n",
+ "* **Output:** Returns a list of relevant chunks, potentially including the original chunk text, similarity score, document source (filename, page number), and chunk metadata.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "88ndL_2wJ5ZD"
+ },
+ "outputs": [],
+ "source": [
+ "def get_relevant_chunks(\n",
+ " query: str,\n",
+ " vector_db: pd.DataFrame,\n",
+ " embedding_client: Any,\n",
+ " embedding_model: str,\n",
+ " top_k: int = 3,\n",
+ ") -> str:\n",
+ " \"\"\"\n",
+ " Retrieve the most relevant document chunks for a query using similarity search.\n",
+ "\n",
+ " Args:\n",
+ " query: The search query string.\n",
+ " vector_db: A pandas DataFrame containing the vectorized document chunks.\n",
+ " It must contain columns named 'embeddings', 'document_name',\n",
+ " 'page_number', and 'chunk_text'.\n",
+ " The 'embeddings' column should contain lists or numpy arrays\n",
+ " representing the embeddings.\n",
+ " embedding_client: The client object used to generate embeddings.\n",
+ " embedding_model: The name of the embedding model to use.\n",
+ " top_k: The number of most similar chunks to retrieve. Defaults to 3.\n",
+ "\n",
+ " Returns:\n",
+ " A formatted string containing the top_k most relevant chunks. Each chunk is\n",
+ " presented with its page number and chunk number. Returns an error message if\n",
+ " the query processing fails or if an error occurs during chunk retrieval.\n",
+ "\n",
+ " Raises:\n",
+ " Exception: If any error occurs during the process (e.g., issues with the embedding client,\n",
+ " data format problems in the vector database).\n",
+ " The specific error is printed to the console.\n",
+ " \"\"\"\n",
+ " try:\n",
+ " query_embedding = get_embeddings(embedding_client, embedding_model, query)\n",
+ "\n",
+ " if query_embedding is None:\n",
+ " return \"Could not process query due to quota issues\"\n",
+ "\n",
+ " similarities = [\n",
+ " cosine_similarity(query_embedding, chunk_emb)[0][0]\n",
+ " for chunk_emb in vector_db[\"embeddings\"]\n",
+ " ]\n",
+ "\n",
+ " top_indices = np.argsort(similarities)[-top_k:]\n",
+ " relevant_chunks = vector_db.iloc[top_indices]\n",
+ "\n",
+ " context = []\n",
+ " for _, row in relevant_chunks.iterrows():\n",
+ " context.append(\n",
+ " {\n",
+ " \"document_name\": row[\"document_name\"],\n",
+ " \"page_number\": row[\"page_number\"],\n",
+ " \"chunk_number\": row[\"chunk_number\"],\n",
+ " \"chunk_text\": row[\"chunk_text\"],\n",
+ " }\n",
+ " )\n",
+ "\n",
+ " return \"\\n\\n\".join(\n",
+ " [\n",
+ " f\"[Page {chunk['page_number']}, Chunk {chunk['chunk_number']}]: {chunk['chunk_text']}\"\n",
+ " for chunk in context\n",
+ " ]\n",
+ " )\n",
+ "\n",
+ " except Exception as e:\n",
+ " print(f\"Error getting relevant chunks: {str(e)}\")\n",
+ " return \"Error retrieving relevant chunks\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3hxyLlTjsstI"
+ },
+ "source": [
+ "Let's test out our retrieval component"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ek4aF0Esck2H"
+ },
+ "source": [
+ "- Let's try the same query for which the model was not able to answer earlier, due to lack of context"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "lSd8ZeH6D7m4"
+ },
+ "outputs": [],
+ "source": [
+ "query = \"What is the price of a basic tune-up at Cymbal Bikes?\"\n",
+ "relevant_context = get_relevant_chunks(\n",
+ " query, vector_db_mini_vertex, client, text_embedding_model, top_k=3\n",
+ ")\n",
+ "relevant_context"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YBxnXReUn8Iy"
+ },
+ "source": [
+ "- You can see, with the help of the relevant context we can derive the answer as it contains the chunks specific to the asked query.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "25eb6422c9cf"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kHzw7_UwzutC"
+ },
+ "source": [
+ "For optimal performance, consider these points:\n",
+ "\n",
+ "* **Context Window:** Considers a context window around the retrieved chunks to provide more comprehensive context. This could involve returning neighboring chunks or a specified window size.\n",
+ "* **Filtering:** Option to filter retrieved chunks based on criteria like minimum similarity score or source document.\n",
+ "* **Efficiency:** Designed for efficient retrieval, especially for large indexes, potentially using optimized search algorithms or data structures."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZEfJkwSqJ5KR"
+ },
+ "source": [
+ "### Generation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "b7OZpv33KBx_"
+ },
+ "source": [
+ "* **Contextual Answer Synthesis:** The core function of the generation component is to synthesize a coherent and informative answer based on the retrieved context. It takes the user's query and the relevant document chunks as input.\n",
+ "* **Large Language Model (LLM) Integration:** It leverages a large language model (LLM) to generate the final answer. The LLM processes both the query and the retrieved context to produce a response. The quality of the answer heavily relies on the capabilities of the chosen LLM.\n",
+ "* **Coherence and Relevance:** A good generation function ensures the generated answer is coherent, factually accurate, and directly addresses the user's query, using only the provided context. It avoids hallucinations (generating information not present in the context).\n",
+ "* **Prompt Engineering:** The effectiveness of the LLM is heavily influenced by the prompt. The generation function likely incorporates prompt engineering techniques to guide the LLM towards generating the desired output. This may involve carefully crafting instructions for the LLM or providing examples.\n",
+ "\n",
+ "For more details on prompt engineering, check out the [documentation](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-design-strategies)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0xs-AQmqm03l"
+ },
+ "source": [
+ "Let's see two use-cases, `Text-In-Text-Out` and `Text-In-Audio-Out`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "xp7doymTJ7Iu"
+ },
+ "outputs": [],
+ "source": [
+ "@retry(wait=wait_random_exponential(multiplier=1, max=120), stop=stop_after_attempt(4))\n",
+ "async def generate_answer(\n",
+ " query: str, context: str, llm_client: Any, modality: str = \"text\"\n",
+ ") -> str:\n",
+ " \"\"\"\n",
+ " Generate answer using LLM with retry logic for API quota management.\n",
+ "\n",
+ " Args:\n",
+ " query: User query.\n",
+ " context: Relevant text providing context for the query.\n",
+ " llm_client: Client for accessing LLM API.\n",
+ " modality: Output modality (text or audio).\n",
+ "\n",
+ " Returns:\n",
+ " Generated answer.\n",
+ "\n",
+ " Raises:\n",
+ " Exception: If an unexpected error occurs during the LLM call (after retry attempts are exhausted).\n",
+ " \"\"\"\n",
+ " try:\n",
+ " # If context indicates earlier quota issues, return early\n",
+ " if context in [\n",
+ " \"Could not process query due to quota issues\",\n",
+ " \"Error retrieving relevant chunks\",\n",
+ " ]:\n",
+ " return \"Can't Process, Quota Issues\"\n",
+ "\n",
+ " prompt = f\"\"\"Based on the following context, please answer the question.\n",
+ "\n",
+ " Context:\n",
+ " {context}\n",
+ "\n",
+ " Question: {query}\n",
+ "\n",
+ " Answer:\"\"\"\n",
+ "\n",
+ " if modality == \"text\":\n",
+ " # Generate text answer using LLM\n",
+ " response = await generate_content(prompt)\n",
+ " return response\n",
+ "\n",
+ " elif modality == \"audio\":\n",
+ " # Generate audio answer using LLM\n",
+ " await generate_audio_content(prompt)\n",
+ "\n",
+ " except Exception as e:\n",
+ " if \"RESOURCE_EXHAUSTED\" in str(e):\n",
+ " return \"Can't Process, Quota Issues\"\n",
+ " print(f\"Error generating answer: {str(e)}\")\n",
+ " return \"Error generating answer\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "11q0Sf0oJ7wL"
+ },
+ "source": [
+ "Let's test our `Generation` component"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "S-iesR2BEHnI"
+ },
+ "outputs": [],
+ "source": [
+ "query = \"What is the price of a basic tune-up at Cymbal Bikes?\"\n",
+ "\n",
+ "generated_answer = await generate_answer(\n",
+ " query, relevant_context, client, modality=\"text\"\n",
+ ")\n",
+ "display(Markdown(generated_answer))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "W7EHYeP-EMpN"
+ },
+ "outputs": [],
+ "source": [
+ "await generate_answer(query, relevant_context, client, modality=\"audio\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CbQB5PbMrrsB"
+ },
+ "source": [
+ "> And the answer is... CORRECT !! 🎉"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1gnr-j-ocxlx"
+ },
+ "source": [
+ "- The accuracy of the generated answer is attributed to the provision of relevant context to the Large Language Model (LLM), enabling it to effectively comprehend the query and produce an appropriate response."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "2MNlAoAHR0Do"
+ },
+ "source": [
+ "### Pipeline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8LemsW6WrOfm"
+ },
+ "source": [
+ "Let's put `Retrieval` and `Generation` components together in a pipeline."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "yoOeqxETR2G_"
+ },
+ "outputs": [],
+ "source": [
+ "async def rag(\n",
+ " question: str,\n",
+ " vector_db: pd.DataFrame,\n",
+ " embedding_client: Any,\n",
+ " embedding_model: str,\n",
+ " llm_client: Any,\n",
+ " top_k: int,\n",
+ " llm_model: str,\n",
+ " modality: str = \"text\",\n",
+ ") -> str | None:\n",
+ " \"\"\"\n",
+ " RAG Pipeline.\n",
+ "\n",
+ " Args:\n",
+ " question: User query.\n",
+ " vector_db: DataFrame containing document chunks and embeddings.\n",
+ " embedding_client: Client for accessing embedding API.\n",
+ " embedding_model: Name of the embedding model.\n",
+ " llm_client: Client for accessing LLM API.\n",
+ " top_k: The number of top relevant chunks to retrieve from the vector database.\n",
+ " llm_model: Name of the LLM model.\n",
+ " modality: Output modality (text or audio).\n",
+ "\n",
+ " Returns:\n",
+ " For text modality, generated answer.\n",
+ " For audio modality, audio playback widget.\n",
+ "\n",
+ " Raises:\n",
+ " Exception: Catches and prints any exceptions during processing. Returns an error message.\n",
+ " \"\"\"\n",
+ "\n",
+ " try:\n",
+ " # Get relevant context for question\n",
+ " relevant_context = get_relevant_chunks(\n",
+ " question, vector_db, embedding_client, embedding_model, top_k=top_k\n",
+ " )\n",
+ "\n",
+ " if modality == \"text\":\n",
+ " # Generate text answer using LLM\n",
+ " generated_answer = await generate_answer(\n",
+ " question,\n",
+ " relevant_context,\n",
+ " llm_client,\n",
+ " )\n",
+ " return generated_answer\n",
+ "\n",
+ " elif modality == \"audio\":\n",
+ " # Generate audio answer using LLM\n",
+ " await generate_answer(\n",
+ " question, relevant_context, llm_client, modality=modality\n",
+ " )\n",
+ " return\n",
+ "\n",
+ " except Exception as e:\n",
+ " print(f\"Error processing question '{question}': {str(e)}\")\n",
+ " return {\"question\": question, \"generated_answer\": \"Error processing question\"}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q8bNzUvbVJcx"
+ },
+ "source": [
+ "Our Retrieval Augmented Generation (RAG) architecture allows for flexible output modality(text and audio) selection. By modifying only the generation component, we can produce both text and audio output while maintaining the same retrieval mechanism. This highlights the adaptability of RAG in catering to diverse content presentation needs."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pkn75-1cFW1J"
+ },
+ "source": [
+ "### Inference"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "QMGtlPWcVXT0"
+ },
+ "source": [
+ "Let's test our simple RAG pipeline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0vwfQbodn89Y"
+ },
+ "source": [
+ "#### Sample Queries"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "Zx_GwXESk9aP"
+ },
+ "outputs": [],
+ "source": [
+ "question_set = [\n",
+ " {\n",
+ " \"question\": \"What is the price of a basic tune-up at Cymbal Bikes?\",\n",
+ " \"answer\": \"A basic tune-up costs $100.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"How much does it cost to replace a tire at Cymbal Bikes?\",\n",
+ " \"answer\": \"Replacing a tire at Cymbal Bikes costs $50 per tire.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"What does gear repair at Cymbal Bikes include?\",\n",
+ " \"answer\": \"Gear repair includes inspection and repair of the gears, including replacement of chainrings, cogs, and cables as needed.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"What is the cost of replacing a tube at Cymbal Bikes?\",\n",
+ " \"answer\": \"Replacing a tube at Cymbal Bikes costs $20.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"Can I return clothing items to Cymbal Bikes?\",\n",
+ " \"answer\": \"Clothing can only be returned if it is unworn and in the original packaging.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"What is the time frame for returning items to Cymbal Bikes?\",\n",
+ " \"answer\": \"Cymbal Bikes offers a 30-day return policy on all items.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"Can I return edible items like energy gels?\",\n",
+ " \"answer\": \"No, edible items are not returnable.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"How can I return an item purchased online from Cymbal Bikes?\",\n",
+ " \"answer\": \"Items purchased online can be returned to any Cymbal Bikes store or mailed back.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"What should I include when returning an item to Cymbal Bikes?\",\n",
+ " \"answer\": \"Please include the original receipt and a copy of your shipping confirmation when returning an item.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"Does Cymbal Bikes offer refunds for shipping charges?\",\n",
+ " \"answer\": \"Cymbal Bikes does not offer refunds for shipping charges, except for defective items.\",\n",
+ " },\n",
+ " {\n",
+ " \"question\": \"How do I process a return for a defective item at Cymbal Bikes?\",\n",
+ " \"answer\": \"To process a return for a defective item, please contact Cymbal Bikes first.\",\n",
+ " },\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZUo_fcNzoAp3"
+ },
+ "source": [
+ "#### Text"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y1RC5-djV0-r"
+ },
+ "source": [
+ "First we will try, `modality='text'`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "dmyN-h18EZdT"
+ },
+ "outputs": [],
+ "source": [
+ "question_set[0]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "-f3hsHqBEbwc"
+ },
+ "outputs": [],
+ "source": [
+ "response = await rag(\n",
+ " question=question_set[0][\"question\"],\n",
+ " vector_db=vector_db_mini_vertex,\n",
+ " embedding_client=client, # For embedding generation\n",
+ " embedding_model=text_embedding_model, # For embedding model\n",
+ " llm_client=client, # For answer generation,\n",
+ " top_k=3,\n",
+ " llm_model=MODEL,\n",
+ " modality=\"text\",\n",
+ ")\n",
+ "display(Markdown(response))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Nb3VytmIyo-1"
+ },
+ "source": [
+ "#### Audio"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kEl80N8VV_6E"
+ },
+ "source": [
+ "Now, let's try `modality='audio'` to get audio response."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "STdO_EtxEhFA"
+ },
+ "outputs": [],
+ "source": [
+ "await rag(\n",
+ " question=question_set[0][\"question\"],\n",
+ " vector_db=vector_db_mini_vertex,\n",
+ " embedding_client=client, # For embedding generation\n",
+ " embedding_model=text_embedding_model, # For embedding model\n",
+ " llm_client=client, # For answer generation,\n",
+ " top_k=3,\n",
+ " llm_model=MODEL,\n",
+ " modality=\"audio\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "l9NMyJm-_0lM"
+ },
+ "source": [
+ "Evaluating Retrieval Augmented Generation (RAG) applications before production is crucial for identifying areas for improvement and ensuring optimal performance.\n",
+ "Check out the Vertex AI [Gen AI evaluation service](https://cloud.google.com/vertex-ai/generative-ai/docs/models/evaluation-overview)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Erp1ImX9Lu1Y"
+ },
+ "source": [
+ "## Conclusion"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "W2A4xXWP1EB4"
+ },
+ "source": [
+ "Congratulations on making it through this notebook!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Uyc3uq1uYHEN"
+ },
+ "source": [
+ "- We have seen how to use the Gemini API in Vertex AI to generate text and Multimodal Live API to generate text and audio output.\n",
+ "- Developed a fully functional Retrieval Augmented Generation (RAG) pipeline capable of answering questions based on provided documents.\n",
+ "- Demonstrated the versatility of the RAG architecture by enabling both text and audio output modalities.\n",
+ "- Ensured the adaptability of the RAG pipeline to various use cases by enabling seamless integration of different context documents.\n",
+ "- Established a foundation for building more advanced RAG systems leveraging larger document sets and sophisticated indexing/retrieval services like Vertex AI Datastore/Agent Builder and Vertex AI Multimodal Live API."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "54e180a34fd0"
+ },
+ "source": [
+ "## What's next\n",
+ "\n",
+ "- Learn how to [build a web application that enables you to use your voice and camera to talk to Gemini 2.0 through the Multimodal Live API.](https://github.com/GoogleCloudPlatform/generative-ai/tree/main/gemini/multimodal-live-api/websocket-demo-app)\n",
+ "- See the [Multimodal Live API reference docs](https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/multimodal-live).\n",
+ "- See the [Google Gen AI SDK reference docs](https://googleapis.github.io/python-genai/).\n",
+ "- Explore other notebooks in the [Google Cloud Generative AI GitHub repository](https://github.com/GoogleCloudPlatform/generative-ai)."
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "name": "real_time_rag_retail_gemini_2_0.ipynb",
+ "toc_visible": true,
+ "provenance": [],
+ "gpuType": "T4"
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "accelerator": "GPU"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
|